
MohamedBayan
commited on
Commit
•
6c7b879
1
Parent(s):
3b57c69
add figure
Browse files- Readme.md +0 -384
- capablities_tasks_datasets.png +0 -0
Readme.md
DELETED
|
@@ -1,384 +0,0 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: cc-by-nc-sa-4.0
|
| 3 |
-
task_categories:
|
| 4 |
-
- text-classification
|
| 5 |
-
language:
|
| 6 |
-
- ar
|
| 7 |
-
tags:
|
| 8 |
-
- Social Media
|
| 9 |
-
- News Media
|
| 10 |
-
- Sentiment
|
| 11 |
-
- Stance
|
| 12 |
-
- Emotion
|
| 13 |
-
pretty_name: 'LlamaLens: Specialized Multilingual LLM for Analyzing News and Social Media Content -- English'
|
| 14 |
-
size_categories:
|
| 15 |
-
- 10K<n<100K
|
| 16 |
-
dataset_info:
|
| 17 |
-
- config_name: QProp
|
| 18 |
-
splits:
|
| 19 |
-
- name: train
|
| 20 |
-
num_examples: 35986
|
| 21 |
-
- name: dev
|
| 22 |
-
num_examples: 5125
|
| 23 |
-
- name: test
|
| 24 |
-
num_examples: 10159
|
| 25 |
-
- config_name: Cyberbullying
|
| 26 |
-
splits:
|
| 27 |
-
- name: train
|
| 28 |
-
num_examples: 32551
|
| 29 |
-
- name: dev
|
| 30 |
-
num_examples: 4751
|
| 31 |
-
- name: test
|
| 32 |
-
num_examples: 9473
|
| 33 |
-
- config_name: clef2024-checkthat-lab
|
| 34 |
-
splits:
|
| 35 |
-
- name: train
|
| 36 |
-
num_examples: 825
|
| 37 |
-
- name: dev
|
| 38 |
-
num_examples: 219
|
| 39 |
-
- name: test
|
| 40 |
-
num_examples: 484
|
| 41 |
-
- config_name: SemEval23T3-subtask1
|
| 42 |
-
splits:
|
| 43 |
-
- name: train
|
| 44 |
-
num_examples: 302
|
| 45 |
-
- name: dev
|
| 46 |
-
num_examples: 130
|
| 47 |
-
- name: test
|
| 48 |
-
num_examples: 83
|
| 49 |
-
- config_name: offensive_language_dataset
|
| 50 |
-
splits:
|
| 51 |
-
- name: train
|
| 52 |
-
num_examples: 29216
|
| 53 |
-
- name: dev
|
| 54 |
-
num_examples: 3653
|
| 55 |
-
- name: test
|
| 56 |
-
num_examples: 3653
|
| 57 |
-
- config_name: xlsum
|
| 58 |
-
splits:
|
| 59 |
-
- name: train
|
| 60 |
-
num_examples: 306493
|
| 61 |
-
- name: dev
|
| 62 |
-
num_examples: 11535
|
| 63 |
-
- name: test
|
| 64 |
-
num_examples: 11535
|
| 65 |
-
- config_name: claim-detection
|
| 66 |
-
splits:
|
| 67 |
-
- name: train
|
| 68 |
-
num_examples: 23224
|
| 69 |
-
- name: dev
|
| 70 |
-
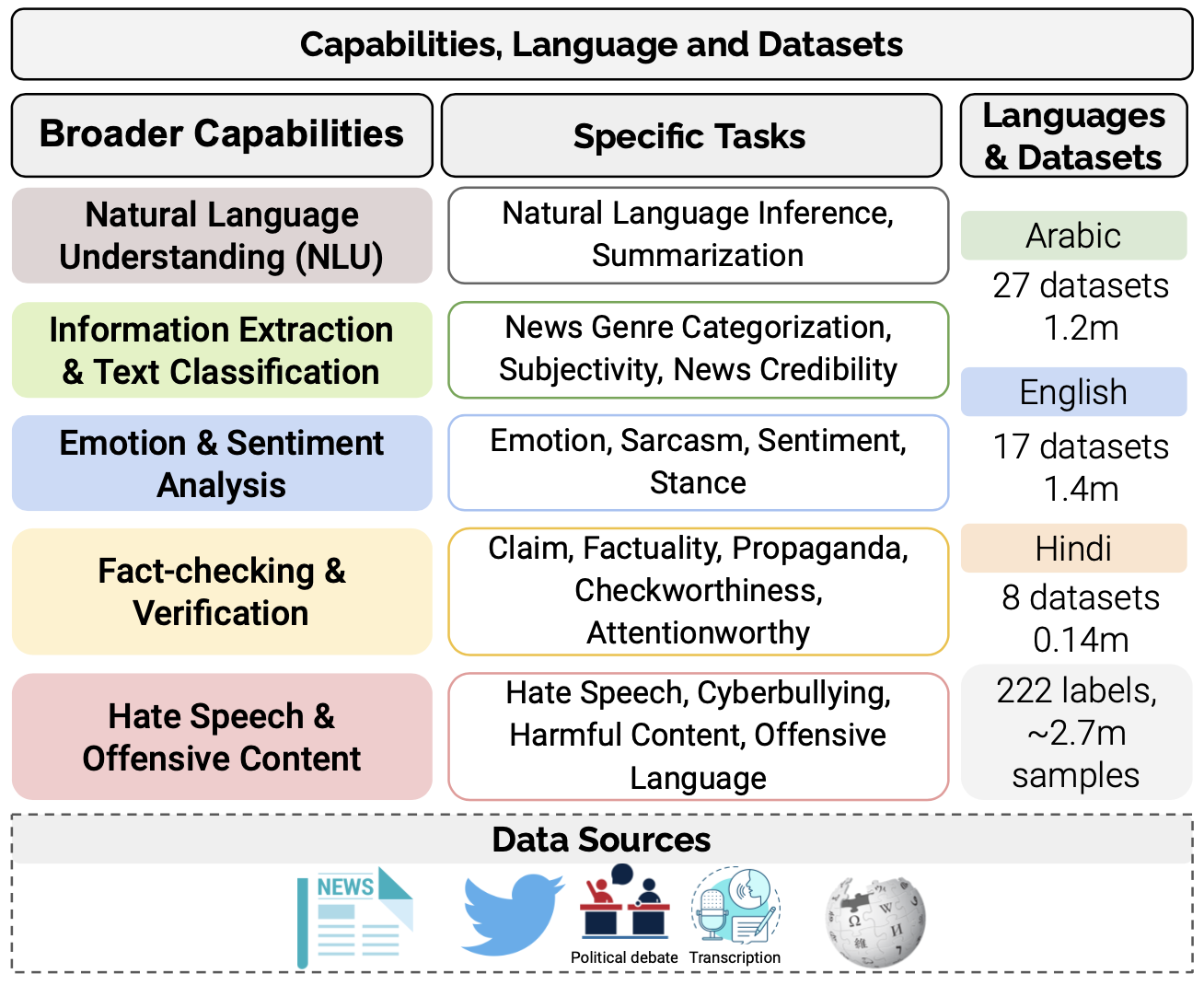
num_examples: 5815
|
| 71 |
-
- name: test
|
| 72 |
-
num_examples: 7267
|
| 73 |
-
- config_name: emotion
|
| 74 |
-
splits:
|
| 75 |
-
- name: train
|
| 76 |
-
num_examples: 280551
|
| 77 |
-
- name: dev
|
| 78 |
-
num_examples: 41429
|
| 79 |
-
- name: test
|
| 80 |
-
num_examples: 82454
|
| 81 |
-
- config_name: Politifact
|
| 82 |
-
splits:
|
| 83 |
-
- name: train
|
| 84 |
-
num_examples: 14799
|
| 85 |
-
- name: dev
|
| 86 |
-
num_examples: 2116
|
| 87 |
-
- name: test
|
| 88 |
-
num_examples: 4230
|
| 89 |
-
- config_name: News_dataset
|
| 90 |
-
splits:
|
| 91 |
-
- name: train
|
| 92 |
-
num_examples: 28147
|
| 93 |
-
- name: dev
|
| 94 |
-
num_examples: 4376
|
| 95 |
-
- name: test
|
| 96 |
-
num_examples: 8616
|
| 97 |
-
- config_name: hate-offensive-speech
|
| 98 |
-
splits:
|
| 99 |
-
- name: train
|
| 100 |
-
num_examples: 48944
|
| 101 |
-
- name: dev
|
| 102 |
-
num_examples: 2802
|
| 103 |
-
- name: test
|
| 104 |
-
num_examples: 2799
|
| 105 |
-
- config_name: CNN_News_Articles_2011-2022
|
| 106 |
-
splits:
|
| 107 |
-
- name: train
|
| 108 |
-
num_examples: 32193
|
| 109 |
-
- name: dev
|
| 110 |
-
num_examples: 9663
|
| 111 |
-
- name: test
|
| 112 |
-
num_examples: 5682
|
| 113 |
-
- config_name: CT24_checkworthy
|
| 114 |
-
splits:
|
| 115 |
-
- name: train
|
| 116 |
-
num_examples: 22403
|
| 117 |
-
- name: dev
|
| 118 |
-
num_examples: 318
|
| 119 |
-
- name: test
|
| 120 |
-
num_examples: 1031
|
| 121 |
-
- config_name: News_Category_Dataset
|
| 122 |
-
splits:
|
| 123 |
-
- name: train
|
| 124 |
-
num_examples: 145748
|
| 125 |
-
- name: dev
|
| 126 |
-
num_examples: 20899
|
| 127 |
-
- name: test
|
| 128 |
-
num_examples: 41740
|
| 129 |
-
- config_name: NewsMTSC-dataset
|
| 130 |
-
splits:
|
| 131 |
-
- name: train
|
| 132 |
-
num_examples: 7739
|
| 133 |
-
- name: dev
|
| 134 |
-
num_examples: 320
|
| 135 |
-
- name: test
|
| 136 |
-
num_examples: 747
|
| 137 |
-
- config_name: Offensive_Hateful_Dataset_New
|
| 138 |
-
splits:
|
| 139 |
-
- name: train
|
| 140 |
-
num_examples: 42000
|
| 141 |
-
- name: dev
|
| 142 |
-
num_examples: 5254
|
| 143 |
-
- name: test
|
| 144 |
-
num_examples: 5252
|
| 145 |
-
- config_name: News-Headlines-Dataset-For-Sarcasm-Detection
|
| 146 |
-
splits:
|
| 147 |
-
- name: train
|
| 148 |
-
num_examples: 19965
|
| 149 |
-
- name: dev
|
| 150 |
-
num_examples: 2858
|
| 151 |
-
- name: test
|
| 152 |
-
num_examples: 5719
|
| 153 |
-
configs:
|
| 154 |
-
- config_name: QProp
|
| 155 |
-
data_files:
|
| 156 |
-
- split: test
|
| 157 |
-
path: QProp/test.json
|
| 158 |
-
- split: dev
|
| 159 |
-
path: QProp/dev.json
|
| 160 |
-
- split: train
|
| 161 |
-
path: QProp/train.json
|
| 162 |
-
- config_name: Cyberbullying
|
| 163 |
-
data_files:
|
| 164 |
-
- split: test
|
| 165 |
-
path: Cyberbullying/test.json
|
| 166 |
-
- split: dev
|
| 167 |
-
path: Cyberbullying/dev.json
|
| 168 |
-
- split: train
|
| 169 |
-
path: Cyberbullying/train.json
|
| 170 |
-
- config_name: clef2024-checkthat-lab
|
| 171 |
-
data_files:
|
| 172 |
-
- split: test
|
| 173 |
-
path: clef2024-checkthat-lab/test.json
|
| 174 |
-
- split: dev
|
| 175 |
-
path: clef2024-checkthat-lab/dev.json
|
| 176 |
-
- split: train
|
| 177 |
-
path: clef2024-checkthat-lab/train.json
|
| 178 |
-
- config_name: SemEval23T3-subtask1
|
| 179 |
-
data_files:
|
| 180 |
-
- split: test
|
| 181 |
-
path: SemEval23T3-subtask1/test.json
|
| 182 |
-
- split: dev
|
| 183 |
-
path: SemEval23T3-subtask1/dev.json
|
| 184 |
-
- split: train
|
| 185 |
-
path: SemEval23T3-subtask1/train.json
|
| 186 |
-
- config_name: offensive_language_dataset
|
| 187 |
-
data_files:
|
| 188 |
-
- split: test
|
| 189 |
-
path: offensive_language_dataset/test.json
|
| 190 |
-
- split: dev
|
| 191 |
-
path: offensive_language_dataset/dev.json
|
| 192 |
-
- split: train
|
| 193 |
-
path: offensive_language_dataset/train.json
|
| 194 |
-
- config_name: xlsum
|
| 195 |
-
data_files:
|
| 196 |
-
- split: test
|
| 197 |
-
path: xlsum/test.json
|
| 198 |
-
- split: dev
|
| 199 |
-
path: xlsum/dev.json
|
| 200 |
-
- split: train
|
| 201 |
-
path: xlsum/train.json
|
| 202 |
-
- config_name: claim-detection
|
| 203 |
-
data_files:
|
| 204 |
-
- split: test
|
| 205 |
-
path: claim-detection/test.json
|
| 206 |
-
- split: dev
|
| 207 |
-
path: claim-detection/dev.json
|
| 208 |
-
- split: train
|
| 209 |
-
path: claim-detection/train.json
|
| 210 |
-
- config_name: emotion
|
| 211 |
-
data_files:
|
| 212 |
-
- split: test
|
| 213 |
-
path: emotion/test.json
|
| 214 |
-
- split: dev
|
| 215 |
-
path: emotion/dev.json
|
| 216 |
-
- split: train
|
| 217 |
-
path: emotion/train.json
|
| 218 |
-
- config_name: Politifact
|
| 219 |
-
data_files:
|
| 220 |
-
- split: test
|
| 221 |
-
path: Politifact/test.json
|
| 222 |
-
- split: dev
|
| 223 |
-
path: Politifact/dev.json
|
| 224 |
-
- split: train
|
| 225 |
-
path: Politifact/train.json
|
| 226 |
-
- config_name: News_dataset
|
| 227 |
-
data_files:
|
| 228 |
-
- split: test
|
| 229 |
-
path: News_dataset/test.json
|
| 230 |
-
- split: dev
|
| 231 |
-
path: News_dataset/dev.json
|
| 232 |
-
- split: train
|
| 233 |
-
path: News_dataset/train.json
|
| 234 |
-
- config_name: hate-offensive-speech
|
| 235 |
-
data_files:
|
| 236 |
-
- split: test
|
| 237 |
-
path: hate-offensive-speech/test.json
|
| 238 |
-
- split: dev
|
| 239 |
-
path: hate-offensive-speech/dev.json
|
| 240 |
-
- split: train
|
| 241 |
-
path: hate-offensive-speech/train.json
|
| 242 |
-
- config_name: CNN_News_Articles_2011-2022
|
| 243 |
-
data_files:
|
| 244 |
-
- split: test
|
| 245 |
-
path: CNN_News_Articles_2011-2022/test.json
|
| 246 |
-
- split: dev
|
| 247 |
-
path: CNN_News_Articles_2011-2022/dev.json
|
| 248 |
-
- split: train
|
| 249 |
-
path: CNN_News_Articles_2011-2022/train.json
|
| 250 |
-
- config_name: CT24_checkworthy
|
| 251 |
-
data_files:
|
| 252 |
-
- split: test
|
| 253 |
-
path: CT24_checkworthy/test.json
|
| 254 |
-
- split: dev
|
| 255 |
-
path: CT24_checkworthy/dev.json
|
| 256 |
-
- split: train
|
| 257 |
-
path: CT24_checkworthy/train.json
|
| 258 |
-
- config_name: News_Category_Dataset
|
| 259 |
-
data_files:
|
| 260 |
-
- split: test
|
| 261 |
-
path: News_Category_Dataset/test.json
|
| 262 |
-
- split: dev
|
| 263 |
-
path: News_Category_Dataset/dev.json
|
| 264 |
-
- split: train
|
| 265 |
-
path: News_Category_Dataset/train.json
|
| 266 |
-
- config_name: NewsMTSC-dataset
|
| 267 |
-
data_files:
|
| 268 |
-
- split: test
|
| 269 |
-
path: NewsMTSC-dataset/test.json
|
| 270 |
-
- split: dev
|
| 271 |
-
path: NewsMTSC-dataset/dev.json
|
| 272 |
-
- split: train
|
| 273 |
-
path: NewsMTSC-dataset/train.json
|
| 274 |
-
- config_name: Offensive_Hateful_Dataset_New
|
| 275 |
-
data_files:
|
| 276 |
-
- split: test
|
| 277 |
-
path: Offensive_Hateful_Dataset_New/test.json
|
| 278 |
-
- split: dev
|
| 279 |
-
path: Offensive_Hateful_Dataset_New/dev.json
|
| 280 |
-
- split: train
|
| 281 |
-
path: Offensive_Hateful_Dataset_New/train.json
|
| 282 |
-
- config_name: News-Headlines-Dataset-For-Sarcasm-Detection
|
| 283 |
-
data_files:
|
| 284 |
-
- split: test
|
| 285 |
-
path: News-Headlines-Dataset-For-Sarcasm-Detection/test.json
|
| 286 |
-
- split: dev
|
| 287 |
-
path: News-Headlines-Dataset-For-Sarcasm-Detection/dev.json
|
| 288 |
-
- split: train
|
| 289 |
-
path: News-Headlines-Dataset-For-Sarcasm-Detection/train.json
|
| 290 |
-
---
|
| 291 |
-
|
| 292 |
-
# LlamaLens: Specialized Multilingual LLM Dataset
|
| 293 |
-
|
| 294 |
-
## Overview
|
| 295 |
-
LlamaLens is a specialized multilingual LLM designed for analyzing news and social media content. It focuses on 19 NLP tasks, leveraging 52 datasets across Arabic, English, and Hindi.
|
| 296 |
-
|
| 297 |
-
|
| 298 |
-
<p align="center"> <img src="./capablities_tasks_datasets.png" style="width: 40%;" id="title-icon"> </p>
|
| 299 |
-
|
| 300 |
-
## LlamaLens
|
| 301 |
-
This repo includes scripts needed to run our full pipeline, including data preprocessing and sampling, instruction dataset creation, model fine-tuning, inference and evaluation.
|
| 302 |
-
|
| 303 |
-
### Features
|
| 304 |
-
- Multilingual support (Arabic, English, Hindi)
|
| 305 |
-
- 19 NLP tasks with 52 datasets
|
| 306 |
-
- Optimized for news and social media content analysis
|
| 307 |
-
|
| 308 |
-
## 📂 Dataset Overview
|
| 309 |
-
|
| 310 |
-
### English Datasets
|
| 311 |
-
|
| 312 |
-
| **Task** | **Dataset** | **# Labels** | **# Train** | **# Test** | **# Dev** |
|
| 313 |
-
|---------------------------|------------------------------|--------------|-------------|------------|-----------|
|
| 314 |
-
| Checkworthiness | CT24_T1 | 2 | 22,403 | 1,031 | 318 |
|
| 315 |
-
| Claim | claim-detection | 2 | 23,224 | 7,267 | 5,815 |
|
| 316 |
-
| Cyberbullying | Cyberbullying | 6 | 32,551 | 9,473 | 4,751 |
|
| 317 |
-
| Emotion | emotion | 6 | 280,551 | 82,454 | 41,429 |
|
| 318 |
-
| Factuality | News_dataset | 2 | 28,147 | 8,616 | 4,376 |
|
| 319 |
-
| Factuality | Politifact | 6 | 14,799 | 4,230 | 2,116 |
|
| 320 |
-
| News Genre Categorization | CNN_News_Articles_2011-2022 | 6 | 32,193 | 5,682 | 9,663 |
|
| 321 |
-
| News Genre Categorization | News_Category_Dataset | 42 | 145,748 | 41,740 | 20,899 |
|
| 322 |
-
| News Genre Categorization | SemEval23T3-subtask1 | 3 | 302 | 83 | 130 |
|
| 323 |
-
| Summarization | xlsum | -- | 306,493 | 11,535 | 11,535 |
|
| 324 |
-
| Offensive Language | Offensive_Hateful_Dataset_New | 2 | 42,000 | 5,252 | 5,254 |
|
| 325 |
-
| Offensive Language | offensive_language_dataset | 2 | 29,216 | 3,653 | 3,653 |
|
| 326 |
-
| Offensive/Hate-Speech | hate-offensive-speech | 3 | 48,944 | 2,799 | 2,802 |
|
| 327 |
-
| Propaganda | QProp | 2 | 35,986 | 10,159 | 5,125 |
|
| 328 |
-
| Sarcasm | News-Headlines-Dataset-For-Sarcasm-Detection | 2 | 19,965 | 5,719 | 2,858 |
|
| 329 |
-
| Sentiment | NewsMTSC-dataset | 3 | 7,739 | 747 | 320 |
|
| 330 |
-
| Subjectivity | clef2024-checkthat-lab | 2 | 825 | 484 | 219 |
|
| 331 |
-
|
| 332 |
-
|
| 333 |
-
## File Format
|
| 334 |
-
|
| 335 |
-
Each JSONL file in the dataset follows a structured format with the following fields:
|
| 336 |
-
|
| 337 |
-
- `id`: Unique identifier for each data entry.
|
| 338 |
-
- `original_id`: Identifier from the original dataset, if available.
|
| 339 |
-
- `input`: The original text that needs to be analyzed.
|
| 340 |
-
- `output`: The label assigned to the text after analysis.
|
| 341 |
-
- `dataset`: Name of the dataset the entry belongs.
|
| 342 |
-
- `task`: The specific task type.
|
| 343 |
-
- `lang`: The language of the input text.
|
| 344 |
-
- `instructions`: A brief set of instructions describing how the text should be labeled.
|
| 345 |
-
- `text`: A formatted structure including instructions and response for the task in a conversation format between the system, user, and assistant, showing the decision process.
|
| 346 |
-
|
| 347 |
-
|
| 348 |
-
**Example entry in JSONL file:**
|
| 349 |
-
|
| 350 |
-
```
|
| 351 |
-
{
|
| 352 |
-
"id": "3fe3eb6a-843e-4a03-b38c-8333c052f4c4",
|
| 353 |
-
"original_id": "nan",
|
| 354 |
-
"input": "You know, I saw a movie - \"Crocodile Dundee.\"",
|
| 355 |
-
"output": "not_checkworthy",
|
| 356 |
-
"dataset": "CT24_checkworthy",
|
| 357 |
-
"task": "Checkworthiness",
|
| 358 |
-
"lang": "en",
|
| 359 |
-
"instructions": "Analyze the given text and label it as 'checkworthy' if it includes a factual statement that is significant or relevant to verify, or 'not_checkworthy' if it's not worth checking. Return only the label without any explanation, justification or additional text.",
|
| 360 |
-
"text": "<|begin_of_text|><|start_header_id|>system<|end_header_id|>You are a social media expert providing accurate analysis and insights.<|eot_id|><|start_header_id|>user<|end_header_id|>Analyze the given text and label it as 'checkworthy' if it includes a factual statement that is significant or relevant to verify, or 'not_checkworthy' if it's not worth checking. Return only the label without any explanation, justification or additional text.\ninput: You know, I saw a movie - \"Crocodile Dundee.\"\nlabel: <|eot_id|><|start_header_id|>assistant<|end_header_id|>not_checkworthy<|eot_id|><|end_of_text|>"
|
| 361 |
-
}
|
| 362 |
-
|
| 363 |
-
```
|
| 364 |
-
|
| 365 |
-
|
| 366 |
-
## 📢 Citation
|
| 367 |
-
|
| 368 |
-
If you use this dataset, please cite our [paper](https://arxiv.org/pdf/2410.15308):
|
| 369 |
-
|
| 370 |
-
```
|
| 371 |
-
@article{kmainasi2024llamalensspecializedmultilingualllm,
|
| 372 |
-
title={LlamaLens: Specialized Multilingual LLM for Analyzing News and Social Media Content},
|
| 373 |
-
author={Mohamed Bayan Kmainasi and Ali Ezzat Shahroor and Maram Hasanain and Sahinur Rahman Laskar and Naeemul Hassan and Firoj Alam},
|
| 374 |
-
year={2024},
|
| 375 |
-
journal={arXiv preprint arXiv:2410.15308},
|
| 376 |
-
volume={},
|
| 377 |
-
number={},
|
| 378 |
-
pages={},
|
| 379 |
-
url={https://arxiv.org/abs/2410.15308},
|
| 380 |
-
eprint={2410.15308},
|
| 381 |
-
archivePrefix={arXiv},
|
| 382 |
-
primaryClass={cs.CL}
|
| 383 |
-
}
|
| 384 |
-
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
capablities_tasks_datasets.png
ADDED
|