
thanks to jadechoghari ❤
Browse files- .gitattributes +7 -0
- README.md +152 -0
- config.json +248 -0
- figures/Computational requirements.PNG +0 -0
- figures/architecture.jpg +3 -0
- figures/architecture.pdf +0 -0
- figures/gif_output/blur.gif +0 -0
- figures/gif_output/blur.jpg +0 -0
- figures/gif_output/blur_back_n_forth.gif +3 -0
- figures/gif_output/haze.gif +0 -0
- figures/gif_output/haze.jpg +0 -0
- figures/gif_output/haze_back_n_forth.gif +3 -0
- figures/gif_output/lowlight.gif +0 -0
- figures/gif_output/lowlight.jpg +0 -0
- figures/gif_output/lowlight_back_n_forth.gif +3 -0
- figures/gif_output/rain.gif +3 -0
- figures/gif_output/rain.jpg +0 -0
- figures/gif_output/rain_back_n_forth.gif +3 -0
- figures/qualitative_result.PNG +3 -0
- figures/seen_dataset_with_synthetic_degradation.PNG +0 -0
- figures/unseen_dataset_with_real_degradation.PNG +0 -0
- figures/unseen_dataset_with_synthetic_degradation.PNG +0 -0
- model.safetensors +3 -0
- preprocessor_config.json +35 -0
- robustsam_checkpoint_h.pth +3 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,10 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
figures/architecture.jpg filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
figures/gif_output/blur_back_n_forth.gif filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
figures/gif_output/haze_back_n_forth.gif filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
figures/gif_output/lowlight_back_n_forth.gif filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
figures/gif_output/rain_back_n_forth.gif filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
figures/gif_output/rain.gif filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
figures/qualitative_result.PNG filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,152 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
library_name: transformers
|
| 3 |
+
license: mit
|
| 4 |
+
---
|
| 5 |
+
|
| 6 |
+
# RobustSAM: Segment Anything Robustly on Degraded Images (CVPR 2024 Highlight)
|
| 7 |
+
# Model Card for ViT Huge (ViT-H) version
|
| 8 |
+
|
| 9 |
+
<a href="https://colab.research.google.com/drive/1mrOjUNFrfZ2vuTnWrfl9ebAQov3a9S6E?usp=sharing"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a>
|
| 10 |
+
[](https://huggingface.co/robustsam/robustsam/tree/main)
|
| 11 |
+
|
| 12 |
+
Official repository for RobustSAM: Segment Anything Robustly on Degraded Images
|
| 13 |
+
|
| 14 |
+
[Project Page](https://robustsam.github.io/) | [Paper](https://arxiv.org/abs/2406.09627) | [Video](https://www.youtube.com/watch?v=Awukqkbs6zM) | [Dataset](https://huggingface.co/robustsam/robustsam/tree/main/dataset)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
## Introduction
|
| 18 |
+
Segment Anything Model (SAM) has emerged as a transformative approach in image segmentation, acclaimed for its robust zero-shot segmentation capabilities and flexible prompting system. Nonetheless, its performance is challenged by images with degraded quality. Addressing this limitation, we propose the Robust Segment Anything Model (RobustSAM), which enhances SAM's performance on low-quality images while preserving its promptability and zero-shot generalization.
|
| 19 |
+
|
| 20 |
+
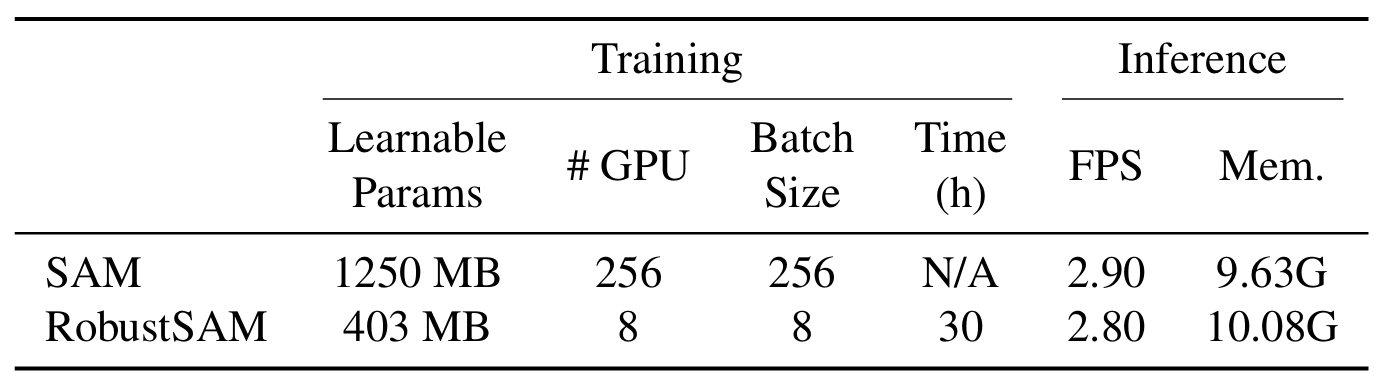
Our method leverages the pre-trained SAM model with only marginal parameter increments and computational requirements. The additional parameters of RobustSAM can be optimized within 30 hours on eight GPUs, demonstrating its feasibility and practicality for typical research laboratories. We also introduce the Robust-Seg dataset, a collection of 688K image-mask pairs with different degradations designed to train and evaluate our model optimally. Extensive experiments across various segmentation tasks and datasets confirm RobustSAM's superior performance, especially under zero-shot conditions, underscoring its potential for extensive real-world application. Additionally, our method has been shown to effectively improve the performance of SAM-based downstream tasks such as single image dehazing and deblurring.
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
**Disclaimer**: Content from **this** model card has been written by the Hugging Face team, and parts of it were copy pasted from the original [SAM model card](https://github.com/facebookresearch/segment-anything).
|
| 24 |
+
|
| 25 |
+
# Model Details
|
| 26 |
+
|
| 27 |
+
The RobustSAM model is made up of 3 modules:
|
| 28 |
+
- The `VisionEncoder`: a VIT based image encoder. It computes the image embeddings using attention on patches of the image. Relative Positional Embedding is used.
|
| 29 |
+
- The `PromptEncoder`: generates embeddings for points and bounding boxes
|
| 30 |
+
- The `MaskDecoder`: a two-ways transformer which performs cross attention between the image embedding and the point embeddings (->) and between the point embeddings and the image embeddings. The outputs are fed
|
| 31 |
+
- The `Neck`: predicts the output masks based on the contextualized masks produced by the `MaskDecoder`.
|
| 32 |
+
# Usage
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
## Prompted-Mask-Generation
|
| 36 |
+
|
| 37 |
+
```python
|
| 38 |
+
from PIL import Image
|
| 39 |
+
import requests
|
| 40 |
+
from transformers import AutoProcessor, AutoModelForMaskGeneration
|
| 41 |
+
|
| 42 |
+
# load the RobustSAM model and processor
|
| 43 |
+
processor = AutoProcessor.from_pretrained("jadechoghari/robustsam-vit-huge")
|
| 44 |
+
model = AutoModelForMaskGeneration.from_pretrained("jadechoghari/robustsam-vit-huge")
|
| 45 |
+
|
| 46 |
+
# load an image from a url
|
| 47 |
+
img_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
|
| 48 |
+
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB")
|
| 49 |
+
|
| 50 |
+
# we define input points (2D localization of an object in the image)
|
| 51 |
+
input_points = [[[450, 600]]] # example point
|
| 52 |
+
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
```python
|
| 57 |
+
# process the image and input points
|
| 58 |
+
inputs = processor(raw_image, input_points=input_points, return_tensors="pt").to("cuda")
|
| 59 |
+
|
| 60 |
+
# generate masks using the model
|
| 61 |
+
with torch.no_grad():
|
| 62 |
+
outputs = model(**inputs)
|
| 63 |
+
masks = processor.image_processor.post_process_masks(outputs.pred_masks.cpu(), inputs["original_sizes"].cpu(), inputs["reshaped_input_sizes"].cpu())
|
| 64 |
+
scores = outputs.iou_scores
|
| 65 |
+
|
| 66 |
+
```
|
| 67 |
+
Among other arguments to generate masks, you can pass 2D locations on the approximate position of your object of interest, a bounding box wrapping the object of interest (the format should be x, y coordinate of the top right and bottom left point of the bounding box), a segmentation mask. At this time of writing, passing a text as input is not supported by the official model according to [the official repository](https://github.com/facebookresearch/segment-anything/issues/4#issuecomment-1497626844).
|
| 68 |
+
For more details, refer to this notebook, which shows a walk throught of how to use the model, with a visual example!
|
| 69 |
+
|
| 70 |
+
## Automatic-Mask-Generation
|
| 71 |
+
|
| 72 |
+
The model can be used for generating segmentation masks in a "zero-shot" fashion, given an input image. The model is automatically prompt with a grid of `1024` points
|
| 73 |
+
which are all fed to the model.
|
| 74 |
+
|
| 75 |
+
The pipeline is made for automatic mask generation. The following snippet demonstrates how easy you can run it (on any device! Simply feed the appropriate `points_per_batch` argument)
|
| 76 |
+
```python
|
| 77 |
+
from transformers import pipeline
|
| 78 |
+
|
| 79 |
+
# initialize the pipeline for mask generation
|
| 80 |
+
generator = pipeline("mask-generation", model="jadechoghari/robustsam-vit-huge", device=0, points_per_batch=256)
|
| 81 |
+
|
| 82 |
+
image_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
|
| 83 |
+
outputs = generator(image_url, points_per_batch=256)
|
| 84 |
+
```
|
| 85 |
+
Now to display the generated mask on the image:
|
| 86 |
+
```python
|
| 87 |
+
import matplotlib.pyplot as plt
|
| 88 |
+
from PIL import Image
|
| 89 |
+
import numpy as np
|
| 90 |
+
|
| 91 |
+
# simple function to display the mask
|
| 92 |
+
def show_mask(mask, ax, random_color=False):
|
| 93 |
+
if random_color:
|
| 94 |
+
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
|
| 95 |
+
else:
|
| 96 |
+
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
|
| 97 |
+
|
| 98 |
+
# get the height and width from the mask
|
| 99 |
+
h, w = mask.shape[-2:]
|
| 100 |
+
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
|
| 101 |
+
ax.imshow(mask_image)
|
| 102 |
+
|
| 103 |
+
# display the original image
|
| 104 |
+
plt.imshow(np.array(raw_image))
|
| 105 |
+
ax = plt.gca()
|
| 106 |
+
|
| 107 |
+
# loop through the masks and display each one
|
| 108 |
+
for mask in outputs["masks"]:
|
| 109 |
+
show_mask(mask, ax=ax, random_color=True)
|
| 110 |
+
|
| 111 |
+
plt.axis("off")
|
| 112 |
+
|
| 113 |
+
# show the image with the masks
|
| 114 |
+
plt.show()
|
| 115 |
+
```
|
| 116 |
+
|
| 117 |
+
## Visual Comparison
|
| 118 |
+
<table>
|
| 119 |
+
<tr>
|
| 120 |
+
<td>
|
| 121 |
+
<img src="figures/gif_output/blur_back_n_forth.gif" width="380">
|
| 122 |
+
</td>
|
| 123 |
+
<td>
|
| 124 |
+
<img src="figures/gif_output/haze_back_n_forth.gif" width="380">
|
| 125 |
+
</td>
|
| 126 |
+
</tr>
|
| 127 |
+
<tr>
|
| 128 |
+
<td>
|
| 129 |
+
<img src="figures/gif_output/lowlight_back_n_forth.gif" width="380">
|
| 130 |
+
</td>
|
| 131 |
+
<td>
|
| 132 |
+
<img src="figures/gif_output/rain_back_n_forth.gif" width="380">
|
| 133 |
+
</td>
|
| 134 |
+
</tr>
|
| 135 |
+
</table>
|
| 136 |
+
|
| 137 |
+
<img width="1096" alt="image" src='figures/qualitative_result.PNG'>
|
| 138 |
+
|
| 139 |
+
## Reference
|
| 140 |
+
If you find this work useful, please consider citing us!
|
| 141 |
+
```python
|
| 142 |
+
@inproceedings{chen2024robustsam,
|
| 143 |
+
title={RobustSAM: Segment Anything Robustly on Degraded Images},
|
| 144 |
+
author={Chen, Wei-Ting and Vong, Yu-Jiet and Kuo, Sy-Yen and Ma, Sizhou and Wang, Jian},
|
| 145 |
+
journal={CVPR},
|
| 146 |
+
year={2024}
|
| 147 |
+
}
|
| 148 |
+
```
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
## Acknowledgements
|
| 152 |
+
We thank the authors of [SAM](https://github.com/facebookresearch/segment-anything) from which our repo is based off of.
|
config.json
ADDED
|
@@ -0,0 +1,248 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_commit_hash": null,
|
| 3 |
+
"architectures": [
|
| 4 |
+
"SamModel"
|
| 5 |
+
],
|
| 6 |
+
"initializer_range": 0.02,
|
| 7 |
+
"mask_decoder_config": {
|
| 8 |
+
"_name_or_path": "",
|
| 9 |
+
"add_cross_attention": false,
|
| 10 |
+
"architectures": null,
|
| 11 |
+
"attention_downsample_rate": 2,
|
| 12 |
+
"bad_words_ids": null,
|
| 13 |
+
"begin_suppress_tokens": null,
|
| 14 |
+
"bos_token_id": null,
|
| 15 |
+
"chunk_size_feed_forward": 0,
|
| 16 |
+
"cross_attention_hidden_size": null,
|
| 17 |
+
"decoder_start_token_id": null,
|
| 18 |
+
"diversity_penalty": 0.0,
|
| 19 |
+
"do_sample": false,
|
| 20 |
+
"early_stopping": false,
|
| 21 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 22 |
+
"eos_token_id": null,
|
| 23 |
+
"exponential_decay_length_penalty": null,
|
| 24 |
+
"finetuning_task": null,
|
| 25 |
+
"forced_bos_token_id": null,
|
| 26 |
+
"forced_eos_token_id": null,
|
| 27 |
+
"hidden_act": "relu",
|
| 28 |
+
"hidden_size": 256,
|
| 29 |
+
"id2label": {
|
| 30 |
+
"0": "LABEL_0",
|
| 31 |
+
"1": "LABEL_1"
|
| 32 |
+
},
|
| 33 |
+
"iou_head_depth": 3,
|
| 34 |
+
"iou_head_hidden_dim": 256,
|
| 35 |
+
"is_decoder": false,
|
| 36 |
+
"is_encoder_decoder": false,
|
| 37 |
+
"label2id": {
|
| 38 |
+
"LABEL_0": 0,
|
| 39 |
+
"LABEL_1": 1
|
| 40 |
+
},
|
| 41 |
+
"layer_norm_eps": 1e-06,
|
| 42 |
+
"length_penalty": 1.0,
|
| 43 |
+
"max_length": 20,
|
| 44 |
+
"min_length": 0,
|
| 45 |
+
"mlp_dim": 2048,
|
| 46 |
+
"model_type": "",
|
| 47 |
+
"no_repeat_ngram_size": 0,
|
| 48 |
+
"num_attention_heads": 8,
|
| 49 |
+
"num_beam_groups": 1,
|
| 50 |
+
"num_beams": 1,
|
| 51 |
+
"num_hidden_layers": 2,
|
| 52 |
+
"num_multimask_outputs": 3,
|
| 53 |
+
"num_return_sequences": 1,
|
| 54 |
+
"output_attentions": false,
|
| 55 |
+
"output_hidden_states": false,
|
| 56 |
+
"output_scores": false,
|
| 57 |
+
"pad_token_id": null,
|
| 58 |
+
"prefix": null,
|
| 59 |
+
"problem_type": null,
|
| 60 |
+
"pruned_heads": {},
|
| 61 |
+
"remove_invalid_values": false,
|
| 62 |
+
"repetition_penalty": 1.0,
|
| 63 |
+
"return_dict": true,
|
| 64 |
+
"return_dict_in_generate": false,
|
| 65 |
+
"sep_token_id": null,
|
| 66 |
+
"suppress_tokens": null,
|
| 67 |
+
"task_specific_params": null,
|
| 68 |
+
"temperature": 1.0,
|
| 69 |
+
"tf_legacy_loss": false,
|
| 70 |
+
"tie_encoder_decoder": false,
|
| 71 |
+
"tie_word_embeddings": true,
|
| 72 |
+
"tokenizer_class": null,
|
| 73 |
+
"top_k": 50,
|
| 74 |
+
"top_p": 1.0,
|
| 75 |
+
"torch_dtype": null,
|
| 76 |
+
"torchscript": false,
|
| 77 |
+
"transformers_version": "4.29.0.dev0",
|
| 78 |
+
"typical_p": 1.0,
|
| 79 |
+
"use_bfloat16": false
|
| 80 |
+
},
|
| 81 |
+
"model_type": "sam",
|
| 82 |
+
"prompt_encoder_config": {
|
| 83 |
+
"_name_or_path": "",
|
| 84 |
+
"add_cross_attention": false,
|
| 85 |
+
"architectures": null,
|
| 86 |
+
"bad_words_ids": null,
|
| 87 |
+
"begin_suppress_tokens": null,
|
| 88 |
+
"bos_token_id": null,
|
| 89 |
+
"chunk_size_feed_forward": 0,
|
| 90 |
+
"cross_attention_hidden_size": null,
|
| 91 |
+
"decoder_start_token_id": null,
|
| 92 |
+
"diversity_penalty": 0.0,
|
| 93 |
+
"do_sample": false,
|
| 94 |
+
"early_stopping": false,
|
| 95 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 96 |
+
"eos_token_id": null,
|
| 97 |
+
"exponential_decay_length_penalty": null,
|
| 98 |
+
"finetuning_task": null,
|
| 99 |
+
"forced_bos_token_id": null,
|
| 100 |
+
"forced_eos_token_id": null,
|
| 101 |
+
"hidden_act": "gelu",
|
| 102 |
+
"hidden_size": 256,
|
| 103 |
+
"id2label": {
|
| 104 |
+
"0": "LABEL_0",
|
| 105 |
+
"1": "LABEL_1"
|
| 106 |
+
},
|
| 107 |
+
"image_embedding_size": 64,
|
| 108 |
+
"image_size": 1024,
|
| 109 |
+
"is_decoder": false,
|
| 110 |
+
"is_encoder_decoder": false,
|
| 111 |
+
"label2id": {
|
| 112 |
+
"LABEL_0": 0,
|
| 113 |
+
"LABEL_1": 1
|
| 114 |
+
},
|
| 115 |
+
"layer_norm_eps": 1e-06,
|
| 116 |
+
"length_penalty": 1.0,
|
| 117 |
+
"mask_input_channels": 16,
|
| 118 |
+
"max_length": 20,
|
| 119 |
+
"min_length": 0,
|
| 120 |
+
"model_type": "",
|
| 121 |
+
"no_repeat_ngram_size": 0,
|
| 122 |
+
"num_beam_groups": 1,
|
| 123 |
+
"num_beams": 1,
|
| 124 |
+
"num_point_embeddings": 4,
|
| 125 |
+
"num_return_sequences": 1,
|
| 126 |
+
"output_attentions": false,
|
| 127 |
+
"output_hidden_states": false,
|
| 128 |
+
"output_scores": false,
|
| 129 |
+
"pad_token_id": null,
|
| 130 |
+
"patch_size": 16,
|
| 131 |
+
"prefix": null,
|
| 132 |
+
"problem_type": null,
|
| 133 |
+
"pruned_heads": {},
|
| 134 |
+
"remove_invalid_values": false,
|
| 135 |
+
"repetition_penalty": 1.0,
|
| 136 |
+
"return_dict": true,
|
| 137 |
+
"return_dict_in_generate": false,
|
| 138 |
+
"sep_token_id": null,
|
| 139 |
+
"suppress_tokens": null,
|
| 140 |
+
"task_specific_params": null,
|
| 141 |
+
"temperature": 1.0,
|
| 142 |
+
"tf_legacy_loss": false,
|
| 143 |
+
"tie_encoder_decoder": false,
|
| 144 |
+
"tie_word_embeddings": true,
|
| 145 |
+
"tokenizer_class": null,
|
| 146 |
+
"top_k": 50,
|
| 147 |
+
"top_p": 1.0,
|
| 148 |
+
"torch_dtype": null,
|
| 149 |
+
"torchscript": false,
|
| 150 |
+
"transformers_version": "4.29.0.dev0",
|
| 151 |
+
"typical_p": 1.0,
|
| 152 |
+
"use_bfloat16": false
|
| 153 |
+
},
|
| 154 |
+
"torch_dtype": "float32",
|
| 155 |
+
"transformers_version": null,
|
| 156 |
+
"vision_config": {
|
| 157 |
+
"_name_or_path": "",
|
| 158 |
+
"add_cross_attention": false,
|
| 159 |
+
"architectures": null,
|
| 160 |
+
"attention_dropout": 0.0,
|
| 161 |
+
"bad_words_ids": null,
|
| 162 |
+
"begin_suppress_tokens": null,
|
| 163 |
+
"bos_token_id": null,
|
| 164 |
+
"chunk_size_feed_forward": 0,
|
| 165 |
+
"cross_attention_hidden_size": null,
|
| 166 |
+
"decoder_start_token_id": null,
|
| 167 |
+
"diversity_penalty": 0.0,
|
| 168 |
+
"do_sample": false,
|
| 169 |
+
"dropout": 0.0,
|
| 170 |
+
"early_stopping": false,
|
| 171 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 172 |
+
"eos_token_id": null,
|
| 173 |
+
"exponential_decay_length_penalty": null,
|
| 174 |
+
"finetuning_task": null,
|
| 175 |
+
"forced_bos_token_id": null,
|
| 176 |
+
"forced_eos_token_id": null,
|
| 177 |
+
"global_attn_indexes": [
|
| 178 |
+
7,
|
| 179 |
+
15,
|
| 180 |
+
23,
|
| 181 |
+
31
|
| 182 |
+
],
|
| 183 |
+
"hidden_act": "gelu",
|
| 184 |
+
"hidden_size": 1280,
|
| 185 |
+
"id2label": {
|
| 186 |
+
"0": "LABEL_0",
|
| 187 |
+
"1": "LABEL_1"
|
| 188 |
+
},
|
| 189 |
+
"image_size": 1024,
|
| 190 |
+
"initializer_factor": 1.0,
|
| 191 |
+
"initializer_range": 1e-10,
|
| 192 |
+
"intermediate_size": 6144,
|
| 193 |
+
"is_decoder": false,
|
| 194 |
+
"is_encoder_decoder": false,
|
| 195 |
+
"label2id": {
|
| 196 |
+
"LABEL_0": 0,
|
| 197 |
+
"LABEL_1": 1
|
| 198 |
+
},
|
| 199 |
+
"layer_norm_eps": 1e-06,
|
| 200 |
+
"length_penalty": 1.0,
|
| 201 |
+
"max_length": 20,
|
| 202 |
+
"min_length": 0,
|
| 203 |
+
"mlp_dim": 5120,
|
| 204 |
+
"mlp_ratio": 4.0,
|
| 205 |
+
"model_type": "",
|
| 206 |
+
"no_repeat_ngram_size": 0,
|
| 207 |
+
"num_attention_heads": 16,
|
| 208 |
+
"num_beam_groups": 1,
|
| 209 |
+
"num_beams": 1,
|
| 210 |
+
"num_channels": 3,
|
| 211 |
+
"num_hidden_layers": 32,
|
| 212 |
+
"num_pos_feats": 128,
|
| 213 |
+
"num_return_sequences": 1,
|
| 214 |
+
"output_attentions": false,
|
| 215 |
+
"output_channels": 256,
|
| 216 |
+
"output_hidden_states": false,
|
| 217 |
+
"output_scores": false,
|
| 218 |
+
"pad_token_id": null,
|
| 219 |
+
"patch_size": 16,
|
| 220 |
+
"prefix": null,
|
| 221 |
+
"problem_type": null,
|
| 222 |
+
"projection_dim": 512,
|
| 223 |
+
"pruned_heads": {},
|
| 224 |
+
"qkv_bias": true,
|
| 225 |
+
"remove_invalid_values": false,
|
| 226 |
+
"repetition_penalty": 1.0,
|
| 227 |
+
"return_dict": true,
|
| 228 |
+
"return_dict_in_generate": false,
|
| 229 |
+
"sep_token_id": null,
|
| 230 |
+
"suppress_tokens": null,
|
| 231 |
+
"task_specific_params": null,
|
| 232 |
+
"temperature": 1.0,
|
| 233 |
+
"tf_legacy_loss": false,
|
| 234 |
+
"tie_encoder_decoder": false,
|
| 235 |
+
"tie_word_embeddings": true,
|
| 236 |
+
"tokenizer_class": null,
|
| 237 |
+
"top_k": 50,
|
| 238 |
+
"top_p": 1.0,
|
| 239 |
+
"torch_dtype": null,
|
| 240 |
+
"torchscript": false,
|
| 241 |
+
"transformers_version": "4.29.0.dev0",
|
| 242 |
+
"typical_p": 1.0,
|
| 243 |
+
"use_abs_pos": true,
|
| 244 |
+
"use_bfloat16": false,
|
| 245 |
+
"use_rel_pos": true,
|
| 246 |
+
"window_size": 14
|
| 247 |
+
}
|
| 248 |
+
}
|
figures/Computational requirements.PNG
ADDED
|
figures/architecture.jpg
ADDED

|
Git LFS Details
|
figures/architecture.pdf
ADDED
|
Binary file (515 kB). View file
|
|
|
figures/gif_output/blur.gif
ADDED

|
figures/gif_output/blur.jpg
ADDED

|
figures/gif_output/blur_back_n_forth.gif
ADDED
|
Git LFS Details
|
figures/gif_output/haze.gif
ADDED

|
figures/gif_output/haze.jpg
ADDED

|
figures/gif_output/haze_back_n_forth.gif
ADDED

|
Git LFS Details
|
figures/gif_output/lowlight.gif
ADDED

|
figures/gif_output/lowlight.jpg
ADDED

|
figures/gif_output/lowlight_back_n_forth.gif
ADDED

|
Git LFS Details
|
figures/gif_output/rain.gif
ADDED

|
Git LFS Details
|
figures/gif_output/rain.jpg
ADDED

|
figures/gif_output/rain_back_n_forth.gif
ADDED

|
Git LFS Details
|
figures/qualitative_result.PNG
ADDED

|
Git LFS Details
|
figures/seen_dataset_with_synthetic_degradation.PNG
ADDED
|
figures/unseen_dataset_with_real_degradation.PNG
ADDED
|
figures/unseen_dataset_with_synthetic_degradation.PNG
ADDED

|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1cf54b58c6e6bb391b3b2032c0ccb4084f36ecac0b9fec362b4abc2f46862761
|
| 3 |
+
size 2564432184
|
preprocessor_config.json
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"do_convert_rgb": true,
|
| 3 |
+
"do_normalize": true,
|
| 4 |
+
"do_pad": true,
|
| 5 |
+
"do_rescale": true,
|
| 6 |
+
"do_resize": true,
|
| 7 |
+
"image_mean": [
|
| 8 |
+
0.485,
|
| 9 |
+
0.456,
|
| 10 |
+
0.406
|
| 11 |
+
],
|
| 12 |
+
"image_processor_type": "SamImageProcessor",
|
| 13 |
+
"image_std": [
|
| 14 |
+
0.229,
|
| 15 |
+
0.224,
|
| 16 |
+
0.225
|
| 17 |
+
],
|
| 18 |
+
"mask_pad_size": {
|
| 19 |
+
"height": 256,
|
| 20 |
+
"width": 256
|
| 21 |
+
},
|
| 22 |
+
"mask_size": {
|
| 23 |
+
"longest_edge": 256
|
| 24 |
+
},
|
| 25 |
+
"pad_size": {
|
| 26 |
+
"height": 1024,
|
| 27 |
+
"width": 1024
|
| 28 |
+
},
|
| 29 |
+
"processor_class": "SamProcessor",
|
| 30 |
+
"resample": 2,
|
| 31 |
+
"rescale_factor": 0.00392156862745098,
|
| 32 |
+
"size": {
|
| 33 |
+
"longest_edge": 1024
|
| 34 |
+
}
|
| 35 |
+
}
|
robustsam_checkpoint_h.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:515e3e7437732b54240fe8fc78562e0b4b633451aaee129cc1450323621cef19
|
| 3 |
+
size 3175817941
|