English | 简体中文
We opensource our **Aquila2** series, now including **Aquila2**, the base language models, namely **Aquila2-7B** and **Aquila2-34B**, as well as **AquilaChat2**, the chat models, namely **AquilaChat2-7B** and **AquilaChat2-34B**, as well as the long-text chat models, namely **AquilaChat2-7B-16k** and **AquilaChat2-34B-16k** 2023.10.25 🔥 **Aquila2-34B v1.2** is based on the previous **Aquila2-34B**. The Aquila2-34B has achieved a 6.9% improvement in comprehensive evaluations, with MMLU(+12%), TruthfulQA(+14%), CSL(+11%), TNEWS(+12%), OCNLI(+28%), and BUSTM(+18%). The additional details of the Aquila model will be presented in the official technical report. Please stay tuned for updates on official channels. ### NoteWe have discovered a data leakage problem with the GSM8K test data in the pre-training task dataset. Therefore, the evaluation results of GSM8K have been removed from the evaluation results. Upon thorough investigation and analysis, it was found that the data leakage occurred in the mathematical dataset A (over 2 million samples), recommended by a team we have collaborated with multiple times. This dataset includes the untreated GSM8K test set (1319 samples). The team only performed routine de-duplication and quality checks but did not conduct an extra filtering check for the presence of the GSM8K test data, resulting in this oversight. Our team has always strictly adhered to the principle that training data should not include test data. Taking this lesson from the error caused by not thoroughly checking the source of external data, we have investigated all 2 trillion tokens of data for various test datasets, including WTM22(en-zh), CLUEWSC, Winograd, HellaSwag, OpenBookQA, PIQA, ARC-e, BUSTSM, BoolQ, TruthfulQA, RAFT, ChID, EPRSTMT, TNEWS, OCNLI, SEM-Chinese, MMLU, C-Eval, CMMLU, CSL and HumanEval.
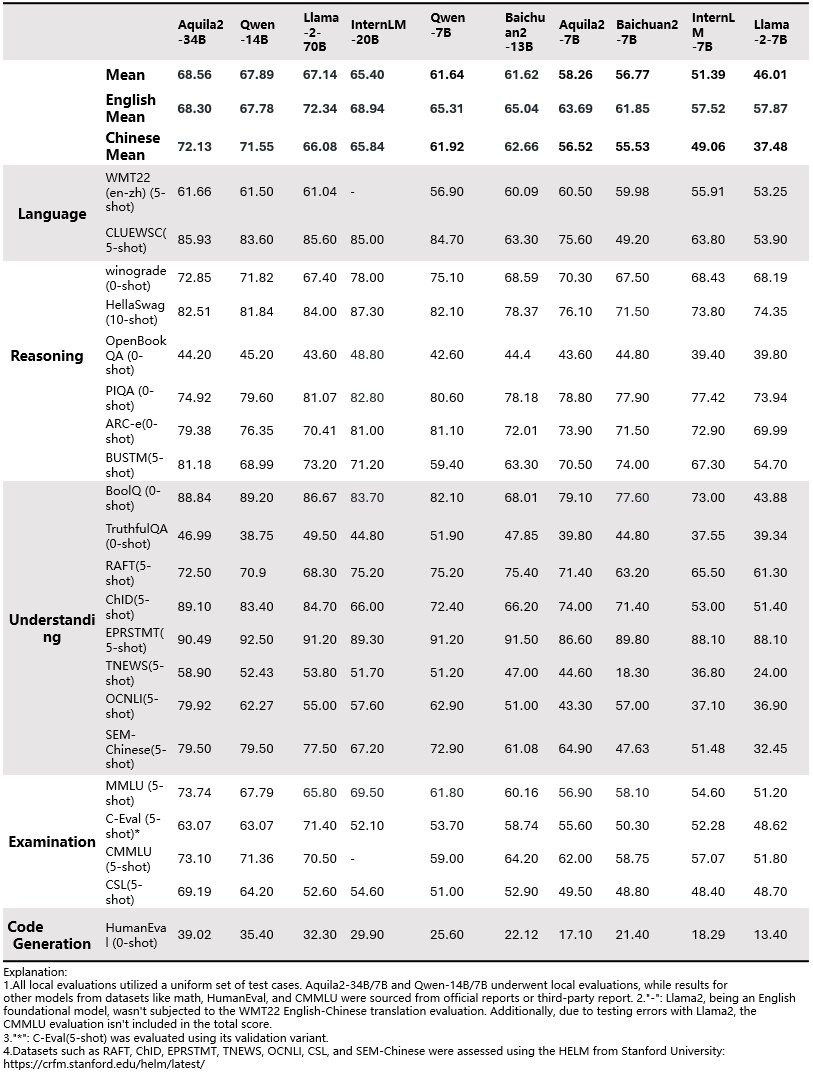
## Chat Model Performance
## Quick Start Aquila2-34B(Chat model)
### 1. Inference
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import BitsAndBytesConfig
device = torch.device("cuda")
model_info = "BAAI/Aquila2-34B"
tokenizer = AutoTokenizer.from_pretrained(model_info, trust_remote_code=True)
quantization_config=BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
model = AutoModelForCausalLM.from_pretrained(model_info, trust_remote_code=True,
# quantization_config=quantization_config, # Uncomment this line for 4bit quantization
)
model.eval()
model.to(device)
text = "请给出10个要到北京旅游的理由。"
tokens = tokenizer.encode_plus(text)['input_ids']
tokens = torch.tensor(tokens)[None,].to(device)
stop_tokens = ["###", "[UNK]", ""]
with torch.no_grad():
out = model.generate(tokens, do_sample=True, max_length=512, eos_token_id=100007, bad_words_ids=[[tokenizer.encode(token)[0] for token in stop_tokens]])[0]
out = tokenizer.decode(out.cpu().numpy().tolist())
print(out)
```
## License
Aquila2 series open-source model is licensed under [ BAAI Aquila Model Licence Agreement](https://huggingface.co/BAAI/Aquila2-34B/blob/main/BAAI-Aquila-Model-License%20-Agreement.pdf)