

Commit
•
46e98ec
1
Parent(s):
9e1bf78
Create README.md (#1)
Browse files- Create README.md (985ee098b6a1a2444cefa4eb1defae84ff92c43a)
Co-authored-by: Amjad <[email protected]>
README.md
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language: en
|
| 3 |
+
tags:
|
| 4 |
+
- EBK-BERT
|
| 5 |
+
license: apache-2.0
|
| 6 |
+
datasets:
|
| 7 |
+
- Araevent(November)
|
| 8 |
+
- Araevent(July)
|
| 9 |
+
---
|
| 10 |
+
|
| 11 |
+
# BK-BERT
|
| 12 |
+
|
| 13 |
+
Event Knowledge-Based BERT (EBK-BERT) leverages knowledge extracted from events-related sentences to mask words that
|
| 14 |
+
are significant to the events detection task. This approach aims to produce a language model that enhances the
|
| 15 |
+
performance of the down-stream event detection task, which is later trained during the fine-tuning process.
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
## Model description
|
| 19 |
+
|
| 20 |
+
The BERT-base configuration is adopted which has 12 encoder blocks, 768 hidden dimensions, 12 attention heads,
|
| 21 |
+
512 maximum sequence length, and a total of 110M parameters.
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
## Pre-training Data
|
| 26 |
+
The pre-training data consists of news articles from the 1.5 billion words corpus by (El-Khair, 2016).
|
| 27 |
+
Due to computation limitations, we only use articles from Alittihad, Riyadh, Almasrya- lyoum, and Alqabas,
|
| 28 |
+
which amount to 10GB of text and about 8M sentences after splitting the articles to approximately
|
| 29 |
+
100 word sentences to accommodate the 128 max_sentence length used when training the model.
|
| 30 |
+
The average number of tokens per sentence is 105.
|
| 31 |
+
|
| 32 |
+
### Pretraining
|
| 33 |
+
As previous studies have shown, contextual representation models that are pre-trained using top Personnel
|
| 34 |
+
Transaction Contact Nature Movement Life Justice Conflict business the MLM training task benefit from masking
|
| 35 |
+
the most significant words, using whole word masking.
|
| 36 |
+
To select the most significant words we use odds-ratio. Only words with greater than 2 odds-ratio are considered
|
| 37 |
+
in the masking, which means the words included are at least twice as likely to appear in one event type than the other.
|
| 38 |
+
|
| 39 |
+
Google Cloud GPU is used for pre-training the model. The selected hyperparameters are: learning rate=1e − 4,
|
| 40 |
+
batch size =16, maxi- mum sequence length = 128 and average se- quence length = 104. In total, we pre-trained
|
| 41 |
+
our models for 500, 000 steps, completing 1 epoch. Pre-training a single model took approximately 2.25 days.
|
| 42 |
+
|
| 43 |
+
## Fine-tuning data
|
| 44 |
+
|
| 45 |
+
Tweets are collected from well-known Arabic news accounts, which are: Al-Arabiya, Sabq,
|
| 46 |
+
CNN Arabic, and BBC Arabic. These accounts belong to television channels and online
|
| 47 |
+
newspapers, where they use Twitter to broadcast news related to real-world events.
|
| 48 |
+
The first collection process tracks tweets from the news accounts for 20 days period,
|
| 49 |
+
between November 2, 2021, and November 22, 2021 and we call this dataset AraEvent(November).
|
| 50 |
+
|
| 51 |
+
## Evaluation results
|
| 52 |
+
|
| 53 |
+
When fine-tuned on down-stream event detection task, this model achieves the following results:
|
| 54 |
+
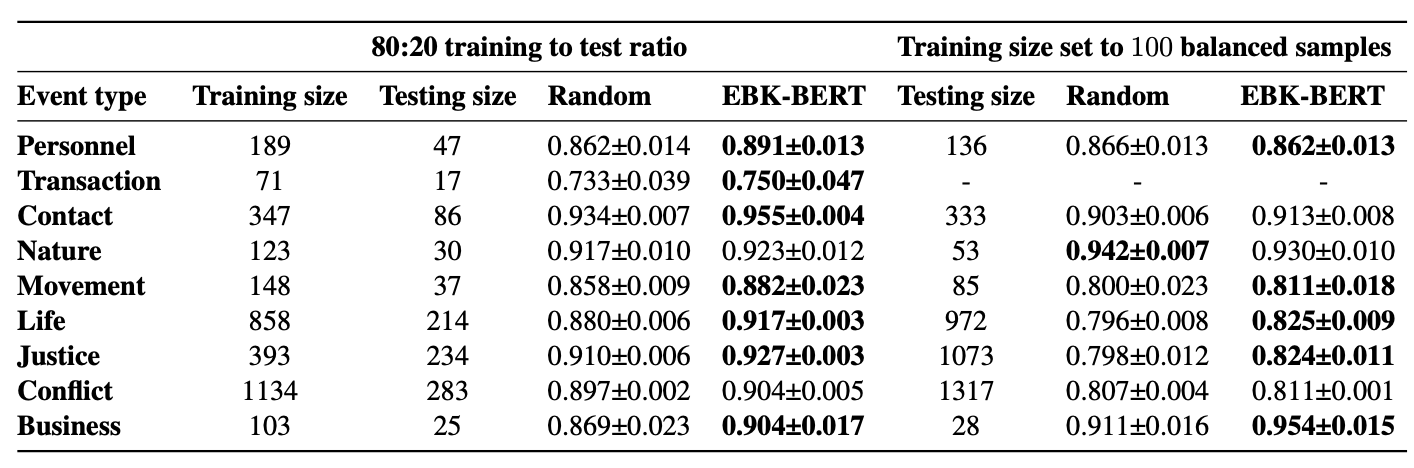
|
| 55 |
+
|
| 56 |
+
## Gradio Demo
|
| 57 |
+
will be released soon
|