
added updates
Browse files
README.md
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
tags:
|
| 4 |
+
- afro-digits-speech
|
| 5 |
+
datasets:
|
| 6 |
+
- crowd-speech-africa
|
| 7 |
+
metrics:
|
| 8 |
+
- accuracy
|
| 9 |
+
model-index:
|
| 10 |
+
- name: afrospeech-wav2vec-yor
|
| 11 |
+
results:
|
| 12 |
+
- task:
|
| 13 |
+
name: Audio Classification
|
| 14 |
+
type: audio-classification
|
| 15 |
+
dataset:
|
| 16 |
+
name: Afro Speech
|
| 17 |
+
type: chrisjay/crowd-speech-africa
|
| 18 |
+
args: no
|
| 19 |
+
metrics:
|
| 20 |
+
- name: Validation Accuracy
|
| 21 |
+
type: accuracy
|
| 22 |
+
value: 0.83
|
| 23 |
+
---
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
# afrospeech-wav2vec-yor
|
| 27 |
+
|
| 28 |
+
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the [crowd-speech-africa](https://huggingface.co/datasets/chrisjay/crowd-speech-africa), which was a crowd-sourced dataset collected using the [afro-speech Space](https://huggingface.co/spaces/chrisjay/afro-speech). It achieves the following results on the [validation set](VALID_yoruba_yor_audio_data.csv):
|
| 29 |
+
|
| 30 |
+
- F1: 0.83
|
| 31 |
+
- Accuracy: 0.83
|
| 32 |
+
|
| 33 |
+
The confusion matrix below helps to give a better look at the model's performance across the digits. Through it, we can see the precision and recall of the model as well as other important insights.
|
| 34 |
+
|
| 35 |
+

|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
## Training and evaluation data
|
| 39 |
+
|
| 40 |
+
The model was trained on a mixed audio data from Yoruba (`yor`).
|
| 41 |
+
|
| 42 |
+
- Size of training set: 22
|
| 43 |
+
- Size of validation set: 6
|
| 44 |
+
|
| 45 |
+
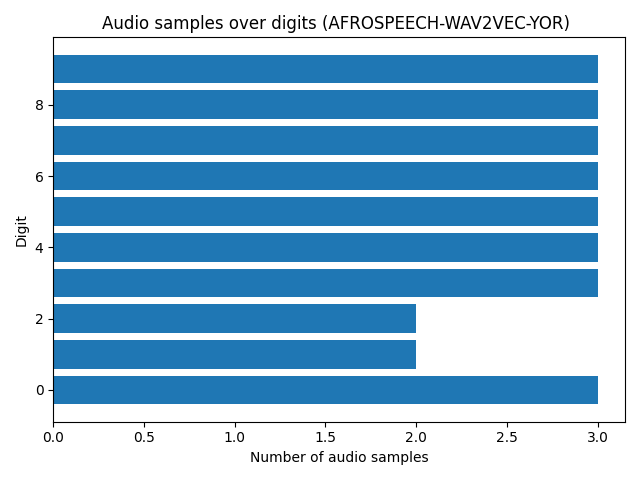
Below is a distribution of the dataset (training and valdation)
|
| 46 |
+
|
| 47 |
+

|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
### Training hyperparameters
|
| 51 |
+
|
| 52 |
+
The following hyperparameters were used during training:
|
| 53 |
+
- learning_rate: 3e-05
|
| 54 |
+
- train_batch_size: 64
|
| 55 |
+
- eval_batch_size: 64
|
| 56 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 57 |
+
- num_epochs: 150
|
| 58 |
+
|
| 59 |
+
### Training results
|
| 60 |
+
|
| 61 |
+
| Training Loss | Epoch | Validation Accuracy |
|
| 62 |
+
|:-------------:|:-----:|:--------:|
|
| 63 |
+
|0.596 | 1 | 0.5 |
|
| 64 |
+
| 0.0220 | 50 | 0.5 |
|
| 65 |
+
|0.00305 | 100 | 0.667 |
|
| 66 |
+
|0.0993 | 150 | 0.667 |
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
### Framework versions
|
| 71 |
+
|
| 72 |
+
- Transformers 4.21.3
|
| 73 |
+
- Pytorch 1.12.0
|
| 74 |
+
- Datasets 1.14.0
|
| 75 |
+
- Tokenizers 0.12.1
|
VALID_yoruba_yor_audio_data.csv
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
audio_path,transcript,lang,lang_code,gender,age,country,accent
|
| 2 |
+
AUDIO_HOMEPATH/data/YEPqZ3CHDppprriDgoGA9MvOgRNMf43F/audio.wav,3,yoruba,yor,Male,,Nigeria,Standard Yoruba
|
| 3 |
+
AUDIO_HOMEPATH/data/Cn8ve720zqPppRPdI2TXbkwHNdmtVUPf/audio.wav,5,yoruba,yor,Male,,Nigeria,Standard Yoruba
|
| 4 |
+
AUDIO_HOMEPATH/data/2mzLDDHVy5zA4cH5NPK0VU3rtZKVZ2kK/audio.wav,7,yoruba,yor,,,Nigeria,Standard Yoruba
|
| 5 |
+
AUDIO_HOMEPATH/data/Xbiq3Nv8JSko22be3orDMcDurESjl5xc/audio.wav,7,yoruba,yor,Female,,United States,
|
| 6 |
+
AUDIO_HOMEPATH/data/zb6CyNeMcgyfSk5LvFzhmjgDbeC2goeM/audio.wav,6,yoruba,yor,Female,,United States,
|
| 7 |
+
AUDIO_HOMEPATH/data/Y2Kr1zV41BVuW3gsaK1LCSS0d8y1P023/audio.wav,9,yoruba,yor,Female,,United States,
|
afrospeech-wav2vec-yor_METRICS_VALID.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"acc": 0.8333333333333334, "f1": 0.8333333333333334}
|
afrospeech-wav2vec-yor_confusion_matrix_VALID.png
ADDED

|
digits-bar-plot-for-afrospeech-wav2vec-yor.png
ADDED
|