
Zack Zhiyuan Li
commited on
Commit
•
9cfb06f
1
Parent(s):
4c0721c
wip
Browse files- README.md +82 -5
- accuracy_plot.jpg +0 -0
- latency_plot.jpg +0 -0
- tool-usage-compressed.png +0 -0
README.md
CHANGED
|
@@ -1,18 +1,95 @@
|
|
| 1 |
---
|
| 2 |
license: other
|
| 3 |
-
base_model: google/gemma-
|
| 4 |
model-index:
|
| 5 |
-
- name: Octopus-
|
| 6 |
results: []
|
| 7 |
tags:
|
| 8 |
- function calling
|
| 9 |
---
|
| 10 |
-
# Octopus
|
| 11 |
<p align="center">
|
| 12 |
-
<a href="https://huggingface.co/NexaAIDev" target="_blank">Nexa AI HF</a> - <a href="https://www.nexa4ai.com/" target="_blank">Nexa AI Product</a> - <a href="https://nexaai.github.io/octopus" target="_blank">Nexa AI Research Page</a> - <a href="https://github.com/NexaAI/Octopus" target="_blank">Nexa AI Github</a>
|
| 13 |
</p>
|
| 14 |
|
| 15 |
<p align="center" width="100%">
|
| 16 |
-
<a><img src="Octopus-logo.
|
| 17 |
</p>
|
| 18 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: other
|
| 3 |
+
base_model: google/gemma-2b
|
| 4 |
model-index:
|
| 5 |
+
- name: Octopus-V2-2B
|
| 6 |
results: []
|
| 7 |
tags:
|
| 8 |
- function calling
|
| 9 |
---
|
| 10 |
+
# Octopus V2: On-device language model for super agent
|
| 11 |
<p align="center">
|
| 12 |
+
<a href="https://huggingface.co/NexaAIDev" target="_blank">Nexa AI HF</a> - <a href="https://www.nexa4ai.com/" target="_blank">Nexa AI Product</a> - <a href="https://nexaai.github.io/octopus" target="_blank">Nexa AI Research Page</a> - <a href="https://nexaai.github.io/octopus" target="_blank">ArXiv</a> - <a href="https://github.com/NexaAI/Octopus" target="_blank">Nexa AI Github</a>
|
| 13 |
</p>
|
| 14 |
|
| 15 |
<p align="center" width="100%">
|
| 16 |
+
<a><img src="Octopus-logo.jpeg" alt="nexa-octopus" style="width: 40%; min-width: 300px; display: block; margin: auto;"></a>
|
| 17 |
</p>
|
| 18 |
|
| 19 |
+
## Introducing Octopus-V2-2B
|
| 20 |
+
Octopus-V2-2B, an advanced open-source language model with 2 billion parameters, represents Nexa AI's research breakthrough in the application of large language models (LLMs) for function calling, specifically tailored for Android APIs. Unlike Retrieval-Augmented Generation (RAG) methods, which require detailed descriptions of potential function arguments—sometimes needing up to tens of thousands of input tokens—Octopus-V2-2B introduces a unique **functional token** strategy for both its training and inference stages. This approach not only allows it to achieve performance levels comparable to GPT-4 but also significantly enhances its inference speed beyond that of RAG-based methods, making it especially beneficial for edge computing devices.
|
| 21 |
+
|
| 22 |
+
📱 **On-device Applications**: Octopus-V2-2B is engineered to operate seamlessly on Android devices, extending its utility across a wide range of applications, from Android system management to the orchestration of multiple devices. Further demonstrations of its capabilities are available on the [Nexa AI Research Page](https://nexaai.github.io/octopus), showcasing its adaptability and potential for on-device integration.
|
| 23 |
+
|
| 24 |
+
🚀 **Inference Speed**: When benchmarked, Octopus-V2-2B demonstrates a remarkable inference speed, outperforming the combination of "Llama7B + RAG solution" by a factor of 36X on a single A100 GPU. Furthermore, compared to GPT-4-turbo (gpt-4-0125-preview), which relies on clusters A100/H100 GPUs, Octopus-V2-2B is 168% faster. This efficiency is attributed to our **functional token** design.
|
| 25 |
+
|
| 26 |
+
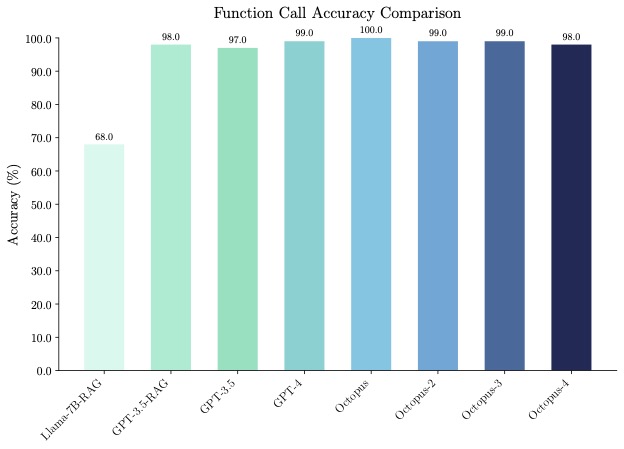
🐙 **Accuracy**: Octopus-V2-2B not only excels in speed but also in accuracy, surpassing the "Llama7B + RAG solution" in function call accuracy by 31%. It achieves a function call accuracy comparable to GPT-4 and RAG + GPT-3.5, with scores ranging between 98% and 100% across benchmark datasets.
|
| 27 |
+
|
| 28 |
+
💪 **Function Calling Capabilities**: Octopus-V2-2B is capable of in generating individual, nested, and parallel function calls across a variety of complex scenarios.
|
| 29 |
+
|
| 30 |
+
## Example Use Cases
|
| 31 |
+
<p align="center" width="100%">
|
| 32 |
+
<a><img src="tool-usage-compressed.png" alt="ondevice" style="width: 80%; min-width: 300px; display: block; margin: auto;"></a>
|
| 33 |
+
</p>
|
| 34 |
+
|
| 35 |
+
You can run the model on a GPU using the following code.
|
| 36 |
+
```python
|
| 37 |
+
from gemma.modeling_gemma import GemmaForCausalLM
|
| 38 |
+
from transformers import AutoTokenizer
|
| 39 |
+
import torch
|
| 40 |
+
import time
|
| 41 |
+
|
| 42 |
+
def inference(input_text):
|
| 43 |
+
start_time = time.time()
|
| 44 |
+
input_ids = tokenizer(input_text, return_tensors="pt").to(model.device)
|
| 45 |
+
input_length = input_ids["input_ids"].shape[1]
|
| 46 |
+
outputs = model.generate(
|
| 47 |
+
input_ids=input_ids["input_ids"],
|
| 48 |
+
max_length=1024,
|
| 49 |
+
do_sample=False)
|
| 50 |
+
generated_sequence = outputs[:, input_length:].tolist()
|
| 51 |
+
res = tokenizer.decode(generated_sequence[0])
|
| 52 |
+
end_time = time.time()
|
| 53 |
+
return {"output": res, "latency": end_time - start_time}
|
| 54 |
+
|
| 55 |
+
model_id = "NexaAIDev/android_API_10k_data"
|
| 56 |
+
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
| 57 |
+
model = GemmaForCausalLM.from_pretrained(
|
| 58 |
+
model_id, torch_dtype=torch.bfloat16, device_map="auto"
|
| 59 |
+
)
|
| 60 |
+
|
| 61 |
+
input_text = "Take a selfie for me with front camera"
|
| 62 |
+
nexa_query = f"Below is the query from the users, please call the correct function and generate the parameters to call the function.\n\nQuery: {input_text} \n\nResponse:"
|
| 63 |
+
start_time = time.time()
|
| 64 |
+
print("nexa model result:\n", inference(nexa_query))
|
| 65 |
+
print("latency:", time.time() - start_time," s")
|
| 66 |
+
```
|
| 67 |
+
|
| 68 |
+
## Evaluation
|
| 69 |
+
<p align="center" width="100%">
|
| 70 |
+
<a><img src="latency_plot.jpg" alt="ondevice" style="width: 80%; min-width: 300px; display: block; margin: auto; margin-bottom: 20px;"></a>
|
| 71 |
+
<a><img src="accuracy_plot.jpg" alt="ondevice" style="width: 80%; min-width: 300px; display: block; margin: auto;"></a>
|
| 72 |
+
</p>
|
| 73 |
+
|
| 74 |
+
## License
|
| 75 |
+
This model was trained on commercially viable data and is licensed under the [Nexa AI community license](TODO).
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
## References
|
| 79 |
+
We thank the Google Gemma team for their amazing models!
|
| 80 |
+
```
|
| 81 |
+
@misc{gemma-2023-open-models,
|
| 82 |
+
author = {{Gemma Team, Google DeepMind}},
|
| 83 |
+
title = {Gemma: Open Models Based on Gemini Research and Technology},
|
| 84 |
+
url = {https://goo.gle/GemmaReport},
|
| 85 |
+
year = {2023},
|
| 86 |
+
}
|
| 87 |
+
```
|
| 88 |
+
|
| 89 |
+
## Citation
|
| 90 |
+
```
|
| 91 |
+
@misc{TODO}
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
## Contact
|
| 95 |
+
Please [contact us]([email protected]) to reach out for any issues and comments!
|
accuracy_plot.jpg
ADDED
|
latency_plot.jpg
ADDED

|
tool-usage-compressed.png
ADDED

|