---
license: mit
language:
- en
tags:
- music
- autoencoder
- variational autoencoder
- music generation
---
# Pivaenist
Pivaenist is a random piano music generator with a VAE architecture.
By the use of the aforementioned autoencoder, it allows the user to encode piano music pieces and to generate new ones.
## Model Details
### Model Description
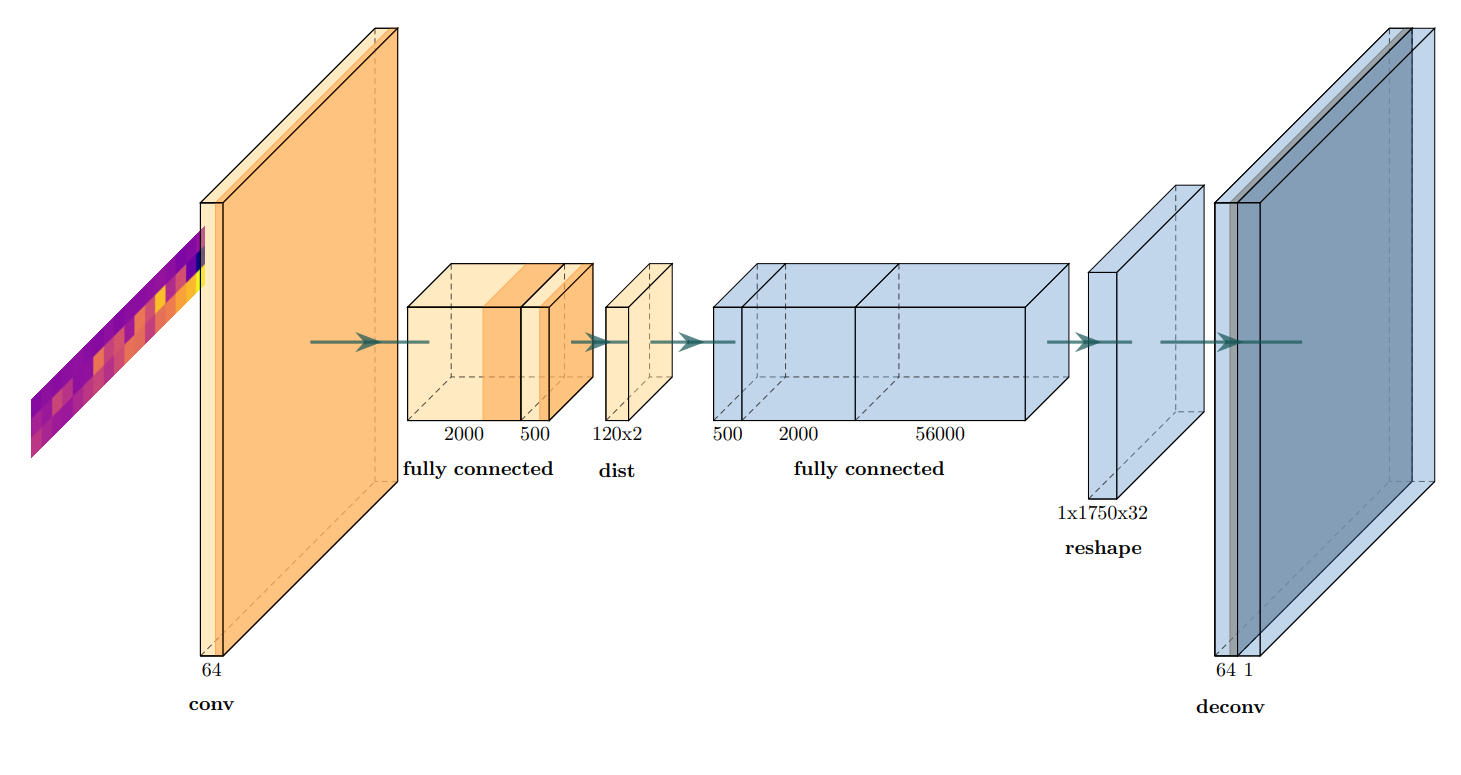
Pivaenist's architecture.
- **Developed by:** TomRB22
- **Model type:** Variational autoencoder
- **License:** MIT
### Sources
**Code:** Some of the code of this repository includes modifications (not the entire code, due to the differences in the architecture) or implementations from the following sites:
1. [TensorFlow. (n.d.). Generate music with an RNN | TensorFlow Core](https://www.tensorflow.org/tutorials/audio/music_generation) - Tensorflow tutorial where pretty-midi is used
2. [Han, X. (2020, September 1). VAE with TensorFlow: 6 Ways](https://towardsdatascience.com/vae-with-tensorflow-6-ways-9c689cb76829) - VAE explanation and code
3. [Li, C. (2019, April 15). Less pain, more gain: A simple method for VAE training with less of that KL-vanishing agony. Microsoft Research.](https://www.microsoft.com/en-us/research/blog/less-pain-more-gain-a-simple-method-for-vae-training-with-less-of-that-kl-vanishing-agony/) - Microsoft article on the KL training schedule which was applied in this model
There might be acknowledgments missing. If you find some other resemblance to a site's code, please notify me and I will make sure of including it.
### Using pivaenist in colab
If you preferred directly using or testing the model without the need to install it, you can use the following colab notebook and follow its instructions. Moreover, this serves as an example of use.
[colab link]
## Installation
To install the model, you will need to **change your working directory to the desired installation location** and execute the following commands:
**_Windows_**
```console
git clone https://huggingface.co/TomRB22/pivaenist
sudo apt install -y fluidsynth
pip install -r ./pivaenist/requirements.txt
```
**_Mac_**
```console
git clone https://huggingface.co/TomRB22/pivaenist
brew install fluidsynth
pip install -r ./pivaenist/requirements.txt
```
The first one will clone the repository. Then, fluidsynth, a real-time MIDI synthesizer, is also set up in order to be used by the pretty-midi library. With the last line, you will make sure to have all dependencies on your system.
[More Information Needed]
## Training Details
Pivaenist was trained on the midi files of the [MAESTRO v2.0.0 dataset](https://magenta.tensorflow.org/datasets/maestro). Their preprocessing involves splitting each note in pitch, duration and step, which compose a column of a 3xN matrix (which we call song map), where N is the number of notes and a row represents sequentially the different pitches, durations and steps. The VAE's objective is to reconstruct these matrices, making it then possible to generate random maps by sampling from the distribution, and then convert them to a MIDI file.
A horizontally cropped example of a song map.
# Documentation
## **_model.VAE_**
### encode
```python
def encode(self, x_input: tf.Tensor) -> tuple[tf.Tensor]:
```
Get a "song map" and make a forward pass through the encoder, in order to return the latent representation and the distribution's parameters.
Parameters:
* x_input (tf.Tensor): Song map to be encoded by the VAE.
Returns:
* tf.Tensor: The parameters of the distribution which encode the song (mu, sd) and a sampled latent representation from this distribution (z_sample).
### generate
```python
def generate(self, z_sample: tf.Tensor=None) -> tf.Tensor:
```
Decode a latent representation of a song.
Parameters:
* z_sample (tf.Tensor): Song encoding outputed by the encoder. If None, this sampling is done over an unit Gaussian distribution.
Returns:
* tf.Tensor: Song map corresponding to the encoding.
## **_audio_**
### midi_to_notes
```python
def midi_to_notes(midi_file: str) -> pd.DataFrame:
```
Convert midi file to "song map" (dataframe where each note is broken
into its components)
Parameters:
* midi_file (str): Path to the midi file.
Returns:
* pd.Dataframe: 3xN matrix where each column is a note, composed of pitch, duration and step.
### display_audio
```python
def display_audio(pm: pretty_midi.PrettyMIDI, seconds=-1) -> display.Audio:
```
Display a song in PrettyMIDI format as a display.Audio object. This method is especially useful in a Jupyter notebook.
Parameters
* pm (pretty_midi.PrettyMIDI): PrettyMIDI object containing a song.
* seconds (int): Time fraction of the song to be displayed. When set to -1, the full length is taken.
Returns:
* display.Audio: Song as an object allowing for display.
### map_to_wav
```python
def map_to_wav(song_map: pd.DataFrame, out_file: str, velocity: int=100) -> pretty_midi.PrettyMIDI:
```
Convert "song map" to midi file (reverse process with respect to
midi_to_notes) and (optionally) save it, generating a PrettyMidi object in the process.
Parameters:
* song_map (pd.DataFrame): 3xN matrix where each column is a note, composed of pitch, duration and step.
* out_file (str): Path or file to write .mid file to. If None, no saving is done.
* velocity (int): Note loudness, i. e. the hardness a piano key is struck with.
Returns:
* pretty_midi.PrettyMIDI: PrettyMIDI object containing the song's representation.
### generate_and_display
```python
def generate_and_display(model: VAE,
out_file: str=None,
z_sample: tf.Tensor=None,
velocity: int=100,
seconds: int=120) -> display.Audio:
```
Generate a song, (optionally) save it and display it.
Parameters:
* model (VAE): Instance of VAE to generate the song with.
* out_file (str): Path or file to write .mid file to. If None, no saving is done.
* z_sample (tf.Tensor): Song encoding used to generate a song. If None, perform generate an unconditioned piece.
* velocity (int): Note loudness, i. e. the hardness a piano key is struck with.
* seconds (int): Time fraction of the song to be displayed. When set to -1, the full length is taken.
Returns:
* display.Audio: Song as an object allowing for display.