---
license: apache-2.0
extra_gated_prompt: "We will release in the nearly future."
extra_gated_fields:
Name: text
Company: text
Title: text
---
# Model Card for MediaTek Research Breeze-7B-FC-v1_0
MediaTek Research Breeze-7B-FC (hereinafter referred to as Breeze-7B-FC) is an advanced language model developed by MediaTek Research, building on [Breeze-7B-Base](https://huggingface.co/MediaTek-Research/Breeze-7B-Base-v1_0). Breeze-7B-FC extends its predecessor by incorporating a key feature: function calling. These enhancements make Breeze-7B-FC more versatile and capable of handling a wider range of tasks efficiently.
## 🏆 Performance
| Models | #Parameters | Organization | License | 🧰 Function Calling? | 💬 Instrustion Following? |
|--------------------------------------------------------------------------------------------|-------------|------------|------------|-------------------|----------|
| [Breeze-7B-Instruct-v1_0](https://huggingface.co/MediaTek-Research/Breeze-7B-Instruct-v1_0)| 7B | MediaTek Research | Apache 2.0 | ❌ | ✅ |
| [**Breeze-7B-FC-v1_0**](https://huggingface.co/MediaTek-Research/Breeze-7B-FC-v1_0) | 7B | MediaTek Research | Apache 2.0 | ✅ | ✅ |
| [Gorilla-OpenFunctions-v2](https://huggingface.co/MediaTek-Research/Breeze-7B-FC-v1_0) | 7B | Gorilla LLM | Apache 2.0 | ✅ | ❌ |
| [GPT-3.5-Turbo-0125](https://openai.com) | | OpenAI | Proprietary| ✅ | ✅ |
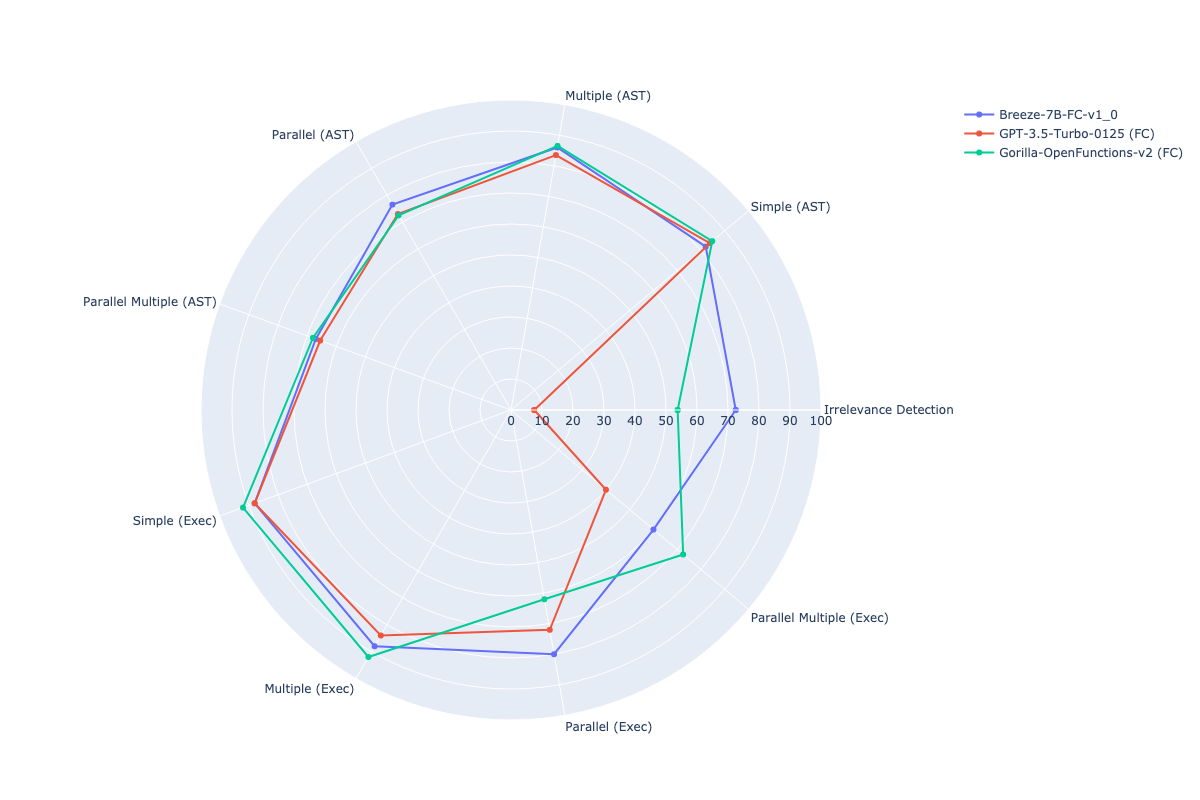
**Evaluate function calling on EN benchmark**
We evaluate the performance of function calling on English with benchmark [Berkeley function-calling leaderboard](https://gorilla.cs.berkeley.edu/blogs/8_berkeley_function_calling_leaderboard.html).
| Models | ↑ Overall | Irrelevance
Detection | AST/
Simple | AST/
Multiple | AST/
Parallel | AST/
Parallel-Multiple | Exec/
Simple | Exec/
Multiple | Exec/
Parallel | Exec/
Parallel-Multiple |
|-----------------------------------|----------|---------------------|------------|--------------|--------------|------------------------|--------------|---------------------|---------------------|-------------------------------|
| **Breeze-7B-FC-v1_0 (FC)** | 86.89 | 76.25 | 90.00 | 93.00 | 84.00 | 84.00 | 100.00 | 92.00 | 88.00 | 77.50 |
| Gorilla-OpenFunctions-v2 (FC) | 85.95 | 60.00 | 94.25 | 95.50 | 86.50 | 86.00 | 97.00 | 96.00 | 80.00 | 75.00 |
| GPT-3.5-Turbo-0125 (FC) | 72.77 | 4.58 | 87.75 | 90.50 | 88.50 | 82.50 | 91.00 | 82.00 | 78.00 | 52.50 |

**Evaluate function calling on ZHTW benchmark**
We evaluate the performance of function calling on Traditional Chinese with benchmark [function-calling-leaderboard-for-zhtw](https://github.com/mtkresearch/function-calling-leaderboard-for-zhtw).
| Models | ↑ Overall | Irrelevance
Detection | AST/
Simple | AST/
Multiple | AST/
Parallel | AST/
Parallel-Multiple | Exec/
Simple | Exec/
Multiple | Exec/
Parallel | Exec/
Parallel-Multiple |
|-----------------------------------|----------|---------------------|------------|--------------|--------------|------------------------|--------------|---------------------|---------------------|-------------------------------|
| **Breeze-7B-FC-v1_0 (FC)** | 78.18 | 72.50 | 82.00 | 86.00 | 76.50|67.00|88.00|88.00|80.00|60.00|
| Gorilla-OpenFunctions-v2 (FC) | 75.68 | 53.75 | 84.75 | 86.50 | 72.50 | 68.00 | 92.00 | 92.00 | 62.00 | 72.50 |
| GPT-3.5-Turbo-0125 (FC) | 66.15 | 7.50 | 83.75 | 83.50 | 73.00 | 65.50 | 88.00 | 84.00 | 72.00 | 40.00 |
**Evaluate instrustion following on EN benchmark**
We evaluate the performance of instruction following on English with benchmark [MT-Bench](https://github.com/lm-sys/FastChat/blob/main/fastchat/llm_judge/README.md).
| | Win | Tie | Lose |
|---|---|---|---|
| **Breeze-7B-FC-v1_0** *v.s.* Breeze-7B-Instruct-v1_0 | 29 (18.1%) | 55 (34.3%) | 76 (47.5%) |
**Evaluate instrustion following on ZHTW benchmark**
We evaluate the performance of instruction following on Traditional Chinese with benchmark [MT-Bench-TC](https://github.com/mtkresearch/TCEval).
| | Win | Tie | Lose |
|---|---|---|---|
| **Breeze-7B-FC-v1_0** *v.s.* Breeze-7B-Instruct-v1_0 | 35 (21.9%) | 73 (45.6%) | 52 (32.5%) |
## 👩💻 How to use
**Demo with Kaggle Kernel**
Start from clicking the "Copy & Edit" button on https://www.kaggle.com/code/ycckaggle/run-breeze-fc
**Dependiency**
Install `mtkresearch` package
```
pip install mtkresearch
```
**Hosting the model by VLLM**
```python
from vllm import LLM, SamplingParams
llm = LLM(
model='MediaTek-Research/Breeze-7B-FC-v1_0',
tensor_parallel_size=num_gpu, # number of gpus
gpu_memory_utilization=0.7,
dtype='half'
)
turn_end_token_id = 61876 # <|im_end|>
params = SamplingParams(
temperature=0.01,
top_p=0.01,
max_tokens=4096,
repetition_penalty=1.1,
stop_token_ids=[turn_end_token_id]
)
def _inference(prompt, llm, params):
return llm.generate(prompt, params)[0].outputs[0].text
```
**Instruction following**
```python
from mtkresearch.llm.prompt import MRPromptV2
sys_prompt = ('You are a helpful AI assistant built by MediaTek Research. '
'The user you are helping speaks Traditional Chinese and comes from Taiwan.')
prompt_engine = MRPromptV2()
conversations = [
{"role": "system", "content": sys_prompt},
{"role": "user", "content": "請問什麼是深度學習?"},
]
prompt = prompt_engine.get_prompt(conversations)
output_str = _inference(prompt, llm, params)
result = prompt_engine.parse_generated_str(output_str)
print(result)
# {'role': 'assistant',
# 'content': '深度學習(Deep Learning)是一種機器學習方法,它模仿人類大腦的神經網路結構來
# 處理複雜的數據和任務。在深度學習中,模型由多層人工神經元組成,每個神經元之間有
# 權重連接,並通過非線性轉換進行計算。這些層與層之間的相互作用使模型能夠學習複雜
# 的函數關係或模式,從而解決各種問題,如圖像識別、自然語言理解、語音辨識等。深度
# 學習通常需要大量的數據和強大的計算能力,因此經常使用圖形處理器(GPU)或特殊的
# 加速器來執行。'}
```
**Function Calling**
```python
import json
from mtkresearch.llm.prompt import MRPromptV2
functions = [
{
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"]
}
},
"required": ["location"]
}
}
]
def fake_get_current_weather(location, unit=None):
return {'temperature': 30}
mapping = {
'get_current_weather': fake_get_current_weather
}
prompt_engine = MRPromptV2()
# stage 1: query
conversations = [
{"role": "user", "content": "請問台北目前溫度是攝氏幾度?"},
]
prompt = prompt_engine.get_prompt(conversations, functions=functions)
output_str = _inference(prompt, llm, params)
result = prompt_engine.parse_generated_str(output_str)
print(result)
# {'role': 'assistant',
# 'tool_calls': [
# {'id': 'call_U9bYCBRAbF639uUqfwehwSbw', 'type': 'function',
# 'function': {'name': 'get_current_weather', 'arguments': '{"location": "台北, 台灣", "unit": "celsius"}'}}]}
# stage 2: execute called functions
conversations.append(result)
tool_call = result['tool_calls'][0]
func_name = tool_call['function']['name']
func = mapping[func_name]
arguments = json.loads(tool_call['function']['arguments'])
called_result = func(**arguments)
# stage 3: put executed results
conversations.append(
{
'role': 'tool',
'tool_call_id': tool_call['id'],
'name': func_name,
'content': json.dumps(called_result)
}
)
prompt = prompt_engine.get_prompt(conversations, functions=functions)
output_str2 = _inference(prompt, llm, params)
result2 = prompt_engine.parse_generated_str(output_str2)
print(result2)
# {'role': 'assistant', 'content': '台北目前的溫度是攝氏30度'}
```