
Upload 2667 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- opencompass-my-api/.codespellrc +5 -0
- opencompass-my-api/.gitignore +129 -0
- opencompass-my-api/.owners.yml +14 -0
- opencompass-my-api/.pre-commit-config-zh-cn.yaml +96 -0
- opencompass-my-api/.pre-commit-config.yaml +96 -0
- opencompass-my-api/.readthedocs.yml +14 -0
- opencompass-my-api/LICENSE +203 -0
- opencompass-my-api/README.md +520 -0
- opencompass-my-api/README_zh-CN.md +522 -0
- opencompass-my-api/build/lib/opencompass/__init__.py +1 -0
- opencompass-my-api/build/lib/opencompass/datasets/FinanceIQ.py +39 -0
- opencompass-my-api/build/lib/opencompass/datasets/GaokaoBench.py +132 -0
- opencompass-my-api/build/lib/opencompass/datasets/NPHardEval/__init__.py +9 -0
- opencompass-my-api/build/lib/opencompass/datasets/NPHardEval/cmp_GCP_D.py +161 -0
- opencompass-my-api/build/lib/opencompass/datasets/NPHardEval/cmp_KSP.py +183 -0
- opencompass-my-api/build/lib/opencompass/datasets/NPHardEval/cmp_TSP_D.py +150 -0
- opencompass-my-api/build/lib/opencompass/datasets/NPHardEval/hard_GCP.py +189 -0
- opencompass-my-api/build/lib/opencompass/datasets/NPHardEval/hard_MSP.py +203 -0
- opencompass-my-api/build/lib/opencompass/datasets/NPHardEval/hard_TSP.py +211 -0
- opencompass-my-api/build/lib/opencompass/datasets/NPHardEval/p_BSP.py +124 -0
- opencompass-my-api/build/lib/opencompass/datasets/NPHardEval/p_EDP.py +145 -0
- opencompass-my-api/build/lib/opencompass/datasets/NPHardEval/p_SPP.py +196 -0
- opencompass-my-api/build/lib/opencompass/datasets/NPHardEval/prompts.py +96 -0
- opencompass-my-api/build/lib/opencompass/datasets/NPHardEval/utils.py +43 -0
- opencompass-my-api/build/lib/opencompass/datasets/OpenFinData.py +47 -0
- opencompass-my-api/build/lib/opencompass/datasets/TheoremQA.py +38 -0
- opencompass-my-api/build/lib/opencompass/datasets/advglue.py +174 -0
- opencompass-my-api/build/lib/opencompass/datasets/afqmcd.py +21 -0
- opencompass-my-api/build/lib/opencompass/datasets/agieval/__init__.py +3 -0
- opencompass-my-api/build/lib/opencompass/datasets/agieval/agieval.py +99 -0
- opencompass-my-api/build/lib/opencompass/datasets/agieval/constructions.py +104 -0
- opencompass-my-api/build/lib/opencompass/datasets/agieval/dataset_loader.py +392 -0
- opencompass-my-api/build/lib/opencompass/datasets/agieval/evaluation.py +43 -0
- opencompass-my-api/build/lib/opencompass/datasets/agieval/math_equivalence.py +161 -0
- opencompass-my-api/build/lib/opencompass/datasets/agieval/post_process.py +198 -0
- opencompass-my-api/build/lib/opencompass/datasets/agieval/utils.py +43 -0
- opencompass-my-api/build/lib/opencompass/datasets/anli.py +18 -0
- opencompass-my-api/build/lib/opencompass/datasets/anthropics_evals.py +63 -0
- opencompass-my-api/build/lib/opencompass/datasets/arc.py +84 -0
- opencompass-my-api/build/lib/opencompass/datasets/ax.py +24 -0
- opencompass-my-api/build/lib/opencompass/datasets/base.py +28 -0
- opencompass-my-api/build/lib/opencompass/datasets/bbh.py +98 -0
- opencompass-my-api/build/lib/opencompass/datasets/boolq.py +56 -0
- opencompass-my-api/build/lib/opencompass/datasets/bustum.py +21 -0
- opencompass-my-api/build/lib/opencompass/datasets/c3.py +80 -0
- opencompass-my-api/build/lib/opencompass/datasets/cb.py +25 -0
- opencompass-my-api/build/lib/opencompass/datasets/ceval.py +76 -0
- opencompass-my-api/build/lib/opencompass/datasets/chid.py +43 -0
- opencompass-my-api/build/lib/opencompass/datasets/cibench.py +511 -0
- opencompass-my-api/build/lib/opencompass/datasets/circular.py +373 -0
opencompass-my-api/.codespellrc
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[codespell]
|
| 2 |
+
skip = *.ipynb
|
| 3 |
+
count =
|
| 4 |
+
quiet-level = 3
|
| 5 |
+
ignore-words-list = nd, ans, ques, rouge, softwares, wit
|
opencompass-my-api/.gitignore
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
output_*/
|
| 3 |
+
outputs/
|
| 4 |
+
icl_inference_output/
|
| 5 |
+
.vscode/
|
| 6 |
+
tmp/
|
| 7 |
+
configs/eval_subjective_alignbench_test.py
|
| 8 |
+
configs/openai_key.py
|
| 9 |
+
configs/secrets.py
|
| 10 |
+
configs/datasets/log.json
|
| 11 |
+
configs/eval_debug*.py
|
| 12 |
+
configs/viz_*.py
|
| 13 |
+
data
|
| 14 |
+
work_dirs
|
| 15 |
+
models/*
|
| 16 |
+
configs/internal/
|
| 17 |
+
# Byte-compiled / optimized / DLL files
|
| 18 |
+
__pycache__/
|
| 19 |
+
*.py[cod]
|
| 20 |
+
*$py.class
|
| 21 |
+
*.ipynb
|
| 22 |
+
|
| 23 |
+
# C extensions
|
| 24 |
+
*.so
|
| 25 |
+
|
| 26 |
+
# Distribution / packaging
|
| 27 |
+
.Python
|
| 28 |
+
build/
|
| 29 |
+
develop-eggs/
|
| 30 |
+
dist/
|
| 31 |
+
downloads/
|
| 32 |
+
eggs/
|
| 33 |
+
.eggs/
|
| 34 |
+
lib/
|
| 35 |
+
lib64/
|
| 36 |
+
parts/
|
| 37 |
+
sdist/
|
| 38 |
+
var/
|
| 39 |
+
wheels/
|
| 40 |
+
*.egg-info/
|
| 41 |
+
.installed.cfg
|
| 42 |
+
*.egg
|
| 43 |
+
MANIFEST
|
| 44 |
+
|
| 45 |
+
# PyInstaller
|
| 46 |
+
# Usually these files are written by a python script from a template
|
| 47 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 48 |
+
*.manifest
|
| 49 |
+
*.spec
|
| 50 |
+
|
| 51 |
+
# Installer logs
|
| 52 |
+
pip-log.txt
|
| 53 |
+
pip-delete-this-directory.txt
|
| 54 |
+
|
| 55 |
+
# Unit test / coverage reports
|
| 56 |
+
htmlcov/
|
| 57 |
+
.tox/
|
| 58 |
+
.coverage
|
| 59 |
+
.coverage.*
|
| 60 |
+
.cache
|
| 61 |
+
nosetests.xml
|
| 62 |
+
coverage.xml
|
| 63 |
+
*.cover
|
| 64 |
+
.hypothesis/
|
| 65 |
+
.pytest_cache/
|
| 66 |
+
|
| 67 |
+
# Translations
|
| 68 |
+
*.mo
|
| 69 |
+
*.pot
|
| 70 |
+
|
| 71 |
+
# Django stuff:
|
| 72 |
+
*.log
|
| 73 |
+
local_settings.py
|
| 74 |
+
db.sqlite3
|
| 75 |
+
|
| 76 |
+
# Flask stuff:
|
| 77 |
+
instance/
|
| 78 |
+
.webassets-cache
|
| 79 |
+
|
| 80 |
+
# Scrapy stuff:
|
| 81 |
+
.scrapy
|
| 82 |
+
|
| 83 |
+
.idea
|
| 84 |
+
|
| 85 |
+
# Auto generate documentation
|
| 86 |
+
docs/en/_build/
|
| 87 |
+
docs/zh_cn/_build/
|
| 88 |
+
|
| 89 |
+
# .zip
|
| 90 |
+
*.zip
|
| 91 |
+
|
| 92 |
+
# sft config ignore list
|
| 93 |
+
configs/sft_cfg/*B_*
|
| 94 |
+
configs/sft_cfg/1B/*
|
| 95 |
+
configs/sft_cfg/7B/*
|
| 96 |
+
configs/sft_cfg/20B/*
|
| 97 |
+
configs/sft_cfg/60B/*
|
| 98 |
+
configs/sft_cfg/100B/*
|
| 99 |
+
|
| 100 |
+
configs/cky/
|
| 101 |
+
# in case llama clone in the opencompass
|
| 102 |
+
llama/
|
| 103 |
+
|
| 104 |
+
# in case ilagent clone in the opencompass
|
| 105 |
+
ilagent/
|
| 106 |
+
|
| 107 |
+
# ignore the config file for criticbench evaluation
|
| 108 |
+
configs/sft_cfg/criticbench_eval/*
|
| 109 |
+
|
| 110 |
+
# path of turbomind's model after runing `lmdeploy.serve.turbomind.deploy`
|
| 111 |
+
turbomind/
|
| 112 |
+
|
| 113 |
+
# cibench output
|
| 114 |
+
*.db
|
| 115 |
+
*.pth
|
| 116 |
+
*.pt
|
| 117 |
+
*.onnx
|
| 118 |
+
*.gz
|
| 119 |
+
*.gz.*
|
| 120 |
+
*.png
|
| 121 |
+
*.txt
|
| 122 |
+
*.jpg
|
| 123 |
+
*.json
|
| 124 |
+
*.csv
|
| 125 |
+
*.npy
|
| 126 |
+
*.c
|
| 127 |
+
|
| 128 |
+
# aliyun
|
| 129 |
+
core.*
|
opencompass-my-api/.owners.yml
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
assign:
|
| 2 |
+
issues: enabled
|
| 3 |
+
pull_requests: disabled
|
| 4 |
+
strategy:
|
| 5 |
+
# random
|
| 6 |
+
daily-shift-based
|
| 7 |
+
scedule:
|
| 8 |
+
'*/1 * * * *'
|
| 9 |
+
assignees:
|
| 10 |
+
- Leymore
|
| 11 |
+
- bittersweet1999
|
| 12 |
+
- yingfhu
|
| 13 |
+
- kennymckormick
|
| 14 |
+
- tonysy
|
opencompass-my-api/.pre-commit-config-zh-cn.yaml
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
exclude: |
|
| 2 |
+
(?x)^(
|
| 3 |
+
tests/data/|
|
| 4 |
+
opencompass/models/internal/|
|
| 5 |
+
opencompass/utils/internal/|
|
| 6 |
+
opencompass/openicl/icl_evaluator/hf_metrics/|
|
| 7 |
+
opencompass/datasets/lawbench/utils|
|
| 8 |
+
opencompass/datasets/lawbench/evaluation_functions/|
|
| 9 |
+
opencompass/datasets/medbench/|
|
| 10 |
+
opencompass/datasets/teval/|
|
| 11 |
+
opencompass/datasets/NPHardEval/|
|
| 12 |
+
docs/zh_cn/advanced_guides/compassbench_intro.md
|
| 13 |
+
)
|
| 14 |
+
repos:
|
| 15 |
+
- repo: https://gitee.com/openmmlab/mirrors-flake8
|
| 16 |
+
rev: 5.0.4
|
| 17 |
+
hooks:
|
| 18 |
+
- id: flake8
|
| 19 |
+
exclude: configs/
|
| 20 |
+
- repo: https://gitee.com/openmmlab/mirrors-isort
|
| 21 |
+
rev: 5.11.5
|
| 22 |
+
hooks:
|
| 23 |
+
- id: isort
|
| 24 |
+
exclude: configs/
|
| 25 |
+
- repo: https://gitee.com/openmmlab/mirrors-yapf
|
| 26 |
+
rev: v0.32.0
|
| 27 |
+
hooks:
|
| 28 |
+
- id: yapf
|
| 29 |
+
exclude: configs/
|
| 30 |
+
- repo: https://gitee.com/openmmlab/mirrors-codespell
|
| 31 |
+
rev: v2.2.1
|
| 32 |
+
hooks:
|
| 33 |
+
- id: codespell
|
| 34 |
+
exclude: |
|
| 35 |
+
(?x)^(
|
| 36 |
+
.*\.jsonl|
|
| 37 |
+
configs/
|
| 38 |
+
)
|
| 39 |
+
- repo: https://gitee.com/openmmlab/mirrors-pre-commit-hooks
|
| 40 |
+
rev: v4.3.0
|
| 41 |
+
hooks:
|
| 42 |
+
- id: trailing-whitespace
|
| 43 |
+
exclude: |
|
| 44 |
+
(?x)^(
|
| 45 |
+
dicts/|
|
| 46 |
+
projects/.*?/dicts/|
|
| 47 |
+
configs/
|
| 48 |
+
)
|
| 49 |
+
- id: check-yaml
|
| 50 |
+
- id: end-of-file-fixer
|
| 51 |
+
exclude: |
|
| 52 |
+
(?x)^(
|
| 53 |
+
dicts/|
|
| 54 |
+
projects/.*?/dicts/|
|
| 55 |
+
configs/
|
| 56 |
+
)
|
| 57 |
+
- id: requirements-txt-fixer
|
| 58 |
+
- id: double-quote-string-fixer
|
| 59 |
+
exclude: configs/
|
| 60 |
+
- id: check-merge-conflict
|
| 61 |
+
- id: fix-encoding-pragma
|
| 62 |
+
args: ["--remove"]
|
| 63 |
+
- id: mixed-line-ending
|
| 64 |
+
args: ["--fix=lf"]
|
| 65 |
+
- id: mixed-line-ending
|
| 66 |
+
args: ["--fix=lf"]
|
| 67 |
+
- repo: https://gitee.com/openmmlab/mirrors-mdformat
|
| 68 |
+
rev: 0.7.9
|
| 69 |
+
hooks:
|
| 70 |
+
- id: mdformat
|
| 71 |
+
args: ["--number", "--table-width", "200"]
|
| 72 |
+
additional_dependencies:
|
| 73 |
+
- mdformat-openmmlab
|
| 74 |
+
- mdformat_frontmatter
|
| 75 |
+
- linkify-it-py
|
| 76 |
+
exclude: configs/
|
| 77 |
+
- repo: https://gitee.com/openmmlab/mirrors-docformatter
|
| 78 |
+
rev: v1.3.1
|
| 79 |
+
hooks:
|
| 80 |
+
- id: docformatter
|
| 81 |
+
args: ["--in-place", "--wrap-descriptions", "79"]
|
| 82 |
+
- repo: local
|
| 83 |
+
hooks:
|
| 84 |
+
- id: update-dataset-suffix
|
| 85 |
+
name: dataset suffix updater
|
| 86 |
+
entry: ./tools/update_dataset_suffix.py
|
| 87 |
+
language: script
|
| 88 |
+
pass_filenames: true
|
| 89 |
+
require_serial: true
|
| 90 |
+
files: ^configs/datasets
|
| 91 |
+
# - repo: https://github.com/open-mmlab/pre-commit-hooks
|
| 92 |
+
# rev: v0.2.0 # Use the ref you want to point at
|
| 93 |
+
# hooks:
|
| 94 |
+
# - id: check-algo-readme
|
| 95 |
+
# - id: check-copyright
|
| 96 |
+
# args: ["mmocr", "tests", "tools"] # these directories will be checked
|
opencompass-my-api/.pre-commit-config.yaml
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
exclude: |
|
| 2 |
+
(?x)^(
|
| 3 |
+
tests/data/|
|
| 4 |
+
opencompass/models/internal/|
|
| 5 |
+
opencompass/utils/internal/|
|
| 6 |
+
opencompass/openicl/icl_evaluator/hf_metrics/|
|
| 7 |
+
opencompass/datasets/lawbench/utils|
|
| 8 |
+
opencompass/datasets/lawbench/evaluation_functions/|
|
| 9 |
+
opencompass/datasets/medbench/|
|
| 10 |
+
opencompass/datasets/teval/|
|
| 11 |
+
opencompass/datasets/NPHardEval/|
|
| 12 |
+
docs/zh_cn/advanced_guides/compassbench_intro.md
|
| 13 |
+
)
|
| 14 |
+
repos:
|
| 15 |
+
- repo: https://github.com/PyCQA/flake8
|
| 16 |
+
rev: 5.0.4
|
| 17 |
+
hooks:
|
| 18 |
+
- id: flake8
|
| 19 |
+
exclude: configs/
|
| 20 |
+
- repo: https://github.com/PyCQA/isort
|
| 21 |
+
rev: 5.11.5
|
| 22 |
+
hooks:
|
| 23 |
+
- id: isort
|
| 24 |
+
exclude: configs/
|
| 25 |
+
- repo: https://github.com/pre-commit/mirrors-yapf
|
| 26 |
+
rev: v0.32.0
|
| 27 |
+
hooks:
|
| 28 |
+
- id: yapf
|
| 29 |
+
exclude: configs/
|
| 30 |
+
- repo: https://github.com/codespell-project/codespell
|
| 31 |
+
rev: v2.2.1
|
| 32 |
+
hooks:
|
| 33 |
+
- id: codespell
|
| 34 |
+
exclude: |
|
| 35 |
+
(?x)^(
|
| 36 |
+
.*\.jsonl|
|
| 37 |
+
configs/
|
| 38 |
+
)
|
| 39 |
+
- repo: https://github.com/pre-commit/pre-commit-hooks
|
| 40 |
+
rev: v4.3.0
|
| 41 |
+
hooks:
|
| 42 |
+
- id: trailing-whitespace
|
| 43 |
+
exclude: |
|
| 44 |
+
(?x)^(
|
| 45 |
+
dicts/|
|
| 46 |
+
projects/.*?/dicts/|
|
| 47 |
+
configs/
|
| 48 |
+
)
|
| 49 |
+
- id: check-yaml
|
| 50 |
+
- id: end-of-file-fixer
|
| 51 |
+
exclude: |
|
| 52 |
+
(?x)^(
|
| 53 |
+
dicts/|
|
| 54 |
+
projects/.*?/dicts/|
|
| 55 |
+
configs/
|
| 56 |
+
)
|
| 57 |
+
- id: requirements-txt-fixer
|
| 58 |
+
- id: double-quote-string-fixer
|
| 59 |
+
exclude: configs/
|
| 60 |
+
- id: check-merge-conflict
|
| 61 |
+
- id: fix-encoding-pragma
|
| 62 |
+
args: ["--remove"]
|
| 63 |
+
- id: mixed-line-ending
|
| 64 |
+
args: ["--fix=lf"]
|
| 65 |
+
- id: mixed-line-ending
|
| 66 |
+
args: ["--fix=lf"]
|
| 67 |
+
- repo: https://github.com/executablebooks/mdformat
|
| 68 |
+
rev: 0.7.9
|
| 69 |
+
hooks:
|
| 70 |
+
- id: mdformat
|
| 71 |
+
args: ["--number", "--table-width", "200"]
|
| 72 |
+
additional_dependencies:
|
| 73 |
+
- mdformat-openmmlab
|
| 74 |
+
- mdformat_frontmatter
|
| 75 |
+
- linkify-it-py
|
| 76 |
+
exclude: configs/
|
| 77 |
+
- repo: https://github.com/myint/docformatter
|
| 78 |
+
rev: v1.3.1
|
| 79 |
+
hooks:
|
| 80 |
+
- id: docformatter
|
| 81 |
+
args: ["--in-place", "--wrap-descriptions", "79"]
|
| 82 |
+
- repo: local
|
| 83 |
+
hooks:
|
| 84 |
+
- id: update-dataset-suffix
|
| 85 |
+
name: dataset suffix updater
|
| 86 |
+
entry: ./tools/update_dataset_suffix.py
|
| 87 |
+
language: script
|
| 88 |
+
pass_filenames: true
|
| 89 |
+
require_serial: true
|
| 90 |
+
files: ^configs/datasets
|
| 91 |
+
# - repo: https://github.com/open-mmlab/pre-commit-hooks
|
| 92 |
+
# rev: v0.2.0 # Use the ref you want to point at
|
| 93 |
+
# hooks:
|
| 94 |
+
# - id: check-algo-readme
|
| 95 |
+
# - id: check-copyright
|
| 96 |
+
# args: ["mmocr", "tests", "tools"] # these directories will be checked
|
opencompass-my-api/.readthedocs.yml
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version: 2
|
| 2 |
+
|
| 3 |
+
# Set the version of Python and other tools you might need
|
| 4 |
+
build:
|
| 5 |
+
os: ubuntu-22.04
|
| 6 |
+
tools:
|
| 7 |
+
python: "3.8"
|
| 8 |
+
|
| 9 |
+
formats:
|
| 10 |
+
- epub
|
| 11 |
+
|
| 12 |
+
python:
|
| 13 |
+
install:
|
| 14 |
+
- requirements: requirements/docs.txt
|
opencompass-my-api/LICENSE
ADDED
|
@@ -0,0 +1,203 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Copyright 2020 OpenCompass Authors. All rights reserved.
|
| 2 |
+
|
| 3 |
+
Apache License
|
| 4 |
+
Version 2.0, January 2004
|
| 5 |
+
http://www.apache.org/licenses/
|
| 6 |
+
|
| 7 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 8 |
+
|
| 9 |
+
1. Definitions.
|
| 10 |
+
|
| 11 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 12 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 13 |
+
|
| 14 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 15 |
+
the copyright owner that is granting the License.
|
| 16 |
+
|
| 17 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 18 |
+
other entities that control, are controlled by, or are under common
|
| 19 |
+
control with that entity. For the purposes of this definition,
|
| 20 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 21 |
+
direction or management of such entity, whether by contract or
|
| 22 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 23 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 24 |
+
|
| 25 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 26 |
+
exercising permissions granted by this License.
|
| 27 |
+
|
| 28 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 29 |
+
including but not limited to software source code, documentation
|
| 30 |
+
source, and configuration files.
|
| 31 |
+
|
| 32 |
+
"Object" form shall mean any form resulting from mechanical
|
| 33 |
+
transformation or translation of a Source form, including but
|
| 34 |
+
not limited to compiled object code, generated documentation,
|
| 35 |
+
and conversions to other media types.
|
| 36 |
+
|
| 37 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 38 |
+
Object form, made available under the License, as indicated by a
|
| 39 |
+
copyright notice that is included in or attached to the work
|
| 40 |
+
(an example is provided in the Appendix below).
|
| 41 |
+
|
| 42 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 43 |
+
form, that is based on (or derived from) the Work and for which the
|
| 44 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 45 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 46 |
+
of this License, Derivative Works shall not include works that remain
|
| 47 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 48 |
+
the Work and Derivative Works thereof.
|
| 49 |
+
|
| 50 |
+
"Contribution" shall mean any work of authorship, including
|
| 51 |
+
the original version of the Work and any modifications or additions
|
| 52 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 53 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 54 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 55 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 56 |
+
means any form of electronic, verbal, or written communication sent
|
| 57 |
+
to the Licensor or its representatives, including but not limited to
|
| 58 |
+
communication on electronic mailing lists, source code control systems,
|
| 59 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 60 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 61 |
+
excluding communication that is conspicuously marked or otherwise
|
| 62 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 63 |
+
|
| 64 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 65 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 66 |
+
subsequently incorporated within the Work.
|
| 67 |
+
|
| 68 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 69 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 70 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 71 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 72 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 73 |
+
Work and such Derivative Works in Source or Object form.
|
| 74 |
+
|
| 75 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 76 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 77 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 78 |
+
(except as stated in this section) patent license to make, have made,
|
| 79 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 80 |
+
where such license applies only to those patent claims licensable
|
| 81 |
+
by such Contributor that are necessarily infringed by their
|
| 82 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 83 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 84 |
+
institute patent litigation against any entity (including a
|
| 85 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 86 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 87 |
+
or contributory patent infringement, then any patent licenses
|
| 88 |
+
granted to You under this License for that Work shall terminate
|
| 89 |
+
as of the date such litigation is filed.
|
| 90 |
+
|
| 91 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 92 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 93 |
+
modifications, and in Source or Object form, provided that You
|
| 94 |
+
meet the following conditions:
|
| 95 |
+
|
| 96 |
+
(a) You must give any other recipients of the Work or
|
| 97 |
+
Derivative Works a copy of this License; and
|
| 98 |
+
|
| 99 |
+
(b) You must cause any modified files to carry prominent notices
|
| 100 |
+
stating that You changed the files; and
|
| 101 |
+
|
| 102 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 103 |
+
that You distribute, all copyright, patent, trademark, and
|
| 104 |
+
attribution notices from the Source form of the Work,
|
| 105 |
+
excluding those notices that do not pertain to any part of
|
| 106 |
+
the Derivative Works; and
|
| 107 |
+
|
| 108 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 109 |
+
distribution, then any Derivative Works that You distribute must
|
| 110 |
+
include a readable copy of the attribution notices contained
|
| 111 |
+
within such NOTICE file, excluding those notices that do not
|
| 112 |
+
pertain to any part of the Derivative Works, in at least one
|
| 113 |
+
of the following places: within a NOTICE text file distributed
|
| 114 |
+
as part of the Derivative Works; within the Source form or
|
| 115 |
+
documentation, if provided along with the Derivative Works; or,
|
| 116 |
+
within a display generated by the Derivative Works, if and
|
| 117 |
+
wherever such third-party notices normally appear. The contents
|
| 118 |
+
of the NOTICE file are for informational purposes only and
|
| 119 |
+
do not modify the License. You may add Your own attribution
|
| 120 |
+
notices within Derivative Works that You distribute, alongside
|
| 121 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 122 |
+
that such additional attribution notices cannot be construed
|
| 123 |
+
as modifying the License.
|
| 124 |
+
|
| 125 |
+
You may add Your own copyright statement to Your modifications and
|
| 126 |
+
may provide additional or different license terms and conditions
|
| 127 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 128 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 129 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 130 |
+
the conditions stated in this License.
|
| 131 |
+
|
| 132 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 133 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 134 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 135 |
+
this License, without any additional terms or conditions.
|
| 136 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 137 |
+
the terms of any separate license agreement you may have executed
|
| 138 |
+
with Licensor regarding such Contributions.
|
| 139 |
+
|
| 140 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 141 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 142 |
+
except as required for reasonable and customary use in describing the
|
| 143 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 144 |
+
|
| 145 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 146 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 147 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 148 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 149 |
+
implied, including, without limitation, any warranties or conditions
|
| 150 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 151 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 152 |
+
appropriateness of using or redistributing the Work and assume any
|
| 153 |
+
risks associated with Your exercise of permissions under this License.
|
| 154 |
+
|
| 155 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 156 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 157 |
+
unless required by applicable law (such as deliberate and grossly
|
| 158 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 159 |
+
liable to You for damages, including any direct, indirect, special,
|
| 160 |
+
incidental, or consequential damages of any character arising as a
|
| 161 |
+
result of this License or out of the use or inability to use the
|
| 162 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 163 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 164 |
+
other commercial damages or losses), even if such Contributor
|
| 165 |
+
has been advised of the possibility of such damages.
|
| 166 |
+
|
| 167 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 168 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 169 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 170 |
+
or other liability obligations and/or rights consistent with this
|
| 171 |
+
License. However, in accepting such obligations, You may act only
|
| 172 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 173 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 174 |
+
defend, and hold each Contributor harmless for any liability
|
| 175 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 176 |
+
of your accepting any such warranty or additional liability.
|
| 177 |
+
|
| 178 |
+
END OF TERMS AND CONDITIONS
|
| 179 |
+
|
| 180 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 181 |
+
|
| 182 |
+
To apply the Apache License to your work, attach the following
|
| 183 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 184 |
+
replaced with your own identifying information. (Don't include
|
| 185 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 186 |
+
comment syntax for the file format. We also recommend that a
|
| 187 |
+
file or class name and description of purpose be included on the
|
| 188 |
+
same "printed page" as the copyright notice for easier
|
| 189 |
+
identification within third-party archives.
|
| 190 |
+
|
| 191 |
+
Copyright 2020 OpenCompass Authors.
|
| 192 |
+
|
| 193 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 194 |
+
you may not use this file except in compliance with the License.
|
| 195 |
+
You may obtain a copy of the License at
|
| 196 |
+
|
| 197 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 198 |
+
|
| 199 |
+
Unless required by applicable law or agreed to in writing, software
|
| 200 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 201 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 202 |
+
See the License for the specific language governing permissions and
|
| 203 |
+
limitations under the License.
|
opencompass-my-api/README.md
ADDED
|
@@ -0,0 +1,520 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
<img src="docs/en/_static/image/logo.svg" width="500px"/>
|
| 3 |
+
<br />
|
| 4 |
+
<br />
|
| 5 |
+
|
| 6 |
+
[](https://opencompass.readthedocs.io/en)
|
| 7 |
+
[](https://github.com/open-compass/opencompass/blob/main/LICENSE)
|
| 8 |
+
|
| 9 |
+
<!-- [](https://pypi.org/project/opencompass/) -->
|
| 10 |
+
|
| 11 |
+
[🌐Website](https://opencompass.org.cn/) |
|
| 12 |
+
[📘Documentation](https://opencompass.readthedocs.io/en/latest/) |
|
| 13 |
+
[🛠️Installation](https://opencompass.readthedocs.io/en/latest/get_started/installation.html) |
|
| 14 |
+
[🤔Reporting Issues](https://github.com/open-compass/opencompass/issues/new/choose)
|
| 15 |
+
|
| 16 |
+
English | [简体中文](README_zh-CN.md)
|
| 17 |
+
|
| 18 |
+
</div>
|
| 19 |
+
|
| 20 |
+
<p align="center">
|
| 21 |
+
👋 join us on <a href="https://discord.gg/KKwfEbFj7U" target="_blank">Discord</a> and <a href="https://r.vansin.top/?r=opencompass" target="_blank">WeChat</a>
|
| 22 |
+
</p>
|
| 23 |
+
|
| 24 |
+
## 📣 OpenCompass 2023 LLM Annual Leaderboard
|
| 25 |
+
|
| 26 |
+
We are honored to have witnessed the tremendous progress of artificial general intelligence together with the community in the past year, and we are also very pleased that **OpenCompass** can help numerous developers and users.
|
| 27 |
+
|
| 28 |
+
We announce the launch of the **OpenCompass 2023 LLM Annual Leaderboard** plan. We expect to release the annual leaderboard of the LLMs in January 2024, systematically evaluating the performance of LLMs in various capabilities such as language, knowledge, reasoning, creation, long-text, and agents.
|
| 29 |
+
|
| 30 |
+
At that time, we will release rankings for both open-source models and commercial API models, aiming to provide a comprehensive, objective, and neutral reference for the industry and research community.
|
| 31 |
+
|
| 32 |
+
We sincerely invite various large models to join the OpenCompass to showcase their performance advantages in different fields. At the same time, we also welcome researchers and developers to provide valuable suggestions and contributions to jointly promote the development of the LLMs. If you have any questions or needs, please feel free to [contact us](mailto:[email protected]). In addition, relevant evaluation contents, performance statistics, and evaluation methods will be open-source along with the leaderboard release.
|
| 33 |
+
|
| 34 |
+
We have provided the more details of the CompassBench 2023 in [Doc](docs/zh_cn/advanced_guides/compassbench_intro.md).
|
| 35 |
+
|
| 36 |
+
Let's look forward to the release of the OpenCompass 2023 LLM Annual Leaderboard!
|
| 37 |
+
|
| 38 |
+
## 🧭 Welcome
|
| 39 |
+
|
| 40 |
+
to **OpenCompass**!
|
| 41 |
+
|
| 42 |
+
Just like a compass guides us on our journey, OpenCompass will guide you through the complex landscape of evaluating large language models. With its powerful algorithms and intuitive interface, OpenCompass makes it easy to assess the quality and effectiveness of your NLP models.
|
| 43 |
+
|
| 44 |
+
🚩🚩🚩 Explore opportunities at OpenCompass! We're currently **hiring full-time researchers/engineers and interns**. If you're passionate about LLM and OpenCompass, don't hesitate to reach out to us via [email](mailto:[email protected]). We'd love to hear from you!
|
| 45 |
+
|
| 46 |
+
🔥🔥🔥 We are delighted to announce that **the OpenCompass has been recommended by the Meta AI**, click [Get Started](https://ai.meta.com/llama/get-started/#validation) of Llama for more information.
|
| 47 |
+
|
| 48 |
+
> **Attention**<br />
|
| 49 |
+
> We launch the OpenCompass Collaboration project, welcome to support diverse evaluation benchmarks into OpenCompass!
|
| 50 |
+
> Clike [Issue](https://github.com/open-compass/opencompass/issues/248) for more information.
|
| 51 |
+
> Let's work together to build a more powerful OpenCompass toolkit!
|
| 52 |
+
|
| 53 |
+
## 🚀 What's New <a><img width="35" height="20" src="https://user-images.githubusercontent.com/12782558/212848161-5e783dd6-11e8-4fe0-bbba-39ffb77730be.png"></a>
|
| 54 |
+
|
| 55 |
+
- **\[2024.01.17\]** We supported the evaluation of [InternLM2](https://github.com/open-compass/opencompass/blob/main/configs/eval_internlm2_keyset.py) and [InternLM2-Chat](https://github.com/open-compass/opencompass/blob/main/configs/eval_internlm2_chat_keyset.py), InternLM2 showed extremely strong performance in these tests, welcome to try! 🔥🔥🔥.
|
| 56 |
+
- **\[2024.01.17\]** We supported the needle in a haystack test with multiple needles, more information can be found [here](https://opencompass.readthedocs.io/en/latest/advanced_guides/needleinahaystack_eval.html#id8) 🔥🔥🔥.
|
| 57 |
+
- **\[2023.12.28\]** We have enabled seamless evaluation of all models developed using [LLaMA2-Accessory](https://github.com/Alpha-VLLM/LLaMA2-Accessory), a powerful toolkit for comprehensive LLM development. 🔥🔥🔥.
|
| 58 |
+
- **\[2023.12.22\]** We have released [T-Eval](https://github.com/open-compass/T-Eval), a step-by-step evaluation benchmark to gauge your LLMs on tool utilization. Welcome to our [Leaderboard](https://open-compass.github.io/T-Eval/leaderboard.html) for more details! 🔥🔥🔥.
|
| 59 |
+
- **\[2023.12.10\]** We have released [VLMEvalKit](https://github.com/open-compass/VLMEvalKit), a toolkit for evaluating vision-language models (VLMs), currently support 20+ VLMs and 7 multi-modal benchmarks (including MMBench series).
|
| 60 |
+
- **\[2023.12.10\]** We have supported Mistral AI's MoE LLM: **Mixtral-8x7B-32K**. Welcome to [MixtralKit](https://github.com/open-compass/MixtralKit) for more details about inference and evaluation.
|
| 61 |
+
|
| 62 |
+
> [More](docs/en/notes/news.md)
|
| 63 |
+
|
| 64 |
+
## ✨ Introduction
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
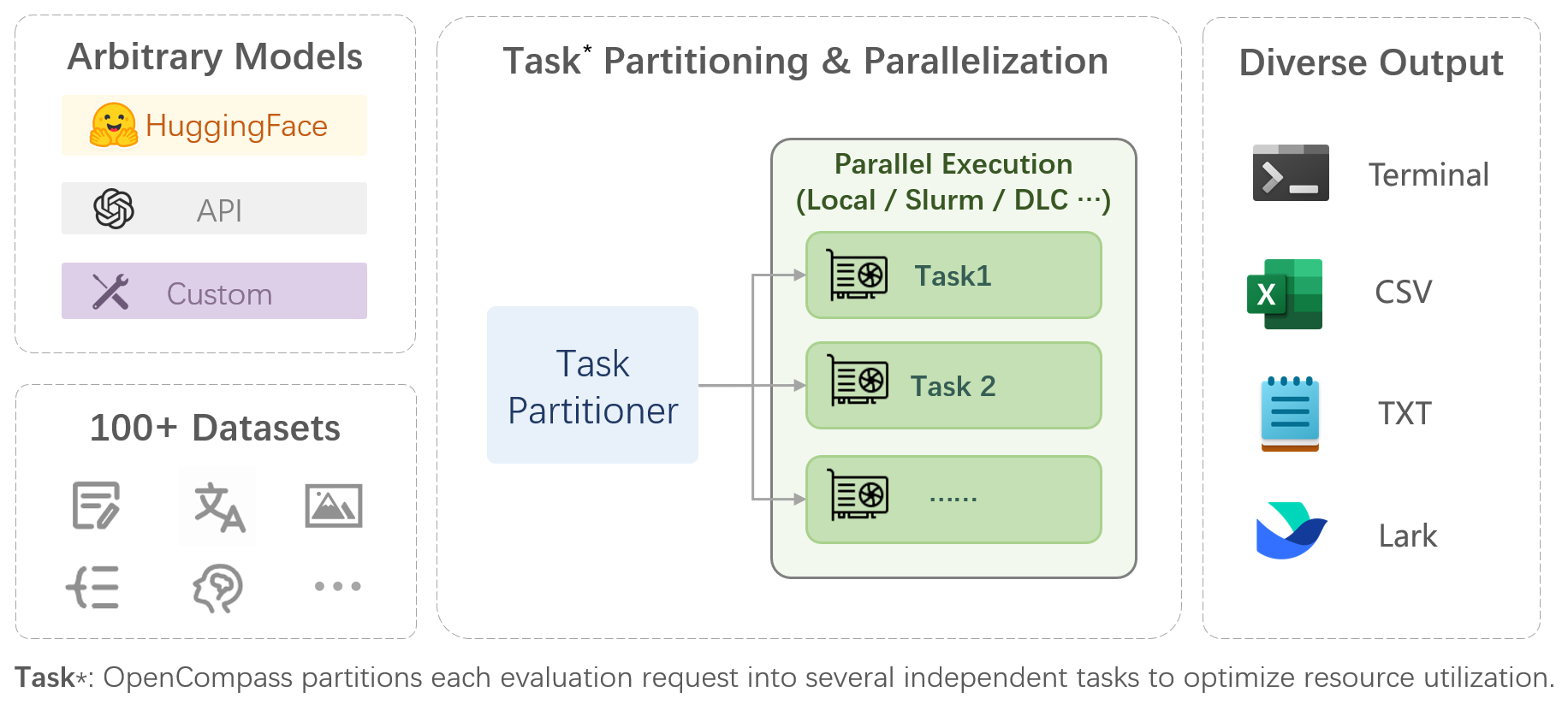
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include:
|
| 69 |
+
|
| 70 |
+
- **Comprehensive support for models and datasets**: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions.
|
| 71 |
+
|
| 72 |
+
- **Efficient distributed evaluation**: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours.
|
| 73 |
+
|
| 74 |
+
- **Diversified evaluation paradigms**: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models.
|
| 75 |
+
|
| 76 |
+
- **Modular design with high extensibility**: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded!
|
| 77 |
+
|
| 78 |
+
- **Experiment management and reporting mechanism**: Use config files to fully record each experiment, and support real-time reporting of results.
|
| 79 |
+
|
| 80 |
+
## 📊 Leaderboard
|
| 81 |
+
|
| 82 |
+
We provide [OpenCompass Leaderboard](https://opencompass.org.cn/rank) for the community to rank all public models and API models. If you would like to join the evaluation, please provide the model repository URL or a standard API interface to the email address `[email protected]`.
|
| 83 |
+
|
| 84 |
+
<p align="right"><a href="#top">🔝Back to top</a></p>
|
| 85 |
+
|
| 86 |
+
## 🛠️ Installation
|
| 87 |
+
|
| 88 |
+
Below are the steps for quick installation and datasets preparation.
|
| 89 |
+
|
| 90 |
+
### 💻 Environment Setup
|
| 91 |
+
|
| 92 |
+
#### Open-source Models with GPU
|
| 93 |
+
|
| 94 |
+
```bash
|
| 95 |
+
conda create --name opencompass python=3.10 pytorch torchvision pytorch-cuda -c nvidia -c pytorch -y
|
| 96 |
+
conda activate opencompass
|
| 97 |
+
git clone https://github.com/open-compass/opencompass opencompass
|
| 98 |
+
cd opencompass
|
| 99 |
+
pip install -e .
|
| 100 |
+
```
|
| 101 |
+
|
| 102 |
+
#### API Models with CPU-only
|
| 103 |
+
|
| 104 |
+
```bash
|
| 105 |
+
conda create -n opencompass python=3.10 pytorch torchvision torchaudio cpuonly -c pytorch -y
|
| 106 |
+
conda activate opencompass
|
| 107 |
+
git clone https://github.com/open-compass/opencompass opencompass
|
| 108 |
+
cd opencompass
|
| 109 |
+
pip install -e .
|
| 110 |
+
# also please install requiresments packages via `pip install -r requirements/api.txt` for API models if needed.
|
| 111 |
+
```
|
| 112 |
+
|
| 113 |
+
### 📂 Data Preparation
|
| 114 |
+
|
| 115 |
+
```bash
|
| 116 |
+
# Download dataset to data/ folder
|
| 117 |
+
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zip
|
| 118 |
+
unzip OpenCompassData-core-20240207.zip
|
| 119 |
+
```
|
| 120 |
+
|
| 121 |
+
Some third-party features, like Humaneval and Llama, may require additional steps to work properly, for detailed steps please refer to the [Installation Guide](https://opencompass.readthedocs.io/en/latest/get_started/installation.html).
|
| 122 |
+
|
| 123 |
+
<p align="right"><a href="#top">🔝Back to top</a></p>
|
| 124 |
+
|
| 125 |
+
## 🏗️ ️Evaluation
|
| 126 |
+
|
| 127 |
+
After ensuring that OpenCompass is installed correctly according to the above steps and the datasets are prepared, you can evaluate the performance of the LLaMA-7b model on the MMLU and C-Eval datasets using the following command:
|
| 128 |
+
|
| 129 |
+
```bash
|
| 130 |
+
python run.py --models hf_llama_7b --datasets mmlu_ppl ceval_ppl
|
| 131 |
+
```
|
| 132 |
+
|
| 133 |
+
OpenCompass has predefined configurations for many models and datasets. You can list all available model and dataset configurations using the [tools](./docs/en/tools.md#list-configs).
|
| 134 |
+
|
| 135 |
+
```bash
|
| 136 |
+
# List all configurations
|
| 137 |
+
python tools/list_configs.py
|
| 138 |
+
# List all configurations related to llama and mmlu
|
| 139 |
+
python tools/list_configs.py llama mmlu
|
| 140 |
+
```
|
| 141 |
+
|
| 142 |
+
You can also evaluate other HuggingFace models via command line. Taking LLaMA-7b as an example:
|
| 143 |
+
|
| 144 |
+
```bash
|
| 145 |
+
python run.py --datasets ceval_ppl mmlu_ppl \
|
| 146 |
+
--hf-path huggyllama/llama-7b \ # HuggingFace model path
|
| 147 |
+
--model-kwargs device_map='auto' \ # Arguments for model construction
|
| 148 |
+
--tokenizer-kwargs padding_side='left' truncation='left' use_fast=False \ # Arguments for tokenizer construction
|
| 149 |
+
--max-out-len 100 \ # Maximum number of tokens generated
|
| 150 |
+
--max-seq-len 2048 \ # Maximum sequence length the model can accept
|
| 151 |
+
--batch-size 8 \ # Batch size
|
| 152 |
+
--no-batch-padding \ # Don't enable batch padding, infer through for loop to avoid performance loss
|
| 153 |
+
--num-gpus 1 # Number of minimum required GPUs
|
| 154 |
+
```
|
| 155 |
+
|
| 156 |
+
> **Note**<br />
|
| 157 |
+
> To run the command above, you will need to remove the comments starting from `# ` first.
|
| 158 |
+
|
| 159 |
+
Through the command line or configuration files, OpenCompass also supports evaluating APIs or custom models, as well as more diversified evaluation strategies. Please read the [Quick Start](https://opencompass.readthedocs.io/en/latest/get_started/quick_start.html) to learn how to run an evaluation task.
|
| 160 |
+
|
| 161 |
+
<p align="right"><a href="#top">🔝Back to top</a></p>
|
| 162 |
+
|
| 163 |
+
## 📖 Dataset Support
|
| 164 |
+
|
| 165 |
+
<table align="center">
|
| 166 |
+
<tbody>
|
| 167 |
+
<tr align="center" valign="bottom">
|
| 168 |
+
<td>
|
| 169 |
+
<b>Language</b>
|
| 170 |
+
</td>
|
| 171 |
+
<td>
|
| 172 |
+
<b>Knowledge</b>
|
| 173 |
+
</td>
|
| 174 |
+
<td>
|
| 175 |
+
<b>Reasoning</b>
|
| 176 |
+
</td>
|
| 177 |
+
<td>
|
| 178 |
+
<b>Examination</b>
|
| 179 |
+
</td>
|
| 180 |
+
</tr>
|
| 181 |
+
<tr valign="top">
|
| 182 |
+
<td>
|
| 183 |
+
<details open>
|
| 184 |
+
<summary><b>Word Definition</b></summary>
|
| 185 |
+
|
| 186 |
+
- WiC
|
| 187 |
+
- SummEdits
|
| 188 |
+
|
| 189 |
+
</details>
|
| 190 |
+
|
| 191 |
+
<details open>
|
| 192 |
+
<summary><b>Idiom Learning</b></summary>
|
| 193 |
+
|
| 194 |
+
- CHID
|
| 195 |
+
|
| 196 |
+
</details>
|
| 197 |
+
|
| 198 |
+
<details open>
|
| 199 |
+
<summary><b>Semantic Similarity</b></summary>
|
| 200 |
+
|
| 201 |
+
- AFQMC
|
| 202 |
+
- BUSTM
|
| 203 |
+
|
| 204 |
+
</details>
|
| 205 |
+
|
| 206 |
+
<details open>
|
| 207 |
+
<summary><b>Coreference Resolution</b></summary>
|
| 208 |
+
|
| 209 |
+
- CLUEWSC
|
| 210 |
+
- WSC
|
| 211 |
+
- WinoGrande
|
| 212 |
+
|
| 213 |
+
</details>
|
| 214 |
+
|
| 215 |
+
<details open>
|
| 216 |
+
<summary><b>Translation</b></summary>
|
| 217 |
+
|
| 218 |
+
- Flores
|
| 219 |
+
- IWSLT2017
|
| 220 |
+
|
| 221 |
+
</details>
|
| 222 |
+
|
| 223 |
+
<details open>
|
| 224 |
+
<summary><b>Multi-language Question Answering</b></summary>
|
| 225 |
+
|
| 226 |
+
- TyDi-QA
|
| 227 |
+
- XCOPA
|
| 228 |
+
|
| 229 |
+
</details>
|
| 230 |
+
|
| 231 |
+
<details open>
|
| 232 |
+
<summary><b>Multi-language Summary</b></summary>
|
| 233 |
+
|
| 234 |
+
- XLSum
|
| 235 |
+
|
| 236 |
+
</details>
|
| 237 |
+
</td>
|
| 238 |
+
<td>
|
| 239 |
+
<details open>
|
| 240 |
+
<summary><b>Knowledge Question Answering</b></summary>
|
| 241 |
+
|
| 242 |
+
- BoolQ
|
| 243 |
+
- CommonSenseQA
|
| 244 |
+
- NaturalQuestions
|
| 245 |
+
- TriviaQA
|
| 246 |
+
|
| 247 |
+
</details>
|
| 248 |
+
</td>
|
| 249 |
+
<td>
|
| 250 |
+
<details open>
|
| 251 |
+
<summary><b>Textual Entailment</b></summary>
|
| 252 |
+
|
| 253 |
+
- CMNLI
|
| 254 |
+
- OCNLI
|
| 255 |
+
- OCNLI_FC
|
| 256 |
+
- AX-b
|
| 257 |
+
- AX-g
|
| 258 |
+
- CB
|
| 259 |
+
- RTE
|
| 260 |
+
- ANLI
|
| 261 |
+
|
| 262 |
+
</details>
|
| 263 |
+
|
| 264 |
+
<details open>
|
| 265 |
+
<summary><b>Commonsense Reasoning</b></summary>
|
| 266 |
+
|
| 267 |
+
- StoryCloze
|
| 268 |
+
- COPA
|
| 269 |
+
- ReCoRD
|
| 270 |
+
- HellaSwag
|
| 271 |
+
- PIQA
|
| 272 |
+
- SIQA
|
| 273 |
+
|
| 274 |
+
</details>
|
| 275 |
+
|
| 276 |
+
<details open>
|
| 277 |
+
<summary><b>Mathematical Reasoning</b></summary>
|
| 278 |
+
|
| 279 |
+
- MATH
|
| 280 |
+
- GSM8K
|
| 281 |
+
|
| 282 |
+
</details>
|
| 283 |
+
|
| 284 |
+
<details open>
|
| 285 |
+
<summary><b>Theorem Application</b></summary>
|
| 286 |
+
|
| 287 |
+
- TheoremQA
|
| 288 |
+
- StrategyQA
|
| 289 |
+
- SciBench
|
| 290 |
+
|
| 291 |
+
</details>
|
| 292 |
+
|
| 293 |
+
<details open>
|
| 294 |
+
<summary><b>Comprehensive Reasoning</b></summary>
|
| 295 |
+
|
| 296 |
+
- BBH
|
| 297 |
+
|
| 298 |
+
</details>
|
| 299 |
+
</td>
|
| 300 |
+
<td>
|
| 301 |
+
<details open>
|
| 302 |
+
<summary><b>Junior High, High School, University, Professional Examinations</b></summary>
|
| 303 |
+
|
| 304 |
+
- C-Eval
|
| 305 |
+
- AGIEval
|
| 306 |
+
- MMLU
|
| 307 |
+
- GAOKAO-Bench
|
| 308 |
+
- CMMLU
|
| 309 |
+
- ARC
|
| 310 |
+
- Xiezhi
|
| 311 |
+
|
| 312 |
+
</details>
|
| 313 |
+
|
| 314 |
+
<details open>
|
| 315 |
+
<summary><b>Medical Examinations</b></summary>
|
| 316 |
+
|
| 317 |
+
- CMB
|
| 318 |
+
|
| 319 |
+
</details>
|
| 320 |
+
</td>
|
| 321 |
+
</tr>
|
| 322 |
+
</td>
|
| 323 |
+
</tr>
|
| 324 |
+
</tbody>
|
| 325 |
+
<tbody>
|
| 326 |
+
<tr align="center" valign="bottom">
|
| 327 |
+
<td>
|
| 328 |
+
<b>Understanding</b>
|
| 329 |
+
</td>
|
| 330 |
+
<td>
|
| 331 |
+
<b>Long Context</b>
|
| 332 |
+
</td>
|
| 333 |
+
<td>
|
| 334 |
+
<b>Safety</b>
|
| 335 |
+
</td>
|
| 336 |
+
<td>
|
| 337 |
+
<b>Code</b>
|
| 338 |
+
</td>
|
| 339 |
+
</tr>
|
| 340 |
+
<tr valign="top">
|
| 341 |
+
<td>
|
| 342 |
+
<details open>
|
| 343 |
+
<summary><b>Reading Comprehension</b></summary>
|
| 344 |
+
|
| 345 |
+
- C3
|
| 346 |
+
- CMRC
|
| 347 |
+
- DRCD
|
| 348 |
+
- MultiRC
|
| 349 |
+
- RACE
|
| 350 |
+
- DROP
|
| 351 |
+
- OpenBookQA
|
| 352 |
+
- SQuAD2.0
|
| 353 |
+
|
| 354 |
+
</details>
|
| 355 |
+
|
| 356 |
+
<details open>
|
| 357 |
+
<summary><b>Content Summary</b></summary>
|
| 358 |
+
|
| 359 |
+
- CSL
|
| 360 |
+
- LCSTS
|
| 361 |
+
- XSum
|
| 362 |
+
- SummScreen
|
| 363 |
+
|
| 364 |
+
</details>
|
| 365 |
+
|
| 366 |
+
<details open>
|
| 367 |
+
<summary><b>Content Analysis</b></summary>
|
| 368 |
+
|
| 369 |
+
- EPRSTMT
|
| 370 |
+
- LAMBADA
|
| 371 |
+
- TNEWS
|
| 372 |
+
|
| 373 |
+
</details>
|
| 374 |
+
</td>
|
| 375 |
+
<td>
|
| 376 |
+
<details open>
|
| 377 |
+
<summary><b>Long Context Understanding</b></summary>
|
| 378 |
+
|
| 379 |
+
- LEval
|
| 380 |
+
- LongBench
|
| 381 |
+
- GovReports
|
| 382 |
+
- NarrativeQA
|
| 383 |
+
- Qasper
|
| 384 |
+
|
| 385 |
+
</details>
|
| 386 |
+
</td>
|
| 387 |
+
<td>
|
| 388 |
+
<details open>
|
| 389 |
+
<summary><b>Safety</b></summary>
|
| 390 |
+
|
| 391 |
+
- CivilComments
|
| 392 |
+
- CrowsPairs
|
| 393 |
+
- CValues
|
| 394 |
+
- JigsawMultilingual
|
| 395 |
+
- TruthfulQA
|
| 396 |
+
|
| 397 |
+
</details>
|
| 398 |
+
<details open>
|
| 399 |
+
<summary><b>Robustness</b></summary>
|
| 400 |
+
|
| 401 |
+
- AdvGLUE
|
| 402 |
+
|
| 403 |
+
</details>
|
| 404 |
+
</td>
|
| 405 |
+
<td>
|
| 406 |
+
<details open>
|
| 407 |
+
<summary><b>Code</b></summary>
|
| 408 |
+
|
| 409 |
+
- HumanEval
|
| 410 |
+
- HumanEvalX
|
| 411 |
+
- MBPP
|
| 412 |
+
- APPs
|
| 413 |
+
- DS1000
|
| 414 |
+
|
| 415 |
+
</details>
|
| 416 |
+
</td>
|
| 417 |
+
</tr>
|
| 418 |
+
</td>
|
| 419 |
+
</tr>
|
| 420 |
+
</tbody>
|
| 421 |
+
</table>
|
| 422 |
+
|
| 423 |
+
## OpenCompass Ecosystem
|
| 424 |
+
|
| 425 |
+
<p align="right"><a href="#top">🔝Back to top</a></p>
|
| 426 |
+
|
| 427 |
+
## 📖 Model Support
|
| 428 |
+
|
| 429 |
+
<table align="center">
|
| 430 |
+
<tbody>
|
| 431 |
+
<tr align="center" valign="bottom">
|
| 432 |
+
<td>
|
| 433 |
+
<b>Open-source Models</b>
|
| 434 |
+
</td>
|
| 435 |
+
<td>
|
| 436 |
+
<b>API Models</b>
|
| 437 |
+
</td>
|
| 438 |
+
<!-- <td>
|
| 439 |
+
<b>Custom Models</b>
|
| 440 |
+
</td> -->
|
| 441 |
+
</tr>
|
| 442 |
+
<tr valign="top">
|
| 443 |
+
<td>
|
| 444 |
+
|
| 445 |
+
- [InternLM](https://github.com/InternLM/InternLM)
|
| 446 |
+
- [LLaMA](https://github.com/facebookresearch/llama)
|
| 447 |
+
- [Vicuna](https://github.com/lm-sys/FastChat)
|
| 448 |
+
- [Alpaca](https://github.com/tatsu-lab/stanford_alpaca)
|
| 449 |
+
- [Baichuan](https://github.com/baichuan-inc)
|
| 450 |
+
- [WizardLM](https://github.com/nlpxucan/WizardLM)
|
| 451 |
+
- [ChatGLM2](https://github.com/THUDM/ChatGLM2-6B)
|
| 452 |
+
- [ChatGLM3](https://github.com/THUDM/ChatGLM3-6B)
|
| 453 |
+
- [TigerBot](https://github.com/TigerResearch/TigerBot)
|
| 454 |
+
- [Qwen](https://github.com/QwenLM/Qwen)
|
| 455 |
+
- [BlueLM](https://github.com/vivo-ai-lab/BlueLM)
|
| 456 |
+
- ...
|
| 457 |
+
|
| 458 |
+
</td>
|
| 459 |
+
<td>
|
| 460 |
+
|
| 461 |
+
- OpenAI
|
| 462 |
+
- Claude
|
| 463 |
+
- ZhipuAI(ChatGLM)
|
| 464 |
+
- Baichuan
|
| 465 |
+
- ByteDance(YunQue)
|
| 466 |
+
- Huawei(PanGu)
|
| 467 |
+
- 360
|
| 468 |
+
- Baidu(ERNIEBot)
|
| 469 |
+
- MiniMax(ABAB-Chat)
|
| 470 |
+
- SenseTime(nova)
|
| 471 |
+
- Xunfei(Spark)
|
| 472 |
+
- ……
|
| 473 |
+
|
| 474 |
+
</td>
|
| 475 |
+
|
| 476 |
+
</tr>
|
| 477 |
+
</tbody>
|
| 478 |
+
</table>
|
| 479 |
+
|
| 480 |
+
<p align="right"><a href="#top">🔝Back to top</a></p>
|
| 481 |
+
|
| 482 |
+
## 🔜 Roadmap
|
| 483 |
+
|
| 484 |
+
- [ ] Subjective Evaluation
|
| 485 |
+
- [ ] Release CompassAreana
|
| 486 |
+
- [ ] Subjective evaluation dataset.
|
| 487 |
+
- [x] Long-context
|
| 488 |
+
- [ ] Long-context evaluation with extensive datasets.
|
| 489 |
+
- [ ] Long-context leaderboard.
|
| 490 |
+
- [ ] Coding
|
| 491 |
+
- [ ] Coding evaluation leaderboard.
|
| 492 |
+
- [x] Non-python language evaluation service.
|
| 493 |
+
- [ ] Agent
|
| 494 |
+
- [ ] Support various agenet framework.
|
| 495 |
+
- [ ] Evaluation of tool use of the LLMs.
|
| 496 |
+
- [x] Robustness
|
| 497 |
+
- [x] Support various attack method
|
| 498 |
+
|
| 499 |
+
## 👷♂️ Contributing
|
| 500 |
+
|
| 501 |
+
We appreciate all contributions to improving OpenCompass. Please refer to the [contributing guideline](https://opencompass.readthedocs.io/en/latest/notes/contribution_guide.html) for the best practice.
|
| 502 |
+
|
| 503 |
+
## 🤝 Acknowledgements
|
| 504 |
+
|
| 505 |
+
Some code in this project is cited and modified from [OpenICL](https://github.com/Shark-NLP/OpenICL).
|
| 506 |
+
|
| 507 |
+
Some datasets and prompt implementations are modified from [chain-of-thought-hub](https://github.com/FranxYao/chain-of-thought-hub) and [instruct-eval](https://github.com/declare-lab/instruct-eval).
|
| 508 |
+
|
| 509 |
+
## 🖊️ Citation
|
| 510 |
+
|
| 511 |
+
```bibtex
|
| 512 |
+
@misc{2023opencompass,
|
| 513 |
+
title={OpenCompass: A Universal Evaluation Platform for Foundation Models},
|
| 514 |
+
author={OpenCompass Contributors},
|
| 515 |
+
howpublished = {\url{https://github.com/open-compass/opencompass}},
|
| 516 |
+
year={2023}
|
| 517 |
+
}
|
| 518 |
+
```
|
| 519 |
+
|
| 520 |
+
<p align="right"><a href="#top">🔝Back to top</a></p>
|
opencompass-my-api/README_zh-CN.md
ADDED
|
@@ -0,0 +1,522 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
<img src="docs/zh_cn/_static/image/logo.svg" width="500px"/>
|
| 3 |
+
<br />
|
| 4 |
+
<br />
|
| 5 |
+
|
| 6 |
+
[](https://opencompass.readthedocs.io/zh_CN)
|
| 7 |
+
[](https://github.com/open-compass/opencompass/blob/main/LICENSE)
|
| 8 |
+
|
| 9 |
+
<!-- [](https://pypi.org/project/opencompass/) -->
|
| 10 |
+
|
| 11 |
+
[🌐Website](https://opencompass.org.cn/) |
|
| 12 |
+
[📘Documentation](https://opencompass.readthedocs.io/zh_CN/latest/index.html) |
|
| 13 |
+
[🛠️Installation](https://opencompass.readthedocs.io/zh_CN/latest/get_started/installation.html) |
|
| 14 |
+
[🤔Reporting Issues](https://github.com/open-compass/opencompass/issues/new/choose)
|
| 15 |
+
|
| 16 |
+
[English](/README.md) | 简体中文
|
| 17 |
+
|
| 18 |
+
</div>
|
| 19 |
+
|
| 20 |
+
<p align="center">
|
| 21 |
+
👋 加入我们的 <a href="https://discord.gg/KKwfEbFj7U" target="_blank">Discord</a> 和 <a href="https://r.vansin.top/?r=opencompass" target="_blank">微信社区</a>
|
| 22 |
+
</p>
|
| 23 |
+
|
| 24 |
+
## 📣 2023 年度榜单计划
|
| 25 |
+
|
| 26 |
+
我们有幸与社区共同见证了通用人工智能在过去一年里的巨大进展,也非常高兴OpenCompass能够帮助广大大模型开发者和使用者。
|
| 27 |
+
|
| 28 |
+
我们宣布将启动**OpenCompass 2023年度大模型榜单**发布计划。我们预计将于2024年1月发布大模型年度榜单,系统性评估大模型在语言、知识、推理、创作、长文本和智能体等多个能力维度的表现。
|
| 29 |
+
|
| 30 |
+
届时,我们将发布开源模型和商业API模型能力榜单,以期为业界提供一份**全面、客观、中立**的参考。
|
| 31 |
+
|
| 32 |
+
我们诚挚邀请各类大模型接入OpenCompass评测体系,以展示其在各个领域的性能优势。同时,也欢迎广大研究者、开发者向我们提供宝贵的意见和建议,共同推动大模型领域的发展。如有任何问题或需求,请随时[联系我们](mailto:[email protected])。此外,相关评测内容,性能数据,评测方法也将随榜单发布一并开源。
|
| 33 |
+
|
| 34 |
+
我们提供了本次评测所使用的部分题目示例,详情请见[CompassBench 2023](docs/zh_cn/advanced_guides/compassbench_intro.md).
|
| 35 |
+
|
| 36 |
+
<p>让我们共同期待OpenCompass 2023年度大模型榜单的发布,期待各大模型在榜单上的精彩表现!</p>
|
| 37 |
+
|
| 38 |
+
## 🧭 欢迎
|
| 39 |
+
|
| 40 |
+
来到**OpenCompass**!
|
| 41 |
+
|
| 42 |
+
就像指南针在我们的旅程中为我们导航一样,我们希望OpenCompass能够帮助你穿越评估大型语言模型的重重迷雾。OpenCompass提供丰富的算法和功能支持,期待OpenCompass能够帮助社区更便捷地对NLP模型的性能进行公平全面的评估。
|
| 43 |
+
|
| 44 |
+
🚩🚩🚩 欢迎加入 OpenCompass!我们目前**招聘全职研究人员/工程师和实习生**。如果您对 LLM 和 OpenCompass 充满热情,请随时通过[电子邮件](mailto:[email protected])与我们联系。我们非常期待与您交流!
|
| 45 |
+
|
| 46 |
+
🔥🔥🔥 祝贺 **OpenCompass 作为大模型标准测试工具被Meta AI官方推荐**, 点击 Llama 的 [入门文档](https://ai.meta.com/llama/get-started/#validation) 获取更多信息.
|
| 47 |
+
|
| 48 |
+
> **注意**<br />
|
| 49 |
+
> 我们正式启动 OpenCompass 共建计划,诚邀社区用户为 OpenCompass 提供更具代表性和可信度的客观评测数据集!
|
| 50 |
+
> 点击 [Issue](https://github.com/open-compass/opencompass/issues/248) 获取更多数据集.
|
| 51 |
+
> 让我们携手共进,打造功能强大易用的大模型评测平台!
|
| 52 |
+
|
| 53 |
+
## 🚀 最新进展 <a><img width="35" height="20" src="https://user-images.githubusercontent.com/12782558/212848161-5e783dd6-11e8-4fe0-bbba-39ffb77730be.png"></a>
|
| 54 |
+
|
| 55 |
+
- **\[2024.01.17\]** 我们支持了 [InternLM2](https://github.com/open-compass/opencompass/blob/main/configs/eval_internlm2_chat_keyset.py) 和 [InternLM2-Chat](https://github.com/open-compass/opencompass/blob/main/configs/eval_internlm2_chat_keyset.py) 的相关评测,InternLM2 在这些测试中表现出非常强劲的性能,欢迎试用!🔥🔥🔥.
|
| 56 |
+
- **\[2024.01.17\]** 我们支持了多根针版本的大海捞针测试,更多信息见[这里](https://opencompass.readthedocs.io/zh-cn/latest/advanced_guides/needleinahaystack_eval.html#id8)🔥🔥🔥.
|
| 57 |
+
- **\[2023.12.28\]** 我们支持了对使用[LLaMA2-Accessory](https://github.com/Alpha-VLLM/LLaMA2-Accessory)(一款强大的LLM开发工具箱)开发的所有模型的无缝评估! 🔥🔥🔥.
|
| 58 |
+
- **\[2023.12.22\]** 我们开源了[T-Eval](https://github.com/open-compass/T-Eval)用于评测大语言模型工具调用能力。欢迎访问T-Eval的官方[Leaderboard](https://open-compass.github.io/T-Eval/leaderboard.html)获取更多信息! 🔥🔥🔥.
|
| 59 |
+
- **\[2023.12.10\]** 我们开源了多模评测框架 [VLMEvalKit](https://github.com/open-compass/VLMEvalKit),目前已支持 20+ 个多模态大模型与包括 MMBench 系列在内的 7 个多模态评测集.
|
| 60 |
+
- **\[2023.12.10\]** 我们已经支持了Mistral AI的MoE模型 **Mixtral-8x7B-32K**。欢迎查阅[MixtralKit](https://github.com/open-compass/MixtralKit)以获取更多关于推理和评测的详细信息.
|
| 61 |
+
|
| 62 |
+
> [更多](docs/zh_cn/notes/news.md)
|
| 63 |
+
|
| 64 |
+
## ✨ 介绍
|
| 65 |
+
|
| 66 |
+

|
| 67 |
+
|
| 68 |
+
OpenCompass 是面向大模型评测的一站式平台。其主要特点如下:
|
| 69 |
+
|
| 70 |
+
- **开源可复现**:提供公平、公开、可复现的大模型评测方案
|
| 71 |
+
|
| 72 |
+
- **全面的能力维度**:五大维度设计,提供 70+ 个数据集约 40 万题的的模型评测方案,全面评估模型能力
|
| 73 |
+
|
| 74 |
+
- **丰富的模型支持**:已支持 20+ HuggingFace 及 API 模型
|
| 75 |
+
|
| 76 |
+
- **分布式高效评测**:一行命令实现任务分割和分布式评测,数小时即可完成千亿模型全量评测
|
| 77 |
+
|
| 78 |
+
- **多样化评测范式**:支持零样本、小样本及思维链评测,结合标准型或对话型提示词模板,轻松激发各种模型最大性能
|
| 79 |
+
|
| 80 |
+
- **灵活化拓展**:想增加新模型或数据集?想要自定义更高级的任务分割策略,甚至接入新的集群管理系统?OpenCompass 的一切均可轻松扩展!
|
| 81 |
+
|
| 82 |
+
## 📊 性能榜单
|
| 83 |
+
|
| 84 |
+
我们将陆续提供开源模型和API模型的具体性能榜单,请见 [OpenCompass Leaderboard](https://opencompass.org.cn/rank) 。如需加入评测,请提供模型仓库地址或标准的 API 接口至邮箱 `[email protected]`.
|
| 85 |
+
|
| 86 |
+
<p align="right"><a href="#top">🔝返回顶部</a></p>
|
| 87 |
+
|
| 88 |
+
## 🛠️ 安装
|
| 89 |
+
|
| 90 |
+
下面展示了快速安装以及准备数据集的步骤。
|
| 91 |
+
|
| 92 |
+
### 💻 环境配置
|
| 93 |
+
|
| 94 |
+
#### 面向开源模型的GPU环境
|
| 95 |
+
|
| 96 |
+
```bash
|
| 97 |
+
conda create --name opencompass python=3.10 pytorch torchvision pytorch-cuda -c nvidia -c pytorch -y
|
| 98 |
+
conda activate opencompass
|
| 99 |
+
git clone https://github.com/open-compass/opencompass opencompass
|
| 100 |
+
cd opencompass
|
| 101 |
+
pip install -e .
|
| 102 |
+
```
|
| 103 |
+
|
| 104 |
+
#### 面向API模型测试的CPU环境
|
| 105 |
+
|
| 106 |
+
```bash
|
| 107 |
+
conda create -n opencompass python=3.10 pytorch torchvision torchaudio cpuonly -c pytorch -y
|
| 108 |
+
conda activate opencompass
|
| 109 |
+
git clone https://github.com/open-compass/opencompass opencompass
|
| 110 |
+
cd opencompass
|
| 111 |
+
pip install -e .
|
| 112 |
+
# 如果需要使用各个API模型,请 `pip install -r requirements/api.txt` 安装API模型的相关依赖
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
### 📂 数据准备
|
| 116 |
+
|
| 117 |
+
```bash
|
| 118 |
+
# 下载数据集到 data/ 处
|
| 119 |
+
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zip
|
| 120 |
+
unzip OpenCompassData-core-20240207.zip
|
| 121 |
+
```
|
| 122 |
+
|
| 123 |
+
有部分第三方功能,如 Humaneval 以及 Llama,可能需要额外步骤才能正常运行,详细步骤请参考[安装指南](https://opencompass.readthedocs.io/zh_CN/latest/get_started/installation.html)。
|
| 124 |
+
|
| 125 |
+
<p align="right"><a href="#top">🔝返回顶部</a></p>
|
| 126 |
+
|
| 127 |
+
## 🏗️ ️评测
|
| 128 |
+
|
| 129 |
+
确保按照上述步骤正确安装 OpenCompass 并准备好数据集后,可以通过以下命令评测 LLaMA-7b 模型在 MMLU 和 C-Eval 数据集上的性能:
|
| 130 |
+
|
| 131 |
+
```bash
|
| 132 |
+
python run.py --models hf_llama_7b --datasets mmlu_ppl ceval_ppl
|
| 133 |
+
```
|
| 134 |
+
|
| 135 |
+
OpenCompass 预定义了许多模型和数据集的配置,你可以通过 [工具](./docs/zh_cn/tools.md#ListConfigs) 列出所有可用的模型和数据集配置。
|
| 136 |
+
|
| 137 |
+
```bash
|
| 138 |
+
# 列出所有配置
|
| 139 |
+
python tools/list_configs.py
|
| 140 |
+
# 列出所有跟 llama 及 mmlu 相关的配置
|
| 141 |
+
python tools/list_configs.py llama mmlu
|
| 142 |
+
```
|
| 143 |
+
|
| 144 |
+
你也可以通过命令行去评测其它 HuggingFace 模型。同样以 LLaMA-7b 为例:
|
| 145 |
+
|
| 146 |
+
```bash
|
| 147 |
+
python run.py --datasets ceval_ppl mmlu_ppl \
|
| 148 |
+
--hf-path huggyllama/llama-7b \ # HuggingFace 模型地址
|
| 149 |
+
--model-kwargs device_map='auto' \ # 构造 model 的参数
|
| 150 |
+
--tokenizer-kwargs padding_side='left' truncation='left' use_fast=False \ # 构造 tokenizer 的参数
|
| 151 |
+
--max-out-len 100 \ # 最长生成 token 数
|
| 152 |
+
--max-seq-len 2048 \ # 模型能接受的最大序列长度
|
| 153 |
+
--batch-size 8 \ # 批次大小
|
| 154 |
+
--no-batch-padding \ # 不打开 batch padding,通过 for loop 推理,避免精度损失
|
| 155 |
+
--num-gpus 1 # 运行该模型所需的最少 gpu 数
|
| 156 |
+
```
|
| 157 |
+
|
| 158 |
+
> **注意**<br />
|
| 159 |
+
> 若需要运行上述命令,你需要删除所有从 `# ` 开始的注释。
|
| 160 |
+
|
| 161 |
+
通过命令行或配置文件,OpenCompass 还支持评测 API 或自定义模型,以及更多样化的评测策略。请阅读[快速开始](https://opencompass.readthedocs.io/zh_CN/latest/get_started/quick_start.html)了解如何运行一个评测任务。
|
| 162 |
+
|
| 163 |
+
更多教程请查看我们的[文档](https://opencompass.readthedocs.io/zh_CN/latest/index.html)。
|
| 164 |
+
|
| 165 |
+
<p align="right"><a href="#top">🔝返回顶部</a></p>
|
| 166 |
+
|
| 167 |
+
## 📖 数据集支持
|
| 168 |
+
|
| 169 |
+
<table align="center">
|
| 170 |
+
<tbody>
|
| 171 |
+
<tr align="center" valign="bottom">
|
| 172 |
+
<td>
|
| 173 |
+
<b>语言</b>
|
| 174 |
+
</td>
|
| 175 |
+
<td>
|
| 176 |
+
<b>知识</b>
|
| 177 |
+
</td>
|
| 178 |
+
<td>
|
| 179 |
+
<b>推理</b>
|
| 180 |
+
</td>
|
| 181 |
+
<td>
|
| 182 |
+
<b>考试</b>
|
| 183 |
+
</td>
|
| 184 |
+
</tr>
|
| 185 |
+
<tr valign="top">
|
| 186 |
+
<td>
|
| 187 |
+
<details open>
|
| 188 |
+
<summary><b>字词释义</b></summary>
|
| 189 |
+
|
| 190 |
+
- WiC
|
| 191 |
+
- SummEdits
|
| 192 |
+
|
| 193 |
+
</details>
|
| 194 |
+
|
| 195 |
+
<details open>
|
| 196 |
+
<summary><b>成语习语</b></summary>
|
| 197 |
+
|
| 198 |
+
- CHID
|
| 199 |
+
|
| 200 |
+
</details>
|
| 201 |
+
|
| 202 |
+
<details open>
|
| 203 |
+
<summary><b>语义相似度</b></summary>
|
| 204 |
+
|
| 205 |
+
- AFQMC
|
| 206 |
+
- BUSTM
|
| 207 |
+
|
| 208 |
+
</details>
|
| 209 |
+
|
| 210 |
+
<details open>
|
| 211 |
+
<summary><b>指代消解</b></summary>
|
| 212 |
+
|
| 213 |
+
- CLUEWSC
|
| 214 |
+
- WSC
|
| 215 |
+
- WinoGrande
|
| 216 |
+
|
| 217 |
+
</details>
|
| 218 |
+
|
| 219 |
+
<details open>
|
| 220 |
+
<summary><b>翻译</b></summary>
|
| 221 |
+
|
| 222 |
+
- Flores
|
| 223 |
+
- IWSLT2017
|
| 224 |
+
|
| 225 |
+
</details>
|
| 226 |
+
|
| 227 |
+
<details open>
|
| 228 |
+
<summary><b>多语种问答</b></summary>
|
| 229 |
+
|
| 230 |
+
- TyDi-QA
|
| 231 |
+
- XCOPA
|
| 232 |
+
|
| 233 |
+
</details>
|
| 234 |
+
|
| 235 |
+
<details open>
|
| 236 |
+
<summary><b>多语种总结</b></summary>
|
| 237 |
+
|
| 238 |
+
- XLSum
|
| 239 |
+
|
| 240 |
+
</details>
|
| 241 |
+
</td>
|
| 242 |
+
<td>
|
| 243 |
+
<details open>
|
| 244 |
+
<summary><b>知识问答</b></summary>
|
| 245 |
+
|
| 246 |
+
- BoolQ
|
| 247 |
+
- CommonSenseQA
|
| 248 |
+
- NaturalQuestions
|
| 249 |
+
- TriviaQA
|
| 250 |
+
|
| 251 |
+
</details>
|
| 252 |
+
</td>
|
| 253 |
+
<td>
|
| 254 |
+
<details open>
|
| 255 |
+
<summary><b>文本蕴含</b></summary>
|
| 256 |
+
|
| 257 |
+
- CMNLI
|
| 258 |
+
- OCNLI
|
| 259 |
+
- OCNLI_FC
|
| 260 |
+
- AX-b
|
| 261 |
+
- AX-g
|
| 262 |
+
- CB
|
| 263 |
+
- RTE
|
| 264 |
+
- ANLI
|
| 265 |
+
|
| 266 |
+
</details>
|
| 267 |
+
|
| 268 |
+
<details open>
|
| 269 |
+
<summary><b>常识推理</b></summary>
|
| 270 |
+
|
| 271 |
+
- StoryCloze
|
| 272 |
+
- COPA
|
| 273 |
+
- ReCoRD
|
| 274 |
+
- HellaSwag
|
| 275 |
+
- PIQA
|
| 276 |
+
- SIQA
|
| 277 |
+
|
| 278 |
+
</details>
|
| 279 |
+
|
| 280 |
+
<details open>
|
| 281 |
+
<summary><b>数学推理</b></summary>
|
| 282 |
+
|
| 283 |
+
- MATH
|
| 284 |
+
- GSM8K
|
| 285 |
+
|
| 286 |
+
</details>
|
| 287 |
+
|
| 288 |
+
<details open>
|
| 289 |
+
<summary><b>定理应用</b></summary>
|
| 290 |
+
|
| 291 |
+
- TheoremQA
|
| 292 |
+
- StrategyQA
|
| 293 |
+
- SciBench
|
| 294 |
+
|
| 295 |
+
</details>
|
| 296 |
+
|
| 297 |
+
<details open>
|
| 298 |
+
<summary><b>综合推理</b></summary>
|
| 299 |
+
|
| 300 |
+
- BBH
|
| 301 |
+
|
| 302 |
+
</details>
|
| 303 |
+
</td>
|
| 304 |
+
<td>
|
| 305 |
+
<details open>
|
| 306 |
+
<summary><b>初中/高中/大学/职业考试</b></summary>
|
| 307 |
+
|
| 308 |
+
- C-Eval
|
| 309 |
+
- AGIEval
|
| 310 |
+
- MMLU
|
| 311 |
+
- GAOKAO-Bench
|
| 312 |
+
- CMMLU
|
| 313 |
+
- ARC
|
| 314 |
+
- Xiezhi
|
| 315 |
+
|
| 316 |
+
</details>
|
| 317 |
+
|
| 318 |
+
<details open>
|
| 319 |
+
<summary><b>医学考试</b></summary>
|
| 320 |
+
|
| 321 |
+
- CMB
|
| 322 |
+
|
| 323 |
+
</details>
|
| 324 |
+
</td>
|
| 325 |
+
</tr>
|
| 326 |
+
</td>
|
| 327 |
+
</tr>
|
| 328 |
+
</tbody>
|
| 329 |
+
<tbody>
|
| 330 |
+
<tr align="center" valign="bottom">
|
| 331 |
+
<td>
|
| 332 |
+
<b>理解</b>
|
| 333 |
+
</td>
|
| 334 |
+
<td>
|
| 335 |
+
<b>长文本</b>
|
| 336 |
+
</td>
|
| 337 |
+
<td>
|
| 338 |
+
<b>安全</b>
|
| 339 |
+
</td>
|
| 340 |
+
<td>
|
| 341 |
+
<b>代码</b>
|
| 342 |
+
</td>
|
| 343 |
+
</tr>
|
| 344 |
+
<tr valign="top">
|
| 345 |
+
<td>
|
| 346 |
+
<details open>
|
| 347 |
+
<summary><b>阅读理解</b></summary>
|
| 348 |
+
|
| 349 |
+
- C3
|
| 350 |
+
- CMRC
|
| 351 |
+
- DRCD
|
| 352 |
+
- MultiRC
|
| 353 |
+
- RACE
|
| 354 |
+
- DROP
|
| 355 |
+
- OpenBookQA
|
| 356 |
+
- SQuAD2.0
|
| 357 |
+
|
| 358 |
+
</details>
|
| 359 |
+
|
| 360 |
+
<details open>
|
| 361 |
+
<summary><b>内容总结</b></summary>
|
| 362 |
+
|
| 363 |
+
- CSL
|
| 364 |
+
- LCSTS
|
| 365 |
+
- XSum
|
| 366 |
+
- SummScreen
|
| 367 |
+
|
| 368 |
+
</details>
|
| 369 |
+
|
| 370 |
+
<details open>
|
| 371 |
+
<summary><b>内容分析</b></summary>
|
| 372 |
+
|
| 373 |
+
- EPRSTMT
|
| 374 |
+
- LAMBADA
|
| 375 |
+
- TNEWS
|
| 376 |
+
|
| 377 |
+
</details>
|
| 378 |
+
</td>
|
| 379 |
+
<td>
|
| 380 |
+
<details open>
|
| 381 |
+
<summary><b>长文本理解</b></summary>
|
| 382 |
+
|
| 383 |
+
- LEval
|
| 384 |
+
- LongBench
|
| 385 |
+
- GovReports
|
| 386 |
+
- NarrativeQA
|
| 387 |
+
- Qasper
|
| 388 |
+
|
| 389 |
+
</details>
|
| 390 |
+
</td>
|
| 391 |
+
<td>
|
| 392 |
+
<details open>
|
| 393 |
+
<summary><b>安全</b></summary>
|
| 394 |
+
|
| 395 |
+
- CivilComments
|
| 396 |
+
- CrowsPairs
|
| 397 |
+
- CValues
|
| 398 |
+
- JigsawMultilingual
|
| 399 |
+
- TruthfulQA
|
| 400 |
+
|
| 401 |
+
</details>
|
| 402 |
+
<details open>
|
| 403 |
+
<summary><b>健壮性</b></summary>
|
| 404 |
+
|
| 405 |
+
- AdvGLUE
|
| 406 |
+
|
| 407 |
+
</details>
|
| 408 |
+
</td>
|
| 409 |
+
<td>
|
| 410 |
+
<details open>
|
| 411 |
+
<summary><b>代码</b></summary>
|
| 412 |
+
|
| 413 |
+
- HumanEval
|
| 414 |
+
- HumanEvalX
|
| 415 |
+
- MBPP
|
| 416 |
+
- APPs
|
| 417 |
+
- DS1000
|
| 418 |
+
|
| 419 |
+
</details>
|
| 420 |
+
</td>
|
| 421 |
+
</tr>
|
| 422 |
+
</td>
|
| 423 |
+
</tr>
|
| 424 |
+
</tbody>
|
| 425 |
+
</table>
|
| 426 |
+
|
| 427 |
+
<p align="right"><a href="#top">🔝返回顶部</a></p>
|
| 428 |
+
|
| 429 |
+
## 📖 模型支持
|
| 430 |
+
|
| 431 |
+
<table align="center">
|
| 432 |
+
<tbody>
|
| 433 |
+
<tr align="center" valign="bottom">
|
| 434 |
+
<td>
|
| 435 |
+
<b>开源模型</b>
|
| 436 |
+
</td>
|
| 437 |
+
<td>
|
| 438 |
+
<b>API 模型</b>
|
| 439 |
+
</td>
|
| 440 |
+
<!-- <td>
|
| 441 |
+
<b>自定义模型</b>
|
| 442 |
+
</td> -->
|
| 443 |
+
</tr>
|
| 444 |
+
<tr valign="top">
|
| 445 |
+
<td>
|
| 446 |
+
|
| 447 |
+
- [InternLM](https://github.com/InternLM/InternLM)
|
| 448 |
+
- [LLaMA](https://github.com/facebookresearch/llama)
|
| 449 |
+
- [Vicuna](https://github.com/lm-sys/FastChat)
|
| 450 |
+
- [Alpaca](https://github.com/tatsu-lab/stanford_alpaca)
|
| 451 |
+
- [Baichuan](https://github.com/baichuan-inc)
|
| 452 |
+
- [WizardLM](https://github.com/nlpxucan/WizardLM)
|
| 453 |
+
- [ChatGLM2](https://github.com/THUDM/ChatGLM2-6B)
|
| 454 |
+
- [ChatGLM3](https://github.com/THUDM/ChatGLM3-6B)
|
| 455 |
+
- [TigerBot](https://github.com/TigerResearch/TigerBot)
|
| 456 |
+
- [Qwen](https://github.com/QwenLM/Qwen)
|
| 457 |
+
- [BlueLM](https://github.com/vivo-ai-lab/BlueLM)
|
| 458 |
+
- ……
|
| 459 |
+
|
| 460 |
+
</td>
|
| 461 |
+
<td>
|
| 462 |
+
|
| 463 |
+
- OpenAI
|
| 464 |
+
- Claude
|
| 465 |
+
- ZhipuAI(ChatGLM)
|
| 466 |
+
- Baichuan
|
| 467 |
+
- ByteDance(YunQue)
|
| 468 |
+
- Huawei(PanGu)
|
| 469 |
+
- 360
|
| 470 |
+
- Baidu(ERNIEBot)
|
| 471 |
+
- MiniMax(ABAB-Chat)
|
| 472 |
+
- SenseTime(nova)
|
| 473 |
+
- Xunfei(Spark)
|
| 474 |
+
- ……
|
| 475 |
+
|
| 476 |
+
</td>
|
| 477 |
+
|
| 478 |
+
</tr>
|
| 479 |
+
</tbody>
|
| 480 |
+
</table>
|
| 481 |
+
|
| 482 |
+
<p align="right"><a href="#top">🔝返回顶部</a></p>
|
| 483 |
+
|
| 484 |
+
## 🔜 路线图
|
| 485 |
+
|
| 486 |
+
- [ ] 主观评测
|
| 487 |
+
- [ ] 发布主观评测榜单
|
| 488 |
+
- [ ] 发布主观评测数据集
|
| 489 |
+
- [x] 长文本
|
| 490 |
+
- [ ] 支持广泛的长文本评测集
|
| 491 |
+
- [ ] 发布长文本评测榜单
|
| 492 |
+
- [ ] 代码能力
|
| 493 |
+
- [ ] 发布代码能力评测榜单
|
| 494 |
+
- [x] 提供非Python语言的评测服务
|
| 495 |
+
- [ ] 智能体
|
| 496 |
+
- [ ] 支持丰富的智能体方案
|
| 497 |
+
- [ ] 提供智能体评测榜单
|
| 498 |
+
- [x] 鲁棒性
|
| 499 |
+
- [x] 支持各类攻击方法
|
| 500 |
+
|
| 501 |
+
## 👷♂️ 贡献
|
| 502 |
+
|
| 503 |
+
我们感谢所有的贡献者为改进和提升 OpenCompass 所作出的努力。请参考[贡献指南](https://opencompass.readthedocs.io/zh_CN/latest/notes/contribution_guide.html)来了解参与项目贡献的相关指引。
|
| 504 |
+
|
| 505 |
+
## 🤝 致谢
|
| 506 |
+
|
| 507 |
+
该项目部分的代码引用并修改自 [OpenICL](https://github.com/Shark-NLP/OpenICL)。
|
| 508 |
+
|
| 509 |
+
该项目部分的数据集和提示词实现修改自 [chain-of-thought-hub](https://github.com/FranxYao/chain-of-thought-hub), [instruct-eval](https://github.com/declare-lab/instruct-eval)
|
| 510 |
+
|
| 511 |
+
## 🖊️ 引用
|
| 512 |
+
|
| 513 |
+
```bibtex
|
| 514 |
+
@misc{2023opencompass,
|
| 515 |
+
title={OpenCompass: A Universal Evaluation Platform for Foundation Models},
|
| 516 |
+
author={OpenCompass Contributors},
|
| 517 |
+
howpublished = {\url{https://github.com/open-compass/opencompass}},
|
| 518 |
+
year={2023}
|
| 519 |
+
}
|
| 520 |
+
```
|
| 521 |
+
|
| 522 |
+
<p align="right"><a href="#top">🔝返回顶部</a></p>
|
opencompass-my-api/build/lib/opencompass/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
__version__ = '0.2.2'
|
opencompass-my-api/build/lib/opencompass/datasets/FinanceIQ.py
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import csv
|
| 2 |
+
import os.path as osp
|
| 3 |
+
|
| 4 |
+
from datasets import Dataset, DatasetDict
|
| 5 |
+
|
| 6 |
+
from opencompass.registry import LOAD_DATASET
|
| 7 |
+
|
| 8 |
+
from .base import BaseDataset
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
@LOAD_DATASET.register_module()
|
| 12 |
+
class FinanceIQDataset(BaseDataset):
|
| 13 |
+
|
| 14 |
+
# @staticmethod
|
| 15 |
+
# def load(path: str):
|
| 16 |
+
# from datasets import load_dataset
|
| 17 |
+
# return load_dataset('csv', data_files={'test': path})
|
| 18 |
+
|
| 19 |
+
@staticmethod
|
| 20 |
+
def load(path: str, name: str):
|
| 21 |
+
dataset = DatasetDict()
|
| 22 |
+
for split in ['dev', 'test']:
|
| 23 |
+
raw_data = []
|
| 24 |
+
filename = osp.join(path, split, f'{name}.csv')
|
| 25 |
+
with open(filename, encoding='utf-8') as f:
|
| 26 |
+
reader = csv.reader(f)
|
| 27 |
+
_ = next(reader) # skip the header
|
| 28 |
+
for row in reader:
|
| 29 |
+
assert len(row) == 7
|
| 30 |
+
raw_data.append({
|
| 31 |
+
'question': row[1],
|
| 32 |
+
'A': row[2],
|
| 33 |
+
'B': row[3],
|
| 34 |
+
'C': row[4],
|
| 35 |
+
'D': row[5],
|
| 36 |
+
'answer': row[6],
|
| 37 |
+
})
|
| 38 |
+
dataset[split] = Dataset.from_list(raw_data)
|
| 39 |
+
return dataset
|
opencompass-my-api/build/lib/opencompass/datasets/GaokaoBench.py
ADDED
|
@@ -0,0 +1,132 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import re
|
| 3 |
+
|
| 4 |
+
from datasets import Dataset
|
| 5 |
+
|
| 6 |
+
from opencompass.openicl.icl_evaluator import BaseEvaluator
|
| 7 |
+
from opencompass.registry import ICL_EVALUATORS, LOAD_DATASET
|
| 8 |
+
|
| 9 |
+
from .base import BaseDataset
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
@LOAD_DATASET.register_module()
|
| 13 |
+
class GaokaoBenchDataset(BaseDataset):
|
| 14 |
+
|
| 15 |
+
@staticmethod
|
| 16 |
+
def load(path: str):
|
| 17 |
+
with open(path, encoding='utf-8') as f:
|
| 18 |
+
data = json.load(f)
|
| 19 |
+
return Dataset.from_list(data['example'])
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
valid_gaokao_bench_question_types = [
|
| 23 |
+
'single_choice', 'multi_choice', 'multi_question_choice',
|
| 24 |
+
'five_out_of_seven', 'cloze', 'subjective', 'correction'
|
| 25 |
+
]
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class GaokaoBenchEvaluator(BaseEvaluator):
|
| 29 |
+
|
| 30 |
+
def __init__(self, question_type) -> None:
|
| 31 |
+
super().__init__()
|
| 32 |
+
assert question_type in valid_gaokao_bench_question_types
|
| 33 |
+
self.question_type = question_type
|
| 34 |
+
|
| 35 |
+
def do_predictions_postprocess(self, model_output, answer_lenth=None):
|
| 36 |
+
if self.question_type == 'single_choice':
|
| 37 |
+
model_answer = []
|
| 38 |
+
temp = re.findall(r'[A-D]', model_output[::-1])
|
| 39 |
+
if len(temp) != 0:
|
| 40 |
+
model_answer.append(temp[0])
|
| 41 |
+
|
| 42 |
+
elif self.question_type == 'multi_question_choice':
|
| 43 |
+
model_answer = []
|
| 44 |
+
temp = re.findall(r'【答案】\s*[::]*\s*[A-Z]', model_output)
|
| 45 |
+
|
| 46 |
+
if len(temp) == answer_lenth:
|
| 47 |
+
for t in temp:
|
| 48 |
+
model_answer.append(re.findall(r'[A-Z]', t)[0])
|
| 49 |
+
else:
|
| 50 |
+
temp = re.findall(r'[A-Z]', model_output)
|
| 51 |
+
if len(temp) > 0:
|
| 52 |
+
for k in range(min(len(temp), answer_lenth)):
|
| 53 |
+
model_answer.append(temp[k])
|
| 54 |
+
|
| 55 |
+
elif self.question_type == 'multi_choice':
|
| 56 |
+
model_answer = []
|
| 57 |
+
answer = ''
|
| 58 |
+
content = re.sub(r'\s+', '', model_output)
|
| 59 |
+
answer_index = content.find('【答案】')
|
| 60 |
+
if answer_index > 0:
|
| 61 |
+
temp = content[answer_index:]
|
| 62 |
+
if len(re.findall(r'[A-D]', temp)) > 0:
|
| 63 |
+
for t in re.findall(r'[A-D]', temp):
|
| 64 |
+
answer += t
|
| 65 |
+
else:
|
| 66 |
+
temp = content[-10:]
|
| 67 |
+
if len(re.findall(r'[A-D]', temp)) > 0:
|
| 68 |
+
for t in re.findall(r'[A-D]', temp):
|
| 69 |
+
answer += t
|
| 70 |
+
if len(answer) != 0:
|
| 71 |
+
model_answer.append(answer)
|
| 72 |
+
|
| 73 |
+
elif self.question_type == 'five_out_of_seven':
|
| 74 |
+
model_answer = []
|
| 75 |
+
temp = re.findall(r'[A-G]', model_output)
|
| 76 |
+
if len(temp) > 0:
|
| 77 |
+
for k in range(min(5, len(temp))):
|
| 78 |
+
model_answer.append(temp[k])
|
| 79 |
+
|
| 80 |
+
return model_answer
|
| 81 |
+
|
| 82 |
+
def ensure_same_length(self, pred, refr):
|
| 83 |
+
if len(pred) == len(refr):
|
| 84 |
+
return pred
|
| 85 |
+
return ['Z'] * len(refr)
|
| 86 |
+
|
| 87 |
+
def score(self, predictions, references):
|
| 88 |
+
if self.question_type not in [
|
| 89 |
+
'single_choice', 'multi_choice', 'multi_question_choice',
|
| 90 |
+
'five_out_of_seven'
|
| 91 |
+
]:
|
| 92 |
+
return {'score': 0}
|
| 93 |
+
elif self.question_type == 'multi_choice':
|
| 94 |
+
correct_score, total_score = 0, 0
|
| 95 |
+
for pred, refr in zip(predictions, references):
|
| 96 |
+
pred = self.do_predictions_postprocess(pred)
|
| 97 |
+
pred = self.ensure_same_length(pred, refr)
|
| 98 |
+
for p, r in zip(pred, refr):
|
| 99 |
+
if p == r:
|
| 100 |
+
correct_score += 2
|
| 101 |
+
else:
|
| 102 |
+
for i in p:
|
| 103 |
+
if i not in r:
|
| 104 |
+
break
|
| 105 |
+
else:
|
| 106 |
+
correct_score += 1
|
| 107 |
+
total_score += 2
|
| 108 |
+
return {'score': correct_score / total_score * 100}
|
| 109 |
+
else:
|
| 110 |
+
correct_score, total_score = 0, 0
|
| 111 |
+
for pred, refr in zip(predictions, references):
|
| 112 |
+
if self.question_type == 'multi_question_choice':
|
| 113 |
+
pred = self.do_predictions_postprocess(pred, len(refr))
|
| 114 |
+
else:
|
| 115 |
+
pred = self.do_predictions_postprocess(pred)
|
| 116 |
+
pred = self.ensure_same_length(pred, refr)
|
| 117 |
+
for p, r in zip(pred, refr):
|
| 118 |
+
if p == r:
|
| 119 |
+
correct_score += 1
|
| 120 |
+
total_score += 1
|
| 121 |
+
return {'score': correct_score / total_score * 100}
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
for question_type in valid_gaokao_bench_question_types:
|
| 125 |
+
# fix classic closure problem
|
| 126 |
+
def _gaokao_register(question_type):
|
| 127 |
+
ICL_EVALUATORS.register_module(
|
| 128 |
+
name='GaokaoBenchEvaluator' + '_' + question_type,
|
| 129 |
+
module=lambda *args, **kwargs: GaokaoBenchEvaluator(
|
| 130 |
+
question_type=question_type, *args, **kwargs))
|
| 131 |
+
|
| 132 |
+
_gaokao_register(question_type)
|
opencompass-my-api/build/lib/opencompass/datasets/NPHardEval/__init__.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .cmp_GCP_D import * # noqa: F401, F403
|
| 2 |
+
from .cmp_KSP import * # noqa: F401, F403
|
| 3 |
+
from .cmp_TSP_D import * # noqa: F401, F403
|
| 4 |
+
from .hard_GCP import * # noqa: F401, F403
|
| 5 |
+
from .hard_MSP import * # noqa: F401, F403
|
| 6 |
+
from .hard_TSP import * # noqa: F401, F403
|
| 7 |
+
from .p_BSP import * # noqa: F401, F403
|
| 8 |
+
from .p_EDP import * # noqa: F401, F403
|
| 9 |
+
from .p_SPP import * # noqa: F401, F403
|
opencompass-my-api/build/lib/opencompass/datasets/NPHardEval/cmp_GCP_D.py
ADDED
|
@@ -0,0 +1,161 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import ast
|
| 2 |
+
|
| 3 |
+
import networkx as nx
|
| 4 |
+
from datasets import Dataset
|
| 5 |
+
|
| 6 |
+
from opencompass.openicl.icl_evaluator import BaseEvaluator
|
| 7 |
+
from opencompass.registry import ICL_EVALUATORS, LOAD_DATASET
|
| 8 |
+
|
| 9 |
+
from ..base import BaseDataset
|
| 10 |
+
from .prompts import gcp_dPrompts
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def q2text(q, p=gcp_dPrompts):
|
| 14 |
+
number_of_colors = q.split('\n')[0].split()[-2] # last character of the first line
|
| 15 |
+
number_of_vertices = q.split('\n')[1].split(' ')[2] # third word of the second line
|
| 16 |
+
prompt_text = p['Intro'] + '\n' + \
|
| 17 |
+
p['Initial_question'].format(total_vertices=number_of_vertices, number_of_colors=number_of_colors) + '\n' + \
|
| 18 |
+
p['Output_content'] + '\n' + \
|
| 19 |
+
p['Output_format'] + '\n' + \
|
| 20 |
+
'\n The graph is below: \n'
|
| 21 |
+
for line in q.split('\n')[2:]:
|
| 22 |
+
vertex_list = line.split(' ')
|
| 23 |
+
this_line = 'Vertex {} is connected to vertex {}.'.format(
|
| 24 |
+
vertex_list[1], vertex_list[2])
|
| 25 |
+
prompt_text += this_line + '\n'
|
| 26 |
+
return prompt_text
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
@LOAD_DATASET.register_module(force=True)
|
| 30 |
+
class cmp_GCP_D_Dataset(BaseDataset):
|
| 31 |
+
|
| 32 |
+
@staticmethod
|
| 33 |
+
def load(path: str):
|
| 34 |
+
raw_data = []
|
| 35 |
+
data_path = path
|
| 36 |
+
all_data = []
|
| 37 |
+
for file_num in range(10):
|
| 38 |
+
with open(data_path + 'decision_data_GCP_{}.txt'.format(file_num)) as f:
|
| 39 |
+
data = f.read()
|
| 40 |
+
sample = data.split('\n\n')[:-1]
|
| 41 |
+
all_data += zip([file_num + 1] * len(sample), sample)
|
| 42 |
+
for (level, q) in all_data:
|
| 43 |
+
prompt = q2text(q)
|
| 44 |
+
raw_data.append({
|
| 45 |
+
'prompt': prompt,
|
| 46 |
+
'q': str(level) + '####\n' + q,
|
| 47 |
+
'level': level
|
| 48 |
+
})
|
| 49 |
+
dataset = Dataset.from_list(raw_data)
|
| 50 |
+
return dataset
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
@ICL_EVALUATORS.register_module(force=True)
|
| 54 |
+
class cmp_GCP_D_Evaluator(BaseEvaluator):
|
| 55 |
+
|
| 56 |
+
def score(self, predictions, references):
|
| 57 |
+
assert len(predictions) == len(references)
|
| 58 |
+
|
| 59 |
+
result = {'pass': 0, 'fail': 0}
|
| 60 |
+
details = {}
|
| 61 |
+
for index, (q, output) in enumerate(zip(references, predictions)):
|
| 62 |
+
output_dict = {}
|
| 63 |
+
level = int(q.split('####\n')[0])
|
| 64 |
+
q = q.split('####\n')[-1]
|
| 65 |
+
try:
|
| 66 |
+
number_of_colors = int(q.split('\n')[0].split()[-2])
|
| 67 |
+
output, reasoning = self.parse_xml_to_dict(output)
|
| 68 |
+
output_dict['output'] = output
|
| 69 |
+
output_dict['correctness'], _ = self.gcp_decision_check(q, output, number_of_colors)
|
| 70 |
+
except Exception as e:
|
| 71 |
+
print(f'Attempt failed: {e}')
|
| 72 |
+
output_dict['correctness'] = False
|
| 73 |
+
output_dict['reasoning'] = reasoning
|
| 74 |
+
|
| 75 |
+
if output_dict['correctness']:
|
| 76 |
+
r = 'pass'
|
| 77 |
+
else:
|
| 78 |
+
r = 'fail'
|
| 79 |
+
result[r] += level
|
| 80 |
+
details[str(index)] = {'q': q, 'output': output, 'result': r}
|
| 81 |
+
|
| 82 |
+
result['score'] = result['pass'] / (result['pass'] + result['fail']) * 100
|
| 83 |
+
result['details'] = details
|
| 84 |
+
final_result = {'Weighted Accuracy': result['score']}
|
| 85 |
+
return final_result
|
| 86 |
+
|
| 87 |
+
def parse_xml_to_dict(self, xml_string):
|
| 88 |
+
try:
|
| 89 |
+
assert '<final_answer>' in xml_string
|
| 90 |
+
assert '</final_answer>' in xml_string
|
| 91 |
+
assert '<reasoning>' in xml_string
|
| 92 |
+
assert '</reasoning>' in xml_string
|
| 93 |
+
final_answer_start = xml_string.index('<final_answer>') + len('<final_answer>')
|
| 94 |
+
final_answer_end = xml_string.index('</final_answer>')
|
| 95 |
+
reasoning_start = xml_string.index('<reasoning>') + len('<reasoning>')
|
| 96 |
+
reasoning_end = xml_string.index('</reasoning>')
|
| 97 |
+
final_answer_element = xml_string[final_answer_start:final_answer_end].rstrip().strip().rstrip()
|
| 98 |
+
reasoning_element = xml_string[reasoning_start:reasoning_end].rstrip().strip().rstrip()
|
| 99 |
+
try:
|
| 100 |
+
final_answer_element = ast.literal_eval(final_answer_element)
|
| 101 |
+
except Exception:
|
| 102 |
+
final_answer_element = ''
|
| 103 |
+
except Exception:
|
| 104 |
+
final_answer_element = ''
|
| 105 |
+
reasoning_element = ''
|
| 106 |
+
|
| 107 |
+
return final_answer_element, reasoning_element
|
| 108 |
+
|
| 109 |
+
def read_dimacs_format(self, dimacs_str):
|
| 110 |
+
lines = dimacs_str.strip().split('\n')
|
| 111 |
+
p_line = next(line for line in lines if line.startswith('p'))
|
| 112 |
+
_, _, num_vertices, num_edges = p_line.split()
|
| 113 |
+
num_vertices, num_edges = int(num_vertices), int(num_edges)
|
| 114 |
+
|
| 115 |
+
adjacency_list = {i: set() for i in range(1, num_vertices + 1)}
|
| 116 |
+
for line in lines:
|
| 117 |
+
if line.startswith('e'):
|
| 118 |
+
_, vertex1, vertex2 = line.split()
|
| 119 |
+
vertex1, vertex2 = int(vertex1), int(vertex2)
|
| 120 |
+
if vertex1 in adjacency_list and vertex2 in adjacency_list:
|
| 121 |
+
adjacency_list[vertex1].add(vertex2)
|
| 122 |
+
adjacency_list[vertex2].add(vertex1)
|
| 123 |
+
|
| 124 |
+
return num_vertices, adjacency_list
|
| 125 |
+
|
| 126 |
+
def gcp_greedy_solution(self, adjacency_list):
|
| 127 |
+
"""Provides a greedy solution to the GCP problem.
|
| 128 |
+
|
| 129 |
+
:param adjacency_list: A dictionary of the adjacency list.
|
| 130 |
+
:return: A tuple of (num_colors, coloring).
|
| 131 |
+
"""
|
| 132 |
+
G = nx.Graph()
|
| 133 |
+
G.add_nodes_from(adjacency_list.keys())
|
| 134 |
+
for vertex, neighbors in adjacency_list.items():
|
| 135 |
+
for neighbor in neighbors:
|
| 136 |
+
G.add_edge(vertex, neighbor)
|
| 137 |
+
coloring = nx.coloring.greedy_color(G, strategy='largest_first')
|
| 138 |
+
num_colors = max(coloring.values()) + 1
|
| 139 |
+
return num_colors, coloring
|
| 140 |
+
|
| 141 |
+
def gcp_decision_check(self, dimacs_str, answer, k_colors):
|
| 142 |
+
"""Check if the given GCP instance is feasible with k_colors.
|
| 143 |
+
|
| 144 |
+
:param dimacs_str: The DIMACS format string of the GCP instance.
|
| 145 |
+
:param answer: The answer returned by the model.
|
| 146 |
+
:param k_colors: The target number of colors.
|
| 147 |
+
:return: A tuple of (is_correct, message).
|
| 148 |
+
"""
|
| 149 |
+
num_vertices, adjacency_list = self.read_dimacs_format(dimacs_str)
|
| 150 |
+
try:
|
| 151 |
+
is_feasible = answer.get('Feasible', 'no').lower() == 'yes'
|
| 152 |
+
except Exception:
|
| 153 |
+
return False, 'Feasible key not found'
|
| 154 |
+
num_colors, coloring = self.gcp_greedy_solution(adjacency_list)
|
| 155 |
+
exist_optimal = num_colors <= k_colors
|
| 156 |
+
if is_feasible != exist_optimal:
|
| 157 |
+
if exist_optimal:
|
| 158 |
+
return False, f'Feasibility mismatch: {coloring}'
|
| 159 |
+
else:
|
| 160 |
+
return False, f'Feasibility mismatch: {is_feasible} vs {exist_optimal}'
|
| 161 |
+
return True, 'Feasible' if is_feasible else 'Infeasible'
|
opencompass-my-api/build/lib/opencompass/datasets/NPHardEval/cmp_KSP.py
ADDED
|
@@ -0,0 +1,183 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import ast
|
| 2 |
+
import json
|
| 3 |
+
|
| 4 |
+
from datasets import Dataset
|
| 5 |
+
|
| 6 |
+
from opencompass.openicl.icl_evaluator import BaseEvaluator
|
| 7 |
+
from opencompass.registry import ICL_EVALUATORS, LOAD_DATASET
|
| 8 |
+
|
| 9 |
+
from ..base import BaseDataset
|
| 10 |
+
from .prompts import kspPrompts
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def q2text(q, p=kspPrompts):
|
| 14 |
+
knapsack_capacity = q['knapsack_capacity']
|
| 15 |
+
items = q['items']
|
| 16 |
+
prompt_text = p['Intro'] + '\n' + \
|
| 17 |
+
p['Initial_question'].format(knapsack_capacity=knapsack_capacity) + '\n' + \
|
| 18 |
+
p['Output_content'] + '\n' + \
|
| 19 |
+
p['Output_format'] + \
|
| 20 |
+
'\n The items details are as below: \n'
|
| 21 |
+
for item in items:
|
| 22 |
+
this_line = f"Item {item['id']} has weight {item['weight']} and value {item['value']}."
|
| 23 |
+
prompt_text += this_line + '\n'
|
| 24 |
+
return prompt_text
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
@LOAD_DATASET.register_module(force=True)
|
| 28 |
+
class cmp_KSP_Dataset(BaseDataset):
|
| 29 |
+
|
| 30 |
+
@staticmethod
|
| 31 |
+
def load(path: str):
|
| 32 |
+
raw_data = []
|
| 33 |
+
data_path = path
|
| 34 |
+
all_data = []
|
| 35 |
+
with open(data_path + 'ksp_instances.json', 'r') as f:
|
| 36 |
+
data = json.load(f)
|
| 37 |
+
for sample in data:
|
| 38 |
+
level = len(sample['items']) - 3
|
| 39 |
+
all_data.append((level, sample))
|
| 40 |
+
for (level, q) in all_data:
|
| 41 |
+
prompt = q2text(q)
|
| 42 |
+
raw_data.append({
|
| 43 |
+
'prompt': prompt,
|
| 44 |
+
'q': str(level) + '####\n' + json.dumps(q),
|
| 45 |
+
'level': level
|
| 46 |
+
})
|
| 47 |
+
dataset = Dataset.from_list(raw_data)
|
| 48 |
+
return dataset
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
@ICL_EVALUATORS.register_module(force=True)
|
| 52 |
+
class cmp_KSP_Evaluator(BaseEvaluator):
|
| 53 |
+
|
| 54 |
+
def score(self, predictions, references):
|
| 55 |
+
assert len(predictions) == len(references)
|
| 56 |
+
|
| 57 |
+
result = {'pass': 0, 'fail': 0}
|
| 58 |
+
details = {}
|
| 59 |
+
for index, (q, output) in enumerate(zip(references, predictions)):
|
| 60 |
+
output_dict = {}
|
| 61 |
+
level = int(q.split('####\n')[0])
|
| 62 |
+
q = json.loads(q.split('####\n')[-1])
|
| 63 |
+
try:
|
| 64 |
+
llm_string = q
|
| 65 |
+
output, reasoning = self.parse_xml_to_dict(llm_string)
|
| 66 |
+
output_dict['output'] = output
|
| 67 |
+
output_dict['correctness'], _ = self.kspCheck(q, output)
|
| 68 |
+
output_dict['reasoning'] = reasoning
|
| 69 |
+
output_dict['level'] = level
|
| 70 |
+
except Exception as e:
|
| 71 |
+
print(f'Attempt failed: {e}')
|
| 72 |
+
if output_dict:
|
| 73 |
+
if output_dict['correctness']:
|
| 74 |
+
r = 'pass'
|
| 75 |
+
else:
|
| 76 |
+
r = 'fail'
|
| 77 |
+
else:
|
| 78 |
+
print(f'Failed to run {q}')
|
| 79 |
+
r = 'fail'
|
| 80 |
+
|
| 81 |
+
result[r] += level
|
| 82 |
+
details[str(index)] = {'q': q, 'output': output, 'result': r}
|
| 83 |
+
|
| 84 |
+
result['score'] = result['pass'] / (result['pass'] + result['fail']) * 100
|
| 85 |
+
result['details'] = details
|
| 86 |
+
final_result = {'Weighted Accuracy': result['score']}
|
| 87 |
+
return final_result
|
| 88 |
+
|
| 89 |
+
def parse_xml_to_dict(self, xml_string):
|
| 90 |
+
try:
|
| 91 |
+
assert '<final_answer>' in xml_string
|
| 92 |
+
assert '</final_answer>' in xml_string
|
| 93 |
+
assert '<reasoning>' in xml_string
|
| 94 |
+
assert '</reasoning>' in xml_string
|
| 95 |
+
final_answer_start = xml_string.index('<final_answer>') + len('<final_answer>')
|
| 96 |
+
final_answer_end = xml_string.index('</final_answer>')
|
| 97 |
+
reasoning_start = xml_string.index('<reasoning>') + len('<reasoning>')
|
| 98 |
+
reasoning_end = xml_string.index('</reasoning>')
|
| 99 |
+
final_answer_element = xml_string[final_answer_start:final_answer_end].rstrip().strip().rstrip()
|
| 100 |
+
reasoning_element = xml_string[reasoning_start:reasoning_end].rstrip().strip().rstrip()
|
| 101 |
+
try:
|
| 102 |
+
final_answer_element = ast.literal_eval(final_answer_element)
|
| 103 |
+
except Exception:
|
| 104 |
+
final_answer_element = ''
|
| 105 |
+
except Exception:
|
| 106 |
+
final_answer_element = ''
|
| 107 |
+
reasoning_element = ''
|
| 108 |
+
|
| 109 |
+
return final_answer_element, reasoning_element
|
| 110 |
+
|
| 111 |
+
def ksp_optimal_solution(self, knapsacks, capacity):
|
| 112 |
+
"""Provides the optimal solution for the KSP instance with dynamic
|
| 113 |
+
programming.
|
| 114 |
+
|
| 115 |
+
:param knapsacks: A dictionary of the knapsacks.
|
| 116 |
+
:param capacity: The capacity of the knapsack.
|
| 117 |
+
:return: The optimal value.
|
| 118 |
+
"""
|
| 119 |
+
# num_knapsacks = len(knapsacks)
|
| 120 |
+
|
| 121 |
+
# Create a one-dimensional array to store intermediate solutions
|
| 122 |
+
dp = [0] * (capacity + 1)
|
| 123 |
+
|
| 124 |
+
for itemId, (weight, value) in knapsacks.items():
|
| 125 |
+
for w in range(capacity, weight - 1, -1):
|
| 126 |
+
dp[w] = max(dp[w], value + dp[w - weight])
|
| 127 |
+
|
| 128 |
+
return dp[capacity]
|
| 129 |
+
|
| 130 |
+
# KSP
|
| 131 |
+
def kspCheck(self, instance, solution):
|
| 132 |
+
"""Validates the solution for the KSP instance.
|
| 133 |
+
|
| 134 |
+
:param instance: A dictionary of the KSP instance.
|
| 135 |
+
:param solution: A dictionary of the solution.
|
| 136 |
+
:return: A tuple of (is_correct, message).
|
| 137 |
+
"""
|
| 138 |
+
# Change string key to integer key and value to boolean
|
| 139 |
+
items = instance.get('items', [])
|
| 140 |
+
knapsacks = {
|
| 141 |
+
item['id']: (item['weight'], item['value'])
|
| 142 |
+
for item in items
|
| 143 |
+
}
|
| 144 |
+
|
| 145 |
+
ksp_optimal_value = self.ksp_optimal_solution(
|
| 146 |
+
knapsacks, instance['knapsack_capacity'])
|
| 147 |
+
|
| 148 |
+
try:
|
| 149 |
+
is_feasible = (solution.get('Feasible', '').lower() == 'yes')
|
| 150 |
+
except Exception:
|
| 151 |
+
return False, f'Output format is incorrect.'
|
| 152 |
+
if is_feasible != (ksp_optimal_value > 0):
|
| 153 |
+
return False, f'The solution is {is_feasible} but the optimal solution is {ksp_optimal_value > 0}.'
|
| 154 |
+
|
| 155 |
+
total_value = int(solution.get('TotalValue', -1))
|
| 156 |
+
selectedItems = list(map(int, solution.get('SelectedItemIds', [])))
|
| 157 |
+
|
| 158 |
+
if len(set(selectedItems)) != len(selectedItems):
|
| 159 |
+
return False, f'Duplicate items are selected.'
|
| 160 |
+
|
| 161 |
+
total_weight = 0
|
| 162 |
+
cum_value = 0
|
| 163 |
+
|
| 164 |
+
# Calculate total weight and value of selected items
|
| 165 |
+
for item in selectedItems:
|
| 166 |
+
if knapsacks.get(item, False):
|
| 167 |
+
weight, value = knapsacks[item]
|
| 168 |
+
total_weight += weight
|
| 169 |
+
cum_value += value
|
| 170 |
+
else:
|
| 171 |
+
return False, f'Item {item} does not exist.'
|
| 172 |
+
|
| 173 |
+
# Check if the item weight exceeds the knapsack capacity
|
| 174 |
+
if total_weight > instance['knapsack_capacity']:
|
| 175 |
+
return False, f"Total weight {total_weight} exceeds knapsack capacity {instance['knapsack_capacity']}."
|
| 176 |
+
|
| 177 |
+
if total_value != cum_value:
|
| 178 |
+
return False, f'The total value {total_value} does not match the cumulative value {cum_value} of the selected items.'
|
| 179 |
+
|
| 180 |
+
if total_value != ksp_optimal_value:
|
| 181 |
+
return False, f'The total value {total_value} does not match the optimal value {ksp_optimal_value}.'
|
| 182 |
+
|
| 183 |
+
return True, f'The solution is valid with total weight {total_weight} and total value {total_value}.'
|
opencompass-my-api/build/lib/opencompass/datasets/NPHardEval/cmp_TSP_D.py
ADDED
|
@@ -0,0 +1,150 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import ast
|
| 2 |
+
import json
|
| 3 |
+
|
| 4 |
+
import networkx as nx
|
| 5 |
+
import pandas as pd
|
| 6 |
+
from datasets import Dataset
|
| 7 |
+
|
| 8 |
+
from opencompass.openicl.icl_evaluator import BaseEvaluator
|
| 9 |
+
from opencompass.registry import ICL_EVALUATORS, LOAD_DATASET
|
| 10 |
+
|
| 11 |
+
from ..base import BaseDataset
|
| 12 |
+
from .prompts import tsp_dPrompts
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def q2text(adj_matrix, distance_limit, p=tsp_dPrompts):
|
| 16 |
+
total_cities = adj_matrix.shape[0] # exclude the last row
|
| 17 |
+
prompt_text = p['Intro'] + '\n' + \
|
| 18 |
+
p['Initial_question'].format(total_cities=total_cities, distance_limit=distance_limit) + '\n' + \
|
| 19 |
+
p['Output_content'] + '\n' + \
|
| 20 |
+
p['Output_format'] + '\n' + \
|
| 21 |
+
'The distances between cities are below: \n'
|
| 22 |
+
|
| 23 |
+
for i in range(adj_matrix.shape[0]):
|
| 24 |
+
for j in range(adj_matrix.shape[1]):
|
| 25 |
+
if i < j: # only use the upper triangle
|
| 26 |
+
this_line = 'The distance between City {} and City {} is {}.'.format(i, j, adj_matrix[i, j])
|
| 27 |
+
prompt_text += this_line + '\n'
|
| 28 |
+
return prompt_text
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
@LOAD_DATASET.register_module(force=True)
|
| 32 |
+
class cmp_TSP_D_Dataset(BaseDataset):
|
| 33 |
+
|
| 34 |
+
@staticmethod
|
| 35 |
+
def load(path: str):
|
| 36 |
+
raw_data = []
|
| 37 |
+
data_path = path
|
| 38 |
+
all_data = []
|
| 39 |
+
for level in range(10):
|
| 40 |
+
for file_num in range(10):
|
| 41 |
+
df = pd.read_csv(data_path + 'decision_data_TSP_level_{}_instance_{}.csv'.format(level, file_num + 1),
|
| 42 |
+
header=None,
|
| 43 |
+
index_col=False)
|
| 44 |
+
all_data.append((level + 1, df))
|
| 45 |
+
|
| 46 |
+
for (level, q) in all_data:
|
| 47 |
+
threshold = q.iloc[-1, 0] # therashold is the last row
|
| 48 |
+
distance_matrix = q.iloc[:
|
| 49 |
+
-1].values # distance matrix is the rest of the rows
|
| 50 |
+
prompt = q2text(distance_matrix, threshold)
|
| 51 |
+
raw_data.append({
|
| 52 |
+
'prompt': prompt,
|
| 53 |
+
'q': str(level) + '####\n' + json.dumps(q.to_json()),
|
| 54 |
+
'level': level
|
| 55 |
+
})
|
| 56 |
+
dataset = Dataset.from_list(raw_data)
|
| 57 |
+
return dataset
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
@ICL_EVALUATORS.register_module(force=True)
|
| 61 |
+
class cmp_TSP_D_Evaluator(BaseEvaluator):
|
| 62 |
+
|
| 63 |
+
def score(self, predictions, references):
|
| 64 |
+
assert len(predictions) == len(references)
|
| 65 |
+
|
| 66 |
+
result = {'pass': 0, 'fail': 0}
|
| 67 |
+
details = {}
|
| 68 |
+
tsp_d_Results = []
|
| 69 |
+
for index, (q, llm_string) in enumerate(zip(references, predictions)):
|
| 70 |
+
output_dict = {}
|
| 71 |
+
output, reasoning = self.parse_xml_to_dict(llm_string)
|
| 72 |
+
level = int(q.split('####\n')[0])
|
| 73 |
+
q = json.loads(q.split('####\n')[-1])
|
| 74 |
+
q = pd.DataFrame(eval(q))
|
| 75 |
+
threshold = q.iloc[-1, 0] # therashold is the last row
|
| 76 |
+
distance_matrix = q.iloc[:-1].values # distance matrix is the rest of the rows
|
| 77 |
+
output_dict['output'] = output
|
| 78 |
+
try:
|
| 79 |
+
output_dict['correctness'], _ = self.tsp_decision_check(distance_matrix, threshold, output)
|
| 80 |
+
except Exception as e:
|
| 81 |
+
print(f'Check failed: {e}')
|
| 82 |
+
output_dict['correctness'] = False
|
| 83 |
+
output_dict['reasoning'] = reasoning
|
| 84 |
+
output_dict['level'] = level
|
| 85 |
+
if output_dict:
|
| 86 |
+
tsp_d_Results.append(output_dict)
|
| 87 |
+
if output_dict['correctness']:
|
| 88 |
+
r = 'pass'
|
| 89 |
+
else:
|
| 90 |
+
r = 'fail'
|
| 91 |
+
|
| 92 |
+
result[r] += level
|
| 93 |
+
details[str(index)] = {'q': q, 'output': output, 'result': r}
|
| 94 |
+
|
| 95 |
+
result['score'] = result['pass'] / (result['pass'] + result['fail']) * 100
|
| 96 |
+
result['details'] = details
|
| 97 |
+
final_result = {'Weighted Accuracy': result['score']}
|
| 98 |
+
return final_result
|
| 99 |
+
|
| 100 |
+
def parse_xml_to_dict(self, xml_string):
|
| 101 |
+
try:
|
| 102 |
+
assert '<final_answer>' in xml_string
|
| 103 |
+
assert '</final_answer>' in xml_string
|
| 104 |
+
assert '<reasoning>' in xml_string
|
| 105 |
+
assert '</reasoning>' in xml_string
|
| 106 |
+
final_answer_start = xml_string.index('<final_answer>') + len('<final_answer>')
|
| 107 |
+
final_answer_end = xml_string.index('</final_answer>')
|
| 108 |
+
reasoning_start = xml_string.index('<reasoning>') + len('<reasoning>')
|
| 109 |
+
reasoning_end = xml_string.index('</reasoning>')
|
| 110 |
+
final_answer_element = xml_string[final_answer_start:final_answer_end].rstrip().strip().rstrip()
|
| 111 |
+
reasoning_element = xml_string[reasoning_start:reasoning_end].rstrip().strip().rstrip()
|
| 112 |
+
try:
|
| 113 |
+
final_answer_element = ast.literal_eval(final_answer_element)
|
| 114 |
+
except Exception:
|
| 115 |
+
final_answer_element = ''
|
| 116 |
+
except Exception:
|
| 117 |
+
final_answer_element = ''
|
| 118 |
+
reasoning_element = ''
|
| 119 |
+
|
| 120 |
+
return final_answer_element, reasoning_element
|
| 121 |
+
|
| 122 |
+
def tsp_approx(self, distance_matrix):
|
| 123 |
+
"""Returns an approximate solution to the TSP problem.
|
| 124 |
+
|
| 125 |
+
:param distance_matrix: A 2D numpy array representing the distance matrix.
|
| 126 |
+
:return: A list of the cities in the order they were visited.
|
| 127 |
+
"""
|
| 128 |
+
G = nx.from_numpy_array(distance_matrix)
|
| 129 |
+
return nx.approximation.traveling_salesman_problem(G)
|
| 130 |
+
|
| 131 |
+
def tsp_decision_check(self, distance_matrix, threshold, tour):
|
| 132 |
+
"""Checks if a given TSP tour is valid and within the threshold
|
| 133 |
+
distance.
|
| 134 |
+
|
| 135 |
+
:param distance_matrix: A 2D numpy array representing the distance matrix.
|
| 136 |
+
:param threshold: The maximum distance allowed.
|
| 137 |
+
:param tour: A dictionary containing the feasibility.
|
| 138 |
+
"""
|
| 139 |
+
try:
|
| 140 |
+
is_feasible = tour.get('Feasible', 'no').lower() == 'yes'
|
| 141 |
+
except Exception:
|
| 142 |
+
return False, 'Output format incorrect'
|
| 143 |
+
|
| 144 |
+
# Calculate the approxed distance of the tour
|
| 145 |
+
tours = self.tsp_approx(distance_matrix)
|
| 146 |
+
tour_distance = sum(distance_matrix[tours[i], tours[i + 1]] for i in range(len(tours) - 1)) + distance_matrix[tours[-1], tours[0]]
|
| 147 |
+
|
| 148 |
+
if is_feasible != (tour_distance <= threshold):
|
| 149 |
+
return False, f'Feasibility mismatch: {is_feasible} vs {tour_distance} > {threshold}'
|
| 150 |
+
return True, 'Feasible: {} <= {}'.format(tour_distance, threshold)
|
opencompass-my-api/build/lib/opencompass/datasets/NPHardEval/hard_GCP.py
ADDED
|
@@ -0,0 +1,189 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import ast
|
| 2 |
+
import xml.etree.ElementTree as ET
|
| 3 |
+
|
| 4 |
+
from datasets import Dataset
|
| 5 |
+
|
| 6 |
+
from opencompass.openicl.icl_evaluator import BaseEvaluator
|
| 7 |
+
from opencompass.registry import ICL_EVALUATORS, LOAD_DATASET
|
| 8 |
+
|
| 9 |
+
from ..base import BaseDataset
|
| 10 |
+
from .prompts import gcpPrompts
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def q2text(q, p=gcpPrompts): # q is the data for the HP-hard question, p is the prompt
|
| 14 |
+
# print(q)
|
| 15 |
+
chromatic_number = q.split('\n')[0][-1] # last character of the first line
|
| 16 |
+
number_of_vertices = q.split('\n')[1].split(' ')[2] # third word of the second line
|
| 17 |
+
prompt_text = p['Intro'] + '\n' \
|
| 18 |
+
+ p['Initial_question'].format(max_vertices=number_of_vertices,max_colors=chromatic_number) + '\n' \
|
| 19 |
+
+ p['Output_content'] + '\n' \
|
| 20 |
+
+ p['Output_format'] + \
|
| 21 |
+
'\n The graph is below: \n'
|
| 22 |
+
for line in q.split('\n')[2:]:
|
| 23 |
+
vertex_list = line.split(' ')
|
| 24 |
+
this_line = 'Vertex {} is connected to vertex {}.'.format(vertex_list[1], vertex_list[2])
|
| 25 |
+
prompt_text += this_line + '\n'
|
| 26 |
+
|
| 27 |
+
return prompt_text
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
@LOAD_DATASET.register_module(force=True)
|
| 31 |
+
class hard_GCP_Dataset(BaseDataset):
|
| 32 |
+
|
| 33 |
+
@staticmethod
|
| 34 |
+
def load(path: str):
|
| 35 |
+
raw_data = []
|
| 36 |
+
data_path = path
|
| 37 |
+
all_data = []
|
| 38 |
+
for file_num in range(10):
|
| 39 |
+
with open(data_path + 'synthesized_data_GCP_{}.txt'.format(file_num)) as f:
|
| 40 |
+
data = f.read()
|
| 41 |
+
sample = data.split('\n\n')[:-1]
|
| 42 |
+
all_data += zip([file_num + 1] * len(sample), sample)
|
| 43 |
+
for (level, q) in all_data:
|
| 44 |
+
prompt = q2text(q)
|
| 45 |
+
raw_data.append({
|
| 46 |
+
'prompt': prompt,
|
| 47 |
+
'q': str(level) + '####\n' + q,
|
| 48 |
+
'level': level
|
| 49 |
+
})
|
| 50 |
+
dataset = Dataset.from_list(raw_data)
|
| 51 |
+
return dataset
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
@ICL_EVALUATORS.register_module(force=True)
|
| 55 |
+
class hard_GCP_Evaluator(BaseEvaluator):
|
| 56 |
+
|
| 57 |
+
def score(self, predictions, references):
|
| 58 |
+
assert len(predictions) == len(references)
|
| 59 |
+
|
| 60 |
+
result = {'pass': 0, 'fail': 0}
|
| 61 |
+
details = {}
|
| 62 |
+
for index, (q, output) in enumerate(zip(references, predictions)):
|
| 63 |
+
output_dict = {}
|
| 64 |
+
level = int(q.split('####\n')[0])
|
| 65 |
+
q = q.split('####\n')[-1]
|
| 66 |
+
|
| 67 |
+
output_dict['output'] = output
|
| 68 |
+
try:
|
| 69 |
+
output_dict['correctness'] = self.gcpCheck(q, output)
|
| 70 |
+
except Exception as e:
|
| 71 |
+
print(f'Check failed: {e}')
|
| 72 |
+
output_dict['correctness'] = False
|
| 73 |
+
output_dict['level'] = level
|
| 74 |
+
|
| 75 |
+
if output_dict['correctness']:
|
| 76 |
+
r = 'pass'
|
| 77 |
+
else:
|
| 78 |
+
r = 'fail'
|
| 79 |
+
result[r] += level
|
| 80 |
+
details[str(index)] = {'q': q, 'output': output, 'result': r}
|
| 81 |
+
|
| 82 |
+
result['score'] = result['pass'] / (result['pass'] + result['fail']) * 100
|
| 83 |
+
result['details'] = details
|
| 84 |
+
final_result = {'Weighted Accuracy': result['score']}
|
| 85 |
+
return final_result
|
| 86 |
+
|
| 87 |
+
def parse_xml_to_dict(self, xml_string):
|
| 88 |
+
try:
|
| 89 |
+
# Parse the XML string
|
| 90 |
+
root = ET.fromstring(xml_string)
|
| 91 |
+
|
| 92 |
+
# Find the 'final_answer' tag
|
| 93 |
+
final_answer_element = root.find('final_answer')
|
| 94 |
+
|
| 95 |
+
# Find the 'reasoning' tag
|
| 96 |
+
reasoning_element = root.find('reasoning')
|
| 97 |
+
except Exception:
|
| 98 |
+
try:
|
| 99 |
+
assert '<final_answer>' in xml_string
|
| 100 |
+
assert '</final_answer>' in xml_string
|
| 101 |
+
assert '<reasoning>' in xml_string
|
| 102 |
+
assert '</reasoning>' in xml_string
|
| 103 |
+
final_answer_start = xml_string.index('<final_answer>') + len('<final_answer>')
|
| 104 |
+
final_answer_end = xml_string.index('</final_answer>')
|
| 105 |
+
reasoning_start = xml_string.index('<reasoning>') + len('<reasoning>')
|
| 106 |
+
reasoning_end = xml_string.index('</reasoning>')
|
| 107 |
+
final_answer_element = xml_string[final_answer_start:final_answer_end]
|
| 108 |
+
reasoning_element = xml_string[reasoning_start:reasoning_end]
|
| 109 |
+
except Exception:
|
| 110 |
+
final_answer_element = ''
|
| 111 |
+
reasoning_element = ''
|
| 112 |
+
|
| 113 |
+
return final_answer_element, reasoning_element
|
| 114 |
+
|
| 115 |
+
def gcpCheck(self, dimacs_str, answer_str):
|
| 116 |
+
num_vertices, adjacency_list = self.read_dimacs_format(dimacs_str)
|
| 117 |
+
answer_colors = self.parse_answer(answer_str)
|
| 118 |
+
# print(adjacency_list)
|
| 119 |
+
# print(answer_colors)
|
| 120 |
+
|
| 121 |
+
# Check if all colors in the answer are valid
|
| 122 |
+
for vertex, neighbors in adjacency_list.items():
|
| 123 |
+
for neighbor in neighbors:
|
| 124 |
+
try:
|
| 125 |
+
if answer_colors[vertex] == answer_colors[neighbor]:
|
| 126 |
+
print(f'Invalid coloring: Vertex {vertex} and {neighbor} have the same color.')
|
| 127 |
+
return False
|
| 128 |
+
except:
|
| 129 |
+
print(f'Invalid input.') # dealing with hullucination
|
| 130 |
+
return False
|
| 131 |
+
|
| 132 |
+
print(f'Valid coloring found with {len(set(answer_colors.values()))} colors: {answer_colors}')
|
| 133 |
+
return True
|
| 134 |
+
|
| 135 |
+
def read_dimacs_format(self, dimacs_str):
|
| 136 |
+
lines = dimacs_str.strip().split('\n')
|
| 137 |
+
# Read the number of vertices and edges
|
| 138 |
+
p_line = next(line for line in lines if line.startswith('p'))
|
| 139 |
+
_, _, num_vertices, num_edges = p_line.split()
|
| 140 |
+
num_vertices, num_edges = int(num_vertices), int(num_edges)
|
| 141 |
+
|
| 142 |
+
# Create adjacency list
|
| 143 |
+
adjacency_list = {i: set() for i in range(1, num_vertices + 1)}
|
| 144 |
+
|
| 145 |
+
# Read the edges and ignore those that reference non-existing vertices
|
| 146 |
+
for line in lines:
|
| 147 |
+
if line.startswith('e'):
|
| 148 |
+
_, vertex1, vertex2 = line.split()
|
| 149 |
+
vertex1, vertex2 = int(vertex1), int(vertex2)
|
| 150 |
+
if vertex1 in adjacency_list and vertex2 in adjacency_list:
|
| 151 |
+
adjacency_list[vertex1].add(vertex2)
|
| 152 |
+
adjacency_list[vertex2].add(vertex1)
|
| 153 |
+
|
| 154 |
+
return num_vertices, adjacency_list
|
| 155 |
+
|
| 156 |
+
def parse_answer(self, llm_string):
|
| 157 |
+
# # Convert the answer string to a dictionary
|
| 158 |
+
# answer_dict = {}
|
| 159 |
+
# # Remove the braces and split the string by commas
|
| 160 |
+
# entries = answer_str.strip("}{").split(', ')
|
| 161 |
+
# for entry in entries:
|
| 162 |
+
# vertex, color = entry.split(':')
|
| 163 |
+
# answer_dict[int(vertex)] = color
|
| 164 |
+
# return answer_dict
|
| 165 |
+
|
| 166 |
+
all_answers, reasoning_element = self.parse_xml_to_dict(llm_string)
|
| 167 |
+
|
| 168 |
+
if all_answers == '':
|
| 169 |
+
return {}
|
| 170 |
+
elif all_answers is None:
|
| 171 |
+
return {}
|
| 172 |
+
else:
|
| 173 |
+
if isinstance(all_answers, str):
|
| 174 |
+
try:
|
| 175 |
+
all_answers = ast.literal_eval(all_answers)
|
| 176 |
+
except Exception:
|
| 177 |
+
try:
|
| 178 |
+
all_answers = ast.literal_eval('{' + all_answers + '}')
|
| 179 |
+
except Exception:
|
| 180 |
+
return {}
|
| 181 |
+
else:
|
| 182 |
+
all_answers = ast.literal_eval(all_answers.text)
|
| 183 |
+
# answer_dict = {}
|
| 184 |
+
# for pair in all_answers:
|
| 185 |
+
# vertex, color = pair.split(":")
|
| 186 |
+
# answer_dict[int(vertex)] = color
|
| 187 |
+
# convert key type to int
|
| 188 |
+
all_answers = {int(k): v for k, v in all_answers.items()}
|
| 189 |
+
return all_answers # answer_dict
|
opencompass-my-api/build/lib/opencompass/datasets/NPHardEval/hard_MSP.py
ADDED
|
@@ -0,0 +1,203 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import ast
|
| 2 |
+
import json
|
| 3 |
+
import xml.etree.ElementTree as ET
|
| 4 |
+
|
| 5 |
+
from datasets import Dataset
|
| 6 |
+
|
| 7 |
+
from opencompass.openicl.icl_evaluator import BaseEvaluator
|
| 8 |
+
from opencompass.registry import ICL_EVALUATORS, LOAD_DATASET
|
| 9 |
+
|
| 10 |
+
from ..base import BaseDataset
|
| 11 |
+
from .prompts import mspPrompts
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def q2text(q, p=mspPrompts): # q is the data for the HP-hard question, p is the prompt
|
| 15 |
+
total_participants = q['participants']
|
| 16 |
+
total_timeslots = q['time_slots']
|
| 17 |
+
prompt_text = p['Intro'] + '\n' \
|
| 18 |
+
+ p['Initial_question'].format(total_participants=total_participants,total_timeslots=total_timeslots) + '\n' \
|
| 19 |
+
+ p['Output_content'] + '\n' \
|
| 20 |
+
+ p['Output_format'] + \
|
| 21 |
+
'\n The meetings and participants details are as below: \n'
|
| 22 |
+
meetings = q['meetings']
|
| 23 |
+
participants = q['participants']
|
| 24 |
+
for meeting in meetings:
|
| 25 |
+
this_line = 'Meeting {} is with duration {}.'.format(meeting['id'], meeting['duration'])
|
| 26 |
+
prompt_text += this_line + '\n'
|
| 27 |
+
for j in participants.keys():
|
| 28 |
+
this_line = 'Participant {} is available at time slots {} and has meetings {}.'.format(j, participants[j]['available_slots'], participants[j]['meetings'])
|
| 29 |
+
prompt_text += this_line + '\n'
|
| 30 |
+
return prompt_text
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
@LOAD_DATASET.register_module(force=True)
|
| 34 |
+
class hard_MSP_Dataset(BaseDataset):
|
| 35 |
+
|
| 36 |
+
@staticmethod
|
| 37 |
+
def load(path: str):
|
| 38 |
+
raw_data = []
|
| 39 |
+
data_path = path
|
| 40 |
+
all_data = []
|
| 41 |
+
with open(data_path + 'msp_instances.json', 'r') as f:
|
| 42 |
+
data = json.load(f)
|
| 43 |
+
all_data = zip([int(d['complexity_level']) for d in data], data)
|
| 44 |
+
|
| 45 |
+
for (level, q) in all_data:
|
| 46 |
+
prompt = q2text(q)
|
| 47 |
+
raw_data.append({
|
| 48 |
+
'prompt': prompt,
|
| 49 |
+
'q': str(level) + '####\n' + json.dumps(q),
|
| 50 |
+
'level': level
|
| 51 |
+
})
|
| 52 |
+
dataset = Dataset.from_list(raw_data)
|
| 53 |
+
return dataset
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
@ICL_EVALUATORS.register_module(force=True)
|
| 57 |
+
class hard_MSP_Evaluator(BaseEvaluator):
|
| 58 |
+
|
| 59 |
+
def score(self, predictions, references):
|
| 60 |
+
assert len(predictions) == len(references)
|
| 61 |
+
|
| 62 |
+
result = {'pass': 0, 'fail': 0}
|
| 63 |
+
for index, (q, output) in enumerate(zip(references, predictions)):
|
| 64 |
+
output_dict = {}
|
| 65 |
+
level = int(q.split('####\n')[0])
|
| 66 |
+
q = json.loads(q.split('####\n')[-1])
|
| 67 |
+
|
| 68 |
+
output_dict['output'] = output
|
| 69 |
+
output_dict['level'] = level
|
| 70 |
+
try:
|
| 71 |
+
output_dict['correctness'], _ = self.mspCheck(q, output)
|
| 72 |
+
except Exception as e:
|
| 73 |
+
print(f'Check failed: {e}')
|
| 74 |
+
output_dict['correctness'] = False
|
| 75 |
+
|
| 76 |
+
if output_dict['correctness']:
|
| 77 |
+
r = 'pass'
|
| 78 |
+
else:
|
| 79 |
+
r = 'fail'
|
| 80 |
+
result[r] += level
|
| 81 |
+
|
| 82 |
+
result['score'] = result['pass'] / (result['pass'] + result['fail']) * 100
|
| 83 |
+
final_result = {'Weighted Accuracy': result['score']}
|
| 84 |
+
return final_result
|
| 85 |
+
|
| 86 |
+
def mspCheck(self, instance, llm_string):
|
| 87 |
+
"""Validate the MSP solution.
|
| 88 |
+
|
| 89 |
+
Parameters:
|
| 90 |
+
- instance: The MSP instance as a dictionary.
|
| 91 |
+
- solution: A dictionary with meeting ids as keys and lists of scheduled time slots as values.
|
| 92 |
+
|
| 93 |
+
Returns:
|
| 94 |
+
- A tuple (is_valid, message). is_valid is True if the solution is valid, False otherwise.
|
| 95 |
+
message contains information about the validity of the solution.
|
| 96 |
+
"""
|
| 97 |
+
# print(llm_string)
|
| 98 |
+
solution, reasoning_element = self.parse_xml_to_dict(llm_string)
|
| 99 |
+
# print(solution.text)
|
| 100 |
+
|
| 101 |
+
# convert solution to dictionary
|
| 102 |
+
if solution == '':
|
| 103 |
+
return False, None
|
| 104 |
+
elif solution is None:
|
| 105 |
+
return False, None
|
| 106 |
+
else:
|
| 107 |
+
if isinstance(solution, str):
|
| 108 |
+
try:
|
| 109 |
+
solution = ast.literal_eval(solution)
|
| 110 |
+
if solution is None:
|
| 111 |
+
return False, None
|
| 112 |
+
except Exception:
|
| 113 |
+
try:
|
| 114 |
+
solution = ast.literal_eval('{' + solution + '}')
|
| 115 |
+
if solution is None:
|
| 116 |
+
return False, None
|
| 117 |
+
except Exception:
|
| 118 |
+
return False, None
|
| 119 |
+
else:
|
| 120 |
+
try:
|
| 121 |
+
solution = ast.literal_eval(solution.text)
|
| 122 |
+
if solution is None:
|
| 123 |
+
return False, None
|
| 124 |
+
except Exception:
|
| 125 |
+
return False, None
|
| 126 |
+
# convert key type to int
|
| 127 |
+
if isinstance(solution, dict):
|
| 128 |
+
print(solution)
|
| 129 |
+
solution = {int(k): v for k, v in solution.items()}
|
| 130 |
+
else:
|
| 131 |
+
return False, None
|
| 132 |
+
|
| 133 |
+
# Check if all meetings are scheduled within the available time slots
|
| 134 |
+
for meeting in instance['meetings']:
|
| 135 |
+
m_id = meeting['id']
|
| 136 |
+
duration = meeting['duration']
|
| 137 |
+
scheduled_slots = solution.get(m_id, None)
|
| 138 |
+
|
| 139 |
+
# Check if the meeting is scheduled
|
| 140 |
+
if scheduled_slots is None:
|
| 141 |
+
return False, f'Meeting {m_id} is not scheduled.'
|
| 142 |
+
|
| 143 |
+
# Check if the meeting fits within the number of total time slots
|
| 144 |
+
if any(slot >= instance['time_slots'] for slot in scheduled_slots):
|
| 145 |
+
return False, f'Meeting {m_id} does not fit within the available time slots.'
|
| 146 |
+
|
| 147 |
+
# Check if the scheduled slots are contiguous and fit the meeting duration
|
| 148 |
+
if len(scheduled_slots) != duration or not all(scheduled_slots[i] + 1 == scheduled_slots[i + 1]
|
| 149 |
+
for i in range(len(scheduled_slots) - 1)):
|
| 150 |
+
return False, f'Meeting {m_id} is not scheduled in contiguous time slots fitting its duration.'
|
| 151 |
+
|
| 152 |
+
# Check if all participants are available at the scheduled time
|
| 153 |
+
for p_id, participant in instance['participants'].items():
|
| 154 |
+
if m_id in participant['meetings']:
|
| 155 |
+
if not all(slot in participant['available_slots'] for slot in scheduled_slots):
|
| 156 |
+
return False, f'Participant {p_id} is not available for meeting {m_id} at the scheduled time.'
|
| 157 |
+
|
| 158 |
+
# Check if any participant is double-booked
|
| 159 |
+
participants_schedule = {p_id: [] for p_id in instance['participants']}
|
| 160 |
+
for m_id, time_slots in solution.items():
|
| 161 |
+
try:
|
| 162 |
+
duration = next(meeting['duration'] for meeting in instance['meetings'] if meeting['id'] == m_id)
|
| 163 |
+
if len(time_slots) != duration:
|
| 164 |
+
return False, f'Meeting {m_id} duration does not match the number of scheduled time slots.'
|
| 165 |
+
for p_id, participant in instance['participants'].items():
|
| 166 |
+
if m_id in participant['meetings']:
|
| 167 |
+
participants_schedule[p_id].extend(time_slots)
|
| 168 |
+
except Exception:
|
| 169 |
+
return False, f'Meeting {m_id} is not in the instance or program error.'
|
| 170 |
+
|
| 171 |
+
for p_id, slots in participants_schedule.items():
|
| 172 |
+
if len(slots) != len(set(slots)):
|
| 173 |
+
return False, f'Participant {p_id} is double-booked.'
|
| 174 |
+
|
| 175 |
+
return True, 'The solution is valid.'
|
| 176 |
+
|
| 177 |
+
def parse_xml_to_dict(self, xml_string):
|
| 178 |
+
try:
|
| 179 |
+
# Parse the XML string
|
| 180 |
+
root = ET.fromstring(xml_string)
|
| 181 |
+
|
| 182 |
+
# Find the 'final_answer' tag
|
| 183 |
+
final_answer_element = root.find('final_answer')
|
| 184 |
+
|
| 185 |
+
# Find the 'reasoning' tag
|
| 186 |
+
reasoning_element = root.find('reasoning')
|
| 187 |
+
except:
|
| 188 |
+
try:
|
| 189 |
+
assert '<final_answer>' in xml_string
|
| 190 |
+
assert '</final_answer>' in xml_string
|
| 191 |
+
assert '<reasoning>' in xml_string
|
| 192 |
+
assert '</reasoning>' in xml_string
|
| 193 |
+
final_answer_start = xml_string.index('<final_answer>') + len('<final_answer>')
|
| 194 |
+
final_answer_end = xml_string.index('</final_answer>')
|
| 195 |
+
reasoning_start = xml_string.index('<reasoning>') + len('<reasoning>')
|
| 196 |
+
reasoning_end = xml_string.index('</reasoning>')
|
| 197 |
+
final_answer_element = xml_string[final_answer_start:final_answer_end]
|
| 198 |
+
reasoning_element = xml_string[reasoning_start:reasoning_end]
|
| 199 |
+
except:
|
| 200 |
+
final_answer_element = ''
|
| 201 |
+
reasoning_element = ''
|
| 202 |
+
|
| 203 |
+
return final_answer_element, reasoning_element
|
opencompass-my-api/build/lib/opencompass/datasets/NPHardEval/hard_TSP.py
ADDED
|
@@ -0,0 +1,211 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import ast
|
| 2 |
+
import json
|
| 3 |
+
import xml.etree.ElementTree as ET
|
| 4 |
+
|
| 5 |
+
import numpy as np
|
| 6 |
+
import pandas as pd
|
| 7 |
+
from datasets import Dataset
|
| 8 |
+
|
| 9 |
+
from opencompass.openicl.icl_evaluator import BaseEvaluator
|
| 10 |
+
from opencompass.registry import ICL_EVALUATORS, LOAD_DATASET
|
| 11 |
+
|
| 12 |
+
from ..base import BaseDataset
|
| 13 |
+
from .prompts import tspPrompts
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def q2text(q, p=tspPrompts): # q is the data for the HP-hard question, p is the prompt
|
| 17 |
+
total_cities = q.shape[0]
|
| 18 |
+
prompt_text = p['Intro'] + '\n' \
|
| 19 |
+
+ p['Initial_question'].format(total_cities=total_cities) + '\n' \
|
| 20 |
+
+ p['Output_content'] + '\n' \
|
| 21 |
+
+ p['Output_format'] + \
|
| 22 |
+
'\n The distances between cities are below: \n'
|
| 23 |
+
for i in range(q.shape[0]):
|
| 24 |
+
for j in range(q.shape[1]):
|
| 25 |
+
if i < j: # only use the upper triangle
|
| 26 |
+
this_line = 'The path between City {} and City {} is with distance {}.'.format(i, j, q.iloc[i, j])
|
| 27 |
+
prompt_text += this_line + '\n'
|
| 28 |
+
return prompt_text
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
@LOAD_DATASET.register_module(force=True)
|
| 32 |
+
class hard_TSP_Dataset(BaseDataset):
|
| 33 |
+
|
| 34 |
+
@staticmethod
|
| 35 |
+
def load(path: str):
|
| 36 |
+
raw_data = []
|
| 37 |
+
data_path = path
|
| 38 |
+
all_data = []
|
| 39 |
+
for level in range(10):
|
| 40 |
+
for file_num in range(10):
|
| 41 |
+
# read np array
|
| 42 |
+
df = pd.read_csv(data_path + 'synthesized_data_TSP_level_{}_instance_{}.csv'.format(level, file_num + 1),
|
| 43 |
+
header=None,
|
| 44 |
+
index_col=False)
|
| 45 |
+
# transform df to
|
| 46 |
+
all_data.append((level + 1, df))
|
| 47 |
+
for (level, q) in all_data:
|
| 48 |
+
prompt = q2text(q)
|
| 49 |
+
raw_data.append({
|
| 50 |
+
'prompt': prompt,
|
| 51 |
+
'q': str(level) + '####\n' + json.dumps(q.to_json()),
|
| 52 |
+
'level': level
|
| 53 |
+
})
|
| 54 |
+
dataset = Dataset.from_list(raw_data)
|
| 55 |
+
return dataset
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
@ICL_EVALUATORS.register_module(force=True)
|
| 59 |
+
class hard_TSP_Evaluator(BaseEvaluator):
|
| 60 |
+
|
| 61 |
+
def score(self, predictions, references):
|
| 62 |
+
assert len(predictions) == len(references)
|
| 63 |
+
|
| 64 |
+
result = {'pass': 0, 'fail': 0}
|
| 65 |
+
for index, (q, output) in enumerate(zip(references, predictions)):
|
| 66 |
+
output_dict = {}
|
| 67 |
+
level = int(q.split('####\n')[0])
|
| 68 |
+
q = json.loads(q.split('####\n')[-1])
|
| 69 |
+
q = pd.DataFrame(eval(q))
|
| 70 |
+
|
| 71 |
+
output_dict['output'] = output
|
| 72 |
+
try:
|
| 73 |
+
output_dict['correctness'], _ = self.tspCheck(q, output)
|
| 74 |
+
except Exception as e:
|
| 75 |
+
print(f'Check failed: {e}')
|
| 76 |
+
output_dict['correctness'] = False
|
| 77 |
+
output_dict['level'] = level
|
| 78 |
+
|
| 79 |
+
if output_dict['correctness']:
|
| 80 |
+
r = 'pass'
|
| 81 |
+
else:
|
| 82 |
+
r = 'fail'
|
| 83 |
+
result[r] += level
|
| 84 |
+
|
| 85 |
+
result['score'] = result['pass'] / (result['pass'] + result['fail']) * 100
|
| 86 |
+
final_result = {'Weighted Accuracy': result['score']}
|
| 87 |
+
return final_result
|
| 88 |
+
|
| 89 |
+
def parse_xml_to_dict(self, xml_string):
|
| 90 |
+
try:
|
| 91 |
+
# Parse the XML string
|
| 92 |
+
root = ET.fromstring(xml_string)
|
| 93 |
+
|
| 94 |
+
# Find the 'final_answer' tag
|
| 95 |
+
final_answer_element = root.find('final_answer')
|
| 96 |
+
|
| 97 |
+
# Find the 'reasoning' tag
|
| 98 |
+
reasoning_element = root.find('reasoning')
|
| 99 |
+
except:
|
| 100 |
+
try:
|
| 101 |
+
assert '<final_answer>' in xml_string
|
| 102 |
+
assert '</final_answer>' in xml_string
|
| 103 |
+
assert '<reasoning>' in xml_string
|
| 104 |
+
assert '</reasoning>' in xml_string
|
| 105 |
+
final_answer_start = xml_string.index('<final_answer>') + len('<final_answer>')
|
| 106 |
+
final_answer_end = xml_string.index('</final_answer>')
|
| 107 |
+
reasoning_start = xml_string.index('<reasoning>') + len('<reasoning>')
|
| 108 |
+
reasoning_end = xml_string.index('</reasoning>')
|
| 109 |
+
final_answer_element = xml_string[final_answer_start:final_answer_end]
|
| 110 |
+
reasoning_element = xml_string[reasoning_start:reasoning_end]
|
| 111 |
+
except:
|
| 112 |
+
final_answer_element = ''
|
| 113 |
+
reasoning_element = ''
|
| 114 |
+
|
| 115 |
+
return final_answer_element, reasoning_element
|
| 116 |
+
|
| 117 |
+
def tspCheck(self, distance_matrix, llm_string):
|
| 118 |
+
"""Check if the TSP solution is complete and if the distance matches
|
| 119 |
+
the greedy solution.
|
| 120 |
+
|
| 121 |
+
:param tour_string: String representing the TSP tour in the format "0->1->2->...->N->0"
|
| 122 |
+
:param distance_matrix: 2D numpy array representing the distances between cities
|
| 123 |
+
:return: Boolean indicating whether the tour is complete and matches the greedy distance
|
| 124 |
+
"""
|
| 125 |
+
# convert distance_matrix to numpy array
|
| 126 |
+
distance_matrix = np.array(distance_matrix)
|
| 127 |
+
|
| 128 |
+
# Convert the tour string to a list of integers
|
| 129 |
+
# print(llm_string)
|
| 130 |
+
final_answer_element, reasoning_element = self.parse_xml_to_dict(llm_string)
|
| 131 |
+
# convert solution to dictionary
|
| 132 |
+
if final_answer_element == '':
|
| 133 |
+
return False, ''
|
| 134 |
+
elif final_answer_element is None:
|
| 135 |
+
return False, ''
|
| 136 |
+
else:
|
| 137 |
+
if isinstance(final_answer_element, str):
|
| 138 |
+
try:
|
| 139 |
+
tour_string = ast.literal_eval(final_answer_element)['Path']
|
| 140 |
+
if tour_string is None:
|
| 141 |
+
return False, ''
|
| 142 |
+
except Exception:
|
| 143 |
+
try:
|
| 144 |
+
tour_string = ast.literal_eval('{' + final_answer_element + '}')['Path']
|
| 145 |
+
if tour_string is None:
|
| 146 |
+
return False, ''
|
| 147 |
+
except Exception:
|
| 148 |
+
return False, ''
|
| 149 |
+
else:
|
| 150 |
+
try:
|
| 151 |
+
tour_string = ast.literal_eval(final_answer_element.text)['Path']
|
| 152 |
+
if tour_string is None:
|
| 153 |
+
return False, ''
|
| 154 |
+
except Exception:
|
| 155 |
+
return False, ''
|
| 156 |
+
try:
|
| 157 |
+
tour = list(map(int, tour_string.split('->')))
|
| 158 |
+
except Exception:
|
| 159 |
+
return False, ''
|
| 160 |
+
# we could also prinpt `reasoning_element` to see the reasoning of the answer
|
| 161 |
+
# we could also print the final distance of the tour by `final_answer_element['Distance']`
|
| 162 |
+
|
| 163 |
+
# Check if tour is a cycle
|
| 164 |
+
if tour[0] != tour[-1]:
|
| 165 |
+
return False, 'The tour must start and end at the same city.'
|
| 166 |
+
|
| 167 |
+
# Check if all cities are visited
|
| 168 |
+
if len(tour) != len(distance_matrix) + 1:
|
| 169 |
+
return False, 'The tour does not visit all cities exactly once.'
|
| 170 |
+
|
| 171 |
+
# Calculate the distance of the provided tour
|
| 172 |
+
tour_distance = sum(distance_matrix[tour[i]][tour[i + 1]]
|
| 173 |
+
for i in range(len(tour) - 1))
|
| 174 |
+
|
| 175 |
+
# Find the greedy tour distance for comparison
|
| 176 |
+
greedy_tour, greedy_distance = self.greedy_tsp(distance_matrix)
|
| 177 |
+
|
| 178 |
+
# Check if the provided tour distance is equal to the greedy tour distance
|
| 179 |
+
if tour_distance != greedy_distance:
|
| 180 |
+
return False, f'The tour distance ({tour_distance}) does not match the greedy solution ({greedy_distance}).'
|
| 181 |
+
|
| 182 |
+
return True, 'The solution is complete and matches the greedy solution distance.'
|
| 183 |
+
|
| 184 |
+
def greedy_tsp(self, distance_matrix):
|
| 185 |
+
"""Solve the Traveling Salesman Problem using a greedy algorithm.
|
| 186 |
+
|
| 187 |
+
:param distance_matrix: 2D numpy array where the element at [i, j] is the distance between city i and j
|
| 188 |
+
:return: A tuple containing a list of the cities in the order they were visited and the total distance
|
| 189 |
+
"""
|
| 190 |
+
num_cities = distance_matrix.shape[0]
|
| 191 |
+
unvisited_cities = set(range(num_cities))
|
| 192 |
+
current_city = np.random.choice(list(unvisited_cities))
|
| 193 |
+
tour = [current_city]
|
| 194 |
+
total_distance = 0
|
| 195 |
+
|
| 196 |
+
while unvisited_cities:
|
| 197 |
+
unvisited_cities.remove(current_city)
|
| 198 |
+
if unvisited_cities:
|
| 199 |
+
# Find the nearest unvisited city
|
| 200 |
+
distances_to_unvisited = distance_matrix[current_city][list(unvisited_cities)]
|
| 201 |
+
nearest_city = list(unvisited_cities)[np.argmin(distances_to_unvisited)]
|
| 202 |
+
tour.append(nearest_city)
|
| 203 |
+
# Update the total distance
|
| 204 |
+
total_distance += distance_matrix[current_city, nearest_city]
|
| 205 |
+
current_city = nearest_city
|
| 206 |
+
|
| 207 |
+
# Return to start
|
| 208 |
+
total_distance += distance_matrix[current_city, tour[0]]
|
| 209 |
+
tour.append(tour[0])
|
| 210 |
+
|
| 211 |
+
return tour, total_distance
|
opencompass-my-api/build/lib/opencompass/datasets/NPHardEval/p_BSP.py
ADDED
|
@@ -0,0 +1,124 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import ast
|
| 2 |
+
import json
|
| 3 |
+
|
| 4 |
+
from datasets import Dataset
|
| 5 |
+
|
| 6 |
+
from opencompass.openicl.icl_evaluator import BaseEvaluator
|
| 7 |
+
from opencompass.registry import ICL_EVALUATORS, LOAD_DATASET
|
| 8 |
+
|
| 9 |
+
from ..base import BaseDataset
|
| 10 |
+
from .prompts import bspPrompts
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def q2text(q, p=bspPrompts):
|
| 14 |
+
target_value = q['target']
|
| 15 |
+
# TO-DO: fix data not being sorted
|
| 16 |
+
array = sorted(q['array'])
|
| 17 |
+
prompt_text = p['Intro'] + '\n' + \
|
| 18 |
+
p['Initial_question'].format(target_value=target_value) + '\n' + \
|
| 19 |
+
p['Output_content'] + '\n' + \
|
| 20 |
+
p['Output_format'] + \
|
| 21 |
+
'\n The sorted array elements are: ' + ', '.join(map(str, array)) + '\n'
|
| 22 |
+
|
| 23 |
+
return prompt_text
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
@LOAD_DATASET.register_module(force=True)
|
| 27 |
+
class p_BSP_Dataset(BaseDataset):
|
| 28 |
+
|
| 29 |
+
@staticmethod
|
| 30 |
+
def load(path: str):
|
| 31 |
+
raw_data = []
|
| 32 |
+
data_path = path
|
| 33 |
+
all_data, newdata = [], []
|
| 34 |
+
with open(data_path + 'bsp_instances.json', 'r') as f:
|
| 35 |
+
data = json.load(f)
|
| 36 |
+
for sample in data:
|
| 37 |
+
level = len(sample['array']) - 2
|
| 38 |
+
all_data.append((level, sample))
|
| 39 |
+
|
| 40 |
+
for level, q in all_data:
|
| 41 |
+
prompt = q2text(q)
|
| 42 |
+
raw_data.append({
|
| 43 |
+
'prompt': prompt,
|
| 44 |
+
'q': str(level) + '####\n' + json.dumps(q),
|
| 45 |
+
'level': level
|
| 46 |
+
})
|
| 47 |
+
dataset = Dataset.from_list(raw_data)
|
| 48 |
+
return dataset
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
@ICL_EVALUATORS.register_module(force=True)
|
| 52 |
+
class p_BSP_Evaluator(BaseEvaluator):
|
| 53 |
+
|
| 54 |
+
def score(self, predictions, references):
|
| 55 |
+
assert len(predictions) == len(references)
|
| 56 |
+
|
| 57 |
+
result = {'pass': 0, 'fail': 0}
|
| 58 |
+
for index, (q, output) in enumerate(zip(references, predictions)):
|
| 59 |
+
output_dict = {}
|
| 60 |
+
level = int(q.split('####\n')[0])
|
| 61 |
+
q = json.loads(q.split('####\n')[-1])
|
| 62 |
+
output, reasoning = self.parse_xml_to_dict(output)
|
| 63 |
+
output_dict['output'] = output
|
| 64 |
+
try:
|
| 65 |
+
output_dict['correctness'], _ = self.bsp_check(q, output)
|
| 66 |
+
except Exception as e:
|
| 67 |
+
print(f'Check failed: {e}')
|
| 68 |
+
output_dict['correctness'] = False
|
| 69 |
+
output_dict['reasoning'] = reasoning
|
| 70 |
+
output_dict['level'] = level
|
| 71 |
+
|
| 72 |
+
if output_dict['correctness']:
|
| 73 |
+
r = 'pass'
|
| 74 |
+
else:
|
| 75 |
+
r = 'fail'
|
| 76 |
+
result[r] += level
|
| 77 |
+
|
| 78 |
+
result['score'] = result['pass'] / (result['pass'] + result['fail']) * 100
|
| 79 |
+
final_result = {'Weighted Accuracy': result['score']}
|
| 80 |
+
return final_result
|
| 81 |
+
|
| 82 |
+
def parse_xml_to_dict(self, xml_string):
|
| 83 |
+
try:
|
| 84 |
+
assert '<final_answer>' in xml_string
|
| 85 |
+
assert '</final_answer>' in xml_string
|
| 86 |
+
assert '<reasoning>' in xml_string
|
| 87 |
+
assert '</reasoning>' in xml_string
|
| 88 |
+
final_answer_start = xml_string.index('<final_answer>') + len('<final_answer>')
|
| 89 |
+
final_answer_end = xml_string.index('</final_answer>')
|
| 90 |
+
reasoning_start = xml_string.index('<reasoning>') + len('<reasoning>')
|
| 91 |
+
reasoning_end = xml_string.index('</reasoning>')
|
| 92 |
+
final_answer_element = xml_string[final_answer_start:final_answer_end].rstrip().strip().rstrip()
|
| 93 |
+
reasoning_element = xml_string[reasoning_start:reasoning_end].rstrip().strip().rstrip()
|
| 94 |
+
try:
|
| 95 |
+
final_answer_element = ast.literal_eval(final_answer_element)
|
| 96 |
+
except Exception:
|
| 97 |
+
final_answer_element = ''
|
| 98 |
+
except Exception:
|
| 99 |
+
final_answer_element = ''
|
| 100 |
+
reasoning_element = ''
|
| 101 |
+
|
| 102 |
+
return final_answer_element, reasoning_element
|
| 103 |
+
|
| 104 |
+
def bsp_check(self, instance, solution):
|
| 105 |
+
"""Check if the binary search solution is valid.
|
| 106 |
+
|
| 107 |
+
:param instance: The instance dictionary with array and target value.
|
| 108 |
+
:param solution: The solution dictionary with the position of the target value.
|
| 109 |
+
:return: A tuple of (is_correct, message).
|
| 110 |
+
"""
|
| 111 |
+
array = sorted(instance['array'])
|
| 112 |
+
target_value = instance['target']
|
| 113 |
+
solution, reasoning = self.parse_xml_to_dict(solution)
|
| 114 |
+
if isinstance(solution, str):
|
| 115 |
+
return False, f'The solution is invalid.'
|
| 116 |
+
try:
|
| 117 |
+
position = int(solution['Position'])
|
| 118 |
+
except Exception:
|
| 119 |
+
return False, f'The solution is invalid.'
|
| 120 |
+
if position == -1 or position >= len(array):
|
| 121 |
+
return False, f'The solution is invalid.'
|
| 122 |
+
elif array[position] != target_value:
|
| 123 |
+
return False, f'The target index is incorrect.'
|
| 124 |
+
return True, 'The solution is valid.'
|
opencompass-my-api/build/lib/opencompass/datasets/NPHardEval/p_EDP.py
ADDED
|
@@ -0,0 +1,145 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import ast
|
| 2 |
+
import json
|
| 3 |
+
|
| 4 |
+
from datasets import Dataset
|
| 5 |
+
|
| 6 |
+
from opencompass.openicl.icl_evaluator import BaseEvaluator
|
| 7 |
+
from opencompass.registry import ICL_EVALUATORS, LOAD_DATASET
|
| 8 |
+
|
| 9 |
+
from ..base import BaseDataset
|
| 10 |
+
from .prompts import edpPrompts
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def q2text(q, p=edpPrompts):
|
| 14 |
+
string_a = q['string_a']
|
| 15 |
+
string_b = q['string_b']
|
| 16 |
+
prompt_text = p['Intro'] + '\n' + \
|
| 17 |
+
p['Initial_question'].format(string_a=string_a, string_b=string_b) + '\n' + \
|
| 18 |
+
p['Output_content'] + '\n' + \
|
| 19 |
+
p['Output_format']
|
| 20 |
+
return prompt_text
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
@LOAD_DATASET.register_module(force=True)
|
| 24 |
+
class p_EDP_Dataset(BaseDataset):
|
| 25 |
+
|
| 26 |
+
@staticmethod
|
| 27 |
+
def load(path: str):
|
| 28 |
+
raw_data = []
|
| 29 |
+
data_path = path
|
| 30 |
+
all_data = []
|
| 31 |
+
with open(data_path + 'edp_instances.json', 'r') as f:
|
| 32 |
+
data = json.load(f)
|
| 33 |
+
for sample in data:
|
| 34 |
+
level = len(sample['string_a']) - 2
|
| 35 |
+
all_data.append((level, sample))
|
| 36 |
+
|
| 37 |
+
for level, q in all_data:
|
| 38 |
+
prompt = q2text(q)
|
| 39 |
+
raw_data.append({
|
| 40 |
+
'prompt': prompt,
|
| 41 |
+
'q': str(level) + '####\n' + json.dumps(q),
|
| 42 |
+
'level': level
|
| 43 |
+
})
|
| 44 |
+
dataset = Dataset.from_list(raw_data)
|
| 45 |
+
return dataset
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
@ICL_EVALUATORS.register_module(force=True)
|
| 49 |
+
class p_EDP_Evaluator(BaseEvaluator):
|
| 50 |
+
|
| 51 |
+
def score(self, predictions, references):
|
| 52 |
+
assert len(predictions) == len(references)
|
| 53 |
+
|
| 54 |
+
result = {'pass': 0, 'fail': 0}
|
| 55 |
+
for index, (q, output) in enumerate(zip(references, predictions)):
|
| 56 |
+
output_dict = {}
|
| 57 |
+
level = int(q.split('####\n')[0])
|
| 58 |
+
q = json.loads(q.split('####\n')[-1])
|
| 59 |
+
output, reasoning = self.parse_xml_to_dict(output)
|
| 60 |
+
output_dict['output'] = output
|
| 61 |
+
try:
|
| 62 |
+
output_dict['correctness'], _ = self.edp_check(q, output)
|
| 63 |
+
except Exception as e:
|
| 64 |
+
print(f'Check failed: {e}')
|
| 65 |
+
output_dict['correctness'] = False
|
| 66 |
+
output_dict['reasoning'] = reasoning
|
| 67 |
+
output_dict['level'] = level
|
| 68 |
+
|
| 69 |
+
if output_dict['correctness']:
|
| 70 |
+
r = 'pass'
|
| 71 |
+
else:
|
| 72 |
+
r = 'fail'
|
| 73 |
+
result[r] += level
|
| 74 |
+
|
| 75 |
+
result['score'] = result['pass'] / (result['pass'] + result['fail']) * 100
|
| 76 |
+
final_result = {'Weighted Accuracy': result['score']}
|
| 77 |
+
return final_result
|
| 78 |
+
|
| 79 |
+
def compute_min_edit_distance(self, string_a, string_b):
|
| 80 |
+
"""Computes the minimum edit distance between two strings using dynamic
|
| 81 |
+
programming."""
|
| 82 |
+
m, n = len(string_a), len(string_b)
|
| 83 |
+
dp = [[0] * (n + 1) for _ in range(m + 1)]
|
| 84 |
+
|
| 85 |
+
for i in range(m + 1):
|
| 86 |
+
for j in range(n + 1):
|
| 87 |
+
if i == 0:
|
| 88 |
+
dp[i][j] = j
|
| 89 |
+
elif j == 0:
|
| 90 |
+
dp[i][j] = i
|
| 91 |
+
elif string_a[i - 1] == string_b[j - 1]:
|
| 92 |
+
dp[i][j] = dp[i - 1][j - 1]
|
| 93 |
+
else:
|
| 94 |
+
dp[i][j] = 1 + min(dp[i - 1][j], dp[i][j - 1], dp[i - 1][j - 1])
|
| 95 |
+
return dp[m][n]
|
| 96 |
+
|
| 97 |
+
def edp_check(self, instance, solution):
|
| 98 |
+
"""Check if the edit distance solution is valid.
|
| 99 |
+
|
| 100 |
+
:param instance: The instance dictionary with 'string_a' and 'string_b'.
|
| 101 |
+
:param solution: The solution dictionary with the reported 'edit_distance'.
|
| 102 |
+
:return: A tuple of (is_correct, message).
|
| 103 |
+
"""
|
| 104 |
+
string_a = instance['string_a']
|
| 105 |
+
string_b = instance['string_b']
|
| 106 |
+
try:
|
| 107 |
+
reported_distance = int(solution.get('Operations', -1))
|
| 108 |
+
except Exception:
|
| 109 |
+
reported_distance = -1
|
| 110 |
+
|
| 111 |
+
actual_distance = self.compute_min_edit_distance(string_a, string_b)
|
| 112 |
+
|
| 113 |
+
if reported_distance == -1:
|
| 114 |
+
return False, 'No solution provided.'
|
| 115 |
+
elif reported_distance != actual_distance:
|
| 116 |
+
return False, f'The reported edit distance ({reported_distance}) is incorrect. Actual distance: {actual_distance}.'
|
| 117 |
+
return True, 'The solution is valid.'
|
| 118 |
+
|
| 119 |
+
def parse_xml_to_dict(self, xml_string):
|
| 120 |
+
try:
|
| 121 |
+
assert '<final_answer>' in xml_string
|
| 122 |
+
assert '</final_answer>' in xml_string
|
| 123 |
+
# assert '<reasoning>' in xml_string
|
| 124 |
+
# assert '</reasoning>' in xml_string
|
| 125 |
+
final_answer_start = xml_string.index('<final_answer>') + len('<final_answer>')
|
| 126 |
+
final_answer_end = xml_string.index('</final_answer>')
|
| 127 |
+
# reasoning_start = xml_string.index('<reasoning>') + len('<reasoning>')
|
| 128 |
+
# reasoning_end = xml_string.index('</reasoning>')
|
| 129 |
+
final_answer_element = xml_string[final_answer_start:final_answer_end].rstrip().strip().rstrip()
|
| 130 |
+
assert '{' in final_answer_element
|
| 131 |
+
assert '}' in final_answer_element
|
| 132 |
+
dic_start = final_answer_element.index('{')
|
| 133 |
+
dic_end = final_answer_element.index('}')
|
| 134 |
+
final_answer_element = final_answer_element[dic_start:dic_end + 1].rstrip().strip().rstrip()
|
| 135 |
+
reasoning_element = xml_string
|
| 136 |
+
# reasoning_element = xml_string[reasoning_start:reasoning_end].rstrip().strip().rstrip()
|
| 137 |
+
try:
|
| 138 |
+
final_answer_element = ast.literal_eval(final_answer_element)
|
| 139 |
+
except Exception:
|
| 140 |
+
final_answer_element = ''
|
| 141 |
+
except Exception:
|
| 142 |
+
final_answer_element = ''
|
| 143 |
+
reasoning_element = ''
|
| 144 |
+
|
| 145 |
+
return final_answer_element, reasoning_element
|
opencompass-my-api/build/lib/opencompass/datasets/NPHardEval/p_SPP.py
ADDED
|
@@ -0,0 +1,196 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import ast
|
| 2 |
+
import json
|
| 3 |
+
|
| 4 |
+
import networkx as nx
|
| 5 |
+
from datasets import Dataset
|
| 6 |
+
|
| 7 |
+
from opencompass.openicl.icl_evaluator import BaseEvaluator
|
| 8 |
+
from opencompass.registry import ICL_EVALUATORS, LOAD_DATASET
|
| 9 |
+
|
| 10 |
+
from ..base import BaseDataset
|
| 11 |
+
from .prompts import sppPrompts
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def q2text(q, p=sppPrompts):
|
| 15 |
+
# start_node = q['start_node']
|
| 16 |
+
# end_node = q['end_node']
|
| 17 |
+
# TO-DO: fix later
|
| 18 |
+
start_node = q['nodes'][0]
|
| 19 |
+
end_node = q['nodes'][-1]
|
| 20 |
+
edges = q['edges']
|
| 21 |
+
prompt_text = p['Intro'] + '\n' + \
|
| 22 |
+
p['Initial_question'].format(start_node=start_node, end_node=end_node) + '\n' + \
|
| 23 |
+
p['Output_content'] + '\n' + \
|
| 24 |
+
p['Output_format'] + \
|
| 25 |
+
"\n The graph's edges and weights are as follows: \n"
|
| 26 |
+
for edge in edges:
|
| 27 |
+
this_line = f"Edge from {edge['from']} to {edge['to']} has a weight of {edge['weight']}."
|
| 28 |
+
prompt_text += this_line + '\n'
|
| 29 |
+
return prompt_text
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
@LOAD_DATASET.register_module(force=True)
|
| 33 |
+
class p_SPP_Dataset(BaseDataset):
|
| 34 |
+
|
| 35 |
+
@staticmethod
|
| 36 |
+
def load(path: str):
|
| 37 |
+
raw_data = []
|
| 38 |
+
data_path = path
|
| 39 |
+
all_data = []
|
| 40 |
+
with open(data_path + 'spp_instances.json', 'r') as f:
|
| 41 |
+
data = json.load(f)
|
| 42 |
+
all_data = zip([int(d['complexity_level']) for d in data], data)
|
| 43 |
+
for level, q in all_data:
|
| 44 |
+
prompt = q2text(q)
|
| 45 |
+
raw_data.append({
|
| 46 |
+
'prompt': prompt,
|
| 47 |
+
'q': str(level) + '####\n' + json.dumps(q),
|
| 48 |
+
'level': level
|
| 49 |
+
})
|
| 50 |
+
dataset = Dataset.from_list(raw_data)
|
| 51 |
+
return dataset
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
@ICL_EVALUATORS.register_module(force=True)
|
| 55 |
+
class p_SPP_Evaluator(BaseEvaluator):
|
| 56 |
+
|
| 57 |
+
def score(self, predictions, references):
|
| 58 |
+
assert len(predictions) == len(references)
|
| 59 |
+
|
| 60 |
+
result = {'pass': 0, 'fail': 0}
|
| 61 |
+
for index, (q, output) in enumerate(zip(references, predictions)):
|
| 62 |
+
output_dict = {}
|
| 63 |
+
level = int(q.split('####\n')[0])
|
| 64 |
+
q = json.loads(q.split('####\n')[-1])
|
| 65 |
+
output, reasoning = self.parse_xml_to_dict(output)
|
| 66 |
+
output_dict['output'] = output
|
| 67 |
+
try:
|
| 68 |
+
output_dict['correctness'], _ = self.spp_check(q, output)
|
| 69 |
+
except Exception as e:
|
| 70 |
+
print(f'Check failed: {e}')
|
| 71 |
+
output_dict['correctness'] = False
|
| 72 |
+
output_dict['reasoning'] = reasoning
|
| 73 |
+
output_dict['level'] = level
|
| 74 |
+
|
| 75 |
+
if output_dict['correctness']:
|
| 76 |
+
r = 'pass'
|
| 77 |
+
else:
|
| 78 |
+
r = 'fail'
|
| 79 |
+
result[r] += level
|
| 80 |
+
|
| 81 |
+
result['score'] = result['pass'] / (result['pass'] + result['fail']) * 100
|
| 82 |
+
final_result = {'Weighted Accuracy': result['score']}
|
| 83 |
+
return final_result
|
| 84 |
+
|
| 85 |
+
def parse_xml_to_dict(self, xml_string):
|
| 86 |
+
try:
|
| 87 |
+
assert '<final_answer>' in xml_string
|
| 88 |
+
assert '</final_answer>' in xml_string
|
| 89 |
+
# assert '<reasoning>' in xml_string
|
| 90 |
+
# assert '</reasoning>' in xml_string
|
| 91 |
+
final_answer_start = xml_string.index('<final_answer>') + len('<final_answer>')
|
| 92 |
+
final_answer_end = xml_string.index('</final_answer>')
|
| 93 |
+
# reasoning_start = xml_string.index('<reasoning>') + len('<reasoning>')
|
| 94 |
+
# reasoning_end = xml_string.index('</reasoning>')
|
| 95 |
+
final_answer_element = xml_string[final_answer_start:final_answer_end].rstrip().strip().rstrip()
|
| 96 |
+
assert '{' in final_answer_element
|
| 97 |
+
assert '}' in final_answer_element
|
| 98 |
+
dic_start = final_answer_element.index('{')
|
| 99 |
+
dic_end = final_answer_element.index('}')
|
| 100 |
+
final_answer_element = final_answer_element[dic_start:dic_end + 1].rstrip().strip().rstrip()
|
| 101 |
+
# reasoning_element = xml_string[reasoning_start:reasoning_end].rstrip().strip().rstrip()
|
| 102 |
+
try:
|
| 103 |
+
final_answer_element = ast.literal_eval(final_answer_element)
|
| 104 |
+
reasoning_element = xml_string
|
| 105 |
+
except Exception:
|
| 106 |
+
final_answer_element = ''
|
| 107 |
+
reasoning_element = xml_string
|
| 108 |
+
except Exception:
|
| 109 |
+
final_answer_element = ''
|
| 110 |
+
reasoning_element = ''
|
| 111 |
+
|
| 112 |
+
return final_answer_element, reasoning_element
|
| 113 |
+
|
| 114 |
+
def ssp_optimal_solution(self, instance, source, target):
|
| 115 |
+
"""Provides the optimal solution for the SSP instance.
|
| 116 |
+
|
| 117 |
+
:param instance: The SSP instance as a dictionary with 'nodes' and 'edges'.
|
| 118 |
+
:param source: The source node.
|
| 119 |
+
:param target: The destination node.
|
| 120 |
+
:return: The optimal shortest path length and path.
|
| 121 |
+
"""
|
| 122 |
+
G = nx.Graph()
|
| 123 |
+
G.add_nodes_from(instance['nodes'])
|
| 124 |
+
G.add_weighted_edges_from([(edge['from'], edge['to'], edge['weight'])
|
| 125 |
+
for edge in instance['edges']])
|
| 126 |
+
shortest_path_length = None
|
| 127 |
+
shortest_path = None
|
| 128 |
+
if nx.has_path(G, source=source, target=target):
|
| 129 |
+
shortest_path_length = nx.shortest_path_length(G, source=source, target=target, weight='weight')
|
| 130 |
+
shortest_path = nx.shortest_path(G, source=source, target=target, weight='weight')
|
| 131 |
+
return shortest_path_length, shortest_path
|
| 132 |
+
|
| 133 |
+
# SPP
|
| 134 |
+
def spp_check(self, instance, solution, start_node=None, end_node=None):
|
| 135 |
+
"""Validate the solution of the SPP problem.
|
| 136 |
+
|
| 137 |
+
:param instance: The instance dictionary with nodes and edges.
|
| 138 |
+
:param solution: The solution dictionary with the path and total distance.
|
| 139 |
+
:param start_node: The start node.
|
| 140 |
+
:param end_node: The end node.
|
| 141 |
+
:return: A tuple of (is_correct, message).
|
| 142 |
+
"""
|
| 143 |
+
# Get the start and end nodes
|
| 144 |
+
# Currently, the start and end nodes are the first and last nodes in the instance
|
| 145 |
+
if start_node is None:
|
| 146 |
+
start_node = instance['nodes'][0]
|
| 147 |
+
if end_node is None:
|
| 148 |
+
end_node = instance['nodes'][-1]
|
| 149 |
+
|
| 150 |
+
# Convert solution to dictionary
|
| 151 |
+
try:
|
| 152 |
+
path_string = solution.get('Path', '')
|
| 153 |
+
cost_string = solution.get('TotalDistance', '')
|
| 154 |
+
except Exception:
|
| 155 |
+
return False, 'The solution is not a dictionary.'
|
| 156 |
+
|
| 157 |
+
# Calculate the optimal solution
|
| 158 |
+
ssp_optimal_length, ssp_optimal_path = self.ssp_optimal_solution(
|
| 159 |
+
instance, start_node, end_node)
|
| 160 |
+
if ssp_optimal_length is None:
|
| 161 |
+
if isinstance(cost_string, int) or cost_string.isdigit():
|
| 162 |
+
return False, f'No path between from node {start_node} to node {end_node}.'
|
| 163 |
+
else:
|
| 164 |
+
return True, 'No path found from node {start_node} to node {end_node}.'
|
| 165 |
+
|
| 166 |
+
try:
|
| 167 |
+
path = list(map(int, path_string.split('->')))
|
| 168 |
+
total_cost = int(cost_string)
|
| 169 |
+
except Exception:
|
| 170 |
+
return False, 'The solution is not a valid dictionary.'
|
| 171 |
+
|
| 172 |
+
# Check if path starts and ends with the correct nodes
|
| 173 |
+
if not path or path[0] != start_node or path[-1] != end_node:
|
| 174 |
+
return False, 'The path does not start or end at the correct nodes.'
|
| 175 |
+
|
| 176 |
+
# Check if the path is continuous and calculate the cost
|
| 177 |
+
calculated_cost = 0
|
| 178 |
+
is_in_edge = lambda edge, from_node, to_node: (edge['from'] == from_node and edge['to'] == to_node) or (edge['from'] == to_node and edge['to'] == from_node)
|
| 179 |
+
for i in range(len(path) - 1):
|
| 180 |
+
from_node, to_node = path[i], path[i + 1]
|
| 181 |
+
edge = next((edge for edge in instance['edges'] if is_in_edge(edge, from_node, to_node)), None)
|
| 182 |
+
|
| 183 |
+
if not edge:
|
| 184 |
+
return False, f'No edge found from node {from_node} to node {to_node}.'
|
| 185 |
+
|
| 186 |
+
calculated_cost += edge['weight']
|
| 187 |
+
|
| 188 |
+
# Check if the calculated cost matches the total cost provided in the solution
|
| 189 |
+
if calculated_cost != total_cost:
|
| 190 |
+
return False, f'The calculated cost ({calculated_cost}) does not match the provided total cost ({total_cost}).'
|
| 191 |
+
|
| 192 |
+
if calculated_cost != ssp_optimal_length:
|
| 193 |
+
# spp_optimal_path = '->'.join(map(str, ssp_optimal_path))
|
| 194 |
+
return False, f'The calculated cost ({calculated_cost}) does not match the optimal solution ({ssp_optimal_length}): {ssp_optimal_path}.'
|
| 195 |
+
|
| 196 |
+
return True, 'The solution is valid.'
|
opencompass-my-api/build/lib/opencompass/datasets/NPHardEval/prompts.py
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Overall fewshot prompts
|
| 2 |
+
FEW_SHOT_SELF = 'Please refer to a few examples of this problem and the corresponding reasoning process. The examples are:'
|
| 3 |
+
FEW_SHOT_OTHERS = 'Please refer to a few examples of another problem and the corresponding reasoning process. The problem is {initial_question}. {output_content}. The examples are:'
|
| 4 |
+
|
| 5 |
+
# P problems
|
| 6 |
+
sppPrompts = {
|
| 7 |
+
'Intro': 'The Shortest Path Problem (SPP) involves finding the shortest path between two nodes in a weighted graph.',
|
| 8 |
+
'Initial_question': "You need to find the shortest path between node {start_node} and node {end_node} in a graph. The graph's edges and their weights are given.",
|
| 9 |
+
'Output_content': 'Please provide the shortest path from {start_node} to {end_node} and its total distance. Offer a concise step-by-step explanation of your reasoning process. Aim for brevity and clarity in your response.',
|
| 10 |
+
'Output_format': "Your output should be enclosed within <root></root> tags. Include your reasoning in <reasoning></reasoning> tags and the final path and total distance in <final_answer></final_answer> tags, like <final_answer>{'Path': 'START->...->END', 'TotalDistance': 'INT_TOTAL_DISTANCE'}</final_answer>.",
|
| 11 |
+
'Few_shot_self': FEW_SHOT_SELF,
|
| 12 |
+
'Few_shot_others': FEW_SHOT_OTHERS
|
| 13 |
+
}
|
| 14 |
+
|
| 15 |
+
mfpPrompts = {
|
| 16 |
+
'Intro': 'The Maximum Flow Problem (MFP) seeks to find the maximum possible flow from a source node to a sink node in a flow network, subject to capacity constraints on the edges.',
|
| 17 |
+
'Initial_question': 'Determine the maximum flow from the source node {source_node} to the sink node {sink_node} in the given flow network. The capacities of the edges are provided.',
|
| 18 |
+
'Output_content': 'Please indicate the maximum flow value and the flow for each edge. Provide a brief explanation of your methodology. Keep your response concise and focused.',
|
| 19 |
+
'Output_format': "Enclose your output within <root></root> tags. Present your reasoning in <reasoning></reasoning> tags and the final maximum flow and edge flows in <final_answer></final_answer> tags, like <final_answer>{'MaxFlow': 'MAX_FLOW_VALUE', 'Flows': {'NODE_1->NODE_2': FLOW, ...}}</final_answer>.",
|
| 20 |
+
'Few_shot_self': FEW_SHOT_SELF,
|
| 21 |
+
'Few_shot_others': FEW_SHOT_OTHERS
|
| 22 |
+
}
|
| 23 |
+
|
| 24 |
+
bspPrompts = {
|
| 25 |
+
'Intro': 'The Binary Search Problem (BSP) deals with finding the position of a target value within a sorted array using a binary search algorithm, which efficiently narrows down the search range.',
|
| 26 |
+
'Initial_question': 'Find the position of the target value {target_value} in the sorted array. The index begins with 0. The array elements are provided.',
|
| 27 |
+
'Output_content': 'Please identify the position of the target value in the array. Offer a brief, step-by-step account of your search process. Aim for conciseness in your response.',
|
| 28 |
+
'Output_format': "Your output should be enclosed in <root></root> tags. Include your search process in <reasoning></reasoning> tags and the final position of the target value in <final_answer></final_answer> tags, like <final_answer>{'Position': 'TARGET_POSITION'}</final_answer>.",
|
| 29 |
+
'Few_shot_self': FEW_SHOT_SELF,
|
| 30 |
+
'Few_shot_others': FEW_SHOT_OTHERS
|
| 31 |
+
}
|
| 32 |
+
|
| 33 |
+
edpPrompts = {
|
| 34 |
+
'Intro': 'The Edit Distance Problem (EDP) involves finding the minimum number of operations required to transform one string into another, where each operation is either an insertion, deletion, or substitution of a single character.',
|
| 35 |
+
'Initial_question': 'Find the minimum number of operations required to transform the first string {string_a} into the second string {string_b}. The operations are insertion, deletion, and substitution of a single character, each requiring 1 edit operation.',
|
| 36 |
+
'Output_content': 'Please provide the minimum number of operations required to transform the first string into the second string. Offer a brief explanation of your methodology. Keep your response concise and focused.',
|
| 37 |
+
'Output_format': "Enclose your output within <root></root> tags. Present your reasoning in <reasoning></reasoning> tags and the final minimum number of operations in <final_answer></final_answer> tags, like <final_answer>{'Operations': 'MINIMUM_NUMBER_OF_OPERATIONS'}</final_answer>.",
|
| 38 |
+
'Few_shot_self': FEW_SHOT_SELF,
|
| 39 |
+
'Few_shot_others': FEW_SHOT_OTHERS
|
| 40 |
+
}
|
| 41 |
+
|
| 42 |
+
# NP-complete problems
|
| 43 |
+
tsp_dPrompts = {
|
| 44 |
+
'Intro': 'The Traveling Salesman Problem (Decision Version, TSP-D) focuses on determining if a salesman can complete a route, visiting each city at least once, with the total travel distance being less than a specified value.',
|
| 45 |
+
'Initial_question': "Check if it's possible for a salesman to visit each of the {total_cities} cities at least once and return to the starting city with the total distance less than {distance_limit}. The distances between each pair of cities are given.",
|
| 46 |
+
'Output_content': 'Provide a yes or no answer, with a succinct explanation of your decision process. Focus on clarity and brevity in your response.',
|
| 47 |
+
'Output_format': "Enclose your output in <root></root> tags. Present your reasoning in <reasoning></reasoning> tags and the final yes/no answer in <final_answer></final_answer> tags, like <final_answer>{'Feasible': 'YES_OR_NO'}</final_answer>.",
|
| 48 |
+
'Few_shot_self': FEW_SHOT_SELF,
|
| 49 |
+
'Few_shot_others': FEW_SHOT_OTHERS
|
| 50 |
+
}
|
| 51 |
+
|
| 52 |
+
gcp_dPrompts = {
|
| 53 |
+
'Intro': 'The Graph Coloring Problem (Decision Version, GCP-D) involves determining if it is possible to color the vertices of a graph using a given number of colors, ensuring no two adjacent vertices have the same color.',
|
| 54 |
+
'Initial_question': 'Find out if the vertices of a graph with {total_vertices} vertices can be colored using only {number_of_colors} colors, such that no adjacent vertices share the same color.',
|
| 55 |
+
'Output_content': 'Provide a yes or no answer, along with a concise explanation of your reasoning. Keep your explanation focused and brief.',
|
| 56 |
+
'Output_format': "Enclose your output in <root></root> tags. Include your reasoning in <reasoning></reasoning> tags and the final yes/no answer in <final_answer></final_answer> tags, like <final_answer>{'Feasible': 'YES_OR_NO'}</final_answer>.",
|
| 57 |
+
'Few_shot_self': FEW_SHOT_SELF,
|
| 58 |
+
'Few_shot_others': FEW_SHOT_OTHERS
|
| 59 |
+
}
|
| 60 |
+
|
| 61 |
+
kspPrompts = {
|
| 62 |
+
'Intro': 'The 0-1 Knapsack Problem (KSP) asks whether a subset of items, each with a given weight and value, can be chosen to fit into a knapsack of fixed capacity, maximizing the total value without exceeding the capacity.',
|
| 63 |
+
'Initial_question': 'Determine if a subset of items can be selected to fit into a knapsack with a capacity of {knapsack_capacity}, maximizing value without exceeding the capacity. Item weights and values are provided.',
|
| 64 |
+
'Output_content': 'Indicate if an optimal subset exists and its total value. Offer a concise explanation of your selection process. Aim for clarity and brevity in your response.',
|
| 65 |
+
'Output_format': "Your output should be enclosed within <root></root> tags. Include your selection process in <reasoning></reasoning> tags and the final decision and total value in <final_answer></final_answer> tags, like <final_answer>{'Feasible': 'YES_OR_NO', 'TotalValue': 'TOTAL_VALUE', 'SelectedItemIds': [0, 1]}</final_answer>.",
|
| 66 |
+
'Few_shot_self': FEW_SHOT_SELF,
|
| 67 |
+
'Few_shot_others': FEW_SHOT_OTHERS
|
| 68 |
+
}
|
| 69 |
+
|
| 70 |
+
# NP-hard problems
|
| 71 |
+
tspPrompts = {
|
| 72 |
+
'Intro': 'The traveling salesman problem (TSP) is a classic optimization problem that aims to find the shortest possible route that visits a set of cities, with each city being visited exactly once and the route returning to the original city.',
|
| 73 |
+
'Initial_question': 'You must find the shortest path that visits all {total_cities} cities, labelled from 1 to {total_cities}. The distances between each pair of cities are provided.',
|
| 74 |
+
'Output_content': 'Please list each city in the order they are visited. Provide the total distance of the trip. You should also provide very short step by step reasoning. Do not use multiple lines and try your best to save output tokens.',
|
| 75 |
+
'Output_format': "Your output should contain two parts enclosed by <root></root>. First, your step by step reasoning like <reasoning>The reasoning process</reasoning>. Second, the final output of the result path and total distance wrapped by final_answer tag, like <final_answer>{'Path': '0->1->2->...->N->0', 'TotalDistance': 'INT_TOTAL_DISTANCE'}</final_answer>",
|
| 76 |
+
'Few_shot_self': FEW_SHOT_SELF,
|
| 77 |
+
'Few_shot_others': FEW_SHOT_OTHERS
|
| 78 |
+
}
|
| 79 |
+
|
| 80 |
+
gcpPrompts = {
|
| 81 |
+
'Intro': 'Graph coloring refers to the problem of coloring vertices of a graph in such a way that no two adjacent vertices have the same color. ',
|
| 82 |
+
'Initial_question': 'There are {max_vertices} vertices 1 to {max_vertices} in a graph. You may use {max_colors} colors with alphabats from A, B, C,... to color the graph.',
|
| 83 |
+
'Output_content': "Please label every vertex, even if it is disconnected from the rest of the graph. Please provide each vertex's color. Do not skip any vertices. You should also provide very short step by step reasoning. Do not use multiple lines and try your best to save output tokens.",
|
| 84 |
+
'Output_format': "Your output should contain two parts enclosed by <root></root>. First, your step by step reasoning wrapped by <reasoning></reasoning>. Second, the final output of all vertex numbers and their associated colors, wrapped by final_answer tag, like <final_answer>{0:'COLOR_1', 1:'COLOR_2', ...}</final_answer>.",
|
| 85 |
+
'Few_shot_self': FEW_SHOT_SELF,
|
| 86 |
+
'Few_shot_others': FEW_SHOT_OTHERS
|
| 87 |
+
}
|
| 88 |
+
|
| 89 |
+
mspPrompts = {
|
| 90 |
+
'Intro': 'The meeting scheduling problem (MSP) is a type of constraint satisfaction problem where the goal is to find a suitable time slot for a meeting that all participants can attend without conflicts in their schedules.',
|
| 91 |
+
'Initial_question': "There are {total_participants} participants with their available time slots. There are {total_timeslots} consecutive non-overlapping time slots. Let's assume all meetings has duration of 1.",
|
| 92 |
+
'Output_content': 'Please provide a time slot where all participants can attend the meeting. You should also provide very short step by step reasoning. Do not use multiple lines and try your best to save output tokens.',
|
| 93 |
+
'Output_format': 'Your output should contain two parts enclosed by <root></root>. First, your step by step reasoning wrapped by <reasoning></reasoning>. Second, the final output of meeting numbers followed by a list of slots, like <final_answer>{0:[1,2], 1:[4], ...}</final_answer>.',
|
| 94 |
+
'Few_shot_self': FEW_SHOT_SELF,
|
| 95 |
+
'Few_shot_others': FEW_SHOT_OTHERS
|
| 96 |
+
}
|
opencompass-my-api/build/lib/opencompass/datasets/NPHardEval/utils.py
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import ast
|
| 2 |
+
import xml.etree.ElementTree as ET
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def append_root_tags(string):
|
| 6 |
+
if not string.strip().startswith('<root>'):
|
| 7 |
+
string = '<root>\n' + string
|
| 8 |
+
if not string.strip().endswith('</root>'):
|
| 9 |
+
string += '\n</root>'
|
| 10 |
+
return string
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def parse_xml_to_dict(xml_string):
|
| 14 |
+
final_answer_element = ''
|
| 15 |
+
reasoning_element = ''
|
| 16 |
+
|
| 17 |
+
try:
|
| 18 |
+
# Parse the XML string
|
| 19 |
+
root = ET.fromstring(xml_string)
|
| 20 |
+
|
| 21 |
+
# Find the 'final_answer' tag
|
| 22 |
+
final_answer_element = root.find('final_answer').text
|
| 23 |
+
|
| 24 |
+
# Find the 'reasoning' tag
|
| 25 |
+
reasoning_element = root.find('reasoning').text
|
| 26 |
+
except Exception:
|
| 27 |
+
try:
|
| 28 |
+
assert '<final_answer>' in xml_string
|
| 29 |
+
assert '</final_answer>' in xml_string
|
| 30 |
+
assert '<reasoning>' in xml_string
|
| 31 |
+
assert '</reasoning>' in xml_string
|
| 32 |
+
final_answer_start = xml_string.index('<final_answer>') + len('<final_answer>')
|
| 33 |
+
final_answer_end = xml_string.index('</final_answer>')
|
| 34 |
+
reasoning_start = xml_string.index('<reasoning>') + len('<reasoning>')
|
| 35 |
+
reasoning_end = xml_string.index('</reasoning>')
|
| 36 |
+
final_answer_element = xml_string[final_answer_start:final_answer_end]
|
| 37 |
+
reasoning_element = xml_string[reasoning_start:reasoning_end]
|
| 38 |
+
except Exception:
|
| 39 |
+
final_answer_element = ''
|
| 40 |
+
reasoning_element = ''
|
| 41 |
+
|
| 42 |
+
final_answer_element = ast.literal_eval(final_answer_element.strip())
|
| 43 |
+
return final_answer_element, reasoning_element
|
opencompass-my-api/build/lib/opencompass/datasets/OpenFinData.py
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import os.path as osp
|
| 3 |
+
|
| 4 |
+
from datasets import Dataset
|
| 5 |
+
|
| 6 |
+
from opencompass.openicl.icl_evaluator import BaseEvaluator
|
| 7 |
+
from opencompass.registry import ICL_EVALUATORS, LOAD_DATASET
|
| 8 |
+
|
| 9 |
+
from .base import BaseDataset
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
@LOAD_DATASET.register_module()
|
| 13 |
+
class OpenFinDataDataset(BaseDataset):
|
| 14 |
+
|
| 15 |
+
@staticmethod
|
| 16 |
+
def load(path: str, name: str):
|
| 17 |
+
with open(osp.join(path, f'{name}.json'), 'r') as f:
|
| 18 |
+
data = json.load(f)
|
| 19 |
+
return Dataset.from_list(data)
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
@ICL_EVALUATORS.register_module()
|
| 23 |
+
class OpenFinDataKWEvaluator(BaseEvaluator):
|
| 24 |
+
|
| 25 |
+
def __init__(self, ):
|
| 26 |
+
super().__init__()
|
| 27 |
+
|
| 28 |
+
def score(self, predictions, references):
|
| 29 |
+
assert len(predictions) == len(references)
|
| 30 |
+
|
| 31 |
+
scores = []
|
| 32 |
+
results = dict()
|
| 33 |
+
|
| 34 |
+
for i in range(len(references)):
|
| 35 |
+
all_hit = True
|
| 36 |
+
judgement = references[i].split('、')
|
| 37 |
+
for item in judgement:
|
| 38 |
+
if item not in predictions[i]:
|
| 39 |
+
all_hit = False
|
| 40 |
+
break
|
| 41 |
+
if all_hit:
|
| 42 |
+
scores.append(True)
|
| 43 |
+
else:
|
| 44 |
+
scores.append(False)
|
| 45 |
+
|
| 46 |
+
results['accuracy'] = round(sum(scores) / len(scores), 4) * 100
|
| 47 |
+
return results
|
opencompass-my-api/build/lib/opencompass/datasets/TheoremQA.py
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
|
| 3 |
+
from datasets import load_dataset
|
| 4 |
+
|
| 5 |
+
from opencompass.registry import LOAD_DATASET, TEXT_POSTPROCESSORS
|
| 6 |
+
|
| 7 |
+
from .base import BaseDataset
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
@LOAD_DATASET.register_module()
|
| 11 |
+
class TheoremQADataset(BaseDataset):
|
| 12 |
+
|
| 13 |
+
@staticmethod
|
| 14 |
+
def load(path: str):
|
| 15 |
+
return load_dataset('csv', data_files={'test': path})
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
@TEXT_POSTPROCESSORS.register_module('TheoremQA')
|
| 19 |
+
def TheoremQA_postprocess(text: str) -> str:
|
| 20 |
+
text = text.strip()
|
| 21 |
+
matches = re.findall(r'answer is ([^\s]+)', text)
|
| 22 |
+
if len(matches) == 0:
|
| 23 |
+
return text
|
| 24 |
+
else:
|
| 25 |
+
text = matches[0].strip().strip('.,?!\"\';:')
|
| 26 |
+
return text
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def TheoremQA_postprocess_v2(text: str) -> str:
|
| 30 |
+
prediction = text.strip().strip('\n').split('\n')[-1]
|
| 31 |
+
tmp = ''
|
| 32 |
+
for entry in prediction.split(' ')[::-1]:
|
| 33 |
+
if entry == 'is' or entry == 'be' or entry == 'are' or entry.endswith(
|
| 34 |
+
':'):
|
| 35 |
+
break
|
| 36 |
+
tmp = entry + ' ' + tmp
|
| 37 |
+
prediction = tmp.strip().strip('.')
|
| 38 |
+
return prediction
|
opencompass-my-api/build/lib/opencompass/datasets/advglue.py
ADDED
|
@@ -0,0 +1,174 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
from typing import List, Union
|
| 3 |
+
|
| 4 |
+
from datasets import Dataset, concatenate_datasets
|
| 5 |
+
|
| 6 |
+
from opencompass.openicl.icl_evaluator import AccEvaluator
|
| 7 |
+
|
| 8 |
+
from .base import BaseDataset
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class AdvDataset(BaseDataset):
|
| 12 |
+
"""Base adv GLUE dataset. Adv GLUE is built on GLUE dataset. The main
|
| 13 |
+
purpose is to eval the accuracy drop on original set and adv set.
|
| 14 |
+
|
| 15 |
+
Args:
|
| 16 |
+
subset (str): The subset task of adv GLUE dataset.
|
| 17 |
+
filter_keys (str): The keys to be filtered to create the original
|
| 18 |
+
set for comparison.
|
| 19 |
+
"""
|
| 20 |
+
|
| 21 |
+
def __init__(
|
| 22 |
+
self,
|
| 23 |
+
subset: str,
|
| 24 |
+
filter_keys: Union[str, List[str]],
|
| 25 |
+
**kwargs,
|
| 26 |
+
):
|
| 27 |
+
self.subset = subset
|
| 28 |
+
if isinstance(filter_keys, str):
|
| 29 |
+
filter_keys = [filter_keys]
|
| 30 |
+
self.filter_keys = filter_keys
|
| 31 |
+
super().__init__(**kwargs)
|
| 32 |
+
|
| 33 |
+
def aug_with_original_data(self, dataset):
|
| 34 |
+
"""Create original dataset and concat to the end."""
|
| 35 |
+
# Remove data without original reference
|
| 36 |
+
dataset = dataset.filter(
|
| 37 |
+
lambda x: any([x[k] for k in self.filter_keys]))
|
| 38 |
+
|
| 39 |
+
def ori_preprocess(example):
|
| 40 |
+
for k in self.filter_keys:
|
| 41 |
+
if example[k]:
|
| 42 |
+
new_k = k.split('original_')[-1]
|
| 43 |
+
example[new_k] = example[k]
|
| 44 |
+
example['type'] = 'original'
|
| 45 |
+
return example
|
| 46 |
+
|
| 47 |
+
original_dataset = dataset.map(ori_preprocess)
|
| 48 |
+
|
| 49 |
+
return concatenate_datasets([dataset, original_dataset])
|
| 50 |
+
|
| 51 |
+
def load(self, path):
|
| 52 |
+
"""Load dataset and aug with original dataset."""
|
| 53 |
+
|
| 54 |
+
with open(path, 'r') as f:
|
| 55 |
+
raw_data = json.load(f)
|
| 56 |
+
subset = raw_data[self.subset]
|
| 57 |
+
|
| 58 |
+
# In case the missing keys in first example causes Dataset
|
| 59 |
+
# to ignore them in the following examples when building.
|
| 60 |
+
for k in self.filter_keys:
|
| 61 |
+
if k not in subset[0]:
|
| 62 |
+
subset[0][k] = None
|
| 63 |
+
|
| 64 |
+
dataset = Dataset.from_list(raw_data[self.subset])
|
| 65 |
+
|
| 66 |
+
dataset = self.aug_with_original_data(dataset)
|
| 67 |
+
|
| 68 |
+
def choices_process(example):
|
| 69 |
+
example['label_option'] = chr(ord('A') + example['label'])
|
| 70 |
+
return example
|
| 71 |
+
|
| 72 |
+
dataset = dataset.map(choices_process)
|
| 73 |
+
return dataset
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
# label 0 for A. negative
|
| 77 |
+
# label 1 for B. positive
|
| 78 |
+
class AdvSst2Dataset(AdvDataset):
|
| 79 |
+
"""Adv GLUE sst2 dataset."""
|
| 80 |
+
|
| 81 |
+
def __init__(self, **kwargs):
|
| 82 |
+
super().__init__(subset='sst2',
|
| 83 |
+
filter_keys='original_sentence',
|
| 84 |
+
**kwargs)
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
# label 0 for not_duplicate, A. no
|
| 88 |
+
# label 1 for duplicate, B. yes
|
| 89 |
+
class AdvQqpDataset(AdvDataset):
|
| 90 |
+
"""Adv GLUE qqp dataset."""
|
| 91 |
+
|
| 92 |
+
def __init__(self, **kwargs):
|
| 93 |
+
super().__init__(
|
| 94 |
+
subset='qqp',
|
| 95 |
+
filter_keys=['original_question1', 'original_question2'],
|
| 96 |
+
**kwargs)
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
# # label 0 for entailment, A. yes
|
| 100 |
+
# # label 1 for neutral, B. maybe
|
| 101 |
+
# # label 2 for contradiction, C. no
|
| 102 |
+
class AdvMnliDataset(AdvDataset):
|
| 103 |
+
"""Adv GLUE mnli dataset."""
|
| 104 |
+
|
| 105 |
+
def __init__(self, **kwargs):
|
| 106 |
+
super().__init__(
|
| 107 |
+
subset='mnli',
|
| 108 |
+
filter_keys=['original_premise', 'original_hypothesis'],
|
| 109 |
+
**kwargs)
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
# # label 0 for entailment, A. yes
|
| 113 |
+
# # label 1 for neutral, B. maybe
|
| 114 |
+
# # label 2 for contradiction, C. no
|
| 115 |
+
class AdvMnliMMDataset(AdvDataset):
|
| 116 |
+
"""Adv GLUE mnli mm dataset."""
|
| 117 |
+
|
| 118 |
+
def __init__(self, **kwargs):
|
| 119 |
+
super().__init__(
|
| 120 |
+
subset='mnli-mm',
|
| 121 |
+
filter_keys=['original_premise', 'original_hypothesis'],
|
| 122 |
+
**kwargs)
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
# # label 0 for entailment, A. yes
|
| 126 |
+
# # label 1 for not entailment, B. no
|
| 127 |
+
class AdvQnliDataset(AdvDataset):
|
| 128 |
+
"""Adv GLUE qnli dataset."""
|
| 129 |
+
|
| 130 |
+
def __init__(self, **kwargs):
|
| 131 |
+
super().__init__(
|
| 132 |
+
subset='qnli',
|
| 133 |
+
filter_keys=['original_question', 'original_sentence'],
|
| 134 |
+
**kwargs)
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
# # label 0 for entailment, A. yes
|
| 138 |
+
# # label 1 for not entailment, B. no
|
| 139 |
+
class AdvRteDataset(AdvDataset):
|
| 140 |
+
"""Adv GLUE rte dataset."""
|
| 141 |
+
|
| 142 |
+
def __init__(self, **kwargs):
|
| 143 |
+
super().__init__(
|
| 144 |
+
subset='rte',
|
| 145 |
+
filter_keys=['original_sentence1', 'original_sentence2'],
|
| 146 |
+
**kwargs)
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
class AccDropEvaluator(AccEvaluator):
|
| 150 |
+
"""Eval accuracy drop."""
|
| 151 |
+
|
| 152 |
+
def __init__(self) -> None:
|
| 153 |
+
super().__init__()
|
| 154 |
+
|
| 155 |
+
def score(self, predictions: List, references: List) -> dict:
|
| 156 |
+
"""Calculate scores and accuracy.
|
| 157 |
+
|
| 158 |
+
Args:
|
| 159 |
+
predictions (List): List of probabilities for each class of each
|
| 160 |
+
sample.
|
| 161 |
+
references (List): List of target labels for each sample.
|
| 162 |
+
|
| 163 |
+
Returns:
|
| 164 |
+
dict: calculated scores.
|
| 165 |
+
"""
|
| 166 |
+
|
| 167 |
+
n = len(predictions)
|
| 168 |
+
assert n % 2 == 0, 'Number of examples should be even.'
|
| 169 |
+
acc_after = super().score(predictions[:n // 2], references[:n // 2])
|
| 170 |
+
acc_before = super().score(predictions[n // 2:], references[n // 2:])
|
| 171 |
+
acc_drop = 1 - acc_after['accuracy'] / acc_before['accuracy']
|
| 172 |
+
return dict(acc_drop=acc_drop,
|
| 173 |
+
acc_after=acc_after['accuracy'],
|
| 174 |
+
acc_before=acc_before['accuracy'])
|
opencompass-my-api/build/lib/opencompass/datasets/afqmcd.py
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
|
| 3 |
+
from datasets import Dataset
|
| 4 |
+
|
| 5 |
+
from opencompass.registry import LOAD_DATASET
|
| 6 |
+
|
| 7 |
+
from .base import BaseDataset
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
@LOAD_DATASET.register_module()
|
| 11 |
+
class AFQMCDataset_V2(BaseDataset):
|
| 12 |
+
|
| 13 |
+
@staticmethod
|
| 14 |
+
def load(path):
|
| 15 |
+
data = []
|
| 16 |
+
with open(path, 'r', encoding='utf-8') as f:
|
| 17 |
+
for line in f:
|
| 18 |
+
line = json.loads(line)
|
| 19 |
+
line['label'] = 'AB'[int(line['label'])]
|
| 20 |
+
data.append(line)
|
| 21 |
+
return Dataset.from_list(data)
|
opencompass-my-api/build/lib/opencompass/datasets/agieval/__init__.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# flake8: noqa
|
| 2 |
+
|
| 3 |
+
from .agieval import * # noqa: F401, F403
|
opencompass-my-api/build/lib/opencompass/datasets/agieval/agieval.py
ADDED
|
@@ -0,0 +1,99 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import os.path as osp
|
| 3 |
+
|
| 4 |
+
from datasets import Dataset
|
| 5 |
+
|
| 6 |
+
from opencompass.openicl.icl_evaluator import BaseEvaluator
|
| 7 |
+
from opencompass.registry import ICL_EVALUATORS, LOAD_DATASET
|
| 8 |
+
|
| 9 |
+
from ..base import BaseDataset
|
| 10 |
+
from .math_equivalence import is_equiv
|
| 11 |
+
from .post_process import parse_math_answer
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
@LOAD_DATASET.register_module()
|
| 15 |
+
class AGIEvalDataset(BaseDataset):
|
| 16 |
+
|
| 17 |
+
@staticmethod
|
| 18 |
+
def load(path: str, name: str, setting_name: str):
|
| 19 |
+
from .dataset_loader import load_dataset, load_dataset_as_result_schema
|
| 20 |
+
|
| 21 |
+
assert setting_name in 'zero-shot', 'only support zero-shot setting'
|
| 22 |
+
dataset_wo_label = load_dataset(name, setting_name, path)
|
| 23 |
+
dataset_with_label = load_dataset_as_result_schema(name, path)
|
| 24 |
+
dataset = []
|
| 25 |
+
for d1, d2 in zip(dataset_wo_label, dataset_with_label):
|
| 26 |
+
dataset.append({
|
| 27 |
+
'id': d2.index,
|
| 28 |
+
'problem_input': d1['context'],
|
| 29 |
+
'label': d2.label,
|
| 30 |
+
})
|
| 31 |
+
dataset = Dataset.from_list(dataset)
|
| 32 |
+
return dataset
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
@LOAD_DATASET.register_module()
|
| 36 |
+
class AGIEvalDataset_v2(BaseDataset):
|
| 37 |
+
|
| 38 |
+
@staticmethod
|
| 39 |
+
def load(path: str, name: str, setting_name: str):
|
| 40 |
+
assert setting_name in 'zero-shot', 'only support zero-shot setting'
|
| 41 |
+
filename = osp.join(path, name + '.jsonl')
|
| 42 |
+
with open(filename, encoding='utf-8') as f:
|
| 43 |
+
data = [json.loads(line.strip()) for line in f]
|
| 44 |
+
dataset = []
|
| 45 |
+
for item in data:
|
| 46 |
+
passage = item['passage'] if item['passage'] else ''
|
| 47 |
+
question = passage + item['question']
|
| 48 |
+
options = '\n'.join(item['options']) if item['options'] else ''
|
| 49 |
+
if item['label']:
|
| 50 |
+
if isinstance(item['label'], list):
|
| 51 |
+
label = ''.join(item['label'])
|
| 52 |
+
else:
|
| 53 |
+
label = item['label']
|
| 54 |
+
else:
|
| 55 |
+
label = item['answer']
|
| 56 |
+
d = {'question': question, 'options': options, 'label': label}
|
| 57 |
+
dataset.append(d)
|
| 58 |
+
dataset = Dataset.from_list(dataset)
|
| 59 |
+
return dataset
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
@ICL_EVALUATORS.register_module()
|
| 63 |
+
class AGIEvalEvaluator(BaseEvaluator):
|
| 64 |
+
|
| 65 |
+
def score(self, predictions, references):
|
| 66 |
+
predictions = [parse_math_answer('', pred) for pred in predictions]
|
| 67 |
+
details = []
|
| 68 |
+
cnt = 0
|
| 69 |
+
for pred, ref in zip(predictions, references):
|
| 70 |
+
detail = {'pred': pred, 'answer': ref, 'correct': False}
|
| 71 |
+
if is_equiv(pred, ref):
|
| 72 |
+
cnt += 1
|
| 73 |
+
detail['correct'] = True
|
| 74 |
+
details.append(detail)
|
| 75 |
+
score = cnt / len(predictions) * 100
|
| 76 |
+
return {'score': score, 'details': details}
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
@ICL_EVALUATORS.register_module()
|
| 80 |
+
class AGIEvalEvaluator_mcq(BaseEvaluator):
|
| 81 |
+
|
| 82 |
+
def score(self, predictions, references):
|
| 83 |
+
if len(predictions) != len(references):
|
| 84 |
+
return {
|
| 85 |
+
'error': 'predictions and references have different '
|
| 86 |
+
'length'
|
| 87 |
+
}
|
| 88 |
+
details = []
|
| 89 |
+
cnt = 0
|
| 90 |
+
for pred, ref in zip(predictions, references):
|
| 91 |
+
detail = {'pred': pred, 'answer': ref, 'correct': False}
|
| 92 |
+
if pred == ref:
|
| 93 |
+
cnt += 1
|
| 94 |
+
detail['correct'] = True
|
| 95 |
+
details.append(detail)
|
| 96 |
+
|
| 97 |
+
score = cnt / len(predictions) * 100
|
| 98 |
+
|
| 99 |
+
return {'score': score, 'details': details}
|
opencompass-my-api/build/lib/opencompass/datasets/agieval/constructions.py
ADDED
|
@@ -0,0 +1,104 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# flake8: noqa
|
| 2 |
+
import pandas as pd
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
class TaskSchema(object):
|
| 6 |
+
|
| 7 |
+
def __init__(self,
|
| 8 |
+
passage=None,
|
| 9 |
+
question=None,
|
| 10 |
+
options=None,
|
| 11 |
+
label=None,
|
| 12 |
+
answer=None,
|
| 13 |
+
other=None):
|
| 14 |
+
self.passage = passage
|
| 15 |
+
self.question = question
|
| 16 |
+
self.options = options
|
| 17 |
+
self.label = label
|
| 18 |
+
self.answer = answer
|
| 19 |
+
self.other = other
|
| 20 |
+
|
| 21 |
+
def to_dict(self):
|
| 22 |
+
return {
|
| 23 |
+
'passage': self.passage,
|
| 24 |
+
'question': self.question,
|
| 25 |
+
'options': self.options,
|
| 26 |
+
'label': self.label,
|
| 27 |
+
'answer': self.answer,
|
| 28 |
+
'other': self.other
|
| 29 |
+
}
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
# define README.json
|
| 33 |
+
class AgiInstance(object):
|
| 34 |
+
|
| 35 |
+
def __init__(self, task_description, data_source, task_schema, output,
|
| 36 |
+
evaluation_metric, task_example):
|
| 37 |
+
self.task_description = task_description
|
| 38 |
+
self.data_source = data_source
|
| 39 |
+
self.task_schema = task_schema
|
| 40 |
+
self.output = output
|
| 41 |
+
self.evaluation_metric = evaluation_metric
|
| 42 |
+
self.task_example = task_example
|
| 43 |
+
|
| 44 |
+
def to_dict(self):
|
| 45 |
+
return {
|
| 46 |
+
'task description': self.task_description,
|
| 47 |
+
'data source': self.data_source,
|
| 48 |
+
'task schema': self.task_schema.to_dict(),
|
| 49 |
+
'output': self.output,
|
| 50 |
+
'evaluation metric': self.evaluation_metric,
|
| 51 |
+
'task example': self.task_example
|
| 52 |
+
}
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
class ChatGPTSchema(object):
|
| 56 |
+
|
| 57 |
+
def __init__(self, context=None, metadata=''):
|
| 58 |
+
self.context = context
|
| 59 |
+
self.metadata = metadata
|
| 60 |
+
|
| 61 |
+
def to_dict(self):
|
| 62 |
+
return {'context': self.context, 'metadata': self.metadata}
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
class ResultsForHumanSchema(object):
|
| 66 |
+
|
| 67 |
+
def __init__(self,
|
| 68 |
+
index,
|
| 69 |
+
problem_input,
|
| 70 |
+
label,
|
| 71 |
+
model_input='',
|
| 72 |
+
model_output='',
|
| 73 |
+
parse_result='',
|
| 74 |
+
first_stage_output='',
|
| 75 |
+
second_stage_input='',
|
| 76 |
+
is_correct=False):
|
| 77 |
+
self.index = index
|
| 78 |
+
self.problem_input = problem_input
|
| 79 |
+
self.model_input = model_input
|
| 80 |
+
self.model_output = model_output
|
| 81 |
+
self.parse_result = parse_result
|
| 82 |
+
self.label = label
|
| 83 |
+
self.first_stage_output = first_stage_output
|
| 84 |
+
self.second_stage_input = second_stage_input
|
| 85 |
+
self.is_correct = is_correct
|
| 86 |
+
|
| 87 |
+
def to_dict(self):
|
| 88 |
+
return {
|
| 89 |
+
'index': self.index,
|
| 90 |
+
'problem_input': self.problem_input,
|
| 91 |
+
'model_input': self.model_input,
|
| 92 |
+
'model_output': self.model_output,
|
| 93 |
+
'parse_result': self.parse_result,
|
| 94 |
+
'label': self.label,
|
| 95 |
+
'is_correct': self.is_correct,
|
| 96 |
+
'first_stage_output': self.first_stage_output,
|
| 97 |
+
'second_stage_input': self.second_stage_input,
|
| 98 |
+
}
|
| 99 |
+
|
| 100 |
+
@staticmethod
|
| 101 |
+
def to_tsv(result_list, path):
|
| 102 |
+
result_json = [item.to_dict() for item in result_list]
|
| 103 |
+
table = pd.json_normalize(result_json)
|
| 104 |
+
table.to_excel(path, index=False)
|
opencompass-my-api/build/lib/opencompass/datasets/agieval/dataset_loader.py
ADDED
|
@@ -0,0 +1,392 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# flake8: noqa
|
| 2 |
+
import ast
|
| 3 |
+
import json
|
| 4 |
+
import os
|
| 5 |
+
|
| 6 |
+
import pandas as pd
|
| 7 |
+
import tiktoken
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
|
| 10 |
+
from .constructions import ChatGPTSchema, ResultsForHumanSchema
|
| 11 |
+
from .utils import extract_answer, read_jsonl, save_jsonl
|
| 12 |
+
|
| 13 |
+
# define the datasets
|
| 14 |
+
english_qa_datasets = [
|
| 15 |
+
'lsat-ar', 'lsat-lr', 'lsat-rc', 'logiqa-en', 'sat-math', 'sat-en',
|
| 16 |
+
'aqua-rat', 'sat-en-without-passage', 'gaokao-english'
|
| 17 |
+
]
|
| 18 |
+
chinese_qa_datasets = [
|
| 19 |
+
'logiqa-zh', 'jec-qa-kd', 'jec-qa-ca', 'gaokao-chinese',
|
| 20 |
+
'gaokao-geography', 'gaokao-history', 'gaokao-biology', 'gaokao-chemistry',
|
| 21 |
+
'gaokao-physics', 'gaokao-mathqa'
|
| 22 |
+
]
|
| 23 |
+
english_cloze_datasets = ['math']
|
| 24 |
+
chinese_cloze_datasets = ['gaokao-mathcloze']
|
| 25 |
+
|
| 26 |
+
multi_choice_datasets = ['jec-qa-kd', 'jec-qa-ca', 'gaokao-physics']
|
| 27 |
+
math_output_datasets = ['gaokao-mathcloze', 'math']
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def convert_zero_shot(line, dataset_name):
|
| 31 |
+
try:
|
| 32 |
+
passage = line['passage'] if line['passage'] is not None else ''
|
| 33 |
+
if dataset_name in english_qa_datasets:
|
| 34 |
+
option_string = 'ABCDEFG'
|
| 35 |
+
count = len(line['options'])
|
| 36 |
+
if count == 1:
|
| 37 |
+
count = 5
|
| 38 |
+
return passage + 'Q: ' + line['question'] + ' ' \
|
| 39 |
+
+ 'Answer Choices: ' + ' '.join(line['options']) + '\n' + \
|
| 40 |
+
'A: Among A through {}, the answer is'.format(option_string[count - 1])
|
| 41 |
+
|
| 42 |
+
elif dataset_name in chinese_qa_datasets:
|
| 43 |
+
option_string = 'ABCDEFG'
|
| 44 |
+
count = len(line['options'])
|
| 45 |
+
if count == 1:
|
| 46 |
+
count = 4
|
| 47 |
+
return passage + '问题:' + line['question'] + ' ' \
|
| 48 |
+
+ '选项:' + ' '.join(line['options']) + '\n' + \
|
| 49 |
+
'答案:从A到{}, 我们应选择'.format(option_string[count - 1])
|
| 50 |
+
|
| 51 |
+
elif dataset_name in english_cloze_datasets:
|
| 52 |
+
return passage + 'Q: ' + line['question'] + '\n' \
|
| 53 |
+
'A: The answer is'
|
| 54 |
+
|
| 55 |
+
elif dataset_name in chinese_cloze_datasets:
|
| 56 |
+
return passage + '问题:' + line['question'] + '\n' \
|
| 57 |
+
'答案:'
|
| 58 |
+
except NameError:
|
| 59 |
+
print('Dataset not defined.')
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
prefix = '该问题为单选题,所有选项中必有一个正确答案,且只有一个正确答案。\n'
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def convert_zero_shot_CoT_stage1(line, dataset_name):
|
| 66 |
+
try:
|
| 67 |
+
passage = line['passage'] if line['passage'] is not None else ''
|
| 68 |
+
if dataset_name in english_qa_datasets:
|
| 69 |
+
return passage + 'Q: ' + line['question'] + ' ' \
|
| 70 |
+
+ 'Answer Choices: ' + ' '.join(line['options']) + '\n' + \
|
| 71 |
+
"Let's think step by step."
|
| 72 |
+
|
| 73 |
+
elif dataset_name in chinese_qa_datasets:
|
| 74 |
+
option_string = 'ABCDEFG'
|
| 75 |
+
count = len(line['options'])
|
| 76 |
+
if count == 1:
|
| 77 |
+
count = 4
|
| 78 |
+
return passage + '问题:' + line['question'] + ' ' \
|
| 79 |
+
+ '选项:' + ' '.join(line['options']) + '\n' + \
|
| 80 |
+
'从A到{}, 我们应选择什么?让我们逐步思考:'.format(option_string[count - 1])
|
| 81 |
+
|
| 82 |
+
elif dataset_name in english_cloze_datasets:
|
| 83 |
+
return passage + 'Q: ' + line['question'] + '\n' \
|
| 84 |
+
"A: Let's think step by step."
|
| 85 |
+
|
| 86 |
+
elif dataset_name in chinese_cloze_datasets:
|
| 87 |
+
return passage + '问题:' + line['question'] + '\n' \
|
| 88 |
+
'答案:让我们逐步思考:'
|
| 89 |
+
except NameError:
|
| 90 |
+
print('Dataset not defined.')
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
# process few-shot raw_prompts
|
| 94 |
+
def combine_prompt(prompt_path,
|
| 95 |
+
dataset_name,
|
| 96 |
+
load_explanation=True,
|
| 97 |
+
chat_mode=False):
|
| 98 |
+
skip_passage = False
|
| 99 |
+
if dataset_name == 'sat-en-without-passage':
|
| 100 |
+
skip_passage = True
|
| 101 |
+
dataset_name = 'sat-en'
|
| 102 |
+
demostrations = []
|
| 103 |
+
# read the prompts by context and explanation
|
| 104 |
+
context_row = [0, 1, 3, 5, 7, 9]
|
| 105 |
+
explanation_row = [0, 2, 4, 6, 8, 10]
|
| 106 |
+
raw_prompts_context = pd.read_csv(prompt_path,
|
| 107 |
+
header=0,
|
| 108 |
+
skiprows=lambda x: x not in context_row,
|
| 109 |
+
keep_default_na=False)
|
| 110 |
+
raw_prompts_explanation = pd.read_csv(
|
| 111 |
+
prompt_path,
|
| 112 |
+
header=0,
|
| 113 |
+
skiprows=lambda x: x not in explanation_row,
|
| 114 |
+
keep_default_na=False).replace(r'\n\n', '\n', regex=True)
|
| 115 |
+
contexts = []
|
| 116 |
+
for line in list(raw_prompts_context[dataset_name]):
|
| 117 |
+
if line:
|
| 118 |
+
# print(line)
|
| 119 |
+
contexts.append(ast.literal_eval(line))
|
| 120 |
+
explanations = [
|
| 121 |
+
exp for exp in raw_prompts_explanation[dataset_name] if exp
|
| 122 |
+
]
|
| 123 |
+
|
| 124 |
+
for idx, (con, exp) in enumerate(zip(contexts, explanations)):
|
| 125 |
+
passage = con['passage'] if con[
|
| 126 |
+
'passage'] is not None and not skip_passage else ''
|
| 127 |
+
question = con['question']
|
| 128 |
+
options = con['options'] if con['options'] is not None else ''
|
| 129 |
+
label = con['label'] if con['label'] is not None else ''
|
| 130 |
+
answer = con[
|
| 131 |
+
'answer'] if 'answer' in con and con['answer'] is not None else ''
|
| 132 |
+
|
| 133 |
+
if dataset_name in english_qa_datasets:
|
| 134 |
+
question_input = 'Problem {}. '.format(idx + 1) + passage + ' ' + question + '\n' \
|
| 135 |
+
+ 'Choose from the following options: ' + ' '.join(options) + '\n'
|
| 136 |
+
question_output = (('Explanation for Problem {}: '.format(idx + 1) + exp + '\n') if load_explanation else '') \
|
| 137 |
+
+ 'The answer is therefore {}'.format(label)
|
| 138 |
+
|
| 139 |
+
elif dataset_name in chinese_qa_datasets:
|
| 140 |
+
question_input = '问题 {}. '.format(idx + 1) + passage + ' ' + question + '\n' \
|
| 141 |
+
+ '从以下选项中选择: ' + ' '.join(options) + '\n'
|
| 142 |
+
question_output = (('问题 {}的解析: '.format(idx + 1) + exp + '\n') if load_explanation else '') \
|
| 143 |
+
+ '答案是 {}'.format(label)
|
| 144 |
+
|
| 145 |
+
elif dataset_name in english_cloze_datasets:
|
| 146 |
+
question_input = 'Problem {}. '.format(idx + 1) + question + '\n'
|
| 147 |
+
question_output = (('Explanation for Problem {}: '.format(idx + 1) + exp + '\n') if load_explanation else '') \
|
| 148 |
+
+ 'The answer is therefore {}'.format(answer)
|
| 149 |
+
|
| 150 |
+
elif dataset_name in chinese_cloze_datasets:
|
| 151 |
+
question_input = '问题 {}. '.format(idx + 1) + question + '\n'
|
| 152 |
+
question_output = (('问题 {}的解析: '.format(idx + 1) + exp + '\n') if load_explanation else '') \
|
| 153 |
+
+ '答案是 {}'.format(answer)
|
| 154 |
+
else:
|
| 155 |
+
raise ValueError(
|
| 156 |
+
f'During loading few-sot examples, found unknown dataset: {dataset_name}'
|
| 157 |
+
)
|
| 158 |
+
if chat_mode:
|
| 159 |
+
demostrations.append((question_input, question_output))
|
| 160 |
+
else:
|
| 161 |
+
demostrations.append(question_input + question_output + '\n')
|
| 162 |
+
|
| 163 |
+
return demostrations
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
enc = None
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
def _lazy_load_enc():
|
| 170 |
+
global enc
|
| 171 |
+
if enc is None:
|
| 172 |
+
enc = tiktoken.encoding_for_model('gpt-4')
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
# cut prompt if reach max token length
|
| 176 |
+
def concat_prompt(demos,
|
| 177 |
+
dataset_name,
|
| 178 |
+
max_tokens,
|
| 179 |
+
end_of_example='\n',
|
| 180 |
+
verbose=False):
|
| 181 |
+
_lazy_load_enc()
|
| 182 |
+
demostration_en = 'Here are the answers for the problems in the exam.\n'
|
| 183 |
+
demostration_zh = '以下是考试中各个问题的答案。\n'
|
| 184 |
+
|
| 185 |
+
for i in range(len(demos)):
|
| 186 |
+
# print(len(enc.encode(demostration_en)), len(enc.encode(demostration_zh)))
|
| 187 |
+
if dataset_name in english_qa_datasets:
|
| 188 |
+
demostration_en = demostration_en + demos[i] + end_of_example
|
| 189 |
+
elif dataset_name in chinese_qa_datasets:
|
| 190 |
+
demostration_zh = demostration_zh + demos[i] + end_of_example
|
| 191 |
+
elif dataset_name in english_cloze_datasets:
|
| 192 |
+
demostration_en = demostration_en + demos[i] + end_of_example
|
| 193 |
+
elif dataset_name in chinese_cloze_datasets:
|
| 194 |
+
demostration_zh = demostration_zh + demos[i] + end_of_example
|
| 195 |
+
# break if reach max token limit
|
| 196 |
+
if len(enc.encode(demostration_en)) < max_tokens and len(
|
| 197 |
+
enc.encode(demostration_zh)) < max_tokens:
|
| 198 |
+
output = demostration_en if len(demostration_en) > len(
|
| 199 |
+
demostration_zh) else demostration_zh
|
| 200 |
+
prompt_num = i + 1
|
| 201 |
+
else:
|
| 202 |
+
break
|
| 203 |
+
if verbose:
|
| 204 |
+
print('max_tokens set as ', max_tokens, 'actual_tokens is',
|
| 205 |
+
len(enc.encode(output)), 'num_shot is', prompt_num)
|
| 206 |
+
return output, prompt_num
|
| 207 |
+
|
| 208 |
+
|
| 209 |
+
def concat_prompt_chat_mode(demos,
|
| 210 |
+
dataset_name,
|
| 211 |
+
max_tokens,
|
| 212 |
+
end_of_example='\n',
|
| 213 |
+
verbose=False):
|
| 214 |
+
_lazy_load_enc()
|
| 215 |
+
answers = []
|
| 216 |
+
sentences = ''
|
| 217 |
+
for i in range(len(demos)):
|
| 218 |
+
answers += [
|
| 219 |
+
{
|
| 220 |
+
'role': 'user',
|
| 221 |
+
'content': demos[i][0]
|
| 222 |
+
},
|
| 223 |
+
{
|
| 224 |
+
'role': 'assistant',
|
| 225 |
+
'content': demos[i][1]
|
| 226 |
+
},
|
| 227 |
+
]
|
| 228 |
+
sentences += json.dumps(answers[-1])
|
| 229 |
+
# break if reach max token limit
|
| 230 |
+
if len(enc.encode(sentences)) > max_tokens:
|
| 231 |
+
answers.pop()
|
| 232 |
+
answers.pop()
|
| 233 |
+
break
|
| 234 |
+
if verbose:
|
| 235 |
+
print('max_tokens set as ', max_tokens, 'actual_tokens is',
|
| 236 |
+
len(enc.encode(sentences)), 'num_shot is',
|
| 237 |
+
len(answers) // 2)
|
| 238 |
+
return answers, len(answers) // 2
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
def convert_few_shot(line, dataset_name, demo, n_shot, chat_mode=False):
|
| 242 |
+
passage = line['passage'] if line['passage'] is not None else ''
|
| 243 |
+
question = line['question']
|
| 244 |
+
options = line['options'] if line['options'] is not None else ''
|
| 245 |
+
|
| 246 |
+
if dataset_name in english_qa_datasets:
|
| 247 |
+
question_input = 'Problem {}. '.format(n_shot + 1) + passage + ' ' + question + '\n' \
|
| 248 |
+
+ 'Choose from the following options: ' + ' '.join(options) + '\n'
|
| 249 |
+
# + "Explanation for Problem {}: ".format(n_shot + 1)
|
| 250 |
+
|
| 251 |
+
if dataset_name in chinese_qa_datasets:
|
| 252 |
+
question_input = '问题 {}. '.format(n_shot + 1) + passage + ' ' + question + '\n' \
|
| 253 |
+
+ '从以下选项中选择: ' + ' '.join(options) + '\n'
|
| 254 |
+
# + "问题 {}的解析: ".format(n_shot + 1)
|
| 255 |
+
|
| 256 |
+
if dataset_name in english_cloze_datasets:
|
| 257 |
+
question_input = 'Problem {}. '.format(n_shot + 1) + question + '\n'
|
| 258 |
+
# + "Explanation for Problem {}: ".format(n_shot + 1)
|
| 259 |
+
|
| 260 |
+
if dataset_name in chinese_cloze_datasets:
|
| 261 |
+
question_input = '问题 {}. '.format(n_shot + 1) + question + '\n'
|
| 262 |
+
# + "问题 {}的解析: ".format(n_shot + 1)
|
| 263 |
+
if chat_mode:
|
| 264 |
+
return demo + [
|
| 265 |
+
{
|
| 266 |
+
'role': 'user',
|
| 267 |
+
'content': question_input
|
| 268 |
+
},
|
| 269 |
+
]
|
| 270 |
+
else:
|
| 271 |
+
return demo + question_input
|
| 272 |
+
|
| 273 |
+
|
| 274 |
+
def load_dataset(dataset_name,
|
| 275 |
+
setting_name,
|
| 276 |
+
parent_path,
|
| 277 |
+
prompt_path=None,
|
| 278 |
+
max_tokens=None,
|
| 279 |
+
end_of_example='\n',
|
| 280 |
+
chat_mode=False,
|
| 281 |
+
verbose=False):
|
| 282 |
+
test_path = os.path.join(parent_path, dataset_name + '.jsonl')
|
| 283 |
+
loaded_jsonl = read_jsonl(test_path)
|
| 284 |
+
processed = []
|
| 285 |
+
if setting_name == 'few-shot-CoT' or setting_name == 'few-shot':
|
| 286 |
+
# process demo once if it is few-shot-CoT
|
| 287 |
+
processed_demos = combine_prompt(
|
| 288 |
+
prompt_path,
|
| 289 |
+
dataset_name,
|
| 290 |
+
load_explanation=setting_name == 'few-shot-CoT',
|
| 291 |
+
chat_mode=chat_mode)
|
| 292 |
+
if chat_mode:
|
| 293 |
+
chosen_prompt, n_shot = concat_prompt_chat_mode(processed_demos,
|
| 294 |
+
dataset_name,
|
| 295 |
+
max_tokens,
|
| 296 |
+
end_of_example,
|
| 297 |
+
verbose=verbose)
|
| 298 |
+
else:
|
| 299 |
+
chosen_prompt, n_shot = concat_prompt(processed_demos,
|
| 300 |
+
dataset_name,
|
| 301 |
+
max_tokens,
|
| 302 |
+
end_of_example,
|
| 303 |
+
verbose=verbose)
|
| 304 |
+
if verbose:
|
| 305 |
+
loaded_jsonl = tqdm(loaded_jsonl)
|
| 306 |
+
for meta_idx, line in enumerate(loaded_jsonl):
|
| 307 |
+
if setting_name == 'zero-shot':
|
| 308 |
+
ctxt = convert_zero_shot(line, dataset_name)
|
| 309 |
+
elif setting_name == 'zero-shot-CoT':
|
| 310 |
+
ctxt = convert_zero_shot_CoT_stage1(line, dataset_name)
|
| 311 |
+
elif setting_name == 'few-shot-CoT' or setting_name == 'few-shot':
|
| 312 |
+
ctxt = convert_few_shot(line, dataset_name, chosen_prompt, n_shot,
|
| 313 |
+
chat_mode)
|
| 314 |
+
try:
|
| 315 |
+
new_instance = ChatGPTSchema(context=ctxt, metadata=meta_idx)
|
| 316 |
+
processed.append(new_instance.to_dict())
|
| 317 |
+
except NameError:
|
| 318 |
+
print('Dataset not defined.')
|
| 319 |
+
return processed
|
| 320 |
+
|
| 321 |
+
|
| 322 |
+
def generate_second_stage_input(dataset_name,
|
| 323 |
+
input_list,
|
| 324 |
+
output_list,
|
| 325 |
+
with_format_prompt=False):
|
| 326 |
+
try:
|
| 327 |
+
english_format_prompt = 'Based on the previous results, your task is to extract the final answer and provide the output enclosed in brackets【】, such as 【0】 or 【A】.'
|
| 328 |
+
chinese_format_prompt = '根据以上内容,你的任务是把最终的答案提取出来并填在【】中,例如【0】或者【A】。'
|
| 329 |
+
if dataset_name in english_qa_datasets:
|
| 330 |
+
prompt_suffix = 'Therefore, among A through E, the answer is'
|
| 331 |
+
if with_format_prompt:
|
| 332 |
+
prompt_suffix = english_format_prompt + prompt_suffix
|
| 333 |
+
elif dataset_name in chinese_qa_datasets:
|
| 334 |
+
prompt_suffix = '因此,从A到D, 我们应选择'
|
| 335 |
+
if with_format_prompt:
|
| 336 |
+
prompt_suffix = chinese_format_prompt + prompt_suffix
|
| 337 |
+
elif dataset_name in english_cloze_datasets:
|
| 338 |
+
prompt_suffix = 'Therefore, the answer is'
|
| 339 |
+
if with_format_prompt:
|
| 340 |
+
prompt_suffix = english_format_prompt + prompt_suffix
|
| 341 |
+
elif dataset_name in chinese_cloze_datasets:
|
| 342 |
+
prompt_suffix = '因此,答案是'
|
| 343 |
+
if with_format_prompt:
|
| 344 |
+
prompt_suffix = chinese_format_prompt + prompt_suffix
|
| 345 |
+
except NameError:
|
| 346 |
+
print('Dataset not defined.')
|
| 347 |
+
processed = []
|
| 348 |
+
for i in range(len(input_list)):
|
| 349 |
+
ctxt = '{0}\n{1}\n{2}'.format(input_list[i]['context'],
|
| 350 |
+
extract_answer(output_list[i]),
|
| 351 |
+
prompt_suffix)
|
| 352 |
+
new_instance = ChatGPTSchema(context=ctxt,
|
| 353 |
+
metadata=input_list[i]['metadata'])
|
| 354 |
+
processed.append(new_instance.to_dict())
|
| 355 |
+
return processed
|
| 356 |
+
|
| 357 |
+
|
| 358 |
+
def load_dataset_as_result_schema(dataset_name, parent_path):
|
| 359 |
+
test_path = os.path.join(parent_path, dataset_name + '.jsonl')
|
| 360 |
+
loaded_jsonl = read_jsonl(test_path)
|
| 361 |
+
|
| 362 |
+
processed = []
|
| 363 |
+
for i, line in enumerate(loaded_jsonl):
|
| 364 |
+
problem_input = convert_zero_shot(line, dataset_name)
|
| 365 |
+
processed.append(
|
| 366 |
+
ResultsForHumanSchema(
|
| 367 |
+
index=i,
|
| 368 |
+
problem_input=problem_input,
|
| 369 |
+
label=line['label'] if line['label'] else line['answer'],
|
| 370 |
+
))
|
| 371 |
+
return processed
|
| 372 |
+
|
| 373 |
+
|
| 374 |
+
if __name__ == '__main__':
|
| 375 |
+
|
| 376 |
+
# set variables
|
| 377 |
+
parent_dir = '../../data/V1_1/'
|
| 378 |
+
raw_prompt_path = '../data/few_shot_prompts.csv'
|
| 379 |
+
|
| 380 |
+
# set dataset name to process
|
| 381 |
+
setting_name = 'few-shot-CoT' # setting_name can be chosen from ["zero-shot", "zero-shot-CoT", "few-shot-CoT"]
|
| 382 |
+
data_name = 'jec-qa-kd'
|
| 383 |
+
save_dir = '../../experiment_input/{}/'.format(setting_name)
|
| 384 |
+
if not os.path.exists(save_dir):
|
| 385 |
+
os.makedirs(save_dir)
|
| 386 |
+
processed_data = load_dataset(data_name,
|
| 387 |
+
setting_name,
|
| 388 |
+
parent_dir,
|
| 389 |
+
prompt_path=raw_prompt_path,
|
| 390 |
+
max_tokens=2048)
|
| 391 |
+
save_jsonl(processed_data,
|
| 392 |
+
os.path.join(save_dir, '{}.jsonl'.format(data_name)))
|
opencompass-my-api/build/lib/opencompass/datasets/agieval/evaluation.py
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# flake8: noqa
|
| 2 |
+
from . import dataset_loader, utils
|
| 3 |
+
from .math_equivalence import is_equiv
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def convert_to_set(item):
|
| 7 |
+
if isinstance(item, list):
|
| 8 |
+
return set(item)
|
| 9 |
+
if isinstance(item, str):
|
| 10 |
+
return {item}
|
| 11 |
+
if item is None:
|
| 12 |
+
return {}
|
| 13 |
+
raise ValueError("Input can't parse:", item)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def evaluate_single_sample(dataset_name, prediction, label):
|
| 17 |
+
if dataset_name in dataset_loader.multi_choice_datasets:
|
| 18 |
+
p = convert_to_set(prediction)
|
| 19 |
+
l = convert_to_set(label)
|
| 20 |
+
return p == l
|
| 21 |
+
elif dataset_name in dataset_loader.math_output_datasets:
|
| 22 |
+
return is_equiv(prediction, label)
|
| 23 |
+
else:
|
| 24 |
+
return prediction == label
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
# def evaluate(dataset_name, prediction_list, label_list):
|
| 28 |
+
# correct = 0
|
| 29 |
+
# if dataset_name in multi_choice_datasets:
|
| 30 |
+
# for prediction, label in zip(prediction_list, label_list):
|
| 31 |
+
# p = convert_to_set(prediction)
|
| 32 |
+
# l = convert_to_set(label)
|
| 33 |
+
# if p == l:
|
| 34 |
+
# correct += 1
|
| 35 |
+
# elif dataset_name in math_output_datasets:
|
| 36 |
+
# for prediction, label in zip(prediction_list, label_list):
|
| 37 |
+
# if is_equiv(prediction, label):
|
| 38 |
+
# correct += 1
|
| 39 |
+
# else:
|
| 40 |
+
# for prediction, label in zip(prediction_list, label_list):
|
| 41 |
+
# if prediction == label:
|
| 42 |
+
# correct += 1
|
| 43 |
+
# return "{0:.2%}".format(correct / len(label_list))
|
opencompass-my-api/build/lib/opencompass/datasets/agieval/math_equivalence.py
ADDED
|
@@ -0,0 +1,161 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# flake8: noqa
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
# code from https://github.com/hendrycks/math/blob/main/modeling/math_equivalence.py
|
| 5 |
+
def _fix_fracs(string):
|
| 6 |
+
substrs = string.split('\\frac')
|
| 7 |
+
new_str = substrs[0]
|
| 8 |
+
if len(substrs) > 1:
|
| 9 |
+
substrs = substrs[1:]
|
| 10 |
+
for substr in substrs:
|
| 11 |
+
new_str += '\\frac'
|
| 12 |
+
if substr[0] == '{':
|
| 13 |
+
new_str += substr
|
| 14 |
+
else:
|
| 15 |
+
try:
|
| 16 |
+
assert len(substr) >= 2
|
| 17 |
+
except:
|
| 18 |
+
return string
|
| 19 |
+
a = substr[0]
|
| 20 |
+
b = substr[1]
|
| 21 |
+
if b != '{':
|
| 22 |
+
if len(substr) > 2:
|
| 23 |
+
post_substr = substr[2:]
|
| 24 |
+
new_str += '{' + a + '}{' + b + '}' + post_substr
|
| 25 |
+
else:
|
| 26 |
+
new_str += '{' + a + '}{' + b + '}'
|
| 27 |
+
else:
|
| 28 |
+
if len(substr) > 2:
|
| 29 |
+
post_substr = substr[2:]
|
| 30 |
+
new_str += '{' + a + '}' + b + post_substr
|
| 31 |
+
else:
|
| 32 |
+
new_str += '{' + a + '}' + b
|
| 33 |
+
string = new_str
|
| 34 |
+
return string
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def _fix_a_slash_b(string):
|
| 38 |
+
if len(string.split('/')) != 2:
|
| 39 |
+
return string
|
| 40 |
+
a = string.split('/')[0]
|
| 41 |
+
b = string.split('/')[1]
|
| 42 |
+
try:
|
| 43 |
+
a = int(a)
|
| 44 |
+
b = int(b)
|
| 45 |
+
assert string == '{}/{}'.format(a, b)
|
| 46 |
+
new_string = '\\frac{' + str(a) + '}{' + str(b) + '}'
|
| 47 |
+
return new_string
|
| 48 |
+
except:
|
| 49 |
+
return string
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def _remove_right_units(string):
|
| 53 |
+
# "\\text{ " only ever occurs (at least in the val set) when describing units
|
| 54 |
+
if '\\text{ ' in string:
|
| 55 |
+
splits = string.split('\\text{ ')
|
| 56 |
+
assert len(splits) == 2
|
| 57 |
+
return splits[0]
|
| 58 |
+
else:
|
| 59 |
+
return string
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def _fix_sqrt(string):
|
| 63 |
+
if '\\sqrt' not in string:
|
| 64 |
+
return string
|
| 65 |
+
splits = string.split('\\sqrt')
|
| 66 |
+
new_string = splits[0]
|
| 67 |
+
for split in splits[1:]:
|
| 68 |
+
if split[0] != '{':
|
| 69 |
+
a = split[0]
|
| 70 |
+
new_substr = '\\sqrt{' + a + '}' + split[1:]
|
| 71 |
+
else:
|
| 72 |
+
new_substr = '\\sqrt' + split
|
| 73 |
+
new_string += new_substr
|
| 74 |
+
return new_string
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def _strip_string(string):
|
| 78 |
+
# linebreaks
|
| 79 |
+
string = string.replace('\n', '')
|
| 80 |
+
# print(string)
|
| 81 |
+
|
| 82 |
+
# remove inverse spaces
|
| 83 |
+
string = string.replace('\\!', '')
|
| 84 |
+
# print(string)
|
| 85 |
+
|
| 86 |
+
# replace \\ with \
|
| 87 |
+
string = string.replace('\\\\', '\\')
|
| 88 |
+
# print(string)
|
| 89 |
+
|
| 90 |
+
# replace tfrac and dfrac with frac
|
| 91 |
+
string = string.replace('tfrac', 'frac')
|
| 92 |
+
string = string.replace('dfrac', 'frac')
|
| 93 |
+
# print(string)
|
| 94 |
+
|
| 95 |
+
# remove \left and \right
|
| 96 |
+
string = string.replace('\\left', '')
|
| 97 |
+
string = string.replace('\\right', '')
|
| 98 |
+
# print(string)
|
| 99 |
+
|
| 100 |
+
# Remove circ (degrees)
|
| 101 |
+
string = string.replace('^{\\circ}', '')
|
| 102 |
+
string = string.replace('^\\circ', '')
|
| 103 |
+
|
| 104 |
+
# remove dollar signs
|
| 105 |
+
string = string.replace('\\$', '')
|
| 106 |
+
|
| 107 |
+
# remove units (on the right)
|
| 108 |
+
string = _remove_right_units(string)
|
| 109 |
+
|
| 110 |
+
# remove percentage
|
| 111 |
+
string = string.replace('\\%', '')
|
| 112 |
+
string = string.replace('\%', '')
|
| 113 |
+
|
| 114 |
+
# " 0." equivalent to " ." and "{0." equivalent to "{." Alternatively, add "0" if "." is the start of the string
|
| 115 |
+
string = string.replace(' .', ' 0.')
|
| 116 |
+
string = string.replace('{.', '{0.')
|
| 117 |
+
# if empty, return empty string
|
| 118 |
+
if len(string) == 0:
|
| 119 |
+
return string
|
| 120 |
+
if string[0] == '.':
|
| 121 |
+
string = '0' + string
|
| 122 |
+
|
| 123 |
+
# to consider: get rid of e.g. "k = " or "q = " at beginning
|
| 124 |
+
if len(string.split('=')) == 2:
|
| 125 |
+
if len(string.split('=')[0]) <= 2:
|
| 126 |
+
string = string.split('=')[1]
|
| 127 |
+
|
| 128 |
+
# fix sqrt3 --> sqrt{3}
|
| 129 |
+
string = _fix_sqrt(string)
|
| 130 |
+
|
| 131 |
+
# remove spaces
|
| 132 |
+
string = string.replace(' ', '')
|
| 133 |
+
|
| 134 |
+
# \frac1b or \frac12 --> \frac{1}{b} and \frac{1}{2}, etc. Even works with \frac1{72} (but not \frac{72}1). Also does a/b --> \\frac{a}{b}
|
| 135 |
+
string = _fix_fracs(string)
|
| 136 |
+
|
| 137 |
+
# manually change 0.5 --> \frac{1}{2}
|
| 138 |
+
if string == '0.5':
|
| 139 |
+
string = '\\frac{1}{2}'
|
| 140 |
+
|
| 141 |
+
# NOTE: X/Y changed to \frac{X}{Y} in dataset, but in simple cases fix in case the model output is X/Y
|
| 142 |
+
string = _fix_a_slash_b(string)
|
| 143 |
+
|
| 144 |
+
return string
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
def is_equiv(str1, str2, verbose=False):
|
| 148 |
+
if str1 is None and str2 is None:
|
| 149 |
+
print('WARNING: Both None')
|
| 150 |
+
return True
|
| 151 |
+
if str1 is None or str2 is None:
|
| 152 |
+
return False
|
| 153 |
+
|
| 154 |
+
try:
|
| 155 |
+
ss1 = _strip_string(str1)
|
| 156 |
+
ss2 = _strip_string(str2)
|
| 157 |
+
if verbose:
|
| 158 |
+
print(ss1, ss2)
|
| 159 |
+
return ss1 == ss2
|
| 160 |
+
except:
|
| 161 |
+
return str1 == str2
|
opencompass-my-api/build/lib/opencompass/datasets/agieval/post_process.py
ADDED
|
@@ -0,0 +1,198 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# flake8: noqa
|
| 2 |
+
import json
|
| 3 |
+
import re
|
| 4 |
+
|
| 5 |
+
from . import dataset_loader
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def extract_last_line(string):
|
| 9 |
+
lines = string.split('\n')
|
| 10 |
+
for item in lines[::-1]:
|
| 11 |
+
if item.strip() != '':
|
| 12 |
+
string = item
|
| 13 |
+
break
|
| 14 |
+
return string
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def remove_few_shot_prefix(string: str):
|
| 18 |
+
prefix_list = ['The answer is therefore', '答案是']
|
| 19 |
+
for prefix in prefix_list:
|
| 20 |
+
if string.startswith(prefix):
|
| 21 |
+
string = string[len(prefix):].strip()
|
| 22 |
+
elif prefix in string:
|
| 23 |
+
index = string.rfind(prefix)
|
| 24 |
+
if index >= 0:
|
| 25 |
+
string = string[index + len(prefix):].strip()
|
| 26 |
+
return string
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def try_parse_few_shot_qa_single_answer(string, setting_name, language='en'):
|
| 30 |
+
if setting_name == 'few-shot-CoT':
|
| 31 |
+
string = extract_last_line(string)
|
| 32 |
+
if language == 'en':
|
| 33 |
+
pattern = 'answer is .*?([A-G])'
|
| 34 |
+
match = re.search(pattern, string)
|
| 35 |
+
elif language == 'zh':
|
| 36 |
+
pattern = '答案是.*?([A-G])'
|
| 37 |
+
match = re.search(pattern, string)
|
| 38 |
+
else:
|
| 39 |
+
raise ValueError('Unknown language {0}'.format(language))
|
| 40 |
+
if match:
|
| 41 |
+
return match.group(1)
|
| 42 |
+
else:
|
| 43 |
+
return None
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def try_parse_few_shot_pattern(string: str, dataset_name, setting_name):
|
| 47 |
+
if setting_name == 'few-shot-CoT':
|
| 48 |
+
string = extract_last_line(string)
|
| 49 |
+
if dataset_name in dataset_loader.chinese_cloze_datasets:
|
| 50 |
+
return string.startswith('答案是')
|
| 51 |
+
elif dataset_name in dataset_loader.english_cloze_datasets:
|
| 52 |
+
return string.startswith('The answer is therefore')
|
| 53 |
+
elif dataset_name in dataset_loader.chinese_qa_datasets:
|
| 54 |
+
pattern = '答案是.*?([A-G])'
|
| 55 |
+
match = re.search(pattern, string)
|
| 56 |
+
return match is not None
|
| 57 |
+
elif dataset_name in dataset_loader.english_qa_datasets:
|
| 58 |
+
pattern = 'answer is .*?([A-G])'
|
| 59 |
+
match = re.search(pattern, string)
|
| 60 |
+
return match is not None
|
| 61 |
+
return False
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def parse_few_shot_qa_single_answer(string, setting_name, language='en'):
|
| 65 |
+
answer = try_parse_few_shot_qa_single_answer(string, setting_name,
|
| 66 |
+
language)
|
| 67 |
+
if answer is None:
|
| 68 |
+
return find_first_capital_letter(string)
|
| 69 |
+
else:
|
| 70 |
+
return answer
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def find_first_capital_letter(answer):
|
| 74 |
+
letter_set = {'A', 'B', 'C', 'D', 'E', 'F'}
|
| 75 |
+
for c in answer:
|
| 76 |
+
if c in letter_set:
|
| 77 |
+
return c
|
| 78 |
+
# print("Can't find capital letter in:", answer)
|
| 79 |
+
return ''
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
def extract_answer_in_bracket(answer, prefix='【', suffix='】'):
|
| 83 |
+
if prefix not in answer and suffix not in answer:
|
| 84 |
+
# print("doesn't found special tokens in:", answer)
|
| 85 |
+
return ''
|
| 86 |
+
s = answer.index(prefix) + len(prefix)
|
| 87 |
+
t = answer.index(suffix)
|
| 88 |
+
ret = answer[s:t]
|
| 89 |
+
return ret
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
def parse_math_answer(setting_name, raw_string):
|
| 93 |
+
if setting_name == 'few-shot-CoT':
|
| 94 |
+
raw_string = extract_last_line(raw_string)
|
| 95 |
+
if setting_name == 'few-shot-CoT' or setting_name == 'few-shot':
|
| 96 |
+
raw_string = remove_few_shot_prefix(raw_string)
|
| 97 |
+
return raw_string
|
| 98 |
+
|
| 99 |
+
def remove_boxed(s):
|
| 100 |
+
left = '\\boxed{'
|
| 101 |
+
try:
|
| 102 |
+
assert s[:len(left)] == left
|
| 103 |
+
assert s[-1] == '}'
|
| 104 |
+
answer = s[len(left):-1]
|
| 105 |
+
if '=' in answer:
|
| 106 |
+
answer = answer.split('=')[-1].lstrip(' ')
|
| 107 |
+
return answer
|
| 108 |
+
except:
|
| 109 |
+
return None
|
| 110 |
+
|
| 111 |
+
def last_boxed_only_string(string):
|
| 112 |
+
idx = string.rfind('\\boxed')
|
| 113 |
+
if idx < 0:
|
| 114 |
+
idx = string.rfind('\\fbox')
|
| 115 |
+
if idx < 0:
|
| 116 |
+
return None
|
| 117 |
+
i = idx
|
| 118 |
+
right_brace_idx = None
|
| 119 |
+
num_left_braces_open = 0
|
| 120 |
+
while i < len(string):
|
| 121 |
+
if string[i] == '{':
|
| 122 |
+
num_left_braces_open += 1
|
| 123 |
+
if string[i] == '}':
|
| 124 |
+
num_left_braces_open -= 1
|
| 125 |
+
if num_left_braces_open == 0:
|
| 126 |
+
right_brace_idx = i
|
| 127 |
+
break
|
| 128 |
+
i += 1
|
| 129 |
+
|
| 130 |
+
if right_brace_idx == None:
|
| 131 |
+
retval = None
|
| 132 |
+
else:
|
| 133 |
+
retval = string[idx:right_brace_idx + 1]
|
| 134 |
+
|
| 135 |
+
return retval
|
| 136 |
+
|
| 137 |
+
def get_answer_with_dollar_sign(s):
|
| 138 |
+
first_pattern = '\$(.*)\$'
|
| 139 |
+
last_match = None
|
| 140 |
+
matches = re.findall(first_pattern, s)
|
| 141 |
+
if matches:
|
| 142 |
+
last_match = matches[-1]
|
| 143 |
+
if '=' in last_match:
|
| 144 |
+
last_match = last_match.split('=')[-1].lstrip(' ')
|
| 145 |
+
return last_match
|
| 146 |
+
|
| 147 |
+
def get_answer_without_dollar_sign(s):
|
| 148 |
+
last_match = None
|
| 149 |
+
if '=' in s:
|
| 150 |
+
last_match = s.split('=')[-1].lstrip(' ').rstrip('.')
|
| 151 |
+
if '\\n' in last_match:
|
| 152 |
+
last_match = last_match.split('\\n')[0]
|
| 153 |
+
else:
|
| 154 |
+
pattern = '(?:\\$)?\d+(?:\.\d+)?(?![\w\d])'
|
| 155 |
+
matches = re.findall(pattern, s)
|
| 156 |
+
if matches:
|
| 157 |
+
last_match = matches[-1]
|
| 158 |
+
return last_match
|
| 159 |
+
|
| 160 |
+
raw_string = remove_few_shot_prefix(raw_string)
|
| 161 |
+
if '\\boxed' in raw_string:
|
| 162 |
+
answer = remove_boxed(last_boxed_only_string(raw_string))
|
| 163 |
+
else:
|
| 164 |
+
answer = get_answer_with_dollar_sign(raw_string)
|
| 165 |
+
if not answer:
|
| 166 |
+
answer = get_answer_without_dollar_sign(raw_string)
|
| 167 |
+
return answer
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
def parse_qa_multiple_answer(string, setting_name):
|
| 171 |
+
if setting_name == 'few-shot-CoT':
|
| 172 |
+
string = extract_last_line(string)
|
| 173 |
+
pattern = '\(*([A-Z])\)*'
|
| 174 |
+
match = re.findall(pattern, string)
|
| 175 |
+
if match:
|
| 176 |
+
return match
|
| 177 |
+
return []
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
def post_process(dataset_name, setting_name, prediction):
|
| 181 |
+
if dataset_name in dataset_loader.english_cloze_datasets or dataset_name in dataset_loader.chinese_cloze_datasets:
|
| 182 |
+
return parse_math_answer(setting_name, prediction)
|
| 183 |
+
|
| 184 |
+
if dataset_name in ['jec-qa-kd', 'jec-qa-ca', 'gaokao-physics']:
|
| 185 |
+
return parse_qa_multiple_answer(prediction, setting_name)
|
| 186 |
+
|
| 187 |
+
# all other datasets are QA problems with single answer
|
| 188 |
+
if 'zero-shot' in setting_name:
|
| 189 |
+
answer = find_first_capital_letter(prediction)
|
| 190 |
+
return answer
|
| 191 |
+
|
| 192 |
+
# all other datasets are QA problems with single answer and setting_name are few-shot
|
| 193 |
+
language = 'en' if dataset_name in dataset_loader.english_qa_datasets else 'zh'
|
| 194 |
+
if dataset_name in dataset_loader.english_qa_datasets or dataset_name in dataset_loader.chinese_qa_datasets:
|
| 195 |
+
return parse_few_shot_qa_single_answer(prediction, setting_name,
|
| 196 |
+
language)
|
| 197 |
+
else:
|
| 198 |
+
raise ValueError(f'Unsupported dataset name {dataset_name}')
|
opencompass-my-api/build/lib/opencompass/datasets/agieval/utils.py
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# flake8: noqa
|
| 2 |
+
import json
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def read_jsonl(path):
|
| 6 |
+
with open(path, encoding='utf8') as fh:
|
| 7 |
+
results = []
|
| 8 |
+
for line in fh:
|
| 9 |
+
if line is None:
|
| 10 |
+
continue
|
| 11 |
+
try:
|
| 12 |
+
results.append(json.loads(line) if line != 'null' else line)
|
| 13 |
+
except Exception as e:
|
| 14 |
+
print(e)
|
| 15 |
+
print(path)
|
| 16 |
+
print(line)
|
| 17 |
+
raise e
|
| 18 |
+
return results
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def save_jsonl(lines, directory):
|
| 22 |
+
with open(directory, 'w', encoding='utf8') as f:
|
| 23 |
+
for line in lines:
|
| 24 |
+
f.write(json.dumps(line, ensure_ascii=False) + '\n')
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def extract_answer(js):
|
| 28 |
+
try:
|
| 29 |
+
if js is None or js == 'null':
|
| 30 |
+
return ''
|
| 31 |
+
answer = ''
|
| 32 |
+
if isinstance(js, str):
|
| 33 |
+
answer = js
|
| 34 |
+
elif 'text' in js['choices'][0]:
|
| 35 |
+
answer = js['choices'][0]['text']
|
| 36 |
+
else:
|
| 37 |
+
answer = js['choices'][0]['message']['content']
|
| 38 |
+
# answer = js['']
|
| 39 |
+
return answer
|
| 40 |
+
except Exception as e:
|
| 41 |
+
# print(e)
|
| 42 |
+
# print(js)
|
| 43 |
+
return ''
|
opencompass-my-api/build/lib/opencompass/datasets/anli.py
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
|
| 3 |
+
from datasets import Dataset
|
| 4 |
+
|
| 5 |
+
from .base import BaseDataset
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class AnliDataset(BaseDataset):
|
| 9 |
+
|
| 10 |
+
@staticmethod
|
| 11 |
+
def load(path: str):
|
| 12 |
+
dataset = []
|
| 13 |
+
with open(path, 'r') as f:
|
| 14 |
+
for line in f:
|
| 15 |
+
line = json.loads(line)
|
| 16 |
+
line['label'] = {'c': 'A', 'e': 'B', 'n': 'C'}[line['label']]
|
| 17 |
+
dataset.append(line)
|
| 18 |
+
return Dataset.from_list(dataset)
|
opencompass-my-api/build/lib/opencompass/datasets/anthropics_evals.py
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from datasets import load_dataset
|
| 2 |
+
|
| 3 |
+
from .base import BaseDataset
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class AiRiskDataset(BaseDataset):
|
| 7 |
+
|
| 8 |
+
@staticmethod
|
| 9 |
+
def load(path: str):
|
| 10 |
+
"""Load dataset."""
|
| 11 |
+
|
| 12 |
+
dataset = load_dataset('json', data_files=path)
|
| 13 |
+
|
| 14 |
+
def choices_process(example):
|
| 15 |
+
# the original answer format is ` (A)`, etc.
|
| 16 |
+
for i in 'ABCDEFGH':
|
| 17 |
+
if i in example['answer_matching_behavior']:
|
| 18 |
+
example['answer_matching_behavior'] = i
|
| 19 |
+
break
|
| 20 |
+
return example
|
| 21 |
+
|
| 22 |
+
dataset = dataset.map(choices_process)
|
| 23 |
+
return dataset
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class PersonaDataset(BaseDataset):
|
| 27 |
+
|
| 28 |
+
@staticmethod
|
| 29 |
+
def load(path: str):
|
| 30 |
+
"""Load dataset."""
|
| 31 |
+
|
| 32 |
+
dataset = load_dataset('json', data_files=path)
|
| 33 |
+
|
| 34 |
+
def choices_process(example):
|
| 35 |
+
# the original answer format is ` No` or ` Yes`.
|
| 36 |
+
if example['answer_matching_behavior'] == ' Yes':
|
| 37 |
+
example['answer_matching_behavior'] = 'A'
|
| 38 |
+
else:
|
| 39 |
+
example['answer_matching_behavior'] = 'B'
|
| 40 |
+
return example
|
| 41 |
+
|
| 42 |
+
dataset = dataset.map(choices_process)
|
| 43 |
+
return dataset
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
class SycophancyDataset(BaseDataset):
|
| 47 |
+
|
| 48 |
+
@staticmethod
|
| 49 |
+
def load(path: str):
|
| 50 |
+
"""Load dataset."""
|
| 51 |
+
|
| 52 |
+
dataset = load_dataset('json', data_files=path)
|
| 53 |
+
|
| 54 |
+
def choices_process(example):
|
| 55 |
+
# the original answer format is ` (A)`, etc.
|
| 56 |
+
for i in 'ABCDEFG':
|
| 57 |
+
if i in example['answer_matching_behavior']:
|
| 58 |
+
example['answer_matching_behavior'] = i
|
| 59 |
+
break
|
| 60 |
+
return example
|
| 61 |
+
|
| 62 |
+
dataset = dataset.map(choices_process)
|
| 63 |
+
return dataset
|
opencompass-my-api/build/lib/opencompass/datasets/arc.py
ADDED
|
@@ -0,0 +1,84 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import os.path as osp
|
| 3 |
+
|
| 4 |
+
from datasets import Dataset
|
| 5 |
+
|
| 6 |
+
from opencompass.registry import LOAD_DATASET
|
| 7 |
+
|
| 8 |
+
from .base import BaseDataset
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
@LOAD_DATASET.register_module()
|
| 12 |
+
class ARCDataset(BaseDataset):
|
| 13 |
+
|
| 14 |
+
@staticmethod
|
| 15 |
+
def load(path: str):
|
| 16 |
+
with open(path, 'r', errors='ignore') as in_f:
|
| 17 |
+
rows = []
|
| 18 |
+
for line in in_f:
|
| 19 |
+
item = json.loads(line.strip())
|
| 20 |
+
question = item['question']
|
| 21 |
+
if len(question['choices']) != 4:
|
| 22 |
+
continue
|
| 23 |
+
labels = [c['label'] for c in question['choices']]
|
| 24 |
+
answerKey = 'ABCD'[labels.index(item['answerKey'])]
|
| 25 |
+
rows.append({
|
| 26 |
+
'question': question['stem'],
|
| 27 |
+
'answerKey': answerKey,
|
| 28 |
+
'textA': question['choices'][0]['text'],
|
| 29 |
+
'textB': question['choices'][1]['text'],
|
| 30 |
+
'textC': question['choices'][2]['text'],
|
| 31 |
+
'textD': question['choices'][3]['text'],
|
| 32 |
+
})
|
| 33 |
+
return Dataset.from_list(rows)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
class ARCDatasetClean(BaseDataset):
|
| 37 |
+
|
| 38 |
+
# load the contamination annotations of CEval from
|
| 39 |
+
# https://github.com/liyucheng09/Contamination_Detector
|
| 40 |
+
@staticmethod
|
| 41 |
+
def load_contamination_annotations(path, split='val'):
|
| 42 |
+
import requests
|
| 43 |
+
|
| 44 |
+
assert split == 'test', 'We only have test set annotation for ARC'
|
| 45 |
+
annotation_cache_path = osp.join(
|
| 46 |
+
path, f'ARC_c_{split}_contamination_annotations.json')
|
| 47 |
+
if osp.exists(annotation_cache_path):
|
| 48 |
+
with open(annotation_cache_path, 'r') as f:
|
| 49 |
+
annotations = json.load(f)
|
| 50 |
+
return annotations
|
| 51 |
+
link_of_annotations = 'https://github.com/liyucheng09/Contamination_Detector/releases/download/v0.1.1rc/ARC_annotations.json' # noqa
|
| 52 |
+
annotations = json.loads(requests.get(link_of_annotations).text)
|
| 53 |
+
with open(annotation_cache_path, 'w') as f:
|
| 54 |
+
json.dump(annotations, f)
|
| 55 |
+
return annotations
|
| 56 |
+
|
| 57 |
+
@staticmethod
|
| 58 |
+
def load(path: str):
|
| 59 |
+
annotations = ARCDatasetClean.load_contamination_annotations(
|
| 60 |
+
osp.dirname(path), 'test')
|
| 61 |
+
with open(path, 'r', errors='ignore') as in_f:
|
| 62 |
+
rows = []
|
| 63 |
+
for line in in_f:
|
| 64 |
+
item = json.loads(line.strip())
|
| 65 |
+
id_ = item['id']
|
| 66 |
+
question = item['question']
|
| 67 |
+
if id_ in annotations:
|
| 68 |
+
is_clean = annotations[id_][0]
|
| 69 |
+
else:
|
| 70 |
+
is_clean = 'not labeled'
|
| 71 |
+
if len(question['choices']) != 4:
|
| 72 |
+
continue
|
| 73 |
+
labels = [c['label'] for c in question['choices']]
|
| 74 |
+
answerKey = 'ABCD'[labels.index(item['answerKey'])]
|
| 75 |
+
rows.append({
|
| 76 |
+
'question': question['stem'],
|
| 77 |
+
'answerKey': answerKey,
|
| 78 |
+
'textA': question['choices'][0]['text'],
|
| 79 |
+
'textB': question['choices'][1]['text'],
|
| 80 |
+
'textC': question['choices'][2]['text'],
|
| 81 |
+
'textD': question['choices'][3]['text'],
|
| 82 |
+
'is_clean': is_clean,
|
| 83 |
+
})
|
| 84 |
+
return Dataset.from_list(rows)
|
opencompass-my-api/build/lib/opencompass/datasets/ax.py
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
|
| 3 |
+
from datasets import Dataset
|
| 4 |
+
|
| 5 |
+
from opencompass.registry import LOAD_DATASET
|
| 6 |
+
|
| 7 |
+
from .base import BaseDataset
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
@LOAD_DATASET.register_module()
|
| 11 |
+
class AXDataset_V2(BaseDataset):
|
| 12 |
+
|
| 13 |
+
@staticmethod
|
| 14 |
+
def load(path: str):
|
| 15 |
+
dataset = []
|
| 16 |
+
with open(path, 'r') as f:
|
| 17 |
+
for line in f:
|
| 18 |
+
line = json.loads(line)
|
| 19 |
+
line['label'] = {
|
| 20 |
+
'entailment': 'A',
|
| 21 |
+
'not_entailment': 'B'
|
| 22 |
+
}[line['label']]
|
| 23 |
+
dataset.append(line)
|
| 24 |
+
return Dataset.from_list(dataset)
|
opencompass-my-api/build/lib/opencompass/datasets/base.py
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from abc import abstractstaticmethod
|
| 2 |
+
from typing import Dict, Optional, Union
|
| 3 |
+
|
| 4 |
+
from datasets import Dataset, DatasetDict
|
| 5 |
+
|
| 6 |
+
from opencompass.openicl import DatasetReader
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class BaseDataset:
|
| 10 |
+
|
| 11 |
+
def __init__(self, reader_cfg: Optional[Dict] = {}, **kwargs):
|
| 12 |
+
self.dataset = self.load(**kwargs)
|
| 13 |
+
self._init_reader(**reader_cfg)
|
| 14 |
+
|
| 15 |
+
def _init_reader(self, **kwargs):
|
| 16 |
+
self.reader = DatasetReader(self.dataset, **kwargs)
|
| 17 |
+
|
| 18 |
+
@property
|
| 19 |
+
def train(self):
|
| 20 |
+
return self.reader.dataset['train']
|
| 21 |
+
|
| 22 |
+
@property
|
| 23 |
+
def test(self):
|
| 24 |
+
return self.reader.dataset['test']
|
| 25 |
+
|
| 26 |
+
@abstractstaticmethod
|
| 27 |
+
def load(**kwargs) -> Union[Dataset, DatasetDict]:
|
| 28 |
+
pass
|
opencompass-my-api/build/lib/opencompass/datasets/bbh.py
ADDED
|
@@ -0,0 +1,98 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import os.path as osp
|
| 3 |
+
import re
|
| 4 |
+
|
| 5 |
+
from datasets import Dataset
|
| 6 |
+
|
| 7 |
+
from opencompass.openicl.icl_evaluator import BaseEvaluator
|
| 8 |
+
from opencompass.registry import (ICL_EVALUATORS, LOAD_DATASET,
|
| 9 |
+
TEXT_POSTPROCESSORS)
|
| 10 |
+
|
| 11 |
+
from .base import BaseDataset
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
@LOAD_DATASET.register_module()
|
| 15 |
+
class BBHDataset(BaseDataset):
|
| 16 |
+
|
| 17 |
+
@staticmethod
|
| 18 |
+
def load(path: str, name: str):
|
| 19 |
+
with open(osp.join(path, f'{name}.json'), 'r') as f:
|
| 20 |
+
data = json.load(f)['examples']
|
| 21 |
+
dataset = Dataset.from_list(data)
|
| 22 |
+
return dataset
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
@TEXT_POSTPROCESSORS.register_module('bbh-mcq')
|
| 26 |
+
def bbh_mcq_postprocess(text: str) -> str:
|
| 27 |
+
ans = text
|
| 28 |
+
ans_line = ans.split('answer is ')
|
| 29 |
+
if len(ans_line) != 1:
|
| 30 |
+
ans = ans_line[1].strip()
|
| 31 |
+
match = re.search(r'\(([A-Z])\)*', ans)
|
| 32 |
+
if match:
|
| 33 |
+
return match.group(1)
|
| 34 |
+
match = re.search(r'([A-Z])', ans)
|
| 35 |
+
if match:
|
| 36 |
+
return match.group(1)
|
| 37 |
+
return ans
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
@TEXT_POSTPROCESSORS.register_module('bbh-freeform')
|
| 41 |
+
def bbh_freeform_postprocess(text: str) -> str:
|
| 42 |
+
ans = text
|
| 43 |
+
ans_line = ans.split('answer is ')
|
| 44 |
+
if len(ans_line) != 1:
|
| 45 |
+
ans = ans_line[1].strip()
|
| 46 |
+
ans = ans.split('\n')[0]
|
| 47 |
+
if ans.endswith('.'):
|
| 48 |
+
ans = ans[:-1]
|
| 49 |
+
return ans
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
@ICL_EVALUATORS.register_module()
|
| 53 |
+
class BBHEvaluator(BaseEvaluator):
|
| 54 |
+
|
| 55 |
+
def score(self, predictions, references):
|
| 56 |
+
if len(predictions) != len(references):
|
| 57 |
+
return {
|
| 58 |
+
'error': 'predictions and references have different '
|
| 59 |
+
'length'
|
| 60 |
+
}
|
| 61 |
+
|
| 62 |
+
predictions = [bbh_freeform_postprocess(pred) for pred in predictions]
|
| 63 |
+
|
| 64 |
+
details = []
|
| 65 |
+
cnt = 0
|
| 66 |
+
for pred, ref in zip(predictions, references):
|
| 67 |
+
detail = {'pred': pred, 'answer': ref, 'correct': False}
|
| 68 |
+
if pred == ref:
|
| 69 |
+
cnt += 1
|
| 70 |
+
detail['correct'] = True
|
| 71 |
+
details.append(detail)
|
| 72 |
+
|
| 73 |
+
score = cnt / len(predictions) * 100
|
| 74 |
+
|
| 75 |
+
return {'score': score, 'details': details}
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
@ICL_EVALUATORS.register_module()
|
| 79 |
+
class BBHEvaluator_mcq(BaseEvaluator):
|
| 80 |
+
|
| 81 |
+
def score(self, predictions, references):
|
| 82 |
+
if len(predictions) != len(references):
|
| 83 |
+
return {
|
| 84 |
+
'error': 'predictions and references have different '
|
| 85 |
+
'length'
|
| 86 |
+
}
|
| 87 |
+
details = []
|
| 88 |
+
cnt = 0
|
| 89 |
+
for pred, ref in zip(predictions, references):
|
| 90 |
+
detail = {'pred': pred, 'answer': ref, 'correct': False}
|
| 91 |
+
if pred == ref:
|
| 92 |
+
cnt += 1
|
| 93 |
+
detail['correct'] = True
|
| 94 |
+
details.append(detail)
|
| 95 |
+
|
| 96 |
+
score = cnt / len(predictions) * 100
|
| 97 |
+
|
| 98 |
+
return {'score': score, 'details': details}
|
opencompass-my-api/build/lib/opencompass/datasets/boolq.py
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
|
| 3 |
+
from datasets import Dataset, load_dataset
|
| 4 |
+
|
| 5 |
+
from opencompass.registry import LOAD_DATASET
|
| 6 |
+
|
| 7 |
+
from .base import BaseDataset
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
@LOAD_DATASET.register_module()
|
| 11 |
+
class BoolQDataset(BaseDataset):
|
| 12 |
+
|
| 13 |
+
@staticmethod
|
| 14 |
+
def load(**kwargs):
|
| 15 |
+
dataset = load_dataset(**kwargs)
|
| 16 |
+
|
| 17 |
+
def preprocess(example):
|
| 18 |
+
if example['label'] == 'true':
|
| 19 |
+
example['answer'] = 1
|
| 20 |
+
else:
|
| 21 |
+
example['answer'] = 0
|
| 22 |
+
return example
|
| 23 |
+
|
| 24 |
+
dataset = dataset.map(preprocess)
|
| 25 |
+
return dataset
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
@LOAD_DATASET.register_module()
|
| 29 |
+
class BoolQDataset_V2(BaseDataset):
|
| 30 |
+
|
| 31 |
+
@staticmethod
|
| 32 |
+
def load(path):
|
| 33 |
+
dataset = []
|
| 34 |
+
with open(path, 'r') as f:
|
| 35 |
+
for line in f:
|
| 36 |
+
line = json.loads(line)
|
| 37 |
+
line['label'] = {'true': 'A', 'false': 'B'}[line['label']]
|
| 38 |
+
dataset.append(line)
|
| 39 |
+
return Dataset.from_list(dataset)
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
@LOAD_DATASET.register_module()
|
| 43 |
+
class BoolQDataset_V3(BaseDataset):
|
| 44 |
+
|
| 45 |
+
@staticmethod
|
| 46 |
+
def load(path):
|
| 47 |
+
dataset = []
|
| 48 |
+
with open(path, 'r') as f:
|
| 49 |
+
for line in f:
|
| 50 |
+
line = json.loads(line)
|
| 51 |
+
line['passage'] = ' -- '.join(
|
| 52 |
+
line['passage'].split(' -- ')[1:])
|
| 53 |
+
line['question'] = line['question'][0].upper(
|
| 54 |
+
) + line['question'][1:]
|
| 55 |
+
dataset.append(line)
|
| 56 |
+
return Dataset.from_list(dataset)
|
opencompass-my-api/build/lib/opencompass/datasets/bustum.py
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
|
| 3 |
+
from datasets import Dataset
|
| 4 |
+
|
| 5 |
+
from opencompass.registry import LOAD_DATASET
|
| 6 |
+
|
| 7 |
+
from .base import BaseDataset
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
@LOAD_DATASET.register_module()
|
| 11 |
+
class bustumDataset_V2(BaseDataset):
|
| 12 |
+
|
| 13 |
+
@staticmethod
|
| 14 |
+
def load(path):
|
| 15 |
+
data = []
|
| 16 |
+
with open(path, 'r', encoding='utf-8') as f:
|
| 17 |
+
for line in f:
|
| 18 |
+
line = json.loads(line)
|
| 19 |
+
line['label'] = 'AB'[int(line['label'])]
|
| 20 |
+
data.append(line)
|
| 21 |
+
return Dataset.from_list(data)
|
opencompass-my-api/build/lib/opencompass/datasets/c3.py
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
|
| 3 |
+
from datasets import Dataset
|
| 4 |
+
|
| 5 |
+
from opencompass.registry import LOAD_DATASET
|
| 6 |
+
|
| 7 |
+
from .base import BaseDataset
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
@LOAD_DATASET.register_module()
|
| 11 |
+
class C3Dataset(BaseDataset):
|
| 12 |
+
|
| 13 |
+
@staticmethod
|
| 14 |
+
def load(path: str):
|
| 15 |
+
|
| 16 |
+
with open(path, 'r', encoding='utf-8') as f:
|
| 17 |
+
data = json.load(f)
|
| 18 |
+
rows = []
|
| 19 |
+
for _, row in enumerate(data):
|
| 20 |
+
content = row[0]
|
| 21 |
+
content_str = ' '.join(
|
| 22 |
+
[''.join(paragraph) for paragraph in content])
|
| 23 |
+
|
| 24 |
+
for question in row[1]:
|
| 25 |
+
label = question['choice'].index(question['answer'])
|
| 26 |
+
length = len(question['choice'])
|
| 27 |
+
if length < 4:
|
| 28 |
+
fill_value = question['choice'][0] # 以第一个值为填充值
|
| 29 |
+
fill_count = 4 - length # 需要填充的数量
|
| 30 |
+
question['choice'] += [fill_value] * fill_count # 填充
|
| 31 |
+
|
| 32 |
+
rows.append({
|
| 33 |
+
'content': content_str,
|
| 34 |
+
'question': question['question'],
|
| 35 |
+
'choices': question['choice'],
|
| 36 |
+
'choice0': question['choice'][0],
|
| 37 |
+
'choice1': question['choice'][1],
|
| 38 |
+
'choice2': question['choice'][2],
|
| 39 |
+
'choice3': question['choice'][3],
|
| 40 |
+
'label': label
|
| 41 |
+
})
|
| 42 |
+
|
| 43 |
+
dataset = Dataset.from_dict({
|
| 44 |
+
'content': [row['content'] for row in rows],
|
| 45 |
+
'question': [row['question'] for row in rows],
|
| 46 |
+
'choice0': [row['choice0'] for row in rows],
|
| 47 |
+
'choice1': [row['choice1'] for row in rows],
|
| 48 |
+
'choice2': [row['choice2'] for row in rows],
|
| 49 |
+
'choice3': [row['choice3'] for row in rows],
|
| 50 |
+
'choices': [row['choices'] for row in rows],
|
| 51 |
+
'label': [row['label'] for row in rows]
|
| 52 |
+
})
|
| 53 |
+
return dataset
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
@LOAD_DATASET.register_module()
|
| 57 |
+
class C3Dataset_V2(BaseDataset):
|
| 58 |
+
|
| 59 |
+
@staticmethod
|
| 60 |
+
def load(path: str):
|
| 61 |
+
with open(path, 'r', encoding='utf-8') as f:
|
| 62 |
+
raw = json.load(f)
|
| 63 |
+
data = []
|
| 64 |
+
for line in raw:
|
| 65 |
+
content = ''.join([''.join(paragraph) for paragraph in line[0]])
|
| 66 |
+
for question in line[1]:
|
| 67 |
+
label = question['choice'].index(question['answer'])
|
| 68 |
+
label = 'ABCD'[label]
|
| 69 |
+
while len(question['choice']) < 4:
|
| 70 |
+
question['choice'].append('[NULL]')
|
| 71 |
+
data.append({
|
| 72 |
+
'content': content,
|
| 73 |
+
'question': question['question'],
|
| 74 |
+
'choice0': question['choice'][0],
|
| 75 |
+
'choice1': question['choice'][1],
|
| 76 |
+
'choice2': question['choice'][2],
|
| 77 |
+
'choice3': question['choice'][3],
|
| 78 |
+
'label': label
|
| 79 |
+
})
|
| 80 |
+
return Dataset.from_list(data)
|
opencompass-my-api/build/lib/opencompass/datasets/cb.py
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
|
| 3 |
+
from datasets import Dataset
|
| 4 |
+
|
| 5 |
+
from opencompass.registry import LOAD_DATASET
|
| 6 |
+
|
| 7 |
+
from .base import BaseDataset
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
@LOAD_DATASET.register_module()
|
| 11 |
+
class CBDataset_V2(BaseDataset):
|
| 12 |
+
|
| 13 |
+
@staticmethod
|
| 14 |
+
def load(path):
|
| 15 |
+
dataset = []
|
| 16 |
+
with open(path, 'r') as f:
|
| 17 |
+
for line in f:
|
| 18 |
+
line = json.loads(line)
|
| 19 |
+
line['label'] = {
|
| 20 |
+
'contradiction': 'A',
|
| 21 |
+
'entailment': 'B',
|
| 22 |
+
'neutral': 'C'
|
| 23 |
+
}[line['label']]
|
| 24 |
+
dataset.append(line)
|
| 25 |
+
return Dataset.from_list(dataset)
|
opencompass-my-api/build/lib/opencompass/datasets/ceval.py
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import csv
|
| 2 |
+
import json
|
| 3 |
+
import os.path as osp
|
| 4 |
+
|
| 5 |
+
from datasets import Dataset, DatasetDict
|
| 6 |
+
|
| 7 |
+
from opencompass.registry import LOAD_DATASET
|
| 8 |
+
|
| 9 |
+
from .base import BaseDataset
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
@LOAD_DATASET.register_module()
|
| 13 |
+
class CEvalDataset(BaseDataset):
|
| 14 |
+
|
| 15 |
+
@staticmethod
|
| 16 |
+
def load(path: str, name: str):
|
| 17 |
+
dataset = {}
|
| 18 |
+
for split in ['dev', 'val', 'test']:
|
| 19 |
+
filename = osp.join(path, split, f'{name}_{split}.csv')
|
| 20 |
+
with open(filename, encoding='utf-8') as f:
|
| 21 |
+
reader = csv.reader(f)
|
| 22 |
+
header = next(reader)
|
| 23 |
+
for row in reader:
|
| 24 |
+
item = dict(zip(header, row))
|
| 25 |
+
item.setdefault('explanation', '')
|
| 26 |
+
item.setdefault('answer', '')
|
| 27 |
+
dataset.setdefault(split, []).append(item)
|
| 28 |
+
dataset = {i: Dataset.from_list(dataset[i]) for i in dataset}
|
| 29 |
+
return DatasetDict(dataset)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
class CEvalDatasetClean(BaseDataset):
|
| 33 |
+
|
| 34 |
+
# load the contamination annotations of CEval from
|
| 35 |
+
# https://github.com/liyucheng09/Contamination_Detector
|
| 36 |
+
@staticmethod
|
| 37 |
+
def load_contamination_annotations(path, split='val'):
|
| 38 |
+
import requests
|
| 39 |
+
|
| 40 |
+
assert split == 'val', 'Now we only have annotations for val set'
|
| 41 |
+
annotation_cache_path = osp.join(
|
| 42 |
+
path, split, 'ceval_contamination_annotations.json')
|
| 43 |
+
if osp.exists(annotation_cache_path):
|
| 44 |
+
with open(annotation_cache_path, 'r') as f:
|
| 45 |
+
annotations = json.load(f)
|
| 46 |
+
return annotations
|
| 47 |
+
link_of_annotations = 'https://github.com/liyucheng09/Contamination_Detector/releases/download/v0.1.1rc/ceval_annotations.json' # noqa
|
| 48 |
+
annotations = json.loads(requests.get(link_of_annotations).text)
|
| 49 |
+
with open(annotation_cache_path, 'w') as f:
|
| 50 |
+
json.dump(annotations, f)
|
| 51 |
+
return annotations
|
| 52 |
+
|
| 53 |
+
@staticmethod
|
| 54 |
+
def load(path: str, name: str):
|
| 55 |
+
dataset = {}
|
| 56 |
+
for split in ['dev', 'val', 'test']:
|
| 57 |
+
if split == 'val':
|
| 58 |
+
annotations = CEvalDatasetClean.load_contamination_annotations(
|
| 59 |
+
path, split)
|
| 60 |
+
filename = osp.join(path, split, f'{name}_{split}.csv')
|
| 61 |
+
with open(filename, encoding='utf-8') as f:
|
| 62 |
+
reader = csv.reader(f)
|
| 63 |
+
header = next(reader)
|
| 64 |
+
for row_index, row in enumerate(reader):
|
| 65 |
+
item = dict(zip(header, row))
|
| 66 |
+
item.setdefault('explanation', '')
|
| 67 |
+
item.setdefault('answer', '')
|
| 68 |
+
if split == 'val':
|
| 69 |
+
row_id = f'{name}-{row_index}'
|
| 70 |
+
if row_id in annotations:
|
| 71 |
+
item['is_clean'] = annotations[row_id][0]
|
| 72 |
+
else:
|
| 73 |
+
item['is_clean'] = 'not labeled'
|
| 74 |
+
dataset.setdefault(split, []).append(item)
|
| 75 |
+
dataset = {i: Dataset.from_list(dataset[i]) for i in dataset}
|
| 76 |
+
return DatasetDict(dataset)
|
opencompass-my-api/build/lib/opencompass/datasets/chid.py
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
|
| 3 |
+
from datasets import Dataset, load_dataset
|
| 4 |
+
|
| 5 |
+
from opencompass.registry import LOAD_DATASET
|
| 6 |
+
|
| 7 |
+
from .base import BaseDataset
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
@LOAD_DATASET.register_module()
|
| 11 |
+
class CHIDDataset(BaseDataset):
|
| 12 |
+
|
| 13 |
+
@staticmethod
|
| 14 |
+
def load(**kwargs):
|
| 15 |
+
|
| 16 |
+
dataset = load_dataset(**kwargs)
|
| 17 |
+
|
| 18 |
+
def preprocess(example):
|
| 19 |
+
content = example['content']
|
| 20 |
+
for i, c in enumerate(example['candidates']):
|
| 21 |
+
example[f'content{i}'] = content.replace('#idiom#', c)
|
| 22 |
+
return example
|
| 23 |
+
|
| 24 |
+
dataset = dataset.map(preprocess)
|
| 25 |
+
return dataset
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
@LOAD_DATASET.register_module()
|
| 29 |
+
class CHIDDataset_V2(BaseDataset):
|
| 30 |
+
|
| 31 |
+
@staticmethod
|
| 32 |
+
def load(path):
|
| 33 |
+
data = []
|
| 34 |
+
with open(path, 'r', encoding='utf-8') as f:
|
| 35 |
+
for line in f:
|
| 36 |
+
line = json.loads(line)
|
| 37 |
+
item = {}
|
| 38 |
+
item['content'] = line['content'].replace('#idiom#', '______')
|
| 39 |
+
for i, c in enumerate(line['candidates']):
|
| 40 |
+
item[chr(ord('A') + i)] = c
|
| 41 |
+
item['answer'] = 'ABCDEFG'[line['answer']]
|
| 42 |
+
data.append(item)
|
| 43 |
+
return Dataset.from_list(data)
|
opencompass-my-api/build/lib/opencompass/datasets/cibench.py
ADDED
|
@@ -0,0 +1,511 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import os
|
| 3 |
+
import os.path as osp
|
| 4 |
+
import re
|
| 5 |
+
import subprocess
|
| 6 |
+
from collections import defaultdict
|
| 7 |
+
from typing import List, Optional
|
| 8 |
+
|
| 9 |
+
import numpy as np
|
| 10 |
+
from datasets import Dataset
|
| 11 |
+
|
| 12 |
+
from opencompass.openicl.icl_evaluator import BaseEvaluator
|
| 13 |
+
from opencompass.registry import ICL_EVALUATORS, LOAD_DATASET
|
| 14 |
+
|
| 15 |
+
from .base import BaseDataset
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def load_experiment(file: str) -> dict:
|
| 19 |
+
"""Load single experiment file with solutions."""
|
| 20 |
+
with open(file, 'r') as f:
|
| 21 |
+
notebook = json.load(f)
|
| 22 |
+
example = notebook['cells']
|
| 23 |
+
metadata = notebook['metadata']
|
| 24 |
+
modules = metadata.get('modules', [])
|
| 25 |
+
if modules:
|
| 26 |
+
# these two annotations should be the same
|
| 27 |
+
assert len(modules) == len(metadata.get('step_types'))
|
| 28 |
+
# reformat annotations
|
| 29 |
+
modules = [[_m.strip() for _m in _modules.split('&')]
|
| 30 |
+
for _modules in modules]
|
| 31 |
+
questions = []
|
| 32 |
+
source_codes = []
|
| 33 |
+
outputs = []
|
| 34 |
+
tags = []
|
| 35 |
+
for cell in example:
|
| 36 |
+
if cell['cell_type'] == 'markdown':
|
| 37 |
+
text = ''.join(cell['source']).strip()
|
| 38 |
+
if modules:
|
| 39 |
+
_modules = modules.pop(0)
|
| 40 |
+
text += f"Please use {' and '.join(_modules)} modules."
|
| 41 |
+
text = text.strip() + '\n'
|
| 42 |
+
# append the formatted text
|
| 43 |
+
questions.append(text)
|
| 44 |
+
elif cell['cell_type'] == 'code':
|
| 45 |
+
source_codes.append(''.join(cell['source']))
|
| 46 |
+
if cell['outputs'] and 'data' in cell['outputs'][-1]:
|
| 47 |
+
if 'image/png' in cell['outputs'][-1]['data']:
|
| 48 |
+
# skip vis temporarily due to lack of evaluation
|
| 49 |
+
tags.append('vis')
|
| 50 |
+
outputs.append(
|
| 51 |
+
cell['outputs'][-1]['data']['image/png'])
|
| 52 |
+
elif 'text/plain' in cell['outputs'][-1]['data']:
|
| 53 |
+
tags.append('general')
|
| 54 |
+
outputs.append(''.join(
|
| 55 |
+
cell['outputs'][-1]['data']['text/plain']))
|
| 56 |
+
else:
|
| 57 |
+
tags.append('exec')
|
| 58 |
+
outputs.append(None)
|
| 59 |
+
return dict(
|
| 60 |
+
experiment=file,
|
| 61 |
+
questions=sum(([
|
| 62 |
+
dict(role='user', content=question),
|
| 63 |
+
dict(role='assistant', content=source_code)
|
| 64 |
+
] for question, source_code in zip(questions, source_codes)), []),
|
| 65 |
+
references=dict(outputs=outputs,
|
| 66 |
+
tags=tags,
|
| 67 |
+
metadata=metadata,
|
| 68 |
+
experiment=file),
|
| 69 |
+
)
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def load_experiment_template(file: str) -> dict:
|
| 73 |
+
"""Load single experiment file with solutions for template experiment."""
|
| 74 |
+
with open(file, 'r') as f:
|
| 75 |
+
notebook = json.load(f)
|
| 76 |
+
example = notebook['cells']
|
| 77 |
+
metadata = notebook['metadata']
|
| 78 |
+
modules = metadata.get('modules', [])
|
| 79 |
+
if modules:
|
| 80 |
+
# these two annotations should be the same
|
| 81 |
+
assert len(modules) == len(metadata.get('step_types'))
|
| 82 |
+
# reformat annotations
|
| 83 |
+
modules = [[_m.strip() for _m in _modules.split('&')]
|
| 84 |
+
for _modules in modules]
|
| 85 |
+
questions = []
|
| 86 |
+
source_codes = []
|
| 87 |
+
outputs = []
|
| 88 |
+
tags = []
|
| 89 |
+
for cell in example:
|
| 90 |
+
if cell['cell_type'] == 'markdown':
|
| 91 |
+
text = ''.join(cell['source']).strip()
|
| 92 |
+
if modules:
|
| 93 |
+
_modules = modules.pop(0)
|
| 94 |
+
if 'chinese' not in file:
|
| 95 |
+
text += f"Please use {' and '.join(_modules)} modules."
|
| 96 |
+
else:
|
| 97 |
+
text += f"请用 {' 和 '.join(_modules)} 模块."
|
| 98 |
+
text = text.strip() + '\n'
|
| 99 |
+
# append the formatted text
|
| 100 |
+
questions.append(text)
|
| 101 |
+
elif cell['cell_type'] == 'code':
|
| 102 |
+
source_codes.append(''.join(cell['source']))
|
| 103 |
+
output_flag = False
|
| 104 |
+
if cell['outputs']:
|
| 105 |
+
for _output in cell['outputs']:
|
| 106 |
+
if _output['output_type'] == 'display_data':
|
| 107 |
+
assert not output_flag
|
| 108 |
+
if 'image/png' in _output['data']:
|
| 109 |
+
output_flag = True
|
| 110 |
+
tags.append('vis')
|
| 111 |
+
outputs.append(_output['data']['image/png'])
|
| 112 |
+
for _output in cell['outputs'][::-1]:
|
| 113 |
+
if output_flag:
|
| 114 |
+
break
|
| 115 |
+
if _output['output_type'] == 'stream' and _output[
|
| 116 |
+
'name'] == 'stdout':
|
| 117 |
+
assert not output_flag
|
| 118 |
+
output_flag = True
|
| 119 |
+
tags.append('general')
|
| 120 |
+
outputs.append(''.join(_output['text']))
|
| 121 |
+
elif _output['output_type'] == 'execute_result':
|
| 122 |
+
assert not output_flag
|
| 123 |
+
output_flag = True
|
| 124 |
+
tags.append('general')
|
| 125 |
+
outputs.append(''.join(
|
| 126 |
+
_output['data']['text/plain']))
|
| 127 |
+
if not output_flag:
|
| 128 |
+
# no output fallback to exec
|
| 129 |
+
tags.append('exec')
|
| 130 |
+
outputs.append(None)
|
| 131 |
+
return dict(
|
| 132 |
+
experiment=file,
|
| 133 |
+
questions=sum(([
|
| 134 |
+
dict(role='user', content=question),
|
| 135 |
+
dict(role='assistant', content=source_code)
|
| 136 |
+
] for question, source_code in zip(questions, source_codes)), []),
|
| 137 |
+
references=dict(outputs=outputs,
|
| 138 |
+
tags=tags,
|
| 139 |
+
metadata=metadata,
|
| 140 |
+
experiment=file),
|
| 141 |
+
)
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
def check_internet():
|
| 145 |
+
"""A tricky way to check internet."""
|
| 146 |
+
import socket
|
| 147 |
+
|
| 148 |
+
import nltk
|
| 149 |
+
socket.setdefaulttimeout(10)
|
| 150 |
+
ret = nltk.download('stopwords', quiet=True)
|
| 151 |
+
socket.setdefaulttimeout(None)
|
| 152 |
+
if not ret:
|
| 153 |
+
raise ConnectionError('CIBench needs internet to get response. Please'
|
| 154 |
+
'check your internet and proxy.')
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
@LOAD_DATASET.register_module()
|
| 158 |
+
class CIBenchDataset(BaseDataset):
|
| 159 |
+
"""Code Interpreter dataset."""
|
| 160 |
+
|
| 161 |
+
@staticmethod
|
| 162 |
+
def load(path: str, internet_check: bool = False):
|
| 163 |
+
"""Load whole dataset.
|
| 164 |
+
|
| 165 |
+
Args:
|
| 166 |
+
path(str): Path of cibench dataset.
|
| 167 |
+
internet_check(bool): Whether to check internet.
|
| 168 |
+
Defaults to False.
|
| 169 |
+
"""
|
| 170 |
+
if internet_check:
|
| 171 |
+
check_internet()
|
| 172 |
+
assert os.path.exists(path), f'Path {path} does not exist.'
|
| 173 |
+
data_list = []
|
| 174 |
+
for cwd, dirs, files in os.walk(path):
|
| 175 |
+
dirs.sort()
|
| 176 |
+
files.sort()
|
| 177 |
+
for f in files:
|
| 178 |
+
if '.ipynb' in f:
|
| 179 |
+
data = load_experiment(os.path.join(cwd, f))
|
| 180 |
+
data_list.append(data)
|
| 181 |
+
|
| 182 |
+
dataset = Dataset.from_list(data_list)
|
| 183 |
+
return dataset
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
@LOAD_DATASET.register_module()
|
| 187 |
+
class CIBenchTemplateDataset(BaseDataset):
|
| 188 |
+
"""Code Interpreter dataset for template dataset."""
|
| 189 |
+
|
| 190 |
+
@staticmethod
|
| 191 |
+
def load(path: str, internet_check: bool = False):
|
| 192 |
+
"""Load whole dataset.
|
| 193 |
+
|
| 194 |
+
Args:
|
| 195 |
+
path(str): Path of cibench dataset.
|
| 196 |
+
internet_check(bool): Whether to check internet.
|
| 197 |
+
Defaults to False.
|
| 198 |
+
"""
|
| 199 |
+
if internet_check:
|
| 200 |
+
check_internet()
|
| 201 |
+
assert os.path.exists(path), f'Path {path} does not exist.'
|
| 202 |
+
data_list = []
|
| 203 |
+
for cwd, dirs, files in os.walk(path):
|
| 204 |
+
dirs.sort()
|
| 205 |
+
files.sort()
|
| 206 |
+
for f in files:
|
| 207 |
+
if '.ipynb' in f:
|
| 208 |
+
data = load_experiment_template(os.path.join(cwd, f))
|
| 209 |
+
data_list.append(data)
|
| 210 |
+
|
| 211 |
+
dataset = Dataset.from_list(data_list)
|
| 212 |
+
return dataset
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
class CIBenchEvaluator(BaseEvaluator):
|
| 216 |
+
"""Evaluator for CI dataset.
|
| 217 |
+
|
| 218 |
+
Args:
|
| 219 |
+
text_evaluator (optional, dict): The text evaluator for text result
|
| 220 |
+
comparison[]. Defaults to None, which use Rouge as defaults.
|
| 221 |
+
Please notice that a extra key for `metric_name` should be set
|
| 222 |
+
to get the exact metric result, such as `rouge1`.
|
| 223 |
+
output_dir (optional, str): The directory to save experiment
|
| 224 |
+
files in a markdown or notebook format.
|
| 225 |
+
with_ipynb (bool): Generate ipynb correspondingly.
|
| 226 |
+
Defaults to False.
|
| 227 |
+
user_data_dir (str): The directory to load local files.
|
| 228 |
+
Defaults to 'ENV', which means use environment variable
|
| 229 |
+
`USER_DATA_DIR` to get the data dir.
|
| 230 |
+
"""
|
| 231 |
+
|
| 232 |
+
def __init__(self,
|
| 233 |
+
text_evaluator: Optional[dict] = None,
|
| 234 |
+
output_dir: Optional[str] = None,
|
| 235 |
+
with_ipynb: bool = False,
|
| 236 |
+
user_data_dir: str = 'ENV') -> None:
|
| 237 |
+
if text_evaluator is None:
|
| 238 |
+
from opencompass.openicl.icl_evaluator import RougeEvaluator
|
| 239 |
+
self.text_evaluator = ICL_EVALUATORS.build(
|
| 240 |
+
dict(type=RougeEvaluator))
|
| 241 |
+
self.text_eval_metric = 'rouge1'
|
| 242 |
+
else:
|
| 243 |
+
self.text_eval_metric = text_evaluator.pop('metric_name')
|
| 244 |
+
self.text_evaluator = ICL_EVALUATORS.build(text_evaluator)
|
| 245 |
+
# TODO: should use work dir for this task.
|
| 246 |
+
self.output_dir = output_dir
|
| 247 |
+
self.user_data_dir = self.check_user_data_dir(user_data_dir)
|
| 248 |
+
self.with_ipynb = with_ipynb
|
| 249 |
+
self.TAG_MAPPING = {
|
| 250 |
+
'exec': ('executable', self.valid_step),
|
| 251 |
+
'general': ('general_correct', self.correct_step),
|
| 252 |
+
'num': ('numeric_correct', self.correct_step),
|
| 253 |
+
'text': ('text_score', self.text_step),
|
| 254 |
+
'vis': ('vis_sim', self.vis_similarity_step),
|
| 255 |
+
}
|
| 256 |
+
|
| 257 |
+
def check_user_data_dir(self, user_data_dir):
|
| 258 |
+
if user_data_dir == 'ENV':
|
| 259 |
+
default_path = osp.abspath('./data/cibench_dataset/datasources')
|
| 260 |
+
user_data_dir = os.environ.get('USER_DATA_DIR', default_path)
|
| 261 |
+
user_data_dir = user_data_dir.rstrip('/')
|
| 262 |
+
basename = osp.basename(user_data_dir)
|
| 263 |
+
if basename and basename != 'data':
|
| 264 |
+
user_data_dir = osp.join(user_data_dir, 'data')
|
| 265 |
+
assert osp.exists(user_data_dir), \
|
| 266 |
+
f'a subfolder named `data` should exist under {user_data_dir}.'
|
| 267 |
+
elif basename:
|
| 268 |
+
assert osp.exists(user_data_dir), \
|
| 269 |
+
f'{user_data_dir} does not exist.'
|
| 270 |
+
return user_data_dir
|
| 271 |
+
|
| 272 |
+
@staticmethod
|
| 273 |
+
def valid_step(step):
|
| 274 |
+
"""Whether the step is executable and valid."""
|
| 275 |
+
# Found the latest code interpreter to determine valid
|
| 276 |
+
for action in step[::-1]:
|
| 277 |
+
if action['type'] == 'IPythonInterpreter':
|
| 278 |
+
if action['errmsg']:
|
| 279 |
+
return False
|
| 280 |
+
else:
|
| 281 |
+
return True
|
| 282 |
+
# No code interpreter for this step, reckon as False
|
| 283 |
+
return False
|
| 284 |
+
|
| 285 |
+
@staticmethod
|
| 286 |
+
def correct_step(step, target):
|
| 287 |
+
"""Whether the step output is correct."""
|
| 288 |
+
# Found the latest code interpreter to determine correct
|
| 289 |
+
for action in step[::-1]:
|
| 290 |
+
if action['type'] == 'IPythonInterpreter':
|
| 291 |
+
if action['result']:
|
| 292 |
+
try:
|
| 293 |
+
pred = action['result']['text']
|
| 294 |
+
match_exec = re.search(
|
| 295 |
+
'execute_result:\n\n```\n(.*?)\n```', pred,
|
| 296 |
+
re.DOTALL)
|
| 297 |
+
match_stdout = re.search('stdout:\n\n```\n(.*?)\n```',
|
| 298 |
+
pred, re.DOTALL)
|
| 299 |
+
# get pred result from execute_result by default
|
| 300 |
+
# else stdout
|
| 301 |
+
if match_exec and match_stdout:
|
| 302 |
+
match = match_exec
|
| 303 |
+
elif match_exec:
|
| 304 |
+
match = match_exec
|
| 305 |
+
elif match_stdout:
|
| 306 |
+
match = match_stdout
|
| 307 |
+
else:
|
| 308 |
+
match = None
|
| 309 |
+
if match:
|
| 310 |
+
out = match.group(1)
|
| 311 |
+
score = (out.strip() == target.strip()
|
| 312 |
+
or target.strip() in out.strip())
|
| 313 |
+
return score
|
| 314 |
+
except Exception:
|
| 315 |
+
return False
|
| 316 |
+
# Fall back to False
|
| 317 |
+
return False
|
| 318 |
+
|
| 319 |
+
def text_step(self, step, target):
|
| 320 |
+
"""Whether the step output is correct."""
|
| 321 |
+
# Found the latest code interpreter to determine correct
|
| 322 |
+
for action in step[::-1]:
|
| 323 |
+
if action['type'] == 'IPythonInterpreter':
|
| 324 |
+
if action['result']:
|
| 325 |
+
try:
|
| 326 |
+
pred = action['result']['text']
|
| 327 |
+
match = re.search('```\n(.*?)\n```', pred, re.DOTALL)
|
| 328 |
+
if match:
|
| 329 |
+
out = match.group(1)
|
| 330 |
+
score = self.text_evaluator.score([out], [target])
|
| 331 |
+
return score[self.text_eval_metric] / 100
|
| 332 |
+
except Exception:
|
| 333 |
+
return False
|
| 334 |
+
# Fall back to False
|
| 335 |
+
return False
|
| 336 |
+
|
| 337 |
+
@staticmethod
|
| 338 |
+
def vis_similarity_step(step, target):
|
| 339 |
+
"""Whether the step output image has the same structure similarity with
|
| 340 |
+
the given images."""
|
| 341 |
+
# Found the latest code interpreter to determine correct
|
| 342 |
+
import base64
|
| 343 |
+
|
| 344 |
+
import skimage
|
| 345 |
+
|
| 346 |
+
for action in step[::-1]:
|
| 347 |
+
if action['type'] == 'IPythonInterpreter':
|
| 348 |
+
if action['result']:
|
| 349 |
+
try:
|
| 350 |
+
pred = action['result']['text']
|
| 351 |
+
match = re.search(r'!\[fig-[0-9]*\]\((.*?)\)', pred,
|
| 352 |
+
re.DOTALL)
|
| 353 |
+
if match:
|
| 354 |
+
img_pred = match.group(1)
|
| 355 |
+
img2 = base64.b64decode(target)
|
| 356 |
+
img2 = skimage.io.imread(img2, plugin='imageio')
|
| 357 |
+
img1 = skimage.io.imread(img_pred, plugin='imageio')
|
| 358 |
+
img1 = skimage.transform.resize(img1, img2.shape[:2])
|
| 359 |
+
img1 = 255 * img1
|
| 360 |
+
# Convert to integer data type pixels.
|
| 361 |
+
img1 = img1.astype(np.uint8)
|
| 362 |
+
ssim = skimage.metrics.structural_similarity(
|
| 363 |
+
img1, img2, channel_axis=-1)
|
| 364 |
+
# mse = skimage.metrics.mean_squared_error(img1, img2)
|
| 365 |
+
# ssim greater better
|
| 366 |
+
# mse smaller better but has no upper bound
|
| 367 |
+
return ssim
|
| 368 |
+
except Exception:
|
| 369 |
+
return 0
|
| 370 |
+
# Fall back to 0
|
| 371 |
+
return 0
|
| 372 |
+
|
| 373 |
+
def save_results(self, origin_prompt, steps):
|
| 374 |
+
"""Save the prediction result in a markdown and notebook format."""
|
| 375 |
+
|
| 376 |
+
def check_jupytext():
|
| 377 |
+
"""Check requirements existence."""
|
| 378 |
+
from shutil import which
|
| 379 |
+
|
| 380 |
+
assert which('jupytext'), (
|
| 381 |
+
"Please install jupytext use 'pip install jupytext' to ensure"
|
| 382 |
+
'the conversion processes.')
|
| 383 |
+
|
| 384 |
+
check_jupytext()
|
| 385 |
+
p_list = []
|
| 386 |
+
from opencompass.lagent.actions.ipython_interpreter import extract_code
|
| 387 |
+
for idx, (example_origin_prompt,
|
| 388 |
+
example_steps) in enumerate(zip(origin_prompt, steps)):
|
| 389 |
+
markdown_lines = []
|
| 390 |
+
for prompt, step in zip(example_origin_prompt, example_steps):
|
| 391 |
+
for action in step[::-1]:
|
| 392 |
+
if action['type'] == 'IPythonInterpreter':
|
| 393 |
+
valid_action = action
|
| 394 |
+
break
|
| 395 |
+
# fall back to final action
|
| 396 |
+
valid_action = step[-1]
|
| 397 |
+
markdown_lines.append(prompt)
|
| 398 |
+
markdown_lines.append('\n')
|
| 399 |
+
code_text = valid_action['args']['text']
|
| 400 |
+
code_text = extract_code(code_text)
|
| 401 |
+
code_text = '```python\n' + code_text + '\n```'
|
| 402 |
+
markdown_lines.append(code_text)
|
| 403 |
+
markdown_lines.append('\n')
|
| 404 |
+
|
| 405 |
+
md_file = f'experiment{idx}.md'
|
| 406 |
+
with open(md_file, 'w') as f:
|
| 407 |
+
f.writelines(markdown_lines)
|
| 408 |
+
|
| 409 |
+
# TODO: be careful for this
|
| 410 |
+
# The result might be different with infer process
|
| 411 |
+
# please check carefully
|
| 412 |
+
# convert markdown to ipynb and exectue with error tolerance
|
| 413 |
+
if self.with_ipynb:
|
| 414 |
+
p = subprocess.Popen(
|
| 415 |
+
'jupytext --to ipynb --pipe-fmt ipynb '
|
| 416 |
+
"--pipe 'jupyter nbconvert --to ipynb --execute "
|
| 417 |
+
f"--allow-errors --stdin --stdout' {md_file}",
|
| 418 |
+
shell=True)
|
| 419 |
+
p_list.append(p)
|
| 420 |
+
# TODO: async wait
|
| 421 |
+
for p in p_list:
|
| 422 |
+
p.wait()
|
| 423 |
+
|
| 424 |
+
def set_data_dir(self, work_dir):
|
| 425 |
+
"""Set work directory and link data files for save notebook results."""
|
| 426 |
+
if self.user_data_dir:
|
| 427 |
+
basename = osp.basename(self.user_data_dir)
|
| 428 |
+
|
| 429 |
+
if not osp.exists(osp.join(self.output_dir, basename)):
|
| 430 |
+
os.symlink(self.user_data_dir,
|
| 431 |
+
osp.join(self.output_dir, basename))
|
| 432 |
+
os.chdir(work_dir)
|
| 433 |
+
|
| 434 |
+
def unset_data_dir(self, work_dir):
|
| 435 |
+
"""Change work directory and keep the symlink."""
|
| 436 |
+
os.chdir(work_dir)
|
| 437 |
+
|
| 438 |
+
def single_exp(self, gold, steps):
|
| 439 |
+
tags = gold['tags']
|
| 440 |
+
outputs = gold['outputs']
|
| 441 |
+
metadata = gold['metadata']
|
| 442 |
+
hard_tags = metadata.get('step_types', [])
|
| 443 |
+
if hard_tags:
|
| 444 |
+
tags = hard_tags
|
| 445 |
+
|
| 446 |
+
# executable: exec succeed
|
| 447 |
+
# general_correct: general correct
|
| 448 |
+
# numeric_correct: numerical correct
|
| 449 |
+
# text_score: text score
|
| 450 |
+
# vis_sim: visual similarity
|
| 451 |
+
|
| 452 |
+
# create empty results
|
| 453 |
+
result = dict()
|
| 454 |
+
if hard_tags:
|
| 455 |
+
check_tags = ['exec', 'num', 'text', 'vis']
|
| 456 |
+
else:
|
| 457 |
+
check_tags = ['exec', 'general', 'vis']
|
| 458 |
+
for tag in check_tags:
|
| 459 |
+
key = self.TAG_MAPPING[tag][0]
|
| 460 |
+
result[key] = []
|
| 461 |
+
|
| 462 |
+
for tag, step, output in zip(tags, steps, outputs):
|
| 463 |
+
# check whether this step is valid
|
| 464 |
+
result['executable'].append(self.valid_step(step))
|
| 465 |
+
if tag != 'exec':
|
| 466 |
+
key, func = self.TAG_MAPPING[tag]
|
| 467 |
+
result[key].append(func(step, output))
|
| 468 |
+
|
| 469 |
+
return result
|
| 470 |
+
|
| 471 |
+
def get_output_dir(self):
|
| 472 |
+
"""Get output dir from eval task.
|
| 473 |
+
|
| 474 |
+
Notice: output dir should be in format xxx/data.
|
| 475 |
+
All the needed files should be
|
| 476 |
+
"""
|
| 477 |
+
# hard hack for get output dir from eval task
|
| 478 |
+
if hasattr(self, '_out_dir') and self.output_dir is None:
|
| 479 |
+
self.output_dir = self._out_dir
|
| 480 |
+
|
| 481 |
+
def score(self, predictions: List, references: List, steps: List,
|
| 482 |
+
origin_prompt: List):
|
| 483 |
+
"""Calculate accuracy."""
|
| 484 |
+
if len(steps) != len(references):
|
| 485 |
+
return {'error': 'steps and refrs have different length'}
|
| 486 |
+
cwd = os.getcwd()
|
| 487 |
+
self.get_output_dir()
|
| 488 |
+
if self.output_dir:
|
| 489 |
+
if not osp.exists(self.output_dir):
|
| 490 |
+
os.makedirs(self.output_dir)
|
| 491 |
+
self.set_data_dir(self.output_dir)
|
| 492 |
+
self.save_results(origin_prompt, steps)
|
| 493 |
+
self.unset_data_dir(cwd)
|
| 494 |
+
|
| 495 |
+
total_results = defaultdict(float)
|
| 496 |
+
total_scores = defaultdict(float)
|
| 497 |
+
total_nums = defaultdict(int)
|
| 498 |
+
for gold, single_steps in zip(references, steps):
|
| 499 |
+
result = self.single_exp(gold, single_steps)
|
| 500 |
+
|
| 501 |
+
for k, v in result.items():
|
| 502 |
+
total_scores[k] += sum(v)
|
| 503 |
+
total_nums[k] += len(v)
|
| 504 |
+
|
| 505 |
+
for k, v in total_scores.items():
|
| 506 |
+
if total_nums[k] > 0:
|
| 507 |
+
total_results[k] = total_scores[k] / total_nums[k] * 100
|
| 508 |
+
else:
|
| 509 |
+
total_results[k] = -1
|
| 510 |
+
|
| 511 |
+
return total_results
|
opencompass-my-api/build/lib/opencompass/datasets/circular.py
ADDED
|
@@ -0,0 +1,373 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import copy
|
| 2 |
+
import itertools
|
| 3 |
+
from typing import Callable, List, Optional, Union
|
| 4 |
+
|
| 5 |
+
from datasets import Dataset, DatasetDict
|
| 6 |
+
|
| 7 |
+
from opencompass.openicl.icl_evaluator import BaseEvaluator
|
| 8 |
+
|
| 9 |
+
from .arc import ARCDataset
|
| 10 |
+
from .ceval import CEvalDataset
|
| 11 |
+
from .cmmlu import CMMLUDataset
|
| 12 |
+
from .commonsenseqa import commonsenseqaDataset
|
| 13 |
+
from .hellaswag import hellaswagDataset_V2
|
| 14 |
+
from .mmlu import MMLUDataset
|
| 15 |
+
from .obqa import OBQADataset
|
| 16 |
+
from .piqa import piqaDataset_V2
|
| 17 |
+
from .race import RaceDataset
|
| 18 |
+
from .siqa import siqaDataset_V3
|
| 19 |
+
from .xiezhi import XiezhiDataset
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def get_origin_patterns(option_keys):
|
| 23 |
+
return [tuple(option_keys)]
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def get_circular_patterns(option_keys):
|
| 27 |
+
double_option_keys = option_keys + option_keys
|
| 28 |
+
circular_patterns = [
|
| 29 |
+
tuple(double_option_keys[i:i + len(option_keys)])
|
| 30 |
+
for i in range(len(option_keys))
|
| 31 |
+
]
|
| 32 |
+
return circular_patterns
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def get_all_possible_patterns(option_keys):
|
| 36 |
+
circular_patterns = list(itertools.permutations(option_keys))
|
| 37 |
+
return circular_patterns
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
class CircularDatasetMeta(type):
|
| 41 |
+
"""This Meta Class is designed to transform a class that reads datasets
|
| 42 |
+
into one that supports reading datasets required for CircularEval. It
|
| 43 |
+
overloads an existing load method for the original class.
|
| 44 |
+
|
| 45 |
+
The Meta Class should possess the following attributes:
|
| 46 |
+
|
| 47 |
+
- `dataset_class` (class): The class for reading datasets, such as
|
| 48 |
+
`CEvalDataset`.
|
| 49 |
+
- `default_circular_splits` (list, optional): The default splits of the
|
| 50 |
+
dataset that need to undergo CircularEval, like ['val', 'test']. If a
|
| 51 |
+
`Dataset` is loaded originally, this field will be ignored.
|
| 52 |
+
- `default_option_keys` (list): The keys for options in the dataset, such
|
| 53 |
+
as ['A', 'B', 'C', 'D'].
|
| 54 |
+
- `default_answer_key` (str, optional): The key for answers in the dataset,
|
| 55 |
+
like 'answer'. This is an alternative to
|
| 56 |
+
`default_answer_key_switch_method`.
|
| 57 |
+
- `default_answer_key_switch_method` (function, optional): The method to
|
| 58 |
+
transform the key for answers in the dataset. This is an alternative to
|
| 59 |
+
`default_answer_key`.
|
| 60 |
+
"""
|
| 61 |
+
|
| 62 |
+
@staticmethod
|
| 63 |
+
def make_circular_items(
|
| 64 |
+
origin_item,
|
| 65 |
+
circular_patterns,
|
| 66 |
+
option_keys,
|
| 67 |
+
answer_key,
|
| 68 |
+
answer_key_switch_method,
|
| 69 |
+
qid,
|
| 70 |
+
):
|
| 71 |
+
items = []
|
| 72 |
+
for circular_pattern in circular_patterns:
|
| 73 |
+
item = copy.deepcopy(origin_item)
|
| 74 |
+
for i in range(len(option_keys)):
|
| 75 |
+
item[circular_pattern[i]] = origin_item[option_keys[i]]
|
| 76 |
+
if answer_key_switch_method is None:
|
| 77 |
+
if origin_item[answer_key] in option_keys:
|
| 78 |
+
item[answer_key] = circular_pattern[option_keys.index(
|
| 79 |
+
origin_item[answer_key])]
|
| 80 |
+
else:
|
| 81 |
+
pass
|
| 82 |
+
else:
|
| 83 |
+
item = answer_key_switch_method(item, circular_pattern)
|
| 84 |
+
item['qid'] = qid
|
| 85 |
+
item['circular_pattern'] = tuple(circular_pattern)
|
| 86 |
+
items.append(item)
|
| 87 |
+
return items
|
| 88 |
+
|
| 89 |
+
@staticmethod
|
| 90 |
+
def make_circular_dataset(dataset, circular_patterns, option_keys,
|
| 91 |
+
answer_key, answer_key_switch_method):
|
| 92 |
+
circulated_items = []
|
| 93 |
+
for i, item in enumerate(dataset):
|
| 94 |
+
item = CircularDatasetMeta.make_circular_items(
|
| 95 |
+
item,
|
| 96 |
+
circular_patterns,
|
| 97 |
+
option_keys,
|
| 98 |
+
answer_key,
|
| 99 |
+
answer_key_switch_method,
|
| 100 |
+
i,
|
| 101 |
+
)
|
| 102 |
+
circulated_items.extend(item)
|
| 103 |
+
return Dataset.from_list(circulated_items)
|
| 104 |
+
|
| 105 |
+
def make_circular(
|
| 106 |
+
dataset: Union[Dataset, DatasetDict],
|
| 107 |
+
circular_splits: Optional[List[str]] = ['test'],
|
| 108 |
+
circular_patterns: str = 'circular',
|
| 109 |
+
option_keys: List[str] = ['A', 'B', 'C', 'D'],
|
| 110 |
+
answer_key: Optional[str] = 'answer',
|
| 111 |
+
answer_key_switch_method: Optional[Callable] = None,
|
| 112 |
+
):
|
| 113 |
+
"""Transform the dataset into one that is compatible with CircularEval.
|
| 114 |
+
In CircularEval, the original multiple-choice questions with options
|
| 115 |
+
ABCD are augmented by shuffling the order of options, such as BCDA,
|
| 116 |
+
CDAB, DABC, etc. A model is considered correct only if it answers all
|
| 117 |
+
augmented questions correctly. This method effectively prevents models
|
| 118 |
+
from memorizing answers.
|
| 119 |
+
|
| 120 |
+
Args:
|
| 121 |
+
datasets: The dataset to be augmented.
|
| 122 |
+
circular_splits: List of splits to make circular. This is only
|
| 123 |
+
effective when the dataset is a DatasetDict.
|
| 124 |
+
circular_patterns: Method for circular processing, can be 'circular'
|
| 125 |
+
for single cycle or 'all_possible' for all permutations, default
|
| 126 |
+
is 'circular'.
|
| 127 |
+
option_keys: List of keys for options, default to ['A', 'B', 'C', 'D'].
|
| 128 |
+
answer_key: Key for the answer, default to 'answer'. When specified,
|
| 129 |
+
ensure that the content of answer_key is among the option_keys.
|
| 130 |
+
It is an alternative to specifying answer_key_switch_method.
|
| 131 |
+
answer_key_switch_method: Function to modify the answer_key. It is an
|
| 132 |
+
alternative to specifying answer_key.
|
| 133 |
+
"""
|
| 134 |
+
|
| 135 |
+
if isinstance(circular_patterns, str):
|
| 136 |
+
if circular_patterns == 'circular':
|
| 137 |
+
circular_patterns = get_circular_patterns(option_keys)
|
| 138 |
+
elif circular_patterns == 'all_possible':
|
| 139 |
+
circular_patterns = get_all_possible_patterns(option_keys)
|
| 140 |
+
else:
|
| 141 |
+
raise ValueError(
|
| 142 |
+
f'Unknown circular_patterns: {circular_patterns}')
|
| 143 |
+
else:
|
| 144 |
+
assert isinstance(circular_patterns, list)
|
| 145 |
+
assert all([isinstance(i, list) for i in circular_patterns])
|
| 146 |
+
# TODO: other necessary sanity checks
|
| 147 |
+
raise NotImplementedError(
|
| 148 |
+
'circular_patterns int list of list has not been tested yet')
|
| 149 |
+
|
| 150 |
+
if answer_key is None and answer_key_switch_method is None:
|
| 151 |
+
raise ValueError(
|
| 152 |
+
'answer_key and answer_key_switch_method cannot be both None')
|
| 153 |
+
if answer_key is not None and answer_key_switch_method is not None:
|
| 154 |
+
raise ValueError(
|
| 155 |
+
'either answer_key or answer_key_switch_method should be None')
|
| 156 |
+
|
| 157 |
+
if isinstance(dataset, Dataset):
|
| 158 |
+
dataset = CircularDatasetMeta.make_circular_dataset(
|
| 159 |
+
dataset,
|
| 160 |
+
circular_patterns,
|
| 161 |
+
option_keys,
|
| 162 |
+
answer_key,
|
| 163 |
+
answer_key_switch_method,
|
| 164 |
+
)
|
| 165 |
+
else:
|
| 166 |
+
assert isinstance(dataset, DatasetDict)
|
| 167 |
+
dataset_dict = {}
|
| 168 |
+
for split in dataset:
|
| 169 |
+
if circular_splits is not None and split in circular_splits:
|
| 170 |
+
dataset_dict[
|
| 171 |
+
split] = CircularDatasetMeta.make_circular_dataset(
|
| 172 |
+
dataset[split],
|
| 173 |
+
circular_patterns,
|
| 174 |
+
option_keys,
|
| 175 |
+
answer_key,
|
| 176 |
+
answer_key_switch_method,
|
| 177 |
+
)
|
| 178 |
+
else:
|
| 179 |
+
dataset_dict[split] = dataset[split]
|
| 180 |
+
dataset = DatasetDict(dataset_dict)
|
| 181 |
+
return dataset
|
| 182 |
+
|
| 183 |
+
def __new__(cls, name, bases, dct):
|
| 184 |
+
new_cls = super().__new__(cls, name, bases, dct)
|
| 185 |
+
|
| 186 |
+
def load(cls, circular_patterns='circular', *args, **kwargs):
|
| 187 |
+
circular_splits = getattr(cls, 'default_circular_splits', None)
|
| 188 |
+
option_keys = getattr(cls, 'default_option_keys', None)
|
| 189 |
+
if 'option_keys' in kwargs:
|
| 190 |
+
option_keys = kwargs.pop('option_keys')
|
| 191 |
+
assert option_keys is not None, 'option_keys cannot be None'
|
| 192 |
+
answer_key = getattr(cls, 'default_answer_key', None)
|
| 193 |
+
if 'answer_key' in kwargs:
|
| 194 |
+
answer_key = kwargs.pop('answer_key')
|
| 195 |
+
answer_key_switch_method = getattr(
|
| 196 |
+
cls, 'default_answer_key_switch_method', None)
|
| 197 |
+
dataset = cls.dataset_class.load(*args, **kwargs)
|
| 198 |
+
return CircularDatasetMeta.make_circular(
|
| 199 |
+
dataset,
|
| 200 |
+
circular_splits,
|
| 201 |
+
circular_patterns,
|
| 202 |
+
option_keys,
|
| 203 |
+
answer_key,
|
| 204 |
+
answer_key_switch_method,
|
| 205 |
+
)
|
| 206 |
+
|
| 207 |
+
setattr(new_cls, 'load', classmethod(load))
|
| 208 |
+
return new_cls
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
class CircularCEvalDataset(CEvalDataset, metaclass=CircularDatasetMeta):
|
| 212 |
+
dataset_class = CEvalDataset
|
| 213 |
+
default_circular_splits = ['val', 'test']
|
| 214 |
+
default_option_keys = ['A', 'B', 'C', 'D']
|
| 215 |
+
default_answer_key = 'answer'
|
| 216 |
+
|
| 217 |
+
|
| 218 |
+
class CircularMMLUDataset(MMLUDataset, metaclass=CircularDatasetMeta):
|
| 219 |
+
dataset_class = MMLUDataset
|
| 220 |
+
default_circular_splits = ['test']
|
| 221 |
+
default_option_keys = ['A', 'B', 'C', 'D']
|
| 222 |
+
default_answer_key = 'target'
|
| 223 |
+
|
| 224 |
+
|
| 225 |
+
class CircularCMMLUDataset(CMMLUDataset, metaclass=CircularDatasetMeta):
|
| 226 |
+
dataset_class = CMMLUDataset
|
| 227 |
+
default_circular_splits = ['test']
|
| 228 |
+
default_option_keys = ['A', 'B', 'C', 'D']
|
| 229 |
+
default_answer_key = 'answer'
|
| 230 |
+
|
| 231 |
+
|
| 232 |
+
class CircularCSQADataset(commonsenseqaDataset, metaclass=CircularDatasetMeta):
|
| 233 |
+
dataset_class = commonsenseqaDataset
|
| 234 |
+
default_circular_splits = ['validation']
|
| 235 |
+
default_option_keys = ['A', 'B', 'C', 'D', 'E']
|
| 236 |
+
default_answer_key = 'answerKey'
|
| 237 |
+
|
| 238 |
+
|
| 239 |
+
class CircularARCDataset(ARCDataset, metaclass=CircularDatasetMeta):
|
| 240 |
+
dataset_class = ARCDataset
|
| 241 |
+
default_circular_splits = None
|
| 242 |
+
default_option_keys = ['textA', 'textB', 'textC', 'textD']
|
| 243 |
+
|
| 244 |
+
def default_answer_key_switch_method(item, circular_pattern):
|
| 245 |
+
circular_pattern = tuple(i[-1] for i in circular_pattern)
|
| 246 |
+
item['answerKey'] = circular_pattern['ABCD'.index(item['answerKey'])]
|
| 247 |
+
return item
|
| 248 |
+
|
| 249 |
+
|
| 250 |
+
class CircularHSWAGDataset(hellaswagDataset_V2, metaclass=CircularDatasetMeta):
|
| 251 |
+
dataset_class = hellaswagDataset_V2
|
| 252 |
+
default_circular_splits = None
|
| 253 |
+
default_option_keys = ['A', 'B', 'C', 'D']
|
| 254 |
+
default_answer_key = 'label'
|
| 255 |
+
|
| 256 |
+
|
| 257 |
+
class CircularOBQADataset(OBQADataset, metaclass=CircularDatasetMeta):
|
| 258 |
+
dataset_class = OBQADataset
|
| 259 |
+
default_circular_splits = None
|
| 260 |
+
default_option_keys = ['A', 'B', 'C', 'D']
|
| 261 |
+
default_answer_key = 'answerKey'
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
class CircularRaceDataset(RaceDataset, metaclass=CircularDatasetMeta):
|
| 265 |
+
dataset_class = RaceDataset
|
| 266 |
+
default_circular_splits = ['test']
|
| 267 |
+
default_option_keys = ['A', 'B', 'C', 'D']
|
| 268 |
+
default_answer_key = 'answer'
|
| 269 |
+
|
| 270 |
+
|
| 271 |
+
class CircularXiezhiDataset(XiezhiDataset, metaclass=CircularDatasetMeta):
|
| 272 |
+
dataset_class = XiezhiDataset
|
| 273 |
+
default_circular_splits = None
|
| 274 |
+
default_option_keys = ['A', 'B', 'C', 'D']
|
| 275 |
+
default_answer_key = 'answer'
|
| 276 |
+
|
| 277 |
+
|
| 278 |
+
class CircularsiqaDataset(siqaDataset_V3, metaclass=CircularDatasetMeta):
|
| 279 |
+
dataset_class = siqaDataset_V3
|
| 280 |
+
default_circular_splits = ['validation']
|
| 281 |
+
default_option_keys = ['A', 'B', 'C']
|
| 282 |
+
default_answer_key = 'answer'
|
| 283 |
+
|
| 284 |
+
|
| 285 |
+
class CircularpiqaDataset(piqaDataset_V2, metaclass=CircularDatasetMeta):
|
| 286 |
+
dataset_class = piqaDataset_V2
|
| 287 |
+
default_circular_splits = ['validation']
|
| 288 |
+
default_option_keys = ['sol1', 'sol2']
|
| 289 |
+
|
| 290 |
+
def default_answer_key_switch_method(item, circular_pattern):
|
| 291 |
+
circular_pattern = tuple(int(i[-1]) - 1 for i in circular_pattern)
|
| 292 |
+
item['answer'] = 'AB'[circular_pattern['AB'.index(item['answer'])]]
|
| 293 |
+
return item
|
| 294 |
+
|
| 295 |
+
|
| 296 |
+
class CircularEvaluator(BaseEvaluator):
|
| 297 |
+
"""This Evaluator assesses datasets post-Circular processing, generating
|
| 298 |
+
the following evaluation metrics:
|
| 299 |
+
|
| 300 |
+
- `acc_{origin|circular|all_possible}`: Treats each question with shuffled
|
| 301 |
+
answer options as separate, calculating accuracy.
|
| 302 |
+
- `perf_{origin|circular|all_possible}`: According Circular logic, a
|
| 303 |
+
question is considered correct only if all its variations with shuffled
|
| 304 |
+
options are answered correctly, calculating accuracy. perf is short for
|
| 305 |
+
perfect.
|
| 306 |
+
- `more_{num}_{origin|circular|all_possible}`: According to Circular logic,
|
| 307 |
+
a question is considered correct only if the number of its variations
|
| 308 |
+
answered correctly is greater than or equal to `num`, calculating
|
| 309 |
+
accuracy.
|
| 310 |
+
|
| 311 |
+
Note that when the `all_possible` method is used to shuffle option order,
|
| 312 |
+
it naturally includes the Circular method, and its metrics will also be
|
| 313 |
+
output.
|
| 314 |
+
|
| 315 |
+
Args:
|
| 316 |
+
circular_pattern: The method of shuffling options, either 'circular' or
|
| 317 |
+
'all_possible', defaulting to 'circular'.
|
| 318 |
+
"""
|
| 319 |
+
|
| 320 |
+
def __init__(self, circular_pattern='circular'):
|
| 321 |
+
super().__init__()
|
| 322 |
+
self.circular_pattern = circular_pattern
|
| 323 |
+
|
| 324 |
+
def score(self, predictions, references, test_set):
|
| 325 |
+
circular_patterns = {}
|
| 326 |
+
circular_patterns['origin'] = get_origin_patterns(
|
| 327 |
+
test_set[0]['circular_pattern'])
|
| 328 |
+
circular_patterns['circular'] = get_circular_patterns(
|
| 329 |
+
test_set[0]['circular_pattern'])
|
| 330 |
+
if self.circular_pattern == 'all_possible':
|
| 331 |
+
circular_patterns['all_possible'] = get_all_possible_patterns(
|
| 332 |
+
test_set[0]['circular_pattern'])
|
| 333 |
+
|
| 334 |
+
metrics = {}
|
| 335 |
+
tmp_metrics = {}
|
| 336 |
+
tmp_metrics.update({f'correct_{k}': 0 for k in circular_patterns})
|
| 337 |
+
tmp_metrics.update({f'count_{k}': 0 for k in circular_patterns})
|
| 338 |
+
# calculate the original accuracy
|
| 339 |
+
for pred, refr, origin_item in zip(predictions, references, test_set):
|
| 340 |
+
circular_pattern = origin_item['circular_pattern']
|
| 341 |
+
for k in circular_patterns:
|
| 342 |
+
if tuple(circular_pattern) in circular_patterns[k]:
|
| 343 |
+
tmp_metrics[f'correct_{k}'] += 1 if pred == refr else 0
|
| 344 |
+
tmp_metrics[f'count_{k}'] += 1
|
| 345 |
+
|
| 346 |
+
for k in circular_patterns:
|
| 347 |
+
metrics[f'acc_{k}'] = (tmp_metrics[f'correct_{k}'] /
|
| 348 |
+
tmp_metrics[f'count_{k}'] * 100)
|
| 349 |
+
|
| 350 |
+
# calculate the circular accuracy
|
| 351 |
+
_details = {k: {} for k in circular_patterns}
|
| 352 |
+
for pred, refr, origin_item in zip(predictions, references, test_set):
|
| 353 |
+
index = origin_item['qid']
|
| 354 |
+
circular_pattern = origin_item['circular_pattern']
|
| 355 |
+
for k in circular_patterns:
|
| 356 |
+
if tuple(circular_pattern) in circular_patterns[k]:
|
| 357 |
+
_details[k].setdefault(
|
| 358 |
+
index, []).append(True if pred == refr else False)
|
| 359 |
+
for k in _details:
|
| 360 |
+
_details[k] = {
|
| 361 |
+
index: sum(_details[k][index])
|
| 362 |
+
for index in _details[k]
|
| 363 |
+
}
|
| 364 |
+
for k in _details:
|
| 365 |
+
for j in range(1, len(circular_patterns[k]) + 1):
|
| 366 |
+
count = sum([_details[k][index] >= j for index in _details[k]])
|
| 367 |
+
total = len(_details[k])
|
| 368 |
+
if j != len(circular_patterns[k]):
|
| 369 |
+
metrics[f'more_{j}_{k}'] = count / total * 100
|
| 370 |
+
else:
|
| 371 |
+
metrics[f'perf_{k}'] = count / total * 100
|
| 372 |
+
|
| 373 |
+
return metrics
|