---
license: apache-2.0
language:
- en
library_name: diffusers
---
# BLIP-Diffusion: Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing
Model card for BLIP-Diffusion, a text to image Diffusion model which enables zero-shot subject-driven generation and control-guided zero-shot generation.
The abstract from the paper is:
*Subject-driven text-to-image generation models create novel renditions of an input subject based on text prompts. Existing models suffer from lengthy fine-tuning and difficulties preserving the subject fidelity. To overcome these limitations, we introduce BLIP-Diffusion, a new subject-driven image generation model that supports multimodal control which consumes inputs of subject images and text prompts. Unlike other subject-driven generation models, BLIP-Diffusion introduces a new multimodal encoder which is pre-trained to provide subject representation. We first pre-train the multimodal encoder following BLIP-2 to produce visual representation aligned with the text. Then we design a subject representation learning task which enables a diffusion model to leverage such visual representation and generates new subject renditions. Compared with previous methods such as DreamBooth, our model enables zero-shot subject-driven generation, and efficient fine-tuning for customized subject with up to 20x speedup. We also demonstrate that BLIP-Diffusion can be flexibly combined with existing techniques such as ControlNet and prompt-to-prompt to enable novel subject-driven generation and editing applications.*
The model is created by Dongxu Li, Junnan Li, Steven C.H. Hoi.
### Model Sources
- **Original Repository:** https://github.com/salesforce/LAVIS/tree/main
- **Project Page:** https://dxli94.github.io/BLIP-Diffusion-website/
## Uses
### Zero-Shot Subject Driven Generation
```python
from diffusers.pipelines import BlipDiffusionPipeline
from diffusers.utils import load_image
blip_diffusion_pipe= BlipDiffusionPipeline.from_pretrained('ayushtues/blipdiffusion')
blip_diffusion_pipe.to('cuda')
cond_subject = "dog"
tgt_subject = "dog"
text_prompt_input = "swimming underwater"
cond_image = load_image("https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/dog.jpg")
guidance_scale = 7.5
num_inference_steps = 50
negative_prompt = "over-exposure, under-exposure, saturated, duplicate, out of frame, lowres, cropped, worst quality, low quality, jpeg artifacts, morbid, mutilated, out of frame, ugly, bad anatomy, bad proportions, deformed, blurry, duplicate"
output = blip_diffusion_pipe(
text_prompt_input,
cond_image,
cond_subject,
tgt_subject,
guidance_scale=guidance_scale,
num_inference_steps=num_inference_steps,
neg_prompt=negative_prompt,
height=512,
width=512,
)
output[0][0].save("image.png")
```
Input Image :  Generatred Image :
Generatred Image :  ### Controlled subject-driven generation
```python
from diffusers.pipelines import BlipDiffusionControlNetPipeline
from diffusers.utils import load_image
from controlnet_aux import CannyDetector
blip_diffusion_pipe= BlipDiffusionControlNetPipeline.from_pretrained("ayushtues/blipdiffusion-controlnet")
blip_diffusion_pipe.to('cuda')
style_subject = "flower" # subject that defines the style
tgt_subject = "teapot" # subject to generate.
text_prompt = "on a marble table"
cldm_cond_image = load_image("https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/kettle.jpg").resize((512, 512))
canny = CannyDetector()
cldm_cond_image = canny(cldm_cond_image, 30, 70, output_type='pil')
style_image = load_image("https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/flower.jpg")
guidance_scale = 7.5
num_inference_steps = 50
negative_prompt = "over-exposure, under-exposure, saturated, duplicate, out of frame, lowres, cropped, worst quality, low quality, jpeg artifacts, morbid, mutilated, out of frame, ugly, bad anatomy, bad proportions, deformed, blurry, duplicate"
output = blip_diffusion_pipe(
text_prompt,
style_image,
cldm_cond_image,
style_subject,
tgt_subject,
guidance_scale=guidance_scale,
num_inference_steps=num_inference_steps,
neg_prompt=negative_prompt,
height=512,
width=512,
)
output[0][0].save("image.png")
```
Input Style Image :
### Controlled subject-driven generation
```python
from diffusers.pipelines import BlipDiffusionControlNetPipeline
from diffusers.utils import load_image
from controlnet_aux import CannyDetector
blip_diffusion_pipe= BlipDiffusionControlNetPipeline.from_pretrained("ayushtues/blipdiffusion-controlnet")
blip_diffusion_pipe.to('cuda')
style_subject = "flower" # subject that defines the style
tgt_subject = "teapot" # subject to generate.
text_prompt = "on a marble table"
cldm_cond_image = load_image("https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/kettle.jpg").resize((512, 512))
canny = CannyDetector()
cldm_cond_image = canny(cldm_cond_image, 30, 70, output_type='pil')
style_image = load_image("https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/flower.jpg")
guidance_scale = 7.5
num_inference_steps = 50
negative_prompt = "over-exposure, under-exposure, saturated, duplicate, out of frame, lowres, cropped, worst quality, low quality, jpeg artifacts, morbid, mutilated, out of frame, ugly, bad anatomy, bad proportions, deformed, blurry, duplicate"
output = blip_diffusion_pipe(
text_prompt,
style_image,
cldm_cond_image,
style_subject,
tgt_subject,
guidance_scale=guidance_scale,
num_inference_steps=num_inference_steps,
neg_prompt=negative_prompt,
height=512,
width=512,
)
output[0][0].save("image.png")
```
Input Style Image :  Canny Edge Input :
Canny Edge Input :  Generated Image :
Generated Image :  ### Controlled subject-driven generation Scribble
```python
from diffusers.pipelines import BlipDiffusionControlNetPipeline
from diffusers.utils import load_image
from controlnet_aux import HEDdetector
blip_diffusion_pipe= BlipDiffusionControlNetPipeline.from_pretrained("ayushtues/blipdiffusion-controlnet")
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-scribble")
blip_diffusion_pipe.controlnet = controlnet
blip_diffusion_pipe.to('cuda')
style_subject = "flower" # subject that defines the style
tgt_subject = "bag" # subject to generate.
text_prompt = "on a table"
cldm_cond_image = load_image("https://huggingface.co/lllyasviel/sd-controlnet-scribble/resolve/main/images/bag.png" ).resize((512, 512))
hed = HEDdetector.from_pretrained("lllyasviel/Annotators")
cldm_cond_image = hed(cldm_cond_image)
style_image = load_image("https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/flower.jpg")
guidance_scale = 7.5
num_inference_steps = 50
negative_prompt = "over-exposure, under-exposure, saturated, duplicate, out of frame, lowres, cropped, worst quality, low quality, jpeg artifacts, morbid, mutilated, out of frame, ugly, bad anatomy, bad proportions, deformed, blurry, duplicate"
output = blip_diffusion_pipe(
text_prompt,
style_image,
cldm_cond_image,
style_subject,
tgt_subject,
guidance_scale=guidance_scale,
num_inference_steps=num_inference_steps,
neg_prompt=negative_prompt,
height=512,
width=512,
)
output[0][0].save("image.png"')
```
Input Style Image :
Scribble Input :
### Controlled subject-driven generation Scribble
```python
from diffusers.pipelines import BlipDiffusionControlNetPipeline
from diffusers.utils import load_image
from controlnet_aux import HEDdetector
blip_diffusion_pipe= BlipDiffusionControlNetPipeline.from_pretrained("ayushtues/blipdiffusion-controlnet")
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-scribble")
blip_diffusion_pipe.controlnet = controlnet
blip_diffusion_pipe.to('cuda')
style_subject = "flower" # subject that defines the style
tgt_subject = "bag" # subject to generate.
text_prompt = "on a table"
cldm_cond_image = load_image("https://huggingface.co/lllyasviel/sd-controlnet-scribble/resolve/main/images/bag.png" ).resize((512, 512))
hed = HEDdetector.from_pretrained("lllyasviel/Annotators")
cldm_cond_image = hed(cldm_cond_image)
style_image = load_image("https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/flower.jpg")
guidance_scale = 7.5
num_inference_steps = 50
negative_prompt = "over-exposure, under-exposure, saturated, duplicate, out of frame, lowres, cropped, worst quality, low quality, jpeg artifacts, morbid, mutilated, out of frame, ugly, bad anatomy, bad proportions, deformed, blurry, duplicate"
output = blip_diffusion_pipe(
text_prompt,
style_image,
cldm_cond_image,
style_subject,
tgt_subject,
guidance_scale=guidance_scale,
num_inference_steps=num_inference_steps,
neg_prompt=negative_prompt,
height=512,
width=512,
)
output[0][0].save("image.png"')
```
Input Style Image :
Scribble Input :  Generated Image :
Generated Image :  ## Model Architecture
Blip-Diffusion learns a **pre-trained subject representation**. uch representation aligns with text embeddings and in the meantime also encodes the subject appearance. This allows efficient fine-tuning of the model for high-fidelity subject-driven applications, such as text-to-image generation, editing and style transfer.
To this end, they design a two-stage pre-training strategy to learn generic subject representation. In the first pre-training stage, they perform multimodal representation learning, which enforces BLIP-2 to produce text-aligned visual features based on the input image. In the second pre-training stage, they design a subject representation learning task, called prompted context generation, where the diffusion model learns to generate novel subject renditions based on the input visual features.
To achieve this, they curate pairs of input-target images with the same subject appearing in different contexts. Specifically, they synthesize input images by composing the subject with a random background. During pre-training, they feed the synthetic input image and the subject class label through BLIP-2 to obtain the multimodal embeddings as subject representation. The subject representation is then combined with a text prompt to guide the generation of the target image.
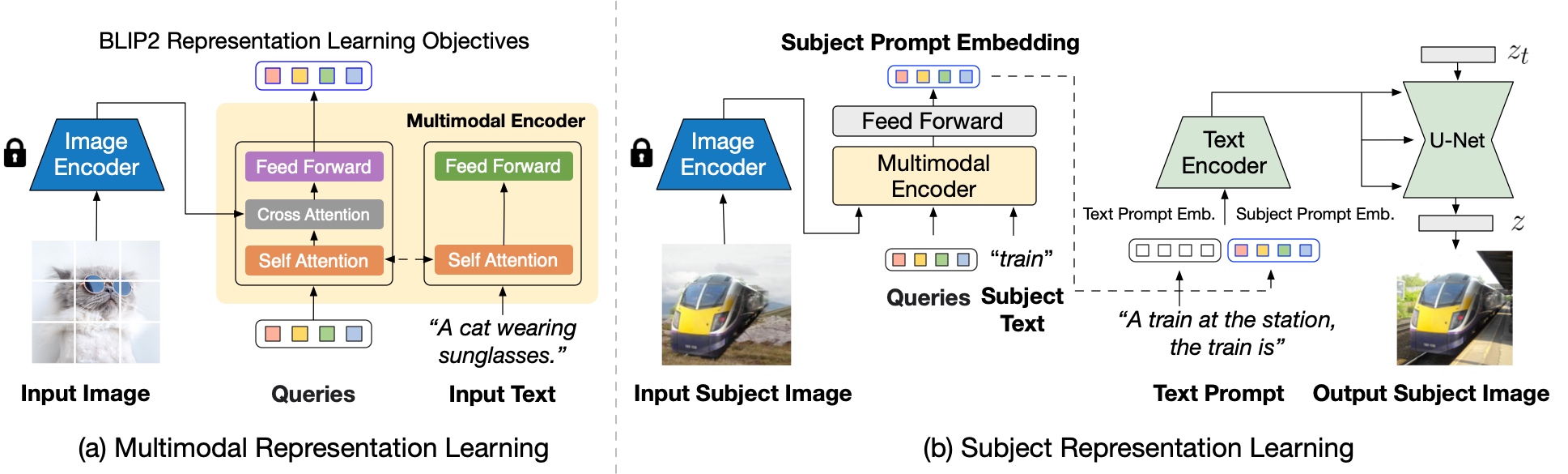
The architecture is also compatible to integrate with established techniques built on top of the diffusion model, such as ControlNet.
They attach the U-Net of the pre-trained ControlNet to that of BLIP-Diffusion via residuals. In this way, the model takes into account the input structure condition, such as edge maps and depth maps, in addition to the subject cues. Since the model inherits the architecture of the original latent diffusion model, they observe satisfying generations using off-the-shelf integration with pre-trained ControlNet without further training.
## Model Architecture
Blip-Diffusion learns a **pre-trained subject representation**. uch representation aligns with text embeddings and in the meantime also encodes the subject appearance. This allows efficient fine-tuning of the model for high-fidelity subject-driven applications, such as text-to-image generation, editing and style transfer.
To this end, they design a two-stage pre-training strategy to learn generic subject representation. In the first pre-training stage, they perform multimodal representation learning, which enforces BLIP-2 to produce text-aligned visual features based on the input image. In the second pre-training stage, they design a subject representation learning task, called prompted context generation, where the diffusion model learns to generate novel subject renditions based on the input visual features.
To achieve this, they curate pairs of input-target images with the same subject appearing in different contexts. Specifically, they synthesize input images by composing the subject with a random background. During pre-training, they feed the synthetic input image and the subject class label through BLIP-2 to obtain the multimodal embeddings as subject representation. The subject representation is then combined with a text prompt to guide the generation of the target image.

The architecture is also compatible to integrate with established techniques built on top of the diffusion model, such as ControlNet.
They attach the U-Net of the pre-trained ControlNet to that of BLIP-Diffusion via residuals. In this way, the model takes into account the input structure condition, such as edge maps and depth maps, in addition to the subject cues. Since the model inherits the architecture of the original latent diffusion model, they observe satisfying generations using off-the-shelf integration with pre-trained ControlNet without further training.
 ## Citation
**BibTeX:**
If you find this repository useful in your research, please cite:
```
@misc{li2023blipdiffusion,
title={BLIP-Diffusion: Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing},
author={Dongxu Li and Junnan Li and Steven C. H. Hoi},
year={2023},
eprint={2305.14720},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
## Citation
**BibTeX:**
If you find this repository useful in your research, please cite:
```
@misc{li2023blipdiffusion,
title={BLIP-Diffusion: Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing},
author={Dongxu Li and Junnan Li and Steven C. H. Hoi},
year={2023},
eprint={2305.14720},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```