
Update README.md
Browse files
README.md
CHANGED
|
@@ -13,9 +13,25 @@ aniscreen, fanart
|
|
| 13 |
```
|
| 14 |
|
| 15 |
For `0324_all_aniscreen_tags`, I accidentally tag all the character images with `aniscreen`.
|
| 16 |
-
For
|
| 17 |
|
| 18 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 19 |
### Setting
|
| 20 |
|
| 21 |
Default settings are
|
|
@@ -30,6 +46,7 @@ The configuration json files can otherwise be found in the `config` subdirectori
|
|
| 30 |
However, some experiments concern the effect of tags for which I regenerate the txt file and the difference can not be seen from the configuration file in this case.
|
| 31 |
For now this concerns `05tag` for which tags are only used with probability 0.5.
|
| 32 |
|
|
|
|
| 33 |
### Some observations
|
| 34 |
|
| 35 |
For a thorough comparison please refer to the `generated_samples` folder.
|
|
@@ -305,10 +322,62 @@ Lykon did show some successful results by only training with anime images on NED
|
|
| 305 |
Clearly, the thing that really matters is how the model is made, and not how the model looks like. A model that is versatile in style does not make it a good base model for whatever kind of training. In fact, VBP2-2 has around 300 styles trained in but LoHa trained on top of it does not transfer well to other models.
|
| 306 |
Similarly, two models that produce similar style do not mean they transfer well to each other. Both MFB and Salt-Mix have strong anime screenshot style but a LoHa trained on MFB does not transfer well to Salt-Mix.
|
| 307 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 308 |
|
| 309 |
#### Training Speed
|
| 310 |
|
| 311 |
-
It is also suggested that you train faster on AnyLora. I try to look into this in several ways but I don't see a clear difference.
|
|
|
|
| 312 |
|
| 313 |
First, I use the 6000step checkpoints for characters
|
| 314 |

|
|
|
|
| 13 |
```
|
| 14 |
|
| 15 |
For `0324_all_aniscreen_tags`, I accidentally tag all the character images with `aniscreen`.
|
| 16 |
+
For the others, things are done correctly (anime screenshots tagged as `aniscreen`, fanart tagged as `fanart`).
|
| 17 |
|
| 18 |
|
| 19 |
+
For reference, this is what each character looks like
|
| 20 |
+
|
| 21 |
+
**Anisphia**
|
| 22 |
+

|
| 23 |
+
|
| 24 |
+
**Euphyllia**
|
| 25 |
+

|
| 26 |
+
|
| 27 |
+
**Tilty**
|
| 28 |
+
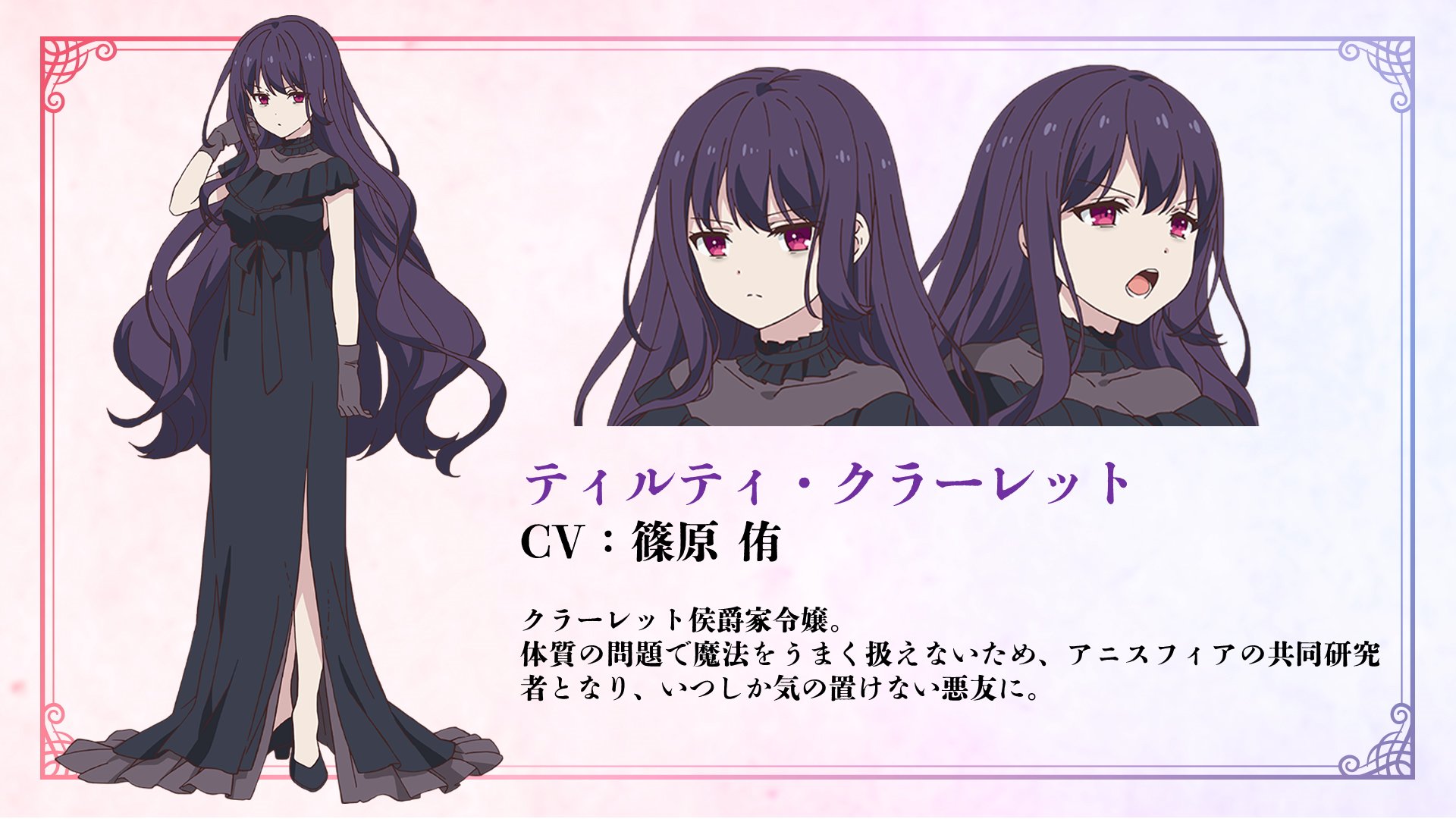
|
| 29 |
+
|
| 30 |
+
**OyamaMahiro (white hair one) and OyamaMihari (black hair one)**
|
| 31 |
+

|
| 32 |
+
|
| 33 |
+
As for the styles please check the artists' pixiv yourself (note there are R-18 images)
|
| 34 |
+
|
| 35 |
### Setting
|
| 36 |
|
| 37 |
Default settings are
|
|
|
|
| 46 |
However, some experiments concern the effect of tags for which I regenerate the txt file and the difference can not be seen from the configuration file in this case.
|
| 47 |
For now this concerns `05tag` for which tags are only used with probability 0.5.
|
| 48 |
|
| 49 |
+
|
| 50 |
### Some observations
|
| 51 |
|
| 52 |
For a thorough comparison please refer to the `generated_samples` folder.
|
|
|
|
| 322 |
Clearly, the thing that really matters is how the model is made, and not how the model looks like. A model that is versatile in style does not make it a good base model for whatever kind of training. In fact, VBP2-2 has around 300 styles trained in but LoHa trained on top of it does not transfer well to other models.
|
| 323 |
Similarly, two models that produce similar style do not mean they transfer well to each other. Both MFB and Salt-Mix have strong anime screenshot style but a LoHa trained on MFB does not transfer well to Salt-Mix.
|
| 324 |
|
| 325 |
+
**A Case Study on Customized Merge Model**
|
| 326 |
+
|
| 327 |
+
To understand whether you can train a style to be used on a group of models by simply merging these models, I pick a few models and merge them myself to see if this is really effective. I especially choose models that are far from each other, and consider both average and add difference merges. Here are the two recipes that I use.
|
| 328 |
+
|
| 329 |
+
```
|
| 330 |
+
# Recipe for average merge
|
| 331 |
+
tmp1 = nai-full-pruned + bp_nman_e29, 0.5, fp16, ckpt
|
| 332 |
+
tmp2 = __O1__ + nep, 0.333, fp16, ckpt
|
| 333 |
+
tmp3 = __O2__ + Pastel-Mix, 0.25, fp16, ckpt
|
| 334 |
+
tmp4 = __O3__ + fantasyBackground_v10PrunedFp16, 0.2, fp16, ckpt
|
| 335 |
+
tmp5 = __O4__ + MyneFactoryBase_V1.0, 0.166, fp16, ckpt
|
| 336 |
+
AleaMix = __O5__ + anylora_FTMSE, 0.142, fp16, ckpt
|
| 337 |
+
```
|
| 338 |
+
|
| 339 |
+
```
|
| 340 |
+
# Recipe for add difference merge
|
| 341 |
+
tmp1 = nai-full-pruned + bp_nman_e29, 0.5, fp16, ckpt
|
| 342 |
+
tmp2-ad = __O1__ + nep + nai-full-pruned, 0.5, fp16, safetensors
|
| 343 |
+
tmp3-ad = __O2__ + Pastel-Mix + nai-full-pruned, 0.5, fp16, safetensors
|
| 344 |
+
tmp4-ad = __O3__ + fantasyBackground_v10PrunedFp16 + nai-full-pruned, 0.5, fp16, safetensors
|
| 345 |
+
tmp5-ad = __O4__ + MyneFactoryBase_V1.0 + nai-full-pruned, 0.5, fp16, safetensors
|
| 346 |
+
AleaMix-ad = __O5__ + anylora_FTMSE + nai-full-pruned, 0.5, fp16, safetensors
|
| 347 |
+
```
|
| 348 |
+
|
| 349 |
+
I then trained on top of tmp3, AleaMix, tmp3-ad, and AleaMix-ad. It turns out that these models are too different so it does not work very well. Getting style transfer to PastelMix and FantasyBackgrond are quite difficult. I however observe the following.
|
| 350 |
+
|
| 351 |
+
- We generally get bad results when applying to NAI. This is in line with previous experiments.
|
| 352 |
+
- We get better transfer to NMFSAN compared to most of previous LoHas that are not trained on BP family.
|
| 353 |
+
- Add difference with too many models (7) with high weight (0.5) blows the model up: you can still train on it and get reasonable result but it does not transfer to individual component.
|
| 354 |
+
- Add difference with a smaller number of models (4) can work. It seems to be more effective then simple average sometimes (note that how the model trained on tmp3-ad manages to cancel out the style of nep and PastelMix in the examples below).
|
| 355 |
+
|
| 356 |
+

|
| 357 |
+

|
| 358 |
+

|
| 359 |
+
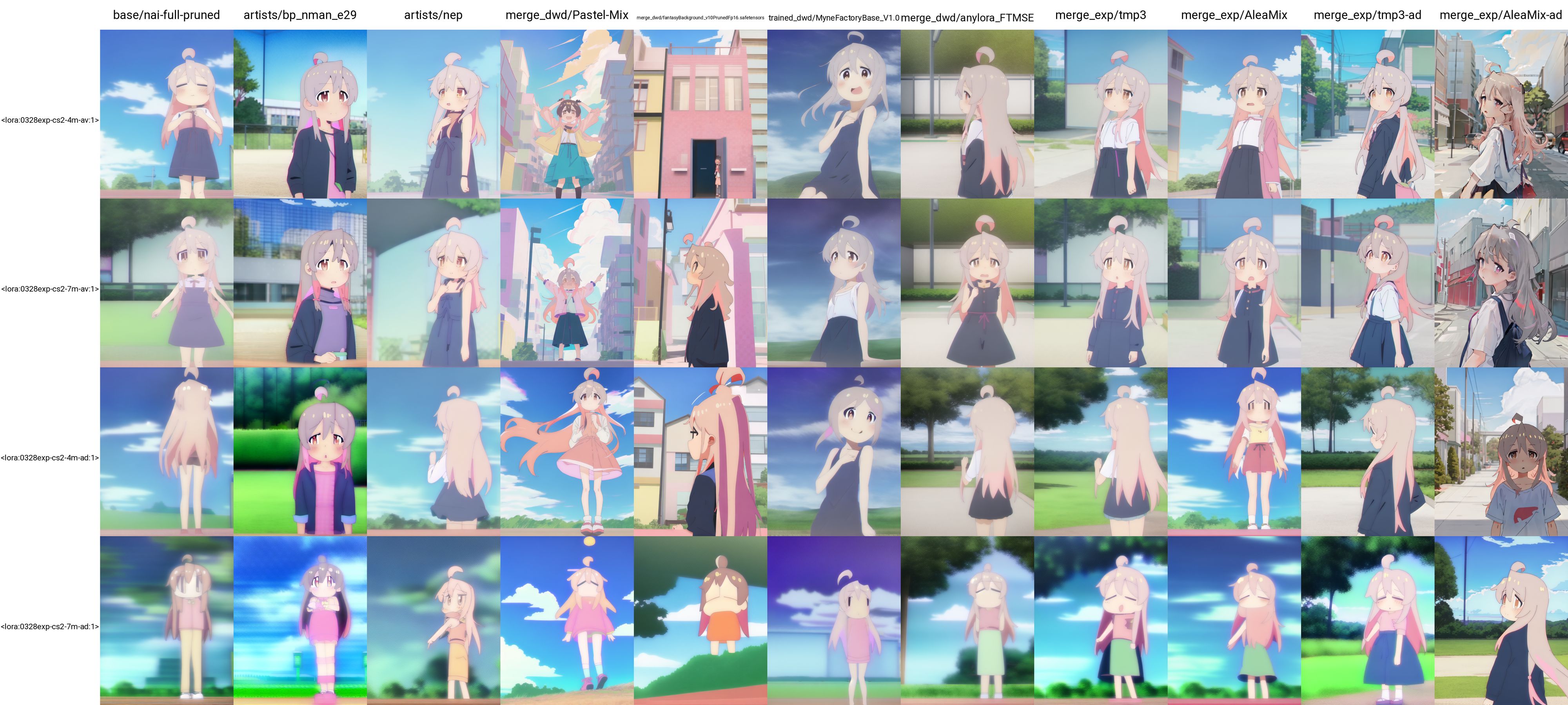
|
| 360 |
+

|
| 361 |
+
|
| 362 |
+
*An interesting observation*
|
| 363 |
+
|
| 364 |
+
While the model AleaMix-ad is barely usable, the LoHa trained on it produces very strong styles and excellent details
|
| 365 |
+
|
| 366 |
+
Results on AleaMix (the weighted sum version)
|
| 367 |
+

|
| 368 |
+
|
| 369 |
+
Results on AleaMix-ad (the add difference version)
|
| 370 |
+
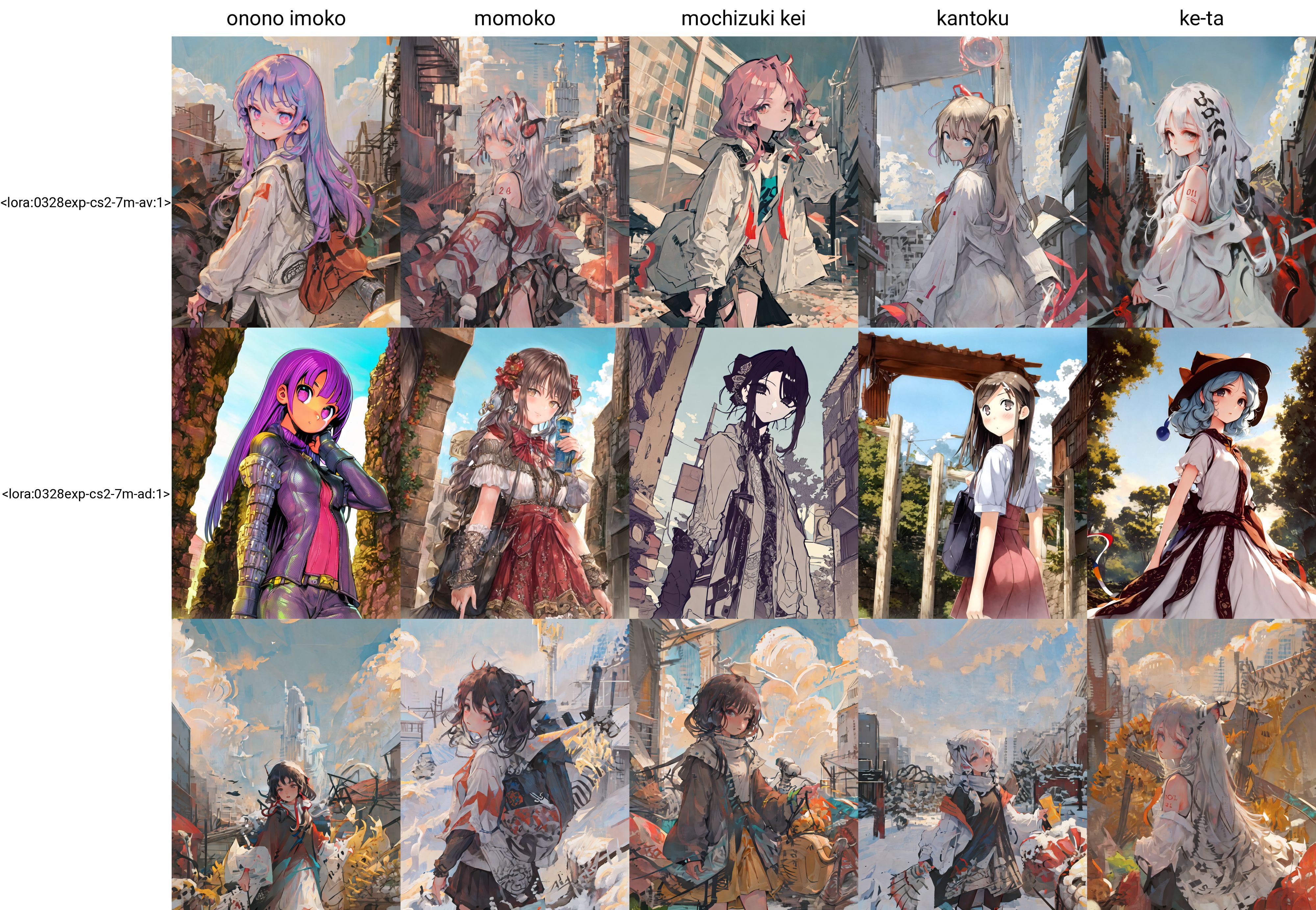
|
| 371 |
+
|
| 372 |
+
However, you may also need to worry about some bad hand in such a model
|
| 373 |
+

|
| 374 |
+
|
| 375 |
+
|
| 376 |
|
| 377 |
#### Training Speed
|
| 378 |
|
| 379 |
+
It is also suggested that you train faster on AnyLora. I try to look into this in several ways but I don't see a clear difference.
|
| 380 |
+
Note that we should mostly focus on the diagonal (LoHa applied on the model used to train it).
|
| 381 |
|
| 382 |
First, I use the 6000step checkpoints for characters
|
| 383 |

|