

Commit
•
f3f8500
1
Parent(s):
d0c5e01
[add]: description
Browse files
README.md
CHANGED
|
@@ -26,4 +26,692 @@ metrics:
|
|
| 26 |
- f1
|
| 27 |
datasets:
|
| 28 |
- EmbeddingStudio/query-parsing-instructions-saiga
|
| 29 |
-
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 26 |
- f1
|
| 27 |
datasets:
|
| 28 |
- EmbeddingStudio/query-parsing-instructions-saiga
|
| 29 |
+
---
|
| 30 |
+
|
| 31 |
+
# Model Card for the Query Parser LLM using Falcon-7B-Instruct
|
| 32 |
+
|
| 33 |
+
EmbeddingStudio is the [open-source framework](https://github.com/EulerSearch/embedding_studio/tree/main), that allows you transform a joint "Embedding Model + Vector DB" into
|
| 34 |
+
a full-cycle search engine: collect clickstream -> improve search experience-> adapt embedding model and repeat out of the box.
|
| 35 |
+
|
| 36 |
+
It's a highly rare case when a company will use unstructured search as is. And by searching `brick red houses san francisco area for april`
|
| 37 |
+
user definitely wants to find some houses in San Francisco for a month-long rent in April, and then maybe brick-red houses.
|
| 38 |
+
Unfortunately, for the 15th January 2024 there is no such accurate embedding model. So, companies need to mix structured and unstructured search.
|
| 39 |
+
|
| 40 |
+
The very first step of mixing it - to parse a search query. Usual approaches are:
|
| 41 |
+
* Implement a bunch of rules, regexps, or grammar parsers (like [NLTK grammar parser](https://www.nltk.org/howto/grammar.html)).
|
| 42 |
+
* Collect search queries and to annotate some dataset for NER task.
|
| 43 |
+
|
| 44 |
+
It takes some time to do, but at the end you can get controllable and very accurate query parser.
|
| 45 |
+
EmbeddingStudio team decided to dive into LLM instruct fine-tuning for `Zero-Shot query parsing` task
|
| 46 |
+
to close the first gap while a company doesn't have any rules and data being collected, or even eliminate exhausted rules implementation, but in the future.
|
| 47 |
+
|
| 48 |
+
The main idea is to align an LLM to being to parse short search queries knowing just a company market and a schema of search filters. Moreover, being oriented on applied NLP,
|
| 49 |
+
we are trying to serve only light-weight LLMs a.k.a `not heavier than 7B parameters`.
|
| 50 |
+
|
| 51 |
+
## Model Details
|
| 52 |
+
|
| 53 |
+
### Model Description
|
| 54 |
+
|
| 55 |
+
This is only [IlyaGusev/saiga_mistral_7b_lora](https://huggingface.co/IlyaGusev/saiga_mistral_7b_lora) aligned to follow instructions like:
|
| 56 |
+
```markdown
|
| 57 |
+
<s>system: Эксперт по разбору поисковых запросов</s>
|
| 58 |
+
<s>user: Преобразование запросов в JSON, соответствие схеме, обеспечение правильного написания.
|
| 59 |
+
Категория: Mobile App Development
|
| 60 |
+
Схема: ```[{"Name": "Project-Budget", "Representations": [{"Name": "Budget-in-USD", "Type": "float", "Examples": [1000.0, 5000.0, 10000.0, "The project is currently on hold", "The project is currently on hold", "The project is currently on hold"]}, {"Name": "Budget-in-EUR", "Type": "float", "Examples": [850.0, 4250.0, 8500.0, "The project is currently on hold", "The project is currently on hold", "The project is currently on hold"]}, {"Name": "Budget-in-JPY", "Type": "float", "Examples": [110000.0, 550000.0, 1100000.0, "The project is currently on hold", "The project is currently on hold", "The project is currently on hold"]}, {"Name": "Budget-in-AUD", "Type": "float", "Examples": [1300.0, 6500.0, 13000.0, "The project is currently on hold", "The project is currently on hold", "The project is currently on hold"]}]}, {"Name": "Project-Duration", "Representations": [{"Name": "Duration-in-Minutes", "Type": "int", "Examples": [43200, 259200, 525600, 5, 5, 5]}]}, {"Name": "Project-End-Date", "Representations": [{"Name": "Day-Month-Year", "Type": "str", "Examples": ["01 January 2022", "15 February 2023", "31 December 2024", "01 января 2022 года", "15 февраля 2023 года", "31 декабря 2024"], "Pattern": ["dd Month YYYY", "дд Месяц ГГГГ"]}]}, {"Name": "Project-Start-Date", "Representations": [{"Name": "Day-Month-Year", "Type": "str", "Examples": ["01 January 2022", "15 February 2023", "31 December 2024", "01 января 2022 года", "15 февраля 2023 года", "31 декабря 2024"], "Pattern": ["dd Month YYYY", "дд Месяц ГГГГ"]}, {"Name": "Month-Day-Year", "Type": "str", "Examples": ["January 01 2022", "February 15 2023", "December 31 2024", "01 января 2022 года", "15 февраля 2023", "31 декабря 2024"], "Pattern": ["Month dd YYYY", "Месяц dd ГГГГ"]}, {"Name": "Month-Day-Year", "Type": "str", "Examples": ["01-01-2022", "02-15-2023", "12-31-2024", "01.01.2022", "15-02-2023", "31-12-2024"], "Pattern": ["mm-dd-YYYY", "mm-dd-YYYY"]}]}]```
|
| 61 |
+
Запрос: приложение для новогодней акции, дедлайн 31 декабря</s>
|
| 62 |
+
<s>bot:
|
| 63 |
+
[{"Value": "приложение для новогодней акции, дедлайн 31 декабря", "Name": "Correct"}, {"Name": "Project-End-Date.Day-Month-Year", "Value": "31 декабря текущего года"}]</s>
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
+
**Important:** Additionally, we are trying to fine-tune the Large Language Model (LLM) to not only parse unstructured search queries but also to correct spelling.
|
| 67 |
+
|
| 68 |
+
- **Developed by EmbeddingStudio team:**
|
| 69 |
+
* Aleksandr Iudaev [[LinkedIn](https://www.linkedin.com/in/alexanderyudaev/)] [[Email](mailto:[email protected])]
|
| 70 |
+
* Andrei Kostin [[LinkedIn](https://www.linkedin.com/in/andrey-kostin/)] [[Email](mailto:[email protected])]
|
| 71 |
+
* ML Doom [AI Assistant]
|
| 72 |
+
- **Funded by EmbeddingStudio team**
|
| 73 |
+
- **Model type:** Instruct Fine-Tuned Large Language Model
|
| 74 |
+
- **Model task:** Zero-shot search query parsing
|
| 75 |
+
- **Language(s) (NLP):** English
|
| 76 |
+
- **License:** apache-2.0
|
| 77 |
+
- **Finetuned from model:** [IlyaGusev/saiga_mistral_7b_lora](https://huggingface.co/IlyaGusev/saiga_mistral_7b_lora)
|
| 78 |
+
- **!Maximal Length Size:** we used 1024 for fine-tuning, this is highly different from the original model `max_seq_length = 2048`
|
| 79 |
+
- **Tuning Epochs:** 3 for now, but will be more later.
|
| 80 |
+
|
| 81 |
+
**Disclaimer:** As a small startup, this direction forms a part of our Minimum Viable Product (MVP). It's more of
|
| 82 |
+
an attempt to test the 'product-market fit' rather than a well-structured scientific endeavor. Once we check it and go with a round, we definitely will:
|
| 83 |
+
* Curating a specific dataset for more precise analysis.
|
| 84 |
+
* Exploring various approaches and Large Language Models (LLMs) to identify the most effective solution.
|
| 85 |
+
* Publishing a detailed paper to ensure our findings and methodologies can be thoroughly reviewed and verified.
|
| 86 |
+
|
| 87 |
+
We acknowledge the complexity involved in utilizing Large Language Models, particularly in the context
|
| 88 |
+
of `Zero-Shot search query parsing` and `AI Alignment`. Given the intricate nature of this technology, we emphasize the importance of rigorous verification.
|
| 89 |
+
Until our work is thoroughly reviewed, we recommend being cautious and critical of the results.
|
| 90 |
+
|
| 91 |
+
### Model Sources
|
| 92 |
+
|
| 93 |
+
- **Repository:** code of inference the model will be [here](https://github.com/EulerSearch/embedding_studio/tree/main)
|
| 94 |
+
- **Paper:** Work In Progress
|
| 95 |
+
- **Demo:** Work In Progress
|
| 96 |
+
|
| 97 |
+
## Uses
|
| 98 |
+
|
| 99 |
+
We strongly recommend only the direct usage of this fine-tuned version of [IlyaGusev/saiga_mistral_7b_lora](https://huggingface.co/IlyaGusev/saiga_mistral_7b_lora):
|
| 100 |
+
* Zero-shot Search Query Parsing with porived company market name and filters schema
|
| 101 |
+
* Search Query Spell Correction
|
| 102 |
+
|
| 103 |
+
For any other needs the behaviour of the model in unpredictable, please utilize the [IlyaGusev/saiga_mistral_7b_lora](https://huggingface.co/IlyaGusev/saiga_mistral_7b_lora) or fine-tune your own.
|
| 104 |
+
|
| 105 |
+
### Instruction format
|
| 106 |
+
|
| 107 |
+
```markdown
|
| 108 |
+
<s>system: Эксперт по разбору поисковых запросов</s>
|
| 109 |
+
<s>user: Преобразование запросов в JSON, соответствие схеме, обеспечение правильного написания.
|
| 110 |
+
Категория: {your_company_category}
|
| 111 |
+
Схема: ```{filters_schema}```
|
| 112 |
+
Запрос: {query}
|
| 113 |
+
<s>bot:
|
| 114 |
+
```
|
| 115 |
+
|
| 116 |
+
Filters schema is JSON-readable line in the format (we highly recommend you to use it):
|
| 117 |
+
List of filters (dict):
|
| 118 |
+
* Name - name of filter (better to be meaningful).
|
| 119 |
+
* Representations - list of possible filter formats (dict):
|
| 120 |
+
* Name - name of representation (better to be meaningful).
|
| 121 |
+
* Type - python base type (int, float, str, bool).
|
| 122 |
+
* Examples - list of examples.
|
| 123 |
+
* Enum - if a representation is enumeration, provide a list of possible values, LLM should map parsed value into this list.
|
| 124 |
+
* Pattern - if a representation is pattern-like (datetime, regexp, etc.) provide a pattern text in any format.
|
| 125 |
+
|
| 126 |
+
Example:
|
| 127 |
+
```json
|
| 128 |
+
[{"Name": "Customer_Ratings", "Representations": [{"Name": "Exact_Rating", "Type": "float", "Examples": [4.5, 3.2, 5.0, "4.5", "Unstructured"]}, {"Name": "Minimum_Rating", "Type": "float", "Examples": [4.0, 3.0, 5.0, "4.5"]}, {"Name": "Star_Rating", "Type": "int", "Examples": [4, 3, 5], "Enum": [1, 2, 3, 4, 5]}]}, {"Name": "Date", "Representations": [{"Name": "Day_Month_Year", "Type": "str", "Examples": ["01.01.2024", "15.06.2023", "31.12.2022", "25.12.2021", "20.07.2024", "15.06.2023"], "Pattern": "dd.mm.YYYY"}, {"Name": "Day_Name", "Type": "str", "Examples": ["Понедельник", "Вторник", "пн", "вт", "Среда", "Четверг"], "Enum": ["Понедельник", "Вторник", "Среда", "Четверг", "Пятница", "Суббота", "Воскресенье"]}]}, {"Name": "Date_Period", "Representations": [{"Name": "Specific_Period", "Type": "str", "Examples": ["01.01.2024 - 31.01.2024", "01.06.2023 - 30.06.2023", "01.12.2022 - 31.12.2022"], "Pattern": "dd.mm.YYYY - dd.mm.YYYY"}, {"Name": "Month", "Type": "str", "Examples": ["Январь", "Янв", "Декабрь"], "Enum": ["Январь", "Февраль", "Март", "Апрель", "Май", "Июнь", "Июль", "Август", "Сентябрь", "Октябрь", "Ноябрь", "Декабрь"]}, {"Name": "Quarter", "Type": "str", "Examples": ["Q1", "Q2", "Q3"], "Enum": ["Q1", "Q2", "Q3", "Q4"]}, {"Name": "Season", "Type": "str", "Examples": ["Winter", "Summer", "Autumn"], "Enum": ["Winter", "Spring", "Summer", "Autumn"]}]}, {"Name": "Destination_Country", "Representations": [{"Name": "Country_Name", "Type": "str", "Examples": ["United States", "Germany", "China"]}, {"Name": "Country_Code", "Type": "str", "Examples": ["US", "DE", "CN"]}, {"Name": "Country_Abbreviation", "Type": "str", "Examples": ["USA", "GER", "CHN"]}]}]
|
| 129 |
+
```
|
| 130 |
+
|
| 131 |
+
As the result, response will be JSON-readable line in the format:
|
| 132 |
+
```json
|
| 133 |
+
[{"Value": "Corrected search phrase", "Name": "Correct"}, {"Name": "filter-name.representation", "Value": "some-value"}]
|
| 134 |
+
```
|
| 135 |
+
|
| 136 |
+
Field and representation names will be aligned with the provided schema. Example:
|
| 137 |
+
```json
|
| 138 |
+
[{"Value": "приложение для новогодней акции, дедлайн 31 декабря", "Name": "Correct"}, {"Name": "Project-End-Date.Day-Month-Year", "Value": "31 декабря текущего года"}]
|
| 139 |
+
```
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
Used for fine-tuning `system` phrases:
|
| 143 |
+
```python
|
| 144 |
+
[
|
| 145 |
+
"Эксперт по разбору поисковых запросов",
|
| 146 |
+
"Мастер анализа поисковых запросов",
|
| 147 |
+
"Первоклассный интерпретатор поисковых запросов",
|
| 148 |
+
"Продвинутый декодер поисковых запросов",
|
| 149 |
+
"Гений разбора поисковых запросов",
|
| 150 |
+
"Волшебник разбора поисковых запросов",
|
| 151 |
+
"Непревзойденный механизм разбора запросов",
|
| 152 |
+
"Виртуоз разбора поисковых запросов",
|
| 153 |
+
"Маэстро разбора запросов",
|
| 154 |
+
]
|
| 155 |
+
```
|
| 156 |
+
|
| 157 |
+
Used for fine-tuning `instruction` phrases:
|
| 158 |
+
```python
|
| 159 |
+
[
|
| 160 |
+
"Преобразование запросов в JSON, соответствие схеме, обеспечение правильного написания.",
|
| 161 |
+
"Анализ и структурирование запросов в JSON, поддержание схемы, проверка орфографии.",
|
| 162 |
+
"Организация запросов в JSON, соблюдение схемы, верификация орфографии.",
|
| 163 |
+
"Декодирование запросов в JSON, следование схеме, исправление орфографии.",
|
| 164 |
+
"Разбор запросов в JSON, соответствие схеме, правильное написание.",
|
| 165 |
+
"Преобразование запросов в структурированный JSON, соответствие схеме и орфографии.",
|
| 166 |
+
"Реструктуризация запросов в JSON, соответствие схеме, точное написание.",
|
| 167 |
+
"Перестановка запросов в JSON, строгое соблюдение схемы, поддержание орфографии.",
|
| 168 |
+
"Гармонизация запросов с JSON схемой, обеспечение точности написания.",
|
| 169 |
+
"Эффективное преобразование запросов в JSON, соответствие схеме, правильная орфография."
|
| 170 |
+
]
|
| 171 |
+
```
|
| 172 |
+
|
| 173 |
+
### Direct Use
|
| 174 |
+
|
| 175 |
+
```python
|
| 176 |
+
import json
|
| 177 |
+
|
| 178 |
+
from json import JSONDecodeError
|
| 179 |
+
|
| 180 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM
|
| 181 |
+
|
| 182 |
+
from transformers import StoppingCriteria
|
| 183 |
+
|
| 184 |
+
class EosListStoppingCriteria(StoppingCriteria):
|
| 185 |
+
def __init__(self, eos_sequence = [2]):
|
| 186 |
+
self.eos_sequence = eos_sequence
|
| 187 |
+
|
| 188 |
+
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
|
| 189 |
+
last_ids = input_ids[:,-len(self.eos_sequence):].tolist()
|
| 190 |
+
return self.eos_sequence in last_ids
|
| 191 |
+
|
| 192 |
+
INSTRUCTION_TEMPLATE = """<s>system: Эксперт по разбору поисковых запросов</s>
|
| 193 |
+
<s>user: Преобразование запросов в JSON, соответствие схеме, обеспечение правильного написания.
|
| 194 |
+
Категория: {0}
|
| 195 |
+
Схема: ```{1}```
|
| 196 |
+
Запрос: {2}
|
| 197 |
+
<s>bot:
|
| 198 |
+
"""
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
def parse(
|
| 202 |
+
query: str,
|
| 203 |
+
company_category: str,
|
| 204 |
+
filter_schema: dict,
|
| 205 |
+
model: AutoModelForCausalLM,
|
| 206 |
+
tokenizer: AutoTokenizer
|
| 207 |
+
):
|
| 208 |
+
input_text = INSTRUCTION_TEMPLATE.format(
|
| 209 |
+
company_category,
|
| 210 |
+
json.dumps(filter_schema),
|
| 211 |
+
query
|
| 212 |
+
)
|
| 213 |
+
input_ids = tokenizer.encode(input_text, return_tensors='pt')
|
| 214 |
+
|
| 215 |
+
# Generating text
|
| 216 |
+
output = model.generate(input_ids.to('cuda'),
|
| 217 |
+
max_new_tokens=1024,
|
| 218 |
+
do_sample=True,
|
| 219 |
+
temperature=0.05
|
| 220 |
+
)
|
| 221 |
+
try:
|
| 222 |
+
generated = tokenizer.decode(output[0]).replace('<s> ', '<s>').split('<s>bot:\n')[-1].replace('</s>', '').strip()
|
| 223 |
+
parsed = json.loads(generated)
|
| 224 |
+
except JSONDecodeError as e:
|
| 225 |
+
parsed = dict()
|
| 226 |
+
|
| 227 |
+
return parsed
|
| 228 |
+
```
|
| 229 |
+
|
| 230 |
+
## Bias, Risks, and Limitations
|
| 231 |
+
|
| 232 |
+
### Bias
|
| 233 |
+
|
| 234 |
+
Again, this model was fine-tuned for following the zero-shot query parsing instructions.
|
| 235 |
+
So, all ethical biases are inherited by the original model.
|
| 236 |
+
|
| 237 |
+
Model was fine-tuned to be able to work with the unknown company domain and filters schema. But, can be better with the training company categories:
|
| 238 |
+
|
| 239 |
+
Artificial Intelligence and Machine Learning, Automotive, Automotive Dealerships, Banking Services, Books and Media, Cloud Computing Services, Cloud-based Development Environments, Collaborative Development Environments, Commercial Real Estate, Continuous Integration/Continuous Deployment, Credit Services, Customer Support Services, Customer Support and Feedback, Cybersecurity Software, Data Analytics and Business Intelligence, Dating Apps, Digital and Mobile Banking, Documentation and Knowledge Sharing, E-commerce Platforms, Eco-Friendly and Sustainable Properties, Educational Institutions, Electronics, Enterprise Software Development, Entertainment and Media Platforms, Event Planning Services, Fashion and Apparel, Financial Planning and Advisory, Food and Grocery, Game Development, Government Services, Health and Beauty, Healthcare Providers, Home and Garden, Image Stock Platforms, Insurance Services, International Real Estate, Internet of Things (IoT) Development, Investment Services, Issue Tracking and Bug Reporting, Job Recruitment Agencies, Land Sales and Acquisitions, Legal Services, Logistics and Supply Chain Management, Luxury and High-End Properties, Market Research Firms, Mobile App Development, Mortgage and Real Estate Services, Payment Processing, Pet Supplies, Professional Social Networks, Project Management Tools, Property Management, Real Estate Consulting, Real Estate Development, Real Estate Investment, Residential Real Estate, Restaurants and Food Delivery Services, Retail Stores (Online and Offline), Risk Management and Compliance, Social Networks, Sports and Outdoors, Task and Time Management, Taxation Services, Team Communication and Chat Tools, Telecommunication Companies, Toys and Games, Travel and Booking Agencies, Travelers and Consumers, User Interface/User Experience Design, Version Control Systems, Video Hosting and Portals, Web Development```
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
### Risks and Limitations
|
| 243 |
+
|
| 244 |
+
Known limitations:
|
| 245 |
+
1. Can add extra spaces or remove spaces: `1-2` -> `1 - 2`.
|
| 246 |
+
2. Can add extra words: `5` -> `5 years`.
|
| 247 |
+
3. Can not differentiate between `<>=` and theirs HTML versions `<`, `>`, `&eq;`.
|
| 248 |
+
4. Bad with abbreviations.
|
| 249 |
+
5. Can add extra `.0` for floats and integers.
|
| 250 |
+
6. Can add extra `0` or remove `0` for integers with a char postfix: `10M` -> `1m`.
|
| 251 |
+
7. Can hallucinate with integers. For the case like `list of positions exactly 7 openings available` result can be
|
| 252 |
+
`{'Name': 'Job_Type.Exact_Match', 'Value': 'Full Time'}`.
|
| 253 |
+
8. We fine-tuned this model with max sequence length = 1024, so it may happen that response will not be JSON-readable.
|
| 254 |
+
|
| 255 |
+
The list will be extended in the future.
|
| 256 |
+
|
| 257 |
+
### Recommendations
|
| 258 |
+
|
| 259 |
+
1. We used synthetic data for the first version of this model. So, we suggest you to precisely test this model on your company's domain, even it's in the list.
|
| 260 |
+
2. Use meaningful names for filters and theirs representations.
|
| 261 |
+
3. Provide examples for each representation.
|
| 262 |
+
4. Try to be compact, model was fine-tuned with max sequence length equal 1024.
|
| 263 |
+
5. During the generation use greedy strategy with tempertature 0.05.
|
| 264 |
+
6. The result will be better if you align a filters schema with a schema type of the training data.
|
| 265 |
+
|
| 266 |
+
## How to Get Started with the Model
|
| 267 |
+
|
| 268 |
+
Use the code below to get started with the model.
|
| 269 |
+
|
| 270 |
+
```python
|
| 271 |
+
MODEL_ID = 'EmbeddingStudio/query-parser-saiga-mistral-7b-lora'
|
| 272 |
+
```
|
| 273 |
+
|
| 274 |
+
Initialize tokenizer:
|
| 275 |
+
```python
|
| 276 |
+
from transformers import AutoTokenizer
|
| 277 |
+
|
| 278 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 279 |
+
MODEL_ID,
|
| 280 |
+
trust_remote_code=True,
|
| 281 |
+
add_prefix_space=True,
|
| 282 |
+
use_fast=False,
|
| 283 |
+
)
|
| 284 |
+
```
|
| 285 |
+
|
| 286 |
+
Initialize model:
|
| 287 |
+
```python
|
| 288 |
+
import torch
|
| 289 |
+
|
| 290 |
+
from peft import LoraConfig
|
| 291 |
+
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
|
| 292 |
+
|
| 293 |
+
peft_config = LoraConfig(
|
| 294 |
+
lora_alpha=16,
|
| 295 |
+
lora_dropout=0.1,
|
| 296 |
+
r=64,
|
| 297 |
+
bias="none",
|
| 298 |
+
task_type="CAUSAL_LM",
|
| 299 |
+
)
|
| 300 |
+
|
| 301 |
+
bnb_config = BitsAndBytesConfig(
|
| 302 |
+
load_in_4bit=True,
|
| 303 |
+
load_4bit_use_double_quant=True,
|
| 304 |
+
bnb_4bit_quant_type="nf4",
|
| 305 |
+
bnb_4bit_compute_dtype=torch.bfloat16,
|
| 306 |
+
)
|
| 307 |
+
|
| 308 |
+
device_map = {"": 0}
|
| 309 |
+
|
| 310 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 311 |
+
MODEL_ID,
|
| 312 |
+
quantization_config=bnb_config,
|
| 313 |
+
device_map=device_map,
|
| 314 |
+
torch_dtype=torch.float16
|
| 315 |
+
)
|
| 316 |
+
```
|
| 317 |
+
|
| 318 |
+
Use for parsing:
|
| 319 |
+
```python
|
| 320 |
+
import json
|
| 321 |
+
|
| 322 |
+
from json import JSONDecodeError
|
| 323 |
+
|
| 324 |
+
from transformers import StoppingCriteria
|
| 325 |
+
|
| 326 |
+
class EosListStoppingCriteria(StoppingCriteria):
|
| 327 |
+
def __init__(self, eos_sequence = [2]):
|
| 328 |
+
self.eos_sequence = eos_sequence
|
| 329 |
+
|
| 330 |
+
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
|
| 331 |
+
last_ids = input_ids[:,-len(self.eos_sequence):].tolist()
|
| 332 |
+
return self.eos_sequence in last_ids
|
| 333 |
+
|
| 334 |
+
INSTRUCTION_TEMPLATE = """<s>system: Эксперт по разбору поисковых запросов</s>
|
| 335 |
+
<s>user: Преобразование запросов в JSON, соответствие схеме, обеспечение правильного написания.
|
| 336 |
+
Категория: {0}
|
| 337 |
+
Схема: ```{1}```
|
| 338 |
+
Запрос: {2}
|
| 339 |
+
<s>bot:
|
| 340 |
+
"""
|
| 341 |
+
|
| 342 |
+
|
| 343 |
+
def parse(
|
| 344 |
+
query: str,
|
| 345 |
+
company_category: str,
|
| 346 |
+
filter_schema: dict,
|
| 347 |
+
model: AutoModelForCausalLM,
|
| 348 |
+
tokenizer: AutoTokenizer
|
| 349 |
+
):
|
| 350 |
+
input_text = INSTRUCTION_TEMPLATE.format(
|
| 351 |
+
company_category,
|
| 352 |
+
json.dumps(filter_schema),
|
| 353 |
+
query
|
| 354 |
+
)
|
| 355 |
+
input_ids = tokenizer.encode(input_text, return_tensors='pt')
|
| 356 |
+
|
| 357 |
+
# Generating text
|
| 358 |
+
output = model.generate(input_ids.to('cuda'),
|
| 359 |
+
max_new_tokens=1024,
|
| 360 |
+
do_sample=True,
|
| 361 |
+
temperature=0.05
|
| 362 |
+
)
|
| 363 |
+
try:
|
| 364 |
+
generated = tokenizer.decode(output[0]).replace('<s> ', '<s>').split('<s>bot:\n')[-1].replace('</s>', '').strip()
|
| 365 |
+
parsed = json.loads(generated)
|
| 366 |
+
except JSONDecodeError as e:
|
| 367 |
+
parsed = dict()
|
| 368 |
+
|
| 369 |
+
return parsed
|
| 370 |
+
|
| 371 |
+
category = 'Mobile App Development'
|
| 372 |
+
query = 'приложение для новогодней акции, дедлайн 31 декабря'
|
| 373 |
+
schema = [{"Name": "Project-Budget", "Representations": [{"Name": "Budget-in-USD", "Type": "float", "Examples": [1000.0, 5000.0, 10000.0, "The project is currently on hold", "The project is currently on hold", "The project is currently on hold"]}, {"Name": "Budget-in-EUR", "Type": "float", "Examples": [850.0, 4250.0, 8500.0, "The project is currently on hold", "The project is currently on hold", "The project is currently on hold"]}, {"Name": "Budget-in-JPY", "Type": "float", "Examples": [110000.0, 550000.0, 1100000.0, "The project is currently on hold", "The project is currently on hold", "The project is currently on hold"]}, {"Name": "Budget-in-AUD", "Type": "float", "Examples": [1300.0, 6500.0, 13000.0, "The project is currently on hold", "The project is currently on hold", "The project is currently on hold"]}]}, {"Name": "Project-Duration", "Representations": [{"Name": "Duration-in-Minutes", "Type": "int", "Examples": [43200, 259200, 525600, 5, 5, 5]}]}, {"Name": "Project-End-Date", "Representations": [{"Name": "Day-Month-Year", "Type": "str", "Examples": ["01 January 2022", "15 February 2023", "31 December 2024", "01 января 2022 года", "15 февраля 2023 года", "31 декабря 2024"], "Pattern": ["dd Month YYYY", "дд Месяц ГГГГ"]}]}, {"Name": "Project-Start-Date", "Representations": [{"Name": "Day-Month-Year", "Type": "str", "Examples": ["01 January 2022", "15 February 2023", "31 December 2024", "01 января 2022 года", "15 февраля 2023 года", "31 декабря 2024"], "Pattern": ["dd Month YYYY", "дд Месяц ГГГГ"]}, {"Name": "Month-Day-Year", "Type": "str", "Examples": ["January 01 2022", "February 15 2023", "December 31 2024", "01 января 2022 года", "15 февраля 2023", "31 декабря 2024"], "Pattern": ["Month dd YYYY", "Месяц dd ГГГГ"]}, {"Name": "Month-Day-Year", "Type": "str", "Examples": ["01-01-2022", "02-15-2023", "12-31-2024", "01.01.2022", "15-02-2023", "31-12-2024"], "Pattern": ["mm-dd-YYYY", "mm-dd-YYYY"]}]}]
|
| 374 |
+
|
| 375 |
+
output = parse(query, category, schema)
|
| 376 |
+
print(output)
|
| 377 |
+
|
| 378 |
+
# [out]: [{"Value": "приложение для новогодней акции, дедлайн 31 декабря", "Name": "Correct"}, {"Name": "Project-End-Date.Day-Month-Year", "Value": "31 декабря текущего года"}]
|
| 379 |
+
```
|
| 380 |
+
|
| 381 |
+
|
| 382 |
+
## Training Details
|
| 383 |
+
|
| 384 |
+
### Training Data
|
| 385 |
+
|
| 386 |
+
We used synthetically generated query parsing instructions:
|
| 387 |
+
* We generated lists of possible filters for 72 company categories:
|
| 388 |
+
* [Raw version of filters dataset](https://huggingface.co/datasets/EmbeddingStudio/synthetic-search-filters-ru-raw)
|
| 389 |
+
* [Split by representations](https://huggingface.co/datasets/EmbeddingStudio/synthetic-search-filters-ru)
|
| 390 |
+
* Select randomly up-to 150 possible combinations (1-3 filters in each combination) of filters, the way each filter's representation appears maximum twice.
|
| 391 |
+
* For a given category and combination we [generated](https://huggingface.co/datasets/EmbeddingStudio/synthetic-search-queries-ru) with GPT-4 Turbo:
|
| 392 |
+
* 2 search queries and theirs parsed version with unstructured parts.
|
| 393 |
+
* 2 search queries and theirs parsed version without unstructured part.
|
| 394 |
+
* Using filters, queries and parsed version we prepared [27.42k saiga format instruction](https://huggingface.co/datasets/EmbeddingStudio/query-parsing-instructions-saiga)
|
| 395 |
+
|
| 396 |
+
**Warning:** EmbeddingStudio team aware you that generated queries **weren't enough curated**, and will be curated later once we finish our product market fit stage
|
| 397 |
+
|
| 398 |
+
#### Principles of train / test splitting
|
| 399 |
+
|
| 400 |
+
As we are trying to fine-tune LLM to follow zero-shot query parsing instructions, so we want to test:
|
| 401 |
+
* Ability to work well with unseen domain
|
| 402 |
+
* Ability to work well with unseen filters
|
| 403 |
+
* Ability to work well with unseen queries
|
| 404 |
+
|
| 405 |
+
For these purposes we:
|
| 406 |
+
1. We put into test split 5 categories, completely separared from train: `Automotive, Educational Institutions, Enterprise Software Development, Payment Processing, Professional Social Networks`.
|
| 407 |
+
2. Also out of each appearing in train company categories, we put aside / removed one filter and queries related to it.
|
| 408 |
+
|
| 409 |
+
#### Filters generation details
|
| 410 |
+
|
| 411 |
+
We used GPT-4 Turbo to generate several possible filters for 63 company categroies. For each filter we also generated some possible representations. For examples filter `Date` can be represented as `dd/mm/YYYY`, `YYYY-mm-dd`, as words `2024 Янв 17`, etc.
|
| 412 |
+
|
| 413 |
+
#### Queries generation details
|
| 414 |
+
|
| 415 |
+
We also used GPT-4 Turbo for generation of search queries and theirs parsed version. Main principles were:
|
| 416 |
+
* If passed schema doesn't contain possible filter, do not generate query itself or a possible filter
|
| 417 |
+
* If a selected representations combination contains enumeration, so we ask to map values in a search query and a parsed version.
|
| 418 |
+
* If a selected representations combination contains pattern, so we ask GPT-4 Turbo to be aligned with a pattern
|
| 419 |
+
|
| 420 |
+
#### Instructions generation details
|
| 421 |
+
|
| 422 |
+
For the generation instructions we used following ideas:
|
| 423 |
+
1. Zero-Shot query parser should be schema agnostic. Cases like `snake_case, CamelCase, http-headers-like` should not ruin generation process.
|
| 424 |
+
2. Zero-Shot query parser should be spelling errors insensitive.
|
| 425 |
+
3. Training instructions should be in the following order:
|
| 426 |
+
* Category
|
| 427 |
+
* Schema
|
| 428 |
+
* Query
|
| 429 |
+
|
| 430 |
+
So LLM can be used in the following way: just generate embedding of category -> schema part, so inference will be faster.
|
| 431 |
+
|
| 432 |
+
We assume, that `schema agnostic` termin means something wider, like to be able to work not only with JSONs, but also with HTML, Markdown, YAML, etc. We are working on it.
|
| 433 |
+
|
| 434 |
+
So, what was our approach as an attempt to achieve these abilities:
|
| 435 |
+
1. For each query we generated a version with a mistake
|
| 436 |
+
2. Passed to each parsed version an additional field `Correct`, which contains a corrected version of a search query.
|
| 437 |
+
3. For each query we randomly selected and used a case for schema fields and a case for filter and representation names.
|
| 438 |
+
4. For each query we additionally generated two instuctions:
|
| 439 |
+
* Where did we remove from a provided schema and parsed version one filter
|
| 440 |
+
* Where did we remove from a provided schema and parsed version all related filters
|
| 441 |
+
|
| 442 |
+
**Warning:** EmbeddingStudio team ask you to curate datasets on your own precisely.
|
| 443 |
+
|
| 444 |
+
### Training Procedure
|
| 445 |
+
|
| 446 |
+
1. Mixed Precision Regime
|
| 447 |
+
2. Supervised Fine-Tuning
|
| 448 |
+
3. Three epochs with cosine scheduler
|
| 449 |
+
|
| 450 |
+
All details in Training Hyperparameters
|
| 451 |
+
|
| 452 |
+
#### Preprocessing [optional]
|
| 453 |
+
|
| 454 |
+
The preprocessing steps are not detailed in the provided code. Typically, preprocessing involves tokenization, normalization, data augmentation, and handling of special tokens. In this training setup, the tokenizer was configured with `add_prefix_space=True` and `use_fast=False`, which might indicate special considerations for tokenizing certain languages or text formats.
|
| 455 |
+
|
| 456 |
+
#### Training Hyperparameters
|
| 457 |
+
| Hyperparameter | Value | Description |
|
| 458 |
+
|--------------------------------------|------------------------------|-------------------------------------------------------|
|
| 459 |
+
| **Training Regime** | Mixed Precision (bfloat16) | Utilizes bfloat16 for efficient memory usage and training speed. |
|
| 460 |
+
| **Model Configuration** | Causal Language Model | Incorporates LoRA (Low-Rank Adaptation) for training efficiency. |
|
| 461 |
+
| **Quantization Configuration** | Bits and Bytes (BnB) | Uses settings like `load_in_4bit` and `bnb_4bit_quant_type` for model quantization. |
|
| 462 |
+
| **Training Environment** | CUDA-enabled Device | Indicates GPU acceleration for training. |
|
| 463 |
+
| **Learning Rate** | 0.003 | Determines the step size at each iteration while moving toward a minimum of a loss function. |
|
| 464 |
+
| **Warmup Ratio** | 0.03 | Fraction of total training steps used for the learning rate warmup. |
|
| 465 |
+
| **Optimizer** | Paged AdamW (32-bit) | Optimizes the training process with efficient memory usage. |
|
| 466 |
+
| **Gradient Accumulation Steps** | 2 | Reduces memory consumption and allows for larger effective batch sizes. |
|
| 467 |
+
| **Max Grad Norm** | 0.3 | Maximum norm for the gradients. |
|
| 468 |
+
| **LR Scheduler Type** | Cosine | Specifies the learning rate schedule. |
|
| 469 |
+
| **PEFT Configurations** | LoraConfig | Details like `lora_alpha`, `lora_dropout`, and `r` for LoRA adaptations. |
|
| 470 |
+
| **Training Dataset Segmentation** | Train and Test Sets | Segmentation of the dataset for training and evaluation. |
|
| 471 |
+
| **Max Sequence Length** | 1024 | Maximum length of the input sequences. |
|
| 472 |
+
|
| 473 |
+
### Testing Data, Factors & Metrics
|
| 474 |
+
|
| 475 |
+
#### Testing Data
|
| 476 |
+
|
| 477 |
+
All information is provided in [Training Data](#training-data) section.
|
| 478 |
+
|
| 479 |
+
### Factors Influencing Saiga-Mistral-7B Model Performance
|
| 480 |
+
|
| 481 |
+
#### 1. Company Category and Domain Knowledge
|
| 482 |
+
- Performance may vary based on the specific company category or domain.
|
| 483 |
+
- Enhanced performance in domains specifically trained on, such as Educational Institutions, Banking Services, Logistics, etc.
|
| 484 |
+
|
| 485 |
+
#### 2. Filter Schema Adaptability
|
| 486 |
+
- Ability to adapt to various filter schemas.
|
| 487 |
+
- Performance in parsing and organizing queries according to different schemas.
|
| 488 |
+
|
| 489 |
+
#### 3. Handling of Spelling and Syntax Errors
|
| 490 |
+
- Robustness in handling spelling errors and syntax variations in queries.
|
| 491 |
+
|
| 492 |
+
#### 4. Representation and Type Handling
|
| 493 |
+
- Capability to handle different data representations (e.g., date formats, enumerations, patterns).
|
| 494 |
+
- Accurate processing of various base types (int, float, str, bool).
|
| 495 |
+
|
| 496 |
+
#### 5. Length and Complexity of Queries
|
| 497 |
+
- Impact of the length and complexity of queries on performance.
|
| 498 |
+
- Maximum sequence length of 1024 could pose limitations for longer or complex queries.
|
| 499 |
+
|
| 500 |
+
#### 6. Bias and Ethical Considerations
|
| 501 |
+
- Inherited ethical biases from the original model.
|
| 502 |
+
- Importance of understanding these biases in different contexts.
|
| 503 |
+
|
| 504 |
+
#### 7. Limitations in Fine-Tuning and Data Curation
|
| 505 |
+
- Limitations such as extra spaces, handling of abbreviations, etc.
|
| 506 |
+
- Influence of the extent of training data curation on model accuracy.
|
| 507 |
+
|
| 508 |
+
#### 8. Specific Use Cases
|
| 509 |
+
- Recommended primarily for zero-shot search query parsing and search query spell correction.
|
| 510 |
+
- Performance in other use cases might be unpredictable.
|
| 511 |
+
|
| 512 |
+
#### 9. Training Data Quality and Diversity
|
| 513 |
+
- Quality and diversity of synthetic training data.
|
| 514 |
+
- Influence on the model's effectiveness across different scenarios.
|
| 515 |
+
|
| 516 |
+
|
| 517 |
+
##### Testing Procedure
|
| 518 |
+
|
| 519 |
+
#### Metrics
|
| 520 |
+
|
| 521 |
+
#### Metric Overview
|
| 522 |
+
|
| 523 |
+
Our zero-shot search query parsing model is designed to extract structured information from unstructured search queries with high precision. The primary metric for evaluating our model's performance is the True Positive (TP) rate, which is assessed using a specialized token-wise Levenshtein distance. This approach is aligned with our goal to achieve semantic accuracy in parsing user queries.
|
| 524 |
+
|
| 525 |
+
#### True Positives (TP)
|
| 526 |
+
|
| 527 |
+
- **Definition**: A True Positive in our model is counted when the model correctly identifies both the 'Name' and 'Value' in a query, matching the expected results.
|
| 528 |
+
- **Measurement Method**: The TP rate is quantified using the `levenshtein_tokenwise` function, which calculates the distance between predicted and actual key-value pairs at a token level. We consider a Levenshtein distance of 0.25 or less as acceptable for matching.
|
| 529 |
+
- **Importance**:
|
| 530 |
+
- **Token-Level Accuracy**: We use token-wise accuracy over traditional character-level Levenshtein distance, which can be overly strict, especially for minor spelling variations. Our token-wise approach prioritizes semantic accuracy.
|
| 531 |
+
- **Relevance to Search Queries**: Accuracy at the token level is more indicative of the model's ability to understand and parse user intent in search queries.
|
| 532 |
+
|
| 533 |
+
#### Generation Strategy
|
| 534 |
+
|
| 535 |
+
- **Approach**: The model generates responses based on input queries with a maximum token length set to 1000, employing a sampling strategy (do_sample=True), and a low temperature setting of 0.05. This controlled randomness in generation ensures a variety of accurate and relevant responses.
|
| 536 |
+
- **Impact on TP**:
|
| 537 |
+
- The low temperature setting directly influences the TP rate by reducing the randomness in the model's predictions. With a lower temperature, the model is more likely to choose the most probable word in a given context, leading to more accurate and consistent outputs. This is particularly crucial in search query parsing, where understanding and interpreting user input with high precision is vital.
|
| 538 |
+
|
| 539 |
+
#### Additional Metrics
|
| 540 |
+
|
| 541 |
+
- **False Positives (FP) and False Negatives (FN)**: These metrics are monitored to provide a comprehensive view of the model's predictive capabilities.
|
| 542 |
+
- **Precision, Recall, F1 Score, Accuracy**: These standard metrics complement our TP-focused assessment, providing a rounded picture of the model's performance in various aspects.
|
| 543 |
+
|
| 544 |
+
#### Motivation for Metric Choice
|
| 545 |
+
|
| 546 |
+
- **Alignment with User Intent**: Focusing on token-wise accuracy ensures the model's performance closely mirrors the structure and intent typical in search queries.
|
| 547 |
+
- **Robustness Against Query Variations**: This metric approach makes the model adaptable to the varied formulations of real-world search queries.
|
| 548 |
+
- **Balancing Precision and Recall**: Our method aims to balance the model's ability not to miss relevant key-value pairs (high recall) while not over-identifying irrelevant ones (high precision).
|
| 549 |
+
|
| 550 |
+
##### Total metrics
|
| 551 |
+
|
| 552 |
+
| Category | Recall | Precision | F1 | Accuracy |
|
| 553 |
+
| ------------------------------------------------ | ------ | --------- | ----- | -------- |
|
| 554 |
+
| Educational Institutions [+] | 0.74 | 0.71 | 0.73 | 0.57 |
|
| 555 |
+
| Enterprise Software Development [+] | 0.80 | 0.73 | 0.76 | 0.62 |
|
| 556 |
+
| Professional Social Networks [+] | 0.82 | 0.72 | 0.76 | 0.62 |
|
| 557 |
+
| Automotive [+] | 0.77 | 0.64 | 0.70 | 0.54 |
|
| 558 |
+
| Payment Processing [+] | 0.80 | 0.73 | 0.76 | 0.62 |
|
| 559 |
+
| Continuous Integration/Continuous Deployment | 0.85 | 0.83 | 0.84 | 0.72 |
|
| 560 |
+
| Digital and Mobile Banking | 0.79 | 0.83 | 0.81 | 0.68 |
|
| 561 |
+
| Web Development | 0.93 | 0.73 | 0.82 | 0.69 |
|
| 562 |
+
| Banking Services | 0.74 | 0.79 | 0.76 | 0.62 |
|
| 563 |
+
| Customer Support and Feedback | 0.88 | 0.93 | 0.90 | 0.83 |
|
| 564 |
+
| Video Hosting and Portals | 0.86 | 0.88 | 0.87 | 0.77 |
|
| 565 |
+
| Cloud Computing Services | 0.72 | 0.62 | 0.67 | 0.50 |
|
| 566 |
+
| Health and Beauty | 0.78 | 0.81 | 0.79 | 0.66 |
|
| 567 |
+
| Game Development | 0.65 | 0.62 | 0.63 | 0.46 |
|
| 568 |
+
| Artificial Intelligence and Machine Learning | 0.80 | 0.83 | 0.82 | 0.69 |
|
| 569 |
+
| Social Networks | 0.92 | 0.82 | 0.87 | 0.76 |
|
| 570 |
+
| Mobile App Development | 0.89 | 0.88 | 0.88 | 0.79 |
|
| 571 |
+
| Customer Support Services | 0.81 | 0.80 | 0.81 | 0.68 |
|
| 572 |
+
| Commercial Real Estate | 0.91 | 0.80 | 0.85 | 0.74 |
|
| 573 |
+
| Cloud-based Development Environments | 0.90 | 0.82 | 0.86 | 0.75 |
|
| 574 |
+
| Event Planning Services | 0.92 | 0.69 | 0.79 | 0.65 |
|
| 575 |
+
| Project Management Tools | 0.88 | 0.83 | 0.86 | 0.75 |
|
| 576 |
+
| Version Control Systems | 0.70 | 0.67 | 0.69 | 0.52 |
|
| 577 |
+
| Automotive Dealerships | 0.60 | 0.67 | 0.63 | 0.46 |
|
| 578 |
+
| Insurance Services | 0.81 | 0.60 | 0.69 | 0.53 |
|
| 579 |
+
| Telecommunication Companies | 0.68 | 0.73 | 0.71 | 0.55 |
|
| 580 |
+
| Image Stock Platforms | 0.95 | 0.91 | 0.93 | 0.87 |
|
| 581 |
+
| Toys and Games | 0.79 | 0.79 | 0.79 | 0.65 |
|
| 582 |
+
| Books and Media | 0.74 | 0.74 | 0.74 | 0.58 |
|
| 583 |
+
| Residential Real Estate | 0.78 | 0.63 | 0.69 | 0.53 |
|
| 584 |
+
| Legal Services | 0.91 | 0.83 | 0.87 | 0.76 |
|
| 585 |
+
| Job Recruitment Agencies | 0.84 | 0.73 | 0.78 | 0.64 |
|
| 586 |
+
| International Real Estate | 0.97 | 0.84 | 0.90 | 0.81 |
|
| 587 |
+
| Dating Apps | 0.92 | 0.84 | 0.88 | 0.79 |
|
| 588 |
+
| Home and Garden | 0.70 | 0.59 | 0.64 | 0.47 |
|
| 589 |
+
| User Interface/User Experience Design | 0.84 | 0.73 | 0.78 | 0.64 |
|
| 590 |
+
| Logistics and Supply Chain Management | 0.78 | 0.69 | 0.73 | 0.57 |
|
| 591 |
+
| Sports and Outdoors | 0.80 | 0.72 | 0.76 | 0.61 |
|
| 592 |
+
| Team Communication and Chat Tools | 0.71 | 0.61 | 0.66 | 0.49 |
|
| 593 |
+
| Mortgage and Real Estate Services | 0.77 | 0.67 | 0.71 | 0.55 |
|
| 594 |
+
| Taxation Services | 0.67 | 0.64 | 0.66 | 0.49 |
|
| 595 |
+
| Electronics | 0.79 | 0.53 | 0.63 | 0.47 |
|
| 596 |
+
| Travelers and Consumers | 0.91 | 0.86 | 0.89 | 0.80 |
|
| 597 |
+
| Financial Planning and Advisory | 0.90 | 0.85 | 0.88 | 0.78 |
|
| 598 |
+
| Real Estate Consulting | 0.77 | 0.69 | 0.73 | 0.57 |
|
| 599 |
+
| Property Management | 0.86 | 0.72 | 0.79 | 0.65 |
|
| 600 |
+
| Government Services | 0.96 | 0.93 | 0.94 | 0.89 |
|
| 601 |
+
| E-commerce Platforms | 0.93 | 0.89 | 0.91 | 0.83 |
|
| 602 |
+
| Data Analytics and Business Intelligence | 0.96 | 0.88 | 0.92 | 0.85 |
|
| 603 |
+
| Documentation and Knowledge Sharing | 0.84 | 0.77 | 0.80 | 0.67 |
|
| 604 |
+
| Real Estate Investment | 0.79 | 0.73 | 0.76 | 0.62 |
|
| 605 |
+
| Eco-Friendly and Sustainable Properties | 0.85 | 0.72 | 0.78 | 0.64 |
|
| 606 |
+
| Task and Time Management | 0.91 | 0.87 | 0.89 | 0.80 |
|
| 607 |
+
| Issue Tracking and Bug Reporting | 0.70 | 0.57 | 0.63 | 0.46 |
|
| 608 |
+
| Restaurants and Food Delivery Services | 0.80 | 0.72 | 0.76 | 0.61 |
|
| 609 |
+
| Luxury and High-End Properties | 0.93 | 0.77 | 0.84 | 0.73 |
|
| 610 |
+
| Food and Grocery | 0.85 | 0.60 | 0.70 | 0.54 |
|
| 611 |
+
| Entertainment and Media Platforms | 0.80 | 0.85 | 0.83 | 0.70 |
|
| 612 |
+
| Real Estate Development | 0.86 | 0.74 | 0.79 | 0.66 |
|
| 613 |
+
| Market Research Firms | 0.90 | 0.82 | 0.86 | 0.75 |
|
| 614 |
+
| Investment Services | 0.76 | 0.86 | 0.81 | 0.67 |
|
| 615 |
+
| Collaborative Development Environments | 0.72 | 0.62 | 0.66 | 0.50 |
|
| 616 |
+
| Retail Stores (Online and Offline) | 0.78 | 0.71 | 0.75 | 0.60 |
|
| 617 |
+
| Fashion and Apparel | 0.68 | 0.72 | 0.70 | 0.54 |
|
| 618 |
+
| Healthcare Providers | 0.68 | 0.61 | 0.64 | 0.48 |
|
| 619 |
+
| Travel and Booking Agencies | 0.80 | 0.72 | 0.76 | 0.61 |
|
| 620 |
+
| Credit Services | 0.94 | 0.94 | 0.94 | 0.88 |
|
| 621 |
+
| Land Sales and Acquisitions | 0.90 | 0.76 | 0.83 | 0.70 |
|
| 622 |
+
| Internet of Things (IoT) Development | 0.90 | 0.92 | 0.91 | 0.83 |
|
| 623 |
+
| Risk Management and Compliance | 0.74 | 0.77 | 0.75 | 0.60 |
|
| 624 |
+
| Pet Supplies | 0.85 | 0.70 | 0.77 | 0.62 |
|
| 625 |
+
| Aggregate | 0.82 | 0.75 | 0.78 | 0.65 |
|
| 626 |
+
|
| 627 |
+
|
| 628 |
+
##### Unseen domains metrics
|
| 629 |
+
|
| 630 |
+
| Category | Recall | Precision | F1 | Accuracy |
|
| 631 |
+
| ----------------------------------- | ------ | --------- | ----- | -------- |
|
| 632 |
+
| Educational Institutions [+] | 0.74 | 0.71 | 0.73 | 0.57 |
|
| 633 |
+
| Enterprise Software Development [+] | 0.80 | 0.73 | 0.76 | 0.62 |
|
| 634 |
+
| Professional Social Networks [+] | 0.82 | 0.72 | 0.76 | 0.62 |
|
| 635 |
+
| Automotive [+] | 0.77 | 0.64 | 0.70 | 0.54 |
|
| 636 |
+
| Payment Processing [+] | 0.80 | 0.73 | 0.76 | 0.62 |
|
| 637 |
+
| Aggregate | 0.78 | 0.71 | 0.74 | 0.59 |
|
| 638 |
+
|
| 639 |
+
|
| 640 |
+
|
| 641 |
+
## Environmental Impact
|
| 642 |
+
|
| 643 |
+
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
|
| 644 |
+
|
| 645 |
+
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
|
| 646 |
+
|
| 647 |
+
- **Hardware Type:** NVIDIA Tesla V100
|
| 648 |
+
- **Hours used:** 72
|
| 649 |
+
- **Cloud Provider:** Google Cloud
|
| 650 |
+
- **Compute Region:** us-west-1
|
| 651 |
+
- **Carbon Emitted:** 6.48
|
| 652 |
+
|
| 653 |
+
## Technical Specifications
|
| 654 |
+
|
| 655 |
+
### Model Architecture and Objective
|
| 656 |
+
|
| 657 |
+
* Base model: [IlyaGusev/saiga_mistral_7b_lora](https://huggingface.co/IlyaGusev/saiga_mistral_7b_lora).
|
| 658 |
+
* Quantization Configuration: Uses settings like `load_in_4bit` and `bnb_4bit_quant_type` for model quantization.
|
| 659 |
+
|
| 660 |
+
### Compute Infrastructure
|
| 661 |
+
|
| 662 |
+
[To be added]
|
| 663 |
+
|
| 664 |
+
#### Hardware
|
| 665 |
+
|
| 666 |
+
[To be added]
|
| 667 |
+
|
| 668 |
+
#### Software
|
| 669 |
+
|
| 670 |
+
* Python 3.9+
|
| 671 |
+
* CUDA 11.7.1
|
| 672 |
+
* NVIDIA [Compatible Drivers](https://www.nvidia.com/download/find.aspx)
|
| 673 |
+
* Torch 2.0.0
|
| 674 |
+
|
| 675 |
+
## More Information / About us
|
| 676 |
+
|
| 677 |
+
EmbeddingStudio is an innovative open-source framework designed to seamlessly convert a combined
|
| 678 |
+
"Embedding Model + Vector DB" into a comprehensive search engine. With built-in functionalities for
|
| 679 |
+
clickstream collection, continuous improvement of search experiences, and automatic adaptation of
|
| 680 |
+
the embedding model, it offers an out-of-the-box solution for a full-cycle search engine.
|
| 681 |
+
|
| 682 |
+
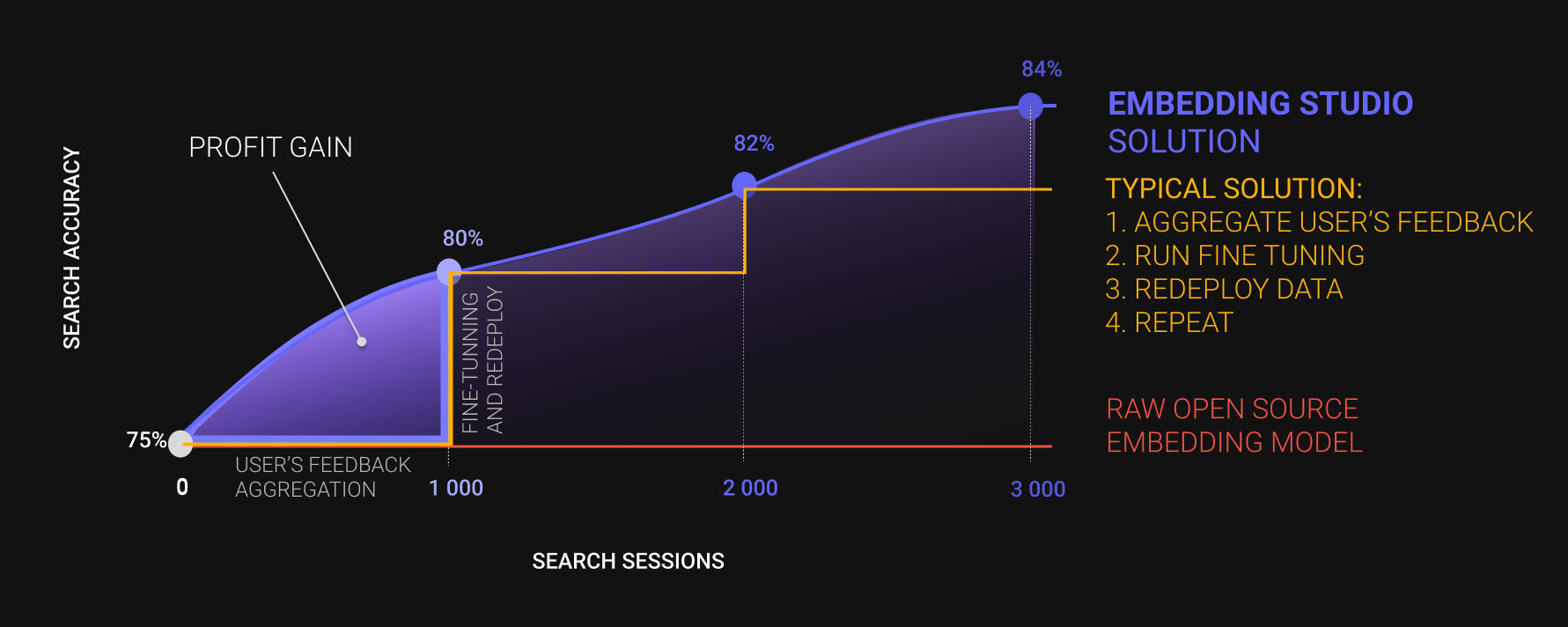
|
| 683 |
+
|
| 684 |
+
### Features
|
| 685 |
+
|
| 686 |
+
1. 🔄 Turn your vector database into a full-cycle search engine
|
| 687 |
+
2. 🖱️ Collect users feedback like clickstream
|
| 688 |
+
3. 🚀 (*) Improve search experience on-the-fly without frustrating wait times
|
| 689 |
+
4. 📊 (*) Monitor your search quality
|
| 690 |
+
5. 🎯 Improve your embedding model through an iterative metric fine-tuning procedure
|
| 691 |
+
6. 🆕 (*) Use the new version of the embedding model for inference
|
| 692 |
+
|
| 693 |
+
(*) - features in development
|
| 694 |
+
|
| 695 |
+
EmbeddingStudio is highly customizable, so you can bring your own:
|
| 696 |
+
|
| 697 |
+
1. Data source
|
| 698 |
+
2. Vector database
|
| 699 |
+
3. Clickstream database
|
| 700 |
+
4. Embedding model
|
| 701 |
+
|
| 702 |
+
For more details visit [GitHub Repo](https://github.com/EulerSearch/embedding_studio/tree/main).
|
| 703 |
+
|
| 704 |
+
## Model Card Authors and Contact
|
| 705 |
+
|
| 706 |
+
* Aleksandr Iudaev [[LinkedIn](https://www.linkedin.com/in/alexanderyudaev/)] [[Email](mailto:[email protected])]
|
| 707 |
+
* Andrei Kostin [[LinkedIn](https://www.linkedin.com/in/andrey-kostin/)] [[Email](mailto:[email protected])]
|
| 708 |
+
* ML Doom [AI Assistant]
|
| 709 |
+
|
| 710 |
+
### Framework versions
|
| 711 |
+
|
| 712 |
+
- PEFT 0.5.0
|
| 713 |
+
- Datasets 2.16.1
|
| 714 |
+
- BitsAndBytes 0.41.0
|
| 715 |
+
- PyTorch 2.0.0
|
| 716 |
+
- Transformers 4.36.2
|
| 717 |
+
- TRL 0.7.7
|