---
license: mit
pipeline_tag: image-text-to-text
library_name: transformers
base_model:
- internlm/internlm2-chat-1_8b
base_model_relation: merge
language:
- multilingual
tags:
- internvl
- vision
- ocr
- custom_code
- moe
---
# Mono-InternVL-2B
[\[⭐️Project Page\]](https://internvl.github.io/blog/2024-10-10-Mono-InternVL/) [\[📜 Mono-InternVL Paper\]](https://arxiv.org/abs/2410.08202) [\[📝 公众号报道\]](https://mp.weixin.qq.com/s/FmjG0Gp5ow7mm2Vzd9ppPg) [\[🚀 Quick Start\]](#quick-start)
[切换至中文版](#简介)
## News🔥🔥🔥
- **2024.11.11**: Mono-InternVL is supported by [lmdeploy](https://github.com/InternLM/lmdeploy/pull/2727)
- **2024.11.3**: Mono-InternVL is supported by [vllm](https://github.com/vllm-project/vllm/pull/9528).
## Introduction
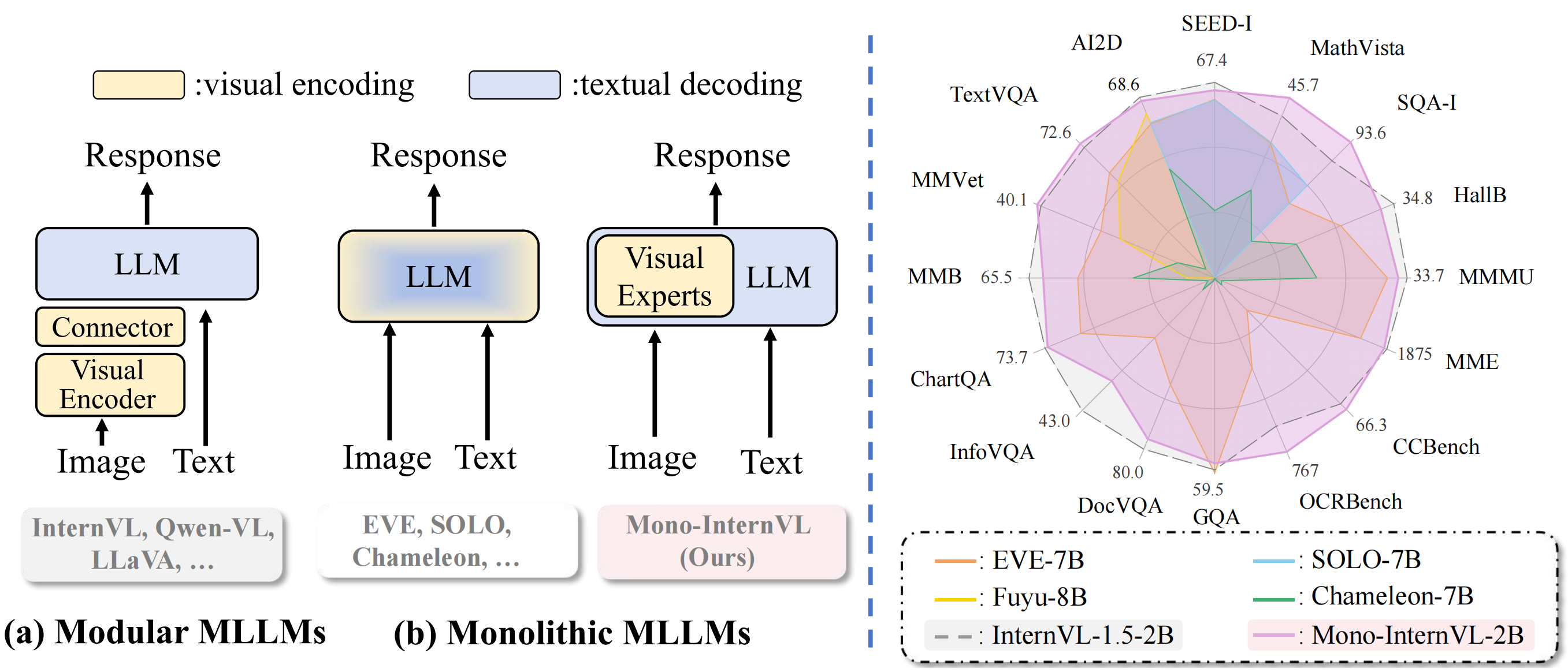
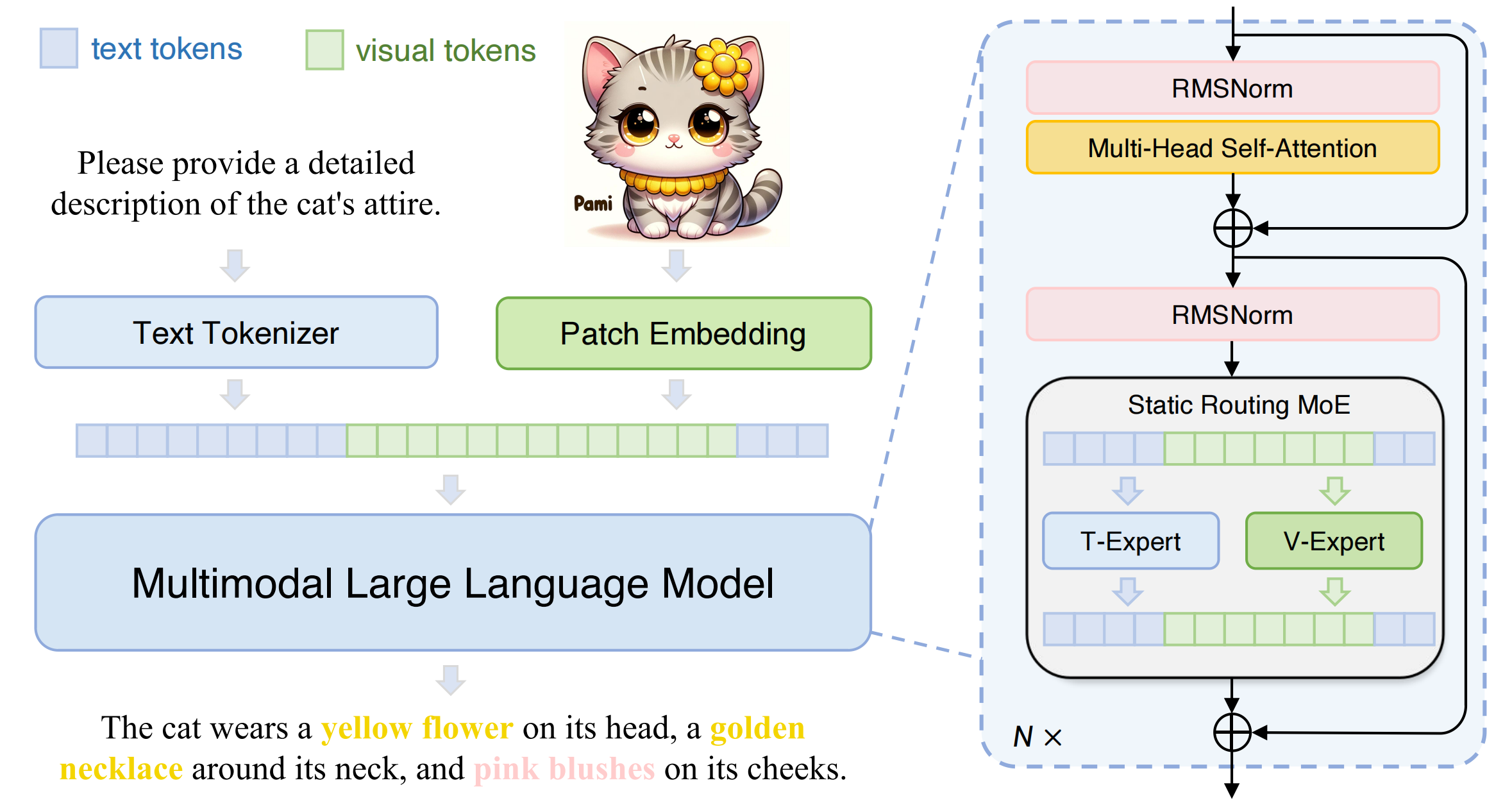
We release Mono-InternVL, a **monolithic** multimodal large language model (MLLM) that integrates visual encoding and textual decoding into a single LLM. In Mono-InternVL, a set of visual experts is embedded into the pre-trained LLM via a mixture-of-experts (MoE) mechanism. By freezing the LLM, Mono-InternVL ensures that visual capabilities are optimized without compromising the pre-trained language knowledge. Based on this structure, an innovative Endogenous Visual Pretraining (EViP) is introduced to realize coarse-to-fine visual learning.
Mono-InternVL achieves superior performance compared to state-of-the-art MLLM Mini-InternVL-2B-1.5 and significantly outperforms other monolithic MLLMs, as shown in the [radar chart](#radar) above. Meanwhile, it achieves better deployment efficiency, with first token latency reduced by up to 67%.
This repository contains the instruction-tuned Mono-InternVL-2B model, which has 1.8B activated parameters (3B in total). It is built upon [internlm2-chat-1_8b](https://huggingface.co/internlm/internlm2-chat-1_8b). For more details, please refer to our [paper](https://arxiv.org/abs/2410.08202).
## Performance
| Benchmark | Chameleon-7B | EVE-7B (HD) | Emu3 | Mini-InternVL-2B-1-5 | Mono-InternVL-2B |
| :--------------------------: | :----------: | :---------: | :--------: | :------------------: | :--------------: |
| Type | Monolithic | Monolithic | Monolithic | Modular | Monolithic |
| #Activated Params | 7B | 7B | 8B | 2.2B | 1.8B |
| | | | | | |
| MMVet | 8.3 | 25.7 | 37.2 | 39.3 | 40.1 |
| MMMUval | 25.4 | 32.6 | 31.6 | 34.6 | 33.7 |
| MMEsum | 170 | 1628 | — | 1902 | 1875 |
| MMBench-ENtest | 31.1 | 52.3 | 58.5 | 70.9 | 65.5 |
| MathVistatestmini | 22.3 | 34.2 | — | 41.1 | 45.7 |
| SEED-Image | 30.6 | 64.6 | 68.2 | 69.8 | 67.4 |
| OCRBench | 7 | 398 | 687 | 654 | 767 |
| Hallusion-Bench | 17.1 | 26.4 | — | 37.5 | 34.8 |
| CCBenchdev | 3.5 | 16.3 | — | 63.5 | 66.3 |
| Avgmultimodal | 16.1 | 38.9 | — | 54.4 | 55.2 |
| | | | | | |
| TextVQAval | 4.8 | 56.8 | 64.7 | 70.5 | 72.6 |
| SQA-Itest | 47.2 | 64.9 | 89.2 | 84.9 | 93.6 |
| GQAtest | — | 62.6 | 60.3 | 61.6 | 59.5 |
| DocVQAtest | 1.5 | 53.0 | 76.3 | 85.0 | 80.0 |
| AI2Dtest | 46.0 | 61.0 | 70.0 | 69.8 | 68.6 |
| ChartQAtest | 2.9 | 59.1 | 68.6 | 74.8 | 73.7 |
| InfoVQAtest | 5.0 | 25.0 | 43.8 | 55.4 | 43.0 |
| AvgVQA | 17.9 | 54.6 | 67.6 | 71.7 | 70.1 |
- Sources of the results include the original papers, our evaluation with [VLMEvalKit](https://github.com/open-compass/VLMEvalKit), and [OpenCompass](https://rank.opencompass.org.cn/leaderboard-multimodal/?m=REALTIME).
- Average scores are computed by normalizing each metric to a range between 0 and 100.
- Please note that evaluating the same model using different testing toolkits can result in slight differences, which is normal. Updates to code versions and variations in environment and hardware can also cause minor discrepancies in results.
Limitations: Although we have made efforts to ensure the safety of the model during the training process and to encourage the model to generate text that complies with ethical and legal requirements, the model may still produce unexpected outputs due to its size and probabilistic generation paradigm. For example, the generated responses may contain biases, discrimination, or other harmful content. Please do not propagate such content. We are not responsible for any consequences resulting from the dissemination of harmful information.
## Quick Start
We provide an example code to run Mono-InternVL-2B inference using `transformers`.
> Please use transformers==4.37.2 to ensure the model works normally.
### Inference with Transformers
```python
import numpy as np
import torch
import torchvision.transforms as T
from decord import VideoReader, cpu
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
from transformers import AutoModel, AutoTokenizer
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
path = 'OpenGVLab/Mono-InternVL-2B'
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True).eval().cuda()
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
# set the max number of tiles in `max_num`
pixel_values = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
generation_config = dict(max_new_tokens=1024, do_sample=True)
# pure-text conversation (纯文本对话)
question = 'Hello, who are you?'
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Can you tell me a story?'
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# single-image single-round conversation (单图单轮对话)
question = '\nPlease describe the image shortly.'
response = model.chat(tokenizer, pixel_values, question, generation_config)
print(f'User: {question}\nAssistant: {response}')
# single-image multi-round conversation (单图多轮对话)
question = '\nPlease describe the image in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Please write a poem according to the image.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
```
### Inference with LMDeploy
Please install lmdeploy>=0.6.3 for Mono-InternVL support.
```python
from lmdeploy import pipeline
from lmdeploy.vl import load_image
image = load_image('./examples/image1.jpg')
pipe = pipeline('OpenGVLab/Mono-InternVL-2B')
response = pipe(('Please describe the image shortly.', image))
print(response.text)
```
## License
This project is released under the MIT license, while InternLM2 is licensed under the Apache-2.0 license.
## Citation
If you find this project useful in your research, please consider citing:
```BibTeX
@article{luo2024mono,
title={Mono-InternVL: Pushing the Boundaries of Monolithic Multimodal Large Language Models with Endogenous Visual Pre-training},
author={Luo, Gen and Yang, Xue and Dou, Wenhan and Wang, Zhaokai and Liu, Jiawen and Dai, Jifeng and Qiao, Yu and Zhu, Xizhou},
journal={arXiv preprint arXiv:2410.08202},
year={2024}
}
@article{chen2024far,
title={How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites},
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others},
journal={arXiv preprint arXiv:2404.16821},
year={2024}
}
@inproceedings{chen2024internvl,
title={Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks},
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and others},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={24185--24198},
year={2024}
}
```
## 简介
我们发布了Mono-InternVL,这是一种**原生**多模态大语言模型,将视觉编码和文本解码集成到一个单一的大语言模型中。在Mono-InternVL中,一组视觉专家通过专家混合机制嵌入到预训练的语言模型中。通过冻结语言模型的语言部分参数,Mono-InternVL确保了视觉能力的优化,同时不会影响预训练的语言知识。基于这一结构,我们引入了内生视觉预训练(Endogenous Visual Pretraining, EViP),实现了由粗粒度到精粒度的视觉学习。
Mono-InternVL在性能上优于当前最先进的多模态语言模型Mini-InternVL-2B-1.5,并且显著超越了其他原生多模态模型,如上方的[雷达图](#radar)所示。同时,它的部署效率也得到了提升,首个单词的延迟降低了最多达67%。
本仓库包含了经过指令微调的Mono-InternVL-2B模型,它是基于[internlm2-chat-1_8b](https://huggingface.co/internlm/internlm2-chat-1_8b)搭建的。更多详细信息,请参阅我们的[论文](https://arxiv.org/abs/2410.08202)和[公众号报道](https://mp.weixin.qq.com/s/FmjG0Gp5ow7mm2Vzd9ppPg)。
## 性能测试
| 评测数据集 | Chameleon-7B | EVE-7B (HD) | Emu3 | Mini-InternVL-2B-1-5 | Mono-InternVL-2B |
| :--------------------------: | :----------: | :---------: | :----: | :------------------: | :--------------: |
| 模型种类 | 原生 | 原生 | 原生 | 非原生 | 原生 |
| 激活参数 | 7B | 7B | 8B | 2.2B | 1.8B |
| | | | | | |
| MMVet | 8.3 | 25.7 | 37.2 | 39.3 | 40.1 |
| MMMUval | 25.4 | 32.6 | 31.6 | 34.6 | 33.7 |
| MMEsum | 170 | 1628 | — | 1902 | 1875 |
| MMBench-ENtest | 31.1 | 52.3 | 58.5 | 70.9 | 65.5 |
| MathVistatestmini | 22.3 | 34.2 | — | 41.1 | 45.7 |
| SEED-Image | 30.6 | 64.6 | 68.2 | 69.8 | 67.4 |
| OCRBench | 7 | 398 | 687 | 654 | 767 |
| Hallusion-Bench | 17.1 | 26.4 | — | 37.5 | 34.8 |
| CCBenchdev | 3.5 | 16.3 | — | 63.5 | 66.3 |
| Avgmultimodal | 16.1 | 38.9 | — | 54.4 | 55.2 |
| | | | | | |
| TextVQAval | 4.8 | 56.8 | 64.7 | 70.5 | 72.6 |
| SQA-Itest | 47.2 | 64.9 | 89.2 | 84.9 | 93.6 |
| GQAtest | — | 62.6 | 60.3 | 61.6 | 59.5 |
| DocVQAtest | 1.5 | 53.0 | 76.3 | 85.0 | 80.0 |
| AI2Dtest | 46.0 | 61.0 | 70.0 | 69.8 | 68.6 |
| ChartQAtest | 2.9 | 59.1 | 68.6 | 74.8 | 73.7 |
| InfoVQAtest | 5.0 | 25.0 | 43.8 | 55.4 | 43.0 |
| AvgVQA | 17.9 | 54.6 | 67.6 | 71.7 | 70.1 |
- 以上结果的来源包括相应的原始论文、我们基于[VLMEvalKit](https://github.com/open-compass/VLMEvalKit)的评测,以及[OpenCompass](https://rank.opencompass.org.cn/leaderboard-multimodal/?m=REALTIME)。
- 平均分数Avg通过将每个指标归一化到0至100之间来计算。
- 请注意,使用不同的测试工具包评估同一模型可能会导致评测结果的细微差异,这是正常的。代码版本的更新、环境和硬件的变化也可能导致结果的微小差异。
## 快速上手
我们提供了一个示例代码,用于使用 `transformers` 进行 Mono-InternVL-2B 推理。
> 请使用 transformers==4.37.2 以确保模型正常运行。
示例代码请[点击这里](#quick-start)。
## 开源许可证
该项目采用 MIT 许可证发布,而 InternLM2 则采用 Apache-2.0 许可证。
## 引用
如果您发现此项目对您的研究有用,可以考虑引用我们的论文:
```BibTeX
@article{luo2024mono,
title={Mono-InternVL: Pushing the Boundaries of Monolithic Multimodal Large Language Models with Endogenous Visual Pre-training},
author={Luo, Gen and Yang, Xue and Dou, Wenhan and Wang, Zhaokai and Liu, Jiawen and Dai, Jifeng and Qiao, Yu and Zhu, Xizhou},
journal={arXiv preprint arXiv:2410.08202},
year={2024}
}
@article{chen2024far,
title={How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites},
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others},
journal={arXiv preprint arXiv:2404.16821},
year={2024}
}
@inproceedings{chen2024internvl,
title={Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks},
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and others},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={24185--24198},
year={2024}
}
```