
End of training
Browse files- README.md +1 -1
- all_results.json +9 -9
- eval_results.json +4 -4
- train_results.json +5 -5
- trainer_state.json +14 -14
- training_eval_loss.png +0 -0
README.md
CHANGED
|
@@ -16,7 +16,7 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 16 |
|
| 17 |
# llama3_8b_baseline_instructskillmix
|
| 18 |
|
| 19 |
-
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B) on
|
| 20 |
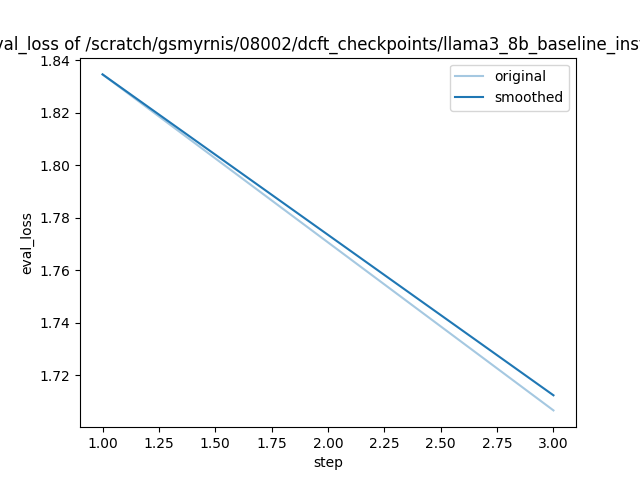
It achieves the following results on the evaluation set:
|
| 21 |
- Loss: 1.7067
|
| 22 |
|
|
|
|
| 16 |
|
| 17 |
# llama3_8b_baseline_instructskillmix
|
| 18 |
|
| 19 |
+
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B) on the PrincetonPLI/Instruct-SkillMix-SDD dataset.
|
| 20 |
It achieves the following results on the evaluation set:
|
| 21 |
- Loss: 1.7067
|
| 22 |
|
all_results.json
CHANGED
|
@@ -1,12 +1,12 @@
|
|
| 1 |
{
|
| 2 |
"epoch": 1.6,
|
| 3 |
-
"eval_loss":
|
| 4 |
-
"eval_runtime":
|
| 5 |
-
"eval_samples_per_second":
|
| 6 |
-
"eval_steps_per_second":
|
| 7 |
-
"total_flos":
|
| 8 |
-
"train_loss":
|
| 9 |
-
"train_runtime":
|
| 10 |
-
"train_samples_per_second":
|
| 11 |
-
"train_steps_per_second": 0.
|
| 12 |
}
|
|
|
|
| 1 |
{
|
| 2 |
"epoch": 1.6,
|
| 3 |
+
"eval_loss": 1.7066795825958252,
|
| 4 |
+
"eval_runtime": 2.1283,
|
| 5 |
+
"eval_samples_per_second": 47.456,
|
| 6 |
+
"eval_steps_per_second": 1.879,
|
| 7 |
+
"total_flos": 9945533644800.0,
|
| 8 |
+
"train_loss": 1.8230679829915364,
|
| 9 |
+
"train_runtime": 538.5669,
|
| 10 |
+
"train_samples_per_second": 10.689,
|
| 11 |
+
"train_steps_per_second": 0.006
|
| 12 |
}
|
eval_results.json
CHANGED
|
@@ -1,7 +1,7 @@
|
|
| 1 |
{
|
| 2 |
"epoch": 1.6,
|
| 3 |
-
"eval_loss":
|
| 4 |
-
"eval_runtime":
|
| 5 |
-
"eval_samples_per_second":
|
| 6 |
-
"eval_steps_per_second":
|
| 7 |
}
|
|
|
|
| 1 |
{
|
| 2 |
"epoch": 1.6,
|
| 3 |
+
"eval_loss": 1.7066795825958252,
|
| 4 |
+
"eval_runtime": 2.1283,
|
| 5 |
+
"eval_samples_per_second": 47.456,
|
| 6 |
+
"eval_steps_per_second": 1.879
|
| 7 |
}
|
train_results.json
CHANGED
|
@@ -1,8 +1,8 @@
|
|
| 1 |
{
|
| 2 |
"epoch": 1.6,
|
| 3 |
-
"total_flos":
|
| 4 |
-
"train_loss":
|
| 5 |
-
"train_runtime":
|
| 6 |
-
"train_samples_per_second":
|
| 7 |
-
"train_steps_per_second": 0.
|
| 8 |
}
|
|
|
|
| 1 |
{
|
| 2 |
"epoch": 1.6,
|
| 3 |
+
"total_flos": 9945533644800.0,
|
| 4 |
+
"train_loss": 1.8230679829915364,
|
| 5 |
+
"train_runtime": 538.5669,
|
| 6 |
+
"train_samples_per_second": 10.689,
|
| 7 |
+
"train_steps_per_second": 0.006
|
| 8 |
}
|
trainer_state.json
CHANGED
|
@@ -10,28 +10,28 @@
|
|
| 10 |
"log_history": [
|
| 11 |
{
|
| 12 |
"epoch": 0.5333333333333333,
|
| 13 |
-
"eval_loss":
|
| 14 |
-
"eval_runtime":
|
| 15 |
-
"eval_samples_per_second":
|
| 16 |
-
"eval_steps_per_second":
|
| 17 |
"step": 1
|
| 18 |
},
|
| 19 |
{
|
| 20 |
"epoch": 1.6,
|
| 21 |
-
"eval_loss":
|
| 22 |
-
"eval_runtime": 2.
|
| 23 |
-
"eval_samples_per_second":
|
| 24 |
-
"eval_steps_per_second": 1.
|
| 25 |
"step": 3
|
| 26 |
},
|
| 27 |
{
|
| 28 |
"epoch": 1.6,
|
| 29 |
"step": 3,
|
| 30 |
-
"total_flos":
|
| 31 |
-
"train_loss":
|
| 32 |
-
"train_runtime":
|
| 33 |
-
"train_samples_per_second":
|
| 34 |
-
"train_steps_per_second": 0.
|
| 35 |
}
|
| 36 |
],
|
| 37 |
"logging_steps": 10,
|
|
@@ -51,7 +51,7 @@
|
|
| 51 |
"attributes": {}
|
| 52 |
}
|
| 53 |
},
|
| 54 |
-
"total_flos":
|
| 55 |
"train_batch_size": 4,
|
| 56 |
"trial_name": null,
|
| 57 |
"trial_params": null
|
|
|
|
| 10 |
"log_history": [
|
| 11 |
{
|
| 12 |
"epoch": 0.5333333333333333,
|
| 13 |
+
"eval_loss": 1.8345630168914795,
|
| 14 |
+
"eval_runtime": 2.0718,
|
| 15 |
+
"eval_samples_per_second": 48.75,
|
| 16 |
+
"eval_steps_per_second": 1.931,
|
| 17 |
"step": 1
|
| 18 |
},
|
| 19 |
{
|
| 20 |
"epoch": 1.6,
|
| 21 |
+
"eval_loss": 1.7066795825958252,
|
| 22 |
+
"eval_runtime": 2.1098,
|
| 23 |
+
"eval_samples_per_second": 47.873,
|
| 24 |
+
"eval_steps_per_second": 1.896,
|
| 25 |
"step": 3
|
| 26 |
},
|
| 27 |
{
|
| 28 |
"epoch": 1.6,
|
| 29 |
"step": 3,
|
| 30 |
+
"total_flos": 9945533644800.0,
|
| 31 |
+
"train_loss": 1.8230679829915364,
|
| 32 |
+
"train_runtime": 538.5669,
|
| 33 |
+
"train_samples_per_second": 10.689,
|
| 34 |
+
"train_steps_per_second": 0.006
|
| 35 |
}
|
| 36 |
],
|
| 37 |
"logging_steps": 10,
|
|
|
|
| 51 |
"attributes": {}
|
| 52 |
}
|
| 53 |
},
|
| 54 |
+
"total_flos": 9945533644800.0,
|
| 55 |
"train_batch_size": 4,
|
| 56 |
"trial_name": null,
|
| 57 |
"trial_params": null
|
training_eval_loss.png
CHANGED
|
|