
AIMv2
Collection
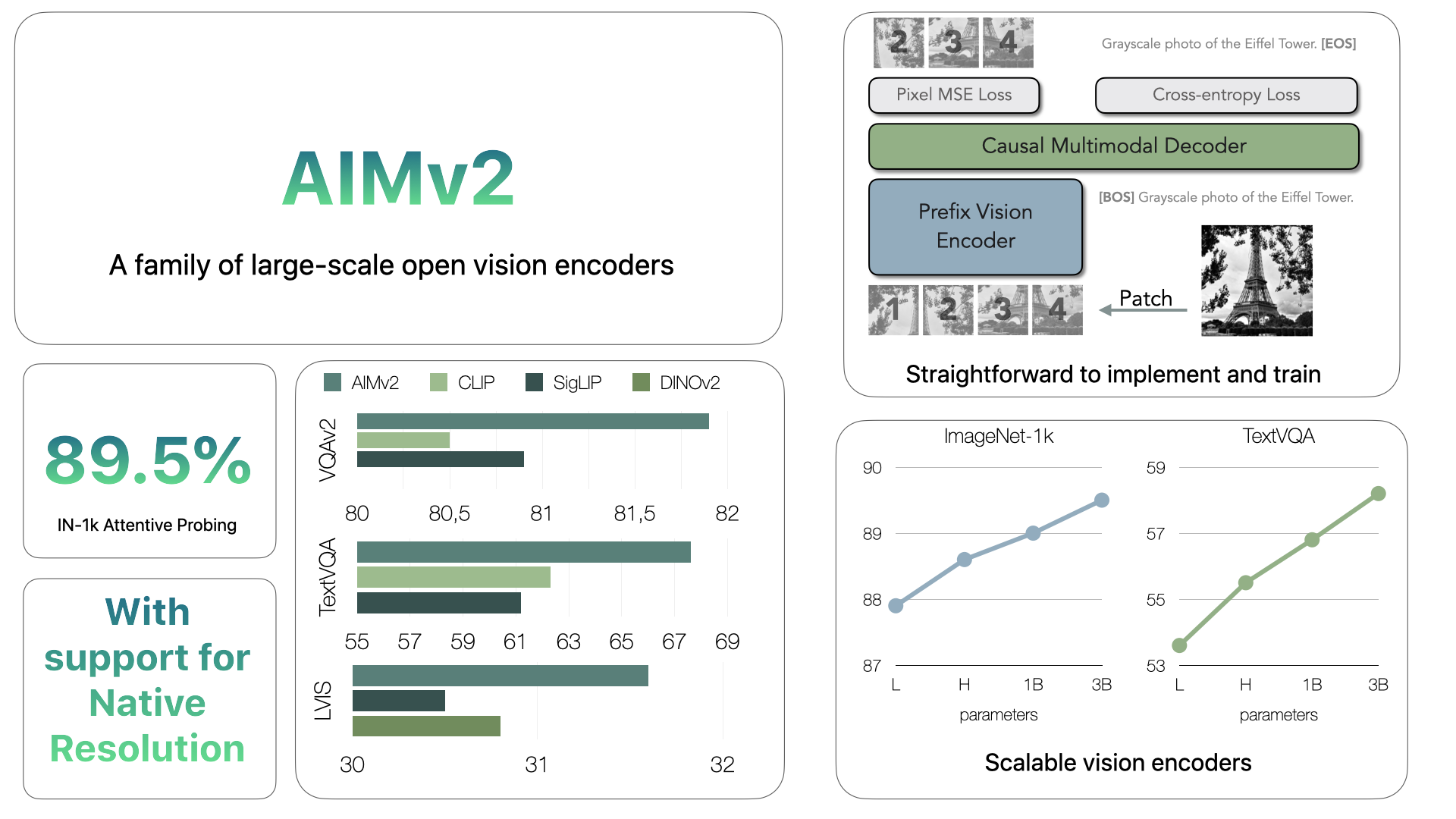
A collection of AIMv2 vision encoders that supports a number of resolutions, native resolution, and a distilled checkpoint.
•
19 items
•
Updated
•
43
[AIMv2 Paper] [BibTeX]
We introduce the AIMv2 family of vision models pre-trained with a multimodal autoregressive objective. AIMv2 pre-training is simple and straightforward to train and scale effectively. Some AIMv2 highlights include:
import requests
from PIL import Image
from transformers import AutoImageProcessor, AutoModel
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
processor = AutoImageProcessor.from_pretrained(
"apple/aimv2-large-patch14-224-distilled",
)
model = AutoModel.from_pretrained(
"apple/aimv2-large-patch14-224-distilled",
trust_remote_code=True,
)
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
import requests
from PIL import Image
from transformers import AutoImageProcessor, FlaxAutoModel
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
processor = AutoImageProcessor.from_pretrained(
"apple/aimv2-large-patch14-224-distilled",
)
model = FlaxAutoModel.from_pretrained(
"apple/aimv2-large-patch14-224-distilled",
trust_remote_code=True,
)
inputs = processor(images=image, return_tensors="jax")
outputs = model(**inputs)
If you find our work useful, please consider citing us as:
@misc{fini2024multimodalautoregressivepretraininglarge,
author = {Fini, Enrico and Shukor, Mustafa and Li, Xiujun and Dufter, Philipp and Klein, Michal and Haldimann, David and Aitharaju, Sai and da Costa, Victor Guilherme Turrisi and Béthune, Louis and Gan, Zhe and Toshev, Alexander T and Eichner, Marcin and Nabi, Moin and Yang, Yinfei and Susskind, Joshua M. and El-Nouby, Alaaeldin},
url = {https://arxiv.org/abs/2411.14402},
eprint = {2411.14402},
eprintclass = {cs.CV},
eprinttype = {arXiv},
title = {Multimodal Autoregressive Pre-training of Large Vision Encoders},
year = {2024},
}