
First model version
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitignore +12 -0
- LICENSE +21 -0
- README.md +289 -1
- lib/__init__.py +0 -0
- lib/config/__init__.py +2 -0
- lib/config/default.py +157 -0
- lib/core/__init__.py +1 -0
- lib/core/activations.py +72 -0
- lib/core/evaluate.py +278 -0
- lib/core/function.py +510 -0
- lib/core/general.py +466 -0
- lib/core/loss.py +237 -0
- lib/core/postprocess.py +244 -0
- lib/dataset/AutoDriveDataset.py +264 -0
- lib/dataset/DemoDataset.py +188 -0
- lib/dataset/__init__.py +3 -0
- lib/dataset/bdd.py +85 -0
- lib/dataset/convert.py +31 -0
- lib/dataset/hust.py +87 -0
- lib/models/YOLOP.py +596 -0
- lib/models/__init__.py +1 -0
- lib/models/common.py +265 -0
- lib/models/light.py +496 -0
- lib/utils/__init__.py +4 -0
- lib/utils/augmentations.py +253 -0
- lib/utils/autoanchor.py +134 -0
- lib/utils/plot.py +113 -0
- lib/utils/split_dataset.py +30 -0
- lib/utils/utils.py +163 -0
- pictures/da.png +0 -0
- pictures/detect.png +0 -0
- pictures/input1.gif +0 -0
- pictures/input2.gif +0 -0
- pictures/ll.png +0 -0
- pictures/output1.gif +0 -0
- pictures/output2.gif +0 -0
- pictures/yolop.png +0 -0
- requirements.txt +15 -0
- toolkits/deploy/CMakeLists.txt +45 -0
- toolkits/deploy/common.hpp +359 -0
- toolkits/deploy/cuda_utils.h +18 -0
- toolkits/deploy/gen_wts.py +21 -0
- toolkits/deploy/infer_files.cpp +200 -0
- toolkits/deploy/logging.h +503 -0
- toolkits/deploy/main.cpp +137 -0
- toolkits/deploy/utils.h +155 -0
- toolkits/deploy/yololayer.cu +333 -0
- toolkits/deploy/yololayer.h +143 -0
- toolkits/deploy/yolov5.hpp +286 -0
- toolkits/deploy/zedcam.hpp +31 -0
.gitignore
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.DS_Store
|
| 2 |
+
__pycache__/
|
| 3 |
+
.idea/
|
| 4 |
+
.tmp/
|
| 5 |
+
.vscode/
|
| 6 |
+
bdd/
|
| 7 |
+
runs/
|
| 8 |
+
inference/
|
| 9 |
+
*.pth
|
| 10 |
+
*.pt
|
| 11 |
+
*.tar
|
| 12 |
+
*.tar.gz
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2021 Hust Visual Learning Team
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
CHANGED
|
@@ -1 +1,289 @@
|
|
| 1 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="left">
|
| 2 |
+
|
| 3 |
+
## You Only :eyes: Once for Panoptic :car: Perception
|
| 4 |
+
> [**You Only Look at Once for Panoptic driving Perception**](https://arxiv.org/abs/2108.11250)
|
| 5 |
+
>
|
| 6 |
+
> by Dong Wu, Manwen Liao, Weitian Zhang, [Xinggang Wang](https://xinggangw.info/)<sup> :email:</sup> [*School of EIC, HUST*](http://eic.hust.edu.cn/English/Home.htm)
|
| 7 |
+
>
|
| 8 |
+
> (<sup>:email:</sup>) corresponding author.
|
| 9 |
+
>
|
| 10 |
+
> *arXiv technical report ([arXiv 2108.11250](https://arxiv.org/abs/2108.11250))*
|
| 11 |
+
|
| 12 |
+
---
|
| 13 |
+
|
| 14 |
+
### The Illustration of YOLOP
|
| 15 |
+
|
| 16 |
+

|
| 17 |
+
|
| 18 |
+
### Contributions
|
| 19 |
+
|
| 20 |
+
* We put forward an efficient multi-task network that can jointly handle three crucial tasks in autonomous driving: object detection, drivable area segmentation and lane detection to save computational costs, reduce inference time as well as improve the performance of each task. Our work is the first to reach real-time on embedded devices while maintaining state-of-the-art level performance on the `BDD100K `dataset.
|
| 21 |
+
|
| 22 |
+
* We design the ablative experiments to verify the effectiveness of our multi-tasking scheme. It is proved that the three tasks can be learned jointly without tedious alternating optimization.
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
### Results
|
| 27 |
+
|
| 28 |
+
#### Traffic Object Detection Result
|
| 29 |
+
|
| 30 |
+
| Model | Recall(%) | mAP50(%) | Speed(fps) |
|
| 31 |
+
| -------------- | --------- | -------- | ---------- |
|
| 32 |
+
| `Multinet` | 81.3 | 60.2 | 8.6 |
|
| 33 |
+
| `DLT-Net` | 89.4 | 68.4 | 9.3 |
|
| 34 |
+
| `Faster R-CNN` | 77.2 | 55.6 | 5.3 |
|
| 35 |
+
| `YOLOv5s` | 86.8 | 77.2 | 82 |
|
| 36 |
+
| `YOLOP(ours)` | 89.2 | 76.5 | 41 |
|
| 37 |
+
#### Drivable Area Segmentation Result
|
| 38 |
+
|
| 39 |
+
| Model | mIOU(%) | Speed(fps) |
|
| 40 |
+
| ------------- | ------- | ---------- |
|
| 41 |
+
| `Multinet` | 71.6 | 8.6 |
|
| 42 |
+
| `DLT-Net` | 71.3 | 9.3 |
|
| 43 |
+
| `PSPNet` | 89.6 | 11.1 |
|
| 44 |
+
| `YOLOP(ours)` | 91.5 | 41 |
|
| 45 |
+
|
| 46 |
+
#### Lane Detection Result:
|
| 47 |
+
|
| 48 |
+
| Model | mIOU(%) | IOU(%) |
|
| 49 |
+
| ------------- | ------- | ------ |
|
| 50 |
+
| `ENet` | 34.12 | 14.64 |
|
| 51 |
+
| `SCNN` | 35.79 | 15.84 |
|
| 52 |
+
| `ENet-SAD` | 36.56 | 16.02 |
|
| 53 |
+
| `YOLOP(ours)` | 70.50 | 26.20 |
|
| 54 |
+
|
| 55 |
+
#### Ablation Studies 1: End-to-end v.s. Step-by-step:
|
| 56 |
+
|
| 57 |
+
| Training_method | Recall(%) | AP(%) | mIoU(%) | Accuracy(%) | IoU(%) |
|
| 58 |
+
| --------------- | --------- | ----- | ------- | ----------- | ------ |
|
| 59 |
+
| `ES-W` | 87.0 | 75.3 | 90.4 | 66.8 | 26.2 |
|
| 60 |
+
| `ED-W` | 87.3 | 76.0 | 91.6 | 71.2 | 26.1 |
|
| 61 |
+
| `ES-D-W` | 87.0 | 75.1 | 91.7 | 68.6 | 27.0 |
|
| 62 |
+
| `ED-S-W` | 87.5 | 76.1 | 91.6 | 68.0 | 26.8 |
|
| 63 |
+
| `End-to-end` | 89.2 | 76.5 | 91.5 | 70.5 | 26.2 |
|
| 64 |
+
|
| 65 |
+
#### Ablation Studies 2: Multi-task v.s. Single task:
|
| 66 |
+
|
| 67 |
+
| Training_method | Recall(%) | AP(%) | mIoU(%) | Accuracy(%) | IoU(%) | Speed(ms/frame) |
|
| 68 |
+
| --------------- | --------- | ----- | ------- | ----------- | ------ | --------------- |
|
| 69 |
+
| `Det(only)` | 88.2 | 76.9 | - | - | - | 15.7 |
|
| 70 |
+
| `Da-Seg(only)` | - | - | 92.0 | - | - | 14.8 |
|
| 71 |
+
| `Ll-Seg(only)` | - | - | - | 79.6 | 27.9 | 14.8 |
|
| 72 |
+
| `Multitask` | 89.2 | 76.5 | 91.5 | 70.5 | 26.2 | 24.4 |
|
| 73 |
+
|
| 74 |
+
**Notes**:
|
| 75 |
+
|
| 76 |
+
- The works we has use for reference including `Multinet` ([paper](https://arxiv.org/pdf/1612.07695.pdf?utm_campaign=affiliate-ir-Optimise%20media%28%20South%20East%20Asia%29%20Pte.%20ltd._156_-99_national_R_all_ACQ_cpa_en&utm_content=&utm_source=%20388939),[code](https://github.com/MarvinTeichmann/MultiNet)),`DLT-Net` ([paper](https://ieeexplore.ieee.org/abstract/document/8937825)),`Faster R-CNN` ([paper](https://proceedings.neurips.cc/paper/2015/file/14bfa6bb14875e45bba028a21ed38046-Paper.pdf),[code](https://github.com/ShaoqingRen/faster_rcnn)),`YOLOv5s`([code](https://github.com/ultralytics/yolov5)) ,`PSPNet`([paper](https://openaccess.thecvf.com/content_cvpr_2017/papers/Zhao_Pyramid_Scene_Parsing_CVPR_2017_paper.pdf),[code](https://github.com/hszhao/PSPNet)) ,`ENet`([paper](https://arxiv.org/pdf/1606.02147.pdf),[code](https://github.com/osmr/imgclsmob)) `SCNN`([paper](https://www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/download/16802/16322),[code](https://github.com/XingangPan/SCNN)) `SAD-ENet`([paper](https://openaccess.thecvf.com/content_ICCV_2019/papers/Hou_Learning_Lightweight_Lane_Detection_CNNs_by_Self_Attention_Distillation_ICCV_2019_paper.pdf),[code](https://github.com/cardwing/Codes-for-Lane-Detection)). Thanks for their wonderful works.
|
| 77 |
+
- In table 4, E, D, S and W refer to Encoder, Detect head, two Segment heads and whole network. So the Algorithm (First, we only train Encoder and Detect head. Then we freeze the Encoder and Detect head as well as train two Segmentation heads. Finally, the entire network is trained jointly for all three tasks.) can be marked as ED-S-W, and the same for others.
|
| 78 |
+
|
| 79 |
+
---
|
| 80 |
+
|
| 81 |
+
### Visualization
|
| 82 |
+
|
| 83 |
+
#### Traffic Object Detection Result
|
| 84 |
+
|
| 85 |
+

|
| 86 |
+
|
| 87 |
+
#### Drivable Area Segmentation Result
|
| 88 |
+
|
| 89 |
+

|
| 90 |
+
|
| 91 |
+
#### Lane Detection Result
|
| 92 |
+
|
| 93 |
+

|
| 94 |
+
|
| 95 |
+
**Notes**:
|
| 96 |
+
|
| 97 |
+
- The visualization of lane detection result has been post processed by quadratic fitting.
|
| 98 |
+
|
| 99 |
+
---
|
| 100 |
+
|
| 101 |
+
### Project Structure
|
| 102 |
+
|
| 103 |
+
```python
|
| 104 |
+
├─inference
|
| 105 |
+
│ ├─images # inference images
|
| 106 |
+
│ ├─output # inference result
|
| 107 |
+
├─lib
|
| 108 |
+
│ ├─config/default # configuration of training and validation
|
| 109 |
+
│ ├─core
|
| 110 |
+
│ │ ├─activations.py # activation function
|
| 111 |
+
│ │ ├─evaluate.py # calculation of metric
|
| 112 |
+
│ │ ├─function.py # training and validation of model
|
| 113 |
+
│ │ ├─general.py #calculation of metric、nms、conversion of data-format、visualization
|
| 114 |
+
│ │ ├─loss.py # loss function
|
| 115 |
+
│ │ ├─postprocess.py # postprocess(refine da-seg and ll-seg, unrelated to paper)
|
| 116 |
+
│ ├─dataset
|
| 117 |
+
│ │ ├─AutoDriveDataset.py # Superclass dataset,general function
|
| 118 |
+
│ │ ├─bdd.py # Subclass dataset,specific function
|
| 119 |
+
│ │ ├─hust.py # Subclass dataset(Campus scene, unrelated to paper)
|
| 120 |
+
│ │ ├─convect.py
|
| 121 |
+
│ │ ├─DemoDataset.py # demo dataset(image, video and stream)
|
| 122 |
+
│ ├─models
|
| 123 |
+
│ │ ├─YOLOP.py # Setup and Configuration of model
|
| 124 |
+
│ │ ├─light.py # Model lightweight(unrelated to paper, zwt)
|
| 125 |
+
│ │ ├─commom.py # calculation module
|
| 126 |
+
│ ├─utils
|
| 127 |
+
│ │ ├─augmentations.py # data augumentation
|
| 128 |
+
│ │ ├─autoanchor.py # auto anchor(k-means)
|
| 129 |
+
│ │ ├─split_dataset.py # (Campus scene, unrelated to paper)
|
| 130 |
+
│ │ ├─utils.py # logging、device_select、time_measure、optimizer_select、model_save&initialize 、Distributed training
|
| 131 |
+
│ ├─run
|
| 132 |
+
│ │ ├─dataset/training time # Visualization, logging and model_save
|
| 133 |
+
├─tools
|
| 134 |
+
│ │ ├─demo.py # demo(folder、camera)
|
| 135 |
+
│ │ ├─test.py
|
| 136 |
+
│ │ ├─train.py
|
| 137 |
+
├─toolkits
|
| 138 |
+
│ │ ├─depoly # Deployment of model
|
| 139 |
+
├─weights # Pretraining model
|
| 140 |
+
```
|
| 141 |
+
|
| 142 |
+
---
|
| 143 |
+
|
| 144 |
+
### Requirement
|
| 145 |
+
|
| 146 |
+
This codebase has been developed with python version 3.7, PyTorch 1.7+ and torchvision 0.8+:
|
| 147 |
+
|
| 148 |
+
```
|
| 149 |
+
conda install pytorch==1.7.0 torchvision==0.8.0 cudatoolkit=10.2 -c pytorch
|
| 150 |
+
```
|
| 151 |
+
|
| 152 |
+
See `requirements.txt` for additional dependencies and version requirements.
|
| 153 |
+
|
| 154 |
+
```setup
|
| 155 |
+
pip install -r requirements.txt
|
| 156 |
+
```
|
| 157 |
+
|
| 158 |
+
### Data preparation
|
| 159 |
+
|
| 160 |
+
#### Download
|
| 161 |
+
|
| 162 |
+
- Download the images from [images](https://bdd-data.berkeley.edu/).
|
| 163 |
+
|
| 164 |
+
- Download the annotations of detection from [det_annotations](https://drive.google.com/file/d/1Ge-R8NTxG1eqd4zbryFo-1Uonuh0Nxyl/view?usp=sharing).
|
| 165 |
+
- Download the annotations of drivable area segmentation from [da_seg_annotations](https://drive.google.com/file/d/1xy_DhUZRHR8yrZG3OwTQAHhYTnXn7URv/view?usp=sharing).
|
| 166 |
+
- Download the annotations of lane line segmentation from [ll_seg_annotations](https://drive.google.com/file/d/1lDNTPIQj_YLNZVkksKM25CvCHuquJ8AP/view?usp=sharing).
|
| 167 |
+
|
| 168 |
+
We recommend the dataset directory structure to be the following:
|
| 169 |
+
|
| 170 |
+
```
|
| 171 |
+
# The id represent the correspondence relation
|
| 172 |
+
├─dataset root
|
| 173 |
+
│ ├─images
|
| 174 |
+
│ │ ├─train
|
| 175 |
+
│ │ ├─val
|
| 176 |
+
│ ├─det_annotations
|
| 177 |
+
│ │ ├─train
|
| 178 |
+
│ │ ├─val
|
| 179 |
+
│ ├─da_seg_annotations
|
| 180 |
+
│ │ ├─train
|
| 181 |
+
│ │ ├─val
|
| 182 |
+
│ ├─ll_seg_annotations
|
| 183 |
+
│ │ ├─train
|
| 184 |
+
│ │ ├─val
|
| 185 |
+
```
|
| 186 |
+
|
| 187 |
+
Update the your dataset path in the `./lib/config/default.py`.
|
| 188 |
+
|
| 189 |
+
### Training
|
| 190 |
+
|
| 191 |
+
You can set the training configuration in the `./lib/config/default.py`. (Including: the loading of preliminary model, loss, data augmentation, optimizer, warm-up and cosine annealing, auto-anchor, training epochs, batch_size).
|
| 192 |
+
|
| 193 |
+
If you want try alternating optimization or train model for single task, please modify the corresponding configuration in `./lib/config/default.py` to `True`. (As following, all configurations is `False`, which means training multiple tasks end to end).
|
| 194 |
+
|
| 195 |
+
```python
|
| 196 |
+
# Alternating optimization
|
| 197 |
+
_C.TRAIN.SEG_ONLY = False # Only train two segmentation branchs
|
| 198 |
+
_C.TRAIN.DET_ONLY = False # Only train detection branch
|
| 199 |
+
_C.TRAIN.ENC_SEG_ONLY = False # Only train encoder and two segmentation branchs
|
| 200 |
+
_C.TRAIN.ENC_DET_ONLY = False # Only train encoder and detection branch
|
| 201 |
+
|
| 202 |
+
# Single task
|
| 203 |
+
_C.TRAIN.DRIVABLE_ONLY = False # Only train da_segmentation task
|
| 204 |
+
_C.TRAIN.LANE_ONLY = False # Only train ll_segmentation task
|
| 205 |
+
_C.TRAIN.DET_ONLY = False # Only train detection task
|
| 206 |
+
```
|
| 207 |
+
|
| 208 |
+
Start training:
|
| 209 |
+
|
| 210 |
+
```shell
|
| 211 |
+
python tools/train.py
|
| 212 |
+
```
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
|
| 216 |
+
### Evaluation
|
| 217 |
+
|
| 218 |
+
You can set the evaluation configuration in the `./lib/config/default.py`. (Including: batch_size and threshold value for nms).
|
| 219 |
+
|
| 220 |
+
Start evaluating:
|
| 221 |
+
|
| 222 |
+
```shell
|
| 223 |
+
python tools/test.py --weights weights/End-to-end.pth
|
| 224 |
+
```
|
| 225 |
+
|
| 226 |
+
|
| 227 |
+
|
| 228 |
+
### Demo Test
|
| 229 |
+
|
| 230 |
+
We provide two testing method.
|
| 231 |
+
|
| 232 |
+
#### Folder
|
| 233 |
+
|
| 234 |
+
You can store the image or video in `--source`, and then save the reasoning result to `--save-dir`
|
| 235 |
+
|
| 236 |
+
```shell
|
| 237 |
+
python tools/demo --source inference/images
|
| 238 |
+
```
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
#### Camera
|
| 243 |
+
|
| 244 |
+
If there are any camera connected to your computer, you can set the `source` as the camera number(The default is 0).
|
| 245 |
+
|
| 246 |
+
```shell
|
| 247 |
+
python tools/demo --source 0
|
| 248 |
+
```
|
| 249 |
+
|
| 250 |
+
|
| 251 |
+
|
| 252 |
+
#### Demonstration
|
| 253 |
+
|
| 254 |
+
<table>
|
| 255 |
+
<tr>
|
| 256 |
+
<th>input</th>
|
| 257 |
+
<th>output</th>
|
| 258 |
+
</tr>
|
| 259 |
+
<tr>
|
| 260 |
+
<td><img src=pictures/input1.gif /></td>
|
| 261 |
+
<td><img src=pictures/output1.gif/></td>
|
| 262 |
+
</tr>
|
| 263 |
+
<tr>
|
| 264 |
+
<td><img src=pictures/input2.gif /></td>
|
| 265 |
+
<td><img src=pictures/output2.gif/></td>
|
| 266 |
+
</tr>
|
| 267 |
+
</table>
|
| 268 |
+
|
| 269 |
+
|
| 270 |
+
|
| 271 |
+
### Deployment
|
| 272 |
+
|
| 273 |
+
Our model can reason in real-time on `Jetson Tx2`, with `Zed Camera` to capture image. We use `TensorRT` tool for speeding up. We provide code for deployment and reasoning of model in `./tools/deploy`.
|
| 274 |
+
|
| 275 |
+
|
| 276 |
+
|
| 277 |
+
## Citation
|
| 278 |
+
|
| 279 |
+
If you find our paper and code useful for your research, please consider giving a star :star: and citation :pencil: :
|
| 280 |
+
|
| 281 |
+
```BibTeX
|
| 282 |
+
@misc{2108.11250,
|
| 283 |
+
Author = {Dong Wu and Manwen Liao and Weitian Zhang and Xinggang Wang},
|
| 284 |
+
Title = {YOLOP: You Only Look Once for Panoptic Driving Perception},
|
| 285 |
+
Year = {2021},
|
| 286 |
+
Eprint = {arXiv:2108.11250},
|
| 287 |
+
}
|
| 288 |
+
```
|
| 289 |
+
|
lib/__init__.py
ADDED
|
File without changes
|
lib/config/__init__.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .default import _C as cfg
|
| 2 |
+
from .default import update_config
|
lib/config/default.py
ADDED
|
@@ -0,0 +1,157 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from yacs.config import CfgNode as CN
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
_C = CN()
|
| 6 |
+
|
| 7 |
+
_C.LOG_DIR = 'runs/'
|
| 8 |
+
_C.GPUS = (0,1)
|
| 9 |
+
_C.WORKERS = 8
|
| 10 |
+
_C.PIN_MEMORY = False
|
| 11 |
+
_C.PRINT_FREQ = 20
|
| 12 |
+
_C.AUTO_RESUME =False # Resume from the last training interrupt
|
| 13 |
+
_C.NEED_AUTOANCHOR = False # Re-select the prior anchor(k-means) When training from scratch (epoch=0), set it to be ture!
|
| 14 |
+
_C.DEBUG = False
|
| 15 |
+
_C.num_seg_class = 2
|
| 16 |
+
|
| 17 |
+
# Cudnn related params
|
| 18 |
+
_C.CUDNN = CN()
|
| 19 |
+
_C.CUDNN.BENCHMARK = True
|
| 20 |
+
_C.CUDNN.DETERMINISTIC = False
|
| 21 |
+
_C.CUDNN.ENABLED = True
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
# common params for NETWORK
|
| 25 |
+
_C.MODEL = CN(new_allowed=True)
|
| 26 |
+
_C.MODEL.NAME = ''
|
| 27 |
+
_C.MODEL.STRU_WITHSHARE = False #add share_block to segbranch
|
| 28 |
+
_C.MODEL.HEADS_NAME = ['']
|
| 29 |
+
_C.MODEL.PRETRAINED = ""
|
| 30 |
+
_C.MODEL.PRETRAINED_DET = ""
|
| 31 |
+
_C.MODEL.IMAGE_SIZE = [640, 640] # width * height, ex: 192 * 256
|
| 32 |
+
_C.MODEL.EXTRA = CN(new_allowed=True)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
# loss params
|
| 36 |
+
_C.LOSS = CN(new_allowed=True)
|
| 37 |
+
_C.LOSS.LOSS_NAME = ''
|
| 38 |
+
_C.LOSS.MULTI_HEAD_LAMBDA = None
|
| 39 |
+
_C.LOSS.FL_GAMMA = 0.0 # focal loss gamma
|
| 40 |
+
_C.LOSS.CLS_POS_WEIGHT = 1.0 # classification loss positive weights
|
| 41 |
+
_C.LOSS.OBJ_POS_WEIGHT = 1.0 # object loss positive weights
|
| 42 |
+
_C.LOSS.SEG_POS_WEIGHT = 1.0 # segmentation loss positive weights
|
| 43 |
+
_C.LOSS.BOX_GAIN = 0.05 # box loss gain
|
| 44 |
+
_C.LOSS.CLS_GAIN = 0.5 # classification loss gain
|
| 45 |
+
_C.LOSS.OBJ_GAIN = 1.0 # object loss gain
|
| 46 |
+
_C.LOSS.DA_SEG_GAIN = 0.2 # driving area segmentation loss gain
|
| 47 |
+
_C.LOSS.LL_SEG_GAIN = 0.2 # lane line segmentation loss gain
|
| 48 |
+
_C.LOSS.LL_IOU_GAIN = 0.2 # lane line iou loss gain
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
# DATASET related params
|
| 52 |
+
_C.DATASET = CN(new_allowed=True)
|
| 53 |
+
_C.DATASET.DATAROOT = '/home/zwt/bdd/bdd100k/images/100k' # the path of images folder
|
| 54 |
+
_C.DATASET.LABELROOT = '/home/zwt/bdd/bdd100k/labels/100k' # the path of det_annotations folder
|
| 55 |
+
_C.DATASET.MASKROOT = '/home/zwt/bdd/bdd_seg_gt' # the path of da_seg_annotations folder
|
| 56 |
+
_C.DATASET.LANEROOT = '/home/zwt/bdd/bdd_lane_gt' # the path of ll_seg_annotations folder
|
| 57 |
+
_C.DATASET.DATASET = 'BddDataset'
|
| 58 |
+
_C.DATASET.TRAIN_SET = 'train'
|
| 59 |
+
_C.DATASET.TEST_SET = 'val'
|
| 60 |
+
_C.DATASET.DATA_FORMAT = 'jpg'
|
| 61 |
+
_C.DATASET.SELECT_DATA = False
|
| 62 |
+
_C.DATASET.ORG_IMG_SIZE = [720, 1280]
|
| 63 |
+
|
| 64 |
+
# training data augmentation
|
| 65 |
+
_C.DATASET.FLIP = True
|
| 66 |
+
_C.DATASET.SCALE_FACTOR = 0.25
|
| 67 |
+
_C.DATASET.ROT_FACTOR = 10
|
| 68 |
+
_C.DATASET.TRANSLATE = 0.1
|
| 69 |
+
_C.DATASET.SHEAR = 0.0
|
| 70 |
+
_C.DATASET.COLOR_RGB = False
|
| 71 |
+
_C.DATASET.HSV_H = 0.015 # image HSV-Hue augmentation (fraction)
|
| 72 |
+
_C.DATASET.HSV_S = 0.7 # image HSV-Saturation augmentation (fraction)
|
| 73 |
+
_C.DATASET.HSV_V = 0.4 # image HSV-Value augmentation (fraction)
|
| 74 |
+
# TODO: more augmet params to add
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
# train
|
| 78 |
+
_C.TRAIN = CN(new_allowed=True)
|
| 79 |
+
_C.TRAIN.LR0 = 0.001 # initial learning rate (SGD=1E-2, Adam=1E-3)
|
| 80 |
+
_C.TRAIN.LRF = 0.2 # final OneCycleLR learning rate (lr0 * lrf)
|
| 81 |
+
_C.TRAIN.WARMUP_EPOCHS = 3.0
|
| 82 |
+
_C.TRAIN.WARMUP_BIASE_LR = 0.1
|
| 83 |
+
_C.TRAIN.WARMUP_MOMENTUM = 0.8
|
| 84 |
+
|
| 85 |
+
_C.TRAIN.OPTIMIZER = 'adam'
|
| 86 |
+
_C.TRAIN.MOMENTUM = 0.937
|
| 87 |
+
_C.TRAIN.WD = 0.0005
|
| 88 |
+
_C.TRAIN.NESTEROV = True
|
| 89 |
+
_C.TRAIN.GAMMA1 = 0.99
|
| 90 |
+
_C.TRAIN.GAMMA2 = 0.0
|
| 91 |
+
|
| 92 |
+
_C.TRAIN.BEGIN_EPOCH = 0
|
| 93 |
+
_C.TRAIN.END_EPOCH = 240
|
| 94 |
+
|
| 95 |
+
_C.TRAIN.VAL_FREQ = 1
|
| 96 |
+
_C.TRAIN.BATCH_SIZE_PER_GPU =24
|
| 97 |
+
_C.TRAIN.SHUFFLE = True
|
| 98 |
+
|
| 99 |
+
_C.TRAIN.IOU_THRESHOLD = 0.2
|
| 100 |
+
_C.TRAIN.ANCHOR_THRESHOLD = 4.0
|
| 101 |
+
|
| 102 |
+
# if training 3 tasks end-to-end, set all parameters as True
|
| 103 |
+
# Alternating optimization
|
| 104 |
+
_C.TRAIN.SEG_ONLY = False # Only train two segmentation branchs
|
| 105 |
+
_C.TRAIN.DET_ONLY = False # Only train detection branch
|
| 106 |
+
_C.TRAIN.ENC_SEG_ONLY = False # Only train encoder and two segmentation branchs
|
| 107 |
+
_C.TRAIN.ENC_DET_ONLY = False # Only train encoder and detection branch
|
| 108 |
+
|
| 109 |
+
# Single task
|
| 110 |
+
_C.TRAIN.DRIVABLE_ONLY = False # Only train da_segmentation task
|
| 111 |
+
_C.TRAIN.LANE_ONLY = False # Only train ll_segmentation task
|
| 112 |
+
_C.TRAIN.DET_ONLY = False # Only train detection task
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
_C.TRAIN.PLOT = True #
|
| 118 |
+
|
| 119 |
+
# testing
|
| 120 |
+
_C.TEST = CN(new_allowed=True)
|
| 121 |
+
_C.TEST.BATCH_SIZE_PER_GPU = 24
|
| 122 |
+
_C.TEST.MODEL_FILE = ''
|
| 123 |
+
_C.TEST.SAVE_JSON = False
|
| 124 |
+
_C.TEST.SAVE_TXT = False
|
| 125 |
+
_C.TEST.PLOTS = True
|
| 126 |
+
_C.TEST.NMS_CONF_THRESHOLD = 0.001
|
| 127 |
+
_C.TEST.NMS_IOU_THRESHOLD = 0.6
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
def update_config(cfg, args):
|
| 131 |
+
cfg.defrost()
|
| 132 |
+
# cfg.merge_from_file(args.cfg)
|
| 133 |
+
|
| 134 |
+
if args.modelDir:
|
| 135 |
+
cfg.OUTPUT_DIR = args.modelDir
|
| 136 |
+
|
| 137 |
+
if args.logDir:
|
| 138 |
+
cfg.LOG_DIR = args.logDir
|
| 139 |
+
|
| 140 |
+
# if args.conf_thres:
|
| 141 |
+
# cfg.TEST.NMS_CONF_THRESHOLD = args.conf_thres
|
| 142 |
+
|
| 143 |
+
# if args.iou_thres:
|
| 144 |
+
# cfg.TEST.NMS_IOU_THRESHOLD = args.iou_thres
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
# cfg.MODEL.PRETRAINED = os.path.join(
|
| 149 |
+
# cfg.DATA_DIR, cfg.MODEL.PRETRAINED
|
| 150 |
+
# )
|
| 151 |
+
#
|
| 152 |
+
# if cfg.TEST.MODEL_FILE:
|
| 153 |
+
# cfg.TEST.MODEL_FILE = os.path.join(
|
| 154 |
+
# cfg.DATA_DIR, cfg.TEST.MODEL_FILE
|
| 155 |
+
# )
|
| 156 |
+
|
| 157 |
+
cfg.freeze()
|
lib/core/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .function import AverageMeter
|
lib/core/activations.py
ADDED
|
@@ -0,0 +1,72 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Activation functions
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
import torch.nn.functional as F
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
# Swish https://arxiv.org/pdf/1905.02244.pdf ---------------------------------------------------------------------------
|
| 9 |
+
class Swish(nn.Module): #
|
| 10 |
+
@staticmethod
|
| 11 |
+
def forward(x):
|
| 12 |
+
return x * torch.sigmoid(x)
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class Hardswish(nn.Module): # export-friendly version of nn.Hardswish()
|
| 16 |
+
@staticmethod
|
| 17 |
+
def forward(x):
|
| 18 |
+
# return x * F.hardsigmoid(x) # for torchscript and CoreML
|
| 19 |
+
return x * F.hardtanh(x + 3, 0., 6.) / 6. # for torchscript, CoreML and ONNX
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
class MemoryEfficientSwish(nn.Module):
|
| 23 |
+
class F(torch.autograd.Function):
|
| 24 |
+
@staticmethod
|
| 25 |
+
def forward(ctx, x):
|
| 26 |
+
ctx.save_for_backward(x)
|
| 27 |
+
return x * torch.sigmoid(x)
|
| 28 |
+
|
| 29 |
+
@staticmethod
|
| 30 |
+
def backward(ctx, grad_output):
|
| 31 |
+
x = ctx.saved_tensors[0]
|
| 32 |
+
sx = torch.sigmoid(x)
|
| 33 |
+
return grad_output * (sx * (1 + x * (1 - sx)))
|
| 34 |
+
|
| 35 |
+
def forward(self, x):
|
| 36 |
+
return self.F.apply(x)
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
# Mish https://github.com/digantamisra98/Mish --------------------------------------------------------------------------
|
| 40 |
+
class Mish(nn.Module):
|
| 41 |
+
@staticmethod
|
| 42 |
+
def forward(x):
|
| 43 |
+
return x * F.softplus(x).tanh()
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
class MemoryEfficientMish(nn.Module):
|
| 47 |
+
class F(torch.autograd.Function):
|
| 48 |
+
@staticmethod
|
| 49 |
+
def forward(ctx, x):
|
| 50 |
+
ctx.save_for_backward(x)
|
| 51 |
+
return x.mul(torch.tanh(F.softplus(x))) # x * tanh(ln(1 + exp(x)))
|
| 52 |
+
|
| 53 |
+
@staticmethod
|
| 54 |
+
def backward(ctx, grad_output):
|
| 55 |
+
x = ctx.saved_tensors[0]
|
| 56 |
+
sx = torch.sigmoid(x)
|
| 57 |
+
fx = F.softplus(x).tanh()
|
| 58 |
+
return grad_output * (fx + x * sx * (1 - fx * fx))
|
| 59 |
+
|
| 60 |
+
def forward(self, x):
|
| 61 |
+
return self.F.apply(x)
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
# FReLU https://arxiv.org/abs/2007.11824 -------------------------------------------------------------------------------
|
| 65 |
+
class FReLU(nn.Module):
|
| 66 |
+
def __init__(self, c1, k=3): # ch_in, kernel
|
| 67 |
+
super().__init__()
|
| 68 |
+
self.conv = nn.Conv2d(c1, c1, k, 1, 1, groups=c1, bias=False)
|
| 69 |
+
self.bn = nn.BatchNorm2d(c1)
|
| 70 |
+
|
| 71 |
+
def forward(self, x):
|
| 72 |
+
return torch.max(x, self.bn(self.conv(x)))
|
lib/core/evaluate.py
ADDED
|
@@ -0,0 +1,278 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Model validation metrics
|
| 2 |
+
|
| 3 |
+
from pathlib import Path
|
| 4 |
+
|
| 5 |
+
import matplotlib.pyplot as plt
|
| 6 |
+
import numpy as np
|
| 7 |
+
import torch
|
| 8 |
+
|
| 9 |
+
from . import general
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def fitness(x):
|
| 13 |
+
# Model fitness as a weighted combination of metrics
|
| 14 |
+
w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, [email protected], [email protected]:0.95]
|
| 15 |
+
return (x[:, :4] * w).sum(1)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def ap_per_class(tp, conf, pred_cls, target_cls, plot=False, save_dir='precision-recall_curve.png', names=[]):
|
| 19 |
+
""" Compute the average precision, given the recall and precision curves.
|
| 20 |
+
Source: https://github.com/rafaelpadilla/Object-Detection-Metrics.
|
| 21 |
+
# Arguments
|
| 22 |
+
tp: True positives (nparray, nx1 or nx10).
|
| 23 |
+
conf: Objectness value from 0-1 (nparray).
|
| 24 |
+
pred_cls: Predicted object classes (nparray).
|
| 25 |
+
target_cls: True object classes (nparray).
|
| 26 |
+
plot: Plot precision-recall curve at [email protected]
|
| 27 |
+
save_dir: Plot save directory
|
| 28 |
+
# Returns
|
| 29 |
+
The average precision as computed in py-faster-rcnn.
|
| 30 |
+
"""
|
| 31 |
+
|
| 32 |
+
# Sort by objectness
|
| 33 |
+
i = np.argsort(-conf) # sorted index from big to small
|
| 34 |
+
tp, conf, pred_cls = tp[i], conf[i], pred_cls[i]
|
| 35 |
+
|
| 36 |
+
# Find unique classes, each number just showed up once
|
| 37 |
+
unique_classes = np.unique(target_cls)
|
| 38 |
+
|
| 39 |
+
# Create Precision-Recall curve and compute AP for each class
|
| 40 |
+
px, py = np.linspace(0, 1, 1000), [] # for plotting
|
| 41 |
+
pr_score = 0.1 # score to evaluate P and R https://github.com/ultralytics/yolov3/issues/898
|
| 42 |
+
s = [unique_classes.shape[0], tp.shape[1]] # number class, number iou thresholds (i.e. 10 for mAP0.5...0.95)
|
| 43 |
+
ap, p, r = np.zeros(s), np.zeros((unique_classes.shape[0], 1000)), np.zeros((unique_classes.shape[0], 1000))
|
| 44 |
+
for ci, c in enumerate(unique_classes):
|
| 45 |
+
i = pred_cls == c
|
| 46 |
+
n_l = (target_cls == c).sum() # number of labels
|
| 47 |
+
n_p = i.sum() # number of predictions
|
| 48 |
+
|
| 49 |
+
if n_p == 0 or n_l == 0:
|
| 50 |
+
continue
|
| 51 |
+
else:
|
| 52 |
+
# Accumulate FPs and TPs
|
| 53 |
+
fpc = (1 - tp[i]).cumsum(0)
|
| 54 |
+
tpc = tp[i].cumsum(0)
|
| 55 |
+
|
| 56 |
+
# Recall
|
| 57 |
+
recall = tpc / (n_l + 1e-16) # recall curve
|
| 58 |
+
r[ci] = np.interp(-px, -conf[i], recall[:, 0], left=0) # r at pr_score, negative x, xp because xp decreases
|
| 59 |
+
|
| 60 |
+
# Precision
|
| 61 |
+
precision = tpc / (tpc + fpc) # precision curve
|
| 62 |
+
p[ci] = np.interp(-px, -conf[i], precision[:, 0], left=1) # p at pr_score
|
| 63 |
+
|
| 64 |
+
# AP from recall-precision curve
|
| 65 |
+
for j in range(tp.shape[1]):
|
| 66 |
+
ap[ci, j], mpre, mrec = compute_ap(recall[:, j], precision[:, j])
|
| 67 |
+
if plot and (j == 0):
|
| 68 |
+
py.append(np.interp(px, mrec, mpre)) # precision at [email protected]
|
| 69 |
+
|
| 70 |
+
# Compute F1 score (harmonic mean of precision and recall)
|
| 71 |
+
f1 = 2 * p * r / (p + r + 1e-16)
|
| 72 |
+
i = r.mean(0).argmax()
|
| 73 |
+
|
| 74 |
+
if plot:
|
| 75 |
+
plot_pr_curve(px, py, ap, save_dir, names)
|
| 76 |
+
|
| 77 |
+
return p[:, i], r[:, i], ap, f1, unique_classes.astype('int32')
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
def compute_ap(recall, precision):
|
| 81 |
+
""" Compute the average precision, given the recall and precision curves
|
| 82 |
+
# Arguments
|
| 83 |
+
recall: The recall curve (list)
|
| 84 |
+
precision: The precision curve (list)
|
| 85 |
+
# Returns
|
| 86 |
+
Average precision, precision curve, recall curve
|
| 87 |
+
"""
|
| 88 |
+
|
| 89 |
+
# Append sentinel values to beginning and end
|
| 90 |
+
mrec = np.concatenate(([0.], recall, [recall[-1] + 0.01]))
|
| 91 |
+
mpre = np.concatenate(([1.], precision, [0.]))
|
| 92 |
+
|
| 93 |
+
# Compute the precision envelope
|
| 94 |
+
mpre = np.flip(np.maximum.accumulate(np.flip(mpre)))
|
| 95 |
+
|
| 96 |
+
# Integrate area under curve
|
| 97 |
+
method = 'interp' # methods: 'continuous', 'interp'
|
| 98 |
+
if method == 'interp':
|
| 99 |
+
x = np.linspace(0, 1, 101) # 101-point interp (COCO)
|
| 100 |
+
ap = np.trapz(np.interp(x, mrec, mpre), x) # integrate
|
| 101 |
+
else: # 'continuous'
|
| 102 |
+
i = np.where(mrec[1:] != mrec[:-1])[0] # points where x axis (recall) changes
|
| 103 |
+
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) # area under curve
|
| 104 |
+
|
| 105 |
+
return ap, mpre, mrec
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
class ConfusionMatrix:
|
| 109 |
+
# Updated version of https://github.com/kaanakan/object_detection_confusion_matrix
|
| 110 |
+
def __init__(self, nc, conf=0.25, iou_thres=0.45):
|
| 111 |
+
self.matrix = np.zeros((nc + 1, nc + 1))
|
| 112 |
+
self.nc = nc # number of classes
|
| 113 |
+
self.conf = conf
|
| 114 |
+
self.iou_thres = iou_thres
|
| 115 |
+
|
| 116 |
+
def process_batch(self, detections, labels):
|
| 117 |
+
"""
|
| 118 |
+
Return intersection-over-union (Jaccard index) of boxes.
|
| 119 |
+
Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
|
| 120 |
+
Arguments:
|
| 121 |
+
detections (Array[N, 6]), x1, y1, x2, y2, conf, class
|
| 122 |
+
labels (Array[M, 5]), class, x1, y1, x2, y2
|
| 123 |
+
Returns:
|
| 124 |
+
None, updates confusion matrix accordingly
|
| 125 |
+
"""
|
| 126 |
+
detections = detections[detections[:, 4] > self.conf]
|
| 127 |
+
gt_classes = labels[:, 0].int()
|
| 128 |
+
detection_classes = detections[:, 5].int()
|
| 129 |
+
iou = general.box_iou(labels[:, 1:], detections[:, :4])
|
| 130 |
+
|
| 131 |
+
x = torch.where(iou > self.iou_thres)
|
| 132 |
+
if x[0].shape[0]:
|
| 133 |
+
matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy()
|
| 134 |
+
if x[0].shape[0] > 1:
|
| 135 |
+
matches = matches[matches[:, 2].argsort()[::-1]]
|
| 136 |
+
matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
|
| 137 |
+
matches = matches[matches[:, 2].argsort()[::-1]]
|
| 138 |
+
matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
|
| 139 |
+
else:
|
| 140 |
+
matches = np.zeros((0, 3))
|
| 141 |
+
|
| 142 |
+
n = matches.shape[0] > 0
|
| 143 |
+
m0, m1, _ = matches.transpose().astype(np.int16)
|
| 144 |
+
for i, gc in enumerate(gt_classes):
|
| 145 |
+
j = m0 == i
|
| 146 |
+
if n and sum(j) == 1:
|
| 147 |
+
self.matrix[gc, detection_classes[m1[j]]] += 1 # correct
|
| 148 |
+
else:
|
| 149 |
+
self.matrix[gc, self.nc] += 1 # background FP
|
| 150 |
+
|
| 151 |
+
if n:
|
| 152 |
+
for i, dc in enumerate(detection_classes):
|
| 153 |
+
if not any(m1 == i):
|
| 154 |
+
self.matrix[self.nc, dc] += 1 # background FN
|
| 155 |
+
|
| 156 |
+
def matrix(self):
|
| 157 |
+
return self.matrix
|
| 158 |
+
|
| 159 |
+
def plot(self, save_dir='', names=()):
|
| 160 |
+
try:
|
| 161 |
+
import seaborn as sn
|
| 162 |
+
|
| 163 |
+
array = self.matrix / (self.matrix.sum(0).reshape(1, self.nc + 1) + 1E-6) # normalize
|
| 164 |
+
array[array < 0.005] = np.nan # don't annotate (would appear as 0.00)
|
| 165 |
+
|
| 166 |
+
fig = plt.figure(figsize=(12, 9), tight_layout=True)
|
| 167 |
+
sn.set(font_scale=1.0 if self.nc < 50 else 0.8) # for label size
|
| 168 |
+
labels = (0 < len(names) < 99) and len(names) == self.nc # apply names to ticklabels
|
| 169 |
+
sn.heatmap(array, annot=self.nc < 30, annot_kws={"size": 8}, cmap='Blues', fmt='.2f', square=True,
|
| 170 |
+
xticklabels=names + ['background FN'] if labels else "auto",
|
| 171 |
+
yticklabels=names + ['background FP'] if labels else "auto").set_facecolor((1, 1, 1))
|
| 172 |
+
fig.axes[0].set_xlabel('True')
|
| 173 |
+
fig.axes[0].set_ylabel('Predicted')
|
| 174 |
+
fig.savefig(Path(save_dir) / 'confusion_matrix.png', dpi=250)
|
| 175 |
+
except Exception as e:
|
| 176 |
+
pass
|
| 177 |
+
|
| 178 |
+
def print(self):
|
| 179 |
+
for i in range(self.nc + 1):
|
| 180 |
+
print(' '.join(map(str, self.matrix[i])))
|
| 181 |
+
|
| 182 |
+
class SegmentationMetric(object):
|
| 183 |
+
'''
|
| 184 |
+
imgLabel [batch_size, height(144), width(256)]
|
| 185 |
+
confusionMatrix [[0(TN),1(FP)],
|
| 186 |
+
[2(FN),3(TP)]]
|
| 187 |
+
'''
|
| 188 |
+
def __init__(self, numClass):
|
| 189 |
+
self.numClass = numClass
|
| 190 |
+
self.confusionMatrix = np.zeros((self.numClass,)*2)
|
| 191 |
+
|
| 192 |
+
def pixelAccuracy(self):
|
| 193 |
+
# return all class overall pixel accuracy
|
| 194 |
+
# acc = (TP + TN) / (TP + TN + FP + TN)
|
| 195 |
+
acc = np.diag(self.confusionMatrix).sum() / self.confusionMatrix.sum()
|
| 196 |
+
return acc
|
| 197 |
+
|
| 198 |
+
def lineAccuracy(self):
|
| 199 |
+
Acc = np.diag(self.confusionMatrix) / (self.confusionMatrix.sum(axis=1) + 1e-12)
|
| 200 |
+
return Acc[1]
|
| 201 |
+
|
| 202 |
+
def classPixelAccuracy(self):
|
| 203 |
+
# return each category pixel accuracy(A more accurate way to call it precision)
|
| 204 |
+
# acc = (TP) / TP + FP
|
| 205 |
+
classAcc = np.diag(self.confusionMatrix) / (self.confusionMatrix.sum(axis=0) + 1e-12)
|
| 206 |
+
return classAcc
|
| 207 |
+
|
| 208 |
+
def meanPixelAccuracy(self):
|
| 209 |
+
classAcc = self.classPixelAccuracy()
|
| 210 |
+
meanAcc = np.nanmean(classAcc)
|
| 211 |
+
return meanAcc
|
| 212 |
+
|
| 213 |
+
def meanIntersectionOverUnion(self):
|
| 214 |
+
# Intersection = TP Union = TP + FP + FN
|
| 215 |
+
# IoU = TP / (TP + FP + FN)
|
| 216 |
+
intersection = np.diag(self.confusionMatrix)
|
| 217 |
+
union = np.sum(self.confusionMatrix, axis=1) + np.sum(self.confusionMatrix, axis=0) - np.diag(self.confusionMatrix)
|
| 218 |
+
IoU = intersection / union
|
| 219 |
+
IoU[np.isnan(IoU)] = 0
|
| 220 |
+
mIoU = np.nanmean(IoU)
|
| 221 |
+
return mIoU
|
| 222 |
+
|
| 223 |
+
def IntersectionOverUnion(self):
|
| 224 |
+
intersection = np.diag(self.confusionMatrix)
|
| 225 |
+
union = np.sum(self.confusionMatrix, axis=1) + np.sum(self.confusionMatrix, axis=0) - np.diag(self.confusionMatrix)
|
| 226 |
+
IoU = intersection / union
|
| 227 |
+
IoU[np.isnan(IoU)] = 0
|
| 228 |
+
return IoU[1]
|
| 229 |
+
|
| 230 |
+
def genConfusionMatrix(self, imgPredict, imgLabel):
|
| 231 |
+
# remove classes from unlabeled pixels in gt image and predict
|
| 232 |
+
# print(imgLabel.shape)
|
| 233 |
+
mask = (imgLabel >= 0) & (imgLabel < self.numClass)
|
| 234 |
+
label = self.numClass * imgLabel[mask] + imgPredict[mask]
|
| 235 |
+
count = np.bincount(label, minlength=self.numClass**2)
|
| 236 |
+
confusionMatrix = count.reshape(self.numClass, self.numClass)
|
| 237 |
+
return confusionMatrix
|
| 238 |
+
|
| 239 |
+
def Frequency_Weighted_Intersection_over_Union(self):
|
| 240 |
+
# FWIOU = [(TP+FN)/(TP+FP+TN+FN)] *[TP / (TP + FP + FN)]
|
| 241 |
+
freq = np.sum(self.confusionMatrix, axis=1) / np.sum(self.confusionMatrix)
|
| 242 |
+
iu = np.diag(self.confusionMatrix) / (
|
| 243 |
+
np.sum(self.confusionMatrix, axis=1) + np.sum(self.confusionMatrix, axis=0) -
|
| 244 |
+
np.diag(self.confusionMatrix))
|
| 245 |
+
FWIoU = (freq[freq > 0] * iu[freq > 0]).sum()
|
| 246 |
+
return FWIoU
|
| 247 |
+
|
| 248 |
+
|
| 249 |
+
def addBatch(self, imgPredict, imgLabel):
|
| 250 |
+
assert imgPredict.shape == imgLabel.shape
|
| 251 |
+
self.confusionMatrix += self.genConfusionMatrix(imgPredict, imgLabel)
|
| 252 |
+
|
| 253 |
+
def reset(self):
|
| 254 |
+
self.confusionMatrix = np.zeros((self.numClass, self.numClass))
|
| 255 |
+
|
| 256 |
+
|
| 257 |
+
|
| 258 |
+
|
| 259 |
+
|
| 260 |
+
# Plots ----------------------------------------------------------------------------------------------------------------
|
| 261 |
+
|
| 262 |
+
def plot_pr_curve(px, py, ap, save_dir='.', names=()):
|
| 263 |
+
fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
|
| 264 |
+
py = np.stack(py, axis=1)
|
| 265 |
+
|
| 266 |
+
if 0 < len(names) < 21: # show mAP in legend if < 10 classes
|
| 267 |
+
for i, y in enumerate(py.T):
|
| 268 |
+
ax.plot(px, y, linewidth=1, label=f'{names[i]} %.3f' % ap[i, 0]) # plot(recall, precision)
|
| 269 |
+
else:
|
| 270 |
+
ax.plot(px, py, linewidth=1, color='grey') # plot(recall, precision)
|
| 271 |
+
|
| 272 |
+
ax.plot(px, py.mean(1), linewidth=3, color='blue', label='all classes %.3f [email protected]' % ap[:, 0].mean())
|
| 273 |
+
ax.set_xlabel('Recall')
|
| 274 |
+
ax.set_ylabel('Precision')
|
| 275 |
+
ax.set_xlim(0, 1)
|
| 276 |
+
ax.set_ylim(0, 1)
|
| 277 |
+
plt.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
|
| 278 |
+
fig.savefig(Path(save_dir) / 'precision_recall_curve.png', dpi=250)
|
lib/core/function.py
ADDED
|
@@ -0,0 +1,510 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import time
|
| 2 |
+
from lib.core.evaluate import ConfusionMatrix,SegmentationMetric
|
| 3 |
+
from lib.core.general import non_max_suppression,check_img_size,scale_coords,xyxy2xywh,xywh2xyxy,box_iou,coco80_to_coco91_class,plot_images,ap_per_class,output_to_target
|
| 4 |
+
from lib.utils.utils import time_synchronized
|
| 5 |
+
from lib.utils import plot_img_and_mask,plot_one_box,show_seg_result
|
| 6 |
+
import torch
|
| 7 |
+
from threading import Thread
|
| 8 |
+
import numpy as np
|
| 9 |
+
from PIL import Image
|
| 10 |
+
from torchvision import transforms
|
| 11 |
+
from pathlib import Path
|
| 12 |
+
import json
|
| 13 |
+
import random
|
| 14 |
+
import cv2
|
| 15 |
+
import os
|
| 16 |
+
import math
|
| 17 |
+
from torch.cuda import amp
|
| 18 |
+
from tqdm import tqdm
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def train(cfg, train_loader, model, criterion, optimizer, scaler, epoch, num_batch, num_warmup,
|
| 22 |
+
writer_dict, logger, device, rank=-1):
|
| 23 |
+
"""
|
| 24 |
+
train for one epoch
|
| 25 |
+
|
| 26 |
+
Inputs:
|
| 27 |
+
- config: configurations
|
| 28 |
+
- train_loader: loder for data
|
| 29 |
+
- model:
|
| 30 |
+
- criterion: (function) calculate all the loss, return total_loss, head_losses
|
| 31 |
+
- writer_dict:
|
| 32 |
+
outputs(2,)
|
| 33 |
+
output[0] len:3, [1,3,32,32,85], [1,3,16,16,85], [1,3,8,8,85]
|
| 34 |
+
output[1] len:1, [2,256,256]
|
| 35 |
+
output[2] len:1, [2,256,256]
|
| 36 |
+
target(2,)
|
| 37 |
+
target[0] [1,n,5]
|
| 38 |
+
target[1] [2,256,256]
|
| 39 |
+
target[2] [2,256,256]
|
| 40 |
+
Returns:
|
| 41 |
+
None
|
| 42 |
+
|
| 43 |
+
"""
|
| 44 |
+
batch_time = AverageMeter()
|
| 45 |
+
data_time = AverageMeter()
|
| 46 |
+
losses = AverageMeter()
|
| 47 |
+
|
| 48 |
+
# switch to train mode
|
| 49 |
+
model.train()
|
| 50 |
+
start = time.time()
|
| 51 |
+
for i, (input, target, paths, shapes) in enumerate(train_loader):
|
| 52 |
+
intermediate = time.time()
|
| 53 |
+
#print('tims:{}'.format(intermediate-start))
|
| 54 |
+
num_iter = i + num_batch * (epoch - 1)
|
| 55 |
+
|
| 56 |
+
if num_iter < num_warmup:
|
| 57 |
+
# warm up
|
| 58 |
+
lf = lambda x: ((1 + math.cos(x * math.pi / cfg.TRAIN.END_EPOCH)) / 2) * \
|
| 59 |
+
(1 - cfg.TRAIN.LRF) + cfg.TRAIN.LRF # cosine
|
| 60 |
+
xi = [0, num_warmup]
|
| 61 |
+
# model.gr = np.interp(ni, xi, [0.0, 1.0]) # iou loss ratio (obj_loss = 1.0 or iou)
|
| 62 |
+
for j, x in enumerate(optimizer.param_groups):
|
| 63 |
+
# bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
|
| 64 |
+
x['lr'] = np.interp(num_iter, xi, [cfg.TRAIN.WARMUP_BIASE_LR if j == 2 else 0.0, x['initial_lr'] * lf(epoch)])
|
| 65 |
+
if 'momentum' in x:
|
| 66 |
+
x['momentum'] = np.interp(num_iter, xi, [cfg.TRAIN.WARMUP_MOMENTUM, cfg.TRAIN.MOMENTUM])
|
| 67 |
+
|
| 68 |
+
data_time.update(time.time() - start)
|
| 69 |
+
if not cfg.DEBUG:
|
| 70 |
+
input = input.to(device, non_blocking=True)
|
| 71 |
+
assign_target = []
|
| 72 |
+
for tgt in target:
|
| 73 |
+
assign_target.append(tgt.to(device))
|
| 74 |
+
target = assign_target
|
| 75 |
+
with amp.autocast(enabled=device.type != 'cpu'):
|
| 76 |
+
outputs = model(input)
|
| 77 |
+
total_loss, head_losses = criterion(outputs, target, shapes,model)
|
| 78 |
+
# print(head_losses)
|
| 79 |
+
|
| 80 |
+
# compute gradient and do update step
|
| 81 |
+
optimizer.zero_grad()
|
| 82 |
+
scaler.scale(total_loss).backward()
|
| 83 |
+
scaler.step(optimizer)
|
| 84 |
+
scaler.update()
|
| 85 |
+
|
| 86 |
+
if rank in [-1, 0]:
|
| 87 |
+
# measure accuracy and record loss
|
| 88 |
+
losses.update(total_loss.item(), input.size(0))
|
| 89 |
+
|
| 90 |
+
# _, avg_acc, cnt, pred = accuracy(output.detach().cpu().numpy(),
|
| 91 |
+
# target.detach().cpu().numpy())
|
| 92 |
+
# acc.update(avg_acc, cnt)
|
| 93 |
+
|
| 94 |
+
# measure elapsed time
|
| 95 |
+
batch_time.update(time.time() - start)
|
| 96 |
+
end = time.time()
|
| 97 |
+
if i % cfg.PRINT_FREQ == 0:
|
| 98 |
+
msg = 'Epoch: [{0}][{1}/{2}]\t' \
|
| 99 |
+
'Time {batch_time.val:.3f}s ({batch_time.avg:.3f}s)\t' \
|
| 100 |
+
'Speed {speed:.1f} samples/s\t' \
|
| 101 |
+
'Data {data_time.val:.3f}s ({data_time.avg:.3f}s)\t' \
|
| 102 |
+
'Loss {loss.val:.5f} ({loss.avg:.5f})'.format(
|
| 103 |
+
epoch, i, len(train_loader), batch_time=batch_time,
|
| 104 |
+
speed=input.size(0)/batch_time.val,
|
| 105 |
+
data_time=data_time, loss=losses)
|
| 106 |
+
logger.info(msg)
|
| 107 |
+
|
| 108 |
+
writer = writer_dict['writer']
|
| 109 |
+
global_steps = writer_dict['train_global_steps']
|
| 110 |
+
writer.add_scalar('train_loss', losses.val, global_steps)
|
| 111 |
+
# writer.add_scalar('train_acc', acc.val, global_steps)
|
| 112 |
+
writer_dict['train_global_steps'] = global_steps + 1
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
def validate(epoch,config, val_loader, val_dataset, model, criterion, output_dir,
|
| 116 |
+
tb_log_dir, writer_dict=None, logger=None, device='cpu', rank=-1):
|
| 117 |
+
"""
|
| 118 |
+
validata
|
| 119 |
+
|
| 120 |
+
Inputs:
|
| 121 |
+
- config: configurations
|
| 122 |
+
- train_loader: loder for data
|
| 123 |
+
- model:
|
| 124 |
+
- criterion: (function) calculate all the loss, return
|
| 125 |
+
- writer_dict:
|
| 126 |
+
|
| 127 |
+
Return:
|
| 128 |
+
None
|
| 129 |
+
"""
|
| 130 |
+
# setting
|
| 131 |
+
max_stride = 32
|
| 132 |
+
weights = None
|
| 133 |
+
|
| 134 |
+
save_dir = output_dir + os.path.sep + 'visualization'
|
| 135 |
+
if not os.path.exists(save_dir):
|
| 136 |
+
os.mkdir(save_dir)
|
| 137 |
+
|
| 138 |
+
# print(save_dir)
|
| 139 |
+
_, imgsz = [check_img_size(x, s=max_stride) for x in config.MODEL.IMAGE_SIZE] #imgsz is multiple of max_stride
|
| 140 |
+
batch_size = config.TRAIN.BATCH_SIZE_PER_GPU * len(config.GPUS)
|
| 141 |
+
test_batch_size = config.TEST.BATCH_SIZE_PER_GPU * len(config.GPUS)
|
| 142 |
+
training = False
|
| 143 |
+
is_coco = False #is coco dataset
|
| 144 |
+
save_conf=False # save auto-label confidences
|
| 145 |
+
verbose=False
|
| 146 |
+
save_hybrid=False
|
| 147 |
+
log_imgs,wandb = min(16,100), None
|
| 148 |
+
|
| 149 |
+
nc = 1
|
| 150 |
+
iouv = torch.linspace(0.5,0.95,10).to(device) #iou vector for [email protected]:0.95
|
| 151 |
+
niou = iouv.numel()
|
| 152 |
+
|
| 153 |
+
try:
|
| 154 |
+
import wandb
|
| 155 |
+
except ImportError:
|
| 156 |
+
wandb = None
|
| 157 |
+
log_imgs = 0
|
| 158 |
+
|
| 159 |
+
seen = 0
|
| 160 |
+
confusion_matrix = ConfusionMatrix(nc=model.nc) #detector confusion matrix
|
| 161 |
+
da_metric = SegmentationMetric(config.num_seg_class) #segment confusion matrix
|
| 162 |
+
ll_metric = SegmentationMetric(2) #segment confusion matrix
|
| 163 |
+
|
| 164 |
+
names = {k: v for k, v in enumerate(model.names if hasattr(model, 'names') else model.module.names)}
|
| 165 |
+
colors = [[random.randint(0, 255) for _ in range(3)] for _ in names]
|
| 166 |
+
coco91class = coco80_to_coco91_class()
|
| 167 |
+
|
| 168 |
+
s = ('%20s' + '%12s' * 6) % ('Class', 'Images', 'Targets', 'P', 'R', '[email protected]', '[email protected]:.95')
|
| 169 |
+
p, r, f1, mp, mr, map50, map, t_inf, t_nms = 0., 0., 0., 0., 0., 0., 0., 0., 0.
|
| 170 |
+
|
| 171 |
+
losses = AverageMeter()
|
| 172 |
+
|
| 173 |
+
da_acc_seg = AverageMeter()
|
| 174 |
+
da_IoU_seg = AverageMeter()
|
| 175 |
+
da_mIoU_seg = AverageMeter()
|
| 176 |
+
|
| 177 |
+
ll_acc_seg = AverageMeter()
|
| 178 |
+
ll_IoU_seg = AverageMeter()
|
| 179 |
+
ll_mIoU_seg = AverageMeter()
|
| 180 |
+
|
| 181 |
+
T_inf = AverageMeter()
|
| 182 |
+
T_nms = AverageMeter()
|
| 183 |
+
|
| 184 |
+
# switch to train mode
|
| 185 |
+
model.eval()
|
| 186 |
+
jdict, stats, ap, ap_class, wandb_images = [], [], [], [], []
|
| 187 |
+
|
| 188 |
+
for batch_i, (img, target, paths, shapes) in tqdm(enumerate(val_loader), total=len(val_loader)):
|
| 189 |
+
if not config.DEBUG:
|
| 190 |
+
img = img.to(device, non_blocking=True)
|
| 191 |
+
assign_target = []
|
| 192 |
+
for tgt in target:
|
| 193 |
+
assign_target.append(tgt.to(device))
|
| 194 |
+
target = assign_target
|
| 195 |
+
nb, _, height, width = img.shape #batch size, channel, height, width
|
| 196 |
+
|
| 197 |
+
with torch.no_grad():
|
| 198 |
+
pad_w, pad_h = shapes[0][1][1]
|
| 199 |
+
pad_w = int(pad_w)
|
| 200 |
+
pad_h = int(pad_h)
|
| 201 |
+
ratio = shapes[0][1][0][0]
|
| 202 |
+
|
| 203 |
+
t = time_synchronized()
|
| 204 |
+
det_out, da_seg_out, ll_seg_out= model(img)
|
| 205 |
+
t_inf = time_synchronized() - t
|
| 206 |
+
if batch_i > 0:
|
| 207 |
+
T_inf.update(t_inf/img.size(0),img.size(0))
|
| 208 |
+
|
| 209 |
+
inf_out,train_out = det_out
|
| 210 |
+
|
| 211 |
+
#driving area segment evaluation
|
| 212 |
+
_,da_predict=torch.max(da_seg_out, 1)
|
| 213 |
+
_,da_gt=torch.max(target[1], 1)
|
| 214 |
+
da_predict = da_predict[:, pad_h:height-pad_h, pad_w:width-pad_w]
|
| 215 |
+
da_gt = da_gt[:, pad_h:height-pad_h, pad_w:width-pad_w]
|
| 216 |
+
|
| 217 |
+
da_metric.reset()
|
| 218 |
+
da_metric.addBatch(da_predict.cpu(), da_gt.cpu())
|
| 219 |
+
da_acc = da_metric.pixelAccuracy()
|
| 220 |
+
da_IoU = da_metric.IntersectionOverUnion()
|
| 221 |
+
da_mIoU = da_metric.meanIntersectionOverUnion()
|
| 222 |
+
|
| 223 |
+
da_acc_seg.update(da_acc,img.size(0))
|
| 224 |
+
da_IoU_seg.update(da_IoU,img.size(0))
|
| 225 |
+
da_mIoU_seg.update(da_mIoU,img.size(0))
|
| 226 |
+
|
| 227 |
+
#lane line segment evaluation
|
| 228 |
+
_,ll_predict=torch.max(ll_seg_out, 1)
|
| 229 |
+
_,ll_gt=torch.max(target[2], 1)
|
| 230 |
+
ll_predict = ll_predict[:, pad_h:height-pad_h, pad_w:width-pad_w]
|
| 231 |
+
ll_gt = ll_gt[:, pad_h:height-pad_h, pad_w:width-pad_w]
|
| 232 |
+
|
| 233 |
+
ll_metric.reset()
|
| 234 |
+
ll_metric.addBatch(ll_predict.cpu(), ll_gt.cpu())
|
| 235 |
+
ll_acc = ll_metric.lineAccuracy()
|
| 236 |
+
ll_IoU = ll_metric.IntersectionOverUnion()
|
| 237 |
+
ll_mIoU = ll_metric.meanIntersectionOverUnion()
|
| 238 |
+
|
| 239 |
+
ll_acc_seg.update(ll_acc,img.size(0))
|
| 240 |
+
ll_IoU_seg.update(ll_IoU,img.size(0))
|
| 241 |
+
ll_mIoU_seg.update(ll_mIoU,img.size(0))
|
| 242 |
+
|
| 243 |
+
total_loss, head_losses = criterion((train_out,da_seg_out, ll_seg_out), target, shapes,model) #Compute loss
|
| 244 |
+
losses.update(total_loss.item(), img.size(0))
|
| 245 |
+
|
| 246 |
+
#NMS
|
| 247 |
+
t = time_synchronized()
|
| 248 |
+
target[0][:, 2:] *= torch.Tensor([width, height, width, height]).to(device) # to pixels
|
| 249 |
+
lb = [target[0][target[0][:, 0] == i, 1:] for i in range(nb)] if save_hybrid else [] # for autolabelling
|
| 250 |
+
output = non_max_suppression(inf_out, conf_thres= config.TEST.NMS_CONF_THRESHOLD, iou_thres=config.TEST.NMS_IOU_THRESHOLD, labels=lb)
|
| 251 |
+
#output = non_max_suppression(inf_out, conf_thres=0.001, iou_thres=0.6)
|
| 252 |
+
#output = non_max_suppression(inf_out, conf_thres=config.TEST.NMS_CONF_THRES, iou_thres=config.TEST.NMS_IOU_THRES)
|
| 253 |
+
t_nms = time_synchronized() - t
|
| 254 |
+
if batch_i > 0:
|
| 255 |
+
T_nms.update(t_nms/img.size(0),img.size(0))
|
| 256 |
+
|
| 257 |
+
if config.TEST.PLOTS:
|
| 258 |
+
if batch_i == 0:
|
| 259 |
+
for i in range(test_batch_size):
|
| 260 |
+
img_test = cv2.imread(paths[i])
|
| 261 |
+
da_seg_mask = da_seg_out[i][:, pad_h:height-pad_h, pad_w:width-pad_w].unsqueeze(0)
|
| 262 |
+
da_seg_mask = torch.nn.functional.interpolate(da_seg_mask, scale_factor=int(1/ratio), mode='bilinear')
|
| 263 |
+
_, da_seg_mask = torch.max(da_seg_mask, 1)
|
| 264 |
+
|
| 265 |
+
da_gt_mask = target[1][i][:, pad_h:height-pad_h, pad_w:width-pad_w].unsqueeze(0)
|
| 266 |
+
da_gt_mask = torch.nn.functional.interpolate(da_gt_mask, scale_factor=int(1/ratio), mode='bilinear')
|
| 267 |
+
_, da_gt_mask = torch.max(da_gt_mask, 1)
|
| 268 |
+
|
| 269 |
+
da_seg_mask = da_seg_mask.int().squeeze().cpu().numpy()
|
| 270 |
+
da_gt_mask = da_gt_mask.int().squeeze().cpu().numpy()
|
| 271 |
+
# seg_mask = seg_mask > 0.5
|
| 272 |
+
# plot_img_and_mask(img_test, seg_mask, i,epoch,save_dir)
|
| 273 |
+
img_test1 = img_test.copy()
|
| 274 |
+
_ = show_seg_result(img_test, da_seg_mask, i,epoch,save_dir)
|
| 275 |
+
_ = show_seg_result(img_test1, da_gt_mask, i, epoch, save_dir, is_gt=True)
|
| 276 |
+
|
| 277 |
+
img_ll = cv2.imread(paths[i])
|
| 278 |
+
ll_seg_mask = ll_seg_out[i][:, pad_h:height-pad_h, pad_w:width-pad_w].unsqueeze(0)
|
| 279 |
+
ll_seg_mask = torch.nn.functional.interpolate(ll_seg_mask, scale_factor=int(1/ratio), mode='bilinear')
|
| 280 |
+
_, ll_seg_mask = torch.max(ll_seg_mask, 1)
|
| 281 |
+
|
| 282 |
+
ll_gt_mask = target[2][i][:, pad_h:height-pad_h, pad_w:width-pad_w].unsqueeze(0)
|
| 283 |
+
ll_gt_mask = torch.nn.functional.interpolate(ll_gt_mask, scale_factor=int(1/ratio), mode='bilinear')
|
| 284 |
+
_, ll_gt_mask = torch.max(ll_gt_mask, 1)
|
| 285 |
+
|
| 286 |
+
ll_seg_mask = ll_seg_mask.int().squeeze().cpu().numpy()
|
| 287 |
+
ll_gt_mask = ll_gt_mask.int().squeeze().cpu().numpy()
|
| 288 |
+
# seg_mask = seg_mask > 0.5
|
| 289 |
+
# plot_img_and_mask(img_test, seg_mask, i,epoch,save_dir)
|
| 290 |
+
img_ll1 = img_ll.copy()
|
| 291 |
+
_ = show_seg_result(img_ll, ll_seg_mask, i,epoch,save_dir, is_ll=True)
|
| 292 |
+
_ = show_seg_result(img_ll1, ll_gt_mask, i, epoch, save_dir, is_ll=True, is_gt=True)
|
| 293 |
+
|
| 294 |
+
img_det = cv2.imread(paths[i])
|
| 295 |
+
img_gt = img_det.copy()
|
| 296 |
+
det = output[i].clone()
|
| 297 |
+
if len(det):
|
| 298 |
+
det[:,:4] = scale_coords(img[i].shape[1:],det[:,:4],img_det.shape).round()
|
| 299 |
+
for *xyxy,conf,cls in reversed(det):
|
| 300 |
+
#print(cls)
|
| 301 |
+
label_det_pred = f'{names[int(cls)]} {conf:.2f}'
|
| 302 |
+
plot_one_box(xyxy, img_det , label=label_det_pred, color=colors[int(cls)], line_thickness=3)
|
| 303 |
+
cv2.imwrite(save_dir+"/batch_{}_{}_det_pred.png".format(epoch,i),img_det)
|
| 304 |
+
|
| 305 |
+
labels = target[0][target[0][:, 0] == i, 1:]
|
| 306 |
+
# print(labels)
|
| 307 |
+
labels[:,1:5]=xywh2xyxy(labels[:,1:5])
|
| 308 |
+
if len(labels):
|
| 309 |
+
labels[:,1:5]=scale_coords(img[i].shape[1:],labels[:,1:5],img_gt.shape).round()
|
| 310 |
+
for cls,x1,y1,x2,y2 in labels:
|
| 311 |
+
#print(names)
|
| 312 |
+
#print(cls)
|
| 313 |
+
label_det_gt = f'{names[int(cls)]}'
|
| 314 |
+
xyxy = (x1,y1,x2,y2)
|
| 315 |
+
plot_one_box(xyxy, img_gt , label=label_det_gt, color=colors[int(cls)], line_thickness=3)
|
| 316 |
+
cv2.imwrite(save_dir+"/batch_{}_{}_det_gt.png".format(epoch,i),img_gt)
|
| 317 |
+
|
| 318 |
+
# Statistics per image
|
| 319 |
+
# output([xyxy,conf,cls])
|
| 320 |
+
# target[0] ([img_id,cls,xyxy])
|
| 321 |
+
for si, pred in enumerate(output):
|
| 322 |
+
labels = target[0][target[0][:, 0] == si, 1:] #all object in one image
|
| 323 |
+
nl = len(labels) # num of object
|
| 324 |
+
tcls = labels[:, 0].tolist() if nl else [] # target class
|
| 325 |
+
path = Path(paths[si])
|
| 326 |
+
seen += 1
|
| 327 |
+
|
| 328 |
+
if len(pred) == 0:
|
| 329 |
+
if nl:
|
| 330 |
+
stats.append((torch.zeros(0, niou, dtype=torch.bool), torch.Tensor(), torch.Tensor(), tcls))
|
| 331 |
+
continue
|
| 332 |
+
|
| 333 |
+
# Predictions
|
| 334 |
+
predn = pred.clone()
|
| 335 |
+
scale_coords(img[si].shape[1:], predn[:, :4], shapes[si][0], shapes[si][1]) # native-space pred
|
| 336 |
+
|
| 337 |
+
# Append to text file
|
| 338 |
+
if config.TEST.SAVE_TXT:
|
| 339 |
+
gn = torch.tensor(shapes[si][0])[[1, 0, 1, 0]] # normalization gain whwh
|
| 340 |
+
for *xyxy, conf, cls in predn.tolist():
|
| 341 |
+
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
|
| 342 |
+
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
|
| 343 |
+
with open(save_dir / 'labels' / (path.stem + '.txt'), 'a') as f:
|
| 344 |
+
f.write(('%g ' * len(line)).rstrip() % line + '\n')
|
| 345 |
+
|
| 346 |
+
# W&B logging
|
| 347 |
+
if config.TEST.PLOTS and len(wandb_images) < log_imgs:
|
| 348 |
+
box_data = [{"position": {"minX": xyxy[0], "minY": xyxy[1], "maxX": xyxy[2], "maxY": xyxy[3]},
|
| 349 |
+
"class_id": int(cls),
|
| 350 |
+
"box_caption": "%s %.3f" % (names[cls], conf),
|
| 351 |
+
"scores": {"class_score": conf},
|
| 352 |
+
"domain": "pixel"} for *xyxy, conf, cls in pred.tolist()]
|
| 353 |
+
boxes = {"predictions": {"box_data": box_data, "class_labels": names}} # inference-space
|
| 354 |
+
wandb_images.append(wandb.Image(img[si], boxes=boxes, caption=path.name))
|
| 355 |
+
|
| 356 |
+
# Append to pycocotools JSON dictionary
|
| 357 |
+
if config.TEST.SAVE_JSON:
|
| 358 |
+
# [{"image_id": 42, "category_id": 18, "bbox": [258.15, 41.29, 348.26, 243.78], "score": 0.236}, ...
|
| 359 |
+
image_id = int(path.stem) if path.stem.isnumeric() else path.stem
|
| 360 |
+
box = xyxy2xywh(predn[:, :4]) # xywh
|
| 361 |
+
box[:, :2] -= box[:, 2:] / 2 # xy center to top-left corner
|
| 362 |
+
for p, b in zip(pred.tolist(), box.tolist()):
|
| 363 |
+
jdict.append({'image_id': image_id,
|
| 364 |
+
'category_id': coco91class[int(p[5])] if is_coco else int(p[5]),
|
| 365 |
+
'bbox': [round(x, 3) for x in b],
|
| 366 |
+
'score': round(p[4], 5)})
|
| 367 |
+
|
| 368 |
+
|
| 369 |
+
# Assign all predictions as incorrect
|
| 370 |
+
correct = torch.zeros(pred.shape[0], niou, dtype=torch.bool, device=device)
|
| 371 |
+
if nl:
|
| 372 |
+
detected = [] # target indices
|
| 373 |
+
tcls_tensor = labels[:, 0]
|
| 374 |
+
|
| 375 |
+
# target boxes
|
| 376 |
+
tbox = xywh2xyxy(labels[:, 1:5])
|
| 377 |
+
scale_coords(img[si].shape[1:], tbox, shapes[si][0], shapes[si][1]) # native-space labels
|
| 378 |
+
if config.TEST.PLOTS:
|
| 379 |
+
confusion_matrix.process_batch(pred, torch.cat((labels[:, 0:1], tbox), 1))
|
| 380 |
+
|
| 381 |
+
# Per target class
|
| 382 |
+
for cls in torch.unique(tcls_tensor):
|
| 383 |
+
ti = (cls == tcls_tensor).nonzero(as_tuple=False).view(-1) # prediction indices
|
| 384 |
+
pi = (cls == pred[:, 5]).nonzero(as_tuple=False).view(-1) # target indices
|
| 385 |
+
|
| 386 |
+
# Search for detections
|
| 387 |
+
if pi.shape[0]:
|
| 388 |
+
# Prediction to target ious
|
| 389 |
+
# n*m n:pred m:label
|
| 390 |
+
ious, i = box_iou(predn[pi, :4], tbox[ti]).max(1) # best ious, indices
|
| 391 |
+
# Append detections
|
| 392 |
+
detected_set = set()
|
| 393 |
+
for j in (ious > iouv[0]).nonzero(as_tuple=False):
|
| 394 |
+
d = ti[i[j]] # detected target
|
| 395 |
+
if d.item() not in detected_set:
|
| 396 |
+
detected_set.add(d.item())
|
| 397 |
+
detected.append(d)
|
| 398 |
+
correct[pi[j]] = ious[j] > iouv # iou_thres is 1xn
|
| 399 |
+
if len(detected) == nl: # all targets already located in image
|
| 400 |
+
break
|
| 401 |
+
|
| 402 |
+
# Append statistics (correct, conf, pcls, tcls)
|
| 403 |
+
stats.append((correct.cpu(), pred[:, 4].cpu(), pred[:, 5].cpu(), tcls))
|
| 404 |
+
|
| 405 |
+
if config.TEST.PLOTS and batch_i < 3:
|
| 406 |
+
f = save_dir +'/'+ f'test_batch{batch_i}_labels.jpg' # labels
|
| 407 |
+
#Thread(target=plot_images, args=(img, target[0], paths, f, names), daemon=True).start()
|
| 408 |
+
f = save_dir +'/'+ f'test_batch{batch_i}_pred.jpg' # predictions
|
| 409 |
+
#Thread(target=plot_images, args=(img, output_to_target(output), paths, f, names), daemon=True).start()
|
| 410 |
+
|
| 411 |
+
# Compute statistics
|
| 412 |
+
# stats : [[all_img_correct]...[all_img_tcls]]
|
| 413 |
+
stats = [np.concatenate(x, 0) for x in zip(*stats)] # to numpy zip(*) :unzip
|
| 414 |
+
|
| 415 |
+
map70 = None
|
| 416 |
+
map75 = None
|
| 417 |
+
if len(stats) and stats[0].any():
|
| 418 |
+
p, r, ap, f1, ap_class = ap_per_class(*stats, plot=False, save_dir=save_dir, names=names)
|
| 419 |
+
ap50, ap70, ap75,ap = ap[:, 0], ap[:,4], ap[:,5],ap.mean(1) # [P, R, [email protected], [email protected]:0.95]
|
| 420 |
+
mp, mr, map50, map70, map75, map = p.mean(), r.mean(), ap50.mean(), ap70.mean(),ap75.mean(),ap.mean()
|
| 421 |
+
nt = np.bincount(stats[3].astype(np.int64), minlength=nc) # number of targets per class
|
| 422 |
+
else:
|
| 423 |
+
nt = torch.zeros(1)
|
| 424 |
+
|
| 425 |
+
# Print results
|
| 426 |
+
pf = '%20s' + '%12.3g' * 6 # print format
|
| 427 |
+
print(pf % ('all', seen, nt.sum(), mp, mr, map50, map))
|
| 428 |
+
#print(map70)
|
| 429 |
+
#print(map75)
|
| 430 |
+
|
| 431 |
+
# Print results per class
|
| 432 |
+
if (verbose or (nc <= 20 and not training)) and nc > 1 and len(stats):
|
| 433 |
+
for i, c in enumerate(ap_class):
|
| 434 |
+
print(pf % (names[c], seen, nt[c], p[i], r[i], ap50[i], ap[i]))
|
| 435 |
+
|
| 436 |
+
# Print speeds
|
| 437 |
+
t = tuple(x / seen * 1E3 for x in (t_inf, t_nms, t_inf + t_nms)) + (imgsz, imgsz, batch_size) # tuple
|
| 438 |
+
if not training:
|
| 439 |
+
print('Speed: %.1f/%.1f/%.1f ms inference/NMS/total per %gx%g image at batch-size %g' % t)
|
| 440 |
+
|
| 441 |
+
# Plots
|
| 442 |
+
if config.TEST.PLOTS:
|
| 443 |
+
confusion_matrix.plot(save_dir=save_dir, names=list(names.values()))
|
| 444 |
+
if wandb and wandb.run:
|
| 445 |
+
wandb.log({"Images": wandb_images})
|
| 446 |
+
wandb.log({"Validation": [wandb.Image(str(f), caption=f.name) for f in sorted(save_dir.glob('test*.jpg'))]})
|
| 447 |
+
|
| 448 |
+
# Save JSON
|
| 449 |
+
if config.TEST.SAVE_JSON and len(jdict):
|
| 450 |
+
w = Path(weights[0] if isinstance(weights, list) else weights).stem if weights is not None else '' # weights
|
| 451 |
+
anno_json = '../coco/annotations/instances_val2017.json' # annotations json
|
| 452 |
+
pred_json = str(save_dir / f"{w}_predictions.json") # predictions json
|
| 453 |
+
print('\nEvaluating pycocotools mAP... saving %s...' % pred_json)
|
| 454 |
+
with open(pred_json, 'w') as f:
|
| 455 |
+
json.dump(jdict, f)
|
| 456 |
+
|
| 457 |
+
try: # https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocoEvalDemo.ipynb
|
| 458 |
+
from pycocotools.coco import COCO
|
| 459 |
+
from pycocotools.cocoeval import COCOeval
|
| 460 |
+
|
| 461 |
+
anno = COCO(anno_json) # init annotations api
|
| 462 |
+
pred = anno.loadRes(pred_json) # init predictions api
|
| 463 |
+
eval = COCOeval(anno, pred, 'bbox')
|
| 464 |
+
if is_coco:
|
| 465 |
+
eval.params.imgIds = [int(Path(x).stem) for x in val_loader.dataset.img_files] # image IDs to evaluate
|
| 466 |
+
eval.evaluate()
|
| 467 |
+
eval.accumulate()
|
| 468 |
+
eval.summarize()
|
| 469 |
+
map, map50 = eval.stats[:2] # update results ([email protected]:0.95, [email protected])
|
| 470 |
+
except Exception as e:
|
| 471 |
+
print(f'pycocotools unable to run: {e}')
|
| 472 |
+
|
| 473 |
+
# Return results
|
| 474 |
+
if not training:
|
| 475 |
+
s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if config.TEST.SAVE_TXT else ''
|
| 476 |
+
print(f"Results saved to {save_dir}{s}")
|
| 477 |
+
model.float() # for training
|
| 478 |
+
maps = np.zeros(nc) + map
|
| 479 |
+
for i, c in enumerate(ap_class):
|
| 480 |
+
maps[c] = ap[i]
|
| 481 |
+
|
| 482 |
+
da_segment_result = (da_acc_seg.avg,da_IoU_seg.avg,da_mIoU_seg.avg)
|
| 483 |
+
ll_segment_result = (ll_acc_seg.avg,ll_IoU_seg.avg,ll_mIoU_seg.avg)
|
| 484 |
+
|
| 485 |
+
# print(da_segment_result)
|
| 486 |
+
# print(ll_segment_result)
|
| 487 |
+
detect_result = np.asarray([mp, mr, map50, map])
|
| 488 |
+
# print('mp:{},mr:{},map50:{},map:{}'.format(mp, mr, map50, map))
|
| 489 |
+
#print segmet_result
|
| 490 |
+
t = [T_inf.avg, T_nms.avg]
|
| 491 |
+
return da_segment_result, ll_segment_result, detect_result, losses.avg, maps, t
|
| 492 |
+
|
| 493 |
+
|
| 494 |
+
|
| 495 |
+
class AverageMeter(object):
|
| 496 |
+
"""Computes and stores the average and current value"""
|
| 497 |
+
def __init__(self):
|
| 498 |
+
self.reset()
|
| 499 |
+
|
| 500 |
+
def reset(self):
|
| 501 |
+
self.val = 0
|
| 502 |
+
self.avg = 0
|
| 503 |
+
self.sum = 0
|
| 504 |
+
self.count = 0
|
| 505 |
+
|
| 506 |
+
def update(self, val, n=1):
|
| 507 |
+
self.val = val
|
| 508 |
+
self.sum += val * n
|
| 509 |
+
self.count += n
|
| 510 |
+
self.avg = self.sum / self.count if self.count != 0 else 0
|
lib/core/general.py
ADDED
|
@@ -0,0 +1,466 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import glob
|
| 2 |
+
import logging
|
| 3 |
+
import os
|
| 4 |
+
import platform
|
| 5 |
+
import random
|
| 6 |
+
import re
|
| 7 |
+
import shutil
|
| 8 |
+
import subprocess
|
| 9 |
+
import time
|
| 10 |
+
import torchvision
|
| 11 |
+
from contextlib import contextmanager
|
| 12 |
+
from copy import copy
|
| 13 |
+
from pathlib import Path
|
| 14 |
+
|
| 15 |
+
import cv2
|
| 16 |
+
import math
|
| 17 |
+
import matplotlib
|
| 18 |
+
import matplotlib.pyplot as plt
|
| 19 |
+
import numpy as np
|
| 20 |
+
import torch
|
| 21 |
+
import torch.nn as nn
|
| 22 |
+
import yaml
|
| 23 |
+
from PIL import Image
|
| 24 |
+
from scipy.cluster.vq import kmeans
|
| 25 |
+
from scipy.signal import butter, filtfilt
|
| 26 |
+
from tqdm import tqdm
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def bbox_iou(box1, box2, x1y1x2y2=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-9):
|
| 30 |
+
# Returns the IoU of box1 to box2. box1 is 4, box2 is nx4
|
| 31 |
+
box2 = box2.T
|
| 32 |
+
|
| 33 |
+
# Get the coordinates of bounding boxes
|
| 34 |
+
if x1y1x2y2: # x1, y1, x2, y2 = box1
|
| 35 |
+
b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
|
| 36 |
+
b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
|
| 37 |
+
else: # transform from xywh to xyxy
|
| 38 |
+
b1_x1, b1_x2 = box1[0] - box1[2] / 2, box1[0] + box1[2] / 2
|
| 39 |
+
b1_y1, b1_y2 = box1[1] - box1[3] / 2, box1[1] + box1[3] / 2
|
| 40 |
+
b2_x1, b2_x2 = box2[0] - box2[2] / 2, box2[0] + box2[2] / 2
|
| 41 |
+
b2_y1, b2_y2 = box2[1] - box2[3] / 2, box2[1] + box2[3] / 2
|
| 42 |
+
|
| 43 |
+
# Intersection area
|
| 44 |
+
inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
|
| 45 |
+
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
|
| 46 |
+
|
| 47 |
+
# Union Area
|
| 48 |
+
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
|
| 49 |
+
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
|
| 50 |
+
union = w1 * h1 + w2 * h2 - inter + eps
|
| 51 |
+
|
| 52 |
+
iou = inter / union
|
| 53 |
+
if GIoU or DIoU or CIoU:
|
| 54 |
+
cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # convex (smallest enclosing box) width
|
| 55 |
+
ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # convex height
|
| 56 |
+
if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
|
| 57 |
+
c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
|
| 58 |
+
rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 +
|
| 59 |
+
(b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center distance squared
|
| 60 |
+
if DIoU:
|
| 61 |
+
return iou - rho2 / c2 # DIoU
|
| 62 |
+
elif CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
|
| 63 |
+
v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / h2) - torch.atan(w1 / h1), 2)
|
| 64 |
+
with torch.no_grad():
|
| 65 |
+
alpha = v / ((1 + eps) - iou + v)
|
| 66 |
+
return iou - (rho2 / c2 + v * alpha) # CIoU
|
| 67 |
+
else: # GIoU https://arxiv.org/pdf/1902.09630.pdf
|
| 68 |
+
c_area = cw * ch + eps # convex area
|
| 69 |
+
return iou - (c_area - union) / c_area # GIoU
|
| 70 |
+
else:
|
| 71 |
+
return iou # IoU
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def box_iou(box1, box2):
|
| 75 |
+
# https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
|
| 76 |
+
"""
|
| 77 |
+
Return intersection-over-union (Jaccard index) of boxes.
|
| 78 |
+
Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
|
| 79 |
+
Arguments:
|
| 80 |
+
box1 (Tensor[N, 4])
|
| 81 |
+
box2 (Tensor[M, 4])
|
| 82 |
+
Returns:
|
| 83 |
+
iou (Tensor[N, M]): the NxM matrix containing the pairwise
|
| 84 |
+
IoU values for every element in boxes1 and boxes2
|
| 85 |
+
"""
|
| 86 |
+
|
| 87 |
+
def box_area(box):
|
| 88 |
+
# box = 4xn
|
| 89 |
+
return (box[2] - box[0]) * (box[3] - box[1]) #(x2-x1)*(y2-y1)
|
| 90 |
+
|
| 91 |
+
area1 = box_area(box1.T)
|
| 92 |
+
area2 = box_area(box2.T)
|
| 93 |
+
|
| 94 |
+
# inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
|
| 95 |
+
inter = (torch.min(box1[:, None, 2:], box2[:, 2:]) - torch.max(box1[:, None, :2], box2[:, :2])).clamp(0).prod(2)
|
| 96 |
+
return inter / (area1[:, None] + area2 - inter) # iou = inter / (area1 + area2 - inter)
|
| 97 |
+
|
| 98 |
+
def non_max_suppression(prediction, conf_thres=0.25, iou_thres=0.45, classes=None, agnostic=False, labels=()):
|
| 99 |
+
"""Performs Non-Maximum Suppression (NMS) on inference results
|
| 100 |
+
|
| 101 |
+
Returns:
|
| 102 |
+
detections with shape: nx6 (x1, y1, x2, y2, conf, cls)
|
| 103 |
+
"""
|
| 104 |
+
|
| 105 |
+
nc = prediction.shape[2] - 5 # number of classes
|
| 106 |
+
xc = prediction[..., 4] > conf_thres # candidates
|
| 107 |
+
|
| 108 |
+
# Settings
|
| 109 |
+
min_wh, max_wh = 2, 4096 # (pixels) minimum and maximum box width and height
|
| 110 |
+
max_det = 300 # maximum number of detections per image
|
| 111 |
+
max_nms = 30000 # maximum number of boxes into torchvision.ops.nms()
|
| 112 |
+
time_limit = 10.0 # seconds to quit after
|
| 113 |
+
redundant = True # require redundant detections
|
| 114 |
+
multi_label = nc > 1 # multiple labels per box (adds 0.5ms/img)
|
| 115 |
+
merge = False # use merge-NMS
|
| 116 |
+
|
| 117 |
+
t = time.time()
|
| 118 |
+
output = [torch.zeros((0, 6), device=prediction.device)] * prediction.shape[0]
|
| 119 |
+
for xi, x in enumerate(prediction): # image index, image inference
|
| 120 |
+
# Apply constraints
|
| 121 |
+
# x[((x[..., 2:4] < min_wh) | (x[..., 2:4] > max_wh)).any(1), 4] = 0 # width-height
|
| 122 |
+
x = x[xc[xi]] # confidence
|
| 123 |
+
|
| 124 |
+
# Cat apriori labels if autolabelling
|
| 125 |
+
if labels and len(labels[xi]):
|
| 126 |
+
l = labels[xi]
|
| 127 |
+
v = torch.zeros((len(l), nc + 5), device=x.device)
|
| 128 |
+
v[:, :4] = l[:, 1:5] # box
|
| 129 |
+
v[:, 4] = 1.0 # conf
|
| 130 |
+
v[range(len(l)), l[:, 0].long() + 5] = 1.0 # cls
|
| 131 |
+
x = torch.cat((x, v), 0)
|
| 132 |
+
|
| 133 |
+
# If none remain process next image
|
| 134 |
+
if not x.shape[0]:
|
| 135 |
+
continue
|
| 136 |
+
|
| 137 |
+
# Compute conf
|
| 138 |
+
x[:, 5:] *= x[:, 4:5] # conf = obj_conf * cls_conf
|
| 139 |
+
|
| 140 |
+
# Box (center x, center y, width, height) to (x1, y1, x2, y2)
|
| 141 |
+
box = xywh2xyxy(x[:, :4])
|
| 142 |
+
|
| 143 |
+
# Detections matrix nx6 (xyxy, conf, cls)
|
| 144 |
+
if multi_label:
|
| 145 |
+
i, j = (x[:, 5:] > conf_thres).nonzero(as_tuple=False).T
|
| 146 |
+
x = torch.cat((box[i], x[i, j + 5, None], j[:, None].float()), 1)
|
| 147 |
+
else: # best class only
|
| 148 |
+
conf, j = x[:, 5:].max(1, keepdim=True)
|
| 149 |
+
x = torch.cat((box, conf, j.float()), 1)[conf.view(-1) > conf_thres]
|
| 150 |
+
|
| 151 |
+
# Filter by class
|
| 152 |
+
if classes is not None:
|
| 153 |
+
x = x[(x[:, 5:6] == torch.tensor(classes, device=x.device)).any(1)]
|
| 154 |
+
|
| 155 |
+
# Apply finite constraint
|
| 156 |
+
# if not torch.isfinite(x).all():
|
| 157 |
+
# x = x[torch.isfinite(x).all(1)]
|
| 158 |
+
|
| 159 |
+
# Check shape
|
| 160 |
+
n = x.shape[0] # number of boxes
|
| 161 |
+
if not n: # no boxes
|
| 162 |
+
continue
|
| 163 |
+
elif n > max_nms: # excess boxes
|
| 164 |
+
x = x[x[:, 4].argsort(descending=True)[:max_nms]] # sort by confidence
|
| 165 |
+
|
| 166 |
+
# Batched NMS
|
| 167 |
+
c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
|
| 168 |
+
boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
|
| 169 |
+
i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
|
| 170 |
+
if i.shape[0] > max_det: # limit detections
|
| 171 |
+
i = i[:max_det]
|
| 172 |
+
if merge and (1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)
|
| 173 |
+
# update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
|
| 174 |
+
iou = box_iou(boxes[i], boxes) > iou_thres # iou matrix
|
| 175 |
+
weights = iou * scores[None] # box weights
|
| 176 |
+
x[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes
|
| 177 |
+
if redundant:
|
| 178 |
+
i = i[iou.sum(1) > 1] # require redundancy
|
| 179 |
+
|
| 180 |
+
output[xi] = x[i]
|
| 181 |
+
if (time.time() - t) > time_limit:
|
| 182 |
+
print(f'WARNING: NMS time limit {time_limit}s exceeded')
|
| 183 |
+
break # time limit exceeded
|
| 184 |
+
|
| 185 |
+
return output
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
def xywh2xyxy(x):
|
| 189 |
+
# Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
|
| 190 |
+
y = torch.zeros_like(x) if isinstance(x, torch.Tensor) else np.zeros_like(x)
|
| 191 |
+
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
|
| 192 |
+
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
|
| 193 |
+
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
|
| 194 |
+
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
|
| 195 |
+
return y
|
| 196 |
+
|
| 197 |
+
def fitness(x):
|
| 198 |
+
# Returns fitness (for use with results.txt or evolve.txt)
|
| 199 |
+
w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, [email protected], [email protected]:0.95]
|
| 200 |
+
return (x[:, :4] * w).sum(1)
|
| 201 |
+
|
| 202 |
+
def check_img_size(img_size, s=32):
|
| 203 |
+
# Verify img_size is a multiple of stride s
|
| 204 |
+
new_size = make_divisible(img_size, int(s)) # ceil gs-multiple
|
| 205 |
+
if new_size != img_size:
|
| 206 |
+
print('WARNING: --img-size %g must be multiple of max stride %g, updating to %g' % (img_size, s, new_size))
|
| 207 |
+
return new_size
|
| 208 |
+
|
| 209 |
+
def scale_coords(img1_shape, coords, img0_shape, ratio_pad=None):
|
| 210 |
+
# Rescale coords (xyxy) from img1_shape to img0_shape
|
| 211 |
+
if ratio_pad is None: # calculate from img0_shape
|
| 212 |
+
gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new
|
| 213 |
+
pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (img1_shape[0] - img0_shape[0] * gain) / 2 # wh padding
|
| 214 |
+
else:
|
| 215 |
+
gain = ratio_pad[0][0]
|
| 216 |
+
pad = ratio_pad[1]
|
| 217 |
+
|
| 218 |
+
coords[:, [0, 2]] -= pad[0] # x padding
|
| 219 |
+
coords[:, [1, 3]] -= pad[1] # y padding
|
| 220 |
+
coords[:, :4] /= gain
|
| 221 |
+
clip_coords(coords, img0_shape)
|
| 222 |
+
return coords
|
| 223 |
+
|
| 224 |
+
def clip_coords(boxes, img_shape):
|
| 225 |
+
# Clip bounding xyxy bounding boxes to image shape (height, width)
|
| 226 |
+
boxes[:, 0].clamp_(0, img_shape[1]) # x1
|
| 227 |
+
boxes[:, 1].clamp_(0, img_shape[0]) # y1
|
| 228 |
+
boxes[:, 2].clamp_(0, img_shape[1]) # x2
|
| 229 |
+
boxes[:, 3].clamp_(0, img_shape[0]) # y2
|
| 230 |
+
|
| 231 |
+
def make_divisible(x, divisor):
|
| 232 |
+
# Returns x evenly divisible by divisor
|
| 233 |
+
return math.ceil(x / divisor) * divisor
|
| 234 |
+
|
| 235 |
+
def xyxy2xywh(x):
|
| 236 |
+
# Convert nx4 boxes from [x1, y1, x2, y2] to [x, y, w, h] where xy1=top-left, xy2=bottom-right
|
| 237 |
+
y = torch.zeros_like(x) if isinstance(x, torch.Tensor) else np.zeros_like(x)
|
| 238 |
+
y[:, 0] = (x[:, 0] + x[:, 2]) / 2 # x center
|
| 239 |
+
y[:, 1] = (x[:, 1] + x[:, 3]) / 2 # y center
|
| 240 |
+
y[:, 2] = x[:, 2] - x[:, 0] # width
|
| 241 |
+
y[:, 3] = x[:, 3] - x[:, 1] # height
|
| 242 |
+
return y
|
| 243 |
+
|
| 244 |
+
def plot_images(images, targets, paths=None, fname='images.jpg', names=None, max_size=640, max_subplots=16):
|
| 245 |
+
# Plot image grid with labels
|
| 246 |
+
|
| 247 |
+
if isinstance(images, torch.Tensor):
|
| 248 |
+
images = images.cpu().float().numpy()
|
| 249 |
+
if isinstance(targets, torch.Tensor):
|
| 250 |
+
targets = targets.cpu().numpy()
|
| 251 |
+
|
| 252 |
+
# un-normalise
|
| 253 |
+
if np.max(images[0]) <= 1:
|
| 254 |
+
images *= 255
|
| 255 |
+
|
| 256 |
+
tl = 3 # line thickness
|
| 257 |
+
tf = max(tl - 1, 1) # font thickness
|
| 258 |
+
bs, _, h, w = images.shape # batch size, _, height, width
|
| 259 |
+
bs = min(bs, max_subplots) # limit plot images
|
| 260 |
+
ns = np.ceil(bs ** 0.5) # number of subplots (square)
|
| 261 |
+
|
| 262 |
+
# Check if we should resize
|
| 263 |
+
scale_factor = max_size / max(h, w)
|
| 264 |
+
if scale_factor < 1:
|
| 265 |
+
h = math.ceil(scale_factor * h)
|
| 266 |
+
w = math.ceil(scale_factor * w)
|
| 267 |
+
|
| 268 |
+
colors = color_list() # list of colors
|
| 269 |
+
mosaic = np.full((int(ns * h), int(ns * w), 3), 255, dtype=np.uint8) # init
|
| 270 |
+
for i, img in enumerate(images):
|
| 271 |
+
if i == max_subplots: # if last batch has fewer images than we expect
|
| 272 |
+
break
|
| 273 |
+
|
| 274 |
+
block_x = int(w * (i // ns))
|
| 275 |
+
block_y = int(h * (i % ns))
|
| 276 |
+
|
| 277 |
+
img = img.transpose(1, 2, 0)
|
| 278 |
+
if scale_factor < 1:
|
| 279 |
+
img = cv2.resize(img, (w, h))
|
| 280 |
+
|
| 281 |
+
mosaic[block_y:block_y + h, block_x:block_x + w, :] = img
|
| 282 |
+
if len(targets) > 0:
|
| 283 |
+
image_targets = targets[targets[:, 0] == i]
|
| 284 |
+
boxes = xywh2xyxy(image_targets[:, 2:6]).T
|
| 285 |
+
classes = image_targets[:, 1].astype('int')
|
| 286 |
+
labels = image_targets.shape[1] == 6 # labels if no conf column
|
| 287 |
+
conf = None if labels else image_targets[:, 6] # check for confidence presence (label vs pred)
|
| 288 |
+
|
| 289 |
+
if boxes.shape[1]:
|
| 290 |
+
if boxes.max() <= 1.01: # if normalized with tolerance 0.01
|
| 291 |
+
boxes[[0, 2]] *= w # scale to pixels
|
| 292 |
+
boxes[[1, 3]] *= h
|
| 293 |
+
elif scale_factor < 1: # absolute coords need scale if image scales
|
| 294 |
+
boxes *= scale_factor
|
| 295 |
+
boxes[[0, 2]] += block_x
|
| 296 |
+
boxes[[1, 3]] += block_y
|
| 297 |
+
for j, box in enumerate(boxes.T):
|
| 298 |
+
cls = int(classes[j])
|
| 299 |
+
color = colors[cls % len(colors)]
|
| 300 |
+
cls = names[cls] if names else cls
|
| 301 |
+
if labels or conf[j] > 0.25: # 0.25 conf thresh
|
| 302 |
+
label = '%s' % cls if labels else '%s %.1f' % (cls, conf[j])
|
| 303 |
+
plot_one_box(box, mosaic, label=label, color=color, line_thickness=tl)
|
| 304 |
+
|
| 305 |
+
# Draw image filename labels
|
| 306 |
+
if paths:
|
| 307 |
+
label = Path(paths[i]).name[:40] # trim to 40 char
|
| 308 |
+
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
|
| 309 |
+
cv2.putText(mosaic, label, (block_x + 5, block_y + t_size[1] + 5), 0, tl / 3, [220, 220, 220], thickness=tf,
|
| 310 |
+
lineType=cv2.LINE_AA)
|
| 311 |
+
|
| 312 |
+
# Image border
|
| 313 |
+
cv2.rectangle(mosaic, (block_x, block_y), (block_x + w, block_y + h), (255, 255, 255), thickness=3)
|
| 314 |
+
|
| 315 |
+
if fname:
|
| 316 |
+
r = min(1280. / max(h, w) / ns, 1.0) # ratio to limit image size
|
| 317 |
+
mosaic = cv2.resize(mosaic, (int(ns * w * r), int(ns * h * r)), interpolation=cv2.INTER_AREA)
|
| 318 |
+
# cv2.imwrite(fname, cv2.cvtColor(mosaic, cv2.COLOR_BGR2RGB)) # cv2 save
|
| 319 |
+
Image.fromarray(mosaic).save(fname) # PIL save
|
| 320 |
+
return mosaic
|
| 321 |
+
|
| 322 |
+
def plot_one_box(x, img, color=None, label=None, line_thickness=None):
|
| 323 |
+
# Plots one bounding box on image img
|
| 324 |
+
tl = line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1 # line/font thickness
|
| 325 |
+
color = color or [random.randint(0, 255) for _ in range(3)]
|
| 326 |
+
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
|
| 327 |
+
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
|
| 328 |
+
if label:
|
| 329 |
+
tf = max(tl - 1, 1) # font thickness
|
| 330 |
+
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
|
| 331 |
+
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
|
| 332 |
+
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
|
| 333 |
+
cv2.putText(img, label, (c1[0], c1[1] - 2), 0, tl / 3, [225, 255, 255], thickness=tf, lineType=cv2.LINE_AA)
|
| 334 |
+
|
| 335 |
+
def color_list():
|
| 336 |
+
# Return first 10 plt colors as (r,g,b) https://stackoverflow.com/questions/51350872/python-from-color-name-to-rgb
|
| 337 |
+
def hex2rgb(h):
|
| 338 |
+
return tuple(int(str(h[1 + i:1 + i + 2]), 16) for i in (0, 2, 4))
|
| 339 |
+
|
| 340 |
+
return [hex2rgb(h) for h in plt.rcParams['axes.prop_cycle'].by_key()['color']]
|
| 341 |
+
|
| 342 |
+
def ap_per_class(tp, conf, pred_cls, target_cls, plot=False, save_dir='precision-recall_curve.png', names=[]):
|
| 343 |
+
""" Compute the average precision, given the recall and precision curves.
|
| 344 |
+
Source: https://github.com/rafaelpadilla/Object-Detection-Metrics.
|
| 345 |
+
# Arguments
|
| 346 |
+
tp: True positives (nparray, nx1 or nx10).
|
| 347 |
+
conf: Objectness value from 0-1 (nparray).
|
| 348 |
+
pred_cls: Predicted object classes (nparray).
|
| 349 |
+
target_cls: True object classes (nparray).
|
| 350 |
+
plot: Plot precision-recall curve at [email protected]
|
| 351 |
+
save_dir: Plot save directory
|
| 352 |
+
# Returns
|
| 353 |
+
The average precision as computed in py-faster-rcnn.
|
| 354 |
+
"""
|
| 355 |
+
|
| 356 |
+
# Sort by objectness
|
| 357 |
+
i = np.argsort(-conf)
|
| 358 |
+
tp, conf, pred_cls = tp[i], conf[i], pred_cls[i]
|
| 359 |
+
|
| 360 |
+
# Find unique classes
|
| 361 |
+
unique_classes = np.unique(target_cls)
|
| 362 |
+
|
| 363 |
+
# Create Precision-Recall curve and compute AP for each class
|
| 364 |
+
px, py = np.linspace(0, 1, 1000), [] # for plotting
|
| 365 |
+
pr_score = 0.1 # score to evaluate P and R https://github.com/ultralytics/yolov3/issues/898
|
| 366 |
+
s = [unique_classes.shape[0], tp.shape[1]] # number class, number iou thresholds (i.e. 10 for mAP0.5...0.95)
|
| 367 |
+
ap, p, r = np.zeros(s), np.zeros((unique_classes.shape[0], 1000)), np.zeros((unique_classes.shape[0], 1000))
|
| 368 |
+
for ci, c in enumerate(unique_classes):
|
| 369 |
+
i = pred_cls == c
|
| 370 |
+
n_l = (target_cls == c).sum() # number of labels
|
| 371 |
+
n_p = i.sum() # number of predictions
|
| 372 |
+
|
| 373 |
+
if n_p == 0 or n_l == 0:
|
| 374 |
+
continue
|
| 375 |
+
else:
|
| 376 |
+
# Accumulate FPs and TPs
|
| 377 |
+
fpc = (1 - tp[i]).cumsum(0)
|
| 378 |
+
tpc = tp[i].cumsum(0)
|
| 379 |
+
|
| 380 |
+
# Recall
|
| 381 |
+
recall = tpc / (n_l + 1e-16) # recall curve
|
| 382 |
+
r[ci] = np.interp(-px, -conf[i], recall[:, 0], left=0) # negative x, xp because xp decreases
|
| 383 |
+
|
| 384 |
+
# Precision
|
| 385 |
+
precision = tpc / (tpc + fpc) # precision curve
|
| 386 |
+
p[ci] = np.interp(-px, -conf[i], precision[:, 0], left=1) # p at pr_score
|
| 387 |
+
# AP from recall-precision curve
|
| 388 |
+
for j in range(tp.shape[1]):
|
| 389 |
+
ap[ci, j], mpre, mrec = compute_ap(recall[:, j], precision[:, j])
|
| 390 |
+
if plot and (j == 0):
|
| 391 |
+
py.append(np.interp(px, mrec, mpre)) # precision at [email protected]
|
| 392 |
+
|
| 393 |
+
# Compute F1 score (harmonic mean of precision and recall)
|
| 394 |
+
f1 = 2 * p * r / (p + r + 1e-16)
|
| 395 |
+
i=r.mean(0).argmax()
|
| 396 |
+
|
| 397 |
+
if plot:
|
| 398 |
+
plot_pr_curve(px, py, ap, save_dir, names)
|
| 399 |
+
|
| 400 |
+
return p[:, i], r[:, i], ap, f1[:, i], unique_classes.astype('int32')
|
| 401 |
+
|
| 402 |
+
def compute_ap(recall, precision):
|
| 403 |
+
""" Compute the average precision, given the recall and precision curves.
|
| 404 |
+
Source: https://github.com/rbgirshick/py-faster-rcnn.
|
| 405 |
+
# Arguments
|
| 406 |
+
recall: The recall curve (list).
|
| 407 |
+
precision: The precision curve (list).
|
| 408 |
+
# Returns
|
| 409 |
+
The average precision as computed in py-faster-rcnn.
|
| 410 |
+
"""
|
| 411 |
+
|
| 412 |
+
# Append sentinel values to beginning and end
|
| 413 |
+
mrec = np.concatenate(([0.], recall, [recall[-1] + 1E-3]))
|
| 414 |
+
mpre = np.concatenate(([1.], precision, [0.]))
|
| 415 |
+
|
| 416 |
+
# Compute the precision envelope
|
| 417 |
+
mpre = np.flip(np.maximum.accumulate(np.flip(mpre)))
|
| 418 |
+
|
| 419 |
+
# Integrate area under curve
|
| 420 |
+
method = 'interp' # methods: 'continuous', 'interp'
|
| 421 |
+
if method == 'interp':
|
| 422 |
+
x = np.linspace(0, 1, 101) # 101-point interp (COCO)
|
| 423 |
+
ap = np.trapz(np.interp(x, mrec, mpre), x) # integrate
|
| 424 |
+
|
| 425 |
+
else: # 'continuous'
|
| 426 |
+
i = np.where(mrec[1:] != mrec[:-1])[0] # points where x axis (recall) changes
|
| 427 |
+
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) # area under curve
|
| 428 |
+
|
| 429 |
+
return ap, mpre, mrec
|
| 430 |
+
|
| 431 |
+
def coco80_to_coco91_class(): # converts 80-index (val2014) to 91-index (paper)
|
| 432 |
+
# https://tech.amikelive.com/node-718/what-object-categories-labels-are-in-coco-dataset/
|
| 433 |
+
# a = np.loadtxt('data/coco.names', dtype='str', delimiter='\n')
|
| 434 |
+
# b = np.loadtxt('data/coco_paper.names', dtype='str', delimiter='\n')
|
| 435 |
+
# x1 = [list(a[i] == b).index(True) + 1 for i in range(80)] # darknet to coco
|
| 436 |
+
# x2 = [list(b[i] == a).index(True) if any(b[i] == a) else None for i in range(91)] # coco to darknet
|
| 437 |
+
x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 27, 28, 31, 32, 33, 34,
|
| 438 |
+
35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63,
|
| 439 |
+
64, 65, 67, 70, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 84, 85, 86, 87, 88, 89, 90]
|
| 440 |
+
return x
|
| 441 |
+
|
| 442 |
+
def output_to_target(output):
|
| 443 |
+
# Convert model output to target format [batch_id, class_id, x, y, w, h, conf]
|
| 444 |
+
targets = []
|
| 445 |
+
for i, o in enumerate(output):
|
| 446 |
+
for *box, conf, cls in o.cpu().numpy():
|
| 447 |
+
targets.append([i, cls, *list(*xyxy2xywh(np.array(box)[None])), conf])
|
| 448 |
+
return np.array(targets)
|
| 449 |
+
|
| 450 |
+
def plot_pr_curve(px, py, ap, save_dir='.', names=()):
|
| 451 |
+
fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
|
| 452 |
+
py = np.stack(py, axis=1)
|
| 453 |
+
|
| 454 |
+
if 0 < len(names) < 21: # show mAP in legend if < 10 classes
|
| 455 |
+
for i, y in enumerate(py.T):
|
| 456 |
+
ax.plot(px, y, linewidth=1, label=f'{names[i]} %.3f' % ap[i, 0]) # plot(recall, precision)
|
| 457 |
+
else:
|
| 458 |
+
ax.plot(px, py, linewidth=1, color='grey') # plot(recall, precision)
|
| 459 |
+
|
| 460 |
+
ax.plot(px, py.mean(1), linewidth=3, color='blue', label='all classes %.3f [email protected]' % ap[:, 0].mean())
|
| 461 |
+
ax.set_xlabel('Recall')
|
| 462 |
+
ax.set_ylabel('Precision')
|
| 463 |
+
ax.set_xlim(0, 1)
|
| 464 |
+
ax.set_ylim(0, 1)
|
| 465 |
+
plt.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
|
| 466 |
+
fig.savefig(Path(save_dir) / 'precision_recall_curve.png', dpi=250)
|
lib/core/loss.py
ADDED
|
@@ -0,0 +1,237 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch.nn as nn
|
| 2 |
+
import torch
|
| 3 |
+
from .general import bbox_iou
|
| 4 |
+
from .postprocess import build_targets
|
| 5 |
+
from lib.core.evaluate import SegmentationMetric
|
| 6 |
+
|
| 7 |
+
class MultiHeadLoss(nn.Module):
|
| 8 |
+
"""
|
| 9 |
+
collect all the loss we need
|
| 10 |
+
"""
|
| 11 |
+
def __init__(self, losses, cfg, lambdas=None):
|
| 12 |
+
"""
|
| 13 |
+
Inputs:
|
| 14 |
+
- losses: (list)[nn.Module, nn.Module, ...]
|
| 15 |
+
- cfg: config object
|
| 16 |
+
- lambdas: (list) + IoU loss, weight for each loss
|
| 17 |
+
"""
|
| 18 |
+
super().__init__()
|
| 19 |
+
# lambdas: [cls, obj, iou, la_seg, ll_seg, ll_iou]
|
| 20 |
+
if not lambdas:
|
| 21 |
+
lambdas = [1.0 for _ in range(len(losses) + 3)]
|
| 22 |
+
assert all(lam >= 0.0 for lam in lambdas)
|
| 23 |
+
|
| 24 |
+
self.losses = nn.ModuleList(losses)
|
| 25 |
+
self.lambdas = lambdas
|
| 26 |
+
self.cfg = cfg
|
| 27 |
+
|
| 28 |
+
def forward(self, head_fields, head_targets, shapes, model):
|
| 29 |
+
"""
|
| 30 |
+
Inputs:
|
| 31 |
+
- head_fields: (list) output from each task head
|
| 32 |
+
- head_targets: (list) ground-truth for each task head
|
| 33 |
+
- model:
|
| 34 |
+
|
| 35 |
+
Returns:
|
| 36 |
+
- total_loss: sum of all the loss
|
| 37 |
+
- head_losses: (tuple) contain all loss[loss1, loss2, ...]
|
| 38 |
+
|
| 39 |
+
"""
|
| 40 |
+
# head_losses = [ll
|
| 41 |
+
# for l, f, t in zip(self.losses, head_fields, head_targets)
|
| 42 |
+
# for ll in l(f, t)]
|
| 43 |
+
#
|
| 44 |
+
# assert len(self.lambdas) == len(head_losses)
|
| 45 |
+
# loss_values = [lam * l
|
| 46 |
+
# for lam, l in zip(self.lambdas, head_losses)
|
| 47 |
+
# if l is not None]
|
| 48 |
+
# total_loss = sum(loss_values) if loss_values else None
|
| 49 |
+
# print(model.nc)
|
| 50 |
+
total_loss, head_losses = self._forward_impl(head_fields, head_targets, shapes, model)
|
| 51 |
+
|
| 52 |
+
return total_loss, head_losses
|
| 53 |
+
|
| 54 |
+
def _forward_impl(self, predictions, targets, shapes, model):
|
| 55 |
+
"""
|
| 56 |
+
|
| 57 |
+
Args:
|
| 58 |
+
predictions: predicts of [[det_head1, det_head2, det_head3], drive_area_seg_head, lane_line_seg_head]
|
| 59 |
+
targets: gts [det_targets, segment_targets, lane_targets]
|
| 60 |
+
model:
|
| 61 |
+
|
| 62 |
+
Returns:
|
| 63 |
+
total_loss: sum of all the loss
|
| 64 |
+
head_losses: list containing losses
|
| 65 |
+
|
| 66 |
+
"""
|
| 67 |
+
cfg = self.cfg
|
| 68 |
+
device = targets[0].device
|
| 69 |
+
lcls, lbox, lobj = torch.zeros(1, device=device), torch.zeros(1, device=device), torch.zeros(1, device=device)
|
| 70 |
+
tcls, tbox, indices, anchors = build_targets(cfg, predictions[0], targets[0], model) # targets
|
| 71 |
+
|
| 72 |
+
# Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
|
| 73 |
+
cp, cn = smooth_BCE(eps=0.0)
|
| 74 |
+
|
| 75 |
+
BCEcls, BCEobj, BCEseg = self.losses
|
| 76 |
+
|
| 77 |
+
# Calculate Losses
|
| 78 |
+
nt = 0 # number of targets
|
| 79 |
+
no = len(predictions[0]) # number of outputs
|
| 80 |
+
balance = [4.0, 1.0, 0.4] if no == 3 else [4.0, 1.0, 0.4, 0.1] # P3-5 or P3-6
|
| 81 |
+
|
| 82 |
+
# calculate detection loss
|
| 83 |
+
for i, pi in enumerate(predictions[0]): # layer index, layer predictions
|
| 84 |
+
b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
|
| 85 |
+
tobj = torch.zeros_like(pi[..., 0], device=device) # target obj
|
| 86 |
+
|
| 87 |
+
n = b.shape[0] # number of targets
|
| 88 |
+
if n:
|
| 89 |
+
nt += n # cumulative targets
|
| 90 |
+
ps = pi[b, a, gj, gi] # prediction subset corresponding to targets
|
| 91 |
+
|
| 92 |
+
# Regression
|
| 93 |
+
pxy = ps[:, :2].sigmoid() * 2. - 0.5
|
| 94 |
+
pwh = (ps[:, 2:4].sigmoid() * 2) ** 2 * anchors[i]
|
| 95 |
+
pbox = torch.cat((pxy, pwh), 1).to(device) # predicted box
|
| 96 |
+
iou = bbox_iou(pbox.T, tbox[i], x1y1x2y2=False, CIoU=True) # iou(prediction, target)
|
| 97 |
+
lbox += (1.0 - iou).mean() # iou loss
|
| 98 |
+
|
| 99 |
+
# Objectness
|
| 100 |
+
tobj[b, a, gj, gi] = (1.0 - model.gr) + model.gr * iou.detach().clamp(0).type(tobj.dtype) # iou ratio
|
| 101 |
+
|
| 102 |
+
# Classification
|
| 103 |
+
# print(model.nc)
|
| 104 |
+
if model.nc > 1: # cls loss (only if multiple classes)
|
| 105 |
+
t = torch.full_like(ps[:, 5:], cn, device=device) # targets
|
| 106 |
+
t[range(n), tcls[i]] = cp
|
| 107 |
+
lcls += BCEcls(ps[:, 5:], t) # BCE
|
| 108 |
+
lobj += BCEobj(pi[..., 4], tobj) * balance[i] # obj loss
|
| 109 |
+
|
| 110 |
+
drive_area_seg_predicts = predictions[1].view(-1)
|
| 111 |
+
drive_area_seg_targets = targets[1].view(-1)
|
| 112 |
+
lseg_da = BCEseg(drive_area_seg_predicts, drive_area_seg_targets)
|
| 113 |
+
|
| 114 |
+
lane_line_seg_predicts = predictions[2].view(-1)
|
| 115 |
+
lane_line_seg_targets = targets[2].view(-1)
|
| 116 |
+
lseg_ll = BCEseg(lane_line_seg_predicts, lane_line_seg_targets)
|
| 117 |
+
|
| 118 |
+
metric = SegmentationMetric(2)
|
| 119 |
+
nb, _, height, width = targets[1].shape
|
| 120 |
+
pad_w, pad_h = shapes[0][1][1]
|
| 121 |
+
pad_w = int(pad_w)
|
| 122 |
+
pad_h = int(pad_h)
|
| 123 |
+
_,lane_line_pred=torch.max(predictions[2], 1)
|
| 124 |
+
_,lane_line_gt=torch.max(targets[2], 1)
|
| 125 |
+
lane_line_pred = lane_line_pred[:, pad_h:height-pad_h, pad_w:width-pad_w]
|
| 126 |
+
lane_line_gt = lane_line_gt[:, pad_h:height-pad_h, pad_w:width-pad_w]
|
| 127 |
+
metric.reset()
|
| 128 |
+
metric.addBatch(lane_line_pred.cpu(), lane_line_gt.cpu())
|
| 129 |
+
IoU = metric.IntersectionOverUnion()
|
| 130 |
+
liou_ll = 1 - IoU
|
| 131 |
+
|
| 132 |
+
s = 3 / no # output count scaling
|
| 133 |
+
lcls *= cfg.LOSS.CLS_GAIN * s * self.lambdas[0]
|
| 134 |
+
lobj *= cfg.LOSS.OBJ_GAIN * s * (1.4 if no == 4 else 1.) * self.lambdas[1]
|
| 135 |
+
lbox *= cfg.LOSS.BOX_GAIN * s * self.lambdas[2]
|
| 136 |
+
|
| 137 |
+
lseg_da *= cfg.LOSS.DA_SEG_GAIN * self.lambdas[3]
|
| 138 |
+
lseg_ll *= cfg.LOSS.LL_SEG_GAIN * self.lambdas[4]
|
| 139 |
+
liou_ll *= cfg.LOSS.LL_IOU_GAIN * self.lambdas[5]
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
if cfg.TRAIN.DET_ONLY or cfg.TRAIN.ENC_DET_ONLY or cfg.TRAIN.DET_ONLY:
|
| 143 |
+
lseg_da = 0 * lseg_da
|
| 144 |
+
lseg_ll = 0 * lseg_ll
|
| 145 |
+
liou_ll = 0 * liou_ll
|
| 146 |
+
|
| 147 |
+
if cfg.TRAIN.SEG_ONLY or cfg.TRAIN.ENC_SEG_ONLY:
|
| 148 |
+
lcls = 0 * lcls
|
| 149 |
+
lobj = 0 * lobj
|
| 150 |
+
lbox = 0 * lbox
|
| 151 |
+
|
| 152 |
+
if cfg.TRAIN.LANE_ONLY:
|
| 153 |
+
lcls = 0 * lcls
|
| 154 |
+
lobj = 0 * lobj
|
| 155 |
+
lbox = 0 * lbox
|
| 156 |
+
lseg_da = 0 * lseg_da
|
| 157 |
+
|
| 158 |
+
if cfg.TRAIN.DRIVABLE_ONLY:
|
| 159 |
+
lcls = 0 * lcls
|
| 160 |
+
lobj = 0 * lobj
|
| 161 |
+
lbox = 0 * lbox
|
| 162 |
+
lseg_ll = 0 * lseg_ll
|
| 163 |
+
liou_ll = 0 * liou_ll
|
| 164 |
+
|
| 165 |
+
loss = lbox + lobj + lcls + lseg_da + lseg_ll + liou_ll
|
| 166 |
+
# loss = lseg
|
| 167 |
+
# return loss * bs, torch.cat((lbox, lobj, lcls, loss)).detach()
|
| 168 |
+
return loss, (lbox.item(), lobj.item(), lcls.item(), lseg_da.item(), lseg_ll.item(), liou_ll.item(), loss.item())
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
def get_loss(cfg, device):
|
| 172 |
+
"""
|
| 173 |
+
get MultiHeadLoss
|
| 174 |
+
|
| 175 |
+
Inputs:
|
| 176 |
+
-cfg: configuration use the loss_name part or
|
| 177 |
+
function part(like regression classification)
|
| 178 |
+
-device: cpu or gpu device
|
| 179 |
+
|
| 180 |
+
Returns:
|
| 181 |
+
-loss: (MultiHeadLoss)
|
| 182 |
+
|
| 183 |
+
"""
|
| 184 |
+
# class loss criteria
|
| 185 |
+
BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.Tensor([cfg.LOSS.CLS_POS_WEIGHT])).to(device)
|
| 186 |
+
# object loss criteria
|
| 187 |
+
BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.Tensor([cfg.LOSS.OBJ_POS_WEIGHT])).to(device)
|
| 188 |
+
# segmentation loss criteria
|
| 189 |
+
BCEseg = nn.BCEWithLogitsLoss(pos_weight=torch.Tensor([cfg.LOSS.SEG_POS_WEIGHT])).to(device)
|
| 190 |
+
# Focal loss
|
| 191 |
+
gamma = cfg.LOSS.FL_GAMMA # focal loss gamma
|
| 192 |
+
if gamma > 0:
|
| 193 |
+
BCEcls, BCEobj = FocalLoss(BCEcls, gamma), FocalLoss(BCEobj, gamma)
|
| 194 |
+
|
| 195 |
+
loss_list = [BCEcls, BCEobj, BCEseg]
|
| 196 |
+
loss = MultiHeadLoss(loss_list, cfg=cfg, lambdas=cfg.LOSS.MULTI_HEAD_LAMBDA)
|
| 197 |
+
return loss
|
| 198 |
+
|
| 199 |
+
# example
|
| 200 |
+
# class L1_Loss(nn.Module)
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
def smooth_BCE(eps=0.1): # https://github.com/ultralytics/yolov3/issues/238#issuecomment-598028441
|
| 204 |
+
# return positive, negative label smoothing BCE targets
|
| 205 |
+
return 1.0 - 0.5 * eps, 0.5 * eps
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
class FocalLoss(nn.Module):
|
| 209 |
+
# Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
|
| 210 |
+
def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
|
| 211 |
+
# alpha balance positive & negative samples
|
| 212 |
+
# gamma focus on difficult samples
|
| 213 |
+
super(FocalLoss, self).__init__()
|
| 214 |
+
self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
|
| 215 |
+
self.gamma = gamma
|
| 216 |
+
self.alpha = alpha
|
| 217 |
+
self.reduction = loss_fcn.reduction
|
| 218 |
+
self.loss_fcn.reduction = 'none' # required to apply FL to each element
|
| 219 |
+
|
| 220 |
+
def forward(self, pred, true):
|
| 221 |
+
loss = self.loss_fcn(pred, true)
|
| 222 |
+
# p_t = torch.exp(-loss)
|
| 223 |
+
# loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stability
|
| 224 |
+
|
| 225 |
+
# TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py
|
| 226 |
+
pred_prob = torch.sigmoid(pred) # prob from logits
|
| 227 |
+
p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
|
| 228 |
+
alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
|
| 229 |
+
modulating_factor = (1.0 - p_t) ** self.gamma
|
| 230 |
+
loss *= alpha_factor * modulating_factor
|
| 231 |
+
|
| 232 |
+
if self.reduction == 'mean':
|
| 233 |
+
return loss.mean()
|
| 234 |
+
elif self.reduction == 'sum':
|
| 235 |
+
return loss.sum()
|
| 236 |
+
else: # 'none'
|
| 237 |
+
return loss
|
lib/core/postprocess.py
ADDED
|
@@ -0,0 +1,244 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from lib.utils import is_parallel
|
| 3 |
+
import numpy as np
|
| 4 |
+
np.set_printoptions(threshold=np.inf)
|
| 5 |
+
import cv2
|
| 6 |
+
from sklearn.cluster import DBSCAN
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def build_targets(cfg, predictions, targets, model):
|
| 10 |
+
'''
|
| 11 |
+
predictions
|
| 12 |
+
[16, 3, 32, 32, 85]
|
| 13 |
+
[16, 3, 16, 16, 85]
|
| 14 |
+
[16, 3, 8, 8, 85]
|
| 15 |
+
torch.tensor(predictions[i].shape)[[3, 2, 3, 2]]
|
| 16 |
+
[32,32,32,32]
|
| 17 |
+
[16,16,16,16]
|
| 18 |
+
[8,8,8,8]
|
| 19 |
+
targets[3,x,7]
|
| 20 |
+
t [index, class, x, y, w, h, head_index]
|
| 21 |
+
'''
|
| 22 |
+
# Build targets for compute_loss(), input targets(image,class,x,y,w,h)
|
| 23 |
+
det = model.module.model[model.module.detector_index] if is_parallel(model) \
|
| 24 |
+
else model.model[model.detector_index] # Detect() module
|
| 25 |
+
# print(type(model))
|
| 26 |
+
# det = model.model[model.detector_index]
|
| 27 |
+
# print(type(det))
|
| 28 |
+
na, nt = det.na, targets.shape[0] # number of anchors, targets
|
| 29 |
+
tcls, tbox, indices, anch = [], [], [], []
|
| 30 |
+
gain = torch.ones(7, device=targets.device) # normalized to gridspace gain
|
| 31 |
+
ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
|
| 32 |
+
targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2) # append anchor indices
|
| 33 |
+
|
| 34 |
+
g = 0.5 # bias
|
| 35 |
+
off = torch.tensor([[0, 0],
|
| 36 |
+
[1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
|
| 37 |
+
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
|
| 38 |
+
], device=targets.device).float() * g # offsets
|
| 39 |
+
|
| 40 |
+
for i in range(det.nl):
|
| 41 |
+
anchors = det.anchors[i] #[3,2]
|
| 42 |
+
gain[2:6] = torch.tensor(predictions[i].shape)[[3, 2, 3, 2]] # xyxy gain
|
| 43 |
+
# Match targets to anchors
|
| 44 |
+
t = targets * gain
|
| 45 |
+
|
| 46 |
+
if nt:
|
| 47 |
+
# Matches
|
| 48 |
+
r = t[:, :, 4:6] / anchors[:, None] # wh ratio
|
| 49 |
+
j = torch.max(r, 1. / r).max(2)[0] < cfg.TRAIN.ANCHOR_THRESHOLD # compare
|
| 50 |
+
# j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
|
| 51 |
+
t = t[j] # filter
|
| 52 |
+
|
| 53 |
+
# Offsets
|
| 54 |
+
gxy = t[:, 2:4] # grid xy
|
| 55 |
+
gxi = gain[[2, 3]] - gxy # inverse
|
| 56 |
+
j, k = ((gxy % 1. < g) & (gxy > 1.)).T
|
| 57 |
+
l, m = ((gxi % 1. < g) & (gxi > 1.)).T
|
| 58 |
+
j = torch.stack((torch.ones_like(j), j, k, l, m))
|
| 59 |
+
t = t.repeat((5, 1, 1))[j]
|
| 60 |
+
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
|
| 61 |
+
else:
|
| 62 |
+
t = targets[0]
|
| 63 |
+
offsets = 0
|
| 64 |
+
|
| 65 |
+
# Define
|
| 66 |
+
b, c = t[:, :2].long().T # image, class
|
| 67 |
+
gxy = t[:, 2:4] # grid xy
|
| 68 |
+
gwh = t[:, 4:6] # grid wh
|
| 69 |
+
gij = (gxy - offsets).long()
|
| 70 |
+
gi, gj = gij.T # grid xy indices
|
| 71 |
+
|
| 72 |
+
# Append
|
| 73 |
+
a = t[:, 6].long() # anchor indices
|
| 74 |
+
indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices
|
| 75 |
+
tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
|
| 76 |
+
anch.append(anchors[a]) # anchors
|
| 77 |
+
tcls.append(c) # class
|
| 78 |
+
|
| 79 |
+
return tcls, tbox, indices, anch
|
| 80 |
+
|
| 81 |
+
def morphological_process(image, kernel_size=5, func_type=cv2.MORPH_CLOSE):
|
| 82 |
+
"""
|
| 83 |
+
morphological process to fill the hole in the binary segmentation result
|
| 84 |
+
:param image:
|
| 85 |
+
:param kernel_size:
|
| 86 |
+
:return:
|
| 87 |
+
"""
|
| 88 |
+
if len(image.shape) == 3:
|
| 89 |
+
raise ValueError('Binary segmentation result image should be a single channel image')
|
| 90 |
+
|
| 91 |
+
if image.dtype is not np.uint8:
|
| 92 |
+
image = np.array(image, np.uint8)
|
| 93 |
+
|
| 94 |
+
kernel = cv2.getStructuringElement(shape=cv2.MORPH_ELLIPSE, ksize=(kernel_size, kernel_size))
|
| 95 |
+
|
| 96 |
+
# close operation fille hole
|
| 97 |
+
closing = cv2.morphologyEx(image, func_type, kernel, iterations=1)
|
| 98 |
+
|
| 99 |
+
return closing
|
| 100 |
+
|
| 101 |
+
def connect_components_analysis(image):
|
| 102 |
+
"""
|
| 103 |
+
connect components analysis to remove the small components
|
| 104 |
+
:param image:
|
| 105 |
+
:return:
|
| 106 |
+
"""
|
| 107 |
+
if len(image.shape) == 3:
|
| 108 |
+
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
|
| 109 |
+
else:
|
| 110 |
+
gray_image = image
|
| 111 |
+
# print(gray_image.dtype)
|
| 112 |
+
return cv2.connectedComponentsWithStats(gray_image, connectivity=8, ltype=cv2.CV_32S)
|
| 113 |
+
|
| 114 |
+
# def if_y(samples_x):
|
| 115 |
+
# for sample_x in samples_x:
|
| 116 |
+
# if len(sample_x):
|
| 117 |
+
# if len(sample_x) != (sample_x[-1] - sample_x[0] + 1):
|
| 118 |
+
# return False
|
| 119 |
+
# return True
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
# def fitlane(mask, sel_labels, labels, stats):
|
| 123 |
+
# for label_group in sel_labels:
|
| 124 |
+
# states = [stats[k] for k in label_group]
|
| 125 |
+
# x_max, y_max, w_max, h_max, _ = np.amax(np.array(states), axis=0)
|
| 126 |
+
# x_min, y_min, w_min, h_min, _ = np.amin(np.array(states), axis=0)
|
| 127 |
+
# # print(np.array(states))
|
| 128 |
+
# x = x_min; y = y_min; w = w_max; h = h_max
|
| 129 |
+
# if len(label_group) > 1:
|
| 130 |
+
# # print(label_group)
|
| 131 |
+
# for m in range(len(label_group)-1):
|
| 132 |
+
# # print(label_group[m+1])
|
| 133 |
+
# # print(label_group[0])
|
| 134 |
+
# labels[labels == label_group[m+1]] = label_group[0]
|
| 135 |
+
# t = label_group[0]
|
| 136 |
+
# if (y_max + h - 1) > 720:
|
| 137 |
+
# samples_y = np.linspace(y, 720-1, 20)
|
| 138 |
+
# else:
|
| 139 |
+
# samples_y = np.linspace(y, y_max+h-1, 20)
|
| 140 |
+
|
| 141 |
+
# samples_x = [np.where(labels[int(sample_y)]==t)[0] for sample_y in samples_y]
|
| 142 |
+
|
| 143 |
+
# if if_y(samples_x):
|
| 144 |
+
# # print('in y')
|
| 145 |
+
# samples_x = [int(np.mean(sample_x)) if len(sample_x) else -1 for sample_x in samples_x]
|
| 146 |
+
# samples_x = np.array(samples_x)
|
| 147 |
+
# samples_y = np.array(samples_y)
|
| 148 |
+
# samples_y = samples_y[samples_x != -1]
|
| 149 |
+
# samples_x = samples_x[samples_x != -1]
|
| 150 |
+
# func = np.polyfit(samples_y, samples_x, 2)
|
| 151 |
+
# # x_limits = np.polyval(func, 0)
|
| 152 |
+
# # if x_limits < 0 or x_limits > 1280:
|
| 153 |
+
# # if (y_max + h - 1) > 720:
|
| 154 |
+
# draw_y = np.linspace(y, 720-1, 720-y)
|
| 155 |
+
# # else:
|
| 156 |
+
# # draw_y = np.linspace(y, y_max+h-1, y_max+h-y)
|
| 157 |
+
# # draw_y = np.linspace(y, 720-1, 720-y)
|
| 158 |
+
# draw_x = np.polyval(func, draw_y)
|
| 159 |
+
# draw_y = draw_y[draw_x < 1280]
|
| 160 |
+
# draw_x = draw_x[draw_x < 1280]
|
| 161 |
+
|
| 162 |
+
# draw_points = (np.asarray([draw_x, draw_y]).T).astype(np.int32)
|
| 163 |
+
# cv2.polylines(mask, [draw_points], False, 1, thickness=15)
|
| 164 |
+
# else:
|
| 165 |
+
# # print('in x')
|
| 166 |
+
# if (x_max + w - 1) > 1280:
|
| 167 |
+
# samples_x = np.linspace(x, 1280-1, 20)
|
| 168 |
+
# else:
|
| 169 |
+
# samples_x = np.linspace(x, x_max+w-1, 20)
|
| 170 |
+
# samples_y = [np.where(labels[:, int(sample_x)]==t)[0] for sample_x in samples_x]
|
| 171 |
+
# samples_y = [int(np.mean(sample_y)) if len(sample_y) else -1 for sample_y in samples_y]
|
| 172 |
+
# samples_x = np.array(samples_x)
|
| 173 |
+
# samples_y = np.array(samples_y)
|
| 174 |
+
# samples_x = samples_x[samples_y != -1]
|
| 175 |
+
# samples_y = samples_y[samples_y != -1]
|
| 176 |
+
# func = np.polyfit(samples_x, samples_y, 2)
|
| 177 |
+
# # y_limits = np.polyval(func, 0)
|
| 178 |
+
# # if y_limits > 720 or y_limits < 0:
|
| 179 |
+
# # if (x_max + w - 1) > 1280:
|
| 180 |
+
# draw_x = np.linspace(x, 1280-1, 1280-x)
|
| 181 |
+
# # else:
|
| 182 |
+
# # y_limits = np.polyval(func, 0)
|
| 183 |
+
# # if y_limits > 720 or y_limits < 0:
|
| 184 |
+
# # draw_x = np.linspace(x, x_max+w-1, w+x_max-x)
|
| 185 |
+
# # else:
|
| 186 |
+
# # if x_max+w-1 < 640:
|
| 187 |
+
# # draw_x = np.linspace(0, x_max+w-1, w+x_max-x)
|
| 188 |
+
# # else:
|
| 189 |
+
# # draw_x = np.linspace(x, 1280-1, 1280-x)
|
| 190 |
+
# draw_y = np.polyval(func, draw_x)
|
| 191 |
+
# draw_x = draw_x[draw_y < 720]
|
| 192 |
+
# draw_y = draw_y[draw_y < 720]
|
| 193 |
+
# draw_points = (np.asarray([draw_x, draw_y]).T).astype(np.int32)
|
| 194 |
+
# cv2.polylines(mask, [draw_points], False, 1, thickness=15)
|
| 195 |
+
# return mask
|
| 196 |
+
|
| 197 |
+
# def connect_lane(image):
|
| 198 |
+
# if len(image.shape) == 3:
|
| 199 |
+
# gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
|
| 200 |
+
# else:
|
| 201 |
+
# gray_image = image
|
| 202 |
+
|
| 203 |
+
# mask = np.zeros((image.shape[0], image.shape[1]), np.uint8)
|
| 204 |
+
# # print(gray_image.dtype)
|
| 205 |
+
# num_labels, labels, stats, centers = cv2.connectedComponentsWithStats(gray_image, connectivity=8, ltype=cv2.CV_32S)
|
| 206 |
+
# ratios = []
|
| 207 |
+
# selected_label = []
|
| 208 |
+
|
| 209 |
+
# for t in range(1, num_labels, 1):
|
| 210 |
+
# x, y, w, h, area = stats[t]
|
| 211 |
+
# center = centers[t]
|
| 212 |
+
# if area > 400:
|
| 213 |
+
# samples_y = [y, y+h-1]
|
| 214 |
+
# selected_label.append(t)
|
| 215 |
+
# samples_x = [np.where(labels[int(m)]==t)[0] for m in samples_y]
|
| 216 |
+
# samples_x = [int(np.median(sample_x)) for sample_x in samples_x]
|
| 217 |
+
# delta_x = samples_x[1] - samples_x[0]
|
| 218 |
+
# if center[0]/1280 > 0.5:
|
| 219 |
+
# ratios.append([0.7 * h / delta_x , h / w, 1.])
|
| 220 |
+
# else:
|
| 221 |
+
# ratios.append([0.7 * h / delta_x , h / w, 0.])
|
| 222 |
+
|
| 223 |
+
# clustering = DBSCAN(eps=0.3, min_samples=1).fit(ratios)
|
| 224 |
+
# # print(clustering.labels_)
|
| 225 |
+
# split_labels = []
|
| 226 |
+
# selected_label = np.array(selected_label)
|
| 227 |
+
# for k in range(len(set(clustering.labels_))):
|
| 228 |
+
# index = np.where(clustering.labels_==k)[0]
|
| 229 |
+
# split_labels.append(selected_label[index])
|
| 230 |
+
|
| 231 |
+
# # for i in range(1, num_labels, 1):
|
| 232 |
+
# # if i not in set(selected_label):
|
| 233 |
+
# # labels[labels == i] = 0
|
| 234 |
+
# # print(split_labels)
|
| 235 |
+
# mask_post = fitlane(mask, split_labels, labels, stats)
|
| 236 |
+
# return mask_post
|
| 237 |
+
|
| 238 |
+
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
|
| 243 |
+
|
| 244 |
+
|
lib/dataset/AutoDriveDataset.py
ADDED
|
@@ -0,0 +1,264 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
import numpy as np
|
| 3 |
+
# np.set_printoptions(threshold=np.inf)
|
| 4 |
+
import random
|
| 5 |
+
import torch
|
| 6 |
+
import torchvision.transforms as transforms
|
| 7 |
+
# from visualization import plot_img_and_mask,plot_one_box,show_seg_result
|
| 8 |
+
from pathlib import Path
|
| 9 |
+
from PIL import Image
|
| 10 |
+
from torch.utils.data import Dataset
|
| 11 |
+
from ..utils import letterbox, augment_hsv, random_perspective, xyxy2xywh, cutout
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class AutoDriveDataset(Dataset):
|
| 15 |
+
"""
|
| 16 |
+
A general Dataset for some common function
|
| 17 |
+
"""
|
| 18 |
+
def __init__(self, cfg, is_train, inputsize=640, transform=None):
|
| 19 |
+
"""
|
| 20 |
+
initial all the characteristic
|
| 21 |
+
|
| 22 |
+
Inputs:
|
| 23 |
+
-cfg: configurations
|
| 24 |
+
-is_train(bool): whether train set or not
|
| 25 |
+
-transform: ToTensor and Normalize
|
| 26 |
+
|
| 27 |
+
Returns:
|
| 28 |
+
None
|
| 29 |
+
"""
|
| 30 |
+
self.is_train = is_train
|
| 31 |
+
self.cfg = cfg
|
| 32 |
+
self.transform = transform
|
| 33 |
+
self.inputsize = inputsize
|
| 34 |
+
self.Tensor = transforms.ToTensor()
|
| 35 |
+
img_root = Path(cfg.DATASET.DATAROOT)
|
| 36 |
+
label_root = Path(cfg.DATASET.LABELROOT)
|
| 37 |
+
mask_root = Path(cfg.DATASET.MASKROOT)
|
| 38 |
+
lane_root = Path(cfg.DATASET.LANEROOT)
|
| 39 |
+
if is_train:
|
| 40 |
+
indicator = cfg.DATASET.TRAIN_SET
|
| 41 |
+
else:
|
| 42 |
+
indicator = cfg.DATASET.TEST_SET
|
| 43 |
+
self.img_root = img_root / indicator
|
| 44 |
+
self.label_root = label_root / indicator
|
| 45 |
+
self.mask_root = mask_root / indicator
|
| 46 |
+
self.lane_root = lane_root / indicator
|
| 47 |
+
# self.label_list = self.label_root.iterdir()
|
| 48 |
+
self.mask_list = self.mask_root.iterdir()
|
| 49 |
+
|
| 50 |
+
self.db = []
|
| 51 |
+
|
| 52 |
+
self.data_format = cfg.DATASET.DATA_FORMAT
|
| 53 |
+
|
| 54 |
+
self.scale_factor = cfg.DATASET.SCALE_FACTOR
|
| 55 |
+
self.rotation_factor = cfg.DATASET.ROT_FACTOR
|
| 56 |
+
self.flip = cfg.DATASET.FLIP
|
| 57 |
+
self.color_rgb = cfg.DATASET.COLOR_RGB
|
| 58 |
+
|
| 59 |
+
# self.target_type = cfg.MODEL.TARGET_TYPE
|
| 60 |
+
self.shapes = np.array(cfg.DATASET.ORG_IMG_SIZE)
|
| 61 |
+
|
| 62 |
+
def _get_db(self):
|
| 63 |
+
"""
|
| 64 |
+
finished on children Dataset(for dataset which is not in Bdd100k format, rewrite children Dataset)
|
| 65 |
+
"""
|
| 66 |
+
raise NotImplementedError
|
| 67 |
+
|
| 68 |
+
def evaluate(self, cfg, preds, output_dir):
|
| 69 |
+
"""
|
| 70 |
+
finished on children dataset
|
| 71 |
+
"""
|
| 72 |
+
raise NotImplementedError
|
| 73 |
+
|
| 74 |
+
def __len__(self,):
|
| 75 |
+
"""
|
| 76 |
+
number of objects in the dataset
|
| 77 |
+
"""
|
| 78 |
+
return len(self.db)
|
| 79 |
+
|
| 80 |
+
def __getitem__(self, idx):
|
| 81 |
+
"""
|
| 82 |
+
Get input and groud-truth from database & add data augmentation on input
|
| 83 |
+
|
| 84 |
+
Inputs:
|
| 85 |
+
-idx: the index of image in self.db(database)(list)
|
| 86 |
+
self.db(list) [a,b,c,...]
|
| 87 |
+
a: (dictionary){'image':, 'information':}
|
| 88 |
+
|
| 89 |
+
Returns:
|
| 90 |
+
-image: transformed image, first passed the data augmentation in __getitem__ function(type:numpy), then apply self.transform
|
| 91 |
+
-target: ground truth(det_gt,seg_gt)
|
| 92 |
+
|
| 93 |
+
function maybe useful
|
| 94 |
+
cv2.imread
|
| 95 |
+
cv2.cvtColor(data, cv2.COLOR_BGR2RGB)
|
| 96 |
+
cv2.warpAffine
|
| 97 |
+
"""
|
| 98 |
+
data = self.db[idx]
|
| 99 |
+
img = cv2.imread(data["image"], cv2.IMREAD_COLOR | cv2.IMREAD_IGNORE_ORIENTATION)
|
| 100 |
+
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
|
| 101 |
+
# seg_label = cv2.imread(data["mask"], 0)
|
| 102 |
+
if self.cfg.num_seg_class == 3:
|
| 103 |
+
seg_label = cv2.imread(data["mask"])
|
| 104 |
+
else:
|
| 105 |
+
seg_label = cv2.imread(data["mask"], 0)
|
| 106 |
+
lane_label = cv2.imread(data["lane"], 0)
|
| 107 |
+
#print(lane_label.shape)
|
| 108 |
+
# print(seg_label.shape)
|
| 109 |
+
# print(lane_label.shape)
|
| 110 |
+
# print(seg_label.shape)
|
| 111 |
+
resized_shape = self.inputsize
|
| 112 |
+
if isinstance(resized_shape, list):
|
| 113 |
+
resized_shape = max(resized_shape)
|
| 114 |
+
h0, w0 = img.shape[:2] # orig hw
|
| 115 |
+
r = resized_shape / max(h0, w0) # resize image to img_size
|
| 116 |
+
if r != 1: # always resize down, only resize up if training with augmentation
|
| 117 |
+
interp = cv2.INTER_AREA if r < 1 else cv2.INTER_LINEAR
|
| 118 |
+
img = cv2.resize(img, (int(w0 * r), int(h0 * r)), interpolation=interp)
|
| 119 |
+
seg_label = cv2.resize(seg_label, (int(w0 * r), int(h0 * r)), interpolation=interp)
|
| 120 |
+
lane_label = cv2.resize(lane_label, (int(w0 * r), int(h0 * r)), interpolation=interp)
|
| 121 |
+
h, w = img.shape[:2]
|
| 122 |
+
|
| 123 |
+
(img, seg_label, lane_label), ratio, pad = letterbox((img, seg_label, lane_label), resized_shape, auto=True, scaleup=self.is_train)
|
| 124 |
+
shapes = (h0, w0), ((h / h0, w / w0), pad) # for COCO mAP rescaling
|
| 125 |
+
# ratio = (w / w0, h / h0)
|
| 126 |
+
# print(resized_shape)
|
| 127 |
+
|
| 128 |
+
det_label = data["label"]
|
| 129 |
+
labels=[]
|
| 130 |
+
|
| 131 |
+
if det_label.size > 0:
|
| 132 |
+
# Normalized xywh to pixel xyxy format
|
| 133 |
+
labels = det_label.copy()
|
| 134 |
+
labels[:, 1] = ratio[0] * w * (det_label[:, 1] - det_label[:, 3] / 2) + pad[0] # pad width
|
| 135 |
+
labels[:, 2] = ratio[1] * h * (det_label[:, 2] - det_label[:, 4] / 2) + pad[1] # pad height
|
| 136 |
+
labels[:, 3] = ratio[0] * w * (det_label[:, 1] + det_label[:, 3] / 2) + pad[0]
|
| 137 |
+
labels[:, 4] = ratio[1] * h * (det_label[:, 2] + det_label[:, 4] / 2) + pad[1]
|
| 138 |
+
|
| 139 |
+
if self.is_train:
|
| 140 |
+
combination = (img, seg_label, lane_label)
|
| 141 |
+
(img, seg_label, lane_label), labels = random_perspective(
|
| 142 |
+
combination=combination,
|
| 143 |
+
targets=labels,
|
| 144 |
+
degrees=self.cfg.DATASET.ROT_FACTOR,
|
| 145 |
+
translate=self.cfg.DATASET.TRANSLATE,
|
| 146 |
+
scale=self.cfg.DATASET.SCALE_FACTOR,
|
| 147 |
+
shear=self.cfg.DATASET.SHEAR
|
| 148 |
+
)
|
| 149 |
+
#print(labels.shape)
|
| 150 |
+
augment_hsv(img, hgain=self.cfg.DATASET.HSV_H, sgain=self.cfg.DATASET.HSV_S, vgain=self.cfg.DATASET.HSV_V)
|
| 151 |
+
# img, seg_label, labels = cutout(combination=combination, labels=labels)
|
| 152 |
+
|
| 153 |
+
if len(labels):
|
| 154 |
+
# convert xyxy to xywh
|
| 155 |
+
labels[:, 1:5] = xyxy2xywh(labels[:, 1:5])
|
| 156 |
+
|
| 157 |
+
# Normalize coordinates 0 - 1
|
| 158 |
+
labels[:, [2, 4]] /= img.shape[0] # height
|
| 159 |
+
labels[:, [1, 3]] /= img.shape[1] # width
|
| 160 |
+
|
| 161 |
+
# if self.is_train:
|
| 162 |
+
# random left-right flip
|
| 163 |
+
lr_flip = True
|
| 164 |
+
if lr_flip and random.random() < 0.5:
|
| 165 |
+
img = np.fliplr(img)
|
| 166 |
+
seg_label = np.fliplr(seg_label)
|
| 167 |
+
lane_label = np.fliplr(lane_label)
|
| 168 |
+
if len(labels):
|
| 169 |
+
labels[:, 1] = 1 - labels[:, 1]
|
| 170 |
+
|
| 171 |
+
# random up-down flip
|
| 172 |
+
ud_flip = False
|
| 173 |
+
if ud_flip and random.random() < 0.5:
|
| 174 |
+
img = np.flipud(img)
|
| 175 |
+
seg_label = np.filpud(seg_label)
|
| 176 |
+
lane_label = np.filpud(lane_label)
|
| 177 |
+
if len(labels):
|
| 178 |
+
labels[:, 2] = 1 - labels[:, 2]
|
| 179 |
+
|
| 180 |
+
else:
|
| 181 |
+
if len(labels):
|
| 182 |
+
# convert xyxy to xywh
|
| 183 |
+
labels[:, 1:5] = xyxy2xywh(labels[:, 1:5])
|
| 184 |
+
|
| 185 |
+
# Normalize coordinates 0 - 1
|
| 186 |
+
labels[:, [2, 4]] /= img.shape[0] # height
|
| 187 |
+
labels[:, [1, 3]] /= img.shape[1] # width
|
| 188 |
+
|
| 189 |
+
labels_out = torch.zeros((len(labels), 6))
|
| 190 |
+
if len(labels):
|
| 191 |
+
labels_out[:, 1:] = torch.from_numpy(labels)
|
| 192 |
+
# Convert
|
| 193 |
+
# img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
|
| 194 |
+
# img = img.transpose(2, 0, 1)
|
| 195 |
+
img = np.ascontiguousarray(img)
|
| 196 |
+
# seg_label = np.ascontiguousarray(seg_label)
|
| 197 |
+
# if idx == 0:
|
| 198 |
+
# print(seg_label[:,:,0])
|
| 199 |
+
|
| 200 |
+
if self.cfg.num_seg_class == 3:
|
| 201 |
+
_,seg0 = cv2.threshold(seg_label[:,:,0],128,255,cv2.THRESH_BINARY)
|
| 202 |
+
_,seg1 = cv2.threshold(seg_label[:,:,1],1,255,cv2.THRESH_BINARY)
|
| 203 |
+
_,seg2 = cv2.threshold(seg_label[:,:,2],1,255,cv2.THRESH_BINARY)
|
| 204 |
+
else:
|
| 205 |
+
_,seg1 = cv2.threshold(seg_label,1,255,cv2.THRESH_BINARY)
|
| 206 |
+
_,seg2 = cv2.threshold(seg_label,1,255,cv2.THRESH_BINARY_INV)
|
| 207 |
+
_,lane1 = cv2.threshold(lane_label,1,255,cv2.THRESH_BINARY)
|
| 208 |
+
_,lane2 = cv2.threshold(lane_label,1,255,cv2.THRESH_BINARY_INV)
|
| 209 |
+
# _,seg2 = cv2.threshold(seg_label[:,:,2],1,255,cv2.THRESH_BINARY)
|
| 210 |
+
# # seg1[cutout_mask] = 0
|
| 211 |
+
# # seg2[cutout_mask] = 0
|
| 212 |
+
|
| 213 |
+
# seg_label /= 255
|
| 214 |
+
# seg0 = self.Tensor(seg0)
|
| 215 |
+
if self.cfg.num_seg_class == 3:
|
| 216 |
+
seg0 = self.Tensor(seg0)
|
| 217 |
+
seg1 = self.Tensor(seg1)
|
| 218 |
+
seg2 = self.Tensor(seg2)
|
| 219 |
+
# seg1 = self.Tensor(seg1)
|
| 220 |
+
# seg2 = self.Tensor(seg2)
|
| 221 |
+
lane1 = self.Tensor(lane1)
|
| 222 |
+
lane2 = self.Tensor(lane2)
|
| 223 |
+
|
| 224 |
+
# seg_label = torch.stack((seg2[0], seg1[0]),0)
|
| 225 |
+
if self.cfg.num_seg_class == 3:
|
| 226 |
+
seg_label = torch.stack((seg0[0],seg1[0],seg2[0]),0)
|
| 227 |
+
else:
|
| 228 |
+
seg_label = torch.stack((seg2[0], seg1[0]),0)
|
| 229 |
+
|
| 230 |
+
lane_label = torch.stack((lane2[0], lane1[0]),0)
|
| 231 |
+
# _, gt_mask = torch.max(seg_label, 0)
|
| 232 |
+
# _ = show_seg_result(img, gt_mask, idx, 0, save_dir='debug', is_gt=True)
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
target = [labels_out, seg_label, lane_label]
|
| 236 |
+
img = self.transform(img)
|
| 237 |
+
|
| 238 |
+
return img, target, data["image"], shapes
|
| 239 |
+
|
| 240 |
+
def select_data(self, db):
|
| 241 |
+
"""
|
| 242 |
+
You can use this function to filter useless images in the dataset
|
| 243 |
+
|
| 244 |
+
Inputs:
|
| 245 |
+
-db: (list)database
|
| 246 |
+
|
| 247 |
+
Returns:
|
| 248 |
+
-db_selected: (list)filtered dataset
|
| 249 |
+
"""
|
| 250 |
+
db_selected = ...
|
| 251 |
+
return db_selected
|
| 252 |
+
|
| 253 |
+
@staticmethod
|
| 254 |
+
def collate_fn(batch):
|
| 255 |
+
img, label, paths, shapes= zip(*batch)
|
| 256 |
+
label_det, label_seg, label_lane = [], [], []
|
| 257 |
+
for i, l in enumerate(label):
|
| 258 |
+
l_det, l_seg, l_lane = l
|
| 259 |
+
l_det[:, 0] = i # add target image index for build_targets()
|
| 260 |
+
label_det.append(l_det)
|
| 261 |
+
label_seg.append(l_seg)
|
| 262 |
+
label_lane.append(l_lane)
|
| 263 |
+
return torch.stack(img, 0), [torch.cat(label_det, 0), torch.stack(label_seg, 0), torch.stack(label_lane, 0)], paths, shapes
|
| 264 |
+
|
lib/dataset/DemoDataset.py
ADDED
|
@@ -0,0 +1,188 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import glob
|
| 2 |
+
import os
|
| 3 |
+
import random
|
| 4 |
+
import shutil
|
| 5 |
+
import time
|
| 6 |
+
from pathlib import Path
|
| 7 |
+
from threading import Thread
|
| 8 |
+
|
| 9 |
+
import cv2
|
| 10 |
+
import math
|
| 11 |
+
import numpy as np
|
| 12 |
+
import torch
|
| 13 |
+
from PIL import Image, ExifTags
|
| 14 |
+
from torch.utils.data import Dataset
|
| 15 |
+
from tqdm import tqdm
|
| 16 |
+
|
| 17 |
+
from ..utils import letterbox_for_img, clean_str
|
| 18 |
+
|
| 19 |
+
img_formats = ['.bmp', '.jpg', '.jpeg', '.png', '.tif', '.tiff', '.dng']
|
| 20 |
+
vid_formats = ['.mov', '.avi', '.mp4', '.mpg', '.mpeg', '.m4v', '.wmv', '.mkv']
|
| 21 |
+
|
| 22 |
+
class LoadImages: # for inference
|
| 23 |
+
def __init__(self, path, img_size=640):
|
| 24 |
+
p = str(Path(path)) # os-agnostic
|
| 25 |
+
p = os.path.abspath(p) # absolute path
|
| 26 |
+
if '*' in p:
|
| 27 |
+
files = sorted(glob.glob(p, recursive=True)) # glob
|
| 28 |
+
elif os.path.isdir(p):
|
| 29 |
+
files = sorted(glob.glob(os.path.join(p, '*.*'))) # dir
|
| 30 |
+
elif os.path.isfile(p):
|
| 31 |
+
files = [p] # files
|
| 32 |
+
else:
|
| 33 |
+
raise Exception('ERROR: %s does not exist' % p)
|
| 34 |
+
|
| 35 |
+
images = [x for x in files if os.path.splitext(x)[-1].lower() in img_formats]
|
| 36 |
+
videos = [x for x in files if os.path.splitext(x)[-1].lower() in vid_formats]
|
| 37 |
+
ni, nv = len(images), len(videos)
|
| 38 |
+
|
| 39 |
+
self.img_size = img_size
|
| 40 |
+
self.files = images + videos
|
| 41 |
+
self.nf = ni + nv # number of files
|
| 42 |
+
self.video_flag = [False] * ni + [True] * nv
|
| 43 |
+
self.mode = 'images'
|
| 44 |
+
if any(videos):
|
| 45 |
+
self.new_video(videos[0]) # new video
|
| 46 |
+
else:
|
| 47 |
+
self.cap = None
|
| 48 |
+
assert self.nf > 0, 'No images or videos found in %s. Supported formats are:\nimages: %s\nvideos: %s' % \
|
| 49 |
+
(p, img_formats, vid_formats)
|
| 50 |
+
|
| 51 |
+
def __iter__(self):
|
| 52 |
+
self.count = 0
|
| 53 |
+
return self
|
| 54 |
+
|
| 55 |
+
def __next__(self):
|
| 56 |
+
if self.count == self.nf:
|
| 57 |
+
raise StopIteration
|
| 58 |
+
path = self.files[self.count]
|
| 59 |
+
|
| 60 |
+
if self.video_flag[self.count]:
|
| 61 |
+
# Read video
|
| 62 |
+
self.mode = 'video'
|
| 63 |
+
ret_val, img0 = self.cap.read()
|
| 64 |
+
if not ret_val:
|
| 65 |
+
self.count += 1
|
| 66 |
+
self.cap.release()
|
| 67 |
+
if self.count == self.nf: # last video
|
| 68 |
+
raise StopIteration
|
| 69 |
+
else:
|
| 70 |
+
path = self.files[self.count]
|
| 71 |
+
self.new_video(path)
|
| 72 |
+
ret_val, img0 = self.cap.read()
|
| 73 |
+
h0, w0 = img0.shape[:2]
|
| 74 |
+
|
| 75 |
+
self.frame += 1
|
| 76 |
+
print('\n video %g/%g (%g/%g) %s: ' % (self.count + 1, self.nf, self.frame, self.nframes, path), end='')
|
| 77 |
+
|
| 78 |
+
else:
|
| 79 |
+
# Read image
|
| 80 |
+
self.count += 1
|
| 81 |
+
img0 = cv2.imread(path, cv2.IMREAD_COLOR | cv2.IMREAD_IGNORE_ORIENTATION) # BGR
|
| 82 |
+
#img0 = cv2.cvtColor(img0, cv2.COLOR_BGR2RGB)
|
| 83 |
+
assert img0 is not None, 'Image Not Found ' + path
|
| 84 |
+
print('image %g/%g %s: \n' % (self.count, self.nf, path), end='')
|
| 85 |
+
h0, w0 = img0.shape[:2]
|
| 86 |
+
|
| 87 |
+
# Padded resize
|
| 88 |
+
img, ratio, pad = letterbox_for_img(img0, new_shape=self.img_size, auto=True)
|
| 89 |
+
h, w = img.shape[:2]
|
| 90 |
+
shapes = (h0, w0), ((h / h0, w / w0), pad)
|
| 91 |
+
|
| 92 |
+
# Convert
|
| 93 |
+
#img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
|
| 94 |
+
img = np.ascontiguousarray(img)
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
# cv2.imwrite(path + '.letterbox.jpg', 255 * img.transpose((1, 2, 0))[:, :, ::-1]) # save letterbox image
|
| 98 |
+
return path, img, img0, self.cap, shapes
|
| 99 |
+
|
| 100 |
+
def new_video(self, path):
|
| 101 |
+
self.frame = 0
|
| 102 |
+
self.cap = cv2.VideoCapture(path)
|
| 103 |
+
self.nframes = int(self.cap.get(cv2.CAP_PROP_FRAME_COUNT))
|
| 104 |
+
|
| 105 |
+
def __len__(self):
|
| 106 |
+
return self.nf # number of files
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
class LoadStreams: # multiple IP or RTSP cameras
|
| 111 |
+
def __init__(self, sources='streams.txt', img_size=640, auto=True):
|
| 112 |
+
self.mode = 'stream'
|
| 113 |
+
self.img_size = img_size
|
| 114 |
+
|
| 115 |
+
if os.path.isfile(sources):
|
| 116 |
+
with open(sources, 'r') as f:
|
| 117 |
+
sources = [x.strip() for x in f.read().strip().splitlines() if len(x.strip())]
|
| 118 |
+
else:
|
| 119 |
+
sources = [sources]
|
| 120 |
+
|
| 121 |
+
n = len(sources)
|
| 122 |
+
self.imgs, self.fps, self.frames, self.threads = [None] * n, [0] * n, [0] * n, [None] * n
|
| 123 |
+
self.sources = [clean_str(x) for x in sources] # clean source names for later
|
| 124 |
+
self.auto = auto
|
| 125 |
+
for i, s in enumerate(sources): # index, source
|
| 126 |
+
# Start thread to read frames from video stream
|
| 127 |
+
print(f'{i + 1}/{n}: {s}... ', end='')
|
| 128 |
+
s = eval(s) if s.isnumeric() else s # i.e. s = '0' local webcam
|
| 129 |
+
cap = cv2.VideoCapture(s)
|
| 130 |
+
assert cap.isOpened(), f'Failed to open {s}'
|
| 131 |
+
w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
|
| 132 |
+
h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
|
| 133 |
+
self.fps[i] = max(cap.get(cv2.CAP_PROP_FPS) % 100, 0) or 30.0 # 30 FPS fallback
|
| 134 |
+
self.frames[i] = max(int(cap.get(cv2.CAP_PROP_FRAME_COUNT)), 0) or float('inf') # infinite stream fallback
|
| 135 |
+
|
| 136 |
+
_, self.imgs[i] = cap.read() # guarantee first frame
|
| 137 |
+
self.threads[i] = Thread(target=self.update, args=([i, cap]), daemon=True)
|
| 138 |
+
print(f" success ({self.frames[i]} frames {w}x{h} at {self.fps[i]:.2f} FPS)")
|
| 139 |
+
self.threads[i].start()
|
| 140 |
+
print('') # newline
|
| 141 |
+
|
| 142 |
+
# check for common shapes
|
| 143 |
+
|
| 144 |
+
s = np.stack([letterbox_for_img(x, self.img_size, auto=self.auto)[0].shape for x in self.imgs], 0) # shapes
|
| 145 |
+
self.rect = np.unique(s, axis=0).shape[0] == 1 # rect inference if all shapes equal
|
| 146 |
+
if not self.rect:
|
| 147 |
+
print('WARNING: Different stream shapes detected. For optimal performance supply similarly-shaped streams.')
|
| 148 |
+
|
| 149 |
+
def update(self, i, cap):
|
| 150 |
+
# Read stream `i` frames in daemon thread
|
| 151 |
+
n, f, read = 0, self.frames[i], 1 # frame number, frame array, inference every 'read' frame
|
| 152 |
+
while cap.isOpened() and n < f:
|
| 153 |
+
n += 1
|
| 154 |
+
# _, self.imgs[index] = cap.read()
|
| 155 |
+
cap.grab()
|
| 156 |
+
if n % read == 0:
|
| 157 |
+
success, im = cap.retrieve()
|
| 158 |
+
self.imgs[i] = im if success else self.imgs[i] * 0
|
| 159 |
+
time.sleep(1 / self.fps[i]) # wait time
|
| 160 |
+
|
| 161 |
+
def __iter__(self):
|
| 162 |
+
self.count = -1
|
| 163 |
+
return self
|
| 164 |
+
|
| 165 |
+
def __next__(self):
|
| 166 |
+
self.count += 1
|
| 167 |
+
if not all(x.is_alive() for x in self.threads) or cv2.waitKey(1) == ord('q'): # q to quit
|
| 168 |
+
cv2.destroyAllWindows()
|
| 169 |
+
raise StopIteration
|
| 170 |
+
|
| 171 |
+
# Letterbox
|
| 172 |
+
img0 = self.imgs.copy()
|
| 173 |
+
|
| 174 |
+
h0, w0 = img0[0].shape[:2]
|
| 175 |
+
img, _, pad = letterbox_for_img(img0[0], self.img_size, auto=self.rect and self.auto)
|
| 176 |
+
|
| 177 |
+
# Stack
|
| 178 |
+
h, w = img.shape[:2]
|
| 179 |
+
shapes = (h0, w0), ((h / h0, w / w0), pad)
|
| 180 |
+
|
| 181 |
+
# Convert
|
| 182 |
+
#img = img[..., ::-1].transpose((0, 3, 1, 2)) # BGR to RGB, BHWC to BCHW
|
| 183 |
+
img = np.ascontiguousarray(img)
|
| 184 |
+
|
| 185 |
+
return self.sources, img, img0[0], None, shapes
|
| 186 |
+
|
| 187 |
+
def __len__(self):
|
| 188 |
+
return len(self.sources) # 1E12 frames = 32 streams at 30 FPS for 30 years
|
lib/dataset/__init__.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .bdd import BddDataset
|
| 2 |
+
from .AutoDriveDataset import AutoDriveDataset
|
| 3 |
+
from .DemoDataset import LoadImages, LoadStreams
|
lib/dataset/bdd.py
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import json
|
| 3 |
+
|
| 4 |
+
from .AutoDriveDataset import AutoDriveDataset
|
| 5 |
+
from .convert import convert, id_dict, id_dict_single
|
| 6 |
+
from tqdm import tqdm
|
| 7 |
+
|
| 8 |
+
single_cls = True # just detect vehicle
|
| 9 |
+
|
| 10 |
+
class BddDataset(AutoDriveDataset):
|
| 11 |
+
def __init__(self, cfg, is_train, inputsize, transform=None):
|
| 12 |
+
super().__init__(cfg, is_train, inputsize, transform)
|
| 13 |
+
self.db = self._get_db()
|
| 14 |
+
self.cfg = cfg
|
| 15 |
+
|
| 16 |
+
def _get_db(self):
|
| 17 |
+
"""
|
| 18 |
+
get database from the annotation file
|
| 19 |
+
|
| 20 |
+
Inputs:
|
| 21 |
+
|
| 22 |
+
Returns:
|
| 23 |
+
gt_db: (list)database [a,b,c,...]
|
| 24 |
+
a: (dictionary){'image':, 'information':, ......}
|
| 25 |
+
image: image path
|
| 26 |
+
mask: path of the segmetation label
|
| 27 |
+
label: [cls_id, center_x//256, center_y//256, w//256, h//256] 256=IMAGE_SIZE
|
| 28 |
+
"""
|
| 29 |
+
print('building database...')
|
| 30 |
+
gt_db = []
|
| 31 |
+
height, width = self.shapes
|
| 32 |
+
for mask in tqdm(list(self.mask_list)):
|
| 33 |
+
mask_path = str(mask)
|
| 34 |
+
label_path = mask_path.replace(str(self.mask_root), str(self.label_root)).replace(".png", ".json")
|
| 35 |
+
image_path = mask_path.replace(str(self.mask_root), str(self.img_root)).replace(".png", ".jpg")
|
| 36 |
+
lane_path = mask_path.replace(str(self.mask_root), str(self.lane_root))
|
| 37 |
+
with open(label_path, 'r') as f:
|
| 38 |
+
label = json.load(f)
|
| 39 |
+
data = label['frames'][0]['objects']
|
| 40 |
+
data = self.filter_data(data)
|
| 41 |
+
gt = np.zeros((len(data), 5))
|
| 42 |
+
for idx, obj in enumerate(data):
|
| 43 |
+
category = obj['category']
|
| 44 |
+
if category == "traffic light":
|
| 45 |
+
color = obj['attributes']['trafficLightColor']
|
| 46 |
+
category = "tl_" + color
|
| 47 |
+
if category in id_dict.keys():
|
| 48 |
+
x1 = float(obj['box2d']['x1'])
|
| 49 |
+
y1 = float(obj['box2d']['y1'])
|
| 50 |
+
x2 = float(obj['box2d']['x2'])
|
| 51 |
+
y2 = float(obj['box2d']['y2'])
|
| 52 |
+
cls_id = id_dict[category]
|
| 53 |
+
if single_cls:
|
| 54 |
+
cls_id=0
|
| 55 |
+
gt[idx][0] = cls_id
|
| 56 |
+
box = convert((width, height), (x1, x2, y1, y2))
|
| 57 |
+
gt[idx][1:] = list(box)
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
rec = [{
|
| 61 |
+
'image': image_path,
|
| 62 |
+
'label': gt,
|
| 63 |
+
'mask': mask_path,
|
| 64 |
+
'lane': lane_path
|
| 65 |
+
}]
|
| 66 |
+
|
| 67 |
+
gt_db += rec
|
| 68 |
+
print('database build finish')
|
| 69 |
+
return gt_db
|
| 70 |
+
|
| 71 |
+
def filter_data(self, data):
|
| 72 |
+
remain = []
|
| 73 |
+
for obj in data:
|
| 74 |
+
if 'box2d' in obj.keys(): # obj.has_key('box2d'):
|
| 75 |
+
if single_cls:
|
| 76 |
+
if obj['category'] in id_dict_single.keys():
|
| 77 |
+
remain.append(obj)
|
| 78 |
+
else:
|
| 79 |
+
remain.append(obj)
|
| 80 |
+
return remain
|
| 81 |
+
|
| 82 |
+
def evaluate(self, cfg, preds, output_dir, *args, **kwargs):
|
| 83 |
+
"""
|
| 84 |
+
"""
|
| 85 |
+
pass
|
lib/dataset/convert.py
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# bdd_labels = {
|
| 2 |
+
# 'unlabeled':0, 'dynamic': 1, 'ego vehicle': 2, 'ground': 3,
|
| 3 |
+
# 'static': 4, 'parking': 5, 'rail track': 6, 'road': 7,
|
| 4 |
+
# 'sidewalk': 8, 'bridge': 9, 'building': 10, 'fence': 11,
|
| 5 |
+
# 'garage': 12, 'guard rail': 13, 'tunnel': 14, 'wall': 15,
|
| 6 |
+
# 'banner': 16, 'billboard': 17, 'lane divider': 18,'parking sign': 19,
|
| 7 |
+
# 'pole': 20, 'polegroup': 21, 'street light': 22, 'traffic cone': 23,
|
| 8 |
+
# 'traffic device': 24, 'traffic light': 25, 'traffic sign': 26, 'traffic sign frame': 27,
|
| 9 |
+
# 'terrain': 28, 'vegetation': 29, 'sky': 30, 'person': 31,
|
| 10 |
+
# 'rider': 32, 'bicycle': 33, 'bus': 34, 'car': 35,
|
| 11 |
+
# 'caravan': 36, 'motorcycle': 37, 'trailer': 38, 'train': 39,
|
| 12 |
+
# 'truck': 40
|
| 13 |
+
# }
|
| 14 |
+
id_dict = {'person': 0, 'rider': 1, 'car': 2, 'bus': 3, 'truck': 4,
|
| 15 |
+
'bike': 5, 'motor': 6, 'tl_green': 7, 'tl_red': 8,
|
| 16 |
+
'tl_yellow': 9, 'tl_none': 10, 'traffic sign': 11, 'train': 12}
|
| 17 |
+
id_dict_single = {'car': 0, 'bus': 1, 'truck': 2,'train': 3}
|
| 18 |
+
# id_dict = {'car': 0, 'bus': 1, 'truck': 2}
|
| 19 |
+
|
| 20 |
+
def convert(size, box):
|
| 21 |
+
dw = 1./(size[0])
|
| 22 |
+
dh = 1./(size[1])
|
| 23 |
+
x = (box[0] + box[1])/2.0
|
| 24 |
+
y = (box[2] + box[3])/2.0
|
| 25 |
+
w = box[1] - box[0]
|
| 26 |
+
h = box[3] - box[2]
|
| 27 |
+
x = x*dw
|
| 28 |
+
w = w*dw
|
| 29 |
+
y = y*dh
|
| 30 |
+
h = h*dh
|
| 31 |
+
return (x,y,w,h)
|
lib/dataset/hust.py
ADDED
|
@@ -0,0 +1,87 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import json
|
| 3 |
+
|
| 4 |
+
from .AutoDriveDataset import AutoDriveDataset
|
| 5 |
+
from .convert import convert, id_dict, id_dict_single
|
| 6 |
+
from tqdm import tqdm
|
| 7 |
+
import os
|
| 8 |
+
|
| 9 |
+
single_cls = False # just detect vehicle
|
| 10 |
+
|
| 11 |
+
class HustDataset(AutoDriveDataset):
|
| 12 |
+
def __init__(self, cfg, is_train, inputsize, transform=None):
|
| 13 |
+
super().__init__(cfg, is_train, inputsize, transform)
|
| 14 |
+
self.db = self._get_db()
|
| 15 |
+
self.cfg = cfg
|
| 16 |
+
|
| 17 |
+
def _get_db(self):
|
| 18 |
+
"""
|
| 19 |
+
get database from the annotation file
|
| 20 |
+
|
| 21 |
+
Inputs:
|
| 22 |
+
|
| 23 |
+
Returns:
|
| 24 |
+
gt_db: (list)database [a,b,c,...]
|
| 25 |
+
a: (dictionary){'image':, 'information':, ......}
|
| 26 |
+
image: image path
|
| 27 |
+
mask: path of the segmetation label
|
| 28 |
+
label: [cls_id, center_x//256, center_y//256, w//256, h//256] 256=IMAGE_SIZE
|
| 29 |
+
"""
|
| 30 |
+
print('building database...')
|
| 31 |
+
gt_db = []
|
| 32 |
+
height, width = self.shapes
|
| 33 |
+
for mask in tqdm(list(self.mask_list)):
|
| 34 |
+
mask_path = str(mask)
|
| 35 |
+
label_path = self.label_root
|
| 36 |
+
# label_path = mask_path.replace(str(self.mask_root), str(self.label_root)).replace(".png", ".json")
|
| 37 |
+
image_path = mask_path.replace(str(self.mask_root), str(self.img_root)).replace(".png", ".jpg")
|
| 38 |
+
lane_path = mask_path.replace(str(self.mask_root), str(self.lane_root))
|
| 39 |
+
with open(label_path, 'r') as f:
|
| 40 |
+
label = json.load(f)
|
| 41 |
+
data = label[int(os.path.basename(image_path)[:-4])]["labels"]
|
| 42 |
+
data = self.filter_data(data)
|
| 43 |
+
gt = np.zeros((len(data), 5))
|
| 44 |
+
for idx, obj in enumerate(data):
|
| 45 |
+
category = obj['category']
|
| 46 |
+
if category == "traffic light":
|
| 47 |
+
color = obj['attributes']['Traffic Light Color'][0]
|
| 48 |
+
category = "tl_" + color
|
| 49 |
+
if category in id_dict.keys():
|
| 50 |
+
x1 = float(obj['box2d']['x1'])
|
| 51 |
+
y1 = float(obj['box2d']['y1'])
|
| 52 |
+
x2 = float(obj['box2d']['x2'])
|
| 53 |
+
y2 = float(obj['box2d']['y2'])
|
| 54 |
+
cls_id = id_dict[category]
|
| 55 |
+
if single_cls:
|
| 56 |
+
cls_id=0
|
| 57 |
+
gt[idx][0] = cls_id
|
| 58 |
+
box = convert((width, height), (x1, x2, y1, y2))
|
| 59 |
+
gt[idx][1:] = list(box)
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
rec = [{
|
| 63 |
+
'image': image_path,
|
| 64 |
+
'label': gt,
|
| 65 |
+
'mask': mask_path,
|
| 66 |
+
'lane': lane_path
|
| 67 |
+
}]
|
| 68 |
+
|
| 69 |
+
gt_db += rec
|
| 70 |
+
print('database build finish')
|
| 71 |
+
return gt_db
|
| 72 |
+
|
| 73 |
+
def filter_data(self, data):
|
| 74 |
+
remain = []
|
| 75 |
+
for obj in data:
|
| 76 |
+
if 'box2d' in obj.keys(): # obj.has_key('box2d'):
|
| 77 |
+
if single_cls:
|
| 78 |
+
if obj['category'] in id_dict_single.keys():
|
| 79 |
+
remain.append(obj)
|
| 80 |
+
else:
|
| 81 |
+
remain.append(obj)
|
| 82 |
+
return remain
|
| 83 |
+
|
| 84 |
+
def evaluate(self, cfg, preds, output_dir, *args, **kwargs):
|
| 85 |
+
"""
|
| 86 |
+
"""
|
| 87 |
+
pass
|
lib/models/YOLOP.py
ADDED
|
@@ -0,0 +1,596 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch import tensor
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import sys,os
|
| 5 |
+
import math
|
| 6 |
+
import sys
|
| 7 |
+
sys.path.append(os.getcwd())
|
| 8 |
+
#sys.path.append("lib/models")
|
| 9 |
+
#sys.path.append("lib/utils")
|
| 10 |
+
#sys.path.append("/workspace/wh/projects/DaChuang")
|
| 11 |
+
from lib.utils import initialize_weights
|
| 12 |
+
# from lib.models.common2 import DepthSeperabelConv2d as Conv
|
| 13 |
+
# from lib.models.common2 import SPP, Bottleneck, BottleneckCSP, Focus, Concat, Detect
|
| 14 |
+
from lib.models.common import Conv, SPP, Bottleneck, BottleneckCSP, Focus, Concat, Detect, SharpenConv
|
| 15 |
+
from torch.nn import Upsample
|
| 16 |
+
from lib.utils import check_anchor_order
|
| 17 |
+
from lib.core.evaluate import SegmentationMetric
|
| 18 |
+
from lib.utils.utils import time_synchronized
|
| 19 |
+
|
| 20 |
+
"""
|
| 21 |
+
MCnet_SPP = [
|
| 22 |
+
[ -1, Focus, [3, 32, 3]],
|
| 23 |
+
[ -1, Conv, [32, 64, 3, 2]],
|
| 24 |
+
[ -1, BottleneckCSP, [64, 64, 1]],
|
| 25 |
+
[ -1, Conv, [64, 128, 3, 2]],
|
| 26 |
+
[ -1, BottleneckCSP, [128, 128, 3]],
|
| 27 |
+
[ -1, Conv, [128, 256, 3, 2]],
|
| 28 |
+
[ -1, BottleneckCSP, [256, 256, 3]],
|
| 29 |
+
[ -1, Conv, [256, 512, 3, 2]],
|
| 30 |
+
[ -1, SPP, [512, 512, [5, 9, 13]]],
|
| 31 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]],
|
| 32 |
+
[ -1, Conv,[512, 256, 1, 1]],
|
| 33 |
+
[ -1, Upsample, [None, 2, 'nearest']],
|
| 34 |
+
[ [-1, 6], Concat, [1]],
|
| 35 |
+
[ -1, BottleneckCSP, [512, 256, 1, False]],
|
| 36 |
+
[ -1, Conv, [256, 128, 1, 1]],
|
| 37 |
+
[ -1, Upsample, [None, 2, 'nearest']],
|
| 38 |
+
[ [-1,4], Concat, [1]],
|
| 39 |
+
[ -1, BottleneckCSP, [256, 128, 1, False]],
|
| 40 |
+
[ -1, Conv, [128, 128, 3, 2]],
|
| 41 |
+
[ [-1, 14], Concat, [1]],
|
| 42 |
+
[ -1, BottleneckCSP, [256, 256, 1, False]],
|
| 43 |
+
[ -1, Conv, [256, 256, 3, 2]],
|
| 44 |
+
[ [-1, 10], Concat, [1]],
|
| 45 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]],
|
| 46 |
+
# [ [17, 20, 23], Detect, [1, [[3,9,5,11,4,20], [7,18,6,39,12,31], [19,50,38,81,68,157]], [128, 256, 512]]],
|
| 47 |
+
[ [17, 20, 23], Detect, [13, [[3,9,5,11,4,20], [7,18,6,39,12,31], [19,50,38,81,68,157]], [128, 256, 512]]],
|
| 48 |
+
[ 17, Conv, [128, 64, 3, 1]],
|
| 49 |
+
[ -1, Upsample, [None, 2, 'nearest']],
|
| 50 |
+
[ [-1,2], Concat, [1]],
|
| 51 |
+
[ -1, BottleneckCSP, [128, 64, 1, False]],
|
| 52 |
+
[ -1, Conv, [64, 32, 3, 1]],
|
| 53 |
+
[ -1, Upsample, [None, 2, 'nearest']],
|
| 54 |
+
[ -1, Conv, [32, 16, 3, 1]],
|
| 55 |
+
[ -1, BottleneckCSP, [16, 8, 1, False]],
|
| 56 |
+
[ -1, Upsample, [None, 2, 'nearest']],
|
| 57 |
+
[ -1, SPP, [8, 2, [5, 9, 13]]] #segmentation output
|
| 58 |
+
]
|
| 59 |
+
# [2,6,3,9,5,13], [7,19,11,26,17,39], [28,64,44,103,61,183]
|
| 60 |
+
|
| 61 |
+
MCnet_0 = [
|
| 62 |
+
[ -1, Focus, [3, 32, 3]],
|
| 63 |
+
[ -1, Conv, [32, 64, 3, 2]],
|
| 64 |
+
[ -1, BottleneckCSP, [64, 64, 1]],
|
| 65 |
+
[ -1, Conv, [64, 128, 3, 2]],
|
| 66 |
+
[ -1, BottleneckCSP, [128, 128, 3]],
|
| 67 |
+
[ -1, Conv, [128, 256, 3, 2]],
|
| 68 |
+
[ -1, BottleneckCSP, [256, 256, 3]],
|
| 69 |
+
[ -1, Conv, [256, 512, 3, 2]],
|
| 70 |
+
[ -1, SPP, [512, 512, [5, 9, 13]]],
|
| 71 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]],
|
| 72 |
+
[ -1, Conv,[512, 256, 1, 1]],
|
| 73 |
+
[ -1, Upsample, [None, 2, 'nearest']],
|
| 74 |
+
[ [-1, 6], Concat, [1]],
|
| 75 |
+
[ -1, BottleneckCSP, [512, 256, 1, False]],
|
| 76 |
+
[ -1, Conv, [256, 128, 1, 1]],
|
| 77 |
+
[ -1, Upsample, [None, 2, 'nearest']],
|
| 78 |
+
[ [-1,4], Concat, [1]],
|
| 79 |
+
[ -1, BottleneckCSP, [256, 128, 1, False]],
|
| 80 |
+
[ -1, Conv, [128, 128, 3, 2]],
|
| 81 |
+
[ [-1, 14], Concat, [1]],
|
| 82 |
+
[ -1, BottleneckCSP, [256, 256, 1, False]],
|
| 83 |
+
[ -1, Conv, [256, 256, 3, 2]],
|
| 84 |
+
[ [-1, 10], Concat, [1]],
|
| 85 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]],
|
| 86 |
+
[ [17, 20, 23], Detect, [1, [[3,9,5,11,4,20], [7,18,6,39,12,31], [19,50,38,81,68,157]], [128, 256, 512]]], #Detect output 24
|
| 87 |
+
|
| 88 |
+
[ 16, Conv, [128, 64, 3, 1]],
|
| 89 |
+
[ -1, Upsample, [None, 2, 'nearest']],
|
| 90 |
+
[ [-1,2], Concat, [1]],
|
| 91 |
+
[ -1, BottleneckCSP, [128, 64, 1, False]],
|
| 92 |
+
[ -1, Conv, [64, 32, 3, 1]],
|
| 93 |
+
[ -1, Upsample, [None, 2, 'nearest']],
|
| 94 |
+
[ -1, Conv, [32, 16, 3, 1]],
|
| 95 |
+
[ -1, BottleneckCSP, [16, 8, 1, False]],
|
| 96 |
+
[ -1, Upsample, [None, 2, 'nearest']],
|
| 97 |
+
[ -1, Conv, [8, 2, 3, 1]], #Driving area segmentation output
|
| 98 |
+
|
| 99 |
+
[ 16, Conv, [128, 64, 3, 1]],
|
| 100 |
+
[ -1, Upsample, [None, 2, 'nearest']],
|
| 101 |
+
[ [-1,2], Concat, [1]],
|
| 102 |
+
[ -1, BottleneckCSP, [128, 64, 1, False]],
|
| 103 |
+
[ -1, Conv, [64, 32, 3, 1]],
|
| 104 |
+
[ -1, Upsample, [None, 2, 'nearest']],
|
| 105 |
+
[ -1, Conv, [32, 16, 3, 1]],
|
| 106 |
+
[ -1, BottleneckCSP, [16, 8, 1, False]],
|
| 107 |
+
[ -1, Upsample, [None, 2, 'nearest']],
|
| 108 |
+
[ -1, Conv, [8, 2, 3, 1]], #Lane line segmentation output
|
| 109 |
+
]
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
# The lane line and the driving area segment branches share information with each other
|
| 113 |
+
MCnet_share = [
|
| 114 |
+
[ -1, Focus, [3, 32, 3]], #0
|
| 115 |
+
[ -1, Conv, [32, 64, 3, 2]], #1
|
| 116 |
+
[ -1, BottleneckCSP, [64, 64, 1]], #2
|
| 117 |
+
[ -1, Conv, [64, 128, 3, 2]], #3
|
| 118 |
+
[ -1, BottleneckCSP, [128, 128, 3]], #4
|
| 119 |
+
[ -1, Conv, [128, 256, 3, 2]], #5
|
| 120 |
+
[ -1, BottleneckCSP, [256, 256, 3]], #6
|
| 121 |
+
[ -1, Conv, [256, 512, 3, 2]], #7
|
| 122 |
+
[ -1, SPP, [512, 512, [5, 9, 13]]], #8
|
| 123 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]], #9
|
| 124 |
+
[ -1, Conv,[512, 256, 1, 1]], #10
|
| 125 |
+
[ -1, Upsample, [None, 2, 'nearest']], #11
|
| 126 |
+
[ [-1, 6], Concat, [1]], #12
|
| 127 |
+
[ -1, BottleneckCSP, [512, 256, 1, False]], #13
|
| 128 |
+
[ -1, Conv, [256, 128, 1, 1]], #14
|
| 129 |
+
[ -1, Upsample, [None, 2, 'nearest']], #15
|
| 130 |
+
[ [-1,4], Concat, [1]], #16
|
| 131 |
+
[ -1, BottleneckCSP, [256, 128, 1, False]], #17
|
| 132 |
+
[ -1, Conv, [128, 128, 3, 2]], #18
|
| 133 |
+
[ [-1, 14], Concat, [1]], #19
|
| 134 |
+
[ -1, BottleneckCSP, [256, 256, 1, False]], #20
|
| 135 |
+
[ -1, Conv, [256, 256, 3, 2]], #21
|
| 136 |
+
[ [-1, 10], Concat, [1]], #22
|
| 137 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]], #23
|
| 138 |
+
[ [17, 20, 23], Detect, [1, [[3,9,5,11,4,20], [7,18,6,39,12,31], [19,50,38,81,68,157]], [128, 256, 512]]], #Detect output 24
|
| 139 |
+
|
| 140 |
+
[ 16, Conv, [256, 64, 3, 1]], #25
|
| 141 |
+
[ -1, Upsample, [None, 2, 'nearest']], #26
|
| 142 |
+
[ [-1,2], Concat, [1]], #27
|
| 143 |
+
[ -1, BottleneckCSP, [128, 64, 1, False]], #28
|
| 144 |
+
[ -1, Conv, [64, 32, 3, 1]], #29
|
| 145 |
+
[ -1, Upsample, [None, 2, 'nearest']], #30
|
| 146 |
+
[ -1, Conv, [32, 16, 3, 1]], #31
|
| 147 |
+
[ -1, BottleneckCSP, [16, 8, 1, False]], #32 driving area segment neck
|
| 148 |
+
|
| 149 |
+
[ 16, Conv, [256, 64, 3, 1]], #33
|
| 150 |
+
[ -1, Upsample, [None, 2, 'nearest']], #34
|
| 151 |
+
[ [-1,2], Concat, [1]], #35
|
| 152 |
+
[ -1, BottleneckCSP, [128, 64, 1, False]], #36
|
| 153 |
+
[ -1, Conv, [64, 32, 3, 1]], #37
|
| 154 |
+
[ -1, Upsample, [None, 2, 'nearest']], #38
|
| 155 |
+
[ -1, Conv, [32, 16, 3, 1]], #39
|
| 156 |
+
[ -1, BottleneckCSP, [16, 8, 1, False]], #40 lane line segment neck
|
| 157 |
+
|
| 158 |
+
[ [31,39], Concat, [1]], #41
|
| 159 |
+
[ -1, Conv, [32, 8, 3, 1]], #42 Share_Block
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
[ [32,42], Concat, [1]], #43
|
| 163 |
+
[ -1, Upsample, [None, 2, 'nearest']], #44
|
| 164 |
+
[ -1, Conv, [16, 2, 3, 1]], #45 Driving area segmentation output
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
[ [40,42], Concat, [1]], #46
|
| 168 |
+
[ -1, Upsample, [None, 2, 'nearest']], #47
|
| 169 |
+
[ -1, Conv, [16, 2, 3, 1]] #48Lane line segmentation output
|
| 170 |
+
]
|
| 171 |
+
|
| 172 |
+
# The lane line and the driving area segment branches without share information with each other
|
| 173 |
+
MCnet_no_share = [
|
| 174 |
+
[ -1, Focus, [3, 32, 3]], #0
|
| 175 |
+
[ -1, Conv, [32, 64, 3, 2]], #1
|
| 176 |
+
[ -1, BottleneckCSP, [64, 64, 1]], #2
|
| 177 |
+
[ -1, Conv, [64, 128, 3, 2]], #3
|
| 178 |
+
[ -1, BottleneckCSP, [128, 128, 3]], #4
|
| 179 |
+
[ -1, Conv, [128, 256, 3, 2]], #5
|
| 180 |
+
[ -1, BottleneckCSP, [256, 256, 3]], #6
|
| 181 |
+
[ -1, Conv, [256, 512, 3, 2]], #7
|
| 182 |
+
[ -1, SPP, [512, 512, [5, 9, 13]]], #8
|
| 183 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]], #9
|
| 184 |
+
[ -1, Conv,[512, 256, 1, 1]], #10
|
| 185 |
+
[ -1, Upsample, [None, 2, 'nearest']], #11
|
| 186 |
+
[ [-1, 6], Concat, [1]], #12
|
| 187 |
+
[ -1, BottleneckCSP, [512, 256, 1, False]], #13
|
| 188 |
+
[ -1, Conv, [256, 128, 1, 1]], #14
|
| 189 |
+
[ -1, Upsample, [None, 2, 'nearest']], #15
|
| 190 |
+
[ [-1,4], Concat, [1]], #16
|
| 191 |
+
[ -1, BottleneckCSP, [256, 128, 1, False]], #17
|
| 192 |
+
[ -1, Conv, [128, 128, 3, 2]], #18
|
| 193 |
+
[ [-1, 14], Concat, [1]], #19
|
| 194 |
+
[ -1, BottleneckCSP, [256, 256, 1, False]], #20
|
| 195 |
+
[ -1, Conv, [256, 256, 3, 2]], #21
|
| 196 |
+
[ [-1, 10], Concat, [1]], #22
|
| 197 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]], #23
|
| 198 |
+
[ [17, 20, 23], Detect, [1, [[3,9,5,11,4,20], [7,18,6,39,12,31], [19,50,38,81,68,157]], [128, 256, 512]]], #Detect output 24
|
| 199 |
+
|
| 200 |
+
[ 16, Conv, [256, 64, 3, 1]], #25
|
| 201 |
+
[ -1, Upsample, [None, 2, 'nearest']], #26
|
| 202 |
+
[ [-1,2], Concat, [1]], #27
|
| 203 |
+
[ -1, BottleneckCSP, [128, 64, 1, False]], #28
|
| 204 |
+
[ -1, Conv, [64, 32, 3, 1]], #29
|
| 205 |
+
[ -1, Upsample, [None, 2, 'nearest']], #30
|
| 206 |
+
[ -1, Conv, [32, 16, 3, 1]], #31
|
| 207 |
+
[ -1, BottleneckCSP, [16, 8, 1, False]], #32 driving area segment neck
|
| 208 |
+
[ -1, Upsample, [None, 2, 'nearest']], #33
|
| 209 |
+
[ -1, Conv, [8, 3, 3, 1]], #34 Driving area segmentation output
|
| 210 |
+
|
| 211 |
+
[ 16, Conv, [256, 64, 3, 1]], #35
|
| 212 |
+
[ -1, Upsample, [None, 2, 'nearest']], #36
|
| 213 |
+
[ [-1,2], Concat, [1]], #37
|
| 214 |
+
[ -1, BottleneckCSP, [128, 64, 1, False]], #38
|
| 215 |
+
[ -1, Conv, [64, 32, 3, 1]], #39
|
| 216 |
+
[ -1, Upsample, [None, 2, 'nearest']], #40
|
| 217 |
+
[ -1, Conv, [32, 16, 3, 1]], #41
|
| 218 |
+
[ -1, BottleneckCSP, [16, 8, 1, False]], #42 lane line segment neck
|
| 219 |
+
[ -1, Upsample, [None, 2, 'nearest']], #43
|
| 220 |
+
[ -1, Conv, [8, 2, 3, 1]] #44 Lane line segmentation output
|
| 221 |
+
]
|
| 222 |
+
|
| 223 |
+
MCnet_feedback = [
|
| 224 |
+
[ -1, Focus, [3, 32, 3]], #0
|
| 225 |
+
[ -1, Conv, [32, 64, 3, 2]], #1
|
| 226 |
+
[ -1, BottleneckCSP, [64, 64, 1]], #2
|
| 227 |
+
[ -1, Conv, [64, 128, 3, 2]], #3
|
| 228 |
+
[ -1, BottleneckCSP, [128, 128, 3]], #4
|
| 229 |
+
[ -1, Conv, [128, 256, 3, 2]], #5
|
| 230 |
+
[ -1, BottleneckCSP, [256, 256, 3]], #6
|
| 231 |
+
[ -1, Conv, [256, 512, 3, 2]], #7
|
| 232 |
+
[ -1, SPP, [512, 512, [5, 9, 13]]], #8
|
| 233 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]], #9
|
| 234 |
+
[ -1, Conv,[512, 256, 1, 1]], #10
|
| 235 |
+
[ -1, Upsample, [None, 2, 'nearest']], #11
|
| 236 |
+
[ [-1, 6], Concat, [1]], #12
|
| 237 |
+
[ -1, BottleneckCSP, [512, 256, 1, False]], #13
|
| 238 |
+
[ -1, Conv, [256, 128, 1, 1]], #14
|
| 239 |
+
[ -1, Upsample, [None, 2, 'nearest']], #15
|
| 240 |
+
[ [-1,4], Concat, [1]], #16
|
| 241 |
+
[ -1, BottleneckCSP, [256, 128, 1, False]], #17
|
| 242 |
+
[ -1, Conv, [128, 128, 3, 2]], #18
|
| 243 |
+
[ [-1, 14], Concat, [1]], #19
|
| 244 |
+
[ -1, BottleneckCSP, [256, 256, 1, False]], #20
|
| 245 |
+
[ -1, Conv, [256, 256, 3, 2]], #21
|
| 246 |
+
[ [-1, 10], Concat, [1]], #22
|
| 247 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]], #23
|
| 248 |
+
[ [17, 20, 23], Detect, [1, [[3,9,5,11,4,20], [7,18,6,39,12,31], [19,50,38,81,68,157]], [128, 256, 512]]], #Detect output 24
|
| 249 |
+
|
| 250 |
+
[ 16, Conv, [256, 128, 3, 1]], #25
|
| 251 |
+
[ -1, Upsample, [None, 2, 'nearest']], #26
|
| 252 |
+
[ -1, BottleneckCSP, [128, 64, 1, False]], #28
|
| 253 |
+
[ -1, Conv, [64, 32, 3, 1]], #29
|
| 254 |
+
[ -1, Upsample, [None, 2, 'nearest']], #30
|
| 255 |
+
[ -1, Conv, [32, 16, 3, 1]], #31
|
| 256 |
+
[ -1, BottleneckCSP, [16, 8, 1, False]], #32 driving area segment neck
|
| 257 |
+
[ -1, Upsample, [None, 2, 'nearest']], #33
|
| 258 |
+
[ -1, Conv, [8, 2, 3, 1]], #34 Driving area segmentation output
|
| 259 |
+
|
| 260 |
+
[ 16, Conv, [256, 128, 3, 1]], #35
|
| 261 |
+
[ -1, Upsample, [None, 2, 'nearest']], #36
|
| 262 |
+
[ -1, BottleneckCSP, [128, 64, 1, False]], #38
|
| 263 |
+
[ -1, Conv, [64, 32, 3, 1]], #39
|
| 264 |
+
[ -1, Upsample, [None, 2, 'nearest']], #40
|
| 265 |
+
[ -1, Conv, [32, 16, 3, 1]], #41
|
| 266 |
+
[ -1, BottleneckCSP, [16, 8, 1, False]], #42 lane line segment neck
|
| 267 |
+
[ -1, Upsample, [None, 2, 'nearest']], #43
|
| 268 |
+
[ -1, Conv, [8, 2, 3, 1]] #44 Lane line segmentation output
|
| 269 |
+
]
|
| 270 |
+
|
| 271 |
+
|
| 272 |
+
MCnet_Da_feedback1 = [
|
| 273 |
+
[46, 26, 35], #Det_out_idx, Da_Segout_idx, LL_Segout_idx
|
| 274 |
+
[ -1, Focus, [3, 32, 3]], #0
|
| 275 |
+
[ -1, Conv, [32, 64, 3, 2]], #1
|
| 276 |
+
[ -1, BottleneckCSP, [64, 64, 1]], #2
|
| 277 |
+
[ -1, Conv, [64, 128, 3, 2]], #3
|
| 278 |
+
[ -1, BottleneckCSP, [128, 128, 3]], #4
|
| 279 |
+
[ -1, Conv, [128, 256, 3, 2]], #5
|
| 280 |
+
[ -1, BottleneckCSP, [256, 256, 3]], #6
|
| 281 |
+
[ -1, Conv, [256, 512, 3, 2]], #7
|
| 282 |
+
[ -1, SPP, [512, 512, [5, 9, 13]]], #8
|
| 283 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]], #9
|
| 284 |
+
[ -1, Conv,[512, 256, 1, 1]], #10
|
| 285 |
+
[ -1, Upsample, [None, 2, 'nearest']], #11
|
| 286 |
+
[ [-1, 6], Concat, [1]], #12
|
| 287 |
+
[ -1, BottleneckCSP, [512, 256, 1, False]], #13
|
| 288 |
+
[ -1, Conv, [256, 128, 1, 1]], #14
|
| 289 |
+
[ -1, Upsample, [None, 2, 'nearest']], #15
|
| 290 |
+
[ [-1,4], Concat, [1]], #16 backbone+fpn
|
| 291 |
+
[ -1,Conv,[256,256,1,1]], #17
|
| 292 |
+
|
| 293 |
+
|
| 294 |
+
[ 16, Conv, [256, 128, 3, 1]], #18
|
| 295 |
+
[ -1, Upsample, [None, 2, 'nearest']], #19
|
| 296 |
+
[ -1, BottleneckCSP, [128, 64, 1, False]], #20
|
| 297 |
+
[ -1, Conv, [64, 32, 3, 1]], #21
|
| 298 |
+
[ -1, Upsample, [None, 2, 'nearest']], #22
|
| 299 |
+
[ -1, Conv, [32, 16, 3, 1]], #23
|
| 300 |
+
[ -1, BottleneckCSP, [16, 8, 1, False]], #24 driving area segment neck
|
| 301 |
+
[ -1, Upsample, [None, 2, 'nearest']], #25
|
| 302 |
+
[ -1, Conv, [8, 2, 3, 1]], #26 Driving area segmentation output
|
| 303 |
+
|
| 304 |
+
|
| 305 |
+
[ 16, Conv, [256, 128, 3, 1]], #27
|
| 306 |
+
[ -1, Upsample, [None, 2, 'nearest']], #28
|
| 307 |
+
[ -1, BottleneckCSP, [128, 64, 1, False]], #29
|
| 308 |
+
[ -1, Conv, [64, 32, 3, 1]], #30
|
| 309 |
+
[ -1, Upsample, [None, 2, 'nearest']], #31
|
| 310 |
+
[ -1, Conv, [32, 16, 3, 1]], #32
|
| 311 |
+
[ -1, BottleneckCSP, [16, 8, 1, False]], #33 lane line segment neck
|
| 312 |
+
[ -1, Upsample, [None, 2, 'nearest']], #34
|
| 313 |
+
[ -1, Conv, [8, 2, 3, 1]], #35Lane line segmentation output
|
| 314 |
+
|
| 315 |
+
|
| 316 |
+
[ 23, Conv, [16, 16, 3, 2]], #36
|
| 317 |
+
[ -1, Conv, [16, 32, 3, 2]], #2 times 2xdownsample 37
|
| 318 |
+
|
| 319 |
+
[ [-1,17], Concat, [1]], #38
|
| 320 |
+
[ -1, BottleneckCSP, [288, 128, 1, False]], #39
|
| 321 |
+
[ -1, Conv, [128, 128, 3, 2]], #40
|
| 322 |
+
[ [-1, 14], Concat, [1]], #41
|
| 323 |
+
[ -1, BottleneckCSP, [256, 256, 1, False]], #42
|
| 324 |
+
[ -1, Conv, [256, 256, 3, 2]], #43
|
| 325 |
+
[ [-1, 10], Concat, [1]], #44
|
| 326 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]], #45
|
| 327 |
+
[ [39, 42, 45], Detect, [1, [[3,9,5,11,4,20], [7,18,6,39,12,31], [19,50,38,81,68,157]], [128, 256, 512]]] #Detect output 46
|
| 328 |
+
]
|
| 329 |
+
|
| 330 |
+
|
| 331 |
+
|
| 332 |
+
# The lane line and the driving area segment branches share information with each other and feedback to det_head
|
| 333 |
+
MCnet_Da_feedback2 = [
|
| 334 |
+
[47, 26, 35], #Det_out_idx, Da_Segout_idx, LL_Segout_idx
|
| 335 |
+
[25, 28, 31, 33], #layer in Da_branch to do SAD
|
| 336 |
+
[34, 37, 40, 42], #layer in LL_branch to do SAD
|
| 337 |
+
[ -1, Focus, [3, 32, 3]], #0
|
| 338 |
+
[ -1, Conv, [32, 64, 3, 2]], #1
|
| 339 |
+
[ -1, BottleneckCSP, [64, 64, 1]], #2
|
| 340 |
+
[ -1, Conv, [64, 128, 3, 2]], #3
|
| 341 |
+
[ -1, BottleneckCSP, [128, 128, 3]], #4
|
| 342 |
+
[ -1, Conv, [128, 256, 3, 2]], #5
|
| 343 |
+
[ -1, BottleneckCSP, [256, 256, 3]], #6
|
| 344 |
+
[ -1, Conv, [256, 512, 3, 2]], #7
|
| 345 |
+
[ -1, SPP, [512, 512, [5, 9, 13]]], #8
|
| 346 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]], #9
|
| 347 |
+
[ -1, Conv,[512, 256, 1, 1]], #10
|
| 348 |
+
[ -1, Upsample, [None, 2, 'nearest']], #11
|
| 349 |
+
[ [-1, 6], Concat, [1]], #12
|
| 350 |
+
[ -1, BottleneckCSP, [512, 256, 1, False]], #13
|
| 351 |
+
[ -1, Conv, [256, 128, 1, 1]], #14
|
| 352 |
+
[ -1, Upsample, [None, 2, 'nearest']], #15
|
| 353 |
+
[ [-1,4], Concat, [1]], #16 backbone+fpn
|
| 354 |
+
[ -1,Conv,[256,256,1,1]], #17
|
| 355 |
+
|
| 356 |
+
|
| 357 |
+
[ 16, Conv, [256, 128, 3, 1]], #18
|
| 358 |
+
[ -1, Upsample, [None, 2, 'nearest']], #19
|
| 359 |
+
[ -1, BottleneckCSP, [128, 64, 1, False]], #20
|
| 360 |
+
[ -1, Conv, [64, 32, 3, 1]], #21
|
| 361 |
+
[ -1, Upsample, [None, 2, 'nearest']], #22
|
| 362 |
+
[ -1, Conv, [32, 16, 3, 1]], #23
|
| 363 |
+
[ -1, BottleneckCSP, [16, 8, 1, False]], #24 driving area segment neck
|
| 364 |
+
[ -1, Upsample, [None, 2, 'nearest']], #25
|
| 365 |
+
[ -1, Conv, [8, 2, 3, 1]], #26 Driving area segmentation output
|
| 366 |
+
|
| 367 |
+
|
| 368 |
+
[ 16, Conv, [256, 128, 3, 1]], #27
|
| 369 |
+
[ -1, Upsample, [None, 2, 'nearest']], #28
|
| 370 |
+
[ -1, BottleneckCSP, [128, 64, 1, False]], #29
|
| 371 |
+
[ -1, Conv, [64, 32, 3, 1]], #30
|
| 372 |
+
[ -1, Upsample, [None, 2, 'nearest']], #31
|
| 373 |
+
[ -1, Conv, [32, 16, 3, 1]], #32
|
| 374 |
+
[ -1, BottleneckCSP, [16, 8, 1, False]], #33 lane line segment neck
|
| 375 |
+
[ -1, Upsample, [None, 2, 'nearest']], #34
|
| 376 |
+
[ -1, Conv, [8, 2, 3, 1]], #35Lane line segmentation output
|
| 377 |
+
|
| 378 |
+
|
| 379 |
+
[ 23, Conv, [16, 64, 3, 2]], #36
|
| 380 |
+
[ -1, Conv, [64, 256, 3, 2]], #2 times 2xdownsample 37
|
| 381 |
+
|
| 382 |
+
[ [-1,17], Concat, [1]], #38
|
| 383 |
+
|
| 384 |
+
[-1, Conv, [512, 256, 3, 1]], #39
|
| 385 |
+
[ -1, BottleneckCSP, [256, 128, 1, False]], #40
|
| 386 |
+
[ -1, Conv, [128, 128, 3, 2]], #41
|
| 387 |
+
[ [-1, 14], Concat, [1]], #42
|
| 388 |
+
[ -1, BottleneckCSP, [256, 256, 1, False]], #43
|
| 389 |
+
[ -1, Conv, [256, 256, 3, 2]], #44
|
| 390 |
+
[ [-1, 10], Concat, [1]], #45
|
| 391 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]], #46
|
| 392 |
+
[ [40, 42, 45], Detect, [1, [[3,9,5,11,4,20], [7,18,6,39,12,31], [19,50,38,81,68,157]], [128, 256, 512]]] #Detect output 47
|
| 393 |
+
]
|
| 394 |
+
|
| 395 |
+
MCnet_share1 = [
|
| 396 |
+
[24, 33, 45], #Det_out_idx, Da_Segout_idx, LL_Segout_idx
|
| 397 |
+
[25, 28, 31, 33], #layer in Da_branch to do SAD
|
| 398 |
+
[34, 37, 40, 42], #layer in LL_branch to do SAD
|
| 399 |
+
[ -1, Focus, [3, 32, 3]], #0
|
| 400 |
+
[ -1, Conv, [32, 64, 3, 2]], #1
|
| 401 |
+
[ -1, BottleneckCSP, [64, 64, 1]], #2
|
| 402 |
+
[ -1, Conv, [64, 128, 3, 2]], #3
|
| 403 |
+
[ -1, BottleneckCSP, [128, 128, 3]], #4
|
| 404 |
+
[ -1, Conv, [128, 256, 3, 2]], #5
|
| 405 |
+
[ -1, BottleneckCSP, [256, 256, 3]], #6
|
| 406 |
+
[ -1, Conv, [256, 512, 3, 2]], #7
|
| 407 |
+
[ -1, SPP, [512, 512, [5, 9, 13]]], #8
|
| 408 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]], #9
|
| 409 |
+
[ -1, Conv,[512, 256, 1, 1]], #10
|
| 410 |
+
[ -1, Upsample, [None, 2, 'nearest']], #11
|
| 411 |
+
[ [-1, 6], Concat, [1]], #12
|
| 412 |
+
[ -1, BottleneckCSP, [512, 256, 1, False]], #13
|
| 413 |
+
[ -1, Conv, [256, 128, 1, 1]], #14
|
| 414 |
+
[ -1, Upsample, [None, 2, 'nearest']], #15
|
| 415 |
+
[ [-1,4], Concat, [1]], #16
|
| 416 |
+
[ -1, BottleneckCSP, [256, 128, 1, False]], #17
|
| 417 |
+
[ -1, Conv, [128, 128, 3, 2]], #18
|
| 418 |
+
[ [-1, 14], Concat, [1]], #19
|
| 419 |
+
[ -1, BottleneckCSP, [256, 256, 1, False]], #20
|
| 420 |
+
[ -1, Conv, [256, 256, 3, 2]], #21
|
| 421 |
+
[ [-1, 10], Concat, [1]], #22
|
| 422 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]], #23
|
| 423 |
+
[ [17, 20, 23], Detect, [1, [[3,9,5,11,4,20], [7,18,6,39,12,31], [19,50,38,81,68,157]], [128, 256, 512]]], #Detect output 24
|
| 424 |
+
|
| 425 |
+
[ 16, Conv, [256, 128, 3, 1]], #25
|
| 426 |
+
[ -1, Upsample, [None, 2, 'nearest']], #26
|
| 427 |
+
[ -1, BottleneckCSP, [128, 64, 1, False]], #27
|
| 428 |
+
[ -1, Conv, [64, 32, 3, 1]], #28
|
| 429 |
+
[ -1, Upsample, [None, 2, 'nearest']], #29
|
| 430 |
+
[ -1, Conv, [32, 16, 3, 1]], #30
|
| 431 |
+
|
| 432 |
+
[ -1, BottleneckCSP, [16, 8, 1, False]], #31 driving area segment neck
|
| 433 |
+
[ -1, Upsample, [None, 2, 'nearest']], #32
|
| 434 |
+
[ -1, Conv, [8, 2, 3, 1]], #33 Driving area segmentation output
|
| 435 |
+
|
| 436 |
+
[ 16, Conv, [256, 128, 3, 1]], #34
|
| 437 |
+
[ -1, Upsample, [None, 2, 'nearest']], #35
|
| 438 |
+
[ -1, BottleneckCSP, [128, 64, 1, False]], #36
|
| 439 |
+
[ -1, Conv, [64, 32, 3, 1]], #37
|
| 440 |
+
[ -1, Upsample, [None, 2, 'nearest']], #38
|
| 441 |
+
[ -1, Conv, [32, 16, 3, 1]], #39
|
| 442 |
+
|
| 443 |
+
[ 30, SharpenConv, [16,16, 3, 1]], #40
|
| 444 |
+
[ -1, Conv, [16, 16, 3, 1]], #41
|
| 445 |
+
[ [-1, 39], Concat, [1]], #42
|
| 446 |
+
[ -1, BottleneckCSP, [32, 8, 1, False]], #43 lane line segment neck
|
| 447 |
+
[ -1, Upsample, [None, 2, 'nearest']], #44
|
| 448 |
+
[ -1, Conv, [8, 2, 3, 1]] #45 Lane line segmentation output
|
| 449 |
+
]"""
|
| 450 |
+
|
| 451 |
+
|
| 452 |
+
# The lane line and the driving area segment branches without share information with each other and without link
|
| 453 |
+
YOLOP = [
|
| 454 |
+
[24, 33, 42], #Det_out_idx, Da_Segout_idx, LL_Segout_idx
|
| 455 |
+
[ -1, Focus, [3, 32, 3]], #0
|
| 456 |
+
[ -1, Conv, [32, 64, 3, 2]], #1
|
| 457 |
+
[ -1, BottleneckCSP, [64, 64, 1]], #2
|
| 458 |
+
[ -1, Conv, [64, 128, 3, 2]], #3
|
| 459 |
+
[ -1, BottleneckCSP, [128, 128, 3]], #4
|
| 460 |
+
[ -1, Conv, [128, 256, 3, 2]], #5
|
| 461 |
+
[ -1, BottleneckCSP, [256, 256, 3]], #6
|
| 462 |
+
[ -1, Conv, [256, 512, 3, 2]], #7
|
| 463 |
+
[ -1, SPP, [512, 512, [5, 9, 13]]], #8
|
| 464 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]], #9
|
| 465 |
+
[ -1, Conv,[512, 256, 1, 1]], #10
|
| 466 |
+
[ -1, Upsample, [None, 2, 'nearest']], #11
|
| 467 |
+
[ [-1, 6], Concat, [1]], #12
|
| 468 |
+
[ -1, BottleneckCSP, [512, 256, 1, False]], #13
|
| 469 |
+
[ -1, Conv, [256, 128, 1, 1]], #14
|
| 470 |
+
[ -1, Upsample, [None, 2, 'nearest']], #15
|
| 471 |
+
[ [-1,4], Concat, [1]], #16 #Encoder
|
| 472 |
+
|
| 473 |
+
[ -1, BottleneckCSP, [256, 128, 1, False]], #17
|
| 474 |
+
[ -1, Conv, [128, 128, 3, 2]], #18
|
| 475 |
+
[ [-1, 14], Concat, [1]], #19
|
| 476 |
+
[ -1, BottleneckCSP, [256, 256, 1, False]], #20
|
| 477 |
+
[ -1, Conv, [256, 256, 3, 2]], #21
|
| 478 |
+
[ [-1, 10], Concat, [1]], #22
|
| 479 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]], #23
|
| 480 |
+
[ [17, 20, 23], Detect, [1, [[3,9,5,11,4,20], [7,18,6,39,12,31], [19,50,38,81,68,157]], [128, 256, 512]]], #Detection head 24
|
| 481 |
+
|
| 482 |
+
[ 16, Conv, [256, 128, 3, 1]], #25
|
| 483 |
+
[ -1, Upsample, [None, 2, 'nearest']], #26
|
| 484 |
+
[ -1, BottleneckCSP, [128, 64, 1, False]], #27
|
| 485 |
+
[ -1, Conv, [64, 32, 3, 1]], #28
|
| 486 |
+
[ -1, Upsample, [None, 2, 'nearest']], #29
|
| 487 |
+
[ -1, Conv, [32, 16, 3, 1]], #30
|
| 488 |
+
[ -1, BottleneckCSP, [16, 8, 1, False]], #31
|
| 489 |
+
[ -1, Upsample, [None, 2, 'nearest']], #32
|
| 490 |
+
[ -1, Conv, [8, 2, 3, 1]], #33 Driving area segmentation head
|
| 491 |
+
|
| 492 |
+
[ 16, Conv, [256, 128, 3, 1]], #34
|
| 493 |
+
[ -1, Upsample, [None, 2, 'nearest']], #35
|
| 494 |
+
[ -1, BottleneckCSP, [128, 64, 1, False]], #36
|
| 495 |
+
[ -1, Conv, [64, 32, 3, 1]], #37
|
| 496 |
+
[ -1, Upsample, [None, 2, 'nearest']], #38
|
| 497 |
+
[ -1, Conv, [32, 16, 3, 1]], #39
|
| 498 |
+
[ -1, BottleneckCSP, [16, 8, 1, False]], #40
|
| 499 |
+
[ -1, Upsample, [None, 2, 'nearest']], #41
|
| 500 |
+
[ -1, Conv, [8, 2, 3, 1]] #42 Lane line segmentation head
|
| 501 |
+
]
|
| 502 |
+
|
| 503 |
+
|
| 504 |
+
class MCnet(nn.Module):
|
| 505 |
+
def __init__(self, block_cfg, **kwargs):
|
| 506 |
+
super(MCnet, self).__init__()
|
| 507 |
+
layers, save= [], []
|
| 508 |
+
self.nc = 1
|
| 509 |
+
self.detector_index = -1
|
| 510 |
+
self.det_out_idx = block_cfg[0][0]
|
| 511 |
+
self.seg_out_idx = block_cfg[0][1:]
|
| 512 |
+
|
| 513 |
+
|
| 514 |
+
# Build model
|
| 515 |
+
for i, (from_, block, args) in enumerate(block_cfg[1:]):
|
| 516 |
+
block = eval(block) if isinstance(block, str) else block # eval strings
|
| 517 |
+
if block is Detect:
|
| 518 |
+
self.detector_index = i
|
| 519 |
+
block_ = block(*args)
|
| 520 |
+
block_.index, block_.from_ = i, from_
|
| 521 |
+
layers.append(block_)
|
| 522 |
+
save.extend(x % i for x in ([from_] if isinstance(from_, int) else from_) if x != -1) # append to savelist
|
| 523 |
+
assert self.detector_index == block_cfg[0][0]
|
| 524 |
+
|
| 525 |
+
self.model, self.save = nn.Sequential(*layers), sorted(save)
|
| 526 |
+
self.names = [str(i) for i in range(self.nc)]
|
| 527 |
+
|
| 528 |
+
# set stride、anchor for detector
|
| 529 |
+
Detector = self.model[self.detector_index] # detector
|
| 530 |
+
if isinstance(Detector, Detect):
|
| 531 |
+
s = 128 # 2x min stride
|
| 532 |
+
# for x in self.forward(torch.zeros(1, 3, s, s)):
|
| 533 |
+
# print (x.shape)
|
| 534 |
+
with torch.no_grad():
|
| 535 |
+
model_out = self.forward(torch.zeros(1, 3, s, s))
|
| 536 |
+
detects, _, _= model_out
|
| 537 |
+
Detector.stride = torch.tensor([s / x.shape[-2] for x in detects]) # forward
|
| 538 |
+
# print("stride"+str(Detector.stride ))
|
| 539 |
+
Detector.anchors /= Detector.stride.view(-1, 1, 1) # Set the anchors for the corresponding scale
|
| 540 |
+
check_anchor_order(Detector)
|
| 541 |
+
self.stride = Detector.stride
|
| 542 |
+
self._initialize_biases()
|
| 543 |
+
|
| 544 |
+
initialize_weights(self)
|
| 545 |
+
|
| 546 |
+
def forward(self, x):
|
| 547 |
+
cache = []
|
| 548 |
+
out = []
|
| 549 |
+
det_out = None
|
| 550 |
+
Da_fmap = []
|
| 551 |
+
LL_fmap = []
|
| 552 |
+
for i, block in enumerate(self.model):
|
| 553 |
+
if block.from_ != -1:
|
| 554 |
+
x = cache[block.from_] if isinstance(block.from_, int) else [x if j == -1 else cache[j] for j in block.from_] #calculate concat detect
|
| 555 |
+
x = block(x)
|
| 556 |
+
if i in self.seg_out_idx: #save driving area segment result
|
| 557 |
+
m=nn.Sigmoid()
|
| 558 |
+
out.append(m(x))
|
| 559 |
+
if i == self.detector_index:
|
| 560 |
+
det_out = x
|
| 561 |
+
cache.append(x if block.index in self.save else None)
|
| 562 |
+
out.insert(0,det_out)
|
| 563 |
+
return out
|
| 564 |
+
|
| 565 |
+
|
| 566 |
+
def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
|
| 567 |
+
# https://arxiv.org/abs/1708.02002 section 3.3
|
| 568 |
+
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
|
| 569 |
+
# m = self.model[-1] # Detect() module
|
| 570 |
+
m = self.model[self.detector_index] # Detect() module
|
| 571 |
+
for mi, s in zip(m.m, m.stride): # from
|
| 572 |
+
b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
|
| 573 |
+
b[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
|
| 574 |
+
b[:, 5:] += math.log(0.6 / (m.nc - 0.99)) if cf is None else torch.log(cf / cf.sum()) # cls
|
| 575 |
+
mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
|
| 576 |
+
|
| 577 |
+
def get_net(cfg, **kwargs):
|
| 578 |
+
m_block_cfg = YOLOP
|
| 579 |
+
model = MCnet(m_block_cfg, **kwargs)
|
| 580 |
+
return model
|
| 581 |
+
|
| 582 |
+
|
| 583 |
+
if __name__ == "__main__":
|
| 584 |
+
from torch.utils.tensorboard import SummaryWriter
|
| 585 |
+
model = get_net(False)
|
| 586 |
+
input_ = torch.randn((1, 3, 256, 256))
|
| 587 |
+
gt_ = torch.rand((1, 2, 256, 256))
|
| 588 |
+
metric = SegmentationMetric(2)
|
| 589 |
+
model_out,SAD_out = model(input_)
|
| 590 |
+
detects, dring_area_seg, lane_line_seg = model_out
|
| 591 |
+
Da_fmap, LL_fmap = SAD_out
|
| 592 |
+
for det in detects:
|
| 593 |
+
print(det.shape)
|
| 594 |
+
print(dring_area_seg.shape)
|
| 595 |
+
print(lane_line_seg.shape)
|
| 596 |
+
|
lib/models/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .YOLOP import get_net
|
lib/models/common.py
ADDED
|
@@ -0,0 +1,265 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import numpy as np
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
from PIL import Image, ImageDraw
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def autopad(k, p=None): # kernel, padding
|
| 9 |
+
# Pad to 'same'
|
| 10 |
+
if p is None:
|
| 11 |
+
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
|
| 12 |
+
return p
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class DepthSeperabelConv2d(nn.Module):
|
| 16 |
+
"""
|
| 17 |
+
DepthSeperable Convolution 2d with residual connection
|
| 18 |
+
"""
|
| 19 |
+
|
| 20 |
+
def __init__(self, inplanes, planes, kernel_size=3, stride=1, downsample=None, act=True):
|
| 21 |
+
super(DepthSeperabelConv2d, self).__init__()
|
| 22 |
+
self.depthwise = nn.Sequential(
|
| 23 |
+
nn.Conv2d(inplanes, inplanes, kernel_size, stride=stride, groups=inplanes, padding=kernel_size//2, bias=False),
|
| 24 |
+
nn.BatchNorm2d(inplanes, momentum=BN_MOMENTUM)
|
| 25 |
+
)
|
| 26 |
+
# self.depthwise = nn.Conv2d(inplanes, inplanes, kernel_size, stride=stride, groups=inplanes, padding=1, bias=False)
|
| 27 |
+
# self.pointwise = nn.Conv2d(inplanes, planes, 1, bias=False)
|
| 28 |
+
|
| 29 |
+
self.pointwise = nn.Sequential(
|
| 30 |
+
nn.Conv2d(inplanes, planes, 1, bias=False),
|
| 31 |
+
nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
|
| 32 |
+
)
|
| 33 |
+
self.downsample = downsample
|
| 34 |
+
self.stride = stride
|
| 35 |
+
try:
|
| 36 |
+
self.act = nn.Hardswish() if act else nn.Identity()
|
| 37 |
+
except:
|
| 38 |
+
self.act = nn.Identity()
|
| 39 |
+
|
| 40 |
+
def forward(self, x):
|
| 41 |
+
#residual = x
|
| 42 |
+
|
| 43 |
+
out = self.depthwise(x)
|
| 44 |
+
out = self.act(out)
|
| 45 |
+
out = self.pointwise(out)
|
| 46 |
+
|
| 47 |
+
if self.downsample is not None:
|
| 48 |
+
residual = self.downsample(x)
|
| 49 |
+
out = self.act(out)
|
| 50 |
+
|
| 51 |
+
return out
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
class SharpenConv(nn.Module):
|
| 56 |
+
# SharpenConv convolution
|
| 57 |
+
def __init__(self, c1, c2, k=3, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
|
| 58 |
+
super(SharpenConv, self).__init__()
|
| 59 |
+
sobel_kernel = np.array([[-1, -1, -1], [-1, 8, -1], [-1, -1, -1]], dtype='float32')
|
| 60 |
+
kenel_weight = np.vstack([sobel_kernel]*c2*c1).reshape(c2,c1,3,3)
|
| 61 |
+
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
|
| 62 |
+
self.conv.weight.data = torch.from_numpy(kenel_weight)
|
| 63 |
+
self.conv.weight.requires_grad = False
|
| 64 |
+
self.bn = nn.BatchNorm2d(c2)
|
| 65 |
+
try:
|
| 66 |
+
self.act = nn.Hardswish() if act else nn.Identity()
|
| 67 |
+
except:
|
| 68 |
+
self.act = nn.Identity()
|
| 69 |
+
|
| 70 |
+
def forward(self, x):
|
| 71 |
+
return self.act(self.bn(self.conv(x)))
|
| 72 |
+
|
| 73 |
+
def fuseforward(self, x):
|
| 74 |
+
return self.act(self.conv(x))
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
class Conv(nn.Module):
|
| 78 |
+
# Standard convolution
|
| 79 |
+
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
|
| 80 |
+
super(Conv, self).__init__()
|
| 81 |
+
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
|
| 82 |
+
self.bn = nn.BatchNorm2d(c2)
|
| 83 |
+
try:
|
| 84 |
+
self.act = nn.Hardswish() if act else nn.Identity()
|
| 85 |
+
except:
|
| 86 |
+
self.act = nn.Identity()
|
| 87 |
+
|
| 88 |
+
def forward(self, x):
|
| 89 |
+
return self.act(self.bn(self.conv(x)))
|
| 90 |
+
|
| 91 |
+
def fuseforward(self, x):
|
| 92 |
+
return self.act(self.conv(x))
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
class Bottleneck(nn.Module):
|
| 96 |
+
# Standard bottleneck
|
| 97 |
+
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
|
| 98 |
+
super(Bottleneck, self).__init__()
|
| 99 |
+
c_ = int(c2 * e) # hidden channels
|
| 100 |
+
self.cv1 = Conv(c1, c_, 1, 1)
|
| 101 |
+
self.cv2 = Conv(c_, c2, 3, 1, g=g)
|
| 102 |
+
self.add = shortcut and c1 == c2
|
| 103 |
+
|
| 104 |
+
def forward(self, x):
|
| 105 |
+
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
class BottleneckCSP(nn.Module):
|
| 109 |
+
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
|
| 110 |
+
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
|
| 111 |
+
super(BottleneckCSP, self).__init__()
|
| 112 |
+
c_ = int(c2 * e) # hidden channels
|
| 113 |
+
self.cv1 = Conv(c1, c_, 1, 1)
|
| 114 |
+
self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
|
| 115 |
+
self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)
|
| 116 |
+
self.cv4 = Conv(2 * c_, c2, 1, 1)
|
| 117 |
+
self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
|
| 118 |
+
self.act = nn.LeakyReLU(0.1, inplace=True)
|
| 119 |
+
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
|
| 120 |
+
|
| 121 |
+
def forward(self, x):
|
| 122 |
+
y1 = self.cv3(self.m(self.cv1(x)))
|
| 123 |
+
y2 = self.cv2(x)
|
| 124 |
+
return self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1))))
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
class SPP(nn.Module):
|
| 128 |
+
# Spatial pyramid pooling layer used in YOLOv3-SPP
|
| 129 |
+
def __init__(self, c1, c2, k=(5, 9, 13)):
|
| 130 |
+
super(SPP, self).__init__()
|
| 131 |
+
c_ = c1 // 2 # hidden channels
|
| 132 |
+
self.cv1 = Conv(c1, c_, 1, 1)
|
| 133 |
+
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
|
| 134 |
+
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
|
| 135 |
+
|
| 136 |
+
def forward(self, x):
|
| 137 |
+
x = self.cv1(x)
|
| 138 |
+
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
class Focus(nn.Module):
|
| 142 |
+
# Focus wh information into c-space
|
| 143 |
+
# slice concat conv
|
| 144 |
+
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
|
| 145 |
+
super(Focus, self).__init__()
|
| 146 |
+
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
|
| 147 |
+
|
| 148 |
+
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
|
| 149 |
+
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
class Concat(nn.Module):
|
| 153 |
+
# Concatenate a list of tensors along dimension
|
| 154 |
+
def __init__(self, dimension=1):
|
| 155 |
+
super(Concat, self).__init__()
|
| 156 |
+
self.d = dimension
|
| 157 |
+
|
| 158 |
+
def forward(self, x):
|
| 159 |
+
""" print("***********************")
|
| 160 |
+
for f in x:
|
| 161 |
+
print(f.shape) """
|
| 162 |
+
return torch.cat(x, self.d)
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
class Detect(nn.Module):
|
| 166 |
+
stride = None # strides computed during build
|
| 167 |
+
|
| 168 |
+
def __init__(self, nc=13, anchors=(), ch=()): # detection layer
|
| 169 |
+
super(Detect, self).__init__()
|
| 170 |
+
self.nc = nc # number of classes
|
| 171 |
+
self.no = nc + 5 # number of outputs per anchor 85
|
| 172 |
+
self.nl = len(anchors) # number of detection layers 3
|
| 173 |
+
self.na = len(anchors[0]) // 2 # number of anchors 3
|
| 174 |
+
self.grid = [torch.zeros(1)] * self.nl # init grid
|
| 175 |
+
a = torch.tensor(anchors).float().view(self.nl, -1, 2)
|
| 176 |
+
self.register_buffer('anchors', a) # shape(nl,na,2)
|
| 177 |
+
self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl,1,na,1,1,2)
|
| 178 |
+
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
|
| 179 |
+
|
| 180 |
+
def forward(self, x):
|
| 181 |
+
z = [] # inference output
|
| 182 |
+
for i in range(self.nl):
|
| 183 |
+
x[i] = self.m[i](x[i]) # conv
|
| 184 |
+
# print(str(i)+str(x[i].shape))
|
| 185 |
+
bs, _, ny, nx = x[i].shape # x(bs,255,w,w) to x(bs,3,w,w,85)
|
| 186 |
+
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
|
| 187 |
+
# print(str(i)+str(x[i].shape))
|
| 188 |
+
|
| 189 |
+
if not self.training: # inference
|
| 190 |
+
if self.grid[i].shape[2:4] != x[i].shape[2:4]:
|
| 191 |
+
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
|
| 192 |
+
y = x[i].sigmoid()
|
| 193 |
+
#print("**")
|
| 194 |
+
#print(y.shape) #[1, 3, w, h, 85]
|
| 195 |
+
#print(self.grid[i].shape) #[1, 3, w, h, 2]
|
| 196 |
+
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i].to(x[i].device)) * self.stride[i] # xy
|
| 197 |
+
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
|
| 198 |
+
"""print("**")
|
| 199 |
+
print(y.shape) #[1, 3, w, h, 85]
|
| 200 |
+
print(y.view(bs, -1, self.no).shape) #[1, 3*w*h, 85]"""
|
| 201 |
+
z.append(y.view(bs, -1, self.no))
|
| 202 |
+
return x if self.training else (torch.cat(z, 1), x)
|
| 203 |
+
|
| 204 |
+
@staticmethod
|
| 205 |
+
def _make_grid(nx=20, ny=20):
|
| 206 |
+
|
| 207 |
+
yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
|
| 208 |
+
return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
"""class Detections:
|
| 212 |
+
# detections class for YOLOv5 inference results
|
| 213 |
+
def __init__(self, imgs, pred, names=None):
|
| 214 |
+
super(Detections, self).__init__()
|
| 215 |
+
d = pred[0].device # device
|
| 216 |
+
gn = [torch.tensor([*[im.shape[i] for i in [1, 0, 1, 0]], 1., 1.], device=d) for im in imgs] # normalizations
|
| 217 |
+
self.imgs = imgs # list of images as numpy arrays
|
| 218 |
+
self.pred = pred # list of tensors pred[0] = (xyxy, conf, cls)
|
| 219 |
+
self.names = names # class names
|
| 220 |
+
self.xyxy = pred # xyxy pixels
|
| 221 |
+
self.xywh = [xyxy2xywh(x) for x in pred] # xywh pixels
|
| 222 |
+
self.xyxyn = [x / g for x, g in zip(self.xyxy, gn)] # xyxy normalized
|
| 223 |
+
self.xywhn = [x / g for x, g in zip(self.xywh, gn)] # xywh normalized
|
| 224 |
+
self.n = len(self.pred)
|
| 225 |
+
|
| 226 |
+
def display(self, pprint=False, show=False, save=False):
|
| 227 |
+
colors = color_list()
|
| 228 |
+
for i, (img, pred) in enumerate(zip(self.imgs, self.pred)):
|
| 229 |
+
str = f'Image {i + 1}/{len(self.pred)}: {img.shape[0]}x{img.shape[1]} '
|
| 230 |
+
if pred is not None:
|
| 231 |
+
for c in pred[:, -1].unique():
|
| 232 |
+
n = (pred[:, -1] == c).sum() # detections per class
|
| 233 |
+
str += f'{n} {self.names[int(c)]}s, ' # add to string
|
| 234 |
+
if show or save:
|
| 235 |
+
img = Image.fromarray(img.astype(np.uint8)) if isinstance(img, np.ndarray) else img # from np
|
| 236 |
+
for *box, conf, cls in pred: # xyxy, confidence, class
|
| 237 |
+
# str += '%s %.2f, ' % (names[int(cls)], conf) # label
|
| 238 |
+
ImageDraw.Draw(img).rectangle(box, width=4, outline=colors[int(cls) % 10]) # plot
|
| 239 |
+
if save:
|
| 240 |
+
f = f'results{i}.jpg'
|
| 241 |
+
str += f"saved to '{f}'"
|
| 242 |
+
img.save(f) # save
|
| 243 |
+
if show:
|
| 244 |
+
img.show(f'Image {i}') # show
|
| 245 |
+
if pprint:
|
| 246 |
+
print(str)
|
| 247 |
+
|
| 248 |
+
def print(self):
|
| 249 |
+
self.display(pprint=True) # print results
|
| 250 |
+
|
| 251 |
+
def show(self):
|
| 252 |
+
self.display(show=True) # show results
|
| 253 |
+
|
| 254 |
+
def save(self):
|
| 255 |
+
self.display(save=True) # save results
|
| 256 |
+
|
| 257 |
+
def __len__(self):
|
| 258 |
+
return self.n
|
| 259 |
+
|
| 260 |
+
def tolist(self):
|
| 261 |
+
# return a list of Detections objects, i.e. 'for result in results.tolist():'
|
| 262 |
+
x = [Detections([self.imgs[i]], [self.pred[i]], self.names) for i in range(self.n)]
|
| 263 |
+
for d in x:
|
| 264 |
+
for k in ['imgs', 'pred', 'xyxy', 'xyxyn', 'xywh', 'xywhn']:
|
| 265 |
+
setattr(d, k, getattr(d, k)[0]) # pop out of list"""
|
lib/models/light.py
ADDED
|
@@ -0,0 +1,496 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch import tensor
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import sys,os
|
| 5 |
+
import math
|
| 6 |
+
import sys
|
| 7 |
+
sys.path.append(os.getcwd())
|
| 8 |
+
from lib.utils import initialize_weights
|
| 9 |
+
# from lib.models.common2 import DepthSeperabelConv2d as Conv
|
| 10 |
+
# from lib.models.common2 import SPP, Bottleneck, BottleneckCSP, Focus, Concat, Detect
|
| 11 |
+
from lib.models.common import Conv, SPP, Bottleneck, BottleneckCSP, Focus, Concat, Detect
|
| 12 |
+
from torch.nn import Upsample
|
| 13 |
+
from lib.utils import check_anchor_order
|
| 14 |
+
from lib.core.evaluate import SegmentationMetric
|
| 15 |
+
from lib.utils.utils import time_synchronized
|
| 16 |
+
|
| 17 |
+
CSPDarknet_s = [
|
| 18 |
+
[ -1, Focus, [3, 32, 3]],
|
| 19 |
+
[ -1, Conv, [32, 64, 3, 2]],
|
| 20 |
+
[ -1, BottleneckCSP, [64, 64, 1]],
|
| 21 |
+
[ -1, Conv, [64, 128, 3, 2]],
|
| 22 |
+
[ -1, BottleneckCSP, [128, 128, 3]],
|
| 23 |
+
[ -1, Conv, [128, 256, 3, 2]],
|
| 24 |
+
[ -1, BottleneckCSP, [256, 256, 3]],
|
| 25 |
+
[ -1, Conv, [256, 512, 3, 2]],
|
| 26 |
+
[ -1, SPP, [512, 512, [5, 9, 13]]],
|
| 27 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]]
|
| 28 |
+
]
|
| 29 |
+
|
| 30 |
+
# MCnet = [
|
| 31 |
+
# [ -1, Focus, [3, 32, 3]],
|
| 32 |
+
# [ -1, Conv, [32, 64, 3, 2]],
|
| 33 |
+
# [ -1, BottleneckCSP, [64, 64, 1]],
|
| 34 |
+
# [ -1, Conv, [64, 128, 3, 2]],
|
| 35 |
+
# [ -1, BottleneckCSP, [128, 128, 3]],
|
| 36 |
+
# [ -1, Conv, [128, 256, 3, 2]],
|
| 37 |
+
# [ -1, BottleneckCSP, [256, 256, 3]],
|
| 38 |
+
# [ -1, Conv, [256, 512, 3, 2]],
|
| 39 |
+
# [ -1, SPP, [512, 512, [5, 9, 13]]],
|
| 40 |
+
# [ -1, BottleneckCSP, [512, 512, 1, False]],
|
| 41 |
+
# [ -1, Conv,[512, 256, 1, 1]],
|
| 42 |
+
# [ -1, Upsample, [None, 2, 'nearest']],
|
| 43 |
+
# [ [-1, 6], Concat, [1]],
|
| 44 |
+
# [ -1, BottleneckCSP, [512, 256, 1, False]],
|
| 45 |
+
# [ -1, Conv, [256, 128, 1, 1]],
|
| 46 |
+
# [ -1, Upsample, [None, 2, 'nearest']],
|
| 47 |
+
# [ [-1,4], Concat, [1]],
|
| 48 |
+
# [ -1, BottleneckCSP, [256, 128, 1, False]],
|
| 49 |
+
# [ -1, Conv, [128, 128, 3, 2]],
|
| 50 |
+
# [ [-1, 14], Concat, [1]],
|
| 51 |
+
# [ -1, BottleneckCSP, [256, 256, 1, False]],
|
| 52 |
+
# [ -1, Conv, [256, 256, 3, 2]],
|
| 53 |
+
# [ [-1, 10], Concat, [1]],
|
| 54 |
+
# [ -1, BottleneckCSP, [512, 512, 1, False]],
|
| 55 |
+
# [ [17, 20, 23], Detect, [1, [[3,9,5,11,4,20], [7,18,6,39,12,31], [19,50,38,81,68,157]], [128, 256, 512]]],
|
| 56 |
+
# [ 17, Conv, [128, 64, 3, 1]],
|
| 57 |
+
# [ -1, Upsample, [None, 2, 'nearest']],
|
| 58 |
+
# [ [-1,2], Concat, [1]],
|
| 59 |
+
# [ -1, BottleneckCSP, [128, 64, 1, False]],
|
| 60 |
+
# [ -1, Conv, [64, 32, 3, 1]],
|
| 61 |
+
# [ -1, Upsample, [None, 2, 'nearest']],
|
| 62 |
+
# [ -1, Conv, [32, 16, 3, 1]],
|
| 63 |
+
# [ -1, BottleneckCSP, [16, 8, 1, False]],
|
| 64 |
+
# [ -1, Upsample, [None, 2, 'nearest']],
|
| 65 |
+
# [ -1, Conv, [8, 2, 3, 1]] #segmentation output
|
| 66 |
+
# ]
|
| 67 |
+
|
| 68 |
+
MCnet_SPP = [
|
| 69 |
+
[ -1, Focus, [3, 32, 3]],
|
| 70 |
+
[ -1, Conv, [32, 64, 3, 2]],
|
| 71 |
+
[ -1, BottleneckCSP, [64, 64, 1]],
|
| 72 |
+
[ -1, Conv, [64, 128, 3, 2]],
|
| 73 |
+
[ -1, BottleneckCSP, [128, 128, 3]],
|
| 74 |
+
[ -1, Conv, [128, 256, 3, 2]],
|
| 75 |
+
[ -1, BottleneckCSP, [256, 256, 3]],
|
| 76 |
+
[ -1, Conv, [256, 512, 3, 2]],
|
| 77 |
+
[ -1, SPP, [512, 512, [5, 9, 13]]],
|
| 78 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]],
|
| 79 |
+
[ -1, Conv,[512, 256, 1, 1]],
|
| 80 |
+
[ -1, Upsample, [None, 2, 'nearest']],
|
| 81 |
+
[ [-1, 6], Concat, [1]],
|
| 82 |
+
[ -1, BottleneckCSP, [512, 256, 1, False]],
|
| 83 |
+
[ -1, Conv, [256, 128, 1, 1]],
|
| 84 |
+
[ -1, Upsample, [None, 2, 'nearest']],
|
| 85 |
+
[ [-1,4], Concat, [1]],
|
| 86 |
+
[ -1, BottleneckCSP, [256, 128, 1, False]],
|
| 87 |
+
[ -1, Conv, [128, 128, 3, 2]],
|
| 88 |
+
[ [-1, 14], Concat, [1]],
|
| 89 |
+
[ -1, BottleneckCSP, [256, 256, 1, False]],
|
| 90 |
+
[ -1, Conv, [256, 256, 3, 2]],
|
| 91 |
+
[ [-1, 10], Concat, [1]],
|
| 92 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]],
|
| 93 |
+
# [ [17, 20, 23], Detect, [1, [[3,9,5,11,4,20], [7,18,6,39,12,31], [19,50,38,81,68,157]], [128, 256, 512]]],
|
| 94 |
+
[ [17, 20, 23], Detect, [13, [[3,9,5,11,4,20], [7,18,6,39,12,31], [19,50,38,81,68,157]], [128, 256, 512]]],
|
| 95 |
+
[ 17, Conv, [128, 64, 3, 1]],
|
| 96 |
+
[ -1, Upsample, [None, 2, 'nearest']],
|
| 97 |
+
[ [-1,2], Concat, [1]],
|
| 98 |
+
[ -1, BottleneckCSP, [128, 64, 1, False]],
|
| 99 |
+
[ -1, Conv, [64, 32, 3, 1]],
|
| 100 |
+
[ -1, Upsample, [None, 2, 'nearest']],
|
| 101 |
+
[ -1, Conv, [32, 16, 3, 1]],
|
| 102 |
+
[ -1, BottleneckCSP, [16, 8, 1, False]],
|
| 103 |
+
[ -1, Upsample, [None, 2, 'nearest']],
|
| 104 |
+
[ -1, SPP, [8, 2, [5, 9, 13]]] #segmentation output
|
| 105 |
+
]
|
| 106 |
+
# [2,6,3,9,5,13], [7,19,11,26,17,39], [28,64,44,103,61,183]
|
| 107 |
+
MCnet_fast = [
|
| 108 |
+
[ -1, Focus, [3, 32, 3]],#0
|
| 109 |
+
[ -1, Conv, [32, 64, 3, 2]],#1
|
| 110 |
+
[ -1, BottleneckCSP, [64, 128, 1, True, True]],#2
|
| 111 |
+
[ -1, BottleneckCSP, [128, 256, 1, True, True]],#4
|
| 112 |
+
[ -1, BottleneckCSP, [256, 512, 1, True, True]],#6
|
| 113 |
+
[ -1, SPP, [512, 512, [5, 9, 13]]],#8
|
| 114 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]],#9
|
| 115 |
+
[ -1, Conv,[512, 256, 1, 1]],#10
|
| 116 |
+
[ -1, Upsample, [None, 2, 'nearest']],#11
|
| 117 |
+
[ [-1, 6], Concat, [1]],#12
|
| 118 |
+
[ -1, BottleneckCSP, [512, 256, 1, False]],#13
|
| 119 |
+
[ -1, Conv, [256, 128, 1, 1]],#14
|
| 120 |
+
[ -1, Upsample, [None, 2, 'nearest']],#15
|
| 121 |
+
[ [-1,4], Concat, [1]],#16
|
| 122 |
+
[ -1, BottleneckCSP, [256, 128, 1, False, True]],#17
|
| 123 |
+
[ [-1, 14], Concat, [1]],#19
|
| 124 |
+
[ -1, BottleneckCSP, [256, 256, 1, False, True]],#20
|
| 125 |
+
[ [-1, 10], Concat, [1]],#22
|
| 126 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]],#23
|
| 127 |
+
[ [17, 20, 23], Detect, [1, [[3,9,5,11,4,20], [7,18,6,39,12,31], [19,50,38,81,68,157]], [128, 256, 512]]], #Detect output 24
|
| 128 |
+
|
| 129 |
+
[ 16, Conv, [256, 64, 3, 1]],#25
|
| 130 |
+
[ -1, Upsample, [None, 2, 'nearest']],#26
|
| 131 |
+
[ [-1,2], Concat, [1]],#27
|
| 132 |
+
[ -1, BottleneckCSP, [128, 32, 1, False]],#28
|
| 133 |
+
# [ -1, Conv, [64, 32, 1, 1]],#29
|
| 134 |
+
[ -1, Upsample, [None, 2, 'nearest']],#30
|
| 135 |
+
# [ -1, Conv, [32, 16, 1, 1]],#31
|
| 136 |
+
[ -1, BottleneckCSP, [32, 8, 1, False]],#32
|
| 137 |
+
[ -1, Upsample, [None, 2, 'nearest']],#33
|
| 138 |
+
[ -1, Conv, [8, 2, 1, 1]], #Driving area segmentation output#34
|
| 139 |
+
|
| 140 |
+
[ 16, Conv, [256, 64, 3, 1]],
|
| 141 |
+
[ -1, Upsample, [None, 2, 'nearest']],
|
| 142 |
+
[ [-1,2], Concat, [1]],
|
| 143 |
+
[ -1, BottleneckCSP, [128, 32, 1, False]],
|
| 144 |
+
# [ -1, Conv, [64, 32, 1, 1]],
|
| 145 |
+
[ -1, Upsample, [None, 2, 'nearest']],
|
| 146 |
+
# [ -1, Conv, [32, 16, 1, 1]],
|
| 147 |
+
[ 31, BottleneckCSP, [32, 8, 1, False]],#35
|
| 148 |
+
[ -1, Upsample, [None, 2, 'nearest']],#36
|
| 149 |
+
[ -1, Conv, [8, 2, 1, 1]], #Lane line segmentation output #37
|
| 150 |
+
]
|
| 151 |
+
|
| 152 |
+
MCnet_light = [
|
| 153 |
+
[ -1, Focus, [3, 32, 3]],#0
|
| 154 |
+
[ -1, Conv, [32, 64, 3, 2]],#1
|
| 155 |
+
[ -1, BottleneckCSP, [64, 64, 1]],#2
|
| 156 |
+
[ -1, Conv, [64, 128, 3, 2]],#3
|
| 157 |
+
[ -1, BottleneckCSP, [128, 128, 3]],#4
|
| 158 |
+
[ -1, Conv, [128, 256, 3, 2]],#5
|
| 159 |
+
[ -1, BottleneckCSP, [256, 256, 3]],#6
|
| 160 |
+
[ -1, Conv, [256, 512, 3, 2]],#7
|
| 161 |
+
[ -1, SPP, [512, 512, [5, 9, 13]]],#8
|
| 162 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]],#9
|
| 163 |
+
[ -1, Conv,[512, 256, 1, 1]],#10
|
| 164 |
+
[ -1, Upsample, [None, 2, 'nearest']],#11
|
| 165 |
+
[ [-1, 6], Concat, [1]],#12
|
| 166 |
+
[ -1, BottleneckCSP, [512, 256, 1, False]],#13
|
| 167 |
+
[ -1, Conv, [256, 128, 1, 1]],#14
|
| 168 |
+
[ -1, Upsample, [None, 2, 'nearest']],#15
|
| 169 |
+
[ [-1,4], Concat, [1]],#16
|
| 170 |
+
[ -1, BottleneckCSP, [256, 128, 1, False]],#17
|
| 171 |
+
[ -1, Conv, [128, 128, 3, 2]],#18
|
| 172 |
+
[ [-1, 14], Concat, [1]],#19
|
| 173 |
+
[ -1, BottleneckCSP, [256, 256, 1, False]],#20
|
| 174 |
+
[ -1, Conv, [256, 256, 3, 2]],#21
|
| 175 |
+
[ [-1, 10], Concat, [1]],#22
|
| 176 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]],#23
|
| 177 |
+
[ [17, 20, 23], Detect, [1, [[4,12,6,18,10,27], [15,38,24,59,39,78], [51,125,73,168,97,292]], [128, 256, 512]]], #Detect output 24
|
| 178 |
+
|
| 179 |
+
[ 16, Conv, [256, 128, 3, 1]],#25
|
| 180 |
+
[ -1, Upsample, [None, 2, 'nearest']],#26
|
| 181 |
+
# [ [-1,2], Concat, [1]],#27
|
| 182 |
+
[ -1, BottleneckCSP, [128, 64, 1, False]],#27
|
| 183 |
+
[ -1, Conv, [64, 32, 3, 1]],#28
|
| 184 |
+
[ -1, Upsample, [None, 2, 'nearest']],#29
|
| 185 |
+
[ -1, Conv, [32, 16, 3, 1]],#30
|
| 186 |
+
[ -1, BottleneckCSP, [16, 8, 1, False]],#31
|
| 187 |
+
[ -1, Upsample, [None, 2, 'nearest']],#32
|
| 188 |
+
[ -1, Conv, [8, 3, 3, 1]], #Driving area segmentation output#33
|
| 189 |
+
|
| 190 |
+
# [ 16, Conv, [128, 64, 3, 1]],
|
| 191 |
+
# [ -1, Upsample, [None, 2, 'nearest']],
|
| 192 |
+
# [ [-1,2], Concat, [1]],
|
| 193 |
+
# [ -1, BottleneckCSP, [128, 64, 1, False]],
|
| 194 |
+
# [ -1, Conv, [64, 32, 3, 1]],
|
| 195 |
+
# [ -1, Upsample, [None, 2, 'nearest']],
|
| 196 |
+
# [ -1, Conv, [32, 16, 3, 1]],
|
| 197 |
+
[ 30, BottleneckCSP, [16, 8, 1, False]],#34
|
| 198 |
+
[ -1, Upsample, [None, 2, 'nearest']],#35
|
| 199 |
+
[ -1, Conv, [8, 2, 3, 1]], #Lane line segmentation output #36
|
| 200 |
+
]
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
# The lane line and the driving area segment branches share information with each other
|
| 204 |
+
MCnet_share = [
|
| 205 |
+
[ -1, Focus, [3, 32, 3]], #0
|
| 206 |
+
[ -1, Conv, [32, 64, 3, 2]], #1
|
| 207 |
+
[ -1, BottleneckCSP, [64, 64, 1]], #2
|
| 208 |
+
[ -1, Conv, [64, 128, 3, 2]], #3
|
| 209 |
+
[ -1, BottleneckCSP, [128, 128, 3]], #4
|
| 210 |
+
[ -1, Conv, [128, 256, 3, 2]], #5
|
| 211 |
+
[ -1, BottleneckCSP, [256, 256, 3]], #6
|
| 212 |
+
[ -1, Conv, [256, 512, 3, 2]], #7
|
| 213 |
+
[ -1, SPP, [512, 512, [5, 9, 13]]], #8
|
| 214 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]], #9
|
| 215 |
+
[ -1, Conv,[512, 256, 1, 1]], #10
|
| 216 |
+
[ -1, Upsample, [None, 2, 'nearest']], #11
|
| 217 |
+
[ [-1, 6], Concat, [1]], #12
|
| 218 |
+
[ -1, BottleneckCSP, [512, 256, 1, False]], #13
|
| 219 |
+
[ -1, Conv, [256, 128, 1, 1]], #14
|
| 220 |
+
[ -1, Upsample, [None, 2, 'nearest']], #15
|
| 221 |
+
[ [-1,4], Concat, [1]], #16
|
| 222 |
+
[ -1, BottleneckCSP, [256, 128, 1, False]], #17
|
| 223 |
+
[ -1, Conv, [128, 128, 3, 2]], #18
|
| 224 |
+
[ [-1, 14], Concat, [1]], #19
|
| 225 |
+
[ -1, BottleneckCSP, [256, 256, 1, False]], #20
|
| 226 |
+
[ -1, Conv, [256, 256, 3, 2]], #21
|
| 227 |
+
[ [-1, 10], Concat, [1]], #22
|
| 228 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]], #23
|
| 229 |
+
[ [17, 20, 23], Detect, [1, [[3,9,5,11,4,20], [7,18,6,39,12,31], [19,50,38,81,68,157]], [128, 256, 512]]], #Detect output 24
|
| 230 |
+
|
| 231 |
+
[ 16, Conv, [256, 64, 3, 1]], #25
|
| 232 |
+
[ -1, Upsample, [None, 2, 'nearest']], #26
|
| 233 |
+
[ [-1,2], Concat, [1]], #27
|
| 234 |
+
[ -1, BottleneckCSP, [128, 64, 1, False]], #28
|
| 235 |
+
[ -1, Conv, [64, 32, 3, 1]], #29
|
| 236 |
+
[ -1, Upsample, [None, 2, 'nearest']], #30
|
| 237 |
+
[ -1, Conv, [32, 16, 3, 1]], #31
|
| 238 |
+
[ -1, BottleneckCSP, [16, 8, 1, False]], #32 driving area segment neck
|
| 239 |
+
|
| 240 |
+
[ 16, Conv, [256, 64, 3, 1]], #33
|
| 241 |
+
[ -1, Upsample, [None, 2, 'nearest']], #34
|
| 242 |
+
[ [-1,2], Concat, [1]], #35
|
| 243 |
+
[ -1, BottleneckCSP, [128, 64, 1, False]], #36
|
| 244 |
+
[ -1, Conv, [64, 32, 3, 1]], #37
|
| 245 |
+
[ -1, Upsample, [None, 2, 'nearest']], #38
|
| 246 |
+
[ -1, Conv, [32, 16, 3, 1]], #39
|
| 247 |
+
[ -1, BottleneckCSP, [16, 8, 1, False]], #40 lane line segment neck
|
| 248 |
+
|
| 249 |
+
[ [31,39], Concat, [1]], #41
|
| 250 |
+
[ -1, Conv, [32, 8, 3, 1]], #42 Share_Block
|
| 251 |
+
|
| 252 |
+
|
| 253 |
+
[ [32,42], Concat, [1]], #43
|
| 254 |
+
[ -1, Upsample, [None, 2, 'nearest']], #44
|
| 255 |
+
[ -1, Conv, [16, 2, 3, 1]], #45 Driving area segmentation output
|
| 256 |
+
|
| 257 |
+
|
| 258 |
+
[ [40,42], Concat, [1]], #46
|
| 259 |
+
[ -1, Upsample, [None, 2, 'nearest']], #47
|
| 260 |
+
[ -1, Conv, [16, 2, 3, 1]] #48Lane line segmentation output
|
| 261 |
+
]
|
| 262 |
+
|
| 263 |
+
# The lane line and the driving area segment branches without share information with each other
|
| 264 |
+
MCnet_no_share = [
|
| 265 |
+
[ -1, Focus, [3, 32, 3]], #0
|
| 266 |
+
[ -1, Conv, [32, 64, 3, 2]], #1
|
| 267 |
+
[ -1, BottleneckCSP, [64, 64, 1]], #2
|
| 268 |
+
[ -1, Conv, [64, 128, 3, 2]], #3
|
| 269 |
+
[ -1, BottleneckCSP, [128, 128, 3]], #4
|
| 270 |
+
[ -1, Conv, [128, 256, 3, 2]], #5
|
| 271 |
+
[ -1, BottleneckCSP, [256, 256, 3]], #6
|
| 272 |
+
[ -1, Conv, [256, 512, 3, 2]], #7
|
| 273 |
+
[ -1, SPP, [512, 512, [5, 9, 13]]], #8
|
| 274 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]], #9
|
| 275 |
+
[ -1, Conv,[512, 256, 1, 1]], #10
|
| 276 |
+
[ -1, Upsample, [None, 2, 'nearest']], #11
|
| 277 |
+
[ [-1, 6], Concat, [1]], #12
|
| 278 |
+
[ -1, BottleneckCSP, [512, 256, 1, False]], #13
|
| 279 |
+
[ -1, Conv, [256, 128, 1, 1]], #14
|
| 280 |
+
[ -1, Upsample, [None, 2, 'nearest']], #15
|
| 281 |
+
[ [-1,4], Concat, [1]], #16
|
| 282 |
+
[ -1, BottleneckCSP, [256, 128, 1, False]], #17
|
| 283 |
+
[ -1, Conv, [128, 128, 3, 2]], #18
|
| 284 |
+
[ [-1, 14], Concat, [1]], #19
|
| 285 |
+
[ -1, BottleneckCSP, [256, 256, 1, False]], #20
|
| 286 |
+
[ -1, Conv, [256, 256, 3, 2]], #21
|
| 287 |
+
[ [-1, 10], Concat, [1]], #22
|
| 288 |
+
[ -1, BottleneckCSP, [512, 512, 1, False]], #23
|
| 289 |
+
[ [17, 20, 23], Detect, [13, [[3,9,5,11,4,20], [7,18,6,39,12,31], [19,50,38,81,68,157]], [128, 256, 512]]], #Detect output 24
|
| 290 |
+
|
| 291 |
+
[ 16, Conv, [256, 64, 3, 1]], #25
|
| 292 |
+
[ -1, Upsample, [None, 2, 'nearest']], #26
|
| 293 |
+
[ [-1,2], Concat, [1]], #27
|
| 294 |
+
[ -1, BottleneckCSP, [128, 64, 1, False]], #28
|
| 295 |
+
[ -1, Conv, [64, 32, 3, 1]], #29
|
| 296 |
+
[ -1, Upsample, [None, 2, 'nearest']], #30
|
| 297 |
+
[ -1, Conv, [32, 16, 3, 1]], #31
|
| 298 |
+
[ -1, BottleneckCSP, [16, 8, 1, False]], #32 driving area segment neck
|
| 299 |
+
[ -1, Upsample, [None, 2, 'nearest']], #33
|
| 300 |
+
[ -1, Conv, [8, 3, 3, 1]], #34 Driving area segmentation output
|
| 301 |
+
|
| 302 |
+
[ 16, Conv, [256, 64, 3, 1]], #35
|
| 303 |
+
[ -1, Upsample, [None, 2, 'nearest']], #36
|
| 304 |
+
[ [-1,2], Concat, [1]], #37
|
| 305 |
+
[ -1, BottleneckCSP, [128, 64, 1, False]], #38
|
| 306 |
+
[ -1, Conv, [64, 32, 3, 1]], #39
|
| 307 |
+
[ -1, Upsample, [None, 2, 'nearest']], #40
|
| 308 |
+
[ -1, Conv, [32, 16, 3, 1]], #41
|
| 309 |
+
[ -1, BottleneckCSP, [16, 8, 1, False]], #42 lane line segment neck
|
| 310 |
+
[ -1, Upsample, [None, 2, 'nearest']], #43
|
| 311 |
+
[ -1, Conv, [8, 2, 3, 1]] #44 Lane line segmentation output
|
| 312 |
+
]
|
| 313 |
+
|
| 314 |
+
|
| 315 |
+
|
| 316 |
+
class MCnet(nn.Module):
|
| 317 |
+
def __init__(self, block_cfg, **kwargs):
|
| 318 |
+
super(MCnet, self).__init__()
|
| 319 |
+
layers, save= [], []
|
| 320 |
+
self.nc = 13
|
| 321 |
+
self.detector_index = -1
|
| 322 |
+
self.Da_out_idx = 45 if len(block_cfg)==49 else 34
|
| 323 |
+
# self.Da_out_idx = 37
|
| 324 |
+
|
| 325 |
+
# Build model
|
| 326 |
+
# print(block_cfg)
|
| 327 |
+
for i, (from_, block, args) in enumerate(block_cfg):
|
| 328 |
+
block = eval(block) if isinstance(block, str) else block # eval strings
|
| 329 |
+
if block is Detect:
|
| 330 |
+
self.detector_index = i
|
| 331 |
+
block_ = block(*args)
|
| 332 |
+
block_.index, block_.from_ = i, from_
|
| 333 |
+
layers.append(block_)
|
| 334 |
+
save.extend(x % i for x in ([from_] if isinstance(from_, int) else from_) if x != -1) # append to savelist
|
| 335 |
+
self.model, self.save = nn.Sequential(*layers), sorted(save)
|
| 336 |
+
self.names = [str(i) for i in range(self.nc)]
|
| 337 |
+
|
| 338 |
+
# set stride、anchor for detector
|
| 339 |
+
Detector = self.model[self.detector_index] # detector
|
| 340 |
+
if isinstance(Detector, Detect):
|
| 341 |
+
s = 128 # 2x min stride
|
| 342 |
+
# for x in self.forward(torch.zeros(1, 3, s, s)):
|
| 343 |
+
# print (x.shape)
|
| 344 |
+
with torch.no_grad():
|
| 345 |
+
detects, _, _= self.forward(torch.zeros(1, 3, s, s))
|
| 346 |
+
Detector.stride = torch.tensor([s / x.shape[-2] for x in detects]) # forward
|
| 347 |
+
# print("stride"+str(Detector.stride ))
|
| 348 |
+
Detector.anchors /= Detector.stride.view(-1, 1, 1) # Set the anchors for the corresponding scale
|
| 349 |
+
check_anchor_order(Detector)
|
| 350 |
+
self.stride = Detector.stride
|
| 351 |
+
self._initialize_biases()
|
| 352 |
+
|
| 353 |
+
initialize_weights(self)
|
| 354 |
+
|
| 355 |
+
def forward(self, x):
|
| 356 |
+
cache = []
|
| 357 |
+
out = []
|
| 358 |
+
#times = []
|
| 359 |
+
for i, block in enumerate(self.model):
|
| 360 |
+
#t0 = time_synchronized()
|
| 361 |
+
if block.from_ != -1:
|
| 362 |
+
x = cache[block.from_] if isinstance(block.from_, int) else [x if j == -1 else cache[j] for j in block.from_] #calculate concat detect
|
| 363 |
+
x = block(x)
|
| 364 |
+
if isinstance(block, Detect): # save detector result
|
| 365 |
+
out.append(x)
|
| 366 |
+
if i == self.Da_out_idx: #save driving area segment result
|
| 367 |
+
m=nn.Sigmoid()
|
| 368 |
+
out.append(m(x))
|
| 369 |
+
cache.append(x if block.index in self.save else None)
|
| 370 |
+
"""t1 = time_synchronized()
|
| 371 |
+
print(str(i) + " : " + str(t1-t0))
|
| 372 |
+
times.append(t1-t0)
|
| 373 |
+
print(sum(times[:25]))
|
| 374 |
+
print(sum(times[25:33]))
|
| 375 |
+
print(sum(times[33:41]))
|
| 376 |
+
print(sum(times[41:43]))
|
| 377 |
+
print(sum(times[43:46]))
|
| 378 |
+
print(sum(times[46:]))"""
|
| 379 |
+
m=nn.Sigmoid()
|
| 380 |
+
out.append(m(x))
|
| 381 |
+
return out
|
| 382 |
+
|
| 383 |
+
def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
|
| 384 |
+
# https://arxiv.org/abs/1708.02002 section 3.3
|
| 385 |
+
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
|
| 386 |
+
# m = self.model[-1] # Detect() module
|
| 387 |
+
m = self.model[self.detector_index] # Detect() module
|
| 388 |
+
for mi, s in zip(m.m, m.stride): # from
|
| 389 |
+
b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
|
| 390 |
+
b[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
|
| 391 |
+
b[:, 5:] += math.log(0.6 / (m.nc - 0.99)) if cf is None else torch.log(cf / cf.sum()) # cls
|
| 392 |
+
mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
|
| 393 |
+
|
| 394 |
+
class CSPDarknet(nn.Module):
|
| 395 |
+
def __init__(self, block_cfg, **kwargs):
|
| 396 |
+
super(CSPDarknet, self).__init__()
|
| 397 |
+
layers, save= [], []
|
| 398 |
+
# self.nc = 13 #output category num
|
| 399 |
+
self.nc = 1
|
| 400 |
+
self.detector_index = -1
|
| 401 |
+
|
| 402 |
+
# Build model
|
| 403 |
+
for i, (from_, block, args) in enumerate(block_cfg):
|
| 404 |
+
block = eval(block) if isinstance(block, str) else block # eval strings
|
| 405 |
+
if block is Detect:
|
| 406 |
+
self.detector_index = i
|
| 407 |
+
block_ = block(*args)
|
| 408 |
+
block_.index, block_.from_ = i, from_
|
| 409 |
+
layers.append(block_)
|
| 410 |
+
save.extend(x % i for x in ([from_] if isinstance(from_, int) else from_) if x != -1) # append to savelist
|
| 411 |
+
self.model, self.save = nn.Sequential(*layers), sorted(save)
|
| 412 |
+
self.names = [str(i) for i in range(self.nc)]
|
| 413 |
+
|
| 414 |
+
# set stride、anchor for detector
|
| 415 |
+
Detector = self.model[self.detector_index] # detector
|
| 416 |
+
if isinstance(Detector, Detect):
|
| 417 |
+
s = 128 # 2x min stride
|
| 418 |
+
# for x in self.forward(torch.zeros(1, 3, s, s)):
|
| 419 |
+
# print (x.shape)
|
| 420 |
+
with torch.no_grad():
|
| 421 |
+
detects, _ = self.forward(torch.zeros(1, 3, s, s))
|
| 422 |
+
Detector.stride = torch.tensor([s / x.shape[-2] for x in detects]) # forward
|
| 423 |
+
# print("stride"+str(Detector.stride ))
|
| 424 |
+
Detector.anchors /= Detector.stride.view(-1, 1, 1) # Set the anchors for the corresponding scale
|
| 425 |
+
check_anchor_order(Detector)
|
| 426 |
+
self.stride = Detector.stride
|
| 427 |
+
self._initialize_biases()
|
| 428 |
+
|
| 429 |
+
initialize_weights(self)
|
| 430 |
+
|
| 431 |
+
def forward(self, x):
|
| 432 |
+
cache = []
|
| 433 |
+
out = []
|
| 434 |
+
for i, block in enumerate(self.model):
|
| 435 |
+
if block.from_ != -1:
|
| 436 |
+
x = cache[block.from_] if isinstance(block.from_, int) else [x if j == -1 else cache[j] for j in block.from_] #calculate concat detect
|
| 437 |
+
start = time.time()
|
| 438 |
+
x = block(x)
|
| 439 |
+
end = time.time()
|
| 440 |
+
print(start-end)
|
| 441 |
+
"""y = None if isinstance(x, list) else x.shape"""
|
| 442 |
+
if isinstance(block, Detect): # save detector result
|
| 443 |
+
out.append(x)
|
| 444 |
+
cache.append(x if block.index in self.save else None)
|
| 445 |
+
m=nn.Sigmoid()
|
| 446 |
+
out.append(m(x))
|
| 447 |
+
# out.append(x)
|
| 448 |
+
# print(out[0][0].shape, out[0][1].shape, out[0][2].shape)
|
| 449 |
+
return out
|
| 450 |
+
|
| 451 |
+
def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
|
| 452 |
+
# https://arxiv.org/abs/1708.02002 section 3.3
|
| 453 |
+
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
|
| 454 |
+
# m = self.model[-1] # Detect() module
|
| 455 |
+
m = self.model[self.detector_index] # Detect() module
|
| 456 |
+
for mi, s in zip(m.m, m.stride): # from
|
| 457 |
+
b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
|
| 458 |
+
b[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
|
| 459 |
+
b[:, 5:] += math.log(0.6 / (m.nc - 0.99)) if cf is None else torch.log(cf / cf.sum()) # cls
|
| 460 |
+
mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
|
| 461 |
+
|
| 462 |
+
|
| 463 |
+
def get_net(cfg, **kwargs):
|
| 464 |
+
# m_block_cfg = MCnet_share if cfg.MODEL.STRU_WITHSHARE else MCnet_no_share
|
| 465 |
+
m_block_cfg = MCnet_no_share
|
| 466 |
+
model = MCnet(m_block_cfg, **kwargs)
|
| 467 |
+
return model
|
| 468 |
+
|
| 469 |
+
|
| 470 |
+
if __name__ == "__main__":
|
| 471 |
+
from torch.utils.tensorboard import SummaryWriter
|
| 472 |
+
model = get_net(False)
|
| 473 |
+
input_ = torch.randn((1, 3, 256, 256))
|
| 474 |
+
gt_ = torch.rand((1, 2, 256, 256))
|
| 475 |
+
metric = SegmentationMetric(2)
|
| 476 |
+
|
| 477 |
+
detects, dring_area_seg, lane_line_seg = model(input_)
|
| 478 |
+
for det in detects:
|
| 479 |
+
print(det.shape)
|
| 480 |
+
print(dring_area_seg.shape)
|
| 481 |
+
print(dring_area_seg.view(-1).shape)
|
| 482 |
+
_,predict=torch.max(dring_area_seg, 1)
|
| 483 |
+
print(predict.shape)
|
| 484 |
+
print(lane_line_seg.shape)
|
| 485 |
+
|
| 486 |
+
_,lane_line_pred=torch.max(lane_line_seg, 1)
|
| 487 |
+
_,lane_line_gt=torch.max(gt_, 1)
|
| 488 |
+
metric.reset()
|
| 489 |
+
metric.addBatch(lane_line_pred.cpu(), lane_line_gt.cpu())
|
| 490 |
+
acc = metric.pixelAccuracy()
|
| 491 |
+
meanAcc = metric.meanPixelAccuracy()
|
| 492 |
+
mIoU = metric.meanIntersectionOverUnion()
|
| 493 |
+
FWIoU = metric.Frequency_Weighted_Intersection_over_Union()
|
| 494 |
+
IoU = metric.IntersectionOverUnion()
|
| 495 |
+
print(IoU)
|
| 496 |
+
print(mIoU)
|
lib/utils/__init__.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .utils import initialize_weights, xyxy2xywh, is_parallel, DataLoaderX, torch_distributed_zero_first, clean_str
|
| 2 |
+
from .autoanchor import check_anchor_order, run_anchor, kmean_anchors
|
| 3 |
+
from .augmentations import augment_hsv, random_perspective, cutout, letterbox,letterbox_for_img
|
| 4 |
+
from .plot import plot_img_and_mask,plot_one_box,show_seg_result
|
lib/utils/augmentations.py
ADDED
|
@@ -0,0 +1,253 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
import cv2
|
| 5 |
+
import random
|
| 6 |
+
import math
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def augment_hsv(img, hgain=0.5, sgain=0.5, vgain=0.5):
|
| 10 |
+
"""change color hue, saturation, value"""
|
| 11 |
+
r = np.random.uniform(-1, 1, 3) * [hgain, sgain, vgain] + 1 # random gains
|
| 12 |
+
hue, sat, val = cv2.split(cv2.cvtColor(img, cv2.COLOR_BGR2HSV))
|
| 13 |
+
dtype = img.dtype # uint8
|
| 14 |
+
|
| 15 |
+
x = np.arange(0, 256, dtype=np.int16)
|
| 16 |
+
lut_hue = ((x * r[0]) % 180).astype(dtype)
|
| 17 |
+
lut_sat = np.clip(x * r[1], 0, 255).astype(dtype)
|
| 18 |
+
lut_val = np.clip(x * r[2], 0, 255).astype(dtype)
|
| 19 |
+
|
| 20 |
+
img_hsv = cv2.merge((cv2.LUT(hue, lut_hue), cv2.LUT(sat, lut_sat), cv2.LUT(val, lut_val))).astype(dtype)
|
| 21 |
+
cv2.cvtColor(img_hsv, cv2.COLOR_HSV2BGR, dst=img) # no return needed
|
| 22 |
+
|
| 23 |
+
# Histogram equalization
|
| 24 |
+
# if random.random() < 0.2:
|
| 25 |
+
# for i in range(3):
|
| 26 |
+
# img[:, :, i] = cv2.equalizeHist(img[:, :, i])
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def random_perspective(combination, targets=(), degrees=10, translate=.1, scale=.1, shear=10, perspective=0.0, border=(0, 0)):
|
| 30 |
+
"""combination of img transform"""
|
| 31 |
+
# torchvision.transforms.RandomAffine(degrees=(-10, 10), translate=(.1, .1), scale=(.9, 1.1), shear=(-10, 10))
|
| 32 |
+
# targets = [cls, xyxy]
|
| 33 |
+
img, gray, line = combination
|
| 34 |
+
height = img.shape[0] + border[0] * 2 # shape(h,w,c)
|
| 35 |
+
width = img.shape[1] + border[1] * 2
|
| 36 |
+
|
| 37 |
+
# Center
|
| 38 |
+
C = np.eye(3)
|
| 39 |
+
C[0, 2] = -img.shape[1] / 2 # x translation (pixels)
|
| 40 |
+
C[1, 2] = -img.shape[0] / 2 # y translation (pixels)
|
| 41 |
+
|
| 42 |
+
# Perspective
|
| 43 |
+
P = np.eye(3)
|
| 44 |
+
P[2, 0] = random.uniform(-perspective, perspective) # x perspective (about y)
|
| 45 |
+
P[2, 1] = random.uniform(-perspective, perspective) # y perspective (about x)
|
| 46 |
+
|
| 47 |
+
# Rotation and Scale
|
| 48 |
+
R = np.eye(3)
|
| 49 |
+
a = random.uniform(-degrees, degrees)
|
| 50 |
+
# a += random.choice([-180, -90, 0, 90]) # add 90deg rotations to small rotations
|
| 51 |
+
s = random.uniform(1 - scale, 1 + scale)
|
| 52 |
+
# s = 2 ** random.uniform(-scale, scale)
|
| 53 |
+
R[:2] = cv2.getRotationMatrix2D(angle=a, center=(0, 0), scale=s)
|
| 54 |
+
|
| 55 |
+
# Shear
|
| 56 |
+
S = np.eye(3)
|
| 57 |
+
S[0, 1] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # x shear (deg)
|
| 58 |
+
S[1, 0] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # y shear (deg)
|
| 59 |
+
|
| 60 |
+
# Translation
|
| 61 |
+
T = np.eye(3)
|
| 62 |
+
T[0, 2] = random.uniform(0.5 - translate, 0.5 + translate) * width # x translation (pixels)
|
| 63 |
+
T[1, 2] = random.uniform(0.5 - translate, 0.5 + translate) * height # y translation (pixels)
|
| 64 |
+
|
| 65 |
+
# Combined rotation matrix
|
| 66 |
+
M = T @ S @ R @ P @ C # order of operations (right to left) is IMPORTANT
|
| 67 |
+
if (border[0] != 0) or (border[1] != 0) or (M != np.eye(3)).any(): # image changed
|
| 68 |
+
if perspective:
|
| 69 |
+
img = cv2.warpPerspective(img, M, dsize=(width, height), borderValue=(114, 114, 114))
|
| 70 |
+
gray = cv2.warpPerspective(gray, M, dsize=(width, height), borderValue=0)
|
| 71 |
+
line = cv2.warpPerspective(line, M, dsize=(width, height), borderValue=0)
|
| 72 |
+
else: # affine
|
| 73 |
+
img = cv2.warpAffine(img, M[:2], dsize=(width, height), borderValue=(114, 114, 114))
|
| 74 |
+
gray = cv2.warpAffine(gray, M[:2], dsize=(width, height), borderValue=0)
|
| 75 |
+
line = cv2.warpAffine(line, M[:2], dsize=(width, height), borderValue=0)
|
| 76 |
+
|
| 77 |
+
# Visualize
|
| 78 |
+
# import matplotlib.pyplot as plt
|
| 79 |
+
# ax = plt.subplots(1, 2, figsize=(12, 6))[1].ravel()
|
| 80 |
+
# ax[0].imshow(img[:, :, ::-1]) # base
|
| 81 |
+
# ax[1].imshow(img2[:, :, ::-1]) # warped
|
| 82 |
+
|
| 83 |
+
# Transform label coordinates
|
| 84 |
+
n = len(targets)
|
| 85 |
+
if n:
|
| 86 |
+
# warp points
|
| 87 |
+
xy = np.ones((n * 4, 3))
|
| 88 |
+
xy[:, :2] = targets[:, [1, 2, 3, 4, 1, 4, 3, 2]].reshape(n * 4, 2) # x1y1, x2y2, x1y2, x2y1
|
| 89 |
+
xy = xy @ M.T # transform
|
| 90 |
+
if perspective:
|
| 91 |
+
xy = (xy[:, :2] / xy[:, 2:3]).reshape(n, 8) # rescale
|
| 92 |
+
else: # affine
|
| 93 |
+
xy = xy[:, :2].reshape(n, 8)
|
| 94 |
+
|
| 95 |
+
# create new boxes
|
| 96 |
+
x = xy[:, [0, 2, 4, 6]]
|
| 97 |
+
y = xy[:, [1, 3, 5, 7]]
|
| 98 |
+
xy = np.concatenate((x.min(1), y.min(1), x.max(1), y.max(1))).reshape(4, n).T
|
| 99 |
+
|
| 100 |
+
# # apply angle-based reduction of bounding boxes
|
| 101 |
+
# radians = a * math.pi / 180
|
| 102 |
+
# reduction = max(abs(math.sin(radians)), abs(math.cos(radians))) ** 0.5
|
| 103 |
+
# x = (xy[:, 2] + xy[:, 0]) / 2
|
| 104 |
+
# y = (xy[:, 3] + xy[:, 1]) / 2
|
| 105 |
+
# w = (xy[:, 2] - xy[:, 0]) * reduction
|
| 106 |
+
# h = (xy[:, 3] - xy[:, 1]) * reduction
|
| 107 |
+
# xy = np.concatenate((x - w / 2, y - h / 2, x + w / 2, y + h / 2)).reshape(4, n).T
|
| 108 |
+
|
| 109 |
+
# clip boxes
|
| 110 |
+
xy[:, [0, 2]] = xy[:, [0, 2]].clip(0, width)
|
| 111 |
+
xy[:, [1, 3]] = xy[:, [1, 3]].clip(0, height)
|
| 112 |
+
|
| 113 |
+
# filter candidates
|
| 114 |
+
i = _box_candidates(box1=targets[:, 1:5].T * s, box2=xy.T)
|
| 115 |
+
targets = targets[i]
|
| 116 |
+
targets[:, 1:5] = xy[i]
|
| 117 |
+
|
| 118 |
+
combination = (img, gray, line)
|
| 119 |
+
return combination, targets
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def cutout(combination, labels):
|
| 123 |
+
# Applies image cutout augmentation https://arxiv.org/abs/1708.04552
|
| 124 |
+
image, gray = combination
|
| 125 |
+
h, w = image.shape[:2]
|
| 126 |
+
|
| 127 |
+
def bbox_ioa(box1, box2):
|
| 128 |
+
# Returns the intersection over box2 area given box1, box2. box1 is 4, box2 is nx4. boxes are x1y1x2y2
|
| 129 |
+
box2 = box2.transpose()
|
| 130 |
+
|
| 131 |
+
# Get the coordinates of bounding boxes
|
| 132 |
+
b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
|
| 133 |
+
b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
|
| 134 |
+
|
| 135 |
+
# Intersection area
|
| 136 |
+
inter_area = (np.minimum(b1_x2, b2_x2) - np.maximum(b1_x1, b2_x1)).clip(0) * \
|
| 137 |
+
(np.minimum(b1_y2, b2_y2) - np.maximum(b1_y1, b2_y1)).clip(0)
|
| 138 |
+
|
| 139 |
+
# box2 area
|
| 140 |
+
box2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1) + 1e-16
|
| 141 |
+
|
| 142 |
+
# Intersection over box2 area
|
| 143 |
+
return inter_area / box2_area
|
| 144 |
+
|
| 145 |
+
# create random masks
|
| 146 |
+
scales = [0.5] * 1 + [0.25] * 2 + [0.125] * 4 + [0.0625] * 8 + [0.03125] * 16 # image size fraction
|
| 147 |
+
for s in scales:
|
| 148 |
+
mask_h = random.randint(1, int(h * s))
|
| 149 |
+
mask_w = random.randint(1, int(w * s))
|
| 150 |
+
|
| 151 |
+
# box
|
| 152 |
+
xmin = max(0, random.randint(0, w) - mask_w // 2)
|
| 153 |
+
ymin = max(0, random.randint(0, h) - mask_h // 2)
|
| 154 |
+
xmax = min(w, xmin + mask_w)
|
| 155 |
+
ymax = min(h, ymin + mask_h)
|
| 156 |
+
# print('xmin:{},ymin:{},xmax:{},ymax:{}'.format(xmin,ymin,xmax,ymax))
|
| 157 |
+
|
| 158 |
+
# apply random color mask
|
| 159 |
+
image[ymin:ymax, xmin:xmax] = [random.randint(64, 191) for _ in range(3)]
|
| 160 |
+
gray[ymin:ymax, xmin:xmax] = -1
|
| 161 |
+
|
| 162 |
+
# return unobscured labels
|
| 163 |
+
if len(labels) and s > 0.03:
|
| 164 |
+
box = np.array([xmin, ymin, xmax, ymax], dtype=np.float32)
|
| 165 |
+
ioa = bbox_ioa(box, labels[:, 1:5]) # intersection over area
|
| 166 |
+
labels = labels[ioa < 0.60] # remove >60% obscured labels
|
| 167 |
+
|
| 168 |
+
return image, gray, labels
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
def letterbox(combination, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True):
|
| 172 |
+
"""Resize the input image and automatically padding to suitable shape :https://zhuanlan.zhihu.com/p/172121380"""
|
| 173 |
+
# Resize image to a 32-pixel-multiple rectangle https://github.com/ultralytics/yolov3/issues/232
|
| 174 |
+
img, gray, line = combination
|
| 175 |
+
shape = img.shape[:2] # current shape [height, width]
|
| 176 |
+
if isinstance(new_shape, int):
|
| 177 |
+
new_shape = (new_shape, new_shape)
|
| 178 |
+
|
| 179 |
+
# Scale ratio (new / old)
|
| 180 |
+
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
|
| 181 |
+
if not scaleup: # only scale down, do not scale up (for better test mAP)
|
| 182 |
+
r = min(r, 1.0)
|
| 183 |
+
|
| 184 |
+
# Compute padding
|
| 185 |
+
ratio = r, r # width, height ratios
|
| 186 |
+
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
|
| 187 |
+
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
|
| 188 |
+
if auto: # minimum rectangle
|
| 189 |
+
dw, dh = np.mod(dw, 32), np.mod(dh, 32) # wh padding
|
| 190 |
+
elif scaleFill: # stretch
|
| 191 |
+
dw, dh = 0.0, 0.0
|
| 192 |
+
new_unpad = (new_shape[1], new_shape[0])
|
| 193 |
+
ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratios
|
| 194 |
+
|
| 195 |
+
dw /= 2 # divide padding into 2 sides
|
| 196 |
+
dh /= 2
|
| 197 |
+
|
| 198 |
+
if shape[::-1] != new_unpad: # resize
|
| 199 |
+
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
|
| 200 |
+
gray = cv2.resize(gray, new_unpad, interpolation=cv2.INTER_LINEAR)
|
| 201 |
+
line = cv2.resize(line, new_unpad, interpolation=cv2.INTER_LINEAR)
|
| 202 |
+
|
| 203 |
+
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
|
| 204 |
+
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
|
| 205 |
+
|
| 206 |
+
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
|
| 207 |
+
gray = cv2.copyMakeBorder(gray, top, bottom, left, right, cv2.BORDER_CONSTANT, value=0) # add border
|
| 208 |
+
line = cv2.copyMakeBorder(line, top, bottom, left, right, cv2.BORDER_CONSTANT, value=0) # add border
|
| 209 |
+
# print(img.shape)
|
| 210 |
+
|
| 211 |
+
combination = (img, gray, line)
|
| 212 |
+
return combination, ratio, (dw, dh)
|
| 213 |
+
|
| 214 |
+
def letterbox_for_img(img, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True):
|
| 215 |
+
# Resize image to a 32-pixel-multiple rectangle https://github.com/ultralytics/yolov3/issues/232
|
| 216 |
+
shape = img.shape[:2] # current shape [height, width]
|
| 217 |
+
if isinstance(new_shape, int):
|
| 218 |
+
new_shape = (new_shape, new_shape)
|
| 219 |
+
|
| 220 |
+
# Scale ratio (new / old)
|
| 221 |
+
|
| 222 |
+
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
|
| 223 |
+
if not scaleup: # only scale down, do not scale up (for better test mAP)
|
| 224 |
+
r = min(r, 1.0)
|
| 225 |
+
|
| 226 |
+
# Compute padding
|
| 227 |
+
ratio = r, r # width, height ratios
|
| 228 |
+
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
|
| 229 |
+
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
|
| 230 |
+
if auto: # minimum rectangle
|
| 231 |
+
dw, dh = np.mod(dw, 32), np.mod(dh, 32) # wh padding
|
| 232 |
+
elif scaleFill: # stretch
|
| 233 |
+
dw, dh = 0.0, 0.0
|
| 234 |
+
new_unpad = (new_shape[1], new_shape[0])
|
| 235 |
+
ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratios
|
| 236 |
+
|
| 237 |
+
dw /= 2 # divide padding into 2 sides
|
| 238 |
+
dh /= 2
|
| 239 |
+
if shape[::-1] != new_unpad: # resize
|
| 240 |
+
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_AREA)
|
| 241 |
+
|
| 242 |
+
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
|
| 243 |
+
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
|
| 244 |
+
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
|
| 245 |
+
return img, ratio, (dw, dh)
|
| 246 |
+
|
| 247 |
+
|
| 248 |
+
def _box_candidates(box1, box2, wh_thr=2, ar_thr=20, area_thr=0.1): # box1(4,n), box2(4,n)
|
| 249 |
+
# Compute candidate boxes: box1 before augment, box2 after augment, wh_thr (pixels), aspect_ratio_thr, area_ratio
|
| 250 |
+
w1, h1 = box1[2] - box1[0], box1[3] - box1[1]
|
| 251 |
+
w2, h2 = box2[2] - box2[0], box2[3] - box2[1]
|
| 252 |
+
ar = np.maximum(w2 / (h2 + 1e-16), h2 / (w2 + 1e-16)) # aspect ratio
|
| 253 |
+
return (w2 > wh_thr) & (h2 > wh_thr) & (w2 * h2 / (w1 * h1 + 1e-16) > area_thr) & (ar < ar_thr) # candidates
|
lib/utils/autoanchor.py
ADDED
|
@@ -0,0 +1,134 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Auto-anchor utils
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
import torch
|
| 5 |
+
import yaml
|
| 6 |
+
from scipy.cluster.vq import kmeans
|
| 7 |
+
from tqdm import tqdm
|
| 8 |
+
from lib.utils import is_parallel
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def check_anchor_order(m):
|
| 12 |
+
# Check anchor order against stride order for YOLOv5 Detect() module m, and correct if necessary
|
| 13 |
+
a = m.anchor_grid.prod(-1).view(-1) # anchor area
|
| 14 |
+
da = a[-1] - a[0] # delta a
|
| 15 |
+
ds = m.stride[-1] - m.stride[0] # delta s
|
| 16 |
+
if da.sign() != ds.sign(): # same order
|
| 17 |
+
print('Reversing anchor order')
|
| 18 |
+
m.anchors[:] = m.anchors.flip(0)
|
| 19 |
+
m.anchor_grid[:] = m.anchor_grid.flip(0)
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def run_anchor(logger,dataset, model, thr=4.0, imgsz=640):
|
| 23 |
+
det = model.module.model[model.module.detector_index] if is_parallel(model) \
|
| 24 |
+
else model.model[model.detector_index]
|
| 25 |
+
anchor_num = det.na * det.nl
|
| 26 |
+
new_anchors = kmean_anchors(dataset, n=anchor_num, img_size=imgsz, thr=thr, gen=1000, verbose=False)
|
| 27 |
+
new_anchors = torch.tensor(new_anchors, device=det.anchors.device).type_as(det.anchors)
|
| 28 |
+
det.anchor_grid[:] = new_anchors.clone().view_as(det.anchor_grid) # for inference
|
| 29 |
+
det.anchors[:] = new_anchors.clone().view_as(det.anchors) / det.stride.to(det.anchors.device).view(-1, 1, 1) # loss
|
| 30 |
+
check_anchor_order(det)
|
| 31 |
+
logger.info(str(det.anchors))
|
| 32 |
+
print('New anchors saved to model. Update model config to use these anchors in the future.')
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def kmean_anchors(path='./data/coco128.yaml', n=9, img_size=640, thr=4.0, gen=1000, verbose=True):
|
| 36 |
+
""" Creates kmeans-evolved anchors from training dataset
|
| 37 |
+
|
| 38 |
+
Arguments:
|
| 39 |
+
path: path to dataset *.yaml, or a loaded dataset
|
| 40 |
+
n: number of anchors
|
| 41 |
+
img_size: image size used for training
|
| 42 |
+
thr: anchor-label wh ratio threshold hyperparameter hyp['anchor_t'] used for training, default=4.0
|
| 43 |
+
gen: generations to evolve anchors using genetic algorithm
|
| 44 |
+
verbose: print all results
|
| 45 |
+
|
| 46 |
+
Return:
|
| 47 |
+
k: kmeans evolved anchors
|
| 48 |
+
|
| 49 |
+
Usage:
|
| 50 |
+
from utils.autoanchor import *; _ = kmean_anchors()
|
| 51 |
+
"""
|
| 52 |
+
thr = 1. / thr
|
| 53 |
+
|
| 54 |
+
def metric(k, wh): # compute metrics
|
| 55 |
+
r = wh[:, None] / k[None]
|
| 56 |
+
x = torch.min(r, 1. / r).min(2)[0] # ratio metric
|
| 57 |
+
# x = wh_iou(wh, torch.tensor(k)) # iou metric
|
| 58 |
+
return x, x.max(1)[0] # x, best_x
|
| 59 |
+
|
| 60 |
+
def anchor_fitness(k): # mutation fitness
|
| 61 |
+
_, best = metric(torch.tensor(k, dtype=torch.float32), wh)
|
| 62 |
+
return (best * (best > thr).float()).mean() # fitness
|
| 63 |
+
|
| 64 |
+
def print_results(k):
|
| 65 |
+
k = k[np.argsort(k.prod(1))] # sort small to large
|
| 66 |
+
x, best = metric(k, wh0)
|
| 67 |
+
bpr, aat = (best > thr).float().mean(), (x > thr).float().mean() * n # best possible recall, anch > thr
|
| 68 |
+
print('thr=%.2f: %.4f best possible recall, %.2f anchors past thr' % (thr, bpr, aat))
|
| 69 |
+
print('n=%g, img_size=%s, metric_all=%.3f/%.3f-mean/best, past_thr=%.3f-mean: ' %
|
| 70 |
+
(n, img_size, x.mean(), best.mean(), x[x > thr].mean()), end='')
|
| 71 |
+
for i, x in enumerate(k):
|
| 72 |
+
print('%i,%i' % (round(x[0]), round(x[1])), end=', ' if i < len(k) - 1 else '\n') # use in *.cfg
|
| 73 |
+
return k
|
| 74 |
+
|
| 75 |
+
if isinstance(path, str): # not class
|
| 76 |
+
raise TypeError('Dataset must be class, but found str')
|
| 77 |
+
else:
|
| 78 |
+
dataset = path # dataset
|
| 79 |
+
|
| 80 |
+
labels = [db['label'] for db in dataset.db]
|
| 81 |
+
labels = np.vstack(labels)
|
| 82 |
+
if not (labels[:, 1:] <= 1).all():
|
| 83 |
+
# normalize label
|
| 84 |
+
labels[:, [2, 4]] /= dataset.shapes[0]
|
| 85 |
+
labels[:, [1, 3]] /= dataset.shapes[1]
|
| 86 |
+
# Get label wh
|
| 87 |
+
shapes = img_size * dataset.shapes / dataset.shapes.max()
|
| 88 |
+
# wh0 = np.concatenate([l[:, 3:5] * shapes for l in labels]) # wh
|
| 89 |
+
wh0 = labels[:, 3:5] * shapes
|
| 90 |
+
# Filter
|
| 91 |
+
i = (wh0 < 3.0).any(1).sum()
|
| 92 |
+
if i:
|
| 93 |
+
print('WARNING: Extremely small objects found. '
|
| 94 |
+
'%g of %g labels are < 3 pixels in width or height.' % (i, len(wh0)))
|
| 95 |
+
wh = wh0[(wh0 >= 2.0).any(1)] # filter > 2 pixels
|
| 96 |
+
|
| 97 |
+
# Kmeans calculation
|
| 98 |
+
print('Running kmeans for %g anchors on %g points...' % (n, len(wh)))
|
| 99 |
+
s = wh.std(0) # sigmas for whitening
|
| 100 |
+
k, dist = kmeans(wh / s, n, iter=30) # points, mean distance
|
| 101 |
+
k *= s
|
| 102 |
+
wh = torch.tensor(wh, dtype=torch.float32) # filtered
|
| 103 |
+
wh0 = torch.tensor(wh0, dtype=torch.float32) # unfiltered
|
| 104 |
+
k = print_results(k)
|
| 105 |
+
|
| 106 |
+
# Plot
|
| 107 |
+
# k, d = [None] * 20, [None] * 20
|
| 108 |
+
# for i in tqdm(range(1, 21)):
|
| 109 |
+
# k[i-1], d[i-1] = kmeans(wh / s, i) # points, mean distance
|
| 110 |
+
# fig, ax = plt.subplots(1, 2, figsize=(14, 7), tight_layout=True)
|
| 111 |
+
# ax = ax.ravel()
|
| 112 |
+
# ax[0].plot(np.arange(1, 21), np.array(d) ** 2, marker='.')
|
| 113 |
+
# fig, ax = plt.subplots(1, 2, figsize=(14, 7)) # plot wh
|
| 114 |
+
# ax[0].hist(wh[wh[:, 0]<100, 0],400)
|
| 115 |
+
# ax[1].hist(wh[wh[:, 1]<100, 1],400)
|
| 116 |
+
# fig.savefig('wh.png', dpi=200)
|
| 117 |
+
|
| 118 |
+
# Evolve
|
| 119 |
+
npr = np.random
|
| 120 |
+
f, sh, mp, s = anchor_fitness(k), k.shape, 0.9, 0.1 # fitness, generations, mutation prob, sigma
|
| 121 |
+
pbar = tqdm(range(gen), desc='Evolving anchors with Genetic Algorithm') # progress bar
|
| 122 |
+
for _ in pbar:
|
| 123 |
+
v = np.ones(sh)
|
| 124 |
+
while (v == 1).all(): # mutate until a change occurs (prevent duplicates)
|
| 125 |
+
v = ((npr.random(sh) < mp) * npr.random() * npr.randn(*sh) * s + 1).clip(0.3, 3.0)
|
| 126 |
+
kg = (k.copy() * v).clip(min=2.0)
|
| 127 |
+
fg = anchor_fitness(kg)
|
| 128 |
+
if fg > f:
|
| 129 |
+
f, k = fg, kg.copy()
|
| 130 |
+
pbar.desc = 'Evolving anchors with Genetic Algorithm: fitness = %.4f' % f
|
| 131 |
+
if verbose:
|
| 132 |
+
print_results(k)
|
| 133 |
+
|
| 134 |
+
return print_results(k)
|
lib/utils/plot.py
ADDED
|
@@ -0,0 +1,113 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## 处理pred结果的.json文件,画图
|
| 2 |
+
import matplotlib.pyplot as plt
|
| 3 |
+
import cv2
|
| 4 |
+
import numpy as np
|
| 5 |
+
import random
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def plot_img_and_mask(img, mask, index,epoch,save_dir):
|
| 9 |
+
classes = mask.shape[2] if len(mask.shape) > 2 else 1
|
| 10 |
+
fig, ax = plt.subplots(1, classes + 1)
|
| 11 |
+
ax[0].set_title('Input image')
|
| 12 |
+
ax[0].imshow(img)
|
| 13 |
+
if classes > 1:
|
| 14 |
+
for i in range(classes):
|
| 15 |
+
ax[i+1].set_title(f'Output mask (class {i+1})')
|
| 16 |
+
ax[i+1].imshow(mask[:, :, i])
|
| 17 |
+
else:
|
| 18 |
+
ax[1].set_title(f'Output mask')
|
| 19 |
+
ax[1].imshow(mask)
|
| 20 |
+
plt.xticks([]), plt.yticks([])
|
| 21 |
+
# plt.show()
|
| 22 |
+
plt.savefig(save_dir+"/batch_{}_{}_seg.png".format(epoch,index))
|
| 23 |
+
|
| 24 |
+
def show_seg_result(img, result, index, epoch, save_dir=None, is_ll=False,palette=None,is_demo=False,is_gt=False):
|
| 25 |
+
# img = mmcv.imread(img)
|
| 26 |
+
# img = img.copy()
|
| 27 |
+
# seg = result[0]
|
| 28 |
+
if palette is None:
|
| 29 |
+
palette = np.random.randint(
|
| 30 |
+
0, 255, size=(3, 3))
|
| 31 |
+
palette[0] = [0, 0, 0]
|
| 32 |
+
palette[1] = [0, 255, 0]
|
| 33 |
+
palette[2] = [255, 0, 0]
|
| 34 |
+
palette = np.array(palette)
|
| 35 |
+
assert palette.shape[0] == 3 # len(classes)
|
| 36 |
+
assert palette.shape[1] == 3
|
| 37 |
+
assert len(palette.shape) == 2
|
| 38 |
+
|
| 39 |
+
if not is_demo:
|
| 40 |
+
color_seg = np.zeros((result.shape[0], result.shape[1], 3), dtype=np.uint8)
|
| 41 |
+
for label, color in enumerate(palette):
|
| 42 |
+
color_seg[result == label, :] = color
|
| 43 |
+
else:
|
| 44 |
+
color_area = np.zeros((result[0].shape[0], result[0].shape[1], 3), dtype=np.uint8)
|
| 45 |
+
|
| 46 |
+
# for label, color in enumerate(palette):
|
| 47 |
+
# color_area[result[0] == label, :] = color
|
| 48 |
+
|
| 49 |
+
color_area[result[0] == 1] = [0, 255, 0]
|
| 50 |
+
color_area[result[1] ==1] = [255, 0, 0]
|
| 51 |
+
color_seg = color_area
|
| 52 |
+
|
| 53 |
+
# convert to BGR
|
| 54 |
+
color_seg = color_seg[..., ::-1]
|
| 55 |
+
# print(color_seg.shape)
|
| 56 |
+
color_mask = np.mean(color_seg, 2)
|
| 57 |
+
img[color_mask != 0] = img[color_mask != 0] * 0.5 + color_seg[color_mask != 0] * 0.5
|
| 58 |
+
# img = img * 0.5 + color_seg * 0.5
|
| 59 |
+
img = img.astype(np.uint8)
|
| 60 |
+
img = cv2.resize(img, (1280,720), interpolation=cv2.INTER_LINEAR)
|
| 61 |
+
|
| 62 |
+
if not is_demo:
|
| 63 |
+
if not is_gt:
|
| 64 |
+
if not is_ll:
|
| 65 |
+
cv2.imwrite(save_dir+"/batch_{}_{}_da_segresult.png".format(epoch,index), img)
|
| 66 |
+
else:
|
| 67 |
+
cv2.imwrite(save_dir+"/batch_{}_{}_ll_segresult.png".format(epoch,index), img)
|
| 68 |
+
else:
|
| 69 |
+
if not is_ll:
|
| 70 |
+
cv2.imwrite(save_dir+"/batch_{}_{}_da_seg_gt.png".format(epoch,index), img)
|
| 71 |
+
else:
|
| 72 |
+
cv2.imwrite(save_dir+"/batch_{}_{}_ll_seg_gt.png".format(epoch,index), img)
|
| 73 |
+
return img
|
| 74 |
+
|
| 75 |
+
def plot_one_box(x, img, color=None, label=None, line_thickness=None):
|
| 76 |
+
# Plots one bounding box on image img
|
| 77 |
+
tl = line_thickness or round(0.0001 * (img.shape[0] + img.shape[1]) / 2) + 1 # line/font thickness
|
| 78 |
+
color = color or [random.randint(0, 255) for _ in range(3)]
|
| 79 |
+
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
|
| 80 |
+
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
|
| 81 |
+
# if label:
|
| 82 |
+
# tf = max(tl - 1, 1) # font thickness
|
| 83 |
+
# t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
|
| 84 |
+
# c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
|
| 85 |
+
# cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
|
| 86 |
+
# print(label)
|
| 87 |
+
# cv2.putText(img, label, (c1[0], c1[1] - 2), 0, tl / 3, [225, 255, 255], thickness=tf, lineType=cv2.LINE_AA)
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
if __name__ == "__main__":
|
| 91 |
+
pass
|
| 92 |
+
# def plot():
|
| 93 |
+
# cudnn.benchmark = cfg.CUDNN.BENCHMARK
|
| 94 |
+
# torch.backends.cudnn.deterministic = cfg.CUDNN.DETERMINISTIC
|
| 95 |
+
# torch.backends.cudnn.enabled = cfg.CUDNN.ENABLED
|
| 96 |
+
|
| 97 |
+
# device = select_device(logger, batch_size=cfg.TRAIN.BATCH_SIZE_PER_GPU) if not cfg.DEBUG \
|
| 98 |
+
# else select_device(logger, 'cpu')
|
| 99 |
+
|
| 100 |
+
# if args.local_rank != -1:
|
| 101 |
+
# assert torch.cuda.device_count() > args.local_rank
|
| 102 |
+
# torch.cuda.set_device(args.local_rank)
|
| 103 |
+
# device = torch.device('cuda', args.local_rank)
|
| 104 |
+
# dist.init_process_group(backend='nccl', init_method='env://') # distributed backend
|
| 105 |
+
|
| 106 |
+
# model = get_net(cfg).to(device)
|
| 107 |
+
# model_file = '/home/zwt/DaChuang/weights/epoch--2.pth'
|
| 108 |
+
# checkpoint = torch.load(model_file)
|
| 109 |
+
# model.load_state_dict(checkpoint['state_dict'])
|
| 110 |
+
# if rank == -1 and torch.cuda.device_count() > 1:
|
| 111 |
+
# model = torch.nn.DataParallel(model, device_ids=cfg.GPUS).cuda()
|
| 112 |
+
# if rank != -1:
|
| 113 |
+
# model = DDP(model, device_ids=[args.local_rank], output_device=args.local_rank)
|
lib/utils/split_dataset.py
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import random
|
| 2 |
+
import shutil
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
def split(path, mask_path, lane_path):
|
| 6 |
+
os.mkdir(path + 'train')
|
| 7 |
+
os.mkdir(path + 'val')
|
| 8 |
+
os.mkdir(mask_path + 'train')
|
| 9 |
+
os.mkdir(mask_path + 'val')
|
| 10 |
+
os.mkdir(lane_path + 'train')
|
| 11 |
+
os.mkdir(lane_path + 'val')
|
| 12 |
+
val_index = random.sample(range(660), 200)
|
| 13 |
+
for i in range(660):
|
| 14 |
+
if i in val_index:
|
| 15 |
+
shutil.move(path+'{}.png'.format(i), path + 'val')
|
| 16 |
+
shutil.move(mask_path+'{}.png'.format(i), mask_path + 'val')
|
| 17 |
+
shutil.move(lane_path+'{}.png'.format(i), lane_path + 'val')
|
| 18 |
+
else:
|
| 19 |
+
shutil.move(path+'{}.png'.format(i), path + 'train')
|
| 20 |
+
shutil.move(mask_path+'{}.png'.format(i), mask_path + 'train')
|
| 21 |
+
shutil.move(lane_path+'{}.png'.format(i), lane_path + 'train')
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
if __name__ == '__main__':
|
| 25 |
+
path = "/home/wqm/bdd/data_hust/"
|
| 26 |
+
mask_path = "/home/wqm/bdd/hust_area/"
|
| 27 |
+
lane_path = "/home/wqm/bdd/hust_lane/"
|
| 28 |
+
split(path, mask_path, lane_path)
|
| 29 |
+
|
| 30 |
+
|
lib/utils/utils.py
ADDED
|
@@ -0,0 +1,163 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import logging
|
| 3 |
+
import time
|
| 4 |
+
from collections import namedtuple
|
| 5 |
+
from pathlib import Path
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
import torch.optim as optim
|
| 9 |
+
import torch.nn as nn
|
| 10 |
+
import numpy as np
|
| 11 |
+
from torch.utils.data import DataLoader
|
| 12 |
+
from prefetch_generator import BackgroundGenerator
|
| 13 |
+
from contextlib import contextmanager
|
| 14 |
+
import re
|
| 15 |
+
|
| 16 |
+
def clean_str(s):
|
| 17 |
+
# Cleans a string by replacing special characters with underscore _
|
| 18 |
+
return re.sub(pattern="[|@#!¡·$€%&()=?¿^*;:,¨´><+]", repl="_", string=s)
|
| 19 |
+
|
| 20 |
+
def create_logger(cfg, cfg_path, phase='train', rank=-1):
|
| 21 |
+
# set up logger dir
|
| 22 |
+
dataset = cfg.DATASET.DATASET
|
| 23 |
+
dataset = dataset.replace(':', '_')
|
| 24 |
+
model = cfg.MODEL.NAME
|
| 25 |
+
cfg_path = os.path.basename(cfg_path).split('.')[0]
|
| 26 |
+
|
| 27 |
+
if rank in [-1, 0]:
|
| 28 |
+
time_str = time.strftime('%Y-%m-%d-%H-%M')
|
| 29 |
+
log_file = '{}_{}_{}.log'.format(cfg_path, time_str, phase)
|
| 30 |
+
# set up tensorboard_log_dir
|
| 31 |
+
tensorboard_log_dir = Path(cfg.LOG_DIR) / dataset / model / \
|
| 32 |
+
(cfg_path + '_' + time_str)
|
| 33 |
+
final_output_dir = tensorboard_log_dir
|
| 34 |
+
if not tensorboard_log_dir.exists():
|
| 35 |
+
print('=> creating {}'.format(tensorboard_log_dir))
|
| 36 |
+
tensorboard_log_dir.mkdir(parents=True)
|
| 37 |
+
|
| 38 |
+
final_log_file = tensorboard_log_dir / log_file
|
| 39 |
+
head = '%(asctime)-15s %(message)s'
|
| 40 |
+
logging.basicConfig(filename=str(final_log_file),
|
| 41 |
+
format=head)
|
| 42 |
+
logger = logging.getLogger()
|
| 43 |
+
logger.setLevel(logging.INFO)
|
| 44 |
+
console = logging.StreamHandler()
|
| 45 |
+
logging.getLogger('').addHandler(console)
|
| 46 |
+
|
| 47 |
+
return logger, str(final_output_dir), str(tensorboard_log_dir)
|
| 48 |
+
else:
|
| 49 |
+
return None, None, None
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def select_device(logger, device='', batch_size=None):
|
| 53 |
+
# device = 'cpu' or '0' or '0,1,2,3'
|
| 54 |
+
cpu_request = device.lower() == 'cpu'
|
| 55 |
+
if device and not cpu_request: # if device requested other than 'cpu'
|
| 56 |
+
os.environ['CUDA_VISIBLE_DEVICES'] = device # set environment variable
|
| 57 |
+
assert torch.cuda.is_available(), 'CUDA unavailable, invalid device %s requested' % device # check availablity
|
| 58 |
+
|
| 59 |
+
cuda = False if cpu_request else torch.cuda.is_available()
|
| 60 |
+
if cuda:
|
| 61 |
+
c = 1024 ** 2 # bytes to MB
|
| 62 |
+
ng = torch.cuda.device_count()
|
| 63 |
+
if ng > 1 and batch_size: # check that batch_size is compatible with device_count
|
| 64 |
+
assert batch_size % ng == 0, 'batch-size %g not multiple of GPU count %g' % (batch_size, ng)
|
| 65 |
+
x = [torch.cuda.get_device_properties(i) for i in range(ng)]
|
| 66 |
+
s = f'Using torch {torch.__version__} '
|
| 67 |
+
for i in range(0, ng):
|
| 68 |
+
if i == 1:
|
| 69 |
+
s = ' ' * len(s)
|
| 70 |
+
if logger:
|
| 71 |
+
logger.info("%sCUDA:%g (%s, %dMB)" % (s, i, x[i].name, x[i].total_memory / c))
|
| 72 |
+
else:
|
| 73 |
+
logger.info(f'Using torch {torch.__version__} CPU')
|
| 74 |
+
|
| 75 |
+
if logger:
|
| 76 |
+
logger.info('') # skip a line
|
| 77 |
+
return torch.device('cuda:0' if cuda else 'cpu')
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
def get_optimizer(cfg, model):
|
| 81 |
+
optimizer = None
|
| 82 |
+
if cfg.TRAIN.OPTIMIZER == 'sgd':
|
| 83 |
+
optimizer = optim.SGD(
|
| 84 |
+
filter(lambda p: p.requires_grad, model.parameters()),
|
| 85 |
+
lr=cfg.TRAIN.LR0,
|
| 86 |
+
momentum=cfg.TRAIN.MOMENTUM,
|
| 87 |
+
weight_decay=cfg.TRAIN.WD,
|
| 88 |
+
nesterov=cfg.TRAIN.NESTEROV
|
| 89 |
+
)
|
| 90 |
+
elif cfg.TRAIN.OPTIMIZER == 'adam':
|
| 91 |
+
optimizer = optim.Adam(
|
| 92 |
+
filter(lambda p: p.requires_grad, model.parameters()),
|
| 93 |
+
#model.parameters(),
|
| 94 |
+
lr=cfg.TRAIN.LR0,
|
| 95 |
+
betas=(cfg.TRAIN.MOMENTUM, 0.999)
|
| 96 |
+
)
|
| 97 |
+
|
| 98 |
+
return optimizer
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def save_checkpoint(epoch, name, model, optimizer, output_dir, filename, is_best=False):
|
| 102 |
+
model_state = model.module.state_dict() if is_parallel(model) else model.state_dict()
|
| 103 |
+
checkpoint = {
|
| 104 |
+
'epoch': epoch,
|
| 105 |
+
'model': name,
|
| 106 |
+
'state_dict': model_state,
|
| 107 |
+
# 'best_state_dict': model.module.state_dict(),
|
| 108 |
+
# 'perf': perf_indicator,
|
| 109 |
+
'optimizer': optimizer.state_dict(),
|
| 110 |
+
}
|
| 111 |
+
torch.save(checkpoint, os.path.join(output_dir, filename))
|
| 112 |
+
if is_best and 'state_dict' in checkpoint:
|
| 113 |
+
torch.save(checkpoint['best_state_dict'],
|
| 114 |
+
os.path.join(output_dir, 'model_best.pth'))
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
def initialize_weights(model):
|
| 118 |
+
for m in model.modules():
|
| 119 |
+
t = type(m)
|
| 120 |
+
if t is nn.Conv2d:
|
| 121 |
+
pass # nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
|
| 122 |
+
elif t is nn.BatchNorm2d:
|
| 123 |
+
m.eps = 1e-3
|
| 124 |
+
m.momentum = 0.03
|
| 125 |
+
elif t in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6]:
|
| 126 |
+
# elif t in [nn.LeakyReLU, nn.ReLU, nn.ReLU6]:
|
| 127 |
+
m.inplace = True
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
def xyxy2xywh(x):
|
| 131 |
+
# Convert nx4 boxes from [x1, y1, x2, y2] to [x, y, w, h] where xy1=top-left, xy2=bottom-right
|
| 132 |
+
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
|
| 133 |
+
y[:, 0] = (x[:, 0] + x[:, 2]) / 2 # x center
|
| 134 |
+
y[:, 1] = (x[:, 1] + x[:, 3]) / 2 # y center
|
| 135 |
+
y[:, 2] = x[:, 2] - x[:, 0] # width
|
| 136 |
+
y[:, 3] = x[:, 3] - x[:, 1] # height
|
| 137 |
+
return y
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
def is_parallel(model):
|
| 141 |
+
return type(model) in (nn.parallel.DataParallel, nn.parallel.DistributedDataParallel)
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
def time_synchronized():
|
| 145 |
+
torch.cuda.synchronize() if torch.cuda.is_available() else None
|
| 146 |
+
return time.time()
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
class DataLoaderX(DataLoader):
|
| 150 |
+
"""prefetch dataloader"""
|
| 151 |
+
def __iter__(self):
|
| 152 |
+
return BackgroundGenerator(super().__iter__())
|
| 153 |
+
|
| 154 |
+
@contextmanager
|
| 155 |
+
def torch_distributed_zero_first(local_rank: int):
|
| 156 |
+
"""
|
| 157 |
+
Decorator to make all processes in distributed training wait for each local_master to do something.
|
| 158 |
+
"""
|
| 159 |
+
if local_rank not in [-1, 0]:
|
| 160 |
+
torch.distributed.barrier()
|
| 161 |
+
yield
|
| 162 |
+
if local_rank == 0:
|
| 163 |
+
torch.distributed.barrier()
|
pictures/da.png
ADDED

|
pictures/detect.png
ADDED

|
pictures/input1.gif
ADDED

|
pictures/input2.gif
ADDED

|
pictures/ll.png
ADDED

|
pictures/output1.gif
ADDED

|
pictures/output2.gif
ADDED

|
pictures/yolop.png
ADDED
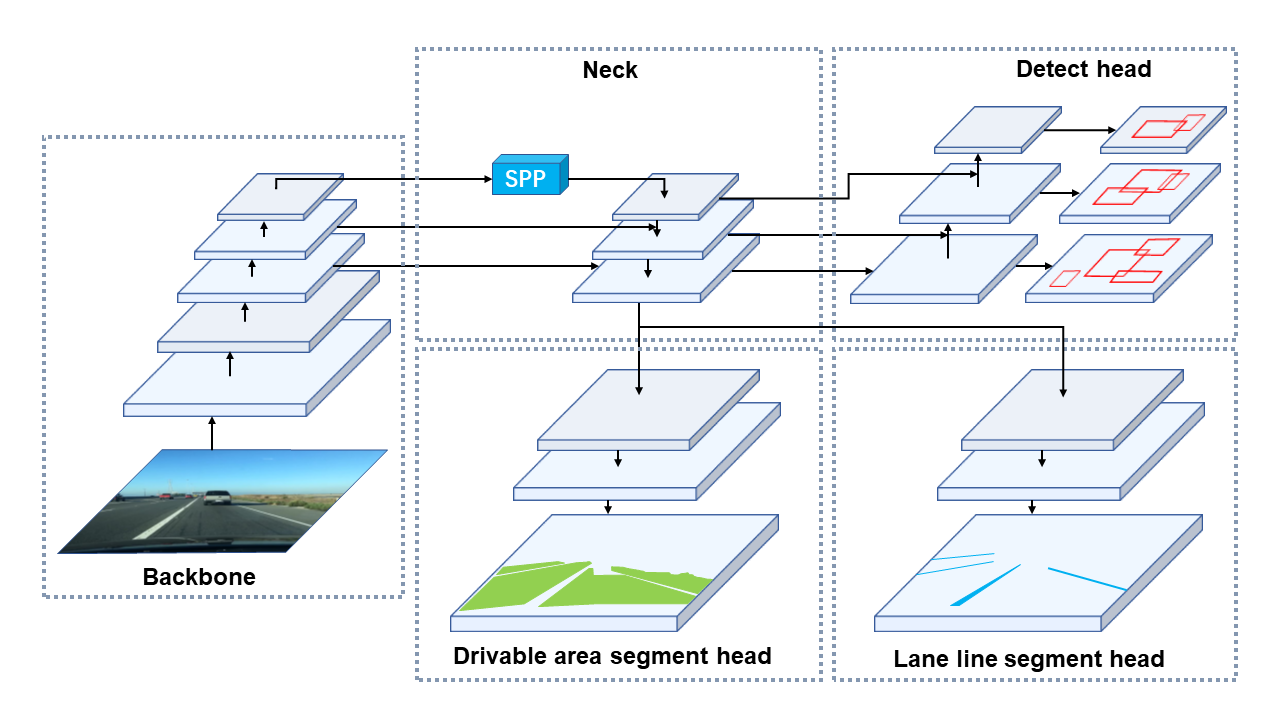
|
requirements.txt
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
scipy
|
| 2 |
+
tqdm
|
| 3 |
+
yacs
|
| 4 |
+
Cython
|
| 5 |
+
matplotlib>=3.2.2
|
| 6 |
+
numpy>=1.18.5
|
| 7 |
+
opencv-python>=4.1.2
|
| 8 |
+
Pillow
|
| 9 |
+
PyYAML>=5.3
|
| 10 |
+
scipy>=1.4.1
|
| 11 |
+
tensorboardX
|
| 12 |
+
seaborn
|
| 13 |
+
prefetch_generator
|
| 14 |
+
imageio
|
| 15 |
+
scikit-learn
|
toolkits/deploy/CMakeLists.txt
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
cmake_minimum_required(VERSION 2.6)
|
| 2 |
+
|
| 3 |
+
project(mcnet)
|
| 4 |
+
|
| 5 |
+
add_definitions(-std=c++11)
|
| 6 |
+
|
| 7 |
+
option(CUDA_USE_STATIC_CUDA_RUNTIME OFF)
|
| 8 |
+
set(CMAKE_CXX_STANDARD 11)
|
| 9 |
+
set(CMAKE_BUILD_TYPE Release)
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
find_package(ZED 3 REQUIRED)
|
| 13 |
+
find_package(CUDA ${ZED_CUDA_VERSION} EXACT REQUIRED)
|
| 14 |
+
|
| 15 |
+
include_directories(${PROJECT_SOURCE_DIR}/include)
|
| 16 |
+
|
| 17 |
+
# cuda
|
| 18 |
+
include_directories(/usr/local/cuda-10.2/include)
|
| 19 |
+
link_directories(/usr/local/cuda-10.2/lib64)
|
| 20 |
+
# tensorrt
|
| 21 |
+
include_directories(/usr/include/aarch64-linux-gnu/)
|
| 22 |
+
link_directories(/usr/lib/aarch64-linux-gnu/)
|
| 23 |
+
# zed
|
| 24 |
+
include_directories(/usr/local/zed/include)
|
| 25 |
+
link_directories(/usr/local/zed/lib)
|
| 26 |
+
|
| 27 |
+
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11 -Wall -Ofast -Wfatal-errors -D_MWAITXINTRIN_H_INCLUDED")
|
| 28 |
+
|
| 29 |
+
set(ZED_LIBS ${ZED_LIBRARIES} ${CUDA_CUDA_LIBRARY} ${CUDA_CUDART_LIBRARY})
|
| 30 |
+
|
| 31 |
+
coda_add_library(myplugins SHARED ${PROJECT_SOURCE_DIR}/yololayer.cu)
|
| 32 |
+
target_link_libraries(myplugins nvinfer cudart)
|
| 33 |
+
|
| 34 |
+
find_package(OpenCV REQUIRED)
|
| 35 |
+
include_directories(${OpenCV_INCLUDE_DIRS})
|
| 36 |
+
|
| 37 |
+
add_executable(mcnet ${PROJECT_SOURCE_DIR}/main.cpp)
|
| 38 |
+
target_link_libraries(mcnet nvinfer)
|
| 39 |
+
target_link_libraries(mcnet ${ZED_LIBS})
|
| 40 |
+
target_link_libraries(mcnet cudart)
|
| 41 |
+
target_link_libraries(mcnet myplugins)
|
| 42 |
+
target_link_libraries(mcnet ${OpenCV_LIBS})
|
| 43 |
+
|
| 44 |
+
add_definitions(-O3 -pthread)
|
| 45 |
+
|
toolkits/deploy/common.hpp
ADDED
|
@@ -0,0 +1,359 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#ifndef YOLOV5_COMMON_H_
|
| 2 |
+
#define YOLOV5_COMMON_H_
|
| 3 |
+
|
| 4 |
+
#include <fstream>
|
| 5 |
+
#include <map>
|
| 6 |
+
#include <sstream>
|
| 7 |
+
#include <vector>
|
| 8 |
+
#include <opencv2/opencv.hpp>
|
| 9 |
+
#include "NvInfer.h"
|
| 10 |
+
#include "yololayer.h"
|
| 11 |
+
|
| 12 |
+
using namespace nvinfer1;
|
| 13 |
+
|
| 14 |
+
cv::Rect get_rect(cv::Mat& img, float bbox[4]) {
|
| 15 |
+
int l, r, t, b;
|
| 16 |
+
float r_w = Yolo::INPUT_W / (img.cols * 1.0);
|
| 17 |
+
float r_h = Yolo::INPUT_H / (img.rows * 1.0);
|
| 18 |
+
if (r_h > r_w) {
|
| 19 |
+
l = bbox[0] - bbox[2] / 2.f;
|
| 20 |
+
r = bbox[0] + bbox[2] / 2.f;
|
| 21 |
+
t = bbox[1] - bbox[3] / 2.f - (Yolo::INPUT_H - r_w * img.rows) / 2;
|
| 22 |
+
b = bbox[1] + bbox[3] / 2.f - (Yolo::INPUT_H - r_w * img.rows) / 2;
|
| 23 |
+
l = l / r_w;
|
| 24 |
+
r = r / r_w;
|
| 25 |
+
t = t / r_w;
|
| 26 |
+
b = b / r_w;
|
| 27 |
+
} else {
|
| 28 |
+
l = bbox[0] - bbox[2] / 2.f - (Yolo::INPUT_W - r_h * img.cols) / 2;
|
| 29 |
+
r = bbox[0] + bbox[2] / 2.f - (Yolo::INPUT_W - r_h * img.cols) / 2;
|
| 30 |
+
t = bbox[1] - bbox[3] / 2.f;
|
| 31 |
+
b = bbox[1] + bbox[3] / 2.f;
|
| 32 |
+
l = l / r_h;
|
| 33 |
+
r = r / r_h;
|
| 34 |
+
t = t / r_h;
|
| 35 |
+
b = b / r_h;
|
| 36 |
+
}
|
| 37 |
+
return cv::Rect(l, t, r - l, b - t);
|
| 38 |
+
}
|
| 39 |
+
|
| 40 |
+
float iou(float lbox[4], float rbox[4]) {
|
| 41 |
+
float interBox[] = {
|
| 42 |
+
(std::max)(lbox[0] - lbox[2] / 2.f , rbox[0] - rbox[2] / 2.f), //left
|
| 43 |
+
(std::min)(lbox[0] + lbox[2] / 2.f , rbox[0] + rbox[2] / 2.f), //right
|
| 44 |
+
(std::max)(lbox[1] - lbox[3] / 2.f , rbox[1] - rbox[3] / 2.f), //top
|
| 45 |
+
(std::min)(lbox[1] + lbox[3] / 2.f , rbox[1] + rbox[3] / 2.f), //bottom
|
| 46 |
+
};
|
| 47 |
+
|
| 48 |
+
if (interBox[2] > interBox[3] || interBox[0] > interBox[1])
|
| 49 |
+
return 0.0f;
|
| 50 |
+
|
| 51 |
+
float interBoxS = (interBox[1] - interBox[0])*(interBox[3] - interBox[2]);
|
| 52 |
+
return interBoxS / (lbox[2] * lbox[3] + rbox[2] * rbox[3] - interBoxS);
|
| 53 |
+
}
|
| 54 |
+
|
| 55 |
+
bool cmp(const Yolo::Detection& a, const Yolo::Detection& b) {
|
| 56 |
+
return a.conf > b.conf;
|
| 57 |
+
}
|
| 58 |
+
|
| 59 |
+
void nms(std::vector<Yolo::Detection>& res, float *output, float conf_thresh, float nms_thresh = 0.5) {
|
| 60 |
+
int det_size = sizeof(Yolo::Detection) / sizeof(float);
|
| 61 |
+
std::map<float, std::vector<Yolo::Detection>> m;
|
| 62 |
+
for (int i = 0; i < output[0] && i < Yolo::MAX_OUTPUT_BBOX_COUNT; i++) {
|
| 63 |
+
if (output[1 + det_size * i + 4] <= conf_thresh) continue;
|
| 64 |
+
Yolo::Detection det;
|
| 65 |
+
memcpy(&det, &output[1 + det_size * i], det_size * sizeof(float));
|
| 66 |
+
if (m.count(det.class_id) == 0) m.emplace(det.class_id, std::vector<Yolo::Detection>());
|
| 67 |
+
m[det.class_id].push_back(det);
|
| 68 |
+
}
|
| 69 |
+
for (auto it = m.begin(); it != m.end(); it++) {
|
| 70 |
+
//std::cout << it->second[0].class_id << " --- " << std::endl;
|
| 71 |
+
auto& dets = it->second;
|
| 72 |
+
std::sort(dets.begin(), dets.end(), cmp);
|
| 73 |
+
for (size_t m = 0; m < dets.size(); ++m) {
|
| 74 |
+
auto& item = dets[m];
|
| 75 |
+
res.push_back(item);
|
| 76 |
+
for (size_t n = m + 1; n < dets.size(); ++n) {
|
| 77 |
+
if (iou(item.bbox, dets[n].bbox) > nms_thresh) {
|
| 78 |
+
dets.erase(dets.begin() + n);
|
| 79 |
+
--n;
|
| 80 |
+
}
|
| 81 |
+
}
|
| 82 |
+
}
|
| 83 |
+
}
|
| 84 |
+
}
|
| 85 |
+
|
| 86 |
+
// TensorRT weight files have a simple space delimited format:
|
| 87 |
+
// [type] [size] <data x size in hex>
|
| 88 |
+
std::map<std::string, Weights> loadWeights(const std::string file) {
|
| 89 |
+
std::cout << "Loading weights: " << file << std::endl;
|
| 90 |
+
std::map<std::string, Weights> weightMap;
|
| 91 |
+
|
| 92 |
+
// Open weights file
|
| 93 |
+
std::ifstream input(file);
|
| 94 |
+
assert(input.is_open() && "Unable to load weight file. please check if the .wts file path is right!!!!!!");
|
| 95 |
+
|
| 96 |
+
// Read number of weight blobs
|
| 97 |
+
int32_t count;
|
| 98 |
+
input >> count;
|
| 99 |
+
assert(count > 0 && "Invalid weight map file.");
|
| 100 |
+
|
| 101 |
+
while (count--)
|
| 102 |
+
{
|
| 103 |
+
Weights wt{ DataType::kFLOAT, nullptr, 0 };
|
| 104 |
+
uint32_t size;
|
| 105 |
+
|
| 106 |
+
// Read name and type of blob
|
| 107 |
+
std::string name;
|
| 108 |
+
input >> name >> std::dec >> size;
|
| 109 |
+
wt.type = DataType::kFLOAT;
|
| 110 |
+
|
| 111 |
+
// Load blob
|
| 112 |
+
uint32_t* val = reinterpret_cast<uint32_t*>(malloc(sizeof(val) * size));
|
| 113 |
+
for (uint32_t x = 0, y = size; x < y; ++x)
|
| 114 |
+
{
|
| 115 |
+
input >> std::hex >> val[x];
|
| 116 |
+
}
|
| 117 |
+
wt.values = val;
|
| 118 |
+
|
| 119 |
+
wt.count = size;
|
| 120 |
+
weightMap[name] = wt;
|
| 121 |
+
}
|
| 122 |
+
|
| 123 |
+
return weightMap;
|
| 124 |
+
}
|
| 125 |
+
|
| 126 |
+
IScaleLayer* addBatchNorm2d(INetworkDefinition *network, std::map<std::string, Weights>& weightMap, ITensor& input, std::string lname, float eps) {
|
| 127 |
+
float *gamma = (float*)weightMap[lname + ".weight"].values;
|
| 128 |
+
float *beta = (float*)weightMap[lname + ".bias"].values;
|
| 129 |
+
float *mean = (float*)weightMap[lname + ".running_mean"].values;
|
| 130 |
+
float *var = (float*)weightMap[lname + ".running_var"].values;
|
| 131 |
+
int len = weightMap[lname + ".running_var"].count;
|
| 132 |
+
|
| 133 |
+
float *scval = reinterpret_cast<float*>(malloc(sizeof(float) * len));
|
| 134 |
+
for (int i = 0; i < len; i++) {
|
| 135 |
+
scval[i] = gamma[i] / sqrt(var[i] + eps);
|
| 136 |
+
}
|
| 137 |
+
Weights scale{ DataType::kFLOAT, scval, len };
|
| 138 |
+
|
| 139 |
+
float *shval = reinterpret_cast<float*>(malloc(sizeof(float) * len));
|
| 140 |
+
for (int i = 0; i < len; i++) {
|
| 141 |
+
shval[i] = beta[i] - mean[i] * gamma[i] / sqrt(var[i] + eps);
|
| 142 |
+
}
|
| 143 |
+
Weights shift{ DataType::kFLOAT, shval, len };
|
| 144 |
+
|
| 145 |
+
float *pval = reinterpret_cast<float*>(malloc(sizeof(float) * len));
|
| 146 |
+
for (int i = 0; i < len; i++) {
|
| 147 |
+
pval[i] = 1.0;
|
| 148 |
+
}
|
| 149 |
+
Weights power{ DataType::kFLOAT, pval, len };
|
| 150 |
+
|
| 151 |
+
weightMap[lname + ".scale"] = scale;
|
| 152 |
+
weightMap[lname + ".shift"] = shift;
|
| 153 |
+
weightMap[lname + ".power"] = power;
|
| 154 |
+
IScaleLayer* scale_1 = network->addScale(input, ScaleMode::kCHANNEL, shift, scale, power);
|
| 155 |
+
assert(scale_1);
|
| 156 |
+
return scale_1;
|
| 157 |
+
}
|
| 158 |
+
|
| 159 |
+
ILayer* convBlock(INetworkDefinition *network, std::map<std::string, Weights>& weightMap, ITensor& input, int outch, int ksize, int s, int g, std::string lname) {
|
| 160 |
+
Weights emptywts{ DataType::kFLOAT, nullptr, 0 };
|
| 161 |
+
int p = ksize / 2;
|
| 162 |
+
IConvolutionLayer* conv1 = network->addConvolutionNd(input, outch, DimsHW{ ksize, ksize }, weightMap[lname + ".conv.weight"], emptywts);
|
| 163 |
+
assert(conv1);
|
| 164 |
+
conv1->setStrideNd(DimsHW{ s, s });
|
| 165 |
+
conv1->setPaddingNd(DimsHW{ p, p });
|
| 166 |
+
conv1->setNbGroups(g);
|
| 167 |
+
IScaleLayer* bn1 = addBatchNorm2d(network, weightMap, *conv1->getOutput(0), lname + ".bn", 1e-3);
|
| 168 |
+
|
| 169 |
+
// silu = x * sigmoid
|
| 170 |
+
// auto sig = network->addActivation(*bn1->getOutput(0), ActivationType::kSIGMOID);
|
| 171 |
+
// assert(sig);
|
| 172 |
+
// auto ew = network->addElementWise(*bn1->getOutput(0), *sig->getOutput(0), ElementWiseOperation::kPROD);
|
| 173 |
+
// assert(ew);
|
| 174 |
+
|
| 175 |
+
// hard_swish = x * hard_sigmoid
|
| 176 |
+
auto hsig = network->addActivation(*bn1->getOutput(0), ActivationType::kHARD_SIGMOID);
|
| 177 |
+
assert(hsig);
|
| 178 |
+
hsig->setAlpha(1.0 / 6.0);
|
| 179 |
+
hsig->setBeta(0.5);
|
| 180 |
+
auto ew = network->addElementWise(*bn1->getOutput(0), *hsig->getOutput(0), ElementWiseOperation::kPROD);
|
| 181 |
+
assert(ew);
|
| 182 |
+
return ew;
|
| 183 |
+
}
|
| 184 |
+
|
| 185 |
+
ILayer* focus(INetworkDefinition *network, std::map<std::string, Weights>& weightMap, ITensor& input, int inch, int outch, int ksize, std::string lname) {
|
| 186 |
+
ISliceLayer *s1 = network->addSlice(input, Dims3{ 0, 0, 0 }, Dims3{ inch, Yolo::INPUT_H / 2, Yolo::INPUT_W / 2 }, Dims3{ 1, 2, 2 });
|
| 187 |
+
ISliceLayer *s2 = network->addSlice(input, Dims3{ 0, 1, 0 }, Dims3{ inch, Yolo::INPUT_H / 2, Yolo::INPUT_W / 2 }, Dims3{ 1, 2, 2 });
|
| 188 |
+
ISliceLayer *s3 = network->addSlice(input, Dims3{ 0, 0, 1 }, Dims3{ inch, Yolo::INPUT_H / 2, Yolo::INPUT_W / 2 }, Dims3{ 1, 2, 2 });
|
| 189 |
+
ISliceLayer *s4 = network->addSlice(input, Dims3{ 0, 1, 1 }, Dims3{ inch, Yolo::INPUT_H / 2, Yolo::INPUT_W / 2 }, Dims3{ 1, 2, 2 });
|
| 190 |
+
ITensor* inputTensors[] = { s1->getOutput(0), s2->getOutput(0), s3->getOutput(0), s4->getOutput(0) };
|
| 191 |
+
auto cat = network->addConcatenation(inputTensors, 4);
|
| 192 |
+
auto conv = convBlock(network, weightMap, *cat->getOutput(0), outch, ksize, 1, 1, lname + ".conv");
|
| 193 |
+
return conv;
|
| 194 |
+
}
|
| 195 |
+
|
| 196 |
+
ILayer* bottleneck(INetworkDefinition *network, std::map<std::string, Weights>& weightMap, ITensor& input, int c1, int c2, bool shortcut, int g, float e, std::string lname) {
|
| 197 |
+
auto cv1 = convBlock(network, weightMap, input, (int)((float)c2 * e), 1, 1, 1, lname + ".cv1");
|
| 198 |
+
auto cv2 = convBlock(network, weightMap, *cv1->getOutput(0), c2, 3, 1, g, lname + ".cv2");
|
| 199 |
+
if (shortcut && c1 == c2) {
|
| 200 |
+
auto ew = network->addElementWise(input, *cv2->getOutput(0), ElementWiseOperation::kSUM);
|
| 201 |
+
return ew;
|
| 202 |
+
}
|
| 203 |
+
return cv2;
|
| 204 |
+
}
|
| 205 |
+
|
| 206 |
+
ILayer* bottleneckCSP(INetworkDefinition *network, std::map<std::string, Weights>& weightMap, ITensor& input, int c1, int c2, int n, bool shortcut, int g, float e, std::string lname) {
|
| 207 |
+
Weights emptywts{ DataType::kFLOAT, nullptr, 0 };
|
| 208 |
+
int c_ = (int)((float)c2 * e);
|
| 209 |
+
auto cv1 = convBlock(network, weightMap, input, c_, 1, 1, 1, lname + ".cv1");
|
| 210 |
+
auto cv2 = network->addConvolutionNd(input, c_, DimsHW{ 1, 1 }, weightMap[lname + ".cv2.weight"], emptywts);
|
| 211 |
+
ITensor *y1 = cv1->getOutput(0);
|
| 212 |
+
for (int i = 0; i < n; i++) {
|
| 213 |
+
auto b = bottleneck(network, weightMap, *y1, c_, c_, shortcut, g, 1.0, lname + ".m." + std::to_string(i));
|
| 214 |
+
y1 = b->getOutput(0);
|
| 215 |
+
}
|
| 216 |
+
auto cv3 = network->addConvolutionNd(*y1, c_, DimsHW{ 1, 1 }, weightMap[lname + ".cv3.weight"], emptywts);
|
| 217 |
+
|
| 218 |
+
ITensor* inputTensors[] = { cv3->getOutput(0), cv2->getOutput(0) };
|
| 219 |
+
auto cat = network->addConcatenation(inputTensors, 2);
|
| 220 |
+
|
| 221 |
+
IScaleLayer* bn = addBatchNorm2d(network, weightMap, *cat->getOutput(0), lname + ".bn", 1e-4);
|
| 222 |
+
auto lr = network->addActivation(*bn->getOutput(0), ActivationType::kLEAKY_RELU);
|
| 223 |
+
lr->setAlpha(0.1);
|
| 224 |
+
|
| 225 |
+
auto cv4 = convBlock(network, weightMap, *lr->getOutput(0), c2, 1, 1, 1, lname + ".cv4");
|
| 226 |
+
return cv4;
|
| 227 |
+
}
|
| 228 |
+
|
| 229 |
+
ILayer* C3(INetworkDefinition *network, std::map<std::string, Weights>& weightMap, ITensor& input, int c1, int c2, int n, bool shortcut, int g, float e, std::string lname) {
|
| 230 |
+
int c_ = (int)((float)c2 * e);
|
| 231 |
+
auto cv1 = convBlock(network, weightMap, input, c_, 1, 1, 1, lname + ".cv1");
|
| 232 |
+
auto cv2 = convBlock(network, weightMap, input, c_, 1, 1, 1, lname + ".cv2");
|
| 233 |
+
ITensor *y1 = cv1->getOutput(0);
|
| 234 |
+
for (int i = 0; i < n; i++) {
|
| 235 |
+
auto b = bottleneck(network, weightMap, *y1, c_, c_, shortcut, g, 1.0, lname + ".m." + std::to_string(i));
|
| 236 |
+
y1 = b->getOutput(0);
|
| 237 |
+
}
|
| 238 |
+
|
| 239 |
+
ITensor* inputTensors[] = { y1, cv2->getOutput(0) };
|
| 240 |
+
auto cat = network->addConcatenation(inputTensors, 2);
|
| 241 |
+
|
| 242 |
+
auto cv3 = convBlock(network, weightMap, *cat->getOutput(0), c2, 1, 1, 1, lname + ".cv3");
|
| 243 |
+
return cv3;
|
| 244 |
+
}
|
| 245 |
+
|
| 246 |
+
ILayer* SPP(INetworkDefinition *network, std::map<std::string, Weights>& weightMap, ITensor& input, int c1, int c2, int k1, int k2, int k3, std::string lname) {
|
| 247 |
+
int c_ = c1 / 2;
|
| 248 |
+
auto cv1 = convBlock(network, weightMap, input, c_, 1, 1, 1, lname + ".cv1");
|
| 249 |
+
|
| 250 |
+
auto pool1 = network->addPoolingNd(*cv1->getOutput(0), PoolingType::kMAX, DimsHW{ k1, k1 });
|
| 251 |
+
pool1->setPaddingNd(DimsHW{ k1 / 2, k1 / 2 });
|
| 252 |
+
pool1->setStrideNd(DimsHW{ 1, 1 });
|
| 253 |
+
auto pool2 = network->addPoolingNd(*cv1->getOutput(0), PoolingType::kMAX, DimsHW{ k2, k2 });
|
| 254 |
+
pool2->setPaddingNd(DimsHW{ k2 / 2, k2 / 2 });
|
| 255 |
+
pool2->setStrideNd(DimsHW{ 1, 1 });
|
| 256 |
+
auto pool3 = network->addPoolingNd(*cv1->getOutput(0), PoolingType::kMAX, DimsHW{ k3, k3 });
|
| 257 |
+
pool3->setPaddingNd(DimsHW{ k3 / 2, k3 / 2 });
|
| 258 |
+
pool3->setStrideNd(DimsHW{ 1, 1 });
|
| 259 |
+
|
| 260 |
+
ITensor* inputTensors[] = { cv1->getOutput(0), pool1->getOutput(0), pool2->getOutput(0), pool3->getOutput(0) };
|
| 261 |
+
auto cat = network->addConcatenation(inputTensors, 4);
|
| 262 |
+
|
| 263 |
+
auto cv2 = convBlock(network, weightMap, *cat->getOutput(0), c2, 1, 1, 1, lname + ".cv2");
|
| 264 |
+
return cv2;
|
| 265 |
+
}
|
| 266 |
+
|
| 267 |
+
ILayer* preprocess_layer(INetworkDefinition *network, std::map<std::string, Weights>& weightMap, ITensor& input) {
|
| 268 |
+
// rescale
|
| 269 |
+
auto rescale = network->addResize(input);
|
| 270 |
+
rescale->setOutputDimensions(Dims3{ 3, Yolo::IMG_H, Yolo::IMG_W });
|
| 271 |
+
rescale->setResizeMode(ResizeMode::kLINEAR);
|
| 272 |
+
// normalize
|
| 273 |
+
// long len = 3 * Yolo::IMG_H * Yolo::IMG_W;
|
| 274 |
+
// float *normval = reinterpret_cast<float*>(malloc(sizeof(float) * len));
|
| 275 |
+
// for (size_t i = 0; i < len; ++i) {
|
| 276 |
+
// normval[i] = 255.0;
|
| 277 |
+
// }
|
| 278 |
+
// Weights norm{ DataType::kFLOAT, normval, len };
|
| 279 |
+
// weightMap["prep.norm"] = norm;
|
| 280 |
+
// auto constant = network->addConstant(Dims3{ 3, Yolo::IMG_H, Yolo::IMG_W }, norm);
|
| 281 |
+
// auto normalize = network->addElementWise(*rescale->getOutput(0), *constant->getOutput(0), ElementWiseOperation::kDIV);
|
| 282 |
+
|
| 283 |
+
//paddng
|
| 284 |
+
auto padding = network->addPaddingNd(*rescale->getOutput(0),
|
| 285 |
+
DimsHW{ (Yolo::INPUT_H - Yolo::IMG_H) / 2, (Yolo::INPUT_W - Yolo::IMG_W) / 2 },
|
| 286 |
+
DimsHW{ (Yolo::INPUT_H - Yolo::IMG_H) / 2, (Yolo::INPUT_W - Yolo::IMG_W) / 2 });
|
| 287 |
+
|
| 288 |
+
assert(padding);
|
| 289 |
+
return padding;
|
| 290 |
+
|
| 291 |
+
}
|
| 292 |
+
|
| 293 |
+
std::vector<float> getAnchors(std::map<std::string, Weights>& weightMap)
|
| 294 |
+
{
|
| 295 |
+
std::vector<float> anchors_yolo;
|
| 296 |
+
Weights Yolo_Anchors = weightMap["model.24.anchor_grid"];
|
| 297 |
+
assert(Yolo_Anchors.count == 18);
|
| 298 |
+
int each_yololayer_anchorsnum = Yolo_Anchors.count / 3;
|
| 299 |
+
const float* tempAnchors = (const float*)(Yolo_Anchors.values);
|
| 300 |
+
for (int i = 0; i < Yolo_Anchors.count; i++)
|
| 301 |
+
{
|
| 302 |
+
if (i < each_yololayer_anchorsnum)
|
| 303 |
+
{
|
| 304 |
+
anchors_yolo.push_back(const_cast<float*>(tempAnchors)[i]);
|
| 305 |
+
}
|
| 306 |
+
if ((i >= each_yololayer_anchorsnum) && (i < (2 * each_yololayer_anchorsnum)))
|
| 307 |
+
{
|
| 308 |
+
anchors_yolo.push_back(const_cast<float*>(tempAnchors)[i]);
|
| 309 |
+
}
|
| 310 |
+
if (i >= (2 * each_yololayer_anchorsnum))
|
| 311 |
+
{
|
| 312 |
+
anchors_yolo.push_back(const_cast<float*>(tempAnchors)[i]);
|
| 313 |
+
}
|
| 314 |
+
}
|
| 315 |
+
|
| 316 |
+
return anchors_yolo;
|
| 317 |
+
}
|
| 318 |
+
|
| 319 |
+
IPluginV2Layer* addYoLoLayer(INetworkDefinition *network, std::map<std::string, Weights>& weightMap, IConvolutionLayer* det0, IConvolutionLayer* det1, IConvolutionLayer* det2)
|
| 320 |
+
{
|
| 321 |
+
auto creator = getPluginRegistry()->getPluginCreator("YoloLayer_TRT", "1");
|
| 322 |
+
std::vector<float> anchors_yolo = getAnchors(weightMap);
|
| 323 |
+
PluginField pluginMultidata[4];
|
| 324 |
+
int NetData[4];
|
| 325 |
+
NetData[0] = Yolo::CLASS_NUM;
|
| 326 |
+
NetData[1] = Yolo::INPUT_W;
|
| 327 |
+
NetData[2] = Yolo::INPUT_H;
|
| 328 |
+
NetData[3] = Yolo::MAX_OUTPUT_BBOX_COUNT;
|
| 329 |
+
pluginMultidata[0].data = NetData;
|
| 330 |
+
pluginMultidata[0].length = 3;
|
| 331 |
+
pluginMultidata[0].name = "netdata";
|
| 332 |
+
pluginMultidata[0].type = PluginFieldType::kFLOAT32;
|
| 333 |
+
int scale[3] = { 8, 16, 32 };
|
| 334 |
+
int plugindata[3][8];
|
| 335 |
+
std::string names[3];
|
| 336 |
+
for (int k = 1; k < 4; k++)
|
| 337 |
+
{
|
| 338 |
+
plugindata[k - 1][0] = Yolo::INPUT_W / scale[k - 1];
|
| 339 |
+
plugindata[k - 1][1] = Yolo::INPUT_H / scale[k - 1];
|
| 340 |
+
for (int i = 2; i < 8; i++)
|
| 341 |
+
{
|
| 342 |
+
plugindata[k - 1][i] = int(anchors_yolo[(k - 1) * 6 + i - 2]);
|
| 343 |
+
}
|
| 344 |
+
pluginMultidata[k].data = plugindata[k - 1];
|
| 345 |
+
pluginMultidata[k].length = 8;
|
| 346 |
+
names[k - 1] = "yolodata" + std::to_string(k);
|
| 347 |
+
pluginMultidata[k].name = names[k - 1].c_str();
|
| 348 |
+
pluginMultidata[k].type = PluginFieldType::kFLOAT32;
|
| 349 |
+
}
|
| 350 |
+
PluginFieldCollection pluginData;
|
| 351 |
+
pluginData.nbFields = 4;
|
| 352 |
+
pluginData.fields = pluginMultidata;
|
| 353 |
+
IPluginV2 *pluginObj = creator->createPlugin("yololayer", &pluginData);
|
| 354 |
+
ITensor* inputTensors_yolo[] = { det2->getOutput(0), det1->getOutput(0), det0->getOutput(0) };
|
| 355 |
+
auto yolo = network->addPluginV2(inputTensors_yolo, 3, *pluginObj);
|
| 356 |
+
return yolo;
|
| 357 |
+
}
|
| 358 |
+
#endif
|
| 359 |
+
|
toolkits/deploy/cuda_utils.h
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#ifndef TRTX_CUDA_UTILS_H_
|
| 2 |
+
#define TRTX_CUDA_UTILS_H_
|
| 3 |
+
|
| 4 |
+
#include <cuda_runtime_api.h>
|
| 5 |
+
|
| 6 |
+
#ifndef CUDA_CHECK
|
| 7 |
+
#define CUDA_CHECK(callstr)\
|
| 8 |
+
{\
|
| 9 |
+
cudaError_t error_code = callstr;\
|
| 10 |
+
if (error_code != cudaSuccess) {\
|
| 11 |
+
std::cerr << "CUDA error " << error_code << " at " << __FILE__ << ":" << __LINE__;\
|
| 12 |
+
assert(0);\
|
| 13 |
+
}\
|
| 14 |
+
}
|
| 15 |
+
#endif // CUDA_CHECK
|
| 16 |
+
|
| 17 |
+
#endif // TRTX_CUDA_UTILS_H_
|
| 18 |
+
|
toolkits/deploy/gen_wts.py
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import struct
|
| 3 |
+
|
| 4 |
+
# Initialize
|
| 5 |
+
device = torch.device('cpu')
|
| 6 |
+
# Load model
|
| 7 |
+
model = torch.load('yolov5s.pt', map_location=device) # ['model'].float()
|
| 8 |
+
# load to FP32
|
| 9 |
+
model.to(device).eval()
|
| 10 |
+
|
| 11 |
+
f = open('yolov5s.wts', 'w')
|
| 12 |
+
f.write('{}\n'.format(len(model.state_dict().keys())))
|
| 13 |
+
for k, v in model.state_dict().items():
|
| 14 |
+
vr = v.reshape(-1).cpu().numpy()
|
| 15 |
+
f.write('{} {} '.format(k, len(vr)))
|
| 16 |
+
for vv in vr:
|
| 17 |
+
f.write(' ')
|
| 18 |
+
f.write(struct.pack('>f',float(vv)).hex())
|
| 19 |
+
f.write('\n')
|
| 20 |
+
|
| 21 |
+
f.close()
|
toolkits/deploy/infer_files.cpp
ADDED
|
@@ -0,0 +1,200 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#include "yolov5.hpp"
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
int main(int argc, char** argv) {
|
| 5 |
+
cudaSetDevice(DEVICE);
|
| 6 |
+
|
| 7 |
+
std::string wts_name = "";
|
| 8 |
+
std::string engine_name = "";
|
| 9 |
+
float gd = 0.0f, gw = 0.0f;
|
| 10 |
+
std::string img_dir;
|
| 11 |
+
if (!parse_args(argc, argv, wts_name, engine_name, gd, gw, img_dir)) {
|
| 12 |
+
std::cerr << "arguments not right!" << std::endl;
|
| 13 |
+
std::cerr << "./yolov5 -s [.wts] [.engine] [s/m/l/x or c gd gw] // serialize model to plan file" << std::endl;
|
| 14 |
+
std::cerr << "./yolov5 -d [.engine] ../samples // deserialize plan file and run inference" << std::endl;
|
| 15 |
+
return -1;
|
| 16 |
+
}
|
| 17 |
+
|
| 18 |
+
// create a model using the API directly and serialize it to a stream
|
| 19 |
+
if (!wts_name.empty()) {
|
| 20 |
+
IHostMemory* modelStream{ nullptr };
|
| 21 |
+
APIToModel(BATCH_SIZE, &modelStream, gd, gw, wts_name);
|
| 22 |
+
assert(modelStream != nullptr);
|
| 23 |
+
std::ofstream p(engine_name, std::ios::binary);
|
| 24 |
+
if (!p) {
|
| 25 |
+
std::cerr << "could not open plan output file" << std::endl;
|
| 26 |
+
return -1;
|
| 27 |
+
}
|
| 28 |
+
p.write(reinterpret_cast<const char*>(modelStream->data()), modelStream->size());
|
| 29 |
+
modelStream->destroy();
|
| 30 |
+
return 0;
|
| 31 |
+
}
|
| 32 |
+
|
| 33 |
+
// deserialize the .engine and run inference
|
| 34 |
+
std::ifstream file(engine_name, std::ios::binary);
|
| 35 |
+
if (!file.good()) {
|
| 36 |
+
std::cerr << "read " << engine_name << " error!" << std::endl;
|
| 37 |
+
return -1;
|
| 38 |
+
}
|
| 39 |
+
char *trtModelStream = nullptr;
|
| 40 |
+
size_t size = 0;
|
| 41 |
+
file.seekg(0, file.end);
|
| 42 |
+
size = file.tellg();
|
| 43 |
+
file.seekg(0, file.beg);
|
| 44 |
+
trtModelStream = new char[size];
|
| 45 |
+
assert(trtModelStream);
|
| 46 |
+
file.read(trtModelStream, size);
|
| 47 |
+
file.close();
|
| 48 |
+
|
| 49 |
+
std::vector<std::string> file_names;
|
| 50 |
+
if (read_files_in_dir(img_dir.c_str(), file_names) < 0) {
|
| 51 |
+
std::cerr << "read_files_in_dir failed." << std::endl;
|
| 52 |
+
return -1;
|
| 53 |
+
}
|
| 54 |
+
|
| 55 |
+
// prepare input data ---------------------------
|
| 56 |
+
static float data[BATCH_SIZE * 3 * INPUT_H * INPUT_W];
|
| 57 |
+
//for (int i = 0; i < 3 * INPUT_H * INPUT_W; i++)
|
| 58 |
+
// data[i] = 1.0;
|
| 59 |
+
static float prob[BATCH_SIZE * OUTPUT_SIZE];
|
| 60 |
+
static int seg_out[BATCH_SIZE * IMG_H * IMG_W];
|
| 61 |
+
static int lane_out[BATCH_SIZE * IMG_H * IMG_W];
|
| 62 |
+
IRuntime* runtime = createInferRuntime(gLogger);
|
| 63 |
+
assert(runtime != nullptr);
|
| 64 |
+
ICudaEngine* engine = runtime->deserializeCudaEngine(trtModelStream, size);
|
| 65 |
+
assert(engine != nullptr);
|
| 66 |
+
IExecutionContext* context = engine->createExecutionContext();
|
| 67 |
+
assert(context != nullptr);
|
| 68 |
+
delete[] trtModelStream;
|
| 69 |
+
assert(engine->getNbBindings() == 4);
|
| 70 |
+
void* buffers[4];
|
| 71 |
+
// In order to bind the buffers, we need to know the names of the input and output tensors.
|
| 72 |
+
// Note that indices are guaranteed to be less than IEngine::getNbBindings()
|
| 73 |
+
const int inputIndex = engine->getBindingIndex(INPUT_BLOB_NAME);
|
| 74 |
+
const int output_det_index = engine->getBindingIndex(OUTPUT_DET_NAME);
|
| 75 |
+
const int output_seg_index = engine->getBindingIndex(OUTPUT_SEG_NAME);
|
| 76 |
+
const int output_lane_index = engine->getBindingIndex(OUTPUT_LANE_NAME);
|
| 77 |
+
assert(inputIndex == 0);
|
| 78 |
+
assert(output_det_index == 1);
|
| 79 |
+
assert(output_seg_index == 2);
|
| 80 |
+
assert(output_lane_index == 3);
|
| 81 |
+
// Create GPU buffers on device
|
| 82 |
+
CUDA_CHECK(cudaMalloc(&buffers[inputIndex], BATCH_SIZE * 3 * INPUT_H * INPUT_W * sizeof(float)));
|
| 83 |
+
CUDA_CHECK(cudaMalloc(&buffers[output_det_index], BATCH_SIZE * OUTPUT_SIZE * sizeof(float)));
|
| 84 |
+
CUDA_CHECK(cudaMalloc(&buffers[output_seg_index], BATCH_SIZE * IMG_H * IMG_W * sizeof(int)));
|
| 85 |
+
CUDA_CHECK(cudaMalloc(&buffers[output_lane_index], BATCH_SIZE * IMG_H * IMG_W * sizeof(int)));
|
| 86 |
+
// Create stream
|
| 87 |
+
cudaStream_t stream;
|
| 88 |
+
CUDA_CHECK(cudaStreamCreate(&stream));
|
| 89 |
+
|
| 90 |
+
// store seg results
|
| 91 |
+
cv::Mat tmp_seg(IMG_H, IMG_W, CV_32S, seg_out);
|
| 92 |
+
// store lane results
|
| 93 |
+
cv::Mat tmp_lane(IMG_H, IMG_W, CV_32S, lane_out);
|
| 94 |
+
// PrintMat(tmp_seg);
|
| 95 |
+
std::vector<cv::Vec3b> segColor;
|
| 96 |
+
segColor.push_back(cv::Vec3b(0, 0, 0));
|
| 97 |
+
segColor.push_back(cv::Vec3b(0, 255, 0));
|
| 98 |
+
segColor.push_back(cv::Vec3b(255, 0, 0));
|
| 99 |
+
|
| 100 |
+
std::vector<cv::Vec3b> laneColor;
|
| 101 |
+
laneColor.push_back(cv::Vec3b(0, 0, 0));
|
| 102 |
+
laneColor.push_back(cv::Vec3b(0, 0, 255));
|
| 103 |
+
laneColor.push_back(cv::Vec3b(0, 0, 0));
|
| 104 |
+
|
| 105 |
+
int fcount = 0; // set for batch-inference
|
| 106 |
+
for (int f = 0; f < (int)file_names.size(); f++) {
|
| 107 |
+
fcount++;
|
| 108 |
+
if (fcount < BATCH_SIZE && f + 1 != (int)file_names.size()) continue;
|
| 109 |
+
|
| 110 |
+
// preprocess ~3ms
|
| 111 |
+
for (int b = 0; b < fcount; b++) {
|
| 112 |
+
cv::Mat img = cv::imread(img_dir + "/" + file_names[f - fcount + 1 + b]); // load image takes ~17ms
|
| 113 |
+
if (img.empty()) continue;
|
| 114 |
+
//cv::cvtColor(img, img, cv::COLOR_BGR2RGB);
|
| 115 |
+
cv::Mat pr_img = preprocess_img(img, INPUT_W, INPUT_H); // letterbox
|
| 116 |
+
int i = 0;
|
| 117 |
+
// BGR to RGB and normalize
|
| 118 |
+
for (int row = 0; row < INPUT_H; ++row) {
|
| 119 |
+
float* uc_pixel = pr_img.ptr<float>(row);
|
| 120 |
+
for (int col = 0; col < INPUT_W; ++col) {
|
| 121 |
+
data[b * 3 * INPUT_H * INPUT_W + i] = uc_pixel[0];
|
| 122 |
+
data[b * 3 * INPUT_H * INPUT_W + i + INPUT_H * INPUT_W] = uc_pixel[1];
|
| 123 |
+
data[b * 3 * INPUT_H * INPUT_W + i + 2 * INPUT_H * INPUT_W] = uc_pixel[2];
|
| 124 |
+
uc_pixel += 3;
|
| 125 |
+
++i;
|
| 126 |
+
}
|
| 127 |
+
}
|
| 128 |
+
}
|
| 129 |
+
|
| 130 |
+
// Run inference
|
| 131 |
+
auto start = std::chrono::system_clock::now();
|
| 132 |
+
doInferenceCpu(*context, stream, buffers, data, prob, seg_out, lane_out, BATCH_SIZE);
|
| 133 |
+
auto end = std::chrono::system_clock::now();
|
| 134 |
+
std::cout << std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count() << "ms" << std::endl;
|
| 135 |
+
|
| 136 |
+
// postprocess ~0ms
|
| 137 |
+
std::vector<std::vector<Yolo::Detection>> batch_res(fcount);
|
| 138 |
+
for (int b = 0; b < fcount; b++) {
|
| 139 |
+
auto& res = batch_res[b];
|
| 140 |
+
nms(res, &prob[b * OUTPUT_SIZE], CONF_THRESH, NMS_THRESH);
|
| 141 |
+
}
|
| 142 |
+
|
| 143 |
+
// show results
|
| 144 |
+
for (int b = 0; b < fcount; ++b) {
|
| 145 |
+
auto& res = batch_res[b];
|
| 146 |
+
//std::cout << res.size() << std::endl;
|
| 147 |
+
cv::Mat img = cv::imread(img_dir + "/" + file_names[f - fcount + 1 + b]);
|
| 148 |
+
// unsigned cnt = 0;
|
| 149 |
+
// for (const auto &item : seg_out)
|
| 150 |
+
// if (item == 1)
|
| 151 |
+
// ++cnt;
|
| 152 |
+
// std::cout << cnt << std::endl;
|
| 153 |
+
|
| 154 |
+
// handling seg and lane results
|
| 155 |
+
cv::Mat seg_res(img.rows, img.cols, CV_32S);
|
| 156 |
+
cv::resize(tmp_seg, seg_res, seg_res.size(), 0, 0, cv::INTER_NEAREST);
|
| 157 |
+
cv::Mat lane_res(img.rows, img.cols, CV_32S);
|
| 158 |
+
cv::resize(tmp_lane, lane_res, lane_res.size(), 0, 0, cv::INTER_NEAREST);
|
| 159 |
+
for (int row = 0; row < img.rows; ++row) {
|
| 160 |
+
uchar* pdata = img.data + row * img.step;
|
| 161 |
+
for (int col = 0; col < img.cols; ++col) {
|
| 162 |
+
int seg_idx = seg_res.at<int>(row, col);
|
| 163 |
+
int lane_idx = lane_res.at<int>(row, col);
|
| 164 |
+
//std::cout << "enter" << ix << std::endl;
|
| 165 |
+
for (int i = 0; i < 3; ++i) {
|
| 166 |
+
if (lane_idx) {
|
| 167 |
+
if (i != 2)
|
| 168 |
+
pdata[i] = pdata[i] / 2 + laneColor[lane_idx][i] / 2;
|
| 169 |
+
}
|
| 170 |
+
else if (seg_idx)
|
| 171 |
+
pdata[i] = pdata[i] / 2 + segColor[seg_idx][i] / 2;
|
| 172 |
+
}
|
| 173 |
+
pdata += 3;
|
| 174 |
+
}
|
| 175 |
+
}
|
| 176 |
+
// handling det results
|
| 177 |
+
|
| 178 |
+
for (size_t j = 0; j < res.size(); ++j) {
|
| 179 |
+
cv::Rect r = get_rect(img, res[j].bbox);
|
| 180 |
+
cv::rectangle(img, r, cv::Scalar(0x27, 0xC1, 0x36), 2);
|
| 181 |
+
cv::putText(img, std::to_string((int)res[j].class_id), cv::Point(r.x, r.y - 1), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0xFF, 0xFF, 0xFF), 2);
|
| 182 |
+
}
|
| 183 |
+
cv::imwrite("../results/_" + file_names[f - fcount + 1 + b], img);
|
| 184 |
+
}
|
| 185 |
+
fcount = 0;
|
| 186 |
+
}
|
| 187 |
+
|
| 188 |
+
// Release stream and buffers
|
| 189 |
+
cudaStreamDestroy(stream);
|
| 190 |
+
CUDA_CHECK(cudaFree(buffers[inputIndex]));
|
| 191 |
+
CUDA_CHECK(cudaFree(buffers[output_det_index]));
|
| 192 |
+
CUDA_CHECK(cudaFree(buffers[output_seg_index]));
|
| 193 |
+
CUDA_CHECK(cudaFree(buffers[output_lane_index]));
|
| 194 |
+
// Destroy the engine
|
| 195 |
+
context->destroy();
|
| 196 |
+
engine->destroy();
|
| 197 |
+
runtime->destroy();
|
| 198 |
+
|
| 199 |
+
return 0;
|
| 200 |
+
}
|
toolkits/deploy/logging.h
ADDED
|
@@ -0,0 +1,503 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright (c) 2019, NVIDIA CORPORATION. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
* you may not use this file except in compliance with the License.
|
| 6 |
+
* You may obtain a copy of the License at
|
| 7 |
+
*
|
| 8 |
+
* http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
*
|
| 10 |
+
* Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
* distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
* See the License for the specific language governing permissions and
|
| 14 |
+
* limitations under the License.
|
| 15 |
+
*/
|
| 16 |
+
|
| 17 |
+
#ifndef TENSORRT_LOGGING_H
|
| 18 |
+
#define TENSORRT_LOGGING_H
|
| 19 |
+
|
| 20 |
+
#include "NvInferRuntimeCommon.h"
|
| 21 |
+
#include <cassert>
|
| 22 |
+
#include <ctime>
|
| 23 |
+
#include <iomanip>
|
| 24 |
+
#include <iostream>
|
| 25 |
+
#include <ostream>
|
| 26 |
+
#include <sstream>
|
| 27 |
+
#include <string>
|
| 28 |
+
|
| 29 |
+
using Severity = nvinfer1::ILogger::Severity;
|
| 30 |
+
|
| 31 |
+
class LogStreamConsumerBuffer : public std::stringbuf
|
| 32 |
+
{
|
| 33 |
+
public:
|
| 34 |
+
LogStreamConsumerBuffer(std::ostream& stream, const std::string& prefix, bool shouldLog)
|
| 35 |
+
: mOutput(stream)
|
| 36 |
+
, mPrefix(prefix)
|
| 37 |
+
, mShouldLog(shouldLog)
|
| 38 |
+
{
|
| 39 |
+
}
|
| 40 |
+
|
| 41 |
+
LogStreamConsumerBuffer(LogStreamConsumerBuffer&& other)
|
| 42 |
+
: mOutput(other.mOutput)
|
| 43 |
+
{
|
| 44 |
+
}
|
| 45 |
+
|
| 46 |
+
~LogStreamConsumerBuffer()
|
| 47 |
+
{
|
| 48 |
+
// std::streambuf::pbase() gives a pointer to the beginning of the buffered part of the output sequence
|
| 49 |
+
// std::streambuf::pptr() gives a pointer to the current position of the output sequence
|
| 50 |
+
// if the pointer to the beginning is not equal to the pointer to the current position,
|
| 51 |
+
// call putOutput() to log the output to the stream
|
| 52 |
+
if (pbase() != pptr())
|
| 53 |
+
{
|
| 54 |
+
putOutput();
|
| 55 |
+
}
|
| 56 |
+
}
|
| 57 |
+
|
| 58 |
+
// synchronizes the stream buffer and returns 0 on success
|
| 59 |
+
// synchronizing the stream buffer consists of inserting the buffer contents into the stream,
|
| 60 |
+
// resetting the buffer and flushing the stream
|
| 61 |
+
virtual int sync()
|
| 62 |
+
{
|
| 63 |
+
putOutput();
|
| 64 |
+
return 0;
|
| 65 |
+
}
|
| 66 |
+
|
| 67 |
+
void putOutput()
|
| 68 |
+
{
|
| 69 |
+
if (mShouldLog)
|
| 70 |
+
{
|
| 71 |
+
// prepend timestamp
|
| 72 |
+
std::time_t timestamp = std::time(nullptr);
|
| 73 |
+
tm* tm_local = std::localtime(×tamp);
|
| 74 |
+
std::cout << "[";
|
| 75 |
+
std::cout << std::setw(2) << std::setfill('0') << 1 + tm_local->tm_mon << "/";
|
| 76 |
+
std::cout << std::setw(2) << std::setfill('0') << tm_local->tm_mday << "/";
|
| 77 |
+
std::cout << std::setw(4) << std::setfill('0') << 1900 + tm_local->tm_year << "-";
|
| 78 |
+
std::cout << std::setw(2) << std::setfill('0') << tm_local->tm_hour << ":";
|
| 79 |
+
std::cout << std::setw(2) << std::setfill('0') << tm_local->tm_min << ":";
|
| 80 |
+
std::cout << std::setw(2) << std::setfill('0') << tm_local->tm_sec << "] ";
|
| 81 |
+
// std::stringbuf::str() gets the string contents of the buffer
|
| 82 |
+
// insert the buffer contents pre-appended by the appropriate prefix into the stream
|
| 83 |
+
mOutput << mPrefix << str();
|
| 84 |
+
// set the buffer to empty
|
| 85 |
+
str("");
|
| 86 |
+
// flush the stream
|
| 87 |
+
mOutput.flush();
|
| 88 |
+
}
|
| 89 |
+
}
|
| 90 |
+
|
| 91 |
+
void setShouldLog(bool shouldLog)
|
| 92 |
+
{
|
| 93 |
+
mShouldLog = shouldLog;
|
| 94 |
+
}
|
| 95 |
+
|
| 96 |
+
private:
|
| 97 |
+
std::ostream& mOutput;
|
| 98 |
+
std::string mPrefix;
|
| 99 |
+
bool mShouldLog;
|
| 100 |
+
};
|
| 101 |
+
|
| 102 |
+
//!
|
| 103 |
+
//! \class LogStreamConsumerBase
|
| 104 |
+
//! \brief Convenience object used to initialize LogStreamConsumerBuffer before std::ostream in LogStreamConsumer
|
| 105 |
+
//!
|
| 106 |
+
class LogStreamConsumerBase
|
| 107 |
+
{
|
| 108 |
+
public:
|
| 109 |
+
LogStreamConsumerBase(std::ostream& stream, const std::string& prefix, bool shouldLog)
|
| 110 |
+
: mBuffer(stream, prefix, shouldLog)
|
| 111 |
+
{
|
| 112 |
+
}
|
| 113 |
+
|
| 114 |
+
protected:
|
| 115 |
+
LogStreamConsumerBuffer mBuffer;
|
| 116 |
+
};
|
| 117 |
+
|
| 118 |
+
//!
|
| 119 |
+
//! \class LogStreamConsumer
|
| 120 |
+
//! \brief Convenience object used to facilitate use of C++ stream syntax when logging messages.
|
| 121 |
+
//! Order of base classes is LogStreamConsumerBase and then std::ostream.
|
| 122 |
+
//! This is because the LogStreamConsumerBase class is used to initialize the LogStreamConsumerBuffer member field
|
| 123 |
+
//! in LogStreamConsumer and then the address of the buffer is passed to std::ostream.
|
| 124 |
+
//! This is necessary to prevent the address of an uninitialized buffer from being passed to std::ostream.
|
| 125 |
+
//! Please do not change the order of the parent classes.
|
| 126 |
+
//!
|
| 127 |
+
class LogStreamConsumer : protected LogStreamConsumerBase, public std::ostream
|
| 128 |
+
{
|
| 129 |
+
public:
|
| 130 |
+
//! \brief Creates a LogStreamConsumer which logs messages with level severity.
|
| 131 |
+
//! Reportable severity determines if the messages are severe enough to be logged.
|
| 132 |
+
LogStreamConsumer(Severity reportableSeverity, Severity severity)
|
| 133 |
+
: LogStreamConsumerBase(severityOstream(severity), severityPrefix(severity), severity <= reportableSeverity)
|
| 134 |
+
, std::ostream(&mBuffer) // links the stream buffer with the stream
|
| 135 |
+
, mShouldLog(severity <= reportableSeverity)
|
| 136 |
+
, mSeverity(severity)
|
| 137 |
+
{
|
| 138 |
+
}
|
| 139 |
+
|
| 140 |
+
LogStreamConsumer(LogStreamConsumer&& other)
|
| 141 |
+
: LogStreamConsumerBase(severityOstream(other.mSeverity), severityPrefix(other.mSeverity), other.mShouldLog)
|
| 142 |
+
, std::ostream(&mBuffer) // links the stream buffer with the stream
|
| 143 |
+
, mShouldLog(other.mShouldLog)
|
| 144 |
+
, mSeverity(other.mSeverity)
|
| 145 |
+
{
|
| 146 |
+
}
|
| 147 |
+
|
| 148 |
+
void setReportableSeverity(Severity reportableSeverity)
|
| 149 |
+
{
|
| 150 |
+
mShouldLog = mSeverity <= reportableSeverity;
|
| 151 |
+
mBuffer.setShouldLog(mShouldLog);
|
| 152 |
+
}
|
| 153 |
+
|
| 154 |
+
private:
|
| 155 |
+
static std::ostream& severityOstream(Severity severity)
|
| 156 |
+
{
|
| 157 |
+
return severity >= Severity::kINFO ? std::cout : std::cerr;
|
| 158 |
+
}
|
| 159 |
+
|
| 160 |
+
static std::string severityPrefix(Severity severity)
|
| 161 |
+
{
|
| 162 |
+
switch (severity)
|
| 163 |
+
{
|
| 164 |
+
case Severity::kINTERNAL_ERROR: return "[F] ";
|
| 165 |
+
case Severity::kERROR: return "[E] ";
|
| 166 |
+
case Severity::kWARNING: return "[W] ";
|
| 167 |
+
case Severity::kINFO: return "[I] ";
|
| 168 |
+
case Severity::kVERBOSE: return "[V] ";
|
| 169 |
+
default: assert(0); return "";
|
| 170 |
+
}
|
| 171 |
+
}
|
| 172 |
+
|
| 173 |
+
bool mShouldLog;
|
| 174 |
+
Severity mSeverity;
|
| 175 |
+
};
|
| 176 |
+
|
| 177 |
+
//! \class Logger
|
| 178 |
+
//!
|
| 179 |
+
//! \brief Class which manages logging of TensorRT tools and samples
|
| 180 |
+
//!
|
| 181 |
+
//! \details This class provides a common interface for TensorRT tools and samples to log information to the console,
|
| 182 |
+
//! and supports logging two types of messages:
|
| 183 |
+
//!
|
| 184 |
+
//! - Debugging messages with an associated severity (info, warning, error, or internal error/fatal)
|
| 185 |
+
//! - Test pass/fail messages
|
| 186 |
+
//!
|
| 187 |
+
//! The advantage of having all samples use this class for logging as opposed to emitting directly to stdout/stderr is
|
| 188 |
+
//! that the logic for controlling the verbosity and formatting of sample output is centralized in one location.
|
| 189 |
+
//!
|
| 190 |
+
//! In the future, this class could be extended to support dumping test results to a file in some standard format
|
| 191 |
+
//! (for example, JUnit XML), and providing additional metadata (e.g. timing the duration of a test run).
|
| 192 |
+
//!
|
| 193 |
+
//! TODO: For backwards compatibility with existing samples, this class inherits directly from the nvinfer1::ILogger
|
| 194 |
+
//! interface, which is problematic since there isn't a clean separation between messages coming from the TensorRT
|
| 195 |
+
//! library and messages coming from the sample.
|
| 196 |
+
//!
|
| 197 |
+
//! In the future (once all samples are updated to use Logger::getTRTLogger() to access the ILogger) we can refactor the
|
| 198 |
+
//! class to eliminate the inheritance and instead make the nvinfer1::ILogger implementation a member of the Logger
|
| 199 |
+
//! object.
|
| 200 |
+
|
| 201 |
+
class Logger : public nvinfer1::ILogger
|
| 202 |
+
{
|
| 203 |
+
public:
|
| 204 |
+
Logger(Severity severity = Severity::kWARNING)
|
| 205 |
+
: mReportableSeverity(severity)
|
| 206 |
+
{
|
| 207 |
+
}
|
| 208 |
+
|
| 209 |
+
//!
|
| 210 |
+
//! \enum TestResult
|
| 211 |
+
//! \brief Represents the state of a given test
|
| 212 |
+
//!
|
| 213 |
+
enum class TestResult
|
| 214 |
+
{
|
| 215 |
+
kRUNNING, //!< The test is running
|
| 216 |
+
kPASSED, //!< The test passed
|
| 217 |
+
kFAILED, //!< The test failed
|
| 218 |
+
kWAIVED //!< The test was waived
|
| 219 |
+
};
|
| 220 |
+
|
| 221 |
+
//!
|
| 222 |
+
//! \brief Forward-compatible method for retrieving the nvinfer::ILogger associated with this Logger
|
| 223 |
+
//! \return The nvinfer1::ILogger associated with this Logger
|
| 224 |
+
//!
|
| 225 |
+
//! TODO Once all samples are updated to use this method to register the logger with TensorRT,
|
| 226 |
+
//! we can eliminate the inheritance of Logger from ILogger
|
| 227 |
+
//!
|
| 228 |
+
nvinfer1::ILogger& getTRTLogger()
|
| 229 |
+
{
|
| 230 |
+
return *this;
|
| 231 |
+
}
|
| 232 |
+
|
| 233 |
+
//!
|
| 234 |
+
//! \brief Implementation of the nvinfer1::ILogger::log() virtual method
|
| 235 |
+
//!
|
| 236 |
+
//! Note samples should not be calling this function directly; it will eventually go away once we eliminate the
|
| 237 |
+
//! inheritance from nvinfer1::ILogger
|
| 238 |
+
//!
|
| 239 |
+
void log(Severity severity, const char* msg) override
|
| 240 |
+
{
|
| 241 |
+
LogStreamConsumer(mReportableSeverity, severity) << "[TRT] " << std::string(msg) << std::endl;
|
| 242 |
+
}
|
| 243 |
+
|
| 244 |
+
//!
|
| 245 |
+
//! \brief Method for controlling the verbosity of logging output
|
| 246 |
+
//!
|
| 247 |
+
//! \param severity The logger will only emit messages that have severity of this level or higher.
|
| 248 |
+
//!
|
| 249 |
+
void setReportableSeverity(Severity severity)
|
| 250 |
+
{
|
| 251 |
+
mReportableSeverity = severity;
|
| 252 |
+
}
|
| 253 |
+
|
| 254 |
+
//!
|
| 255 |
+
//! \brief Opaque handle that holds logging information for a particular test
|
| 256 |
+
//!
|
| 257 |
+
//! This object is an opaque handle to information used by the Logger to print test results.
|
| 258 |
+
//! The sample must call Logger::defineTest() in order to obtain a TestAtom that can be used
|
| 259 |
+
//! with Logger::reportTest{Start,End}().
|
| 260 |
+
//!
|
| 261 |
+
class TestAtom
|
| 262 |
+
{
|
| 263 |
+
public:
|
| 264 |
+
TestAtom(TestAtom&&) = default;
|
| 265 |
+
|
| 266 |
+
private:
|
| 267 |
+
friend class Logger;
|
| 268 |
+
|
| 269 |
+
TestAtom(bool started, const std::string& name, const std::string& cmdline)
|
| 270 |
+
: mStarted(started)
|
| 271 |
+
, mName(name)
|
| 272 |
+
, mCmdline(cmdline)
|
| 273 |
+
{
|
| 274 |
+
}
|
| 275 |
+
|
| 276 |
+
bool mStarted;
|
| 277 |
+
std::string mName;
|
| 278 |
+
std::string mCmdline;
|
| 279 |
+
};
|
| 280 |
+
|
| 281 |
+
//!
|
| 282 |
+
//! \brief Define a test for logging
|
| 283 |
+
//!
|
| 284 |
+
//! \param[in] name The name of the test. This should be a string starting with
|
| 285 |
+
//! "TensorRT" and containing dot-separated strings containing
|
| 286 |
+
//! the characters [A-Za-z0-9_].
|
| 287 |
+
//! For example, "TensorRT.sample_googlenet"
|
| 288 |
+
//! \param[in] cmdline The command line used to reproduce the test
|
| 289 |
+
//
|
| 290 |
+
//! \return a TestAtom that can be used in Logger::reportTest{Start,End}().
|
| 291 |
+
//!
|
| 292 |
+
static TestAtom defineTest(const std::string& name, const std::string& cmdline)
|
| 293 |
+
{
|
| 294 |
+
return TestAtom(false, name, cmdline);
|
| 295 |
+
}
|
| 296 |
+
|
| 297 |
+
//!
|
| 298 |
+
//! \brief A convenience overloaded version of defineTest() that accepts an array of command-line arguments
|
| 299 |
+
//! as input
|
| 300 |
+
//!
|
| 301 |
+
//! \param[in] name The name of the test
|
| 302 |
+
//! \param[in] argc The number of command-line arguments
|
| 303 |
+
//! \param[in] argv The array of command-line arguments (given as C strings)
|
| 304 |
+
//!
|
| 305 |
+
//! \return a TestAtom that can be used in Logger::reportTest{Start,End}().
|
| 306 |
+
static TestAtom defineTest(const std::string& name, int argc, char const* const* argv)
|
| 307 |
+
{
|
| 308 |
+
auto cmdline = genCmdlineString(argc, argv);
|
| 309 |
+
return defineTest(name, cmdline);
|
| 310 |
+
}
|
| 311 |
+
|
| 312 |
+
//!
|
| 313 |
+
//! \brief Report that a test has started.
|
| 314 |
+
//!
|
| 315 |
+
//! \pre reportTestStart() has not been called yet for the given testAtom
|
| 316 |
+
//!
|
| 317 |
+
//! \param[in] testAtom The handle to the test that has started
|
| 318 |
+
//!
|
| 319 |
+
static void reportTestStart(TestAtom& testAtom)
|
| 320 |
+
{
|
| 321 |
+
reportTestResult(testAtom, TestResult::kRUNNING);
|
| 322 |
+
assert(!testAtom.mStarted);
|
| 323 |
+
testAtom.mStarted = true;
|
| 324 |
+
}
|
| 325 |
+
|
| 326 |
+
//!
|
| 327 |
+
//! \brief Report that a test has ended.
|
| 328 |
+
//!
|
| 329 |
+
//! \pre reportTestStart() has been called for the given testAtom
|
| 330 |
+
//!
|
| 331 |
+
//! \param[in] testAtom The handle to the test that has ended
|
| 332 |
+
//! \param[in] result The result of the test. Should be one of TestResult::kPASSED,
|
| 333 |
+
//! TestResult::kFAILED, TestResult::kWAIVED
|
| 334 |
+
//!
|
| 335 |
+
static void reportTestEnd(const TestAtom& testAtom, TestResult result)
|
| 336 |
+
{
|
| 337 |
+
assert(result != TestResult::kRUNNING);
|
| 338 |
+
assert(testAtom.mStarted);
|
| 339 |
+
reportTestResult(testAtom, result);
|
| 340 |
+
}
|
| 341 |
+
|
| 342 |
+
static int reportPass(const TestAtom& testAtom)
|
| 343 |
+
{
|
| 344 |
+
reportTestEnd(testAtom, TestResult::kPASSED);
|
| 345 |
+
return EXIT_SUCCESS;
|
| 346 |
+
}
|
| 347 |
+
|
| 348 |
+
static int reportFail(const TestAtom& testAtom)
|
| 349 |
+
{
|
| 350 |
+
reportTestEnd(testAtom, TestResult::kFAILED);
|
| 351 |
+
return EXIT_FAILURE;
|
| 352 |
+
}
|
| 353 |
+
|
| 354 |
+
static int reportWaive(const TestAtom& testAtom)
|
| 355 |
+
{
|
| 356 |
+
reportTestEnd(testAtom, TestResult::kWAIVED);
|
| 357 |
+
return EXIT_SUCCESS;
|
| 358 |
+
}
|
| 359 |
+
|
| 360 |
+
static int reportTest(const TestAtom& testAtom, bool pass)
|
| 361 |
+
{
|
| 362 |
+
return pass ? reportPass(testAtom) : reportFail(testAtom);
|
| 363 |
+
}
|
| 364 |
+
|
| 365 |
+
Severity getReportableSeverity() const
|
| 366 |
+
{
|
| 367 |
+
return mReportableSeverity;
|
| 368 |
+
}
|
| 369 |
+
|
| 370 |
+
private:
|
| 371 |
+
//!
|
| 372 |
+
//! \brief returns an appropriate string for prefixing a log message with the given severity
|
| 373 |
+
//!
|
| 374 |
+
static const char* severityPrefix(Severity severity)
|
| 375 |
+
{
|
| 376 |
+
switch (severity)
|
| 377 |
+
{
|
| 378 |
+
case Severity::kINTERNAL_ERROR: return "[F] ";
|
| 379 |
+
case Severity::kERROR: return "[E] ";
|
| 380 |
+
case Severity::kWARNING: return "[W] ";
|
| 381 |
+
case Severity::kINFO: return "[I] ";
|
| 382 |
+
case Severity::kVERBOSE: return "[V] ";
|
| 383 |
+
default: assert(0); return "";
|
| 384 |
+
}
|
| 385 |
+
}
|
| 386 |
+
|
| 387 |
+
//!
|
| 388 |
+
//! \brief returns an appropriate string for prefixing a test result message with the given result
|
| 389 |
+
//!
|
| 390 |
+
static const char* testResultString(TestResult result)
|
| 391 |
+
{
|
| 392 |
+
switch (result)
|
| 393 |
+
{
|
| 394 |
+
case TestResult::kRUNNING: return "RUNNING";
|
| 395 |
+
case TestResult::kPASSED: return "PASSED";
|
| 396 |
+
case TestResult::kFAILED: return "FAILED";
|
| 397 |
+
case TestResult::kWAIVED: return "WAIVED";
|
| 398 |
+
default: assert(0); return "";
|
| 399 |
+
}
|
| 400 |
+
}
|
| 401 |
+
|
| 402 |
+
//!
|
| 403 |
+
//! \brief returns an appropriate output stream (cout or cerr) to use with the given severity
|
| 404 |
+
//!
|
| 405 |
+
static std::ostream& severityOstream(Severity severity)
|
| 406 |
+
{
|
| 407 |
+
return severity >= Severity::kINFO ? std::cout : std::cerr;
|
| 408 |
+
}
|
| 409 |
+
|
| 410 |
+
//!
|
| 411 |
+
//! \brief method that implements logging test results
|
| 412 |
+
//!
|
| 413 |
+
static void reportTestResult(const TestAtom& testAtom, TestResult result)
|
| 414 |
+
{
|
| 415 |
+
severityOstream(Severity::kINFO) << "&&&& " << testResultString(result) << " " << testAtom.mName << " # "
|
| 416 |
+
<< testAtom.mCmdline << std::endl;
|
| 417 |
+
}
|
| 418 |
+
|
| 419 |
+
//!
|
| 420 |
+
//! \brief generate a command line string from the given (argc, argv) values
|
| 421 |
+
//!
|
| 422 |
+
static std::string genCmdlineString(int argc, char const* const* argv)
|
| 423 |
+
{
|
| 424 |
+
std::stringstream ss;
|
| 425 |
+
for (int i = 0; i < argc; i++)
|
| 426 |
+
{
|
| 427 |
+
if (i > 0)
|
| 428 |
+
ss << " ";
|
| 429 |
+
ss << argv[i];
|
| 430 |
+
}
|
| 431 |
+
return ss.str();
|
| 432 |
+
}
|
| 433 |
+
|
| 434 |
+
Severity mReportableSeverity;
|
| 435 |
+
};
|
| 436 |
+
|
| 437 |
+
namespace
|
| 438 |
+
{
|
| 439 |
+
|
| 440 |
+
//!
|
| 441 |
+
//! \brief produces a LogStreamConsumer object that can be used to log messages of severity kVERBOSE
|
| 442 |
+
//!
|
| 443 |
+
//! Example usage:
|
| 444 |
+
//!
|
| 445 |
+
//! LOG_VERBOSE(logger) << "hello world" << std::endl;
|
| 446 |
+
//!
|
| 447 |
+
inline LogStreamConsumer LOG_VERBOSE(const Logger& logger)
|
| 448 |
+
{
|
| 449 |
+
return LogStreamConsumer(logger.getReportableSeverity(), Severity::kVERBOSE);
|
| 450 |
+
}
|
| 451 |
+
|
| 452 |
+
//!
|
| 453 |
+
//! \brief produces a LogStreamConsumer object that can be used to log messages of severity kINFO
|
| 454 |
+
//!
|
| 455 |
+
//! Example usage:
|
| 456 |
+
//!
|
| 457 |
+
//! LOG_INFO(logger) << "hello world" << std::endl;
|
| 458 |
+
//!
|
| 459 |
+
inline LogStreamConsumer LOG_INFO(const Logger& logger)
|
| 460 |
+
{
|
| 461 |
+
return LogStreamConsumer(logger.getReportableSeverity(), Severity::kINFO);
|
| 462 |
+
}
|
| 463 |
+
|
| 464 |
+
//!
|
| 465 |
+
//! \brief produces a LogStreamConsumer object that can be used to log messages of severity kWARNING
|
| 466 |
+
//!
|
| 467 |
+
//! Example usage:
|
| 468 |
+
//!
|
| 469 |
+
//! LOG_WARN(logger) << "hello world" << std::endl;
|
| 470 |
+
//!
|
| 471 |
+
inline LogStreamConsumer LOG_WARN(const Logger& logger)
|
| 472 |
+
{
|
| 473 |
+
return LogStreamConsumer(logger.getReportableSeverity(), Severity::kWARNING);
|
| 474 |
+
}
|
| 475 |
+
|
| 476 |
+
//!
|
| 477 |
+
//! \brief produces a LogStreamConsumer object that can be used to log messages of severity kERROR
|
| 478 |
+
//!
|
| 479 |
+
//! Example usage:
|
| 480 |
+
//!
|
| 481 |
+
//! LOG_ERROR(logger) << "hello world" << std::endl;
|
| 482 |
+
//!
|
| 483 |
+
inline LogStreamConsumer LOG_ERROR(const Logger& logger)
|
| 484 |
+
{
|
| 485 |
+
return LogStreamConsumer(logger.getReportableSeverity(), Severity::kERROR);
|
| 486 |
+
}
|
| 487 |
+
|
| 488 |
+
//!
|
| 489 |
+
//! \brief produces a LogStreamConsumer object that can be used to log messages of severity kINTERNAL_ERROR
|
| 490 |
+
// ("fatal" severity)
|
| 491 |
+
//!
|
| 492 |
+
//! Example usage:
|
| 493 |
+
//!
|
| 494 |
+
//! LOG_FATAL(logger) << "hello world" << std::endl;
|
| 495 |
+
//!
|
| 496 |
+
inline LogStreamConsumer LOG_FATAL(const Logger& logger)
|
| 497 |
+
{
|
| 498 |
+
return LogStreamConsumer(logger.getReportableSeverity(), Severity::kINTERNAL_ERROR);
|
| 499 |
+
}
|
| 500 |
+
|
| 501 |
+
} // anonymous namespace
|
| 502 |
+
|
| 503 |
+
#endif // TENSORRT_LOGGING_H
|
toolkits/deploy/main.cpp
ADDED
|
@@ -0,0 +1,137 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#include "yolov5.hpp"
|
| 2 |
+
#include "zedcam.hpp"
|
| 3 |
+
#include <csignal>
|
| 4 |
+
|
| 5 |
+
static volatile bool keep_running = true;
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
void keyboard_handler(int sig) {
|
| 9 |
+
// handle keyboard interrupt
|
| 10 |
+
if (sig == SIGINT)
|
| 11 |
+
keep_running = false;
|
| 12 |
+
}
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
int main(int argc, char** argv) {
|
| 16 |
+
signal(SIGINT, keyboard_handler);
|
| 17 |
+
cudaSetDevice(DEVICE);
|
| 18 |
+
// CUcontext ctx;
|
| 19 |
+
// CUdevice device;
|
| 20 |
+
// cuInit(0);
|
| 21 |
+
// cuDeviceGet(&device, 0);
|
| 22 |
+
// cuCtxCreate(&ctx, 0, device);
|
| 23 |
+
|
| 24 |
+
std::string engine_name = "../mcnet.engine";
|
| 25 |
+
|
| 26 |
+
// deserialize the .engine and run inference
|
| 27 |
+
std::ifstream file(engine_name, std::ios::binary);
|
| 28 |
+
if (!file.good()) {
|
| 29 |
+
std::cerr << "read " << engine_name << " error!" << std::endl;
|
| 30 |
+
return -1;
|
| 31 |
+
}
|
| 32 |
+
char *trtModelStream = nullptr;
|
| 33 |
+
size_t size = 0;
|
| 34 |
+
file.seekg(0, file.end);
|
| 35 |
+
size = file.tellg();
|
| 36 |
+
file.seekg(0, file.beg);
|
| 37 |
+
trtModelStream = new char[size];
|
| 38 |
+
assert(trtModelStream);
|
| 39 |
+
file.read(trtModelStream, size);
|
| 40 |
+
file.close();
|
| 41 |
+
|
| 42 |
+
// prepare data ---------------------------
|
| 43 |
+
static float det_out[BATCH_SIZE * OUTPUT_SIZE];
|
| 44 |
+
static int seg_out[BATCH_SIZE * IMG_H * IMG_W];
|
| 45 |
+
static int lane_out[BATCH_SIZE * IMG_H * IMG_W];
|
| 46 |
+
IRuntime* runtime = createInferRuntime(gLogger);
|
| 47 |
+
assert(runtime != nullptr);
|
| 48 |
+
ICudaEngine* engine = runtime->deserializeCudaEngine(trtModelStream, size);
|
| 49 |
+
assert(engine != nullptr);
|
| 50 |
+
IExecutionContext* context = engine->createExecutionContext();
|
| 51 |
+
assert(context != nullptr);
|
| 52 |
+
delete[] trtModelStream;
|
| 53 |
+
assert(engine->getNbBindings() == 4);
|
| 54 |
+
void* buffers[4];
|
| 55 |
+
// In order to bind the buffers, we need to know the names of the input and output tensors.
|
| 56 |
+
// Note that indices are guaranteed to be less than IEngine::getNbBindings()
|
| 57 |
+
const int inputIndex = engine->getBindingIndex(INPUT_BLOB_NAME);
|
| 58 |
+
const int output_det_index = engine->getBindingIndex(OUTPUT_DET_NAME);
|
| 59 |
+
const int output_seg_index = engine->getBindingIndex(OUTPUT_SEG_NAME);
|
| 60 |
+
const int output_lane_index = engine->getBindingIndex(OUTPUT_LANE_NAME);
|
| 61 |
+
assert(inputIndex == 0);
|
| 62 |
+
assert(output_det_index == 1);
|
| 63 |
+
assert(output_seg_index == 2);
|
| 64 |
+
assert(output_lane_index == 3);
|
| 65 |
+
// Create GPU buffers on device
|
| 66 |
+
CUDA_CHECK(cudaMalloc(&buffers[inputIndex], BATCH_SIZE * 3 * INPUT_H * INPUT_W * sizeof(float)));
|
| 67 |
+
CUDA_CHECK(cudaMalloc(&buffers[output_det_index], BATCH_SIZE * OUTPUT_SIZE * sizeof(float)));
|
| 68 |
+
CUDA_CHECK(cudaMalloc(&buffers[output_seg_index], BATCH_SIZE * IMG_H * IMG_W * sizeof(int)));
|
| 69 |
+
CUDA_CHECK(cudaMalloc(&buffers[output_lane_index], BATCH_SIZE * IMG_H * IMG_W * sizeof(int)));
|
| 70 |
+
// Create stream
|
| 71 |
+
cudaStream_t stream;
|
| 72 |
+
CUDA_CHECK(cudaStreamCreate(&stream));
|
| 73 |
+
|
| 74 |
+
// create zed
|
| 75 |
+
auto zed = create_camera();
|
| 76 |
+
sl::Resolution image_size = zed->getCameraInformation().camera_configuration.resolution;
|
| 77 |
+
sl::Mat img_zed(image_size.width, image_size.height, sl::MAT_TYPE::U8_C4, sl::MEM::GPU);
|
| 78 |
+
cv::cuda::GpuMat img_ocv = slMat2cvMatGPU(img_zed);
|
| 79 |
+
cv::cuda::GpuMat cvt_img(image_size.height, image_size.width, CV_8UC3);
|
| 80 |
+
|
| 81 |
+
// store seg results
|
| 82 |
+
cv::Mat tmp_seg(IMG_H, IMG_W, CV_32S, seg_out);
|
| 83 |
+
// sotore lane results
|
| 84 |
+
cv::Mat tmp_lane(IMG_H, IMG_W, CV_32S, lane_out);
|
| 85 |
+
cv::Mat seg_res(image_size.height, image_size.width, CV_32S);
|
| 86 |
+
cv::Mat lane_res(image_size.height, image_size.width, CV_32S);
|
| 87 |
+
|
| 88 |
+
char key = ' ';
|
| 89 |
+
while (keep_running and key != 'q') {
|
| 90 |
+
// retrieve img
|
| 91 |
+
if (zed->grab() != sl::ERROR_CODE::SUCCESS) continue;
|
| 92 |
+
zed->retrieveImage(img_zed, sl::VIEW::LEFT, sl::MEM::GPU);
|
| 93 |
+
cudaSetDevice(DEVICE);
|
| 94 |
+
cv::cuda::cvtColor(img_ocv, cvt_img, cv::COLOR_BGRA2BGR);
|
| 95 |
+
|
| 96 |
+
// preprocess ~3ms
|
| 97 |
+
preprocess_img_gpu(cvt_img, (float*)buffers[inputIndex], INPUT_W, INPUT_H); // letterbox
|
| 98 |
+
|
| 99 |
+
// buffers[inputIndex] = pr_img.data;
|
| 100 |
+
// Run inference
|
| 101 |
+
auto start = std::chrono::system_clock::now();
|
| 102 |
+
// cuCtxPushCurrent(ctx);
|
| 103 |
+
doInference(*context, stream, buffers, det_out, seg_out, lane_out, BATCH_SIZE);
|
| 104 |
+
// cuCtxPopCurrent(&ctx);
|
| 105 |
+
auto end = std::chrono::system_clock::now();
|
| 106 |
+
std::cout << std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count() << "ms" << std::endl;
|
| 107 |
+
|
| 108 |
+
// postprocess ~0ms
|
| 109 |
+
std::vector<Yolo::Detection> batch_res;
|
| 110 |
+
nms(batch_res, det_out, CONF_THRESH, NMS_THRESH);
|
| 111 |
+
cv::resize(tmp_seg, seg_res, seg_res.size(), 0, 0, cv::INTER_NEAREST);
|
| 112 |
+
cv::resize(tmp_lane, lane_res, lane_res.size(), 0, 0, cv::INTER_NEAREST);
|
| 113 |
+
|
| 114 |
+
// show results
|
| 115 |
+
//std::cout << res.size() << std::endl;
|
| 116 |
+
visualization(cvt_img, seg_res, lane_res, batch_res, key);
|
| 117 |
+
}
|
| 118 |
+
// destroy windows
|
| 119 |
+
#ifdef SHOW_IMG
|
| 120 |
+
cv::destroyAllWindows();
|
| 121 |
+
#endif
|
| 122 |
+
// close camera
|
| 123 |
+
img_zed.free();
|
| 124 |
+
zed->close();
|
| 125 |
+
delete zed;
|
| 126 |
+
// Release stream and buffers
|
| 127 |
+
cudaStreamDestroy(stream);
|
| 128 |
+
CUDA_CHECK(cudaFree(buffers[inputIndex]));
|
| 129 |
+
CUDA_CHECK(cudaFree(buffers[output_det_index]));
|
| 130 |
+
CUDA_CHECK(cudaFree(buffers[output_seg_index]));
|
| 131 |
+
CUDA_CHECK(cudaFree(buffers[output_lane_index]));
|
| 132 |
+
// Destroy the engine
|
| 133 |
+
context->destroy();
|
| 134 |
+
engine->destroy();
|
| 135 |
+
runtime->destroy();
|
| 136 |
+
return 0;
|
| 137 |
+
}
|
toolkits/deploy/utils.h
ADDED
|
@@ -0,0 +1,155 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#ifndef TRTX_YOLOV5_UTILS_H_
|
| 2 |
+
#define TRTX_YOLOV5_UTILS_H_
|
| 3 |
+
|
| 4 |
+
#include <dirent.h>
|
| 5 |
+
#include <opencv2/opencv.hpp>
|
| 6 |
+
#include <opencv2/cudawarping.hpp>
|
| 7 |
+
#include <opencv2/cudaimgproc.hpp>
|
| 8 |
+
#include <opencv2/cudaarithm.hpp>
|
| 9 |
+
#include <opencv2/highgui.hpp>
|
| 10 |
+
#include <iostream>
|
| 11 |
+
#include "common.hpp"
|
| 12 |
+
|
| 13 |
+
#define SHOW_IMG
|
| 14 |
+
|
| 15 |
+
static inline cv::Mat preprocess_img(cv::Mat& img, int input_w, int input_h) {
|
| 16 |
+
int w, h, x, y;
|
| 17 |
+
float r_w = input_w / (img.cols*1.0);
|
| 18 |
+
float r_h = input_h / (img.rows*1.0);
|
| 19 |
+
if (r_h > r_w) {
|
| 20 |
+
w = input_w;
|
| 21 |
+
h = r_w * img.rows;
|
| 22 |
+
x = 0;
|
| 23 |
+
y = (input_h - h) / 2;
|
| 24 |
+
} else {
|
| 25 |
+
w = r_h * img.cols;
|
| 26 |
+
h = input_h;
|
| 27 |
+
x = (input_w - w) / 2;
|
| 28 |
+
y = 0;
|
| 29 |
+
}
|
| 30 |
+
cv::Mat re(h, w, CV_8UC3);
|
| 31 |
+
cv::resize(img, re, re.size(), 0, 0, cv::INTER_LINEAR);
|
| 32 |
+
cv::Mat out(input_h, input_w, CV_8UC3, cv::Scalar(114, 114, 114));
|
| 33 |
+
re.copyTo(out(cv::Rect(x, y, re.cols, re.rows)));
|
| 34 |
+
cv::Mat tensor;
|
| 35 |
+
out.convertTo(tensor, CV_32FC3, 1.f / 255.f);
|
| 36 |
+
|
| 37 |
+
cv::subtract(tensor, cv::Scalar(0.485, 0.456, 0.406), tensor, cv::noArray(), -1);
|
| 38 |
+
cv::divide(tensor, cv::Scalar(0.229, 0.224, 0.225), tensor, 1, -1);
|
| 39 |
+
// std::cout << cv::format(out, cv::Formatter::FMT_NUMPY)<< std::endl;
|
| 40 |
+
// assert(false);
|
| 41 |
+
// cv::Mat out(input_h, input_w, CV_8UC3);
|
| 42 |
+
// cv::copyMakeBorder(re, out, y, y, x, x, cv::BORDER_CONSTANT, cv::Scalar(128, 128, 128));
|
| 43 |
+
return tensor;
|
| 44 |
+
}
|
| 45 |
+
|
| 46 |
+
void preprocess_img_gpu(cv::cuda::GpuMat& img, float* gpu_input, int input_w, int input_h) {
|
| 47 |
+
int w, h, x, y;
|
| 48 |
+
float r_w = input_w / (img.cols*1.0);
|
| 49 |
+
float r_h = input_h / (img.rows*1.0);
|
| 50 |
+
if (r_h > r_w) {
|
| 51 |
+
w = input_w;
|
| 52 |
+
h = r_w * img.rows;
|
| 53 |
+
x = 0;
|
| 54 |
+
y = (input_h - h) / 2;
|
| 55 |
+
} else {
|
| 56 |
+
w = r_h * img.cols;
|
| 57 |
+
h = input_h;
|
| 58 |
+
x = (input_w - w) / 2;
|
| 59 |
+
y = 0;
|
| 60 |
+
}
|
| 61 |
+
cv::cuda::GpuMat re(h, w, CV_8UC3);
|
| 62 |
+
cv::cuda::resize(img, re, re.size(), 0, 0, cv::INTER_LINEAR);
|
| 63 |
+
cv::cuda::GpuMat out(input_h, input_w, CV_8UC3, cv::Scalar(114, 114, 114));
|
| 64 |
+
cv::cuda::GpuMat tensor;
|
| 65 |
+
re.copyTo(out(cv::Rect(x, y, re.cols, re.rows)));
|
| 66 |
+
out.convertTo(tensor, CV_32FC3, 1.f / 255.f);
|
| 67 |
+
cv::cuda::subtract(tensor, cv::Scalar(0.485, 0.456, 0.406), tensor, cv::noArray(), -1);
|
| 68 |
+
cv::cuda::divide(tensor, cv::Scalar(0.229, 0.224, 0.225), tensor, 1, -1);
|
| 69 |
+
// cv::Mat out(input_h, input_w, CV_8UC3);
|
| 70 |
+
// cv::copyMakeBorder(re, out, y, y, x, x, cv::BORDER_CONSTANT, cv::Scalar(128, 128, 128));
|
| 71 |
+
|
| 72 |
+
// to tensor
|
| 73 |
+
std::vector<cv::cuda::GpuMat> chw;
|
| 74 |
+
for (size_t i = 0; i < 3; ++i)
|
| 75 |
+
{
|
| 76 |
+
chw.emplace_back(cv::cuda::GpuMat(tensor.size(), CV_32FC1, gpu_input + i * input_w * input_h));
|
| 77 |
+
}
|
| 78 |
+
cv::cuda::split(tensor, chw);
|
| 79 |
+
}
|
| 80 |
+
|
| 81 |
+
static inline int read_files_in_dir(const char *p_dir_name, std::vector<std::string> &file_names) {
|
| 82 |
+
DIR *p_dir = opendir(p_dir_name);
|
| 83 |
+
if (p_dir == nullptr) {
|
| 84 |
+
return -1;
|
| 85 |
+
}
|
| 86 |
+
|
| 87 |
+
struct dirent* p_file = nullptr;
|
| 88 |
+
while ((p_file = readdir(p_dir)) != nullptr) {
|
| 89 |
+
if (strcmp(p_file->d_name, ".") != 0 &&
|
| 90 |
+
strcmp(p_file->d_name, "..") != 0) {
|
| 91 |
+
//std::string cur_file_name(p_dir_name);
|
| 92 |
+
//cur_file_name += "/";
|
| 93 |
+
//cur_file_name += p_file->d_name;
|
| 94 |
+
std::string cur_file_name(p_file->d_name);
|
| 95 |
+
file_names.push_back(cur_file_name);
|
| 96 |
+
}
|
| 97 |
+
}
|
| 98 |
+
|
| 99 |
+
closedir(p_dir);
|
| 100 |
+
return 0;
|
| 101 |
+
}
|
| 102 |
+
|
| 103 |
+
void PrintMat(cv::Mat &A)
|
| 104 |
+
{
|
| 105 |
+
for(int i=0; i<A.rows; i++)
|
| 106 |
+
{
|
| 107 |
+
for(int j=0; j<A.cols; j++)
|
| 108 |
+
std::cout << A.at<int>(i,j) << ' ';
|
| 109 |
+
std::cout << std::endl;
|
| 110 |
+
}
|
| 111 |
+
std::cout << std::endl;
|
| 112 |
+
}
|
| 113 |
+
|
| 114 |
+
void visualization(cv::cuda::GpuMat& cvt_img, cv::Mat& seg_res, cv::Mat& lane_res, std::vector<Yolo::Detection>& res, char& key)
|
| 115 |
+
{
|
| 116 |
+
static const std::vector<cv::Vec3b> segColor{cv::Vec3b(0, 0, 0), cv::Vec3b(0, 255, 0), cv::Vec3b(255, 0, 0)};
|
| 117 |
+
static const std::vector<cv::Vec3b> laneColor{cv::Vec3b(0, 0, 0), cv::Vec3b(0, 0, 255), cv::Vec3b(0, 0, 0)};
|
| 118 |
+
cv::Mat cvt_img_cpu;
|
| 119 |
+
cvt_img.download(cvt_img_cpu);
|
| 120 |
+
|
| 121 |
+
// handling seg and lane results
|
| 122 |
+
for (int row = 0; row < cvt_img_cpu.rows; ++row) {
|
| 123 |
+
uchar* pdata = cvt_img_cpu.data + row * cvt_img_cpu.step;
|
| 124 |
+
for (int col = 0; col < cvt_img_cpu.cols; ++col) {
|
| 125 |
+
int seg_idx = seg_res.at<int>(row, col);
|
| 126 |
+
int lane_idx = lane_res.at<int>(row, col);
|
| 127 |
+
//std::cout << "enter" << ix << std::endl;
|
| 128 |
+
for (int i = 0; i < 3; ++i) {
|
| 129 |
+
if (lane_idx) {
|
| 130 |
+
if (i != 2)
|
| 131 |
+
pdata[i] = pdata[i] / 2 + laneColor[lane_idx][i] / 2;
|
| 132 |
+
}
|
| 133 |
+
else if (seg_idx)
|
| 134 |
+
pdata[i] = pdata[i] / 2 + segColor[seg_idx][i] / 2;
|
| 135 |
+
}
|
| 136 |
+
pdata += 3;
|
| 137 |
+
}
|
| 138 |
+
}
|
| 139 |
+
|
| 140 |
+
// handling det results
|
| 141 |
+
for (size_t j = 0; j < res.size(); ++j) {
|
| 142 |
+
cv::Rect r = get_rect(cvt_img_cpu, res[j].bbox);
|
| 143 |
+
cv::rectangle(cvt_img_cpu, r, cv::Scalar(0x27, 0xC1, 0x36), 2);
|
| 144 |
+
cv::putText(cvt_img_cpu, std::to_string((int)res[j].class_id), cv::Point(r.x, r.y - 1), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0xFF, 0xFF, 0xFF), 2);
|
| 145 |
+
}
|
| 146 |
+
|
| 147 |
+
#ifdef SHOW_IMG
|
| 148 |
+
cv::imshow("img", cvt_img_cpu);
|
| 149 |
+
key = cv::waitKey(1);
|
| 150 |
+
#else
|
| 151 |
+
cv::imwrite("../zed_result.jpg", cvt_img_cpu);
|
| 152 |
+
#endif
|
| 153 |
+
}
|
| 154 |
+
|
| 155 |
+
#endif // TRTX_YOLOV5_UTILS_H_
|
toolkits/deploy/yololayer.cu
ADDED
|
@@ -0,0 +1,333 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#include <assert.h>
|
| 2 |
+
#include <vector>
|
| 3 |
+
#include <iostream>
|
| 4 |
+
#include "yololayer.h"
|
| 5 |
+
#include "cuda_utils.h"
|
| 6 |
+
|
| 7 |
+
namespace Tn
|
| 8 |
+
{
|
| 9 |
+
template<typename T>
|
| 10 |
+
void write(char*& buffer, const T& val)
|
| 11 |
+
{
|
| 12 |
+
*reinterpret_cast<T*>(buffer) = val;
|
| 13 |
+
buffer += sizeof(T);
|
| 14 |
+
}
|
| 15 |
+
|
| 16 |
+
template<typename T>
|
| 17 |
+
void read(const char*& buffer, T& val)
|
| 18 |
+
{
|
| 19 |
+
val = *reinterpret_cast<const T*>(buffer);
|
| 20 |
+
buffer += sizeof(T);
|
| 21 |
+
}
|
| 22 |
+
}
|
| 23 |
+
|
| 24 |
+
using namespace Yolo;
|
| 25 |
+
|
| 26 |
+
namespace nvinfer1
|
| 27 |
+
{
|
| 28 |
+
YoloLayerPlugin::YoloLayerPlugin(int classCount, int netWidth, int netHeight, int maxOut, const std::vector<Yolo::YoloKernel>& vYoloKernel)
|
| 29 |
+
{
|
| 30 |
+
mClassCount = classCount;
|
| 31 |
+
mYoloV5NetWidth = netWidth;
|
| 32 |
+
mYoloV5NetHeight = netHeight;
|
| 33 |
+
mMaxOutObject = maxOut;
|
| 34 |
+
mYoloKernel = vYoloKernel;
|
| 35 |
+
mKernelCount = vYoloKernel.size();
|
| 36 |
+
|
| 37 |
+
CUDA_CHECK(cudaMallocHost(&mAnchor, mKernelCount * sizeof(void*)));
|
| 38 |
+
size_t AnchorLen = sizeof(float)* CHECK_COUNT * 2;
|
| 39 |
+
for (int ii = 0; ii < mKernelCount; ii++)
|
| 40 |
+
{
|
| 41 |
+
CUDA_CHECK(cudaMalloc(&mAnchor[ii], AnchorLen));
|
| 42 |
+
const auto& yolo = mYoloKernel[ii];
|
| 43 |
+
CUDA_CHECK(cudaMemcpy(mAnchor[ii], yolo.anchors, AnchorLen, cudaMemcpyHostToDevice));
|
| 44 |
+
}
|
| 45 |
+
}
|
| 46 |
+
YoloLayerPlugin::~YoloLayerPlugin()
|
| 47 |
+
{
|
| 48 |
+
for (int ii = 0; ii < mKernelCount; ii++)
|
| 49 |
+
{
|
| 50 |
+
CUDA_CHECK(cudaFree(mAnchor[ii]));
|
| 51 |
+
}
|
| 52 |
+
CUDA_CHECK(cudaFreeHost(mAnchor));
|
| 53 |
+
}
|
| 54 |
+
|
| 55 |
+
// create the plugin at runtime from a byte stream
|
| 56 |
+
YoloLayerPlugin::YoloLayerPlugin(const void* data, size_t length)
|
| 57 |
+
{
|
| 58 |
+
using namespace Tn;
|
| 59 |
+
const char *d = reinterpret_cast<const char *>(data), *a = d;
|
| 60 |
+
read(d, mClassCount);
|
| 61 |
+
read(d, mThreadCount);
|
| 62 |
+
read(d, mKernelCount);
|
| 63 |
+
read(d, mYoloV5NetWidth);
|
| 64 |
+
read(d, mYoloV5NetHeight);
|
| 65 |
+
read(d, mMaxOutObject);
|
| 66 |
+
mYoloKernel.resize(mKernelCount);
|
| 67 |
+
auto kernelSize = mKernelCount * sizeof(YoloKernel);
|
| 68 |
+
memcpy(mYoloKernel.data(), d, kernelSize);
|
| 69 |
+
d += kernelSize;
|
| 70 |
+
CUDA_CHECK(cudaMallocHost(&mAnchor, mKernelCount * sizeof(void*)));
|
| 71 |
+
size_t AnchorLen = sizeof(float)* CHECK_COUNT * 2;
|
| 72 |
+
for (int ii = 0; ii < mKernelCount; ii++)
|
| 73 |
+
{
|
| 74 |
+
CUDA_CHECK(cudaMalloc(&mAnchor[ii], AnchorLen));
|
| 75 |
+
const auto& yolo = mYoloKernel[ii];
|
| 76 |
+
CUDA_CHECK(cudaMemcpy(mAnchor[ii], yolo.anchors, AnchorLen, cudaMemcpyHostToDevice));
|
| 77 |
+
}
|
| 78 |
+
assert(d == a + length);
|
| 79 |
+
}
|
| 80 |
+
|
| 81 |
+
void YoloLayerPlugin::serialize(void* buffer) const
|
| 82 |
+
{
|
| 83 |
+
using namespace Tn;
|
| 84 |
+
char* d = static_cast<char*>(buffer), *a = d;
|
| 85 |
+
write(d, mClassCount);
|
| 86 |
+
write(d, mThreadCount);
|
| 87 |
+
write(d, mKernelCount);
|
| 88 |
+
write(d, mYoloV5NetWidth);
|
| 89 |
+
write(d, mYoloV5NetHeight);
|
| 90 |
+
write(d, mMaxOutObject);
|
| 91 |
+
auto kernelSize = mKernelCount * sizeof(YoloKernel);
|
| 92 |
+
memcpy(d, mYoloKernel.data(), kernelSize);
|
| 93 |
+
d += kernelSize;
|
| 94 |
+
|
| 95 |
+
assert(d == a + getSerializationSize());
|
| 96 |
+
}
|
| 97 |
+
|
| 98 |
+
size_t YoloLayerPlugin::getSerializationSize() const
|
| 99 |
+
{
|
| 100 |
+
return sizeof(mClassCount) + sizeof(mThreadCount) + sizeof(mKernelCount) + sizeof(Yolo::YoloKernel) * mYoloKernel.size() + sizeof(mYoloV5NetWidth) + sizeof(mYoloV5NetHeight) + sizeof(mMaxOutObject);
|
| 101 |
+
}
|
| 102 |
+
|
| 103 |
+
int YoloLayerPlugin::initialize()
|
| 104 |
+
{
|
| 105 |
+
return 0;
|
| 106 |
+
}
|
| 107 |
+
|
| 108 |
+
Dims YoloLayerPlugin::getOutputDimensions(int index, const Dims* inputs, int nbInputDims)
|
| 109 |
+
{
|
| 110 |
+
//output the result to channel
|
| 111 |
+
int totalsize = mMaxOutObject * sizeof(Detection) / sizeof(float);
|
| 112 |
+
|
| 113 |
+
return Dims3(totalsize + 1, 1, 1);
|
| 114 |
+
}
|
| 115 |
+
|
| 116 |
+
// Set plugin namespace
|
| 117 |
+
void YoloLayerPlugin::setPluginNamespace(const char* pluginNamespace)
|
| 118 |
+
{
|
| 119 |
+
mPluginNamespace = pluginNamespace;
|
| 120 |
+
}
|
| 121 |
+
|
| 122 |
+
const char* YoloLayerPlugin::getPluginNamespace() const
|
| 123 |
+
{
|
| 124 |
+
return mPluginNamespace;
|
| 125 |
+
}
|
| 126 |
+
|
| 127 |
+
// Return the DataType of the plugin output at the requested index
|
| 128 |
+
DataType YoloLayerPlugin::getOutputDataType(int index, const nvinfer1::DataType* inputTypes, int nbInputs) const
|
| 129 |
+
{
|
| 130 |
+
return DataType::kFLOAT;
|
| 131 |
+
}
|
| 132 |
+
|
| 133 |
+
// Return true if output tensor is broadcast across a batch.
|
| 134 |
+
bool YoloLayerPlugin::isOutputBroadcastAcrossBatch(int outputIndex, const bool* inputIsBroadcasted, int nbInputs) const
|
| 135 |
+
{
|
| 136 |
+
return false;
|
| 137 |
+
}
|
| 138 |
+
|
| 139 |
+
// Return true if plugin can use input that is broadcast across batch without replication.
|
| 140 |
+
bool YoloLayerPlugin::canBroadcastInputAcrossBatch(int inputIndex) const
|
| 141 |
+
{
|
| 142 |
+
return false;
|
| 143 |
+
}
|
| 144 |
+
|
| 145 |
+
void YoloLayerPlugin::configurePlugin(const PluginTensorDesc* in, int nbInput, const PluginTensorDesc* out, int nbOutput)
|
| 146 |
+
{
|
| 147 |
+
}
|
| 148 |
+
|
| 149 |
+
// Attach the plugin object to an execution context and grant the plugin the access to some context resource.
|
| 150 |
+
void YoloLayerPlugin::attachToContext(cudnnContext* cudnnContext, cublasContext* cublasContext, IGpuAllocator* gpuAllocator)
|
| 151 |
+
{
|
| 152 |
+
}
|
| 153 |
+
|
| 154 |
+
// Detach the plugin object from its execution context.
|
| 155 |
+
void YoloLayerPlugin::detachFromContext() {}
|
| 156 |
+
|
| 157 |
+
const char* YoloLayerPlugin::getPluginType() const
|
| 158 |
+
{
|
| 159 |
+
return "YoloLayer_TRT";
|
| 160 |
+
}
|
| 161 |
+
|
| 162 |
+
const char* YoloLayerPlugin::getPluginVersion() const
|
| 163 |
+
{
|
| 164 |
+
return "1";
|
| 165 |
+
}
|
| 166 |
+
|
| 167 |
+
void YoloLayerPlugin::destroy()
|
| 168 |
+
{
|
| 169 |
+
delete this;
|
| 170 |
+
}
|
| 171 |
+
|
| 172 |
+
// Clone the plugin
|
| 173 |
+
IPluginV2IOExt* YoloLayerPlugin::clone() const
|
| 174 |
+
{
|
| 175 |
+
YoloLayerPlugin* p = new YoloLayerPlugin(mClassCount, mYoloV5NetWidth, mYoloV5NetHeight, mMaxOutObject, mYoloKernel);
|
| 176 |
+
p->setPluginNamespace(mPluginNamespace);
|
| 177 |
+
return p;
|
| 178 |
+
}
|
| 179 |
+
|
| 180 |
+
__device__ float Logist(float data) { return 1.0f / (1.0f + expf(-data)); };
|
| 181 |
+
|
| 182 |
+
__global__ void CalDetection(const float *input, float *output, int noElements,
|
| 183 |
+
const int netwidth, const int netheight, int maxoutobject, int yoloWidth, int yoloHeight, const float anchors[CHECK_COUNT * 2], int classes, int outputElem)
|
| 184 |
+
{
|
| 185 |
+
|
| 186 |
+
int idx = threadIdx.x + blockDim.x * blockIdx.x;
|
| 187 |
+
if (idx >= noElements) return;
|
| 188 |
+
|
| 189 |
+
int total_grid = yoloWidth * yoloHeight;
|
| 190 |
+
int bnIdx = idx / total_grid;
|
| 191 |
+
idx = idx - total_grid * bnIdx;
|
| 192 |
+
int info_len_i = 5 + classes;
|
| 193 |
+
const float* curInput = input + bnIdx * (info_len_i * total_grid * CHECK_COUNT);
|
| 194 |
+
|
| 195 |
+
for (int k = 0; k < 3; ++k) {
|
| 196 |
+
float box_prob = Logist(curInput[idx + k * info_len_i * total_grid + 4 * total_grid]);
|
| 197 |
+
if (box_prob < IGNORE_THRESH) continue;
|
| 198 |
+
int class_id = 0;
|
| 199 |
+
float max_cls_prob = 0.0;
|
| 200 |
+
for (int i = 5; i < info_len_i; ++i) {
|
| 201 |
+
float p = Logist(curInput[idx + k * info_len_i * total_grid + i * total_grid]);
|
| 202 |
+
if (p > max_cls_prob) {
|
| 203 |
+
max_cls_prob = p;
|
| 204 |
+
class_id = i - 5;
|
| 205 |
+
}
|
| 206 |
+
}
|
| 207 |
+
float *res_count = output + bnIdx * outputElem;
|
| 208 |
+
int count = (int)atomicAdd(res_count, 1);
|
| 209 |
+
if (count >= maxoutobject) return;
|
| 210 |
+
char* data = (char *)res_count + sizeof(float) + count * sizeof(Detection);
|
| 211 |
+
Detection* det = (Detection*)(data);
|
| 212 |
+
|
| 213 |
+
int row = idx / yoloWidth;
|
| 214 |
+
int col = idx % yoloWidth;
|
| 215 |
+
|
| 216 |
+
//Location
|
| 217 |
+
// pytorch:
|
| 218 |
+
// y = x[i].sigmoid()
|
| 219 |
+
// y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i].to(x[i].device)) * self.stride[i] # xy
|
| 220 |
+
// y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
|
| 221 |
+
// X: (sigmoid(tx) + cx)/FeaturemapW * netwidth
|
| 222 |
+
det->bbox[0] = (col - 0.5f + 2.0f * Logist(curInput[idx + k * info_len_i * total_grid + 0 * total_grid])) * netwidth / yoloWidth;
|
| 223 |
+
det->bbox[1] = (row - 0.5f + 2.0f * Logist(curInput[idx + k * info_len_i * total_grid + 1 * total_grid])) * netheight / yoloHeight;
|
| 224 |
+
|
| 225 |
+
// W: (Pw * e^tw) / FeaturemapW * netwidth
|
| 226 |
+
// v5: https://github.com/ultralytics/yolov5/issues/471
|
| 227 |
+
det->bbox[2] = 2.0f * Logist(curInput[idx + k * info_len_i * total_grid + 2 * total_grid]);
|
| 228 |
+
det->bbox[2] = det->bbox[2] * det->bbox[2] * anchors[2 * k];
|
| 229 |
+
det->bbox[3] = 2.0f * Logist(curInput[idx + k * info_len_i * total_grid + 3 * total_grid]);
|
| 230 |
+
det->bbox[3] = det->bbox[3] * det->bbox[3] * anchors[2 * k + 1];
|
| 231 |
+
det->conf = box_prob * max_cls_prob;
|
| 232 |
+
det->class_id = class_id;
|
| 233 |
+
}
|
| 234 |
+
}
|
| 235 |
+
|
| 236 |
+
void YoloLayerPlugin::forwardGpu(const float *const * inputs, float* output, cudaStream_t stream, int batchSize)
|
| 237 |
+
{
|
| 238 |
+
int outputElem = 1 + mMaxOutObject * sizeof(Detection) / sizeof(float);
|
| 239 |
+
for (int idx = 0; idx < batchSize; ++idx) {
|
| 240 |
+
CUDA_CHECK(cudaMemset(output + idx * outputElem, 0, sizeof(float)));
|
| 241 |
+
}
|
| 242 |
+
int numElem = 0;
|
| 243 |
+
for (unsigned int i = 0; i < mYoloKernel.size(); ++i)
|
| 244 |
+
{
|
| 245 |
+
const auto& yolo = mYoloKernel[i];
|
| 246 |
+
numElem = yolo.width*yolo.height*batchSize;
|
| 247 |
+
if (numElem < mThreadCount)
|
| 248 |
+
mThreadCount = numElem;
|
| 249 |
+
|
| 250 |
+
//printf("Net: %d %d \n", mYoloV5NetWidth, mYoloV5NetHeight);
|
| 251 |
+
CalDetection << < (yolo.width*yolo.height*batchSize + mThreadCount - 1) / mThreadCount, mThreadCount >> >
|
| 252 |
+
(inputs[i], output, numElem, mYoloV5NetWidth, mYoloV5NetHeight, mMaxOutObject, yolo.width, yolo.height, (float *)mAnchor[i], mClassCount, outputElem);
|
| 253 |
+
}
|
| 254 |
+
}
|
| 255 |
+
|
| 256 |
+
|
| 257 |
+
int YoloLayerPlugin::enqueue(int batchSize, const void*const * inputs, void** outputs, void* workspace, cudaStream_t stream)
|
| 258 |
+
{
|
| 259 |
+
forwardGpu((const float *const *)inputs, (float*)outputs[0], stream, batchSize);
|
| 260 |
+
return 0;
|
| 261 |
+
}
|
| 262 |
+
|
| 263 |
+
PluginFieldCollection YoloPluginCreator::mFC{};
|
| 264 |
+
std::vector<PluginField> YoloPluginCreator::mPluginAttributes;
|
| 265 |
+
|
| 266 |
+
YoloPluginCreator::YoloPluginCreator()
|
| 267 |
+
{
|
| 268 |
+
mPluginAttributes.clear();
|
| 269 |
+
|
| 270 |
+
mFC.nbFields = mPluginAttributes.size();
|
| 271 |
+
mFC.fields = mPluginAttributes.data();
|
| 272 |
+
}
|
| 273 |
+
|
| 274 |
+
const char* YoloPluginCreator::getPluginName() const
|
| 275 |
+
{
|
| 276 |
+
return "YoloLayer_TRT";
|
| 277 |
+
}
|
| 278 |
+
|
| 279 |
+
const char* YoloPluginCreator::getPluginVersion() const
|
| 280 |
+
{
|
| 281 |
+
return "1";
|
| 282 |
+
}
|
| 283 |
+
|
| 284 |
+
const PluginFieldCollection* YoloPluginCreator::getFieldNames()
|
| 285 |
+
{
|
| 286 |
+
return &mFC;
|
| 287 |
+
}
|
| 288 |
+
|
| 289 |
+
IPluginV2IOExt* YoloPluginCreator::createPlugin(const char* name, const PluginFieldCollection* fc)
|
| 290 |
+
{
|
| 291 |
+
int class_count = -1;
|
| 292 |
+
int input_w = -1;
|
| 293 |
+
int input_h = -1;
|
| 294 |
+
int max_output_object_count = -1;
|
| 295 |
+
std::vector<Yolo::YoloKernel> yolo_kernels(3);
|
| 296 |
+
|
| 297 |
+
const PluginField* fields = fc->fields;
|
| 298 |
+
for (int i = 0; i < fc->nbFields; i++) {
|
| 299 |
+
if (strcmp(fields[i].name, "netdata") == 0) {
|
| 300 |
+
assert(fields[i].type == PluginFieldType::kFLOAT32);
|
| 301 |
+
int *tmp = (int*)(fields[i].data);
|
| 302 |
+
class_count = tmp[0];
|
| 303 |
+
input_w = tmp[1];
|
| 304 |
+
input_h = tmp[2];
|
| 305 |
+
max_output_object_count = tmp[3];
|
| 306 |
+
} else if (strstr(fields[i].name, "yolodata") != NULL) {
|
| 307 |
+
assert(fields[i].type == PluginFieldType::kFLOAT32);
|
| 308 |
+
int *tmp = (int*)(fields[i].data);
|
| 309 |
+
YoloKernel kernel;
|
| 310 |
+
kernel.width = tmp[0];
|
| 311 |
+
kernel.height = tmp[1];
|
| 312 |
+
for (int j = 0; j < fields[i].length - 2; j++) {
|
| 313 |
+
kernel.anchors[j] = tmp[j + 2];
|
| 314 |
+
}
|
| 315 |
+
yolo_kernels[2 - (fields[i].name[8] - '1')] = kernel;
|
| 316 |
+
}
|
| 317 |
+
}
|
| 318 |
+
assert(class_count && input_w && input_h && max_output_object_count);
|
| 319 |
+
YoloLayerPlugin* obj = new YoloLayerPlugin(class_count, input_w, input_h, max_output_object_count, yolo_kernels);
|
| 320 |
+
obj->setPluginNamespace(mNamespace.c_str());
|
| 321 |
+
return obj;
|
| 322 |
+
}
|
| 323 |
+
|
| 324 |
+
IPluginV2IOExt* YoloPluginCreator::deserializePlugin(const char* name, const void* serialData, size_t serialLength)
|
| 325 |
+
{
|
| 326 |
+
// This object will be deleted when the network is destroyed, which will
|
| 327 |
+
// call YoloLayerPlugin::destroy()
|
| 328 |
+
YoloLayerPlugin* obj = new YoloLayerPlugin(serialData, serialLength);
|
| 329 |
+
obj->setPluginNamespace(mNamespace.c_str());
|
| 330 |
+
return obj;
|
| 331 |
+
}
|
| 332 |
+
}
|
| 333 |
+
|
toolkits/deploy/yololayer.h
ADDED
|
@@ -0,0 +1,143 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#ifndef _YOLO_LAYER_H
|
| 2 |
+
#define _YOLO_LAYER_H
|
| 3 |
+
|
| 4 |
+
#include <vector>
|
| 5 |
+
#include <string>
|
| 6 |
+
#include "NvInfer.h"
|
| 7 |
+
|
| 8 |
+
namespace Yolo
|
| 9 |
+
{
|
| 10 |
+
static constexpr int CHECK_COUNT = 3;
|
| 11 |
+
static constexpr float IGNORE_THRESH = 0.1f;
|
| 12 |
+
struct YoloKernel
|
| 13 |
+
{
|
| 14 |
+
int width;
|
| 15 |
+
int height;
|
| 16 |
+
float anchors[CHECK_COUNT * 2];
|
| 17 |
+
};
|
| 18 |
+
static constexpr int MAX_OUTPUT_BBOX_COUNT = 1000;
|
| 19 |
+
static constexpr int CLASS_NUM = 13;
|
| 20 |
+
static constexpr int INPUT_H = 384;
|
| 21 |
+
static constexpr int INPUT_W = 640;
|
| 22 |
+
static constexpr int IMG_H = 360;
|
| 23 |
+
static constexpr int IMG_W = 640;
|
| 24 |
+
// static constexpr int INPUT_H = 192;
|
| 25 |
+
// static constexpr int INPUT_W = 320;
|
| 26 |
+
// static constexpr int IMG_H = 180;
|
| 27 |
+
// static constexpr int IMG_W = 320;
|
| 28 |
+
|
| 29 |
+
static constexpr int LOCATIONS = 4;
|
| 30 |
+
struct alignas(float) Detection {
|
| 31 |
+
//center_x center_y w h
|
| 32 |
+
float bbox[LOCATIONS];
|
| 33 |
+
float conf; // bbox_conf * cls_conf
|
| 34 |
+
float class_id;
|
| 35 |
+
};
|
| 36 |
+
}
|
| 37 |
+
|
| 38 |
+
namespace nvinfer1
|
| 39 |
+
{
|
| 40 |
+
class YoloLayerPlugin : public IPluginV2IOExt
|
| 41 |
+
{
|
| 42 |
+
public:
|
| 43 |
+
YoloLayerPlugin(int classCount, int netWidth, int netHeight, int maxOut, const std::vector<Yolo::YoloKernel>& vYoloKernel);
|
| 44 |
+
YoloLayerPlugin(const void* data, size_t length);
|
| 45 |
+
~YoloLayerPlugin();
|
| 46 |
+
|
| 47 |
+
int getNbOutputs() const override
|
| 48 |
+
{
|
| 49 |
+
return 1;
|
| 50 |
+
}
|
| 51 |
+
|
| 52 |
+
Dims getOutputDimensions(int index, const Dims* inputs, int nbInputDims) override;
|
| 53 |
+
|
| 54 |
+
int initialize() override;
|
| 55 |
+
|
| 56 |
+
virtual void terminate() override {};
|
| 57 |
+
|
| 58 |
+
virtual size_t getWorkspaceSize(int maxBatchSize) const override { return 0; }
|
| 59 |
+
|
| 60 |
+
virtual int enqueue(int batchSize, const void*const * inputs, void** outputs, void* workspace, cudaStream_t stream) override;
|
| 61 |
+
|
| 62 |
+
virtual size_t getSerializationSize() const override;
|
| 63 |
+
|
| 64 |
+
virtual void serialize(void* buffer) const override;
|
| 65 |
+
|
| 66 |
+
bool supportsFormatCombination(int pos, const PluginTensorDesc* inOut, int nbInputs, int nbOutputs) const override {
|
| 67 |
+
return inOut[pos].format == TensorFormat::kLINEAR && inOut[pos].type == DataType::kFLOAT;
|
| 68 |
+
}
|
| 69 |
+
|
| 70 |
+
const char* getPluginType() const override;
|
| 71 |
+
|
| 72 |
+
const char* getPluginVersion() const override;
|
| 73 |
+
|
| 74 |
+
void destroy() override;
|
| 75 |
+
|
| 76 |
+
IPluginV2IOExt* clone() const override;
|
| 77 |
+
|
| 78 |
+
void setPluginNamespace(const char* pluginNamespace) override;
|
| 79 |
+
|
| 80 |
+
const char* getPluginNamespace() const override;
|
| 81 |
+
|
| 82 |
+
DataType getOutputDataType(int index, const nvinfer1::DataType* inputTypes, int nbInputs) const override;
|
| 83 |
+
|
| 84 |
+
bool isOutputBroadcastAcrossBatch(int outputIndex, const bool* inputIsBroadcasted, int nbInputs) const override;
|
| 85 |
+
|
| 86 |
+
bool canBroadcastInputAcrossBatch(int inputIndex) const override;
|
| 87 |
+
|
| 88 |
+
void attachToContext(
|
| 89 |
+
cudnnContext* cudnnContext, cublasContext* cublasContext, IGpuAllocator* gpuAllocator) override;
|
| 90 |
+
|
| 91 |
+
void configurePlugin(const PluginTensorDesc* in, int nbInput, const PluginTensorDesc* out, int nbOutput) override;
|
| 92 |
+
|
| 93 |
+
void detachFromContext() override;
|
| 94 |
+
|
| 95 |
+
private:
|
| 96 |
+
void forwardGpu(const float *const * inputs, float * output, cudaStream_t stream, int batchSize = 1);
|
| 97 |
+
int mThreadCount = 256;
|
| 98 |
+
const char* mPluginNamespace;
|
| 99 |
+
int mKernelCount;
|
| 100 |
+
int mClassCount;
|
| 101 |
+
int mYoloV5NetWidth;
|
| 102 |
+
int mYoloV5NetHeight;
|
| 103 |
+
int mMaxOutObject;
|
| 104 |
+
std::vector<Yolo::YoloKernel> mYoloKernel;
|
| 105 |
+
void** mAnchor;
|
| 106 |
+
};
|
| 107 |
+
|
| 108 |
+
class YoloPluginCreator : public IPluginCreator
|
| 109 |
+
{
|
| 110 |
+
public:
|
| 111 |
+
YoloPluginCreator();
|
| 112 |
+
|
| 113 |
+
~YoloPluginCreator() override = default;
|
| 114 |
+
|
| 115 |
+
const char* getPluginName() const override;
|
| 116 |
+
|
| 117 |
+
const char* getPluginVersion() const override;
|
| 118 |
+
|
| 119 |
+
const PluginFieldCollection* getFieldNames() override;
|
| 120 |
+
|
| 121 |
+
IPluginV2IOExt* createPlugin(const char* name, const PluginFieldCollection* fc) override;
|
| 122 |
+
|
| 123 |
+
IPluginV2IOExt* deserializePlugin(const char* name, const void* serialData, size_t serialLength) override;
|
| 124 |
+
|
| 125 |
+
void setPluginNamespace(const char* libNamespace) override
|
| 126 |
+
{
|
| 127 |
+
mNamespace = libNamespace;
|
| 128 |
+
}
|
| 129 |
+
|
| 130 |
+
const char* getPluginNamespace() const override
|
| 131 |
+
{
|
| 132 |
+
return mNamespace.c_str();
|
| 133 |
+
}
|
| 134 |
+
|
| 135 |
+
private:
|
| 136 |
+
std::string mNamespace;
|
| 137 |
+
static PluginFieldCollection mFC;
|
| 138 |
+
static std::vector<PluginField> mPluginAttributes;
|
| 139 |
+
};
|
| 140 |
+
REGISTER_TENSORRT_PLUGIN(YoloPluginCreator);
|
| 141 |
+
};
|
| 142 |
+
|
| 143 |
+
#endif
|
toolkits/deploy/yolov5.hpp
ADDED
|
@@ -0,0 +1,286 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#ifndef YOLOV5_H_
|
| 2 |
+
#define YOLOV5_H_
|
| 3 |
+
|
| 4 |
+
#include <chrono>
|
| 5 |
+
#include "cuda_utils.h"
|
| 6 |
+
#include "logging.h"
|
| 7 |
+
#include "utils.h"
|
| 8 |
+
#include "calibrator.h"
|
| 9 |
+
|
| 10 |
+
#define USE_FP16 // set USE_INT8 or USE_FP16 or USE_FP32
|
| 11 |
+
#define DEVICE 0 // GPU id
|
| 12 |
+
#define NMS_THRESH 0.45
|
| 13 |
+
#define CONF_THRESH 0.25
|
| 14 |
+
#define BATCH_SIZE 1
|
| 15 |
+
|
| 16 |
+
// stuff we know about the network and the input/output blobs
|
| 17 |
+
static const int INPUT_H = Yolo::INPUT_H;
|
| 18 |
+
static const int INPUT_W = Yolo::INPUT_W;
|
| 19 |
+
static const int IMG_H = Yolo::IMG_H;
|
| 20 |
+
static const int IMG_W = Yolo::IMG_W;
|
| 21 |
+
static const int CLASS_NUM = Yolo::CLASS_NUM;
|
| 22 |
+
static const int OUTPUT_SIZE = Yolo::MAX_OUTPUT_BBOX_COUNT * sizeof(Yolo::Detection) / sizeof(float) + 1; // we assume the yololayer outputs no more than MAX_OUTPUT_BBOX_COUNT boxes that conf >= 0.1
|
| 23 |
+
const char* INPUT_BLOB_NAME = "data";
|
| 24 |
+
const char* OUTPUT_DET_NAME = "det";
|
| 25 |
+
const char* OUTPUT_SEG_NAME = "seg";
|
| 26 |
+
const char* OUTPUT_LANE_NAME = "lane";
|
| 27 |
+
static Logger gLogger;
|
| 28 |
+
|
| 29 |
+
ICudaEngine* build_engine(unsigned int maxBatchSize, IBuilder* builder, IBuilderConfig* config, DataType dt, float& gd, float& gw, std::string& wts_name) {
|
| 30 |
+
INetworkDefinition* network = builder->createNetworkV2(0U);
|
| 31 |
+
|
| 32 |
+
// Create input tensor of shape {3, INPUT_H, INPUT_W} with name INPUT_BLOB_NAME
|
| 33 |
+
ITensor* data = network->addInput(INPUT_BLOB_NAME, dt, Dims3{ 3, INPUT_H, INPUT_W });
|
| 34 |
+
assert(data);
|
| 35 |
+
// auto shuffle = network->addShuffle(*data);
|
| 36 |
+
// shuffle->setReshapeDimensions(Dims3{ 3, INPUT_H, INPUT_W });
|
| 37 |
+
// shuffle->setFirstTranspose(Permutation{ 2, 0, 1 });
|
| 38 |
+
|
| 39 |
+
std::map<std::string, Weights> weightMap = loadWeights(wts_name);
|
| 40 |
+
Weights emptywts{ DataType::kFLOAT, nullptr, 0 };
|
| 41 |
+
|
| 42 |
+
// yolov5 backbone
|
| 43 |
+
// auto focus0 = focus(network, weightMap, *shuffle->getOutput(0), 3, 32, 3, "model.0");
|
| 44 |
+
auto focus0 = focus(network, weightMap, *data, 3, 32, 3, "model.0");
|
| 45 |
+
auto conv1 = convBlock(network, weightMap, *focus0->getOutput(0), 64, 3, 2, 1, "model.1");
|
| 46 |
+
auto bottleneck_CSP2 = bottleneckCSP(network, weightMap, *conv1->getOutput(0), 64, 64, 1, true, 1, 0.5, "model.2");
|
| 47 |
+
auto conv3 = convBlock(network, weightMap, *bottleneck_CSP2->getOutput(0), 128, 3, 2, 1, "model.3");
|
| 48 |
+
auto bottleneck_csp4 = bottleneckCSP(network, weightMap, *conv3->getOutput(0), 128, 128, 3, true, 1, 0.5, "model.4");
|
| 49 |
+
auto conv5 = convBlock(network, weightMap, *bottleneck_csp4->getOutput(0), 256, 3, 2, 1, "model.5");
|
| 50 |
+
auto bottleneck_csp6 = bottleneckCSP(network, weightMap, *conv5->getOutput(0), 256, 256, 3, true, 1, 0.5, "model.6");
|
| 51 |
+
auto conv7 = convBlock(network, weightMap, *bottleneck_csp6->getOutput(0), 512, 3, 2, 1, "model.7");
|
| 52 |
+
auto spp8 = SPP(network, weightMap, *conv7->getOutput(0), 512, 512, 5, 9, 13, "model.8");
|
| 53 |
+
|
| 54 |
+
// yolov5 head
|
| 55 |
+
auto bottleneck_csp9 = bottleneckCSP(network, weightMap, *spp8->getOutput(0), 512, 512, 1, false, 1, 0.5, "model.9");
|
| 56 |
+
auto conv10 = convBlock(network, weightMap, *bottleneck_csp9->getOutput(0), 256, 1, 1, 1, "model.10");
|
| 57 |
+
|
| 58 |
+
float *deval = reinterpret_cast<float*>(malloc(sizeof(float) * 256 * 2 * 2));
|
| 59 |
+
for (int i = 0; i < 256 * 2 * 2; i++) {
|
| 60 |
+
deval[i] = 1.0;
|
| 61 |
+
}
|
| 62 |
+
Weights deconvwts11{ DataType::kFLOAT, deval, 256 * 2 * 2 };
|
| 63 |
+
IDeconvolutionLayer* deconv11 = network->addDeconvolutionNd(*conv10->getOutput(0), 256, DimsHW{ 2, 2 }, deconvwts11, emptywts);
|
| 64 |
+
deconv11->setStrideNd(DimsHW{ 2, 2 });
|
| 65 |
+
deconv11->setNbGroups(256);
|
| 66 |
+
weightMap["deconv11"] = deconvwts11;
|
| 67 |
+
|
| 68 |
+
ITensor* inputTensors12[] = { deconv11->getOutput(0), bottleneck_csp6->getOutput(0) };
|
| 69 |
+
auto cat12 = network->addConcatenation(inputTensors12, 2);
|
| 70 |
+
auto bottleneck_csp13 = bottleneckCSP(network, weightMap, *cat12->getOutput(0), 512, 256, 1, false, 1, 0.5, "model.13");
|
| 71 |
+
auto conv14 = convBlock(network, weightMap, *bottleneck_csp13->getOutput(0), 128, 1, 1, 1, "model.14");
|
| 72 |
+
|
| 73 |
+
Weights deconvwts15{ DataType::kFLOAT, deval, 128 * 2 * 2 };
|
| 74 |
+
IDeconvolutionLayer* deconv15 = network->addDeconvolutionNd(*conv14->getOutput(0), 128, DimsHW{ 2, 2 }, deconvwts15, emptywts);
|
| 75 |
+
deconv15->setStrideNd(DimsHW{ 2, 2 });
|
| 76 |
+
deconv15->setNbGroups(128);
|
| 77 |
+
|
| 78 |
+
ITensor* inputTensors16[] = { deconv15->getOutput(0), bottleneck_csp4->getOutput(0) };
|
| 79 |
+
auto cat16 = network->addConcatenation(inputTensors16, 2);
|
| 80 |
+
auto bottleneck_csp17 = bottleneckCSP(network, weightMap, *cat16->getOutput(0), 256, 128, 1, false, 1, 0.5, "model.17");
|
| 81 |
+
IConvolutionLayer* det0 = network->addConvolutionNd(*bottleneck_csp17->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.24.m.0.weight"], weightMap["model.24.m.0.bias"]);
|
| 82 |
+
|
| 83 |
+
auto conv18 = convBlock(network, weightMap, *bottleneck_csp17->getOutput(0), 128, 3, 2, 1, "model.18");
|
| 84 |
+
ITensor* inputTensors19[] = { conv18->getOutput(0), conv14->getOutput(0) };
|
| 85 |
+
auto cat19 = network->addConcatenation(inputTensors19, 2);
|
| 86 |
+
auto bottleneck_csp20 = bottleneckCSP(network, weightMap, *cat19->getOutput(0), 256, 256, 1, false, 1, 0.5, "model.20");
|
| 87 |
+
IConvolutionLayer* det1 = network->addConvolutionNd(*bottleneck_csp20->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.24.m.1.weight"], weightMap["model.24.m.1.bias"]);
|
| 88 |
+
|
| 89 |
+
auto conv21 = convBlock(network, weightMap, *bottleneck_csp20->getOutput(0), 256, 3, 2, 1, "model.21");
|
| 90 |
+
ITensor* inputTensors22[] = { conv21->getOutput(0), conv10->getOutput(0) };
|
| 91 |
+
auto cat22 = network->addConcatenation(inputTensors22, 2);
|
| 92 |
+
auto bottleneck_csp23 = bottleneckCSP(network, weightMap, *cat22->getOutput(0), 512, 512, 1, false, 1, 0.5, "model.23");
|
| 93 |
+
IConvolutionLayer* det2 = network->addConvolutionNd(*bottleneck_csp23->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.24.m.2.weight"], weightMap["model.24.m.2.bias"]);
|
| 94 |
+
|
| 95 |
+
auto detect24 = addYoLoLayer(network, weightMap, det0, det1, det2);
|
| 96 |
+
detect24->getOutput(0)->setName(OUTPUT_DET_NAME);
|
| 97 |
+
|
| 98 |
+
auto conv25 = convBlock(network, weightMap, *cat16->getOutput(0), 64, 3, 1, 1, "model.25");
|
| 99 |
+
// upsample 26
|
| 100 |
+
Weights deconvwts26{ DataType::kFLOAT, deval, 64 * 2 * 2 };
|
| 101 |
+
IDeconvolutionLayer* deconv26 = network->addDeconvolutionNd(*conv25->getOutput(0), 64, DimsHW{ 2, 2 }, deconvwts26, emptywts);
|
| 102 |
+
deconv26->setStrideNd(DimsHW{ 2, 2 });
|
| 103 |
+
deconv26->setNbGroups(64);
|
| 104 |
+
|
| 105 |
+
ITensor* inputTensors27[] = { deconv26->getOutput(0), bottleneck_CSP2->getOutput(0) };
|
| 106 |
+
auto cat27 = network->addConcatenation(inputTensors27, 2);
|
| 107 |
+
auto bottleneck_csp28 = bottleneckCSP(network, weightMap, *cat27->getOutput(0), 128, 64, 1, false, 1, 0.5, "model.28");
|
| 108 |
+
auto conv29 = convBlock(network, weightMap, *bottleneck_csp28->getOutput(0), 32, 3, 1, 1, "model.29");
|
| 109 |
+
// upsample 30
|
| 110 |
+
Weights deconvwts30{ DataType::kFLOAT, deval, 32 * 2 * 2 };
|
| 111 |
+
IDeconvolutionLayer* deconv30 = network->addDeconvolutionNd(*conv29->getOutput(0), 32, DimsHW{ 2, 2 }, deconvwts30, emptywts);
|
| 112 |
+
deconv30->setStrideNd(DimsHW{ 2, 2 });
|
| 113 |
+
deconv30->setNbGroups(32);
|
| 114 |
+
|
| 115 |
+
auto conv31 = convBlock(network, weightMap, *deconv30->getOutput(0), 16, 3, 1, 1, "model.31");
|
| 116 |
+
auto bottleneck_csp32 = bottleneckCSP(network, weightMap, *conv31->getOutput(0), 16, 8, 1, false, 1, 0.5, "model.32");
|
| 117 |
+
|
| 118 |
+
// upsample33
|
| 119 |
+
Weights deconvwts33{ DataType::kFLOAT, deval, 8 * 2 * 2 };
|
| 120 |
+
IDeconvolutionLayer* deconv33 = network->addDeconvolutionNd(*bottleneck_csp32->getOutput(0), 8, DimsHW{ 2, 2 }, deconvwts33, emptywts);
|
| 121 |
+
deconv33->setStrideNd(DimsHW{ 2, 2 });
|
| 122 |
+
deconv33->setNbGroups(8);
|
| 123 |
+
|
| 124 |
+
auto conv34 = convBlock(network, weightMap, *deconv33->getOutput(0), 3, 3, 1, 1, "model.34");
|
| 125 |
+
// segmentation output
|
| 126 |
+
ISliceLayer *slicelayer = network->addSlice(*conv34->getOutput(0), Dims3{ 0, (Yolo::INPUT_H - Yolo::IMG_H) / 2, 0 }, Dims3{ 3, Yolo::IMG_H, Yolo::IMG_W }, Dims3{ 1, 1, 1 });
|
| 127 |
+
auto segout = network->addTopK(*slicelayer->getOutput(0), TopKOperation::kMAX, 1, 1);
|
| 128 |
+
segout->getOutput(1)->setName(OUTPUT_SEG_NAME);
|
| 129 |
+
|
| 130 |
+
auto conv35 = convBlock(network, weightMap, *cat16->getOutput(0), 64, 3, 1, 1, "model.35");
|
| 131 |
+
|
| 132 |
+
// upsample36
|
| 133 |
+
Weights deconvwts36{ DataType::kFLOAT, deval, 64 * 2 * 2 };
|
| 134 |
+
IDeconvolutionLayer* deconv36 = network->addDeconvolutionNd(*conv35->getOutput(0), 64, DimsHW{ 2, 2 }, deconvwts36, emptywts);
|
| 135 |
+
deconv36->setStrideNd(DimsHW{ 2, 2 });
|
| 136 |
+
deconv36->setNbGroups(64);
|
| 137 |
+
|
| 138 |
+
ITensor* inputTensors37[] = { deconv36->getOutput(0), bottleneck_CSP2->getOutput(0) };
|
| 139 |
+
auto cat37 = network->addConcatenation(inputTensors37, 2);
|
| 140 |
+
auto bottleneck_csp38 = bottleneckCSP(network, weightMap, *cat37->getOutput(0), 128, 64, 1, false, 1, 0.5, "model.38");
|
| 141 |
+
auto conv39 = convBlock(network, weightMap, *bottleneck_csp38->getOutput(0), 32, 3, 1, 1, "model.39");
|
| 142 |
+
|
| 143 |
+
// upsample40
|
| 144 |
+
Weights deconvwts40{ DataType::kFLOAT, deval, 32 * 2 * 2 };
|
| 145 |
+
IDeconvolutionLayer* deconv40 = network->addDeconvolutionNd(*conv39->getOutput(0), 32, DimsHW{ 2, 2 }, deconvwts40, emptywts);
|
| 146 |
+
deconv40->setStrideNd(DimsHW{ 2, 2 });
|
| 147 |
+
deconv40->setNbGroups(32);
|
| 148 |
+
|
| 149 |
+
auto conv41 = convBlock(network, weightMap, *deconv40->getOutput(0), 16, 3, 1, 1, "model.41");
|
| 150 |
+
auto bottleneck_csp42 = bottleneckCSP(network, weightMap, *conv41->getOutput(0), 16, 8, 1, false, 1, 0.5, "model.42");
|
| 151 |
+
|
| 152 |
+
// upsample43
|
| 153 |
+
Weights deconvwts43{ DataType::kFLOAT, deval, 8 * 2 * 2 };
|
| 154 |
+
IDeconvolutionLayer* deconv43 = network->addDeconvolutionNd(*bottleneck_csp42->getOutput(0), 8, DimsHW{ 2, 2 }, deconvwts43, emptywts);
|
| 155 |
+
deconv43->setStrideNd(DimsHW{ 2, 2 });
|
| 156 |
+
deconv43->setNbGroups(8);
|
| 157 |
+
|
| 158 |
+
auto conv44 = convBlock(network, weightMap, *deconv43->getOutput(0), 2, 3, 1, 1, "model.44");
|
| 159 |
+
// lane-det output
|
| 160 |
+
ISliceLayer *laneSlice = network->addSlice(*conv44->getOutput(0), Dims3{ 0, (Yolo::INPUT_H - Yolo::IMG_H) / 2, 0 }, Dims3{ 2, Yolo::IMG_H, Yolo::IMG_W }, Dims3{ 1, 1, 1 });
|
| 161 |
+
auto laneout = network->addTopK(*laneSlice->getOutput(0), TopKOperation::kMAX, 1, 1);
|
| 162 |
+
laneout->getOutput(1)->setName(OUTPUT_LANE_NAME);
|
| 163 |
+
|
| 164 |
+
// // std::cout << std::to_string(slicelayer->getOutput(0)->getDimensions().d[0]) << std::endl;
|
| 165 |
+
// // ISliceLayer *tmp1 = network->addSlice(*slicelayer->getOutput(0), Dims3{ 0, 0, 0 }, Dims3{ 1, (Yolo::INPUT_H - 2 * Yolo::PAD_H), Yolo::INPUT_W }, Dims3{ 1, 1, 1 });
|
| 166 |
+
// // ISliceLayer *tmp2 = network->addSlice(*slicelayer->getOutput(0), Dims3{ 1, 0, 0 }, Dims3{ 1, (Yolo::INPUT_H - 2 * Yolo::PAD_H), Yolo::INPUT_W }, Dims3{ 1, 1, 1 });
|
| 167 |
+
// // auto segout = network->addElementWise(*tmp1->getOutput(0), *tmp2->getOutput(0), ElementWiseOperation::kLESS);
|
| 168 |
+
// std::cout << std::to_string(conv44->getOutput(0)->getDimensions().d[0]) << std::endl;
|
| 169 |
+
// std::cout << std::to_string(conv44->getOutput(0)->getDimensions().d[1]) << std::endl;
|
| 170 |
+
// std::cout << std::to_string(conv44->getOutput(0)->getDimensions().d[2]) << std::endl;
|
| 171 |
+
// assert(false);
|
| 172 |
+
// // segout->setOutputType(1, DataType::kFLOAT);
|
| 173 |
+
// segout->getOutput(1)->setName(OUTPUT_SEG_NAME);
|
| 174 |
+
// // std::cout << std::to_string(segout->getOutput(1)->getDimensions().d[0]) << std::endl;
|
| 175 |
+
|
| 176 |
+
// detection output
|
| 177 |
+
network->markOutput(*detect24->getOutput(0));
|
| 178 |
+
// segmentation output
|
| 179 |
+
network->markOutput(*segout->getOutput(1));
|
| 180 |
+
// lane output
|
| 181 |
+
network->markOutput(*laneout->getOutput(1));
|
| 182 |
+
|
| 183 |
+
assert(false);
|
| 184 |
+
|
| 185 |
+
// Build engine
|
| 186 |
+
builder->setMaxBatchSize(maxBatchSize);
|
| 187 |
+
config->setMaxWorkspaceSize(2L * (1L << 30)); // 2GB
|
| 188 |
+
#if defined(USE_FP16)
|
| 189 |
+
config->setFlag(BuilderFlag::kFP16);
|
| 190 |
+
// #elif defined(USE_INT8)
|
| 191 |
+
// std::cout << "Your platform support int8: " << (builder->platformHasFastInt8() ? "true" : "false") << std::endl;
|
| 192 |
+
// assert(builder->platformHasFastInt8());
|
| 193 |
+
// config->setFlag(BuilderFlag::kINT8);
|
| 194 |
+
// Int8EntropyCalibrator2* calibrator = new Int8EntropyCalibrator2(1, INPUT_W, INPUT_H, "./coco_calib/", "int8calib.table", INPUT_BLOB_NAME);
|
| 195 |
+
// config->setInt8Calibrator(calibrator);
|
| 196 |
+
#endif
|
| 197 |
+
|
| 198 |
+
std::cout << "Building engine, please wait for a while..." << std::endl;
|
| 199 |
+
ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
|
| 200 |
+
std::cout << "Build engine successfully!" << std::endl;
|
| 201 |
+
|
| 202 |
+
// Don't need the network any more
|
| 203 |
+
network->destroy();
|
| 204 |
+
|
| 205 |
+
// Release host memory
|
| 206 |
+
for (auto& mem : weightMap)
|
| 207 |
+
{
|
| 208 |
+
free((void*)(mem.second.values));
|
| 209 |
+
}
|
| 210 |
+
|
| 211 |
+
return engine;
|
| 212 |
+
}
|
| 213 |
+
|
| 214 |
+
void APIToModel(unsigned int maxBatchSize, IHostMemory** modelStream, float& gd, float& gw, std::string& wts_name) {
|
| 215 |
+
// Create builder
|
| 216 |
+
IBuilder* builder = createInferBuilder(gLogger);
|
| 217 |
+
IBuilderConfig* config = builder->createBuilderConfig();
|
| 218 |
+
|
| 219 |
+
// Create model to populate the network, then set the outputs and create an engine
|
| 220 |
+
ICudaEngine* engine = build_engine(maxBatchSize, builder, config, DataType::kFLOAT, gd, gw, wts_name);
|
| 221 |
+
assert(engine != nullptr);
|
| 222 |
+
|
| 223 |
+
// Serialize the engine
|
| 224 |
+
(*modelStream) = engine->serialize();
|
| 225 |
+
|
| 226 |
+
// Close everything down
|
| 227 |
+
engine->destroy();
|
| 228 |
+
builder->destroy();
|
| 229 |
+
config->destroy();
|
| 230 |
+
}
|
| 231 |
+
|
| 232 |
+
void doInference(IExecutionContext& context, cudaStream_t& stream, void **buffers, float* det_output, int* seg_output, int* lane_output, int batchSize) {
|
| 233 |
+
// DMA input batch data to device, infer on the batch asynchronously, and DMA output back to host
|
| 234 |
+
// CUDA_CHECK(cudaMemcpyAsync(buffers[0], input, batchSize * 3 * INPUT_H * INPUT_W * sizeof(float), cudaMemcpyHostToDevice, stream));
|
| 235 |
+
context.enqueue(batchSize, buffers, stream, nullptr);
|
| 236 |
+
CUDA_CHECK(cudaMemcpyAsync(det_output, buffers[1], batchSize * OUTPUT_SIZE * sizeof(float), cudaMemcpyDeviceToHost, stream));
|
| 237 |
+
CUDA_CHECK(cudaMemcpyAsync(seg_output, buffers[2], batchSize * IMG_H * IMG_W * sizeof(int), cudaMemcpyDeviceToHost, stream));
|
| 238 |
+
CUDA_CHECK(cudaMemcpyAsync(lane_output, buffers[3], batchSize * IMG_H * IMG_W * sizeof(int), cudaMemcpyDeviceToHost, stream));
|
| 239 |
+
cudaStreamSynchronize(stream);
|
| 240 |
+
}
|
| 241 |
+
|
| 242 |
+
void doInferenceCpu(IExecutionContext& context, cudaStream_t& stream, void **buffers, float* input, float* det_output, int* seg_output, int* lane_output, int batchSize) {
|
| 243 |
+
// DMA input batch data to device, infer on the batch asynchronously, and DMA output back to host
|
| 244 |
+
CUDA_CHECK(cudaMemcpyAsync(buffers[0], input, batchSize * 3 * INPUT_H * INPUT_W * sizeof(float), cudaMemcpyHostToDevice, stream));
|
| 245 |
+
context.enqueue(batchSize, buffers, stream, nullptr);
|
| 246 |
+
CUDA_CHECK(cudaMemcpyAsync(det_output, buffers[1], batchSize * OUTPUT_SIZE * sizeof(float), cudaMemcpyDeviceToHost, stream));
|
| 247 |
+
CUDA_CHECK(cudaMemcpyAsync(seg_output, buffers[2], batchSize * IMG_H * IMG_W * sizeof(int), cudaMemcpyDeviceToHost, stream));
|
| 248 |
+
CUDA_CHECK(cudaMemcpyAsync(lane_output, buffers[3], batchSize * IMG_H * IMG_W * sizeof(int), cudaMemcpyDeviceToHost, stream));
|
| 249 |
+
cudaStreamSynchronize(stream);
|
| 250 |
+
}
|
| 251 |
+
|
| 252 |
+
bool parse_args(int argc, char** argv, std::string& wts, std::string& engine, float& gd, float& gw, std::string& img_dir) {
|
| 253 |
+
if (argc < 4) return false;
|
| 254 |
+
if (std::string(argv[1]) == "-s" && (argc == 5 || argc == 7)) {
|
| 255 |
+
wts = std::string(argv[2]);
|
| 256 |
+
engine = std::string(argv[3]);
|
| 257 |
+
auto net = std::string(argv[4]);
|
| 258 |
+
if (net == "s") {
|
| 259 |
+
gd = 0.33;
|
| 260 |
+
gw = 0.50;
|
| 261 |
+
} else if (net == "m") {
|
| 262 |
+
gd = 0.67;
|
| 263 |
+
gw = 0.75;
|
| 264 |
+
} else if (net == "l") {
|
| 265 |
+
gd = 1.0;
|
| 266 |
+
gw = 1.0;
|
| 267 |
+
} else if (net == "x") {
|
| 268 |
+
gd = 1.33;
|
| 269 |
+
gw = 1.25;
|
| 270 |
+
} else if (net == "c" && argc == 7) {
|
| 271 |
+
gd = atof(argv[5]);
|
| 272 |
+
gw = atof(argv[6]);
|
| 273 |
+
} else {
|
| 274 |
+
return false;
|
| 275 |
+
}
|
| 276 |
+
} else if (std::string(argv[1]) == "-d" && argc == 4) {
|
| 277 |
+
engine = std::string(argv[2]);
|
| 278 |
+
img_dir = std::string(argv[3]);
|
| 279 |
+
} else {
|
| 280 |
+
return false;
|
| 281 |
+
}
|
| 282 |
+
return true;
|
| 283 |
+
}
|
| 284 |
+
|
| 285 |
+
|
| 286 |
+
#endif
|
toolkits/deploy/zedcam.hpp
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#ifndef ZEDCAM_H
|
| 2 |
+
#define ZEDCAM_H
|
| 3 |
+
|
| 4 |
+
#include <sl/Camera.hpp>
|
| 5 |
+
|
| 6 |
+
sl::Camera* create_camera() {
|
| 7 |
+
sl::Camera* cam = new sl::Camera();
|
| 8 |
+
sl::InitParameters init_params;
|
| 9 |
+
init_params.camera_resolution = sl::RESOLUTION::HD720;
|
| 10 |
+
init_params.camera_fps = 60;
|
| 11 |
+
sl::ERROR_CODE err = cam->open(init_params);
|
| 12 |
+
if (err != sl::ERROR_CODE::SUCCESS) {
|
| 13 |
+
std::cout << sl::toString(err) << std::endl; // Display the error
|
| 14 |
+
exit(-1);
|
| 15 |
+
}
|
| 16 |
+
return cam;
|
| 17 |
+
}
|
| 18 |
+
|
| 19 |
+
cv::Mat slMat2cvMat(sl::Mat& input) {
|
| 20 |
+
// Since cv::Mat data requires a uchar* pointer, we get the uchar1 pointer from sl::Mat (getPtr<T>())
|
| 21 |
+
// cv::Mat and sl::Mat will share a single memory structure
|
| 22 |
+
return cv::Mat(input.getHeight(), input.getWidth(), CV_8UC4, input.getPtr<sl::uchar1>(sl::MEM::CPU), input.getStepBytes(sl::MEM::CPU));
|
| 23 |
+
}
|
| 24 |
+
|
| 25 |
+
cv::cuda::GpuMat slMat2cvMatGPU(sl::Mat& input) {
|
| 26 |
+
// Since cv::Mat data requires a uchar* pointer, we get the uchar1 pointer from sl::Mat (getPtr<T>())
|
| 27 |
+
// cv::Mat and sl::Mat will share a single memory structure
|
| 28 |
+
return cv::cuda::GpuMat(input.getHeight(), input.getWidth(), CV_8UC4, input.getPtr<sl::uchar1>(sl::MEM::GPU), input.getStepBytes(sl::MEM::GPU));
|
| 29 |
+
}
|
| 30 |
+
|
| 31 |
+
#endif
|