

Commit
•
34485f9
1
Parent(s):
0dc7409
Add .cache notice.
Browse files
README.md
CHANGED
|
@@ -8,7 +8,15 @@ tags:
|
|
| 8 |
- text-generation-inference
|
| 9 |
---
|
| 10 |
|
| 11 |
-
**
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 12 |
|
| 13 |
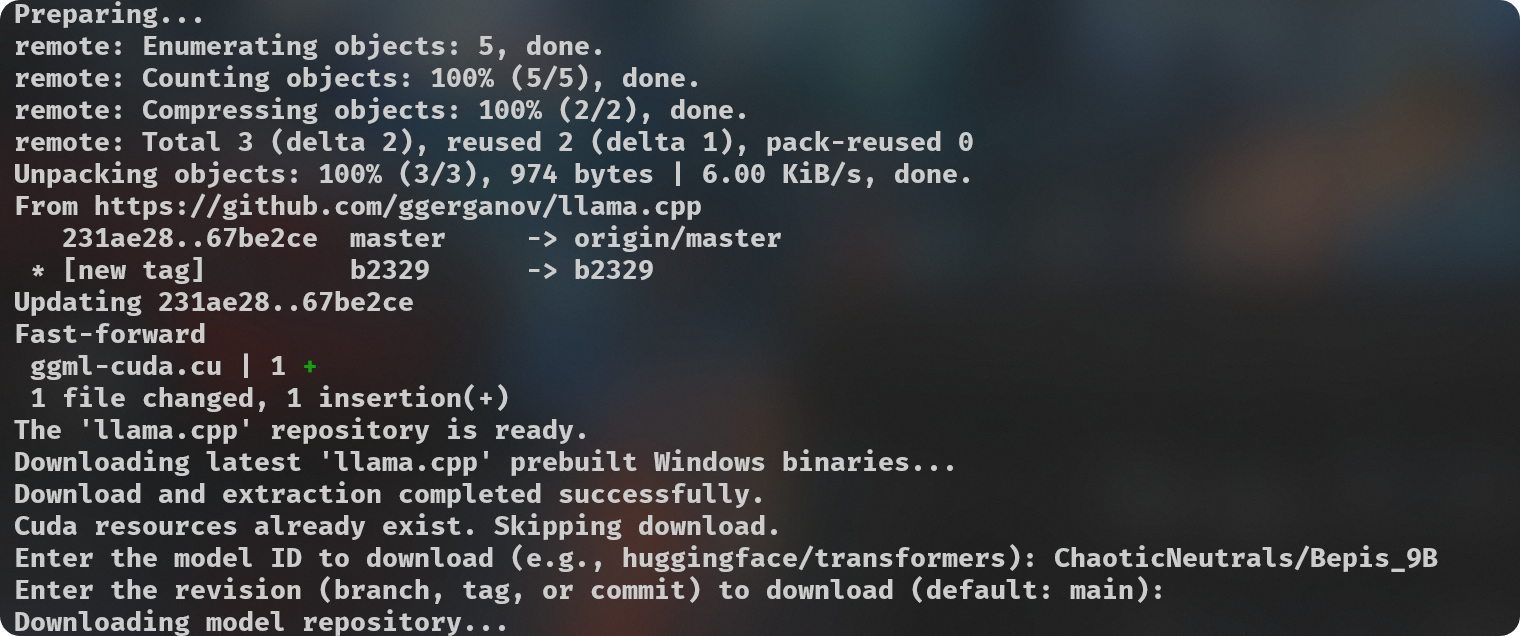
|
| 14 |
|
|
@@ -20,6 +28,10 @@ Your `imatrix.txt` is expected to be located inside the `imatrix` folder. I have
|
|
| 20 |
|
| 21 |
Adjust `quantization_options` in [**line 133**](https://huggingface.co/FantasiaFoundry/GGUF-Quantization-Script/blob/main/gguf-imat.py#L133).
|
| 22 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 23 |
**Hardware:**
|
| 24 |
|
| 25 |
- NVIDIA GPU with 8GB of VRAM.
|
|
@@ -35,12 +47,4 @@ Adjust `quantization_options` in [**line 133**](https://huggingface.co/FantasiaF
|
|
| 35 |
python .\gguf-imat.py
|
| 36 |
```
|
| 37 |
Quantizations will be output into the created `models\{model-name}-GGUF` folder.
|
| 38 |
-
<br><br>
|
| 39 |
-
|
| 40 |
-
### **Credits:**
|
| 41 |
-
|
| 42 |
-
Feel free to Pull Request with your own features and improvements to this script.
|
| 43 |
-
|
| 44 |
-
**If this proves useful for you, feel free to credit and share the repository.**
|
| 45 |
-
|
| 46 |
-
**Made in conjunction with [@Lewdiculous](https://huggingface.co/Lewdiculous).**
|
|
|
|
| 8 |
- text-generation-inference
|
| 9 |
---
|
| 10 |
|
| 11 |
+
### **Credits:**
|
| 12 |
+
|
| 13 |
+
Feel free to Pull Request with your own features and improvements to this script.
|
| 14 |
+
|
| 15 |
+
**If this proves useful for you, feel free to credit and share the repository.**
|
| 16 |
+
|
| 17 |
+
**Made in conjunction with [@Lewdiculous](https://huggingface.co/Lewdiculous).**
|
| 18 |
+
|
| 19 |
+
# GGUF-IQ-Imatrix-Quantization-Script:
|
| 20 |
|
| 21 |

|
| 22 |
|
|
|
|
| 28 |
|
| 29 |
Adjust `quantization_options` in [**line 133**](https://huggingface.co/FantasiaFoundry/GGUF-Quantization-Script/blob/main/gguf-imat.py#L133).
|
| 30 |
|
| 31 |
+
> [!NOTE]
|
| 32 |
+
> Models downloaded to be used for quantization are cached at `C:\Users\{{User}}\.cache\huggingface\hub`. You can delete these files manually as needed after you're done with your quantizations, you can do it directly from your Terminal if you prefer with the `rmdir "C:\Users\{{User}}\.cache\huggingface\hub"` command. You can put it into another script or alias it to a convenient command if you prefer.
|
| 33 |
+
|
| 34 |
+
|
| 35 |
**Hardware:**
|
| 36 |
|
| 37 |
- NVIDIA GPU with 8GB of VRAM.
|
|
|
|
| 47 |
python .\gguf-imat.py
|
| 48 |
```
|
| 49 |
Quantizations will be output into the created `models\{model-name}-GGUF` folder.
|
| 50 |
+
<br><br>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|