

Commit
•
f4e28a6
1
Parent(s):
78faefb
Update README.md
Browse files
README.md
CHANGED
|
@@ -1,3 +1,46 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: openrail
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: openrail
|
| 3 |
+
datasets:
|
| 4 |
+
- Skylion007/openwebtext
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# Bamboo 400M
|
| 8 |
+
This is a WIP model trained only on public domain (CC0) datasets, primarily in the English language.
|
| 9 |
+
Further training is planned & ongoing, but currently no multi-language datasets are in use or planned; though this may change in the future and the current datasets *can* contain languages other than English.
|
| 10 |
+
|
| 11 |
+
## License
|
| 12 |
+
Though the training data of this model is CC0, the model itself is not. The model is released under the OpenRAIL license, as tagged.
|
| 13 |
+
|
| 14 |
+
## Planned updates
|
| 15 |
+
As mentioned, a few updates are planned:
|
| 16 |
+
* Further training on more CC0 data, this model's weights will be updated as we pretrain on more of the listed datasets.
|
| 17 |
+
* Experiment with exteding the context length using YaRN to 32k tokens.
|
| 18 |
+
* Fine-tuning the resulting model for instruct, code and storywriting. These will then be combined using MergeKit to create a MoE model.
|
| 19 |
+
* Release a GGUF version and an extended context version of the base model
|
| 20 |
+
|
| 21 |
+
## Test Results
|
| 22 |
+
TBD
|
| 23 |
+
|
| 24 |
+
# Tokenizer
|
| 25 |
+
Our tokenizer was trained from scratch on 500,000 samples from the Openwebtext dataset. Like Mistral, we use the LlamaTokenizerFast as our tokenizer class; in legacy mode.
|
| 26 |
+
|
| 27 |
+
## Tokenization Analysis
|
| 28 |
+
|
| 29 |
+
The histogram below illustrates the distribution of token counts per sample in our Mistral tokenizer, trained on 500,000 samples. This analysis provides insights into the tokenizer's behavior and its ability to handle various sentence lengths.
|
| 30 |
+
The histogram was created using 10,000 samples of tokenization.
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
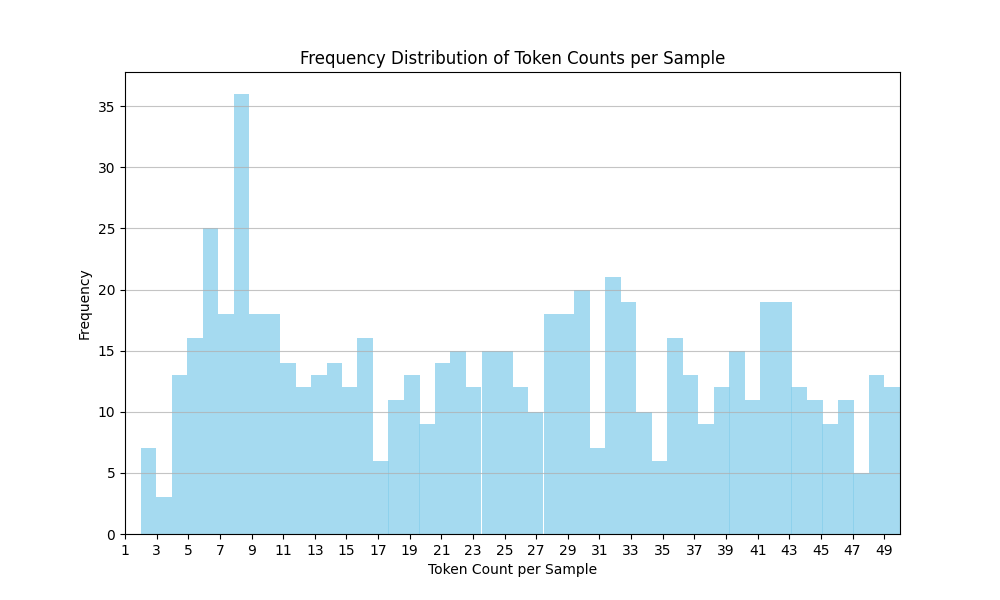
|
| 34 |
+
|
| 35 |
+
**Key Observations:**
|
| 36 |
+
|
| 37 |
+
- **Broad Range:** The tokenizer effectively handles a wide range of sentence lengths, with token counts spanning from 1 to over 50.
|
| 38 |
+
- **Smooth Distribution:** The distribution is relatively smooth, indicating consistent tokenization across different sentence lengths.
|
| 39 |
+
- **Short Sequence Preference:** Most sequences fall below 20 tokens, aligning with the efficiency goals of Mistral models.
|
| 40 |
+
- **Peak at 7 Tokens:** A peak around 7 tokens suggests the tokenizer might have a preference for splitting sentences at this length. This could be investigated further if preserving longer contexts is a priority.
|
| 41 |
+
|
| 42 |
+
**Overall:** The tokenizer demonstrates a balanced approach, predominantly producing shorter sequences while still accommodating longer and more complex sentences. This balance promotes both computational efficiency and the ability to capture meaningful context.
|
| 43 |
+
|
| 44 |
+
**Further Analysis:** While the tokenizer performs well overall, further analysis of the peak at 7 tokens and the lower frequency of very short sequences (1-3 tokens) could provide additional insights into its behavior and potential areas for refinement.
|
| 45 |
+
|
| 46 |
+
**Theory On 7-token peak:** Since English sentences have an average of 15-20 words, our tokenizer may be splitting them into 7-9 tokens, which would possibly explain this peak.
|