

Upload folder using huggingface_hub (#2)
Browse files- 13ddc92e6403318238dc0ba08029d13e17ee4e590fa7f58d903223f502a5616b (cbdb9c2579962a00b2cb3758f826bf34831ab5d0)
- ddc110f21c55262db75d4b2b4cfa85273f147dd374fdccace31c91410d92602b (de6221a61514daf47e02aa67eca1bde0cabe75b3)
- config.json +1 -1
- plots.png +0 -0
- results.json +24 -24
- smash_config.json +5 -5
config.json
CHANGED
|
@@ -1,5 +1,5 @@
|
|
| 1 |
{
|
| 2 |
-
"_name_or_path": "/tmp/
|
| 3 |
"architectures": [
|
| 4 |
"LlamaForCausalLM"
|
| 5 |
],
|
|
|
|
| 1 |
{
|
| 2 |
+
"_name_or_path": "/tmp/tmpls270se6",
|
| 3 |
"architectures": [
|
| 4 |
"LlamaForCausalLM"
|
| 5 |
],
|
plots.png
CHANGED
|

|
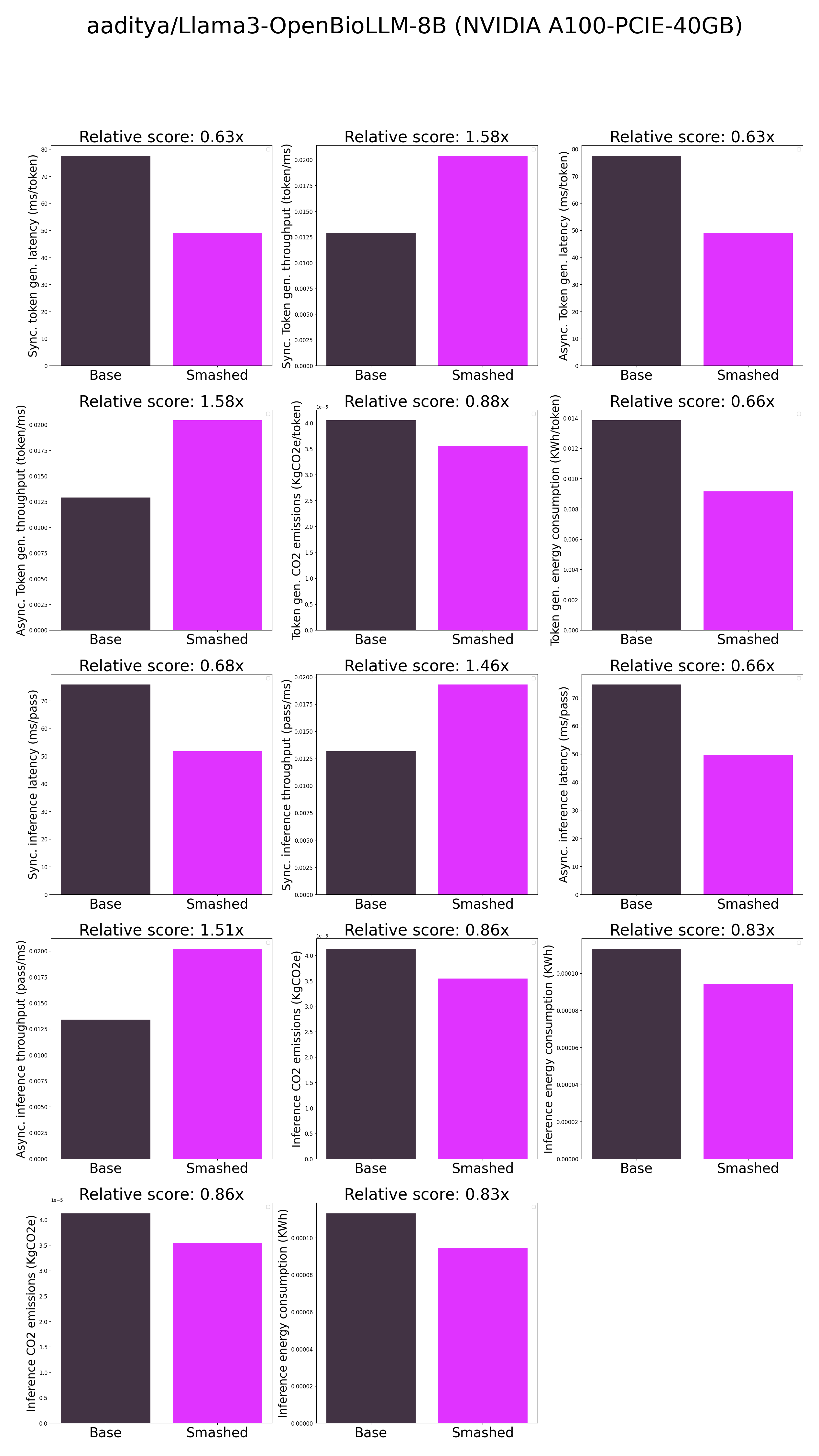
results.json
CHANGED
|
@@ -1,30 +1,30 @@
|
|
| 1 |
{
|
| 2 |
"base_current_gpu_type": "NVIDIA A100-PCIE-40GB",
|
| 3 |
"base_current_gpu_total_memory": 40339.3125,
|
| 4 |
-
"base_token_generation_latency_sync":
|
| 5 |
-
"base_token_generation_latency_async":
|
| 6 |
-
"base_token_generation_throughput_sync": 0.
|
| 7 |
-
"base_token_generation_throughput_async": 0.
|
| 8 |
-
"base_token_generation_CO2_emissions":
|
| 9 |
-
"base_token_generation_energy_consumption":
|
| 10 |
-
"base_inference_latency_sync":
|
| 11 |
-
"base_inference_latency_async":
|
| 12 |
-
"base_inference_throughput_sync": 0.
|
| 13 |
-
"base_inference_throughput_async": 0.
|
| 14 |
-
"base_inference_CO2_emissions":
|
| 15 |
-
"base_inference_energy_consumption":
|
| 16 |
"smashed_current_gpu_type": "NVIDIA A100-PCIE-40GB",
|
| 17 |
"smashed_current_gpu_total_memory": 40339.3125,
|
| 18 |
-
"smashed_token_generation_latency_sync":
|
| 19 |
-
"smashed_token_generation_latency_async":
|
| 20 |
-
"smashed_token_generation_throughput_sync": 0.
|
| 21 |
-
"smashed_token_generation_throughput_async": 0.
|
| 22 |
-
"smashed_token_generation_CO2_emissions":
|
| 23 |
-
"smashed_token_generation_energy_consumption":
|
| 24 |
-
"smashed_inference_latency_sync": 51.
|
| 25 |
-
"smashed_inference_latency_async":
|
| 26 |
-
"smashed_inference_throughput_sync": 0.
|
| 27 |
-
"smashed_inference_throughput_async": 0.
|
| 28 |
-
"smashed_inference_CO2_emissions":
|
| 29 |
-
"smashed_inference_energy_consumption":
|
| 30 |
}
|
|
|
|
| 1 |
{
|
| 2 |
"base_current_gpu_type": "NVIDIA A100-PCIE-40GB",
|
| 3 |
"base_current_gpu_total_memory": 40339.3125,
|
| 4 |
+
"base_token_generation_latency_sync": 56.28690795898437,
|
| 5 |
+
"base_token_generation_latency_async": 56.298492290079594,
|
| 6 |
+
"base_token_generation_throughput_sync": 0.017766120688823207,
|
| 7 |
+
"base_token_generation_throughput_async": 0.01776246502033254,
|
| 8 |
+
"base_token_generation_CO2_emissions": null,
|
| 9 |
+
"base_token_generation_energy_consumption": null,
|
| 10 |
+
"base_inference_latency_sync": 55.02095375061035,
|
| 11 |
+
"base_inference_latency_async": 53.02169322967529,
|
| 12 |
+
"base_inference_throughput_sync": 0.01817489396008347,
|
| 13 |
+
"base_inference_throughput_async": 0.018860204929108487,
|
| 14 |
+
"base_inference_CO2_emissions": null,
|
| 15 |
+
"base_inference_energy_consumption": null,
|
| 16 |
"smashed_current_gpu_type": "NVIDIA A100-PCIE-40GB",
|
| 17 |
"smashed_current_gpu_total_memory": 40339.3125,
|
| 18 |
+
"smashed_token_generation_latency_sync": 42.081617736816405,
|
| 19 |
+
"smashed_token_generation_latency_async": 40.63092991709709,
|
| 20 |
+
"smashed_token_generation_throughput_sync": 0.023763344989589576,
|
| 21 |
+
"smashed_token_generation_throughput_async": 0.024611792101248708,
|
| 22 |
+
"smashed_token_generation_CO2_emissions": null,
|
| 23 |
+
"smashed_token_generation_energy_consumption": null,
|
| 24 |
+
"smashed_inference_latency_sync": 51.81982650756836,
|
| 25 |
+
"smashed_inference_latency_async": 40.34445285797119,
|
| 26 |
+
"smashed_inference_throughput_sync": 0.019297633114498145,
|
| 27 |
+
"smashed_inference_throughput_async": 0.024786555007212635,
|
| 28 |
+
"smashed_inference_CO2_emissions": null,
|
| 29 |
+
"smashed_inference_energy_consumption": null
|
| 30 |
}
|
smash_config.json
CHANGED
|
@@ -2,19 +2,19 @@
|
|
| 2 |
"api_key": null,
|
| 3 |
"verify_url": "http://johnrachwan.pythonanywhere.com",
|
| 4 |
"smash_config": {
|
| 5 |
-
"pruners": "
|
| 6 |
"pruning_ratio": 0.0,
|
| 7 |
-
"factorizers": "
|
| 8 |
"quantizers": "['awq']",
|
| 9 |
"weight_quantization_bits": 4,
|
| 10 |
-
"output_deviation": 0.
|
| 11 |
-
"compilers": "
|
| 12 |
"static_batch": true,
|
| 13 |
"static_shape": true,
|
| 14 |
"controlnet": "None",
|
| 15 |
"unet_dim": 4,
|
| 16 |
"device": "cuda",
|
| 17 |
-
"cache_dir": "/ceph/hdd/staff/charpent/.cache/
|
| 18 |
"batch_size": 1,
|
| 19 |
"model_name": "aaditya/Llama3-OpenBioLLM-8B",
|
| 20 |
"task": "text_text_generation",
|
|
|
|
| 2 |
"api_key": null,
|
| 3 |
"verify_url": "http://johnrachwan.pythonanywhere.com",
|
| 4 |
"smash_config": {
|
| 5 |
+
"pruners": "None",
|
| 6 |
"pruning_ratio": 0.0,
|
| 7 |
+
"factorizers": "None",
|
| 8 |
"quantizers": "['awq']",
|
| 9 |
"weight_quantization_bits": 4,
|
| 10 |
+
"output_deviation": 0.005,
|
| 11 |
+
"compilers": "None",
|
| 12 |
"static_batch": true,
|
| 13 |
"static_shape": true,
|
| 14 |
"controlnet": "None",
|
| 15 |
"unet_dim": 4,
|
| 16 |
"device": "cuda",
|
| 17 |
+
"cache_dir": "/ceph/hdd/staff/charpent/.cache/modelskfqi18ew",
|
| 18 |
"batch_size": 1,
|
| 19 |
"model_name": "aaditya/Llama3-OpenBioLLM-8B",
|
| 20 |
"task": "text_text_generation",
|