---
license: cc-by-sa-4.0
dataset_info:
- config_name: E2H-AMC
features:
- name: contest
dtype: string
- name: rating
dtype: float64
- name: rating_std
dtype: float64
- name: rating_quantile
dtype: float64
- name: tag
dtype: string
- name: subtest
dtype: string
- name: year
dtype: int64
- name: month
dtype: string
- name: index
dtype: int64
- name: problem
dtype: string
- name: answer
dtype: string
- name: solution
dtype: string
- name: rating_tag
dtype: string
- name: test_tag
dtype: string
- name: item_difficulty
dtype: float64
- name: unnorm_rating
dtype: float64
- name: unnorm_rating_std
dtype: float64
- name: unnorm_rating_lower
dtype: float64
- name: unnorm_rating_upper
dtype: float64
- name: ever_exist
dtype: bool
splits:
- name: train
num_bytes: 1306215
num_examples: 1000
- name: eval
num_bytes: 3935954
num_examples: 2975
download_size: 2811269
dataset_size: 5242169
- config_name: E2H-ARC
features:
- name: rating
dtype: float64
- name: rating_std
dtype: float64
- name: rating_quantile
dtype: float64
- name: id
dtype: string
- name: question
dtype: string
- name: choices
struct:
- name: label
sequence: string
- name: text
sequence: string
- name: answerKey
dtype: string
- name: model_avg_acc
dtype: float64
- name: unnorm_rating
dtype: float64
- name: unnorm_rating_std
dtype: float64
splits:
- name: eval
num_bytes: 431767
num_examples: 1172
download_size: 253021
dataset_size: 431767
- config_name: E2H-Codeforces
features:
- name: contest_id
dtype: int64
- name: problem_index
dtype: string
- name: rating
dtype: float64
- name: rating_std
dtype: float64
- name: rating_volatility
dtype: float64
- name: rating_quantile
dtype: float64
- name: tag
dtype: string
- name: detailed_tag
dtype: string
- name: problem_name
dtype: string
- name: problem_main
dtype: string
- name: problem_note
dtype: string
- name: input_spec
dtype: string
- name: output_spec
dtype: string
- name: sample_inputs
sequence: string
- name: sample_outputs
sequence: string
- name: inputs
sequence: string
- name: answers
sequence: string
- name: input_output
struct:
- name: inputs
sequence: string
- name: outputs
sequence: string
- name: solution_id_0
dtype: int64
- name: solution_0
dtype: string
- name: outputs_0
sequence: string
- name: solution_id_1
dtype: int64
- name: solution_1
dtype: string
- name: outputs_1
sequence: string
- name: solution_id_2
dtype: int64
- name: solution_2
dtype: string
- name: outputs_2
sequence: string
- name: unnorm_rating
dtype: float64
- name: unnorm_rating_std
dtype: float64
- name: unnorm_rating_volatility
dtype: float64
- name: reference_rating
dtype: float64
- name: original_tags
sequence: string
- name: ever_exist
dtype: bool
splits:
- name: train
num_bytes: 25286548
num_examples: 3663
- name: eval
num_bytes: 52688262
num_examples: 4000
download_size: 33577472
dataset_size: 77974810
- config_name: E2H-GSM8K
features:
- name: rating
dtype: float64
- name: rating_std
dtype: float64
- name: rating_quantile
dtype: float64
- name: question
dtype: string
- name: answer
dtype: string
- name: model_avg_acc
dtype: float64
- name: unnorm_rating
dtype: float64
- name: unnorm_rating_std
dtype: float64
splits:
- name: eval
num_bytes: 777044
num_examples: 1319
download_size: 475944
dataset_size: 777044
- config_name: E2H-Lichess
features:
- name: puzzle_id
dtype: string
- name: rating
dtype: float64
- name: rating_std
dtype: float64
- name: rating_quantile
dtype: float64
- name: tag
dtype: string
- name: fen
dtype: string
- name: pgn
dtype: string
- name: annotated_pgn
dtype: string
- name: uci_seq
dtype: string
- name: san_seq
dtype: string
- name: answer_san
dtype: string
- name: answer_uci
dtype: string
- name: init_num_moves
dtype: int64
- name: player
dtype: string
- name: popularity_score
dtype: int64
- name: puzzle_num_plays
dtype: int64
- name: motif_tags
sequence: string
- name: phase_tags
sequence: string
- name: mate_tags
sequence: string
- name: special_move_tags
sequence: string
- name: game_origin_tags
sequence: string
- name: opening_tags
sequence: string
- name: game_hash
dtype: string
- name: game_url
dtype: string
- name: game_pgn
dtype: string
- name: game_annotated_pgn
dtype: string
- name: unnorm_rating
dtype: int64
- name: unnorm_rating_std
dtype: int64
- name: previous_fen
dtype: string
- name: last_move_uci
dtype: string
splits:
- name: train
num_bytes: 633749139
num_examples: 71763
- name: eval
num_bytes: 44154200
num_examples: 5000
download_size: 297840777
dataset_size: 677903339
- config_name: E2H-Winogrande
features:
- name: rating
dtype: float64
- name: rating_std
dtype: float64
- name: rating_quantile
dtype: float64
- name: sentence
dtype: string
- name: option1
dtype: string
- name: option2
dtype: string
- name: answer
dtype: string
- name: model_avg_acc
dtype: float64
- name: unnorm_rating
dtype: float64
- name: unnorm_rating_std
dtype: float64
splits:
- name: eval
num_bytes: 224999
num_examples: 1267
download_size: 141808
dataset_size: 224999
configs:
- config_name: E2H-AMC
data_files:
- split: train
path: E2H-AMC/train-*
- split: eval
path: E2H-AMC/eval-*
- config_name: E2H-ARC
data_files:
- split: eval
path: E2H-ARC/eval-*
- config_name: E2H-Codeforces
data_files:
- split: train
path: E2H-Codeforces/train-*
- split: eval
path: E2H-Codeforces/eval-*
- config_name: E2H-GSM8K
data_files:
- split: eval
path: E2H-GSM8K/eval-*
- config_name: E2H-Lichess
data_files:
- split: train
path: E2H-Lichess/train-*
- split: eval
path: E2H-Lichess/eval-*
- config_name: E2H-Winogrande
data_files:
- split: eval
path: E2H-Winogrande/eval-*
---
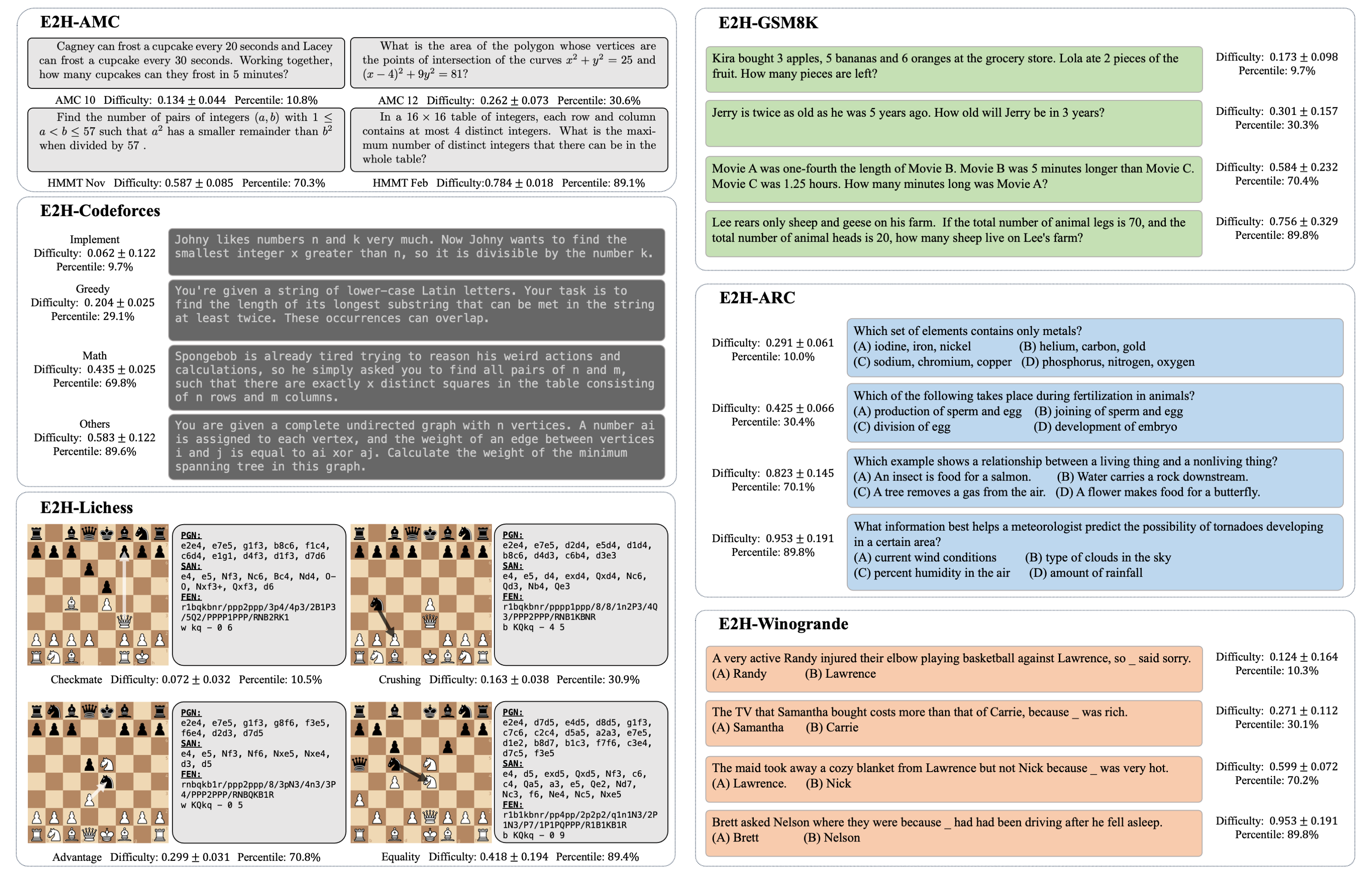
# Easy2Hard-Bench
## Dataset Description
[Easy2Hard-Bench](https://arxiv.org/abs) is a benchmark consisting with 6 datasets in different domain (mathematics, programming, chess, and various reasoning tasks). The problems from each dataset are labeled with continuous-valued difficulty levels.
| | Topic | Source | Statistics Used to Infer Difficulty | Source Type | Estimation Method |
|----------------|-------------------------|-----------------|------------------------------------------------------------------------------|-------------|-------------------|
| E2H-AMC | Math Competitions | AMC, AIME, HMMT | Item difficulties | Human | IRT |
| E2H-Codeforces | Competitive Programming | Codeforces | Submission status, contestant ratings | Human | Glicko-2 |
| E2H-Lichess | Chess Puzzles | Lichess | Player ratings, puzzle ratings | Human | Glicko-2 |
| E2H-GSM8K | Math Word Problems | GSM8K | Sample-wise evaluation results of thousands of LLMs on Open LLM Leaderboard | LLMs | IRT |
| E2H-ARC | Natural Science QA | ARC | Sample-wise evaluation results of thousands of LLMs on Open LLM Leaderboard | LLMs | IRT |
| E2H-Winograde | Commonsense Reasoning | Winogrande | Sample-wise evaluation results of thousands of LLMs on Open LLM Leaderboard | LLMs | IRT |
This can be used to profile the ability of language models over varying difficulties and explore the generalization of LLMs from easy to hard.
## Languages
The datasets are mainly in English. Some texts are LaTeX-rendered. The code solutions in E2H-Codeforces are in Python. The games in E2H-Lichess are given in serveral prevalent notations (PGN, UCI, FEN).
## Dataset Structure
```python
from datasets import load_dataset
load_dataset("furonghuang-lab/Easy2Hard-Bench", "E2H-AMC")
DatasetDict({
train: Dataset({
features: ['contest', 'rating', 'rating_std', 'rating_quantile', 'tag', 'subtest', 'year', 'month', 'index', 'problem', 'answer', 'solution', 'rating_tag', 'test_tag', 'item_difficulty', 'unnorm_rating', 'unnorm_rating_std', 'unnorm_rating_lower', 'unnorm_rating_upper', 'ever_exist'],
num_rows: 1000
})
eval: Dataset({
features: ['contest', 'rating', 'rating_std', 'rating_quantile', 'tag', 'subtest', 'year', 'month', 'index', 'problem', 'answer', 'solution', 'rating_tag', 'test_tag', 'item_difficulty', 'unnorm_rating', 'unnorm_rating_std', 'unnorm_rating_lower', 'unnorm_rating_upper', 'ever_exist'],
num_rows: 2975
})
})
load_dataset("furonghuang-lab/Easy2Hard-Bench", "E2H-Codeforces")
DatasetDict({
train: Dataset({
features: ['contest_id', 'problem_index', 'rating', 'rating_std', 'rating_volatility', 'rating_quantile', 'tag', 'detailed_tag', 'problem_name', 'problem_main', 'problem_note', 'input_spec', 'output_spec', 'sample_inputs', 'sample_outputs', 'inputs', 'answers', 'input_output', 'solution_id_0', 'solution_0', 'outputs_0', 'solution_id_1', 'solution_1', 'outputs_1', 'solution_id_2', 'solution_2', 'outputs_2', 'unnorm_rating', 'unnorm_rating_std', 'unnorm_rating_volatility', 'reference_rating', 'original_tags', 'ever_exist'],
num_rows: 3663
})
eval: Dataset({
features: ['contest_id', 'problem_index', 'rating', 'rating_std', 'rating_volatility', 'rating_quantile', 'tag', 'detailed_tag', 'problem_name', 'problem_main', 'problem_note', 'input_spec', 'output_spec', 'sample_inputs', 'sample_outputs', 'inputs', 'answers', 'input_output', 'solution_id_0', 'solution_0', 'outputs_0', 'solution_id_1', 'solution_1', 'outputs_1', 'solution_id_2', 'solution_2', 'outputs_2', 'unnorm_rating', 'unnorm_rating_std', 'unnorm_rating_volatility', 'reference_rating', 'original_tags', 'ever_exist'],
num_rows: 4000
})
})
load_dataset("furonghuang-lab/Easy2Hard-Bench", "E2H-Lichess")
DatasetDict({
train: Dataset({
features: ['puzzle_id', 'rating', 'rating_std', 'rating_quantile', 'tag', 'fen', 'pgn', 'annotated_pgn', 'uci_seq', 'san_seq', 'answer_san', 'answer_uci', 'init_num_moves', 'player', 'popularity_score', 'puzzle_num_plays', 'motif_tags', 'phase_tags', 'mate_tags', 'special_move_tags', 'game_origin_tags', 'opening_tags', 'game_hash', 'game_url', 'game_pgn', 'game_annotated_pgn', 'unnorm_rating', 'unnorm_rating_std', 'previous_fen', 'last_move_uci'],
num_rows: 71763
})
eval: Dataset({
features: ['puzzle_id', 'rating', 'rating_std', 'rating_quantile', 'tag', 'fen', 'pgn', 'annotated_pgn', 'uci_seq', 'san_seq', 'answer_san', 'answer_uci', 'init_num_moves', 'player', 'popularity_score', 'puzzle_num_plays', 'motif_tags', 'phase_tags', 'mate_tags', 'special_move_tags', 'game_origin_tags', 'opening_tags', 'game_hash', 'game_url', 'game_pgn', 'game_annotated_pgn', 'unnorm_rating', 'unnorm_rating_std', 'previous_fen', 'last_move_uci'],
num_rows: 5000
})
})
load_dataset("furonghuang-lab/Easy2Hard-Bench", "E2H-GSM8K")
DatasetDict({
eval: Dataset({
features: ['rating', 'rating_std', 'rating_quantile', 'question', 'answer', 'model_avg_acc', 'unnorm_rating', 'unnorm_rating_std'],
num_rows: 1319
})
})
load_dataset("furonghuang-lab/Easy2Hard-Bench", "E2H-ARC")
DatasetDict({
eval: Dataset({
features: ['rating', 'rating_std', 'rating_quantile', 'id', 'question', 'choices', 'answerKey', 'model_avg_acc', 'unnorm_rating', 'unnorm_rating_std'],
num_rows: 1172
})
})
```
## Data Fields
### E2H-AMC
|Field|Type|Description|
|---|---|---|
|contest|string|name of the contest|
|rating|float|estimated difficulty|
|rating_std|float|standard deviation of estimated difficulty|
|rating_quantile|float|quantile of estimated difficulty|
|tag|string|type of the contest|
|subtest|string|name of the subtest|
|year|int|year of the contest|
|month|string|month of the contest|
|index|string|problem index in the subtest|
|problem|string|textual description of problem|
|answer|string|answer of problem|
|solution|string|textual solution of the problem|
|rating_tag|string|tag about problem rating|
|test_tag|string|tag about test type|
|item difficulty|float|item difficulty of the problem|
|unnorm_rating|float|unnormalized estimated difficulty|
|unnorm_rating_std|float|standard deviation of unnormalized estimated difficulty|
|unnorm_rating_lower|float|lower threshold of difficulty suggested by AoPS|
|unnorm_rating_upper|float|upper threshold of difficulty suggested by AoPS|
|ever_exist|bool|whether the problem exists in the MATH dataset|
### E2H-Codeforces
|Field|Type|Description|
|---|---|---|
|contest_id|int|Codeforce contest id|
|problem_index|string|problem index in the contest|
|rating|float|estimated difficulty|
|rating_std|float|standard deviation of estimated difficulty|
|rating_volatility|float|volatility of estimated difficulty|
|rating_quantile|float|quantile of estimated difficulty|
|tag|string|type of the problem|
|detailed_tag|string|detailed type of the problem|
|problem_name|string|name of the problem|
|problem_main|string|main text of the problem|
|problem_note|string|note of the problem|
|input_spec|string|input specifications of the problem|
|output_spec|string|output specifications of the problem|
|sample_inputs|string|example inputs of the problem|
|sample_outputs|string|example outputs of the problem|
|inputs|string|inputs in the test cases|
|answers|string|standard outputs in the test cases|
|input_output|string|standard inputs and outputs in the test cases|
|outputs|string|standard outputs in the test cases|
|solution_id_0|int|Codeforces submission id of selected solution 0|
|solution_0|string|source code of selected solution 0|
|outputs_0|string|outputs of selected solution 0|
|solution_id_1|int|Codeforces submission id of seleted solution 1|
|solution_1|string|source code of selected solution 1|
|outputs_1|string|outputs of selected solution 1|
|solution_id_2|int|Codeforces submission id of selected solution 2|
|solution_2|string|source code of selected solution 2|
|outputs_2|string|outputs of selected solution 2|
|unnorm_rating|float|unnormalized estimated difficulty|
|unnorm_rating_std|float|standard deviation of unnormalized estimated difficulty|
|unnorm_rating_volatility|float|volatility of unnormalized estimated difficulty|
|reference_rating|float|coarse reference difficulty rating on Codeforces|
|original_tags|string|original tags on Codeforces|
|ever_exist|bool|whether the problem exists in the APPS dataset|
### E2H-Lichess
|Field|Type|Description|
|---|---|---|
|puzzle_id|string|id of the puzzle on Lichess|
|rating|float|estimated difficulty|
|rating_std|float|standard deviation of estimated difficulty|
|rating_quantile|float|quantile of estimated difficulty|
|tag|string|type of the puzzle|
|fen|string|Forsyth–Edwards notation (FEN) of the puzzle|
|pgn|string|portable game notation (PGN) of the puzzle|
|annotated_pgn|string|annotated portable game notation (PGN) of the puzzle|
|uci_seq|string|universal chess interface (UCI) notation of the puzzle|
|san_seq|string|standard algebraic notation (SAN) of the puzzle|
|answer_san|string|standard algebraic notation (SAN) of the answer|
|answer_uci|string|universal chess interface (UCI) notation of answer|
|init_num_moves|int|number of moves from initial chess board to form the puzzle|
|player|string|side to solve the puzzle, either `black` or `white`|
|populartity_score|int|popularity score of the puzzle on Lichess|
|puzzle_num_plays|int|number of times the puzzle is played on Lichess|
|motif_tags|string|tags about the puzzle motifs|
|phase_tags|string|tags about the phase of the puzzle|
|mate_tags|string|tags about the type of checkmate|
|special_move_tags|string|tags about special moves involved in the puzzle|
|game_origin_tags|string|tags about the origin of the puzzle|
|opening_tags|string|tags about the type of opening|
|game_hash|string|hash code of the corresponding game on Lichess|
|game_url|string|URL link of the corresponding game on Lichess|
|game_pgn|string|portable game notation (PGN) of the entire game|
|game_annotated_pgn|string|annotated portable game notation (PGN) of the entire game|
|unnorm_rating|float|unnormalized estimated difficulty|
|unnorm_rating_std|float|standard deviation of unnormalized estimated difficulty|
|previous_fen|string|Forsyth–Edwards notation (FEN) of the puzzle before last move by the opponent|
|last_move_uci|string|universal chess interface (UCI) notation of last move by the opponent|
### E2H-GSM8K, E2H-ARC, E2H-Winogrande
Besides the data fields from the original datasets, all of these three datasets have the following difficulty-realted data fields:
|Field|Type|Description|
|---|---|---|
|rating|float|estimated difficulty|
|rating_std|float|standard deviation of estimated difficulty|
|rating_quantile|float|quantile of estimated difficulty|
|model_avg_acc|float|average accuracy of selected models on the Open LLM Leaderboard|
|unnorm_rating|float|unnormalized estimated difficulty|
|unnorm_rating_std|float|standard deviation of unnormalized estimated difficulty|
## Data Splits
For the newly crafted datasets, E2H-AMC, E2H-Codeforces and E2H-Lichess, all of them contain a train and evaluation splits.
For the datasets, E2H-GSM8K, E2H-ARC and E2H-Winogrande, all of them only have evaluation splits with size of that in the original dataset.
| | Train Size | Eval Size |
|----------------|-----------:|----------:|
| E2H-AMC | 1,000 | 2,975 |
| E2H-Codeforces | 3,663 | 4,000 |
| E2H-Lichess | 71,763 | 5,000 |
| E2H-GSM8K | N.A. | 1,319 |
| E2H-ARC | N.A. | 1,172 |
| E2H-Winogrande | N.A. | 1,267 |
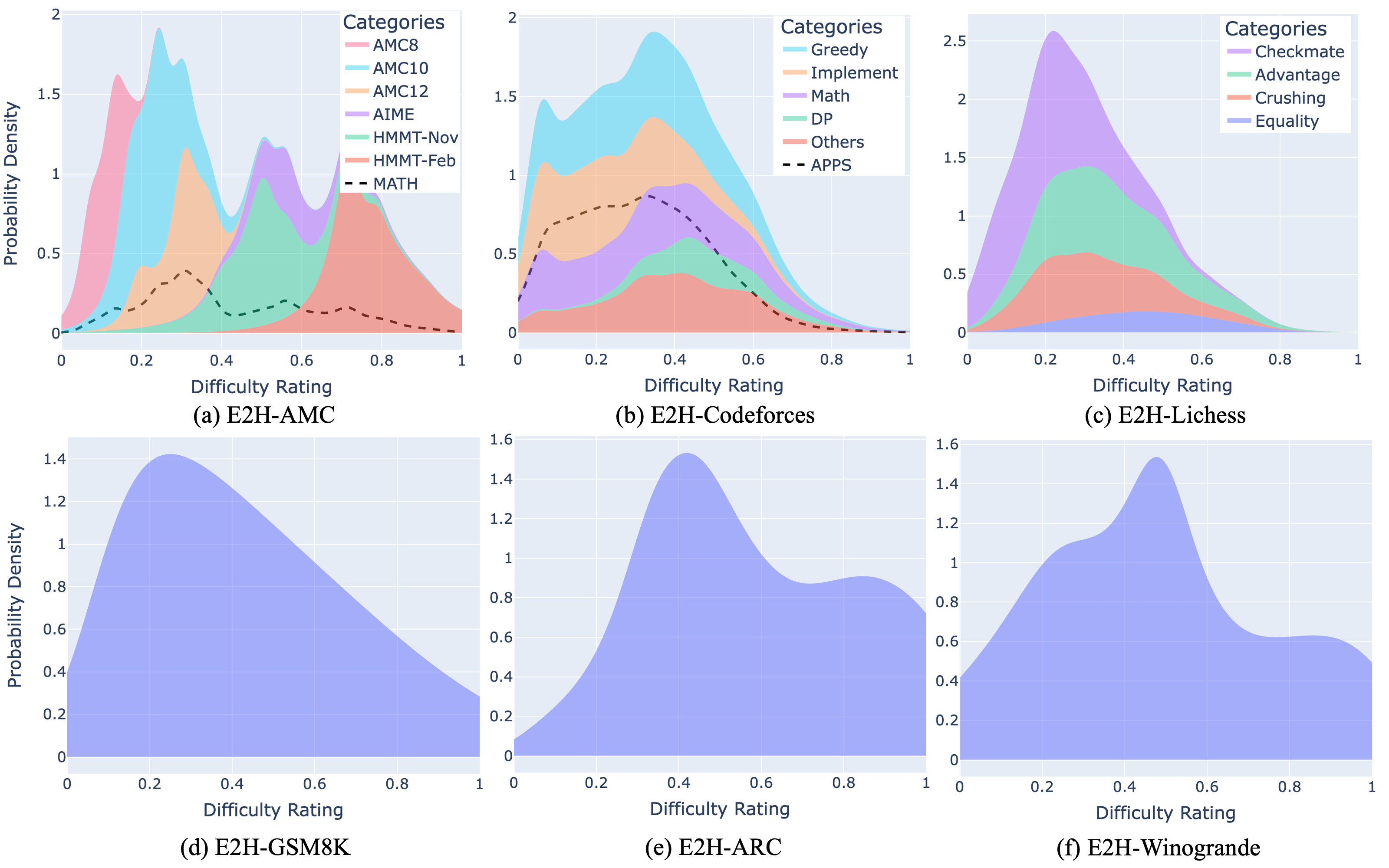
## Data Difficulty Distribution
## Dataset Creation
- E2H-AMC: We collect the problems from AMC 8/10/12, AIME I/II and HMMT Feb/Nov, and estimate the difficulties by IRT based on AoPS rating of competitions and item difficulties from the official reports.
- E2H-Codeforces: We collect the problems from contests on Codeforces, and estimate the difficulties by Glicko-2 based on contestants' ratings and submission status from Codeforces.
- E2H-Lichess: We collect the one-step puzzle from Lichess, and estimate the difficulties by Glicko-2 based on puzzle ratings and player ratings from Lichess.
- E2H-GSM8K, E2H-ARC, E2H-Winogrande: We inherit the original datasets, and estimate the dififculties by IRT based on sample-wise evluation results of LLMs on Open LLM leaderboard.
## Citation Information
```
TBD
```