
Commit
•
f698873
1
Parent(s):
5ead62c
Upload 15 files
Browse files- .gitattributes +3 -35
- LICENSE +21 -0
- README.md +54 -3
- case-studies/Wiki-text.md +9 -0
- case-studies/poem.md +44 -0
- fig/BanglaAutoKG.png +0 -0
- fig/KGs.png +0 -0
- fig/Poem.png +0 -0
- fig/Wiki.png +0 -0
- model/components/denoiser/FeatureDN.py +221 -0
- model/components/relation_extractors/LocalRE.py +130 -0
- model/components/relation_extractors/TopologicalRE.py +77 -0
- model/components/semantic_info_conv/Semantic_IC.py +298 -0
- model/metric/A_SFAS.py +34 -0
- poster/BanglaAutoKG.png +3 -0
.gitattributes
CHANGED
|
@@ -1,35 +1,3 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
-
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
-
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
-
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
-
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
-
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
-
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
-
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
-
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
-
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
-
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
-
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
-
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
-
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
-
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
-
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
-
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
-
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
-
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
-
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
-
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
-
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
-
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
-
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
-
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
-
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
-
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
-
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
-
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
-
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
-
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
-
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
| 1 |
+
# Auto detect text files and perform LF normalization
|
| 2 |
+
* text=auto
|
| 3 |
+
poster/BanglaAutoKG.png filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2024 Azmine Toushik Wasi
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
CHANGED
|
@@ -1,3 +1,54 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ***BanglaAutoKG*: Automatic Bangla Knowledge Graph Construction with Semantic Neural Graph Filtering**
|
| 2 |
+
- **Authors:** Azmine Toushik Wasi, Taki Hasan Rafi, Raima Islam and Dong-Kyu Chae
|
| 3 |
+
- **ACL Anthology**: https://aclanthology.org/2024.lrec-main.189/
|
| 4 |
+
- **arXiv**: https://arxiv.org/abs/2404.03528
|
| 5 |
+
|
| 6 |
+
---
|
| 7 |
+
**Abstract:** Knowledge Graphs (KGs) have proven essential in information processing and reasoning applications because they link related entities and give context-rich information, supporting efficient information retrieval and knowledge discovery; presenting information flow in a very effective manner. Despite being widely used globally, Bangla is relatively underrepresented in KGs due to a lack of comprehensive datasets, encoders, NER (named entity recognition) models, POS (part-of-speech) taggers, and lemmatizers, hindering efficient information processing and reasoning applications in the language. Addressing the KG scarcity in Bengali, we propose BanglaAutoKG, a pioneering framework that is able to automatically construct Bengali KGs from any Bangla text. We utilize multilingual LLMs to understand various languages and correlate entities and relations universally. By employing a translation dictionary to identify English equivalents and extracting word features from pre-trained BERT models, we construct the foundational KG. To reduce noise and align word embeddings with our goal, we employ graph-based polynomial filters. Lastly, we implement a GNN-based semantic filter, which elevates contextual understanding and trims unnecessary edges, culminating in the formation of the definitive KG. Empirical findings and case studies demonstrate the universal effectiveness of our model, capable of autonomously constructing semantically enriched KGs from any text.
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
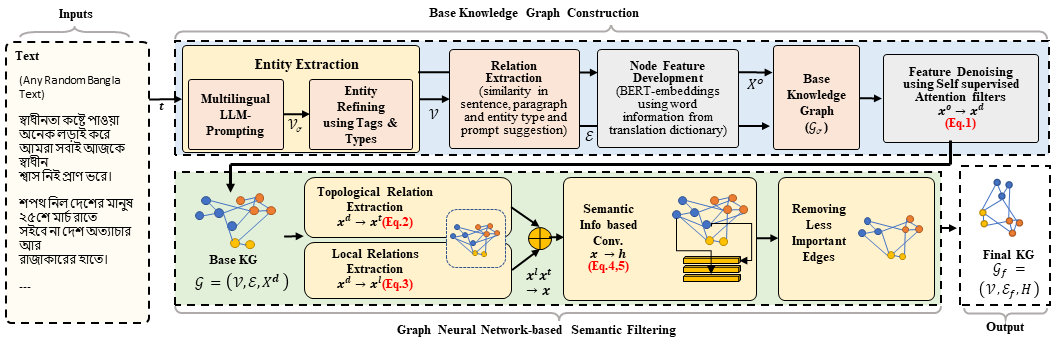
## Architecture
|
| 11 |
+
Pipeline of *BanglaAutoKG*.
|
| 12 |
+
|
| 13 |
+
<p align="center">
|
| 14 |
+
<img src="fig/BanglaAutoKG.png" width="1000"/>
|
| 15 |
+
</p>
|
| 16 |
+
|
| 17 |
+
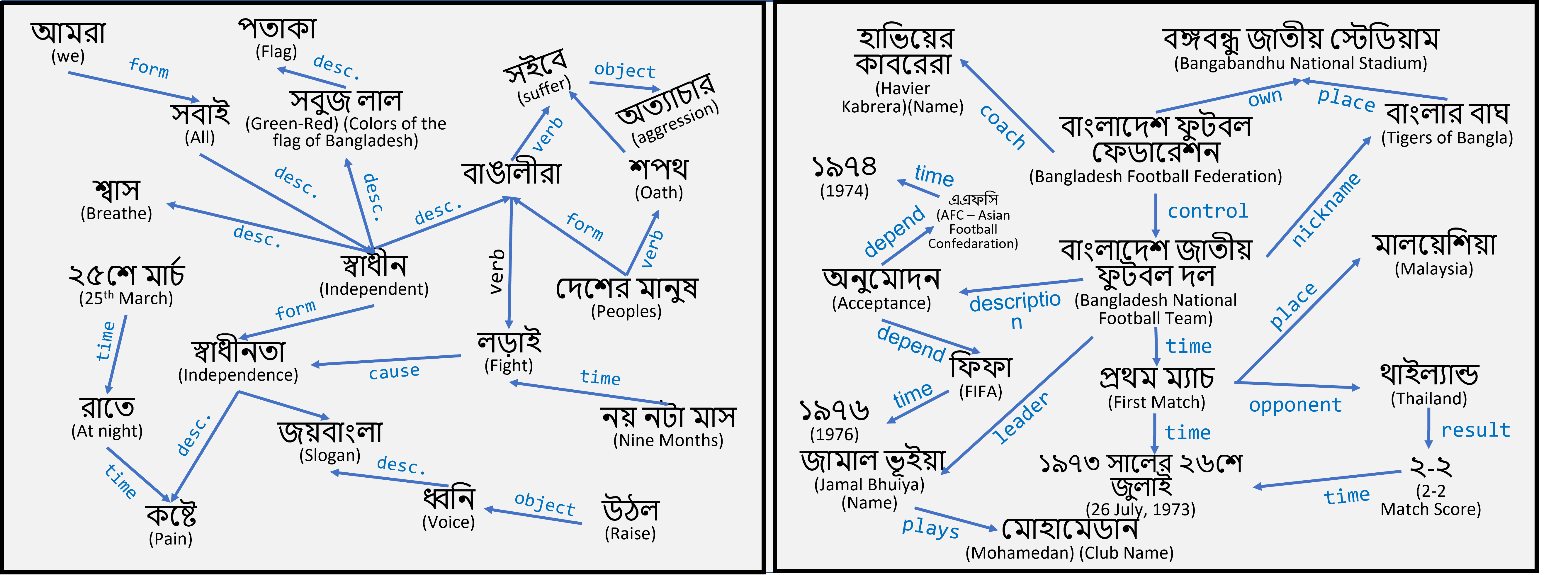
## Example Case Studies
|
| 18 |
+
Example uses of *BanglaAutoKG*.
|
| 19 |
+
|
| 20 |
+
<p align="center">
|
| 21 |
+
<img src="fig/KGs.png" width="1000"/>
|
| 22 |
+
</p>
|
| 23 |
+
|
| 24 |
+
Texts are available in `.\case-studies\` folder.
|
| 25 |
+
|
| 26 |
+
---
|
| 27 |
+
|
| 28 |
+
## Citation
|
| 29 |
+
- **ACL** :
|
| 30 |
+
```
|
| 31 |
+
Azmine Toushik Wasi, Taki Hasan Rafi, Raima Islam, and Dong-Kyu Chae. 2024. BanglaAutoKG: Automatic Bangla Knowledge Graph Construction with Semantic Neural Graph Filtering. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 2100–2106, Torino, Italia. ELRA and ICCL.
|
| 32 |
+
```
|
| 33 |
+
- **BIBTEX** :
|
| 34 |
+
```
|
| 35 |
+
@inproceedings{wasi-etal-2024-banglaautokg-automatic,
|
| 36 |
+
title = "{B}angla{A}uto{KG}: Automatic {B}angla Knowledge Graph Construction with Semantic Neural Graph Filtering",
|
| 37 |
+
author = "Wasi, Azmine Toushik and Rafi, Taki Hasan and Islam, Raima and Chae, Dong-Kyu",
|
| 38 |
+
booktitle = "Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)",
|
| 39 |
+
month = may,
|
| 40 |
+
year = "2024",
|
| 41 |
+
address = "Torino, Italia",
|
| 42 |
+
publisher = "ELRA and ICCL",
|
| 43 |
+
url = "https://aclanthology.org/2024.lrec-main.189",
|
| 44 |
+
pages = "2100--2106",
|
| 45 |
+
code = "https://github.com/azminewasi/BanglaAutoKG",
|
| 46 |
+
}
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
---
|
| 50 |
+
|
| 51 |
+
# Poster
|
| 52 |
+
<p align="center">
|
| 53 |
+
<img src="poster/BanglaAutoKG.png" width="1000"/>
|
| 54 |
+
</p>
|
case-studies/Wiki-text.md
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
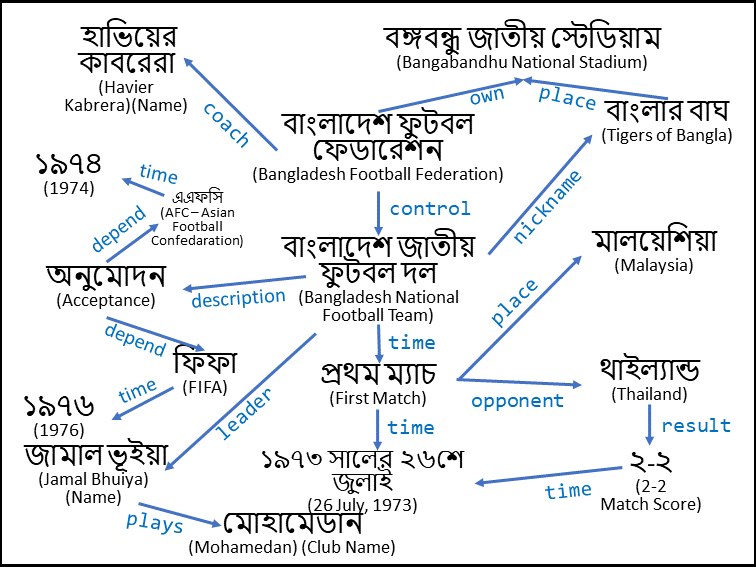
# Wikipedia Article Part: বাংলাদেশ জাতীয় ফুটবল দল
|
| 2 |
+
- Collected from: [URL](https://bn.wikipedia.org/s/1cmz)
|
| 3 |
+
|
| 4 |
+
---
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
বাংলাদেশ জাতীয় ফুটবল দল হচ্ছে আন্তর্জাতিক ফুটবলে বাংলাদেশের প্রতিনিধিত্বকারী পুরুষদের জাতীয় দল, যার সকল কার্যক্রম বাংলাদেশের ফুটবলের সর্বোচ্চ নিয়ন্ত্রক সংস্থা বাংলাদেশ ফুটবল ফেডারেশন দ্বারা নিয়ন্ত্রিত হয়। এই দলটি ১৯৭৬ সাল হতে ফুটবলের সর্বোচ্চ সংস্থা ফিফার এবং ১৯৭৪ সাল হতে তাদের আঞ্চলিক সংস্থা এশিয়ান ফুটবল কনফেডারেশনের সদস্য হিসেবে রয়েছে। ১৯৭৩ সালের ২৬শে জুলাই তারিখে, বাংলাদেশ প্রথমবারের মতো আন্তর্জাতিক খেলায় অংশগ্রহণ করেছে; মালয়েশিয়ার কুয়ালালামপুরে অনুষ্ঠিত বাংলাদেশ এবং থাইল্যান্ডের মধ্যকার উক্ত ম্যাচটি ২–২ গোলে ড্র হয়েছে।
|
| 8 |
+
|
| 9 |
+
৩৬,০০০ ধারণক্ষমতাবিশিষ্ট বঙ্গবন্ধু জাতীয় স্টেডিয়ামে বাংলার বাঘ নামে পরিচিত এই দলটি তাদের সকল হোম ম্যাচ আয়োজন করে থাকে। এই দলের প্রধান কার্যালয় বাংলাদেশের রাজধানী ঢাকার মতিঝিলের বঙ্গবন্ধু জাতীয় স্টেডিয়ামের নিকটবর্তী বিএফএফ ভবনে অবস্থিত। বর্তমানে এই দলের ম্যানেজারের দায়িত্ব পালন করছেন হাভিয়ের কাবরেরা এবং অধিনায়কের দায়িত্ব পালন করছেন কলকাতা মোহামেডানের মধ্যমাঠের খেলোয়াড় জামাল ভূইয়া।
|
case-studies/poem.md
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
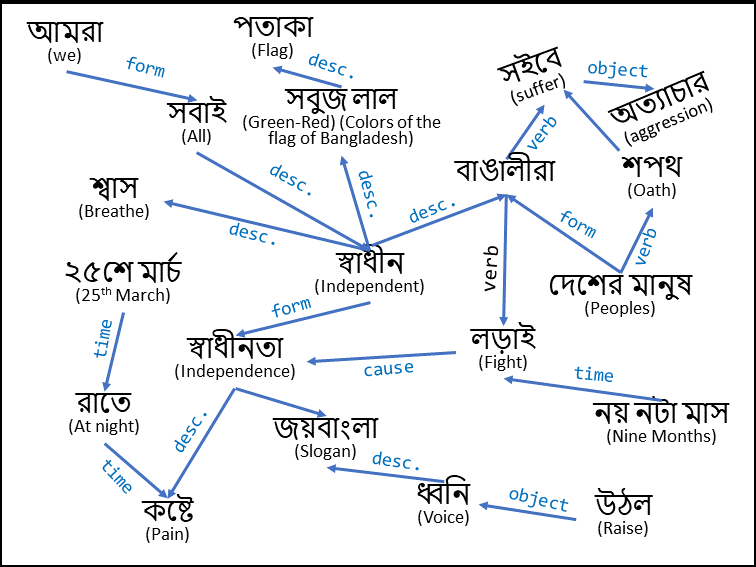
# কবিতা (Poem): স্বাধীনতার খুশি
|
| 2 |
+
- কবি (Poet): অমরেশ বিশ্বাস
|
| 3 |
+
- Collected from: [URL](https://www.poetrystate.com/amaresh/%E0%A6%B8%E0%A7%8D%E0%A6%AC%E0%A6%BE%E0%A6%A7%E0%A7%80%E0%A6%A8%E0%A6%A4%E0%A6%BE%E0%A6%B0-%E0%A6%96%E0%A7%81%E0%A6%B6%E0%A6%BF/)
|
| 4 |
+
|
| 5 |
+
---
|
| 6 |
+
---
|
| 7 |
+
|
| 8 |
+
স্বাধীনতা কষ্টে পাওয়া
|
| 9 |
+
|
| 10 |
+
অনেক লড়াই করে
|
| 11 |
+
|
| 12 |
+
আমরা সবাই আজকে স্বাধীন
|
| 13 |
+
|
| 14 |
+
শ্বাস নিই প্রাণ ভরে।
|
| 15 |
+
|
| 16 |
+
---
|
| 17 |
+
|
| 18 |
+
শপথ নিল দেশের মানুষ
|
| 19 |
+
|
| 20 |
+
২৫শে মার্চ রাতে
|
| 21 |
+
|
| 22 |
+
সইবে না দেশ অত্যাচার আর
|
| 23 |
+
|
| 24 |
+
রাজাকারের হাতে।
|
| 25 |
+
|
| 26 |
+
---
|
| 27 |
+
|
| 28 |
+
উঠল ধ্বনি জয়বাংলার
|
| 29 |
+
|
| 30 |
+
পাকিস্তান আর নয়
|
| 31 |
+
|
| 32 |
+
বাঙালীরা ফেলল মুছে
|
| 33 |
+
|
| 34 |
+
প্রাণের থেকে ভয়।
|
| 35 |
+
|
| 36 |
+
---
|
| 37 |
+
|
| 38 |
+
নয় নটা মাস চলল লড়াই
|
| 39 |
+
|
| 40 |
+
স্বাধীন হল দেশ
|
| 41 |
+
|
| 42 |
+
উড়ছে সবুজ লাল পতাকা
|
| 43 |
+
|
| 44 |
+
নেই আজ খুশির শেষ।
|
fig/BanglaAutoKG.png
ADDED
|
fig/KGs.png
ADDED
|
fig/Poem.png
ADDED
|
fig/Wiki.png
ADDED
|
model/components/denoiser/FeatureDN.py
ADDED
|
@@ -0,0 +1,221 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
from typing import Optional
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn.functional as F
|
| 6 |
+
from torch import Tensor
|
| 7 |
+
from torch.nn import Parameter
|
| 8 |
+
|
| 9 |
+
from torch_geometric.nn.conv import MessagePassing
|
| 10 |
+
from torch_geometric.nn.dense.linear import Linear
|
| 11 |
+
from torch_geometric.nn.inits import glorot, zeros
|
| 12 |
+
from torch_geometric.typing import Adj, OptTensor, SparseTensor, torch_sparse
|
| 13 |
+
from torch_geometric.utils import (
|
| 14 |
+
add_self_loops,
|
| 15 |
+
batched_negative_sampling,
|
| 16 |
+
dropout_edge,
|
| 17 |
+
is_undirected,
|
| 18 |
+
negative_sampling,
|
| 19 |
+
remove_self_loops,
|
| 20 |
+
softmax,
|
| 21 |
+
to_undirected,
|
| 22 |
+
)
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
class FeatureDeNoisingLayer(MessagePassing):
|
| 26 |
+
|
| 27 |
+
att_x: OptTensor
|
| 28 |
+
att_y: OptTensor
|
| 29 |
+
|
| 30 |
+
def __init__(self, in_channels: int, out_channels: int, heads: int = 1,
|
| 31 |
+
concat: bool = True, negative_slope: float = 0.2,
|
| 32 |
+
dropout: float = 0.0, add_self_loops: bool = True,
|
| 33 |
+
bias: bool = True, attention_type: str = 'MX',
|
| 34 |
+
neg_sample_ratio: float = 0.5, edge_sample_ratio: float = 1.0,
|
| 35 |
+
is_undirected: bool = False, **kwargs):
|
| 36 |
+
kwargs.setdefault('aggr', 'add')
|
| 37 |
+
super().__init__(node_dim=0, **kwargs)
|
| 38 |
+
|
| 39 |
+
self.in_channels = in_channels
|
| 40 |
+
self.out_channels = out_channels
|
| 41 |
+
self.heads = heads
|
| 42 |
+
self.concat = concat
|
| 43 |
+
self.negative_slope = negative_slope
|
| 44 |
+
self.dropout = dropout
|
| 45 |
+
self.add_self_loops = add_self_loops
|
| 46 |
+
self.attention_type = attention_type
|
| 47 |
+
self.neg_sample_ratio = neg_sample_ratio
|
| 48 |
+
self.edge_sample_ratio = edge_sample_ratio
|
| 49 |
+
self.is_undirected = is_undirected
|
| 50 |
+
|
| 51 |
+
assert attention_type in ['MX', 'SD']
|
| 52 |
+
assert 0.0 < neg_sample_ratio and 0.0 < edge_sample_ratio <= 1.0
|
| 53 |
+
|
| 54 |
+
self.lin = Linear(in_channels, heads * out_channels, bias=False,
|
| 55 |
+
weight_initializer='glorot')
|
| 56 |
+
|
| 57 |
+
if self.attention_type == 'MX':
|
| 58 |
+
self.att_l = Parameter(torch.empty(1, heads, out_channels))
|
| 59 |
+
self.att_r = Parameter(torch.empty(1, heads, out_channels))
|
| 60 |
+
else: # self.attention_type == 'SD'
|
| 61 |
+
self.register_parameter('att_l', None)
|
| 62 |
+
self.register_parameter('att_r', None)
|
| 63 |
+
|
| 64 |
+
self.att_x = self.att_y = None # x/y for self-supervision
|
| 65 |
+
|
| 66 |
+
if bias and concat:
|
| 67 |
+
self.bias = Parameter(torch.empty(heads * out_channels))
|
| 68 |
+
elif bias and not concat:
|
| 69 |
+
self.bias = Parameter(torch.empty(out_channels))
|
| 70 |
+
else:
|
| 71 |
+
self.register_parameter('bias', None)
|
| 72 |
+
|
| 73 |
+
self.reset_parameters()
|
| 74 |
+
|
| 75 |
+
def reset_parameters(self):
|
| 76 |
+
super().reset_parameters()
|
| 77 |
+
self.lin.reset_parameters()
|
| 78 |
+
glorot(self.att_l)
|
| 79 |
+
glorot(self.att_r)
|
| 80 |
+
zeros(self.bias)
|
| 81 |
+
|
| 82 |
+
def forward(
|
| 83 |
+
self,
|
| 84 |
+
x: Tensor,
|
| 85 |
+
edge_index: Adj,
|
| 86 |
+
neg_edge_index: OptTensor = None,
|
| 87 |
+
batch: OptTensor = None,
|
| 88 |
+
) -> Tensor:
|
| 89 |
+
r"""Runs the forward pass of the module.
|
| 90 |
+
|
| 91 |
+
Args:
|
| 92 |
+
x (torch.Tensor): The input node features.
|
| 93 |
+
edge_index (torch.Tensor or SparseTensor): The edge indices.
|
| 94 |
+
neg_edge_index (torch.Tensor, optional): The negative edges to
|
| 95 |
+
train against. If not given, uses negative sampling to
|
| 96 |
+
calculate negative edges. (default: :obj:`None`)
|
| 97 |
+
batch (torch.Tensor, optional): The batch vector
|
| 98 |
+
:math:`\mathbf{b} \in {\{ 0, \ldots, B-1\}}^N`, which assigns
|
| 99 |
+
each element to a specific example.
|
| 100 |
+
Used when sampling negatives on-the-fly in mini-batch
|
| 101 |
+
scenarios. (default: :obj:`None`)
|
| 102 |
+
"""
|
| 103 |
+
N, H, C = x.size(0), self.heads, self.out_channels
|
| 104 |
+
|
| 105 |
+
if self.add_self_loops:
|
| 106 |
+
if isinstance(edge_index, SparseTensor):
|
| 107 |
+
edge_index = torch_sparse.fill_diag(edge_index, 1.)
|
| 108 |
+
else:
|
| 109 |
+
edge_index, _ = remove_self_loops(edge_index)
|
| 110 |
+
edge_index, _ = add_self_loops(edge_index, num_nodes=N)
|
| 111 |
+
|
| 112 |
+
x = self.lin(x).view(-1, H, C)
|
| 113 |
+
|
| 114 |
+
# propagate_type: (x: Tensor)
|
| 115 |
+
out = self.propagate(edge_index, x=x)
|
| 116 |
+
|
| 117 |
+
if self.training:
|
| 118 |
+
if isinstance(edge_index, SparseTensor):
|
| 119 |
+
col, row, _ = edge_index.coo()
|
| 120 |
+
edge_index = torch.stack([row, col], dim=0)
|
| 121 |
+
pos_edge_index = self.positive_sampling(edge_index)
|
| 122 |
+
|
| 123 |
+
pos_att = self.get_attention(
|
| 124 |
+
edge_index_i=pos_edge_index[1],
|
| 125 |
+
x_i=x[pos_edge_index[1]],
|
| 126 |
+
x_j=x[pos_edge_index[0]],
|
| 127 |
+
num_nodes=x.size(0),
|
| 128 |
+
return_logits=True,
|
| 129 |
+
)
|
| 130 |
+
|
| 131 |
+
if neg_edge_index is None:
|
| 132 |
+
neg_edge_index = self.negative_sampling(edge_index, N, batch)
|
| 133 |
+
|
| 134 |
+
neg_att = self.get_attention(
|
| 135 |
+
edge_index_i=neg_edge_index[1],
|
| 136 |
+
x_i=x[neg_edge_index[1]],
|
| 137 |
+
x_j=x[neg_edge_index[0]],
|
| 138 |
+
num_nodes=x.size(0),
|
| 139 |
+
return_logits=True,
|
| 140 |
+
)
|
| 141 |
+
|
| 142 |
+
self.att_x = torch.cat([pos_att, neg_att], dim=0)
|
| 143 |
+
self.att_y = self.att_x.new_zeros(self.att_x.size(0))
|
| 144 |
+
self.att_y[:pos_edge_index.size(1)] = 1.
|
| 145 |
+
|
| 146 |
+
if self.concat is True:
|
| 147 |
+
out = out.view(-1, self.heads * self.out_channels)
|
| 148 |
+
else:
|
| 149 |
+
out = out.mean(dim=1)
|
| 150 |
+
|
| 151 |
+
if self.bias is not None:
|
| 152 |
+
out = out + self.bias
|
| 153 |
+
|
| 154 |
+
return out
|
| 155 |
+
|
| 156 |
+
def message(self, edge_index_i: Tensor, x_i: Tensor, x_j: Tensor,
|
| 157 |
+
size_i: Optional[int]) -> Tensor:
|
| 158 |
+
alpha = self.get_attention(edge_index_i, x_i, x_j, num_nodes=size_i)
|
| 159 |
+
alpha = F.dropout(alpha, p=self.dropout, training=self.training)
|
| 160 |
+
return x_j * alpha.view(-1, self.heads, 1)
|
| 161 |
+
|
| 162 |
+
def negative_sampling(self, edge_index: Tensor, num_nodes: int,
|
| 163 |
+
batch: OptTensor = None) -> Tensor:
|
| 164 |
+
|
| 165 |
+
num_neg_samples = int(self.neg_sample_ratio * self.edge_sample_ratio *
|
| 166 |
+
edge_index.size(1))
|
| 167 |
+
|
| 168 |
+
if not self.is_undirected and not is_undirected(
|
| 169 |
+
edge_index, num_nodes=num_nodes):
|
| 170 |
+
edge_index = to_undirected(edge_index, num_nodes=num_nodes)
|
| 171 |
+
|
| 172 |
+
if batch is None:
|
| 173 |
+
neg_edge_index = negative_sampling(edge_index, num_nodes,
|
| 174 |
+
num_neg_samples=num_neg_samples)
|
| 175 |
+
else:
|
| 176 |
+
neg_edge_index = batched_negative_sampling(
|
| 177 |
+
edge_index, batch, num_neg_samples=num_neg_samples)
|
| 178 |
+
|
| 179 |
+
return neg_edge_index
|
| 180 |
+
|
| 181 |
+
def positive_sampling(self, edge_index: Tensor) -> Tensor:
|
| 182 |
+
pos_edge_index, _ = dropout_edge(edge_index,
|
| 183 |
+
p=1. - self.edge_sample_ratio,
|
| 184 |
+
training=self.training)
|
| 185 |
+
return pos_edge_index
|
| 186 |
+
|
| 187 |
+
def get_attention(self, edge_index_i: Tensor, x_i: Tensor, x_j: Tensor,
|
| 188 |
+
num_nodes: Optional[int],
|
| 189 |
+
return_logits: bool = False) -> Tensor:
|
| 190 |
+
|
| 191 |
+
if self.attention_type == 'MX':
|
| 192 |
+
logits = (x_i * x_j).sum(dim=-1)
|
| 193 |
+
if return_logits:
|
| 194 |
+
return logits
|
| 195 |
+
|
| 196 |
+
alpha = (x_j * self.att_l).sum(-1) + (x_i * self.att_r).sum(-1)
|
| 197 |
+
alpha = alpha * logits.sigmoid()
|
| 198 |
+
|
| 199 |
+
else: # self.attention_type == 'SD'
|
| 200 |
+
alpha = (x_i * x_j).sum(dim=-1) / math.sqrt(self.out_channels)
|
| 201 |
+
if return_logits:
|
| 202 |
+
return alpha
|
| 203 |
+
|
| 204 |
+
alpha = F.leaky_relu(alpha, self.negative_slope)
|
| 205 |
+
alpha = softmax(alpha, edge_index_i, num_nodes=num_nodes)
|
| 206 |
+
return alpha
|
| 207 |
+
|
| 208 |
+
def get_attention_loss(self) -> Tensor:
|
| 209 |
+
r"""Computes the self-supervised graph attention loss."""
|
| 210 |
+
if not self.training:
|
| 211 |
+
return torch.tensor([0], device=self.lin.weight.device)
|
| 212 |
+
|
| 213 |
+
return F.binary_cross_entropy_with_logits(
|
| 214 |
+
self.att_x.mean(dim=-1),
|
| 215 |
+
self.att_y,
|
| 216 |
+
)
|
| 217 |
+
|
| 218 |
+
def __repr__(self) -> str:
|
| 219 |
+
return (f'{self.__class__.__name__}({self.in_channels}, '
|
| 220 |
+
f'{self.out_channels}, heads={self.heads}, '
|
| 221 |
+
f'type={self.attention_type})')
|
model/components/relation_extractors/LocalRE.py
ADDED
|
@@ -0,0 +1,130 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Optional
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from torch import Tensor
|
| 5 |
+
from torch.nn import Parameter
|
| 6 |
+
|
| 7 |
+
from torch_geometric.nn.conv import MessagePassing
|
| 8 |
+
from torch_geometric.nn.dense.linear import Linear
|
| 9 |
+
from torch_geometric.nn.inits import zeros
|
| 10 |
+
from torch_geometric.typing import OptTensor
|
| 11 |
+
from torch_geometric.utils import get_laplacian
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class LocalRelationExtractionLayer(MessagePassing):
|
| 15 |
+
|
| 16 |
+
def __init__(
|
| 17 |
+
self,
|
| 18 |
+
in_channels: int,
|
| 19 |
+
out_channels: int,
|
| 20 |
+
K: int,
|
| 21 |
+
normalization: Optional[str] = 'sym',
|
| 22 |
+
bias: bool = True,
|
| 23 |
+
**kwargs,
|
| 24 |
+
):
|
| 25 |
+
kwargs.setdefault('aggr', 'add')
|
| 26 |
+
super().__init__(**kwargs)
|
| 27 |
+
|
| 28 |
+
assert K > 0
|
| 29 |
+
assert normalization in [None, 'sym', 'rw'], 'Invalid normalization'
|
| 30 |
+
|
| 31 |
+
self.in_channels = in_channels
|
| 32 |
+
self.out_channels = out_channels
|
| 33 |
+
self.normalization = normalization
|
| 34 |
+
self.lins = torch.nn.ModuleList([
|
| 35 |
+
Linear(in_channels, out_channels, bias=False,
|
| 36 |
+
weight_initializer='glorot') for _ in range(K)
|
| 37 |
+
])
|
| 38 |
+
|
| 39 |
+
if bias:
|
| 40 |
+
self.bias = Parameter(Tensor(out_channels))
|
| 41 |
+
else:
|
| 42 |
+
self.register_parameter('bias', None)
|
| 43 |
+
|
| 44 |
+
self.reset_parameters()
|
| 45 |
+
|
| 46 |
+
def reset_parameters(self):
|
| 47 |
+
super().reset_parameters()
|
| 48 |
+
for lin in self.lins:
|
| 49 |
+
lin.reset_parameters()
|
| 50 |
+
zeros(self.bias)
|
| 51 |
+
|
| 52 |
+
def __norm__(
|
| 53 |
+
self,
|
| 54 |
+
edge_index: Tensor,
|
| 55 |
+
num_nodes: Optional[int],
|
| 56 |
+
edge_weight: OptTensor,
|
| 57 |
+
normalization: Optional[str],
|
| 58 |
+
lambda_max: OptTensor = None,
|
| 59 |
+
dtype: Optional[int] = None,
|
| 60 |
+
batch: OptTensor = None,
|
| 61 |
+
):
|
| 62 |
+
edge_index, edge_weight = get_laplacian(edge_index, edge_weight,
|
| 63 |
+
normalization, dtype,
|
| 64 |
+
num_nodes)
|
| 65 |
+
assert edge_weight is not None
|
| 66 |
+
|
| 67 |
+
if lambda_max is None:
|
| 68 |
+
lambda_max = 2.0 * edge_weight.max()
|
| 69 |
+
elif not isinstance(lambda_max, Tensor):
|
| 70 |
+
lambda_max = torch.tensor(lambda_max, dtype=dtype,
|
| 71 |
+
device=edge_index.device)
|
| 72 |
+
assert lambda_max is not None
|
| 73 |
+
|
| 74 |
+
if batch is not None and lambda_max.numel() > 1:
|
| 75 |
+
lambda_max = lambda_max[batch[edge_index[0]]]
|
| 76 |
+
|
| 77 |
+
edge_weight = (2.0 * edge_weight) / lambda_max
|
| 78 |
+
edge_weight.masked_fill_(edge_weight == float('inf'), 0)
|
| 79 |
+
|
| 80 |
+
loop_mask = edge_index[0] == edge_index[1]
|
| 81 |
+
edge_weight[loop_mask] -= 1
|
| 82 |
+
|
| 83 |
+
return edge_index, edge_weight
|
| 84 |
+
|
| 85 |
+
def forward(
|
| 86 |
+
self,
|
| 87 |
+
x: Tensor,
|
| 88 |
+
edge_index: Tensor,
|
| 89 |
+
edge_weight: OptTensor = None,
|
| 90 |
+
batch: OptTensor = None,
|
| 91 |
+
lambda_max: OptTensor = None,
|
| 92 |
+
) -> Tensor:
|
| 93 |
+
|
| 94 |
+
edge_index, norm = self.__norm__(
|
| 95 |
+
edge_index,
|
| 96 |
+
x.size(self.node_dim),
|
| 97 |
+
edge_weight,
|
| 98 |
+
self.normalization,
|
| 99 |
+
lambda_max,
|
| 100 |
+
dtype=x.dtype,
|
| 101 |
+
batch=batch,
|
| 102 |
+
)
|
| 103 |
+
|
| 104 |
+
Tx_0 = x
|
| 105 |
+
Tx_1 = x # Dummy.
|
| 106 |
+
out = self.lins[0](Tx_0)
|
| 107 |
+
|
| 108 |
+
# propagate_type: (x: Tensor, norm: Tensor)
|
| 109 |
+
if len(self.lins) > 1:
|
| 110 |
+
Tx_1 = self.propagate(edge_index, x=x, norm=norm)
|
| 111 |
+
out = out + self.lins[1](Tx_1)
|
| 112 |
+
|
| 113 |
+
for lin in self.lins[2:]:
|
| 114 |
+
Tx_2 = self.propagate(edge_index, x=Tx_1, norm=norm)
|
| 115 |
+
Tx_2 = 2. * Tx_2 - Tx_0
|
| 116 |
+
out = out + lin.forward(Tx_2)
|
| 117 |
+
Tx_0, Tx_1 = Tx_1, Tx_2
|
| 118 |
+
|
| 119 |
+
if self.bias is not None:
|
| 120 |
+
out = out + self.bias
|
| 121 |
+
|
| 122 |
+
return out
|
| 123 |
+
|
| 124 |
+
def message(self, x_j: Tensor, norm: Tensor) -> Tensor:
|
| 125 |
+
return norm.view(-1, 1) * x_j
|
| 126 |
+
|
| 127 |
+
def __repr__(self) -> str:
|
| 128 |
+
return (f'{self.__class__.__name__}({self.in_channels}, '
|
| 129 |
+
f'{self.out_channels}, K={len(self.lins)}, '
|
| 130 |
+
f'normalization={self.normalization})')
|
model/components/relation_extractors/TopologicalRE.py
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Final, Tuple, Union
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from torch import Tensor
|
| 5 |
+
|
| 6 |
+
from torch_geometric import EdgeIndex
|
| 7 |
+
from torch_geometric.nn.conv import MessagePassing
|
| 8 |
+
from torch_geometric.nn.dense.linear import Linear
|
| 9 |
+
from torch_geometric.typing import Adj, OptPairTensor, OptTensor, Size
|
| 10 |
+
from torch_geometric.utils import spmm
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class TopologicalRelationExtractionLayer(MessagePassing):
|
| 14 |
+
SUPPORTS_FUSED_EDGE_INDEX: Final[bool] = True
|
| 15 |
+
|
| 16 |
+
def __init__(
|
| 17 |
+
self,
|
| 18 |
+
in_channels: Union[int, Tuple[int, int]],
|
| 19 |
+
out_channels: int,
|
| 20 |
+
aggr: str = 'add',
|
| 21 |
+
bias: bool = True,
|
| 22 |
+
**kwargs,
|
| 23 |
+
):
|
| 24 |
+
super().__init__(aggr=aggr, **kwargs)
|
| 25 |
+
|
| 26 |
+
self.in_channels = in_channels
|
| 27 |
+
self.out_channels = out_channels
|
| 28 |
+
|
| 29 |
+
if isinstance(in_channels, int):
|
| 30 |
+
in_channels = (in_channels, in_channels)
|
| 31 |
+
|
| 32 |
+
self.lin_rel = Linear(in_channels[0], out_channels, bias=bias)
|
| 33 |
+
self.lin_root = Linear(in_channels[1], out_channels, bias=False)
|
| 34 |
+
|
| 35 |
+
self.reset_parameters()
|
| 36 |
+
|
| 37 |
+
def reset_parameters(self):
|
| 38 |
+
super().reset_parameters()
|
| 39 |
+
self.lin_rel.reset_parameters()
|
| 40 |
+
self.lin_root.reset_parameters()
|
| 41 |
+
|
| 42 |
+
def forward(self, x: Union[Tensor, OptPairTensor], edge_index: Adj,
|
| 43 |
+
edge_weight: OptTensor = None, size: Size = None) -> Tensor:
|
| 44 |
+
|
| 45 |
+
if isinstance(x, Tensor):
|
| 46 |
+
x = (x, x)
|
| 47 |
+
|
| 48 |
+
# propagate_type: (x: OptPairTensor, edge_weight: OptTensor)
|
| 49 |
+
out = self.propagate(edge_index, x=x, edge_weight=edge_weight,
|
| 50 |
+
size=size)
|
| 51 |
+
out = self.lin_rel(out)
|
| 52 |
+
|
| 53 |
+
x_r = x[1]
|
| 54 |
+
if x_r is not None:
|
| 55 |
+
out = out + self.lin_root(x_r)
|
| 56 |
+
|
| 57 |
+
return out
|
| 58 |
+
|
| 59 |
+
def message(self, x_j: Tensor, edge_weight: OptTensor) -> Tensor:
|
| 60 |
+
return x_j if edge_weight is None else edge_weight.view(-1, 1) * x_j
|
| 61 |
+
|
| 62 |
+
def message_and_aggregate(
|
| 63 |
+
self,
|
| 64 |
+
edge_index: Adj,
|
| 65 |
+
x: OptPairTensor,
|
| 66 |
+
edge_weight: OptTensor,
|
| 67 |
+
) -> Tensor:
|
| 68 |
+
|
| 69 |
+
if not torch.jit.is_scripting() and isinstance(edge_index, EdgeIndex):
|
| 70 |
+
return edge_index.matmul(
|
| 71 |
+
other=x[0],
|
| 72 |
+
input_value=edge_weight,
|
| 73 |
+
reduce=self.aggr,
|
| 74 |
+
transpose=True,
|
| 75 |
+
)
|
| 76 |
+
|
| 77 |
+
return spmm(edge_index, x[0], reduce=self.aggr)
|
model/components/semantic_info_conv/Semantic_IC.py
ADDED
|
@@ -0,0 +1,298 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import typing
|
| 2 |
+
from typing import Optional, Tuple, Union
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn.functional as F
|
| 6 |
+
from torch import Tensor
|
| 7 |
+
from torch.nn import Parameter
|
| 8 |
+
|
| 9 |
+
from torch_geometric.nn.conv import MessagePassing
|
| 10 |
+
from torch_geometric.nn.dense.linear import Linear
|
| 11 |
+
from torch_geometric.nn.inits import glorot, zeros
|
| 12 |
+
from torch_geometric.typing import (
|
| 13 |
+
Adj,
|
| 14 |
+
NoneType,
|
| 15 |
+
OptPairTensor,
|
| 16 |
+
OptTensor,
|
| 17 |
+
Size,
|
| 18 |
+
SparseTensor,
|
| 19 |
+
torch_sparse,
|
| 20 |
+
)
|
| 21 |
+
from torch_geometric.utils import (
|
| 22 |
+
add_self_loops,
|
| 23 |
+
is_torch_sparse_tensor,
|
| 24 |
+
remove_self_loops,
|
| 25 |
+
softmax,
|
| 26 |
+
)
|
| 27 |
+
from torch_geometric.utils.sparse import set_sparse_value
|
| 28 |
+
|
| 29 |
+
if typing.TYPE_CHECKING:
|
| 30 |
+
from typing import overload
|
| 31 |
+
else:
|
| 32 |
+
from torch.jit import _overload_method as overload
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
class SemanticInformationConvolutionLayer(MessagePassing):
|
| 36 |
+
|
| 37 |
+
def __init__(
|
| 38 |
+
self,
|
| 39 |
+
in_channels: Union[int, Tuple[int, int]],
|
| 40 |
+
out_channels: int,
|
| 41 |
+
heads: int = 1,
|
| 42 |
+
concat: bool = True,
|
| 43 |
+
negative_slope: float = 0.2,
|
| 44 |
+
dropout: float = 0.0,
|
| 45 |
+
add_self_loops: bool = True,
|
| 46 |
+
edge_dim: Optional[int] = None,
|
| 47 |
+
fill_value: Union[float, Tensor, str] = 'mean',
|
| 48 |
+
bias: bool = True,
|
| 49 |
+
**kwargs,
|
| 50 |
+
):
|
| 51 |
+
kwargs.setdefault('aggr', 'add')
|
| 52 |
+
super().__init__(node_dim=0, **kwargs)
|
| 53 |
+
|
| 54 |
+
self.in_channels = in_channels
|
| 55 |
+
self.out_channels = out_channels
|
| 56 |
+
self.heads = heads
|
| 57 |
+
self.concat = concat
|
| 58 |
+
self.negative_slope = negative_slope
|
| 59 |
+
self.dropout = dropout
|
| 60 |
+
self.add_self_loops = add_self_loops
|
| 61 |
+
self.edge_dim = edge_dim
|
| 62 |
+
self.fill_value = fill_value
|
| 63 |
+
|
| 64 |
+
# In case we are operating in bipartite graphs, we apply separate
|
| 65 |
+
# transformations 'lin_src' and 'lin_dst' to source and target nodes:
|
| 66 |
+
self.lin = self.lin_src = self.lin_dst = None
|
| 67 |
+
if isinstance(in_channels, int):
|
| 68 |
+
self.lin = Linear(in_channels, heads * out_channels, bias=False,
|
| 69 |
+
weight_initializer='glorot')
|
| 70 |
+
else:
|
| 71 |
+
self.lin_src = Linear(in_channels[0], heads * out_channels, False,
|
| 72 |
+
weight_initializer='glorot')
|
| 73 |
+
self.lin_dst = Linear(in_channels[1], heads * out_channels, False,
|
| 74 |
+
weight_initializer='glorot')
|
| 75 |
+
|
| 76 |
+
# The learnable parameters to compute attention coefficients:
|
| 77 |
+
self.att_src = Parameter(torch.empty(1, heads, out_channels))
|
| 78 |
+
self.att_dst = Parameter(torch.empty(1, heads, out_channels))
|
| 79 |
+
|
| 80 |
+
if edge_dim is not None:
|
| 81 |
+
self.lin_edge = Linear(edge_dim, heads * out_channels, bias=False,
|
| 82 |
+
weight_initializer='glorot')
|
| 83 |
+
self.att_edge = Parameter(torch.empty(1, heads, out_channels))
|
| 84 |
+
else:
|
| 85 |
+
self.lin_edge = None
|
| 86 |
+
self.register_parameter('att_edge', None)
|
| 87 |
+
|
| 88 |
+
if bias and concat:
|
| 89 |
+
self.bias = Parameter(torch.empty(heads * out_channels))
|
| 90 |
+
elif bias and not concat:
|
| 91 |
+
self.bias = Parameter(torch.empty(out_channels))
|
| 92 |
+
else:
|
| 93 |
+
self.register_parameter('bias', None)
|
| 94 |
+
|
| 95 |
+
self.reset_parameters()
|
| 96 |
+
|
| 97 |
+
def reset_parameters(self):
|
| 98 |
+
super().reset_parameters()
|
| 99 |
+
if self.lin is not None:
|
| 100 |
+
self.lin.reset_parameters()
|
| 101 |
+
if self.lin_src is not None:
|
| 102 |
+
self.lin_src.reset_parameters()
|
| 103 |
+
if self.lin_dst is not None:
|
| 104 |
+
self.lin_dst.reset_parameters()
|
| 105 |
+
if self.lin_edge is not None:
|
| 106 |
+
self.lin_edge.reset_parameters()
|
| 107 |
+
glorot(self.att_src)
|
| 108 |
+
glorot(self.att_dst)
|
| 109 |
+
glorot(self.att_edge)
|
| 110 |
+
zeros(self.bias)
|
| 111 |
+
|
| 112 |
+
@overload
|
| 113 |
+
def forward(
|
| 114 |
+
self,
|
| 115 |
+
x: Union[Tensor, OptPairTensor],
|
| 116 |
+
edge_index: Adj,
|
| 117 |
+
edge_attr: OptTensor = None,
|
| 118 |
+
size: Size = None,
|
| 119 |
+
return_attention_weights: NoneType = None,
|
| 120 |
+
) -> Tensor:
|
| 121 |
+
pass
|
| 122 |
+
|
| 123 |
+
@overload
|
| 124 |
+
def forward( # noqa: F811
|
| 125 |
+
self,
|
| 126 |
+
x: Union[Tensor, OptPairTensor],
|
| 127 |
+
edge_index: Tensor,
|
| 128 |
+
edge_attr: OptTensor = None,
|
| 129 |
+
size: Size = None,
|
| 130 |
+
return_attention_weights: bool = None,
|
| 131 |
+
) -> Tuple[Tensor, Tuple[Tensor, Tensor]]:
|
| 132 |
+
pass
|
| 133 |
+
|
| 134 |
+
@overload
|
| 135 |
+
def forward( # noqa: F811
|
| 136 |
+
self,
|
| 137 |
+
x: Union[Tensor, OptPairTensor],
|
| 138 |
+
edge_index: SparseTensor,
|
| 139 |
+
edge_attr: OptTensor = None,
|
| 140 |
+
size: Size = None,
|
| 141 |
+
return_attention_weights: bool = None,
|
| 142 |
+
) -> Tuple[Tensor, SparseTensor]:
|
| 143 |
+
pass
|
| 144 |
+
|
| 145 |
+
def forward( # noqa: F811
|
| 146 |
+
self,
|
| 147 |
+
x: Union[Tensor, OptPairTensor],
|
| 148 |
+
edge_index: Adj,
|
| 149 |
+
edge_attr: OptTensor = None,
|
| 150 |
+
size: Size = None,
|
| 151 |
+
return_attention_weights: Optional[bool] = None,
|
| 152 |
+
) -> Union[
|
| 153 |
+
Tensor,
|
| 154 |
+
Tuple[Tensor, Tuple[Tensor, Tensor]],
|
| 155 |
+
Tuple[Tensor, SparseTensor],
|
| 156 |
+
]:
|
| 157 |
+
r"""Runs the forward pass of the module.
|
| 158 |
+
|
| 159 |
+
Args:
|
| 160 |
+
x (torch.Tensor or (torch.Tensor, torch.Tensor)): The input node
|
| 161 |
+
features.
|
| 162 |
+
edge_index (torch.Tensor or SparseTensor): The edge indices.
|
| 163 |
+
edge_attr (torch.Tensor, optional): The edge features.
|
| 164 |
+
(default: :obj:`None`)
|
| 165 |
+
size ((int, int), optional): The shape of the adjacency matrix.
|
| 166 |
+
(default: :obj:`None`)
|
| 167 |
+
return_attention_weights (bool, optional): If set to :obj:`True`,
|
| 168 |
+
will additionally return the tuple
|
| 169 |
+
:obj:`(edge_index, attention_weights)`, holding the computed
|
| 170 |
+
attention weights for each edge. (default: :obj:`None`)
|
| 171 |
+
"""
|
| 172 |
+
# NOTE: attention weights will be returned whenever
|
| 173 |
+
# `return_attention_weights` is set to a value, regardless of its
|
| 174 |
+
# actual value (might be `True` or `False`). This is a current somewhat
|
| 175 |
+
# hacky workaround to allow for TorchScript support via the
|
| 176 |
+
# `torch.jit._overload` decorator, as we can only change the output
|
| 177 |
+
# arguments conditioned on type (`None` or `bool`), not based on its
|
| 178 |
+
# actual value.
|
| 179 |
+
|
| 180 |
+
H, C = self.heads, self.out_channels
|
| 181 |
+
|
| 182 |
+
# We first transform the input node features. If a tuple is passed, we
|
| 183 |
+
# transform source and target node features via separate weights:
|
| 184 |
+
if isinstance(x, Tensor):
|
| 185 |
+
assert x.dim() == 2, "Static graphs not supported in 'GATConv'"
|
| 186 |
+
|
| 187 |
+
if self.lin is not None:
|
| 188 |
+
x_src = x_dst = self.lin(x).view(-1, H, C)
|
| 189 |
+
else:
|
| 190 |
+
# If the module is initialized as bipartite, transform source
|
| 191 |
+
# and destination node features separately:
|
| 192 |
+
assert self.lin_src is not None and self.lin_dst is not None
|
| 193 |
+
x_src = self.lin_src(x).view(-1, H, C)
|
| 194 |
+
x_dst = self.lin_dst(x).view(-1, H, C)
|
| 195 |
+
|
| 196 |
+
else: # Tuple of source and target node features:
|
| 197 |
+
x_src, x_dst = x
|
| 198 |
+
assert x_src.dim() == 2, "Static graphs not supported in 'GATConv'"
|
| 199 |
+
|
| 200 |
+
if self.lin is not None:
|
| 201 |
+
# If the module is initialized as non-bipartite, we expect that
|
| 202 |
+
# source and destination node features have the same shape and
|
| 203 |
+
# that they their transformations are shared:
|
| 204 |
+
x_src = self.lin(x_src).view(-1, H, C)
|
| 205 |
+
if x_dst is not None:
|
| 206 |
+
x_dst = self.lin(x_dst).view(-1, H, C)
|
| 207 |
+
else:
|
| 208 |
+
assert self.lin_src is not None and self.lin_dst is not None
|
| 209 |
+
|
| 210 |
+
x_src = self.lin_src(x_src).view(-1, H, C)
|
| 211 |
+
if x_dst is not None:
|
| 212 |
+
x_dst = self.lin_dst(x_dst).view(-1, H, C)
|
| 213 |
+
|
| 214 |
+
x = (x_src, x_dst)
|
| 215 |
+
|
| 216 |
+
# Next, we compute node-level attention coefficients, both for source
|
| 217 |
+
# and target nodes (if present):
|
| 218 |
+
alpha_src = (x_src * self.att_src).sum(dim=-1)
|
| 219 |
+
alpha_dst = None if x_dst is None else (x_dst * self.att_dst).sum(-1)
|
| 220 |
+
alpha = (alpha_src, alpha_dst)
|
| 221 |
+
|
| 222 |
+
if self.add_self_loops:
|
| 223 |
+
if isinstance(edge_index, Tensor):
|
| 224 |
+
# We only want to add self-loops for nodes that appear both as
|
| 225 |
+
# source and target nodes:
|
| 226 |
+
num_nodes = x_src.size(0)
|
| 227 |
+
if x_dst is not None:
|
| 228 |
+
num_nodes = min(num_nodes, x_dst.size(0))
|
| 229 |
+
num_nodes = min(size) if size is not None else num_nodes
|
| 230 |
+
edge_index, edge_attr = remove_self_loops(
|
| 231 |
+
edge_index, edge_attr)
|
| 232 |
+
edge_index, edge_attr = add_self_loops(
|
| 233 |
+
edge_index, edge_attr, fill_value=self.fill_value,
|
| 234 |
+
num_nodes=num_nodes)
|
| 235 |
+
elif isinstance(edge_index, SparseTensor):
|
| 236 |
+
if self.edge_dim is None:
|
| 237 |
+
edge_index = torch_sparse.set_diag(edge_index)
|
| 238 |
+
else:
|
| 239 |
+
raise NotImplementedError(
|
| 240 |
+
"The usage of 'edge_attr' and 'add_self_loops' "
|
| 241 |
+
"simultaneously is currently not yet supported for "
|
| 242 |
+
"'edge_index' in a 'SparseTensor' form")
|
| 243 |
+
|
| 244 |
+
# edge_updater_type: (alpha: OptPairTensor, edge_attr: OptTensor)
|
| 245 |
+
alpha = self.edge_updater(edge_index, alpha=alpha, edge_attr=edge_attr,
|
| 246 |
+
size=size)
|
| 247 |
+
|
| 248 |
+
# propagate_type: (x: OptPairTensor, alpha: Tensor)
|
| 249 |
+
out = self.propagate(edge_index, x=x, alpha=alpha, size=size)
|
| 250 |
+
|
| 251 |
+
if self.concat:
|
| 252 |
+
out = out.view(-1, self.heads * self.out_channels)
|
| 253 |
+
else:
|
| 254 |
+
out = out.mean(dim=1)
|
| 255 |
+
|
| 256 |
+
if self.bias is not None:
|
| 257 |
+
out = out + self.bias
|
| 258 |
+
|
| 259 |
+
if isinstance(return_attention_weights, bool):
|
| 260 |
+
if isinstance(edge_index, Tensor):
|
| 261 |
+
if is_torch_sparse_tensor(edge_index):
|
| 262 |
+
# TODO TorchScript requires to return a tuple
|
| 263 |
+
adj = set_sparse_value(edge_index, alpha)
|
| 264 |
+
return out, (adj, alpha)
|
| 265 |
+
else:
|
| 266 |
+
return out, (edge_index, alpha)
|
| 267 |
+
elif isinstance(edge_index, SparseTensor):
|
| 268 |
+
return out, edge_index.set_value(alpha, layout='coo')
|
| 269 |
+
else:
|
| 270 |
+
return out
|
| 271 |
+
|
| 272 |
+
def edge_update(self, alpha_j: Tensor, alpha_i: OptTensor,
|
| 273 |
+
edge_attr: OptTensor, index: Tensor, ptr: OptTensor,
|
| 274 |
+
dim_size: Optional[int]) -> Tensor:
|
| 275 |
+
# Given edge-level attention coefficients for source and target nodes,
|
| 276 |
+
# we simply need to sum them up to "emulate" concatenation:
|
| 277 |
+
alpha = alpha_j if alpha_i is None else alpha_j + alpha_i
|
| 278 |
+
if index.numel() == 0:
|
| 279 |
+
return alpha
|
| 280 |
+
if edge_attr is not None and self.lin_edge is not None:
|
| 281 |
+
if edge_attr.dim() == 1:
|
| 282 |
+
edge_attr = edge_attr.view(-1, 1)
|
| 283 |
+
edge_attr = self.lin_edge(edge_attr)
|
| 284 |
+
edge_attr = edge_attr.view(-1, self.heads, self.out_channels)
|
| 285 |
+
alpha_edge = (edge_attr * self.att_edge).sum(dim=-1)
|
| 286 |
+
alpha = alpha + alpha_edge
|
| 287 |
+
|
| 288 |
+
alpha = F.leaky_relu(alpha, self.negative_slope)
|
| 289 |
+
alpha = softmax(alpha, index, ptr, dim_size)
|
| 290 |
+
alpha = F.dropout(alpha, p=self.dropout, training=self.training)
|
| 291 |
+
return alpha
|
| 292 |
+
|
| 293 |
+
def message(self, x_j: Tensor, alpha: Tensor) -> Tensor:
|
| 294 |
+
return alpha.unsqueeze(-1) * x_j
|
| 295 |
+
|
| 296 |
+
def __repr__(self) -> str:
|
| 297 |
+
return (f'{self.__class__.__name__}({self.in_channels}, '
|
| 298 |
+
f'{self.out_channels}, heads={self.heads})')
|
model/metric/A_SFAS.py
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
|
| 3 |
+
def calculate_A_SFAS(tensor1, tensor2):
|
| 4 |
+
"""
|
| 5 |
+
Computes the Average Semantic Feature Alignment scores between two n-dimensional tensors.
|
| 6 |
+
|
| 7 |
+
Parameters:
|
| 8 |
+
tensor1 (numpy.ndarray): The first tensor.
|
| 9 |
+
tensor2 (numpy.ndarray): The second tensor.
|
| 10 |
+
|
| 11 |
+
Returns:
|
| 12 |
+
float: The Average Semantic Feature Alignment scores between tensor1 and tensor2.
|
| 13 |
+
"""
|
| 14 |
+
# Flatten the tensors to 1-dimensional arrays
|
| 15 |
+
flat_tensor1 = tensor1.flatten()
|
| 16 |
+
flat_tensor2 = tensor2.flatten()
|
| 17 |
+
|
| 18 |
+
# Compute the dot product
|
| 19 |
+
dot_product = np.dot(flat_tensor1, flat_tensor2)
|
| 20 |
+
|
| 21 |
+
# Compute the magnitudes (norms) of the tensors
|
| 22 |
+
norm_tensor1 = np.linalg.norm(flat_tensor1)
|
| 23 |
+
norm_tensor2 = np.linalg.norm(flat_tensor2)
|
| 24 |
+
|
| 25 |
+
# Compute the cosine similarity
|
| 26 |
+
cosine_sim = dot_product / (norm_tensor1 * norm_tensor2)
|
| 27 |
+
|
| 28 |
+
return cosine_sim
|
| 29 |
+
|
| 30 |
+
# Example usage:
|
| 31 |
+
tensor1 = np.array([[1, 2, 3], [4, 5, 6]])
|
| 32 |
+
tensor2 = np.array([[1, 0, 0], [0, 1, 0]])
|
| 33 |
+
similarity = cosine_similarity(tensor1, tensor2)
|
| 34 |
+
print("Cosine Similarity:", similarity)
|
poster/BanglaAutoKG.png
ADDED

|
Git LFS Details
|