
Commit
•
f49945e
1
Parent(s):
f3f6652
Update README.md
Browse files
README.md
CHANGED
|
@@ -37,6 +37,28 @@ configs:
|
|
| 37 |
---
|
| 38 |
|
| 39 |
|
| 40 |
-
# REBUS
|
|
|
|
| 41 |
|
| 42 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 37 |
---
|
| 38 |
|
| 39 |
|
| 40 |
+
# REBUS
|
| 41 |
+
REBUS: A Robust Evaluation Benchmark of Understanding Symbols
|
| 42 |
|
| 43 |
+
[**Paper**](https://arxiv.org/abs/2401.05604) | [**🤗 Dataset**](https://huggingface.co/datasets/cavendishlabs/rebus) | [**GitHub**](https://github.com/cvndsh/rebus) | [**Website**](https://cavendishlabs.org/rebus/)
|
| 44 |
+
|
| 45 |
+
## Introduction
|
| 46 |
+
|
| 47 |
+
Recent advances in large language models have led to the development of multimodal LLMs (MLLMs), which take both image data and text as an input. Virtually all of these models have been announced within the past year, leading to a significant need for benchmarks evaluating the abilities of these models to reason truthfully and accurately on a diverse set of tasks. When Google announced Gemini Pro (Gemini Team et al., 2023), they displayed its ability to solve rebuses—wordplay puzzles which involve creatively adding and subtracting letters from words derived from text and images. The diversity of rebuses allows for a broad evaluation of multimodal reasoning capabilities, including image recognition, multi-step reasoning, and understanding the human creator's intent.
|
| 48 |
+
|
| 49 |
+
We present REBUS: a collection of 333 hand-crafted rebuses spanning 13 diverse categories, including hand-drawn and digital images created by nine contributors. Samples are presented in the table below. Notably, GPT-4V, the most powerful model we evaluated, answered only 24% of puzzles correctly, highlighting the poor capabilities of MLLMs in new and unexpected domains to which human reasoning generalizes with comparative ease. Open-source models perform even worse, with a median accuracy below 1%. We notice that models often give faithless explanations, fail to change their minds after an initial approach doesn't work, and remain highly uncalibrated on their own abilities.
|
| 50 |
+
|
| 51 |
+
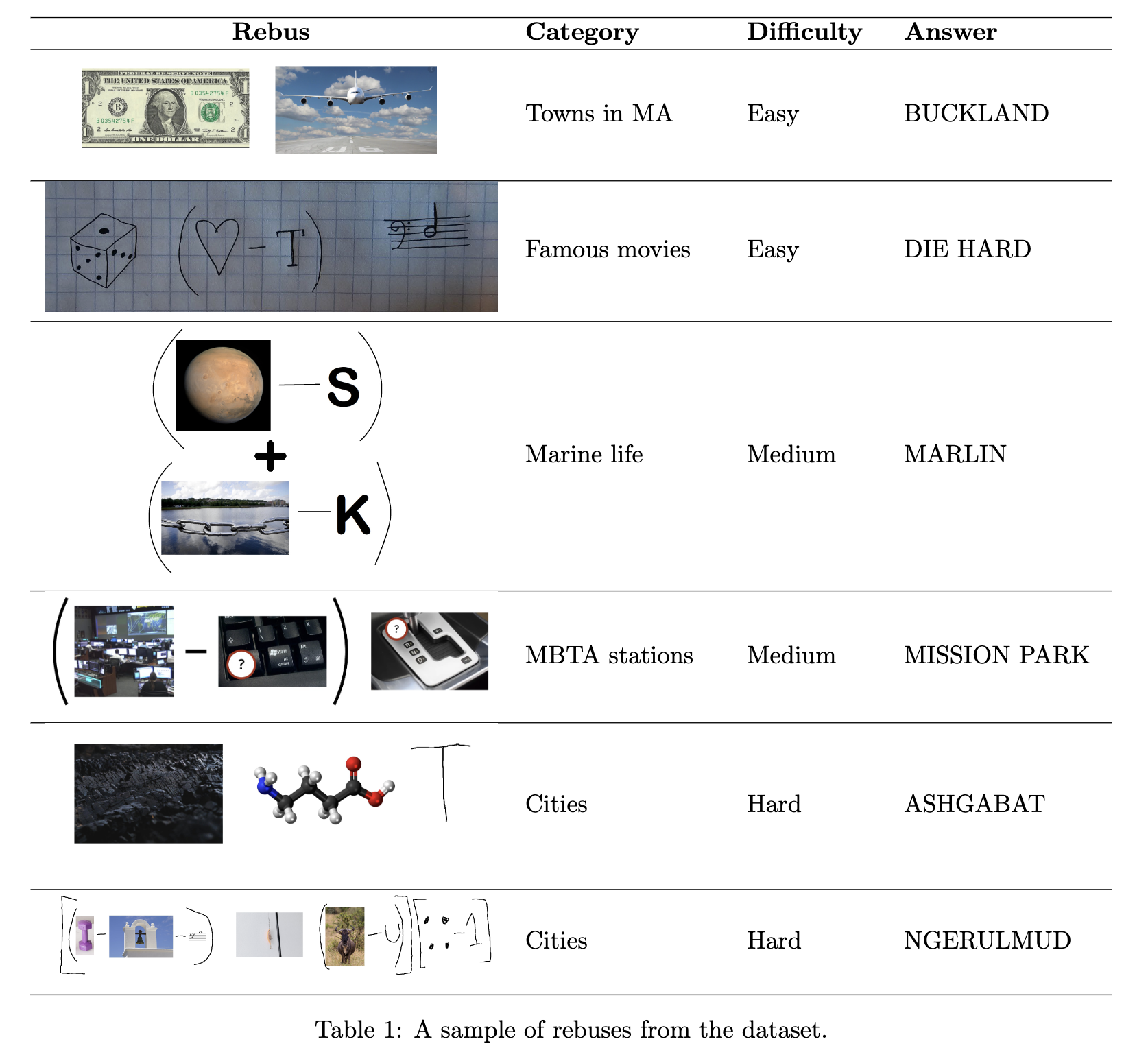
|
| 52 |
+
|
| 53 |
+
## Evaluation results
|
| 54 |
+
|
| 55 |
+
| Model | Overall | Easy | Medium | Hard |
|
| 56 |
+
| ----------------- | ------------- | ------------- | ------------- | ------------ |
|
| 57 |
+
| GPT-4V | **24.0** | **33.0** | **13.2** | **7.1** |
|
| 58 |
+
| Gemini Pro | 13.2 | 19.4 | 5.3 | 3.6 |
|
| 59 |
+
| LLaVa-1.5-13B | 1.8 | 2.6 | 0.9 | 0.0 |
|
| 60 |
+
| LLaVa-1.5-7B | 1.5 | 2.6 | 0.0 | 0.0 |
|
| 61 |
+
| BLIP2-FLAN-T5-XXL | 0.9 | 0.5 | 1.8 | 0.0 |
|
| 62 |
+
| CogVLM | 0.9 | 1.6 | 0.0 | 0.0 |
|
| 63 |
+
| QWEN | 0.9 | 1.6 | 0.0 | 0.0 |
|
| 64 |
+
| InstructBLIP | 0.6 | 0.5 | 0.9 | 0.0 |
|