

Commit
•
c5a5c56
1
Parent(s):
8b32ab4
Upload folder using huggingface_hub
Browse files- README.md +242 -0
- config.json +40 -0
- configuration_btlm.py +201 -0
- figure_1_memory_footprint.png +0 -0
- figure_2_half_the_size_twice_the_speed.png +0 -0
- figure_3_performance_vs_3b_models.png +0 -0
- figure_4_performance_vs_7b_models.jpg +0 -0
- figure_5_xentropy_with_sequence_lengths.png +0 -0
- figure_5_xentropy_with_sequence_lengths.svg +0 -0
- generation_config.json +6 -0
- merges.txt +0 -0
- modeling_btlm.py +1605 -0
- pytorch_model-00001-of-00002.bin +3 -0
- pytorch_model-00002-of-00002.bin +3 -0
- pytorch_model.bin.index.json +460 -0
- special_tokens_map.json +5 -0
- table_1_downstream_performance_3b.png +0 -0
- table_2_downstream_performance_7b.png +0 -0
- tokenizer_config.json +9 -0
- vocab.json +0 -0
README.md
ADDED
|
@@ -0,0 +1,242 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language:
|
| 3 |
+
- en
|
| 4 |
+
inference: false
|
| 5 |
+
tags:
|
| 6 |
+
- pytorch
|
| 7 |
+
- causal-lm
|
| 8 |
+
- Cerebras
|
| 9 |
+
- BTLM
|
| 10 |
+
datasets:
|
| 11 |
+
- cerebras/SlimPajama-627B
|
| 12 |
+
pipeline_tag: text-generation
|
| 13 |
+
license: apache-2.0
|
| 14 |
+
---
|
| 15 |
+
|
| 16 |
+
# BTLM-3B-8k-base
|
| 17 |
+
|
| 18 |
+
[Bittensor Language Model (BTLM-3B-8k-base)](https://www.cerebras.net/blog/btlm-3b-8k-7b-performance-in-a-3-billion-parameter-model/) is a 3 billion parameter language model with an 8k context length trained on 627B tokens of [SlimPajama](https://huggingface.co/datasets/cerebras/SlimPajama-627B). BTLM-3B-8k-base sets a new standard for 3B parameter models, outperforming models trained on hundreds of billions more tokens and achieving comparable performance to open 7B parameter models. BTLM-3B-8k-base can also be quantized to 4-bit to fit in devices with as little as 3GB of memory. The model is made available with an Apache 2.0 license for commercial use.
|
| 19 |
+
|
| 20 |
+
BTLM was trained by [Cerebras](https://www.cerebras.net/) in partnership with [Opentensor](https://opentensor.ai/) on the newly unveiled [Condor Galaxy 1 (CG-1) supercomputer](https://www.cerebras.net/blog/introducing-condor-galaxy-1-a-4-exaflop-supercomputer-for-generative-ai/), the first public deliverable of the G42-Cerebras strategic partnership.
|
| 21 |
+
|
| 22 |
+
BTLM-3B-8k was trained with a similar architecture to [CerebrasGPT](https://arxiv.org/abs/2304.03208) with the addition of [SwiGLU](https://arxiv.org/abs/2002.05202) nonlinearity, [ALiBi](https://arxiv.org/abs/2108.12409) position embeddings, and [maximal update parameterization (muP)](https://arxiv.org/abs/2203.03466). The model was trained for 1 epoch of SlimPajama-627B. 75% of training was performed with 2k sequence length. The final 25% of training was performed at 8k sequence length to enable long sequence applications
|
| 23 |
+
|
| 24 |
+
Read [our paper](https://arxiv.org/abs/2309.11568) for more details!
|
| 25 |
+
|
| 26 |
+
## BTLM-3B-8k Highlights
|
| 27 |
+
|
| 28 |
+
BTLM-3B-8k-base:
|
| 29 |
+
- **Licensed for commercial use** (Apache 2.0).
|
| 30 |
+
- **[State of the art 3B parameter model](#performance-vs-3b-models)**.
|
| 31 |
+
- **Provides 7B model performance in a 3B model** via performance enhancements from [ALiBi](https://arxiv.org/abs/2108.12409), [SwiGLU](https://arxiv.org/abs/2002.05202), [maximal update parameterization (muP)](https://arxiv.org/abs/2203.03466) and the the extensively deduplicated and cleaned [SlimPajama-627B dataset](https://huggingface.co/datasets/cerebras/SlimPajama-627B).
|
| 32 |
+
- **[Fits in devices with as little as 3GB of memory](#memory-requirements) when quantized to 4-bit**.
|
| 33 |
+
- **One of few 3B models that supports 8k sequence length** thanks to ALiBi.
|
| 34 |
+
- **Requires 71% fewer training FLOPs, has 58% smaller memory footprint** for inference than comparable 7B models.
|
| 35 |
+
|
| 36 |
+
## Usage
|
| 37 |
+
*Note: Transformers does not support muP for all models, so BTLM-3B-8k-base requires a custom model class. This causes a situation where users must either (1) enable `trust_remote_code=True` when loading the model or (2) acknowledge the warning about code execution upon loading the model.*
|
| 38 |
+
|
| 39 |
+
#### With generate():
|
| 40 |
+
```python
|
| 41 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM
|
| 42 |
+
|
| 43 |
+
# Load the tokenizer and model
|
| 44 |
+
tokenizer = AutoTokenizer.from_pretrained("cerebras/btlm-3b-8k-base")
|
| 45 |
+
model = AutoModelForCausalLM.from_pretrained("cerebras/btlm-3b-8k-base", trust_remote_code=True, torch_dtype="auto")
|
| 46 |
+
|
| 47 |
+
# Set the prompt for generating text
|
| 48 |
+
prompt = "Albert Einstein was known for "
|
| 49 |
+
|
| 50 |
+
# Tokenize the prompt and convert to PyTorch tensors
|
| 51 |
+
inputs = tokenizer(prompt, return_tensors="pt")
|
| 52 |
+
|
| 53 |
+
# Generate text using the model
|
| 54 |
+
outputs = model.generate(
|
| 55 |
+
**inputs,
|
| 56 |
+
num_beams=5,
|
| 57 |
+
max_new_tokens=50,
|
| 58 |
+
early_stopping=True,
|
| 59 |
+
no_repeat_ngram_size=2
|
| 60 |
+
)
|
| 61 |
+
|
| 62 |
+
# Convert the generated token IDs back to text
|
| 63 |
+
generated_text = tokenizer.batch_decode(outputs, skip_special_tokens=True)
|
| 64 |
+
|
| 65 |
+
# Print the generated text
|
| 66 |
+
print(generated_text[0])
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
#### With pipeline:
|
| 70 |
+
```python
|
| 71 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM
|
| 72 |
+
from transformers import pipeline
|
| 73 |
+
|
| 74 |
+
# Load the tokenizer and model
|
| 75 |
+
tokenizer = AutoTokenizer.from_pretrained("cerebras/btlm-3b-8k-base")
|
| 76 |
+
model = AutoModelForCausalLM.from_pretrained("cerebras/btlm-3b-8k-base", trust_remote_code=True, torch_dtype="auto")
|
| 77 |
+
|
| 78 |
+
# Set the prompt for text generation
|
| 79 |
+
prompt = """Isaac Newton was a """
|
| 80 |
+
|
| 81 |
+
# Create a text generation pipeline
|
| 82 |
+
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
|
| 83 |
+
|
| 84 |
+
# Generate text using the pipeline
|
| 85 |
+
generated_text = pipe(
|
| 86 |
+
prompt,
|
| 87 |
+
max_length=50,
|
| 88 |
+
do_sample=False,
|
| 89 |
+
no_repeat_ngram_size=2)[0]
|
| 90 |
+
|
| 91 |
+
# Print the generated text
|
| 92 |
+
print(generated_text['generated_text'])
|
| 93 |
+
```
|
| 94 |
+
|
| 95 |
+
## Evaluations and Comparisons to Other Models
|
| 96 |
+
|
| 97 |
+
### Memory Requirements
|
| 98 |
+

|
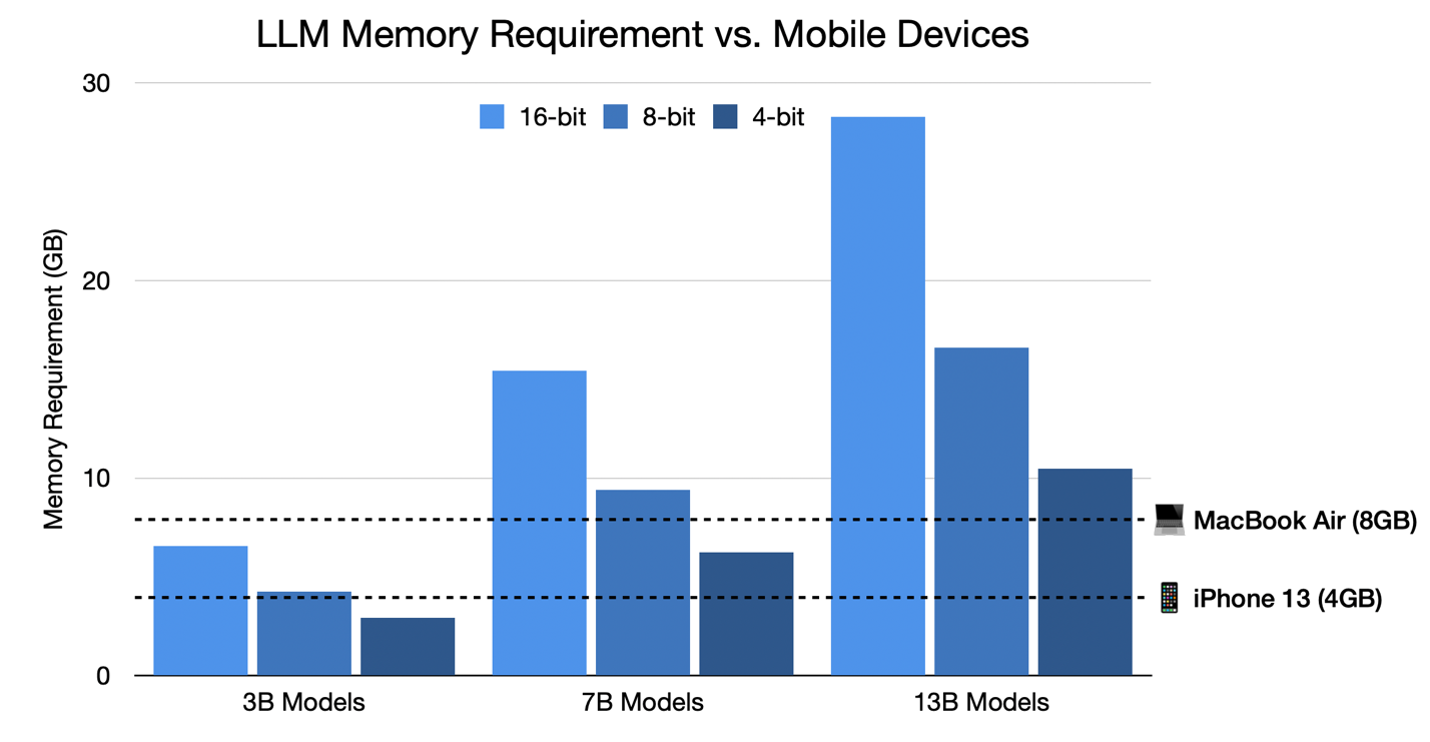
| 99 |
+
Figure 1. Memory requirements of different model sizes and quantization schemes
|
| 100 |
+
|
| 101 |
+
### Quality, Training Cost, Memory Footprint, Inference Speed
|
| 102 |
+

|
| 103 |
+
Figure 2: Comparisons of quality, memory footprint & inference cost between BTLM-3B-8K and 7B model families.
|
| 104 |
+
|
| 105 |
+
### Performance vs 3B models
|
| 106 |
+

|
| 107 |
+
Table 1: Performance at 3B model size. Detailed down-stream tasks comparisons. MMLU task performance is reported using 5-shot, other tasks are 0-shot.
|
| 108 |
+
|
| 109 |
+

|
| 110 |
+
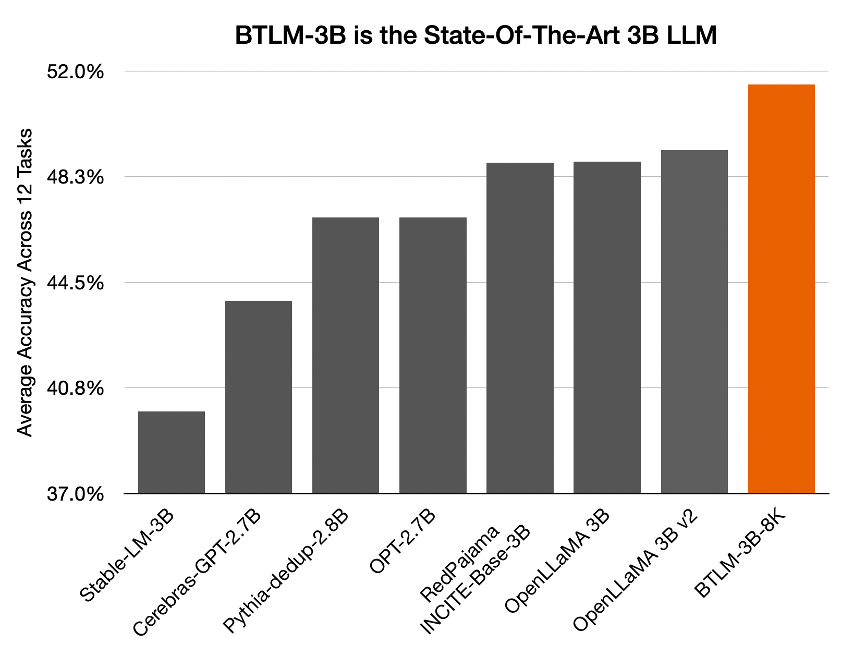
Figure 3: Performance at 3B model size
|
| 111 |
+
|
| 112 |
+
### Performance vs 7B models
|
| 113 |
+

|
| 114 |
+
Table 2: Performance at 7B model size. Detailed down-stream tasks comparisons. MMLU task performance is reported using 5-shot, everything else is 0-shot.
|
| 115 |
+
|
| 116 |
+

|
| 117 |
+
Figure 4: Performance at 7B model size
|
| 118 |
+
|
| 119 |
+
## Long Sequence Lengths
|
| 120 |
+
To enable long sequence applications, we use ALiBi position embeddings and trained on 470B tokens at the context length of 2,048 followed by 157B of tokens trained at 8,192 context length. To assess BTLM’s long sequence capability, we evaluate it on SlimPajama test set with 32,768 context length and plot loss at each token position. Although ALiBi allows extrapolation in theory, 2,048 context length training alone does not extrapolate well in practice. Thankfully variable sequence length training allows for substantially improved extrapolation. BTLM-3B extrapolates well up to 10k context length but the performance degrades slightly beyond this.
|
| 121 |
+
|
| 122 |
+

|
| 123 |
+
Figure 5: BTLM-3B model's cross-entropy evaluation on the SlimPajama’s test set. Inference performed on the extrapolated sequence length of 32,768 tokens.
|
| 124 |
+
|
| 125 |
+
## Model Details
|
| 126 |
+
- Developed by: [Cerebras Systems](https://www.cerebras.net/) and [Opentensor](https://opentensor.ai/) with generous support from [G42 Cloud](https://www.g42cloud.com/) and [IIAI](https://www.inceptioniai.org/en/)
|
| 127 |
+
- License: Apache 2.0
|
| 128 |
+
- Model type: Decoder-only Language Model
|
| 129 |
+
- Architecture: GPT-2 style architecture with SwiGLU, ALiBi, and muP
|
| 130 |
+
- Data set: SlimPajama-627B
|
| 131 |
+
- Tokenizer: Byte Pair Encoding
|
| 132 |
+
- Vocabulary Size: 50257
|
| 133 |
+
- Sequence Length: 8192
|
| 134 |
+
- Optimizer: AdamW
|
| 135 |
+
- Positional Encoding: ALiBi
|
| 136 |
+
- Language: English
|
| 137 |
+
- Learn more: [BTLM-3B-8k blog](https://www.cerebras.net/blog/btlm-3b-8k-7b-performance-in-a-3-billion-parameter-model/)
|
| 138 |
+
- Paper: [BTLM-3B-8K: 7B Parameter Performance in a 3B Parameter Model](https://arxiv.org/abs/2309.11568)
|
| 139 |
+
|
| 140 |
+
## To continue training with PyTorch and Maximal Update Parameterization
|
| 141 |
+
|
| 142 |
+
```python
|
| 143 |
+
from transformers import AutoModelForCausalLM
|
| 144 |
+
import torch
|
| 145 |
+
|
| 146 |
+
model = AutoModelForCausalLM.from_pretrained("cerebras/btlm-3b-8k-base", trust_remote_code=True)
|
| 147 |
+
|
| 148 |
+
# Get the parameter groups for the muP optimizer
|
| 149 |
+
param_groups = model.get_mup_param_groups(lr=1e-3, weight_decay=0.1)
|
| 150 |
+
|
| 151 |
+
# Set up the optimizer using AdamW with muP parameters
|
| 152 |
+
optimizer = torch.optim.AdamW(
|
| 153 |
+
param_groups,
|
| 154 |
+
betas=(0.9, 0.95),
|
| 155 |
+
eps=1e-8
|
| 156 |
+
)
|
| 157 |
+
```
|
| 158 |
+
|
| 159 |
+
Ensure the following muP parameters are passed in your config, otherwise your model will default to standard parameterization
|
| 160 |
+
- `mup_width_scale: <float>`
|
| 161 |
+
- `mup_embeddings_scale: <float>`
|
| 162 |
+
- `mup_output_alpha: <float>`
|
| 163 |
+
- `mup_scale_qk_dot_by_d: true`
|
| 164 |
+
|
| 165 |
+
## To extend the context length with Position Interpolation
|
| 166 |
+
|
| 167 |
+
### During inference (without fine-tuning):
|
| 168 |
+
It's possible to extend the context length to 2x the training context length without degradation in performance using dynamic linear scaling. Dynamic linear scaling adjusts the slopes of ALiBi with a factor of `input_seq_len/train_seq_len` when `input_seq_len` is larger than `train_seq_len`. Check the details in our paper [Position Interpolation Improves ALiBi Extrapolation](https://arxiv.org/abs/2310.13017). To enable dynamic linear scaling, update `config.json` as follows:
|
| 169 |
+
```json
|
| 170 |
+
# update `n_positions` with the maximum context length will be
|
| 171 |
+
# encountered during inference (e.g. 16384 tokens)
|
| 172 |
+
"n_positions": 16384,
|
| 173 |
+
|
| 174 |
+
# specify `train_seq_len` in `alibi_scaling` parameter
|
| 175 |
+
"alibi_scaling": {
|
| 176 |
+
"type": "linear",
|
| 177 |
+
"train_seq_len": 8192
|
| 178 |
+
}
|
| 179 |
+
```
|
| 180 |
+
|
| 181 |
+
### Using fine-tuning + position interpolation:
|
| 182 |
+
Performing fine-tuning with position interpolation can help achieve greater extrapolation lengths. The scaling factor should be fixed to `finetuning_seq_len/train_seq_len`. To enable fixed linear scaling, update `config.json` as follows:
|
| 183 |
+
```json
|
| 184 |
+
# update `n_positions` with the fine-tuning context length (e.g. 32768 tokens)
|
| 185 |
+
"n_positions": 32768,
|
| 186 |
+
|
| 187 |
+
# specify the scaling `factor` in `alibi_scaling` parameter
|
| 188 |
+
"alibi_scaling": {
|
| 189 |
+
"type": "linear",
|
| 190 |
+
"factor": 4.0
|
| 191 |
+
}
|
| 192 |
+
```
|
| 193 |
+
|
| 194 |
+
## Uses and Limitations
|
| 195 |
+
|
| 196 |
+
### Intended Use
|
| 197 |
+
The primary intended use is to further research into large language models. BTLM-3B-8k-base can be used as a foundation model for NLP, applications, ethics, and alignment research. We release these models with a fully permissive Apache license for the community to use freely.
|
| 198 |
+
|
| 199 |
+
You may fine-tune and adapt BTLM-3B-8k-base model via either Cerebras [Model Studio](https://www.cerebras.net/product-cloud/) or third-party libraries. Further safety-related testing and mitigations should be applied before using the BTLM-3B-8k-base in production downstream applications.
|
| 200 |
+
|
| 201 |
+
### Out of Scope Use
|
| 202 |
+
BTLM-3B-8k-base was trained on SlimPajama, with primarily English language, and is not recommended for machine translation tasks. BTLM-3B-8k-base has not been tuned for instruction-following or chat-based use cases.
|
| 203 |
+
|
| 204 |
+
### Generation Samples
|
| 205 |
+
```
|
| 206 |
+
Prompt: What is a manometer?"
|
| 207 |
+
Generation: "A manometric device is an instrument that measures the pressure of a fluid."
|
| 208 |
+
```
|
| 209 |
+
|
| 210 |
+
```
|
| 211 |
+
Prompt: "What Robert Oppenheimer is famous for?"
|
| 212 |
+
Generation: “Robert Opperman was a physicist who was the director of the Manhattan Project, which was responsible for the development of nuclear weapons.”
|
| 213 |
+
```
|
| 214 |
+
|
| 215 |
+
```
|
| 216 |
+
Prompt: "What was Albert Einstein known for?"
|
| 217 |
+
Generation: “Albert Einstein was a German-born theoretical physicist who developed the theory of relativity, one of the two pillars of modern physics (alongside quantum mechanics).”
|
| 218 |
+
```
|
| 219 |
+
|
| 220 |
+
```
|
| 221 |
+
Prompt: “Who is Isaac Newton?”
|
| 222 |
+
Generation: “Isaac Newton was an English physicist, mathematician, astronomer, alchemist, and theologian. He is widely recognized as one of the most influential scientists of all time and as a key figure in the scientific revolution.”
|
| 223 |
+
```
|
| 224 |
+
|
| 225 |
+
```
|
| 226 |
+
Prompt: "Where does the blood get pumped to after it leaves the right ventricle?"
|
| 227 |
+
Generation: “The right atrium receives the deoxygenated blood from the pulmonary artery. The right side of the heart is the only side that receives de-oxygened...”
|
| 228 |
+
```
|
| 229 |
+
|
| 230 |
+
```
|
| 231 |
+
Prompt: "Peter lost his wallet after attending a local concert. To help him, Bob gave David 10 dollars. David then passed it on to Peter. Now what is the total amount of money Peter has?"
|
| 232 |
+
Generation: “A. $10”
|
| 233 |
+
```
|
| 234 |
+
|
| 235 |
+
## Risk, Bias, Ethical Considerations
|
| 236 |
+
- **Human life:** The outputs from this model may or may not align with human values. The risk needs to be thoroughly investigated before deploying this model in a production environment where it can directly impact human life.
|
| 237 |
+
- **Risks and harms:** There may be distributional bias in the [RedPajama dataset](https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T) that can manifest in various forms in the downstream model deployment. There are other risks associated with large language models such as amplifying stereotypes, memorizing training data, or revealing private or secure information.
|
| 238 |
+
|
| 239 |
+
## Acknowledgements
|
| 240 |
+
We are thankful to all Cerebras engineers that made this work possible.
|
| 241 |
+
|
| 242 |
+
We would like to acknowledge the generous support of G42 Cloud and the Inception Institute of Artificial Intelligence for providing compute time on Condor Galaxy 1.
|
config.json
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "cerebras/btlm-3b-8k-base",
|
| 3 |
+
"activation_function": "swiglu",
|
| 4 |
+
"architectures": [
|
| 5 |
+
"BTLMLMHeadModel"
|
| 6 |
+
],
|
| 7 |
+
"attn_pdrop": 0.0,
|
| 8 |
+
"auto_map": {
|
| 9 |
+
"AutoConfig": "configuration_btlm.BTLMConfig",
|
| 10 |
+
"AutoModel": "modeling_btlm.BTLMModel",
|
| 11 |
+
"AutoModelForCausalLM": "modeling_btlm.BTLMLMHeadModel",
|
| 12 |
+
"AutoModelForQuestionAnswering": "modeling_btlm.BTLMForQuestionAnswering",
|
| 13 |
+
"AutoModelForSequenceClassification": "modeling_btlm.BTLMForSequenceClassification",
|
| 14 |
+
"AutoModelForTokenClassification": "modeling_btlm.BTLMForTokenClassification"
|
| 15 |
+
},
|
| 16 |
+
"bos_token_id": 50256,
|
| 17 |
+
"embd_pdrop": 0.0,
|
| 18 |
+
"mup_embeddings_scale": 14.6,
|
| 19 |
+
"eos_token_id": 50256,
|
| 20 |
+
"initializer_range": 0.073,
|
| 21 |
+
"layer_norm_epsilon": 1e-05,
|
| 22 |
+
"model_type": "btlm",
|
| 23 |
+
"n_embd": 2560,
|
| 24 |
+
"n_head": 32,
|
| 25 |
+
"n_inner": 6826,
|
| 26 |
+
"n_layer": 32,
|
| 27 |
+
"n_positions": 8192,
|
| 28 |
+
"mup_output_alpha": 2.2200000000000003,
|
| 29 |
+
"position_embedding_type": "alibi",
|
| 30 |
+
"reorder_and_upcast_attn": false,
|
| 31 |
+
"resid_pdrop": 0.0,
|
| 32 |
+
"scale_attn_by_inverse_layer_idx": false,
|
| 33 |
+
"scale_attn_weights": true,
|
| 34 |
+
"mup_scale_qk_dot_by_d": true,
|
| 35 |
+
"torch_dtype": "bfloat16",
|
| 36 |
+
"transformers_version": "4.30.0",
|
| 37 |
+
"use_cache": true,
|
| 38 |
+
"vocab_size": 50257,
|
| 39 |
+
"mup_width_scale": 0.1
|
| 40 |
+
}
|
configuration_btlm.py
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2023 The OpenAI Team Authors and HuggingFace Inc. team.
|
| 3 |
+
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
|
| 4 |
+
# Copyright 2023 Cerebras Systems.
|
| 5 |
+
#
|
| 6 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 7 |
+
# you may not use this file except in compliance with the License.
|
| 8 |
+
# You may obtain a copy of the License at
|
| 9 |
+
#
|
| 10 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 11 |
+
#
|
| 12 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 13 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 14 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 15 |
+
# See the License for the specific language governing permissions and
|
| 16 |
+
# limitations under the License.
|
| 17 |
+
""" BTLM configuration"""
|
| 18 |
+
|
| 19 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 20 |
+
from transformers.utils import logging
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
logger = logging.get_logger(__name__)
|
| 24 |
+
|
| 25 |
+
BTLM_PRETRAINED_CONFIG_ARCHIVE_MAP = {
|
| 26 |
+
"cerebras/btlm-3b-8k-base": "https://huggingface.co/cerebras/btlm-3b-8k-base/resolve/main/config.json",
|
| 27 |
+
}
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
class BTLMConfig(PretrainedConfig):
|
| 31 |
+
"""
|
| 32 |
+
This is the configuration class to store the configuration of a [`BTLMModel`]. It is used to instantiate a BTLM
|
| 33 |
+
model according to the specified arguments, defining the model architecture.
|
| 34 |
+
|
| 35 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 36 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
Args:
|
| 40 |
+
vocab_size (`int`, *optional*, defaults to 50257):
|
| 41 |
+
Vocabulary size of the BTLM model. Defines the number of different tokens that can be represented by the
|
| 42 |
+
`inputs_ids` passed when calling [`BTLMModel`].
|
| 43 |
+
n_positions (`int`, *optional*, defaults to 1024):
|
| 44 |
+
The maximum sequence length that this model might ever be used with. Typically set this to something large
|
| 45 |
+
just in case (e.g., 512 or 1024 or 2048).
|
| 46 |
+
n_embd (`int`, *optional*, defaults to 768):
|
| 47 |
+
Dimensionality of the embeddings and hidden states.
|
| 48 |
+
n_layer (`int`, *optional*, defaults to 12):
|
| 49 |
+
Number of hidden layers in the Transformer encoder.
|
| 50 |
+
n_head (`int`, *optional*, defaults to 12):
|
| 51 |
+
Number of attention heads for each attention layer in the Transformer encoder.
|
| 52 |
+
n_inner (`int`, *optional*, defaults to None):
|
| 53 |
+
Dimensionality of the inner feed-forward layers. `None` will set it to 4 times n_embd
|
| 54 |
+
activation_function (`str`, *optional*, defaults to `"gelu"`):
|
| 55 |
+
Activation function, to be selected in the list `["relu", "silu", "gelu", "tanh", "gelu_new", "swiglu"]`.
|
| 56 |
+
resid_pdrop (`float`, *optional*, defaults to 0.1):
|
| 57 |
+
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
|
| 58 |
+
embd_pdrop (`float`, *optional*, defaults to 0.1):
|
| 59 |
+
The dropout ratio for the embeddings.
|
| 60 |
+
attn_pdrop (`float`, *optional*, defaults to 0.1):
|
| 61 |
+
The dropout ratio for the attention.
|
| 62 |
+
layer_norm_epsilon (`float`, *optional*, defaults to 1e-5):
|
| 63 |
+
The epsilon to use in the layer normalization layers.
|
| 64 |
+
initializer_range (`float`, *optional*, defaults to 0.02):
|
| 65 |
+
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
| 66 |
+
scale_attn_weights (`bool`, *optional*, defaults to `True`):
|
| 67 |
+
Scale attention weights by dividing by sqrt(hidden_size)..
|
| 68 |
+
use_cache (`bool`, *optional*, defaults to `True`):
|
| 69 |
+
Whether or not the model should return the last key/values attentions (not used by all models).
|
| 70 |
+
scale_attn_by_inverse_layer_idx (`bool`, *optional*, defaults to `False`):
|
| 71 |
+
Whether to additionally scale attention weights by `1 / layer_idx + 1`.
|
| 72 |
+
reorder_and_upcast_attn (`bool`, *optional*, defaults to `False`):
|
| 73 |
+
Whether to scale keys (K) prior to computing attention (dot-product) and upcast attention
|
| 74 |
+
dot-product/softmax to float() when training with mixed precision.
|
| 75 |
+
position_embedding_type (`str`, *optional*, defaults to `"learned"`):
|
| 76 |
+
Positional embedding can be either `"alibi"` or `"learned"`.
|
| 77 |
+
mup_width_scale (`float`, *optional*, defaults to 1.0):
|
| 78 |
+
muP parameter to scale learning rate and initializers. Calculated as (`d_model,0 / d_model`), where
|
| 79 |
+
`d_model` is the model's width and `d_model,0` is the proxy model's width.
|
| 80 |
+
mup_embeddings_scale (`float`, *optional*, defaults to 1.0):
|
| 81 |
+
muP parameter to scale token and position embeddings.
|
| 82 |
+
mup_output_alpha (`float`, *optional*, defaults to 1.0):
|
| 83 |
+
muP parameter to scale output logits (`output_logits_scale = mup_output_alpha * mup_width_scale`).
|
| 84 |
+
mup_scale_qk_dot_by_d (`bool`, *optional*, defaults to `False`):
|
| 85 |
+
Scale attention weights by dividing by hidden_size instead of sqrt(hidden_size). Need to set
|
| 86 |
+
scale_attn_weights to `True` as well.
|
| 87 |
+
alibi_scaling (`Dict`, *optional*):
|
| 88 |
+
Dictionary containing the scaling configuration for ALiBi embeddings. Currently only supports linear
|
| 89 |
+
scaling strategy. Can specify either the scaling `factor` (must be a float greater than 1) for fixed scaling
|
| 90 |
+
or `train_seq_len` for dynamic scaling on input samples with sequence length > `train_seq_len`. The expected
|
| 91 |
+
formats are `{"type": strategy name, "factor": scaling factor}` or
|
| 92 |
+
`{"type": strategy name, "train_seq_len": training sequence length}`.
|
| 93 |
+
|
| 94 |
+
Example:
|
| 95 |
+
|
| 96 |
+
```python
|
| 97 |
+
>>> from transformers import BTLMConfig, BTLMModel
|
| 98 |
+
|
| 99 |
+
>>> # Initializing a BTLM configuration
|
| 100 |
+
>>> configuration = BTLMConfig()
|
| 101 |
+
|
| 102 |
+
>>> # Initializing a model (with random weights) from the configuration
|
| 103 |
+
>>> model = BTLMModel(configuration)
|
| 104 |
+
|
| 105 |
+
>>> # Accessing the model configuration
|
| 106 |
+
>>> configuration = model.config
|
| 107 |
+
```"""
|
| 108 |
+
|
| 109 |
+
model_type = "btlm"
|
| 110 |
+
keys_to_ignore_at_inference = ["past_key_values"]
|
| 111 |
+
attribute_map = {
|
| 112 |
+
"hidden_size": "n_embd",
|
| 113 |
+
"max_position_embeddings": "n_positions",
|
| 114 |
+
"num_attention_heads": "n_head",
|
| 115 |
+
"num_hidden_layers": "n_layer",
|
| 116 |
+
}
|
| 117 |
+
|
| 118 |
+
def __init__(
|
| 119 |
+
self,
|
| 120 |
+
vocab_size=50257,
|
| 121 |
+
n_positions=1024,
|
| 122 |
+
n_embd=768,
|
| 123 |
+
n_layer=12,
|
| 124 |
+
n_head=12,
|
| 125 |
+
n_inner=None,
|
| 126 |
+
activation_function="gelu_new",
|
| 127 |
+
resid_pdrop=0.1,
|
| 128 |
+
embd_pdrop=0.1,
|
| 129 |
+
attn_pdrop=0.1,
|
| 130 |
+
layer_norm_epsilon=1e-5,
|
| 131 |
+
initializer_range=0.02,
|
| 132 |
+
scale_attn_weights=True,
|
| 133 |
+
use_cache=True,
|
| 134 |
+
bos_token_id=50256,
|
| 135 |
+
eos_token_id=50256,
|
| 136 |
+
scale_attn_by_inverse_layer_idx=False,
|
| 137 |
+
reorder_and_upcast_attn=False,
|
| 138 |
+
position_embedding_type="learned",
|
| 139 |
+
mup_width_scale=1.0,
|
| 140 |
+
mup_embeddings_scale=1.0,
|
| 141 |
+
mup_output_alpha=1.0,
|
| 142 |
+
mup_scale_qk_dot_by_d=False,
|
| 143 |
+
alibi_scaling=None,
|
| 144 |
+
**kwargs,
|
| 145 |
+
):
|
| 146 |
+
self.vocab_size = vocab_size
|
| 147 |
+
self.n_positions = n_positions
|
| 148 |
+
self.n_embd = n_embd
|
| 149 |
+
self.n_layer = n_layer
|
| 150 |
+
self.n_head = n_head
|
| 151 |
+
self.n_inner = n_inner
|
| 152 |
+
self.activation_function = activation_function
|
| 153 |
+
self.resid_pdrop = resid_pdrop
|
| 154 |
+
self.embd_pdrop = embd_pdrop
|
| 155 |
+
self.attn_pdrop = attn_pdrop
|
| 156 |
+
self.layer_norm_epsilon = layer_norm_epsilon
|
| 157 |
+
self.initializer_range = initializer_range
|
| 158 |
+
self.scale_attn_weights = scale_attn_weights
|
| 159 |
+
self.use_cache = use_cache
|
| 160 |
+
self.scale_attn_by_inverse_layer_idx = scale_attn_by_inverse_layer_idx
|
| 161 |
+
self.reorder_and_upcast_attn = reorder_and_upcast_attn
|
| 162 |
+
|
| 163 |
+
self.bos_token_id = bos_token_id
|
| 164 |
+
self.eos_token_id = eos_token_id
|
| 165 |
+
|
| 166 |
+
self.position_embedding_type = position_embedding_type
|
| 167 |
+
self.mup_width_scale = mup_width_scale
|
| 168 |
+
self.mup_embeddings_scale = mup_embeddings_scale
|
| 169 |
+
self.mup_output_alpha = mup_output_alpha
|
| 170 |
+
self.mup_scale_qk_dot_by_d = mup_scale_qk_dot_by_d
|
| 171 |
+
|
| 172 |
+
self.alibi_scaling = alibi_scaling
|
| 173 |
+
self._alibi_scaling_validation()
|
| 174 |
+
|
| 175 |
+
super().__init__(bos_token_id=bos_token_id, eos_token_id=eos_token_id, **kwargs)
|
| 176 |
+
|
| 177 |
+
def _alibi_scaling_validation(self):
|
| 178 |
+
"""
|
| 179 |
+
Validate the `alibi_scaling` configuration.
|
| 180 |
+
"""
|
| 181 |
+
if self.alibi_scaling is None:
|
| 182 |
+
return
|
| 183 |
+
|
| 184 |
+
if not isinstance(self.alibi_scaling, dict) or len(self.alibi_scaling) != 2:
|
| 185 |
+
raise ValueError(
|
| 186 |
+
"`alibi_scaling` must be a dictionary with two fields, `type` and `factor` or `type` and `train_seq_len`, "
|
| 187 |
+
f"got {self.alibi_scaling}"
|
| 188 |
+
)
|
| 189 |
+
alibi_scaling_type = self.alibi_scaling.get("type", None)
|
| 190 |
+
alibi_scaling_factor = self.alibi_scaling.get("factor", None)
|
| 191 |
+
alibi_dynamic_scaling = self.alibi_scaling.get("train_seq_len", None)
|
| 192 |
+
if alibi_scaling_type is None or alibi_scaling_type != "linear":
|
| 193 |
+
raise ValueError(
|
| 194 |
+
f"`alibi_scaling`'s type field must be 'linear', got {alibi_scaling_type}"
|
| 195 |
+
)
|
| 196 |
+
if alibi_scaling_factor is not None:
|
| 197 |
+
if not isinstance(alibi_scaling_factor, float) or alibi_scaling_factor <= 1.0:
|
| 198 |
+
raise ValueError(f"`alibi_scaling`'s factor field must be a float > 1.0, got {alibi_scaling_factor}")
|
| 199 |
+
if alibi_dynamic_scaling is not None:
|
| 200 |
+
if not isinstance(alibi_dynamic_scaling, int) or alibi_dynamic_scaling <= 1:
|
| 201 |
+
raise ValueError(f"`alibi_scaling`'s `train_seq_len` field must be an integer > 1, got {alibi_dynamic_scaling}")
|
figure_1_memory_footprint.png
ADDED
|
figure_2_half_the_size_twice_the_speed.png
ADDED

|
figure_3_performance_vs_3b_models.png
ADDED
|
figure_4_performance_vs_7b_models.jpg
ADDED

|
figure_5_xentropy_with_sequence_lengths.png
ADDED

|
figure_5_xentropy_with_sequence_lengths.svg
ADDED

|
generation_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 50256,
|
| 4 |
+
"eos_token_id": 50256,
|
| 5 |
+
"transformers_version": "4.30.0"
|
| 6 |
+
}
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
modeling_btlm.py
ADDED
|
@@ -0,0 +1,1605 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2023 The OpenAI Team Authors and HuggingFace Inc. team.
|
| 3 |
+
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
|
| 4 |
+
# Copyright 2023 Cerebras Systems.
|
| 5 |
+
#
|
| 6 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 7 |
+
# you may not use this file except in compliance with the License.
|
| 8 |
+
# You may obtain a copy of the License at
|
| 9 |
+
#
|
| 10 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 11 |
+
#
|
| 12 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 13 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 14 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 15 |
+
# See the License for the specific language governing permissions and
|
| 16 |
+
# limitations under the License.
|
| 17 |
+
""" PyTorch BTLM model."""
|
| 18 |
+
|
| 19 |
+
import math
|
| 20 |
+
import os
|
| 21 |
+
import warnings
|
| 22 |
+
from typing import Optional, Tuple, Union
|
| 23 |
+
|
| 24 |
+
import torch
|
| 25 |
+
from torch import Tensor, nn
|
| 26 |
+
from torch.cuda.amp import autocast
|
| 27 |
+
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
|
| 28 |
+
|
| 29 |
+
from transformers.activations import ACT2FN
|
| 30 |
+
from transformers.modeling_outputs import (
|
| 31 |
+
BaseModelOutputWithPastAndCrossAttentions,
|
| 32 |
+
CausalLMOutputWithCrossAttentions,
|
| 33 |
+
QuestionAnsweringModelOutput,
|
| 34 |
+
SequenceClassifierOutputWithPast,
|
| 35 |
+
TokenClassifierOutput,
|
| 36 |
+
)
|
| 37 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 38 |
+
from transformers.pytorch_utils import Conv1D, find_pruneable_heads_and_indices, prune_conv1d_layer
|
| 39 |
+
from transformers.utils import (
|
| 40 |
+
add_code_sample_docstrings,
|
| 41 |
+
add_start_docstrings,
|
| 42 |
+
add_start_docstrings_to_model_forward,
|
| 43 |
+
logging,
|
| 44 |
+
)
|
| 45 |
+
from transformers.utils.model_parallel_utils import assert_device_map, get_device_map
|
| 46 |
+
from .configuration_btlm import BTLMConfig
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
logger = logging.get_logger(__name__)
|
| 50 |
+
|
| 51 |
+
_CHECKPOINT_FOR_DOC = "cerebras/btlm-3b-8k-base"
|
| 52 |
+
_CONFIG_FOR_DOC = "BTLMConfig"
|
| 53 |
+
|
| 54 |
+
BTLM_PRETRAINED_MODEL_ARCHIVE_LIST = [
|
| 55 |
+
"cerebras/btlm-3b-8k-base",
|
| 56 |
+
# See all BTLM models at https://huggingface.co/models?filter=btlm
|
| 57 |
+
]
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
class SwiGLUActivation(nn.Module):
|
| 61 |
+
def forward(self, x1: Tensor, x2: Tensor) -> Tensor:
|
| 62 |
+
return x1 * nn.functional.silu(x2)
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
class AlibiPositionEmbeddingLayer(nn.Module):
|
| 66 |
+
def __init__(self, num_heads, alibi_scaling=None):
|
| 67 |
+
super(AlibiPositionEmbeddingLayer, self).__init__()
|
| 68 |
+
|
| 69 |
+
self.num_heads = num_heads
|
| 70 |
+
self.alibi_scaling = alibi_scaling
|
| 71 |
+
slopes = torch.tensor(AlibiPositionEmbeddingLayer._get_alibi_slopes(num_heads)).unsqueeze(-1)
|
| 72 |
+
self.slopes = nn.parameter.Parameter(slopes, requires_grad=False)
|
| 73 |
+
|
| 74 |
+
def forward(
|
| 75 |
+
self,
|
| 76 |
+
seq_length,
|
| 77 |
+
key_length,
|
| 78 |
+
cached_qk_len,
|
| 79 |
+
):
|
| 80 |
+
context_position = torch.arange(
|
| 81 |
+
cached_qk_len, cached_qk_len + seq_length, device=self.slopes.device
|
| 82 |
+
)[:, None]
|
| 83 |
+
memory_position = torch.arange(
|
| 84 |
+
key_length + cached_qk_len, device=self.slopes.device
|
| 85 |
+
)[None, :]
|
| 86 |
+
relative_position = memory_position - context_position
|
| 87 |
+
relative_position = torch.abs(relative_position).unsqueeze(0).expand(self.num_heads, -1, -1)
|
| 88 |
+
|
| 89 |
+
if self.alibi_scaling is None:
|
| 90 |
+
scale = 1.0
|
| 91 |
+
elif self.alibi_scaling.get("factor") is not None:
|
| 92 |
+
scale = self.alibi_scaling["factor"]
|
| 93 |
+
elif relative_position.shape[-1] > self.alibi_scaling["train_seq_len"]:
|
| 94 |
+
scale = relative_position.shape[-1] / self.alibi_scaling["train_seq_len"]
|
| 95 |
+
else:
|
| 96 |
+
scale = 1.0
|
| 97 |
+
|
| 98 |
+
alibi = (self.slopes / -scale).unsqueeze(1) * relative_position
|
| 99 |
+
return alibi
|
| 100 |
+
|
| 101 |
+
@staticmethod
|
| 102 |
+
def _get_alibi_slopes(n):
|
| 103 |
+
def get_slopes_power_of_2(n):
|
| 104 |
+
start = 2 ** (-(2 ** -(math.log2(n) - 3)))
|
| 105 |
+
ratio = start
|
| 106 |
+
return [start * ratio**i for i in range(n)]
|
| 107 |
+
|
| 108 |
+
if math.log2(n).is_integer():
|
| 109 |
+
return get_slopes_power_of_2(
|
| 110 |
+
n
|
| 111 |
+
) # In the paper, we only train models that have 2^a heads for some a. This function has
|
| 112 |
+
else: # some good properties that only occur when the input is a power of 2. To maintain that even
|
| 113 |
+
closest_power_of_2 = 2 ** math.floor(
|
| 114 |
+
math.log2(n)
|
| 115 |
+
) # when the number of heads is not a power of 2, we use this workaround.
|
| 116 |
+
return (
|
| 117 |
+
get_slopes_power_of_2(closest_power_of_2)
|
| 118 |
+
+ AlibiPositionEmbeddingLayer._get_alibi_slopes(2 * closest_power_of_2)[0::2][: n - closest_power_of_2]
|
| 119 |
+
)
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def load_tf_weights_in_btlm(model, config, btlm_checkpoint_path):
|
| 123 |
+
"""Load tf checkpoints in a pytorch model"""
|
| 124 |
+
try:
|
| 125 |
+
import re
|
| 126 |
+
|
| 127 |
+
import tensorflow as tf
|
| 128 |
+
except ImportError:
|
| 129 |
+
logger.error(
|
| 130 |
+
"Loading a TensorFlow model in PyTorch, requires TensorFlow to be installed. Please see "
|
| 131 |
+
"https://www.tensorflow.org/install/ for installation instructions."
|
| 132 |
+
)
|
| 133 |
+
raise
|
| 134 |
+
tf_path = os.path.abspath(btlm_checkpoint_path)
|
| 135 |
+
logger.info(f"Converting TensorFlow checkpoint from {tf_path}")
|
| 136 |
+
# Load weights from TF model
|
| 137 |
+
init_vars = tf.train.list_variables(tf_path)
|
| 138 |
+
names = []
|
| 139 |
+
arrays = []
|
| 140 |
+
for name, shape in init_vars:
|
| 141 |
+
logger.info(f"Loading TF weight {name} with shape {shape}")
|
| 142 |
+
array = tf.train.load_variable(tf_path, name)
|
| 143 |
+
names.append(name)
|
| 144 |
+
arrays.append(array.squeeze())
|
| 145 |
+
|
| 146 |
+
for name, array in zip(names, arrays):
|
| 147 |
+
name = name[6:] # skip "model/"
|
| 148 |
+
name = name.split("/")
|
| 149 |
+
pointer = model
|
| 150 |
+
for m_name in name:
|
| 151 |
+
if re.fullmatch(r"[A-Za-z]+\d+", m_name):
|
| 152 |
+
scope_names = re.split(r"(\d+)", m_name)
|
| 153 |
+
else:
|
| 154 |
+
scope_names = [m_name]
|
| 155 |
+
if scope_names[0] == "w" or scope_names[0] == "g":
|
| 156 |
+
pointer = getattr(pointer, "weight")
|
| 157 |
+
elif scope_names[0] == "b":
|
| 158 |
+
pointer = getattr(pointer, "bias")
|
| 159 |
+
elif scope_names[0] == "wpe" or scope_names[0] == "wte":
|
| 160 |
+
pointer = getattr(pointer, scope_names[0])
|
| 161 |
+
pointer = getattr(pointer, "weight")
|
| 162 |
+
else:
|
| 163 |
+
pointer = getattr(pointer, scope_names[0])
|
| 164 |
+
if len(scope_names) >= 2:
|
| 165 |
+
num = int(scope_names[1])
|
| 166 |
+
pointer = pointer[num]
|
| 167 |
+
try:
|
| 168 |
+
assert (
|
| 169 |
+
pointer.shape == array.shape
|
| 170 |
+
), f"Pointer shape {pointer.shape} and array shape {array.shape} mismatched"
|
| 171 |
+
except AssertionError as e:
|
| 172 |
+
e.args += (pointer.shape, array.shape)
|
| 173 |
+
raise
|
| 174 |
+
logger.info(f"Initialize PyTorch weight {name}")
|
| 175 |
+
pointer.data = torch.from_numpy(array)
|
| 176 |
+
return model
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
class BTLMAttention(nn.Module):
|
| 180 |
+
def __init__(self, config, is_cross_attention=False, layer_idx=None):
|
| 181 |
+
super().__init__()
|
| 182 |
+
|
| 183 |
+
max_positions = config.max_position_embeddings
|
| 184 |
+
self.register_buffer(
|
| 185 |
+
"bias",
|
| 186 |
+
torch.tril(torch.ones((max_positions, max_positions), dtype=torch.bool)).view(
|
| 187 |
+
1, 1, max_positions, max_positions
|
| 188 |
+
),
|
| 189 |
+
persistent=False,
|
| 190 |
+
)
|
| 191 |
+
self.register_buffer("masked_bias", torch.tensor(-1e4), persistent=False)
|
| 192 |
+
|
| 193 |
+
self.embed_dim = config.hidden_size
|
| 194 |
+
self.num_heads = config.num_attention_heads
|
| 195 |
+
self.head_dim = self.embed_dim // self.num_heads
|
| 196 |
+
self.split_size = self.embed_dim
|
| 197 |
+
if self.head_dim * self.num_heads != self.embed_dim:
|
| 198 |
+
raise ValueError(
|
| 199 |
+
f"`embed_dim` must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:"
|
| 200 |
+
f" {self.num_heads})."
|
| 201 |
+
)
|
| 202 |
+
|
| 203 |
+
self.scale_attn_weights = config.scale_attn_weights
|
| 204 |
+
self.is_cross_attention = is_cross_attention
|
| 205 |
+
|
| 206 |
+
# Layer-wise attention scaling, reordering, and upcasting
|
| 207 |
+
self.scale_attn_by_inverse_layer_idx = config.scale_attn_by_inverse_layer_idx
|
| 208 |
+
self.layer_idx = layer_idx
|
| 209 |
+
self.reorder_and_upcast_attn = config.reorder_and_upcast_attn
|
| 210 |
+
|
| 211 |
+
if self.is_cross_attention:
|
| 212 |
+
self.c_attn = Conv1D(2 * self.embed_dim, self.embed_dim)
|
| 213 |
+
self.q_attn = Conv1D(self.embed_dim, self.embed_dim)
|
| 214 |
+
else:
|
| 215 |
+
self.c_attn = Conv1D(3 * self.embed_dim, self.embed_dim)
|
| 216 |
+
self.c_proj = Conv1D(self.embed_dim, self.embed_dim)
|
| 217 |
+
|
| 218 |
+
self.attn_dropout = nn.Dropout(config.attn_pdrop)
|
| 219 |
+
self.resid_dropout = nn.Dropout(config.resid_pdrop)
|
| 220 |
+
|
| 221 |
+
self.pruned_heads = set()
|
| 222 |
+
|
| 223 |
+
self.attn_scale_power = 1.0 if config.mup_scale_qk_dot_by_d else 0.5
|
| 224 |
+
|
| 225 |
+
def prune_heads(self, heads):
|
| 226 |
+
if len(heads) == 0:
|
| 227 |
+
return
|
| 228 |
+
heads, index = find_pruneable_heads_and_indices(heads, self.num_heads, self.head_dim, self.pruned_heads)
|
| 229 |
+
index_attn = torch.cat([index, index + self.split_size, index + (2 * self.split_size)])
|
| 230 |
+
|
| 231 |
+
# Prune conv1d layers
|
| 232 |
+
self.c_attn = prune_conv1d_layer(self.c_attn, index_attn, dim=1)
|
| 233 |
+
self.c_proj = prune_conv1d_layer(self.c_proj, index, dim=0)
|
| 234 |
+
|
| 235 |
+
# Update hyper params
|
| 236 |
+
self.split_size = (self.split_size // self.num_heads) * (self.num_heads - len(heads))
|
| 237 |
+
self.num_heads = self.num_heads - len(heads)
|
| 238 |
+
self.pruned_heads = self.pruned_heads.union(heads)
|
| 239 |
+
|
| 240 |
+
def _attn(self, query, key, value, attention_mask=None, head_mask=None, position_bias=None):
|
| 241 |
+
attn_weights = torch.matmul(query, key.transpose(-1, -2))
|
| 242 |
+
|
| 243 |
+
if self.scale_attn_weights:
|
| 244 |
+
attn_weights = attn_weights / torch.full(
|
| 245 |
+
[], value.size(-1) ** self.attn_scale_power, dtype=attn_weights.dtype, device=attn_weights.device
|
| 246 |
+
)
|
| 247 |
+
|
| 248 |
+
# Layer-wise attention scaling
|
| 249 |
+
if self.scale_attn_by_inverse_layer_idx:
|
| 250 |
+
attn_weights = attn_weights / float(self.layer_idx + 1)
|
| 251 |
+
|
| 252 |
+
if not self.is_cross_attention:
|
| 253 |
+
# if only "normal" attention layer implements causal mask
|
| 254 |
+
query_length, key_length = query.size(-2), key.size(-2)
|
| 255 |
+
causal_mask = self.bias[:, :, key_length - query_length : key_length, :key_length]
|
| 256 |
+
mask_value = torch.finfo(attn_weights.dtype).min
|
| 257 |
+
# Need to be a tensor, otherwise we get error: `RuntimeError: expected scalar type float but found double`.
|
| 258 |
+
# Need to be on the same device, otherwise `RuntimeError: ..., x and y to be on the same device`
|
| 259 |
+
mask_value = torch.full([], mask_value, dtype=attn_weights.dtype).to(attn_weights.device)
|
| 260 |
+
attn_weights = torch.where(causal_mask, attn_weights.to(attn_weights.dtype), mask_value)
|
| 261 |
+
|
| 262 |
+
if attention_mask is not None:
|
| 263 |
+
# Apply the attention mask
|
| 264 |
+
attn_weights = attn_weights + attention_mask
|
| 265 |
+
|
| 266 |
+
if position_bias is not None:
|
| 267 |
+
attn_weights += position_bias.type_as(attn_weights).unsqueeze(0)
|
| 268 |
+
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
|
| 269 |
+
|
| 270 |
+
# Downcast (if necessary) back to V's dtype (if in mixed-precision) -- No-Op otherwise
|
| 271 |
+
attn_weights = attn_weights.type(value.dtype)
|
| 272 |
+
attn_weights = self.attn_dropout(attn_weights)
|
| 273 |
+
|
| 274 |
+
# Mask heads if we want to
|
| 275 |
+
if head_mask is not None:
|
| 276 |
+
attn_weights = attn_weights * head_mask
|
| 277 |
+
|
| 278 |
+
attn_output = torch.matmul(attn_weights, value)
|
| 279 |
+
|
| 280 |
+
return attn_output, attn_weights
|
| 281 |
+
|
| 282 |
+
def _upcast_and_reordered_attn(self, query, key, value, attention_mask=None, head_mask=None, position_bias=None):
|
| 283 |
+
# Use `torch.baddbmm` (a bit more efficient w/ alpha param for scaling -- from Megatron-LM)
|
| 284 |
+
bsz, num_heads, q_seq_len, dk = query.size()
|
| 285 |
+
_, _, k_seq_len, _ = key.size()
|
| 286 |
+
|
| 287 |
+
# Preallocate attn_weights for `baddbmm`
|
| 288 |
+
attn_weights = torch.empty(bsz * num_heads, q_seq_len, k_seq_len, dtype=torch.float32, device=query.device)
|
| 289 |
+
|
| 290 |
+
# Compute Scale Factor
|
| 291 |
+
scale_factor = 1.0
|
| 292 |
+
if self.scale_attn_weights:
|
| 293 |
+
scale_factor /= float(value.size(-1)) ** self.attn_scale_power
|
| 294 |
+
|
| 295 |
+
if self.scale_attn_by_inverse_layer_idx:
|
| 296 |
+
scale_factor /= float(self.layer_idx + 1)
|
| 297 |
+
|
| 298 |
+
# Upcast (turn off autocast) and reorder (Scale K by 1 / root(dk))
|
| 299 |
+
with autocast(enabled=False):
|
| 300 |
+
q, k = query.reshape(-1, q_seq_len, dk), key.transpose(-1, -2).reshape(-1, dk, k_seq_len)
|
| 301 |
+
attn_weights = torch.baddbmm(attn_weights, q.float(), k.float(), beta=0, alpha=scale_factor)
|
| 302 |
+
attn_weights = attn_weights.reshape(bsz, num_heads, q_seq_len, k_seq_len)
|
| 303 |
+
|
| 304 |
+
if not self.is_cross_attention:
|
| 305 |
+
# if only "normal" attention layer implements causal mask
|
| 306 |
+
query_length, key_length = query.size(-2), key.size(-2)
|
| 307 |
+
causal_mask = self.bias[:, :, key_length - query_length : key_length, :key_length]
|
| 308 |
+
mask_value = torch.finfo(attn_weights.dtype).min
|
| 309 |
+
# Need to be a tensor, otherwise we get error: `RuntimeError: expected scalar type float but found double`.
|
| 310 |
+
# Need to be on the same device, otherwise `RuntimeError: ..., x and y to be on the same device`
|
| 311 |
+
mask_value = torch.tensor(mask_value, dtype=attn_weights.dtype).to(attn_weights.device)
|
| 312 |
+
attn_weights = torch.where(causal_mask, attn_weights, mask_value)
|
| 313 |
+
|
| 314 |
+
if attention_mask is not None:
|
| 315 |
+
# Apply the attention mask
|
| 316 |
+
attn_weights = attn_weights + attention_mask
|
| 317 |
+
|
| 318 |
+
if position_bias is not None:
|
| 319 |
+
attn_weights += position_bias.type_as(attn_weights).unsqueeze(0)
|
| 320 |
+
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
|
| 321 |
+
|
| 322 |
+
# Downcast (if necessary) back to V's dtype (if in mixed-precision) -- No-Op if otherwise
|
| 323 |
+
if attn_weights.dtype != torch.float32:
|
| 324 |
+
raise RuntimeError("Error with upcasting, attn_weights does not have dtype torch.float32")
|
| 325 |
+
attn_weights = attn_weights.type(value.dtype)
|
| 326 |
+
attn_weights = self.attn_dropout(attn_weights)
|
| 327 |
+
|
| 328 |
+
# Mask heads if we want to
|
| 329 |
+
if head_mask is not None:
|
| 330 |
+
attn_weights = attn_weights * head_mask
|
| 331 |
+
|
| 332 |
+
attn_output = torch.matmul(attn_weights, value)
|
| 333 |
+
|
| 334 |
+
return attn_output, attn_weights
|
| 335 |
+
|
| 336 |
+
def _split_heads(self, tensor, num_heads, attn_head_size):
|
| 337 |
+
"""
|
| 338 |
+
Splits hidden_size dim into attn_head_size and num_heads
|
| 339 |
+
"""
|
| 340 |
+
new_shape = tensor.size()[:-1] + (num_heads, attn_head_size)
|
| 341 |
+
tensor = tensor.view(new_shape)
|
| 342 |
+
return tensor.permute(0, 2, 1, 3) # (batch, head, seq_length, head_features)
|
| 343 |
+
|
| 344 |
+
def _merge_heads(self, tensor, num_heads, attn_head_size):
|
| 345 |
+
"""
|
| 346 |
+
Merges attn_head_size dim and num_attn_heads dim into hidden_size
|
| 347 |
+
"""
|
| 348 |
+
tensor = tensor.permute(0, 2, 1, 3).contiguous()
|
| 349 |
+
new_shape = tensor.size()[:-2] + (num_heads * attn_head_size,)
|
| 350 |
+
return tensor.view(new_shape)
|
| 351 |
+
|
| 352 |
+
def forward(
|
| 353 |
+
self,
|
| 354 |
+
hidden_states: Optional[Tuple[torch.FloatTensor]],
|
| 355 |
+
layer_past: Optional[Tuple[torch.Tensor]] = None,
|
| 356 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 357 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 358 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 359 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 360 |
+
use_cache: Optional[bool] = False,
|
| 361 |
+
output_attentions: Optional[bool] = False,
|
| 362 |
+
position_bias: Optional[torch.FloatTensor] = None,
|
| 363 |
+
) -> Tuple[Union[torch.Tensor, Tuple[torch.Tensor]], ...]:
|
| 364 |
+
if encoder_hidden_states is not None:
|
| 365 |
+
if not hasattr(self, "q_attn"):
|
| 366 |
+
raise ValueError(
|
| 367 |
+
"If class is used as cross attention, the weights `q_attn` have to be defined. "
|
| 368 |
+
"Please make sure to instantiate class with `BTLMAttention(..., is_cross_attention=True)`."
|
| 369 |
+
)
|
| 370 |
+
|
| 371 |
+
query = self.q_attn(hidden_states)
|
| 372 |
+
key, value = self.c_attn(encoder_hidden_states).split(self.split_size, dim=2)
|
| 373 |
+
attention_mask = encoder_attention_mask
|
| 374 |
+
else:
|
| 375 |
+
query, key, value = self.c_attn(hidden_states).split(self.split_size, dim=2)
|
| 376 |
+
|
| 377 |
+
query = self._split_heads(query, self.num_heads, self.head_dim)
|
| 378 |
+
key = self._split_heads(key, self.num_heads, self.head_dim)
|
| 379 |
+
value = self._split_heads(value, self.num_heads, self.head_dim)
|
| 380 |
+
|
| 381 |
+
if layer_past is not None:
|
| 382 |
+
past_key, past_value = layer_past
|
| 383 |
+
key = torch.cat((past_key, key), dim=-2)
|
| 384 |
+
value = torch.cat((past_value, value), dim=-2)
|
| 385 |
+
|
| 386 |
+
if use_cache is True:
|
| 387 |
+
present = (key, value)
|
| 388 |
+
else:
|
| 389 |
+
present = None
|
| 390 |
+
|
| 391 |
+
if self.reorder_and_upcast_attn:
|
| 392 |
+
attn_output, attn_weights = self._upcast_and_reordered_attn(
|
| 393 |
+
query, key, value, attention_mask, head_mask, position_bias
|
| 394 |
+
)
|
| 395 |
+
else:
|
| 396 |
+
attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask, position_bias)
|
| 397 |
+
|
| 398 |
+
attn_output = self._merge_heads(attn_output, self.num_heads, self.head_dim)
|
| 399 |
+
attn_output = self.c_proj(attn_output)
|
| 400 |
+
attn_output = self.resid_dropout(attn_output)
|
| 401 |
+
|
| 402 |
+
outputs = (attn_output, present)
|
| 403 |
+
if output_attentions:
|
| 404 |
+
outputs += (attn_weights,)
|
| 405 |
+
|
| 406 |
+
return outputs # a, present, (attentions)
|
| 407 |
+
|
| 408 |
+
|
| 409 |
+
class BTLMMLP(nn.Module):
|
| 410 |
+
def __init__(self, intermediate_size, config):
|
| 411 |
+
super().__init__()
|
| 412 |
+
embed_dim = config.hidden_size
|
| 413 |
+
self.swiglu = config.activation_function == "swiglu"
|
| 414 |
+
self.c_fc = Conv1D(intermediate_size, embed_dim)
|
| 415 |
+
self.c_fc2 = Conv1D(intermediate_size, embed_dim) if self.swiglu else None
|
| 416 |
+
self.c_proj = Conv1D(embed_dim, intermediate_size)
|
| 417 |
+
self.act = SwiGLUActivation() if self.swiglu else ACT2FN[config.activation_function]
|
| 418 |
+
self.dropout = nn.Dropout(config.resid_pdrop)
|
| 419 |
+
|
| 420 |
+
def forward(self, hidden_states: Optional[Tuple[torch.FloatTensor]]) -> torch.FloatTensor:
|
| 421 |
+
if self.swiglu:
|
| 422 |
+
hidden_states2 = self.c_fc2(hidden_states)
|
| 423 |
+
hidden_states = self.c_fc(hidden_states)
|
| 424 |
+
hidden_states = self.act(hidden_states, hidden_states2) if self.swiglu else self.act(hidden_states)
|
| 425 |
+
hidden_states = self.c_proj(hidden_states)
|
| 426 |
+
hidden_states = self.dropout(hidden_states)
|
| 427 |
+
return hidden_states
|
| 428 |
+
|
| 429 |
+
|
| 430 |
+
class BTLMBlock(nn.Module):
|
| 431 |
+
def __init__(self, config, layer_idx=None):
|
| 432 |
+
super().__init__()
|
| 433 |
+
hidden_size = config.hidden_size
|
| 434 |
+
inner_dim = config.n_inner if config.n_inner is not None else 4 * hidden_size
|
| 435 |
+
|
| 436 |
+
self.ln_1 = nn.LayerNorm(hidden_size, eps=config.layer_norm_epsilon)
|
| 437 |
+
self.attn = BTLMAttention(config, layer_idx=layer_idx)
|
| 438 |
+
self.ln_2 = nn.LayerNorm(hidden_size, eps=config.layer_norm_epsilon)
|
| 439 |
+
|
| 440 |
+
if config.add_cross_attention:
|
| 441 |
+
self.crossattention = BTLMAttention(config, is_cross_attention=True, layer_idx=layer_idx)
|
| 442 |
+
self.ln_cross_attn = nn.LayerNorm(hidden_size, eps=config.layer_norm_epsilon)
|
| 443 |
+
|
| 444 |
+
self.mlp = BTLMMLP(inner_dim, config)
|
| 445 |
+
|
| 446 |
+
def forward(
|
| 447 |
+
self,
|
| 448 |
+
hidden_states: Optional[Tuple[torch.FloatTensor]],
|
| 449 |
+
layer_past: Optional[Tuple[torch.Tensor]] = None,
|
| 450 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 451 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 452 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 453 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 454 |
+
use_cache: Optional[bool] = False,
|
| 455 |
+
output_attentions: Optional[bool] = False,
|
| 456 |
+
position_bias: Optional[torch.FloatTensor] = None,
|
| 457 |
+
) -> Union[Tuple[torch.Tensor], Optional[Tuple[torch.Tensor, Tuple[torch.FloatTensor, ...]]]]:
|
| 458 |
+
residual = hidden_states
|
| 459 |
+
hidden_states = self.ln_1(hidden_states)
|
| 460 |
+
attn_outputs = self.attn(
|
| 461 |
+
hidden_states,
|
| 462 |
+
layer_past=layer_past,
|
| 463 |
+
attention_mask=attention_mask,
|
| 464 |
+
head_mask=head_mask,
|
| 465 |
+
use_cache=use_cache,
|
| 466 |
+
output_attentions=output_attentions,
|
| 467 |
+
position_bias=position_bias,
|
| 468 |
+
)
|
| 469 |
+
attn_output = attn_outputs[0] # output_attn: a, present, (attentions)
|
| 470 |
+
outputs = attn_outputs[1:]
|
| 471 |
+
# residual connection
|
| 472 |
+
hidden_states = attn_output + residual
|
| 473 |
+
|
| 474 |
+
if encoder_hidden_states is not None:
|
| 475 |
+
# add one self-attention block for cross-attention
|
| 476 |
+
if not hasattr(self, "crossattention"):
|
| 477 |
+
raise ValueError(
|
| 478 |
+
f"If `encoder_hidden_states` are passed, {self} has to be instantiated with "
|
| 479 |
+
"cross-attention layers by setting `config.add_cross_attention=True`"
|
| 480 |
+
)
|
| 481 |
+
residual = hidden_states
|
| 482 |
+
hidden_states = self.ln_cross_attn(hidden_states)
|
| 483 |
+
cross_attn_outputs = self.crossattention(
|
| 484 |
+
hidden_states,
|
| 485 |
+
attention_mask=attention_mask,
|
| 486 |
+
head_mask=head_mask,
|
| 487 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 488 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 489 |
+
output_attentions=output_attentions,
|
| 490 |
+
position_bias=position_bias,
|
| 491 |
+
)
|
| 492 |
+
attn_output = cross_attn_outputs[0]
|
| 493 |
+
# residual connection
|
| 494 |
+
hidden_states = residual + attn_output
|
| 495 |
+
outputs = outputs + cross_attn_outputs[2:] # add cross attentions if we output attention weights
|
| 496 |
+
|
| 497 |
+
residual = hidden_states
|
| 498 |
+
hidden_states = self.ln_2(hidden_states)
|
| 499 |
+
feed_forward_hidden_states = self.mlp(hidden_states)
|
| 500 |
+
# residual connection
|
| 501 |
+
hidden_states = residual + feed_forward_hidden_states
|
| 502 |
+
|
| 503 |
+
if use_cache:
|
| 504 |
+
outputs = (hidden_states,) + outputs
|
| 505 |
+
else:
|
| 506 |
+
outputs = (hidden_states,) + outputs[1:]
|
| 507 |
+
|
| 508 |
+
return outputs # hidden_states, present, (attentions, cross_attentions)
|
| 509 |
+
|
| 510 |
+
|
| 511 |
+
class BTLMPreTrainedModel(PreTrainedModel):
|
| 512 |
+
"""
|
| 513 |
+
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
|
| 514 |
+
models.
|
| 515 |
+
"""
|
| 516 |
+
|
| 517 |
+
config_class = BTLMConfig
|
| 518 |
+
load_tf_weights = load_tf_weights_in_btlm
|
| 519 |
+
base_model_prefix = "transformer"
|
| 520 |
+
is_parallelizable = True
|
| 521 |
+
supports_gradient_checkpointing = True
|
| 522 |
+
_no_split_modules = ["BTLMBlock"]
|
| 523 |
+
_skip_keys_device_placement = "past_key_values"
|
| 524 |
+
|
| 525 |
+
def __init__(self, *inputs, **kwargs):
|
| 526 |
+
super().__init__(*inputs, **kwargs)
|
| 527 |
+
|
| 528 |
+
def _init_weights(self, module):
|
| 529 |
+
"""Initialize the weights."""
|
| 530 |
+
mup_init_scale = math.sqrt(self.config.mup_width_scale)
|
| 531 |
+
if isinstance(module, (nn.Linear, Conv1D)):
|
| 532 |
+
# Slightly different from the TF version which uses truncated_normal for initialization
|
| 533 |
+
# cf https://github.com/pytorch/pytorch/pull/5617
|
| 534 |
+
module.weight.data.normal_(mean=0.0, std=(self.config.initializer_range * mup_init_scale))
|
| 535 |
+
if module.bias is not None:
|
| 536 |
+
module.bias.data.zero_()
|
| 537 |
+
elif isinstance(module, nn.Embedding):
|
| 538 |
+
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
|
| 539 |
+
if module.padding_idx is not None:
|
| 540 |
+
module.weight.data[module.padding_idx].zero_()
|
| 541 |
+
elif isinstance(module, nn.LayerNorm):
|
| 542 |
+
module.bias.data.zero_()
|
| 543 |
+
module.weight.data.fill_(1.0)
|
| 544 |
+
|
| 545 |
+
# Reinitialize selected weights subject to the OpenAI GPT-2 Paper Scheme:
|
| 546 |
+
# > A modified initialization which accounts for the accumulation on the residual path with model depth. Scale
|
| 547 |
+
# > the weights of residual layers at initialization by a factor of 1/√N where N is the # of residual layers.
|
| 548 |
+
# > -- GPT-2 :: https://openai.com/blog/better-language-models/
|
| 549 |
+
#
|
| 550 |
+
# Reference (Megatron-LM): https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/model/gpt_model.py
|
| 551 |
+
for name, p in module.named_parameters():
|
| 552 |
+
if name == "c_proj.weight":
|
| 553 |
+
# Special Scaled Initialization --> There are 2 Layer Norms per Transformer Block
|
| 554 |
+
stddev = self.config.initializer_range * mup_init_scale / math.sqrt(2 * self.config.n_layer)
|
| 555 |
+
p.data.normal_(mean=0.0, std=stddev)
|
| 556 |
+
|
| 557 |
+
def _set_gradient_checkpointing(self, module, value=False):
|
| 558 |
+
if isinstance(module, BTLMModel):
|
| 559 |
+
module.gradient_checkpointing = value
|
| 560 |
+
|
| 561 |
+
def get_mup_param_groups(self, lr, weight_decay=0.0, decoupled_wd=True):
|
| 562 |
+
"""
|
| 563 |
+
Returns list of dicts defining parameter groups for muP:
|
| 564 |
+
group 0: most model params get scaled learning rate and weight decay.
|
| 565 |
+
group 1: embedding layer gets non-scaled learning rate and weight decay.
|
| 566 |
+
group 2: normalization layers and biases get non-scaled learning rate only.
|
| 567 |
+
|
| 568 |
+
The output can be passed to Adam-base optimizers
|
| 569 |
+
e.g.
|
| 570 |
+
param_groups = model.get_mup_param_groups(lr=1e-3, weight_decay=0.1)
|
| 571 |
+
torch.optim.AdamW(param_groups, betas=(0.9, 0.95), eps=1e-8)
|
| 572 |
+
"""
|
| 573 |
+
norm_modules = (
|
| 574 |
+
torch.nn.LayerNorm,
|
| 575 |
+
torch.nn.BatchNorm1d,
|
| 576 |
+
torch.nn.BatchNorm2d,
|
| 577 |
+
torch.nn.BatchNorm3d,
|
| 578 |
+
torch.nn.InstanceNorm1d,
|
| 579 |
+
torch.nn.InstanceNorm2d,
|
| 580 |
+
torch.nn.InstanceNorm3d,
|
| 581 |
+
torch.nn.GroupNorm,
|
| 582 |
+
torch.nn.SyncBatchNorm,
|
| 583 |
+
torch.nn.LocalResponseNorm,
|
| 584 |
+
)
|
| 585 |
+
|
| 586 |
+
def get_group_index(param_name):
|
| 587 |
+
for name, module in self.named_modules():
|
| 588 |
+
if name in param_name:
|
| 589 |
+
if isinstance(module, norm_modules):
|
| 590 |
+
return 2
|
| 591 |
+
elif isinstance(module, torch.nn.Embedding):
|
| 592 |
+
return 1
|
| 593 |
+
return 0
|
| 594 |
+
|
| 595 |
+
width_scale = self.config.mup_width_scale
|
| 596 |
+
new_param_groups = []
|
| 597 |
+
new_param_groups.append({"params": [], "lr": lr * width_scale, "weight_decay": weight_decay})
|
| 598 |
+
if not decoupled_wd:
|
| 599 |
+
new_param_groups[0]["weight_decay"] /= width_scale
|
| 600 |
+
new_param_groups.append({"params": [], "lr": lr, "weight_decay": weight_decay})
|
| 601 |
+
new_param_groups.append({"params": [], "lr": lr, "weight_decay": 0.0})
|
| 602 |
+
|
| 603 |
+
for name, param in self.named_parameters():
|
| 604 |
+
if not param.requires_grad:
|
| 605 |
+
continue
|
| 606 |
+
|
| 607 |
+
if name.endswith("bias"):
|
| 608 |
+
new_param_groups[2]["params"].append(param)
|
| 609 |
+
else:
|
| 610 |
+
new_param_groups[get_group_index(name)]["params"].append(param)
|
| 611 |
+
|
| 612 |
+
for idx, param_group in enumerate(new_param_groups):
|
| 613 |
+
if len(param_group["params"]) == 0:
|
| 614 |
+
del new_param_groups[idx]
|
| 615 |
+
|
| 616 |
+
return new_param_groups
|
| 617 |
+
|
| 618 |
+
|
| 619 |
+
BTLM_START_DOCSTRING = r"""
|
| 620 |
+
|
| 621 |
+
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
|
| 622 |
+
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
|
| 623 |
+
etc.)
|
| 624 |
+
|
| 625 |
+
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
|
| 626 |
+
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
|
| 627 |
+
and behavior.
|
| 628 |
+
|
| 629 |
+
Parameters:
|
| 630 |
+
config ([`BTLMConfig`]): Model configuration class with all the parameters of the model.
|
| 631 |
+
Initializing with a config file does not load the weights associated with the model, only the
|
| 632 |
+
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
|
| 633 |
+
"""
|
| 634 |
+
|
| 635 |
+
BTLM_INPUTS_DOCSTRING = r"""
|
| 636 |
+
Args:
|
| 637 |
+
input_ids (`torch.LongTensor` of shape `(batch_size, input_ids_length)`):
|
| 638 |
+
`input_ids_length` = `sequence_length` if `past_key_values` is `None` else
|
| 639 |
+
`past_key_values[0][0].shape[-2]` (`sequence_length` of input past key value states). Indices of input
|
| 640 |
+
sequence tokens in the vocabulary.
|
| 641 |
+
|
| 642 |
+
If `past_key_values` is used, only `input_ids` that do not have their past calculated should be passed as
|
| 643 |
+
`input_ids`.
|
| 644 |
+
|
| 645 |
+
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
|
| 646 |
+
[`PreTrainedTokenizer.__call__`] for details.
|
| 647 |
+
|
| 648 |
+
[What are input IDs?](../glossary#input-ids)
|
| 649 |
+
past_key_values (`Tuple[Tuple[torch.Tensor]]` of length `config.n_layers`):
|
| 650 |
+
Contains precomputed hidden-states (key and values in the attention blocks) as computed by the model (see
|
| 651 |
+
`past_key_values` output below). Can be used to speed up sequential decoding. The `input_ids` which have
|
| 652 |
+
their past given to this model should not be passed as `input_ids` as they have already been computed.
|
| 653 |
+
attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 654 |
+
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
|
| 655 |
+
|
| 656 |
+
- 1 for tokens that are **not masked**,
|
| 657 |
+
- 0 for tokens that are **masked**.
|
| 658 |
+
|
| 659 |
+
If `past_key_values` is used, `attention_mask` needs to contain the masking strategy that was used for
|
| 660 |
+
`past_key_values`. In other words, the `attention_mask` always has to have the length:
|
| 661 |
+
`len(past_key_values) + len(input_ids)`
|
| 662 |
+
|
| 663 |
+
[What are attention masks?](../glossary#attention-mask)
|
| 664 |
+
token_type_ids (`torch.LongTensor` of shape `(batch_size, input_ids_length)`, *optional*):
|
| 665 |
+
Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0,
|
| 666 |
+
1]`:
|
| 667 |
+
|
| 668 |
+
- 0 corresponds to a *sentence A* token,
|
| 669 |
+
- 1 corresponds to a *sentence B* token.
|
| 670 |
+
|
| 671 |
+
[What are token type IDs?](../glossary#token-type-ids)
|
| 672 |
+
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 673 |
+
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
|
| 674 |
+
config.max_position_embeddings - 1]`.
|
| 675 |
+
|
| 676 |
+
[What are position IDs?](../glossary#position-ids)
|
| 677 |
+
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
|
| 678 |
+
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
|
| 679 |
+
|
| 680 |
+
- 1 indicates the head is **not masked**,
|
| 681 |
+
- 0 indicates the head is **masked**.
|
| 682 |
+
|
| 683 |
+
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
|
| 684 |
+
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
|
| 685 |
+
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
|
| 686 |
+
model's internal embedding lookup matrix.
|
| 687 |
+
|
| 688 |
+
If `past_key_values` is used, optionally only the last `inputs_embeds` have to be input (see
|
| 689 |
+
`past_key_values`).
|
| 690 |
+
use_cache (`bool`, *optional*):
|
| 691 |
+
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
|
| 692 |
+
`past_key_values`).
|
| 693 |
+
output_attentions (`bool`, *optional*):
|
| 694 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
|
| 695 |
+
tensors for more detail.
|
| 696 |
+
output_hidden_states (`bool`, *optional*):
|
| 697 |
+
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
|
| 698 |
+
more detail.
|
| 699 |
+
return_dict (`bool`, *optional*):
|
| 700 |
+
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
| 701 |
+
"""
|
| 702 |
+
PARALLELIZE_DOCSTRING = r"""
|
| 703 |
+
This is an experimental feature and is a subject to change at a moment's notice.
|
| 704 |
+
|
| 705 |
+
Uses a device map to distribute attention modules of the model across several devices. If no device map is given,
|
| 706 |
+
it will evenly distribute blocks across all devices.
|
| 707 |
+
|
| 708 |
+
Args:
|
| 709 |
+
device_map (`Dict[int, list]`, optional, defaults to None):
|
| 710 |
+
A dictionary that maps attention modules to devices. Note that the embedding module and LMHead are always
|
| 711 |
+
automatically mapped to the first device (for esoteric reasons). That means that the first device should
|
| 712 |
+
have fewer attention modules mapped to it than other devices. For reference, the gpt2 models have the
|
| 713 |
+
following number of attention modules:
|
| 714 |
+
|
| 715 |
+
- gpt2: 12
|
| 716 |
+
- gpt2-medium: 24
|
| 717 |
+
- gpt2-large: 36
|
| 718 |
+
- gpt2-xl: 48
|
| 719 |
+
|
| 720 |
+
Example:
|
| 721 |
+
|
| 722 |
+
```python
|
| 723 |
+
# Here is an example of a device map on a machine with 4 GPUs using gpt2-xl, which has a total of 48 attention modules:
|
| 724 |
+
model = GPT2LMHeadModel.from_pretrained("gpt2-xl")
|
| 725 |
+
device_map = {
|
| 726 |
+
0: [0, 1, 2, 3, 4, 5, 6, 7, 8],
|
| 727 |
+
1: [9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21],
|
| 728 |
+
2: [22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34],
|
| 729 |
+
3: [35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47],
|
| 730 |
+
}
|
| 731 |
+
model.parallelize(device_map)
|
| 732 |
+
```
|
| 733 |
+
"""
|
| 734 |
+
DEPARALLELIZE_DOCSTRING = r"""
|
| 735 |
+
Moves the model to cpu from a model parallel state.
|
| 736 |
+
|
| 737 |
+
Example:
|
| 738 |
+
|
| 739 |
+
```python
|
| 740 |
+
# On a 4 GPU machine with gpt2-large:
|
| 741 |
+
model = GPT2LMHeadModel.from_pretrained("gpt2-large")
|
| 742 |
+
device_map = {
|
| 743 |
+
0: [0, 1, 2, 3, 4, 5, 6, 7],
|
| 744 |
+
1: [8, 9, 10, 11, 12, 13, 14, 15],
|
| 745 |
+
2: [16, 17, 18, 19, 20, 21, 22, 23],
|
| 746 |
+
3: [24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35],
|
| 747 |
+
}
|
| 748 |
+
model.parallelize(device_map) # Splits the model across several devices
|
| 749 |
+
model.deparallelize() # Put the model back on cpu and cleans memory by calling torch.cuda.empty_cache()
|
| 750 |
+
```
|
| 751 |
+
"""
|
| 752 |
+
|
| 753 |
+
|
| 754 |
+
@add_start_docstrings(
|
| 755 |
+
"The bare BTLM Model transformer outputting raw hidden-states without any specific head on top.",
|
| 756 |
+
BTLM_START_DOCSTRING,
|
| 757 |
+
)
|
| 758 |
+
class BTLMModel(BTLMPreTrainedModel):
|
| 759 |
+
_keys_to_ignore_on_load_unexpected = [r"h\.\d+\.attn\.bias", r"h\.\d+\.attn\.masked_bias"]
|
| 760 |
+
_keys_to_ignore_on_load_missing = [r"attn.masked_bias", r"h\.\d+\.attn\.masked_bias", r"h\.\d+\.attn\.bias"]
|
| 761 |
+
|
| 762 |
+
def __init__(self, config):
|
| 763 |
+
super().__init__(config)
|
| 764 |
+
|
| 765 |
+
self.embed_dim = config.hidden_size
|
| 766 |
+
|
| 767 |
+
self.wte = nn.Embedding(config.vocab_size, self.embed_dim)
|
| 768 |
+
self.wpe = (
|
| 769 |
+
nn.Embedding(config.max_position_embeddings, self.embed_dim)
|
| 770 |
+
if config.position_embedding_type != "alibi"
|
| 771 |
+
else None
|
| 772 |
+
)
|
| 773 |
+
self.embeddings_scale = config.mup_embeddings_scale
|
| 774 |
+
|
| 775 |
+
self.drop = nn.Dropout(config.embd_pdrop)
|
| 776 |
+
self.h = nn.ModuleList([BTLMBlock(config, layer_idx=i) for i in range(config.num_hidden_layers)])
|
| 777 |
+
self.ln_f = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_epsilon)
|
| 778 |
+
|
| 779 |
+
self.relative_pe = (
|
| 780 |
+
AlibiPositionEmbeddingLayer(config.num_attention_heads, config.alibi_scaling)
|
| 781 |
+
if config.position_embedding_type == "alibi"
|
| 782 |
+
else None
|
| 783 |
+
)
|
| 784 |
+
|
| 785 |
+
# Model parallel
|
| 786 |
+
self.model_parallel = False
|
| 787 |
+
self.device_map = None
|
| 788 |
+
self.gradient_checkpointing = False
|
| 789 |
+
|
| 790 |
+
# Initialize weights and apply final processing
|
| 791 |
+
self.post_init()
|
| 792 |
+
|
| 793 |
+
@add_start_docstrings(PARALLELIZE_DOCSTRING)
|
| 794 |
+
def parallelize(self, device_map=None):
|
| 795 |
+
# Check validity of device_map
|
| 796 |
+
warnings.warn(
|
| 797 |
+
"`BTLMModel.parallelize` is deprecated and will be removed in v5 of Transformers, you should load your"
|
| 798 |
+
" model with `device_map='balanced'` in the call to `from_pretrained`. You can also provide your own"
|
| 799 |
+
" `device_map` but it needs to be a dictionary module_name to device, so for instance {'h.0': 0, 'h.1': 1,"
|
| 800 |
+
" ...}",
|
| 801 |
+
FutureWarning,
|
| 802 |
+
)
|
| 803 |
+
self.device_map = (
|
| 804 |
+
get_device_map(len(self.h), range(torch.cuda.device_count())) if device_map is None else device_map
|
| 805 |
+
)
|
| 806 |
+
assert_device_map(self.device_map, len(self.h))
|
| 807 |
+
self.model_parallel = True
|
| 808 |
+
self.first_device = "cpu" if "cpu" in self.device_map.keys() else "cuda:" + str(min(self.device_map.keys()))
|
| 809 |
+
self.last_device = "cuda:" + str(max(self.device_map.keys()))
|
| 810 |
+
self.wte = self.wte.to(self.first_device)
|
| 811 |
+
if self.wpe is not None:
|
| 812 |
+
self.wpe = self.wpe.to(self.first_device)
|
| 813 |
+
# Load onto devices
|
| 814 |
+
for k, v in self.device_map.items():
|
| 815 |
+
for block in v:
|
| 816 |
+
cuda_device = "cuda:" + str(k)
|
| 817 |
+
self.h[block] = self.h[block].to(cuda_device)
|
| 818 |
+
# ln_f to last
|
| 819 |
+
self.ln_f = self.ln_f.to(self.last_device)
|
| 820 |
+
|
| 821 |
+
@add_start_docstrings(DEPARALLELIZE_DOCSTRING)
|
| 822 |
+
def deparallelize(self):
|
| 823 |
+
warnings.warn(
|
| 824 |
+
"Like `parallelize`, `deparallelize` is deprecated and will be removed in v5 of Transformers.",
|
| 825 |
+
FutureWarning,
|
| 826 |
+
)
|
| 827 |
+
self.model_parallel = False
|
| 828 |
+
self.device_map = None
|
| 829 |
+
self.first_device = "cpu"
|
| 830 |
+
self.last_device = "cpu"
|
| 831 |
+
self.wte = self.wte.to("cpu")
|
| 832 |
+
if self.wpe is not None:
|
| 833 |
+
self.wpe = self.wpe.to("cpu")
|
| 834 |
+
for index in range(len(self.h)):
|
| 835 |
+
self.h[index] = self.h[index].to("cpu")
|
| 836 |
+
self.ln_f = self.ln_f.to("cpu")
|
| 837 |
+
torch.cuda.empty_cache()
|
| 838 |
+
|
| 839 |
+
def get_input_embeddings(self):
|
| 840 |
+
return self.wte
|
| 841 |
+
|
| 842 |
+
def set_input_embeddings(self, new_embeddings):
|
| 843 |
+
self.wte = new_embeddings
|
| 844 |
+
|
| 845 |
+
def _prune_heads(self, heads_to_prune):
|
| 846 |
+
"""
|
| 847 |
+
Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer}
|
| 848 |
+
"""
|
| 849 |
+
for layer, heads in heads_to_prune.items():
|
| 850 |
+
self.h[layer].attn.prune_heads(heads)
|
| 851 |
+
|
| 852 |
+
@add_start_docstrings_to_model_forward(BTLM_INPUTS_DOCSTRING)
|
| 853 |
+
@add_code_sample_docstrings(
|
| 854 |
+
checkpoint=_CHECKPOINT_FOR_DOC,
|
| 855 |
+
output_type=BaseModelOutputWithPastAndCrossAttentions,
|
| 856 |
+
config_class=_CONFIG_FOR_DOC,
|
| 857 |
+
)
|
| 858 |
+
def forward(
|
| 859 |
+
self,
|
| 860 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 861 |
+
past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
|
| 862 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 863 |
+
token_type_ids: Optional[torch.LongTensor] = None,
|
| 864 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 865 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 866 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 867 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 868 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 869 |
+
use_cache: Optional[bool] = None,
|
| 870 |
+
output_attentions: Optional[bool] = None,
|
| 871 |
+
output_hidden_states: Optional[bool] = None,
|
| 872 |
+
return_dict: Optional[bool] = None,
|
| 873 |
+
) -> Union[Tuple, BaseModelOutputWithPastAndCrossAttentions]:
|
| 874 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 875 |
+
output_hidden_states = (
|
| 876 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 877 |
+
)
|
| 878 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 879 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 880 |
+
|
| 881 |
+
if input_ids is not None and inputs_embeds is not None:
|
| 882 |
+
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
|
| 883 |
+
elif input_ids is not None:
|
| 884 |
+
input_shape = input_ids.size()
|
| 885 |
+
input_ids = input_ids.view(-1, input_shape[-1])
|
| 886 |
+
batch_size = input_ids.shape[0]
|
| 887 |
+
elif inputs_embeds is not None:
|
| 888 |
+
input_shape = inputs_embeds.size()[:-1]
|
| 889 |
+
batch_size = inputs_embeds.shape[0]
|
| 890 |
+
else:
|
| 891 |
+
raise ValueError("You have to specify either input_ids or inputs_embeds")
|
| 892 |
+
|
| 893 |
+
device = input_ids.device if input_ids is not None else inputs_embeds.device
|
| 894 |
+
|
| 895 |
+
if token_type_ids is not None:
|
| 896 |
+
token_type_ids = token_type_ids.view(-1, input_shape[-1])
|
| 897 |
+
if position_ids is not None:
|
| 898 |
+
position_ids = position_ids.view(-1, input_shape[-1])
|
| 899 |
+
|
| 900 |
+
if past_key_values is None:
|
| 901 |
+
past_length = 0
|
| 902 |
+
past_key_values = tuple([None] * len(self.h))
|
| 903 |
+
else:
|
| 904 |
+
past_length = past_key_values[0][0].size(-2)
|
| 905 |
+
if position_ids is None:
|
| 906 |
+
position_ids = torch.arange(past_length, input_shape[-1] + past_length, dtype=torch.long, device=device)
|
| 907 |
+
position_ids = position_ids.unsqueeze(0).view(-1, input_shape[-1])
|
| 908 |
+
|
| 909 |
+
# BTLMAttention mask.
|
| 910 |
+
if attention_mask is not None:
|
| 911 |
+
if batch_size <= 0:
|
| 912 |
+
raise ValueError("batch_size has to be defined and > 0")
|
| 913 |
+
attention_mask = attention_mask.view(batch_size, -1)
|
| 914 |
+
# We create a 3D attention mask from a 2D tensor mask.
|
| 915 |
+
# Sizes are [batch_size, 1, 1, to_seq_length]
|
| 916 |
+
# So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
|
| 917 |
+
# this attention mask is more simple than the triangular masking of causal attention
|
| 918 |
+
# used in OpenAI GPT, we just need to prepare the broadcast dimension here.
|
| 919 |
+
attention_mask = attention_mask[:, None, None, :]
|
| 920 |
+
|
| 921 |
+
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
|
| 922 |
+
# masked positions, this operation will create a tensor which is 0.0 for
|
| 923 |
+
# positions we want to attend and the dtype's smallest value for masked positions.
|
| 924 |
+
# Since we are adding it to the raw scores before the softmax, this is
|
| 925 |
+
# effectively the same as removing these entirely.
|
| 926 |
+
attention_mask = attention_mask.to(dtype=self.dtype) # fp16 compatibility
|
| 927 |
+
attention_mask = (1.0 - attention_mask) * torch.finfo(self.dtype).min
|
| 928 |
+
|
| 929 |
+
# If a 2D or 3D attention mask is provided for the cross-attention
|
| 930 |
+
# we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
|
| 931 |
+
if self.config.add_cross_attention and encoder_hidden_states is not None:
|
| 932 |
+
encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
|
| 933 |
+
encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
|
| 934 |
+
if encoder_attention_mask is None:
|
| 935 |
+
encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
|
| 936 |
+
encoder_attention_mask = self.invert_attention_mask(encoder_attention_mask)
|
| 937 |
+
else:
|
| 938 |
+
encoder_attention_mask = None
|
| 939 |
+
|
| 940 |
+
# Prepare head mask if needed
|
| 941 |
+
# 1.0 in head_mask indicate we keep the head
|
| 942 |
+
# attention_probs has shape bsz x n_heads x N x N
|
| 943 |
+
# head_mask has shape n_layer x batch x n_heads x N x N
|
| 944 |
+
head_mask = self.get_head_mask(head_mask, self.config.n_layer)
|
| 945 |
+
|
| 946 |
+
if inputs_embeds is None:
|
| 947 |
+
inputs_embeds = self.wte(input_ids)
|
| 948 |
+
if self.wpe is not None:
|
| 949 |
+
position_embeds = self.wpe(position_ids)
|
| 950 |
+
hidden_states = inputs_embeds + position_embeds
|
| 951 |
+
else:
|
| 952 |
+
hidden_states = inputs_embeds
|
| 953 |
+
hidden_states *= torch.tensor(
|
| 954 |
+
float(self.embeddings_scale), dtype=hidden_states.dtype, device=hidden_states.device
|
| 955 |
+
)
|
| 956 |
+
|
| 957 |
+
if token_type_ids is not None:
|
| 958 |
+
token_type_embeds = self.wte(token_type_ids)
|
| 959 |
+
hidden_states = hidden_states + token_type_embeds
|
| 960 |
+
|
| 961 |
+
hidden_states = self.drop(hidden_states)
|
| 962 |
+
|
| 963 |
+
if self.relative_pe is not None:
|
| 964 |
+
length = input_ids.shape[1]
|
| 965 |
+
cached_kv_length = 0
|
| 966 |
+
cached_kv = past_key_values[0]
|
| 967 |
+
if cached_kv is not None:
|
| 968 |
+
cached_kv_length = cached_kv[0].shape[-2]
|
| 969 |
+
position_bias = self.relative_pe(length, length, cached_kv_length)
|
| 970 |
+
else:
|
| 971 |
+
position_bias = None
|
| 972 |
+
|
| 973 |
+
output_shape = input_shape + (hidden_states.size(-1),)
|
| 974 |
+
|
| 975 |
+
if self.gradient_checkpointing and self.training:
|
| 976 |
+
if use_cache:
|
| 977 |
+
logger.warning_once(
|
| 978 |
+
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
|
| 979 |
+
)
|
| 980 |
+
use_cache = False
|
| 981 |
+
|
| 982 |
+
presents = () if use_cache else None
|
| 983 |
+
all_self_attentions = () if output_attentions else None
|
| 984 |
+
all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
|
| 985 |
+
all_hidden_states = () if output_hidden_states else None
|
| 986 |
+
for i, (block, layer_past) in enumerate(zip(self.h, past_key_values)):
|
| 987 |
+
# Model parallel
|
| 988 |
+
if self.model_parallel:
|
| 989 |
+
torch.cuda.set_device(hidden_states.device)
|
| 990 |
+
# Ensure layer_past is on same device as hidden_states (might not be correct)
|
| 991 |
+
if layer_past is not None:
|
| 992 |
+
layer_past = tuple(past_state.to(hidden_states.device) for past_state in layer_past)
|
| 993 |
+
# Ensure that attention_mask is always on the same device as hidden_states
|
| 994 |
+
if attention_mask is not None:
|
| 995 |
+
attention_mask = attention_mask.to(hidden_states.device)
|
| 996 |
+
if isinstance(head_mask, torch.Tensor):
|
| 997 |
+
head_mask = head_mask.to(hidden_states.device)
|
| 998 |
+
if output_hidden_states:
|
| 999 |
+
all_hidden_states = all_hidden_states + (hidden_states,)
|
| 1000 |
+
|
| 1001 |
+
if self.gradient_checkpointing and self.training:
|
| 1002 |
+
|
| 1003 |
+
def create_custom_forward(module):
|
| 1004 |
+
def custom_forward(*inputs):
|
| 1005 |
+
# None for past_key_value
|
| 1006 |
+
return module(*inputs, use_cache, output_attentions)
|
| 1007 |
+
|
| 1008 |
+
return custom_forward
|
| 1009 |
+
|
| 1010 |
+
outputs = torch.utils.checkpoint.checkpoint(
|
| 1011 |
+
create_custom_forward(block),
|
| 1012 |
+
hidden_states,
|
| 1013 |
+
None,
|
| 1014 |
+
attention_mask,
|
| 1015 |
+
head_mask[i],
|
| 1016 |
+
encoder_hidden_states,
|
| 1017 |
+
encoder_attention_mask,
|
| 1018 |
+
)
|
| 1019 |
+
else:
|
| 1020 |
+
outputs = block(
|
| 1021 |
+
hidden_states,
|
| 1022 |
+
layer_past=layer_past,
|
| 1023 |
+
attention_mask=attention_mask,
|
| 1024 |
+
head_mask=head_mask[i],
|
| 1025 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1026 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1027 |
+
use_cache=use_cache,
|
| 1028 |
+
output_attentions=output_attentions,
|
| 1029 |
+
position_bias=position_bias,
|
| 1030 |
+
)
|
| 1031 |
+
|
| 1032 |
+
hidden_states = outputs[0]
|
| 1033 |
+
if use_cache is True:
|
| 1034 |
+
presents = presents + (outputs[1],)
|
| 1035 |
+
|
| 1036 |
+
if output_attentions:
|
| 1037 |
+
all_self_attentions = all_self_attentions + (outputs[2 if use_cache else 1],)
|
| 1038 |
+
if self.config.add_cross_attention:
|
| 1039 |
+
all_cross_attentions = all_cross_attentions + (outputs[3 if use_cache else 2],)
|
| 1040 |
+
|
| 1041 |
+
# Model Parallel: If it's the last layer for that device, put things on the next device
|
| 1042 |
+
if self.model_parallel:
|
| 1043 |
+
for k, v in self.device_map.items():
|
| 1044 |
+
if i == v[-1] and "cuda:" + str(k) != self.last_device:
|
| 1045 |
+
hidden_states = hidden_states.to("cuda:" + str(k + 1))
|
| 1046 |
+
|
| 1047 |
+
hidden_states = self.ln_f(hidden_states)
|
| 1048 |
+
|
| 1049 |
+
hidden_states = hidden_states.view(output_shape)
|
| 1050 |
+
# Add last hidden state
|
| 1051 |
+
if output_hidden_states:
|
| 1052 |
+
all_hidden_states = all_hidden_states + (hidden_states,)
|
| 1053 |
+
|
| 1054 |
+
if not return_dict:
|
| 1055 |
+
return tuple(
|
| 1056 |
+
v
|
| 1057 |
+
for v in [hidden_states, presents, all_hidden_states, all_self_attentions, all_cross_attentions]
|
| 1058 |
+
if v is not None
|
| 1059 |
+
)
|
| 1060 |
+
|
| 1061 |
+
return BaseModelOutputWithPastAndCrossAttentions(
|
| 1062 |
+
last_hidden_state=hidden_states,
|
| 1063 |
+
past_key_values=presents,
|
| 1064 |
+
hidden_states=all_hidden_states,
|
| 1065 |
+
attentions=all_self_attentions,
|
| 1066 |
+
cross_attentions=all_cross_attentions,
|
| 1067 |
+
)
|
| 1068 |
+
|
| 1069 |
+
|
| 1070 |
+
@add_start_docstrings(
|
| 1071 |
+
"""
|
| 1072 |
+
The BTLM Model transformer with a language modeling head on top (linear layer with weights tied to the input
|
| 1073 |
+
embeddings).
|
| 1074 |
+
""",
|
| 1075 |
+
BTLM_START_DOCSTRING,
|
| 1076 |
+
)
|
| 1077 |
+
class BTLMLMHeadModel(BTLMPreTrainedModel):
|
| 1078 |
+
_keys_to_ignore_on_load_missing = [r"lm_head.weight"]
|
| 1079 |
+
_keys_to_ignore_on_load_unexpected = [r"h\.\d+\.attn\.masked_bias", r"h\.\d+\.attn\.bias"]
|
| 1080 |
+
|
| 1081 |
+
def __init__(self, config):
|
| 1082 |
+
super().__init__(config)
|
| 1083 |
+
self.transformer = BTLMModel(config)
|
| 1084 |
+
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
|
| 1085 |
+
self.output_logits_scale = config.mup_output_alpha * config.mup_width_scale
|
| 1086 |
+
|
| 1087 |
+
# Model parallel
|
| 1088 |
+
self.model_parallel = False
|
| 1089 |
+
self.device_map = None
|
| 1090 |
+
|
| 1091 |
+
# Initialize weights and apply final processing
|
| 1092 |
+
self.post_init()
|
| 1093 |
+
|
| 1094 |
+
@add_start_docstrings(PARALLELIZE_DOCSTRING)
|
| 1095 |
+
def parallelize(self, device_map=None):
|
| 1096 |
+
warnings.warn(
|
| 1097 |
+
"`BTLMLMHeadModel.parallelize` is deprecated and will be removed in v5 of Transformers, you should load"
|
| 1098 |
+
" your model with `device_map='balanced'` in the call to `from_pretrained`. You can also provide your own"
|
| 1099 |
+
" `device_map` but it needs to be a dictionary module_name to device, so for instance {'transformer.h.0':"
|
| 1100 |
+
" 0, 'transformer.h.1': 1, ...}",
|
| 1101 |
+
FutureWarning,
|
| 1102 |
+
)
|
| 1103 |
+
self.device_map = (
|
| 1104 |
+
get_device_map(len(self.transformer.h), range(torch.cuda.device_count()))
|
| 1105 |
+
if device_map is None
|
| 1106 |
+
else device_map
|
| 1107 |
+
)
|
| 1108 |
+
assert_device_map(self.device_map, len(self.transformer.h))
|
| 1109 |
+
self.transformer.parallelize(self.device_map)
|
| 1110 |
+
self.lm_head = self.lm_head.to(self.transformer.first_device)
|
| 1111 |
+
self.model_parallel = True
|
| 1112 |
+
|
| 1113 |
+
@add_start_docstrings(DEPARALLELIZE_DOCSTRING)
|
| 1114 |
+
def deparallelize(self):
|
| 1115 |
+
warnings.warn(
|
| 1116 |
+
"Like `parallelize`, `deparallelize` is deprecated and will be removed in v5 of Transformers.",
|
| 1117 |
+
FutureWarning,
|
| 1118 |
+
)
|
| 1119 |
+
self.transformer.deparallelize()
|
| 1120 |
+
self.transformer = self.transformer.to("cpu")
|
| 1121 |
+
self.lm_head = self.lm_head.to("cpu")
|
| 1122 |
+
self.model_parallel = False
|
| 1123 |
+
torch.cuda.empty_cache()
|
| 1124 |
+
|
| 1125 |
+
def get_output_embeddings(self):
|
| 1126 |
+
return self.lm_head
|
| 1127 |
+
|
| 1128 |
+
def set_output_embeddings(self, new_embeddings):
|
| 1129 |
+
self.lm_head = new_embeddings
|
| 1130 |
+
|
| 1131 |
+
def prepare_inputs_for_generation(self, input_ids, past_key_values=None, inputs_embeds=None, **kwargs):
|
| 1132 |
+
token_type_ids = kwargs.get("token_type_ids", None)
|
| 1133 |
+
# only last token for inputs_ids if past is defined in kwargs
|
| 1134 |
+
if past_key_values:
|
| 1135 |
+
input_ids = input_ids[:, -1].unsqueeze(-1)
|
| 1136 |
+
if token_type_ids is not None:
|
| 1137 |
+
token_type_ids = token_type_ids[:, -1].unsqueeze(-1)
|
| 1138 |
+
|
| 1139 |
+
attention_mask = kwargs.get("attention_mask", None)
|
| 1140 |
+
position_ids = kwargs.get("position_ids", None)
|
| 1141 |
+
|
| 1142 |
+
if attention_mask is not None and position_ids is None:
|
| 1143 |
+
# create position_ids on the fly for batch generation
|
| 1144 |
+
position_ids = attention_mask.long().cumsum(-1) - 1
|
| 1145 |
+
position_ids.masked_fill_(attention_mask == 0, 1)
|
| 1146 |
+
if past_key_values:
|
| 1147 |
+
position_ids = position_ids[:, -1].unsqueeze(-1)
|
| 1148 |
+
else:
|
| 1149 |
+
position_ids = None
|
| 1150 |
+
|
| 1151 |
+
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
|
| 1152 |
+
if inputs_embeds is not None and past_key_values is None:
|
| 1153 |
+
model_inputs = {"inputs_embeds": inputs_embeds}
|
| 1154 |
+
else:
|
| 1155 |
+
model_inputs = {"input_ids": input_ids}
|
| 1156 |
+
|
| 1157 |
+
model_inputs.update(
|
| 1158 |
+
{
|
| 1159 |
+
"past_key_values": past_key_values,
|
| 1160 |
+
"use_cache": kwargs.get("use_cache"),
|
| 1161 |
+
"position_ids": position_ids,
|
| 1162 |
+
"attention_mask": attention_mask,
|
| 1163 |
+
"token_type_ids": token_type_ids,
|
| 1164 |
+
}
|
| 1165 |
+
)
|
| 1166 |
+
return model_inputs
|
| 1167 |
+
|
| 1168 |
+
@add_start_docstrings_to_model_forward(BTLM_INPUTS_DOCSTRING)
|
| 1169 |
+
@add_code_sample_docstrings(
|
| 1170 |
+
checkpoint=_CHECKPOINT_FOR_DOC,
|
| 1171 |
+
output_type=CausalLMOutputWithCrossAttentions,
|
| 1172 |
+
config_class=_CONFIG_FOR_DOC,
|
| 1173 |
+
)
|
| 1174 |
+
def forward(
|
| 1175 |
+
self,
|
| 1176 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 1177 |
+
past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
|
| 1178 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 1179 |
+
token_type_ids: Optional[torch.LongTensor] = None,
|
| 1180 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 1181 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 1182 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 1183 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 1184 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 1185 |
+
labels: Optional[torch.LongTensor] = None,
|
| 1186 |
+
use_cache: Optional[bool] = None,
|
| 1187 |
+
output_attentions: Optional[bool] = None,
|
| 1188 |
+
output_hidden_states: Optional[bool] = None,
|
| 1189 |
+
return_dict: Optional[bool] = None,
|
| 1190 |
+
) -> Union[Tuple, CausalLMOutputWithCrossAttentions]:
|
| 1191 |
+
r"""
|
| 1192 |
+
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 1193 |
+
Labels for language modeling. Note that the labels **are shifted** inside the model, i.e. you can set
|
| 1194 |
+
`labels = input_ids` Indices are selected in `[-100, 0, ..., config.vocab_size]` All labels set to `-100`
|
| 1195 |
+
are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size]`
|
| 1196 |
+
"""
|
| 1197 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1198 |
+
|
| 1199 |
+
transformer_outputs = self.transformer(
|
| 1200 |
+
input_ids,
|
| 1201 |
+
past_key_values=past_key_values,
|
| 1202 |
+
attention_mask=attention_mask,
|
| 1203 |
+
token_type_ids=token_type_ids,
|
| 1204 |
+
position_ids=position_ids,
|
| 1205 |
+
head_mask=head_mask,
|
| 1206 |
+
inputs_embeds=inputs_embeds,
|
| 1207 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1208 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1209 |
+
use_cache=use_cache,
|
| 1210 |
+
output_attentions=output_attentions,
|
| 1211 |
+
output_hidden_states=output_hidden_states,
|
| 1212 |
+
return_dict=return_dict,
|
| 1213 |
+
)
|
| 1214 |
+
hidden_states = transformer_outputs[0]
|
| 1215 |
+
|
| 1216 |
+
# Set device for model parallelism
|
| 1217 |
+
if self.model_parallel:
|
| 1218 |
+
torch.cuda.set_device(self.transformer.first_device)
|
| 1219 |
+
hidden_states = hidden_states.to(self.lm_head.weight.device)
|
| 1220 |
+
|
| 1221 |
+
lm_logits = self.lm_head(hidden_states)
|
| 1222 |
+
lm_logits *= torch.tensor(float(self.output_logits_scale), dtype=lm_logits.dtype, device=lm_logits.device)
|
| 1223 |
+
|
| 1224 |
+
loss = None
|
| 1225 |
+
if labels is not None:
|
| 1226 |
+
# move labels to correct device to enable model parallelism
|
| 1227 |
+
labels = labels.to(lm_logits.device)
|
| 1228 |
+
# Shift so that tokens < n predict n
|
| 1229 |
+
shift_logits = lm_logits[..., :-1, :].contiguous()
|
| 1230 |
+
shift_labels = labels[..., 1:].contiguous()
|
| 1231 |
+
# Flatten the tokens
|
| 1232 |
+
loss_fct = CrossEntropyLoss()
|
| 1233 |
+
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
|
| 1234 |
+
|
| 1235 |
+
if not return_dict:
|
| 1236 |
+
output = (lm_logits,) + transformer_outputs[1:]
|
| 1237 |
+
return ((loss,) + output) if loss is not None else output
|
| 1238 |
+
|
| 1239 |
+
return CausalLMOutputWithCrossAttentions(
|
| 1240 |
+
loss=loss,
|
| 1241 |
+
logits=lm_logits,
|
| 1242 |
+
past_key_values=transformer_outputs.past_key_values,
|
| 1243 |
+
hidden_states=transformer_outputs.hidden_states,
|
| 1244 |
+
attentions=transformer_outputs.attentions,
|
| 1245 |
+
cross_attentions=transformer_outputs.cross_attentions,
|
| 1246 |
+
)
|
| 1247 |
+
|
| 1248 |
+
@staticmethod
|
| 1249 |
+
def _reorder_cache(
|
| 1250 |
+
past_key_values: Tuple[Tuple[torch.Tensor]], beam_idx: torch.Tensor
|
| 1251 |
+
) -> Tuple[Tuple[torch.Tensor]]:
|
| 1252 |
+
"""
|
| 1253 |
+
This function is used to re-order the `past_key_values` cache if [`~PreTrainedModel.beam_search`] or
|
| 1254 |
+
[`~PreTrainedModel.beam_sample`] is called. This is required to match `past_key_values` with the correct
|
| 1255 |
+
beam_idx at every generation step.
|
| 1256 |
+
"""
|
| 1257 |
+
return tuple(
|
| 1258 |
+
tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past)
|
| 1259 |
+
for layer_past in past_key_values
|
| 1260 |
+
)
|
| 1261 |
+
|
| 1262 |
+
|
| 1263 |
+
@add_start_docstrings(
|
| 1264 |
+
"""
|
| 1265 |
+
The BTLM Model transformer with a sequence classification head on top (linear layer).
|
| 1266 |
+
|
| 1267 |
+
[`BTLMForSequenceClassification`] uses the last token in order to do the classification, as other causal models
|
| 1268 |
+
(e.g. GPT-1) do.
|
| 1269 |
+
|
| 1270 |
+
Since it does classification on the last token, it requires to know the position of the last token. If a
|
| 1271 |
+
`pad_token_id` is defined in the configuration, it finds the last token that is not a padding token in each row. If
|
| 1272 |
+
no `pad_token_id` is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
|
| 1273 |
+
padding tokens when `inputs_embeds` are passed instead of `input_ids`, it does the same (take the last value in
|
| 1274 |
+
each row of the batch).
|
| 1275 |
+
""",
|
| 1276 |
+
BTLM_START_DOCSTRING,
|
| 1277 |
+
)
|
| 1278 |
+
class BTLMForSequenceClassification(BTLMPreTrainedModel):
|
| 1279 |
+
_keys_to_ignore_on_load_unexpected = [r"h\.\d+\.attn\.bias", r"h\.\d+\.attn\.masked_bias"]
|
| 1280 |
+
_keys_to_ignore_on_load_missing = [r"h\.\d+\.attn\.masked_bias", r"lm_head.weight"]
|
| 1281 |
+
|
| 1282 |
+
def __init__(self, config):
|
| 1283 |
+
super().__init__(config)
|
| 1284 |
+
self.num_labels = config.num_labels
|
| 1285 |
+
self.transformer = BTLMModel(config)
|
| 1286 |
+
self.score = nn.Linear(config.n_embd, self.num_labels, bias=False)
|
| 1287 |
+
self.output_logits_scale = config.mup_output_alpha * config.mup_width_scale
|
| 1288 |
+
|
| 1289 |
+
# Model parallel
|
| 1290 |
+
self.model_parallel = False
|
| 1291 |
+
self.device_map = None
|
| 1292 |
+
|
| 1293 |
+
# Initialize weights and apply final processing
|
| 1294 |
+
self.post_init()
|
| 1295 |
+
|
| 1296 |
+
@add_start_docstrings_to_model_forward(BTLM_INPUTS_DOCSTRING)
|
| 1297 |
+
@add_code_sample_docstrings(
|
| 1298 |
+
checkpoint="microsoft/DialogRPT-updown",
|
| 1299 |
+
output_type=SequenceClassifierOutputWithPast,
|
| 1300 |
+
config_class=_CONFIG_FOR_DOC,
|
| 1301 |
+
)
|
| 1302 |
+
def forward(
|
| 1303 |
+
self,
|
| 1304 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 1305 |
+
past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
|
| 1306 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 1307 |
+
token_type_ids: Optional[torch.LongTensor] = None,
|
| 1308 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 1309 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 1310 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 1311 |
+
labels: Optional[torch.LongTensor] = None,
|
| 1312 |
+
use_cache: Optional[bool] = None,
|
| 1313 |
+
output_attentions: Optional[bool] = None,
|
| 1314 |
+
output_hidden_states: Optional[bool] = None,
|
| 1315 |
+
return_dict: Optional[bool] = None,
|
| 1316 |
+
) -> Union[Tuple, SequenceClassifierOutputWithPast]:
|
| 1317 |
+
r"""
|
| 1318 |
+
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
|
| 1319 |
+
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
|
| 1320 |
+
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
|
| 1321 |
+
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
|
| 1322 |
+
"""
|
| 1323 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1324 |
+
|
| 1325 |
+
transformer_outputs = self.transformer(
|
| 1326 |
+
input_ids,
|
| 1327 |
+
past_key_values=past_key_values,
|
| 1328 |
+
attention_mask=attention_mask,
|
| 1329 |
+
token_type_ids=token_type_ids,
|
| 1330 |
+
position_ids=position_ids,
|
| 1331 |
+
head_mask=head_mask,
|
| 1332 |
+
inputs_embeds=inputs_embeds,
|
| 1333 |
+
use_cache=use_cache,
|
| 1334 |
+
output_attentions=output_attentions,
|
| 1335 |
+
output_hidden_states=output_hidden_states,
|
| 1336 |
+
return_dict=return_dict,
|
| 1337 |
+
)
|
| 1338 |
+
hidden_states = transformer_outputs[0]
|
| 1339 |
+
logits = self.score(hidden_states)
|
| 1340 |
+
logits *= torch.tensor(float(self.output_logits_scale), dtype=logits.dtype, device=logits.device)
|
| 1341 |
+
|
| 1342 |
+
if input_ids is not None:
|
| 1343 |
+
batch_size, sequence_length = input_ids.shape[:2]
|
| 1344 |
+
else:
|
| 1345 |
+
batch_size, sequence_length = inputs_embeds.shape[:2]
|
| 1346 |
+
|
| 1347 |
+
assert (
|
| 1348 |
+
self.config.pad_token_id is not None or batch_size == 1
|
| 1349 |
+
), "Cannot handle batch sizes > 1 if no padding token is defined."
|
| 1350 |
+
if self.config.pad_token_id is None:
|
| 1351 |
+
sequence_lengths = -1
|
| 1352 |
+
else:
|
| 1353 |
+
if input_ids is not None:
|
| 1354 |
+
sequence_lengths = (torch.ne(input_ids, self.config.pad_token_id).sum(-1) - 1).to(logits.device)
|
| 1355 |
+
else:
|
| 1356 |
+
sequence_lengths = -1
|
| 1357 |
+
logger.warning(
|
| 1358 |
+
f"{self.__class__.__name__} will not detect padding tokens in `inputs_embeds`. Results may be "
|
| 1359 |
+
"unexpected if using padding tokens in conjunction with `inputs_embeds.`"
|
| 1360 |
+
)
|
| 1361 |
+
|
| 1362 |
+
pooled_logits = logits[torch.arange(batch_size, device=logits.device), sequence_lengths]
|
| 1363 |
+
|
| 1364 |
+
loss = None
|
| 1365 |
+
if labels is not None:
|
| 1366 |
+
if self.config.problem_type is None:
|
| 1367 |
+
if self.num_labels == 1:
|
| 1368 |
+
self.config.problem_type = "regression"
|
| 1369 |
+
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
|
| 1370 |
+
self.config.problem_type = "single_label_classification"
|
| 1371 |
+
else:
|
| 1372 |
+
self.config.problem_type = "multi_label_classification"
|
| 1373 |
+
|
| 1374 |
+
if self.config.problem_type == "regression":
|
| 1375 |
+
loss_fct = MSELoss()
|
| 1376 |
+
if self.num_labels == 1:
|
| 1377 |
+
loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())
|
| 1378 |
+
else:
|
| 1379 |
+
loss = loss_fct(pooled_logits, labels)
|
| 1380 |
+
elif self.config.problem_type == "single_label_classification":
|
| 1381 |
+
loss_fct = CrossEntropyLoss()
|
| 1382 |
+
loss = loss_fct(pooled_logits.view(-1, self.num_labels), labels.view(-1))
|
| 1383 |
+
elif self.config.problem_type == "multi_label_classification":
|
| 1384 |
+
loss_fct = BCEWithLogitsLoss()
|
| 1385 |
+
loss = loss_fct(pooled_logits, labels)
|
| 1386 |
+
if not return_dict:
|
| 1387 |
+
output = (pooled_logits,) + transformer_outputs[1:]
|
| 1388 |
+
return ((loss,) + output) if loss is not None else output
|
| 1389 |
+
|
| 1390 |
+
return SequenceClassifierOutputWithPast(
|
| 1391 |
+
loss=loss,
|
| 1392 |
+
logits=pooled_logits,
|
| 1393 |
+
past_key_values=transformer_outputs.past_key_values,
|
| 1394 |
+
hidden_states=transformer_outputs.hidden_states,
|
| 1395 |
+
attentions=transformer_outputs.attentions,
|
| 1396 |
+
)
|
| 1397 |
+
|
| 1398 |
+
|
| 1399 |
+
@add_start_docstrings(
|
| 1400 |
+
"""
|
| 1401 |
+
BTLM Model with a token classification head on top (a linear layer on top of the hidden-states output) e.g. for
|
| 1402 |
+
Named-Entity-Recognition (NER) tasks.
|
| 1403 |
+
""",
|
| 1404 |
+
BTLM_START_DOCSTRING,
|
| 1405 |
+
)
|
| 1406 |
+
class BTLMForTokenClassification(BTLMPreTrainedModel):
|
| 1407 |
+
def __init__(self, config):
|
| 1408 |
+
super().__init__(config)
|
| 1409 |
+
self.num_labels = config.num_labels
|
| 1410 |
+
|
| 1411 |
+
self.transformer = BTLMModel(config)
|
| 1412 |
+
if hasattr(config, "classifier_dropout") and config.classifier_dropout is not None:
|
| 1413 |
+
classifier_dropout = config.classifier_dropout
|
| 1414 |
+
elif hasattr(config, "hidden_dropout") and config.hidden_dropout is not None:
|
| 1415 |
+
classifier_dropout = config.hidden_dropout
|
| 1416 |
+
else:
|
| 1417 |
+
classifier_dropout = 0.1
|
| 1418 |
+
self.dropout = nn.Dropout(classifier_dropout)
|
| 1419 |
+
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
|
| 1420 |
+
self.output_logits_scale = config.mup_output_alpha * config.mup_width_scale
|
| 1421 |
+
|
| 1422 |
+
# Model parallel
|
| 1423 |
+
self.model_parallel = False
|
| 1424 |
+
self.device_map = None
|
| 1425 |
+
|
| 1426 |
+
# Initialize weights and apply final processing
|
| 1427 |
+
self.post_init()
|
| 1428 |
+
|
| 1429 |
+
@add_start_docstrings_to_model_forward(BTLM_INPUTS_DOCSTRING)
|
| 1430 |
+
# fmt: off
|
| 1431 |
+
@add_code_sample_docstrings(
|
| 1432 |
+
checkpoint="brad1141/gpt2-finetuned-comp2",
|
| 1433 |
+
output_type=TokenClassifierOutput,
|
| 1434 |
+
config_class=_CONFIG_FOR_DOC,
|
| 1435 |
+
expected_loss=0.25,
|
| 1436 |
+
expected_output=["Lead", "Lead", "Lead", "Position", "Lead", "Lead", "Lead", "Lead", "Lead", "Lead", "Lead", "Lead"],
|
| 1437 |
+
)
|
| 1438 |
+
# fmt: on
|
| 1439 |
+
def forward(
|
| 1440 |
+
self,
|
| 1441 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 1442 |
+
past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
|
| 1443 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 1444 |
+
token_type_ids: Optional[torch.LongTensor] = None,
|
| 1445 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 1446 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 1447 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 1448 |
+
labels: Optional[torch.LongTensor] = None,
|
| 1449 |
+
use_cache: Optional[bool] = None,
|
| 1450 |
+
output_attentions: Optional[bool] = None,
|
| 1451 |
+
output_hidden_states: Optional[bool] = None,
|
| 1452 |
+
return_dict: Optional[bool] = None,
|
| 1453 |
+
) -> Union[Tuple, TokenClassifierOutput]:
|
| 1454 |
+
r"""
|
| 1455 |
+
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 1456 |
+
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
|
| 1457 |
+
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
|
| 1458 |
+
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
|
| 1459 |
+
"""
|
| 1460 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1461 |
+
|
| 1462 |
+
transformer_outputs = self.transformer(
|
| 1463 |
+
input_ids,
|
| 1464 |
+
past_key_values=past_key_values,
|
| 1465 |
+
attention_mask=attention_mask,
|
| 1466 |
+
token_type_ids=token_type_ids,
|
| 1467 |
+
position_ids=position_ids,
|
| 1468 |
+
head_mask=head_mask,
|
| 1469 |
+
inputs_embeds=inputs_embeds,
|
| 1470 |
+
use_cache=use_cache,
|
| 1471 |
+
output_attentions=output_attentions,
|
| 1472 |
+
output_hidden_states=output_hidden_states,
|
| 1473 |
+
return_dict=return_dict,
|
| 1474 |
+
)
|
| 1475 |
+
|
| 1476 |
+
hidden_states = transformer_outputs[0]
|
| 1477 |
+
hidden_states = self.dropout(hidden_states)
|
| 1478 |
+
logits = self.classifier(hidden_states)
|
| 1479 |
+
logits *= torch.tensor(float(self.output_logits_scale), dtype=logits.dtype, device=logits.device)
|
| 1480 |
+
|
| 1481 |
+
loss = None
|
| 1482 |
+
if labels is not None:
|
| 1483 |
+
labels = labels.to(logits.device)
|
| 1484 |
+
loss_fct = CrossEntropyLoss()
|
| 1485 |
+
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
|
| 1486 |
+
|
| 1487 |
+
if not return_dict:
|
| 1488 |
+
output = (logits,) + transformer_outputs[2:]
|
| 1489 |
+
return ((loss,) + output) if loss is not None else output
|
| 1490 |
+
|
| 1491 |
+
return TokenClassifierOutput(
|
| 1492 |
+
loss=loss,
|
| 1493 |
+
logits=logits,
|
| 1494 |
+
hidden_states=transformer_outputs.hidden_states,
|
| 1495 |
+
attentions=transformer_outputs.attentions,
|
| 1496 |
+
)
|
| 1497 |
+
|
| 1498 |
+
|
| 1499 |
+
@add_start_docstrings(
|
| 1500 |
+
"""
|
| 1501 |
+
The BTLM Model transformer with a span classification head on top for extractive question-answering tasks like
|
| 1502 |
+
SQuAD (a linear layer on top of the hidden-states output to compute `span start logits` and `span end logits`).
|
| 1503 |
+
""",
|
| 1504 |
+
BTLM_START_DOCSTRING,
|
| 1505 |
+
)
|
| 1506 |
+
class BTLMForQuestionAnswering(BTLMPreTrainedModel):
|
| 1507 |
+
_keys_to_ignore_on_load_unexpected = [r"h\.\d+\.attn\.bias", r"h\.\d+\.attn\.masked_bias"]
|
| 1508 |
+
_keys_to_ignore_on_load_missing = [r"h\.\d+\.attn\.masked_bias", r"h\.\d+\.attn\.bias", r"lm_head.weight"]
|
| 1509 |
+
|
| 1510 |
+
def __init__(self, config):
|
| 1511 |
+
super().__init__(config)
|
| 1512 |
+
self.num_labels = config.num_labels
|
| 1513 |
+
self.transformer = BTLMModel(config)
|
| 1514 |
+
self.qa_outputs = nn.Linear(config.hidden_size, 2)
|
| 1515 |
+
self.output_logits_scale = config.mup_output_alpha * config.mup_width_scale
|
| 1516 |
+
|
| 1517 |
+
# Model parallel
|
| 1518 |
+
self.model_parallel = False
|
| 1519 |
+
self.device_map = None
|
| 1520 |
+
self.gradient_checkpointing = False
|
| 1521 |
+
|
| 1522 |
+
# Initialize weights and apply final processing
|
| 1523 |
+
self.post_init()
|
| 1524 |
+
|
| 1525 |
+
@add_start_docstrings_to_model_forward(BTLM_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
|
| 1526 |
+
@add_code_sample_docstrings(
|
| 1527 |
+
checkpoint=_CHECKPOINT_FOR_DOC,
|
| 1528 |
+
output_type=QuestionAnsweringModelOutput,
|
| 1529 |
+
config_class=_CONFIG_FOR_DOC,
|
| 1530 |
+
real_checkpoint=_CHECKPOINT_FOR_DOC,
|
| 1531 |
+
)
|
| 1532 |
+
def forward(
|
| 1533 |
+
self,
|
| 1534 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 1535 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 1536 |
+
token_type_ids: Optional[torch.LongTensor] = None,
|
| 1537 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 1538 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 1539 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 1540 |
+
start_positions: Optional[torch.LongTensor] = None,
|
| 1541 |
+
end_positions: Optional[torch.LongTensor] = None,
|
| 1542 |
+
output_attentions: Optional[bool] = None,
|
| 1543 |
+
output_hidden_states: Optional[bool] = None,
|
| 1544 |
+
return_dict: Optional[bool] = None,
|
| 1545 |
+
) -> Union[Tuple, QuestionAnsweringModelOutput]:
|
| 1546 |
+
r"""
|
| 1547 |
+
start_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
|
| 1548 |
+
Labels for position (index) of the start of the labelled span for computing the token classification loss.
|
| 1549 |
+
Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
|
| 1550 |
+
are not taken into account for computing the loss.
|
| 1551 |
+
end_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
|
| 1552 |
+
Labels for position (index) of the end of the labelled span for computing the token classification loss.
|
| 1553 |
+
Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
|
| 1554 |
+
are not taken into account for computing the loss.
|
| 1555 |
+
"""
|
| 1556 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1557 |
+
|
| 1558 |
+
outputs = self.transformer(
|
| 1559 |
+
input_ids,
|
| 1560 |
+
attention_mask=attention_mask,
|
| 1561 |
+
token_type_ids=token_type_ids,
|
| 1562 |
+
position_ids=position_ids,
|
| 1563 |
+
head_mask=head_mask,
|
| 1564 |
+
inputs_embeds=inputs_embeds,
|
| 1565 |
+
output_attentions=output_attentions,
|
| 1566 |
+
output_hidden_states=output_hidden_states,
|
| 1567 |
+
return_dict=return_dict,
|
| 1568 |
+
)
|
| 1569 |
+
|
| 1570 |
+
sequence_output = outputs[0]
|
| 1571 |
+
|
| 1572 |
+
logits = self.qa_outputs(sequence_output)
|
| 1573 |
+
logits *= torch.tensor(float(self.output_logits_scale), dtype=logits.dtype, device=logits.device)
|
| 1574 |
+
start_logits, end_logits = logits.split(1, dim=-1)
|
| 1575 |
+
start_logits = start_logits.squeeze(-1).contiguous()
|
| 1576 |
+
end_logits = end_logits.squeeze(-1).contiguous()
|
| 1577 |
+
|
| 1578 |
+
total_loss = None
|
| 1579 |
+
if start_positions is not None and end_positions is not None:
|
| 1580 |
+
# If we are on multi-GPU, split add a dimension
|
| 1581 |
+
if len(start_positions.size()) > 1:
|
| 1582 |
+
start_positions = start_positions.squeeze(-1).to(start_logits.device)
|
| 1583 |
+
if len(end_positions.size()) > 1:
|
| 1584 |
+
end_positions = end_positions.squeeze(-1).to(end_logits.device)
|
| 1585 |
+
# sometimes the start/end positions are outside our model inputs, we ignore these terms
|
| 1586 |
+
ignored_index = start_logits.size(1)
|
| 1587 |
+
start_positions = start_positions.clamp(0, ignored_index)
|
| 1588 |
+
end_positions = end_positions.clamp(0, ignored_index)
|
| 1589 |
+
|
| 1590 |
+
loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
|
| 1591 |
+
start_loss = loss_fct(start_logits, start_positions)
|
| 1592 |
+
end_loss = loss_fct(end_logits, end_positions)
|
| 1593 |
+
total_loss = (start_loss + end_loss) / 2
|
| 1594 |
+
|
| 1595 |
+
if not return_dict:
|
| 1596 |
+
output = (start_logits, end_logits) + outputs[2:]
|
| 1597 |
+
return ((total_loss,) + output) if total_loss is not None else output
|
| 1598 |
+
|
| 1599 |
+
return QuestionAnsweringModelOutput(
|
| 1600 |
+
loss=total_loss,
|
| 1601 |
+
start_logits=start_logits,
|
| 1602 |
+
end_logits=end_logits,
|
| 1603 |
+
hidden_states=outputs.hidden_states,
|
| 1604 |
+
attentions=outputs.attentions,
|
| 1605 |
+
)
|
pytorch_model-00001-of-00002.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0dfc739884ff3afedd0100385ac333d3ff818023a6d510585bde46eaa1892b79
|
| 3 |
+
size 4977957219
|
pytorch_model-00002-of-00002.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d0cd26d660615150c5617635971824c86e54b72256fd4c8c89c88d041d8fe023
|
| 3 |
+
size 314709300
|
pytorch_model.bin.index.json
ADDED
|
@@ -0,0 +1,460 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 5292511552
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "pytorch_model-00001-of-00002.bin",
|
| 7 |
+
"transformer.h.0.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 8 |
+
"transformer.h.0.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 9 |
+
"transformer.h.0.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 10 |
+
"transformer.h.0.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 11 |
+
"transformer.h.0.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 12 |
+
"transformer.h.0.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 13 |
+
"transformer.h.0.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 14 |
+
"transformer.h.0.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 15 |
+
"transformer.h.0.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 16 |
+
"transformer.h.0.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 17 |
+
"transformer.h.0.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 18 |
+
"transformer.h.0.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 19 |
+
"transformer.h.0.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 20 |
+
"transformer.h.0.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 21 |
+
"transformer.h.1.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 22 |
+
"transformer.h.1.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 23 |
+
"transformer.h.1.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 24 |
+
"transformer.h.1.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 25 |
+
"transformer.h.1.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 26 |
+
"transformer.h.1.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 27 |
+
"transformer.h.1.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 28 |
+
"transformer.h.1.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 29 |
+
"transformer.h.1.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 30 |
+
"transformer.h.1.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 31 |
+
"transformer.h.1.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 32 |
+
"transformer.h.1.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 33 |
+
"transformer.h.1.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 34 |
+
"transformer.h.1.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 35 |
+
"transformer.h.10.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 36 |
+
"transformer.h.10.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 37 |
+
"transformer.h.10.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 38 |
+
"transformer.h.10.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 39 |
+
"transformer.h.10.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 40 |
+
"transformer.h.10.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 41 |
+
"transformer.h.10.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 42 |
+
"transformer.h.10.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 43 |
+
"transformer.h.10.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 44 |
+
"transformer.h.10.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 45 |
+
"transformer.h.10.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 46 |
+
"transformer.h.10.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 47 |
+
"transformer.h.10.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 48 |
+
"transformer.h.10.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 49 |
+
"transformer.h.11.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 50 |
+
"transformer.h.11.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 51 |
+
"transformer.h.11.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 52 |
+
"transformer.h.11.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 53 |
+
"transformer.h.11.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 54 |
+
"transformer.h.11.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 55 |
+
"transformer.h.11.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 56 |
+
"transformer.h.11.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 57 |
+
"transformer.h.11.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 58 |
+
"transformer.h.11.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 59 |
+
"transformer.h.11.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 60 |
+
"transformer.h.11.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 61 |
+
"transformer.h.11.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 62 |
+
"transformer.h.11.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 63 |
+
"transformer.h.12.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 64 |
+
"transformer.h.12.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 65 |
+
"transformer.h.12.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 66 |
+
"transformer.h.12.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 67 |
+
"transformer.h.12.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 68 |
+
"transformer.h.12.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 69 |
+
"transformer.h.12.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 70 |
+
"transformer.h.12.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 71 |
+
"transformer.h.12.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 72 |
+
"transformer.h.12.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 73 |
+
"transformer.h.12.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 74 |
+
"transformer.h.12.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 75 |
+
"transformer.h.12.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 76 |
+
"transformer.h.12.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 77 |
+
"transformer.h.13.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 78 |
+
"transformer.h.13.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 79 |
+
"transformer.h.13.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 80 |
+
"transformer.h.13.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 81 |
+
"transformer.h.13.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 82 |
+
"transformer.h.13.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 83 |
+
"transformer.h.13.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 84 |
+
"transformer.h.13.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 85 |
+
"transformer.h.13.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 86 |
+
"transformer.h.13.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 87 |
+
"transformer.h.13.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 88 |
+
"transformer.h.13.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 89 |
+
"transformer.h.13.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 90 |
+
"transformer.h.13.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 91 |
+
"transformer.h.14.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 92 |
+
"transformer.h.14.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 93 |
+
"transformer.h.14.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 94 |
+
"transformer.h.14.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 95 |
+
"transformer.h.14.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 96 |
+
"transformer.h.14.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 97 |
+
"transformer.h.14.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 98 |
+
"transformer.h.14.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 99 |
+
"transformer.h.14.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 100 |
+
"transformer.h.14.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 101 |
+
"transformer.h.14.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 102 |
+
"transformer.h.14.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 103 |
+
"transformer.h.14.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 104 |
+
"transformer.h.14.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 105 |
+
"transformer.h.15.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 106 |
+
"transformer.h.15.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 107 |
+
"transformer.h.15.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 108 |
+
"transformer.h.15.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 109 |
+
"transformer.h.15.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 110 |
+
"transformer.h.15.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 111 |
+
"transformer.h.15.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 112 |
+
"transformer.h.15.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 113 |
+
"transformer.h.15.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 114 |
+
"transformer.h.15.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 115 |
+
"transformer.h.15.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 116 |
+
"transformer.h.15.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 117 |
+
"transformer.h.15.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 118 |
+
"transformer.h.15.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 119 |
+
"transformer.h.16.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 120 |
+
"transformer.h.16.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 121 |
+
"transformer.h.16.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 122 |
+
"transformer.h.16.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 123 |
+
"transformer.h.16.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 124 |
+
"transformer.h.16.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 125 |
+
"transformer.h.16.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 126 |
+
"transformer.h.16.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 127 |
+
"transformer.h.16.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 128 |
+
"transformer.h.16.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 129 |
+
"transformer.h.16.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 130 |
+
"transformer.h.16.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 131 |
+
"transformer.h.16.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 132 |
+
"transformer.h.16.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 133 |
+
"transformer.h.17.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 134 |
+
"transformer.h.17.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 135 |
+
"transformer.h.17.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 136 |
+
"transformer.h.17.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 137 |
+
"transformer.h.17.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 138 |
+
"transformer.h.17.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 139 |
+
"transformer.h.17.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 140 |
+
"transformer.h.17.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 141 |
+
"transformer.h.17.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 142 |
+
"transformer.h.17.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 143 |
+
"transformer.h.17.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 144 |
+
"transformer.h.17.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 145 |
+
"transformer.h.17.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 146 |
+
"transformer.h.17.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 147 |
+
"transformer.h.18.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 148 |
+
"transformer.h.18.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 149 |
+
"transformer.h.18.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 150 |
+
"transformer.h.18.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 151 |
+
"transformer.h.18.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 152 |
+
"transformer.h.18.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 153 |
+
"transformer.h.18.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 154 |
+
"transformer.h.18.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 155 |
+
"transformer.h.18.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 156 |
+
"transformer.h.18.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 157 |
+
"transformer.h.18.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 158 |
+
"transformer.h.18.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 159 |
+
"transformer.h.18.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 160 |
+
"transformer.h.18.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 161 |
+
"transformer.h.19.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 162 |
+
"transformer.h.19.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 163 |
+
"transformer.h.19.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 164 |
+
"transformer.h.19.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 165 |
+
"transformer.h.19.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 166 |
+
"transformer.h.19.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 167 |
+
"transformer.h.19.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 168 |
+
"transformer.h.19.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 169 |
+
"transformer.h.19.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 170 |
+
"transformer.h.19.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 171 |
+
"transformer.h.19.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 172 |
+
"transformer.h.19.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 173 |
+
"transformer.h.19.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 174 |
+
"transformer.h.19.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 175 |
+
"transformer.h.2.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 176 |
+
"transformer.h.2.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 177 |
+
"transformer.h.2.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 178 |
+
"transformer.h.2.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 179 |
+
"transformer.h.2.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 180 |
+
"transformer.h.2.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 181 |
+
"transformer.h.2.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 182 |
+
"transformer.h.2.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 183 |
+
"transformer.h.2.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 184 |
+
"transformer.h.2.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 185 |
+
"transformer.h.2.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 186 |
+
"transformer.h.2.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 187 |
+
"transformer.h.2.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 188 |
+
"transformer.h.2.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 189 |
+
"transformer.h.20.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 190 |
+
"transformer.h.20.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 191 |
+
"transformer.h.20.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 192 |
+
"transformer.h.20.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 193 |
+
"transformer.h.20.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 194 |
+
"transformer.h.20.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 195 |
+
"transformer.h.20.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 196 |
+
"transformer.h.20.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 197 |
+
"transformer.h.20.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 198 |
+
"transformer.h.20.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 199 |
+
"transformer.h.20.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 200 |
+
"transformer.h.20.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 201 |
+
"transformer.h.20.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 202 |
+
"transformer.h.20.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 203 |
+
"transformer.h.21.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 204 |
+
"transformer.h.21.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 205 |
+
"transformer.h.21.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 206 |
+
"transformer.h.21.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 207 |
+
"transformer.h.21.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 208 |
+
"transformer.h.21.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 209 |
+
"transformer.h.21.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 210 |
+
"transformer.h.21.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 211 |
+
"transformer.h.21.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 212 |
+
"transformer.h.21.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 213 |
+
"transformer.h.21.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 214 |
+
"transformer.h.21.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 215 |
+
"transformer.h.21.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 216 |
+
"transformer.h.21.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 217 |
+
"transformer.h.22.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 218 |
+
"transformer.h.22.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 219 |
+
"transformer.h.22.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 220 |
+
"transformer.h.22.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 221 |
+
"transformer.h.22.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 222 |
+
"transformer.h.22.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 223 |
+
"transformer.h.22.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 224 |
+
"transformer.h.22.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 225 |
+
"transformer.h.22.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 226 |
+
"transformer.h.22.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 227 |
+
"transformer.h.22.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 228 |
+
"transformer.h.22.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 229 |
+
"transformer.h.22.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 230 |
+
"transformer.h.22.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 231 |
+
"transformer.h.23.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 232 |
+
"transformer.h.23.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 233 |
+
"transformer.h.23.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 234 |
+
"transformer.h.23.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 235 |
+
"transformer.h.23.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 236 |
+
"transformer.h.23.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 237 |
+
"transformer.h.23.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 238 |
+
"transformer.h.23.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 239 |
+
"transformer.h.23.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 240 |
+
"transformer.h.23.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 241 |
+
"transformer.h.23.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 242 |
+
"transformer.h.23.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 243 |
+
"transformer.h.23.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 244 |
+
"transformer.h.23.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 245 |
+
"transformer.h.24.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 246 |
+
"transformer.h.24.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 247 |
+
"transformer.h.24.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 248 |
+
"transformer.h.24.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 249 |
+
"transformer.h.24.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 250 |
+
"transformer.h.24.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 251 |
+
"transformer.h.24.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 252 |
+
"transformer.h.24.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 253 |
+
"transformer.h.24.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 254 |
+
"transformer.h.24.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 255 |
+
"transformer.h.24.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 256 |
+
"transformer.h.24.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 257 |
+
"transformer.h.24.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 258 |
+
"transformer.h.24.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 259 |
+
"transformer.h.25.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 260 |
+
"transformer.h.25.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 261 |
+
"transformer.h.25.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 262 |
+
"transformer.h.25.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 263 |
+
"transformer.h.25.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 264 |
+
"transformer.h.25.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 265 |
+
"transformer.h.25.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 266 |
+
"transformer.h.25.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 267 |
+
"transformer.h.25.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 268 |
+
"transformer.h.25.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 269 |
+
"transformer.h.25.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 270 |
+
"transformer.h.25.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 271 |
+
"transformer.h.25.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 272 |
+
"transformer.h.25.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 273 |
+
"transformer.h.26.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 274 |
+
"transformer.h.26.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 275 |
+
"transformer.h.26.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 276 |
+
"transformer.h.26.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 277 |
+
"transformer.h.26.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 278 |
+
"transformer.h.26.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 279 |
+
"transformer.h.26.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 280 |
+
"transformer.h.26.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 281 |
+
"transformer.h.26.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 282 |
+
"transformer.h.26.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 283 |
+
"transformer.h.26.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 284 |
+
"transformer.h.26.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 285 |
+
"transformer.h.26.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 286 |
+
"transformer.h.26.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 287 |
+
"transformer.h.27.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 288 |
+
"transformer.h.27.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 289 |
+
"transformer.h.27.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 290 |
+
"transformer.h.27.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 291 |
+
"transformer.h.27.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 292 |
+
"transformer.h.27.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 293 |
+
"transformer.h.27.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 294 |
+
"transformer.h.27.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 295 |
+
"transformer.h.27.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 296 |
+
"transformer.h.27.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 297 |
+
"transformer.h.27.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 298 |
+
"transformer.h.27.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 299 |
+
"transformer.h.27.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 300 |
+
"transformer.h.27.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 301 |
+
"transformer.h.28.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 302 |
+
"transformer.h.28.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 303 |
+
"transformer.h.28.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 304 |
+
"transformer.h.28.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 305 |
+
"transformer.h.28.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 306 |
+
"transformer.h.28.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 307 |
+
"transformer.h.28.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 308 |
+
"transformer.h.28.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 309 |
+
"transformer.h.28.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 310 |
+
"transformer.h.28.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 311 |
+
"transformer.h.28.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 312 |
+
"transformer.h.28.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 313 |
+
"transformer.h.28.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 314 |
+
"transformer.h.28.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 315 |
+
"transformer.h.29.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 316 |
+
"transformer.h.29.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 317 |
+
"transformer.h.29.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 318 |
+
"transformer.h.29.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 319 |
+
"transformer.h.29.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 320 |
+
"transformer.h.29.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 321 |
+
"transformer.h.29.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 322 |
+
"transformer.h.29.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 323 |
+
"transformer.h.29.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 324 |
+
"transformer.h.29.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 325 |
+
"transformer.h.29.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 326 |
+
"transformer.h.29.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 327 |
+
"transformer.h.29.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 328 |
+
"transformer.h.29.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 329 |
+
"transformer.h.3.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 330 |
+
"transformer.h.3.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 331 |
+
"transformer.h.3.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 332 |
+
"transformer.h.3.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 333 |
+
"transformer.h.3.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 334 |
+
"transformer.h.3.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 335 |
+
"transformer.h.3.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 336 |
+
"transformer.h.3.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 337 |
+
"transformer.h.3.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 338 |
+
"transformer.h.3.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 339 |
+
"transformer.h.3.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 340 |
+
"transformer.h.3.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 341 |
+
"transformer.h.3.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 342 |
+
"transformer.h.3.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 343 |
+
"transformer.h.30.attn.c_attn.bias": "pytorch_model-00002-of-00002.bin",
|
| 344 |
+
"transformer.h.30.attn.c_attn.weight": "pytorch_model-00002-of-00002.bin",
|
| 345 |
+
"transformer.h.30.attn.c_proj.bias": "pytorch_model-00002-of-00002.bin",
|
| 346 |
+
"transformer.h.30.attn.c_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 347 |
+
"transformer.h.30.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 348 |
+
"transformer.h.30.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 349 |
+
"transformer.h.30.ln_2.bias": "pytorch_model-00002-of-00002.bin",
|
| 350 |
+
"transformer.h.30.ln_2.weight": "pytorch_model-00002-of-00002.bin",
|
| 351 |
+
"transformer.h.30.mlp.c_fc.bias": "pytorch_model-00002-of-00002.bin",
|
| 352 |
+
"transformer.h.30.mlp.c_fc.weight": "pytorch_model-00002-of-00002.bin",
|
| 353 |
+
"transformer.h.30.mlp.c_fc2.bias": "pytorch_model-00002-of-00002.bin",
|
| 354 |
+
"transformer.h.30.mlp.c_fc2.weight": "pytorch_model-00002-of-00002.bin",
|
| 355 |
+
"transformer.h.30.mlp.c_proj.bias": "pytorch_model-00002-of-00002.bin",
|
| 356 |
+
"transformer.h.30.mlp.c_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 357 |
+
"transformer.h.31.attn.c_attn.bias": "pytorch_model-00002-of-00002.bin",
|
| 358 |
+
"transformer.h.31.attn.c_attn.weight": "pytorch_model-00002-of-00002.bin",
|
| 359 |
+
"transformer.h.31.attn.c_proj.bias": "pytorch_model-00002-of-00002.bin",
|
| 360 |
+
"transformer.h.31.attn.c_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 361 |
+
"transformer.h.31.ln_1.bias": "pytorch_model-00002-of-00002.bin",
|
| 362 |
+
"transformer.h.31.ln_1.weight": "pytorch_model-00002-of-00002.bin",
|
| 363 |
+
"transformer.h.31.ln_2.bias": "pytorch_model-00002-of-00002.bin",
|
| 364 |
+
"transformer.h.31.ln_2.weight": "pytorch_model-00002-of-00002.bin",
|
| 365 |
+
"transformer.h.31.mlp.c_fc.bias": "pytorch_model-00002-of-00002.bin",
|
| 366 |
+
"transformer.h.31.mlp.c_fc.weight": "pytorch_model-00002-of-00002.bin",
|
| 367 |
+
"transformer.h.31.mlp.c_fc2.bias": "pytorch_model-00002-of-00002.bin",
|
| 368 |
+
"transformer.h.31.mlp.c_fc2.weight": "pytorch_model-00002-of-00002.bin",
|
| 369 |
+
"transformer.h.31.mlp.c_proj.bias": "pytorch_model-00002-of-00002.bin",
|
| 370 |
+
"transformer.h.31.mlp.c_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 371 |
+
"transformer.h.4.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 372 |
+
"transformer.h.4.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 373 |
+
"transformer.h.4.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 374 |
+
"transformer.h.4.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 375 |
+
"transformer.h.4.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 376 |
+
"transformer.h.4.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 377 |
+
"transformer.h.4.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 378 |
+
"transformer.h.4.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 379 |
+
"transformer.h.4.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 380 |
+
"transformer.h.4.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 381 |
+
"transformer.h.4.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 382 |
+
"transformer.h.4.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 383 |
+
"transformer.h.4.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 384 |
+
"transformer.h.4.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 385 |
+
"transformer.h.5.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 386 |
+
"transformer.h.5.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 387 |
+
"transformer.h.5.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 388 |
+
"transformer.h.5.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 389 |
+
"transformer.h.5.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 390 |
+
"transformer.h.5.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 391 |
+
"transformer.h.5.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 392 |
+
"transformer.h.5.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 393 |
+
"transformer.h.5.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 394 |
+
"transformer.h.5.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 395 |
+
"transformer.h.5.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 396 |
+
"transformer.h.5.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 397 |
+
"transformer.h.5.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 398 |
+
"transformer.h.5.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 399 |
+
"transformer.h.6.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 400 |
+
"transformer.h.6.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 401 |
+
"transformer.h.6.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 402 |
+
"transformer.h.6.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 403 |
+
"transformer.h.6.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 404 |
+
"transformer.h.6.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 405 |
+
"transformer.h.6.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 406 |
+
"transformer.h.6.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 407 |
+
"transformer.h.6.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 408 |
+
"transformer.h.6.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 409 |
+
"transformer.h.6.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 410 |
+
"transformer.h.6.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 411 |
+
"transformer.h.6.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 412 |
+
"transformer.h.6.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 413 |
+
"transformer.h.7.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 414 |
+
"transformer.h.7.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 415 |
+
"transformer.h.7.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 416 |
+
"transformer.h.7.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 417 |
+
"transformer.h.7.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 418 |
+
"transformer.h.7.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 419 |
+
"transformer.h.7.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 420 |
+
"transformer.h.7.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 421 |
+
"transformer.h.7.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 422 |
+
"transformer.h.7.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 423 |
+
"transformer.h.7.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 424 |
+
"transformer.h.7.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 425 |
+
"transformer.h.7.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 426 |
+
"transformer.h.7.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 427 |
+
"transformer.h.8.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 428 |
+
"transformer.h.8.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 429 |
+
"transformer.h.8.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 430 |
+
"transformer.h.8.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 431 |
+
"transformer.h.8.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 432 |
+
"transformer.h.8.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 433 |
+
"transformer.h.8.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 434 |
+
"transformer.h.8.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 435 |
+
"transformer.h.8.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 436 |
+
"transformer.h.8.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 437 |
+
"transformer.h.8.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 438 |
+
"transformer.h.8.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 439 |
+
"transformer.h.8.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 440 |
+
"transformer.h.8.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 441 |
+
"transformer.h.9.attn.c_attn.bias": "pytorch_model-00001-of-00002.bin",
|
| 442 |
+
"transformer.h.9.attn.c_attn.weight": "pytorch_model-00001-of-00002.bin",
|
| 443 |
+
"transformer.h.9.attn.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 444 |
+
"transformer.h.9.attn.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 445 |
+
"transformer.h.9.ln_1.bias": "pytorch_model-00001-of-00002.bin",
|
| 446 |
+
"transformer.h.9.ln_1.weight": "pytorch_model-00001-of-00002.bin",
|
| 447 |
+
"transformer.h.9.ln_2.bias": "pytorch_model-00001-of-00002.bin",
|
| 448 |
+
"transformer.h.9.ln_2.weight": "pytorch_model-00001-of-00002.bin",
|
| 449 |
+
"transformer.h.9.mlp.c_fc.bias": "pytorch_model-00001-of-00002.bin",
|
| 450 |
+
"transformer.h.9.mlp.c_fc.weight": "pytorch_model-00001-of-00002.bin",
|
| 451 |
+
"transformer.h.9.mlp.c_fc2.bias": "pytorch_model-00001-of-00002.bin",
|
| 452 |
+
"transformer.h.9.mlp.c_fc2.weight": "pytorch_model-00001-of-00002.bin",
|
| 453 |
+
"transformer.h.9.mlp.c_proj.bias": "pytorch_model-00001-of-00002.bin",
|
| 454 |
+
"transformer.h.9.mlp.c_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 455 |
+
"transformer.ln_f.bias": "pytorch_model-00002-of-00002.bin",
|
| 456 |
+
"transformer.ln_f.weight": "pytorch_model-00002-of-00002.bin",
|
| 457 |
+
"transformer.relative_pe.slopes": "pytorch_model-00002-of-00002.bin",
|
| 458 |
+
"transformer.wte.weight": "pytorch_model-00001-of-00002.bin"
|
| 459 |
+
}
|
| 460 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": "<|endoftext|>",
|
| 3 |
+
"eos_token": "<|endoftext|>",
|
| 4 |
+
"unk_token": "<|endoftext|>"
|
| 5 |
+
}
|
table_1_downstream_performance_3b.png
ADDED

|
table_2_downstream_performance_7b.png
ADDED
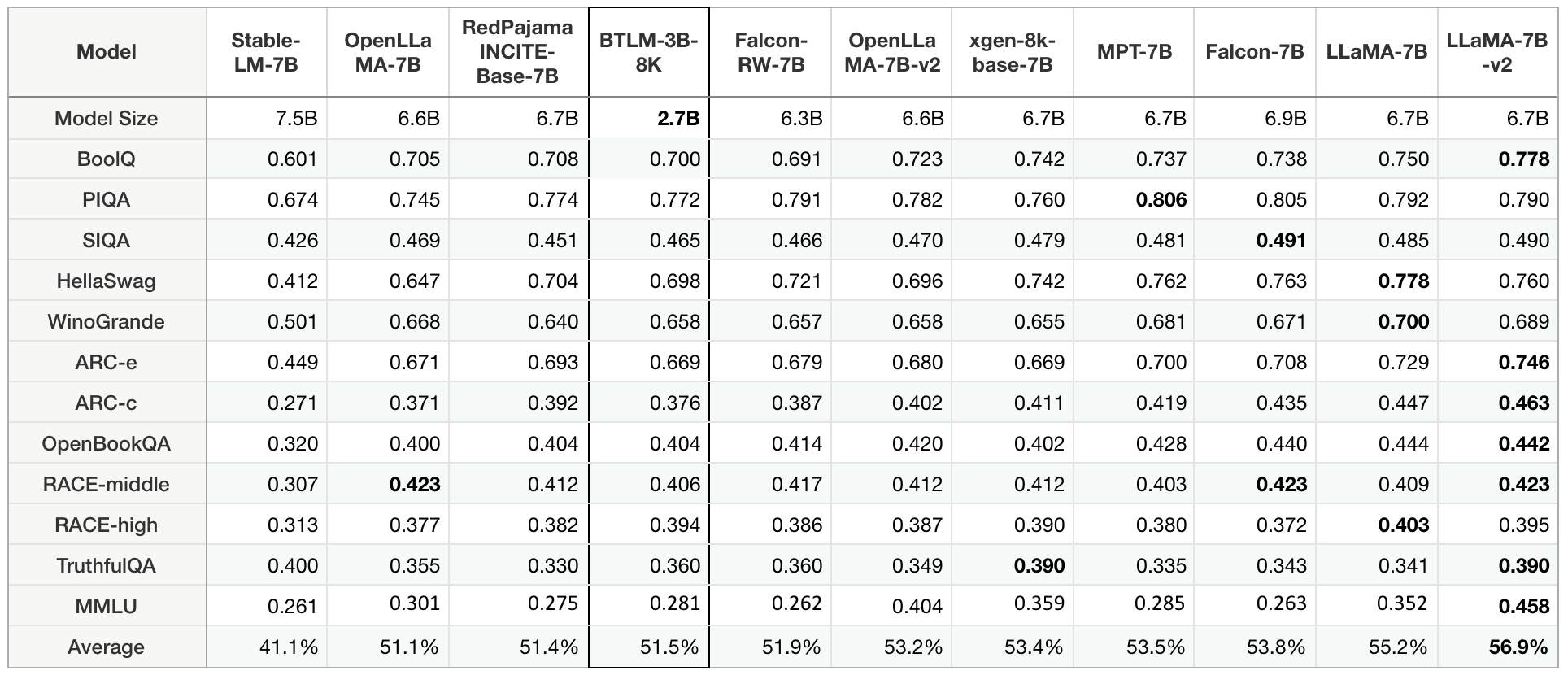
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"bos_token": "<|endoftext|>",
|
| 4 |
+
"clean_up_tokenization_spaces": true,
|
| 5 |
+
"eos_token": "<|endoftext|>",
|
| 6 |
+
"model_max_length": 8192,
|
| 7 |
+
"tokenizer_class": "GPT2Tokenizer",
|
| 8 |
+
"unk_token": "<|endoftext|>"
|
| 9 |
+
}
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|