---
license: cc-by-4.0
---
## Mission: Open and Good ML
In our mission to democratize good machine learning (ML), we examine how supporting ML community work also empowers examining and preventing possible harms. Open development and science decentralizes power so that many people can collectively work on AI that reflects their needs and values. While [openness enables broader perspectives to contribute to research and AI overall, it faces the tension of less risk control](https://arxiv.org/abs/2302.04844).
Moderating ML artifacts presents unique challenges due to the dynamic and rapidly evolving nature of these systems. In fact, as ML models become more advanced and capable of producing increasingly diverse content, the potential for harmful or unintended outputs grows, necessitating the development of robust moderation and evaluation strategies. Moreover, the complexity of ML models and the vast amounts of data they process exacerbate the challenge of identifying and addressing potential biases and ethical concerns.
As hosts, we recognize the responsibility that comes with potentially amplifying harm to our users and the world more broadly. Often these harms disparately impact minority communities in a context-dependent manner. We have taken the approach of analyzing the tensions in play for each context, open to discussion across the company and Hugging Face community. While many models can amplify harm, especially discriminatory content, we are taking a series of steps to identify highest risk models and what action to take. Importantly, active perspectives from many backgrounds is key to understanding, measuring, and mitigating potential harms that affect different groups of people.
We are crafting tools and safeguards in addition to improving our documentation practices to ensure open source science empowers individuals and continues to minimize potential harms.
## Ethical Categories
The first major aspect of our work to foster good open ML consists in promoting the tools and positive examples of ML development that prioritize values and consideration for its stakeholders. This helps users take concrete steps to address outstanding issues, and present plausible alternatives to de facto damaging practices in ML development.
To help our users discover and engage with ethics-related ML work, we have compiled a set of tags. These 6 high-level categories are based on our analysis of Spaces that community members had contributed. They are designed to give you a jargon-free way of thinking about ethical technology:
- Rigorous work pays special attention to developing with best practices in mind. In ML, this can mean examining failure cases (including conducting bias and fairness audits), protecting privacy through security measures, and ensuring that potential users (technical and non-technical) are informed about the project's limitations.
- Consentful work [supports](https://www.consentfultech.io/) the self-determination of people who use and are affected by these technologies.
- Socially Conscious work shows us how technology can support social, environmental, and scientific efforts.
- Sustainable work highlights and explores techniques for making machine learning ecologically sustainable.
- Inclusive work broadens the scope of who builds and benefits in the machine learning world.
- Inquisitive work shines a light on inequities and power structures which challenge the community to rethink its relationship to technology.
Read more at https://huggingface.co/ethics
Look for these terms as we’ll be using these tags, and updating them based on community contributions, across some new projects on the Hub!
## Safeguards
Taking an “all-or-nothing” view of open releases ignores the wide variety of contexts that determine an ML artifact’s positive or negative impacts. Having more levers of control over how ML systems are shared and re-used supports collaborative development and analysis with less risk of promoting harmful uses or misuses; allowing for more openness and participation in innovation for shared benefits.
We engage directly with contributors and have addressed pressing issues. To bring this to the next level, we are building community-based processes. This approach empowers both Hugging Face contributors, and those affected by contributions, to inform the limitations, sharing, and additional mechanisms necessary for models and data made available on our platform. The three main aspects we will pay attention to are: the origin of the artifact, how the artifact is handled by its developers, and how the artifact has been used. In that respect we:
- launched a [flagging feature](https://twitter.com/GiadaPistilli/status/1571865167092396033) for our community to determine whether ML artifacts or community content (model, dataset, space, or discussion) violate our [content guidelines](https://huggingface.co/content-guidelines),
- monitor our community discussion boards to ensure Hub users abide by the [code of conduct](https://huggingface.co/code-of-conduct),
- robustly document our most-downloaded models with model cards that detail social impacts, biases, and intended and out-of-scope use cases,
- create audience-guiding tags, such as the “Not For All Audiences” tag that can be added to the repository’s card metadata to avoid un-requested violent and sexual content,
- promote use of [Open Responsible AI Licenses (RAIL)](https://huggingface.co/blog/open_rail) for [models](https://www.licenses.ai/blog/2022/8/26/bigscience-open-rail-m-license), such as with LLMs ([BLOOM](https://huggingface.co/spaces/bigscience/license), [BigCode](https://huggingface.co/spaces/bigcode/license)),
- conduct research that [analyzes](https://arxiv.org/abs/2302.04844) which models and datasets have the highest potential for, or track record of, misuse and malicious use.
**How to use the flagging function:**
Click on the flag icon on any Model, Dataset, Space, or Discussion:
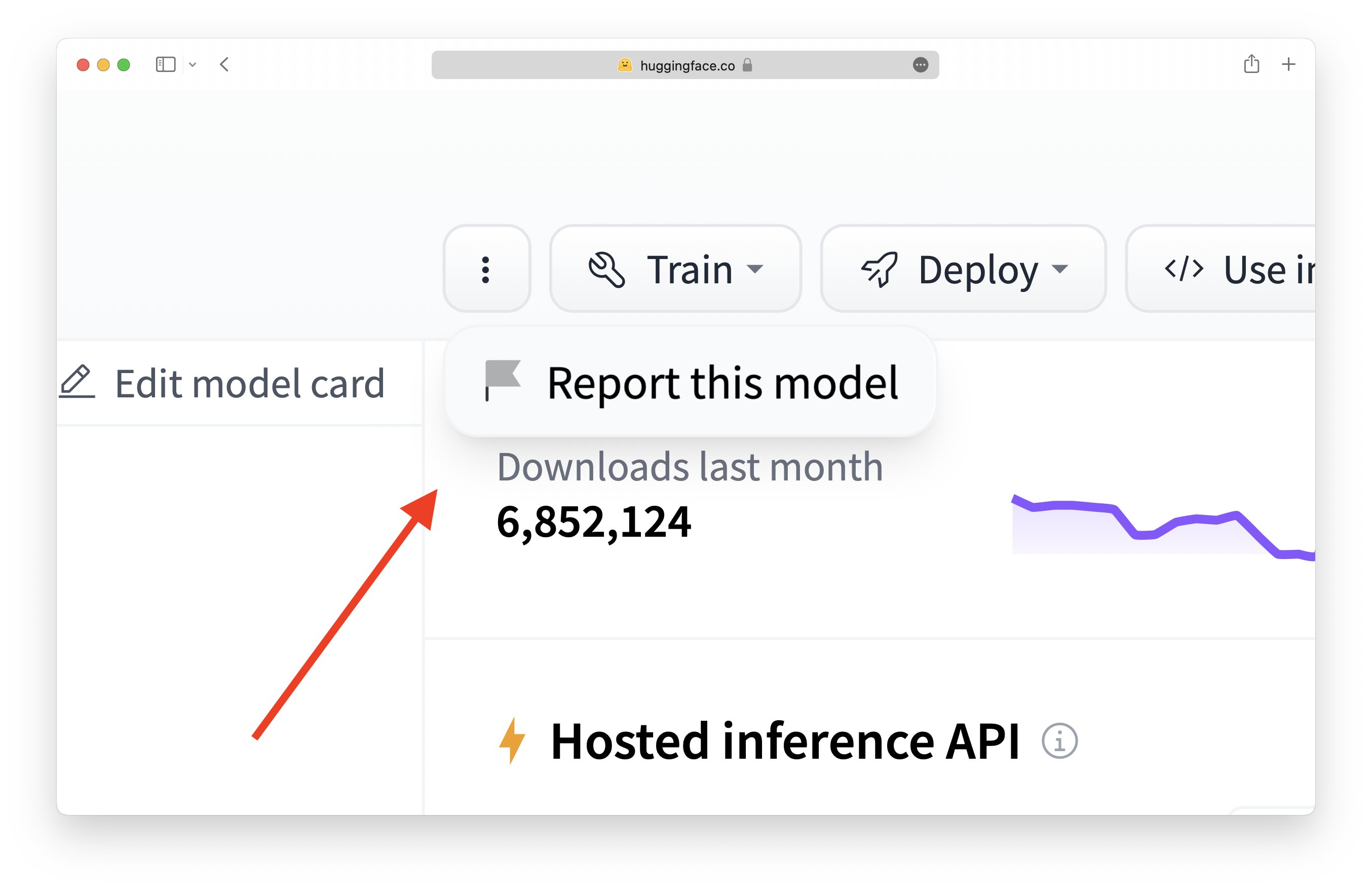
Share why you flagged this item:
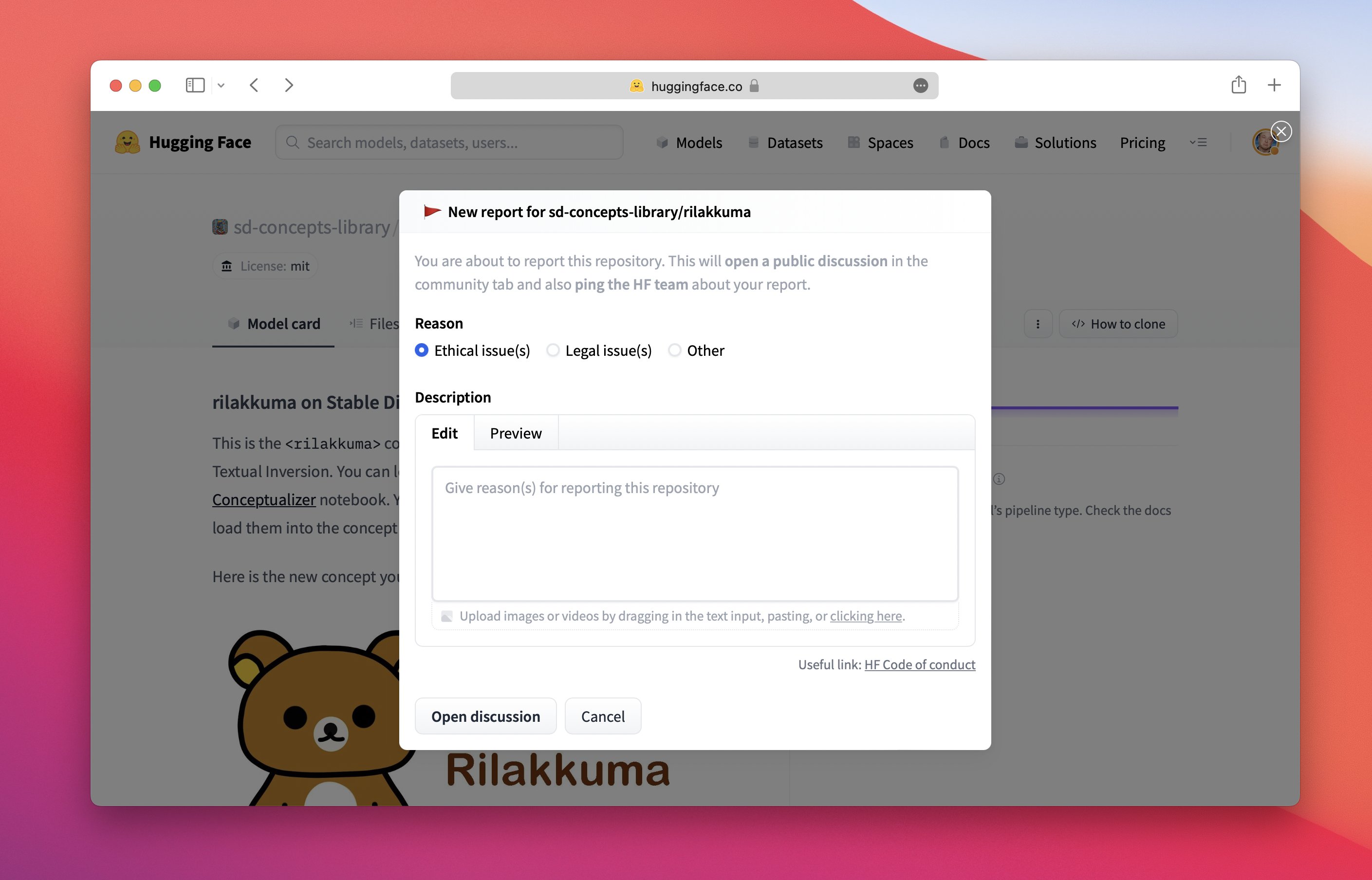
In prioritizing open science, we examine potential harm on a case-by-case basis. When users flag a system, developers can directly and transparently respond to concerns. Moderators are able to disengage from discussions should behavior become hateful and/or abusive (see [code of conduct](https://huggingface.co/code-of-conduct)).
Should a specific model be flagged as high risk by our community, we consider:
- Downgrading the ML artifact’s visibility across the Hub in the trending tab and in feeds,
- Requesting that the models be made private,
- Gating access to ML artifacts (see documentation for [models](https://huggingface.co/docs/hub/models-gated) and [datasets](https://huggingface.co/docs/hub/datasets-gated)),
- Disabling access.
**How to add the “Not For All Audiences” tag:**
Edit the model/data card → add `not-for-all-audiences` in the tags section → open the PR and wait for the authors to merge it. Once merged, the following tag will be displayed on the repository:

Any repository tagged `not-for-all-audiences` will display the following popup when visited:
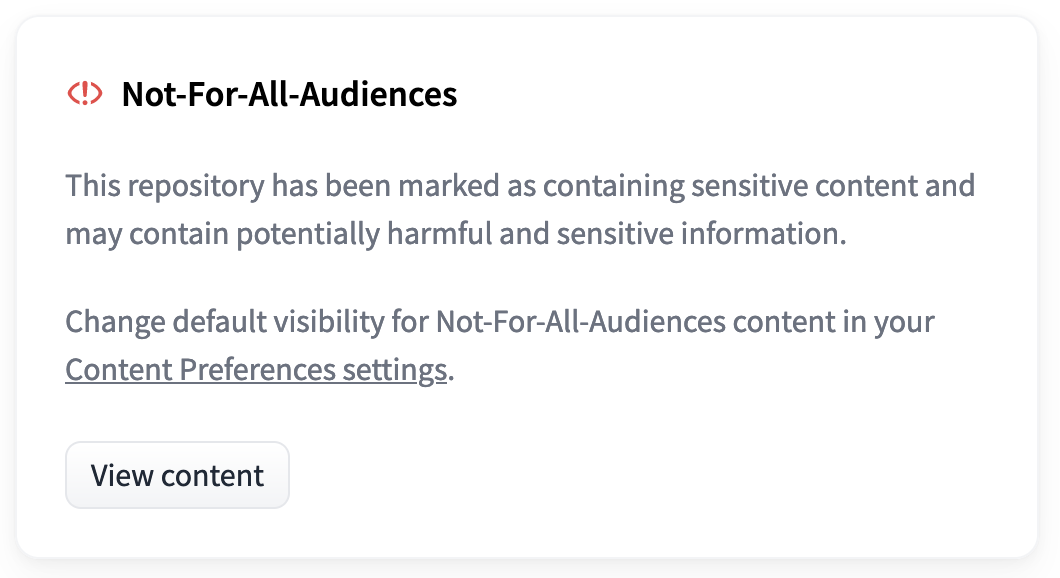
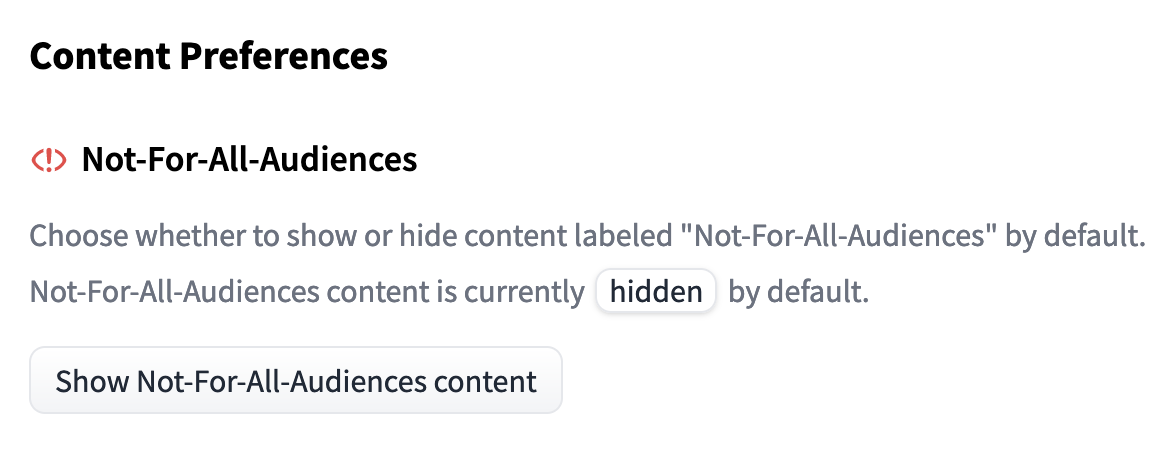
Clicking "View Content" will allow you to view the repository as normal. If you wish to always view `not-for-all-audiences`-tagged repositories without the popup, this setting can be changed in a user's [Content Preferences](https://huggingface.co/settings/content-preferences)
Open science requires safeguards, and one of our goals is to create an environment informed by tradeoffs with different values. Hosting and providing access to models in addition to cultivating community and discussion empowers diverse groups to assess social implications and guide what is good machine learning.
## Are you working on safeguards? Share them on Hugging Face Hub!
The most important part of Hugging Face is our community. If you’re a researcher working on making ML safer to use, especially for open science, we want to support and showcase your work!
Here are some recent demos and tools from researchers in the Hugging Face community:
- [A Watermark for LLMs](https://huggingface.co/spaces/tomg-group-umd/lm-watermarking) by John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, Tom Goldstein ([paper](https://arxiv.org/abs/2301.10226))
- [Generate Model Cards Tool](https://huggingface.co/spaces/huggingface/Model_Cards_Writing_Tool) by the Hugging Face team
- [Photoguard](https://huggingface.co/spaces/RamAnanth1/photoguard) to safeguard images against manipulation by Ram Ananth
Thanks for reading! 🤗
~ Irene, Nima, Giada, Yacine, and Elizabeth, on behalf of the Ethics and Society regulars
If you want to cite this blog post, please use the following:
```
@misc{hf_ethics_soc_blog_3,
author = {Irene Solaiman and
Giada Pistilli and
Nima Boscarino and
Yacine Jernite and
Elizabeth Allendorf and
Margaret Mitchell and
Carlos Muñoz Ferrandis and
Nathan Lambert and
Alexandra Sasha Luccioni
},
title = {Hugging Face Ethics and Society Newsletter 3: Ethical Openness at Hugging Face},
booktitle = {Hugging Face Blog},
year = {2023},
url = {https://doi.org/10.57967/hf/0487},
doi = {10.57967/hf/0487}
}
```