SeeMoE: Implementing a MoE Vision Language Model from Scratch







TL;DR: In this blog I implement a mixture of experts vision language model consisting of an image encoder, a multimodal projection module and a mixture of experts decoder language model in pure pytorch. Thus, the resulting implementation could be thought of as a scaled down version of Grok 1.5 Vision and GPT-4 Vision (both have vision encoders connected to a MoE Decoder model via a projection module). The name ‘seeMoE’ is my way of paying homage to Andrej Karpathy’s project ‘makemore’ because for the decoder used here I implement a character level autoregressive language model much like in his nanoGPT/ makemore implementation but with a twist. The twist being that it's a mixture of experts Decoder (much like DBRX, Mixtral and Grok). My goal is for you to have an intuitive understanding of how this seemingly state of the art implementation works so that you can improve upon it or use the key takeaways to build more useful systems.
The entire implementation can be found in seeMoE_from_Scratch.ipynb in the following repo: https://github.com/AviSoori1x/seemore

If you've read my other blogs on implementing mixture of experts LLMs from scratch: https://huggingface.co/blog/AviSoori1x/makemoe-from-scratch and implementing a vision language model from scratch: https://huggingface.co/blog/AviSoori1x/seemore-vision-language-model, you'll realize that I'm combining the two to implement seeMoE. Essentially, all I'm doing here is replacing the feed-forward neural network in each transformer block of the decoder with a mixture of experts module with noisy Top-K gating. More information on how this is implemented, is given here: https://huggingface.co/blog/AviSoori1x/makemoe-from-scratch. I strongly encourage you to read these two blogs and carefully go through the repos linked to both the blogs before diving into this.
In ‘seeMoE’, my simple implementation of a Mixture of Experts vision language model (VLM), there are 3 main components.

Image Encoder to extract visual features from images. In this case I use a from scratch implementation of the original vision transformer used in CLIP. This is actually a popular choice in many modern VLMs. The one notable exception is Fuyu series of models from Adept, that passes the patchified images directly to the projection layer.
Vision-Language Projector - Image embeddings are not of the same shape as text embeddings used by the decoder. So we need to ‘project’ i.e. change dimensionality of image features extracted by the image encoder to match what’s observed in the text embedding space. So image features become ‘visual tokens’ for the decoder. This could be a single layer or an MLP. I’ve used an MLP because it’s worth showing.
A decoder only language model with the mixture of experts architecture. This is the component that ultimately generates text. In my implementation I’ve deviated from what you see in LLaVA a bit by incorporating the projection module to my decoder. Typically this is not observed, and you leave the architecture of the decoder (which is usually an already pretrained model) untouched. The biggest change here is that, as mentioned before, the feed forward neural net / MLP in each transformer block is replaced by a mixture of experts block with a noisy top-k gating mechanism. Basically each token (text tokens + visual tokens that have been mapped to the same embedding space as text tokens) are only processed by top-k of the n experts in each transformer block. So if it's a MoE architecture with 8 experts and top 2 gating, only 2 of the experts will be activated.
Since the Image Encoder and Vision Language Projector are unchanged from seemore (Linked above. Repo here: https://github.com/AviSoori1x/seemore), I encourage you to read the blog/ go through the notebooks for details on those.
Now let's revisit the components of a sparse mixture of experts module:
- Experts - just n vanilla MLPs
- A gating/ routing mechanism
- weighted summation of activated experts based on the routing mechanism
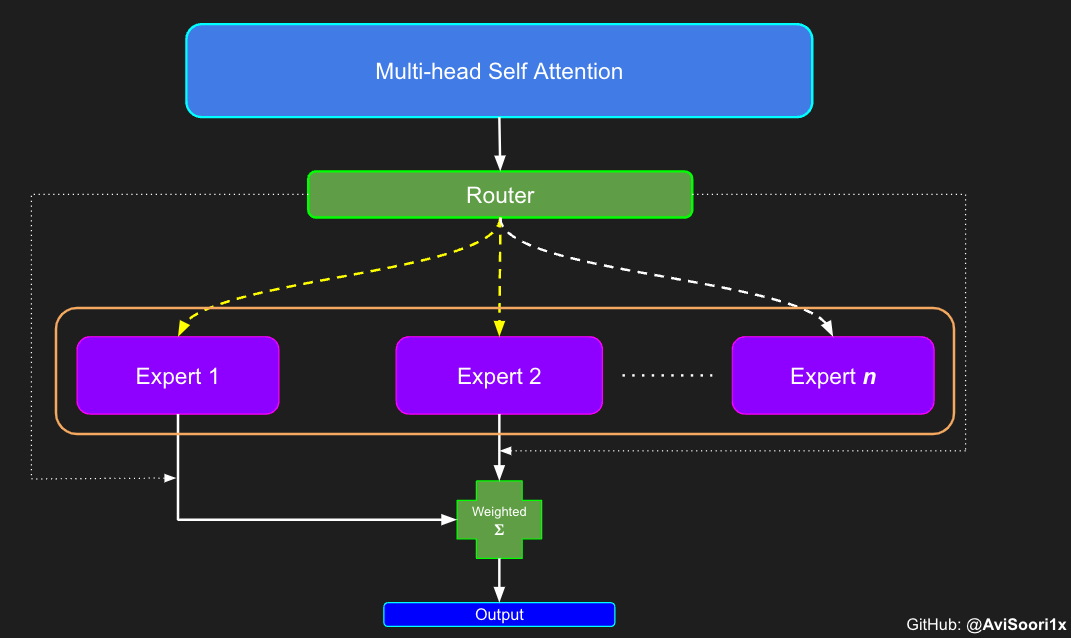
First, the 'Expert' which is just an MLP like we saw earlier when implementing the Encoder.
#Expert module
class Expert(nn.Module):
""" An MLP is a simple linear layer followed by a non-linearity i.e. each Expert """
def __init__(self, n_embed):
super().__init__()
self.net = nn.Sequential(
nn.Linear(n_embed, 4 * n_embed),
nn.ReLU(),
nn.Linear(4 * n_embed, n_embed),
nn.Dropout(dropout),
)
def forward(self, x):
return self.net(x)
The routing module decides which experts will be activated. Noisy top k gating/ routing adds a bit of gaussian noise to ensure that there's a fine balance between exploration and exploitation in picking the top-k experts for each token. This reduces the odds of the same n experts getting picked everytime, which defeats the purpose of having a larger parameter count with sparse activation for better generalizability.
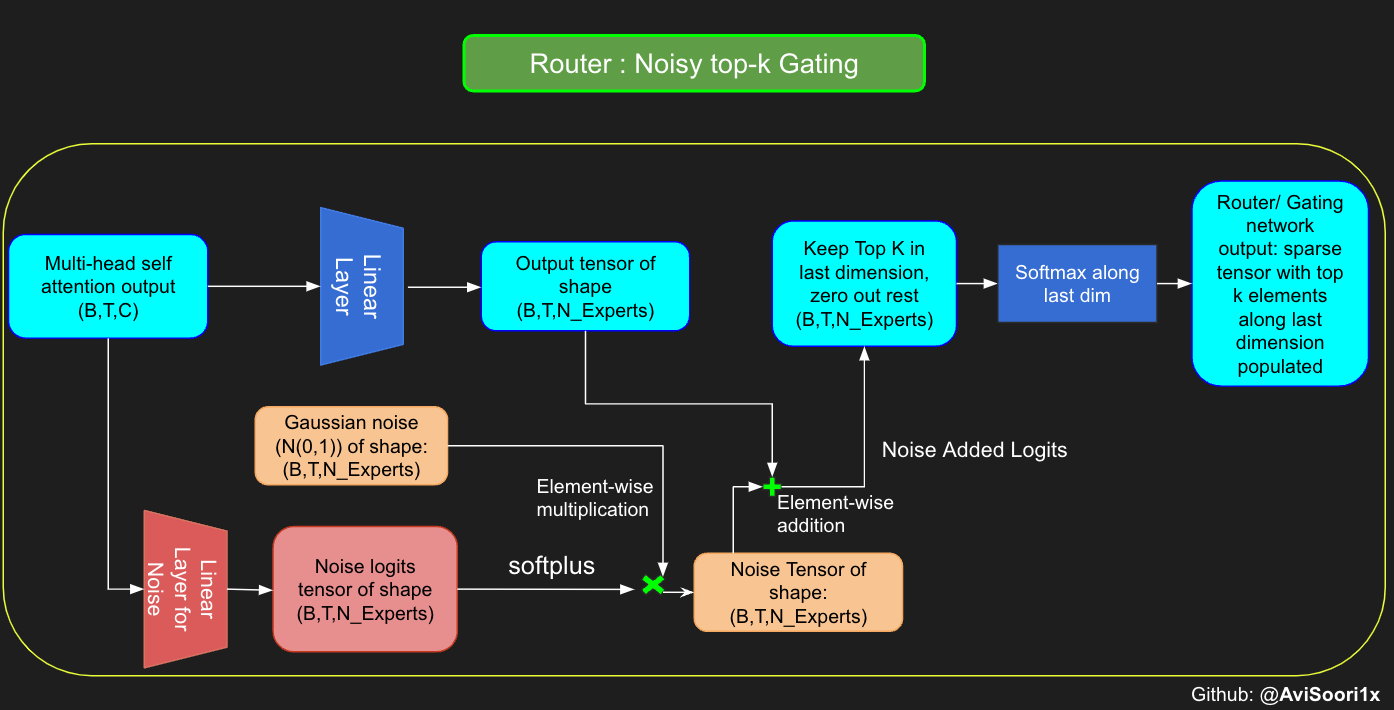
#noisy top-k gating
class NoisyTopkRouter(nn.Module):
def __init__(self, n_embed, num_experts, top_k):
super(NoisyTopkRouter, self).__init__()
self.top_k = top_k
#layer for router logits
self.topkroute_linear = nn.Linear(n_embed, num_experts)
self.noise_linear =nn.Linear(n_embed, num_experts)
def forward(self, mh_output):
# mh_ouput is the output tensor from multihead self attention block
logits = self.topkroute_linear(mh_output)
#Noise logits
noise_logits = self.noise_linear(mh_output)
#Adding scaled unit gaussian noise to the logits
noise = torch.randn_like(logits)*F.softplus(noise_logits)
noisy_logits = logits + noise
top_k_logits, indices = noisy_logits.topk(self.top_k, dim=-1)
zeros = torch.full_like(noisy_logits, float('-inf'))
sparse_logits = zeros.scatter(-1, indices, top_k_logits)
router_output = F.softmax(sparse_logits, dim=-1)
return router_output, indices
Now both noisy-top-k gating and experts can be combined to create a sparse Mixture of Experts module. Note that weighted summation calculation has been incorporated to yield the output for each token in the forward pass.
#Now create the sparse mixture of experts module
class SparseMoE(nn.Module):
def __init__(self, n_embed, num_experts, top_k):
super(SparseMoE, self).__init__()
self.router = NoisyTopkRouter(n_embed, num_experts, top_k)
self.experts = nn.ModuleList([Expert(n_embed) for _ in range(num_experts)])
self.top_k = top_k
def forward(self, x):
gating_output, indices = self.router(x)
final_output = torch.zeros_like(x)
# Reshape inputs for batch processing
flat_x = x.view(-1, x.size(-1))
flat_gating_output = gating_output.view(-1, gating_output.size(-1))
# Process each expert in parallel
for i, expert in enumerate(self.experts):
# Create a mask for the inputs where the current expert is in top-k
expert_mask = (indices == i).any(dim=-1)
flat_mask = expert_mask.view(-1)
if flat_mask.any():
expert_input = flat_x[flat_mask]
expert_output = expert(expert_input)
# Extract and apply gating scores
gating_scores = flat_gating_output[flat_mask, i].unsqueeze(1)
weighted_output = expert_output * gating_scores
# Update final output additively by indexing and adding
final_output[expert_mask] += weighted_output.squeeze(1)
return final_output
This can now be combined with multihead self attention to create a sparse MoE transformer block.
class SparseMoEBlock(nn.Module):
def __init__(self, n_embd, num_heads, num_experts, top_k, dropout=0.1, is_decoder=False):
super().__init__()
# Layer normalization for the input to the attention layer
self.ln1 = nn.LayerNorm(n_embd)
# Multi-head attention module
self.attn = MultiHeadAttention(n_embd, num_heads, dropout, is_decoder)
# Layer normalization for the input to the FFN
self.ln2 = nn.LayerNorm(n_embd)
# Feed-forward neural network (FFN)
self.sparseMoE = SparseMoE(n_embd, num_experts, top_k)
def forward(self, x):
original_x = x # Save the input for the residual connection
# Apply layer normalization to the input
x = self.ln1(x)
# Apply multi-head attention
attn_output = self.attn(x)
# Add the residual connection (original input) to the attention output
x = original_x + attn_output
# Apply layer normalization to the input to the FFN
x = self.ln2(x)
# Apply the FFN
sparseMoE_output = self.sparseMoE(x)
# Add the residual connection (input to FFN) to the FFN output
x = x + sparseMoE_output
return x
Now we combine the sparse MoE transformer architecture language decoder model that has been modified to accomodate 'visual tokens' created by the vision-language projector module. Typically, the decoder language model (sparse MoE or dense) will be kept unmodified and will receive embeddings, I've incorportated the vision-langauge projector to the model architecture to keep things simple. A detailed write-up is found in this blog: https://huggingface.co/blog/AviSoori1x/seemore-vision-language-model
class MoEDecoderLanguageModel(nn.Module):
def __init__(self, n_embd, image_embed_dim, vocab_size, num_heads, n_layer, num_experts, top_k, use_images=False):
super().__init__()
self.use_images = use_images
# Token embedding table
self.token_embedding_table = nn.Embedding(vocab_size, n_embd)
# Position embedding table
self.position_embedding_table = nn.Embedding(1000, n_embd)
if use_images:
# Image projection layer to align image embeddings with text embeddings
self.image_projection = MultiModalProjector(n_embd, image_embed_dim)
# Stack of transformer decoder blocks
self.sparseMoEBlocks = nn.Sequential(*[SparseMoEBlock(n_embd, num_heads, num_experts, top_k, is_decoder=True) for _ in range(n_layer)])
# Final layer normalization
self.ln_f = nn.LayerNorm(n_embd)
# Language modeling head
self.lm_head = nn.Linear(n_embd, vocab_size)
def forward(self, idx, image_embeds=None, targets=None):
# Get token embeddings from the input indices
tok_emb = self.token_embedding_table(idx)
if self.use_images and image_embeds is not None:
# Project and concatenate image embeddings with token embeddings
img_emb = self.image_projection(image_embeds).unsqueeze(1)
tok_emb = torch.cat([img_emb, tok_emb], dim=1)
# Get position embeddings
pos_emb = self.position_embedding_table(torch.arange(tok_emb.size(1), device=device)).unsqueeze(0)
# Add position embeddings to token embeddings
x = tok_emb + pos_emb
# Pass through the transformer decoder blocks
x = self.sparseMoEBlocks(x)
# Apply final layer normalization
x = self.ln_f(x)
# Get the logits from the language modeling head
logits = self.lm_head(x)
if targets is not None:
if self.use_images and image_embeds is not None:
# Prepare targets by concatenating a dummy target for the image embedding
batch_size = idx.size(0)
targets = torch.cat([torch.full((batch_size, 1), -100, dtype=torch.long, device=device), targets], dim=1)
# Compute the cross-entropy loss
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-100)
return logits, loss
return logits
def generate(self, idx, image_embeds, max_new_tokens):
# The autoregressive character level generation function is just like in any other decoder model implementation
return generated
Now that we have our three key components, we can put it all together into a sparse Mixture of Experts Vision Language Model. The full implementation is given below. If you were to remove the assert statements for error handling, this is very simple. Coming back full circle to the outline I’ve given at the beginning of the blog, all that’s happening here is:
Get image features from the vision encoder (Here it’s a vision transformer, but it could be any model that could generate features from an image input such as a ResNet or a traditional convolutional neural network (needless to say performance may suffer))
A projection module for projecting image tokens to the same embedding space as text embeddings for the decoder (this projector is integrated with the decoder in this implementation)
A decoder language model with a sparseMoE architecture for generating text conditioned on a preceding image.
class VisionMoELanguageModel(nn.Module):
def __init__(self, n_embd, image_embed_dim, vocab_size, n_layer, img_size, patch_size, num_heads, num_blks, emb_dropout, blk_dropout, num_experts, top_k):
super().__init__()
# Set num_hiddens equal to image_embed_dim
num_hiddens = image_embed_dim
# Assert that num_hiddens is divisible by num_heads
assert num_hiddens % num_heads == 0, "num_hiddens must be divisible by num_heads"
# Initialize the vision encoder (ViT)
self.vision_encoder = ViT(img_size, patch_size, num_hiddens, num_heads, num_blks, emb_dropout, blk_dropout)
# Initialize the language model decoder (DecoderLanguageModel)
self.decoder = MoEDecoderLanguageModel(n_embd, image_embed_dim, vocab_size, num_heads, n_layer,num_experts, top_k, use_images=True)
def forward(self, img_array, idx, targets=None):
# Get the image embeddings from the vision encoder
image_embeds = self.vision_encoder(img_array)
# Check if the image embeddings are valid
if image_embeds.nelement() == 0 or image_embeds.shape[1] == 0:
raise ValueError("Something is wrong with the ViT model. It's returning an empty tensor or the embedding dimension is empty.")
if targets is not None:
# If targets are provided, compute the logits and loss
logits, loss = self.decoder(idx, image_embeds, targets)
return logits, loss
else:
# If targets are not provided, compute only the logits
logits = self.decoder(idx, image_embeds)
return logits
def generate(self, img_array, idx, max_new_tokens):
# Get the image embeddings from the vision encoder
image_embeds = self.vision_encoder(img_array)
# Check if the image embeddings are valid
if image_embeds.nelement() == 0 or image_embeds.shape[1] == 0:
raise ValueError("Something is wrong with the ViT model. It's returning an empty tensor or the embedding dimension is empty.")
# Generate new tokens using the language model decoder
generated_tokens = self.decoder.generate(idx, image_embeds, max_new_tokens)
return generated_tokens
Now back to where we started. The above VisionMoELanguageModel class neatly wraps up all the components we set out to put together.
The training loop is exactly as you see in the original vision language blog linked at the top. Please check out seeMoE_from_Scratch.ipynb in the following repo: https://github.com/AviSoori1x/seemore
PS: There are newer approaches such as mixed-modal early-fusion models e.g. https://arxiv.org/abs/2405.09818. I plan to implement a simplistic version of this in the future.
Thanks for reading!





