

Commit
•
72f4950
1
Parent(s):
93cf6ab
Update README.md
Browse files
README.md
CHANGED
|
@@ -6,7 +6,7 @@ license: apache-2.0
|
|
| 6 |
|
| 7 |
These files are GGML format model files for [THUDM's chatglm 6B](https://huggingface.co/THUDM/chatglm-6b).
|
| 8 |
|
| 9 |
-
GGML files are for CPU + GPU inference using [chatglm.cpp](https://github.com/li-plus/chatglm.cpp) and
|
| 10 |
|
| 11 |
# Prompt template
|
| 12 |
**NOTE**: prompt template is not available yet since the system prompt is hard coded in chatglm.cpp for now.
|
|
@@ -22,8 +22,26 @@ GGML files are for CPU + GPU inference using [chatglm.cpp](https://github.com/li
|
|
| 22 |
| chatglm-ggml-q5_1.bin | q8_0 | 8 | 6.6 GB |
|
| 23 |
|
| 24 |
|
| 25 |
-
# How to run in
|
| 26 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 27 |
|
| 28 |
# Slack
|
| 29 |
For further support, and discussions on these models and AI in general, join our [slack channel](https://join.slack.com/t/xorbitsio/shared_invite/zt-1o3z9ucdh-RbfhbPVpx7prOVdM1CAuxg)!
|
|
|
|
| 6 |
|
| 7 |
These files are GGML format model files for [THUDM's chatglm 6B](https://huggingface.co/THUDM/chatglm-6b).
|
| 8 |
|
| 9 |
+
GGML files are for CPU + GPU inference using [chatglm.cpp](https://github.com/li-plus/chatglm.cpp) and [Xorbits Inference](https://github.com/xorbitsai/inference).
|
| 10 |
|
| 11 |
# Prompt template
|
| 12 |
**NOTE**: prompt template is not available yet since the system prompt is hard coded in chatglm.cpp for now.
|
|
|
|
| 22 |
| chatglm-ggml-q5_1.bin | q8_0 | 8 | 6.6 GB |
|
| 23 |
|
| 24 |
|
| 25 |
+
# How to run in Xorbits Inference
|
| 26 |
+
|
| 27 |
+
## Install
|
| 28 |
+
Xinference can be installed via pip from PyPI. It is highly recommended to create a new virtual environment to avoid conflicts.
|
| 29 |
+
|
| 30 |
+
```bash
|
| 31 |
+
$ pip install "xinference[all]"
|
| 32 |
+
$ pip install chatglm-cpp
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
## Start Xorbits Inference
|
| 36 |
+
To start a local instance of Xinference, run the following command:
|
| 37 |
+
```bash
|
| 38 |
+
$ xinference
|
| 39 |
+
```
|
| 40 |
+
|
| 41 |
+
Once Xinference is running, an endpoint will be accessible for model management via CLI or Xinference client. The default endpoint is `http://localhost:9997`. You can also view a web UI using the Xinference endpoint to chat with all the builtin models. You can even chat with two cutting-edge AI models side-by-side to compare their performance!
|
| 42 |
+
|
| 43 |
+
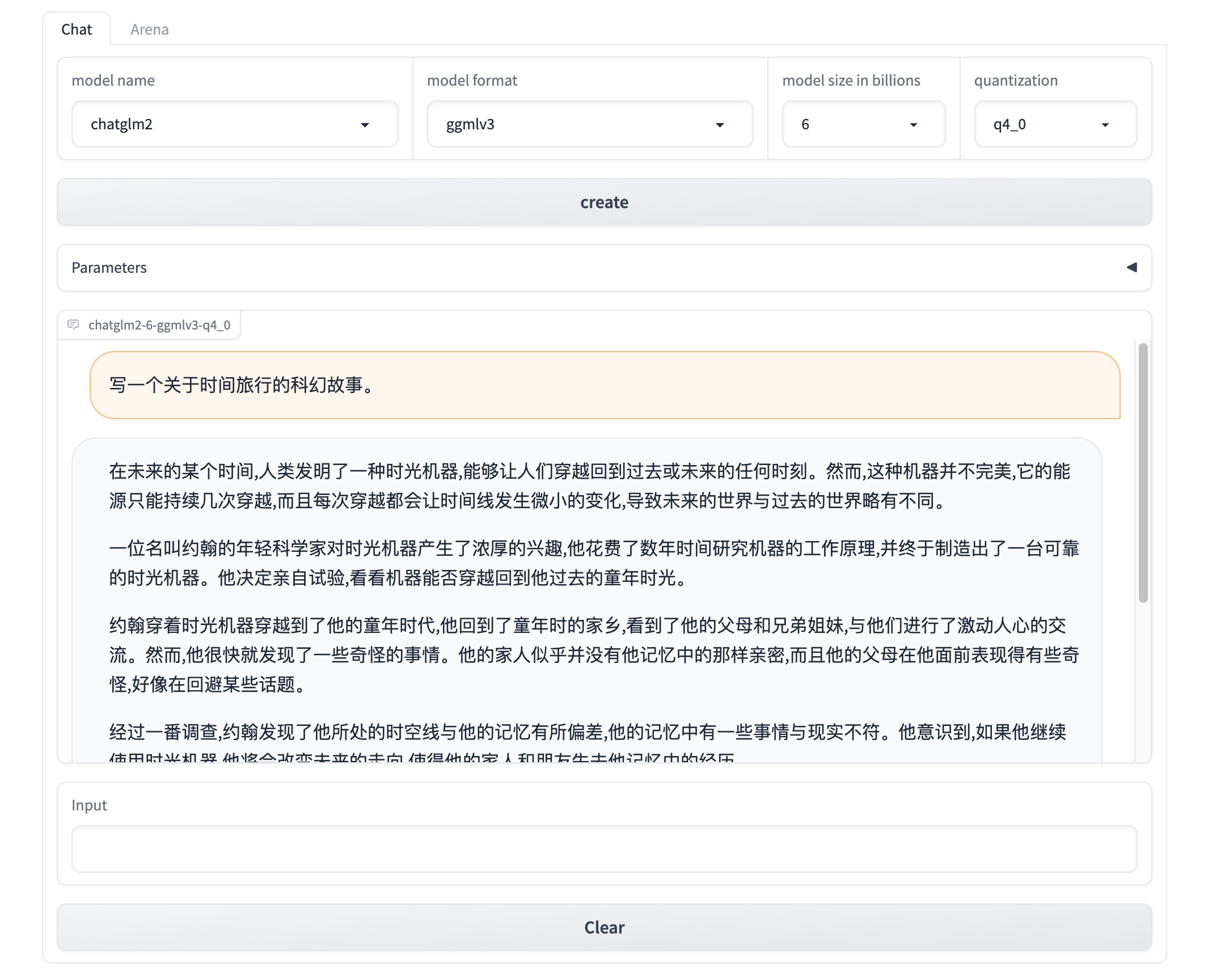
|
| 44 |
+
|
| 45 |
|
| 46 |
# Slack
|
| 47 |
For further support, and discussions on these models and AI in general, join our [slack channel](https://join.slack.com/t/xorbitsio/shared_invite/zt-1o3z9ucdh-RbfhbPVpx7prOVdM1CAuxg)!
|