---
tags:
- text-to-image
- Sana
- 512px_based_image_size
language:
- en
- zh
base_model:
- Efficient-Large-Model/Sana_1600M_512px
pipeline_tag: text-to-image
---

# 🐱 Sana Model Card

## Model
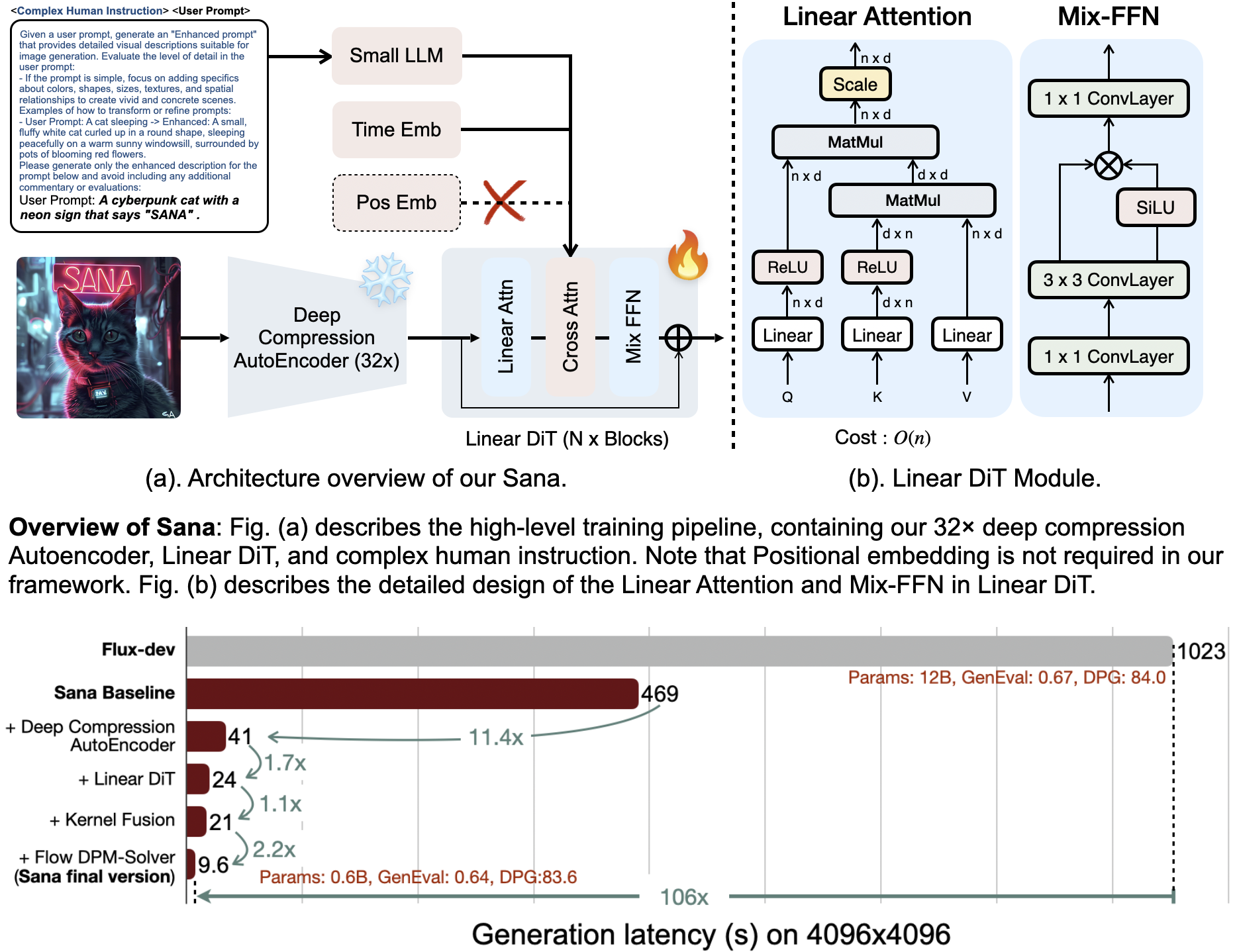
We introduce **Sana**, a text-to-image framework that can efficiently generate images up to 4096 × 4096 resolution.
Sana can synthesize high-resolution, high-quality images with strong text-image alignment at a remarkably fast speed, deployable on laptop GPU.
Source code is available at https://github.com/NVlabs/Sana.
### Model Description
- **Developed by:** NVIDIA, Sana
- **Model type:** Linear-Diffusion-Transformer-based text-to-image generative model
- **Model size:** 1648M parameters
- **Model resolution:** This model is developed to generate 512px based images with multi-scale heigh and width.
- **License:** [CC BY-NC-SA 4.0 License](./LICENSE.txt)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts.
It is a Linear Diffusion Transformer that uses one fixed, pretrained text encoders ([Gemma2-2B-IT](https://huggingface.co/google/gemma-2-2b-it))
and one 32x spatial-compressed latent feature encoder ([DC-AE](https://hanlab.mit.edu/projects/dc-ae)).
- **Resources for more information:** Check out our [GitHub Repository](https://github.com/NVlabs/Sana) and the [Sana report on arXiv](https://arxiv.org/abs/2410.10629).
### Model Sources
For research purposes, we recommend our `generative-models` Github repository (https://github.com/NVlabs/Sana),
which is more suitable for both training and inference and for which most advanced diffusion sampler like Flow-DPM-Solver is integrated.
[MIT Han-Lab](https://nv-sana.mit.edu/) provides free Sana inference.
- **Repository:** ttps://github.com/NVlabs/Sana
- **Demo:** https://nv-sana.mit.edu/
### 🧨 Diffusers
PR developing: [Sana](https://github.com/huggingface/diffusers/pull/9982) and [DC-AE](https://github.com/huggingface/diffusers/pull/9708)
## Uses
### Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
Excluded uses are described below.
### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render complex legible text
- fingers, .etc in general may not be generated properly.
- The autoencoding part of the model is lossy.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.





