
Índice
- Introducción
- Google Collab
- Instalación Local (Windows + Nvidia)
- Conceptos Esenciales
- Extensiones
- Loras
- Imágenes Grandes
- Scripts
- ControlNet
- Entrenamiento de Loras para novatos
- ...vtubers?
Introducción ▲
Stable Diffusion es una poderosa herramienta de generación de imágenes a través de inteligencia artificial (IA), la cual puedes usar en tu propio hogar. Ésta utiliza "modelos", los cuales son el cerebro de la IA y pueden crear casi cualquier cosa, siempre y cuando alguien los haya entrenado para ello. Los usos más populares son generación de arte anime, de fotorealismo, y de contenido para adultos.
Las imágenes que creas pueden ser usadas para cualquier propósito, siempre y cuando sigan la licencia del modelo utilizado. Estas imágenes puede o no que sean "tuyas" en un sentido legal, dependiendo de las leyes de tu país, y comúnmente es inconcluso. Ni yo ni nadie asociado con Stable Diffusion y sus modelos somos responsables por el contenido que generes, y se te prohibe usar estas herramientas para generar contenido ilegal o dañino.
Esta guía está actualizada hasta Marzo de 2023. Una semana es como un año para el desarrollo de IAs, así que espero que siga siendo útil para cuando la leas.
Google Collab ▲
La manera más facil de usar Stable Diffusion es a través de Google Collab. Con él tomas prestado los computadores de Google para usar la IA, con tiempo limitado, comúnmente varias horas al día. Necesitarás al menos una cuenta de Google y utilizaremos el Google Drive para guardar tus imágenes.
Si en su lugar deseas correr el programa en tu propio computador, baja aquí ▼.
Aquí las instrucciones del collab. Estaremos usando el stable-diffusion-webui de Automatic1111.
Abre esta página.
Cerca de arriba clickea Copiar a mi Drive. Espera que se abra la ventana nueva y cierra la vieja. Ahora tienes tu propio collab el cual puedes configurar a tu gusto, y deberás abrir desde tu Google Drive. En caso de actualizaciones deberás ver el original.
Activa las siguientes casillas bajo Configurations:
output_to_drive, configs_in_drive, no_custom_theme. Luego, activa las siguientes casillas bajo Models, etc:anything_vae,wd_vae,sd_vae.Si ya conoces Stable Diffusion puedes pegar los enlaces a tus recursos deseados en la casilla de
custom_urls. Vamos a añadir enlaces aquí más adelante en la guía. Los enlaces deben ser descargas directas a cada archivo (idealmente de los sitios civitai o huggingface), y deben separarse por comas.Presiona el botón de reproducción a la izquierda, en cualquier lugar dentro de la gran sección llamada Start 🚀. Espera un par de minutos para que se instale y corra el programa. Verás aparecer mensajes de progreso más abajo. Eventualmente uno de estos mensajes será un public link lo cual indica que está listo, y puedes abrir este enlace en una nueva pestaña para utilizar Stable Diffusion. Mantén la pestaña del collab abierta! (esto puede ser difícil si intentas usarlo desde un teléfono)
Ahora puedes hacer algunas imágenes decentes gracias al modelo por defecto llamado Anything 4.5. Pero podemos hacer más que ello, y además, ¿qué son todas estas opciones? Baja aquí ▼ para aprender las bases.
Instalación Local (Windows + Nvidia) ▲
Para correr Stable Diffusion en tu propio computador necesitarás al menos 16 GB de RAM y 4 GB de VRAM (idealmente 8). Por ahora sólo voy a explicar el caso en que uses Windows 10/11 y poseas una tarjeta gráfica NVIDIA de serie 10XX o mayor. Mis disculpas si tienes AMD o usas Linux o Mac, pero con ellos es más complejo. Si no cumples estas condiciones aún puedes usar el Google Collab aquí arriba ▲.
Aquí las instrucciones de instalación. Utilizaremos un launcher para correr el stable-diffusion-webui de Automatic1111.
Obtén el instalador más reciente desde esta página.
Corre el instalador (dile a Windows que no es un virus) y selecciona una ubicación sencilla y accesible en donde instalar. Espera a que termine.
Corre el programa, éste es el launcher. Verás algunas opciones. Primero activa medvram y xformers. Si tu gráfica tiene 12 GB de VRAM o más no es necesario medvram.
En la casilla de texto que dice Additional Launch Options pega lo siguiente:
--opt-channelslast --no-half-vae --theme dark. Si añades más opciones sepáralas con espacios.- Si tu gráfica tiene 4 o 6 GB de VRAM añade
--opt-split-attention-v1lo cual puede ayudar un poco. - Si deseas correr el programa en un dispositivo y usarlo a través de otro dispositivo en la misma red de WiFi (como en tu teléfono), puedes añadir
--listen --enable-insecure-extension-access. Tras iniciar el programa podrás conectarte desde el navegador usando la IP local en el puerto 7860. También puedes añadir una contraseña con--gradio-auth nombre:contr. - Puedes encontrar todas las opciones aquí.
- Si tu gráfica tiene 4 o 6 GB de VRAM añade
Presiona Launch y espera a que cargue y/o termine de instalar. Cuando termine se abrirá una ventana en tu navegador.
La página está abierta, es tu propio sitio web privado. Aquí en la pestaña principal (txt2img) es donde harás casi todas tus imágenes. Pero primero iremos a la pestaña Settings, y veremos algunas secciones del lado izquierdo.
- En la sección de Stable Diffusion baja al final y aumenta el Clip skip de 1 a 2. Se dice que produce mejores imágenes.
- En la sección User Interface, baja hasta Quicksettings list y cámbialo a
sd_model_checkpoint, sd_vae. - Vuelve a subir y presiona el gran Apply settings, luego Reload UI.
Ahora estás más que listo para generar imágenes, pero sólo tienes el modelo básico. No es muy bueno, sirve para pinturas entre otras cosas. Además, ¿qué son todas estas opciones? Ve aquí abajo ▼ para aprender las bases.
Conceptos Esenciales ▲
Antes o después de hacer tus primeras imágenes, querrás leer la información de aquí abajo para mejorar tu experiencia y resultados. Si seguiste las instrucciones de esta guía, la parte de arriba de tu página de Stable Diffusion WebUI debería verse parecida a esto:

Aquí puedes seleccionar un checkpoint y un VAE. Ahora explicaré qué son ambas cosas y cómo obtenerlas. El collab tiene más opciones aquí arriba pero puedes ignorarlas.
Modelos ▲
El modelo, también llamado checkpoint, es el cerebro de tu IA, diseñado para producir cierto tipo de imágenes. Hay muchas opciones, las cuales puedes encontrar aquí en huggingface o en civitai. Ya que aún no sabes elegir, estas son mis recomendaciones:
- Para hacer anime, 7th Heaven Mix tiene un estilo placentero, estéticamente parecido a las películas de anime, mientras que Abyss Orange Mix 3 (Nota: Baja allí y elige la opción AOM3) ofrece más realismo con luces suaves, y más lascivia. Personalmente mezclé estas dos opciones creando así Heaven Orange Mix.
- Aunque AOM3 es extremadamente capaz de hacer contenido para adultos, el popular modelo de hentai Grapefruit también puede cumplir tus deseos.
- Para arte en general elige DreamShaper, no hay nada que se le acerque en términos de creatividad. También está Pastel Mix, el cual tiene una hermosa y única estética con un poco de anime.
- Para el fotorealismo recomiendo Deliberate. Puede hacer casi cualquier cosa, pero fotos en especial. Muy detallado.
- El modelo URPM es la mayor concentración de pornografía que vas a encontrar.
Si estás usando el collab de está guía, copia el enlace directo a la descarga y pégalo en la casilla llamada
custom_urls. Separa múltiples enlaces usando comas.En una instalación local, comúnmente los modelos deben ir dentro de la carpeta
stable-diffusion-webui/models/Stable-diffusion.Una nota importante es que los checkpoints deben estar en formato
.safetensors, ya que algunos archivos.ckptpueden contener virus. Ten cuidado. Además, cuando elijas modelos a veces verás varias opciones tales comoo fp32, fp16 y pruned. Para generar imágenes todas funcionan igual, así que elige el archivo más pequeño (pruned-fp16). Para mezclar o entrenar modelos se recomienda el archivo más grande.Consejo: Tras añadir el archivo de un recurso a las carpetas del programa, podrás encontrarlo tras presionar 🔃 junto al lugar donde lo selecciones.
VAEs ▲
La mayoría de checkpoints no viene con VAE incluído. El VAE es un pequeño modelo aparte, el cual "convierte tu imagen a formato humano". Sin un VAE tus imágenes van a tener malos colores y detalles.
Si usas el collab de esta guía, te hice elegir todos los VAEs antes de iniciar el programa.
Prácticamente sólo hay 3 VAEs en circulamiento:
- anything vae, también conocido como orangemix vae. Todos los modelos de anime lo utilizan.
- vae-ft-mse, el oficial de Stable Diffusion, utilizado comúnmente por modelos realistas.
- kl-f8-anime2, también conocido como el vae de Waifu Diffusion, es más viejo y tiene colores más brillantes. Lo utiliza Pastel Mix.
Si usas el launcher puedes elegir el VAE antes de iniciar el programa, de otra forma los VAEs deben ir en la carpeta
stable-diffusion-webui/models/VAE.Si no has seguido esta guía hasta este punto, dentro de tu página deberás ir a la pestaña Settings, luego la seccción Stable Difussion, y allí escoger tu VAE y guardar los cambios.
Consejo: Tras añadir el archivo de un recurso a las carpetas del programa, podrás encontrarlo tras presionar 🔃 junto al lugar donde lo selecciones.
Prompts ▲
Harás casi todas tus imágenes en la primera pestaña de tu página, txt2img. Aquí verás dos grandes casillas que llamamos prompt y prompt negativo. Aquí deberás describir lo que deseas que aparezca y no aparezca en tu imagen, y debe ser en inglés.
Stable Diffusion no es como Midjourney u otros servicios populares, no puedes solo decir lo que quieres, sino que debes ser muy específico.
Debido a esto la mayoría de personas se aferran a algún prompt que le funcione bien a ellos, muchas veces recomendado por otra persona. Aquí recomiendo mis propios prompts y prompts negativos:Anime
2d, masterpiece, best quality, anime, highly detailed face, highly detailed eyes, highly detailed background, perfect lightingEasyNegative, worst quality, low quality, 3d, realistic, photorealistic, (loli, child, teen, baby face), zombie, animal, multiple views, text, watermark, signature, artist name, artist logo, censored
Fotorealismo
best quality, 4k, 8k, ultra highres, (realistic, photorealistic, RAW photo:1.4), (hdr, sharp focus:1.2), intricate texture, skin imperfectionsEasyNegative, worst quality, low quality, normal quality, child, painting, drawing, sketch, cartoon, anime, render, 3d, blurry, deformed, disfigured, morbid, mutated, bad anatomy, bad art
EasyNegative: El prompt negativo que recomiendo utiliza EasyNegative, un embedding o "palabra mágica" que codifica muchas cosas malas para así mejorar tus imágenes. De otra forma tu prompt negativo sería enorme.
- Si usas el collab de esta guía, ya tienes instalado EasyNegative. Sino, es un archivo diminuto que puedes descargar aquí y debes colocar en la carpeta
stable-diffusion-webui/embeddings. Finalmente debes reiniciar el programa para así poder usar esta palabra mágica.
- Si usas el collab de esta guía, ya tienes instalado EasyNegative. Sino, es un archivo diminuto que puedes descargar aquí y debes colocar en la carpeta
Puedes ver una comparación de prompts negativos incluyendo EasyNegative más abajo en Prompt Matrix ▼.

Después de un "prompt base" como los que te he mostrado, puedes comenzar a escribir lo que desees. Por ejemplo,
young woman in a bikini in the beach, full body shot. También puedes añadir más términos negativos, comoold, ugly, futanari, furry, etc.
Puedes guardar tus prompts usando los botones debajo de Generate. Presiona el pequeño 💾 Save style y asigna un nombre al prompt actual. Tras ello podrás abrir tus Styles para elegirlo, y luego presionar 📋 Apply selected styles to the current prompt para añadirlo.Debes saber que cuando encierras algo en
(paréntesis), tendrá más peso o énfasis/intensidad en tu imagen, lo cual equivale al valor de1.1. El valor base para todas las palabras es 1, y cada paréntesis multiplica por 1.1 nuevamente. También puedes especificar el peso tú mismo, por ejemplo:(full body:1.4). También puedes ir menor a 1 para quitar énfasis; los[corchetes]multiplican por 0.9, pero si quieres ser preciso también necesitas paréntssis, como(así:0.5).Podrás notar que la IA es famosamente mala para hacer manos y pies. Con estos buenos prompt mejorarán un poco, pero quizá debas usar photoshop, inpainting, o técnicas avanzadas como ControlNet ▼ para perfeccionar tu imagen.
Opciones de generación ▲
Ya te enseñé a elegir un modelo, VAE y escribir tus prompt, ahora podrás saber sobre todo el resto de las opciones disponibles antes de generar una imagen.
Esperando traducción.
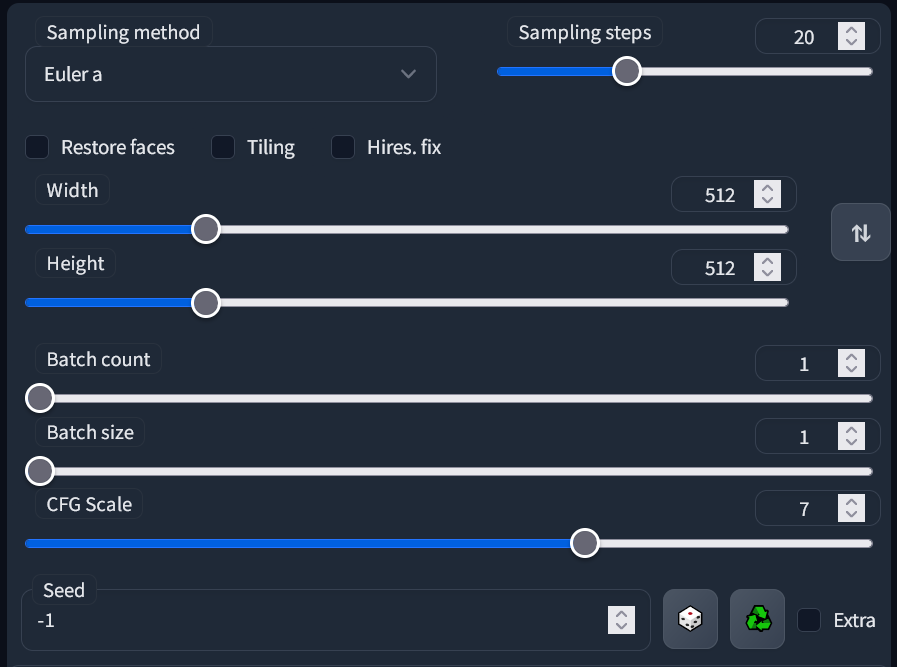
- Sampling method: Es el algoritmo que genera tu imagen, cada uno con resultados distintos. El por defecto de
Euler acasi siempre es el mejor, y también obtendrás muy buenos resultados conDPM++ 2M KarrasyDPM++ SDE Karras. - Sampling steps: La cantidad de pasos, son "calculados" con anticipacicón y por lo tanto más pasos no siempre es mejor. Yo siempre uso 30 pasos, pero de 20 a 50 encontrarás resultados consistentemente buenos.
- Width and Height: La resolución de 512x512 es lo normal. Si superas el ancho o alto de 768 tu imagen puede ser distorsionada y deformada. Para producir imágenes más grandes está la opción
Hires fix. - Batch Count and Batch Size: El size es cuántas imágenes tu tarjeta gráfica producirá al mismo tiempo, lo cual se limita for su VRAM. El count son las repeticiones del valor anterior. Los batches tienen seeds consecutivas, más abajo verás las seeds.
- CFG Scale: "Los valores menores producen resultados más creativos". Casi siempre debes dejarlo en 7, pero de 4 a 10 es un rango aceptable.
- Seed: Un número que dicta la generación de tu imagen. La misma seed con el mismo prompt y opciones siempre producirá la misma imagen, salvo detalles menores y algunas excepciones.
Hires fix: Esta opción te permite crear imágenes más grandes sin problemas. Por lo general se ocupa para duplicar el ancho y alto. Cuando la actives, aparecerán más opciones:
- Upscaler: El algoritmo para agrandar la imagen. Se dice que
Latentcrea resultados creativos. Puede que también te gusteR-ESRGAN 4x+y su variante para anime. Recomiendo el upscaler llamado Remacri, del cual hablo más abajo ▼. - Hires steps: Recomiendo al menos la mitad de tus pasos normales. Más pasos no siempre es mejor, y son bastante lentos, así que sé conservador.
- Denoising strength: El valor más importante. Cera de 0.0 tu imagen no tendrá ningún detalle nuevo. Cerca de 1.0, tu imagen cambiará completamente. Recomiendo un valor entre 0.2 y 0.6 dependiendo del caso, lo cual añade suficiente detalle sin destruir los detalles existentes que te gusten.
Others:
- Restore faces: Puede mejorar los rostros reales. Nunca lo he necesitado con los prompt de esta guía y con hires fix.
- Tiling: Sirve para hacer patrones repetitivos como baldosas, no es muy útil.
- Script: Te permite acceder a funciones y extensiones muy útiles, las cuales explico más abajo ▼. Por ejemplo, X/Y/Z Plot permite comparar una cuadrícula de imágenes con diferentes opciones. Muy poderoso.
- Sampling method: Es el algoritmo que genera tu imagen, cada uno con resultados distintos. El por defecto de


Extensiones ▲
Stable Diffusion WebUI es el programa que estamos ocupando y éste permite añadir extensiones muy útiles. Para ello dirígete a la pestaña Extensions luego a Install from URL, y pega allí estos enlaces de github. Luego presiona Install y espera que se instale. Finalmente ve a Installed y presiona Apply and restart UI.

Aquí hay algunas extensiones útiles. Si usas el collab de esta guía la mayoría ya están instaladas, sino, recomiendo enormemente instalar manualmente las primeras 2.
- Image Browser (bugfix) - Navegador de Imágenes, permite ver todas las imágenes wue has creado y rápidamente enviarlas con sus parámetros a txt2img, img2img, etc.
- TagComplete - Completamente esencial para hacer anime, te muestra las tags de booru existentes mientras escribes tu prompt. Los modelos de anime funcionan a través de estos tags, haciendo de ésta una de las mejores extensiones. Ojo que no todas las tags funcionan siempre, sobre todo si son poco comunes.
- ControlNet - Enorme extensión con su propia guía ▼. Te permite analizar cualquier imagen existente y usarla como muestra para guiar tus propias imágenes. En términos prácticos, te permite replicar cualquier pose o ambiente que desees.
- Ultimate Upscale - Un script usable desde img2img que permite hacer imágenes enormes aunque tengas poca vram, dividiéndolas en secciones aunque sea más lento. Ver su guía aquí ▼.
- Two-shot - Normalmente no es posible crear escenas de dos personajes, ya que el prompt hace que se fusionen sus características. Esta extensión permite dividir la imagen en: todo, izquierda, derecha; permitiendo así tener escenas naturales con 2 personajes o temas al mismo tiempo.
- Dynamic Prompts - Un script para tener prompts semi-aleatorios. Un poco complejo.
- Model Converter - Permite convertir modelos de 7 GB o 4 GB a 2 GB, seleccionando
safetensors,fp16, yno-ema. Estos modelos "pruneados" funcionan prácticamente igual para generar imágenes. La mayoría de modelos hoy en día vienen en este formato de todas formas.
Loras ▲
Los Loras son una tecnología moderna y un tipo de Extra Network que permite añadir una especie de modelo pequeño a cualquiera de tus modelos principales. Son similares a los embeddings, uno de los cuales te mostré antes ▲, pero los Loras son más grandes y comúnmente más capaces. No entraré en detalles técnicos.
Un Lora puede representar un personaje, estilo, pose, ropa, o incluso un rostro humano (aunque no estoy de acuerdo con ello). Los checkpoints son bastante capaces para contenido general, pero para detalles como estos es donde comienzan a fallar y necesitarás un Lora. Podrás descargar Loras desde civitai u otros lugares (NSFW) y su tamaño es de 144 MB por defecto, pero pueden ser tan pequeños como 1 MB. Los Loras más grandes no son necesariamente mejores. Los Loras vienen en formato .safetensors de igual forma que los checkpoints.
Coloca tus archivos de Lora en la carpeta stable-diffusion-webui/models/Lora, o si estás usando el collab de esta guía pega el enlace directo a la descarga en la casilla custom_urls. Luego encuentra el botón 🎴 Show extra networks bajo el gran botón naranjo, el cual abrirá una nueva sección de extra networks. Presiona la pestaña Lora y presiona Refresh para escanear nuevos Loras. Cuando hagas click en uno de tus Loras se añadirá a tu prompt, y se verá así: <lora:archivo:1> . Siempre se verán así, donde "archivo" es el nombre exacto del archivo en tu sistema (antes de .safetensors). Finalmente, el número es el peso, lo cual expliqué previamente ▲. La mayoría de Loras funcionan con un peso entre 0.5 y 1, y los valores muy grandes pueden "cocinar" tu imagen, especialmente si usas más de uno al mismo tiempo.

Además, muchos Loras tendrán una "palabra de activación" para que tomen efecto, por ejemplo el nombre del personaje en caso de ser un Lora de personaje.
Un ejemplo de Lora es Thicker Lines Anime Style, un gran estilo de ánime clásico si deseas probarlo. No tiene palabra de activación.
Imágenes Grandes ▲
Como mencionamos anteriormente ▲, normalmente no debes generar imágenes sobre 768 de ancho y alto. Debes usar Hires fix, con un "upscaler" (algoritmo) y denoising (intensidad) apropiados. Hires fix está limitado por tu VRAM, por lo que te puede interesar Ultimate Upscaler ▼.
Es posible descargar upscalers adicionales y ponerlos en tu carpeta stable-diffusion-webui/models/ESRGAN. Así funcionarán con Hires fix, Ultimate Upscaler, y Extras.
El collab de esta guía viene con varios de estos, incluyendo Remacri, uno de los mejores para todo tipo de imágenes. Se puede encontrar aquí abajo.
- Algunos upscalers notables se pueden encontrar aquí.
- LDSR es un upscaler avanzado pero lento, sus dos archivos se encuentran aquí y deben ser puestos en
stable-diffusion-webui/models/LDSR. - La Upscale Wiki contiene docenas de opciones históricas.
En el futuro puede que muestre una comparación de diferentes upscalers.
Scripts ▲
Esperando traducción.
Scripts can be found at the bottom of your generation parameters in txt2img or img2img.
X/Y/Z Plot ▲
Capable of generating a series of images, usually with the exact same seed, but varying parameters of your choice. Can compare almost anything you want, including different models, parts of your prompt, sampler, upscaler and much more. You can have 1, 2, or 3 variable parameters, hence the X, Y and Z.
Your parameters in X/Y/Z Plot are separated by commas, but anything else can go inbetween. The most common parameter to compare is S/R Prompt, where the first term is a phrase in your prompt and each term afterwards will replace the original. Knowing this, you can compare, say, Lora intensity, like this:
<lora:my lora:0.4>, <lora:my lora:0.6>, <lora:my lora:0.8>, <lora:my lora:1>Here I made a comparison between different models (columns) and faces of different ethnicities via S/R Prompt (rows):
X/Y/Z Plot example, click to expand

Tip: It appears possible to do S/R with commas by using quotes like this (note no spaces between the commas and quotes):
"term 1, term 2","term 3, term 4","term 5, term 6"Prompt Matrix ▲
Similar conceptually to S/R from before, but more in-depth. It works by showing each possible combination of terms listed between the
|symbol in your prompt, for example:young man|tree|citywill always contain "young man", but we'll see what happens when we add or remove "tree" and "city". You can use commas and spaces just fine between the|.Inside the script, you will choose either your prompt or your negative prompt to make a matrix of, and whether the variable terms should be put at the start or the end.
Here is a comparison using the negative prompts I showed you in Prompts ▲. We can see how EasyNegative affects the image, as well as how the rest of the prompt affects the image, then both together:
Prompt matrix examples, click to expand


Ultimate Upscale ▲
An improved version of a builtin script, it can be added as an [extension ▲] and used from within img2img. Its purpose is to resize an image and add more detail way past the normal limits of your VRAM by splitting it into chunks, although slower. Here are the steps:
Generate your image normally up to 768 width and height, you can then apply hires fix if you are able to.
From txt2img or the Image Browser extension send it directly into img2img, along with its prompt and parameters.
Set the Denoising somewhere between 0.1 and 0.4. If you go higher you most likely will experience mutations.
Go down to Scripts and choose Ultimate SD Upscale. Then, set your parameters like this, with your desired size and upscaler, and the "Chess" Type:
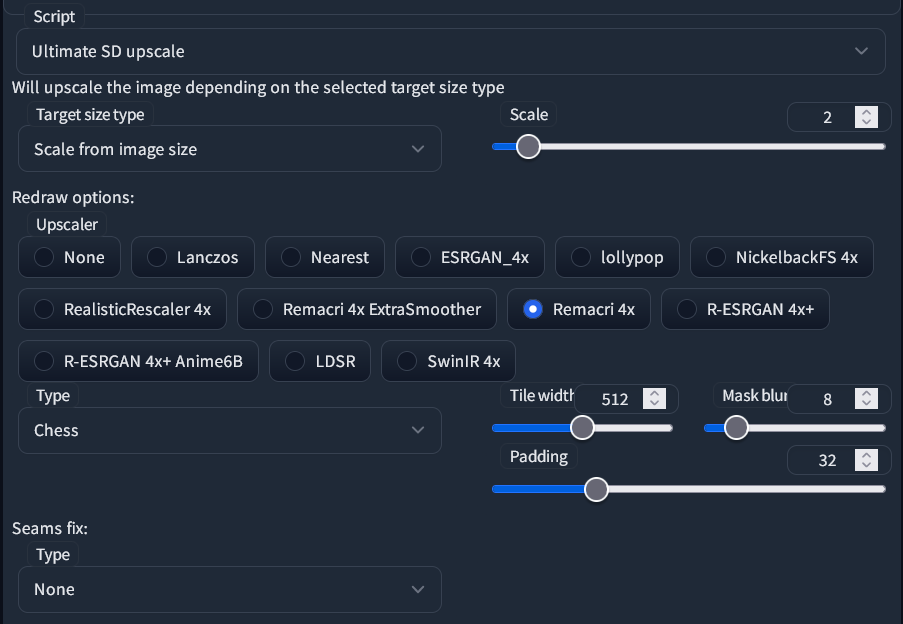
If you have enough VRAM, you may increase the Tile width as well as the Padding. For example, doubling both of them. Tile height can remain at 0 and it'll match the width.
It is not necessary to set the Seams fix unless you encounter visible seams between regions in the final image.
Generate your image and wait. You can watch the squares get sharper if you have image previews enabled.




ControlNet ▲
ControlNet es una tecnología reciente extremadamente poderosa. Te permite analizar una imagen para guiar la creación de tus propias imágenes con Stable Diffusion. Veremos qué significa esto en un momento.
Si estás usando el collab de esta guía activa la casilla de all_control_models. Sino, deberás instalar la extension ControlNet ▲, luego ir aquí y descargar modelos de controlnet que deberás poner en la carpeta stable-diffusion-webui/extensions/sd-webui-controlnet/models. Recomiendo los modelos Canny, Depth, Openpose y Scribble, los cuales veremos en un momento.
Voy a demostrar cómo ControlNet puede ser usado. Para ello tomaré una imagen popular en internet como nuestra "imagen de muestra". No es necesario que me sigas paso a paso, pero puedes descargar las imágenes y ponerlas en la pestaña PNG Info para ver los datos de generación.
Primero, debes estar en txt2img y bajar para presionar el menú ControlNet. Una vez abierto presiona Enable, y elige un preprocessor y model con el mismo nombre. Para empezar elegiré Canny para ambos. Finalmente añadiré mi imagen de muestra. Asegúrate de no clickear sobre la imagen de muestra o comenzarás a dibujar. Podemos ignorar el resto de las opciones.

Canny
El método Canny extrae los detalles de la imagen de muestra. Es útil para imitar todo tipo de imágenes. Observa:
Ejemplo de Canny, click para expandir


Depth
El método Depth extrae los elementos 3D de la imagen de muestra. Es de enorme utilidad cuando deseas imitar ambientes complejos y la composición general de una imagen. Observa:
Ejemplo de Depth, click para expandir


Openpose
El método Openpose extrae las poses humanas de la imagen de muestra. Es de extrema utilidad para obtener la toma deseada y composición de uno de tus personajes. Observa:
Ejemplo de Openpose, click para expandir


Scribble
Scribble te permite hacer un bosquejo y convertirlo en una pieza terminada con ayuda de tu prompt. Este es el único ejemplo de aquí que no comparte la misma imagen de muestra.
Ejemplo de Scribble, click para expandir










Podrás notar que hay 2 resultados para cada método. El primero es en paso intermedio llamado la "imagen pre-procesada", la cual se usa para producir la imagen final. Puedes entregar una imagen pre-procesada tú mismo, en tal caso deberás elegir un preprocessor de None. Esto puede ser tremendamente poderoso tomando en cuenta herramientas externas tales como Blender y Photoshop.
En la pestaña Settings habrá una sección ControlNet donde podrás activar múltiples controlnets al mismo tiempo. Un uso particularmente útil es cuando uno de ellos es Openpose, para obtener tanto la pose deseada como el ambiente deseado, o con la posición exacta de manos u otros detalles. Observa:
Ejemplo de Openpose+Canny, click para expandir

También puedes usar ControlNet en img2img, en tal caso la imagen de entrada y la imagen de muestra ambas tendrán ciertos efectos en el resultado. No tengo mucha experiencia con este método.
Además, existen la version diff de los modelos de controlnet, los cuales producen resultados ligeramente distintos. Puedes probarlos si deseas, pero yo no lo he hecho.
Entrenamiento de Loras para novatos ▲
Entrenar un Lora ▲ tú mismo es una especie de logro. No es la gran cosa, pero hay muchas variables involucradas, y mucho trabajo dependiendo de las técnicas que utilices. Es una mezcla entre un arte y una ciencia.
Puedes entranar Loras en tu propio computador si tienes al menos 8 GB de VRAM. Sin embargo utilizaré un documento de Google Collab por motivos educacionales.
He aquí unos recursos clásicos si deseas leer sobre el tema en profundidad. Puede que Rentry esté bloqueado por tu proveedor de internet, en tal caso puedes usar un VPN o intentar poner la página a través de Google Translate.
- Entrenamiento de Loras, en Rentry
- Ciencia de Loras, en Rentry
- Entrenador original de Kohya (método Dreambooth)
- Lista de parámetros del entrenador
Con dichos recursos mucho más inteligentes puestos de lado, intentaré producir una guía simple para que puedas hacer tu propio Lora, de un personaje, concepto o estilo.

Utilizaremos ESTE COLLAB. Puedes copiarlo a tu Google Drive si deseas.
Presiona el botón de reproducción de A: Montar tu google drive y dale acceso cuando lo pida. Haz lo mismo con B: Instalación. Mientras se instala, sigue al siguiente paso.
Baja a C: Configuración pero aún no lo actives. Aquí en Inicio puedes darle cualquier nombre a tu proyecto. También puedes cambiar el modelo base que utilizaremos, pero para esta guía utilizaremos AnythingV3_fp16 ya que es la base de todos los modelos anime y produce los mejores resultados para ello. Si deseas entrenar con fotografías puedes copiar el enlace al modelo base de Stable Diffusion 1.5 o al modelo realista que desees utilizar (tal como Deliberate). Recuerda también cambiar el
model_typea safetensors en tal caso.Archivos de entrenamiento ▲
Esta es la mayor parte del entrenamiento de Loras. Necesitarás recopilar un "dataset" o archivos de entrenamiento, los cuales consisten en imágenes y sus correspondientes descripciones (con tags en el caso de anime).
Encuentra imágenes online que representes el personaje/concepto/estilo que deseas entrenar, posiblemente en sitios tales como safebooru, gelbooru o danbooru. Necesitas al menos 10 imágenes, idealmente 20 o más, pero puedes usar cientos si deseas.
Puedes crear los tags tú mismo, lo cual es lento y poco preciso. Opcionalmente puedes agregar la extensión Tagger a tu programa, la cual analiza todas tus imágenes de entranemiento y genera tags para ellas.
Opcionalmente puedes agregar otra extensión llamada Tag Editor la cual te permite editar los tags de todos tus archivos al mismo tiempo.
Una vez que tus imágenes y descripciones estén listos, ponlos en una carpeta con la siguiente estructura: Una carpeta con el nombre de tu proyecto, la cual contiene al menos 1 carpeta en el formato
repeticiones_nombre, la cual contiene tus archivos de entrenamiento. Así:
Decide tu número de repeticiones. Asumiendo que tienes alrededor de 20 imágenes, recomiendo al menos 10 repeticiones. En tal caso, tu carpeta interior se llamará
10_minuevolorao algo similar.Sube la carpeta exterior y todos sus contenidos (la que tiene el nombre de tu proyecto) a tu Google Drive, en la carpeta
lora_training/datasets/.
Opciones de entrenamiento ▲
- Bajo Archivos, no necesitas cambiar nada.
- Bajo Pasos de Entrenamiento, sigue las instrucciones para calcular tus pasos totales (
max_train_steps). Recomiendo al menos 400 pasos totales, lo cual debería tomar 15 o 20 minutos. Puedes editarlr_warmup_stepspara que sea igual a tu cantidad de imágenes. - Bajo Opciones de Entrenamiento, el
unet_lror "learning rate" (velocidad de aprendizaje) es el parámetro más importanto. 1e-3 es el valor por defecto y funciona cuando tienes pocas imágenes, pero puede ir hasta 1e-5. - Nota sobre
network_dim: El dim es el tamaño de tu Lora. La mayoría de personas entrena Loras con dim 128, los cuales pesan 144 MB, y es totalmente innecesario. Recomiendo un dim de 16 en la mayoría de casos. Puedes incluso bajar a 1 y aún obtener resultados decentes.
Ahora puedes activar C: Configuración, esperar que el modelo se descarge, y finalmente comenzar el entrenamiento con D: Cocinar el Lora. Esperemos que todo salga bien. Sino, intenta contactarme o buscar ayuda para resolver errores.
Probar tus resultados ▲
Ha pasado un rato y tu Lora terminó de entrenar/cocinar. Ve y descárgalo de la carpeta
lora_training/outputen tu google drive. Pero verás que hay más de uno; por defecto, se guarda una copia de tu Lora cada 2 epochs, permitiéndote así comparar su progreso. Si entrenas tu Lora por muchos epochs, podrás identificar el punto óptimo entre que esté "crudo" o "recocido".Cuando un Lora está "crudo", no alcanzará a imitar tus datos de entrenamiento. Cuando está "recocido", imita tus datos de entrenamiento demasiado, lo cual evita que pueda hacer cualquier otra cosa. Y si no añadiste suficientes datos o datos de baja calidad, ¡puede que esté crudo y recocido al mismo tiempo!
Usando lo aprendido en X/Y/Z Plot ▲, podemos hacer una comparación del progreso de nuestro Lora:

Mira eso, ¡se vuelve cada vez más detallado! La última imagen no tiene ningún Lora para comparar. Este parece ser un Lora de personaje exitoso, pero necesitaríamos probar una variedad de semillas, prompts y escenas para estar seguros.
Es común que tu Lora "queme" o distorsione tus imágenes al ser usado con pesos altos como 1, sobre todo si está recocido. Un peso entre 0.5 y 0.8 es aceptable para nosotros. Puede que necesites ajustar la velocidad de aprendizaje o el dim para esto, u otras variables no encontradas en este collab. Si estás leyendo esto y conoces los secretos de los Lora, háznoslo saber.
Después de acostumbrarse a hacer Loras, e interactuar on la comunidad y sus variados recursos, estarás listo para usar otro método más avanzado como el collab original todo-en-uno de kohya. Buena suerte.

Consejos adicionales ▲
La parte más importante para un personaje son los tags. Claro que necesitas imágenes con variadas poses y lugares, pero si las descripciones están mal no servirá de nada.
Cuando entrenas un personaje o concepto deberías definir una palabra de activación, y ajustar el valor de
keep_tokensa 1. Una palabra de activación es como podremos invocar a tu Lora para que funcione. Habiendo hecho eso, quieres quitar o "limpiar" las tags que son intrínsicas a tu personaje o concepto, tales como el color de pelo y ojos. Por ejemplo, si una chica siempre tiene orejas de gato, quieres quitar las tags tales comoanimal ears, animal ear fluff, cat ears, y así éstas serán "absorbidas" por tu palabra de activación.También puedes limpiar las tags de atuendo, dejando así sólo los aspectos más relevantes de la ropa y eliminando las redundancias, por ejemplo dejar "tie" pero quitar "red tie". Esto facilitará que estas ropas absorban los detalles relevantes. Incluso puedes definir una palabra de activación para cada atuendo importante, por ejemplo personaje-normal, personaje-bikini, etc. Pero hay más de una manera de lograr esto. En cualquier caso, con el uso correcto de tags, tu personaje debería ser capaz de cambiar de ropa fácilmente.
Mientras tanto, los Loras de estilo no necesitan palabra de activación, ya que deseamos que siempre estén activos. Absorberán el estilo artístico de forma natural, y funcionará con variados pesos.
Esta "absorción" de detalles no entregados por los tags es la forma en que los Loras funcionan en general, ya que logran aprender y representar los detalles imperceptibles o difíciles de explicar tales como el rostro, acccesorios, composición, etc.
...vtubers? ▲
Y así llegamos la final de la guía. Gracias por leer. Si tienes correcciones o contribuciones puedes abrir un Issue o un Pull Request en esta página y echaré un vistazo pronto.
Tengo otra página dedicada a Loras de vtubers, en especial Hololive. Si es que es de tu interés.
Saludos.