
repo_id
stringlengths 4
110
| author
stringlengths 2
27
⌀ | model_type
stringlengths 2
29
⌀ | files_per_repo
int64 2
15.4k
| downloads_30d
int64 0
19.9M
| library
stringlengths 2
37
⌀ | likes
int64 0
4.34k
| pipeline
stringlengths 5
30
⌀ | pytorch
bool 2
classes | tensorflow
bool 2
classes | jax
bool 2
classes | license
stringlengths 2
30
| languages
stringlengths 4
1.63k
⌀ | datasets
stringlengths 2
2.58k
⌀ | co2
stringclasses 29
values | prs_count
int64 0
125
| prs_open
int64 0
120
| prs_merged
int64 0
15
| prs_closed
int64 0
28
| discussions_count
int64 0
218
| discussions_open
int64 0
148
| discussions_closed
int64 0
70
| tags
stringlengths 2
513
| has_model_index
bool 2
classes | has_metadata
bool 1
class | has_text
bool 1
class | text_length
int64 401
598k
| is_nc
bool 1
class | readme
stringlengths 0
598k
| hash
stringlengths 32
32
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
emilios/whisper-md-hu | emilios | whisper | 24 | 2 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['hu'] | ['mozilla-foundation/common_voice_11_0', 'google/fleurs'] | null | 1 | 0 | 1 | 0 | 0 | 0 | 0 | ['whisper-event', 'generated_from_trainer'] | true | true | true | 1,919 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper medium Hungarian El Greco
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the mozilla-foundation/common_voice_11_0,google/fleurs hu,hu_hu dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3428
- Wer: 18.6422
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-06
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|
| 0.0621 | 1.05 | 1000 | 0.2690 | 20.5099 |
| 0.0174 | 2.1 | 2000 | 0.2705 | 19.2292 |
| 0.006 | 3.15 | 3000 | 0.2954 | 18.9890 |
| 0.0028 | 4.2 | 4000 | 0.3093 | 18.8023 |
| 0.0016 | 5.25 | 5000 | 0.3240 | 18.9653 |
| 0.0018 | 6.3 | 6000 | 0.3313 | 18.6451 |
| 0.0014 | 7.35 | 7000 | 0.3330 | 18.9446 |
| 0.0016 | 8.39 | 8000 | 0.3428 | 18.6422 |
| 0.0015 | 9.44 | 9000 | 0.3508 | 18.9564 |
| 0.001 | 10.49 | 10000 | 0.3569 | 18.8556 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 2.0.0.dev20221216+cu116
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
| 048ba60184a4972f12b605ebadcb9810 |
fathyshalab/all-roberta-large-v1-small_talk-4-16-5 | fathyshalab | roberta | 11 | 3 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,515 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# all-roberta-large-v1-small_talk-4-16-5
This model is a fine-tuned version of [sentence-transformers/all-roberta-large-v1](https://huggingface.co/sentence-transformers/all-roberta-large-v1) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3566
- Accuracy: 0.3855
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.7259 | 1.0 | 1 | 2.5917 | 0.2551 |
| 2.217 | 2.0 | 2 | 2.5059 | 0.3275 |
| 1.7237 | 3.0 | 3 | 2.4355 | 0.3768 |
| 1.4001 | 4.0 | 4 | 2.3837 | 0.3739 |
| 1.1937 | 5.0 | 5 | 2.3566 | 0.3855 |
### Framework versions
- Transformers 4.20.0
- Pytorch 1.11.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
| c9475561f73f747809f916eb745a5f4b |
izumi-lab/electra-small-paper-japanese-discriminator | izumi-lab | electra | 7 | 2 | transformers | 1 | null | true | false | false | cc-by-sa-4.0 | ['ja'] | ['wikipedia'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 1,883 | false |
# ELECTRA small Japanese discriminator
This is a [ELECTRA](https://github.com/google-research/electra) model pretrained on texts in the Japanese language.
The codes for the pretraining are available at [retarfi/language-pretraining](https://github.com/retarfi/language-pretraining/tree/v1.0).
## Model architecture
The model architecture is the same as ELECTRA small in the [original ELECTRA paper](https://arxiv.org/abs/2003.10555); 12 layers, 256 dimensions of hidden states, and 4 attention heads.
## Training Data
The models are trained on the Japanese version of Wikipedia.
The training corpus is generated from the Japanese version of Wikipedia, using Wikipedia dump file as of June 1, 2021.
The corpus file is 2.9GB, consisting of approximately 20M sentences.
## Tokenization
The texts are first tokenized by MeCab with IPA dictionary and then split into subwords by the WordPiece algorithm.
The vocabulary size is 32768.
## Training
The models are trained with the same configuration as ELECTRA small in the [original ELECTRA paper](https://arxiv.org/abs/2003.10555); 128 tokens per instance, 128 instances per batch, and 1M training steps.
The size of the generator is 1/4 of the size of the discriminator.
## Citation
```
@article{Suzuki-etal-2023-ipm,
title = {Constructing and analyzing domain-specific language model for financial text mining}
author = {Masahiro Suzuki and Hiroki Sakaji and Masanori Hirano and Kiyoshi Izumi},
journal = {Information Processing & Management},
volume = {60},
number = {2},
pages = {103194},
year = {2023},
doi = {10.1016/j.ipm.2022.103194}
}
```
## Licenses
The pretrained models are distributed under the terms of the [Creative Commons Attribution-ShareAlike 4.0](https://creativecommons.org/licenses/by-sa/4.0/).
## Acknowledgments
This work was supported by JSPS KAKENHI Grant Number JP21K12010.
| d70713d25806f33491dc6f35afa6548d |
google/vit-large-patch32-224-in21k | google | vit | 7 | 178 | transformers | 0 | feature-extraction | true | true | true | apache-2.0 | null | ['imagenet-21k'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['vision'] | false | true | true | 4,911 | false |
# Vision Transformer (large-sized model)
Vision Transformer (ViT) model pre-trained on ImageNet-21k (14 million images, 21,843 classes) at resolution 224x224. It was introduced in the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Dosovitskiy et al. and first released in [this repository](https://github.com/google-research/vision_transformer). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman, who already converted the weights from JAX to PyTorch. Credits go to him.
Disclaimer: The team releasing ViT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pretrained on a large collection of images in a supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels.
Images are presented to the model as a sequence of fixed-size patches (resolution 32x32), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
Note that this model does not provide any fine-tuned heads, as these were zero'd by Google researchers. However, the model does include the pre-trained pooler, which can be used for downstream tasks (such as image classification).
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=google/vit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
from transformers import ViTFeatureExtractor, ViTModel
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224-in21k')
model = ViTModel.from_pretrained('google/vit-base-patch16-224-in21k')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
last_hidden_state = outputs.last_hidden_state
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon, and the API of ViTFeatureExtractor might change.
## Training data
The ViT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/google-research/vision_transformer/blob/master/vit_jax/input_pipeline.py).
Images are resized/rescaled to the same resolution (224x224) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
The model was trained on TPUv3 hardware (8 cores). All model variants are trained with a batch size of 4096 and learning rate warmup of 10k steps. For ImageNet, the authors found it beneficial to additionally apply gradient clipping at global norm 1. Pre-training resolution is 224.
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 2 and 5 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | 84091ad5428754341e4553cacf13c19f |
SetFit/distilbert-base-uncased__sst2__train-8-8 | SetFit | distilbert | 10 | 6 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,888 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased__sst2__train-8-8
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6925
- Accuracy: 0.5200
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.7061 | 1.0 | 3 | 0.6899 | 0.75 |
| 0.6627 | 2.0 | 6 | 0.7026 | 0.25 |
| 0.644 | 3.0 | 9 | 0.7158 | 0.25 |
| 0.6087 | 4.0 | 12 | 0.7325 | 0.25 |
| 0.5602 | 5.0 | 15 | 0.7555 | 0.25 |
| 0.5034 | 6.0 | 18 | 0.7725 | 0.25 |
| 0.4672 | 7.0 | 21 | 0.7983 | 0.25 |
| 0.403 | 8.0 | 24 | 0.8314 | 0.25 |
| 0.3571 | 9.0 | 27 | 0.8555 | 0.25 |
| 0.2792 | 10.0 | 30 | 0.9065 | 0.25 |
| 0.2373 | 11.0 | 33 | 0.9286 | 0.25 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2
- Tokenizers 0.10.3
| 3d128a710b293768f077c9011f60cbef |
Helsinki-NLP/opus-mt-fr-gaa | Helsinki-NLP | marian | 10 | 8 | transformers | 0 | translation | true | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['translation'] | false | true | true | 776 | false |
### opus-mt-fr-gaa
* source languages: fr
* target languages: gaa
* OPUS readme: [fr-gaa](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/fr-gaa/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-09.zip](https://object.pouta.csc.fi/OPUS-MT-models/fr-gaa/opus-2020-01-09.zip)
* test set translations: [opus-2020-01-09.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-gaa/opus-2020-01-09.test.txt)
* test set scores: [opus-2020-01-09.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-gaa/opus-2020-01-09.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.fr.gaa | 27.8 | 0.473 |
| afed9b58ae82a983b513301878ff26ad |
KarelDO/roberta-base.CEBaB_confounding.observational.sa.5-class.seed_43 | KarelDO | roberta | 15 | 2 | transformers | 0 | null | true | false | false | mit | ['en'] | ['OpenTable'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,108 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base.CEBaB_confounding.observational.sa.5-class.seed_43
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the OpenTable OPENTABLE dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8001
- Accuracy: 0.6987
- Macro-f1: 0.6805
- Weighted-macro-f1: 0.6922
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 43
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.2+cu102
- Datasets 2.5.2
- Tokenizers 0.12.1
| 1bdb004791cf26de3d6a0111ecd62c03 |
JeremiahZ/bert-base-uncased-mrpc | JeremiahZ | bert | 17 | 1 | transformers | 0 | text-classification | true | false | false | apache-2.0 | ['en'] | ['glue'] | null | 2 | 0 | 2 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,712 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-mrpc
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the GLUE MRPC dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5572
- Accuracy: 0.8578
- F1: 0.9024
- Combined Score: 0.8801
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.06
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Combined Score |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:--------------:|
| No log | 1.0 | 230 | 0.4111 | 0.8088 | 0.8704 | 0.8396 |
| No log | 2.0 | 460 | 0.3762 | 0.8480 | 0.8942 | 0.8711 |
| 0.4287 | 3.0 | 690 | 0.5572 | 0.8578 | 0.9024 | 0.8801 |
| 0.4287 | 4.0 | 920 | 0.6087 | 0.8554 | 0.8977 | 0.8766 |
| 0.1172 | 5.0 | 1150 | 0.6524 | 0.8456 | 0.8901 | 0.8678 |
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
| 015e27db50493ea3793fa508cf3d2723 |
k3nneth/finetuning-sentiment-model-3000-samples | k3nneth | distilbert | 16 | 11 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | ['imdb'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,053 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3046
- Accuracy: 0.87
- F1: 0.8713
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.1
- Tokenizers 0.13.2
| cae0bec1c7620c8a11b9a9291ffc0f43 |
anas-awadalla/bart-base-few-shot-k-128-finetuned-squad-seed-4 | anas-awadalla | bart | 16 | 3 | transformers | 0 | question-answering | true | false | false | apache-2.0 | null | ['squad'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 991 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-base-few-shot-k-128-finetuned-squad-seed-4
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 200
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.11.6
| b40162d679d8964e5786eb649f403fd8 |
GItaf/bert-base-uncased-bert-base-uncased-mc-weight0.25-epoch2 | GItaf | bert | 17 | 2 | transformers | 0 | text-generation | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 924 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-bert-base-uncased-mc-weight0.25-epoch2
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1
| 11f2e10f4179c3321644f7f61a745c3f |
InternalMegaT/Brazier_Diffusion | InternalMegaT | null | 3 | 0 | null | 2 | text-to-image | false | false | false | creativeml-openrail-m | ['en'] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['stable-diffusion', 'text-to-image', 'image-to-image'] | false | true | true | 2,285 | false | #MODEL BY InternalMegaT
How to use: **_brazier_** "your prompt" **_, by Svetoslav Roerich, generative art, aspect ratio 16:9, fortnite art style, stylized layered shapes, warm color scheme art rendition, an ai generated image, by jake parker_**
Training on V1 - 3000 steps, 512x512, v1-5 Base, 13 images
Uploaded on 12/9/22
Thanks To Liam Brazier for theses art styles.
Examples:-





## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license) | 4670641c94bd4122173365bd91fa05d9 |
arijitx/wav2vec2-xls-r-300m-bengali | arijitx | wav2vec2 | 37 | 64 | transformers | 1 | automatic-speech-recognition | true | false | false | apache-2.0 | ['bn'] | ['openslr', 'SLR53', 'AI4Bharat/IndicCorp'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['automatic-speech-recognition', 'bn', 'hf-asr-leaderboard', 'openslr_SLR53', 'robust-speech-event'] | true | true | true | 2,368 | false | This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the OPENSLR_SLR53 - bengali dataset.
It achieves the following results on the evaluation set.
Without language model :
- WER: 0.21726385291857586
- CER: 0.04725010353701041
With 5 gram language model trained on 30M sentences randomly chosen from [AI4Bharat IndicCorp](https://indicnlp.ai4bharat.org/corpora/) dataset :
- WER: 0.15322879016421437
- CER: 0.03413696666806267
Note : 5% of a total 10935 samples have been used for evaluation. Evaluation set has 10935 examples which was not part of training training was done on first 95% and eval was done on last 5%. Training was stopped after 180k steps. Output predictions are available under files section.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset_name="openslr"
- model_name_or_path="facebook/wav2vec2-xls-r-300m"
- dataset_config_name="SLR53"
- output_dir="./wav2vec2-xls-r-300m-bengali"
- overwrite_output_dir
- num_train_epochs="50"
- per_device_train_batch_size="32"
- per_device_eval_batch_size="32"
- gradient_accumulation_steps="1"
- learning_rate="7.5e-5"
- warmup_steps="2000"
- length_column_name="input_length"
- evaluation_strategy="steps"
- text_column_name="sentence"
- chars_to_ignore , ? . ! \- \; \: \" “ % ‘ ” � — ’ … –
- save_steps="2000"
- eval_steps="3000"
- logging_steps="100"
- layerdrop="0.0"
- activation_dropout="0.1"
- save_total_limit="3"
- freeze_feature_encoder
- feat_proj_dropout="0.0"
- mask_time_prob="0.75"
- mask_time_length="10"
- mask_feature_prob="0.25"
- mask_feature_length="64"
- preprocessing_num_workers 32
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.17.1.dev0
- Tokenizers 0.11.0
Notes
- Training and eval code modified from : https://github.com/huggingface/transformers/tree/master/examples/research_projects/robust-speech-event.
- Bengali speech data was not available from common voice or librispeech multilingual datasets, so OpenSLR53 has been used.
- Minimum audio duration of 0.5s has been used to filter the training data which excluded may be 10-20 samples.
- OpenSLR53 transcripts are *not* part of LM training and LM used to evaluate. | 460637fc234bcbb0796671ebcd5886cd |
tensorspeech/tts-mb_melgan-kss-ko | tensorspeech | null | 4 | 0 | tensorflowtts | 1 | text-to-speech | false | false | false | apache-2.0 | ['ko'] | ['KSS'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['tensorflowtts', 'audio', 'text-to-speech', 'mel-to-wav'] | false | true | true | 2,193 | false |
# Multi-band MelGAN trained on KSS (Korean)
This repository provides a pretrained [Multi-band MelGAN](https://arxiv.org/abs/2005.05106) trained on KSS dataset (ko). For a detail of the model, we encourage you to read more about
[TensorFlowTTS](https://github.com/TensorSpeech/TensorFlowTTS).
## Install TensorFlowTTS
First of all, please install TensorFlowTTS with the following command:
```
pip install TensorFlowTTS
```
### Converting your Text to Wav
```python
import soundfile as sf
import numpy as np
import tensorflow as tf
from tensorflow_tts.inference import AutoProcessor
from tensorflow_tts.inference import TFAutoModel
processor = AutoProcessor.from_pretrained("tensorspeech/tts-tacotron2-kss-ko")
tacotron2 = TFAutoModel.from_pretrained("tensorspeech/tts-tacotron2-kss-ko")
mb_melgan = TFAutoModel.from_pretrained("tensorspeech/tts-mb_melgan-kss-ko")
text = "신은 우리의 수학 문제에는 관심이 없다. 신은 다만 경험적으로 통합할 뿐이다."
input_ids = processor.text_to_sequence(text)
# tacotron2 inference (text-to-mel)
decoder_output, mel_outputs, stop_token_prediction, alignment_history = tacotron2.inference(
input_ids=tf.expand_dims(tf.convert_to_tensor(input_ids, dtype=tf.int32), 0),
input_lengths=tf.convert_to_tensor([len(input_ids)], tf.int32),
speaker_ids=tf.convert_to_tensor([0], dtype=tf.int32),
)
# melgan inference (mel-to-wav)
audio = mb_melgan.inference(mel_outputs)[0, :, 0]
# save to file
sf.write('./audio.wav', audio, 22050, "PCM_16")
```
#### Referencing Multi-band MelGAN
```
@misc{yang2020multiband,
title={Multi-band MelGAN: Faster Waveform Generation for High-Quality Text-to-Speech},
author={Geng Yang and Shan Yang and Kai Liu and Peng Fang and Wei Chen and Lei Xie},
year={2020},
eprint={2005.05106},
archivePrefix={arXiv},
primaryClass={cs.SD}
}
```
#### Referencing TensorFlowTTS
```
@misc{TFTTS,
author = {Minh Nguyen, Alejandro Miguel Velasquez, Erogol, Kuan Chen, Dawid Kobus, Takuya Ebata,
Trinh Le and Yunchao He},
title = {TensorflowTTS},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\\url{https://github.com/TensorSpeech/TensorFlowTTS}},
}
``` | 6c4035ee6c1382614de9a1402229653b |
tomXBE/bert-finetuned-squad_2 | tomXBE | distilbert | 12 | 5 | transformers | 0 | question-answering | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 980 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-squad_2
This model is a fine-tuned version of [tomXBE/distilbert-base-uncased-finetuned-squad](https://huggingface.co/tomXBE/distilbert-base-uncased-finetuned-squad) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.1
- Tokenizers 0.13.2
| b88491c289b4e5f95b4c4581222bc0ad |
gcmsrc/distilbert-base-uncased-finetuned-emotion | gcmsrc | distilbert | 12 | 1 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | ['emotion'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,345 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2179
- Accuracy: 0.9245
- F1: 0.9248
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8178 | 1.0 | 250 | 0.3219 | 0.9035 | 0.8996 |
| 0.2526 | 2.0 | 500 | 0.2179 | 0.9245 | 0.9248 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.12.1+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
| 35c8a0b594224be94b670854b7b356d4 |
SebastianS/distilbert-base-uncased-finetuned-imdb | SebastianS | distilbert | 8 | 4 | transformers | 0 | fill-mask | true | false | false | apache-2.0 | null | ['imdb'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,159 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.0122
- eval_runtime: 27.9861
- eval_samples_per_second: 35.732
- eval_steps_per_second: 0.572
- epoch: 2.13
- step: 334
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
| 3d58d1d71998e3c696f1888733f26f0c |
venetis/distilbert-base-uncased_finetuned_disaster_tweets | venetis | distilbert | 14 | 3 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,422 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_finetuned_disaster_tweets
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4007
- Accuracy: 0.8399
- F1: 0.8384
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.4594 | 1.0 | 191 | 0.4059 | 0.8163 | 0.8164 |
| 0.3399 | 2.0 | 382 | 0.3905 | 0.8346 | 0.8333 |
| 0.2859 | 3.0 | 573 | 0.4007 | 0.8399 | 0.8384 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
| 17c967052e73d9b0df89f4a2fa871c7e |
vumichien/mobilebert-uncased-squad-v2 | vumichien | mobilebert | 7 | 165 | transformers | 0 | question-answering | false | true | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_keras_callback'] | true | true | true | 865 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# tf-mobilebert-uncased-squad-v2
This model is a fine-tuned version of [csarron/mobilebert-uncased-squad-v2](https://huggingface.co/csarron/mobilebert-uncased-squad-v2) on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.17.0
- TensorFlow 2.8.0
- Tokenizers 0.11.6
| 29ca6f1566af31915c4c0cec1a7e478c |
Chikashi/t5-small-finetuned-cnndm1 | Chikashi | t5 | 11 | 1 | transformers | 0 | text2text-generation | true | false | false | apache-2.0 | null | ['cnn_dailymail'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 2,055 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-cnndm1
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the cnn_dailymail dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6853
- Rouge1: 24.4246
- Rouge2: 11.6944
- Rougel: 20.1717
- Rougelsum: 23.0424
- Gen Len: 18.9996
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 1.912 | 0.14 | 5000 | 1.7167 | 24.4232 | 11.7049 | 20.1758 | 23.0345 | 18.9997 |
| 1.8784 | 0.28 | 10000 | 1.7018 | 24.4009 | 11.6918 | 20.1561 | 23.0073 | 18.9997 |
| 1.8628 | 0.42 | 15000 | 1.6934 | 24.385 | 11.683 | 20.1285 | 22.9823 | 18.9997 |
| 1.8594 | 0.56 | 20000 | 1.6902 | 24.4407 | 11.6835 | 20.1734 | 23.0369 | 18.9996 |
| 1.8537 | 0.7 | 25000 | 1.6864 | 24.3635 | 11.658 | 20.1318 | 22.9782 | 18.9993 |
| 1.8505 | 0.84 | 30000 | 1.6856 | 24.4267 | 11.6991 | 20.1629 | 23.0361 | 18.9994 |
| 1.8505 | 0.98 | 35000 | 1.6853 | 24.4246 | 11.6944 | 20.1717 | 23.0424 | 18.9996 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
| 13b7bba082c5507b11d0b67975323d15 |
pcuenq/coreml-stable-diffusion-2-1-base | pcuenq | null | 104 | 0 | null | 1 | text-to-image | false | false | false | other | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['stable-diffusion', 'text-to-image', 'core-ml'] | false | true | true | 8,867 | false |
# Stable Diffusion v2 Model Card
This model was generated by Hugging Face using [Apple’s repository](https://github.com/apple/ml-stable-diffusion) which has [ASCL](https://github.com/apple/ml-stable-diffusion/blob/main/LICENSE.md).
This model card focuses on the model associated with the Stable Diffusion v2.1 model, codebase available [here](https://github.com/Stability-AI/stablediffusion).
This stable-diffusion-2-1 model is fine-tuned from stable-diffusion-2 (768-v-ema.ckpt) with an additional 55k steps on the same dataset (with punsafe=0.1), and then fine-tuned for another 155k extra steps with punsafe=0.98.
These weights here have been converted to Core ML for use on Apple Silicon hardware.
There are 4 variants of the Core ML weights:
```
coreml-stable-diffusion-2-base
├── original
│ ├── compiled # Swift inference, "original" attention
│ └── packages # Python inference, "original" attention
└── split_einsum
├── compiled # Swift inference, "split_einsum" attention
└── packages # Python inference, "split_einsum" attention
```
Please, refer to https://huggingface.co/blog/diffusers-coreml for details.
- Use it with 🧨 [`diffusers`](https://huggingface.co/stabilityai/stable-diffusion-2-base#examples)
- Use it with the [`stablediffusion`](https://github.com/Stability-AI/stablediffusion) repository: download the `512-base-ema.ckpt` [here](https://huggingface.co/stabilityai/stable-diffusion-2-base/resolve/main/512-base-ema.ckpt).
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/LICENSE-MODEL)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([OpenCLIP-ViT/H](https://github.com/mlfoundations/open_clip)).
- **Resources for more information:** [GitHub Repository](https://github.com/Stability-AI/).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is originally taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), was used for Stable Diffusion v1, but applies in the same way to Stable Diffusion v2_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a subset of the large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/), which contains adult, violent and sexual content. To partially mitigate this, we have filtered the dataset using LAION's NFSW detector (see Training section).
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion vw was primarily trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
Stable Diffusion v2 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-5B and subsets (details below). The training data is further filtered using LAION's NSFW detector, with a "p_unsafe" score of 0.1 (conservative). For more details, please refer to LAION-5B's [NeurIPS 2022](https://openreview.net/forum?id=M3Y74vmsMcY) paper and reviewer discussions on the topic.
**Training Procedure**
Stable Diffusion v2 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through the OpenCLIP-ViT/H text-encoder.
- The output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet. We also use the so-called _v-objective_, see https://arxiv.org/abs/2202.00512.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 200000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 15000 kg CO2 eq.
## Citation
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
*This model card was written by: Robin Rombach, Patrick Esser and David Ha and is based on the [Stable Diffusion v1](https://github.com/CompVis/stable-diffusion/blob/main/Stable_Diffusion_v1_Model_Card.md) and [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).* | 7b768279bed0250608e9410cd9d91eb3 |
Drazcat/whisper-small-es | Drazcat | whisper | 19 | 5 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['es'] | ['Drazcat/Cencosud'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['hf-asr-leaderboard', 'generated_from_trainer'] | true | true | true | 1,462 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Es - GoCloud
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the 30seg dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0028
- Wer: 0.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 25
- training_steps: 200
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.2944 | 5.56 | 50 | 0.1392 | 79.6117 |
| 0.08 | 11.11 | 100 | 0.0569 | 46.0472 |
| 0.0204 | 16.67 | 150 | 0.0086 | 0.0 |
| 0.0028 | 22.22 | 200 | 0.0028 | 0.0 |
### Framework versions
- Transformers 4.25.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.7.1
- Tokenizers 0.13.2
| f705a626d461edc70ce27b7f7afc31d7 |
sentence-transformers/distiluse-base-multilingual-cased-v1 | sentence-transformers | distilbert | 15 | 174,180 | sentence-transformers | 14 | sentence-similarity | true | true | false | apache-2.0 | ['multilingual'] | null | null | 1 | 1 | 0 | 0 | 1 | 1 | 0 | ['sentence-transformers', 'feature-extraction', 'sentence-similarity', 'transformers'] | false | true | true | 2,205 | false |
# sentence-transformers/distiluse-base-multilingual-cased-v1
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 512 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/distiluse-base-multilingual-cased-v1')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/distiluse-base-multilingual-cased-v1)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Dense({'in_features': 768, 'out_features': 512, 'bias': True, 'activation_function': 'torch.nn.modules.activation.Tanh'})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` | 6e4503b762b84a2a4e2692ddbcebbdc1 |
yuhuizhang/finetuned_gpt2-large_sst2_negation0.2 | yuhuizhang | gpt2 | 11 | 5 | transformers | 0 | text-generation | true | false | false | mit | null | ['sst2'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,248 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned_gpt2-large_sst2_negation0.2
This model is a fine-tuned version of [gpt2-large](https://huggingface.co/gpt2-large) on the sst2 dataset.
It achieves the following results on the evaluation set:
- Loss: 3.6892
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.431 | 1.0 | 1072 | 3.3426 |
| 1.8756 | 2.0 | 2144 | 3.5903 |
| 1.6223 | 3.0 | 3216 | 3.6892 |
### Framework versions
- Transformers 4.22.2
- Pytorch 1.12.1+cu113
- Datasets 2.5.2
- Tokenizers 0.12.1
| 9603b4d930836579e429523e1f82eda2 |
Helsinki-NLP/opus-mt-fi-no | Helsinki-NLP | marian | 11 | 38 | transformers | 0 | translation | true | true | false | apache-2.0 | ['fi', False] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['translation'] | false | true | true | 2,099 | false |
### fin-nor
* source group: Finnish
* target group: Norwegian
* OPUS readme: [fin-nor](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/fin-nor/README.md)
* model: transformer-align
* source language(s): fin
* target language(s): nno nob
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm4k,spm4k)
* a sentence initial language token is required in the form of `>>id<<` (id = valid target language ID)
* download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/fin-nor/opus-2020-06-17.zip)
* test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/fin-nor/opus-2020-06-17.test.txt)
* test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/fin-nor/opus-2020-06-17.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.fin.nor | 23.5 | 0.426 |
### System Info:
- hf_name: fin-nor
- source_languages: fin
- target_languages: nor
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/fin-nor/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['fi', 'no']
- src_constituents: {'fin'}
- tgt_constituents: {'nob', 'nno'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm4k,spm4k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/fin-nor/opus-2020-06-17.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/fin-nor/opus-2020-06-17.test.txt
- src_alpha3: fin
- tgt_alpha3: nor
- short_pair: fi-no
- chrF2_score: 0.426
- bleu: 23.5
- brevity_penalty: 1.0
- ref_len: 14768.0
- src_name: Finnish
- tgt_name: Norwegian
- train_date: 2020-06-17
- src_alpha2: fi
- tgt_alpha2: no
- prefer_old: False
- long_pair: fin-nor
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41 | f5982d0dd4f5d39b7382e88c4f849f4a |
pig4431/IMDB_DistilBERT_5E | pig4431 | distilbert | 10 | 7 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | ['imdb'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 10,815 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# IMDB_DistilBERT_5EE
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2023
- Accuracy: 0.94
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6748 | 0.03 | 50 | 0.5955 | 0.88 |
| 0.4404 | 0.06 | 100 | 0.2853 | 0.9 |
| 0.3065 | 0.1 | 150 | 0.2208 | 0.9 |
| 0.3083 | 0.13 | 200 | 0.2023 | 0.9333 |
| 0.2922 | 0.16 | 250 | 0.1530 | 0.94 |
| 0.2761 | 0.19 | 300 | 0.2035 | 0.9267 |
| 0.2145 | 0.22 | 350 | 0.2450 | 0.9 |
| 0.258 | 0.26 | 400 | 0.1680 | 0.9267 |
| 0.2702 | 0.29 | 450 | 0.1607 | 0.9333 |
| 0.2587 | 0.32 | 500 | 0.1496 | 0.9467 |
| 0.2822 | 0.35 | 550 | 0.1405 | 0.9333 |
| 0.2538 | 0.38 | 600 | 0.1396 | 0.9467 |
| 0.2707 | 0.42 | 650 | 0.1626 | 0.9333 |
| 0.2408 | 0.45 | 700 | 0.1623 | 0.9067 |
| 0.2531 | 0.48 | 750 | 0.1300 | 0.9467 |
| 0.2014 | 0.51 | 800 | 0.1529 | 0.9333 |
| 0.2454 | 0.54 | 850 | 0.1365 | 0.94 |
| 0.2282 | 0.58 | 900 | 0.1447 | 0.9533 |
| 0.2554 | 0.61 | 950 | 0.1321 | 0.9467 |
| 0.24 | 0.64 | 1000 | 0.1256 | 0.9467 |
| 0.2239 | 0.67 | 1050 | 0.1290 | 0.9467 |
| 0.2865 | 0.7 | 1100 | 0.1288 | 0.9667 |
| 0.2456 | 0.74 | 1150 | 0.1299 | 0.9533 |
| 0.2407 | 0.77 | 1200 | 0.1565 | 0.9267 |
| 0.2256 | 0.8 | 1250 | 0.1262 | 0.96 |
| 0.238 | 0.83 | 1300 | 0.1599 | 0.9333 |
| 0.2151 | 0.86 | 1350 | 0.1252 | 0.9333 |
| 0.187 | 0.9 | 1400 | 0.1132 | 0.9467 |
| 0.2218 | 0.93 | 1450 | 0.1030 | 0.9533 |
| 0.2371 | 0.96 | 1500 | 0.1036 | 0.9467 |
| 0.2264 | 0.99 | 1550 | 0.1041 | 0.9467 |
| 0.2159 | 1.02 | 1600 | 0.1338 | 0.9267 |
| 0.1773 | 1.06 | 1650 | 0.1218 | 0.94 |
| 0.1381 | 1.09 | 1700 | 0.1593 | 0.94 |
| 0.1582 | 1.12 | 1750 | 0.1445 | 0.9533 |
| 0.1921 | 1.15 | 1800 | 0.1355 | 0.94 |
| 0.206 | 1.18 | 1850 | 0.1511 | 0.9467 |
| 0.1679 | 1.22 | 1900 | 0.1394 | 0.94 |
| 0.1691 | 1.25 | 1950 | 0.1403 | 0.9333 |
| 0.2301 | 1.28 | 2000 | 0.1169 | 0.9467 |
| 0.1764 | 1.31 | 2050 | 0.1507 | 0.9333 |
| 0.1772 | 1.34 | 2100 | 0.1148 | 0.96 |
| 0.1749 | 1.38 | 2150 | 0.1203 | 0.94 |
| 0.1912 | 1.41 | 2200 | 0.1037 | 0.94 |
| 0.1614 | 1.44 | 2250 | 0.1006 | 0.9533 |
| 0.1975 | 1.47 | 2300 | 0.0985 | 0.9533 |
| 0.1843 | 1.5 | 2350 | 0.0922 | 0.9533 |
| 0.1764 | 1.54 | 2400 | 0.1259 | 0.9467 |
| 0.1855 | 1.57 | 2450 | 0.1243 | 0.96 |
| 0.1272 | 1.6 | 2500 | 0.2107 | 0.9267 |
| 0.241 | 1.63 | 2550 | 0.1142 | 0.9533 |
| 0.1584 | 1.66 | 2600 | 0.1194 | 0.9467 |
| 0.1568 | 1.7 | 2650 | 0.1196 | 0.9533 |
| 0.1896 | 1.73 | 2700 | 0.1311 | 0.9533 |
| 0.143 | 1.76 | 2750 | 0.1140 | 0.9533 |
| 0.227 | 1.79 | 2800 | 0.1482 | 0.9333 |
| 0.1404 | 1.82 | 2850 | 0.1366 | 0.94 |
| 0.1865 | 1.86 | 2900 | 0.1174 | 0.94 |
| 0.1659 | 1.89 | 2950 | 0.1189 | 0.94 |
| 0.1882 | 1.92 | 3000 | 0.1144 | 0.9467 |
| 0.1403 | 1.95 | 3050 | 0.1358 | 0.94 |
| 0.2193 | 1.98 | 3100 | 0.1092 | 0.9533 |
| 0.1392 | 2.02 | 3150 | 0.1278 | 0.9267 |
| 0.1292 | 2.05 | 3200 | 0.1186 | 0.96 |
| 0.0939 | 2.08 | 3250 | 0.1183 | 0.94 |
| 0.1356 | 2.11 | 3300 | 0.1939 | 0.94 |
| 0.1175 | 2.14 | 3350 | 0.1499 | 0.94 |
| 0.1285 | 2.18 | 3400 | 0.1538 | 0.94 |
| 0.1018 | 2.21 | 3450 | 0.1796 | 0.9333 |
| 0.1342 | 2.24 | 3500 | 0.1540 | 0.94 |
| 0.17 | 2.27 | 3550 | 0.1261 | 0.94 |
| 0.1548 | 2.3 | 3600 | 0.1375 | 0.9267 |
| 0.1415 | 2.34 | 3650 | 0.1264 | 0.9333 |
| 0.1096 | 2.37 | 3700 | 0.1252 | 0.9333 |
| 0.1001 | 2.4 | 3750 | 0.1546 | 0.94 |
| 0.0934 | 2.43 | 3800 | 0.1534 | 0.94 |
| 0.1287 | 2.46 | 3850 | 0.1735 | 0.9333 |
| 0.0872 | 2.5 | 3900 | 0.1475 | 0.9467 |
| 0.0994 | 2.53 | 3950 | 0.1735 | 0.9467 |
| 0.1558 | 2.56 | 4000 | 0.1585 | 0.9467 |
| 0.1517 | 2.59 | 4050 | 0.2021 | 0.9333 |
| 0.1246 | 2.62 | 4100 | 0.1594 | 0.9267 |
| 0.1228 | 2.66 | 4150 | 0.1338 | 0.9533 |
| 0.1064 | 2.69 | 4200 | 0.1421 | 0.9467 |
| 0.1466 | 2.72 | 4250 | 0.1383 | 0.9467 |
| 0.1243 | 2.75 | 4300 | 0.1604 | 0.9533 |
| 0.1434 | 2.78 | 4350 | 0.1736 | 0.9333 |
| 0.1127 | 2.82 | 4400 | 0.1909 | 0.9267 |
| 0.0908 | 2.85 | 4450 | 0.1958 | 0.9333 |
| 0.1134 | 2.88 | 4500 | 0.1596 | 0.94 |
| 0.1345 | 2.91 | 4550 | 0.1604 | 0.9533 |
| 0.1913 | 2.94 | 4600 | 0.1852 | 0.9267 |
| 0.1382 | 2.98 | 4650 | 0.1852 | 0.9333 |
| 0.1109 | 3.01 | 4700 | 0.1905 | 0.9333 |
| 0.1144 | 3.04 | 4750 | 0.1655 | 0.94 |
| 0.074 | 3.07 | 4800 | 0.2034 | 0.9333 |
| 0.0926 | 3.1 | 4850 | 0.1929 | 0.94 |
| 0.0911 | 3.13 | 4900 | 0.1703 | 0.9333 |
| 0.0933 | 3.17 | 4950 | 0.1826 | 0.9333 |
| 0.1003 | 3.2 | 5000 | 0.1716 | 0.94 |
| 0.0889 | 3.23 | 5050 | 0.1843 | 0.9267 |
| 0.0841 | 3.26 | 5100 | 0.1670 | 0.94 |
| 0.0918 | 3.29 | 5150 | 0.1595 | 0.9467 |
| 0.0795 | 3.33 | 5200 | 0.1504 | 0.96 |
| 0.0978 | 3.36 | 5250 | 0.1317 | 0.96 |
| 0.1202 | 3.39 | 5300 | 0.1641 | 0.9533 |
| 0.0935 | 3.42 | 5350 | 0.1473 | 0.96 |
| 0.0673 | 3.45 | 5400 | 0.1684 | 0.9533 |
| 0.0729 | 3.49 | 5450 | 0.1414 | 0.9533 |
| 0.077 | 3.52 | 5500 | 0.1669 | 0.9533 |
| 0.1264 | 3.55 | 5550 | 0.1364 | 0.96 |
| 0.1282 | 3.58 | 5600 | 0.1575 | 0.9467 |
| 0.0553 | 3.61 | 5650 | 0.1440 | 0.9467 |
| 0.0953 | 3.65 | 5700 | 0.1526 | 0.9533 |
| 0.0886 | 3.68 | 5750 | 0.1633 | 0.94 |
| 0.0901 | 3.71 | 5800 | 0.1704 | 0.9467 |
| 0.0986 | 3.74 | 5850 | 0.1674 | 0.94 |
| 0.0849 | 3.77 | 5900 | 0.1989 | 0.9333 |
| 0.0815 | 3.81 | 5950 | 0.1942 | 0.94 |
| 0.0973 | 3.84 | 6000 | 0.1611 | 0.94 |
| 0.0599 | 3.87 | 6050 | 0.1807 | 0.9267 |
| 0.1068 | 3.9 | 6100 | 0.1966 | 0.94 |
| 0.0889 | 3.93 | 6150 | 0.1979 | 0.9333 |
| 0.0854 | 3.97 | 6200 | 0.2012 | 0.9333 |
| 0.1207 | 4.0 | 6250 | 0.1983 | 0.9333 |
| 0.0735 | 4.03 | 6300 | 0.1795 | 0.94 |
| 0.1148 | 4.06 | 6350 | 0.1966 | 0.94 |
| 0.0725 | 4.09 | 6400 | 0.2290 | 0.94 |
| 0.0576 | 4.13 | 6450 | 0.1936 | 0.9333 |
| 0.0477 | 4.16 | 6500 | 0.2090 | 0.9333 |
| 0.0722 | 4.19 | 6550 | 0.1878 | 0.9333 |
| 0.0936 | 4.22 | 6600 | 0.2087 | 0.94 |
| 0.0715 | 4.25 | 6650 | 0.2040 | 0.94 |
| 0.0586 | 4.29 | 6700 | 0.1862 | 0.9333 |
| 0.0548 | 4.32 | 6750 | 0.1801 | 0.9267 |
| 0.0527 | 4.35 | 6800 | 0.1912 | 0.9333 |
| 0.0813 | 4.38 | 6850 | 0.1941 | 0.9333 |
| 0.0531 | 4.41 | 6900 | 0.1932 | 0.9267 |
| 0.0606 | 4.45 | 6950 | 0.2195 | 0.94 |
| 0.1213 | 4.48 | 7000 | 0.1975 | 0.9333 |
| 0.0807 | 4.51 | 7050 | 0.1915 | 0.9333 |
| 0.076 | 4.54 | 7100 | 0.1987 | 0.9333 |
| 0.0595 | 4.57 | 7150 | 0.2052 | 0.9333 |
| 0.0832 | 4.61 | 7200 | 0.2039 | 0.9333 |
| 0.0657 | 4.64 | 7250 | 0.2186 | 0.94 |
| 0.0684 | 4.67 | 7300 | 0.2063 | 0.94 |
| 0.0429 | 4.7 | 7350 | 0.2056 | 0.94 |
| 0.0531 | 4.73 | 7400 | 0.2139 | 0.94 |
| 0.0556 | 4.77 | 7450 | 0.2153 | 0.94 |
| 0.0824 | 4.8 | 7500 | 0.2010 | 0.9333 |
| 0.039 | 4.83 | 7550 | 0.2079 | 0.94 |
| 0.068 | 4.86 | 7600 | 0.2140 | 0.94 |
| 0.065 | 4.89 | 7650 | 0.2108 | 0.94 |
| 0.0359 | 4.93 | 7700 | 0.2058 | 0.94 |
| 0.0592 | 4.96 | 7750 | 0.2029 | 0.94 |
| 0.0793 | 4.99 | 7800 | 0.2023 | 0.94 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
| 4b33fabf17949e00311f38ce43b256b2 |
nishantyadav/cls_crossencoder_zeshel | nishantyadav | null | 3 | 0 | null | 0 | null | false | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 441 | false | This repo contains the cross-encoder model which uses \[cls\]-token based pooling to score a query-item pair.
This model is used in the experiments for our EMNLP 2022 paper titled "[Efficient Nearest Neighbor Search for Cross-Encoder Models using Matrix Factorization](https://arxiv.org/pdf/2210.12579.pdf)".
See [paper](https://arxiv.org/pdf/2210.12579.pdf) and/or [code](https://github.com/iesl/anncur) for more details about the model. | 08bb62b7d34ed7537d6fa044d37f534d |
espnet/simpleoier_chime4_enh_asr_convtasnet_init_noenhloss_wavlm_transformer_init_raw_en_char | espnet | null | 34 | 1 | espnet | 0 | null | false | false | false | cc-by-4.0 | ['en'] | ['chime4'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['espnet', 'audio', 'speech-enhancement-recognition'] | false | true | true | 13,323 | false |
## ESPnet2 EnhS2T model
### `espnet/simpleoier_chime4_enh_asr_convtasnet_init_noenhloss_wavlm_transformer_init_raw_en_char`
This model was trained by simpleoier using chime4 recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```bash
cd espnet
git checkout 2b663318cd1773fb8685b1e03295b6bc6889c283
pip install -e .
cd egs2/chime4/enh_asr1
./run.sh --skip_data_prep false --skip_train true --download_model espnet/simpleoier_chime4_enh_asr_convtasnet_init_noenhloss_wavlm_transformer_init_raw_en_char
```
<!-- Generated by scripts/utils/show_asr_result.sh -->
# RESULTS
## Environments
- date: `Thu Apr 28 08:15:30 EDT 2022`
- python version: `3.7.11 (default, Jul 27 2021, 14:32:16) [GCC 7.5.0]`
- espnet version: `espnet 202204`
- pytorch version: `pytorch 1.8.1`
- Git hash: ``
- Commit date: ``
## enh_asr_train_enh_asr_convtasnet_init_noenhloss_wavlm_transformer_init_lr1e-4_accum1_adam_specaug_bypass0_raw_en_char
### WER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/dt05_real_beamformit_2mics|1640|27119|98.5|1.2|0.3|0.2|1.7|19.6|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/dt05_real_beamformit_5mics|1640|27119|98.6|1.1|0.3|0.2|1.5|18.7|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/dt05_real_isolated_1ch_track|1640|27119|98.3|1.3|0.4|0.2|1.9|21.8|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/dt05_simu_beamformit_2mics|1640|27120|97.9|1.5|0.5|0.2|2.3|25.2|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/dt05_simu_beamformit_5mics|1640|27120|98.4|1.2|0.4|0.1|1.7|19.9|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/dt05_simu_isolated_1ch_track|1640|27120|97.2|2.1|0.7|0.3|3.1|28.9|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/et05_real_beamformit_2mics|1320|21409|97.4|2.0|0.6|0.3|2.9|27.3|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/et05_real_beamformit_5mics|1320|21409|97.8|1.8|0.4|0.2|2.5|24.3|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/et05_real_isolated_1ch_track|1320|21409|96.7|2.6|0.7|0.4|3.7|31.6|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/et05_simu_beamformit_2mics|1320|21416|96.6|2.5|1.0|0.3|3.7|32.5|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/et05_simu_beamformit_5mics|1320|21416|97.5|1.9|0.7|0.3|2.9|28.9|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/et05_simu_isolated_1ch_track|1320|21416|94.6|3.7|1.6|0.5|5.9|37.3|
### CER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/dt05_real_beamformit_2mics|1640|160390|99.5|0.2|0.3|0.2|0.7|19.6|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/dt05_real_beamformit_5mics|1640|160390|99.6|0.1|0.3|0.2|0.6|18.7|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/dt05_real_isolated_1ch_track|1640|160390|99.4|0.2|0.4|0.2|0.8|21.8|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/dt05_simu_beamformit_2mics|1640|160400|99.2|0.3|0.5|0.2|1.1|25.2|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/dt05_simu_beamformit_5mics|1640|160400|99.5|0.2|0.3|0.1|0.7|19.9|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/dt05_simu_isolated_1ch_track|1640|160400|98.8|0.5|0.7|0.3|1.5|28.9|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/et05_real_beamformit_2mics|1320|126796|98.9|0.4|0.7|0.3|1.4|27.3|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/et05_real_beamformit_5mics|1320|126796|99.1|0.4|0.5|0.2|1.1|24.3|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/et05_real_isolated_1ch_track|1320|126796|98.6|0.6|0.8|0.4|1.8|31.7|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/et05_simu_beamformit_2mics|1320|126812|98.2|0.6|1.1|0.4|2.1|32.5|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/et05_simu_beamformit_5mics|1320|126812|98.8|0.4|0.8|0.3|1.5|28.9|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/et05_simu_isolated_1ch_track|1320|126812|97.0|1.2|1.9|0.6|3.7|37.3|
## EnhS2T config
<details><summary>expand</summary>
```
config: conf/tuning/train_enh_asr_convtasnet_init_noenhloss_wavlm_transformer_init_lr1e-4_accum1_adam_specaug_bypass0.yaml
print_config: false
log_level: INFO
dry_run: false
iterator_type: sequence
output_dir: exp/enh_asr_train_enh_asr_convtasnet_init_noenhloss_wavlm_transformer_init_lr1e-4_accum1_adam_specaug_bypass0_raw_en_char
ngpu: 1
seed: 0
num_workers: 1
num_att_plot: 3
dist_backend: nccl
dist_init_method: env://
dist_world_size: null
dist_rank: null
local_rank: 0
dist_master_addr: null
dist_master_port: null
dist_launcher: null
multiprocessing_distributed: false
unused_parameters: true
sharded_ddp: false
cudnn_enabled: true
cudnn_benchmark: false
cudnn_deterministic: true
collect_stats: false
write_collected_feats: false
max_epoch: 12
patience: 10
val_scheduler_criterion:
- valid
- loss
early_stopping_criterion:
- valid
- loss
- min
best_model_criterion:
- - valid
- acc
- max
- - train
- loss
- min
keep_nbest_models: 10
nbest_averaging_interval: 0
grad_clip: 5
grad_clip_type: 2.0
grad_noise: false
accum_grad: 2
no_forward_run: false
resume: true
train_dtype: float32
use_amp: false
log_interval: null
use_matplotlib: true
use_tensorboard: true
use_wandb: false
wandb_project: null
wandb_id: null
wandb_entity: null
wandb_name: null
wandb_model_log_interval: -1
detect_anomaly: false
pretrain_path: null
init_param:
- ../enh1/exp/enh_train_enh_convtasnet_small_raw/valid.loss.ave_1best.pth:encoder:enh_model.encoder
- ../enh1/exp/enh_train_enh_convtasnet_small_raw/valid.loss.ave_1best.pth:separator:enh_model.separator
- ../enh1/exp/enh_train_enh_convtasnet_small_raw/valid.loss.ave_1best.pth:decoder:enh_model.decoder
- ../asr1/exp/asr_train_asr_transformer_wavlm_lr1e-3_specaug_accum1_preenc128_warmup20k_raw_en_char/valid.acc.ave.pth:frontend:s2t_model.frontend
- ../asr1/exp/asr_train_asr_transformer_wavlm_lr1e-3_specaug_accum1_preenc128_warmup20k_raw_en_char/valid.acc.ave.pth:preencoder:s2t_model.preencoder
- ../asr1/exp/asr_train_asr_transformer_wavlm_lr1e-3_specaug_accum1_preenc128_warmup20k_raw_en_char/valid.acc.ave.pth:encoder:s2t_model.encoder
- ../asr1/exp/asr_train_asr_transformer_wavlm_lr1e-3_specaug_accum1_preenc128_warmup20k_raw_en_char/valid.acc.ave.pth:ctc:s2t_model.ctc
- ../asr1/exp/asr_train_asr_transformer_wavlm_lr1e-3_specaug_accum1_preenc128_warmup20k_raw_en_char/valid.acc.ave.pth:decoder:s2t_model.decoder
ignore_init_mismatch: false
freeze_param:
- s2t_model.frontend.upstream
num_iters_per_epoch: null
batch_size: 12
valid_batch_size: null
batch_bins: 1000000
valid_batch_bins: null
train_shape_file:
- exp/enh_asr_stats_raw_en_char/train/speech_shape
- exp/enh_asr_stats_raw_en_char/train/speech_ref1_shape
- exp/enh_asr_stats_raw_en_char/train/text_shape.char
valid_shape_file:
- exp/enh_asr_stats_raw_en_char/valid/speech_shape
- exp/enh_asr_stats_raw_en_char/valid/speech_ref1_shape
- exp/enh_asr_stats_raw_en_char/valid/text_shape.char
batch_type: folded
valid_batch_type: null
fold_length:
- 80000
- 80000
- 150
sort_in_batch: descending
sort_batch: descending
multiple_iterator: false
chunk_length: 500
chunk_shift_ratio: 0.5
num_cache_chunks: 1024
train_data_path_and_name_and_type:
- - dump/raw/tr05_multi_noisy_si284/wav.scp
- speech
- sound
- - dump/raw/tr05_multi_noisy_si284/spk1.scp
- speech_ref1
- sound
- - dump/raw/tr05_multi_noisy_si284/text
- text
- text
valid_data_path_and_name_and_type:
- - dump/raw/dt05_multi_isolated_1ch_track/wav.scp
- speech
- sound
- - dump/raw/dt05_multi_isolated_1ch_track/spk1.scp
- speech_ref1
- sound
- - dump/raw/dt05_multi_isolated_1ch_track/text
- text
- text
allow_variable_data_keys: false
max_cache_size: 0.0
max_cache_fd: 32
valid_max_cache_size: null
optim: adam
optim_conf:
lr: 0.0001
scheduler: null
scheduler_conf: {}
token_list: data/en_token_list/char/tokens.txt
src_token_list: null
init: xavier_uniform
input_size: null
ctc_conf:
dropout_rate: 0.0
ctc_type: builtin
reduce: true
ignore_nan_grad: true
enh_criterions:
- name: si_snr
conf: {}
wrapper: fixed_order
wrapper_conf: {}
enh_model_conf:
stft_consistency: false
loss_type: mask_mse
mask_type: null
asr_model_conf:
ctc_weight: 0.3
lsm_weight: 0.1
length_normalized_loss: false
extract_feats_in_collect_stats: false
st_model_conf:
stft_consistency: false
loss_type: mask_mse
mask_type: null
subtask_series:
- enh
- asr
model_conf:
calc_enh_loss: false
bypass_enh_prob: 0.0
use_preprocessor: true
token_type: char
bpemodel: null
src_token_type: bpe
src_bpemodel: null
non_linguistic_symbols: data/nlsyms.txt
cleaner: null
g2p: null
enh_encoder: conv
enh_encoder_conf:
channel: 256
kernel_size: 40
stride: 20
enh_separator: tcn
enh_separator_conf:
num_spk: 1
layer: 4
stack: 2
bottleneck_dim: 256
hidden_dim: 512
kernel: 3
causal: false
norm_type: gLN
nonlinear: relu
enh_decoder: conv
enh_decoder_conf:
channel: 256
kernel_size: 40
stride: 20
frontend: s3prl
frontend_conf:
frontend_conf:
upstream: wavlm_large
download_dir: ./hub
multilayer_feature: true
fs: 16k
specaug: specaug
specaug_conf:
apply_time_warp: true
time_warp_window: 5
time_warp_mode: bicubic
apply_freq_mask: true
freq_mask_width_range:
- 0
- 100
num_freq_mask: 4
apply_time_mask: true
time_mask_width_range:
- 0
- 40
num_time_mask: 2
normalize: utterance_mvn
normalize_conf: {}
asr_preencoder: linear
asr_preencoder_conf:
input_size: 1024
output_size: 128
asr_encoder: transformer
asr_encoder_conf:
output_size: 256
attention_heads: 4
linear_units: 2048
num_blocks: 12
dropout_rate: 0.1
attention_dropout_rate: 0.0
input_layer: conv2d2
normalize_before: true
asr_postencoder: null
asr_postencoder_conf: {}
asr_decoder: transformer
asr_decoder_conf:
input_layer: embed
attention_heads: 4
linear_units: 2048
num_blocks: 6
dropout_rate: 0.1
positional_dropout_rate: 0.0
self_attention_dropout_rate: 0.0
src_attention_dropout_rate: 0.0
st_preencoder: null
st_preencoder_conf: {}
st_encoder: rnn
st_encoder_conf: {}
st_postencoder: null
st_postencoder_conf: {}
st_decoder: rnn
st_decoder_conf: {}
st_extra_asr_decoder: rnn
st_extra_asr_decoder_conf: {}
st_extra_mt_decoder: rnn
st_extra_mt_decoder_conf: {}
required:
- output_dir
- token_list
version: '202204'
distributed: false
```
</details>
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
| 7c63a6b381aa05b947ba012c6ae9621a |
jbreunig/xlm-roberta-base-finetuned-panx-de | jbreunig | xlm-roberta | 16 | 5 | transformers | 0 | token-classification | true | false | false | mit | null | ['xtreme'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,314 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1370
- F1: 0.8625
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.26 | 1.0 | 525 | 0.1565 | 0.8218 |
| 0.1276 | 2.0 | 1050 | 0.1409 | 0.8486 |
| 0.0817 | 3.0 | 1575 | 0.1370 | 0.8625 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.1
- Datasets 1.16.1
- Tokenizers 0.10.3
| 45c0c78c58705d301b013ed518f7066e |
anas-awadalla/distilroberta-base-task-specific-distilation-on-squad | anas-awadalla | roberta | 32 | 5 | transformers | 0 | question-answering | true | false | false | apache-2.0 | null | ['squad'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 962 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilroberta-base-task-specific-distilation-on-squad
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2.0
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.11.6
| d7cc6c1af862bd8ba74b5caf040cd7b1 |
csarron/roberta-base-squad-v1 | csarron | roberta | 10 | 181 | transformers | 0 | question-answering | true | false | true | mit | ['en'] | ['squad'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['question-answering', 'roberta', 'roberta-base'] | false | true | true | 2,411 | false |
## RoBERTa-base fine-tuned on SQuAD v1
This model was fine-tuned from the HuggingFace [RoBERTa](https://arxiv.org/abs/1907.11692) base checkpoint on [SQuAD1.1](https://rajpurkar.github.io/SQuAD-explorer).
This model is case-sensitive: it makes a difference between english and English.
## Details
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| SQuAD1.1 | train | 96.8K |
| SQuAD1.1 | eval | 11.8k |
### Fine-tuning
- Python: `3.7.5`
- Machine specs:
`CPU: Intel(R) Core(TM) i7-6800K CPU @ 3.40GHz`
`Memory: 32 GiB`
`GPUs: 2 GeForce GTX 1070, each with 8GiB memory`
`GPU driver: 418.87.01, CUDA: 10.1`
- script:
```shell
# after install https://github.com/huggingface/transformers
cd examples/question-answering
mkdir -p data
wget -O data/train-v1.1.json https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v1.1.json
wget -O data/dev-v1.1.json https://rajpurkar.github.io/SQuAD-explorer/dataset/dev-v1.1.json
python run_energy_squad.py \
--model_type roberta \
--model_name_or_path roberta-base \
--do_train \
--do_eval \
--train_file train-v1.1.json \
--predict_file dev-v1.1.json \
--per_gpu_train_batch_size 12 \
--per_gpu_eval_batch_size 16 \
--learning_rate 3e-5 \
--num_train_epochs 2.0 \
--max_seq_length 320 \
--doc_stride 128 \
--data_dir data \
--output_dir data/roberta-base-squad-v1 2>&1 | tee train-roberta-base-squad-v1.log
```
It took about 2 hours to finish.
### Results
**Model size**: `477M`
| Metric | # Value |
| ------ | --------- |
| **EM** | **83.0** |
| **F1** | **90.4** |
Note that the above results didn't involve any hyperparameter search.
## Example Usage
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="csarron/roberta-base-squad-v1",
tokenizer="csarron/roberta-base-squad-v1"
)
predictions = qa_pipeline({
'context': "The game was played on February 7, 2016 at Levi's Stadium in the San Francisco Bay Area at Santa Clara, California.",
'question': "What day was the game played on?"
})
print(predictions)
# output:
# {'score': 0.8625259399414062, 'start': 23, 'end': 39, 'answer': 'February 7, 2016'}
```
> Created by [Qingqing Cao](https://awk.ai/) | [GitHub](https://github.com/csarron) | [Twitter](https://twitter.com/sysnlp)
> Made with ❤️ in New York.
| 14e8fcc27a5ed545053ccaadb923abd2 |
Helsinki-NLP/opus-mt-zh-en | Helsinki-NLP | marian | 12 | 162,987 | transformers | 70 | translation | true | true | false | cc-by-4.0 | ['zh', 'en'] | null | null | 3 | 1 | 1 | 1 | 1 | 1 | 0 | ['translation'] | false | true | true | 3,102 | false |
### zho-eng
## Table of Contents
- [Model Details](#model-details)
- [Uses](#uses)
- [Risks, Limitations and Biases](#risks-limitations-and-biases)
- [Training](#training)
- [Evaluation](#evaluation)
- [Citation Information](#citation-information)
- [How to Get Started With the Model](#how-to-get-started-with-the-model)
## Model Details
- **Model Description:**
- **Developed by:** Language Technology Research Group at the University of Helsinki
- **Model Type:** Translation
- **Language(s):**
- Source Language: Chinese
- Target Language: English
- **License:** CC-BY-4.0
- **Resources for more information:**
- [GitHub Repo](https://github.com/Helsinki-NLP/OPUS-MT-train)
## Uses
#### Direct Use
This model can be used for translation and text-to-text generation.
## Risks, Limitations and Biases
**CONTENT WARNING: Readers should be aware this section contains content that is disturbing, offensive, and can propagate historical and current stereotypes.**
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)).
Further details about the dataset for this model can be found in the OPUS readme: [zho-eng](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/zho-eng/README.md)
## Training
#### System Information
* helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
* transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
* port_machine: brutasse
* port_time: 2020-08-21-14:41
* src_multilingual: False
* tgt_multilingual: False
#### Training Data
##### Preprocessing
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* ref_len: 82826.0
* dataset: [opus](https://github.com/Helsinki-NLP/Opus-MT)
* download original weights: [opus-2020-07-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/zho-eng/opus-2020-07-17.zip)
* test set translations: [opus-2020-07-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/zho-eng/opus-2020-07-17.test.txt)
## Evaluation
#### Results
* test set scores: [opus-2020-07-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/zho-eng/opus-2020-07-17.eval.txt)
* brevity_penalty: 0.948
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.zho.eng | 36.1 | 0.548 |
## Citation Information
```bibtex
@InProceedings{TiedemannThottingal:EAMT2020,
author = {J{\"o}rg Tiedemann and Santhosh Thottingal},
title = {{OPUS-MT} — {B}uilding open translation services for the {W}orld},
booktitle = {Proceedings of the 22nd Annual Conferenec of the European Association for Machine Translation (EAMT)},
year = {2020},
address = {Lisbon, Portugal}
}
```
## How to Get Started With the Model
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("Helsinki-NLP/opus-mt-zh-en")
model = AutoModelForSeq2SeqLM.from_pretrained("Helsinki-NLP/opus-mt-zh-en")
```
| 3ec52a58e11a0072e5ec5de1a9e888d9 |
neelan-elucidate-ai/wav2vec2-tcrs | neelan-elucidate-ai | wav2vec2 | 10 | 7 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 2,980 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-tcrs
This model is a fine-tuned version of [facebook/wav2vec2-large-lv60](https://huggingface.co/facebook/wav2vec2-large-lv60) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.9550
- Wer: 1.0657
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 100
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 13.6613 | 3.38 | 500 | 3.2415 | 1.0 |
| 2.9524 | 6.76 | 1000 | 3.0199 | 1.0 |
| 2.9425 | 10.14 | 1500 | 3.0673 | 1.0 |
| 2.9387 | 13.51 | 2000 | 3.0151 | 1.0 |
| 2.9384 | 16.89 | 2500 | 3.0320 | 1.0 |
| 2.929 | 20.27 | 3000 | 2.9691 | 1.0 |
| 2.9194 | 23.65 | 3500 | 2.9596 | 1.0 |
| 2.9079 | 27.03 | 4000 | 2.9279 | 1.0 |
| 2.8957 | 30.41 | 4500 | 2.9647 | 1.0 |
| 2.8385 | 33.78 | 5000 | 2.8114 | 1.0193 |
| 2.6546 | 37.16 | 5500 | 2.6744 | 1.0983 |
| 2.5866 | 40.54 | 6000 | 2.6192 | 1.1071 |
| 2.5475 | 43.92 | 6500 | 2.5777 | 1.0950 |
| 2.5177 | 47.3 | 7000 | 2.5845 | 1.1220 |
| 2.482 | 50.68 | 7500 | 2.5730 | 1.1264 |
| 2.4343 | 54.05 | 8000 | 2.5722 | 1.0955 |
| 2.3754 | 57.43 | 8500 | 2.5781 | 1.1353 |
| 2.3055 | 60.81 | 9000 | 2.6177 | 1.0972 |
| 2.2446 | 64.19 | 9500 | 2.6351 | 1.1027 |
| 2.1625 | 67.57 | 10000 | 2.6924 | 1.0756 |
| 2.1078 | 70.95 | 10500 | 2.6817 | 1.0795 |
| 2.0366 | 74.32 | 11000 | 2.7629 | 1.0657 |
| 1.9899 | 77.7 | 11500 | 2.7972 | 1.0845 |
| 1.9309 | 81.08 | 12000 | 2.8450 | 1.0734 |
| 1.8861 | 84.46 | 12500 | 2.8703 | 1.0668 |
| 1.8437 | 87.84 | 13000 | 2.9308 | 1.0917 |
| 1.8192 | 91.22 | 13500 | 2.9298 | 1.0701 |
| 1.7952 | 94.59 | 14000 | 2.9488 | 1.0685 |
| 1.7745 | 97.97 | 14500 | 2.9550 | 1.0657 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.9.1
- Datasets 1.18.3
- Tokenizers 0.10.3
| 083b67d4eb21983fa41f50b6403ecb45 |
anas-awadalla/bert-base-uncased-few-shot-k-64-finetuned-squad-seed-4 | anas-awadalla | bert | 16 | 5 | transformers | 0 | question-answering | true | false | false | apache-2.0 | null | ['squad'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,000 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-few-shot-k-64-finetuned-squad-seed-4
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 200
### Training results
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.17.0
- Tokenizers 0.10.3
| 6ca0dc834e39a7313276f3ed8fa8f903 |
jonatasgrosman/exp_w2v2t_fa_vp-fr_s165 | jonatasgrosman | wav2vec2 | 10 | 7 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['fa'] | ['mozilla-foundation/common_voice_7_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['automatic-speech-recognition', 'fa'] | false | true | true | 469 | false | # exp_w2v2t_fa_vp-fr_s165
Fine-tuned [facebook/wav2vec2-large-fr-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-fr-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (fa)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
| 8c903bff2661e6e0b135851d9e57d8c9 |
ThatGuyVanquish/mt5-base-finetuned-rabbi-kook-nave-4 | ThatGuyVanquish | mt5 | 11 | 5 | transformers | 0 | text2text-generation | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,397 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-base-finetuned-rabbi-kook-nave-4
This model is a fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: nan
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.0 | 1.0 | 1784 | nan |
| 0.0 | 2.0 | 3568 | nan |
| 0.0 | 3.0 | 5352 | nan |
| 0.0 | 4.0 | 7136 | nan |
| 0.0 | 5.0 | 8920 | nan |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.11.0
| e6c887d58be0c023daca439cba1fc002 |
sschet/biomedical-ner-all | sschet | distilbert | 8 | 7 | transformers | 0 | token-classification | true | false | false | apache-2.0 | ['en'] | ['tner/bc5cdr', 'commanderstrife/jnlpba', 'bc2gm_corpus', 'drAbreu/bc4chemd_ner', 'linnaeus', 'chintagunta85/ncbi_disease'] | 0.0279399890043426 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['Token Classification'] | false | true | true | 1,449 | false |
## About the Model
An English Named Entity Recognition model, trained on Maccrobat to recognize the bio-medical entities (107 entities) from a given text corpus (case reports etc.). This model was built on top of distilbert-base-uncased
- Dataset: Maccrobat https://figshare.com/articles/dataset/MACCROBAT2018/9764942
- Carbon emission: 0.0279399890043426 Kg
- Training time: 30.16527 minutes
- GPU used : 1 x GeForce RTX 3060 Laptop GPU
Checkout the tutorial video for explanation of this model and corresponding python library: https://youtu.be/xpiDPdBpS18
## Usage
The easiest way is to load the inference api from huggingface and second method is through the pipeline object offered by transformers library.
```python
from transformers import pipeline
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("d4data/biomedical-ner-all")
model = AutoModelForTokenClassification.from_pretrained("d4data/biomedical-ner-all")
pipe = pipeline("ner", model=model, tokenizer=tokenizer, aggregation_strategy="simple") # pass device=0 if using gpu
pipe("""The patient reported no recurrence of palpitations at follow-up 6 months after the ablation.""")
```
## Author
This model is part of the Research topic "AI in Biomedical field" conducted by Deepak John Reji, Shaina Raza. If you use this work (code, model or dataset), please star at:
> https://github.com/dreji18/Bio-Epidemiology-NER | 21d0b25d28068dccbee2e11a4e02ff3e |
Geotrend/bert-base-en-de-cased | Geotrend | bert | 8 | 1,451 | transformers | 0 | fill-mask | true | true | true | apache-2.0 | ['multilingual'] | ['wikipedia'] | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 1,292 | false |
# bert-base-en-de-cased
We are sharing smaller versions of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) that handle a custom number of languages.
Unlike [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased), our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/bert-base-en-de-cased")
model = AutoModel.from_pretrained("Geotrend/bert-base-en-de-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact [email protected] for any question, feedback or request.
| 6cad93fd4e52515edb7d3fe3a86f865f |
l3cube-pune/hindi-tweets-bert-v2 | l3cube-pune | bert | 8 | 4 | transformers | 0 | fill-mask | true | false | false | cc-by-4.0 | ['hi'] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 552 | false |
## HindTweetBERT
A HindBERT (l3cube-pune/hindi-bert-v2) model finetuned on Hindi Tweets.<br>
More details on the dataset, models, and baseline results can be found in our [paper] (<a href='https://arxiv.org/abs/2210.04267'> link </a>)<br>
```
@article{gokhale2022spread,
title={Spread Love Not Hate: Undermining the Importance of Hateful Pre-training for Hate Speech Detection},
author={Gokhale, Omkar and Kane, Aditya and Patankar, Shantanu and Chavan, Tanmay and Joshi, Raviraj},
journal={arXiv preprint arXiv:2210.04267},
year={2022}
}
```
| 1b457a9014efcb374a37cacfd8c694da |
Graphcore/lxmert-vqa-uncased | Graphcore | lxmert | 14 | 1 | transformers | 0 | question-answering | true | false | false | apache-2.0 | null | ['Graphcore/vqa-lxmert'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 3,944 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Graphcore/lxmert-vqa-uncased
Optimum Graphcore is a new open-source library and toolkit that enables developers to access IPU-optimized models certified by Hugging Face. It is an extension of Transformers, providing a set of performance optimization tools enabling maximum efficiency to train and run models on Graphcore’s IPUs - a completely new kind of massively parallel processor to accelerate machine intelligence. Learn more about how to take train Transformer models faster with IPUs at [hf.co/hardware/graphcore](https://huggingface.co/hardware/graphcore).
Through HuggingFace Optimum, Graphcore released ready-to-use IPU-trained model checkpoints and IPU configuration files to make it easy to train models with maximum efficiency in the IPU. Optimum shortens the development lifecycle of your AI models by letting you plug-and-play any public dataset and allows a seamless integration to our State-of-the-art hardware giving you a quicker time-to-value for your AI project.
## Model description
LXMERT is a transformer model for learning vision-and-language cross-modality representations. It has a Transformer model that has three encoders: object relationship encoder, a language encoder, and a cross-modality encoder. It is pretrained via a combination of masked language modelling, visual-language text alignment, ROI-feature regression, masked visual-attribute modelling, masked visual-object modelling, and visual-question answering objectives. It achieves the state-of-the-art results on VQA and GQA.
Paper link : [LXMERT: Learning Cross-Modality Encoder Representations from Transformers](https://arxiv.org/pdf/1908.07490.pdf)
## Intended uses & limitations
This model is a fine-tuned version of [unc-nlp/lxmert-base-uncased](https://huggingface.co/unc-nlp/lxmert-base-uncased) on the [Graphcore/vqa-lxmert](https://huggingface.co/datasets/Graphcore/vqa-lxmert) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0009
- Accuracy: 0.7242
## Training and evaluation data
- [Graphcore/vqa-lxmert](https://huggingface.co/datasets/Graphcore/vqa-lxmert) dataset
## Training procedure
Trained on 16 Graphcore Mk2 IPUs using [optimum-graphcore](https://github.com/huggingface/optimum-graphcore).
Command line:
```
python examples/question-answering/run_vqa.py \
--model_name_or_path unc-nlp/lxmert-base-uncased \
--ipu_config_name Graphcore/lxmert-base-ipu \
--dataset_name Graphcore/vqa-lxmert \
--do_train \
--do_eval \
--max_seq_length 512 \
--per_device_train_batch_size 1 \
--num_train_epochs 4 \
--dataloader_num_workers 64 \
--logging_steps 5 \
--learning_rate 5e-5 \
--lr_scheduler_type linear \
--loss_scaling 16384 \
--weight_decay 0.01 \
--warmup_ratio 0.1 \
--output_dir /tmp/vqa/ \
--dataloader_drop_last \
--replace_qa_head \
--pod_type pod16
```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- distributed_type: IPU
- total_train_batch_size: 64
- total_eval_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 4.0
- training precision: Mixed Precision
### Training results
```
***** train metrics *****
"epoch": 4.0,
"train_loss": 0.0060005393999575125,
"train_runtime": 13854.802,
"train_samples": 443757,
"train_samples_per_second": 128.116,
"train_steps_per_second": 2.002
***** eval metrics *****
"eval_accuracy": 0.7242196202278137,
"eval_loss": 0.0008745193481445312,
"eval_samples": 214354,
```
### Framework versions
- Transformers 4.18.0.dev0
- Pytorch 1.10.0+cpu
- Datasets 2.0.0
- Tokenizers 0.11.6
| d8e35078e8ee0cc0645dae920da9c20e |
Matthijs/mobilevit-small | Matthijs | mobilevit | 8 | 6 | transformers | 0 | image-classification | true | false | false | other | null | ['imagenet-1k'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['vision', 'image-classification'] | false | true | true | 4,423 | false |
# MobileViT (small-sized model)
MobileViT model pre-trained on ImageNet-1k at resolution 256x256. It was introduced in [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari, and first released in [this repository](https://github.com/apple/ml-cvnets). The license used is [Apple sample code license](https://github.com/apple/ml-cvnets/blob/main/LICENSE).
Disclaimer: The team releasing MobileViT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
MobileViT is a light-weight, low latency convolutional neural network that combines MobileNetV2-style layers with a new block that replaces local processing in convolutions with global processing using transformers. As with ViT (Vision Transformer), the image data is converted into flattened patches before it is processed by the transformer layers. Afterwards, however, the patches are "unflattened" back into feature maps. This allows the MobileViT-block to be placed anywhere inside a CNN. MobileViT does not require any positional embeddings.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=mobilevit) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import MobileViTFeatureExtractor, MobileViTForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = MobileViTFeatureExtractor.from_pretrained('Matthijs/mobilevit-small')
model = MobileViTForImageClassification.from_pretrained('Matthijs/mobilevit-small')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch.
## Training data
The MobileViT model was pretrained on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k), a dataset consisting of 1 million images and 1,000 classes.
## Training procedure
### Preprocessing
Training requires only basic data augmentation, i.e. random resized cropping and horizontal flipping.
To learn multi-scale representations without requiring fine-tuning, a multi-scale sampler was used during training, with image sizes randomly sampled from: (160, 160), (192, 192), (256, 256), (288, 288), (320, 320).
At inference time, images are resized/rescaled to the same resolution (288x288), and center-cropped at 256x256.
Pixels are normalized to the range [0, 1]. Images are expected to be in BGR pixel order, not RGB.
### Pretraining
The MobileViT networks are trained from scratch for 300 epochs on ImageNet-1k on 8 NVIDIA GPUs with an effective batch size of 1024 and learning rate warmup for 3k steps, followed by cosine annealing. Also used were label smoothing cross-entropy loss and L2 weight decay. Training resolution varies from 160x160 to 320x320, using multi-scale sampling.
## Evaluation results
| Model | ImageNet top-1 accuracy | ImageNet top-5 accuracy | # params | URL |
|------------------|-------------------------|-------------------------|-----------|----------------------------------------------------|
| MobileViT-XXS | 69.0 | 88.9 | 1.3 M | https://huggingface.co/Matthijs/mobilevit-xx-small |
| MobileViT-XS | 74.8 | 92.3 | 2.3 M | https://huggingface.co/Matthijs/mobilevit-x-small |
| **MobileViT-S** | **78.4** | **94.1** | **5.6 M** | https://huggingface.co/Matthijs/mobilevit-small |
### BibTeX entry and citation info
```bibtex
@inproceedings{vision-transformer,
title = {MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer},
author = {Sachin Mehta and Mohammad Rastegari},
year = {2022},
URL = {https://arxiv.org/abs/2110.02178}
}
```
| 91fbbc2e6e5447f91edb7186368ec6f3 |
W4nkel/distilbertBase128KTrain | W4nkel | distilbert | 8 | 1 | transformers | 0 | text-classification | false | true | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_keras_callback'] | true | true | true | 1,615 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# W4nkel/distilbertBase128KTrain
This model is a fine-tuned version of [dbmdz/distilbert-base-turkish-cased](https://huggingface.co/dbmdz/distilbert-base-turkish-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.7462
- Validation Loss: 0.5115
- Train Accuracy: 0.7675
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 1500, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Accuracy | Epoch |
|:----------:|:---------------:|:--------------:|:-----:|
| 0.7462 | 0.5115 | 0.7675 | 0 |
### Framework versions
- Transformers 4.25.1
- TensorFlow 2.11.0
- Datasets 2.8.0
- Tokenizers 0.13.2
| a6c2e7d6b835faa64c075bdbe0f8e761 |
kompactss/JeBERT_ko_je_v2 | kompactss | encoder-decoder | 7 | 1 | transformers | 0 | text2text-generation | true | false | false | afl-3.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 732 | false |
# 🍊 제주 방언 번역 모델 🍊
- 표준어 -> 제주어
- Made by. 구름 자연어처리 과정 3기 3조!!
- github link : https://github.com/Goormnlpteam3/JeBERT
## 1. Seq2Seq Transformer Model
- encoder : BertConfig
- decoder : BertConfig
- Tokenizer : WordPiece Tokenizer
## 2. Dataset
- Jit Dataset
- AI HUB(+아래아 문자)_v2
## 3. Hyper Parameters
- Epoch : 10 epochs(best at 7 epoch)
- Random Seed : 42
- Learning Rate : 5e-5
- Warm up Ratio : 0.1
- Batch Size : 32
## 4. BLEU Score
- Jit + AI HUB(+아래아 문자) Dataset : 67.6
---
### CREDIT
- 주형준 : [email protected]
- 강가람 : [email protected]
- 고광연 : [email protected]
- 김수연 : [email protected]
- 이원경 : [email protected]
- 조성은 : [email protected] | a5b95519c32c5ac5fffe4732cd9b31d8 |
anas-awadalla/t5-base-few-shot-k-256-finetuned-squad-infilling-seed-4 | anas-awadalla | t5 | 17 | 1 | transformers | 0 | text2text-generation | true | false | false | apache-2.0 | null | ['squad'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 965 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-few-shot-k-256-finetuned-squad-infilling-seed-4
This model is a fine-tuned version of [google/t5-v1_1-base](https://huggingface.co/google/t5-v1_1-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 35.0
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.11.6
| 5dcb7a2d61a3d8cde604553b3150832f |
zhiguoxu/chinese-macbert-base-finetuned-ner | zhiguoxu | bert | 218 | 6 | transformers | 0 | token-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 2,357 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# chinese-macbert-base-finetuned-ner
This model is a fine-tuned version of [hfl/chinese-macbert-base](https://huggingface.co/hfl/chinese-macbert-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2420
- F1: 0.9224
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 57
- eval_batch_size: 57
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.6141 | 1.0 | 1 | 2.6454 | 0.0 |
| 2.7076 | 2.0 | 2 | 2.0034 | 0.0 |
| 2.0979 | 3.0 | 3 | 1.6276 | 0.0 |
| 1.7264 | 4.0 | 4 | 1.3419 | 0.3522 |
| 1.4691 | 5.0 | 5 | 1.1239 | 0.4091 |
| 1.2504 | 6.0 | 6 | 0.9532 | 0.5514 |
| 1.0798 | 7.0 | 7 | 0.8129 | 0.5895 |
| 0.9279 | 8.0 | 8 | 0.6987 | 0.625 |
| 0.8179 | 9.0 | 9 | 0.6081 | 0.6392 |
| 0.7202 | 10.0 | 10 | 0.5346 | 0.6667 |
| 0.6377 | 11.0 | 11 | 0.4731 | 0.7451 |
| 0.5751 | 12.0 | 12 | 0.4226 | 0.7925 |
| 0.5202 | 13.0 | 13 | 0.3804 | 0.7685 |
| 0.4733 | 14.0 | 14 | 0.3447 | 0.7928 |
| 0.44 | 15.0 | 15 | 0.3145 | 0.8509 |
| 0.4047 | 16.0 | 16 | 0.2899 | 0.8918 |
| 0.3773 | 17.0 | 17 | 0.2707 | 0.8966 |
| 0.353 | 18.0 | 18 | 0.2563 | 0.9052 |
| 0.3413 | 19.0 | 19 | 0.2468 | 0.9224 |
| 0.3314 | 20.0 | 20 | 0.2420 | 0.9224 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.12.0+cu102
- Datasets 1.18.4
- Tokenizers 0.12.1
| 2a463960b4873fcfcfd597ff81f9c2f7 |
Helsinki-NLP/opus-mt-tc-big-en-pt | Helsinki-NLP | marian | 13 | 3,251 | transformers | 4 | translation | true | true | false | cc-by-4.0 | ['en', 'pt', 'pt_br'] | null | null | 1 | 0 | 1 | 0 | 0 | 0 | 0 | ['translation', 'opus-mt-tc'] | true | true | true | 5,634 | false | # opus-mt-tc-big-en-pt
Neural machine translation model for translating from English (en) to Portuguese (pt).
This model is part of the [OPUS-MT project](https://github.com/Helsinki-NLP/Opus-MT), an effort to make neural machine translation models widely available and accessible for many languages in the world. All models are originally trained using the amazing framework of [Marian NMT](https://marian-nmt.github.io/), an efficient NMT implementation written in pure C++. The models have been converted to pyTorch using the transformers library by huggingface. Training data is taken from [OPUS](https://opus.nlpl.eu/) and training pipelines use the procedures of [OPUS-MT-train](https://github.com/Helsinki-NLP/Opus-MT-train).
* Publications: [OPUS-MT – Building open translation services for the World](https://aclanthology.org/2020.eamt-1.61/) and [The Tatoeba Translation Challenge – Realistic Data Sets for Low Resource and Multilingual MT](https://aclanthology.org/2020.wmt-1.139/) (Please, cite if you use this model.)
```
@inproceedings{tiedemann-thottingal-2020-opus,
title = "{OPUS}-{MT} {--} Building open translation services for the World",
author = {Tiedemann, J{\"o}rg and Thottingal, Santhosh},
booktitle = "Proceedings of the 22nd Annual Conference of the European Association for Machine Translation",
month = nov,
year = "2020",
address = "Lisboa, Portugal",
publisher = "European Association for Machine Translation",
url = "https://aclanthology.org/2020.eamt-1.61",
pages = "479--480",
}
@inproceedings{tiedemann-2020-tatoeba,
title = "The Tatoeba Translation Challenge {--} Realistic Data Sets for Low Resource and Multilingual {MT}",
author = {Tiedemann, J{\"o}rg},
booktitle = "Proceedings of the Fifth Conference on Machine Translation",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.wmt-1.139",
pages = "1174--1182",
}
```
## Model info
* Release: 2022-03-13
* source language(s): eng
* target language(s): pob por
* valid target language labels: >>pob<< >>por<<
* model: transformer-big
* data: opusTCv20210807+bt ([source](https://github.com/Helsinki-NLP/Tatoeba-Challenge))
* tokenization: SentencePiece (spm32k,spm32k)
* original model: [opusTCv20210807+bt_transformer-big_2022-03-13.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-por/opusTCv20210807+bt_transformer-big_2022-03-13.zip)
* more information released models: [OPUS-MT eng-por README](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-por/README.md)
* more information about the model: [MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)
This is a multilingual translation model with multiple target languages. A sentence initial language token is required in the form of `>>id<<` (id = valid target language ID), e.g. `>>pob<<`
## Usage
A short example code:
```python
from transformers import MarianMTModel, MarianTokenizer
src_text = [
">>por<< Tom tried to stab me.",
">>por<< He has been to Hawaii several times."
]
model_name = "pytorch-models/opus-mt-tc-big-en-pt"
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
for t in translated:
print( tokenizer.decode(t, skip_special_tokens=True) )
# expected output:
# O Tom tentou esfaquear-me.
# Ele já esteve no Havaí várias vezes.
```
You can also use OPUS-MT models with the transformers pipelines, for example:
```python
from transformers import pipeline
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-tc-big-en-pt")
print(pipe(">>por<< Tom tried to stab me."))
# expected output: O Tom tentou esfaquear-me.
```
## Benchmarks
* test set translations: [opusTCv20210807+bt_transformer-big_2022-03-13.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-por/opusTCv20210807+bt_transformer-big_2022-03-13.test.txt)
* test set scores: [opusTCv20210807+bt_transformer-big_2022-03-13.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-por/opusTCv20210807+bt_transformer-big_2022-03-13.eval.txt)
* benchmark results: [benchmark_results.txt](benchmark_results.txt)
* benchmark output: [benchmark_translations.zip](benchmark_translations.zip)
| langpair | testset | chr-F | BLEU | #sent | #words |
|----------|---------|-------|-------|-------|--------|
| eng-por | tatoeba-test-v2021-08-07 | 0.69320 | 49.6 | 13222 | 105265 |
| eng-por | flores101-devtest | 0.71673 | 50.4 | 1012 | 26519 |
## Acknowledgements
The work is supported by the [European Language Grid](https://www.european-language-grid.eu/) as [pilot project 2866](https://live.european-language-grid.eu/catalogue/#/resource/projects/2866), by the [FoTran project](https://www.helsinki.fi/en/researchgroups/natural-language-understanding-with-cross-lingual-grounding), funded by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 771113), and the [MeMAD project](https://memad.eu/), funded by the European Union’s Horizon 2020 Research and Innovation Programme under grant agreement No 780069. We are also grateful for the generous computational resources and IT infrastructure provided by [CSC -- IT Center for Science](https://www.csc.fi/), Finland.
## Model conversion info
* transformers version: 4.16.2
* OPUS-MT git hash: 3405783
* port time: Wed Apr 13 17:48:54 EEST 2022
* port machine: LM0-400-22516.local
| f45be0cd5669a4b113d710e511bf949e |
gokuls/bert-base-uncased-mrpc | gokuls | bert | 17 | 73 | transformers | 0 | text-classification | true | false | false | apache-2.0 | ['en'] | ['glue'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 2,061 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-mrpc
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the GLUE MRPC dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3693
- Accuracy: 0.8407
- F1: 0.8825
- Combined Score: 0.8616
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Combined Score |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:--------------:|
| 0.5716 | 1.0 | 29 | 0.5020 | 0.7475 | 0.8437 | 0.7956 |
| 0.3969 | 2.0 | 58 | 0.3693 | 0.8407 | 0.8825 | 0.8616 |
| 0.2182 | 3.0 | 87 | 0.5412 | 0.8235 | 0.88 | 0.8518 |
| 0.1135 | 4.0 | 116 | 0.5104 | 0.8260 | 0.8748 | 0.8504 |
| 0.0772 | 5.0 | 145 | 0.6428 | 0.8186 | 0.8655 | 0.8420 |
| 0.049 | 6.0 | 174 | 0.6366 | 0.8260 | 0.8725 | 0.8493 |
| 0.0356 | 7.0 | 203 | 0.8414 | 0.8358 | 0.8896 | 0.8627 |
| 0.0335 | 8.0 | 232 | 0.8573 | 0.8137 | 0.8676 | 0.8407 |
| 0.0234 | 9.0 | 261 | 0.8893 | 0.8309 | 0.8856 | 0.8582 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.9.0
- Tokenizers 0.13.2
| 8d7a27554db4dfb535b333e658cfded3 |
transformersbook/distilbert-base-uncased-finetuned-clinc | transformersbook | distilbert | 47 | 53 | transformers | 1 | text-classification | true | false | false | apache-2.0 | null | ['clinc_oos'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,838 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-clinc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the clinc_oos dataset. The model is used in Chapter 8: Making Transformers Efficient in Production in the [NLP with Transformers book](https://learning.oreilly.com/library/view/natural-language-processing/9781098103231/). You can find the full code in the accompanying [Github repository](https://github.com/nlp-with-transformers/notebooks/blob/main/08_model-compression.ipynb).
It achieves the following results on the evaluation set:
- Loss: 0.7773
- Accuracy: 0.9174
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 4.2923 | 1.0 | 318 | 3.2893 | 0.7423 |
| 2.6307 | 2.0 | 636 | 1.8837 | 0.8281 |
| 1.5483 | 3.0 | 954 | 1.1583 | 0.8968 |
| 1.0153 | 4.0 | 1272 | 0.8618 | 0.9094 |
| 0.7958 | 5.0 | 1590 | 0.7773 | 0.9174 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.9.1+cu102
- Datasets 1.13.0
- Tokenizers 0.10.3
| f347d9bc19ca04737cd515774e8f2231 |
gcmsrc/xlm-roberta-base-finetuned-panx-fr | gcmsrc | xlm-roberta | 10 | 13 | transformers | 0 | token-classification | true | false | false | mit | null | ['xtreme'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,320 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-fr
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1388
- F1: 0.9069
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.7753 | 1.0 | 96 | 0.3149 | 0.7673 |
| 0.3286 | 2.0 | 192 | 0.1819 | 0.8707 |
| 0.2197 | 3.0 | 288 | 0.1388 | 0.9069 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.1+cu102
- Datasets 1.16.1
- Tokenizers 0.10.3
| 1140ef4f8127d67f70b904f222ee2b96 |
m-aliabbas/idrak_wav2vec_tr | m-aliabbas | wav2vec2 | 13 | 7 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | null | ['common_voice'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,058 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# idrak_wav2vec_tr
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu113
- Datasets 1.18.3
- Tokenizers 0.10.3
| 6e4bb4a8c2691c05cfcd139b600ecc59 |
SetFit/distilbert-base-uncased__sst2__train-32-2 | SetFit | distilbert | 10 | 5 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 2,137 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased__sst2__train-32-2
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4805
- Accuracy: 0.7699
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.7124 | 1.0 | 13 | 0.6882 | 0.5385 |
| 0.6502 | 2.0 | 26 | 0.6715 | 0.5385 |
| 0.6001 | 3.0 | 39 | 0.6342 | 0.6154 |
| 0.455 | 4.0 | 52 | 0.5713 | 0.7692 |
| 0.2605 | 5.0 | 65 | 0.5562 | 0.7692 |
| 0.1258 | 6.0 | 78 | 0.6799 | 0.7692 |
| 0.0444 | 7.0 | 91 | 0.8096 | 0.7692 |
| 0.0175 | 8.0 | 104 | 0.9281 | 0.6923 |
| 0.0106 | 9.0 | 117 | 0.9826 | 0.6923 |
| 0.0077 | 10.0 | 130 | 1.0254 | 0.7692 |
| 0.0056 | 11.0 | 143 | 1.0667 | 0.7692 |
| 0.0042 | 12.0 | 156 | 1.1003 | 0.7692 |
| 0.0036 | 13.0 | 169 | 1.1299 | 0.7692 |
| 0.0034 | 14.0 | 182 | 1.1623 | 0.6923 |
| 0.003 | 15.0 | 195 | 1.1938 | 0.6923 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2
- Tokenizers 0.10.3
| 0d3d33e01df81430bc0ebe65da897672 |
anton-l/wav2vec2-large-xlsr-53-chuvash | anton-l | wav2vec2 | 9 | 8 | transformers | 0 | automatic-speech-recognition | true | false | true | apache-2.0 | ['cv'] | ['common_voice'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | true | true | true | 3,724 | false |
# Wav2Vec2-Large-XLSR-53-Chuvash
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Chuvash using the [Common Voice](https://huggingface.co/datasets/common_voice) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "cv", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("anton-l/wav2vec2-large-xlsr-53-chuvash")
model = Wav2Vec2ForCTC.from_pretrained("anton-l/wav2vec2-large-xlsr-53-chuvash")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Chuvash test data of Common Voice.
```python
import torch
import torchaudio
import urllib.request
import tarfile
import pandas as pd
from tqdm.auto import tqdm
from datasets import load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
# Download the raw data instead of using HF datasets to save disk space
data_url = "https://voice-prod-bundler-ee1969a6ce8178826482b88e843c335139bd3fb4.s3.amazonaws.com/cv-corpus-6.1-2020-12-11/cv.tar.gz"
filestream = urllib.request.urlopen(data_url)
data_file = tarfile.open(fileobj=filestream, mode="r|gz")
data_file.extractall()
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("anton-l/wav2vec2-large-xlsr-53-chuvash")
model = Wav2Vec2ForCTC.from_pretrained("anton-l/wav2vec2-large-xlsr-53-chuvash")
model.to("cuda")
cv_test = pd.read_csv("cv-corpus-6.1-2020-12-11/cv/test.tsv", sep='\t')
clips_path = "cv-corpus-6.1-2020-12-11/cv/clips/"
def clean_sentence(sent):
sent = sent.lower()
# replace non-alpha characters with space
sent = "".join(ch if ch.isalpha() else " " for ch in sent)
# remove repeated spaces
sent = " ".join(sent.split())
return sent
targets = []
preds = []
for i, row in tqdm(cv_test.iterrows(), total=cv_test.shape[0]):
row["sentence"] = clean_sentence(row["sentence"])
speech_array, sampling_rate = torchaudio.load(clips_path + row["path"])
resampler = torchaudio.transforms.Resample(sampling_rate, 16_000)
row["speech"] = resampler(speech_array).squeeze().numpy()
inputs = processor(row["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
targets.append(row["sentence"])
preds.append(processor.batch_decode(pred_ids)[0])
print("WER: {:2f}".format(100 * wer.compute(predictions=preds, references=targets)))
```
**Test Result**: 40.01 %
## Training
The Common Voice `train` and `validation` datasets were used for training.
The script used for training can be found [here](github.com)
| 7efeceeea52fc8412ced499ef42a9c9f |
WALIDALI/asmagalally-with-protogen-v2-2 | WALIDALI | null | 18 | 8 | diffusers | 0 | text-to-image | false | false | false | creativeml-openrail-m | null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 | ['text-to-image', 'stable-diffusion'] | false | true | true | 441 | false | ### Asmagalally-with-Protogen-v2.2- Dreambooth model trained by WALIDALI with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 1aa2f288e4a2d94761f2a31e558b2849 |
muhtasham/tiny-mlm-glue-stsb-target-glue-mrpc | muhtasham | bert | 10 | 1 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,643 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-stsb-target-glue-mrpc
This model is a fine-tuned version of [muhtasham/tiny-mlm-glue-stsb](https://huggingface.co/muhtasham/tiny-mlm-glue-stsb) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2364
- Accuracy: 0.7132
- F1: 0.8047
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- num_epochs: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.5901 | 4.35 | 500 | 0.5567 | 0.7108 | 0.8072 |
| 0.4581 | 8.7 | 1000 | 0.5798 | 0.7377 | 0.8283 |
| 0.3115 | 13.04 | 1500 | 0.6576 | 0.7426 | 0.8247 |
| 0.197 | 17.39 | 2000 | 0.7977 | 0.7255 | 0.8152 |
| 0.1153 | 21.74 | 2500 | 1.0637 | 0.7059 | 0.7973 |
| 0.0843 | 26.09 | 3000 | 1.2364 | 0.7132 | 0.8047 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
| e7d94714f8f33eb35efcc8610a09e800 |
asapp/sew-d-mid-400k | asapp | sew-d | 5 | 31 | transformers | 1 | feature-extraction | true | false | false | apache-2.0 | ['en'] | ['librispeech_asr'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['speech'] | false | true | true | 1,699 | false |
# SEW-D-mid
[SEW-D by ASAPP Research](https://github.com/asappresearch/sew)
The base model pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz. Note that this model should be fine-tuned on a downstream task, like Automatic Speech Recognition, Speaker Identification, Intent Classification, Emotion Recognition, etc...
Paper: [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870)
Authors: Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi
**Abstract**
This paper is a study of performance-efficiency trade-offs in pre-trained models for automatic speech recognition (ASR). We focus on wav2vec 2.0, and formalize several architecture designs that influence both the model performance and its efficiency. Putting together all our observations, we introduce SEW (Squeezed and Efficient Wav2vec), a pre-trained model architecture with significant improvements along both performance and efficiency dimensions across a variety of training setups. For example, under the 100h-960h semi-supervised setup on LibriSpeech, SEW achieves a 1.9x inference speedup compared to wav2vec 2.0, with a 13.5% relative reduction in word error rate. With a similar inference time, SEW reduces word error rate by 25-50% across different model sizes.
The original model can be found under https://github.com/asappresearch/sew#model-checkpoints .
# Usage
See [this blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) for more information on how to fine-tune the model. Note that the class `Wav2Vec2ForCTC` has to be replaced by `SEWDForCTC`.
| 3ea3c5d66233dfbfb7aff8575436b206 |
MarioPenguin/bert-model-english1 | MarioPenguin | bert | 8 | 7 | transformers | 0 | text-classification | false | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_keras_callback'] | true | true | true | 1,462 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# bert-model-english1
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0274
- Train Accuracy: 0.9914
- Validation Loss: 0.3493
- Validation Accuracy: 0.9303
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': 5e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train Accuracy | Validation Loss | Validation Accuracy | Epoch |
|:----------:|:--------------:|:---------------:|:-------------------:|:-----:|
| 0.0366 | 0.9885 | 0.3013 | 0.9299 | 0 |
| 0.0261 | 0.9912 | 0.3445 | 0.9351 | 1 |
| 0.0274 | 0.9914 | 0.3493 | 0.9303 | 2 |
### Framework versions
- Transformers 4.16.2
- TensorFlow 2.7.0
- Datasets 1.18.3
- Tokenizers 0.11.0
| 0b852fec4a973ed5dc1425d625b8d9e5 |
anas-awadalla/roberta-base-few-shot-k-16-finetuned-squad-seed-10 | anas-awadalla | roberta | 17 | 6 | transformers | 0 | question-answering | true | false | false | mit | null | ['squad'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 986 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-few-shot-k-16-finetuned-squad-seed-10
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 200
### Training results
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.17.0
- Tokenizers 0.10.3
| 43e7b551d18145546b48735148db9da6 |
scasutt/wav2vec2-base_toy_train_data_augmented | scasutt | wav2vec2 | 7 | 5 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 2,390 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base_toy_train_data_augmented
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0238
- Wer: 0.6969
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.12 | 1.05 | 250 | 3.3998 | 0.9982 |
| 3.0727 | 2.1 | 500 | 3.1261 | 0.9982 |
| 1.9729 | 3.15 | 750 | 1.4868 | 0.9464 |
| 1.3213 | 4.2 | 1000 | 1.2598 | 0.8833 |
| 1.0508 | 5.25 | 1250 | 1.0014 | 0.8102 |
| 0.8483 | 6.3 | 1500 | 0.9475 | 0.7944 |
| 0.7192 | 7.35 | 1750 | 0.9493 | 0.7686 |
| 0.6447 | 8.4 | 2000 | 0.9872 | 0.7573 |
| 0.6064 | 9.45 | 2250 | 0.9587 | 0.7447 |
| 0.5384 | 10.5 | 2500 | 0.9332 | 0.7320 |
| 0.4985 | 11.55 | 2750 | 0.9926 | 0.7315 |
| 0.4643 | 12.6 | 3000 | 1.0008 | 0.7292 |
| 0.4565 | 13.65 | 3250 | 0.9522 | 0.7171 |
| 0.449 | 14.7 | 3500 | 0.9685 | 0.7140 |
| 0.4307 | 15.75 | 3750 | 1.0080 | 0.7077 |
| 0.4239 | 16.81 | 4000 | 0.9950 | 0.7023 |
| 0.389 | 17.86 | 4250 | 1.0260 | 0.7007 |
| 0.3471 | 18.91 | 4500 | 1.0012 | 0.6966 |
| 0.3276 | 19.96 | 4750 | 1.0238 | 0.6969 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu102
- Datasets 2.0.0
- Tokenizers 0.11.6
| cfc6e71bd7ab5e9f7c8b82a44c4c74e2 |
sd-concepts-library/roblox-avatar | sd-concepts-library | null | 10 | 0 | null | 1 | null | false | false | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 1,257 | false | ### Roblox avatar on Stable Diffusion
why am i spending time making these?, anyways.
This is the `<roblox-avatar>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
photos were taken from pinterest.
Here is the new concept you will be able to use as an `object`:





| b24717809dc59e098e97bcd19616a555 |
adityavithaldas/distilbert-base-uncased-finetuned-ner | adityavithaldas | distilbert | 11 | 13 | transformers | 1 | token-classification | true | false | false | apache-2.0 | null | ['conll2003'] | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | false | true | true | 930 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ner
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the conll2003 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Framework versions
- Transformers 4.10.2
- Pytorch 1.9.0+cu102
- Datasets 1.12.1
- Tokenizers 0.10.3
| 7a2173108a35872520c76a54cb3813ec |
polejowska/swin-tiny-patch4-window7-224-lcbsi-wbc-new | polejowska | swin | 11 | 1 | transformers | 0 | image-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,709 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-lcbsi-wbc-new
This model is a fine-tuned version of [polejowska/swin-tiny-patch4-window7-224-lcbsi-wbc](https://huggingface.co/polejowska/swin-tiny-patch4-window7-224-lcbsi-wbc) on the WBC dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0457
- Accuracy: 0.992
- Precision: 0.9920
- Recall: 0.992
- F1: 0.9920
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002562
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 0.0936 | 0.98 | 27 | 0.0724 | 0.984 | 0.9841 | 0.984 | 0.9840 |
| 0.0276 | 1.98 | 54 | 0.0768 | 0.984 | 0.9841 | 0.984 | 0.9839 |
| 0.0133 | 2.98 | 81 | 0.0457 | 0.992 | 0.9920 | 0.992 | 0.9920 |
### Framework versions
- Transformers 4.25.1
- Pytorch 2.0.0.dev20230107
- Datasets 2.8.0
- Tokenizers 0.13.2
| 571c16bb87d562f958279ef3fd7e2997 |
AkashKhamkar/InSumT510k | AkashKhamkar | t5 | 7 | 1 | transformers | 0 | text2text-generation | true | false | false | afl-3.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 888 | false | ---
About :
This model can be used for text summarization.
The dataset on which it was fine tuned consisted of 10,323 articles.
The Data Fields :
- "Headline" : title of the article
- "articleBody" : the main article content
- "source" : the link to the readmore page.
The data splits were :
- Train : 8258.
- Vaildation : 2065.
### How to use along with pipeline
```python
from transformers import pipeline
from transformers import AutoTokenizer, AutoModelForSeq2Seq
tokenizer = AutoTokenizer.from_pretrained("AkashKhamkar/InSumT510k")
model = AutoModelForSeq2SeqLM.from_pretrained("AkashKhamkar/InSumT510k")
summarizer = pipeline("summarization", model=model, tokenizer=tokenizer)
summarizer("Text for summarization...", min_length=5, max_length=50)
```
language:
- English
library_name: Pytorch
tags:
- Summarization
- T5-base
- Conditional Modelling
-
| f19a50db7e0b912f0f5a488eff5c7e5f |
anas-awadalla/roberta-large-data-seed-0 | anas-awadalla | roberta | 17 | 3 | transformers | 0 | question-answering | true | false | false | mit | null | ['squad'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,028 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-large-data-seed-0
This model is a fine-tuned version of [roberta-large](https://huggingface.co/roberta-large) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 12
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- total_train_batch_size: 24
- total_eval_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2.0
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.0.0
- Tokenizers 0.11.6
| fdde17cdd471889cf7d09d07bc5348d2 |
anas-awadalla/roberta-base-few-shot-k-128-finetuned-squad-seed-42 | anas-awadalla | roberta | 13 | 5 | transformers | 0 | question-answering | true | false | false | mit | null | ['squad'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,041 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-few-shot-k-128-finetuned-squad-seed-42
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 200
### Training results
{'exact_match': 39.04446546830653, 'f1': 49.90230650794353}
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
| 16650d889caab94e4ea52460c9d251e3 |
lmqg/flan-t5-small-squad-ae | lmqg | t5 | 13 | 5 | transformers | 0 | text2text-generation | true | false | false | cc-by-4.0 | ['en'] | ['lmqg/qg_squad'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['answer extraction'] | true | true | true | 4,375 | false |
# Model Card of `lmqg/flan-t5-small-squad-ae`
This model is fine-tuned version of [google/flan-t5-small](https://huggingface.co/google/flan-t5-small) for answer extraction on the [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) (dataset_name: default) via [`lmqg`](https://github.com/asahi417/lm-question-generation).
### Overview
- **Language model:** [google/flan-t5-small](https://huggingface.co/google/flan-t5-small)
- **Language:** en
- **Training data:** [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) (default)
- **Online Demo:** [https://autoqg.net/](https://autoqg.net/)
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
### Usage
- With [`lmqg`](https://github.com/asahi417/lm-question-generation#lmqg-language-model-for-question-generation-)
```python
from lmqg import TransformersQG
# initialize model
model = TransformersQG(language="en", model="lmqg/flan-t5-small-squad-ae")
# model prediction
answers = model.generate_a("William Turner was an English painter who specialised in watercolour landscapes")
```
- With `transformers`
```python
from transformers import pipeline
pipe = pipeline("text2text-generation", "lmqg/flan-t5-small-squad-ae")
output = pipe("extract answers: <hl> Beyonce further expanded her acting career, starring as blues singer Etta James in the 2008 musical biopic, Cadillac Records. <hl> Her performance in the film received praise from critics, and she garnered several nominations for her portrayal of James, including a Satellite Award nomination for Best Supporting Actress, and a NAACP Image Award nomination for Outstanding Supporting Actress.")
```
## Evaluation
- ***Metric (Answer Extraction)***: [raw metric file](https://huggingface.co/lmqg/flan-t5-small-squad-ae/raw/main/eval/metric.first.answer.paragraph_sentence.answer.lmqg_qg_squad.default.json)
| | Score | Type | Dataset |
|:-----------------|--------:|:--------|:---------------------------------------------------------------|
| AnswerExactMatch | 55.83 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| AnswerF1Score | 68.13 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| BERTScore | 91.1 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_1 | 48.25 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_2 | 43.39 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_3 | 38.64 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_4 | 34.6 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| METEOR | 42.59 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| MoverScore | 80.54 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| ROUGE_L | 67.61 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
## Training hyperparameters
The following hyperparameters were used during fine-tuning:
- dataset_path: lmqg/qg_squad
- dataset_name: default
- input_types: ['paragraph_sentence']
- output_types: ['answer']
- prefix_types: ['ae']
- model: google/flan-t5-small
- max_length: 512
- max_length_output: 32
- epoch: 8
- batch: 64
- lr: 0.0001
- fp16: False
- random_seed: 1
- gradient_accumulation_steps: 1
- label_smoothing: 0.15
The full configuration can be found at [fine-tuning config file](https://huggingface.co/lmqg/flan-t5-small-squad-ae/raw/main/trainer_config.json).
## Citation
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
```
| 224f7ad3a025255cbe91c101491e0314 |
WillHeld/t5-base-vanilla-cstop_artificial | WillHeld | mt5 | 11 | 4 | transformers | 0 | text2text-generation | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,953 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-vanilla-cstop_artificial
This model is a fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1598
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 64
- total_train_batch_size: 512
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 3000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 1.2724 | 28.5 | 200 | 0.0776 |
| 0.0151 | 57.13 | 400 | 0.1004 |
| 0.1727 | 85.63 | 600 | 0.1202 |
| 0.0133 | 114.25 | 800 | 0.1005 |
| 0.0044 | 142.75 | 1000 | 0.1131 |
| 0.0022 | 171.38 | 1200 | 0.1285 |
| 0.0018 | 199.88 | 1400 | 0.1349 |
| 0.0014 | 228.5 | 1600 | 0.1451 |
| 0.003 | 257.13 | 1800 | 0.1215 |
| 0.003 | 285.63 | 2000 | 0.1345 |
| 0.0012 | 314.25 | 2200 | 0.1520 |
| 0.001 | 342.75 | 2400 | 0.1486 |
| 0.0008 | 371.38 | 2600 | 0.1559 |
| 0.0007 | 399.88 | 2800 | 0.1590 |
| 0.0006 | 428.5 | 3000 | 0.1598 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0+cu117
- Datasets 2.7.0
- Tokenizers 0.13.2
| d57079ed1326c09958e679b24d89c6ab |
muhtasham/tiny-vanilla-target-glue-wnli | muhtasham | bert | 10 | 1 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,438 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-vanilla-target-glue-wnli
This model is a fine-tuned version of [google/bert_uncased_L-2_H-128_A-2](https://huggingface.co/google/bert_uncased_L-2_H-128_A-2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7580
- Accuracy: 0.0986
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- num_epochs: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6894 | 25.0 | 500 | 0.7552 | 0.3099 |
| 0.6681 | 50.0 | 1000 | 0.9797 | 0.1549 |
| 0.6258 | 75.0 | 1500 | 1.3863 | 0.1127 |
| 0.5659 | 100.0 | 2000 | 1.7580 | 0.0986 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
| 88a346a2792f245696171a00f6d98940 |
kohya-ss/kawase-hasui-diffusion | kohya-ss | null | 8 | 0 | null | 5 | text-to-image | false | false | false | creativeml-openrail-m | ['en'] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['stable-diffusion', 'text-to-image'] | false | true | true | 1,323 | false |
Kawase Hasui Diffusion is trained on pantings by [KAWASE Hasui(川瀬巴水)](https://en.wikipedia.org/wiki/Hasui_Kawase).
The model has been trained on Stable Diffusion v2-1 with DreamBooth method with a learning rate of 1.0e-6 for 2,600 steps with the batch size of 8 (8 train or reg images) on 169 training images and 664 regularization images.
This model is based on SD2.1 768/v, so if you use this model in the poplular Web UI, please rename 'v2-inference-v.yaml' to 'kawase-hasui-epoch-000003.yaml' (or ~_fp16.yaml) and place it to the same folder to .safetensors.
The training prompt is "picture by lvl".
## Examples

```
picture by lvl, japan tourism poster
seed : 968191097, sampler: k_euler_a, steps : 160, CFG scale : 5.5
```

```
picture by lvl, cyberpunk akihabara
seed : 1418478714, sampler: k_euler_a, steps : 160, CFG scale : 5.5
```

```
picture by lvl, ruined castle, fantasy, dawn
seed : 897433524, sampler: k_euler_a, steps : 160, CFG scale : 5.5
```

```
picture by lvl, fantasy, party of adventurers, ready to fight, in front of ruined temple
seed : 1814292911, sampler: k_euler_a, steps : 160, CFG scale : 5.5
```
## License
CreativeML Open RAIL-M
| 086d7eb54501527320b043b047d1b708 |
sd-concepts-library/thunderdome-cover | sd-concepts-library | null | 42 | 0 | null | 2 | null | false | false | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 5,178 | false | ### thunderdome-cover on Stable Diffusion
This is the `<thunderdome-cover>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:





































| d03f878f97e393d669e915a38a430438 |
ali2066/finetuned_token_2e-05_16_02_2022-14_25_47 | ali2066 | distilbert | 13 | 10 | transformers | 0 | token-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,787 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned_token_2e-05_16_02_2022-14_25_47
This model is a fine-tuned version of [distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1722
- Precision: 0.3378
- Recall: 0.3615
- F1: 0.3492
- Accuracy: 0.9448
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 38 | 0.3781 | 0.1512 | 0.2671 | 0.1931 | 0.8216 |
| No log | 2.0 | 76 | 0.3020 | 0.1748 | 0.2938 | 0.2192 | 0.8551 |
| No log | 3.0 | 114 | 0.2723 | 0.1938 | 0.3339 | 0.2452 | 0.8663 |
| No log | 4.0 | 152 | 0.2574 | 0.2119 | 0.3506 | 0.2642 | 0.8727 |
| No log | 5.0 | 190 | 0.2521 | 0.2121 | 0.3623 | 0.2676 | 0.8756 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.1+cu113
- Datasets 1.18.0
- Tokenizers 0.10.3
| 41bca4d58f49ff76cc57d3a5caf88950 |
keras-io/pointnet_segmentation | keras-io | null | 6 | 8 | keras | 2 | null | false | false | false | cc0-1.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['pointnet', 'segmentation', '3d', 'image'] | false | true | true | 1,990 | false | ## Point cloud segmentation with PointNet
This repo contains [an Implementation of a PointNet-based model for segmenting point clouds.](https://keras.io/examples/vision/pointnet_segmentation/).
Full credits to [Soumik Rakshit](https://github.com/soumik12345), [Sayak Paul](https://github.com/sayakpaul)
## Background Information
A "point cloud" is an important type of data structure for storing geometric shape data. Due to its irregular format, it's often transformed into regular 3D voxel grids or collections of images before being used in deep learning applications, a step which makes the data unnecessarily large. The PointNet family of models solves this problem by directly consuming point clouds, respecting the permutation-invariance property of the point data. The PointNet family of models provides a simple, unified architecture for applications ranging from object classification, part segmentation, to scene semantic parsing.
In this example, we demonstrate the implementation of the PointNet architecture for shape segmentation.
**References**
* [PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation](https://arxiv.org/abs/1612.00593)
* [Point cloud classification with PointNet](https://keras.io/examples/vision/pointnet/)
* [Spatial Transformer Networks](https://arxiv.org/abs/1506.02025)

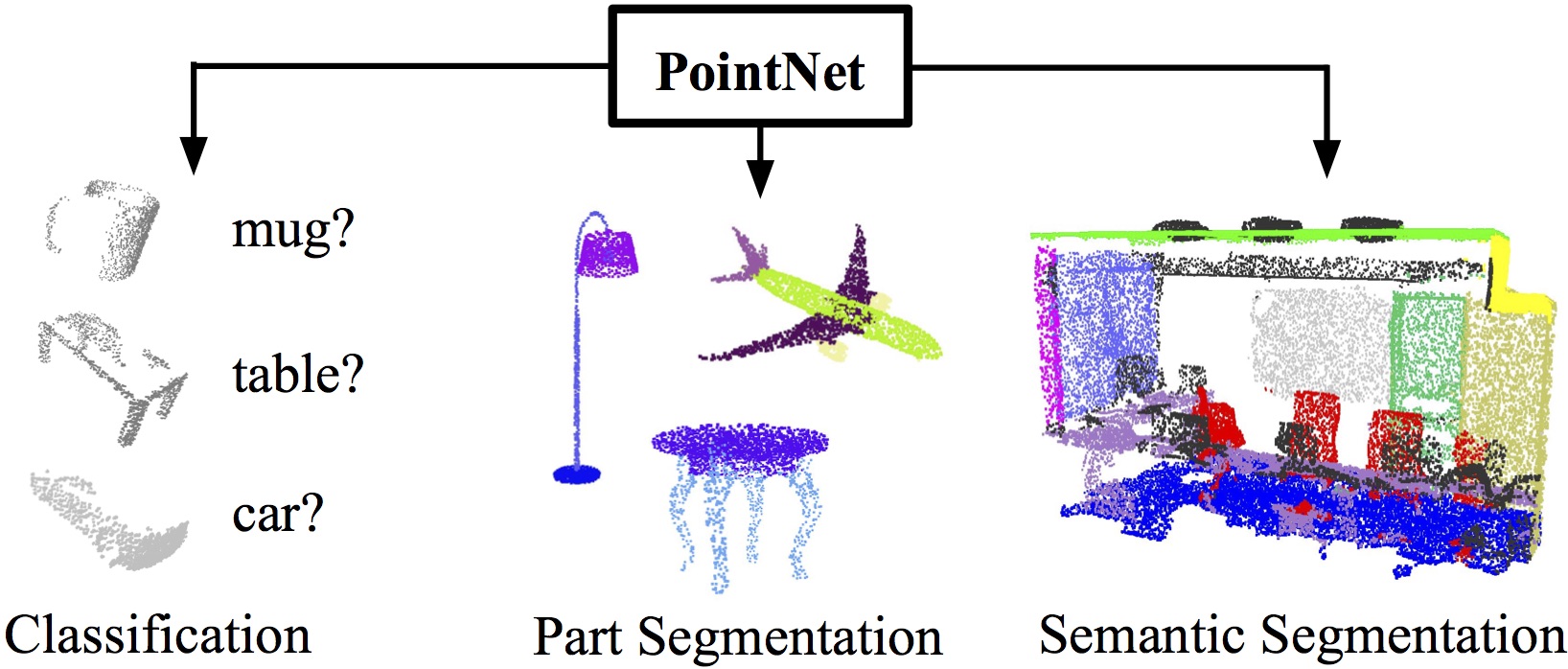
## Training Dataset
This model was trained on the [ShapeNet dataset](https://shapenet.org/).
The ShapeNet dataset is an ongoing effort to establish a richly-annotated, large-scale dataset of 3D shapes. ShapeNetCore is a subset of the full ShapeNet dataset with clean single 3D models and manually verified category and alignment annotations. It covers 55 common object categories, with about 51,300 unique 3D models.
**Prediction example**
| 42b96852d159c991508ee0650972b821 |
timm/convnext_large.fb_in1k | timm | null | 4 | 471 | timm | 0 | image-classification | true | false | false | apache-2.0 | null | ['imagenet-1k'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['image-classification', 'timm'] | false | true | true | 21,330 | false | # Model card for convnext_large.fb_in1k
A ConvNeXt image classification model. Pretrained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 197.8
- GMACs: 34.4
- Activations (M): 43.1
- Image size: 224 x 224
- **Papers:**
- A ConvNet for the 2020s: https://arxiv.org/abs/2201.03545
- **Original:** https://github.com/facebookresearch/ConvNeXt
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model('convnext_large.fb_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model(
'convnext_large.fb_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g. for convnext_base:
# torch.Size([1, 128, 56, 56])
# torch.Size([1, 256, 28, 28])
# torch.Size([1, 512, 14, 14])
# torch.Size([1, 1024, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model(
'convnext_large.fb_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, num_features, H, W) tensor
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
### By Top-1
All timing numbers from eager model PyTorch 1.13 on RTX 3090 w/ AMP.
|model |top1 |top5 |img_size|param_count|gmacs |macts |samples_per_sec|batch_size|
|----------------------------------------------|------|------|--------|-----------|------|------|---------------|----------|
|[convnextv2_huge.fcmae_ft_in22k_in1k_512](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_512)|88.848|98.742|512 |660.29 |600.81|413.07|28.58 |48 |
|[convnextv2_huge.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_384)|88.668|98.738|384 |660.29 |337.96|232.35|50.56 |64 |
|[convnextv2_large.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k_384)|88.196|98.532|384 |197.96 |101.1 |126.74|128.94 |128 |
|[convnext_xlarge.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k_384)|87.75 |98.556|384 |350.2 |179.2 |168.99|124.85 |192 |
|[convnextv2_base.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k_384)|87.646|98.422|384 |88.72 |45.21 |84.49 |209.51 |256 |
|[convnext_large.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k_384)|87.476|98.382|384 |197.77 |101.1 |126.74|194.66 |256 |
|[convnext_large_mlp.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_augreg_ft_in1k)|87.344|98.218|256 |200.13 |44.94 |56.33 |438.08 |256 |
|[convnextv2_large.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k)|87.26 |98.248|224 |197.96 |34.4 |43.13 |376.84 |256 |
|[convnext_xlarge.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k)|87.002|98.208|224 |350.2 |60.98 |57.5 |368.01 |256 |
|[convnext_base.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k_384)|86.796|98.264|384 |88.59 |45.21 |84.49 |366.54 |256 |
|[convnextv2_base.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k)|86.74 |98.022|224 |88.72 |15.38 |28.75 |624.23 |256 |
|[convnext_large.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k)|86.636|98.028|224 |197.77 |34.4 |43.13 |581.43 |256 |
|[convnext_base.clip_laiona_augreg_ft_in1k_384](https://huggingface.co/timm/convnext_base.clip_laiona_augreg_ft_in1k_384)|86.504|97.97 |384 |88.59 |45.21 |84.49 |368.14 |256 |
|[convnextv2_huge.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in1k)|86.256|97.75 |224 |660.29 |115.0 |79.07 |154.72 |256 |
|[convnext_small.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_small.in12k_ft_in1k_384)|86.182|97.92 |384 |50.22 |25.58 |63.37 |516.19 |256 |
|[convnext_base.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in1k)|86.154|97.68 |256 |88.59 |20.09 |37.55 |819.86 |256 |
|[convnext_base.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k)|85.822|97.866|224 |88.59 |15.38 |28.75 |1037.66 |256 |
|[convnext_small.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k_384)|85.778|97.886|384 |50.22 |25.58 |63.37 |518.95 |256 |
|[convnextv2_large.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in1k)|85.742|97.584|224 |197.96 |34.4 |43.13 |375.23 |256 |
|[convnext_small.in12k_ft_in1k](https://huggingface.co/timm/convnext_small.in12k_ft_in1k)|85.174|97.506|224 |50.22 |8.71 |21.56 |1474.31 |256 |
|[convnext_tiny.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k_384)|85.118|97.608|384 |28.59 |13.14 |39.48 |856.76 |256 |
|[convnextv2_tiny.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k_384)|85.112|97.63 |384 |28.64 |13.14 |39.48 |491.32 |256 |
|[convnextv2_base.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in1k)|84.874|97.09 |224 |88.72 |15.38 |28.75 |625.33 |256 |
|[convnext_small.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k)|84.562|97.394|224 |50.22 |8.71 |21.56 |1478.29 |256 |
|[convnext_large.fb_in1k](https://huggingface.co/timm/convnext_large.fb_in1k)|84.282|96.892|224 |197.77 |34.4 |43.13 |584.28 |256 |
|[convnext_tiny.in12k_ft_in1k](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k)|84.186|97.124|224 |28.59 |4.47 |13.44 |2433.7 |256 |
|[convnext_tiny.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k_384)|84.084|97.14 |384 |28.59 |13.14 |39.48 |862.95 |256 |
|[convnextv2_tiny.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k)|83.894|96.964|224 |28.64 |4.47 |13.44 |1452.72 |256 |
|[convnext_base.fb_in1k](https://huggingface.co/timm/convnext_base.fb_in1k)|83.82 |96.746|224 |88.59 |15.38 |28.75 |1054.0 |256 |
|[convnextv2_nano.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k_384)|83.37 |96.742|384 |15.62 |7.22 |24.61 |801.72 |256 |
|[convnext_small.fb_in1k](https://huggingface.co/timm/convnext_small.fb_in1k)|83.142|96.434|224 |50.22 |8.71 |21.56 |1464.0 |256 |
|[convnextv2_tiny.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in1k)|82.92 |96.284|224 |28.64 |4.47 |13.44 |1425.62 |256 |
|[convnext_tiny.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k)|82.898|96.616|224 |28.59 |4.47 |13.44 |2480.88 |256 |
|[convnext_nano.in12k_ft_in1k](https://huggingface.co/timm/convnext_nano.in12k_ft_in1k)|82.282|96.344|224 |15.59 |2.46 |8.37 |3926.52 |256 |
|[convnext_tiny_hnf.a2h_in1k](https://huggingface.co/timm/convnext_tiny_hnf.a2h_in1k)|82.216|95.852|224 |28.59 |4.47 |13.44 |2529.75 |256 |
|[convnext_tiny.fb_in1k](https://huggingface.co/timm/convnext_tiny.fb_in1k)|82.066|95.854|224 |28.59 |4.47 |13.44 |2346.26 |256 |
|[convnextv2_nano.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k)|82.03 |96.166|224 |15.62 |2.46 |8.37 |2300.18 |256 |
|[convnextv2_nano.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in1k)|81.83 |95.738|224 |15.62 |2.46 |8.37 |2321.48 |256 |
|[convnext_nano_ols.d1h_in1k](https://huggingface.co/timm/convnext_nano_ols.d1h_in1k)|80.866|95.246|224 |15.65 |2.65 |9.38 |3523.85 |256 |
|[convnext_nano.d1h_in1k](https://huggingface.co/timm/convnext_nano.d1h_in1k)|80.768|95.334|224 |15.59 |2.46 |8.37 |3915.58 |256 |
|[convnextv2_pico.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_pico.fcmae_ft_in1k)|80.304|95.072|224 |9.07 |1.37 |6.1 |3274.57 |256 |
|[convnext_pico.d1_in1k](https://huggingface.co/timm/convnext_pico.d1_in1k)|79.526|94.558|224 |9.05 |1.37 |6.1 |5686.88 |256 |
|[convnext_pico_ols.d1_in1k](https://huggingface.co/timm/convnext_pico_ols.d1_in1k)|79.522|94.692|224 |9.06 |1.43 |6.5 |5422.46 |256 |
|[convnextv2_femto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_femto.fcmae_ft_in1k)|78.488|93.98 |224 |5.23 |0.79 |4.57 |4264.2 |256 |
|[convnext_femto_ols.d1_in1k](https://huggingface.co/timm/convnext_femto_ols.d1_in1k)|77.86 |93.83 |224 |5.23 |0.82 |4.87 |6910.6 |256 |
|[convnext_femto.d1_in1k](https://huggingface.co/timm/convnext_femto.d1_in1k)|77.454|93.68 |224 |5.22 |0.79 |4.57 |7189.92 |256 |
|[convnextv2_atto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_atto.fcmae_ft_in1k)|76.664|93.044|224 |3.71 |0.55 |3.81 |4728.91 |256 |
|[convnext_atto_ols.a2_in1k](https://huggingface.co/timm/convnext_atto_ols.a2_in1k)|75.88 |92.846|224 |3.7 |0.58 |4.11 |7963.16 |256 |
|[convnext_atto.d2_in1k](https://huggingface.co/timm/convnext_atto.d2_in1k)|75.664|92.9 |224 |3.7 |0.55 |3.81 |8439.22 |256 |
### By Throughput (samples / sec)
All timing numbers from eager model PyTorch 1.13 on RTX 3090 w/ AMP.
|model |top1 |top5 |img_size|param_count|gmacs |macts |samples_per_sec|batch_size|
|----------------------------------------------|------|------|--------|-----------|------|------|---------------|----------|
|[convnext_atto.d2_in1k](https://huggingface.co/timm/convnext_atto.d2_in1k)|75.664|92.9 |224 |3.7 |0.55 |3.81 |8439.22 |256 |
|[convnext_atto_ols.a2_in1k](https://huggingface.co/timm/convnext_atto_ols.a2_in1k)|75.88 |92.846|224 |3.7 |0.58 |4.11 |7963.16 |256 |
|[convnext_femto.d1_in1k](https://huggingface.co/timm/convnext_femto.d1_in1k)|77.454|93.68 |224 |5.22 |0.79 |4.57 |7189.92 |256 |
|[convnext_femto_ols.d1_in1k](https://huggingface.co/timm/convnext_femto_ols.d1_in1k)|77.86 |93.83 |224 |5.23 |0.82 |4.87 |6910.6 |256 |
|[convnext_pico.d1_in1k](https://huggingface.co/timm/convnext_pico.d1_in1k)|79.526|94.558|224 |9.05 |1.37 |6.1 |5686.88 |256 |
|[convnext_pico_ols.d1_in1k](https://huggingface.co/timm/convnext_pico_ols.d1_in1k)|79.522|94.692|224 |9.06 |1.43 |6.5 |5422.46 |256 |
|[convnextv2_atto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_atto.fcmae_ft_in1k)|76.664|93.044|224 |3.71 |0.55 |3.81 |4728.91 |256 |
|[convnextv2_femto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_femto.fcmae_ft_in1k)|78.488|93.98 |224 |5.23 |0.79 |4.57 |4264.2 |256 |
|[convnext_nano.in12k_ft_in1k](https://huggingface.co/timm/convnext_nano.in12k_ft_in1k)|82.282|96.344|224 |15.59 |2.46 |8.37 |3926.52 |256 |
|[convnext_nano.d1h_in1k](https://huggingface.co/timm/convnext_nano.d1h_in1k)|80.768|95.334|224 |15.59 |2.46 |8.37 |3915.58 |256 |
|[convnext_nano_ols.d1h_in1k](https://huggingface.co/timm/convnext_nano_ols.d1h_in1k)|80.866|95.246|224 |15.65 |2.65 |9.38 |3523.85 |256 |
|[convnextv2_pico.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_pico.fcmae_ft_in1k)|80.304|95.072|224 |9.07 |1.37 |6.1 |3274.57 |256 |
|[convnext_tiny_hnf.a2h_in1k](https://huggingface.co/timm/convnext_tiny_hnf.a2h_in1k)|82.216|95.852|224 |28.59 |4.47 |13.44 |2529.75 |256 |
|[convnext_tiny.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k)|82.898|96.616|224 |28.59 |4.47 |13.44 |2480.88 |256 |
|[convnext_tiny.in12k_ft_in1k](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k)|84.186|97.124|224 |28.59 |4.47 |13.44 |2433.7 |256 |
|[convnext_tiny.fb_in1k](https://huggingface.co/timm/convnext_tiny.fb_in1k)|82.066|95.854|224 |28.59 |4.47 |13.44 |2346.26 |256 |
|[convnextv2_nano.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in1k)|81.83 |95.738|224 |15.62 |2.46 |8.37 |2321.48 |256 |
|[convnextv2_nano.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k)|82.03 |96.166|224 |15.62 |2.46 |8.37 |2300.18 |256 |
|[convnext_small.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k)|84.562|97.394|224 |50.22 |8.71 |21.56 |1478.29 |256 |
|[convnext_small.in12k_ft_in1k](https://huggingface.co/timm/convnext_small.in12k_ft_in1k)|85.174|97.506|224 |50.22 |8.71 |21.56 |1474.31 |256 |
|[convnext_small.fb_in1k](https://huggingface.co/timm/convnext_small.fb_in1k)|83.142|96.434|224 |50.22 |8.71 |21.56 |1464.0 |256 |
|[convnextv2_tiny.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k)|83.894|96.964|224 |28.64 |4.47 |13.44 |1452.72 |256 |
|[convnextv2_tiny.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in1k)|82.92 |96.284|224 |28.64 |4.47 |13.44 |1425.62 |256 |
|[convnext_base.fb_in1k](https://huggingface.co/timm/convnext_base.fb_in1k)|83.82 |96.746|224 |88.59 |15.38 |28.75 |1054.0 |256 |
|[convnext_base.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k)|85.822|97.866|224 |88.59 |15.38 |28.75 |1037.66 |256 |
|[convnext_tiny.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k_384)|84.084|97.14 |384 |28.59 |13.14 |39.48 |862.95 |256 |
|[convnext_tiny.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k_384)|85.118|97.608|384 |28.59 |13.14 |39.48 |856.76 |256 |
|[convnext_base.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in1k)|86.154|97.68 |256 |88.59 |20.09 |37.55 |819.86 |256 |
|[convnextv2_nano.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k_384)|83.37 |96.742|384 |15.62 |7.22 |24.61 |801.72 |256 |
|[convnextv2_base.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in1k)|84.874|97.09 |224 |88.72 |15.38 |28.75 |625.33 |256 |
|[convnextv2_base.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k)|86.74 |98.022|224 |88.72 |15.38 |28.75 |624.23 |256 |
|[convnext_large.fb_in1k](https://huggingface.co/timm/convnext_large.fb_in1k)|84.282|96.892|224 |197.77 |34.4 |43.13 |584.28 |256 |
|[convnext_large.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k)|86.636|98.028|224 |197.77 |34.4 |43.13 |581.43 |256 |
|[convnext_small.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k_384)|85.778|97.886|384 |50.22 |25.58 |63.37 |518.95 |256 |
|[convnext_small.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_small.in12k_ft_in1k_384)|86.182|97.92 |384 |50.22 |25.58 |63.37 |516.19 |256 |
|[convnextv2_tiny.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k_384)|85.112|97.63 |384 |28.64 |13.14 |39.48 |491.32 |256 |
|[convnext_large_mlp.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_augreg_ft_in1k)|87.344|98.218|256 |200.13 |44.94 |56.33 |438.08 |256 |
|[convnextv2_large.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k)|87.26 |98.248|224 |197.96 |34.4 |43.13 |376.84 |256 |
|[convnextv2_large.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in1k)|85.742|97.584|224 |197.96 |34.4 |43.13 |375.23 |256 |
|[convnext_base.clip_laiona_augreg_ft_in1k_384](https://huggingface.co/timm/convnext_base.clip_laiona_augreg_ft_in1k_384)|86.504|97.97 |384 |88.59 |45.21 |84.49 |368.14 |256 |
|[convnext_xlarge.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k)|87.002|98.208|224 |350.2 |60.98 |57.5 |368.01 |256 |
|[convnext_base.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k_384)|86.796|98.264|384 |88.59 |45.21 |84.49 |366.54 |256 |
|[convnextv2_base.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k_384)|87.646|98.422|384 |88.72 |45.21 |84.49 |209.51 |256 |
|[convnext_large.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k_384)|87.476|98.382|384 |197.77 |101.1 |126.74|194.66 |256 |
|[convnextv2_huge.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in1k)|86.256|97.75 |224 |660.29 |115.0 |79.07 |154.72 |256 |
|[convnextv2_large.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k_384)|88.196|98.532|384 |197.96 |101.1 |126.74|128.94 |128 |
|[convnext_xlarge.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k_384)|87.75 |98.556|384 |350.2 |179.2 |168.99|124.85 |192 |
|[convnextv2_huge.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_384)|88.668|98.738|384 |660.29 |337.96|232.35|50.56 |64 |
|[convnextv2_huge.fcmae_ft_in22k_in1k_512](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_512)|88.848|98.742|512 |660.29 |600.81|413.07|28.58 |48 |
## Citation
```bibtex
@article{liu2022convnet,
author = {Zhuang Liu and Hanzi Mao and Chao-Yuan Wu and Christoph Feichtenhofer and Trevor Darrell and Saining Xie},
title = {A ConvNet for the 2020s},
journal = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022},
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/rwightman/pytorch-image-models}}
}
```
| d53d486a6ab822a34689167675fbd898 |
sztanki/hulk-style-v3 | sztanki | null | 37 | 10 | diffusers | 0 | text-to-image | false | false | false | creativeml-openrail-m | null | null | null | 2 | 1 | 1 | 0 | 0 | 0 | 0 | ['text-to-image'] | false | true | true | 2,211 | false | ### hulk-style-v3 Dreambooth model trained by sztanki with [Hugging Face Dreambooth Training Space](https://huggingface.co/spaces/multimodalart/dreambooth-training) with the v1-5 base model
You run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb). Don't forget to use the concept prompts!
Sample pictures of:
hulk (use that on your prompt)

| 41e38a897ea87b586fe7a4356e3484c5 |
flamesbob/rimu_model | flamesbob | null | 3 | 0 | null | 0 | null | false | false | false | creativeml-openrail-m | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 945 | false | Token class word for this model is `rimu` using this will draw attention to the training data that was used and help increase the quality of the image.
License This embedding is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage. The CreativeML OpenRAIL License specifies:
You can't use the embedding to deliberately produce nor share illegal or harmful outputs or content The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license You may re-distribute the weights and use the embedding commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully) Please read the full license here | c33132429820d76803cdf9d449148e20 |
anas-awadalla/bart-base-finetuned-squad-infilling-lr-5e-6-decay-01 | anas-awadalla | bart | 18 | 1 | transformers | 0 | text2text-generation | true | false | false | apache-2.0 | null | ['squad'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,065 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-base-finetuned-squad-infilling-lr-5e-6-decay-01
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 12
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- total_train_batch_size: 24
- total_eval_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2.0
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.11.6
| ce91f9ffaac74170882cded277d86aef |
KoichiYasuoka/roberta-classical-chinese-large-upos | KoichiYasuoka | roberta | 8 | 9 | transformers | 0 | token-classification | true | false | false | apache-2.0 | ['lzh'] | ['universal_dependencies'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['classical chinese', 'literary chinese', 'ancient chinese', 'token-classification', 'pos', 'dependency-parsing'] | false | true | true | 1,239 | false |
# roberta-classical-chinese-large-upos
## Model Description
This is a RoBERTa model pre-trained on Classical Chinese texts for POS-tagging and dependency-parsing, derived from [roberta-classical-chinese-large-char](https://huggingface.co/KoichiYasuoka/roberta-classical-chinese-large-char). Every word is tagged by [UPOS](https://universaldependencies.org/u/pos/) (Universal Part-Of-Speech) and [FEATS](https://universaldependencies.org/u/feat/).
## How to Use
```py
from transformers import AutoTokenizer,AutoModelForTokenClassification
tokenizer=AutoTokenizer.from_pretrained("KoichiYasuoka/roberta-classical-chinese-large-upos")
model=AutoModelForTokenClassification.from_pretrained("KoichiYasuoka/roberta-classical-chinese-large-upos")
```
or
```py
import esupar
nlp=esupar.load("KoichiYasuoka/roberta-classical-chinese-large-upos")
```
## Reference
Koichi Yasuoka: [Universal Dependencies Treebank of the Four Books in Classical Chinese](http://hdl.handle.net/2433/245217), DADH2019: 10th International Conference of Digital Archives and Digital Humanities (December 2019), pp.20-28.
## See Also
[esupar](https://github.com/KoichiYasuoka/esupar): Tokenizer POS-tagger and Dependency-parser with BERT/RoBERTa/DeBERTa models
| 5669f9d115e4e069f6ffb4250b49e876 |
kaisuke/finetuning-sentiment-model-3000-samples | kaisuke | distilbert | 13 | 9 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | ['imdb'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,053 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3120
- Accuracy: 0.87
- F1: 0.8696
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
| 29d831044ffcad3b4eb00868a8707eaa |
nandysoham/Gregorian_calendar-theme-finetuned-overfinetuned | nandysoham | distilbert | 10 | 4 | transformers | 0 | question-answering | false | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_keras_callback'] | true | true | true | 3,273 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# nandysoham/Gregorian_calendar-theme-finetuned-overfinetuned
This model is a fine-tuned version of [nandysoham/distilbert-base-uncased-finetuned-squad](https://huggingface.co/nandysoham/distilbert-base-uncased-finetuned-squad) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.1838
- Train End Logits Accuracy: 0.9500
- Train Start Logits Accuracy: 0.9688
- Validation Loss: 2.0017
- Validation End Logits Accuracy: 0.5238
- Validation Start Logits Accuracy: 0.4762
- Epoch: 8
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 100, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train End Logits Accuracy | Train Start Logits Accuracy | Validation Loss | Validation End Logits Accuracy | Validation Start Logits Accuracy | Epoch |
|:----------:|:-------------------------:|:---------------------------:|:---------------:|:------------------------------:|:--------------------------------:|:-----:|
| 2.2861 | 0.3688 | 0.4062 | 1.6038 | 0.5952 | 0.5714 | 0 |
| 1.2774 | 0.5938 | 0.5938 | 1.4240 | 0.5952 | 0.5714 | 1 |
| 0.8752 | 0.7000 | 0.7375 | 1.4402 | 0.5952 | 0.5476 | 2 |
| 0.5245 | 0.8250 | 0.8438 | 1.5027 | 0.6429 | 0.5952 | 3 |
| 0.4132 | 0.8313 | 0.8938 | 1.6252 | 0.5714 | 0.5 | 4 |
| 0.3140 | 0.9000 | 0.9062 | 1.7524 | 0.5476 | 0.4762 | 5 |
| 0.2534 | 0.9688 | 0.9312 | 1.8646 | 0.5238 | 0.4762 | 6 |
| 0.1999 | 0.9500 | 0.9563 | 1.9513 | 0.5238 | 0.4762 | 7 |
| 0.1838 | 0.9500 | 0.9688 | 2.0017 | 0.5238 | 0.4762 | 8 |
### Framework versions
- Transformers 4.25.1
- TensorFlow 2.9.2
- Datasets 2.8.0
- Tokenizers 0.13.2
| e253d57aad2cb713c9187105fcaf9a99 |
asi/albert-act-base | asi | albert_act | 9 | 2 | transformers | 1 | null | true | true | false | apache-2.0 | ['en'] | ['wikipedia', 'bookcorpus'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | true | true | true | 2,690 | false |
# Adaptive Depth Transformers
Implementation of the paper "How Many Layers and Why? An Analysis of the Model Depth in Transformers". In this study, we investigate the role of the multiple layers in deep transformer models. We design a variant of ALBERT that dynamically adapts the number of layers for each token of the input.
## Model architecture
We augment a multi-layer transformer encoder with a halting mechanism, which dynamically adjusts the number of layers for each token.
We directly adapted this mechanism from Graves ([2016](#graves-2016)). At each iteration, we compute a probability for each token to stop updating its state.
## Model use
The architecture is not yet directly included in the Transformers library. The code used for pre-training is available in the following [github repository](https://github.com/AntoineSimoulin/adaptive-depth-transformers). So you should install the code implementation first:
```bash
!pip install git+https://github.com/AntoineSimoulin/adaptive-depth-transformers$
```
Then you can use the model directly.
```python
from act import AlbertActConfig, AlbertActModel, TFAlbertActModel
from transformers import AlbertTokenizer
tokenizer = AlbertTokenizer.from_pretrained('asi/albert-act-base')
model = AlbertActModel.from_pretrained('asi/albert-act-base')
_ = model.eval()
inputs = tokenizer("a lump in the middle of the monkeys stirred and then fell quiet .", return_tensors="pt")
outputs = model(**inputs)
outputs.updates
# tensor([[[[15., 9., 10., 7., 3., 8., 5., 7., 12., 10., 6., 8., 8., 9., 5., 8.]]]])
```
## Citations
### BibTeX entry and citation info
If you use our iterative transformer model for your scientific publication or your industrial applications, please cite the following [paper](https://aclanthology.org/2021.acl-srw.23/):
```bibtex
@inproceedings{simoulin-crabbe-2021-many,
title = "How Many Layers and Why? {A}n Analysis of the Model Depth in Transformers",
author = "Simoulin, Antoine and
Crabb{\'e}, Benoit",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: Student Research Workshop",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-srw.23",
doi = "10.18653/v1/2021.acl-srw.23",
pages = "221--228",
}
```
### References
><div id="graves-2016">Alex Graves. 2016. <a href="https://arxiv.org/abs/1603.08983" target="_blank">Adaptive computation time for recurrent neural networks.</a> CoRR, abs/1603.08983.</div>
| f563522b392d36031d7aee2be607b42c |
nimrah/wav2vec2-large-xls-r-300m-my_hindi_home-colab | nimrah | wav2vec2 | 12 | 7 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | null | ['common_voice'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,111 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-my_hindi_home-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
| 6a5b1094b45d4a59effe4ebf57c576ea |
muhtasham/small-vanilla-target-glue-cola-linear-probe | muhtasham | bert | 10 | 5 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,538 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# small-vanilla-target-glue-cola-linear-probe
This model is a fine-tuned version of [google/bert_uncased_L-4_H-512_A-8](https://huggingface.co/google/bert_uncased_L-4_H-512_A-8) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6097
- Matthews Correlation: 0.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.6185 | 1.87 | 500 | 0.6137 | 0.0 |
| 0.6093 | 3.73 | 1000 | 0.6125 | 0.0 |
| 0.6073 | 5.6 | 1500 | 0.6100 | 0.0 |
| 0.6052 | 7.46 | 2000 | 0.6097 | 0.0 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
| 95290fcccf9b2a6e42778bf11525917e |
timm/efficientformer_l3.snap_dist_in1k | timm | null | 4 | 17 | timm | 0 | image-classification | true | false | false | apache-2.0 | null | ['imagenet-1k'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['image-classification', 'timm'] | false | true | true | 3,519 | false | # Model card for efficientformer_l3.snap_dist_in1k
A EfficientFormer image classification model. Pretrained with distillation on ImageNet-1k.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 31.4
- GMACs: 3.9
- Activations (M): 12.0
- Image size: 224 x 224
- **Original:** https://github.com/snap-research/EfficientFormer
- **Papers:**
- EfficientFormer: Vision Transformers at MobileNet Speed: https://arxiv.org/abs/2206.01191
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model('efficientformer_l3.snap_dist_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model(
'efficientformer_l3.snap_dist_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, num_features, H, W) tensor
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
|model |top1 |top5 |param_count|img_size|
|-----------------------------------|------|------|-----------|--------|
|efficientformerv2_l.snap_dist_in1k |83.628|96.54 |26.32 |224 |
|efficientformer_l7.snap_dist_in1k |83.368|96.534|82.23 |224 |
|efficientformer_l3.snap_dist_in1k |82.572|96.24 |31.41 |224 |
|efficientformerv2_s2.snap_dist_in1k|82.128|95.902|12.71 |224 |
|efficientformer_l1.snap_dist_in1k |80.496|94.984|12.29 |224 |
|efficientformerv2_s1.snap_dist_in1k|79.698|94.698|6.19 |224 |
|efficientformerv2_s0.snap_dist_in1k|76.026|92.77 |3.6 |224 |
## Citation
```bibtex
@article{li2022efficientformer,
title={EfficientFormer: Vision Transformers at MobileNet Speed},
author={Li, Yanyu and Yuan, Geng and Wen, Yang and Hu, Ju and Evangelidis, Georgios and Tulyakov, Sergey and Wang, Yanzhi and Ren, Jian},
journal={arXiv preprint arXiv:2206.01191},
year={2022}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/rwightman/pytorch-image-models}}
}
```
| 12a7131f375305df7256d1d2191b6b34 |
porpaul/t5-small-finetuned-xsum | porpaul | t5 | 11 | 4 | transformers | 0 | text2text-generation | true | false | false | apache-2.0 | null | ['xlsum'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,365 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-xsum
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the xlsum dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2188
- Rouge1: 0.5217
- Rouge2: 0.0464
- Rougel: 0.527
- Rougelsum: 0.5215
- Gen Len: 6.7441
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 5
- eval_batch_size: 5
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| 1.3831 | 1.0 | 7475 | 1.2188 | 0.5217 | 0.0464 | 0.527 | 0.5215 | 6.7441 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
| 293a1b2f0a69971006c77c5f10b9fea0 |
jonatasgrosman/exp_w2v2t_pt_wavlm_s118 | jonatasgrosman | wavlm | 10 | 3 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['pt'] | ['mozilla-foundation/common_voice_7_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['automatic-speech-recognition', 'pt'] | false | true | true | 439 | false | # exp_w2v2t_pt_wavlm_s118
Fine-tuned [microsoft/wavlm-large](https://huggingface.co/microsoft/wavlm-large) for speech recognition using the train split of [Common Voice 7.0 (pt)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
| e6edf14121895ca2912118f15ca05a88 |
UGARIT/grc-alignment | UGARIT | xlm-roberta | 8 | 8 | transformers | 0 | fill-mask | true | false | false | cc-by-4.0 | null | null | null | 1 | 0 | 0 | 1 | 0 | 0 | 0 | [] | false | true | true | 2,759 | false | # Automatic Translation Alignment of Ancient Greek Texts
GRC-ALIGNMENT model is an XLM-RoBERTa-based model, fine-tuned for automatic multilingual text alignment at the word level.
The model is trained on 12 million monolingual ancient Greek tokens with Masked Language Model (MLM) training objective. Further, the model is fine-tuned on 45k parallel sentences, mainly in ancient Greek-English, Greek-Latin, and Greek-Georgian.
### Multilingual Training Dataset
| Languages |Sentences | Source |
|:---------------------------------------|:-----------:|:--------------------------------------------------------------------------------|
| GRC-ENG | 32.500 | Perseus Digital Library (Iliad, Odyssey, Xenophon, New Testament) |
| GRC-LAT | 8.200 | [Digital Fragmenta Historicorum Graecorum project](https://www.dfhg-project.org/) |
| GRC-KAT <br>GRC-ENG <br>GRC-LAT<br>GRC-ITA<br>GRC-POR | 4.000 | [UGARIT Translation Alignment Editor](https://ugarit.ialigner.com/ ) |
### Model Performance
| Languages | Alignment Error Rate |
|:---------:|:--------------------:|
| GRC-ENG | 19.73% (IterMax) |
| GRC-POR | 23.91% (IterMax) |
| GRC-LAT | 10.60% (ArgMax) |
The gold standard datasets are available on [Github](https://github.com/UgaritAlignment/Alignment-Gold-Standards).
If you use this model, please cite our papers:
<pre>
@InProceedings{yousef-EtAl:2022:LREC,
author = {Yousef, Tariq and Palladino, Chiara and Shamsian, Farnoosh and d’Orange Ferreira, Anise and Ferreira dos Reis, Michel},
title = {An automatic model and Gold Standard for translation alignment of Ancient Greek},
booktitle = {Proceedings of the Language Resources and Evaluation Conference},
month = {June},
year = {2022},
address = {Marseille, France},
publisher = {European Language Resources Association},
pages = {5894--5905},
url = {https://aclanthology.org/2022.lrec-1.634}
}
@InProceedings{yousef-EtAl:2022:LT4HALA2022,
author = {Yousef, Tariq and Palladino, Chiara and Wright, David J. and Berti, Monica},
title = {Automatic Translation Alignment for Ancient Greek and Latin},
booktitle = {Proceedings of the Second Workshop on Language Technologies for Historical and Ancient Languages},
month = {June},
year = {2022},
address = {Marseille, France},
publisher = {European Language Resources Association},
pages = {101--107},
url = {https://aclanthology.org/2022.lt4hala2022-1.14}
}
</pre> | 2740ef2bd51db4cd72b5cab55969a1fc |
IsaMaks/distilbert-base-uncased-finetuned-ner | IsaMaks | distilbert | 15 | 9 | transformers | 0 | token-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 6,873 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ner
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8874
- Precision: 0.2534
- Recall: 0.3333
- F1: 0.2879
- Accuracy: 0.7603
- True predictions: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
- True labels: [0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 2, 2, 0, 0, 0, 1, 2, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 2, 0, 1, 2, 2, 2, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 2, 2, 2, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 2, 0, 0, 0, 0, 0, 0, 1, 2, 2, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy | True predictions | True labels |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|
| No log | 1.0 | 2 | 0.9937 | 0.2839 | 0.3072 | 0.2951 | 0.6712 | [0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 2] | [0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 2, 2, 0, 0, 0, 1, 2, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 2, 0, 1, 2, 2, 2, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 2, 2, 2, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 2, 0, 0, 0, 0, 0, 0, 1, 2, 2, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] |
| No log | 2.0 | 4 | 0.9155 | 0.2523 | 0.3273 | 0.2850 | 0.7466 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] | [0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 2, 2, 0, 0, 0, 1, 2, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 2, 0, 1, 2, 2, 2, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 2, 2, 2, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 2, 0, 0, 0, 0, 0, 0, 1, 2, 2, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] |
| No log | 3.0 | 6 | 0.8874 | 0.2534 | 0.3333 | 0.2879 | 0.7603 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] | [0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 2, 2, 0, 0, 0, 1, 2, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 2, 0, 1, 2, 2, 2, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 2, 2, 2, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 2, 0, 0, 0, 0, 0, 0, 1, 2, 2, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
| 1d9d092daaf12928d97ca9d0c02225e7 |
tftransformers/albert-xxlarge-v1 | tftransformers | null | 6 | 2 | null | 0 | null | false | false | false | apache-2.0 | ['en'] | ['bookcorpus', 'wikipedia'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 6,481 | false |
# ALBERT XXLarge v1
Pretrained model on English language using a masked language modeling (MLM) objective. It was introduced in
[this paper](https://arxiv.org/abs/1909.11942) and first released in
[this repository](https://github.com/google-research/albert). This model, as all ALBERT models, is uncased: it does not make a difference
between english and English.
Disclaimer: The team releasing ALBERT did not write a model card for this model so this model card has been written by
the Hugging Face team.
## Model description
ALBERT is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run
the entire masked sentence through the model and has to predict the masked words. This is different from traditional
recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like
GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the
sentence.
- Sentence Ordering Prediction (SOP): ALBERT uses a pretraining loss based on predicting the ordering of two consecutive segments of text.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the ALBERT model as inputs.
ALBERT is particular in that it shares its layers across its Transformer. Therefore, all layers have the same weights. Using repeating layers results in a small memory footprint, however, the computational cost remains similar to a BERT-like architecture with the same number of hidden layers as it has to iterate through the same number of (repeating) layers.
This is the second version of the base model. Version 2 is different from version 1 due to different dropout rates, additional training data, and longer training. It has better results in nearly all downstream tasks.
This model has the following configuration:
- 12 repeating layers
- 128 embedding dimension
- 768 hidden dimension
- 12 attention heads
- 11M parameters
## Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=albert) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
You can use this model directly with a pipeline for masked language modeling:
In tf_transformers
```python
from tf_transformers.models import AlbertModel
from transformers import AlbertTokenizer
tokenizer = AlbertTokenizer.from_pretrained('albert-xxlarge-v1')
model = AlbertModel.from_pretrained("albert-xxlarge-v1")
text = "Replace me by any text you'd like."
inputs_tf = {}
inputs = tokenizer(text, return_tensors='tf')
inputs_tf["input_ids"] = inputs["input_ids"]
inputs_tf["input_type_ids"] = inputs["token_type_ids"]
inputs_tf["input_mask"] = inputs["attention_mask"]
outputs_tf = model(inputs_tf)
```
## Training data
The ALBERT model was pretrained on [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038
unpublished books and [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and
headers).
## Training procedure
### Preprocessing
The texts are lowercased and tokenized using SentencePiece and a vocabulary size of 30,000. The inputs of the model are
then of the form:
```
[CLS] Sentence A [SEP] Sentence B [SEP]
```
### Training
The ALBERT procedure follows the BERT setup.
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
## Evaluation results
When fine-tuned on downstream tasks, the ALBERT models achieve the following results:
| | Average | SQuAD1.1 | SQuAD2.0 | MNLI | SST-2 | RACE |
|----------------|----------|----------|----------|----------|----------|----------|
|V2 |
|ALBERT-base |82.3 |90.2/83.2 |82.1/79.3 |84.6 |92.9 |66.8 |
|ALBERT-large |85.7 |91.8/85.2 |84.9/81.8 |86.5 |94.9 |75.2 |
|ALBERT-xlarge |87.9 |92.9/86.4 |87.9/84.1 |87.9 |95.4 |80.7 |
|ALBERT-xxlarge |90.9 |94.6/89.1 |89.8/86.9 |90.6 |96.8 |86.8 |
|V1 |
|ALBERT-base |80.1 |89.3/82.3 | 80.0/77.1|81.6 |90.3 | 64.0 |
|ALBERT-large |82.4 |90.6/83.9 | 82.3/79.4|83.5 |91.7 | 68.5 |
|ALBERT-xlarge |85.5 |92.5/86.1 | 86.1/83.1|86.4 |92.4 | 74.8 |
|ALBERT-xxlarge |91.0 |94.8/89.3 | 90.2/87.4|90.8 |96.9 | 86.5 |
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-1909-11942,
author = {Zhenzhong Lan and
Mingda Chen and
Sebastian Goodman and
Kevin Gimpel and
Piyush Sharma and
Radu Soricut},
title = {{ALBERT:} {A} Lite {BERT} for Self-supervised Learning of Language
Representations},
journal = {CoRR},
volume = {abs/1909.11942},
year = {2019},
url = {http://arxiv.org/abs/1909.11942},
archivePrefix = {arXiv},
eprint = {1909.11942},
timestamp = {Fri, 27 Sep 2019 13:04:21 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-1909-11942.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | e66851dd6b5079b79877ab72ab0e02c4 |
Kugos/KgSelfie_lr_15e-6 | Kugos | null | 35 | 2 | diffusers | 0 | null | true | false | false | mit | null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 | ['pytorch', 'diffusers', 'dreambooth'] | false | true | true | 2,151 | false |
# Model Card for Dreambooth model trained on My pet Pintu's images
This model is a diffusion model for unconditional image generation of my cute pet dog Pintu trained using Dreambooth concept. The token to use is sks .
## Usage
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained(Kugos/KgSelfie_lr_15e-6)
image = pipeline('a photo of sks dog').images[0]
image
These are the images on which the dreambooth model is trained on

| 11f97347539e3820b3fc0389ac78c145 |
Sebabrata/donut-base-sroie-s | Sebabrata | vision-encoder-decoder | 14 | 0 | transformers | 0 | null | true | false | false | mit | null | ['imagefolder'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 972 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# donut-base-sroie-s
This model is a fine-tuned version of [naver-clova-ix/donut-base](https://huggingface.co/naver-clova-ix/donut-base) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0
- Datasets 2.6.1
- Tokenizers 0.13.2
| a35b7618bcb67fcf969d3511a177420a |
jonatasgrosman/exp_w2v2t_en_xls-r_s957 | jonatasgrosman | wav2vec2 | 10 | 5 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['en'] | ['mozilla-foundation/common_voice_7_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['automatic-speech-recognition', 'en'] | false | true | true | 459 | false | # exp_w2v2t_en_xls-r_s957
Fine-tuned [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) for speech recognition on English using the train split of [Common Voice 7.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
| b67a18c09274f143a8405bac952104d8 |
anas-awadalla/roberta-large-houlsby-few-shot-k-1024-finetuned-squad-seed-2 | anas-awadalla | null | 19 | 0 | null | 0 | null | false | false | false | mit | null | ['squad'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,095 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-large-houlsby-few-shot-k-1024-finetuned-squad-seed-2
This model is a fine-tuned version of [roberta-large](https://huggingface.co/roberta-large) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 128
- seed: 2
- distributed_type: multi-GPU
- num_devices: 2
- total_train_batch_size: 64
- total_eval_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 20.0
### Training results
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.0.0
- Tokenizers 0.11.6
| 53a7152803e402f5f1e24046f75677f9 |
maastrichtlawtech/legal-distilcamembert | maastrichtlawtech | camembert | 8 | 12 | transformers | 0 | fill-mask | true | false | false | cc-by-sa-4.0 | ['fr'] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['legal'] | false | true | true | 1,322 | false |
# Legal-CamemBERT
* Legal-DistilCamemBERT is a [DistilCamemBERT](https://huggingface.co/cmarkea/distilcamembert-base)-based model further pre-trained on [23,000+ statutory articles](https://huggingface.co/datasets/maastrichtlawtech/bsard) from the Belgian legislation.
* We chose the following training set-up: 50k training steps (200 epochs) with batches of 32 sequences of length 512 with an initial learning rate of 5e-5.
* Training was performed on one Tesla V100 GPU with 32 GB using the [code](https://github.com/huggingface/transformers/blob/main/examples/pytorch/language-modeling/run_mlm.py) provided by Hugging Face.
---
### Load Pretrained Model
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("maastrichtlawtech/legal-distilcamembert")
model = AutoModel.from_pretrained("maastrichtlawtech/legal-distilcamembert")
```
### About Us
The [Maastricht Law & Tech Lab](https://www.maastrichtuniversity.nl/about-um/faculties/law/research/law-and-tech-lab) develops algorithms, models, and systems that allow computers to process natural language texts from the legal domain.
Author: [Antoine Louis](https://antoinelouis.co) on behalf of the [Maastricht Law & Tech Lab](https://www.maastrichtuniversity.nl/about-um/faculties/law/research/law-and-tech-lab). | 2b3c207eb61eae2001c201b283162afa |
DOOGLAK/Tagged_One_50v8_NER_Model_3Epochs_AUGMENTED | DOOGLAK | bert | 13 | 5 | transformers | 0 | token-classification | true | false | false | apache-2.0 | null | ['tagged_one50v8_wikigold_split'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,563 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_One_50v8_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_one50v8_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5935
- Precision: 0.0917
- Recall: 0.0054
- F1: 0.0102
- Accuracy: 0.7849
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 19 | 0.7198 | 0.0 | 0.0 | 0.0 | 0.7786 |
| No log | 2.0 | 38 | 0.6263 | 0.0727 | 0.0010 | 0.0019 | 0.7798 |
| No log | 3.0 | 57 | 0.5935 | 0.0917 | 0.0054 | 0.0102 | 0.7849 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
| 907b2dca38fd3e287e0d41f27fb66188 |
devtanumisra/finetuning-profane-model-deberta | devtanumisra | deberta-v2 | 14 | 9 | transformers | 0 | text-classification | true | false | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,108 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-profane-model-deberta
This model is a fine-tuned version of [yangheng/deberta-v3-base-absa-v1.1](https://huggingface.co/yangheng/deberta-v3-base-absa-v1.1) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6243
- Accuracy: 0.8322
- F1: 0.8455
- Precision: 0.8015
- Recall: 0.8946
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.2
| a528d7a8cb1e379db04173edd1ab2b0f |
MatsUy/wav2vec2-common_voice-nl-demo | MatsUy | wav2vec2 | 15 | 10 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['nl'] | ['common_voice'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['automatic-speech-recognition', 'common_voice', 'generated_from_trainer'] | true | true | true | 2,098 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-common_voice-nl-demo
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the COMMON_VOICE - NL dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3523
- Wer: 0.2046
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 15.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.0536 | 1.12 | 500 | 0.5349 | 0.4338 |
| 0.2543 | 2.24 | 1000 | 0.3859 | 0.3029 |
| 0.1472 | 3.36 | 1500 | 0.3471 | 0.2818 |
| 0.1088 | 4.47 | 2000 | 0.3489 | 0.2731 |
| 0.0855 | 5.59 | 2500 | 0.3582 | 0.2558 |
| 0.0721 | 6.71 | 3000 | 0.3457 | 0.2471 |
| 0.0653 | 7.83 | 3500 | 0.3299 | 0.2357 |
| 0.0527 | 8.95 | 4000 | 0.3440 | 0.2334 |
| 0.0444 | 10.07 | 4500 | 0.3417 | 0.2289 |
| 0.0404 | 11.19 | 5000 | 0.3691 | 0.2204 |
| 0.0345 | 12.3 | 5500 | 0.3453 | 0.2102 |
| 0.0288 | 13.42 | 6000 | 0.3634 | 0.2089 |
| 0.027 | 14.54 | 6500 | 0.3532 | 0.2044 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.3
- Tokenizers 0.11.0
| fb73f6cabe9295250a4c6bc31690ab44 |
jonfrank/mt5-small-finetuned-amazon-en-es | jonfrank | mt5 | 16 | 4 | transformers | 0 | summarization | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['summarization', 'generated_from_trainer'] | true | true | true | 2,101 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-small-finetuned-amazon-en-es
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the None dataset.
It was created by following the [huggingface tutorial](https://huggingface.co/course/chapter7/5?fw=pt).
It achieves the following results on the evaluation set:
- Loss: 3.0173
- Rouge1: 16.7977
- Rouge2: 8.6849
- Rougel: 16.4822
- Rougelsum: 16.4975
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:|
| 3.4693 | 1.0 | 1209 | 3.1215 | 17.5363 | 8.3875 | 17.0229 | 16.9653 |
| 3.4231 | 2.0 | 2418 | 3.0474 | 16.7927 | 8.3533 | 16.2748 | 16.2379 |
| 3.271 | 3.0 | 3627 | 3.0440 | 16.7233 | 7.9129 | 16.2385 | 16.1915 |
| 3.1885 | 4.0 | 4836 | 3.0264 | 16.3078 | 7.5751 | 15.844 | 15.889 |
| 3.1216 | 5.0 | 6045 | 3.0277 | 17.259 | 8.7504 | 16.8293 | 16.8543 |
| 3.0739 | 6.0 | 7254 | 3.0188 | 16.8374 | 8.6457 | 16.4407 | 16.4743 |
| 3.0393 | 7.0 | 8463 | 3.0161 | 17.3064 | 8.7822 | 16.9423 | 16.9543 |
| 3.0202 | 8.0 | 9672 | 3.0173 | 16.7977 | 8.6849 | 16.4822 | 16.4975 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.1
- Tokenizers 0.12.1
| 798d2fcf6401e16b6ddd2db209ea4e66 |
bergurth/IceBERT-finetuned-ner | bergurth | roberta | 15 | 7 | transformers | 0 | token-classification | true | false | false | gpl-3.0 | null | ['mim_gold_ner'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,528 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# IceBERT-finetuned-ner
This model is a fine-tuned version of [vesteinn/IceBERT](https://huggingface.co/vesteinn/IceBERT) on the mim_gold_ner dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0783
- Precision: 0.8873
- Recall: 0.8627
- F1: 0.8748
- Accuracy: 0.9848
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0539 | 1.0 | 2904 | 0.0768 | 0.8732 | 0.8453 | 0.8590 | 0.9833 |
| 0.0281 | 2.0 | 5808 | 0.0737 | 0.8781 | 0.8492 | 0.8634 | 0.9838 |
| 0.0166 | 3.0 | 8712 | 0.0783 | 0.8873 | 0.8627 | 0.8748 | 0.9848 |
### Framework versions
- Transformers 4.11.2
- Pytorch 1.9.0+cu102
- Datasets 1.12.1
- Tokenizers 0.10.3
| 9af5931d296106a9f419529cae812339 |
Ramos-Ramos/emb-gam-vit | Ramos-Ramos | null | 5 | 0 | sklearn | 0 | tabular-classification | false | false | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['sklearn', 'skops', 'tabular-classification', 'visual emb-gam'] | false | true | true | 9,821 | false |
# Model description
This is a LogisticRegressionCV model trained on averages of patch embeddings from the Imagenette dataset. This forms the GAM of an [Emb-GAM](https://arxiv.org/abs/2209.11799) extended to images. Patch embeddings are meant to be extracted with the [`google/vit-base-patch16-224` ViT checkpoint](https://huggingface.co/google/vit-base-patch16-224).
## Intended uses & limitations
This model is not intended to be used in production.
## Training Procedure
### Hyperparameters
The model is trained with below hyperparameters.
<details>
<summary> Click to expand </summary>
| Hyperparameter | Value |
|-------------------|-----------------------------------------------------------|
| Cs | 10 |
| class_weight | |
| cv | StratifiedKFold(n_splits=5, random_state=1, shuffle=True) |
| dual | False |
| fit_intercept | True |
| intercept_scaling | 1.0 |
| l1_ratios | |
| max_iter | 100 |
| multi_class | auto |
| n_jobs | |
| penalty | l2 |
| random_state | 1 |
| refit | False |
| scoring | |
| solver | lbfgs |
| tol | 0.0001 |
| verbose | 0 |
</details>
### Model Plot
The model plot is below.
<style>#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e {color: black;background-color: white;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e pre{padding: 0;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e div.sk-toggleable {background-color: white;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e label.sk-toggleable__label {cursor: pointer;display: block;width: 100%;margin-bottom: 0;padding: 0.3em;box-sizing: border-box;text-align: center;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e label.sk-toggleable__label-arrow:before {content: "▸";float: left;margin-right: 0.25em;color: #696969;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e label.sk-toggleable__label-arrow:hover:before {color: black;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e div.sk-estimator:hover label.sk-toggleable__label-arrow:before {color: black;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e div.sk-toggleable__content {max-height: 0;max-width: 0;overflow: hidden;text-align: left;background-color: #f0f8ff;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e div.sk-toggleable__content pre {margin: 0.2em;color: black;border-radius: 0.25em;background-color: #f0f8ff;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e input.sk-toggleable__control:checked~div.sk-toggleable__content {max-height: 200px;max-width: 100%;overflow: auto;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e input.sk-toggleable__control:checked~label.sk-toggleable__label-arrow:before {content: "▾";}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e div.sk-estimator input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e div.sk-label input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e input.sk-hidden--visually {border: 0;clip: rect(1px 1px 1px 1px);clip: rect(1px, 1px, 1px, 1px);height: 1px;margin: -1px;overflow: hidden;padding: 0;position: absolute;width: 1px;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e div.sk-estimator {font-family: monospace;background-color: #f0f8ff;border: 1px dotted black;border-radius: 0.25em;box-sizing: border-box;margin-bottom: 0.5em;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e div.sk-estimator:hover {background-color: #d4ebff;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e div.sk-parallel-item::after {content: "";width: 100%;border-bottom: 1px solid gray;flex-grow: 1;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e div.sk-label:hover label.sk-toggleable__label {background-color: #d4ebff;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e div.sk-serial::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 2em;bottom: 0;left: 50%;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e div.sk-serial {display: flex;flex-direction: column;align-items: center;background-color: white;padding-right: 0.2em;padding-left: 0.2em;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e div.sk-item {z-index: 1;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e div.sk-parallel {display: flex;align-items: stretch;justify-content: center;background-color: white;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e div.sk-parallel::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 2em;bottom: 0;left: 50%;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e div.sk-parallel-item {display: flex;flex-direction: column;position: relative;background-color: white;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e div.sk-parallel-item:first-child::after {align-self: flex-end;width: 50%;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e div.sk-parallel-item:last-child::after {align-self: flex-start;width: 50%;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e div.sk-parallel-item:only-child::after {width: 0;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e div.sk-dashed-wrapped {border: 1px dashed gray;margin: 0 0.4em 0.5em 0.4em;box-sizing: border-box;padding-bottom: 0.4em;background-color: white;position: relative;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e div.sk-label label {font-family: monospace;font-weight: bold;background-color: white;display: inline-block;line-height: 1.2em;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e div.sk-label-container {position: relative;z-index: 2;text-align: center;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e div.sk-container {/* jupyter's `normalize.less` sets `[hidden] { display: none; }` but bootstrap.min.css set `[hidden] { display: none !important; }` so we also need the `!important` here to be able to override the default hidden behavior on the sphinx rendered scikit-learn.org. See: https://github.com/scikit-learn/scikit-learn/issues/21755 */display: inline-block !important;position: relative;}#sk-57980b4f-6828-4a54-ae50-b50e1f9f097e div.sk-text-repr-fallback {display: none;}</style><div id="sk-57980b4f-6828-4a54-ae50-b50e1f9f097e" class="sk-top-container"><div class="sk-text-repr-fallback"><pre>LogisticRegressionCV(cv=StratifiedKFold(n_splits=5, random_state=1, shuffle=True),random_state=1, refit=False)</pre><b>Please rerun this cell to show the HTML repr or trust the notebook.</b></div><div class="sk-container" hidden><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="51ec5e46-9aaa-4487-adda-6718142c9f85" type="checkbox" checked><label for="51ec5e46-9aaa-4487-adda-6718142c9f85" class="sk-toggleable__label sk-toggleable__label-arrow">LogisticRegressionCV</label><div class="sk-toggleable__content"><pre>LogisticRegressionCV(cv=StratifiedKFold(n_splits=5, random_state=1, shuffle=True),random_state=1, refit=False)</pre></div></div></div></div></div>
## Evaluation Results
You can find the details about evaluation process and the evaluation results.
| Metric | Value |
|----------|---------|
| accuracy | 0.99465 |
| f1 score | 0.99465 |
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
from PIL import Image
from skops import hub_utils
import torch
from transformers import AutoFeatureExtractor, AutoModel
import pickle
import os
# load embedding model
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
feature_extractor = AutoFeatureExtractor.from_pretrained("google/vit-base-patch16-224")
model = AutoModel.from_pretrained("google/vit-base-patch16-224").eval().to(device)
# load logistic regression
os.mkdir("emb-gam-vit")
hub_utils.download(repo_id="Ramos-Ramos/emb-gam-vit", dst="emb-gam-vit")
with open("emb-gam-vit/model.pkl", "rb") as file:
logistic_regression = pickle.load(file)
# load image
img = Image.open("examples/english_springer.png")
# preprocess image
inputs = {k: v.to(device) for k, v in feature_extractor(img, return_tensors='pt').items()}
# extract patch embeddings
with torch.no_grad():
patch_embeddings = model(**inputs).last_hidden_state[0, 1:].cpu()
# classify
pred = logistic_regression.predict(patch_embeddings.sum(dim=0, keepdim=True))
# get patch contributions
patch_contributions = logistic_regression.coef_ @ patch_embeddings.T.numpy()
```
</details>
# Model Card Authors
This model card is written by following authors:
Patrick Ramos and Ryan Ramos
# Model Card Contact
You can contact the model card authors through following channels:
[More Information Needed]
# Citation
Below you can find information related to citation.
**BibTeX:**
```
@article{singh2022emb,
title={Emb-GAM: an Interpretable and Efficient Predictor using Pre-trained Language Models},
author={Singh, Chandan and Gao, Jianfeng},
journal={arXiv preprint arXiv:2209.11799},
year={2022}
}
```
# Additional Content
## confusion_matrix
 | 7f24989726caf0368bca27d6590c1261 |
unicamp-dl/ptt5-base-en-pt-msmarco-100k-v2 | unicamp-dl | t5 | 7 | 3 | transformers | 0 | text2text-generation | true | false | false | mit | ['pt'] | ['msmarco'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['msmarco', 't5', 'pytorch', 'tensorflow', 'pt', 'pt-br'] | false | true | true | 1,366 | false | # PTT5-base Reranker finetuned on both English and Portuguese MS MARCO
## Introduction
ptt5-base-msmarco-en-pt-100k-v2 is a T5-based model pretrained in the BrWac corpus, fine-tuned on both English and Portuguese translated version of MS MARCO passage dataset. In the v2 version, the Portuguese dataset was translated using Google Translate. This model was finetuned for 100k steps.
Further information about the dataset or the translation method can be found on our [**mMARCO: A Multilingual Version of MS MARCO Passage Ranking Dataset**](https://arxiv.org/abs/2108.13897) and [mMARCO](https://github.com/unicamp-dl/mMARCO) repository.
## Usage
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
model_name = 'unicamp-dl/ptt5-base-msmarco-en-pt-100k-v2'
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name)
```
# Citation
If you use ptt5-base-msmarco-en-pt-100k-v2, please cite:
@misc{bonifacio2021mmarco,
title={mMARCO: A Multilingual Version of MS MARCO Passage Ranking Dataset},
author={Luiz Henrique Bonifacio and Vitor Jeronymo and Hugo Queiroz Abonizio and Israel Campiotti and Marzieh Fadaee and and Roberto Lotufo and Rodrigo Nogueira},
year={2021},
eprint={2108.13897},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
| 0f3761d0cec355b8bd58401f3ccc3e4b |
gokuls/mobilebert_add_GLUE_Experiment_mrpc | gokuls | mobilebert | 17 | 4 | transformers | 0 | text-classification | true | false | false | apache-2.0 | ['en'] | ['glue'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 2,178 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mobilebert_add_GLUE_Experiment_mrpc
This model is a fine-tuned version of [google/mobilebert-uncased](https://huggingface.co/google/mobilebert-uncased) on the GLUE MRPC dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6197
- Accuracy: 0.6838
- F1: 0.8122
- Combined Score: 0.7480
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Combined Score |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:--------------:|
| 0.6387 | 1.0 | 29 | 0.6245 | 0.6838 | 0.8122 | 0.7480 |
| 0.6307 | 2.0 | 58 | 0.6234 | 0.6838 | 0.8122 | 0.7480 |
| 0.6307 | 3.0 | 87 | 0.6233 | 0.6838 | 0.8122 | 0.7480 |
| 0.6295 | 4.0 | 116 | 0.6231 | 0.6838 | 0.8122 | 0.7480 |
| 0.6261 | 5.0 | 145 | 0.6197 | 0.6838 | 0.8122 | 0.7480 |
| 0.6147 | 6.0 | 174 | 0.6344 | 0.6838 | 0.8122 | 0.7480 |
| 0.6209 | 7.0 | 203 | 0.6398 | 0.6838 | 0.8122 | 0.7480 |
| 0.6007 | 8.0 | 232 | 0.6338 | 0.6324 | 0.7517 | 0.6920 |
| 0.5795 | 9.0 | 261 | 0.6377 | 0.625 | 0.7429 | 0.6839 |
| 0.5712 | 10.0 | 290 | 0.6290 | 0.6814 | 0.8036 | 0.7425 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.8.0
- Tokenizers 0.13.2
| aa9b228bae9640748f4fb0680ac55cba |