
Update README.md
Browse files
README.md
CHANGED
|
@@ -6,26 +6,38 @@ tags:
|
|
| 6 |
model-index:
|
| 7 |
- name: opus-mt-zh-en-Chinese_to_English
|
| 8 |
results: []
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 9 |
---
|
| 10 |
|
| 11 |
-
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 12 |
-
should probably proofread and complete it, then remove this comment. -->
|
| 13 |
-
|
| 14 |
# opus-mt-zh-en-Chinese_to_English
|
| 15 |
|
| 16 |
-
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-zh-en](https://huggingface.co/Helsinki-NLP/opus-mt-zh-en)
|
| 17 |
|
| 18 |
## Model description
|
| 19 |
|
| 20 |
-
|
| 21 |
|
| 22 |
## Intended uses & limitations
|
| 23 |
|
| 24 |
-
|
| 25 |
|
| 26 |
## Training and evaluation data
|
| 27 |
|
| 28 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 29 |
|
| 30 |
## Training procedure
|
| 31 |
|
|
@@ -45,10 +57,13 @@ The following hyperparameters were used during training:
|
|
| 45 |
### Training results
|
| 46 |
|
| 47 |
|
|
|
|
|
|
|
|
|
|
| 48 |
|
| 49 |
### Framework versions
|
| 50 |
|
| 51 |
- Transformers 4.31.0
|
| 52 |
- Pytorch 2.0.1+cu118
|
| 53 |
- Datasets 2.14.4
|
| 54 |
-
- Tokenizers 0.13.3
|
|
|
|
| 6 |
model-index:
|
| 7 |
- name: opus-mt-zh-en-Chinese_to_English
|
| 8 |
results: []
|
| 9 |
+
datasets:
|
| 10 |
+
- GEM/wiki_lingua
|
| 11 |
+
language:
|
| 12 |
+
- en
|
| 13 |
+
- zh
|
| 14 |
+
metrics:
|
| 15 |
+
- bleu
|
| 16 |
+
- rouge
|
| 17 |
+
pipeline_tag: translation
|
| 18 |
---
|
| 19 |
|
|
|
|
|
|
|
|
|
|
| 20 |
# opus-mt-zh-en-Chinese_to_English
|
| 21 |
|
| 22 |
+
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-zh-en](https://huggingface.co/Helsinki-NLP/opus-mt-zh-en).
|
| 23 |
|
| 24 |
## Model description
|
| 25 |
|
| 26 |
+
For more information on how it was created, check out the following link: https://github.com/DunnBC22/NLP_Projects/blob/main/Machine%20Translation/Chinese%20to%20English%20Translation/Chinese_to_English_Translation.ipynb
|
| 27 |
|
| 28 |
## Intended uses & limitations
|
| 29 |
|
| 30 |
+
This model is intended to demonstrate my ability to solve a complex problem using technology.
|
| 31 |
|
| 32 |
## Training and evaluation data
|
| 33 |
|
| 34 |
+
Dataset Source: https://huggingface.co/datasets/GEM/wiki_lingua
|
| 35 |
+
|
| 36 |
+
__Chinese Text Length__
|
| 37 |
+
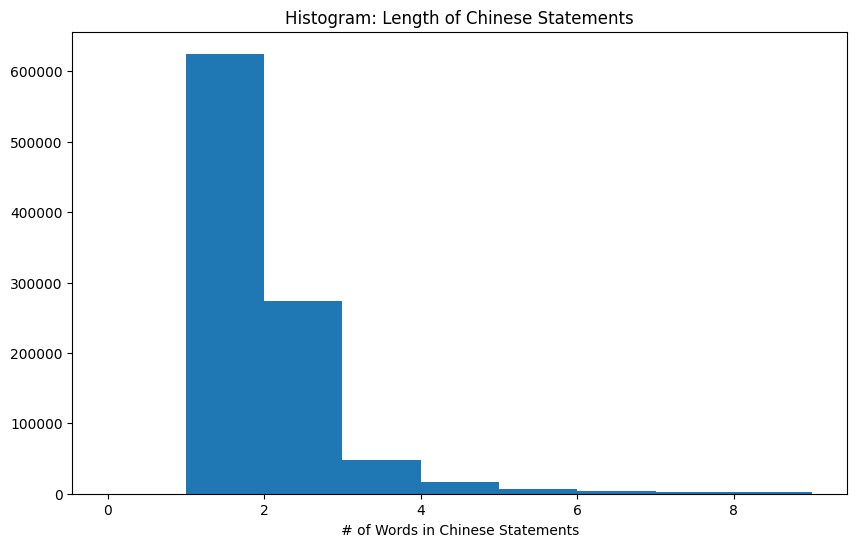
|
| 38 |
+
|
| 39 |
+
__English Text Length__
|
| 40 |
+
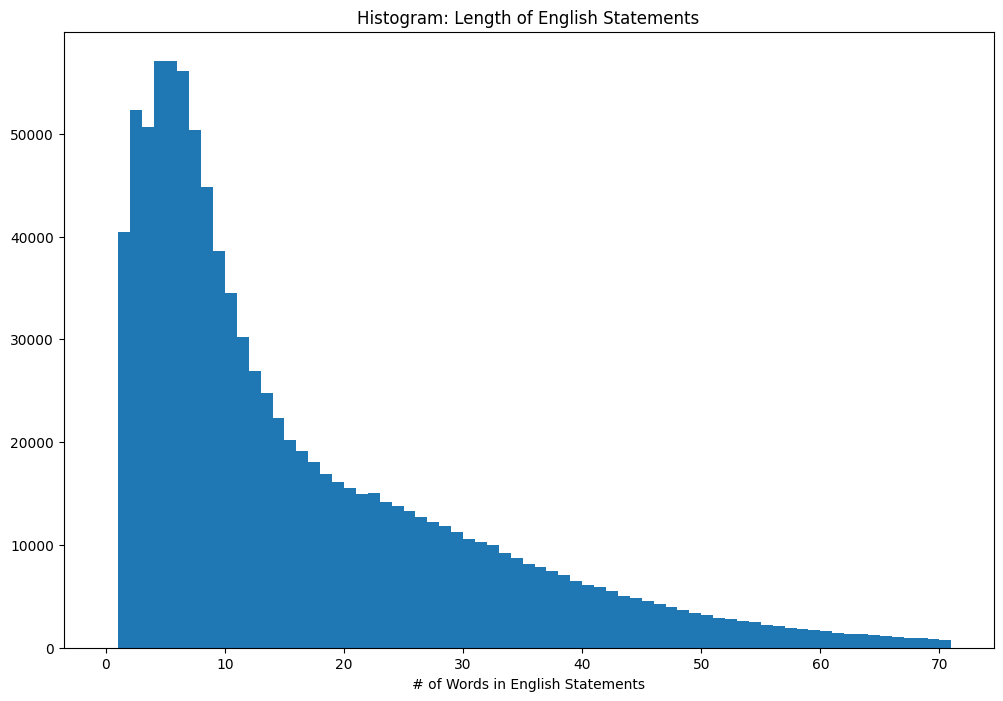
|
| 41 |
|
| 42 |
## Training procedure
|
| 43 |
|
|
|
|
| 57 |
### Training results
|
| 58 |
|
| 59 |
|
| 60 |
+
| Epoch | Validation Loss | Bleu | Rouge1 | Rouge2 | RougeL | RougeLsum | Avg. Prediction Lengths |
|
| 61 |
+
|:-----:|:-----:|:-----:|:-----:|:-----:|:-----:|:-----:|:-----:|
|
| 62 |
+
| 1.0 | 1.0113 | 45.2808 | 0.6201 | 0.4198 | 0.5927 | 0.5927 | 24.5581 |
|
| 63 |
|
| 64 |
### Framework versions
|
| 65 |
|
| 66 |
- Transformers 4.31.0
|
| 67 |
- Pytorch 2.0.1+cu118
|
| 68 |
- Datasets 2.14.4
|
| 69 |
+
- Tokenizers 0.13.3
|