
File size: 582 Bytes
0500b85 fea69c5 844aac6 0500b85 3911988 a1f7ff5 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
---
library_name: transformers
license: llama2
tags:
- code
---
Converted version of [CodeLlama-70b](https://huggingface.co/meta-llama/CodeLlama-70b-hf) to 4-bit using bitsandbytes. For more information about the model, refer to the model's page.
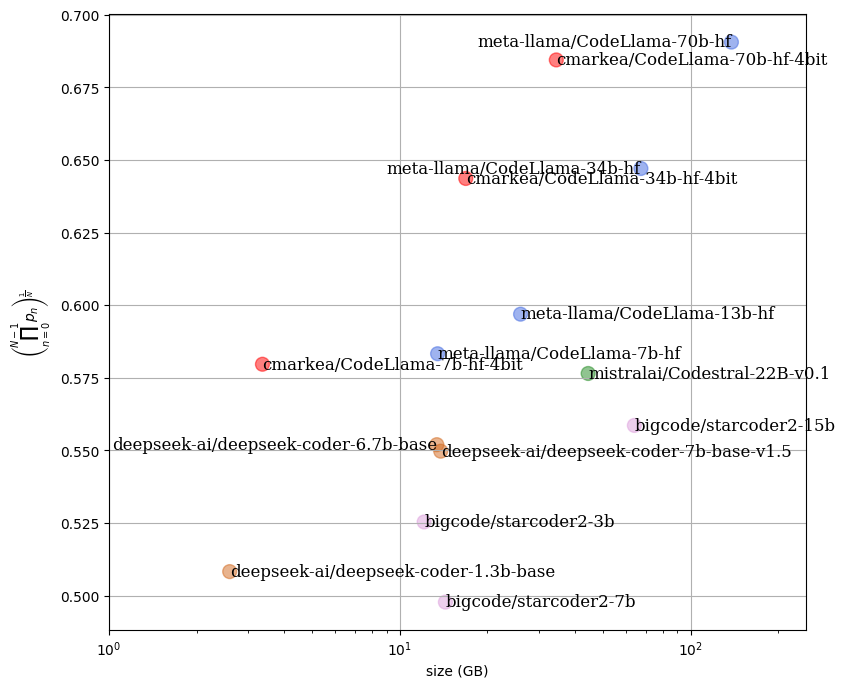
## Impact on performance
In the following figure, we can see the impact on the performance of a set of models relative to the required RAM space. It is noticeable that the quantized models have equivalent performance while providing a significant gain in RAM usage.
 |