---
language:
- en
license: mit
library_name: transformers
tags:
- audio
- automatic-speech-recognition
- transformers.js
widget:
- example_title: LibriSpeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: LibriSpeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
pipeline_tag: automatic-speech-recognition
---
This is a working space for a fine tune of Distil-Whisper-Large for medical speech recognition. The model will change often, so duplicate the space if you find it useful for your needs as it is.
# Distil-Whisper: distil-large-v3
Distil-Whisper was proposed in the paper [Robust Knowledge Distillation via Large-Scale Pseudo Labelling](https://arxiv.org/abs/2311.00430).
This is the third and final installment of the Distil-Whisper English series. It the knowledge distilled version of
OpenAI's [Whisper large-v3](https://huggingface.co/openai/whisper-large-v3), the latest and most performant Whisper model
to date.
Compared to previous Distil-Whisper models, the distillation procedure for distil-large-v3 has been adapted to give
**superior long-form transcription accuracy** with OpenAI's **sequential long-form algorithm**.
The result is a distilled model that performs to within 1% WER of large-v3 on long-form audio using both the sequential
and chunked algorithms, and outperforms distil-large-v2 by 4.8% using the sequential algorithm. The model is also faster
than previous Distil-Whisper models: **6.3x faster than large-v3**, and 1.1x faster than distil-large-v2.
| Model | Params / M | Rel. Latency | Short-Form | Sequential Long-Form | Chunked Long-Form |
|------------------------------------------------------------------------------|------------|--------------|------------|----------------------|-------------------|
| [large-v3](https://huggingface.co/openai/whisper-large-v3) | 1550 | 1.0 | 8.4 | 10.0 | 11.0 |
| **[distil-large-v3](https://huggingface.co/distil-whisper/distil-large-v3)** | **756** | **6.3** | **9.7** | **10.8** | **10.9** |
| [distil-large-v2](https://huggingface.co/distil-whisper/distil-large-v2) | 756 | 5.8 | 10.1 | 15.6 | 11.6 |
Since the sequential algorithm is the "de-facto" transcription algorithm across the most popular Whisper libraries
(Whisper cpp, Faster-Whisper, OpenAI Whisper), this distilled model is designed to be compatible with these libraries.
You can expect significant performance gains by switching from previous Distil-Whisper checkpoints to distil-large-v3
when using these libraries. For convenience, the weights for the most popular libraries are already converted,
with instructions for getting started below.
## Table of Contents
1. [Transformers Usage](#transformers-usage)
* [Short-Form Transcription](#short-form-transcription)
* [Sequential Long-Form](#sequential-long-form)
* [Chunked Long-Form](#chunked-long-form)
* [Speculative Decoding](#speculative-decoding)
* [Additional Speed and Memory Improvements](#additional-speed--memory-improvements)
2. [Library Integrations](#library-integrations)
* [Whisper cpp](#whispercpp)
* [Faster Whisper](#faster-whisper)
* [OpenAI Whisper](#openai-whisper)
* [Transformers.js](#transformersjs)
* [Candle](#candle)
3. [Model Details](#model-details)
4. [License](#license)
## Transformers Usage
distil-large-v3 is supported in the Hugging Face 🤗 Transformers library from version 4.39 onwards. To run the model, first
install the latest version of Transformers. For this example, we'll also install 🤗 Datasets to load a toy audio dataset
from the Hugging Face Hub:
```bash
pip install --upgrade pip
pip install --upgrade transformers accelerate datasets[audio]
```
### Short-Form Transcription
The model can be used with the [`pipeline`](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.AutomaticSpeechRecognitionPipeline)
class to transcribe short-form audio files (< 30-seconds) as follows:
```python
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
```
To transcribe a local audio file, simply pass the path to your audio file when you call the pipeline:
```diff
- result = pipe(sample)
+ result = pipe("audio.mp3")
```
For segment-level timestamps, pass the argument `return_timestamps=True` and return the `"chunks"` output:
```python
result = pipe(sample, return_timestamps=True)
print(result["chunks"])
```
For more control over the generation parameters, use the model + processor API directly:
Ad-hoc generation arguments can be passed to `model.generate`, including `num_beams` for beam-search, `return_timestamps`
for segment-level timestamps, and `prompt_ids` for prompting. See the [docstrings](https://huggingface.co/docs/transformers/en/model_doc/whisper#transformers.WhisperForConditionalGeneration.generate)
for more details.
```python
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
from datasets import Audio, load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
dataset = dataset.cast_column("audio", Audio(processor.feature_extractor.sampling_rate))
sample = dataset[0]["audio"]
input_features = processor(
sample["array"], sampling_rate=sample["sampling_rate"], return_tensors="pt"
).input_features
input_features = input_features.to(device, dtype=torch_dtype)
gen_kwargs = {
"max_new_tokens": 128,
"num_beams": 1,
"return_timestamps": False,
}
pred_ids = model.generate(input_features, **gen_kwargs)
pred_text = processor.batch_decode(pred_ids, skip_special_tokens=True, decode_with_timestamps=gen_kwargs["return_timestamps"])
print(pred_text)
```
### Sequential Long-Form
Unlike previous Distil-Whisper releases, distil-large-v3 is specifically designed to be compatible with OpenAI's sequential
long-form transcription algorithm. This algorithm uses a sliding window for buffered inference of long audio files (> 30-seconds),
and returns more accurate transcriptions compared to the [chunked long-form algorithm](#chunked-long-form).
The sequential long-form algorithm should be used in either of the following scenarios:
1. Transcription accuracy is the most important factor, and latency is less of a consideration
2. You are transcribing **batches** of long audio files, in which case the latency of sequential is comparable to chunked, while being up to 0.5% WER more accurate
If you are transcribing single long audio files and latency is the most important factor, you should use the chunked algorithm
described [below](#chunked-long-form). For a detailed explanation of the different algorithms, refer to Sections 5 of
the [Distil-Whisper paper](https://arxiv.org/pdf/2311.00430.pdf).
The [`pipeline`](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.AutomaticSpeechRecognitionPipeline)
class can be used to transcribe long audio files with the sequential algorithm as follows:
```python
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("distil-whisper/librispeech_long", "clean", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
```
For more control over the generation parameters, use the model + processor API directly:
```python
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
from datasets import Audio, load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
dataset = dataset.cast_column("audio", Audio(processor.feature_extractor.sampling_rate))
sample = dataset[0]["audio"]
inputs = processor(
sample["array"],
sampling_rate=sample["sampling_rate"],
return_tensors="pt",
truncation=False,
padding="longest",
return_attention_mask=True,
)
inputs = inputs.to(device, dtype=torch_dtype)
gen_kwargs = {
"max_new_tokens": 448,
"num_beams": 1,
"condition_on_prev_tokens": False,
"compression_ratio_threshold": 1.35, # zlib compression ratio threshold (in token space)
"temperature": (0.0, 0.2, 0.4, 0.6, 0.8, 1.0),
"logprob_threshold": -1.0,
"no_speech_threshold": 0.6,
"return_timestamps": True,
}
pred_ids = model.generate(**i nputs, **gen_kwargs)
pred_text = processor.batch_decode(pred_ids, skip_special_tokens=True, decode_with_timestamps=False)
print(pred_text)
```
### Chunked Long-Form
distil-large-v3 remains compatible with the Transformers chunked long-form algorithm. This algorithm should be used when
a single large audio file is being transcribed and the fastest possible inference is required. In such circumstances,
the chunked algorithm is up to 9x faster than OpenAI's sequential long-form implementation (see Table 7 of the
[Distil-Whisper paper](https://arxiv.org/pdf/2311.00430.pdf)).
To enable chunking, pass the `chunk_length_s` parameter to the `pipeline`. For distil-large-v3, a chunk length of 25-seconds
is optimal. To activate batching over long audio files, pass the argument `batch_size`:
```python
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
chunk_length_s=25,
batch_size=16,
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("distil-whisper/librispeech_long", "clean", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
```
### Speculative Decoding
distil-large-v3 is the first Distil-Whisper model that can be used as an assistant to Whisper large-v3 for [speculative decoding](https://huggingface.co/blog/whisper-speculative-decoding).
Speculative decoding mathematically ensures that exactly the same outputs as Whisper are obtained, while being 2 times faster.
This makes it the perfect drop-in replacement for existing Whisper pipelines, since the same outputs are guaranteed.
In the following code-snippet, we load the assistant Distil-Whisper model standalone to the main Whisper pipeline. We then
specify it as the "assistant model" for generation:
```python
from transformers import pipeline, AutoModelForCausalLM, AutoModelForSpeechSeq2Seq, AutoProcessor
import torch
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
assistant_model_id = "distil-whisper/distil-large-v3"
assistant_model = AutoModelForCausalLM.from_pretrained(
assistant_model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
assistant_model.to(device)
model_id = "openai/whisper-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
generate_kwargs={"assistant_model": assistant_model},
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
```
For more details on speculative decoding, refer to the blog post [Speculative Decoding for 2x Faster Whisper Inference](https://huggingface.co/blog/whisper-speculative-decoding).
### Additional Speed & Memory Improvements
You can apply additional speed and memory improvements to Distil-Whisper to further reduce the inference speed and VRAM
requirements. These optimisations primarily target the attention kernel, swapping it from an eager implementation to a
more efficient flash attention version.
#### Flash Attention 2
We recommend using [Flash-Attention 2](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#flashattention-2)
if your GPU allows for it. To do so, you first need to install [Flash Attention](https://github.com/Dao-AILab/flash-attention):
```
pip install flash-attn --no-build-isolation
```
Then pass `attn_implementation="flash_attention_2"` to `from_pretrained`:
```diff
- model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True)
+ model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True, attn_implementation="flash_attention_2")
```
#### Torch Scale-Product-Attention (SDPA)
If your GPU does not support Flash Attention, we recommend making use of PyTorch [scaled dot-product attention (SDPA)](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html).
This attention implementation is activated **by default** for PyTorch versions 2.1.1 or greater. To check
whether you have a compatible PyTorch version, run the following Python code snippet:
```python
from transformers.utils import is_torch_sdpa_available
print(is_torch_sdpa_available())
```
If the above returns `True`, you have a valid version of PyTorch installed and SDPA is activated by default. If it
returns `False`, you need to upgrade your PyTorch version according to the [official instructions](https://pytorch.org/get-started/locally/)
Once a valid PyTorch version is installed, SDPA is activated by default. It can also be set explicitly by specifying
`attn_implementation="sdpa"` as follows:
```diff
- model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True)
+ model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True, attn_implementation="sdpa")
```
#### Torch compile
Coming soon...
#### 4-bit and 8-bit Inference
Coming soon...
## Library Integrations
### Whisper.cpp
Distil-Whisper can be run with the [Whisper.cpp](https://github.com/ggerganov/whisper.cpp) package with the original
sequential long-form transcription algorithm. In a provisional benchmark on Mac M1, distil-large-v3 is over 5x faster
than Whisper large-v3, while performing to within 0.8% WER over long-form audio.
Steps for getting started:
1. Clone the Whisper.cpp repository:
```
git clone https://github.com/ggerganov/whisper.cpp.git
cd whisper.cpp
```
2. Install the Hugging Face Hub Python package:
```bash
pip install --upgrade huggingface_hub
```
And download the GGML weights for distil-large-v3 using the following Python snippet:
```python
from huggingface_hub import hf_hub_download
hf_hub_download(repo_id='distil-whisper/distil-large-v3-ggml', filename='ggml-distil-large-v3.bin', local_dir='./models')
```
Note that if you do not have a Python environment set-up, you can also download the weights directly with `wget`:
```bash
wget https://huggingface.co/distil-whisper/distil-large-v3-ggml/resolve/main/ggml-distil-large-v3.bin -P ./models
```
3. Run inference using the provided sample audio:
```bash
make -j && ./main -m models/ggml-distil-large-v3.bin -f samples/jfk.wav
```
### Faster-Whisper
Faster-Whisper is a reimplementation of Whisper using [CTranslate2](https://github.com/OpenNMT/CTranslate2/), a fast
inference engine for Transformer models.
First, install the Faster-Whisper package according to the [official instructions](https://github.com/SYSTRAN/faster-whisper#installation).
For this example, we'll also install 🤗 Datasets to load a toy audio dataset from the Hugging Face Hub:
```bash
pip install --upgrade pip
pip install --upgrade git+https://github.com/SYSTRAN/faster-whisper datasets[audio]
```
The following code snippet loads the distil-large-v3 model and runs inference on an example file from the LibriSpeech ASR
dataset:
```python
import torch
from faster_whisper import WhisperModel
from datasets import load_dataset
# define our torch configuration
device = "cuda:0" if torch.cuda.is_available() else "cpu"
compute_type = "float16" if torch.cuda.is_available() else "float32"
# load model on GPU if available, else cpu
model = WhisperModel("distil-large-v3", device=device, compute_type=compute_type)
# load toy dataset for example
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = dataset[1]["audio"]["path"]
segments, info = model.transcribe(sample, beam_size=1)
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
```
To transcribe a local audio file, simply pass the path to the audio file as the `audio` argument to transcribe:
```python
segments, info = model.transcribe("audio.mp3", beam_size=1)
```
### OpenAI Whisper
To use the model in the original Whisper format, first ensure you have the [`openai-whisper`](https://pypi.org/project/openai-whisper/) package installed.
For this example, we'll also install 🤗 Datasets to load a toy audio dataset from the Hugging Face Hub:
```bash
pip install --upgrade pip
pip install --upgrade openai-whisper datasets[audio]
```
The following code-snippet demonstrates how to transcribe a sample file from the LibriSpeech dataset loaded using
🤗 Datasets:
```python
from huggingface_hub import hf_hub_download
from datasets import load_dataset
from whisper import load_model, transcribe
model_path = hf_hub_download(repo_id="distil-whisper/distil-large-v3-openai", filename="model.bin")
model = load_model(model_path)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = dataset[0]["audio"]["path"]
pred_out = transcribe(model, audio=sample, language="en")
print(pred_out["text"])
```
Note that the model weights will be downloaded and saved to your cache the first time you run the example. Subsequently,
you can re-use the same example, and the weights will be loaded directly from your cache without having to download them
again.
To transcribe a local audio file, simply pass the path to the audio file as the `audio` argument to transcribe:
```python
pred_out = transcribe(model, audio=sample, language="en")
```
The Distil-Whisper model can also be used with the OpenAI Whisper CLI. Refer to the [following instructions](https://huggingface.co/distil-whisper/distil-large-v3-openai#cli-usage)
for details.
### Transformers.js
Distil-Whisper can be run completely in your web browser with [Transformers.js](http://github.com/xenova/transformers.js):
1. Install Transformers.js from [NPM](https://www.npmjs.com/package/@xenova/transformers):
```bash
npm i @xenova/transformers
```
2. Import the library and perform inference with the pipeline API.
```js
import { pipeline } from '@xenova/transformers';
const transcriber = await pipeline('automatic-speech-recognition', 'distil-whisper/distil-large-v3');
const url = 'https://huggingface.co/datasets/Xenova/transformers.js-docs/resolve/main/jfk.wav';
const output = await transcriber(url);
// { text: " And so, my fellow Americans, ask not what your country can do for you. Ask what you can do for your country." }
```
Check out the online [Distil-Whisper Web Demo](https://huggingface.co/spaces/Xenova/distil-whisper-web) to try it out yourself.
As you'll see, it runs locally in your browser: no server required!
Refer to the Transformers.js [docs](https://huggingface.co/docs/transformers.js/api/pipelines#module_pipelines.AutomaticSpeechRecognitionPipeline)
for further information.
### Candle
Through an integration with Hugging Face [Candle](https://github.com/huggingface/candle/tree/main) 🕯️, Distil-Whisper is
available in the Rust library 🦀
Benefit from:
* Optimised CPU backend with optional MKL support for Linux x86 and Accelerate for Macs
* Metal support for efficiently running on Macs
* CUDA backend for efficiently running on GPUs, multiple GPU distribution via NCCL
* WASM support: run Distil-Whisper in a browser
Steps for getting started:
1. Install [`candle-core`](https://github.com/huggingface/candle/tree/main/candle-core) as explained [here](https://huggingface.github.io/candle/guide/installation.html)
2. Clone the `candle` repository locally:
```
git clone https://github.com/huggingface/candle.git
```
3. Enter the example directory for [Whisper](https://github.com/huggingface/candle/tree/main/candle-examples/examples/whisper):
```
cd candle/candle-examples/examples/whisper
```
4. Run an example:
```
cargo run --example whisper --release --features symphonia -- --model distil-large-v3
```
5. To specify your own audio file, add the `--input` flag:
```
cargo run --example whisper --release --features symphonia -- --model distil-large-v3 --input audio.wav
```
**Tip:** for compiling using Apple Metal, specify the `metal` feature when you run the example:
```
cargo run --example whisper --release --features="symphonia,metal" -- --model distil-large-v3
```
Note that if you encounter the error:
```
error: target `whisper` in package `candle-examples` requires the features: `symphonia`
Consider enabling them by passing, e.g., `--features="symphonia"`
```
You should clean your `cargo` installation:
```
cargo clean
```
And subsequently recompile:
```
cargo run --example whisper --release --features symphonia -- --model distil-large-v3
```
## Model Details
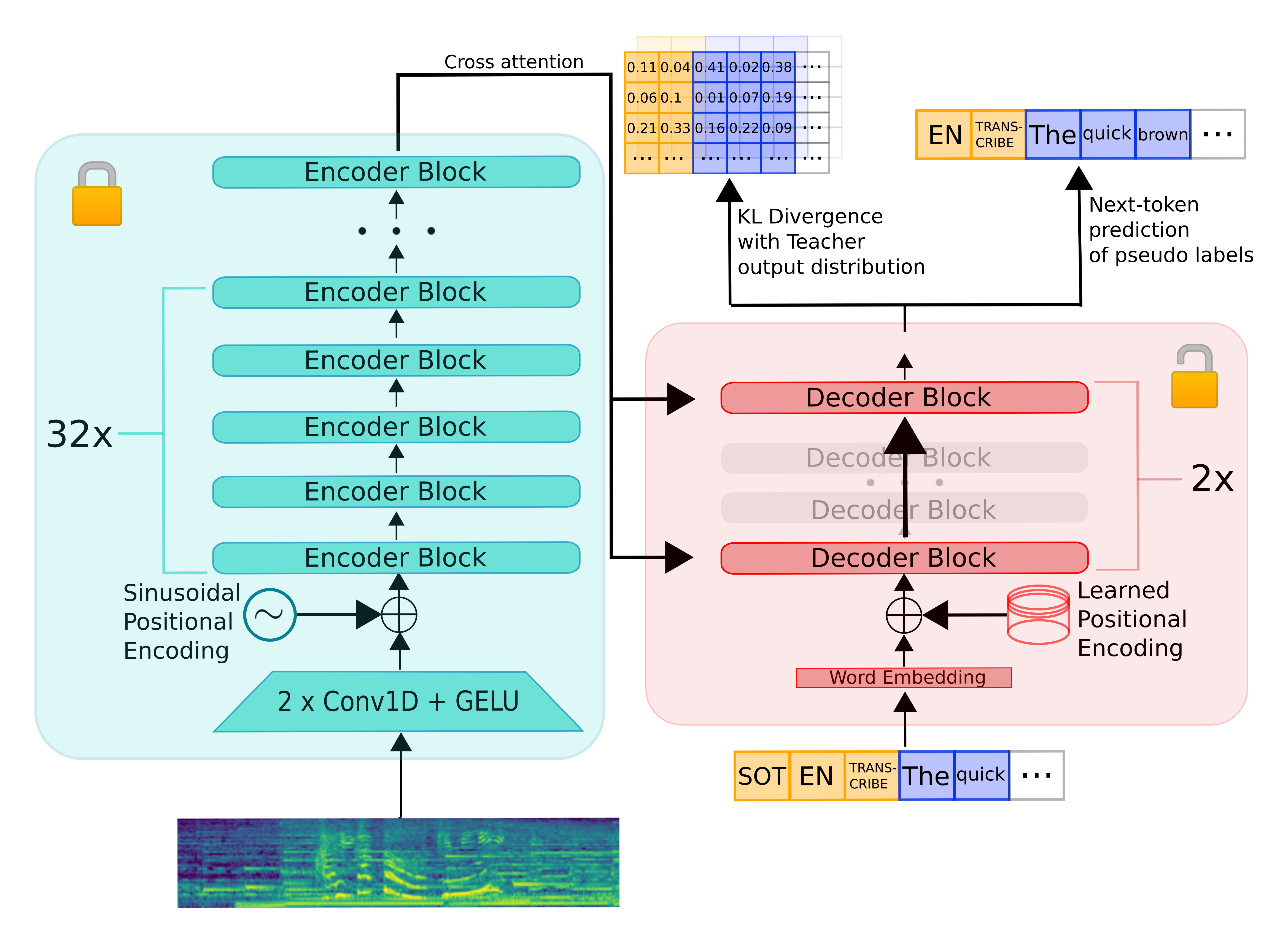
Distil-Whisper inherits the encoder-decoder architecture from Whisper. The encoder maps a sequence of speech vector
inputs to a sequence of hidden-state vectors. The decoder auto-regressively predicts text tokens, conditional on all
previous tokens and the encoder hidden-states. Consequently, the encoder is only run forward once, whereas the decoder
is run as many times as the number of tokens generated. In practice, this means the decoder accounts for over 90% of
total inference time. Thus, to optimise for latency, the focus is on minimising the inference time of the decoder.
To distill the Whisper model, we reduce the number of decoder layers while keeping the encoder fixed.
The encoder (shown in green) is entirely copied from the teacher to the student and frozen during training.
The student's decoder consists of a subset of the teacher decoder layers, which are intialised from maximally spaced layers.
The model is then trained on a weighted sum of the KL divergence and pseudo-label loss terms.
## Differences with distil-large-v2
Compared to previous version of Distil-Whisper, distil-large-v3 is specifically designed to target the OpenAI sequential
long-form transcription algorithm. There are no architectural differences compared to distil-large-v2, other than the fact
the model layers are intialised from the latest large-v3 model rather than the older large-v2 one. The differences lie
in the way the model was trained.
Previous Distil-Whisper models were trained on a mean input length of 7-seconds, whereas the original Whisper models were
pre-trained on 30-second inputs. During distillation, we shift the distribution of the model weights to the distribution
of our training data. If our training data contains shorter utterances (e.g. on average 7-seconds audio instead of 30-seconds),
then the predicted distribution shifts to this shorter context length. At inference time, the optimal context window for
distil-large-v2 was an interpolation of these two values: 15-seconds. Beyond this time, the predictions for the distil-large-v2
model were largely inaccurate, particularly for the timestamp predictions. However, the sequential long-form algorithm
uses 30-second sliding windows for inference, with the window shifted according to the last predicted timestamp. Since the
last timestamp typically occurs after the 15-second mark, it was predicted with low accuracy, causing the long-form
transcription to often fail.
To preserve Whisper's ability to transcribe sliding 30-second windows, as is done with sequential decoding, we need to
ensure the context length of distil-large-v3 is also 30-seconds. This was primarily achieved with four strategies:
1. **Packing the audio samples in the training dataset to 30-seconds:** since the model is both pre-trained and distilled on audio data packed to 30-seconds, distil-large-v3 now operates on the same ideal context window as Whisper, predicting accurate timestamps up to and including 30-seconds.
2. **Freezing the decoder input embeddings:** we use the same input embeds representation as the original model, which is designed to handle longer context lengths than previous Distil-Whisper iterations.
3. **Using a longer maximum context length during training:** instead of training on a maximum target length of 128, we train on a maximum of 256. This helps distil-large-v3 transcribe 30-second segments where the number of tokens possibly exceeds 128.
4. **Appending prompt conditioning to 50% of the training samples:** enables the model to be used with the `condition_on_prev_tokens` argument, and context windows up to 448 tokens.
There were further tricks that were employed to improve the performance of distil-large-v3 under the sequential decoding
algorithm, which we be explained fully in an upcoming blog post.
## Evaluation
The following code-snippets demonstrates how to evaluate the Distil-Whisper model on the LibriSpeech validation-clean
dataset with [streaming mode](https://huggingface.co/blog/audio-datasets#streaming-mode-the-silver-bullet), meaning no
audio data has to be downloaded to your local device.
First, we need to install the required packages, including 🤗 Datasets to stream and load the audio data, and 🤗 Evaluate to
perform the WER calculation:
```bash
pip install --upgrade pip
pip install --upgrade transformers datasets[audio] evaluate jiwer
```
Evaluation can then be run end-to-end with the following example:
```python
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
from datasets import load_dataset
from evaluate import load
import torch
from tqdm import tqdm
# define our torch configuration
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-large-v3"
# load the model + processor
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, use_safetensors=True, low_cpu_mem_usage=True)
model = model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
# load the dataset with streaming mode
dataset = load_dataset("librispeech_asr", "clean", split="validation", streaming=True)
# define the evaluation metric
wer_metric = load("wer")
def inference(batch):
# 1. Pre-process the audio data to log-mel spectrogram inputs
audio = [sample["array"] for sample in batch["audio"]]
input_features = processor(audio, sampling_rate=batch["audio"][0]["sampling_rate"], return_tensors="pt").input_features
input_features = input_features.to(device, dtype=torch_dtype)
# 2. Auto-regressively generate the predicted token ids
pred_ids = model.generate(input_features, max_new_tokens=128)
# 3. Decode the token ids to the final transcription
batch["transcription"] = processor.batch_decode(pred_ids, skip_special_tokens=True)
batch["reference"] = batch["text"]
return batch
# batch size 16 inference
dataset = dataset.map(function=inference, batched=True, batch_size=16)
all_transcriptions = []
all_references = []
# iterate over the dataset and run inference
for result in tqdm(dataset, desc="Evaluating..."):
all_transcriptions.append(result["transcription"])
all_references.append(result["reference"])
# normalize predictions and references
all_transcriptions = [processor.normalize(transcription) for transcription in all_transcriptions]
all_references = [processor.normalize(reference) for reference in all_references]
# compute the WER metric
wer = 100 * wer_metric.compute(predictions=all_transcriptions, references=all_references)
print(wer)
```
**Print Output:**
```
2.428920763531516
```
## Intended Use
Distil-Whisper is intended to be a drop-in replacement for Whisper large-v3 on English speech recognition. In particular, it
achieves comparable WER results over out-of-distribution (OOD) test data, while being 6x faster on both short and long-form audio.
## Data
Distil-Whisper is trained on 22,000 hours of audio data from nine open-source, permissively licensed speech datasets on the
Hugging Face Hub:
| Dataset | Size / h | Speakers | Domain | Licence |
|-----------------------------------------------------------------------------------------|----------|----------|-----------------------------|-----------------|
| [People's Speech](https://huggingface.co/datasets/MLCommons/peoples_speech) | 12,000 | unknown | Internet Archive | CC-BY-SA-4.0 |
| [Common Voice 13](https://huggingface.co/datasets/mozilla-foundation/common_voice_13_0) | 3,000 | unknown | Narrated Wikipedia | CC0-1.0 |
| [GigaSpeech](https://huggingface.co/datasets/speechcolab/gigaspeech) | 2,500 | unknown | Audiobook, podcast, YouTube | apache-2.0 |
| Fisher | 1,960 | 11,900 | Telephone conversations | LDC |
| [LibriSpeech](https://huggingface.co/datasets/librispeech_asr) | 960 | 2,480 | Audiobooks | CC-BY-4.0 |
| [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) | 540 | 1,310 | European Parliament | CC0 |
| [TED-LIUM](https://huggingface.co/datasets/LIUM/tedlium) | 450 | 2,030 | TED talks | CC-BY-NC-ND 3.0 |
| SwitchBoard | 260 | 540 | Telephone conversations | LDC |
| [AMI](https://huggingface.co/datasets/edinburghcstr/ami) | 100 | unknown | Meetings | CC-BY-4.0 |
||||||
| **Total** | 21,770 | 18,260+ | | |
The combined dataset spans 10 distinct domains and over 50k speakers. The diversity of this dataset is crucial to ensuring
the distilled model is robust to audio distributions and noise.
The audio data is then pseudo-labelled using the Whisper large-v3 model: we use Whisper to generate predictions for all
the audio in our training set and use these as the target labels during training. Using pseudo-labels ensures that the
transcriptions are consistently formatted across datasets and provides sequence-level distillation signal during training.
## WER Filter
The Whisper pseudo-label predictions are subject to mis-transcriptions and hallucinations. To ensure we only train on
accurate pseudo-labels, we employ a simple WER heuristic during training. First, we normalise the Whisper pseudo-labels
and the ground truth labels provided by each dataset. We then compute the WER between these labels. If the WER exceeds
a specified threshold, we discard the training example. Otherwise, we keep it for training.
Section 9.2 of the [Distil-Whisper paper](https://arxiv.org/abs/2311.00430) demonstrates the effectiveness of this filter
for improving downstream performance of the distilled model. We also partially attribute Distil-Whisper's robustness to
hallucinations to this filter.
## Training
The model was trained for 80,000 optimisation steps (or 11 epochs) with batch size 256. The Tensorboard training logs can
be found under: https://huggingface.co/distil-whisper/distil-large-v3/tensorboard?params=scalars#frame
## Results
The distilled model performs to within 1.5% WER of Whisper large-v3 on out-of-distribution (OOD) short-form audio, within
1% WER on sequential long-form decoding, and outperforms large-v3 by 0.1% on chunked long-form. This performance gain is
attributed to lower hallucinations.
For a detailed per-dataset breakdown of the evaluation results, refer to Tables 16 and 17 of the [Distil-Whisper paper](https://arxiv.org/abs/2311.00430)
Distil-Whisper is also evaluated on the [ESB benchmark](https://arxiv.org/abs/2210.13352) datasets as part of the [OpenASR leaderboard](https://huggingface.co/spaces/hf-audio/open_asr_leaderboard),
where it performs to within 0.2% WER of Whisper.
## Reproducing Distil-Whisper
Training and evaluation code to reproduce Distil-Whisper is available under the Distil-Whisper repository: https://github.com/huggingface/distil-whisper/tree/main/training
This code will shortly be updated to include the training updates described in the section [Differences with distil-large-v2](#differences-with-distil-large-v2).
## License
Distil-Whisper inherits the [MIT license](https://github.com/huggingface/distil-whisper/blob/main/LICENSE) from OpenAI's Whisper model.
## Citation
If you use this model, please consider citing the [Distil-Whisper paper](https://arxiv.org/abs/2311.00430):
```
@misc{gandhi2023distilwhisper,
title={Distil-Whisper: Robust Knowledge Distillation via Large-Scale Pseudo Labelling},
author={Sanchit Gandhi and Patrick von Platen and Alexander M. Rush},
year={2023},
eprint={2311.00430},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## Acknowledgements
* OpenAI for the Whisper [model](https://huggingface.co/openai/whisper-large-v3), in particular Jong Wook Kim for the [original codebase](https://github.com/openai/whisper) and training discussions
* Hugging Face 🤗 [Transformers](https://github.com/huggingface/transformers) for the model integration
* [Georgi Gerganov](https://huggingface.co/ggerganov) for the Whisper cpp integration
* [Systran team](https://github.com/SYSTRAN) for the Faster-Whisper integration
* [Joshua Lochner](https://huggingface.co/xenova) for the Transformers.js integration
* [Laurent Mazare](https://huggingface.co/lmz) for the Candle integration
* [Vaibhav Srivastav](https://huggingface.co/reach-vb) for Distil-Whisper distribution
* Google's [TPU Research Cloud (TRC)](https://sites.research.google/trc/about/) programme for Cloud TPU v4 compute resource
* [Raghav Sonavane](https://huggingface.co/rsonavane/distil-whisper-large-v2-8-ls) for an early iteration of Distil-Whisper on the LibriSpeech dataset