

Commit
•
971f503
1
Parent(s):
38704b5
Upload README.md with huggingface_hub
Browse files
README.md
CHANGED
|
@@ -1,3 +1,212 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU
|
| 2 |
+
|
| 3 |
+
## TL;DR
|
| 4 |
+
PowerInfer is a CPU/GPU LLM inference engine leveraging **activation locality** for your device.
|
| 5 |
+
|
| 6 |
+
## Demo 🔥
|
| 7 |
+
|
| 8 |
+
https://github.com/SJTU-IPADS/PowerInfer/assets/34213478/fe441a42-5fce-448b-a3e5-ea4abb43ba23
|
| 9 |
+
|
| 10 |
+
PowerInfer v.s. llama.cpp on a single RTX 4090(24G) running Falcon(ReLU)-40B-FP16 with a 11x speedup!
|
| 11 |
+
|
| 12 |
+
<sub>Both PowerInfer and llama.cpp were running on the same hardware and fully utilized VRAM on RTX 4090.</sub>
|
| 13 |
+
|
| 14 |
+
## Abstract
|
| 15 |
+
|
| 16 |
+
We introduce PowerInfer, a high-speed Large Language Model (LLM) inference engine on a personal computer (PC)
|
| 17 |
+
equipped with a single consumer-grade GPU. The key underlying the design of PowerInfer is exploiting the high **locality**
|
| 18 |
+
inherent in LLM inference, characterized by a power-law distribution in neuron activation.
|
| 19 |
+
|
| 20 |
+
This distribution indicates that a small subset of neurons, termed hot neurons, are consistently activated
|
| 21 |
+
across inputs, while the majority, cold neurons, vary based on specific inputs.
|
| 22 |
+
PowerInfer exploits such an insight to design a GPU-CPU hybrid inference engine:
|
| 23 |
+
hot-activated neurons are preloaded onto the GPU for fast access, while cold-activated neurons are computed
|
| 24 |
+
on the CPU, thus significantly reducing GPU memory demands and CPU-GPU data transfers.
|
| 25 |
+
PowerInfer further integrates adaptive predictors and neuron-aware sparse operators,
|
| 26 |
+
optimizing the efficiency of neuron activation and computational sparsity.
|
| 27 |
+
|
| 28 |
+
Evaluation shows that PowerInfer attains an average token generation rate of 13.20 tokens/s, with a peak of 29.08 tokens/s, across various LLMs (including OPT-175B) on a single NVIDIA RTX 4090 GPU,
|
| 29 |
+
only 18\% lower than that achieved by a top-tier server-grade A100 GPU.
|
| 30 |
+
This significantly outperforms llama.cpp by up to 11.69x while retaining model accuracy.
|
| 31 |
+
|
| 32 |
+
## Features
|
| 33 |
+
PowerInfer is a high-speed and easy-to-use inference engine for deploying LLMs locally.
|
| 34 |
+
|
| 35 |
+
PowerInfer is fast with:
|
| 36 |
+
|
| 37 |
+
- **Locality-centric design**: Utilizes sparse activation and 'hot'/'cold' neuron concept for efficient LLM inference, ensuring high speed with lower resource demands.
|
| 38 |
+
- **Hybrid CPU/GPU Utilization**: Seamlessly integrates memory/computation capabilities of CPU and GPU for a balanced workload and faster processing.
|
| 39 |
+
|
| 40 |
+
PowerInfer is flexible and easy to use with:
|
| 41 |
+
|
| 42 |
+
- **Easy Integration**: Compatible with popular [ReLU-sparse models](https://huggingface.co/SparseLLM).
|
| 43 |
+
- **Local Deployment Ease**: Designed and deeply optimized for local deployment on consumer-grade hardware, enabling low-latency LLM inference and serving on a single GPU.
|
| 44 |
+
- **Backward Compatibility**: While distinct from llama.cpp, you can make use of most of `examples/` the same way as llama.cpp such as server and batched generation. PowerInfer also supports inference with llama.cpp's model weights for compatibility purposes, but there will be no performance gain.
|
| 45 |
+
|
| 46 |
+
You can use these models with PowerInfer today:
|
| 47 |
+
|
| 48 |
+
- Falcon-40B
|
| 49 |
+
- Llama2 family
|
| 50 |
+
|
| 51 |
+
We have tested PowerInfer on the following platforms:
|
| 52 |
+
|
| 53 |
+
- x86-64 CPU (with AVX2 instructions) on Linux
|
| 54 |
+
- x86-64 CPU and NVIDIA GPU on Linux
|
| 55 |
+
- Apple M Chips on macOS (As we do not optimize for Mac, the performance improvement is not significant now.)
|
| 56 |
+
|
| 57 |
+
And new features coming soon:
|
| 58 |
+
|
| 59 |
+
- Mistral-7B model
|
| 60 |
+
- Metal backend for sparse inference on macOS
|
| 61 |
+
|
| 62 |
+
## Getting Started
|
| 63 |
+
|
| 64 |
+
- [Installation](#setup-and-installation)
|
| 65 |
+
- [Model Weights](#model-weights)
|
| 66 |
+
|
| 67 |
+
## Setup and Installation
|
| 68 |
+
### Get the Code
|
| 69 |
+
|
| 70 |
+
```bash
|
| 71 |
+
git clone https://github.com/SJTU-IPADS/PowerInfer
|
| 72 |
+
cd PowerInfer
|
| 73 |
+
pip install -r requirements.txt # install Python helpers' dependencies
|
| 74 |
+
```
|
| 75 |
+
### Build
|
| 76 |
+
In order to build PowerInfer you have two different options. These commands are supposed to be run from the root directory of the project.
|
| 77 |
+
|
| 78 |
+
Using `CMake`(3.13+) on Linux or macOS:
|
| 79 |
+
* If you have an NVIDIA GPU:
|
| 80 |
+
```bash
|
| 81 |
+
cmake -S . -B build -DLLAMA_CUBLAS=ON
|
| 82 |
+
cmake --build build --config Release
|
| 83 |
+
```
|
| 84 |
+
* If you just CPU:
|
| 85 |
+
```bash
|
| 86 |
+
cmake -S . -B build
|
| 87 |
+
cmake --build build --config Release
|
| 88 |
+
```
|
| 89 |
+
|
| 90 |
+
## Model Weights
|
| 91 |
+
|
| 92 |
+
PowerInfer models are stored in a special format called *PowerInfer GGUF* based on GGUF format, consisting of both LLM weights and predictor weights.
|
| 93 |
+
|
| 94 |
+
### Download PowerInfer GGUF via Hugging Face
|
| 95 |
+
|
| 96 |
+
You can obtain PowerInfer GGUF weights at `*.powerinfer.gguf` as well as profiled model activation statistics for 'hot'-neuron offloading from each Hugging Face repo below.
|
| 97 |
+
|
| 98 |
+
| Base Model | PowerInfer GGUF |
|
| 99 |
+
|------------|------------------|
|
| 100 |
+
| LLaMA(ReLU)-2-7B | [PowerInfer/ReluLLaMA-7B-PowerInfer-GGUF](https://huggingface.co/PowerInfer/ReluLLaMA-7B-PowerInfer-GGUF) |
|
| 101 |
+
| LLaMA(ReLU)-2-13B | [PowerInfer/ReluLLaMA-13B-PowerInfer-GGUF](https://huggingface.co/PowerInfer/ReluLLaMA-13B-PowerInfer-GGUF) |
|
| 102 |
+
| Falcon(ReLU)-40B | [PowerInfer/ReluFalcon-40B-PowerInfer-GGUF](https://huggingface.co/PowerInfer/ReluFalcon-40B-PowerInfer-GGUF) |
|
| 103 |
+
| LLaMA(ReLU)-2-70B | [PowerInfer/ReluLLaMA-70B-PowerInfer-GGUF](https://huggingface.co/PowerInfer/ReluLLaMA-70B-PowerInfer-GGUF) |
|
| 104 |
+
|
| 105 |
+
We suggest downloading/cloning the whole repo so PowerInfer can automatically make use of such directory structure for feature-complete model offloading:
|
| 106 |
+
```
|
| 107 |
+
.
|
| 108 |
+
├── *.powerinfer.gguf (Unquantized PowerInfer model)
|
| 109 |
+
├── *.q4.powerinfer.gguf (INT4 quantized PowerInfer model, if available)
|
| 110 |
+
├── activation (Profiled activation statistics for fine-grained FFN offloading)
|
| 111 |
+
│ ├── activation_x.pt (Profiled activation statistics for layer x)
|
| 112 |
+
│ └── ...
|
| 113 |
+
├── *.[q4].powerinfer.gguf.generated.gpuidx (Generated GPU index at runtime for corresponding model)
|
| 114 |
+
```
|
| 115 |
+
|
| 116 |
+
### Convert from Original Model Weights + Predictor Weights
|
| 117 |
+
|
| 118 |
+
Hugging Face limits single model weight to 50GiB. For unquantized models >= 40B, you can convert PowerInfer GGUF from the original model weights and predictor weights obtained from Hugging Face.
|
| 119 |
+
|
| 120 |
+
| Base Model | Original Model | Predictor |
|
| 121 |
+
|------------|----------------|---------------------|
|
| 122 |
+
| LLaMA(ReLU)-2-7B | [SparseLLM/ReluLLaMA-7B](https://huggingface.co/SparseLLM/ReluLLaMA-7B) | [PowerInfer/ReluLLaMA-7B-Predictor](https://huggingface.co/PowerInfer/ReluLLaMA-7B-Predictor)
|
| 123 |
+
| LLaMA(ReLU)-2-13B | [SparseLLM/ReluLLaMA-13B](https://huggingface.co/SparseLLM/ReluLLaMA-13B) | [PowerInfer/ReluLLaMA-13B-Predictor](https://huggingface.co/PowerInfer/ReluLLaMA-13B-Predictor)
|
| 124 |
+
| Falcon(ReLU)-40B | [SparseLLM/ReluFalcon-40B](https://huggingface.co/SparseLLM/ReluFalcon-40B) | [PowerInfer/ReluFalcon-40B-Predictor](https://huggingface.co/PowerInfer/ReluFalcon-40B-Predictor)
|
| 125 |
+
| LLaMA(ReLU)-2-70B | [SparseLLM/ReluLLaMA-70B](https://huggingface.co/SparseLLM/ReluLLaMA-70B) | [PowerInfer/ReluLLaMA-70B-Predictor](https://huggingface.co/PowerInfer/ReluLLaMA-70B-Predictor)
|
| 126 |
+
|
| 127 |
+
You can use the following command to convert the original model weights and predictor weights to PowerInfer GGUF:
|
| 128 |
+
```bash
|
| 129 |
+
# make sure that you have done `pip install -r requirements.txt`
|
| 130 |
+
python convert.py --outfile /PATH/TO/POWERINFER/GGUF/REPO/MODELNAME.powerinfer.gguf /PATH/TO/ORIGINAL/MODEL /PATH/TO/PREDICTOR
|
| 131 |
+
# python convert.py --outfile ./ReluLLaMA-70B-PowerInfer-GGUF/llama-70b-relu.powerinfer.gguf ./SparseLLM/ReluLLaMA-70B ./PowerInfer/ReluLLaMA-70B-Predictor
|
| 132 |
+
```
|
| 133 |
+
For the same reason, we suggest keeping the same directory structure as PowerInfer GGUF repos after conversion.
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
## Inference
|
| 137 |
+
|
| 138 |
+
For CPU-only and CPU-GPU hybrid inference with all available VRAM, you can use the following instructions to run PowerInfer:
|
| 139 |
+
```bash
|
| 140 |
+
./build/bin/main -m /PATH/TO/MODEL -n $output_token_count -t $thread_num -p $prompt
|
| 141 |
+
# ./build/bin/main -m ./ReluFalcon-40B-PowerInfer-GGUF/falcon-40b-relu.q4.powerinfer.gguf -n 128 -t 8 -p "Once upon a time"
|
| 142 |
+
```
|
| 143 |
+
|
| 144 |
+
If you want to limit the VRAM usage of GPU:
|
| 145 |
+
```bash
|
| 146 |
+
./build/bin/main -m /PATH/TO/MODEL -n $output_token_count -t $thread_num -p $prompt --vram-budget $vram_gb
|
| 147 |
+
# ./build/bin/main -m ./ReluLLaMA-7B-PowerInfer-GGUF/llama-7b-relu.powerinfer.gguf -n 128 -t 8 -p "Once upon a time" --vram-budget 8
|
| 148 |
+
```
|
| 149 |
+
Under CPU-GPU hybrid inference, PowerInfer will automatically offload all dense activation blocks to GPU, then split FFN and offload to GPU if possible.
|
| 150 |
+
|
| 151 |
+
## Quantization
|
| 152 |
+
|
| 153 |
+
PowerInfer has optimized quantization support for INT4(`Q4_0`) models. You can use the following instructions to quantize PowerInfer GGUF model:
|
| 154 |
+
```bash
|
| 155 |
+
./build/bin/quantize /PATH/TO/MODEL /PATH/TO/OUTPUT/QUANTIZED/MODEL Q4_0
|
| 156 |
+
# ./build/bin/quantize ./ReluFalcon-40B-PowerInfer-GGUF/falcon-40b-relu.powerinfer.gguf ./ReluFalcon-40B-PowerInfer-GGUF/falcon-40b-relu.q4.powerinfer.gguf Q4_0
|
| 157 |
+
```
|
| 158 |
+
Then you can use the quantized model for inference with PowerInfer with the same instructions as above.
|
| 159 |
+
|
| 160 |
+
## Evaluation
|
| 161 |
+
|
| 162 |
+
We evaluated PowerInfer vs. llama.cpp on a single RTX 4090(24G) with a series of FP16 ReLU models under inputs of length 64, and the results are shown below. PowerInfer achieves up to 11x speedup on Falcon 40B and up to 3x speedup on Llama 2 70B.
|
| 163 |
+
|
| 164 |
+
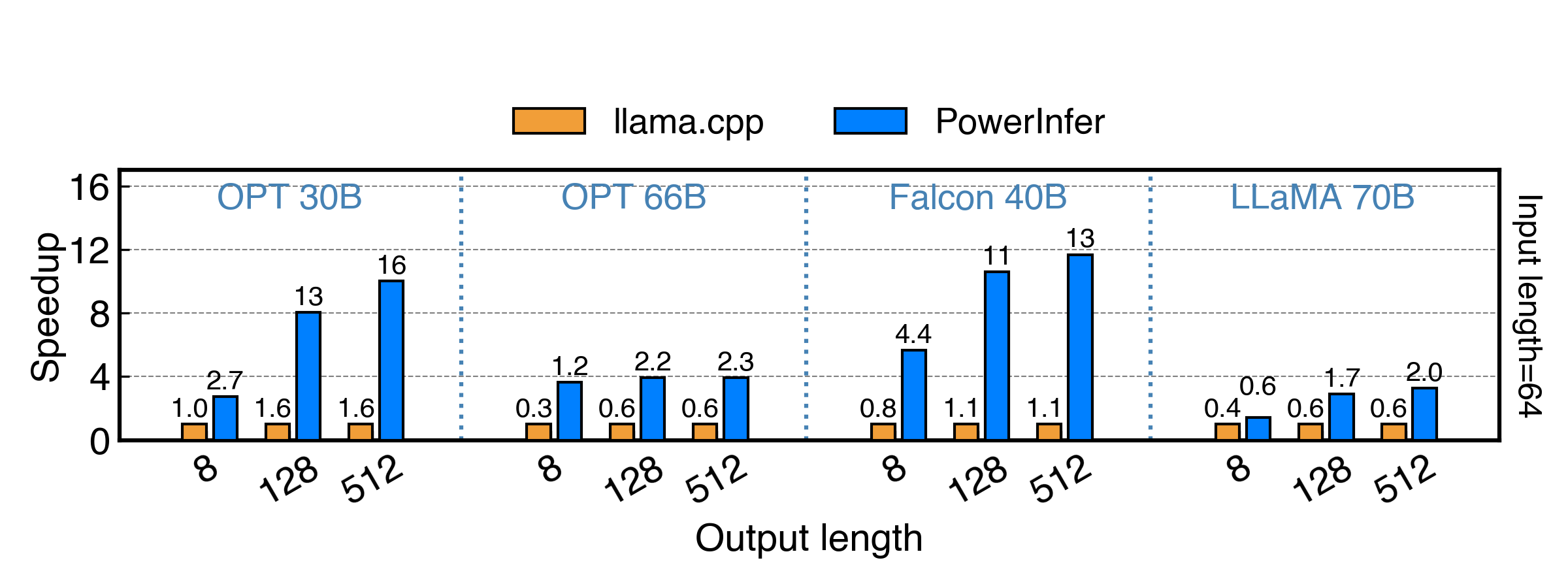
|
| 165 |
+
<sub>The X axis indicates the output length, and the Y axis represents the speedup compared with llama.cpp. The number above each bar indicates the end-to-end generation speed (total prompting + generation time / total tokens generated, in tokens/s).</sub>
|
| 166 |
+
|
| 167 |
+
We also evaluated PowerInfer on a single RTX 2080Ti(11G) with INT4 ReLU models under inputs of length 8, and the results are illustrated in the same way as above. PowerInfer achieves up to 8x speedup on Falcon 40B and up to 3x speedup on Llama 2 70B.
|
| 168 |
+
|
| 169 |
+
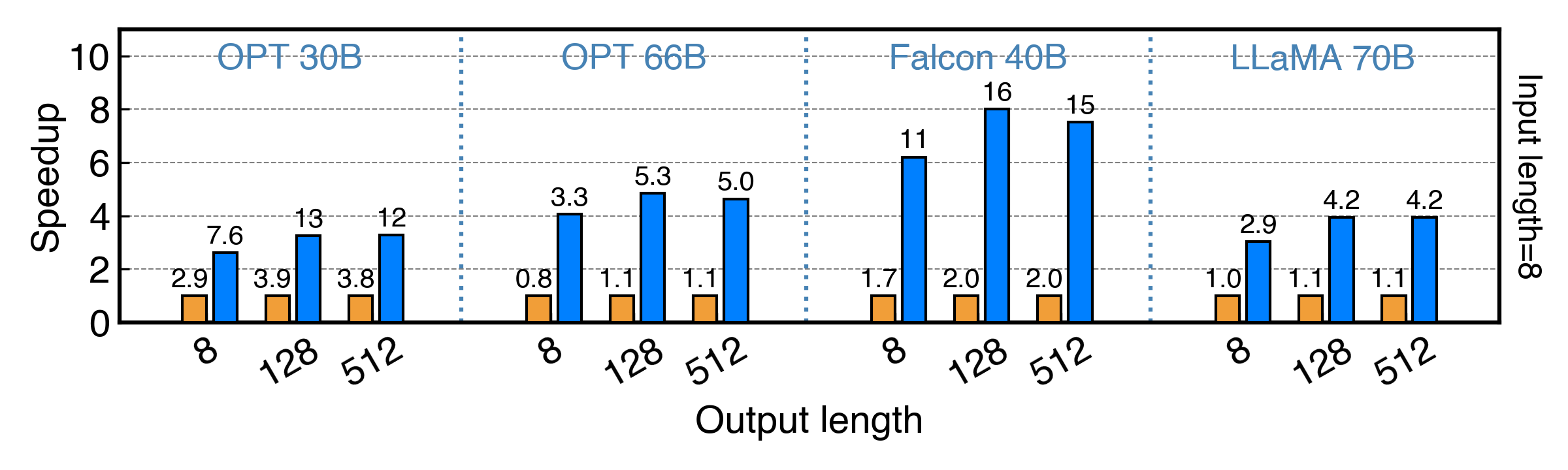
|
| 170 |
+
|
| 171 |
+
Please refer to our [paper](https://ipads.se.sjtu.edu.cn/_media/publications/powerinfer-20231219.pdf) for more evaluation details.
|
| 172 |
+
|
| 173 |
+
## FAQs
|
| 174 |
+
1. What if I encountered `CUDA_ERROR_OUT_OF_MEMORY`?
|
| 175 |
+
- You can try to run with `--reset-gpu-index` argument to rebuild the GPU index for this model to avoid any stale cache.
|
| 176 |
+
- Due to our current implementation, model offloading might not be as accurate as expected. You can try with `--vram-budget` with a slightly lower value or `--disable-gpu-index` to disable FFN offloading.
|
| 177 |
+
2. What if...
|
| 178 |
+
- Issues are welcomed! Please feel free to open an issue and attach your running environment and running parameters. We will try our best to help you.
|
| 179 |
+
|
| 180 |
+
## TODOs
|
| 181 |
+
We will release the code and data in the following order, please stay tuned!
|
| 182 |
+
|
| 183 |
+
- [x] Release core code of PowerInfer, supporting Llama-2, Falcon-40B.
|
| 184 |
+
- [ ] Support Mistral-7B
|
| 185 |
+
- [ ] Support Windows
|
| 186 |
+
- [ ] Support text-generation-webui
|
| 187 |
+
- [ ] Release perplexity evaluation code
|
| 188 |
+
- [ ] Support Metal for Mac
|
| 189 |
+
- [ ] Release code for OPT models
|
| 190 |
+
- [ ] Release predictor training code
|
| 191 |
+
- [x] Support online split for FFN network
|
| 192 |
+
- [ ] Support Multi-GPU
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
## Paper and Citation
|
| 196 |
+
More technical details can be found in our [paper](https://ipads.se.sjtu.edu.cn/_media/publications/powerinfer-20231219.pdf).
|
| 197 |
+
|
| 198 |
+
If you find PowerInfer useful or relevant to your project and research, please kindly cite our paper:
|
| 199 |
+
|
| 200 |
+
```bibtex
|
| 201 |
+
@misc{song2023powerinfer,
|
| 202 |
+
title={PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU},
|
| 203 |
+
author={Yixin Song and Zeyu Mi and Haotong Xie and Haibo Chen},
|
| 204 |
+
year={2023},
|
| 205 |
+
eprint={2312.12456},
|
| 206 |
+
archivePrefix={arXiv},
|
| 207 |
+
primaryClass={cs.LG}
|
| 208 |
+
}
|
| 209 |
+
```
|
| 210 |
+
|
| 211 |
+
## Acknowledgement
|
| 212 |
+
We are thankful for the easily modifiable operator library [ggml](https://github.com/ggerganov/ggml) and execution runtime provided by [llama.cpp](https://github.com/ggerganov/llama.cpp). We also extend our gratitude to [THUNLP](https://nlp.csai.tsinghua.edu.cn/) for their support of ReLU-based sparse models. We also appreciate the research of [Deja Vu](https://proceedings.mlr.press/v202/liu23am.html), which inspires PowerInfer.
|