

Upload folder using huggingface_hub (#2)
Browse files- 038cda9f69d7e2a6997034d7d0501f025ba2eef495c3a35214a2267e3c6f14fc (b6ceb025d6fa2e67c76b001f5ebee9d77294789d)
- 792e27e99c3a539d58aa2695e0dbfeb1c366d108a437240ea82fee626b46de74 (1514ed1b514a6776af4a0a2bcc5910ff096e5b35)
- README.md +2 -2
- config.json +2 -2
- plots.png +0 -0
- smash_config.json +1 -1
README.md
CHANGED
|
@@ -34,7 +34,7 @@ tags:
|
|
| 34 |
|
| 35 |
## Results
|
| 36 |
|
| 37 |
-
|
| 38 |
|
| 39 |
**Frequently Asked Questions**
|
| 40 |
- ***How does the compression work?*** The model is compressed with llm-int8.
|
|
@@ -61,7 +61,7 @@ You can run the smashed model with these steps:
|
|
| 61 |
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 62 |
|
| 63 |
model = AutoModelForCausalLM.from_pretrained("PrunaAI/WizardLM-WizardCoder-Python-7B-V1.0-bnb-8bit-smashed",
|
| 64 |
-
trust_remote_code=True)
|
| 65 |
tokenizer = AutoTokenizer.from_pretrained("WizardLM/WizardCoder-Python-7B-V1.0")
|
| 66 |
|
| 67 |
input_ids = tokenizer("What is the color of prunes?,", return_tensors='pt').to(model.device)["input_ids"]
|
|
|
|
| 34 |
|
| 35 |
## Results
|
| 36 |
|
| 37 |
+

|
| 38 |
|
| 39 |
**Frequently Asked Questions**
|
| 40 |
- ***How does the compression work?*** The model is compressed with llm-int8.
|
|
|
|
| 61 |
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 62 |
|
| 63 |
model = AutoModelForCausalLM.from_pretrained("PrunaAI/WizardLM-WizardCoder-Python-7B-V1.0-bnb-8bit-smashed",
|
| 64 |
+
trust_remote_code=True, device_map='auto')
|
| 65 |
tokenizer = AutoTokenizer.from_pretrained("WizardLM/WizardCoder-Python-7B-V1.0")
|
| 66 |
|
| 67 |
input_ids = tokenizer("What is the color of prunes?,", return_tensors='pt').to(model.device)["input_ids"]
|
config.json
CHANGED
|
@@ -1,5 +1,5 @@
|
|
| 1 |
{
|
| 2 |
-
"_name_or_path": "/tmp/
|
| 3 |
"architectures": [
|
| 4 |
"LlamaForCausalLM"
|
| 5 |
],
|
|
@@ -21,7 +21,7 @@
|
|
| 21 |
"quantization_config": {
|
| 22 |
"bnb_4bit_compute_dtype": "bfloat16",
|
| 23 |
"bnb_4bit_quant_type": "fp4",
|
| 24 |
-
"bnb_4bit_use_double_quant":
|
| 25 |
"llm_int8_enable_fp32_cpu_offload": false,
|
| 26 |
"llm_int8_has_fp16_weight": false,
|
| 27 |
"llm_int8_skip_modules": [
|
|
|
|
| 1 |
{
|
| 2 |
+
"_name_or_path": "/tmp/tmpm1ctgsha",
|
| 3 |
"architectures": [
|
| 4 |
"LlamaForCausalLM"
|
| 5 |
],
|
|
|
|
| 21 |
"quantization_config": {
|
| 22 |
"bnb_4bit_compute_dtype": "bfloat16",
|
| 23 |
"bnb_4bit_quant_type": "fp4",
|
| 24 |
+
"bnb_4bit_use_double_quant": false,
|
| 25 |
"llm_int8_enable_fp32_cpu_offload": false,
|
| 26 |
"llm_int8_has_fp16_weight": false,
|
| 27 |
"llm_int8_skip_modules": [
|
plots.png
ADDED
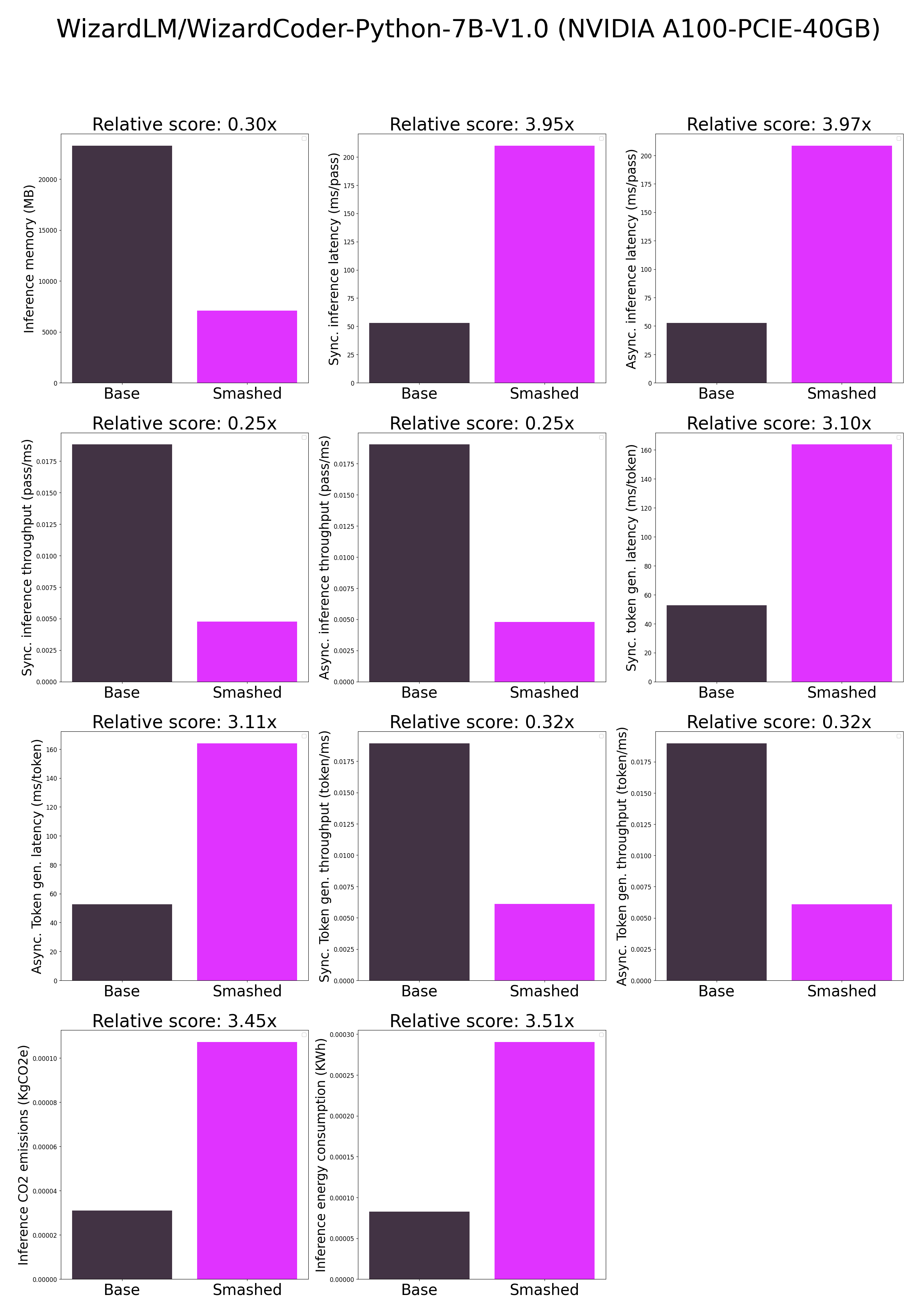
|
smash_config.json
CHANGED
|
@@ -8,7 +8,7 @@
|
|
| 8 |
"compilers": "None",
|
| 9 |
"task": "text_text_generation",
|
| 10 |
"device": "cuda",
|
| 11 |
-
"cache_dir": "/ceph/hdd/staff/charpent/.cache/
|
| 12 |
"batch_size": 1,
|
| 13 |
"model_name": "WizardLM/WizardCoder-Python-7B-V1.0",
|
| 14 |
"pruning_ratio": 0.0,
|
|
|
|
| 8 |
"compilers": "None",
|
| 9 |
"task": "text_text_generation",
|
| 10 |
"device": "cuda",
|
| 11 |
+
"cache_dir": "/ceph/hdd/staff/charpent/.cache/modelsk9kaj3bj",
|
| 12 |
"batch_size": 1,
|
| 13 |
"model_name": "WizardLM/WizardCoder-Python-7B-V1.0",
|
| 14 |
"pruning_ratio": 0.0,
|