

Upload folder using huggingface_hub (#4)
Browse files- 872995b413b53a6ce2891f491054b2b2c80627f72f24343e9744da519d584f88 (51d6c2b686b73e3479fbe46c4640cfbdd84cca84)
- a53eecaa316f75d30ff366f5d820294a9d503905c949f7b342de3f4b178b4a5c (3920125c5988ca2ebc09da14abd5d1d3000020d1)
- README.md +45 -18
- config.json +1 -1
- model → model/optimized_model.pkl +2 -2
- model/smash_config.json +3 -0
- plots.png +0 -0
README.md
CHANGED
|
@@ -19,40 +19,67 @@ metrics:
|
|
| 19 |
</div>
|
| 20 |
<!-- header end -->
|
| 21 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 22 |
# Simply make AI models cheaper, smaller, faster, and greener!
|
| 23 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 24 |
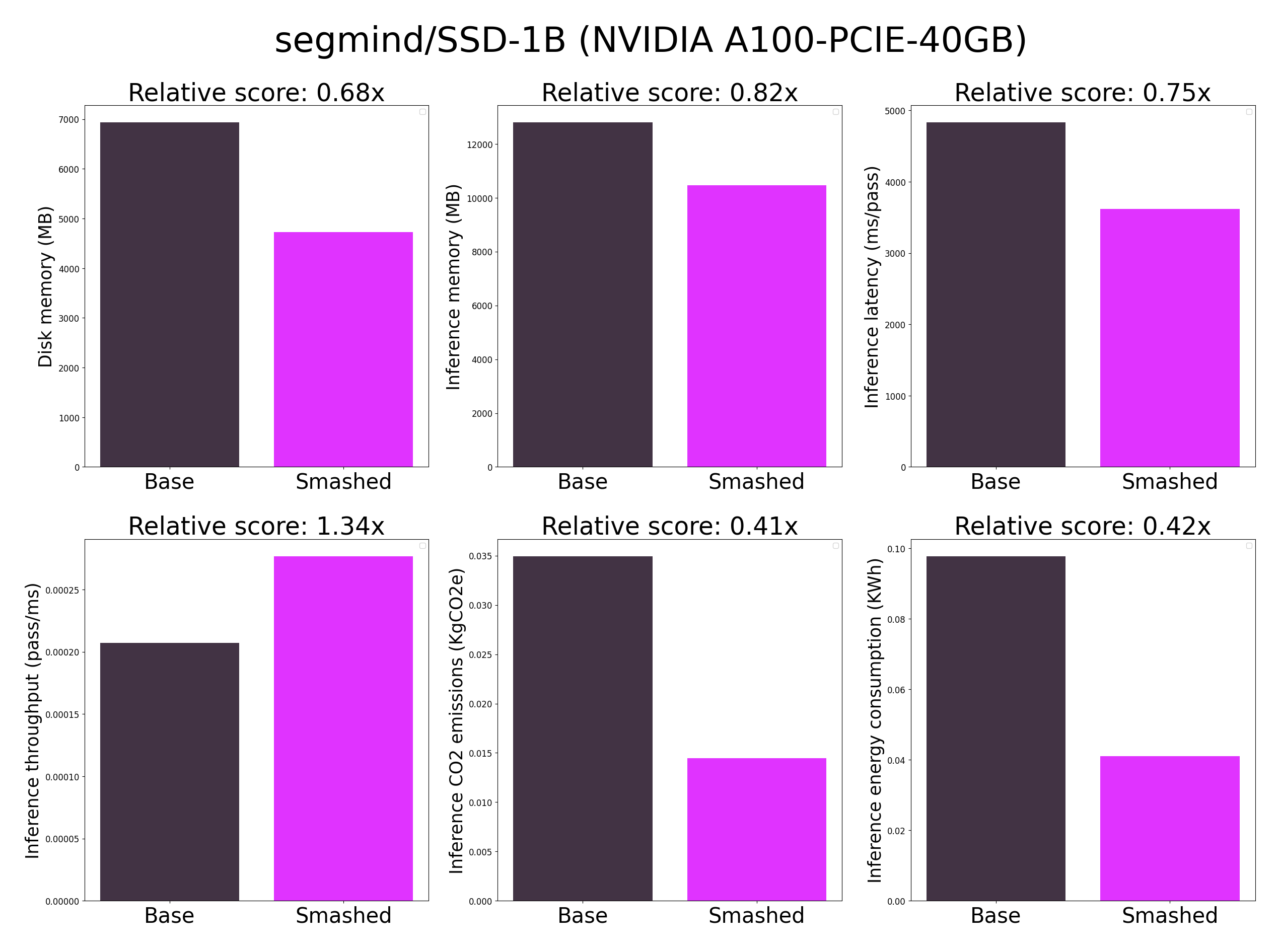
## Results
|
| 25 |
|
| 26 |

|
| 27 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 28 |
## Setup
|
| 29 |
|
| 30 |
-
You can run the smashed model
|
| 31 |
-
|
| 32 |
-
|
|
|
|
| 33 |
```bash
|
| 34 |
-
|
| 35 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 36 |
```
|
| 37 |
-
Alternatively, you can download them manually.
|
| 38 |
-
3. Loading the model.
|
| 39 |
-
4. Running the model.
|
| 40 |
-
You can achieve this by running the following code:
|
| 41 |
-
|
| 42 |
-
```python
|
| 43 |
-
from pruna_engine.PrunaModel import PrunaModel # Step (1): install and import `pruna-engine` package.
|
| 44 |
-
model_path = "segmind-SSD-1B-turbo-tiny-green-smashed/model" # Step (2): specify the downloaded model path.
|
| 45 |
-
smashed_model = PrunaModel.load_model(model_path) # Step (3): load the model.
|
| 46 |
-
y = smashed_model(prompt="an astronaut riding a horse on mars", image_height=1024, image_width=1024)[0] # Step (4): run the model.
|
| 47 |
-
```
|
| 48 |
|
| 49 |
## Configurations
|
| 50 |
|
| 51 |
The configuration info are in `config.json`.
|
| 52 |
|
| 53 |
-
## License
|
| 54 |
|
| 55 |
-
We follow the same license as the original model. Please check the license of the original model before using this model.
|
| 56 |
|
| 57 |
## Want to compress other models?
|
| 58 |
|
|
|
|
| 19 |
</div>
|
| 20 |
<!-- header end -->
|
| 21 |
|
| 22 |
+
[](https://twitter.com/PrunaAI)
|
| 23 |
+
[](https://github.com/PrunaAI)
|
| 24 |
+
[](https://www.linkedin.com/company/93832878/admin/feed/posts/?feedType=following)
|
| 25 |
+
[](https://discord.gg/CP4VSgck)
|
| 26 |
+
|
| 27 |
# Simply make AI models cheaper, smaller, faster, and greener!
|
| 28 |
|
| 29 |
+
- Give a thumbs up if you like this model!
|
| 30 |
+
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
|
| 31 |
+
- Request access to easily compress your *own* AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
| 32 |
+
- Read the documentations to know more [here](https://pruna-ai-pruna.readthedocs-hosted.com/en/latest/)
|
| 33 |
+
- Join Pruna AI community on Discord [here](https://discord.gg/CP4VSgck) to share feedback/suggestions or get help.
|
| 34 |
+
|
| 35 |
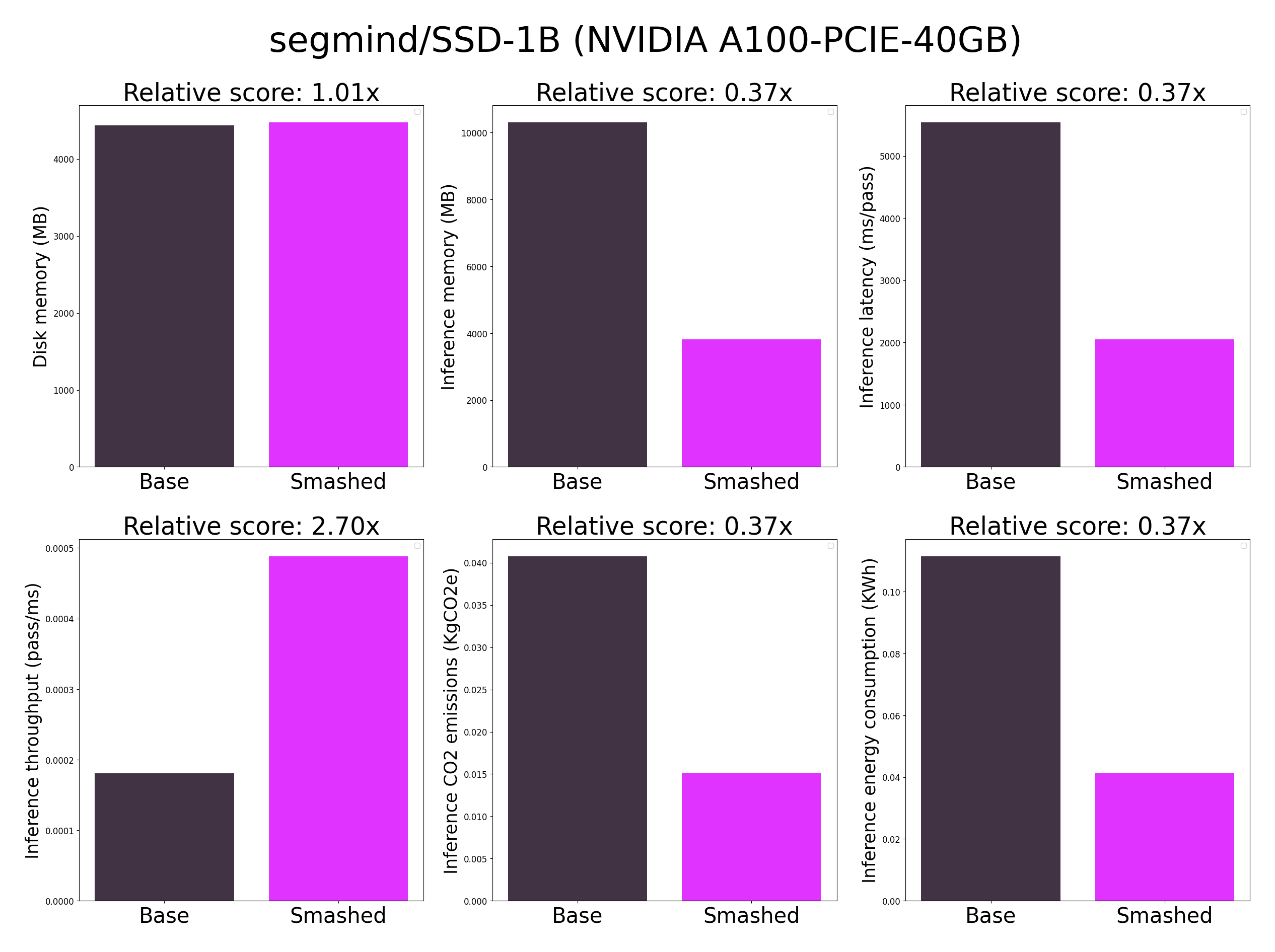
## Results
|
| 36 |
|
| 37 |

|
| 38 |
|
| 39 |
+
**Important remarks:**
|
| 40 |
+
- The quality of the model output might slightly vary compared to the base model. There might be minimal quality loss.
|
| 41 |
+
- These results were obtained on NVIDIA A100-PCIE-40GB with configuration described in config.json and are obtained after a hardware warmup. Efficiency results may vary in other settings (e.g. other hardware, image size, batch size, ...).
|
| 42 |
+
- You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
| 43 |
+
|
| 44 |
## Setup
|
| 45 |
|
| 46 |
+
You can run the smashed model with these steps:
|
| 47 |
+
|
| 48 |
+
0. Check cuda, torch, packaging requirements are installed. For cuda, check with `nvcc --version` and install with `conda install nvidia/label/cuda-12.1.0::cuda`. For packaging and torch, run `pip install packaging torch`.
|
| 49 |
+
1. Install the `pruna-engine` available [here](https://pypi.org/project/pruna-engine/) on Pypi. It might take 15 minutes to install.
|
| 50 |
```bash
|
| 51 |
+
pip install pruna-engine[gpu]==0.6.0 --extra-index-url https://pypi.nvidia.com --extra-index-url https://pypi.ngc.nvidia.com --extra-index-url https://prunaai.pythonanywhere.com/
|
| 52 |
+
```
|
| 53 |
+
3. Download the model files using one of these three options.
|
| 54 |
+
- Option 1 - Use command line interface (CLI):
|
| 55 |
+
```bash
|
| 56 |
+
mkdir segmind-SSD-1B-turbo-tiny-green-smashed
|
| 57 |
+
huggingface-cli download PrunaAI/segmind-SSD-1B-turbo-tiny-green-smashed --local-dir segmind-SSD-1B-turbo-tiny-green-smashed --local-dir-use-symlinks False
|
| 58 |
+
```
|
| 59 |
+
- Option 2 - Use Python:
|
| 60 |
+
```python
|
| 61 |
+
import subprocess
|
| 62 |
+
repo_name = "segmind-SSD-1B-turbo-tiny-green-smashed"
|
| 63 |
+
subprocess.run(["mkdir", repo_name])
|
| 64 |
+
subprocess.run(["huggingface-cli", "download", 'PrunaAI/'+ repo_name, "--local-dir", repo_name, "--local-dir-use-symlinks", "False"])
|
| 65 |
+
```
|
| 66 |
+
- Option 3 - Download them manually on the HuggingFace model page.
|
| 67 |
+
3. Load & run the model.
|
| 68 |
+
```python
|
| 69 |
+
from pruna_engine.PrunaModel import PrunaModel
|
| 70 |
+
|
| 71 |
+
model_path = "segmind-SSD-1B-turbo-tiny-green-smashed/model" # Specify the downloaded model path.
|
| 72 |
+
smashed_model = PrunaModel.load_model(model_path) # Load the model.
|
| 73 |
+
smashed_model(prompt='Beautiful fruits in trees', height=1024, width=1024)[0][0] # Run the model where x is the expected input of.
|
| 74 |
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 75 |
|
| 76 |
## Configurations
|
| 77 |
|
| 78 |
The configuration info are in `config.json`.
|
| 79 |
|
| 80 |
+
## Credits & License
|
| 81 |
|
| 82 |
+
We follow the same license as the original model. Please check the license of the original model segmind/SSD-1B before using this model which provided the base model.
|
| 83 |
|
| 84 |
## Want to compress other models?
|
| 85 |
|
config.json
CHANGED
|
@@ -1 +1 @@
|
|
| 1 |
-
{"
|
|
|
|
| 1 |
+
{"pruners": "None", "pruning_ratio": 0.0, "factorizers": "None", "quantizers": "None", "n_quantization_bits": 32, "output_deviation": 0.005, "compilers": "['diffusers2', 'tiling', 'step_caching']", "static_batch": true, "static_shape": false, "controlnet": "None", "unet_dim": 4, "device": "cuda", "batch_size": 1, "max_batch_size": 1, "image_height": 1024, "image_width": 1024, "version": "xl-1.0", "scheduler": "DDIM", "task": "txt2imgxl", "model_name": "segmind/SSD-1B", "weight_name": "None", "save_load_fn": "stable_fast"}
|
model → model/optimized_model.pkl
RENAMED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fb9c7cca88d136c4220a2e7c39f898d117eeb439c7263a725c93b4f91fcafba7
|
| 3 |
+
size 4470556353
|
model/smash_config.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9b204d22b90e6eed84e4762b0f1e04a52cded9a8b7a9539facdde272a60a4859
|
| 3 |
+
size 695
|
plots.png
CHANGED
|
|