

init commit
Browse files- LICENSE +21 -0
- README.md +141 -0
- config.yaml +226 -0
- example/example.wav +0 -0
- fig/framework.png +0 -0
- model.pth +3 -0
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023 Alibaba Inc.
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
CHANGED
|
@@ -1,3 +1,144 @@
|
|
| 1 |
---
|
|
|
|
|
|
|
|
|
|
| 2 |
license: mit
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
language: en
|
| 3 |
+
tags:
|
| 4 |
+
- speech quantization
|
| 5 |
license: mit
|
| 6 |
+
datasets:
|
| 7 |
+
- LibriTTS
|
| 8 |
---
|
| 9 |
+
|
| 10 |
+
# Highlights
|
| 11 |
+
This model is used for speech codec or quantization on English utterances.
|
| 12 |
+
- Frequency domain model, fully using short-time structures of speech signals
|
| 13 |
+
- Fewer model parameters (4.50 M), lower computation complexity (2.18G flops) while maintaining comparable speech quality (ViSQOL score 3.81 ~ 4.31)
|
| 14 |
+
- Training with structured dropout, enabling various band widths during inference with a single model
|
| 15 |
+
- Quantizing a raw speech waveform into a sequence of discrete tokens
|
| 16 |
+
|
| 17 |
+
# FunCodec model
|
| 18 |
+
This model is trained with [FunCodec](https://github.com/alibaba-damo-academy/FunCodec),
|
| 19 |
+
an open-source toolkits for speech quantization (codec) from the Damo academy, Alibaba Group.
|
| 20 |
+
This repository provides a pre-trained model on the LibriTTS corpus.
|
| 21 |
+
It can be applied to low-band-width speech communication, speech quantization, zero-shot speech synthesis
|
| 22 |
+
and other academic research topics.
|
| 23 |
+
Compared with [EnCodec](https://arxiv.org/abs/2210.13438) and [SoundStream](https://arxiv.org/abs/2107.03312),
|
| 24 |
+
the following improved techniques are utilized to train the model, resulting in higher codec quality and
|
| 25 |
+
[ViSQOL](https://github.com/google/visqol) scores under the same band width:
|
| 26 |
+
- The magnitude spectrum loss is employed to enhance the middle and high frequency signals
|
| 27 |
+
- Structured dropout is employed to smooth the code space, as well as enable various band widths in a single model
|
| 28 |
+
- Codes are initialized by k-means clusters rather than random values
|
| 29 |
+
- Codebooks are maintained with exponential moving average and dead-code-elimination mechanism, resulting in high utilization factor for codebooks.
|
| 30 |
+
|
| 31 |
+
## Model description
|
| 32 |
+
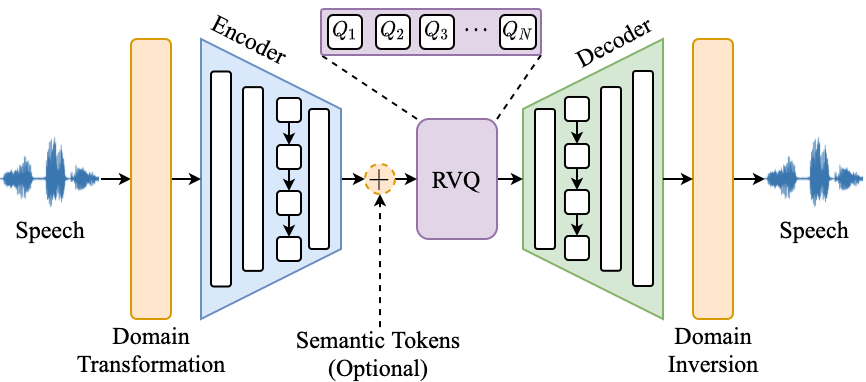
This model is a variational autoencoder that uses residual vector quantisation (RVQ) to obtain
|
| 33 |
+
several parallel sequences of discrete latent representations. Here is an overview of FunCodec models.
|
| 34 |
+
<p align="center">
|
| 35 |
+
<img src="fig/framework.png" alt="FunCodec architecture"/>
|
| 36 |
+
</p>
|
| 37 |
+
|
| 38 |
+
In general, FunCodec models consist of five modules: a domain transformation module,
|
| 39 |
+
an encoder, a RVQ module, a decoder and a domain inversion module.
|
| 40 |
+
- Domain Transformation:transfer signals into time domain, short-time frequency domain, magnitude-angle domain or magnitude-phase domain.
|
| 41 |
+
- Encoder:encode signals into compact representations with stacked convolutional and LSTM layers.
|
| 42 |
+
- Semantic tokens (Optional): augment encoder outputs with semantic tokens to enhance the content information, not used in this model.
|
| 43 |
+
- RVQ:quantize the representations into parallel sequences of discrete tokens with cascaded vector quantizers.
|
| 44 |
+
- Decoder:decode quantized embeddings into different signal domains the same as inputs.
|
| 45 |
+
- Domain Inversion:re-synthesize perceptible waveforms from different domains.
|
| 46 |
+
|
| 47 |
+
More details can be found at:
|
| 48 |
+
- Paper: [FunCodec: A Fundamental, Reproducible and Integrable Open-source Toolkit for Neural Speech Codec](https://arxiv.org/abs/2309.07405)
|
| 49 |
+
- Codebase: [FunCodec](https://github.com/alibaba-damo-academy/FunCodec)
|
| 50 |
+
|
| 51 |
+
## Intended uses & sceneries
|
| 52 |
+
### Inference with FunCodec
|
| 53 |
+
|
| 54 |
+
You can extract codecs and reconstruct them back to waveforms with FunCodec repository.
|
| 55 |
+
|
| 56 |
+
#### FunCodec installation
|
| 57 |
+
```sh
|
| 58 |
+
# Install Pytorch GPU (version >= 1.12.0):
|
| 59 |
+
conda install pytorch==1.12.0
|
| 60 |
+
# for other versions, please refer: https://pytorch.org/get-started/locally
|
| 61 |
+
|
| 62 |
+
# Download codebase:
|
| 63 |
+
git clone https://github.com/alibaba-damo-academy/FunCodec.git
|
| 64 |
+
|
| 65 |
+
# Install FunCodec codebase:
|
| 66 |
+
cd FunCodec
|
| 67 |
+
pip install --editable ./
|
| 68 |
+
```
|
| 69 |
+
|
| 70 |
+
#### Codec extraction
|
| 71 |
+
```sh
|
| 72 |
+
# Enter the example directory
|
| 73 |
+
cd egs/LibriTTS/codec
|
| 74 |
+
# Specify the model name
|
| 75 |
+
model_name="audio_codec-encodec-en-libritts-16k-nq32ds320-pytorch"
|
| 76 |
+
# Download the model
|
| 77 |
+
git lfs install
|
| 78 |
+
git clone https://huggingface.co/alibaba-damo/${model_name}
|
| 79 |
+
mkdir exp
|
| 80 |
+
mv ${model_name} exp/$model_name
|
| 81 |
+
# Extracting codec within the input file "input_wav.scp" and the codecs are saved under "outputs/codecs"
|
| 82 |
+
bash encoding_decoding.sh --stage 1 --batch_size 16 --num_workers 4 --gpu_devices "0,1" \
|
| 83 |
+
--model_dir exp/${model_name} --bit_width 16000 --file_sampling_rate 16000 \
|
| 84 |
+
--wav_scp input_wav.scp --out_dir outputs/codecs
|
| 85 |
+
# input_wav.scp has the following format:
|
| 86 |
+
# uttid1 path/to/file1.wav
|
| 87 |
+
# uttid2 path/to/file2.wav
|
| 88 |
+
# ...
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
### Reconstruct waveforms from codecs
|
| 92 |
+
```shell
|
| 93 |
+
# Reconstruct waveforms into "outputs/recon_wavs"
|
| 94 |
+
bash encoding_decoding.sh --stage 2 --batch_size 16 --num_workers 4 --gpu_devices "0,1" \
|
| 95 |
+
--model_dir exp/${model_name} --bit_width 16000 --file_sampling_rate 16000 \
|
| 96 |
+
--wav_scp outputs/codecs/codecs.txt --out_dir outputs/recon_wavs
|
| 97 |
+
# codecs.txt is the output of stage 1, which has the following format:
|
| 98 |
+
# uttid1 [[[1, 2, 3, ...],[2, 3, 4, ...], ...]]
|
| 99 |
+
# uttid2 [[[9, 7, 5, ...],[3, 1, 2, ...], ...]]
|
| 100 |
+
# ...
|
| 101 |
+
```
|
| 102 |
+
|
| 103 |
+
### Inference with Huggingface Transformers
|
| 104 |
+
Inference with Huggingface transformers package is under development.
|
| 105 |
+
|
| 106 |
+
### Application sceneries
|
| 107 |
+
Running environment
|
| 108 |
+
- Currently, the model only passed the tests on Linux-x86_64. Mac and Windows systems are not tested.
|
| 109 |
+
|
| 110 |
+
Intended using sceneries
|
| 111 |
+
- This model is suitable for academic usages
|
| 112 |
+
- Speech quantization, codec and tokenization for English utterances
|
| 113 |
+
|
| 114 |
+
## Evaluation results
|
| 115 |
+
|
| 116 |
+
### Training configuration
|
| 117 |
+
- Feature info: raw waveform input
|
| 118 |
+
- Train info: Adam, lr 3e-4, batch_size 32, 2 gpu(Tesla V100), acc_grad 1, 300000 steps, speech_max_length 51200
|
| 119 |
+
- Loss info: L1, L2, discriminative loss
|
| 120 |
+
- Model info: SEANet, Conv, LSTM
|
| 121 |
+
- Train config: config.yaml
|
| 122 |
+
- Model size: 4.50 M parameters
|
| 123 |
+
|
| 124 |
+
### Experimental Results
|
| 125 |
+
Test set: LibriTTS-test, ViSQOL scores
|
| 126 |
+
|
| 127 |
+
| testset | 50 tk/s | 100 tk/s | 200 tk/s | 400 tk/s |
|
| 128 |
+
|:--------:|:--------:|:--------:|:--------:|:--------:|
|
| 129 |
+
| LibriTTS | 3.32 | 3.81 | 4.11 | 4.31 |
|
| 130 |
+
|
| 131 |
+
### Limitations and bias
|
| 132 |
+
- Not very robust to background noises and reverberation
|
| 133 |
+
|
| 134 |
+
### BibTeX entry and citation info
|
| 135 |
+
```BibTeX
|
| 136 |
+
@misc{du2023funcodec,
|
| 137 |
+
title={FunCodec: A Fundamental, Reproducible and Integrable Open-source Toolkit for Neural Speech Codec},
|
| 138 |
+
author={Zhihao Du, Shiliang Zhang, Kai Hu, Siqi Zheng},
|
| 139 |
+
year={2023},
|
| 140 |
+
eprint={2309.07405},
|
| 141 |
+
archivePrefix={arXiv},
|
| 142 |
+
primaryClass={cs.Sound}
|
| 143 |
+
}
|
| 144 |
+
```
|
config.yaml
ADDED
|
@@ -0,0 +1,226 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
config: conf/encodec2d_dwconv_groupratio8_mag_phase_16k_n32_600k_step_rmseg_use_power.yaml
|
| 2 |
+
print_config: false
|
| 3 |
+
log_level: INFO
|
| 4 |
+
dry_run: false
|
| 5 |
+
iterator_type: sequence
|
| 6 |
+
output_dir: exp/encodec2d_dwconv_groupratio8_mag_phase_16k_n32_600k_step_rmseg_use_power_raw_en_libritts
|
| 7 |
+
ngpu: 2
|
| 8 |
+
seed: 0
|
| 9 |
+
num_workers: 8
|
| 10 |
+
num_att_plot: 0
|
| 11 |
+
dist_backend: nccl
|
| 12 |
+
dist_init_method: env://
|
| 13 |
+
dist_world_size: null
|
| 14 |
+
dist_rank: null
|
| 15 |
+
local_rank: 0
|
| 16 |
+
dist_master_addr: null
|
| 17 |
+
dist_master_port: null
|
| 18 |
+
dist_launcher: null
|
| 19 |
+
multiprocessing_distributed: true
|
| 20 |
+
unused_parameters: true
|
| 21 |
+
sharded_ddp: false
|
| 22 |
+
cudnn_enabled: true
|
| 23 |
+
cudnn_benchmark: false
|
| 24 |
+
cudnn_deterministic: false
|
| 25 |
+
collect_stats: false
|
| 26 |
+
write_collected_feats: false
|
| 27 |
+
max_epoch: 60
|
| 28 |
+
max_update: 9223372036854775807
|
| 29 |
+
patience: null
|
| 30 |
+
val_scheduler_criterion:
|
| 31 |
+
- valid
|
| 32 |
+
- loss
|
| 33 |
+
early_stopping_criterion:
|
| 34 |
+
- valid
|
| 35 |
+
- loss
|
| 36 |
+
- min
|
| 37 |
+
best_model_criterion:
|
| 38 |
+
- - valid
|
| 39 |
+
- generator_multi_spectral_recon_loss
|
| 40 |
+
- min
|
| 41 |
+
keep_nbest_models: 60
|
| 42 |
+
nbest_averaging_interval: 0
|
| 43 |
+
grad_clip: -1
|
| 44 |
+
grad_clip_type: 2.0
|
| 45 |
+
grad_noise: false
|
| 46 |
+
accum_grad: 1
|
| 47 |
+
no_forward_run: false
|
| 48 |
+
resume: true
|
| 49 |
+
train_dtype: float32
|
| 50 |
+
use_amp: false
|
| 51 |
+
log_interval: 50
|
| 52 |
+
use_tensorboard: true
|
| 53 |
+
use_wandb: false
|
| 54 |
+
wandb_project: null
|
| 55 |
+
wandb_id: null
|
| 56 |
+
wandb_entity: null
|
| 57 |
+
wandb_name: null
|
| 58 |
+
wandb_model_log_interval: -1
|
| 59 |
+
detect_anomaly: false
|
| 60 |
+
pretrain_path: null
|
| 61 |
+
init_param: []
|
| 62 |
+
ignore_init_mismatch: true
|
| 63 |
+
freeze_param: []
|
| 64 |
+
num_iters_per_epoch: 10000
|
| 65 |
+
batch_size: 32
|
| 66 |
+
valid_batch_size: null
|
| 67 |
+
batch_bins: 2000000
|
| 68 |
+
valid_batch_bins: null
|
| 69 |
+
drop_last: true
|
| 70 |
+
train_shape_file:
|
| 71 |
+
- exp/tokenizer_states_16k/train/speech_shape
|
| 72 |
+
valid_shape_file:
|
| 73 |
+
- exp/tokenizer_states_16k/dev/speech_shape
|
| 74 |
+
batch_type: unsorted
|
| 75 |
+
valid_batch_type: null
|
| 76 |
+
speech_length_min: -1
|
| 77 |
+
speech_length_max: -1
|
| 78 |
+
fold_length:
|
| 79 |
+
- 512
|
| 80 |
+
- 150
|
| 81 |
+
sort_in_batch: descending
|
| 82 |
+
sort_batch: descending
|
| 83 |
+
multiple_iterator: false
|
| 84 |
+
chunk_length: 500
|
| 85 |
+
chunk_shift_ratio: 0.5
|
| 86 |
+
num_cache_chunks: 1024
|
| 87 |
+
dataset_type: small
|
| 88 |
+
dataset_conf: {}
|
| 89 |
+
train_data_file: null
|
| 90 |
+
valid_data_file: null
|
| 91 |
+
train_data_path_and_name_and_type:
|
| 92 |
+
- - dump/raw_16k/train/wav.scp.pai
|
| 93 |
+
- speech
|
| 94 |
+
- kaldi_ark
|
| 95 |
+
valid_data_path_and_name_and_type:
|
| 96 |
+
- - dump/raw_16k/dev/wav.scp.pai
|
| 97 |
+
- speech
|
| 98 |
+
- kaldi_ark
|
| 99 |
+
allow_variable_data_keys: false
|
| 100 |
+
max_cache_size: 0.0
|
| 101 |
+
max_cache_fd: 32
|
| 102 |
+
valid_max_cache_size: null
|
| 103 |
+
optim: adam
|
| 104 |
+
optim_conf:
|
| 105 |
+
lr: 0.0003
|
| 106 |
+
betas:
|
| 107 |
+
- 0.5
|
| 108 |
+
- 0.9
|
| 109 |
+
scheduler: null
|
| 110 |
+
scheduler_conf:
|
| 111 |
+
step_size: 8
|
| 112 |
+
gamma: 0.1
|
| 113 |
+
optim2: adam
|
| 114 |
+
optim2_conf:
|
| 115 |
+
lr: 0.0003
|
| 116 |
+
betas:
|
| 117 |
+
- 0.5
|
| 118 |
+
- 0.9
|
| 119 |
+
scheduler2: null
|
| 120 |
+
scheduler2_conf:
|
| 121 |
+
step_size: 8
|
| 122 |
+
gamma: 0.1
|
| 123 |
+
use_pai: true
|
| 124 |
+
simple_ddp: false
|
| 125 |
+
num_worker_count: 1
|
| 126 |
+
generator_first: false
|
| 127 |
+
input_size: 3
|
| 128 |
+
cmvn_file: null
|
| 129 |
+
disc_grad_clip: -1
|
| 130 |
+
disc_grad_clip_type: 2.0
|
| 131 |
+
gen_train_interval: 1
|
| 132 |
+
disc_train_interval: 1
|
| 133 |
+
stat_flops: false
|
| 134 |
+
use_preprocessor: true
|
| 135 |
+
speech_volume_normalize: null
|
| 136 |
+
speech_rms_normalize: false
|
| 137 |
+
speech_max_length: 40800
|
| 138 |
+
sampling_rate: 16000
|
| 139 |
+
valid_max_length: 40800
|
| 140 |
+
frontend: null
|
| 141 |
+
frontend_conf: {}
|
| 142 |
+
normalize: null
|
| 143 |
+
normalize_conf: {}
|
| 144 |
+
encoder: encodec_seanet_encoder_2d
|
| 145 |
+
encoder_conf:
|
| 146 |
+
ratios:
|
| 147 |
+
- - 4
|
| 148 |
+
- 1
|
| 149 |
+
- - 4
|
| 150 |
+
- 1
|
| 151 |
+
- - 4
|
| 152 |
+
- 2
|
| 153 |
+
- - 4
|
| 154 |
+
- 1
|
| 155 |
+
norm: time_group_norm
|
| 156 |
+
norm_params:
|
| 157 |
+
num_groups: 1
|
| 158 |
+
causal: false
|
| 159 |
+
dilation_base: 2
|
| 160 |
+
kernel_size: 3
|
| 161 |
+
last_kernel_size: 3
|
| 162 |
+
seq_model: none
|
| 163 |
+
quantizer: costume_quantizer
|
| 164 |
+
quantizer_conf:
|
| 165 |
+
codebook_size: 1024
|
| 166 |
+
num_quantizers: 32
|
| 167 |
+
ema_decay: 0.99
|
| 168 |
+
kmeans_init: true
|
| 169 |
+
sampling_rate: 16000
|
| 170 |
+
quantize_dropout: true
|
| 171 |
+
rand_num_quant:
|
| 172 |
+
- 1
|
| 173 |
+
- 2
|
| 174 |
+
- 4
|
| 175 |
+
- 8
|
| 176 |
+
- 16
|
| 177 |
+
- 32
|
| 178 |
+
use_ddp: true
|
| 179 |
+
encoder_hop_length: 320
|
| 180 |
+
decoder: encodec_seanet_decoder_2d
|
| 181 |
+
decoder_conf:
|
| 182 |
+
ratios:
|
| 183 |
+
- - 4
|
| 184 |
+
- 1
|
| 185 |
+
- - 4
|
| 186 |
+
- 1
|
| 187 |
+
- - 4
|
| 188 |
+
- 2
|
| 189 |
+
- - 4
|
| 190 |
+
- 1
|
| 191 |
+
norm: time_group_norm
|
| 192 |
+
norm_params:
|
| 193 |
+
num_groups: 1
|
| 194 |
+
causal: false
|
| 195 |
+
channels: 3
|
| 196 |
+
dilation_base: 2
|
| 197 |
+
kernel_size: 3
|
| 198 |
+
last_kernel_size: 3
|
| 199 |
+
tr_conv_group_ratio: 8
|
| 200 |
+
seq_model: none
|
| 201 |
+
model: freq_codec
|
| 202 |
+
model_conf:
|
| 203 |
+
odim: 128
|
| 204 |
+
multi_spectral_window_powers_of_two:
|
| 205 |
+
- 5
|
| 206 |
+
- 6
|
| 207 |
+
- 7
|
| 208 |
+
- 8
|
| 209 |
+
- 9
|
| 210 |
+
- 10
|
| 211 |
+
target_sample_hz: 16000
|
| 212 |
+
audio_normalize: true
|
| 213 |
+
segment_dur: null
|
| 214 |
+
overlap_ratio: null
|
| 215 |
+
use_power_spec_loss: true
|
| 216 |
+
codec_domain:
|
| 217 |
+
- mag_phase
|
| 218 |
+
- mag_phase
|
| 219 |
+
discriminator: multiple_disc
|
| 220 |
+
discriminator_conf:
|
| 221 |
+
input_size: 1
|
| 222 |
+
disc_conf_list:
|
| 223 |
+
- filters: 32
|
| 224 |
+
name: encodec_multi_scale_stft_discriminator
|
| 225 |
+
distributed: true
|
| 226 |
+
version: 0.2.0
|
example/example.wav
ADDED
|
Binary file (161 kB). View file
|
|
|
fig/framework.png
ADDED
|
model.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8aff94a8efc27157df3b1fa33a8e4da5cc3eaceb79f4e0c13a697c33e7cbdfd9
|
| 3 |
+
size 53762961
|