What's Automatic Differentiation?





Clarification
Before we begin, this blog is technically and mathematically involved—covering topics related to Calculus, Linear Algebra, and machine learning (ML). For example, we discuss partial derivatives, gradients, multivariate functions, and loss functions. To save on time, I assume you have some basic knowledge or familiarity with these subjects.
TL;DR
The main premise behind this blog is to highlight automatic differentiation (AD) and how it can be utilized for gradient-based optimization seen in training neural networks. I cover:
Numeric Differentiation as a process approximating the derivative of a function that's avoided for neural network optimization because of issues like truncation and round-off error.
Symbolic Differentiation being a systematic way to derive the derivative of an expression through transformations. It's avoided for gradient-based optimization because of code constraints, expression swell, and repeated computations.
Automatic Differentiation (AD) as a method augmenting arithmetic computation by interleaving derivatives with the elementary operations of functions. I also describe the evaluation trace and computational graph—useful in forward and reverse mode AD.
Forward Mode AD being one way to apply automatic differentiation by computing the partial derivatives of variables during the forward pass of functions. It's observed to be useful, but not optimal for gradient-based optimization since it's slow under certain conditions.
Reverse Mode AD as the alternative mode that computes the partial derivatives of variables during the reverse pass, after function evaluation. This mode is faster than forward mode under the context of optimizing neural networks due to features like the reverse pass and vector-Jacobian product.
Wrapping up the blog, I implement forward and reverse mode AD in python using operator overloading. Gaining insight on how AD is built in code, I contrast the implementation with that of a familiar ML framework.
Introduction
In ML, neural networks implement a breadth of mathematical, and even scientific techniques, to make the AI tools we have today (e.g. LLMs) possible. The field has evolved from using simple neural networks to classify handwritten digits, to transformer architectures that are sometimes considered "sentient". What remains at its core is solving the problem of optimization—that is, how can we teach these models to learn?
There's likely better ways to solve this problem that some genius will one day discover, but the consensus today is through gradient descent. Gradient descent is an optimization algorithm that aims to improve a model's performance through iterative incremental steps. Here's a breakdown:
Gradient Descent
Using an objective [loss] function, compute the loss (error) between a model's predictions over a set of inputs and the ground truth of those inputs.
Find the model's influence on the loss by computing the partial derivatives of the loss w.r.t. every parameter of the model (the gradients).
Move the model's parameters in the direction that minimizes the loss by subtracting each parameter with its respective gradient scaled by a hyperparameter called the learning rate.
Clear all the gradients, and repeat the process until the model converges; in better words, until the model no longer improves and achieves optimal performance.
This process has evidently built robust deep neural networks, however, it requires a difficult procedure, and that's finding the gradients to update the model's parameters. In a mathematical sense, how can we differentiate the loss w.r.t. the model's parameters? To that, I welcome automatic differentiation.
In this blog, I'll provide an explanation as to what automatic differentiation is, and we'll also take a dive into its implementation. But before we progress further, we need to understand two alternative approaches and why they fail to meet the demands of gradient-based optimization for neural networks, numeric and symbolic differentiation.
Numeric Differentiation
Numeric differentiation is one approach we can utilize to help us compute gradients to optimize neural networks by using the limit definition of a derivative.
To evaluate the derivative of a function for an input , we find the slope of the tangent line at . The tangent line can be broken down into the quotient of the rise and run of the function at . To compute the rise, we evaluate the function at two inputs, one with the original input and the other with the input nudged by a small constant ; this is observed in the numerator of eq. 1. Next, we divide by the run; since we pushed the input by , the run is . As approaches zero, by taking the limit, the approximation for the derivative of at becomes more accurate.
In practice, neural networks apply arithmetic operations to multi-dimensional arrays—tensors as they're often called—and it wouldn't make sense to programmatically take the limit, so we discard the limit and rewrite the expression to operate on a network's parameters.
Above is the forward difference method to compute the partial derivative of a multivariate function
w.r.t. a single parameter , from a vector of parameters . The symbol represents a unit vector, where the element is one while all other elements are zero. Computing the partial derivative for the parameter in is now as easy as evaluating eq. 2 with . In the realms of neural networks, is a representation of the objective loss function, while is the parameterization of the model. By evaluating eq. 2 on all the model's parameters, we'd obtain the gradients required for one step of gradient descent.
What I have yet to mention is the big-O term added to the end of eq. 2. This symbol—outside the domain of time and space complexity for algorithms—is a function on that expresses the truncation error. Truncation error is defined as the error caused by cutting off some values from the Taylor series of . More concretely, because we're taking an approximation for the partial derivative for using , we're mis-approximating it with some error dependent on . Additionally, the truncation error is directly proportional to , meaning whatever factor is scaled by, the truncation error will be scaled by the same factor.
Now, there's ways to minimize this error. For starters, we can change our approximation to the central difference method seen below.
The central difference is the combination of the forward difference from eq 2. and the backward difference. By subtracting the backward difference from the forward difference and simplifying, the first order error terms in will cancel out, leaving the second order error term as dominant. The error is now proportional to the square of , meaning if decreases by an order of magnitude, the error will decrease by two orders of magnitude.
Derivative Approximations
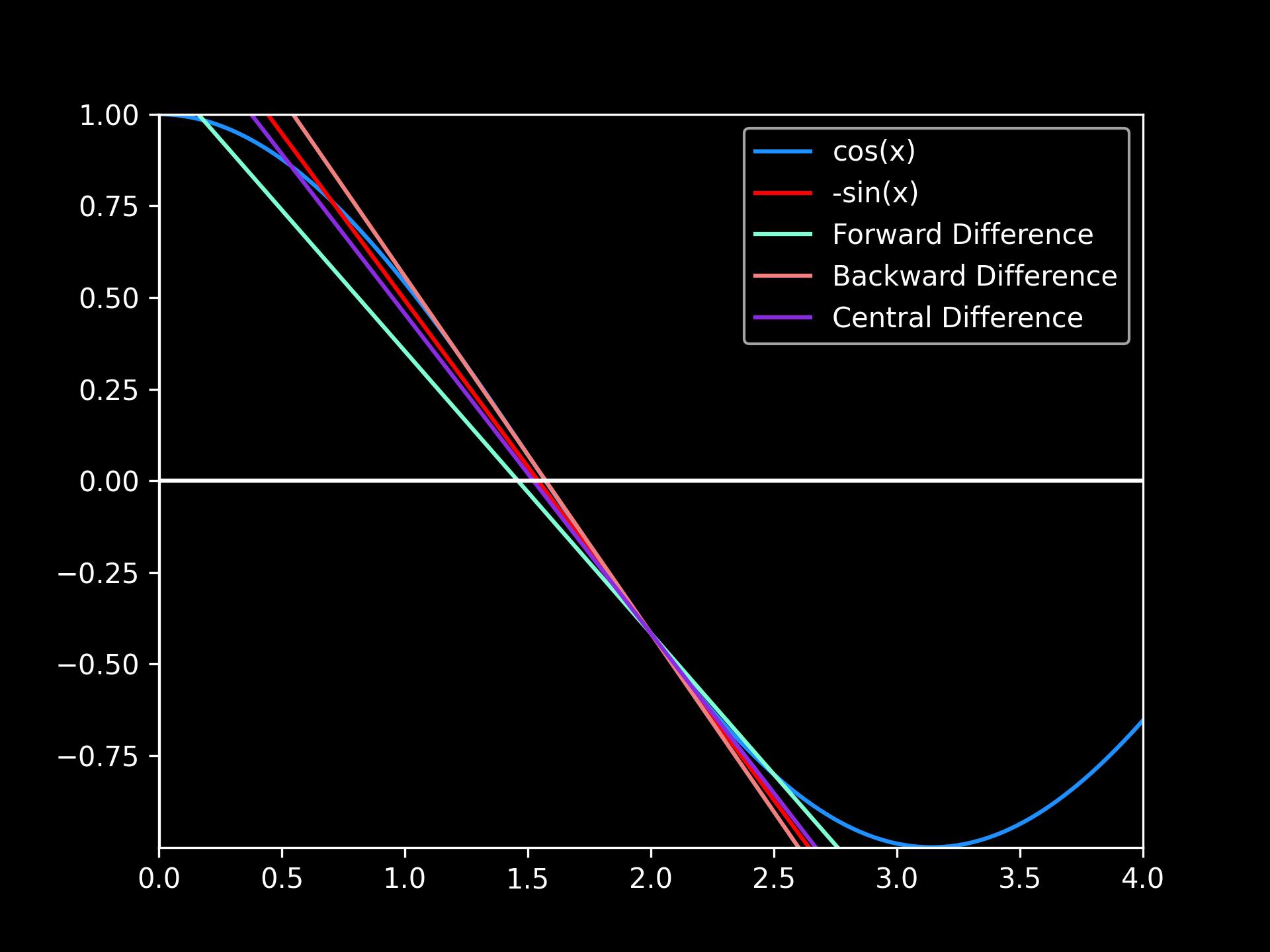
Derivative Approximations: pictured are the derivatives for at , using for the numeric differentiation methods (all computations used 32-bit floats). The graph highlights a better approximation in taking the central difference over the forward and backward difference. In addition, the discrepancies between the actual derivative and the approximated derivatives caused by truncation error can be viewed.
As another way to stabilize this approach, we could just reduce since the truncation error becomes nonexistent as . In theory, this should eliminate the error we're facing with numeric differentiation. However, doing such has side-effects leading us into the next section.
Issues with Numeric Differentiation
With an understanding of numeric differentiation, we can explore why it's avoided in the implementation of neural network optimization. In reference to decreasing as a solution to mitigate truncation error, we also introduce another error known as round-off error.
Round-off error is the error induced due to the inaccuracies of how numbers can be represented within computers. Standards such as the IEEE 754 have popularized the use of single precision floats (float32) to represent real numbers in programs. Neural networks depend on these representations, however, they're limited. Floats are allocated a fixed amount of space (32 bits in most cases), preventing certain levels of precision for arbitrarily large or small values. Tying this into numerical differentiation, if numbers get too small they'll underflow into zero and lose numerical information in the process.
This is significant because as we try to decrease to alleviate the truncation error, we increase our round-off error. In fact, the round-off error is inversely proportional to the scale of . For example, if we halve , we double the round-off error. This balance between truncation and round-off error introduces a trade-off to consider when choosing a viable to compute accurate gradients.
Truncation vs. Round-off Error
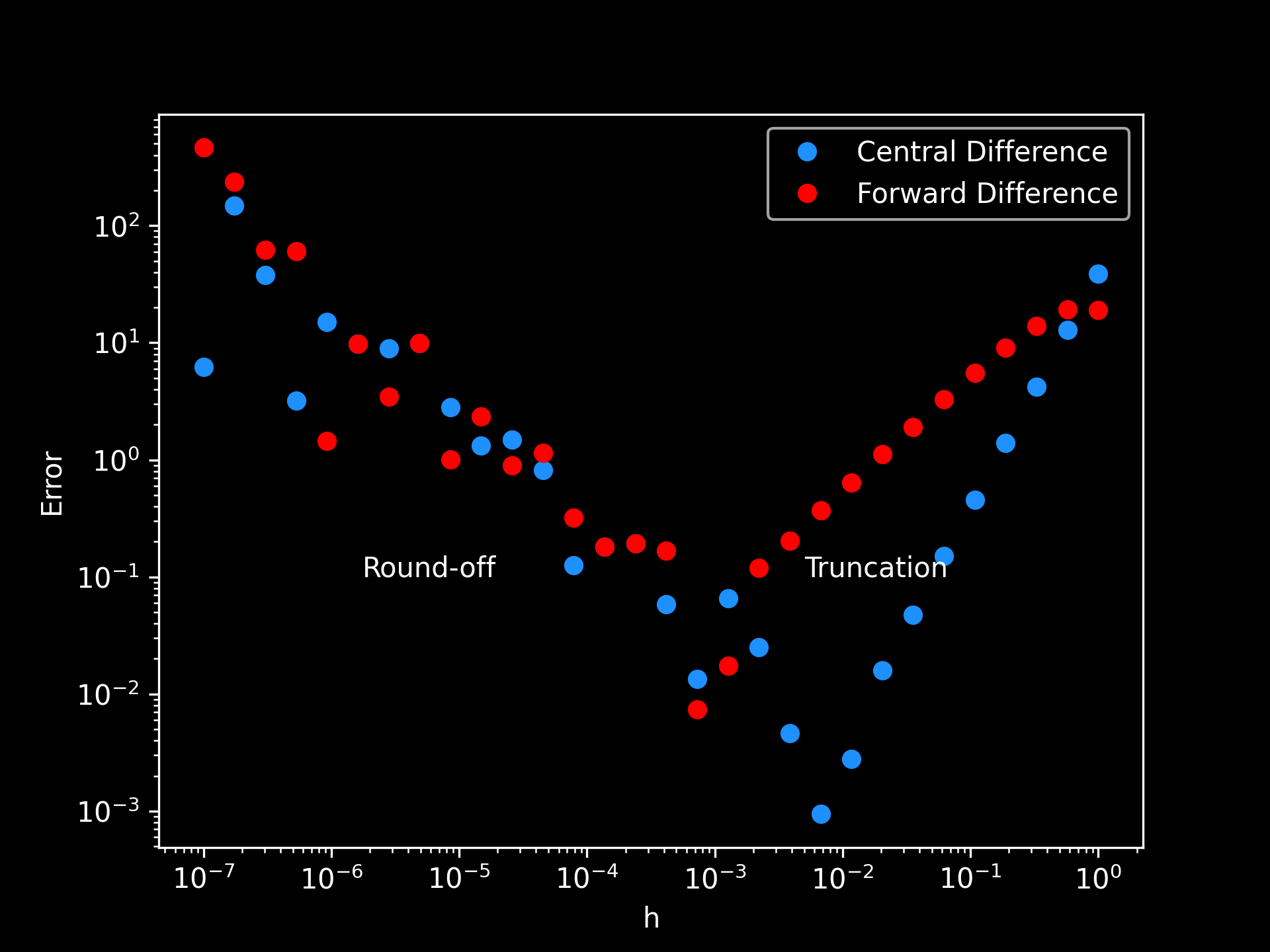
Truncation vs. Round-off Error: above are sampled errors present in the computation of the forward difference method (eq. 2) and the central difference method (eq. 3) for the function . Single precision floating-point values in the range were used for . It's seen as decreases, the truncation error decreases with the introduction of round-off error and vice-versa when grows.
One could make the suggestion of using a higher precision data type (e.g. float64), but this increases hardware constraints due to more memory requirements and additional computations—another tradeoff that's completely unnecessary. Pivoting, another issue arises from the runtime complexity of numerical differentiation.
To actually compute the gradients, we have to evaluate the function of interest. In the case of finding the gradients for a function with inputs and a scalar output, we'd require operations. This doesn't even consider vector-valued functions seen in neural networks. For example, if we have the function , we'd require roughly operations to compute the gradients, making the total computation inefficient for large values of and .
With the context that gradient descent is an iterative process applied to millions or even billions of parameters, we can see that numeric differentiation doesn't scale well enough for neural network optimization. Knowing where it comes short, we can shift towards an alternate approach in symbolic differentiation.
Symbolic Differentiation
Symbolic differentiation is the next approach we'll unpack for gradient computation. It's a systematic process that transforms an expression composed of arithmetic operations and symbols, into an expression representing its derivative. This is achieved by applying the derivative rules of Calculus (e.g. sum rule) to closed-form expressions.
In reality, symbolic differentiation is a computer's way of how we hand derive the derivative of an expression. For example with the two functions and below, we can use Calculus to derive an expression for its derivative.
To find the derivative for an input of , we'd just plug it into the transformed expression above and evaluate it. In practice, we'd programmatically implement this process, and the variables represented would be more than just scalars (e.g. vectors, matrices, or tensors). Below is an example of how we'd symbolically differentiate eq. 4 to get eq. 5 using sympy in python*.
from sympy import symbols, cos, exp, diff
x = symbols("x")
fog = 4 * (cos(x) + 2 * x - exp(x)) ** 2
dfdx = diff(fog, x)
print(dfdx)
4*(2*x - exp(x) + cos(x))*(-2*exp(x) - 2*sin(x) + 4)
* The derivative expression might appear different than eq. 5, but they're actually the same. The terms are slightly reordered and the from gets distributed to .
This solves the issue of numerical inaccuracies and instabilities seen in numerical differentiation (view Derivative Approximations and Truncation vs. Round-off Error depictions) because we have an expression that can directly compute the gradients of a function. Still, we face issues limiting its viability for optimizing neural networks that we will dissolve in the next section.
Issues with Symbolic Differentiation
The leading issue we can see with symbolic differentiation is expression swell. Expression swell causes the derivative expression, through transformations, to exponentially grow as a penalty of systematically applying the derivative rules to the original expression. Take for example the product rule below.
The derivative expression has grown not only in terms, but in computation. This doesn't even consider that either or can be complex functions themselves—potentially adding more expression swell.
We saw a bit of expression swell when we derived , and this was a relatively simple function. Now imagine trying to do the same for many composite functions that may apply the derivative rules over and over again. Doing this, knowing neural networks represent many complex composite functions, is extremely impractical.
Expression Swell
Expression Swell: shown is a linear projection seen in neural networks, followed by the nonlinear activation function . It's shown, without simplification and optimizations, that finding the gradients to update the weights can lead to an egregious amount of expression swell and duplicate computations.
Another drawback faced is the fact that symbolic differentiation is confined to closed-form expressions. What makes programming useful is the ability to use control flow to change how a program behaves depending on its state, and the same principle is often applied to neural networks. What if we wanted to change how an operation is applied when a certain input is passed or wanted a model to behave differently depending on its mode? This functionality isn't symbolically differentiable, and as a consequence, we'd lose any dynamics necessary for the implementation of various model architectures.
No Control Flow
from sympy import symbols, diff
def f(x):
if x > 2:
return x * 2 + 5
return x / 2 + 5
x = symbols("x")
dfdx = diff(f(x))
print(dfdx)
TypeError: cannot determine truth value of Relational
The last drawback, hinted in the Expression Swell example, is the fact we could incur repeated computations. In the case of eq. 4 and 5, we evaluate three times: once in the computation of
eq. 4 and twice in the computation of eq. 5. This could carry on a larger scale for more complex functions, creating more impracticalities for symbolic differentiation. We could reduce this issue by caching results, but this doesn't necessarily resolve expression swell.
As a whole, it's expression swell, the requirement that expressions are in closed-form, and repeated computations that limits symbolic differentiation for neural network optimization. But, the intuition of applying the derivative rules and caching (as a solution for repeated computations), form the foundations of automatic differentiation.
Automatic Differentiation
Automatic Differentiation, or AD for short, expresses composite functions into the variables and elementary operations* that form them. All numeric computation is centered around these operations, and since we know their derivatives, we can chain them together to arrive at the derivative for the entire function. In short, AD is an enhanced version of numeric computation that not only evaluates mathematical functions, but also computes their derivatives beside them.
* Elementary operations are the atomic mathematical operations: addition, subtraction, multiplication, and division which have well-defined derivatives. Transcendental functions (e.g. natural log and cosine) are not technically considered elementary operations, but in the context of AD, they typically are because their derivatives are well-defined.
To implement this, we can leverage an evaluation trace. An evaluation trace is a special table that keeps track of intermediate variables as well as the operations that created them. Every row corresponds to an intermediate variable and the elementary operation that caused it. These variables, called primals, are typically denoted for functions and follow these rules:
- Input variables:
- Intermediate variables:
- Output variables:
Below, I've left an example showing just the primal computation of an evaluation trace for a function accepting two inputs and .
Forward Primal Trace (eq. 6)
| Forward Primal Trace | Output |
|---|---|
| v₋₁ = x₁ | 2 |
| v₀ = x₂ | 4 |
| v₁ = v₋₁v₀ | 2(4) = 8 |
| v₂ = ln(v₋₁) | ln(2) = 0.693 |
| v₃ = v₁ + v₀ | 8 + 4 = 12 |
| v₄ = v₃ − v₂ | 12 - 0.693 = 11.307 |
| y = v₄ | 11.307 |
On top of the evaluation trace, we can use a Directed Acyclic Graph (DAG) as a data structure to algorithmically represent the evaluation trace. Nodes in the DAG represent input variables, intermediate variables, and output variables, while edges describe the computational hierarchy of input to output transformations. Finally, the graph must be directed and acyclic to ensure the correct flow of computation. In its entirety, this type of DAG is commonly known as the computational graph.
Computational Graph (eq. 6)
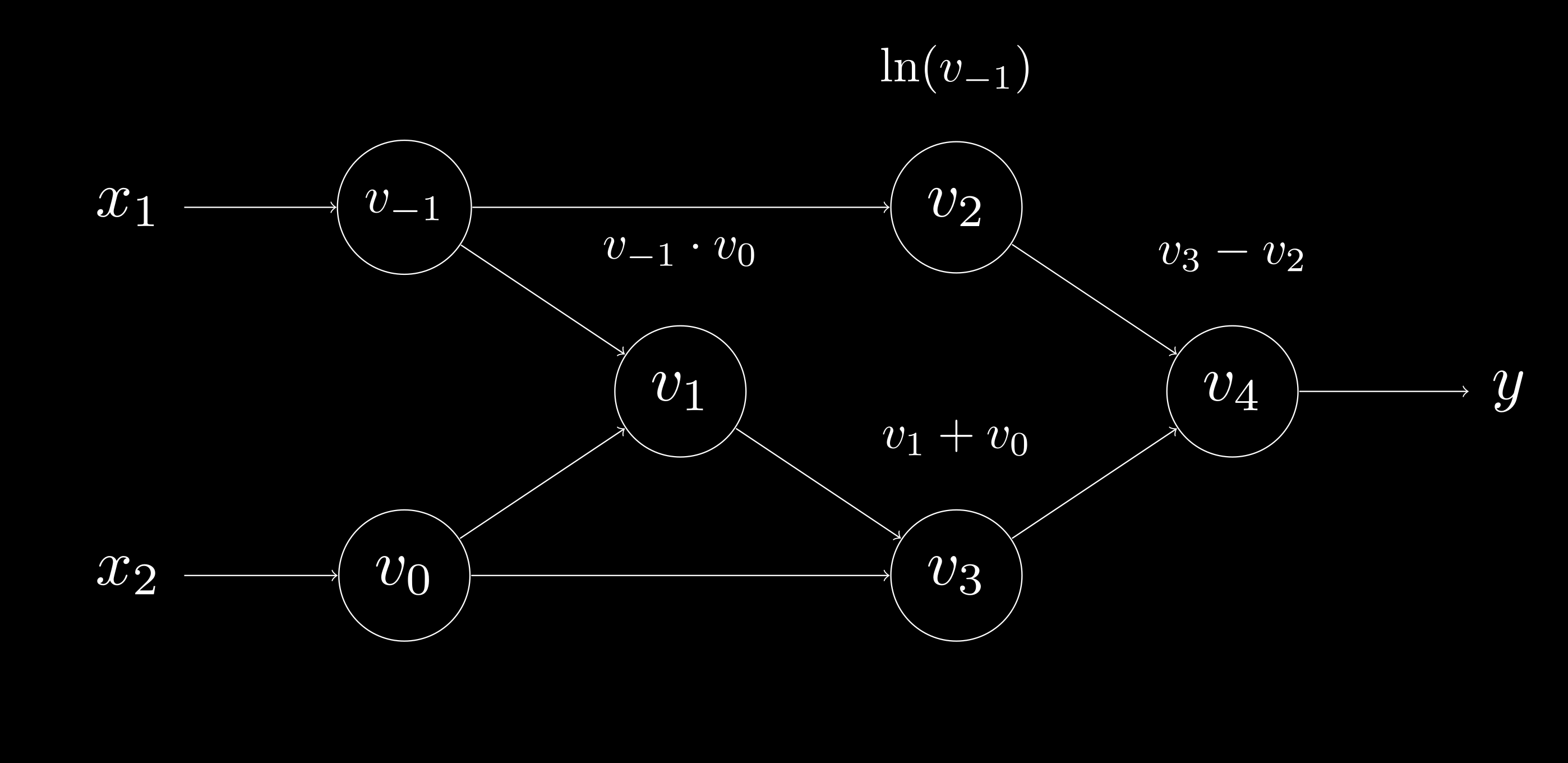
The introduction of these tools, both the evaluation trace and computational graph, are important for understanding and implementing AD—in particular, its two modes: forward and reverse mode.
Forward Mode AD
Forward mode AD adopts the principles we previously covered from the evaluation trace, but introduces the tangent, denoted , corresponding to a primal . These tangents carry the partial derivative information of a primal w.r.t. a particular input variable of interest.
Referencing back to eq. 6, we'd have the following definition of tangents if we were interested in finding :
Continuing from this definition, we can build out the forward primal and forward tangent trace to compute when , , , and .
Forward Mode Trace (eq. 6)
| Forward Primal Trace | Output | Forward Tangent Trace | Output |
|---|---|---|---|
| v₋₁ = x₁ | 3 | v̇₋₁ = ẋ₋₁ | 0 |
| v₀ = x₂ | -4 | v̇₀ = ẋ₂ | 1 |
| v₁ = v₋₁v₀ | 3 ⋅ -4 = -12 | v̇₁ = v̇₋₁v₀ + v̇₀v₋₁ | 0 ⋅ -4 + 1 ⋅ 3 = 3 |
| v₂ = ln(v₋₁) | ln(3) = 1.10 | v̇₂ = v̇₋₁ ⋅ (1 / v₋₁) | 0 ⋅ (1 / 3) = 0 |
| v₃ = v₁ + v₀ | -12 + -4 = -16 | v̇₃ = v̇₁ + v̇₀ | 3 + 1 = 4 |
| v₄ = v₃ − v₂ | -16 - 1.10 = -17.10 | v̇₄ = v̇₃ − v̇₂ | 4 - 0 = 4 |
| y = v₄ | -17.10 | ẏ = v̇₄ | 4 |
This process is the essence of forward mode AD. At every elementary operation for a given function, compute intermediate variables (primals) by applying basic arithmetic operations, and in synchrony, compute their derivatives (tangents) by using what we know from Calculus.
With this approach, we can do more than just compute derivatives, but we can compute Jacobians. For a vector-valued function , we choose a set of inputs —where and tangents for . Applying these inputs to our function in forward mode now generates the partial derivatives of the all output variables for w.r.t. a single input variable . Essentially, every forward pass in forward mode AD generates one column of the Jacobian—correlating to the partial derivatives of all outputs w.r.t. a single input.
Jacobian Matrix
Because the function has inputs and one forward pass in forward mode generates a column of the Jacobian, it requires evaluations to compute the full Jacobian matrix. If you don't recall from Linear Algebra, the full Jacobian represents the partial derivatives of all outputs w.r.t. to all inputs; for our purposes, the gradients we're trying to derive for optimization.
This feature generalizes to the Jacobian-vector product (JVP). JVPs are the dot-product between the Jacobian of a function , and a column vector . The result of the dot product returns a -dimensional column vector encoding the change of the outputs when the inputs are perturbed. In better words, it describes the change in the outputs when the inputs are directionally nudged by .
What makes this special, specifically in forward mode AD, is that we don't need to compute the full Jacobian. By choosing a set of inputs, and setting the perturbation vector , one evaluation in forward mode for a function outputs the JVP without ever computing the entire Jacobian.
Jacobian-vector Product
Altogether, this makes forward mode AD practical in certain cases. To be specific, forward mode AD is effective when evaluating a function when . For example, a function with one input and outputs requires a single forward pass in this mode to compute its Jacobian. On the opposite end, a function with inputs and one output ( ) requires forward passes in forward mode to obtain its Jacobian.
This case is important to examine because, oftentimes, the parameters of a neural network represent while the scalar loss—caused by the model's parameters—represents . Thus, if we were to use forward mode AD for gradient-based optimization, we'd be using it when it's suboptimal.
Wrapping up, forward mode AD is preferred over numeric and symbolic differentiation because it doesn't have issues like numerical instabilities or expression swell (see the Truncation vs. Round-off Error depiction and the Expression Swell example). But since it lacks the scalability we need for neural network optimization, we can pivot to AD's second mode, reverse mode.
Reverse Mode AD
Arriving at this point, we have reverse mode AD—alike forward mode, yet different methodically. We begin by defining adjoints representing the partial derivative of an output w.r.t. an intermediate variable for a function —where and . We can formally define the adjoints as:
In reverse mode AD, we perform the forward pass by applying elementary operations to compute intermediate variables, but during this stage, adjoints are not computed alongside their primal counterparts like we observed with the tangents in forward mode AD. Rather, any dependencies required for the derivative computation of are stored in the computational graph.
Progressing, we use our familiarity with the derivatives of elementary operations, the chain rule, and the cached dependencies (from the forward pass) to compute the adjoints. Adjoints are computed in the order starting from an output variable and ending with all input variables that caused the output variable. This stage is commonly referred as the reverse pass. If you couldn't tell already, the "reverse" pass is what gives this mode of AD its name—in which derivatives are computed in a reversed fashion.
With intuition behind reverse mode AD, let's take a look at the reverse mode evaluation trace of
eq. 6 using the same values for the input variables from the Forward Mode Trace.
Reverse Mode Trace (eq. 6)
| Forward Primal Trace | Output | Reverse Adjoint Trace | Output |
|---|---|---|---|
| v₋₁ = x₁ | 3 | v̅₋₁ = x̅₁ = v̅₂ ⋅ (1 / v₋₁) + v̅₁ ⋅ v₀ | -1 ⋅ (1 / 3) + 1 ⋅ -4 = -4.33 |
| v₀ = x₂ | -4 | v̅₀ = x̅₂ = v̅₃ ⋅ 1 + v̅₁ ⋅ v₋₁ | 1 ⋅ 1 + 1 ⋅ 3 = 4 |
| v₁ = v₋₁v₀ | 3 ⋅ -4 = -12 | v̅₁ = v̅₃ ⋅ 1 | 1 ⋅ 1 = 1 |
| v₂ = ln(v₋₁) | ln(3) = 1.10 | v̅₂ = v̅₄ ⋅ −1 | 1 ⋅ -1 = -1 |
| v₃ = v₁ + v₀ | -12 + -4 = -16 | v̅₃ = v̅₄ ⋅ 1 | 1 ⋅ 1 = 1 |
| v₄ = v₃ − v₂ | -16 - 1.10 = -17.10 | v̅₄ = y̅ | 1 |
| y = v₄ | -17.10 | y̅ | 1 |
In this particular trace, we start with the adjoint and send it down to any of its dependencies (variables that caused it) by applying the derivative rules. Eventually, any input variable that contributed to the output will have its adjoint populated.
You might be confused by the computation of and . This is slightly unintuitive in my opinion, but since their primals contribute to the output through multiple paths—seen in the computation of and —they'll each have two incoming derivatives. We don't discard any derivative information, favoring one over the other, because we'd lose how and * influence . Instead, we accumulate their respective derivatives. In doing so, the total contribution of and are contained in their adjoints and .
* Recall that and are just aliases for and respectively; the same is said for their adjoints.
As seen in forward mode, Jacobians can also be computed for vector-valued functions
. By choosing inputs , assigning , and setting for
—each reverse pass generates the partial derivative of the output w.r.t. all input variables for . Because there's rows, and each reverse pass computes a row of the Jacobian, it would require evaluations in reverse mode AD to achieve the full Jacobian of .
Expanding on above, we can compute the vector-Jacobian product (VJP). The VJP is the left multiply of a transposed row vector —often referred as the cotangent vector—and the Jacobian of a function . The computation of the VJP generates a -dimensional row vector containing the partial derivatives of an output w.r.t. all its inputs when perturbed by .
Vector-Jacobian Product
Vector-Jacobian Product (Alt. Form)
VJPs tie directly into optimizing neural networks because we can represent as the partial derivatives of a model's outputs w.r.t. its inputs and as the partial derivatives of an objective loss function's output w.r.t. the model's outputs. Applying the VJP under this context produces the gradients needed for optimization. Also, like JVPs, VJPs don't require the full Jacobian of a function and can be computed in a single reverse pass.
Rounding off what we've discussed with reverse mode AD, it requires a single reverse pass to compute the gradients of an output w.r.t. all inputs and reverse passes when computing such for outputs. Because of these properties, reverse mode AD is best utilized when . As a matter of fact, this makes reverse mode optimal for optimizing neural networks. It would only require one reverse pass to compute the gradients of a scalar producing loss function w.r.t. to the
-parameters of a model influencing it; recall the case of .
Note: since dependencies for derivative computations must be stored in the computational graph, there's a memory complexity proportional to the number of operations for a function. This is a drawback, but doesn't undermine its practically for optimizing neural networks.
All things considered, reverse mode AD is clearly the best option for gradient-based optimization. We only need one reverse pass for one step of gradient descent, with the addition of added memory—an acceptable trade-off given we favor time over space.
Implementation
Having forward mode and reverse mode AD covered, we can delve into the implementation of the two in code. A couple of ways we might achieve this is via special-purpose compilers or source code transformation. Both implementations work, but are more involved than what's needed for a basic demonstration. Instead, we will opt for the operator overloading approach.
Operator overloading—in the context of AD—involves overriding the methods of operators for a custom type such that the functionality of AD is incorporated in them. You can think of this type as a user-defined class, struct, or object—depending on the language—with properties enabling AD. With the right implementation of operator overloading, any arithmetic operations applied on the AD enabled type(s) will allow for effortless derivations.
Python is a relatively simple language and supports operator overloading which is why we'll use it for our implementation of forward and reverse mode AD.
Forward Mode AD Implementation
class Variable:
def __init__(self, primal, tangent):
self.primal = primal
self.tangent = tangent
def __add__(self, other):
primal = self.primal + other.primal
tangent = self.tangent + other.tangent
return Variable(primal, tangent)
def __sub__(self, other):
primal = self.primal - other.primal
tangent = self.tangent - other.tangent
return Variable(primal, tangent)
def __mul__(self, other):
primal = self.primal * other.primal
tangent = self.tangent * other.primal + other.tangent * self.primal
return Variable(primal, tangent)
def __truediv__(self, other):
primal = self.primal / other.primal
tangent = (self.tangent / other.primal) + (
-self.primal / other.primal**2
) * other.tangent
return Variable(primal, tangent)
def __repr__(self):
return f"primal: {self.primal}, tangent: {self.tangent}"
Beginning with the Variable type (our AD type), we will take two arguments, primal and tangent, and initialize them as attributes for later use. Rather obvious, primal represents the primal used during the forward pass of an arithmetic operation. Likewise, tangent is the tangent used for the derivative computation during the forward pass of an arithmetic operation. For simplicity, both attributes will be scalars, but one can extend the functionality to operate on multi-dimensional arrays using numpy.
Moving on, we begin to overload the builtin arithmetic operators in python. In particular, we only overload* +, -, *, and /—correlating to __add__, __sub__, __mul__, and __truediv__ respectively. Just briefly, overloading these operators defines the behavior when (in the case of __add__) a + b is encountered—where a (self argument) is of type Variable and b (other argument) is some other type. For the sake of simplicity, b will always be of type Variable. As mentioned before, we can add more functionality by overloading more operators (e.g. __pow__ for a ** b), but I'm trying to keep things simple.
*
__repr__is also overloaded which dictates the behavior wheneverrepr(),print(), orstr()is called on aVariableobject. This is added just so we can representVariablewhenever we print it.
For each overloaded arithmetic operator, we implement the following procedure below.
Forward Mode AD Procedure:
Evaluate the operator with its operands (
selfandother).Apply the derivative rules of Calculus and compute the partial derivative of the output w.r.t. each input.
Sum the derivatives together to get
tangent—the derivative of the output w.r.t. to both inputs.Create and return a new
Variableobject with the result of forward computation and the derived tangent.
Let's use __mul__—the multiplication of two numbers—to help us understand this procedure by breaking it down into each component.
Procedure for Multiply:
We evaluate the operator with its operands by computing
self.primal * other.primaland then store the result in another variableprimal.We find the partial derivative of the output w.r.t. to each input by computing
self.tangent * other.primalandother.tangent * self.primal.Next, we sum the values from step 2 and store them in
tangent. This is the derivative of the output w.r.t to both inputs.Lastly, we return a new variable carrying the output of the arithmetic operation, and the associated
tangentinreturn Variable(primal, tangent).
If operator overloading is implemented correctly on elementary arithmetic operations with well-defined derivatives, operations can be composed together to form differentiable composite functions. Down below, I've left some basic functions that test Variable's ability to help compute the evaluation of an expression and its derivative.
AD Computation in Forward Mode
def mul_add(a, b, c):
return a * b + c * a
def div_sub(a, b, c):
return a / b - c
a, b, c = Variable(25.0, 1.0), Variable(4.0, 0.0), Variable(-5.0, 0.0)
print(f"{a = }, {b = }, {c = }")
print(f"{mul_add(a, b, c) = }")
a.tangent, b.tangent, c.tangent = 0.0, 1.0, 0.0
print(f"{div_sub(a, b, c) = }")
a = primal: 25.0, tangent: 1.0, b = primal: 4.0, tangent: 0.0, c = primal: -5.0, tangent: 0.0
mul_add(a, b, c) = primal: -25.0, tangent: -1.0
div_sub(a, b, c) = primal: 11.25, tangent: -1.5625
AD Computation in Forward Mode: In the first function we compute and derive . In the following function, we compute and derive .
Reverse Mode AD Implementation
class Variable:
def __init__(self, primal, adjoint=0.0):
self.primal = primal
self.adjoint = adjoint
def backward(self, adjoint):
self.adjoint += adjoint
def __add__(self, other):
variable = Variable(self.primal + other.primal)
def backward(adjoint):
variable.adjoint += adjoint
self_adjoint = adjoint * 1.0
other_adjoint = adjoint * 1.0
self.backward(self_adjoint)
other.backward(other_adjoint)
variable.backward = backward
return variable
def __sub__(self, other):
variable = Variable(self.primal - other.primal)
def backward(adjoint):
variable.adjoint += adjoint
self_adjoint = adjoint * 1.0
other_adjoint = adjoint * -1.0
self.backward(self_adjoint)
other.backward(other_adjoint)
variable.backward = backward
return variable
def __mul__(self, other):
variable = Variable(self.primal * other.primal)
def backward(adjoint):
variable.adjoint += adjoint
self_adjoint = adjoint * other.primal
other_adjoint = adjoint * self.primal
self.backward(self_adjoint)
other.backward(other_adjoint)
variable.backward = backward
return variable
def __truediv__(self, other):
variable = Variable(self.primal / other.primal)
def backward(adjoint):
variable.adjoint += adjoint
self_adjoint = adjoint * (1.0 / other.primal)
other_adjoint = adjoint * (-1.0 * self.primal / other.primal**2)
self.backward(self_adjoint)
other.backward(other_adjoint)
variable.backward = backward
return variable
def __repr__(self) -> str:
return f"primal: {self.primal}, adjoint: {self.adjoint}"
The reverse mode AD implementation is rather similar to the forward mode implementation—granted adjoint and tangent serve the same purpose. Where the two diverge is the fact we default adjoint to 0. This is because in reverse mode, we propagate derivatives from output to input then accumulate them; we don't know the derivative(s) to accumulate for a Variable at the time of its creation, so it gets set to zero for the time being.
Let's also touch on the default backward method for the Variable type. All this method does is take the adjoint argument, and accumulates it into the adjoint attribute of the Variable object invoking it. Essentially, its purpose is to accumulate the derivative for the leaf* Variables that don't have a custom backward method. This may not make sense at the moment, but as we explore the reverse mode AD implementation, its purpose will be clearer.
* Think of leaf
Variables as the independent input variables that we discussed in the Automatic Differentiation section.
With enough background, let's look into the procedure to enable reverse mode AD for our Variable type.
Reverse Mode AD Procedure:
Create a
Variableobject holding the result of the operator and its operands.Define a closure function
backwardthat does the following:- Accepts an
adjointas an argument and accumulates it into theadjointof theVariableobject from 1. - Computes the partial derivative of the output w.r.t. to each input using the operator's derivative and the
adjointto chain incoming derivatives. - Calls
backward()on each input with their respective derivatives (second bullet) to continue the reverse pass.
- Accepts an
Return the resultant
Variableobject from 1. with itsbackwardmethod overwritten with the closure function defined in 2.
To further our grasp, let's examine this procedure implemented in __truediv__—the floating-point division between two numbers.
Procedure for Division:
We create a new
Variablewith the result of the arithmetic operator applied with its operands invariable = Variable(self.primal / other.primal).Moving to the next step, we create the closure function
backward(adjoint)where we:Accumulate the
adjointargument intovariableby doingvariable.adjoint += adjoint.Compute the partial derivative for each input using the quotient rule and
adjoint—to chain derivatives—by definingself_adjoint = adjoint * (1.0 / other.primal)andother_adjoint = adjoint * (-1.0 * self.primal / other.primal**2).Continue the reverse pass on both inputs by calling
self.backward(self_adjoint)andother.backward(other_adjoint).
Lastly, we bind the closure function and return the modified
Variableobject equipped for reverse mode derivation invariable.backward = backwardandreturn variable.
Referencing back, this implementation is why we need the default backward method. Eventually, the derivatives will propagate to leaf Variables, and since they don't need to propagate derivatives themselves, we'd just accumulate their derivatives passed from backward when a closure function calls them.
Like before, the proper implementation of operator overloading on elementary arithmetic operations (with well-defined derivatives) enables the automatic differentiation of differentiable composite functions. Below is the same test code from the forward mode example, but using our reverse mode implementation instead.
AD Computation in Reverse Mode
def mul_add(a, b, c):
return a * b + c * a
def div_sub(a, b, c):
return a / b - c
a, b, c = Variable(25.0, 1.0), Variable(4.0, 0.0), Variable(-5.0, 0.0)
print(f"{a = }, {b = }, {c = }")
d = mul_add(a, b, c)
d.backward(1.0)
print(f"{d = }")
print(f"{a.adjoint = }, {b.adjoint = }, {c.adjoint = }")
a.adjoint, b.adjoint, c.adjoint = 0.0, 0.0, 0.0
e = div_sub(a, b, c)
e.backward(1.0)
print(f"{e = }")
print(f"{a.adjoint = }, {b.adjoint = }, {c.adjoint = }")
a = primal: 25.0, adjoint: 0.0, b = primal: 4.0, adjoint: 0.0, c = primal: -5.0, adjoint: 0.0
d = primal: -25.0, adjoint: 1.0
a.adjoint = -1.0, b.adjoint = 25.0, c.adjoint = 25.0
e = primal: 11.25, adjoint: 1.0
a.adjoint = 0.25, b.adjoint = -1.5625, c.adjoint = -1.0
AD Computation in Reverse Mode: the code follows the same functions from the forward mode implementation ( and ), but now we've computed the partial derivatives for all the inputs and not just one as seen in forward mode. Also, note that we zero the
adjoints before we calldiv_sub. If we hadn't, we'd accumulate the partial derivatives from it with those computed frommul_add.
Autograd
Hinting at it a bit, this implementation draws inspiration from PyTorch's autograd API. If you've trained a model using their framework, you've probably encountered loss.backward() before. This method (at least to me) looked like some form of magic, but in reality it's automatically differentiating the loss w.r.t. a model's parameters using an approach similar to our's above. The only difference is that PyTorch's implementation is more advanced and extends its functionality beyond the basic arithmetic operators to make it a viable framework for ML research...unlike ours.
Amazed by the PyTorch framework, I decided to develop my own in nura. It's far from complete, but it's a fun project which shows how an autograd engine and ML framework can be built with just numpy. Its main capabilities provide reverse and forward mode AD functionalities, but it also includes the ability to create neural networks similar to the torch.nn interface in PyTorch. To give you more of an idea, below is a snippet showing how one can evaluate and compute the Jacobian of a function using forward mode AD.
import nura
from nura.autograd.functional import jacfwd
def fn(a, b, c):
return a * b + c
a = nura.tensor([1.0, 2.0, 3.0, 4.0])
b = nura.tensor([5.0, 6.0, 7.0, 8.0])
c = nura.tensor(1.0)
r = nura.ones(4).double()
output, jacobian = jacfwd((a, b, c), fn, pos=1)
print(f"output:\n{output}\n\njacobian:\n{jacobian}")
output:
tensor([ 6. 13. 22. 33.]) dtype=double)
jacobian:
tensor([[1. 0. 0. 0.]
[0. 2. 0. 0.]
[0. 0. 3. 0.]
[0. 0. 0. 4.]]) dtype=double)
Conclusion
In this blog, we unpacked the challenge of efficiently computing gradients to optimize neural networks. We found numerical and symbolic differentiation as potential solutions, but their issues led us to automatic differentiation. In AD, we learned how to leverage the evaluation trace and computational graph to compute partial derivatives in forward mode. However, we noticed the properties of reverse mode handled this task more efficiently when it came to neural networks and gradient descent. Lastly, we strengthened our understanding of AD by implementing and testing both modes with our Variable type in python.
In closing, I hope this blog not only highlights the practicality of AD for neural network optimization via gradient descent, but also how we can leverage mathematics and a system design thought process to solve challenging problems in the field of ML.