
## CodeFuse-VLM
CodeFuse-VLM is a Multimodal LLM(MLLM) framework that provides users with multiple vision encoders, multimodal alignment adapters, and LLMs. Through CodeFuse-VLM framework, users are able to customize their own MLLM model to adapt their own tasks.
As more and more models are published on Huggingface community, there will be more open-source vision encoders and LLMs. Each of these models has their own specialties, e.g. Code-LLama is good at code-related tasks but has poor performance for Chinese tasks. Therefore, we built CodeFuse-VLM framework to support multiple vision encoders, multimodal alignment adapters, and LLMs to adapt different types of tasks.

Under CodeFuse-VLM framework, we use cross attention multimodal adapter, Qwen-14B LLM, and Qwen-VL's vision encoder to train CodeFuse-VLM-14B model. On multiple benchmarks, our CodeFuse-VLM-14B shows superior performances over Qwen-VL and LLAVA-1.5.
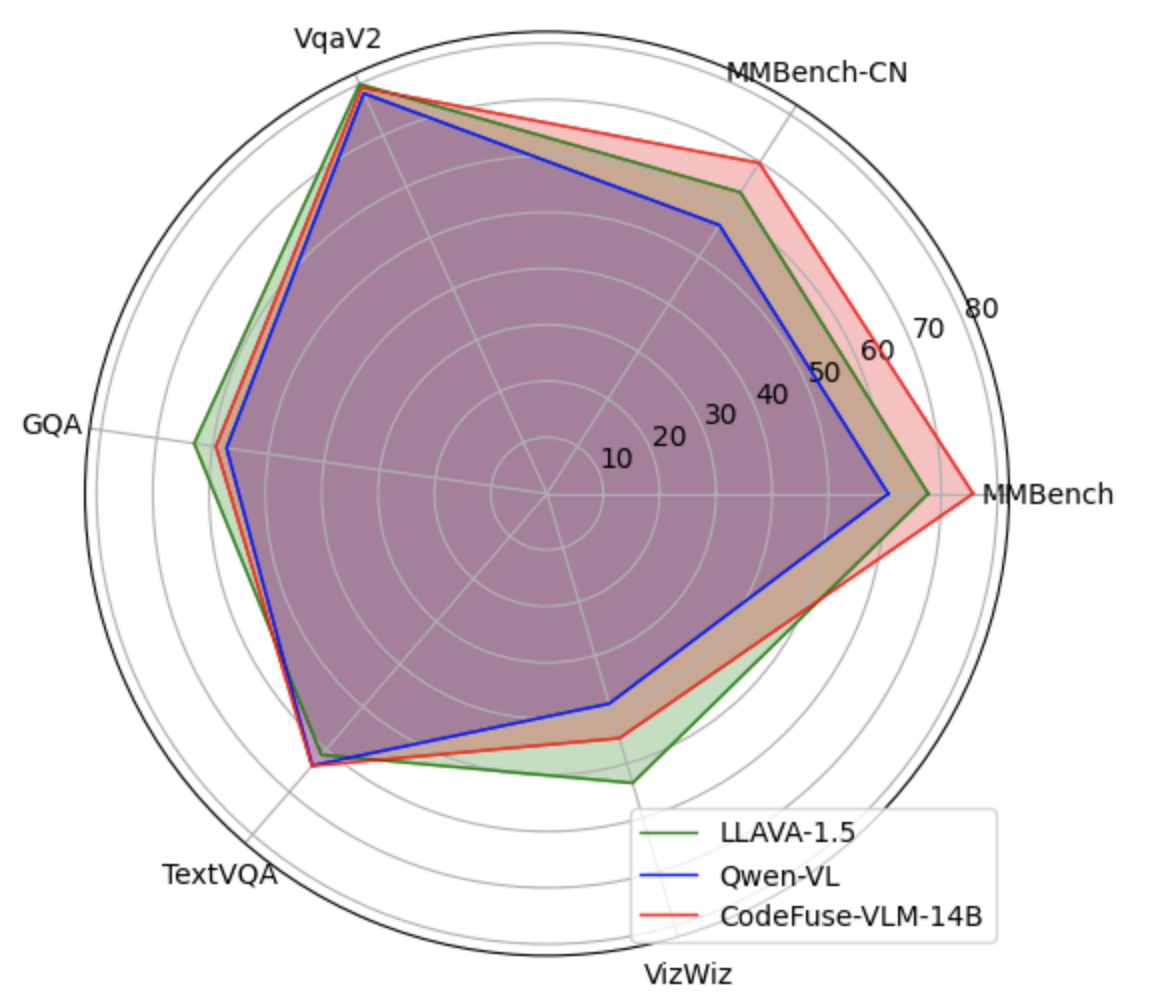
Here is the table for different MLLM model's performance on benchmarks
Model | MMBench | MMBench-CN | VqaV2 | GQA | TextVQA | Vizwiz
| ------------- | ------------- | ------------- | ------------- | ------------- | ------------- | ------------- |
LLAVA-1.5 | 67.7 | 63.6 | 80.0 | 63.3 | 61.3 | 53.6
Qwen-VL | 60.6 | 56.7 | 78.2 | 57.5 | 63.8 | 38.9
CodeFuse-VLM-14B | 75.7 | 69.8 | 79.3 | 59.4 | 63.9 | 45.3
## Contents
- [Install](#Install)
- [Datasets](#Datasets)
- [Multimodal Alignment](#Multimodal-Alignment)
- [Visual Instruction Tuning](#Visual-Instruction-Tuning)
- [Evaluation](#Evaluation)
## Install
Please run sh init\_env.sh
## Datasets
Here's the table of datasets we used to train CodeFuse-VLM-14B:
Dataset | Task Type | Number of Samples
| ------------- | ------------- | ------------- |
synthdog-en | OCR | 800,000
synthdog-zh | OCR | 800,000
cc3m(downsampled)| Image Caption | 600,000
cc3m(downsampled)| Image Caption | 600,000
SBU | Image Caption | 850,000
Visual Genome VQA (Downsampled) | Visual Question Answer(VQA) | 500,000
Visual Genome Region descriptions (Downsampled) | Reference Grouding | 500,000
Visual Genome objects (Downsampled) | Grounded Caption | 500,000
OCR VQA (Downsampled) | OCR and VQA | 500,000
Please download these datasets on their own official websites.
## Multimodal Alignment
Please run sh scripts/pretrain.sh or sh scripts/pretrain\_multinode.sh
## Visual Instruction Tuning
Please run sh scripts/finetune.sh or sh scripts/finetune\_multinode.sh
## Evaluation
Please run python scripts in directory llava/eval/. Our pre-trained CodeFuse-VLM-14B can be loaded with the following code:
```
import os
from llava.model.builder import load_mixed_pretrained_model
model_path = '/pretrained/model/path'
tokenizer, model, image_processor, context_len = load_mixed_pretrained_model(model_path, None, 'qwen-vl-14b', os.path.join(model_path, 'Qwen-VL-visual'), 'cross_attn', os.path.join(model_path, 'mm_projector/mm_projector.bin'))
```