Datasets:

Commit
•
54e34c2
1
Parent(s):
ddd928c
Upload folder using huggingface_hub
Browse files- README.md +51 -0
- dataset_info.json +112 -0
- duration_distribution.png +3 -0
- train_0.parquet +3 -0
- train_1.parquet +3 -0
- train_10.parquet +3 -0
- train_11.parquet +3 -0
- train_12.parquet +3 -0
- train_13.parquet +3 -0
- train_14.parquet +3 -0
- train_15.parquet +3 -0
- train_16.parquet +3 -0
- train_17.parquet +3 -0
- train_18.parquet +3 -0
- train_19.parquet +3 -0
- train_2.parquet +3 -0
- train_20.parquet +3 -0
- train_21.parquet +3 -0
- train_22.parquet +3 -0
- train_23.parquet +3 -0
- train_24.parquet +3 -0
- train_25.parquet +3 -0
- train_26.parquet +3 -0
- train_27.parquet +3 -0
- train_28.parquet +3 -0
- train_29.parquet +3 -0
- train_3.parquet +3 -0
- train_30.parquet +3 -0
- train_31.parquet +3 -0
- train_32.parquet +3 -0
- train_33.parquet +3 -0
- train_34.parquet +3 -0
- train_35.parquet +3 -0
- train_36.parquet +3 -0
- train_4.parquet +3 -0
- train_5.parquet +3 -0
- train_6.parquet +3 -0
- train_7.parquet +3 -0
- train_8.parquet +3 -0
- train_9.parquet +3 -0
- validation_0.parquet +3 -0
- validation_1.parquet +3 -0
- validation_2.parquet +3 -0
- validation_3.parquet +3 -0
- validation_4.parquet +3 -0
- validation_5.parquet +3 -0
- validation_6.parquet +3 -0
- validation_7.parquet +3 -0
- validation_8.parquet +3 -0
- validation_9.parquet +3 -0
README.md
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language:
|
| 3 |
+
- ja
|
| 4 |
+
license: cc0-1.0
|
| 5 |
+
|
| 6 |
+
tags:
|
| 7 |
+
- audio
|
| 8 |
+
- speaker diarization
|
| 9 |
+
|
| 10 |
+
source_datasets:
|
| 11 |
+
- commonvoice
|
| 12 |
+
|
| 13 |
+
task_categories:
|
| 14 |
+
- automatic-speech-recognition
|
| 15 |
+
|
| 16 |
+
annotations_creators:
|
| 17 |
+
- crowdsourced
|
| 18 |
+
|
| 19 |
+
language_creators:
|
| 20 |
+
- crowdsourced
|
| 21 |
+
---
|
| 22 |
+
# cv-corpus-17.0-ja-client_id-grouped
|
| 23 |
+
|
| 24 |
+
This dataset is a subset of the Common Voice dataset, filtered and grouped based on the client ID (treated as speaker ID).
|
| 25 |
+
|
| 26 |
+
## Dataset Details
|
| 27 |
+
|
| 28 |
+
- The dataset is derived from the Common Voice dataset.
|
| 29 |
+
- The original dataset is available at [Common Voice Dataset](https://commonvoice.mozilla.org/en/datasets).
|
| 30 |
+
- The dataset is grouped by client ID, which is treated as the speaker ID for this dataset.
|
| 31 |
+
- Each group is filtered to include only client IDs with a minimum of 30 samples and a maximum of 300 samples.
|
| 32 |
+
- The dataset is split into train and validation sets for each client ID group, with a ratio of 8:2.
|
| 33 |
+
- The same client IDs exist in both the train and validation sets.
|
| 34 |
+
- The dataset is split into batches of 1,000 samples and saved as Parquet files.
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
## Dataset Statistics
|
| 38 |
+
|
| 39 |
+
- Filtered client_id count: 649
|
| 40 |
+
- Filtered total entry count: 45,668
|
| 41 |
+
- Original total entry count: 89,310
|
| 42 |
+
|
| 43 |
+
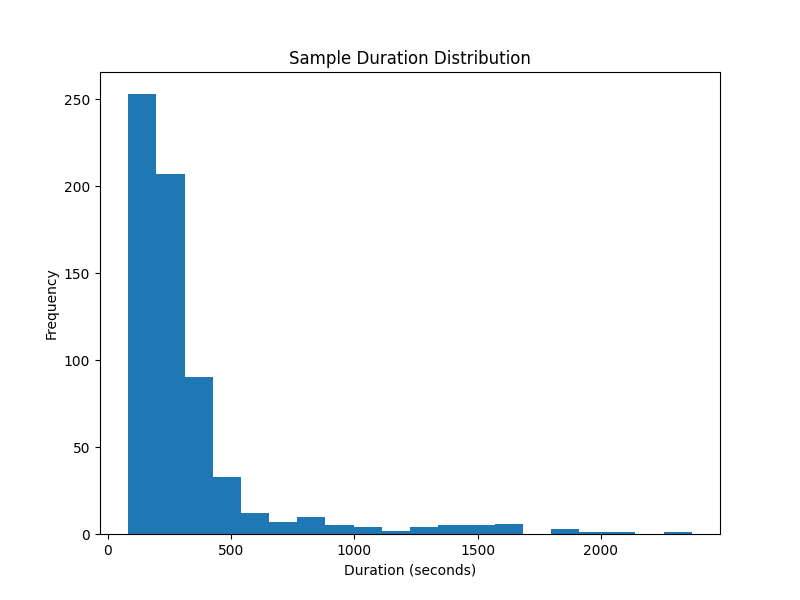
## Sample Duration Distribution
|
| 44 |
+
|
| 45 |
+

|
| 46 |
+
|
| 47 |
+
The histogram shows the distribution of sample durations in the dataset.
|
| 48 |
+
|
| 49 |
+
## License
|
| 50 |
+
|
| 51 |
+
The Common Voice dataset is licensed under the Creative Commons Zero (CC0) license.
|
dataset_info.json
ADDED
|
@@ -0,0 +1,112 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"description": "Common Voice subset dataset for speaker diarization",
|
| 3 |
+
"license": "CC0 1.0",
|
| 4 |
+
"features": {
|
| 5 |
+
"client_id": {
|
| 6 |
+
"dtype": "string",
|
| 7 |
+
"_type": "Value"
|
| 8 |
+
},
|
| 9 |
+
"sentence": {
|
| 10 |
+
"dtype": "string",
|
| 11 |
+
"_type": "Value"
|
| 12 |
+
},
|
| 13 |
+
"up_votes": {
|
| 14 |
+
"dtype": "int64",
|
| 15 |
+
"_type": "Value"
|
| 16 |
+
},
|
| 17 |
+
"down_votes": {
|
| 18 |
+
"dtype": "int64",
|
| 19 |
+
"_type": "Value"
|
| 20 |
+
},
|
| 21 |
+
"age": {
|
| 22 |
+
"dtype": "string",
|
| 23 |
+
"_type": "Value"
|
| 24 |
+
},
|
| 25 |
+
"gender": {
|
| 26 |
+
"dtype": "string",
|
| 27 |
+
"_type": "Value"
|
| 28 |
+
},
|
| 29 |
+
"accents": {
|
| 30 |
+
"dtype": "string",
|
| 31 |
+
"_type": "Value"
|
| 32 |
+
},
|
| 33 |
+
"variant": {
|
| 34 |
+
"dtype": "float64",
|
| 35 |
+
"_type": "Value"
|
| 36 |
+
},
|
| 37 |
+
"locale": {
|
| 38 |
+
"dtype": "string",
|
| 39 |
+
"_type": "Value"
|
| 40 |
+
},
|
| 41 |
+
"segment": {
|
| 42 |
+
"dtype": "string",
|
| 43 |
+
"_type": "Value"
|
| 44 |
+
},
|
| 45 |
+
"audio": {
|
| 46 |
+
"_type": "Audio"
|
| 47 |
+
}
|
| 48 |
+
},
|
| 49 |
+
"splits": [
|
| 50 |
+
{
|
| 51 |
+
"name": "train",
|
| 52 |
+
"num_examples": 36293,
|
| 53 |
+
"dataset_name": "train",
|
| 54 |
+
"filenames": [
|
| 55 |
+
"train_0.parquet",
|
| 56 |
+
"train_1.parquet",
|
| 57 |
+
"train_2.parquet",
|
| 58 |
+
"train_3.parquet",
|
| 59 |
+
"train_4.parquet",
|
| 60 |
+
"train_5.parquet",
|
| 61 |
+
"train_6.parquet",
|
| 62 |
+
"train_7.parquet",
|
| 63 |
+
"train_8.parquet",
|
| 64 |
+
"train_9.parquet",
|
| 65 |
+
"train_10.parquet",
|
| 66 |
+
"train_11.parquet",
|
| 67 |
+
"train_12.parquet",
|
| 68 |
+
"train_13.parquet",
|
| 69 |
+
"train_14.parquet",
|
| 70 |
+
"train_15.parquet",
|
| 71 |
+
"train_16.parquet",
|
| 72 |
+
"train_17.parquet",
|
| 73 |
+
"train_18.parquet",
|
| 74 |
+
"train_19.parquet",
|
| 75 |
+
"train_20.parquet",
|
| 76 |
+
"train_21.parquet",
|
| 77 |
+
"train_22.parquet",
|
| 78 |
+
"train_23.parquet",
|
| 79 |
+
"train_24.parquet",
|
| 80 |
+
"train_25.parquet",
|
| 81 |
+
"train_26.parquet",
|
| 82 |
+
"train_27.parquet",
|
| 83 |
+
"train_28.parquet",
|
| 84 |
+
"train_29.parquet",
|
| 85 |
+
"train_30.parquet",
|
| 86 |
+
"train_31.parquet",
|
| 87 |
+
"train_32.parquet",
|
| 88 |
+
"train_33.parquet",
|
| 89 |
+
"train_34.parquet",
|
| 90 |
+
"train_35.parquet",
|
| 91 |
+
"train_36.parquet"
|
| 92 |
+
]
|
| 93 |
+
},
|
| 94 |
+
{
|
| 95 |
+
"name": "validation",
|
| 96 |
+
"num_examples": 9375,
|
| 97 |
+
"dataset_name": "validation",
|
| 98 |
+
"filenames": [
|
| 99 |
+
"validation_0.parquet",
|
| 100 |
+
"validation_1.parquet",
|
| 101 |
+
"validation_2.parquet",
|
| 102 |
+
"validation_3.parquet",
|
| 103 |
+
"validation_4.parquet",
|
| 104 |
+
"validation_5.parquet",
|
| 105 |
+
"validation_6.parquet",
|
| 106 |
+
"validation_7.parquet",
|
| 107 |
+
"validation_8.parquet",
|
| 108 |
+
"validation_9.parquet"
|
| 109 |
+
]
|
| 110 |
+
}
|
| 111 |
+
]
|
| 112 |
+
}
|
duration_distribution.png
ADDED
|
Git LFS Details
|
train_0.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8fa6b79dbb4859ee833dfc0f022ac1b75239bc397983c7ccf757637e786e328f
|
| 3 |
+
size 29165444
|
train_1.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b0fb233ace142cc2ec3cd3518345401ca17e0772a3c9b351163c03981259a101
|
| 3 |
+
size 28129187
|
train_10.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3002dbad7ccc8fe480a152764de0e240b3572b3706642c001b3dd269474f7daa
|
| 3 |
+
size 29330970
|
train_11.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:658cf4a284b7c901038c8f65f7d2214f41c8e54fa254f82bfb675506b8c01a5a
|
| 3 |
+
size 27494445
|
train_12.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6fdbe0703c5ab8796898e0a5ec7f8fa1426ceb3f31650b33ac0690ed9961594d
|
| 3 |
+
size 28741600
|
train_13.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f2d0ed4e05dfee3b6e2018af9f2833030e2106a84658865f5fb9234787c76bee
|
| 3 |
+
size 28345873
|
train_14.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dc076ec8f77c51ae2b5673816521ca109d794e66c786665b4a320803fb7d66c5
|
| 3 |
+
size 28680587
|
train_15.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ef0f29e577a8d7f823b1583a89d5ad4df100711c0056236213594d9bbfe49e67
|
| 3 |
+
size 28174952
|
train_16.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3fd1722c7bda64d10e88529f33f7eb8e5884e9defc23b2cc68fd172bf74f3dcd
|
| 3 |
+
size 28809261
|
train_17.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e1a5e6a58cb10e5be9ef2cf511fecd8634215e93cf6319737ad469a02206a550
|
| 3 |
+
size 28814920
|
train_18.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:846872aacaad24ccf70b5fccf53538374c3eba475162b661924dd609311b5c75
|
| 3 |
+
size 28292637
|
train_19.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8215b999b37a640bb1ff7fc37aeeace1db6cbc2db21750e608e398899d79de62
|
| 3 |
+
size 28087871
|
train_2.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6eec5e249bb0a97ce57361007ab24f37679f918854dac3addf56dbefaef63dbd
|
| 3 |
+
size 28026036
|
train_20.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c8ad7bad20514523df380400d802fe99c0aab54cbdbf7753527bf733a8744b5d
|
| 3 |
+
size 28407108
|
train_21.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b5b220a12776c339c8d7ed7930d7d7467f84ac581a599aa4b72de4b134690c49
|
| 3 |
+
size 28004496
|
train_22.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:35e7747be67c2076f2381a44d47f8564bbdb045cd6f18a682942be44ca5a6029
|
| 3 |
+
size 27932203
|
train_23.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8e28d5995bd2ca7216925f12fa2676166d284ac3ade6d8b4e51780d3200441bc
|
| 3 |
+
size 27777705
|
train_24.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:10efa8a13fd77bb6118369941aef1ca476c5cbad3c9eaacb9930883bcba13bff
|
| 3 |
+
size 28490098
|
train_25.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:54f502d613c05ddef0a240b0421dbd52f35292a5e2992ed2958bf5e1ecc101f0
|
| 3 |
+
size 28402590
|
train_26.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e0c4f8984d60a60bdf1359c982f4a73506810d0bc4cd0b13ef916ad95c80ff87
|
| 3 |
+
size 27805738
|
train_27.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7de4e30ce1fb0473d020af98c33e9f16bda40bab50632721167fe1acd1cbad76
|
| 3 |
+
size 27914618
|
train_28.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1a074a3a3d3f7a9ad9639af720c3de10c28f2bcd569ccb0a4b43c56a17793fae
|
| 3 |
+
size 28262003
|
train_29.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e2c1f6fc91d168e8d3daf77962f313e4e27d5e1605db8c726bcc087c071cb214
|
| 3 |
+
size 27540192
|
train_3.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:da766b83d52741bfebfb72fd0ebb7f403bcb25b2a3d6fb83bb8ae955003b5b5c
|
| 3 |
+
size 27616159
|
train_30.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d8e6475984023982b836121933c5debc6807b30adaa8328f08e86bf52f24008e
|
| 3 |
+
size 28563772
|
train_31.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6f195cd21e328ee9b131c48f5b06ae06163abaa1d21d436bcf709aff1372bc42
|
| 3 |
+
size 28604293
|
train_32.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e7949cf51d98e7dd543ce7ef422b18c726c345f7f0cd467e7c8dbee06632276c
|
| 3 |
+
size 28790969
|
train_33.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:76606962c34e3091d08dd5171d67a1ebf5f3f1a0e01dc66d1d500ee35bff71f5
|
| 3 |
+
size 28351579
|
train_34.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c73907cd2fd6d74333387abaf1427f67e8c1d7681fe560b3ef5bd3e3c326d871
|
| 3 |
+
size 27967744
|
train_35.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:18e6bbcd891f19fc2b28bae40a0430f820402cafe12af82f92f6542b5074e2ca
|
| 3 |
+
size 28089233
|
train_36.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:69a3c11cfa651393d0220c1fbb72f997c3fe1b71daea4fcc967110dd3d965654
|
| 3 |
+
size 8517271
|
train_4.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:59fad71d66a86b4ca059d5e0972c7910ccba46feaae664515ac4e719fea6ed4e
|
| 3 |
+
size 28790803
|
train_5.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:685fbeb3cb269ed94b919b3022d4e6032822a833758885b0e3cfe778fc88ebec
|
| 3 |
+
size 28793801
|
train_6.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:bbb6023b41f0f4d76d549e544496304c8a0885136c1d89ed8aad8b2576e284b6
|
| 3 |
+
size 27964405
|
train_7.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:51b8543c50e2f8c4481ee5cd9a9bbb0c38236b692667a8690cc3cf8eaa23e9d4
|
| 3 |
+
size 28653251
|
train_8.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b44ea5f78b443b274008b1582210e9e547d940c1e1af85fe32a647a599a37174
|
| 3 |
+
size 28145010
|
train_9.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4cf112e4a1c44a5a008b4909290259a3d7e31824b657338b69a5af3c1ae3ff5a
|
| 3 |
+
size 28249501
|
validation_0.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4b3486f2da62655abe54bbb1e74f9df479d4823b698fb95c3dfd31a210808f6a
|
| 3 |
+
size 28830940
|
validation_1.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:929603182b5a03d2b77e3e0e39dc6e514e96b6e6007b490568c8e6d500382fed
|
| 3 |
+
size 28291099
|
validation_2.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:34eba9e0f65ab91db3b2785ad2c8300c0fa8aaf9d663d6e07f067725e76857f0
|
| 3 |
+
size 27505943
|
validation_3.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:963ac8b4a1a5e0154daf833952fe3cdc46fd094744dea980112268e4ebd0d561
|
| 3 |
+
size 27670083
|
validation_4.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ca106578527a8d7c6a363f77261c72f6da31e459336d582728c061e36c979034
|
| 3 |
+
size 28815574
|
validation_5.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4694de3968ca1d83f75aed764f85f9a514b591a84e55e2e4f5254d0171859abd
|
| 3 |
+
size 28485726
|
validation_6.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:23793002a12206448afbec8e590e46b7f4db8fc9407027d48e0127f23f612939
|
| 3 |
+
size 29104808
|
validation_7.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:561586f4a3fe3f4a6736babee74cc710f5304567d9dfe708b196335620387901
|
| 3 |
+
size 28301667
|
validation_8.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b2a29d7b529d7e10ad58673992ce5dfcbd39cf6e90023a7108933e5845075962
|
| 3 |
+
size 28330415
|
validation_9.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:eceaf72b6f1e90203aafe32085775f08fb0be71ba7405429ca51c718436d3bd7
|
| 3 |
+
size 10456204
|