English 简体中文 |
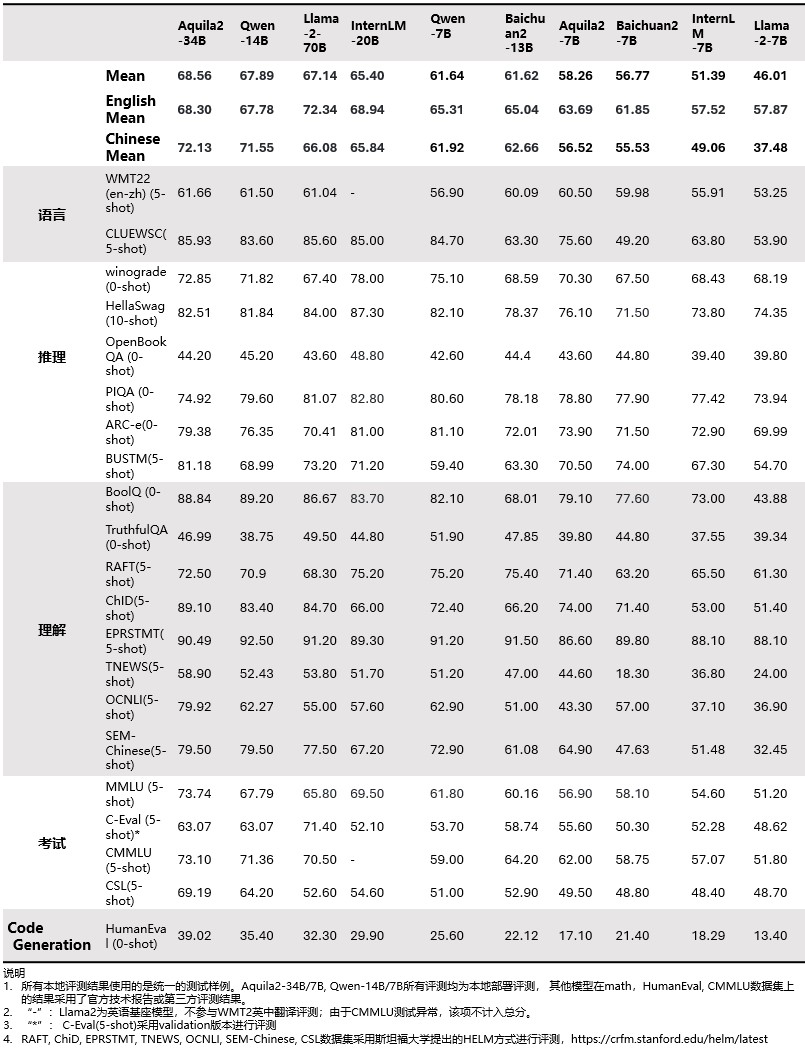
# 悟道·天鹰(Aquila2) 我们开源了我们的 **Aquila2** 系列,现在包括基础语言模型 **Aquila2-7B** 和 **Aquila2-34B** ,对话模型 **AquilaChat2-7B** 和 **AquilaChat2-34B**,长文本对话模型**AquilaChat2-7B-16k** 和 **AquilaChat2-34B-16k** 基于Aquila2初始版本的开发经验,我们对Aquila2进行了全面升级并发布1.2版本。评测结果显示, Aquila2基础模型综合客观评测提升 6.9%,Aquila2-34B v1.2 在 MMLU、TruthfulQA、CSL、TNEWS、OCNLI、BUSTM 等考试、 理解及推理评测数据集上的评测结果分别增加 12%、14%、11%、12%、28%、18%。 悟道 · 天鹰 Aquila 模型的更多细节将在官方技术报告中呈现。请关注官方渠道更新。 注:发现在预训练任务数据集中存在GSM8K测试数据泄露问题,从评测结果中删除GSM8K的评估结果。 经彻查分析,数据泄露发生于某多次合作数据团队所推荐的数学数据集A(超过2百万样本),其包含未经过处理的GSM8K测试集(1319样本)。团队只进行了常规去重和质量检测,未就是否混入GSM8K测试数据进行额外过滤检查而导致失误,实为工作中的疏漏。 团队一直严格遵循训练数据不能包含测试数据的工作原则。汲取本次因未对外部数据来源进行查证而发生的失误教训,我们在2万亿token全量数据上完成了针对21个测试数据集的排查,所涉数据集包括WTM22(en-zh)、CLUEWSC、winograde、HellaSwag、OpenBookQA、PIQA、ARC-e、BUSTSM、BoolQ、TruthfulQA、RAFT、ChID、EPRSTMT、TNEWS、OCNLI、SEM-Chinese、MMLU、C-Eval、CMMLU、CSL和HumanEval。 ## 对话模型性能
## 快速开始使用 Aquila2-34B
## 使用方式/How to use
### 1. 推理/Inference
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
device = torch.device("cuda")
model_info = "BAAI/Aquila2-34B"
tokenizer = AutoTokenizer.from_pretrained(model_info, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_info, trust_remote_code=True)
model.eval()
model.to(device)
text = "请给出10个要到北京旅游的理由。"
tokens = tokenizer.encode_plus(text)['input_ids']
tokens = torch.tensor(tokens)[None,].to(device)
stop_tokens = ["###", "[UNK]", ""]
with torch.no_grad():
out = model.generate(tokens, do_sample=True, max_length=512, eos_token_id=100007, bad_words_ids=[[tokenizer.encode(token)[0] for token in stop_tokens]])[0]
out = tokenizer.decode(out.cpu().numpy().tolist())
print(out)
```
## 证书/License
Aquila2系列开源模型使用 [智源Aquila系列模型许可协议](https://huggingface.co/BAAI/Aquila2-34B/blob/main/BAAI-Aquila-Model-License%20-Agreement.pdf)