---
license: apache-2.0
---
# MedJamba
Multilingual Medical Model Based On Jamba
👨🏻💻Github •📃 Paper

## 🌈 Update
* **[2024.04.25]** MedJamba Model is published!🎉
## Results
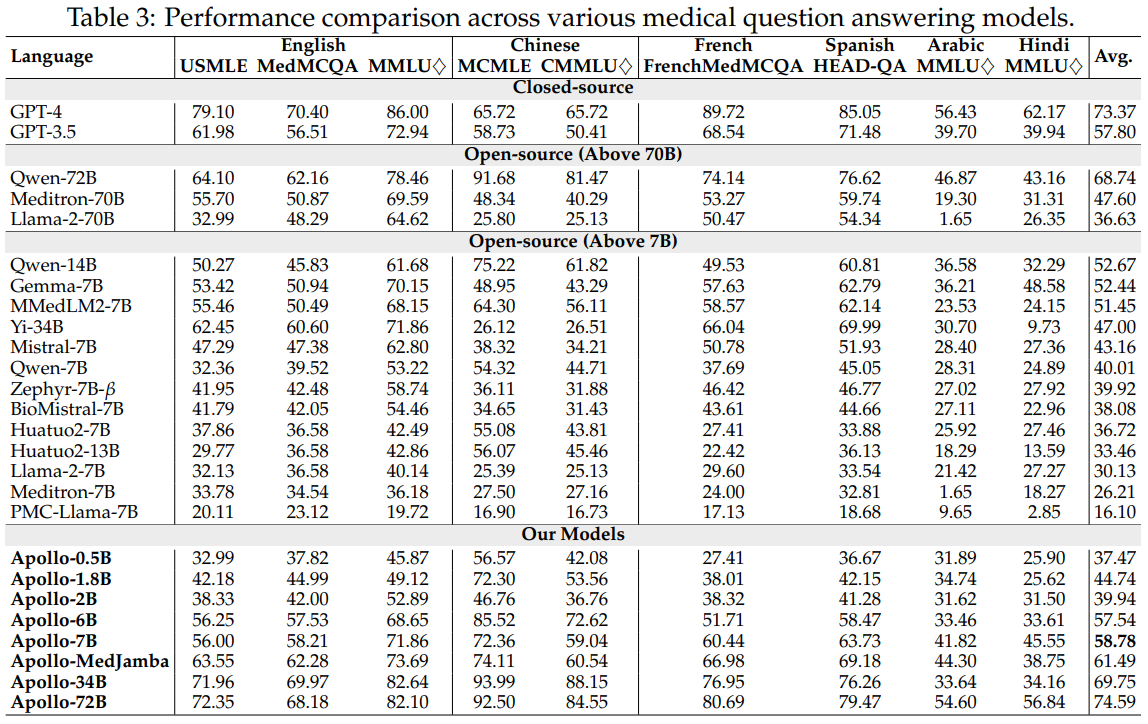
🤗 Apollo-0.5B • 🤗 Apollo-1.8B • 🤗 Apollo-2B • 🤗 Apollo-6B • 🤗 Apollo-7B • 🤗 Apollo-34B • 🤗 Apollo-72B
🤗 MedJamba
🤗 Apollo-0.5B-GGUF • 🤗 Apollo-2B-GGUF • 🤗 Apollo-6B-GGUF • 🤗 Apollo-7B-GGUF
## Dataset & Evaluation
- Dataset
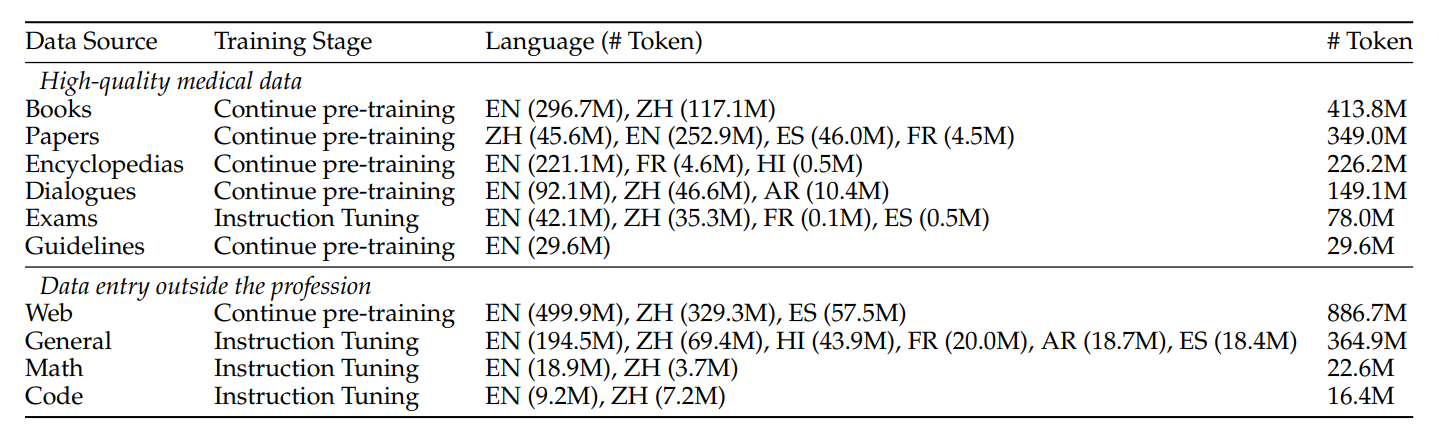
🤗 ApolloCorpus
Click to expand
- [Zip File](https://huggingface.co/datasets/FreedomIntelligence/Medbase_data/blob/main/Medbase_data-datasets.zip)
- [Data category](https://huggingface.co/datasets/FreedomIntelligence/Medbase_data/tree/main/train)
- Pretrain:
- data item:
- json_name: {data_source}_{language}_{data_type}.json
- data_type: medicalBook, medicalGuideline, medicalPaper, medicalWeb(from online forum), medicalWiki
- language: en(English), zh(chinese), es(spanish), fr(french), hi(Hindi)
- data_type: qa(generated qa from text)
- data_type==text: list of string
```
[
"string1",
"string2",
...
]
```
- data_type==qa: list of qa pairs(list of string)
```
[
[
"q1",
"a1",
"q2",
"a2",
...
],
...
]
```
- SFT:
- json_name: {data_source}_{language}.json
- data_type: code, general, math, medicalExam, medicalPatient
- data item: list of qa pairs(list of string)
```
[
[
"q1",
"a1",
"q2",
"a2",
...
],
...
]
```
Click to expand
- EN:
- [MedQA-USMLE](https://huggingface.co/datasets/GBaker/MedQA-USMLE-4-options)
- [MedMCQA](https://huggingface.co/datasets/medmcqa/viewer/default/test)
- [PubMedQA](https://huggingface.co/datasets/pubmed_qa): Because the results fluctuated too much, they were not used in the paper.
- [MMLU-Medical](https://huggingface.co/datasets/cais/mmlu)
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
- ZH:
- [MedQA-MCMLE](https://huggingface.co/datasets/bigbio/med_qa/viewer/med_qa_zh_4options_bigbio_qa/test)
- [CMB-single](https://huggingface.co/datasets/FreedomIntelligence/CMB): Not used in the paper
- Randomly sample 2,000 multiple-choice questions with single answer.
- [CMMLU-Medical](https://huggingface.co/datasets/haonan-li/cmmlu)
- Anatomy, Clinical_knowledge, College_medicine, Genetics, Nutrition, Traditional_chinese_medicine, Virology
- [CExam](https://github.com/williamliujl/CMExam): Not used in the paper
- Randomly sample 2,000 multiple-choice questions
- ES: [Head_qa](https://huggingface.co/datasets/head_qa)
- FR: [Frenchmedmcqa](https://github.com/qanastek/FrenchMedMCQA)
- HI: [MMLU_HI](https://huggingface.co/datasets/FreedomIntelligence/MMLU_Arabic)
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
- AR: [MMLU_Ara](https://huggingface.co/datasets/FreedomIntelligence/MMLU_Hindi)
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
Click to expand
1. Download Dataset for project:
```
bash 0.download_data.sh
```
2. Prepare test and dev for specific model:
- Create test data for with special token, you can use ./util/check.ipynb to check models' special tokens
```
bash 1.data_process_test&dev.sh
```
3. Prepare train data for specific model (Create tokenized data in advance):
- You can adjust data Training order and Training Epoch in this step
```
bash 2.data_process_train.sh
```
4. Train the model
- Multi Nodes refer to ./scripts/multi_node_train_*.sh
```
pip install causal-conv1d>=1.2.0
pip install mamba-ssm
```
Node 0:
```
bash ./scripts/3.multinode_train_jamba_rank0.sh
```
...
Node 4:
```
bash ./scripts/3.multinode_train_jamba_rank4.sh
```
5. Evaluate your model: Generate score for benchmark
```
bash 4.eval.sh
```
6. Evaluate your model: Play with your ckpts in bash
```
python ./src/evaluate/cli_demo.py --model_name='./ckpts/your/path/tfmr'
```