

Uploading trained parameters, config and model related images
Browse files
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
multi_temporal_crop_classification.png filter=lfs diff=lfs merge=lfs -text
|
multi_temporal_crop_classification.png
ADDED
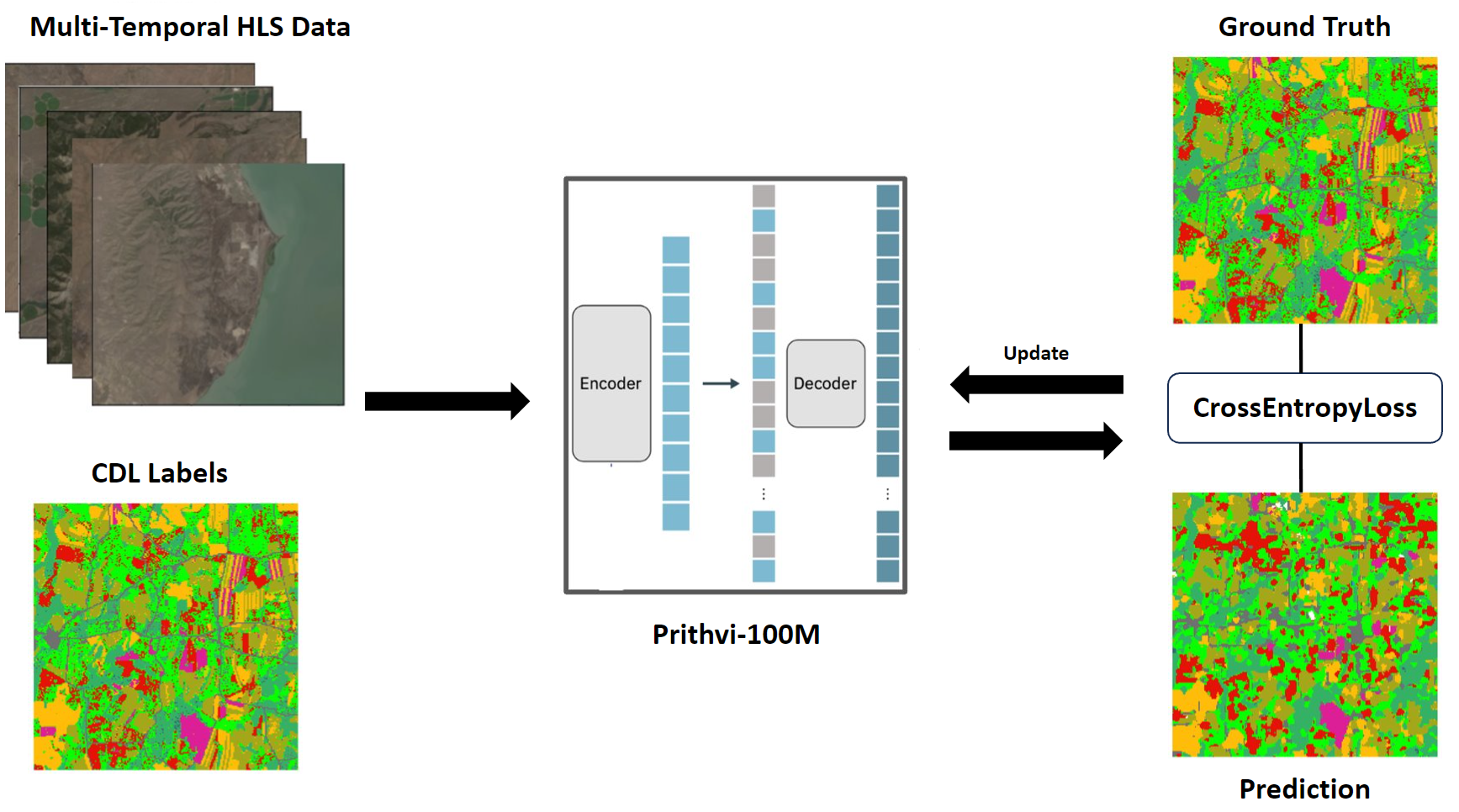
|
Git LFS Details
|
multi_temporal_crop_classification_Prithvi_100M.py
ADDED
|
@@ -0,0 +1,394 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
dist_params = dict(backend='nccl')
|
| 2 |
+
log_level = 'INFO'
|
| 3 |
+
load_from = None
|
| 4 |
+
resume_from = None
|
| 5 |
+
cudnn_benchmark = True
|
| 6 |
+
custom_imports = dict(imports=['geospatial_fm'])
|
| 7 |
+
num_frames = 3
|
| 8 |
+
img_size = 224
|
| 9 |
+
num_workers = 2
|
| 10 |
+
pretrained_weights_path = '/home/ubuntu/hls-loss-weights/Prithvi_100M.pt'
|
| 11 |
+
num_layers = 6
|
| 12 |
+
patch_size = 16
|
| 13 |
+
embed_dim = 768
|
| 14 |
+
num_heads = 8
|
| 15 |
+
tubelet_size = 1
|
| 16 |
+
epochs = 80
|
| 17 |
+
eval_epoch_interval = 2
|
| 18 |
+
experiment = 'multiclass_exp_newSplit'
|
| 19 |
+
work_dir = '/home/ubuntu/clark_gfm_eval/multiclass_exp_newSplit'
|
| 20 |
+
save_path = '/home/ubuntu/clark_gfm_eval/multiclass_exp_newSplit'
|
| 21 |
+
gpu_ids = range(0, 1)
|
| 22 |
+
dataset_type = 'GeospatialDataset'
|
| 23 |
+
data_root = '/home/ubuntu/hls_cdl_reclassed/'
|
| 24 |
+
img_norm_cfg = dict(
|
| 25 |
+
means=[
|
| 26 |
+
494.905781, 815.239594, 924.335066, 2968.881459, 2634.621962,
|
| 27 |
+
1739.579917, 494.905781, 815.239594, 924.335066, 2968.881459,
|
| 28 |
+
2634.621962, 1739.579917, 494.905781, 815.239594, 924.335066,
|
| 29 |
+
2968.881459, 2634.621962, 1739.579917
|
| 30 |
+
],
|
| 31 |
+
stds=[
|
| 32 |
+
284.925432, 357.84876, 575.566823, 896.601013, 951.900334, 921.407808,
|
| 33 |
+
284.925432, 357.84876, 575.566823, 896.601013, 951.900334, 921.407808,
|
| 34 |
+
284.925432, 357.84876, 575.566823, 896.601013, 951.900334, 921.407808
|
| 35 |
+
])
|
| 36 |
+
splits = dict(
|
| 37 |
+
train=
|
| 38 |
+
'/home/ubuntu/hls-foundation-os/fine-tuning-examples/data_splits/crop_classification/training_data.txt',
|
| 39 |
+
val=
|
| 40 |
+
'/home/ubuntu/hls-foundation-os/fine-tuning-examples/data_splits/crop_classification/validation_data.txt',
|
| 41 |
+
test=
|
| 42 |
+
'/home/ubuntu/hls-foundation-os/fine-tuning-examples/data_splits/crop_classification/validation_data.txt'
|
| 43 |
+
)
|
| 44 |
+
bands = [0, 1, 2, 3, 4, 5]
|
| 45 |
+
tile_size = 224
|
| 46 |
+
orig_nsize = 512
|
| 47 |
+
crop_size = (224, 224)
|
| 48 |
+
train_pipeline = [
|
| 49 |
+
dict(type='LoadGeospatialImageFromFile', to_float32=True),
|
| 50 |
+
dict(type='LoadGeospatialAnnotations', reduce_zero_label=True),
|
| 51 |
+
dict(type='RandomFlip', prob=0.5),
|
| 52 |
+
dict(type='ToTensor', keys=['img', 'gt_semantic_seg']),
|
| 53 |
+
dict(
|
| 54 |
+
type='TorchNormalize',
|
| 55 |
+
means=[
|
| 56 |
+
494.905781, 815.239594, 924.335066, 2968.881459, 2634.621962,
|
| 57 |
+
1739.579917, 494.905781, 815.239594, 924.335066, 2968.881459,
|
| 58 |
+
2634.621962, 1739.579917, 494.905781, 815.239594, 924.335066,
|
| 59 |
+
2968.881459, 2634.621962, 1739.579917
|
| 60 |
+
],
|
| 61 |
+
stds=[
|
| 62 |
+
284.925432, 357.84876, 575.566823, 896.601013, 951.900334,
|
| 63 |
+
921.407808, 284.925432, 357.84876, 575.566823, 896.601013,
|
| 64 |
+
951.900334, 921.407808, 284.925432, 357.84876, 575.566823,
|
| 65 |
+
896.601013, 951.900334, 921.407808
|
| 66 |
+
]),
|
| 67 |
+
dict(type='TorchRandomCrop', crop_size=(224, 224)),
|
| 68 |
+
dict(type='Reshape', keys=['img'], new_shape=(6, 3, 224, 224)),
|
| 69 |
+
dict(type='Reshape', keys=['gt_semantic_seg'], new_shape=(1, 224, 224)),
|
| 70 |
+
dict(
|
| 71 |
+
type='CastTensor',
|
| 72 |
+
keys=['gt_semantic_seg'],
|
| 73 |
+
new_type='torch.LongTensor'),
|
| 74 |
+
dict(type='Collect', keys=['img', 'gt_semantic_seg'])
|
| 75 |
+
]
|
| 76 |
+
val_pipeline = [
|
| 77 |
+
dict(type='LoadGeospatialImageFromFile', to_float32=True),
|
| 78 |
+
dict(type='LoadGeospatialAnnotations', reduce_zero_label=True),
|
| 79 |
+
dict(type='ToTensor', keys=['img', 'gt_semantic_seg']),
|
| 80 |
+
dict(
|
| 81 |
+
type='TorchNormalize',
|
| 82 |
+
means=[
|
| 83 |
+
494.905781, 815.239594, 924.335066, 2968.881459, 2634.621962,
|
| 84 |
+
1739.579917, 494.905781, 815.239594, 924.335066, 2968.881459,
|
| 85 |
+
2634.621962, 1739.579917, 494.905781, 815.239594, 924.335066,
|
| 86 |
+
2968.881459, 2634.621962, 1739.579917
|
| 87 |
+
],
|
| 88 |
+
stds=[
|
| 89 |
+
284.925432, 357.84876, 575.566823, 896.601013, 951.900334,
|
| 90 |
+
921.407808, 284.925432, 357.84876, 575.566823, 896.601013,
|
| 91 |
+
951.900334, 921.407808, 284.925432, 357.84876, 575.566823,
|
| 92 |
+
896.601013, 951.900334, 921.407808
|
| 93 |
+
]),
|
| 94 |
+
dict(type='TorchRandomCrop', crop_size=(224, 224)),
|
| 95 |
+
dict(type='Reshape', keys=['img'], new_shape=(6, 3, 224, 224)),
|
| 96 |
+
dict(type='Reshape', keys=['gt_semantic_seg'], new_shape=(1, 224, 224)),
|
| 97 |
+
dict(
|
| 98 |
+
type='CastTensor',
|
| 99 |
+
keys=['gt_semantic_seg'],
|
| 100 |
+
new_type='torch.LongTensor'),
|
| 101 |
+
dict(
|
| 102 |
+
type='Collect',
|
| 103 |
+
keys=['img', 'gt_semantic_seg'],
|
| 104 |
+
meta_keys=[
|
| 105 |
+
'img_info', 'ann_info', 'seg_fields', 'img_prefix', 'seg_prefix',
|
| 106 |
+
'filename', 'ori_filename', 'img', 'img_shape', 'ori_shape',
|
| 107 |
+
'pad_shape', 'scale_factor', 'img_norm_cfg', 'gt_semantic_seg'
|
| 108 |
+
])
|
| 109 |
+
]
|
| 110 |
+
test_pipeline = [
|
| 111 |
+
dict(type='LoadGeospatialImageFromFile', to_float32=True),
|
| 112 |
+
dict(type='ToTensor', keys=['img']),
|
| 113 |
+
dict(
|
| 114 |
+
type='TorchNormalize',
|
| 115 |
+
means=[
|
| 116 |
+
494.905781, 815.239594, 924.335066, 2968.881459, 2634.621962,
|
| 117 |
+
1739.579917, 494.905781, 815.239594, 924.335066, 2968.881459,
|
| 118 |
+
2634.621962, 1739.579917, 494.905781, 815.239594, 924.335066,
|
| 119 |
+
2968.881459, 2634.621962, 1739.579917
|
| 120 |
+
],
|
| 121 |
+
stds=[
|
| 122 |
+
284.925432, 357.84876, 575.566823, 896.601013, 951.900334,
|
| 123 |
+
921.407808, 284.925432, 357.84876, 575.566823, 896.601013,
|
| 124 |
+
951.900334, 921.407808, 284.925432, 357.84876, 575.566823,
|
| 125 |
+
896.601013, 951.900334, 921.407808
|
| 126 |
+
]),
|
| 127 |
+
dict(
|
| 128 |
+
type='Reshape',
|
| 129 |
+
keys=['img'],
|
| 130 |
+
new_shape=(6, 3, -1, -1),
|
| 131 |
+
look_up=dict({
|
| 132 |
+
'2': 1,
|
| 133 |
+
'3': 2
|
| 134 |
+
})),
|
| 135 |
+
dict(type='CastTensor', keys=['img'], new_type='torch.FloatTensor'),
|
| 136 |
+
dict(
|
| 137 |
+
type='CollectTestList',
|
| 138 |
+
keys=['img'],
|
| 139 |
+
meta_keys=[
|
| 140 |
+
'img_info', 'seg_fields', 'img_prefix', 'seg_prefix', 'filename',
|
| 141 |
+
'ori_filename', 'img', 'img_shape', 'ori_shape', 'pad_shape',
|
| 142 |
+
'scale_factor', 'img_norm_cfg'
|
| 143 |
+
])
|
| 144 |
+
]
|
| 145 |
+
CLASSES = (1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13)
|
| 146 |
+
data = dict(
|
| 147 |
+
samples_per_gpu=2,
|
| 148 |
+
workers_per_gpu=1,
|
| 149 |
+
train=dict(
|
| 150 |
+
type='GeospatialDataset',
|
| 151 |
+
CLASSES=(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13),
|
| 152 |
+
reduce_zero_label=True,
|
| 153 |
+
data_root='/home/ubuntu/hls_cdl_reclassed/',
|
| 154 |
+
img_dir='/home/ubuntu/hls_cdl_reclassed/training_chips',
|
| 155 |
+
ann_dir='/home/ubuntu/hls_cdl_reclassed/training_chips',
|
| 156 |
+
pipeline=[
|
| 157 |
+
dict(type='LoadGeospatialImageFromFile', to_float32=True),
|
| 158 |
+
dict(type='LoadGeospatialAnnotations', reduce_zero_label=True),
|
| 159 |
+
dict(type='RandomFlip', prob=0.5),
|
| 160 |
+
dict(type='ToTensor', keys=['img', 'gt_semantic_seg']),
|
| 161 |
+
dict(
|
| 162 |
+
type='TorchNormalize',
|
| 163 |
+
means=[
|
| 164 |
+
494.905781, 815.239594, 924.335066, 2968.881459,
|
| 165 |
+
2634.621962, 1739.579917, 494.905781, 815.239594,
|
| 166 |
+
924.335066, 2968.881459, 2634.621962, 1739.579917,
|
| 167 |
+
494.905781, 815.239594, 924.335066, 2968.881459,
|
| 168 |
+
2634.621962, 1739.579917
|
| 169 |
+
],
|
| 170 |
+
stds=[
|
| 171 |
+
284.925432, 357.84876, 575.566823, 896.601013, 951.900334,
|
| 172 |
+
921.407808, 284.925432, 357.84876, 575.566823, 896.601013,
|
| 173 |
+
951.900334, 921.407808, 284.925432, 357.84876, 575.566823,
|
| 174 |
+
896.601013, 951.900334, 921.407808
|
| 175 |
+
]),
|
| 176 |
+
dict(type='TorchRandomCrop', crop_size=(224, 224)),
|
| 177 |
+
dict(type='Reshape', keys=['img'], new_shape=(6, 3, 224, 224)),
|
| 178 |
+
dict(
|
| 179 |
+
type='Reshape',
|
| 180 |
+
keys=['gt_semantic_seg'],
|
| 181 |
+
new_shape=(1, 224, 224)),
|
| 182 |
+
dict(
|
| 183 |
+
type='CastTensor',
|
| 184 |
+
keys=['gt_semantic_seg'],
|
| 185 |
+
new_type='torch.LongTensor'),
|
| 186 |
+
dict(type='Collect', keys=['img', 'gt_semantic_seg'])
|
| 187 |
+
],
|
| 188 |
+
img_suffix='_merged.tif',
|
| 189 |
+
seg_map_suffix='.mask.tif',
|
| 190 |
+
split=
|
| 191 |
+
'/home/ubuntu/hls-foundation-os/fine-tuning-examples/data_splits/crop_classification/training_data.txt'
|
| 192 |
+
),
|
| 193 |
+
val=dict(
|
| 194 |
+
type='GeospatialDataset',
|
| 195 |
+
CLASSES=(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13),
|
| 196 |
+
reduce_zero_label=True,
|
| 197 |
+
data_root='/home/ubuntu/hls_cdl_reclassed/',
|
| 198 |
+
img_dir='/home/ubuntu/hls_cdl_reclassed/validation_chips',
|
| 199 |
+
ann_dir='/home/ubuntu/hls_cdl_reclassed/validation_chips',
|
| 200 |
+
pipeline=[
|
| 201 |
+
dict(type='LoadGeospatialImageFromFile', to_float32=True),
|
| 202 |
+
dict(type='ToTensor', keys=['img']),
|
| 203 |
+
dict(
|
| 204 |
+
type='TorchNormalize',
|
| 205 |
+
means=[
|
| 206 |
+
494.905781, 815.239594, 924.335066, 2968.881459,
|
| 207 |
+
2634.621962, 1739.579917, 494.905781, 815.239594,
|
| 208 |
+
924.335066, 2968.881459, 2634.621962, 1739.579917,
|
| 209 |
+
494.905781, 815.239594, 924.335066, 2968.881459,
|
| 210 |
+
2634.621962, 1739.579917
|
| 211 |
+
],
|
| 212 |
+
stds=[
|
| 213 |
+
284.925432, 357.84876, 575.566823, 896.601013, 951.900334,
|
| 214 |
+
921.407808, 284.925432, 357.84876, 575.566823, 896.601013,
|
| 215 |
+
951.900334, 921.407808, 284.925432, 357.84876, 575.566823,
|
| 216 |
+
896.601013, 951.900334, 921.407808
|
| 217 |
+
]),
|
| 218 |
+
dict(
|
| 219 |
+
type='Reshape',
|
| 220 |
+
keys=['img'],
|
| 221 |
+
new_shape=(6, 3, -1, -1),
|
| 222 |
+
look_up=dict({
|
| 223 |
+
'2': 1,
|
| 224 |
+
'3': 2
|
| 225 |
+
})),
|
| 226 |
+
dict(
|
| 227 |
+
type='CastTensor', keys=['img'], new_type='torch.FloatTensor'),
|
| 228 |
+
dict(
|
| 229 |
+
type='CollectTestList',
|
| 230 |
+
keys=['img'],
|
| 231 |
+
meta_keys=[
|
| 232 |
+
'img_info', 'seg_fields', 'img_prefix', 'seg_prefix',
|
| 233 |
+
'filename', 'ori_filename', 'img', 'img_shape',
|
| 234 |
+
'ori_shape', 'pad_shape', 'scale_factor', 'img_norm_cfg'
|
| 235 |
+
])
|
| 236 |
+
],
|
| 237 |
+
img_suffix='_merged.tif',
|
| 238 |
+
seg_map_suffix='.mask.tif',
|
| 239 |
+
split=
|
| 240 |
+
'/home/ubuntu/hls-foundation-os/fine-tuning-examples/data_splits/crop_classification/validation_data.txt'
|
| 241 |
+
),
|
| 242 |
+
test=dict(
|
| 243 |
+
type='GeospatialDataset',
|
| 244 |
+
CLASSES=(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13),
|
| 245 |
+
reduce_zero_label=True,
|
| 246 |
+
data_root='/home/ubuntu/hls_cdl_reclassed/',
|
| 247 |
+
img_dir='/home/ubuntu/hls_cdl_reclassed/validation_chips',
|
| 248 |
+
ann_dir='/home/ubuntu/hls_cdl_reclassed/validation_chips',
|
| 249 |
+
pipeline=[
|
| 250 |
+
dict(type='LoadGeospatialImageFromFile', to_float32=True),
|
| 251 |
+
dict(type='ToTensor', keys=['img']),
|
| 252 |
+
dict(
|
| 253 |
+
type='TorchNormalize',
|
| 254 |
+
means=[
|
| 255 |
+
494.905781, 815.239594, 924.335066, 2968.881459,
|
| 256 |
+
2634.621962, 1739.579917, 494.905781, 815.239594,
|
| 257 |
+
924.335066, 2968.881459, 2634.621962, 1739.579917,
|
| 258 |
+
494.905781, 815.239594, 924.335066, 2968.881459,
|
| 259 |
+
2634.621962, 1739.579917
|
| 260 |
+
],
|
| 261 |
+
stds=[
|
| 262 |
+
284.925432, 357.84876, 575.566823, 896.601013, 951.900334,
|
| 263 |
+
921.407808, 284.925432, 357.84876, 575.566823, 896.601013,
|
| 264 |
+
951.900334, 921.407808, 284.925432, 357.84876, 575.566823,
|
| 265 |
+
896.601013, 951.900334, 921.407808
|
| 266 |
+
]),
|
| 267 |
+
dict(
|
| 268 |
+
type='Reshape',
|
| 269 |
+
keys=['img'],
|
| 270 |
+
new_shape=(6, 3, -1, -1),
|
| 271 |
+
look_up=dict({
|
| 272 |
+
'2': 1,
|
| 273 |
+
'3': 2
|
| 274 |
+
})),
|
| 275 |
+
dict(
|
| 276 |
+
type='CastTensor', keys=['img'], new_type='torch.FloatTensor'),
|
| 277 |
+
dict(
|
| 278 |
+
type='CollectTestList',
|
| 279 |
+
keys=['img'],
|
| 280 |
+
meta_keys=[
|
| 281 |
+
'img_info', 'seg_fields', 'img_prefix', 'seg_prefix',
|
| 282 |
+
'filename', 'ori_filename', 'img', 'img_shape',
|
| 283 |
+
'ori_shape', 'pad_shape', 'scale_factor', 'img_norm_cfg'
|
| 284 |
+
])
|
| 285 |
+
],
|
| 286 |
+
img_suffix='_merged.tif',
|
| 287 |
+
seg_map_suffix='.mask.tif',
|
| 288 |
+
split=
|
| 289 |
+
'/home/ubuntu/hls-foundation-os/fine-tuning-examples/data_splits/crop_classification/validation_data.txt'
|
| 290 |
+
))
|
| 291 |
+
optimizer = dict(
|
| 292 |
+
type='Adam', lr=1.5e-05, betas=(0.9, 0.999), weight_decay=0.05)
|
| 293 |
+
optimizer_config = dict(grad_clip=None)
|
| 294 |
+
lr_config = dict(
|
| 295 |
+
policy='poly',
|
| 296 |
+
warmup='linear',
|
| 297 |
+
warmup_iters=1500,
|
| 298 |
+
warmup_ratio=1e-06,
|
| 299 |
+
power=1.0,
|
| 300 |
+
min_lr=0.0,
|
| 301 |
+
by_epoch=False)
|
| 302 |
+
log_config = dict(
|
| 303 |
+
interval=10,
|
| 304 |
+
hooks=[dict(type='TextLoggerHook'),
|
| 305 |
+
dict(type='TensorboardLoggerHook')])
|
| 306 |
+
checkpoint_config = dict(
|
| 307 |
+
by_epoch=True,
|
| 308 |
+
interval=10,
|
| 309 |
+
out_dir='/home/ubuntu/clark_gfm_eval/multiclass_exp_newSplit')
|
| 310 |
+
evaluation = dict(interval=2, metric='mIoU', pre_eval=True, save_best='mIoU')
|
| 311 |
+
reduce_train_set = dict(reduce_train_set=False)
|
| 312 |
+
reduce_factor = dict(reduce_factor=1)
|
| 313 |
+
runner = dict(type='EpochBasedRunner', max_epochs=80)
|
| 314 |
+
workflow = [('train', 1), ('val', 1)]
|
| 315 |
+
norm_cfg = dict(type='BN', requires_grad=True)
|
| 316 |
+
loss_weights_multi = [
|
| 317 |
+
0.386375, 0.661126, 0.548184, 0.640482, 0.876862, 0.925186, 3.249462,
|
| 318 |
+
1.542289, 2.175141, 2.272419, 3.062762, 3.626097, 1.198702
|
| 319 |
+
]
|
| 320 |
+
loss_func = dict(
|
| 321 |
+
type='CrossEntropyLoss',
|
| 322 |
+
use_sigmoid=False,
|
| 323 |
+
class_weight=[
|
| 324 |
+
0.386375, 0.661126, 0.548184, 0.640482, 0.876862, 0.925186, 3.249462,
|
| 325 |
+
1.542289, 2.175141, 2.272419, 3.062762, 3.626097, 1.198702
|
| 326 |
+
],
|
| 327 |
+
avg_non_ignore=True)
|
| 328 |
+
output_embed_dim = 2304
|
| 329 |
+
model = dict(
|
| 330 |
+
type='TemporalEncoderDecoder',
|
| 331 |
+
frozen_backbone=False,
|
| 332 |
+
backbone=dict(
|
| 333 |
+
type='TemporalViTEncoder',
|
| 334 |
+
pretrained='/home/ubuntu/hls-loss-weights/Prithvi_100M.pt',
|
| 335 |
+
img_size=224,
|
| 336 |
+
patch_size=16,
|
| 337 |
+
num_frames=3,
|
| 338 |
+
tubelet_size=1,
|
| 339 |
+
in_chans=6,
|
| 340 |
+
embed_dim=768,
|
| 341 |
+
depth=6,
|
| 342 |
+
num_heads=8,
|
| 343 |
+
mlp_ratio=4.0,
|
| 344 |
+
norm_pix_loss=False),
|
| 345 |
+
neck=dict(
|
| 346 |
+
type='ConvTransformerTokensToEmbeddingNeck',
|
| 347 |
+
embed_dim=2304,
|
| 348 |
+
output_embed_dim=2304,
|
| 349 |
+
drop_cls_token=True,
|
| 350 |
+
Hp=14,
|
| 351 |
+
Wp=14),
|
| 352 |
+
decode_head=dict(
|
| 353 |
+
num_classes=13,
|
| 354 |
+
in_channels=2304,
|
| 355 |
+
type='FCNHead',
|
| 356 |
+
in_index=-1,
|
| 357 |
+
channels=256,
|
| 358 |
+
num_convs=1,
|
| 359 |
+
concat_input=False,
|
| 360 |
+
dropout_ratio=0.1,
|
| 361 |
+
norm_cfg=dict(type='BN', requires_grad=True),
|
| 362 |
+
align_corners=False,
|
| 363 |
+
loss_decode=dict(
|
| 364 |
+
type='CrossEntropyLoss',
|
| 365 |
+
use_sigmoid=False,
|
| 366 |
+
class_weight=[
|
| 367 |
+
0.386375, 0.661126, 0.548184, 0.640482, 0.876862, 0.925186,
|
| 368 |
+
3.249462, 1.542289, 2.175141, 2.272419, 3.062762, 3.626097,
|
| 369 |
+
1.198702
|
| 370 |
+
],
|
| 371 |
+
avg_non_ignore=True)),
|
| 372 |
+
auxiliary_head=dict(
|
| 373 |
+
num_classes=13,
|
| 374 |
+
in_channels=2304,
|
| 375 |
+
type='FCNHead',
|
| 376 |
+
in_index=-1,
|
| 377 |
+
channels=256,
|
| 378 |
+
num_convs=2,
|
| 379 |
+
concat_input=False,
|
| 380 |
+
dropout_ratio=0.1,
|
| 381 |
+
norm_cfg=dict(type='BN', requires_grad=True),
|
| 382 |
+
align_corners=False,
|
| 383 |
+
loss_decode=dict(
|
| 384 |
+
type='CrossEntropyLoss',
|
| 385 |
+
use_sigmoid=False,
|
| 386 |
+
class_weight=[
|
| 387 |
+
0.386375, 0.661126, 0.548184, 0.640482, 0.876862, 0.925186,
|
| 388 |
+
3.249462, 1.542289, 2.175141, 2.272419, 3.062762, 3.626097,
|
| 389 |
+
1.198702
|
| 390 |
+
],
|
| 391 |
+
avg_non_ignore=True)),
|
| 392 |
+
train_cfg=dict(),
|
| 393 |
+
test_cfg=dict(mode='slide', stride=(112, 112), crop_size=(224, 224)))
|
| 394 |
+
auto_resume = False
|
multi_temporal_crop_classification_best_mIoU_epoch_66.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ec4bbbdca96bbd7a588c78b4a6c98dfa5969e4f870b705fa256047b7203a703d
|
| 3 |
+
size 1680477067
|
multi_temporal_crop_classification_latest.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:298953c90e6fd2c135303644e548c479c30eddccb81f350ce3b992b8df2aacb7
|
| 3 |
+
size 1680477067
|