
Commit
•
bfac6fe
1
Parent(s):
48d1b23
Upload 16 files
Browse files- .gitattributes +2 -0
- README.md +553 -1
- README_en.md +544 -0
- images/1-pretrain-512.png +0 -0
- images/1-pretrain-768.png +0 -0
- images/2-sft-512.png +0 -0
- images/2-sft-768.png +0 -0
- images/3-eval_chat.png +0 -0
- images/VLM-structure-moe.png +0 -0
- images/VLM-structure.png +0 -0
- images/llava-structure.png +0 -0
- images/logo-minimind-v.png +0 -0
- images/minimind-v-input.png +0 -0
- images/modelscope-demo.gif +3 -0
- images/web_server.gif +3 -0
- images/web_server1.png +0 -0
- images/web_server2.png +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
images/modelscope-demo.gif filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
images/web_server.gif filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,3 +1,555 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
-
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
|
| 3 |
+

|
| 4 |
+
|
| 5 |
+
</div>
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
<div align="center">
|
| 9 |
+
|
| 10 |
+

|
| 11 |
+
[](https://github.com/jingyaogong/minimind-v/stargazers)
|
| 12 |
+
[](LICENSE)
|
| 13 |
+
[](https://github.com/jingyaogong/minimind-v/commits/master)
|
| 14 |
+
[](https://github.com/jingyaogong/minimind-v/pulls)
|
| 15 |
+
|
| 16 |
+
</div>
|
| 17 |
+
|
| 18 |
+
<div align="center">
|
| 19 |
+
<h3>"大道至简"</h3>
|
| 20 |
+
</div>
|
| 21 |
+
|
| 22 |
+
<div align="center">
|
| 23 |
+
|
| 24 |
+
中文 | [English](./README_en.md)
|
| 25 |
+
|
| 26 |
+
</div>
|
| 27 |
+
|
| 28 |
+
* 本开源项目旨在从0开始,最快3小时训练一个小参数量的,具备视觉模态能力的语言模型**MiniMind-V**
|
| 29 |
+
* **MiniMind-V**同样极其轻量,最小版本体积仅为 GPT3 的约 $\frac{1}{7000}$,力求做到个人GPU也可快速推理甚至训练。
|
| 30 |
+
* 这不仅是一个开源模型的实现,也是入门视觉语言模型(VLM)的教程。
|
| 31 |
+
* 希望此项目能为研究者提供一个抛砖引玉的入门示例,帮助大家快速上手并对VLM领域产生更多的探索与创新。
|
| 32 |
+
|
| 33 |
+
> 为防止误读,「从0开始」特指基于纯语言模型MiniMind(这是一个完全从0训练的类GPT模型)做进一步的,从0到1的视觉能力拓展。
|
| 34 |
+
> 若需详细了解后者,请参考孪生项目[MiniMind](https://github.com/jingyaogong/minimind)。
|
| 35 |
+
|
| 36 |
+
> 为防止误读,「最快3小时」是指您需要具备>本人硬件配置的机器,具体规格的详细信息将在下文提供。
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+

|
| 41 |
+
|
| 42 |
+
<div align="center">
|
| 43 |
+
|
| 44 |
+
Demo已部署至ModelScope创空间,可以在此网站上体验:
|
| 45 |
+
|
| 46 |
+
[ModelScope在线体验](https://modelscope.cn/studios/gongjy/minimind-v)
|
| 47 |
+
|
| 48 |
+
</div>
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
# 📌 Introduction
|
| 52 |
+
|
| 53 |
+
视觉语言模型(VLM)如 GPT-4V、Qwen-VL、LlaVA 等,虽然在效果上令人惊艳,
|
| 54 |
+
但这些动辄 100 亿级参数的庞大模型,往往需要极高的硬件配置。
|
| 55 |
+
对于个人设备来说,不仅显存远远不足以支持训练,甚至连推理都十分困难。
|
| 56 |
+
我们通过阅读论文或公众号讲解来了解略显新颖的 VLM,
|
| 57 |
+
往往只能一知半解云里雾里。
|
| 58 |
+
而我们真正需要了解的是:
|
| 59 |
+
为多模态大模型是否真的如想象中那样复杂?它的代码实现到底如何?
|
| 60 |
+
训练过程究竟难不难?如果我只有一张 2080Ti 显卡,能否从0开始进行训练?
|
| 61 |
+
|
| 62 |
+
通过 **MiniMind-V**,本项目希望回答这些问题,
|
| 63 |
+
帮助研究者在有限的硬件条件下理解视觉语言模型的核心原理。
|
| 64 |
+
|
| 65 |
+
> [!TIP]
|
| 66 |
+
> (截至2024-10-04)MiniMind-V 系列已完成了 2 个型号模型的预训练,最小仅需27M(0.027B),即可具备识图和对话的能力!
|
| 67 |
+
|
| 68 |
+
| 模型 (大小) | tokenizer长度 | 推理占用 | release | 主观评分(/100) |
|
| 69 |
+
|---------------------------|-------------|--------|------------|------------|
|
| 70 |
+
| minimind-v-v1-small (27M) | 6400 | 0.6 GB | 2024.10.04 | 50' |
|
| 71 |
+
| minimind-v-v1 (109M) | 6400 | 1.1 GB | 2024.10.04 | 60' |
|
| 72 |
+
|
| 73 |
+
> 该分析在具有Torch 2.1.2、CUDA 12.2和Flash Attention 2的2×RTX 3090 GPU上进行。
|
| 74 |
+
|
| 75 |
+
### 👉**最近更新**
|
| 76 |
+
|
| 77 |
+
<details close>
|
| 78 |
+
<summary> <b>2024-10-05 (newest 🎉)</b> </summary>
|
| 79 |
+
|
| 80 |
+
- MiniMind-V如期而至,首次开源
|
| 81 |
+
|
| 82 |
+
</details>
|
| 83 |
+
|
| 84 |
+
# 📌 Environment
|
| 85 |
+
|
| 86 |
+
仅是我个人的软硬件环境配置,自行酌情变动:
|
| 87 |
+
|
| 88 |
+
```bash
|
| 89 |
+
CPU: Intel(R) Core(TM) i9-10980XE CPU @ 3.00GHz
|
| 90 |
+
内存:128 GB
|
| 91 |
+
显卡:NVIDIA GeForce RTX 3090(24GB) * 2
|
| 92 |
+
环境:python 3.9 + Torch 2.1.2 + DDP单机多卡训练
|
| 93 |
+
```
|
| 94 |
+
|
| 95 |
+
* Ubuntu == 20.04
|
| 96 |
+
* Python == 3.9
|
| 97 |
+
* Pytorch == 2.1.2
|
| 98 |
+
* CUDA == 12.2
|
| 99 |
+
* [requirements.txt](./requirements.txt)
|
| 100 |
+
|
| 101 |
+
# 📌 Quick Test
|
| 102 |
+
|
| 103 |
+
1.克隆项目
|
| 104 |
+
|
| 105 |
+
```bash
|
| 106 |
+
# step 1
|
| 107 |
+
git clone https://github.com/jingyaogong/minimind-v & cd minimind-v
|
| 108 |
+
```
|
| 109 |
+
|
| 110 |
+
2.下载预训练的模型权重文件到项目根目录 `minimind-v-v1`
|
| 111 |
+
|
| 112 |
+
```bash
|
| 113 |
+
# step 2
|
| 114 |
+
git clone https://huggingface.co/jingyaogong/minimind-v-v1
|
| 115 |
+
```
|
| 116 |
+
|
| 117 |
+
3.下载预训练的`clip-vit-base-patch32` 模型,在 `model/clip_model` 目录下:
|
| 118 |
+
|
| 119 |
+
```bash
|
| 120 |
+
# step 3
|
| 121 |
+
cd model/clip_model & git clone https://hf-mirror.com/openai/clip-vit-base-patch32
|
| 122 |
+
```
|
| 123 |
+
|
| 124 |
+
4.启动聊天网页测试对话
|
| 125 |
+
|
| 126 |
+
```bash
|
| 127 |
+
# step 4
|
| 128 |
+
python web_server.py
|
| 129 |
+
```
|
| 130 |
+
|
| 131 |
+

|
| 132 |
+
|
| 133 |
+
# 📌 Quick Start Train
|
| 134 |
+
|
| 135 |
+
* 0、环境安装
|
| 136 |
+
```bash
|
| 137 |
+
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
|
| 138 |
+
```
|
| 139 |
+
* 1、克隆项目代码
|
| 140 |
+
```text
|
| 141 |
+
git clone https://github.com/jingyaogong/minimind-v
|
| 142 |
+
```
|
| 143 |
+
* 2、如果需要自己训练
|
| 144 |
+
|
| 145 |
+
* 2.1 下载[数据集](https://pan.baidu.com/s/1Nz36OBBvVBGEx-PwIb7ofg?pwd=6666)的所有内容到`./dataset`
|
| 146 |
+
目录下,解压`pretrain_images.zip` 和 `sft_images.zip`
|
| 147 |
+
* 2.2 在`./model/LMConfig.py` 中调整model的参数配置
|
| 148 |
+
> 这里仅需调整dim和n_layers参数,分别是`(512+8)`或`(768+16)`,对应于`minimind-v-v1-small`和`minimind-v-v1`
|
| 149 |
+
* 2.3 下载MiniMind语言模型的[预训练权重文件](https://pan.baidu.com/s/1LE1SPoPYGS7VNtT1tpf7DA?pwd=6666)
|
| 150 |
+
,放到到`./out/`目录下,命名为`*_llm.pth`
|
| 151 |
+
* 2.4 `python 1-pretrain_vlm.py` 执行预训练,得到 `*_vlm_pretrain.pth` 作为预训练的输出权重
|
| 152 |
+
* 2.5 `python 2-sft_vlm.py` 执行指令微调,得到 `*_vlm_sft.pth` 作为指令微调的输出权重
|
| 153 |
+
|
| 154 |
+
* 3、测试自己训练的模型推理效果
|
| 155 |
+
* 确保需要使用的,训练完成的参数权重`*.pth`文件位于`./out/`目录下
|
| 156 |
+
* 也可以直接去[训练完成的模型权重](https://pan.baidu.com/s/1LE1SPoPYGS7VNtT1tpf7DA?pwd=6666)
|
| 157 |
+
下载使用我训练好的`*.pth`权重文件
|
| 158 |
+
```text
|
| 159 |
+
minimind-v/out
|
| 160 |
+
├── 512_llm.pth
|
| 161 |
+
├── 512_vlm_pretrain.pth
|
| 162 |
+
├── 512_vlm_sft.pth
|
| 163 |
+
├── 768_llm.pth
|
| 164 |
+
├── 768_vlm_pretrain.pth
|
| 165 |
+
├── 768_vlm_sft.pth
|
| 166 |
+
```
|
| 167 |
+
* `python 3-eval_chat.py`测试模型的对话效果,其中测试图片在`./dataset/eval_images`下,可自行更换
|
| 168 |
+

|
| 169 |
+
|
| 170 |
+
🍭 【Tip】预训练和全参指令微调pretrain和sft均支持多卡加速
|
| 171 |
+
|
| 172 |
+
* 单机N卡启动训练(DDP)
|
| 173 |
+
```bash
|
| 174 |
+
torchrun --nproc_per_node N 1-pretrain_vlm.py
|
| 175 |
+
# and
|
| 176 |
+
torchrun --nproc_per_node N 2-sft_vlm.py
|
| 177 |
+
```
|
| 178 |
+
|
| 179 |
+
* 记录训练过程
|
| 180 |
+
```bash
|
| 181 |
+
torchrun --nproc_per_node N 1-pretrain_vlm.py --use_wandb
|
| 182 |
+
# and
|
| 183 |
+
python 1-pretrain_vlm.py --use_wandb
|
| 184 |
+
```
|
| 185 |
+
通过添加`--use_wandb`参数,可以记录训练过程,训练完成后,可以在wandb网站上查看训练过程。通过修改`wandb_project`
|
| 186 |
+
和`wandb_run_name`参数,可以指定项目名称和运行名称。
|
| 187 |
+
|
| 188 |
+
# 📌 VLM Detail
|
| 189 |
+
|
| 190 |
+
MiniMind-V (VLM)的基座语言模型MiniMind (LLM)来自孪生项目[minimind](https://github.com/jingyaogong/minimind),
|
| 191 |
+
具体的模型结构、训练细节、原理、测试效果等均可移步[minimind](https://github.com/jingyaogong/minimind)项目查阅。
|
| 192 |
+
此处为减少冗余,省略讨论LLM的相关部分,默认您已对MiniMind (LLM)的细节有基本的了解。
|
| 193 |
+
|
| 194 |
+
> PS: 即使您不希望了解MiniMind (LLM)的细节,也可直接参考Quick Test和Quick Start中快速测试或训练MiniMind-V,
|
| 195 |
+
> 这并不受太大影响。
|
| 196 |
+
|
| 197 |
+
MiniMind-V的结构几乎不变,仅增加Visual Encoder和特征投影两个子模块,增加模态混合分支,以支持多种模态信息的输入:
|
| 198 |
+

|
| 199 |
+

|
| 200 |
+
|
| 201 |
+
此时,不妨思考2个很有意思的问题:什么叫做**L**arge **L**anguage **M**odel(LLM)?什么叫做多模态模型?
|
| 202 |
+
|
| 203 |
+
* [这篇文章](https://www.jiqizhixin.com/articles/2024-09-15-3)完美吐露了本人的想法,即LLM这个命名很不准确!
|
| 204 |
+
|
| 205 |
+
> 大语言模型(LLM)名字虽然带有语言二字,但它们其实与语言关系不大,这只是历史问题,更确切的名字应该是自回归 Transformer
|
| 206 |
+
或者其他。
|
| 207 |
+
LLM 更多是一种统计建模的通用技术,它们主要通过自回归 Transformer 来模拟 token 流,而这些 token
|
| 208 |
+
可以代表文本、图片、音频、动作选择、甚至是分子等任何东西。
|
| 209 |
+
因此,只要能将问题转化为模拟一系列离散 token 的流程,理论上都可以应用 LLM 来解决。
|
| 210 |
+
实际上,随着大型语言模型技术栈的日益成熟,我们可能会看到越来越多的问题被纳入这种建模范式。也就是说,问题固定在使用 LLM
|
| 211 |
+
进行『下一个 token 的预测』,只是每个领域中 token 的用途和含义有所不同。
|
| 212 |
+
|
| 213 |
+
* [李玺老师](https://person.zju.edu.cn/xilics#694283)同样佐证了本人的观点(原话不记得了,大意如下):
|
| 214 |
+
|
| 215 |
+
> 文本、视频、语音、动作等在人类看来属于「多模态」信号,但所谓的「模态」其实只是人类在信息存储方式上的一种分类概念。
|
| 216 |
+
就像`.txt`和`.png`文件,虽然在视觉呈现和高级表现形式上有所不同,但它们本质上并没有根本区别。
|
| 217 |
+
之所以出现「多模态」这个概念,仅仅是因为人类在不同的感知层面上对这些信号的分类需求。
|
| 218 |
+
然而,对于机器来说,无论信号来自何种「模态」,最终它们都只是以一串二进制的「单模态」数字序列来呈现。
|
| 219 |
+
机器并不会区分这些信号的模态来源,而只是处理和分析这些序列背后所承载的信息内容。
|
| 220 |
+
|
| 221 |
---
|
| 222 |
+
私以为,**G**enerative **P**retrained **T**ransformer (GPT) 比 **L**arge **L**anguage **M**odel (LLM)更为���切,
|
| 223 |
+
因此本人表达上更习惯用"GPT"去代表LLM/VLM/类GPT架构的系列模型,而非为了蹭OpenAI的热度。
|
| 224 |
---
|
| 225 |
+
至此,我们可以用一句话总结GPT的所作所为:
|
| 226 |
+
GPT模型根据现有token预测输出下一个下下一个下下下一个token ...,直到模型输出结束符;此处的"token"其实并不需要一定是文本!
|
| 227 |
+
---
|
| 228 |
+
|
| 229 |
+
* 对于LLM模型,如果需要理解"图片",我们只要把"图片"作为对一种特殊的从来没见过的"外国语言",通过"外语词典"翻译后即可作为特殊的语言输入LLM
|
| 230 |
+
* 对于LLM模型,如果需要理解"音频",我们只要把"音频"作为对一种特殊的从来没见过的"外国语言",通过"外语词典"翻译后即可作为特殊的语言输入LLM
|
| 231 |
+
* ...
|
| 232 |
+
|
| 233 |
+
---
|
| 234 |
+
|
| 235 |
+
<u>**所以,为了得到MiniMind-V,我们只需要完成2件事即可:**</u>
|
| 236 |
+
|
| 237 |
+
1. 借助擅长翻译图片的 **"外语词典"** ,把图片从 **"外国语言"** 翻译为模型便于理解的 **"LLM语言"**
|
| 238 |
+
2. 训练微调LLM,使其和 **"外语词典"** 度过磨合期,从而更好的理解图片
|
| 239 |
+
|
| 240 |
+
---
|
| 241 |
+
|
| 242 |
+
"外语词典"一般称之为Visual Encoder模型。
|
| 243 |
+
和LlaVA、Qwen-VL等视觉语言模型类似,MiniMind-V同样选用开源Clip系列模型作为Visual Encoder。
|
| 244 |
+
具体使用[clip-vit-base-patch32](https://huggingface.co/openai/clip-vit-base-patch32),
|
| 245 |
+
一种基于 ViT-B/32 架构的经典Visual Encoder用于描述图像文本信息。
|
| 246 |
+
输入的图像尺寸为224x224,因为划分的Patch是32×32,所以会产生7*7+1(cls_token)=50个token作为encoder编码层的输入,
|
| 247 |
+
最终产生1×768维的嵌入向量用于和文本对计算误差。
|
| 248 |
+
我们并不需要最终嵌入表示,因此只取encoder层的输出,也就是VIT核心主干的输出特征即可。
|
| 249 |
+
在代码中对应[./model/vision_utils.py](./model/vision_utils.py)的get_img_embedding中的hook函数。
|
| 250 |
+
它拿到前一层维度50×768大小的特征,我们把它作为50个visual token输入MiniMind-V。
|
| 251 |
+
也有clip-vit-large-patch14这种更大,图像理解能力更强的Clip模型,
|
| 252 |
+
但是单图片会产生257个token,对于minimind这种量级模型,图片token的上下文占比太长,反倒不利于训练。
|
| 253 |
+
|
| 254 |
+
与LLM的结合在获取图像encoder特征后,一方面需要把768维度的visual token对齐到LLM的文本token,
|
| 255 |
+
另一方面,要将图像特征映射到与文本embedding相同的空间,即文本token和原生的视觉token需要磨合并不能直接地一视同仁,
|
| 256 |
+
可以称之为跨模态的特征对齐。
|
| 257 |
+
[LlaVA-1](https://arxiv.org/pdf/2304.08485)使用简单的无偏线性变换完成了这一操作,效果很不错,MiniMind-V同样如此。
|
| 258 |
+
|
| 259 |
+

|
| 260 |
+
|
| 261 |
+
至此,MiniMind-V的内部结构变化已经呈现完毕。
|
| 262 |
+
|
| 263 |
+
---
|
| 264 |
+
|
| 265 |
+
下面,我们简单讨论MiniMind-V的外部输入输出的变化。
|
| 266 |
+
|
| 267 |
+
VLM的输入依然是一段文本,其中包含特殊的<image>占位符。
|
| 268 |
+
在计算文本嵌入后,可以将图像编码器生成的向量投影到该占位符对应的嵌入部分,替换掉原先的占位符embedding。
|
| 269 |
+
例如:
|
| 270 |
+
|
| 271 |
+
```text
|
| 272 |
+
<image>\n这个图像中有什么内容?
|
| 273 |
+
```
|
| 274 |
+
|
| 275 |
+
minimind-v使用50个字符组成的 `<<<...>>>` 占位符代替图像,
|
| 276 |
+
之所以是50个字符,前面有所提及:
|
| 277 |
+
任何图像都被clip模型encoder为50×768维的token。
|
| 278 |
+
因此minimind-v的prompt:
|
| 279 |
+
|
| 280 |
+
```text
|
| 281 |
+
<<<<<<<<<<<<<<<<<<<<<<<<<>>>>>>>>>>>>>>>>>>>>>>>>>\n这个图片描述的是什么内容?
|
| 282 |
+
```
|
| 283 |
+
|
| 284 |
+
计算完embedding和projection,并对图像部分token替换后
|
| 285 |
+
整个计算过程到输出则和LLM部分没有任何区别。
|
| 286 |
+
|
| 287 |
+

|
| 288 |
+
|
| 289 |
+
<u>至此,MiniMind-V的所有细节已经呈现完毕。</u>
|
| 290 |
+
|
| 291 |
+
<u>MiniMind-V的实现未参考 **任何** 第三方代码,完全基于MiniMind尽可能做最小改动产生,故代码实现和LlaVA等模型必然存在很大区别。
|
| 292 |
+
MiniMind-V与MiniMind的代码核心改动不超过100行,上手难度低。</u>
|
| 293 |
+
|
| 294 |
+
# 📌 Experiment
|
| 295 |
+
|
| 296 |
+
## 数据集
|
| 297 |
+
|
| 298 |
+
来源:[Chinese-LLaVA-Vision](https://huggingface.co/datasets/LinkSoul/Chinese-LLaVA-Vision-Instructions)
|
| 299 |
+
包含约60万张预训练图像和<10万张指令微调图像,来自CC-3M和COCO 2014,问答内容经过翻译,对中文支持更友好。并进一步经过resize和整理压缩。
|
| 300 |
+
|
| 301 |
+
预训练数据集格式:
|
| 302 |
+
|
| 303 |
+
```json
|
| 304 |
+
{
|
| 305 |
+
"id": "GCC_train_000644518",
|
| 306 |
+
"image": "GCC_train_000644518.jpg",
|
| 307 |
+
"conversations": [
|
| 308 |
+
{
|
| 309 |
+
"from": "human",
|
| 310 |
+
"value": "写一篇简短但有益的图片摘要.\n<image>"
|
| 311 |
+
},
|
| 312 |
+
{
|
| 313 |
+
"from": "gpt",
|
| 314 |
+
"value": "在黑色背景的金属锅中加入盐水,慢动作fps"
|
| 315 |
+
}
|
| 316 |
+
]
|
| 317 |
+
}
|
| 318 |
+
```
|
| 319 |
+
|
| 320 |
+
指令微调数据集格式:
|
| 321 |
+
|
| 322 |
+
```json
|
| 323 |
+
{
|
| 324 |
+
"id": "000000334872",
|
| 325 |
+
"image": "000000334872.jpg",
|
| 326 |
+
"conversations": [
|
| 327 |
+
{
|
| 328 |
+
"from": "human",
|
| 329 |
+
"value": "<image>\n照片中的人们在下山滑雪还是越野滑雪?"
|
| 330 |
+
},
|
| 331 |
+
{
|
| 332 |
+
"from": "gpt",
|
| 333 |
+
"value": "照片中的人们在森林里越野滑雪,因为他们在一条小径上而不是在陡坡上滑雪。"
|
| 334 |
+
}
|
| 335 |
+
]
|
| 336 |
+
}
|
| 337 |
+
```
|
| 338 |
+
|
| 339 |
+
注:对于指令微调,仅保留了一轮对话,训练单轮对话模型,防止小模型性能被长文本拉低。
|
| 340 |
+
|
| 341 |
+
最终的数据集下载地址:[百度网盘](https://pan.baidu.com/s/1Nz36OBBvVBGEx-PwIb7ofg?pwd=6666) | [HuggingFace](https://huggingface.co/datasets/jingyaogong/minimind-v_dataset)
|
| 342 |
+
|
| 343 |
+
## 训练
|
| 344 |
+
|
| 345 |
+
预训练从595K条数据集中学习图片的通用知识,比如鹿是鹿,狗是狗。
|
| 346 |
+
|
| 347 |
+
指令微调从230K条真实对话数据集中学习对图片提问的真实问答格式。
|
| 348 |
+
|
| 349 |
+
`1-pretrain_vlm.py` 执行预训练,得到 `*_vlm_pretrain.pth` 作为预训练的输出权重。
|
| 350 |
+
|
| 351 |
+
`2-sft_vlm.py` 执行指令微调,得到 `*_vlm_sft.pth` 作为指令微调的输出权重。
|
| 352 |
+
|
| 353 |
+
训练时均冻结visual encoder也就是clip模型,只微调Projection和LLM两部分。
|
| 354 |
+
|
| 355 |
+
> Pretrain 512+8 模型 (训练时间和Loss参考图)
|
| 356 |
+

|
| 357 |
+
> Pretrain 768+16 模型 (训练时间和Loss参考图)
|
| 358 |
+

|
| 359 |
+
> SFT 512+8 模型 (训练时间和Loss参考图)
|
| 360 |
+

|
| 361 |
+
> SFT 768+16 模型 (训练时间和Loss参考图)
|
| 362 |
+

|
| 363 |
+
|
| 364 |
+
## 训练完成的模型权重
|
| 365 |
+
|
| 366 |
+
(`.pth`权重文件) 下载地址:[百度网盘](https://pan.baidu.com/s/1a7_C7HdCMfnG2Dia3q85FQ?pwd=6666)
|
| 367 |
+
|
| 368 |
+
(`transformers`模型文件)
|
| 369 |
+
下载地址:[HuggingFace](https://huggingface.co/collections/jingyaogong/minimind-v-67000833fb60b3a2e1f3597d)
|
| 370 |
+
|
| 371 |
+
> 注:HuggingFace版本均为指令微调后的MiniMind-V模型
|
| 372 |
+
|
| 373 |
+
| Model Name | params | Config | file_name |
|
| 374 |
+
|---------------------|--------|-----------------------------|-----------------------------------------------------|
|
| 375 |
+
| minimind-v-v1-small | 27M | d_model=512<br/>n_layers=8 | 预训练:512_vllm_pretrain.pth<br/>指令微调:512_vllm_sft.pth |
|
| 376 |
+
| minimind-v-v1 | 109M | d_model=768<br/>n_layers=16 | 预训练:768_vllm_pretrain.pth<br/>指令微调:768_vllm_sft.pth |
|
| 377 |
+
|
| 378 |
+
# 📌 Test
|
| 379 |
+
|
| 380 |
+
### 效果测试
|
| 381 |
+
|
| 382 |
+
<table>
|
| 383 |
+
<thead>
|
| 384 |
+
<tr>
|
| 385 |
+
<th>图片</th>
|
| 386 |
+
<th>512_pretrain</th>
|
| 387 |
+
<th>512_sft</th>
|
| 388 |
+
<th>768_pretrain</th>
|
| 389 |
+
<th>768_sft</th>
|
| 390 |
+
</tr>
|
| 391 |
+
</thead>
|
| 392 |
+
<tbody>
|
| 393 |
+
<tr>
|
| 394 |
+
<td><img src="./dataset/eval_images/一个女子.png" alt="a-girl.png" style="width: 200px;"></td>
|
| 395 |
+
<td>头发和化妆,我喜欢她的自然头发!</td>
|
| 396 |
+
<td>这个图片描绘了一个年轻的女人,她穿着一套西装,戴着一条领带,这表明她可能正在参加一个特别的时装活动或庆祝活动。</td>
|
| 397 |
+
<td>人为出演员的冒险片。</td>
|
| 398 |
+
<td>这个图片描绘了一个女人的肖像,她穿着一件粉红色的裙子。</td>
|
| 399 |
+
</tr>
|
| 400 |
+
<tr>
|
| 401 |
+
<td><img src="./dataset/eval_images/一个海星.png" alt="a-girl.png" ></td>
|
| 402 |
+
<td>水中的化石, 一个由环绕的环形化石团组成的静止线.</td>
|
| 403 |
+
<td>图片显示一只大型的 octopus, 一个大型的 octopus, 可能是一个潜在的海洋生物, 它在水面上, 或在海洋中 。</td>
|
| 404 |
+
<td>海星和触角。</td>
|
| 405 |
+
<td>图片显示了海星在海滩上,包括海星,以及一个水下物体。</td>
|
| 406 |
+
</tr>
|
| 407 |
+
<tr>
|
| 408 |
+
<td><img src="./dataset/eval_images/一个熊.png" alt="a-girl.png" ></td>
|
| 409 |
+
<td>在野外,在山谷里。</td>
|
| 410 |
+
<td>图片中的植物和一只灰熊坐在草地上。</td>
|
| 411 |
+
<td>一只灰熊的近景</td>
|
| 412 |
+
<td>图片显示一只灰熊站在一片开放的草地上,周围有树木和草丛,还有一只背包放在上面。</td>
|
| 413 |
+
</tr>
|
| 414 |
+
<tr>
|
| 415 |
+
<td><img src="./dataset/eval_images/一些海豚.png" alt="a-girl.png" ></td>
|
| 416 |
+
<td>一群游客观看了这部电影。</td>
|
| 417 |
+
<td>这个图片描绘了一群海鸥在水面飞翔,在水面上。海鸥的出现表明,它们正在寻找食物。海鸥在水面上筑巢,可能是为了保护自己免受潜在的危险,如海鸥的尖锐牙齿和爬行动物。</td>
|
| 418 |
+
<td>一群海豚或绵羊在一天的航行中乘船捕鱼</td>
|
| 419 |
+
<td>这个图片显示一群人在海豚和海豚附近的大群中游泳。</td>
|
| 420 |
+
</tr>
|
| 421 |
+
<tr>
|
| 422 |
+
<td><img src="./dataset/eval_images/三个女孩.png" alt="a-girl.png" ></td>
|
| 423 |
+
<td>一个女孩和她的朋友坐在一张长凳上,穿着长长的白色长袍。</td>
|
| 424 |
+
<td>这个场景描绘了一个充满活力的年轻女孩,她们穿着一件黑色和白色的服装,在一群人中间站着,他们都穿着黑色和白色的服装,这表明他们的服装是生动的、优雅的,在他们身边。在场景中,有两个女孩在背后,一个女人在背后,另一个女人站着,他们都穿着黑色的服装。这表明他们正在享受他们的服装和服装,可能正在参加一个特别的节日或庆祝活动。</td>
|
| 425 |
+
<td>女孩们在城市的街道上。</td>
|
| 426 |
+
<td>这个图片描绘了一个穿着传统服装的男人和女人,站在他们旁边,他们正在一起度过一个家庭时光。在整个场景中,可以看到一个小男孩和一个女孩,他们穿着牛仔帽,这表明他们正在参加一个家庭聚会,这可能是一次聚会或庆祝,或者他们可能正在讨论一个有趣的活动或活动。</td>
|
| 427 |
+
</tr>
|
| 428 |
+
<tr>
|
| 429 |
+
<td><img src="./dataset/eval_images/两头鹿.png" alt="a-girl.png" ></td>
|
| 430 |
+
<td>这张照片中有几只鹿。</td>
|
| 431 |
+
<td>这个图片记录了一只白尾鹿, 它坐在草地上, 用它的照片来捕捉一只红鹿.</td>
|
| 432 |
+
<td>这只动物看起来好像准备躲在树后面,他看上去很威严,因为他无法控制自己。</td>
|
| 433 |
+
<td>这个图片描绘了一只母鹿和一只鹿,这只母鹿在树林中站着,一只羊和一只鹿。</td>
|
| 434 |
+
</tr>
|
| 435 |
+
<tr>
|
| 436 |
+
<td><img src="./dataset/eval_images/两朵红花.png" alt="a-girl.png" ></td>
|
| 437 |
+
<td>这个花束的花期几乎没有进数。</td>
|
| 438 |
+
<td>图片显示一只红色和黄色的花朵, 它们被称为“花瓶”。</td>
|
| 439 |
+
<td>花头的贴近。</td>
|
| 440 |
+
<td>图片显示了红色的花朵,周围有几个玫瑰花。</td>
|
| 441 |
+
</tr>
|
| 442 |
+
<tr>
|
| 443 |
+
<td><img src="./dataset/eval_images/太空宇航员.png" alt="a-girl.png" ></td>
|
| 444 |
+
<td>宇航员在太空任务中与地球相姿态。</td>
|
| 445 |
+
<td>这个图像描绘了一个充满活力的月球,在月球上散步。</td>
|
| 446 |
+
<td>宇航员在任务期间在摇篮上休息,与他的团队在背景。</td>
|
| 447 |
+
<td>这个图片描绘了一个宇航员在太空站的形象。</td>
|
| 448 |
+
</tr>
|
| 449 |
+
<tr>
|
| 450 |
+
<td><img src="./dataset/eval_images/老虎在水里.png" alt="a-girl.png" ></td>
|
| 451 |
+
<td>一只老虎在水里看着摄像机。</td>
|
| 452 |
+
<td>图片显示一只大棕色的海豹在水里游泳,在水里休息。</td>
|
| 453 |
+
<td>动物园里被囚禁的老虎</td>
|
| 454 |
+
<td>图片显示一只小熊,躺在一棵树枝上。</td>
|
| 455 |
+
</tr>
|
| 456 |
+
<tr>
|
| 457 |
+
<td><img src="./dataset/eval_images/豹子在悬崖.png" alt="a-girl.png" ></td>
|
| 458 |
+
<td>这个是濒危物种。</td>
|
| 459 |
+
<td>图片中,一只黑白的猫在岩石上散步。</td>
|
| 460 |
+
<td>野外云层的豹在洞穴外的岩石上,在日出时</td>
|
| 461 |
+
<td>该图片展示了一只小熊猫在岩石上散步的照片。</td>
|
| 462 |
+
</tr>
|
| 463 |
+
</tbody>
|
| 464 |
+
</table>
|
| 465 |
+
|
| 466 |
+
### 启动推理
|
| 467 |
+
|
| 468 |
+
```bash
|
| 469 |
+
python web_server.py
|
| 470 |
+
```
|
| 471 |
+
|
| 472 |
+

|
| 473 |
+

|
| 474 |
+
|
| 475 |
+
### 效果总结
|
| 476 |
+
|
| 477 |
+
---
|
| 478 |
+
根据提供的表格数据,四个模型的表现可以总结如下:
|
| 479 |
+
|
| 480 |
+
1. **512_pretrain**:
|
| 481 |
+
- **描述简略且不准确**:大部分描述无法清晰表达图像内容,常常给出一些不相关的叙述。例如,在海星的图像中描述为“水中的化石”,与实际内容偏差较大。
|
| 482 |
+
- **缺乏细节**:大多数情况下,只给出简单的、模糊的描述,无法深入解释图像的细节或背景。例如,对于老虎的图像,仅说“在水里看着摄像机”。
|
| 483 |
+
|
| 484 |
+
2. **512_sft**:
|
| 485 |
+
- **描述更具体**:相比512_pretrain,512_sft在描述图像内容时更加详细,并尝试捕捉场景的具体元素。比如描述女子图像时,提到了“西装”和“领带”,细节较为清晰。
|
| 486 |
+
- **偶尔出错或冗余**:部分描述显得过于复杂甚至与图片无关,如描述海豚图像时,提到海鸥、筑巢等不相关的内容。
|
| 487 |
+
|
| 488 |
+
3. **768_pretrain**:
|
| 489 |
+
- **信息不连贯**:该模型的表现较为散乱,描述经常模糊且不完整。例如,在描述女子图像时,只提到“人为出演员的冒险片”,没有清楚地解释图像内容。
|
| 490 |
+
- **部分准确,但总体信息量少**:一些描述虽然与图像相关,但非常简短。例如,海星的描述只有“海星和触角”,无法提供完整的画面感。
|
| 491 |
+
|
| 492 |
+
4. **768_sft**:
|
| 493 |
+
- **描述全面且具体**:该模型的描述是四个模型中最详细和精确的。比如,描述熊的图像时提到了“站在一片开放的草地上,周围有树木和草丛,还有一只背包”,能够准确捕捉到多个图像元素。
|
| 494 |
+
- **具备更强的理解力**:该模型能够识别图像的场景和背景,提供合理的解释和推测。例如,描述“家庭聚会”或“庆祝活动”,这些解释让图像更具上下文联系。
|
| 495 |
+
|
| 496 |
+
### 总结:
|
| 497 |
+
|
| 498 |
+
- **512_pretrain**的表现最差,描述简单且不准确。
|
| 499 |
+
- **512_sft**的描述详细度有所提升,但偶尔出现不相关信息。
|
| 500 |
+
- **768_pretrain**信息连贯性差,但在某些方面能提供基本描述。
|
| 501 |
+
- **768_sft**表现最佳,能够给出详细、准确的描述,并且能够很好地推测图像的上下文。
|
| 502 |
+
|
| 503 |
+
---
|
| 504 |
+
|
| 505 |
+
# 📌 Acknowledge
|
| 506 |
+
|
| 507 |
+
> [!TIP]
|
| 508 |
+
> 如果您觉得 `MiniMind-V`对您有所帮助,可以在 GitHub 上加一个⭐<br/>
|
| 509 |
+
> ��幅不短水平有限难免纰漏,欢迎在Issues交流指正或提交PR改进项目<br/>
|
| 510 |
+
> 您的支持就是持续改进项目的动力
|
| 511 |
+
|
| 512 |
+
## 🤝[贡献者](https://github.com/jingyaogong/minimind/graphs/contributors)
|
| 513 |
+
|
| 514 |
+
<a href="https://github.com/jingyaogong"><img src="https://avatars.githubusercontent.com/u/62287848" width="70px" height="70px"/></a>
|
| 515 |
+
|
| 516 |
+
|
| 517 |
+
## 😊鸣谢
|
| 518 |
+
|
| 519 |
+
<details close>
|
| 520 |
+
<summary> <b>参考链接 & 感谢以下优秀的论文或项目</b> </summary>
|
| 521 |
+
|
| 522 |
+
- 排名不分任何先后顺序
|
| 523 |
+
- [LlaVA](https://arxiv.org/pdf/2304.08485)
|
| 524 |
+
- [LlaVA-VL](https://arxiv.org/pdf/2310.03744)
|
| 525 |
+
- [Chinese-LLaVA-Vision-Instructions](https://huggingface.co/datasets/LinkSoul/Chinese-LLaVA-Vision-Instructions)
|
| 526 |
+
|
| 527 |
+
</details>
|
| 528 |
+
|
| 529 |
+
## 🫶支持者
|
| 530 |
+
|
| 531 |
+
<a href="https://github.com/jingyaogong/minimind-v/stargazers">
|
| 532 |
+
<picture>
|
| 533 |
+
<source media="(prefers-color-scheme: dark)" srcset="https://reporoster.com/stars/dark/jingyaogong/minimind-v"/>
|
| 534 |
+
<source media="(prefers-color-scheme: light)" srcset="https://reporoster.com/stars/jingyaogong/minimind-v"/>
|
| 535 |
+
<img alt="github contribution grid snake animation" src="https://reporoster.com/stars/jingyaogong/minimind-v"/>
|
| 536 |
+
</picture>
|
| 537 |
+
</a>
|
| 538 |
+
|
| 539 |
+
<a href="https://github.com/jingyaogong/minimind-v/network/members">
|
| 540 |
+
<picture>
|
| 541 |
+
<source media="(prefers-color-scheme: dark)" srcset="https://reporoster.com/forks/dark/jingyaogong/minimind-v"/>
|
| 542 |
+
<source media="(prefers-color-scheme: light)" srcset="https://reporoster.com/forks/jingyaogong/minimind-v"/>
|
| 543 |
+
<img alt="github contribution grid snake animation" src="https://reporoster.com/forks/jingyaogong/minimind-v"/>
|
| 544 |
+
</picture>
|
| 545 |
+
</a>
|
| 546 |
+
|
| 547 |
+
<picture>
|
| 548 |
+
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=jingyaogong/minimind-v&type=Date&theme=dark"/>
|
| 549 |
+
<source media="(prefers-color-scheme: light)" srcset="https://api.star-history.com/svg?repos=jingyaogong/minimind-v&type=Date"/>
|
| 550 |
+
<img alt="Star History Chart" src="https://api.star-history.com/svg?repos=jingyaogong/minimind-v&type=Date"/>
|
| 551 |
+
</picture>
|
| 552 |
+
|
| 553 |
+
# License
|
| 554 |
+
|
| 555 |
+
This repository is licensed under the [Apache-2.0 License](LICENSE).
|
README_en.md
ADDED
|
@@ -0,0 +1,544 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
|
| 3 |
+

|
| 4 |
+
|
| 5 |
+
</div>
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
<div align="center">
|
| 9 |
+
|
| 10 |
+

|
| 11 |
+
[](https://github.com/jingyaogong/minimind-v/stargazers)
|
| 12 |
+
[](LICENSE)
|
| 13 |
+
[](https://github.com/jingyaogong/minimind-v/commits/master)
|
| 14 |
+
[](https://github.com/jingyaogong/minimind-v/pulls)
|
| 15 |
+
|
| 16 |
+
</div>
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
<div align="center">
|
| 20 |
+
<h3>"The Greatest Path is the Simplest"</h3>
|
| 21 |
+
</div>
|
| 22 |
+
|
| 23 |
+
<div align="center">
|
| 24 |
+
|
| 25 |
+
[中文](./README.md) | English
|
| 26 |
+
|
| 27 |
+
</div>
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
* This open-source project aims to train a small-parameter visual modal capable language model, **MiniMind-V**, from scratch within as fast as 3 hours.
|
| 31 |
+
* **MiniMind-V** is extremely lightweight, with the smallest version being about $\frac{1}{7000}$ the size of GPT-3, aiming to be quickly inferable and trainable even on personal GPUs.
|
| 32 |
+
* This is not only an implementation of an open-source model but also a tutorial for getting started with Visual Language Models (VLMs).
|
| 33 |
+
* We hope this project can provide researchers with a starting example, helping everyone to get up to speed and generate more exploration and innovation in the VLM field.
|
| 34 |
+
|
| 35 |
+
> To avoid misunderstanding, "from scratch" specifically refers to further developing the pure language model MiniMind (which is a fully from-scratch trained GPT-like model) with visual capabilities.
|
| 36 |
+
> For more details on the latter, please refer to the twin project [MiniMind](https://github.com/jingyaogong/minimind).
|
| 37 |
+
|
| 38 |
+
> To avoid misunderstanding, "as fast as 3 hours" means you need to have a machine with a hardware configuration higher than mine. The detailed specifications will be provided below.
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+

|
| 43 |
+
|
| 44 |
+
<div align="center">
|
| 45 |
+
|
| 46 |
+
The demo has been deployed to ModelScope's creative space, where you can experience it on this website:
|
| 47 |
+
|
| 48 |
+
[ModelScope Online Experience](https://modelscope.cn/studios/gongjy/minimind-v)
|
| 49 |
+
|
| 50 |
+
</div>
|
| 51 |
+
|
| 52 |
+
# 📌 Introduction
|
| 53 |
+
|
| 54 |
+
Visual Language Models (VLMs) like GPT-4V, Qwen-VL, LlaVA, etc., although impressive in performance, often require extremely high hardware configurations.
|
| 55 |
+
For personal devices, not only is the GPU memory far from sufficient to support training, but even inference can be very difficult.
|
| 56 |
+
We learn about the somewhat novel VLMs through reading papers or public account explanations, but often end up with a vague understanding.
|
| 57 |
+
What we really need to know is:
|
| 58 |
+
Is multimodal large models really as complex as imagined? What is their code implementation like?
|
| 59 |
+
Is the training process really that difficult? Can I start training from scratch with just one 2080Ti GPU?
|
| 60 |
+
|
| 61 |
+
Through **MiniMind-V**, this project hopes to answer these questions and help researchers understand the core principles of visual language models under limited hardware conditions.
|
| 62 |
+
|
| 63 |
+
> [!TIP]
|
| 64 |
+
> (As of 2024-10-04) The MiniMind-V series has completed pre-training of 2 model versions, requiring as little as 27M (0.027B) to have image recognition and dialogue capabilities!
|
| 65 |
+
|
| 66 |
+
| Model (Size) | Tokenizer Length | Inference Usage | Release | Subjective Rating (/100) |
|
| 67 |
+
| --------------------------- | ------------- | -------- | ------------ | ------------ |
|
| 68 |
+
| minimind-v-v1-small (27M) | 6400 | 0.6 GB | 2024.10.04 | 50' |
|
| 69 |
+
| minimind-v-v1 (109M) | 6400 | 1.1 GB | 2024.10.04 | 60' |
|
| 70 |
+
|
| 71 |
+
> This analysis was conducted on 2×RTX 3090 GPUs with Torch 2.1.2, CUDA 12.2, and Flash Attention 2.
|
| 72 |
+
|
| 73 |
+
### 👉**Recent Updates**
|
| 74 |
+
|
| 75 |
+
<details close>
|
| 76 |
+
<summary> <b>2024-10-05 (newest 🎉)</b> </summary>
|
| 77 |
+
|
| 78 |
+
- MiniMind-V arrives as scheduled, first open-source release
|
| 79 |
+
|
| 80 |
+
</details>
|
| 81 |
+
|
| 82 |
+
# 📌 Environment
|
| 83 |
+
|
| 84 |
+
This is my personal software and hardware configuration; adjust as necessary:
|
| 85 |
+
|
| 86 |
+
```bash
|
| 87 |
+
CPU: Intel(R) Core(TM) i9-10980XE CPU @ 3.00GHz
|
| 88 |
+
Memory: 128 GB
|
| 89 |
+
GPU: NVIDIA GeForce RTX 3090(24GB) * 2
|
| 90 |
+
Environment: python 3.9 + Torch 2.1.2 + DDP single-machine multi-GPU training
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
* Ubuntu == 20.04
|
| 94 |
+
* Python == 3.9
|
| 95 |
+
* Pytorch == 2.1.2
|
| 96 |
+
* CUDA == 12.2
|
| 97 |
+
* [requirements.txt](./requirements.txt)
|
| 98 |
+
|
| 99 |
+
# 📌 Quick Test
|
| 100 |
+
|
| 101 |
+
1. Clone the project
|
| 102 |
+
|
| 103 |
+
```bash
|
| 104 |
+
# step 1
|
| 105 |
+
git clone https://github.com/jingyaogong/minimind-v & cd minimind-v
|
| 106 |
+
```
|
| 107 |
+
|
| 108 |
+
2. Download the pre-trained model weight files to the root directory `minimind-v-v1` of the project
|
| 109 |
+
|
| 110 |
+
```bash
|
| 111 |
+
# step 2
|
| 112 |
+
git clone https://huggingface.co/jingyaogong/minimind-v-v1
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
3. Download the pre-trained `clip-vit-base-patch32` model into the `model/clip_model` directory:
|
| 116 |
+
|
| 117 |
+
```bash
|
| 118 |
+
# step 3
|
| 119 |
+
cd model/clip_model & git clone https://hf-mirror.com/openai/clip-vit-base-patch32
|
| 120 |
+
```
|
| 121 |
+
|
| 122 |
+
4. Start the chat web page to test the conversation
|
| 123 |
+
|
| 124 |
+
```bash
|
| 125 |
+
# step 4
|
| 126 |
+
python web_server.py
|
| 127 |
+
```
|
| 128 |
+
|
| 129 |
+
[web_server](images/web_server.gif)
|
| 130 |
+
|
| 131 |
+
# 📌 Quick Start Train
|
| 132 |
+
|
| 133 |
+
* 0. Environment setup
|
| 134 |
+
```bash
|
| 135 |
+
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
|
| 136 |
+
```
|
| 137 |
+
* 1. Clone the project code
|
| 138 |
+
```text
|
| 139 |
+
git clone https://github.com/jingyaogong/minimind-v
|
| 140 |
+
```
|
| 141 |
+
* 2. If you want to train it yourself
|
| 142 |
+
|
| 143 |
+
* 2.1 Download all contents of the [dataset](https://pan.baidu.com/s/1Nz36OBBvVBGEx-PwIb7ofg?pwd=6666) to the `./dataset` directory, and unzip `pretrain_images.zip` and `sft_images.zip`
|
| 144 |
+
* 2.2 Adjust the model parameters in `./model/LMConfig.py`
|
| 145 |
+
> Only need to adjust the dim and n_layers parameters, which are `(512+8)` or `(768+16)`, corresponding to `minimind-v-v1-small` and `minimind-v-v1`
|
| 146 |
+
* 2.3 Download the [pre-trained weight file](https://pan.baidu.com/s/1LE1SPoPYGS7VNtT1tpf7DA?pwd=6666) of the MiniMind language model and place it in the `./out/` directory, named `*_llm.pth`
|
| 147 |
+
* 2.4 Execute `python 1-pretrain_vlm.py` for pre-training, obtaining `*_vlm_pretrain.pth` as the output weights
|
| 148 |
+
* 2.5 Execute `python 2-sft_vlm.py` for instruction fine-tuning, obtaining `*_vlm_sft.pth` as the output weights for fine-tuning
|
| 149 |
+
|
| 150 |
+
* 3. Test the inference effect of the self-trained model
|
| 151 |
+
* Ensure that the used, completed training parameter weights `*.pth` files are located in the `./out/` directory
|
| 152 |
+
* You can also directly download the [completed model weight files](https://pan.baidu.com/s/1LE1SPoPYGS7VNtT1tpf7DA?pwd=6666) and use the `*.pth` weight files I have trained
|
| 153 |
+
```text
|
| 154 |
+
minimind-v/out
|
| 155 |
+
├── 512_llm.pth
|
| 156 |
+
├── 512_vlm_pretrain.pth
|
| 157 |
+
├── 512_vlm_sft.pth
|
| 158 |
+
├── 768_llm.pth
|
| 159 |
+
├── 768_vlm_pretrain.pth
|
| 160 |
+
├── 768_vlm_sft.pth
|
| 161 |
+
```
|
| 162 |
+
* Use `python 3-eval_chat.py` to test the conversation effect of the model, where the test images are in `./dataset/eval_images`, and you can replace them as needed
|
| 163 |
+
[eval_chat](images/3-eval_chat.png)
|
| 164 |
+
|
| 165 |
+
🍭 【Tip】Both pretraining and full-parameter instruction fine-tuning (pretrain and sft) support multi-GPU acceleration
|
| 166 |
+
|
| 167 |
+
* Single machine N-card training launch (DDP)
|
| 168 |
+
```bash
|
| 169 |
+
torchrun --nproc_per_node N 1-pretrain_vlm.py
|
| 170 |
+
# and
|
| 171 |
+
torchrun --nproc_per_node N 2-sft_vlm.py
|
| 172 |
+
```
|
| 173 |
+
|
| 174 |
+
* Record the training process
|
| 175 |
+
```bash
|
| 176 |
+
torchrun --nproc_per_node N 1-pretrain_vlm.py --use_wandb
|
| 177 |
+
# and
|
| 178 |
+
python 1-pretrain_vlm.py --use_wandb
|
| 179 |
+
```
|
| 180 |
+
By adding the `--use_wandb` parameter, you can record the training process, and after the training is complete, you can view the training process on the wandb website. You can specify the project name and run name by modifying the `wandb_project` and `wandb_run_name` parameters.
|
| 181 |
+
|
| 182 |
+
# 📌 VLM Detail
|
| 183 |
+
|
| 184 |
+
The base language model MiniMind (LLM) for MiniMind-V (VLM) comes from the twin project [minimind](https://github.com/jingyaogong/minimind). For specific details on the model architecture, training specifics, principles, and test results, please refer to the [minimind](https://github.com/jingyaogong/minimind) project. To avoid redundancy, we will not discuss the LLM-related parts here, assuming you have a basic understanding of MiniMind (LLM).
|
| 185 |
+
|
| 186 |
+
> PS: Even if you do not wish to delve into the details of MiniMind (LLM), you can directly refer to Quick Test and Quick Start to quickly test or train MiniMind-V. This will not be significantly affected.
|
| 187 |
+
|
| 188 |
+
The structure of MiniMind-V remains almost unchanged, with only two additional sub-modules added: Visual Encoder and feature projection, as well as a multimodal fusion branch, to support input from multiple modalities:
|
| 189 |
+
[LLM-structure](./images/VLM-structure.png)
|
| 190 |
+
[LLM-structure](./images/VLM-structure-moe.png)
|
| 191 |
+
|
| 192 |
+
At this point, it's interesting to ponder two questions: What is a **L**arge **L**anguage **M**odel (LLM)? And what is a multimodal model?
|
| 193 |
+
|
| 194 |
+
* [This article](https://www.jiqizhixin.com/articles/2024-09-15-3) perfectly articulates my thoughts, suggesting that the term LLM is quite inaccurate!
|
| 195 |
+
|
| 196 |
+
> Although Large Language Models (LLMs) carry the word "language" in their name, they are actually not very related to language; this is merely a historical issue. A more accurate name would be autoregressive Transformer or something similar.
|
| 197 |
+
LLMs are more of a general statistical modeling technique, primarily using autoregressive Transformers to simulate token streams, and these tokens can represent text, images, audio, action choices, or even molecules, among other things.
|
| 198 |
+
Therefore, theoretically, any problem that can be framed as a process of simulating a series of discrete tokens can be addressed using LLMs.
|
| 199 |
+
In fact, as the large language model technology stack matures, we may see an increasing number of problems being brought into this modeling paradigm. That is, the problem is fixed on using LLMs for 'predicting the next token', with the usage and meaning of tokens varying across different domains.
|
| 200 |
+
|
| 201 |
+
* [Professor Li Xi](https://person.zju.edu.cn/xilics#694283) similarly corroborates my view (the exact wording is not recalled, but the gist is as follows):
|
| 202 |
+
|
| 203 |
+
> Text, video, speech, and actions, which appear to humans as "multimodal" signals, are essentially just a classification concept for information storage by humans.
|
| 204 |
+
Just like `.txt` and `.png` files, although they differ in visual presentation and higher-level representation, there is no fundamental difference at their core.
|
| 205 |
+
The notion of "multimodality" arises simply because of the human need to categorize these signals at different perceptual levels.
|
| 206 |
+
However, for machines, regardless of the "modality" of the signal, they ultimately present as a string of binary "unimodal" digital sequences.
|
| 207 |
+
Machines do not differentiate the modality source of these signals but rather process and analyze the information content carried by these sequences.
|
| 208 |
+
|
| 209 |
+
---
|
| 210 |
+
I personally believe that **G**enerative **P**retrained **T**ransformer (GPT) is a more fitting term than **L**arge **L**anguage **M**odel (LLM),
|
| 211 |
+
and thus I prefer to use "GPT" to represent LLM/VLM/GPT-like architectures, rather than to piggyback on OpenAI's popularity.
|
| 212 |
+
---
|
| 213 |
+
In summary, we can encapsulate what GPT does in one sentence:
|
| 214 |
+
GPT models predict the next, and the next, and the next token... until the model outputs an end token; here, the "token" does not necessarily have to be text!
|
| 215 |
+
---
|
| 216 |
+
|
| 217 |
+
* For LLM models, if understanding "images" is required, we can treat "images" as a special kind of "foreign language" never seen before, translating them through a "foreign dictionary" into a special language input for the LLM.
|
| 218 |
+
* For LLM models, if understanding "audio" is required, we can treat "audio" as a special kind of "foreign language" never seen before, translating them through a "foreign dictionary" into a special language input for the LLM.
|
| 219 |
+
* ...
|
| 220 |
+
|
| 221 |
+
---
|
| 222 |
+
|
| 223 |
+
<u>**So, to get MiniMind-V, we only need to accomplish two things:**</u>
|
| 224 |
+
|
| 225 |
+
1. Use a "foreign dictionary" proficient in translating images to translate the "foreign language" of images into the "LLM language" that the model can understand.
|
| 226 |
+
2. Fine-tune the LLM so that it goes through a period of adjustment with the "foreign dictionary," thereby better understanding images.
|
| 227 |
+
|
| 228 |
+
---
|
| 229 |
+
|
| 230 |
+
The "foreign dictionary" is generally referred to as the Visual Encoder model.
|
| 231 |
+
Similar to visual-language models such as LlaVA and Qwen-VL, MiniMind-V also selects open-source Clip series models as the Visual Encoder.
|
| 232 |
+
Specifically, it uses [clip-vit-base-patch32](https://huggingface.co/openai/clip-vit-base-patch32), a classic Visual Encoder based on the ViT-B/32 architecture, for describing image-text information.
|
| 233 |
+
The input image size is 224x224, and since the patches are 32×32, it generates 7*7+1(cls_token)=50 tokens as input to the encoder layer,
|
| 234 |
+
ultimately producing a 1×768 dimensional embedding vector for calculating error with text.
|
| 235 |
+
We do not need the final embedding representation, so we only take the output of the encoder layer, which is the output features of the VIT backbone.
|
| 236 |
+
In the code, this corresponds to the hook function in [./model/vision_utils.py](./model/vision_utils.py)'s get_img_embedding.
|
| 237 |
+
It retrieves the 50×768 dimensional features from the previous layer, which we then input as 50 visual tokens into MiniMind-V.
|
| 238 |
+
There are also larger Clip models like clip-vit-large-patch14, which have a stronger image understanding capability,
|
| 239 |
+
but a single image would generate 257 tokens, which, for a model of MiniMind's scale, would result in too long a context of image tokens, which is not conducive to training.
|
| 240 |
+
|
| 241 |
+
After obtaining the image encoder features, on one hand, it is necessary to align the 768-dimensional visual tokens with the text tokens of the LLM,
|
| 242 |
+
on the other hand, the image features must be mapped to the same space as the text embeddings, i.e., the text tokens and the native visual tokens need to be aligned and cannot be treated equally; this can be called cross-modal feature alignment.
|
| 243 |
+
[LlaVA-1](https://arxiv.org/pdf/2304.08485) accomplished this with a simple unbiased linear transformation, and the results were excellent; MiniMind-V does the same.
|
| 244 |
+
|
| 245 |
+
[llava-structure](./images/llava-structure.png)
|
| 246 |
+
|
| 247 |
+
With this, the internal structural changes of MiniMind-V have been presented.
|
| 248 |
+
|
| 249 |
+
---
|
| 250 |
+
|
| 251 |
+
Next, we briefly discuss the changes in the external input and output of MiniMind-V.
|
| 252 |
+
|
| 253 |
+
The input for VLM is still a piece of text, which includes a special <image> placeholder.
|
| 254 |
+
After computing the text embedding, the vector generated by the image encoder can be projected into the part of the embedding corresponding to the placeholder, replacing the original placeholder embedding.
|
| 255 |
+
For example:
|
| 256 |
+
|
| 257 |
+
```text
|
| 258 |
+
<image>\nWhat is the content of this image?
|
| 259 |
+
```
|
| 260 |
+
|
| 261 |
+
minimind-v uses a 50-character `<<<...>>>` placeholder to replace the image,
|
| 262 |
+
the reason for 50 characters was mentioned earlier:
|
| 263 |
+
any image is encoded by the clip model into 50×768 dimensional tokens.
|
| 264 |
+
Therefore, the prompt for minimind-v:
|
| 265 |
+
|
| 266 |
+
```text
|
| 267 |
+
<<<<<<<<<<<<<<<<<<<<<<<<<>>>>>>>>>>>>>>>>>>>>>>>>>\nWhat is the description of this picture?
|
| 268 |
+
```
|
| 269 |
+
|
| 270 |
+
After computing the embedding and projection, and replacing the image part tokens,
|
| 271 |
+
the entire computation process to output is no different from the LLM part.
|
| 272 |
+
|
| 273 |
+
[input](./images/minimind-v-input.png)
|
| 274 |
+
|
| 275 |
+
<u>With this, all the details of MiniMind-V have been presented.</u>
|
| 276 |
+
|
| 277 |
+
<u>The implementation of MiniMind-V did not reference any third-party code; it is based on MiniMind with minimal modifications, hence the code implementation is significantly different from models like LlaVA.
|
| 278 |
+
The core changes between MiniMind-V and MiniMind do not exceed 100 lines, making it easy to get started.</u>
|
| 279 |
+
|
| 280 |
+
# 📌 Experiment
|
| 281 |
+
|
| 282 |
+
## Dataset
|
| 283 |
+
|
| 284 |
+
Source: [Chinese-LLaVA-Vision](https://huggingface.co/datasets/LinkSoul/Chinese-LLaVA-Vision-Instructions)
|
| 285 |
+
Contains approximately 600,000 pre-training images and <100,000 instruction fine-tuning images, derived from CC-3M and COCO 2014, with translated Q&A content for better support of the Chinese language. The dataset has been further resized, organized, and compressed.
|
| 286 |
+
|
| 287 |
+
Pre-training dataset format:
|
| 288 |
+
|
| 289 |
+
```json
|
| 290 |
+
{
|
| 291 |
+
"id": "GCC_train_000644518",
|
| 292 |
+
"image": "GCC_train_000644518.jpg",
|
| 293 |
+
"conversations": [
|
| 294 |
+
{
|
| 295 |
+
"from": "human",
|
| 296 |
+
"value": "Write a brief but informative image summary.\n<image>"
|
| 297 |
+
},
|
| 298 |
+
{
|
| 299 |
+
"from": "gpt",
|
| 300 |
+
"value": "Adding saltwater to a metal pot with a black background, in slow motion fps"
|
| 301 |
+
}
|
| 302 |
+
]
|
| 303 |
+
}
|
| 304 |
+
```
|
| 305 |
+
|
| 306 |
+
Instruction fine-tuning dataset format:
|
| 307 |
+
|
| 308 |
+
```json
|
| 309 |
+
{
|
| 310 |
+
"id": "000000334872",
|
| 311 |
+
"image": "000000334872.jpg",
|
| 312 |
+
"conversations": [
|
| 313 |
+
{
|
| 314 |
+
"from": "human",
|
| 315 |
+
"value": "<image>\nAre people in the photo going downhill skiing or cross-country skiing?"
|
| 316 |
+
},
|
| 317 |
+
{
|
| 318 |
+
"from": "gpt",
|
| 319 |
+
"value": "People in the photo are cross-country skiing in the forest because they are on a trail rather than on a steep slope."
|
| 320 |
+
}
|
| 321 |
+
]
|
| 322 |
+
}
|
| 323 |
+
```
|
| 324 |
+
|
| 325 |
+
Note: For instruction fine-tuning, only one round of conversation is retained, training a single-turn dialogue model, to prevent the performance of small models from being dragged down by long text.
|
| 326 |
+
|
| 327 |
+
Final dataset download link: [Baidu Netdisk](https://pan.baidu.com/s/1Nz36OBBvVBGEx-PwIb7ofg?pwd=6666) | [HuggingFace](https://huggingface.co/datasets/jingyaogong/minimind-v_dataset)
|
| 328 |
+
|
| 329 |
+
## Training
|
| 330 |
+
|
| 331 |
+
The pre-training learns general knowledge about images, such as what a deer or dog is, from 595K datasets.
|
| 332 |
+
|
| 333 |
+
The instruction fine-tuning learns the real Q&A format for asking questions about images from 230K real dialogue datasets.
|
| 334 |
+
|
| 335 |
+
`1-pretrain_vlm.py` executes pre-training, yielding `*_vlm_pretrain.pth` as the output weights of pre-training.
|
| 336 |
+
|
| 337 |
+
`2-sft_vlm.py` performs instruction fine-tuning, resulting in `*_vlm_sft.pth` as the output weights of instruction fine-tuning.
|
| 338 |
+
|
| 339 |
+
During training, the visual encoder, which is the CLIP model, is frozen, and only the Projection and LLM parts are fine-tuned.
|
| 340 |
+
|
| 341 |
+
> Pretrain 512+8 Model (Training Time and Loss Reference Chart)
|
| 342 |
+
[input](./images/1-pretrain-512.png)
|
| 343 |
+
> Pretrain 768+16 Model (Training Time and Loss Reference Chart)
|
| 344 |
+
[input](./images/1-pretrain-768.png)
|
| 345 |
+
> SFT 512+8 Model (Training Time and Loss Reference Chart)
|
| 346 |
+
[input](./images/2-sft-512.png)
|
| 347 |
+
> SFT 768+16 Model (Training Time and Loss Reference Chart)
|
| 348 |
+
[input](./images/2-sft-768.png)
|
| 349 |
+
|
| 350 |
+
## Trained Model Weights
|
| 351 |
+
|
| 352 |
+
(`.pth` weight files) Download link: [Baidu Netdisk](https://pan.baidu.com/s/1a7_C7HdCMfnG2Dia3q85FQ?pwd=6666)
|
| 353 |
+
|
| 354 |
+
(`transformers` model files)
|
| 355 |
+
Download link: [HuggingFace](https://huggingface.co/collections/jingyaogong/minimind-v-67000833fb60b3a2e1f3597d)
|
| 356 |
+
|
| 357 |
+
> Note: HuggingFace versions are all post-instruction fine-tuned MiniMind-V models
|
| 358 |
+
|
| 359 |
+
| Model Name | params | Config | file_name |
|
| 360 |
+
|------------------------|--------|-----------------------------|-----------------------------------------------------|
|
| 361 |
+
| minimind-v-v1-small | 27M | d_model=512<br/>n_layers=8 | Pre-trained: 512_vllm_pretrain.pth<br/>Fine-tuned: 512_vllm_sft.pth |
|
| 362 |
+
| minimind-v-v1 | 109M | d_model=768<br/>n_layers=16 | Pre-trained: 768_vllm_pretrain.pth<br/>Fine-tuned: 768_vllm_sft.pth |
|
| 363 |
+
|
| 364 |
+
# 📌 Test
|
| 365 |
+
|
| 366 |
+
### Effectiveness Testing
|
| 367 |
+
|
| 368 |
+
<table>
|
| 369 |
+
<thead>
|
| 370 |
+
<tr>
|
| 371 |
+
<th>Image</th>
|
| 372 |
+
<th>512_pretrain</th>
|
| 373 |
+
<th>512_sft</th>
|
| 374 |
+
<th>768_pretrain</th>
|
| 375 |
+
<th>768_sft</th>
|
| 376 |
+
</tr>
|
| 377 |
+
</thead>
|
| 378 |
+
<tbody>
|
| 379 |
+
<tr>
|
| 380 |
+
<td><img src="./dataset/eval_images/一个女子.png" alt="a-girl.png" style="width: 200px;"></td>
|
| 381 |
+
<td>Hair and makeup, I like her natural hair!</td>
|
| 382 |
+
<td>This picture depicts a young woman, she is wearing a suit, and a tie, which indicates that she may be attending a special fashion event or celebration.</td>
|
| 383 |
+
<td>A human-made actor's adventure movie.</td>
|
| 384 |
+
<td>This picture portrays a portrait of a woman, who is wearing a pink dress.</td>
|
| 385 |
+
</tr>
|
| 386 |
+
<tr>
|
| 387 |
+
<td><img src="./dataset/eval_images/一个海星.png" alt="a-starfish.png"></td>
|
| 388 |
+
<td>Fossils in water, a still line composed of a ring of fossil clusters.</td>
|
| 389 |
+
<td>The picture shows a large octopus, a potential marine creature, it is either on the surface of the water or in the ocean.</td>
|
| 390 |
+
<td>Starfish and tentacles.</td>
|
| 391 |
+
<td>The picture shows a starfish on the beach, including the starfish, and an underwater object.</td>
|
| 392 |
+
</tr>
|
| 393 |
+
<tr>
|
| 394 |
+
<td><img src="./dataset/eval_images/一个熊.png" alt="a-bear.png"></td>
|
| 395 |
+
<td>In the wild, in the valley.</td>
|
| 396 |
+
<td>The picture features plants and a grizzly bear sitting on the grass.</td>
|
| 397 |
+
<td>A close-up of a grizzly bear</td>
|
| 398 |
+
<td>The picture shows a grizzly bear standing in an open field of grass, surrounded by trees and bushes, with a backpack placed on top of it.</td>
|
| 399 |
+
</tr>
|
| 400 |
+
<tr>
|
| 401 |
+
<td><img src="./dataset/eval_images/一些海豚.png" alt="some-dolphins.png"></td>
|
| 402 |
+
<td>A group of tourists watched this movie.</td>
|
| 403 |
+
<td>This picture depicts a flock of seagulls flying over the water, on the water. The presence of seagulls suggests that they are looking for food. Seagulls nest on the water, possibly to protect themselves from potential dangers, such as sharp teeth and reptiles of seagulls.</td>
|
| 404 |
+
<td>A group of dolphins or sheep fishing by boat during a day's voyage</td>
|
| 405 |
+
<td>This picture shows a group of people swimming among a large group of dolphins and dolphins nearby.</td>
|
| 406 |
+
</tr>
|
| 407 |
+
<tr>
|
| 408 |
+
<td><img src="./dataset/eval_images/三个女孩.png" alt="three-girls.png"></td>
|
| 409 |
+
<td>A girl and her friends are sitting on a bench, wearing long white robes.</td>
|
| 410 |
+
<td>This scene depicts a vibrant young girl, they are dressed in black and white attire, standing in the middle of a crowd, all of whom are also dressed in black and white, indicating their outfits are lively and elegant. In the scene, there are two girls in the background, a woman behind, and another woman standing, all wearing black clothes. This suggests they are enjoying their outfits and attire, possibly attending a special festival or celebration.</td>
|
| 411 |
+
<td>The girls are on the city streets.</td>
|
| 412 |
+
<td>This picture portrays a man and a woman in traditional clothing, standing next to them, they are spending family time together. Throughout the scene, you can see a little boy and a girl, both wearing cowboy hats, which suggests they are participating in a family gathering, which could be a party or celebration, or they might be discussing an interesting activity or event.</td>
|
| 413 |
+
</tr>
|
| 414 |
+
<tr>
|
| 415 |
+
<td><img src="./dataset/eval_images/两头鹿.png" alt="two-deer.png"></td>
|
| 416 |
+
<td>This photo contains several deer.</td>
|
| 417 |
+
<td>This picture captures a white-tailed deer, sitting on the grass, using its photo to capture a red deer.</td>
|
| 418 |
+
<td>The animal looks as if it is about to hide behind a tree, he looks majestic, as he cannot control himself.</td>
|
| 419 |
+
<td>This picture depicts a doe and a deer, the doe is standing in the woods, a sheep, and a deer.</td>
|
| 420 |
+
</tr>
|
| 421 |
+
<tr>
|
| 422 |
+
<td><img src="./dataset/eval_images/两朵红花.png" alt="two-red-flowers.png"></td>
|
| 423 |
+
<td>The bouquet's flowers have barely bloomed.</td>
|
| 424 |
+
<td>The picture shows red and yellow flowers, which are called "vase".</td>
|
| 425 |
+
<td>The flower heads are close together.</td>
|
| 426 |
+
<td>The picture shows red flowers, surrounded by several roses.</td>
|
| 427 |
+
</tr>
|
| 428 |
+
<tr>
|
| 429 |
+
<td><img src="./dataset/eval_images/太空宇航员.png" alt="an-astronaut.png"></td>
|
| 430 |
+
<td>An astronaut posing with Earth during a space mission.</td>
|
| 431 |
+
<td>This image depicts a dynamic moon, walking on the moon.</td>
|
| 432 |
+
<td>An astronaut resting in a cradle during a mission, with his team in the background.</td>
|
| 433 |
+
<td>This picture portrays an astronaut in the image of a space station.</td>
|
| 434 |
+
</tr>
|
| 435 |
+
<tr>
|
| 436 |
+
<td><img src="./dataset/eval_images/老虎在水里.png" alt="a-tiger-in-water.png"></td>
|
| 437 |
+
<td>A tiger in the water looking at the camera.</td>
|
| 438 |
+
<td>The picture shows a large brown seal swimming in the water, resting in the water.</td>
|
| 439 |
+
<td>A tiger caged in a zoo</td>
|
| 440 |
+
<td>The picture shows a small bear, lying on a branch of a tree.</td>
|
| 441 |
+
</tr>
|
| 442 |
+
<tr>
|
| 443 |
+
<td><img src="./dataset/eval_images/豹子在悬崖.png" alt="a-leopard-on-cliff.png"></td>
|
| 444 |
+
<td>This is an endangered species.</td>
|
| 445 |
+
<td>In the picture, a black and white cat is walking on the rocks.</td>
|
| 446 |
+
<td>A leopard in the wild on the rocks outside a cave, at sunrise</td>
|
| 447 |
+
<td>This picture shows a red panda walking on the rocks.</td>
|
| 448 |
+
</tr>
|
| 449 |
+
</tbody>
|
| 450 |
+
</table>
|
| 451 |
+
|
| 452 |
+
### Start Inference
|
| 453 |
+
|
| 454 |
+
```bash
|
| 455 |
+
python web_server.py
|
| 456 |
+
```
|
| 457 |
+
|
| 458 |
+
[web_server1](./images/web_server1.png)
|
| 459 |
+
[web_server2](./images/web_server2.png)
|
| 460 |
+
|
| 461 |
+
### Summary of Effects
|
| 462 |
+
|
| 463 |
+
---
|
| 464 |
+
Based on the provided table data, the performance of the four models can be summarized as follows:
|
| 465 |
+
|
| 466 |
+
1. **512_pretrain**:
|
| 467 |
+
- **Brief and inaccurate descriptions**: Most descriptions fail to clearly convey the image content, often providing unrelated narratives. For example, the starfish image is described as "fossils in water," which is far off the mark.
|
| 468 |
+
- **Lack of detail**: In most cases, only simple, vague descriptions are given, failing to delve into the details or context of the image. For instance, for the tiger image, it simply says "looking at the camera in the water."
|
| 469 |
+
|
| 470 |
+
2. **512_sft**:
|
| 471 |
+
- **More specific descriptions**: Compared to 512_pretrain, 512_sft provides more detailed explanations and attempts to capture specific elements of the scene. For example, when describing the woman image, it mentions "suit" and "tie," giving a clearer depiction.
|
| 472 |
+
- **Occasional errors or redundancy**: Some descriptions are overly complex or even irrelevant to the image, such as mentioning seagulls, nesting, etc., in the dolphin image, which are not related.
|
| 473 |
+
|
| 474 |
+
3. **768_pretrain**:
|
| 475 |
+
- **Incoherent information**: The performance of this model is quite scattered, with descriptions often being vague and incomplete. For example, in describing the woman image, it only mentions "a human-made actor's adventure movie," without clearly explaining the image content.
|
| 476 |
+
- **Partially accurate but with less overall information**: Some descriptions, although relevant to the image, are very brief. For example, the starfish description only states "starfish and tentacles," lacking a full sense of the scene.
|
| 477 |
+
|
| 478 |
+
4. **768_sft**:
|
| 479 |
+
- **Comprehensive and specific descriptions**: This model's descriptions are the most detailed and precise among the four. For instance, when describing the bear image, it mentions "standing in an open field of grass, surrounded by trees and bushes, with a backpack," capturing multiple elements of the image.
|
| 480 |
+
- **Stronger comprehension ability**: This model can identify the scene and context of the image, providing reasonable interpretations and speculations. For example, describing a "family gathering" or "celebration" gives the image a more contextual connection.
|
| 481 |
+
|
| 482 |
+
### Summary:
|
| 483 |
+
|
| 484 |
+
- **512_pretrain** performs the worst, with simple and inaccurate descriptions.
|
| 485 |
+
- **512_sft** has improved detail in descriptions but occasionally includes irrelevant information.
|
| 486 |
+
- **768_pretrain** has poor coherence in information, yet provides basic descriptions in some aspects.
|
| 487 |
+
- **768_sft** performs the best, offering detailed, accurate descriptions, and is able to make good context-based inferences.
|
| 488 |
+
|
| 489 |
+
---
|
| 490 |
+
|
| 491 |
+
# 📌 Acknowledge
|
| 492 |
+
|
| 493 |
+
> [!TIP]
|
| 494 |
+
> If you find `MiniMind-V` helpful, please add a ⭐ on GitHub<br/>
|
| 495 |
+
> Due to the length and limited proficiency, there may be oversights; feel free to discuss corrections or submit PRs to improve the project on Issues<br/>
|
| 496 |
+
> Your support is the driving force for continuous improvement of the project
|
| 497 |
+
|
| 498 |
+
## 🤝 [Contributors](https://github.com/jingyaogong/minimind/graphs/contributors)
|
| 499 |
+
|
| 500 |
+
<a href="https://github.com/jingyaogong"><img src="https://avatars.githubusercontent.com/u/62287848" width="70px" height="70px"/></a>
|
| 501 |
+
|
| 502 |
+
|
| 503 |
+
## 😊 Acknowledgments
|
| 504 |
+
|
| 505 |
+
<details close>
|
| 506 |
+
<summary> <b>Reference Links & Thanks to the following excellent papers or projects</b> </summary>
|
| 507 |
+
|
| 508 |
+
- No particular order
|
| 509 |
+
- [LlaVA](https://arxiv.org/pdf/2304.08485)
|
| 510 |
+
- [LlaVA-VL](https://arxiv.org/pdf/2310.03744)
|
| 511 |
+
- [Chinese-LLaVA-Vision-Instructions](https://huggingface.co/datasets/LinkSoul/Chinese-LLaVA-Vision-Instructions)
|
| 512 |
+
|
| 513 |
+
</details>
|
| 514 |
+
|
| 515 |
+
|
| 516 |
+
## 🫶Supporter
|
| 517 |
+
|
| 518 |
+
<a href="https://github.com/jingyaogong/minimind-v/stargazers">
|
| 519 |
+
<picture>
|
| 520 |
+
<source media="(prefers-color-scheme: dark)" srcset="https://reporoster.com/stars/dark/jingyaogong/minimind-v"/>
|
| 521 |
+
<source media="(prefers-color-scheme: light)" srcset="https://reporoster.com/stars/jingyaogong/minimind-v"/>
|
| 522 |
+
<img alt="github contribution grid snake animation" src="https://reporoster.com/stars/jingyaogong/minimind-v"/>
|
| 523 |
+
</picture>
|
| 524 |
+
</a>
|
| 525 |
+
|
| 526 |
+
<a href="https://github.com/jingyaogong/minimind-v/network/members">
|
| 527 |
+
<picture>
|
| 528 |
+
<source media="(prefers-color-scheme: dark)" srcset="https://reporoster.com/forks/dark/jingyaogong/minimind-v"/>
|
| 529 |
+
<source media="(prefers-color-scheme: light)" srcset="https://reporoster.com/forks/jingyaogong/minimind-v"/>
|
| 530 |
+
<img alt="github contribution grid snake animation" src="https://reporoster.com/forks/jingyaogong/minimind-v"/>
|
| 531 |
+
</picture>
|
| 532 |
+
</a>
|
| 533 |
+
|
| 534 |
+
<picture>
|
| 535 |
+
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=jingyaogong/minimind-v&type=Date&theme=dark"/>
|
| 536 |
+
<source media="(prefers-color-scheme: light)" srcset="https://api.star-history.com/svg?repos=jingyaogong/minimind-v&type=Date"/>
|
| 537 |
+
<img alt="Star History Chart" src="https://api.star-history.com/svg?repos=jingyaogong/minimind-v&type=Date"/>
|
| 538 |
+
</picture>
|
| 539 |
+
|
| 540 |
+
|
| 541 |
+
# License
|
| 542 |
+
|
| 543 |
+
This repository is licensed under the [Apache-2.0 License](LICENSE).
|
| 544 |
+
|
images/1-pretrain-512.png
ADDED
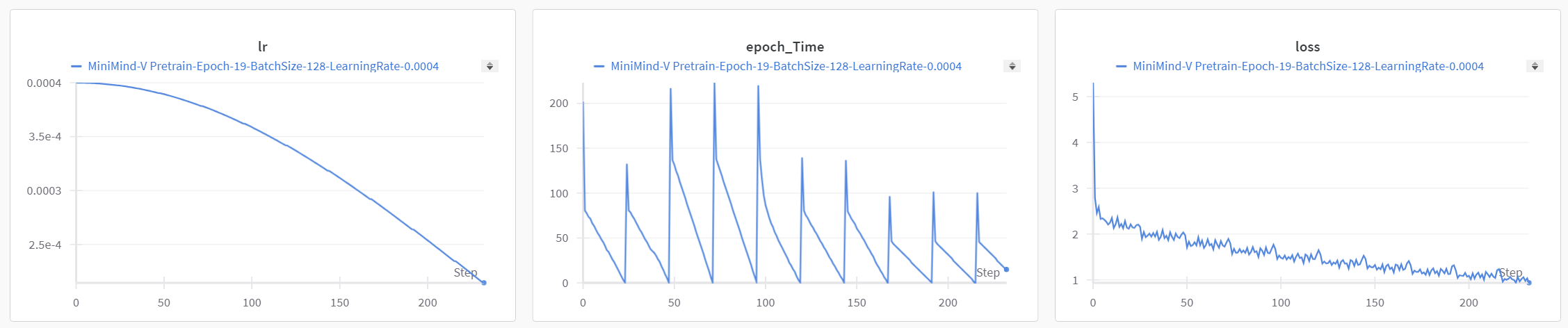
|
images/1-pretrain-768.png
ADDED

|
images/2-sft-512.png
ADDED
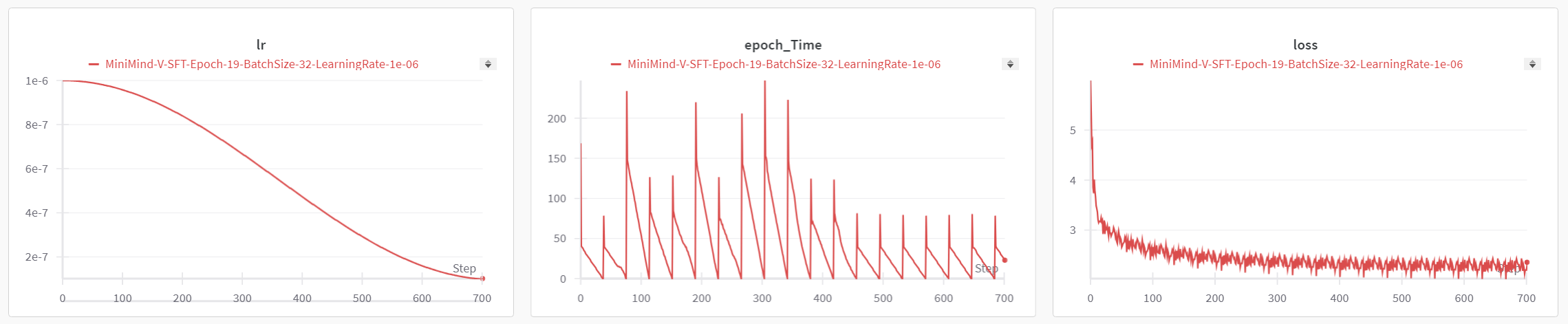
|
images/2-sft-768.png
ADDED
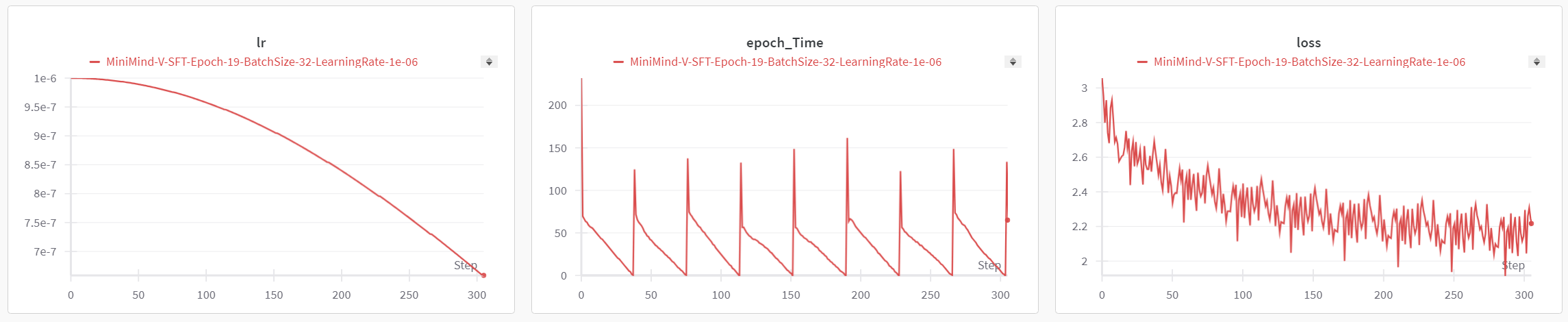
|
images/3-eval_chat.png
ADDED

|
images/VLM-structure-moe.png
ADDED
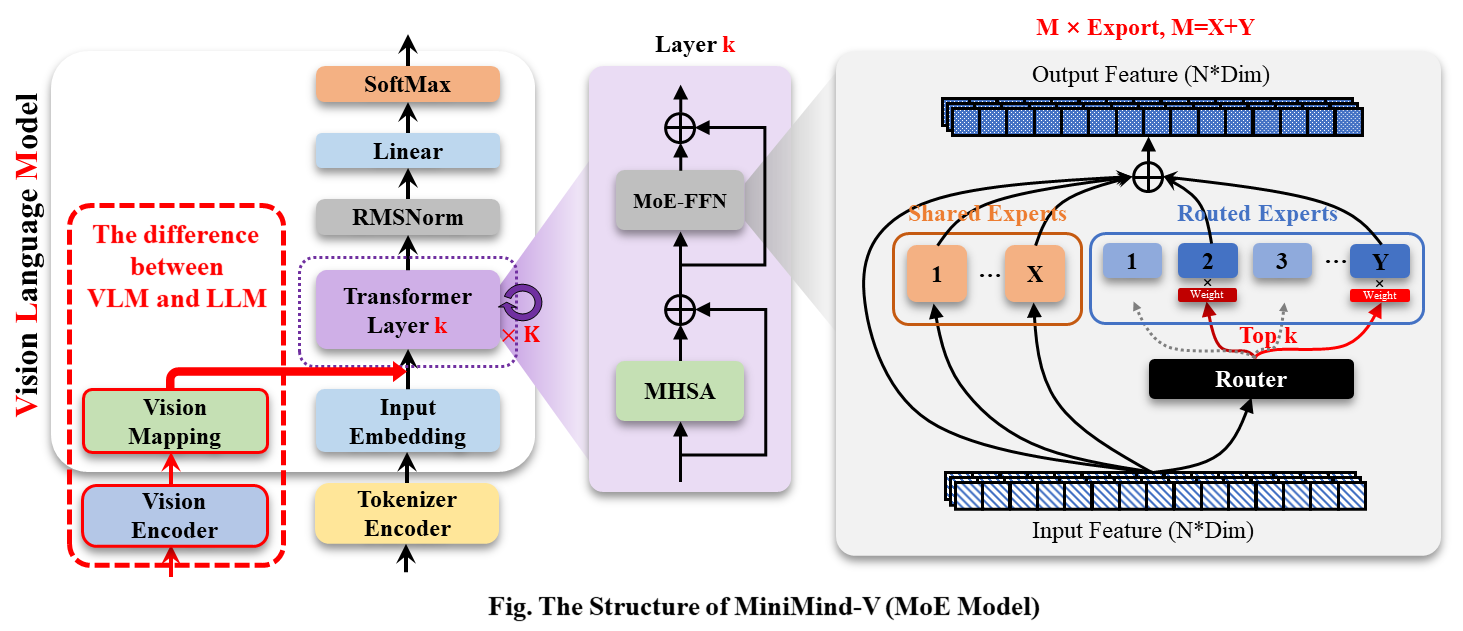
|
images/VLM-structure.png
ADDED
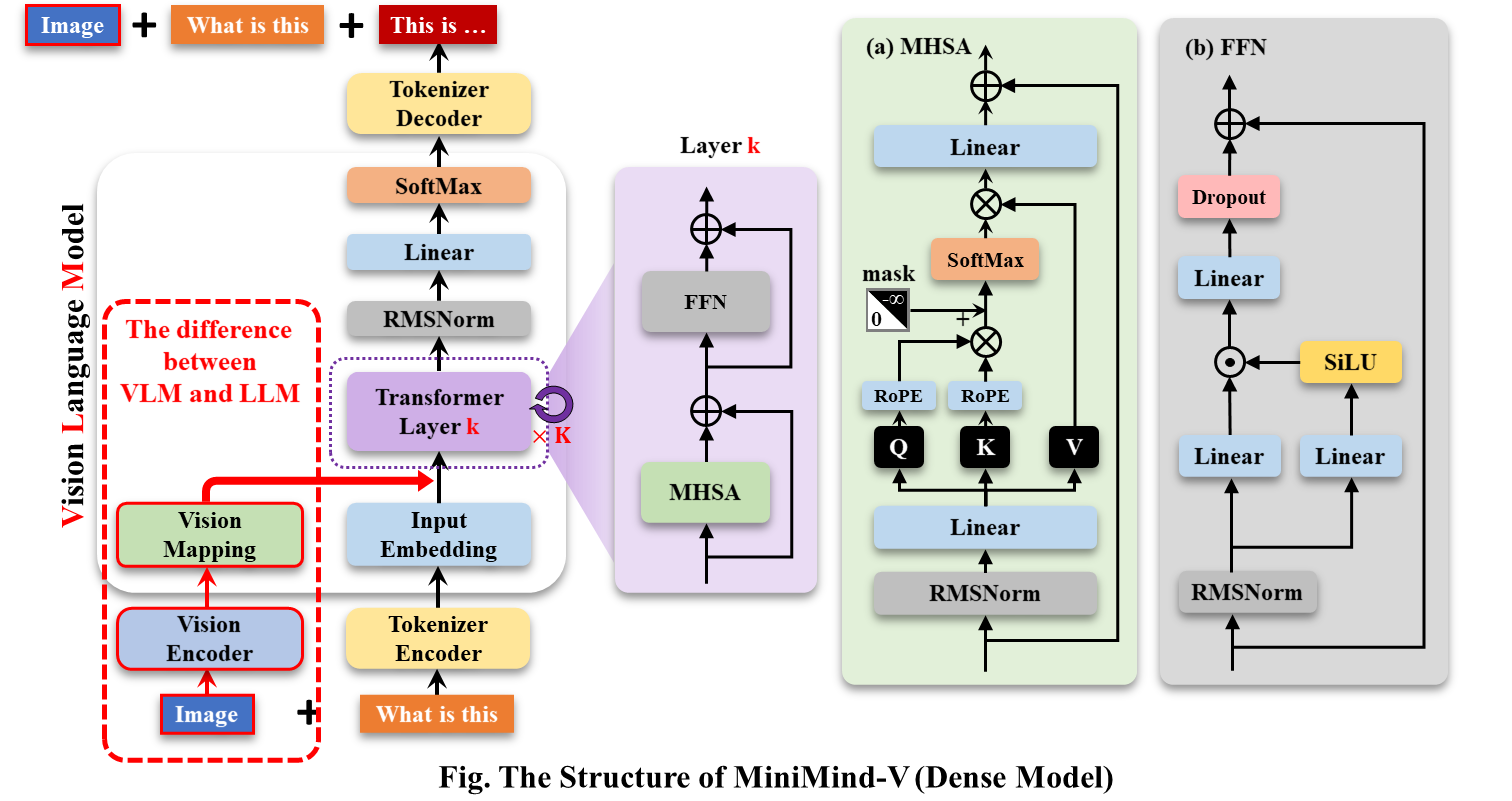
|
images/llava-structure.png
ADDED
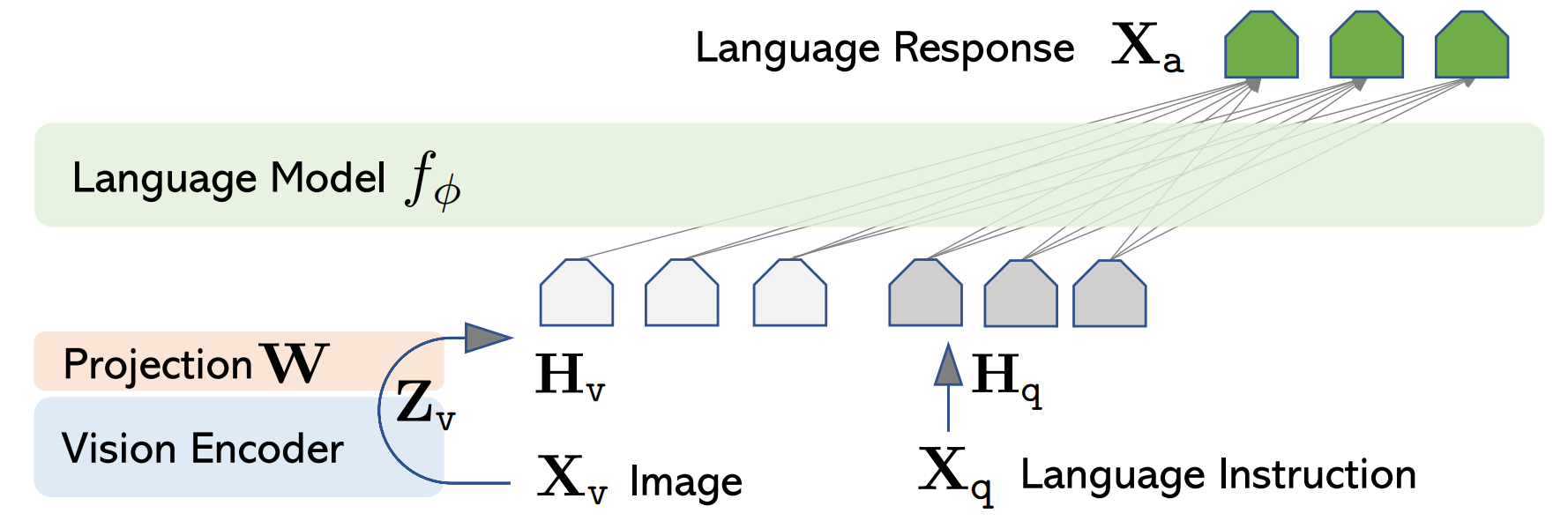
|
images/logo-minimind-v.png
ADDED
|
|
images/minimind-v-input.png
ADDED
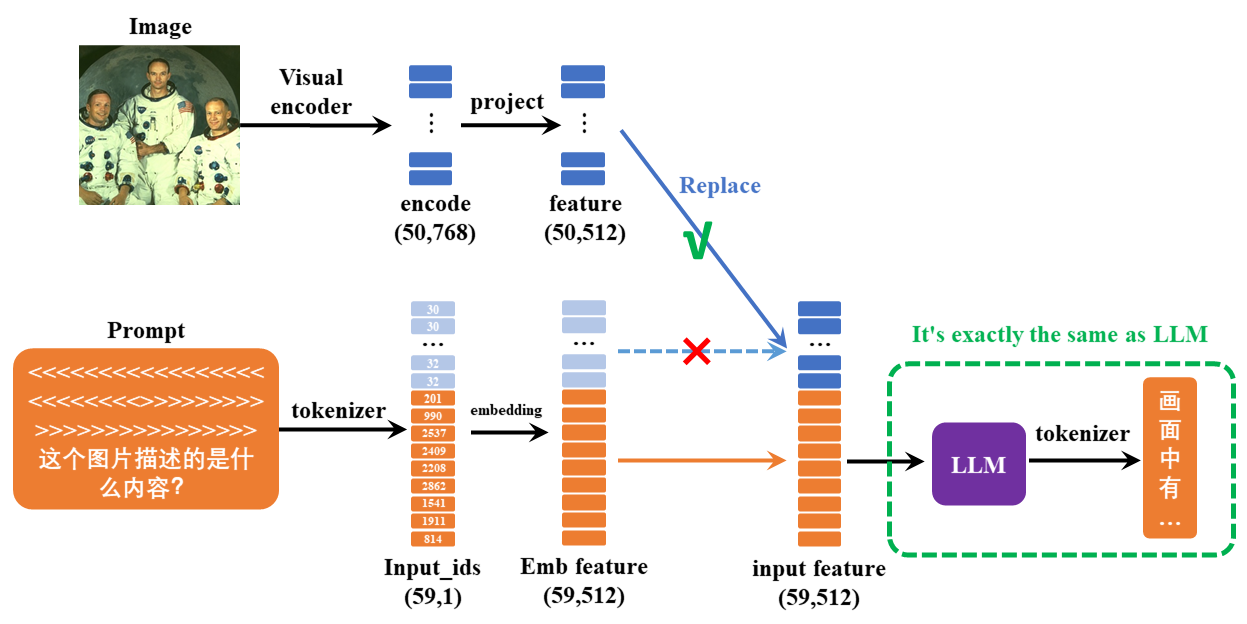
|
images/modelscope-demo.gif
ADDED
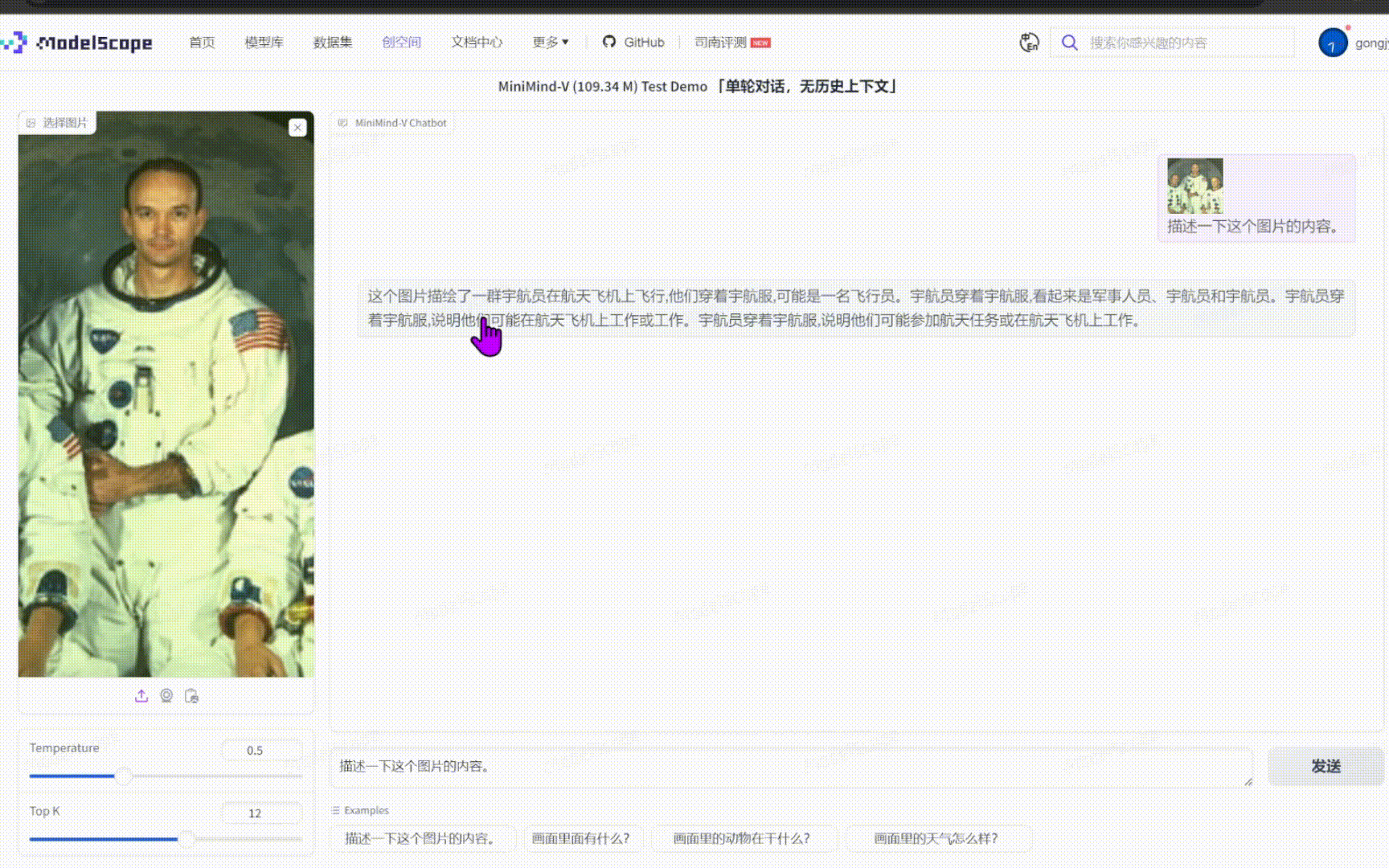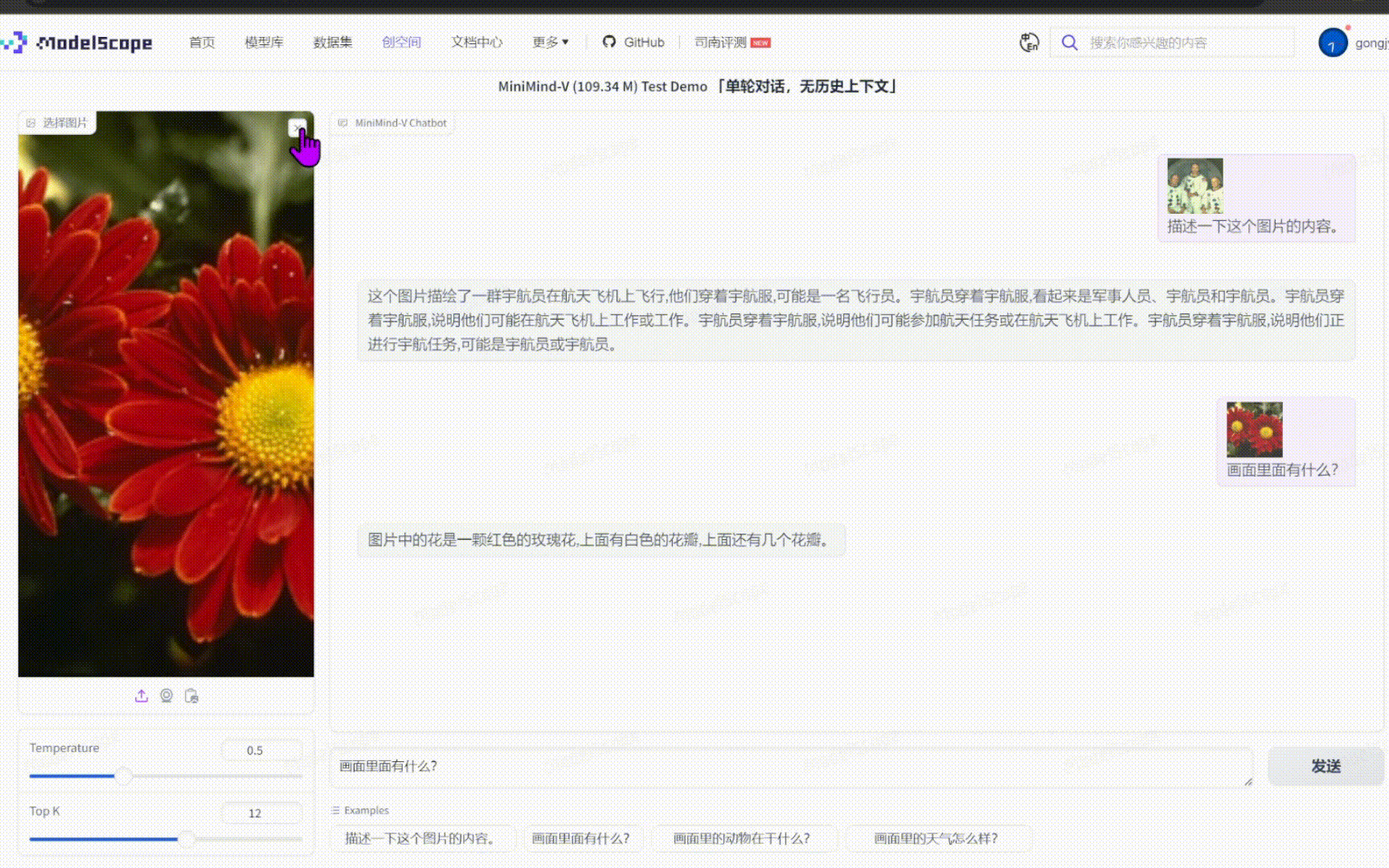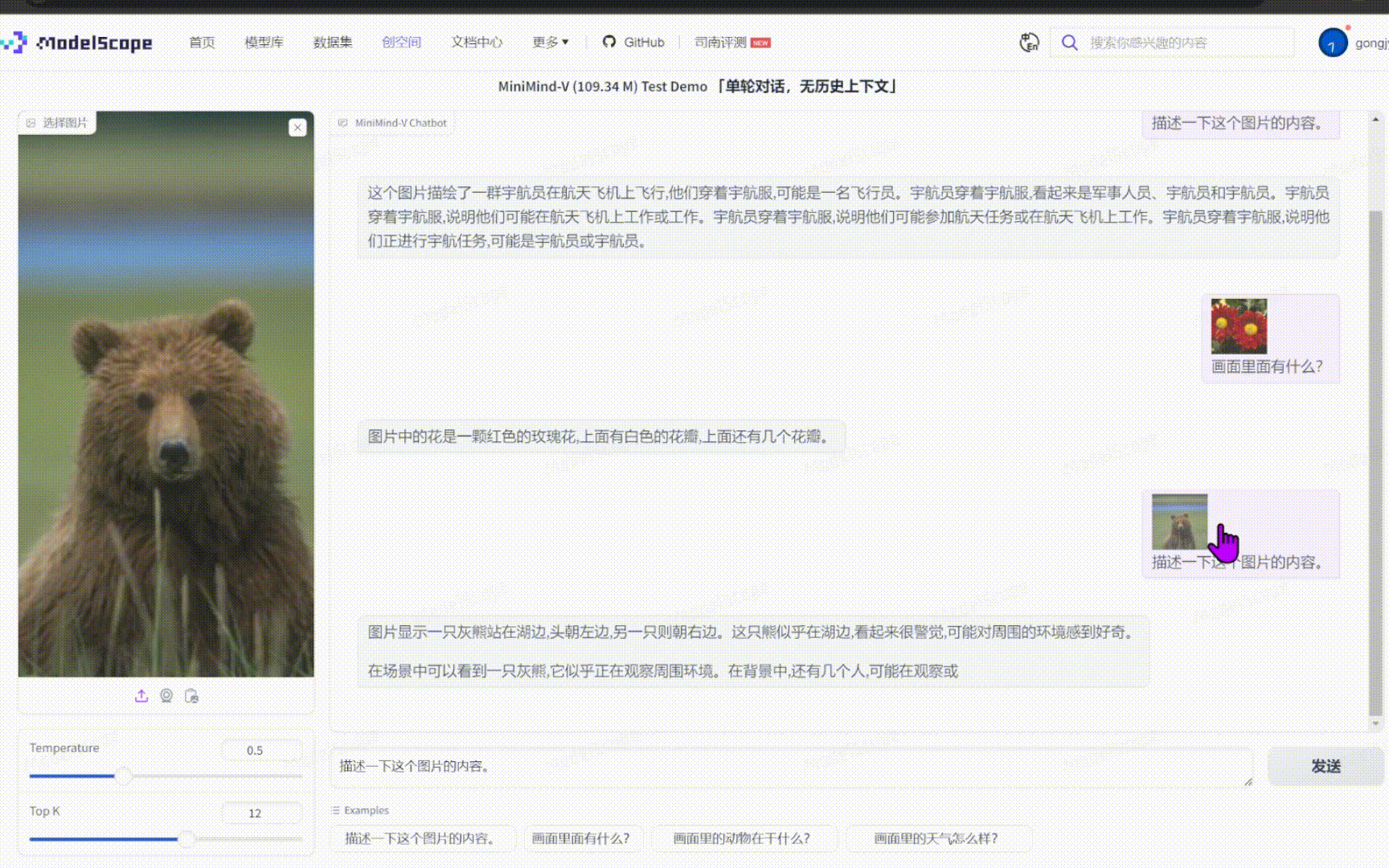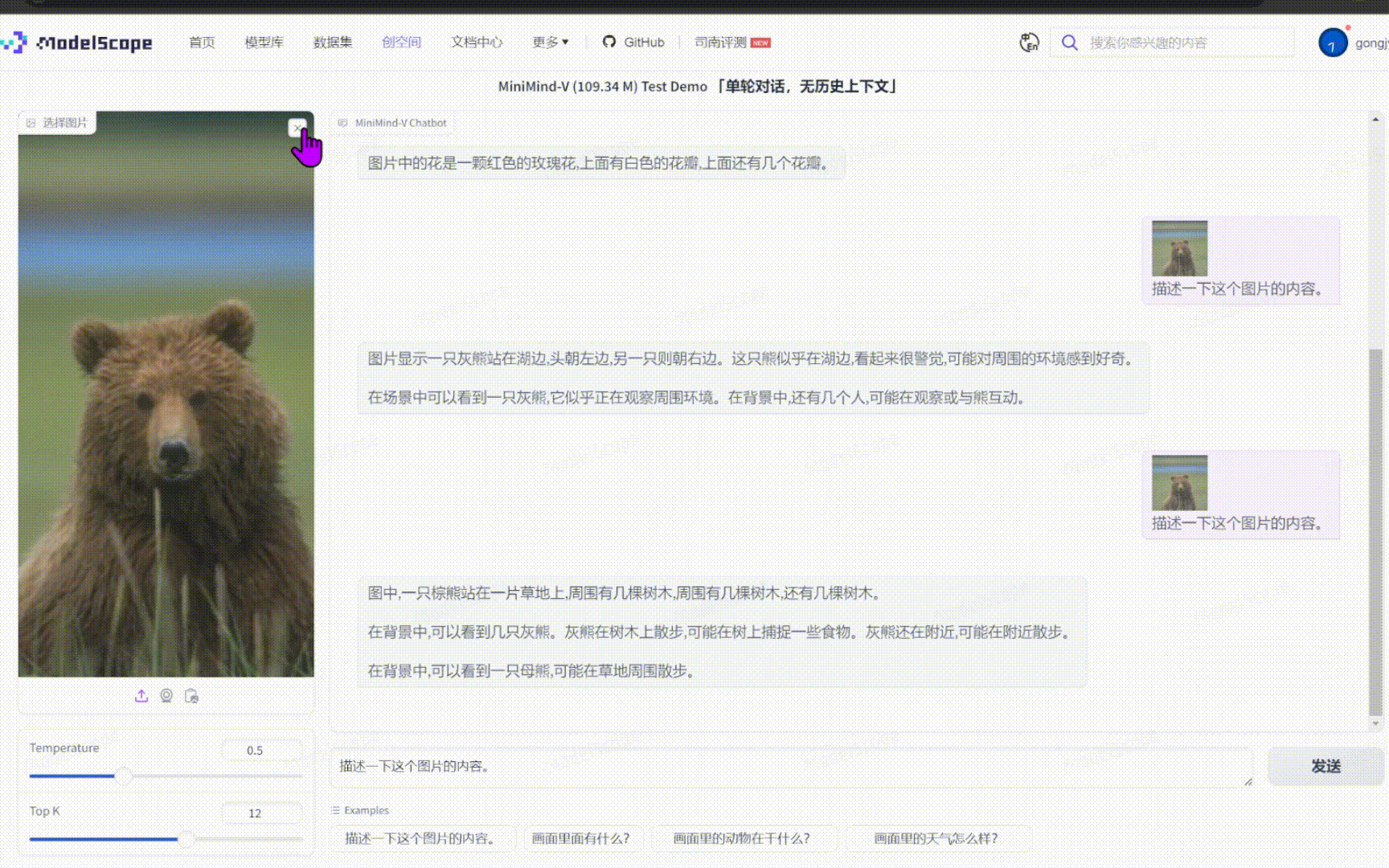
|
Git LFS Details
|
images/web_server.gif
ADDED
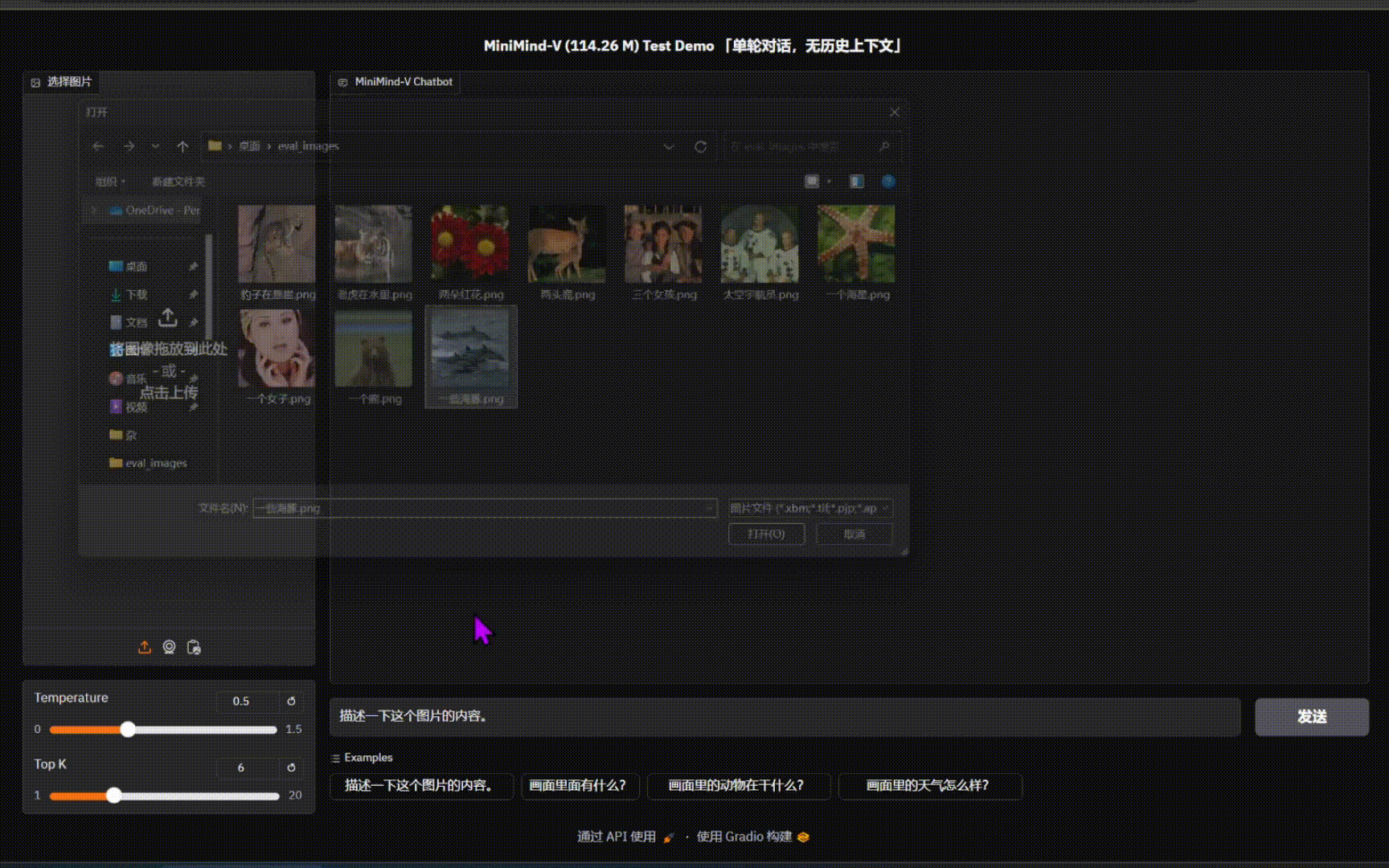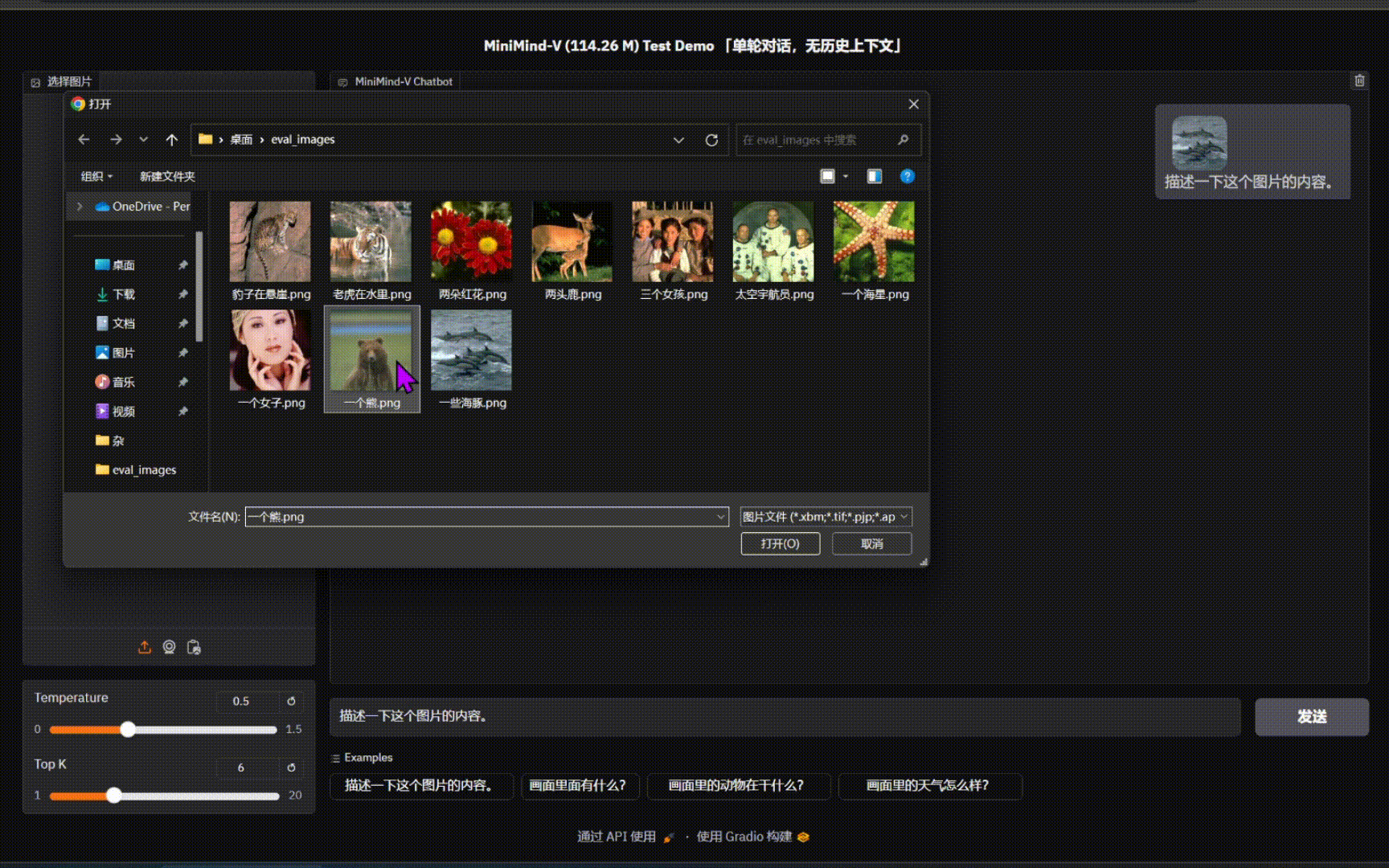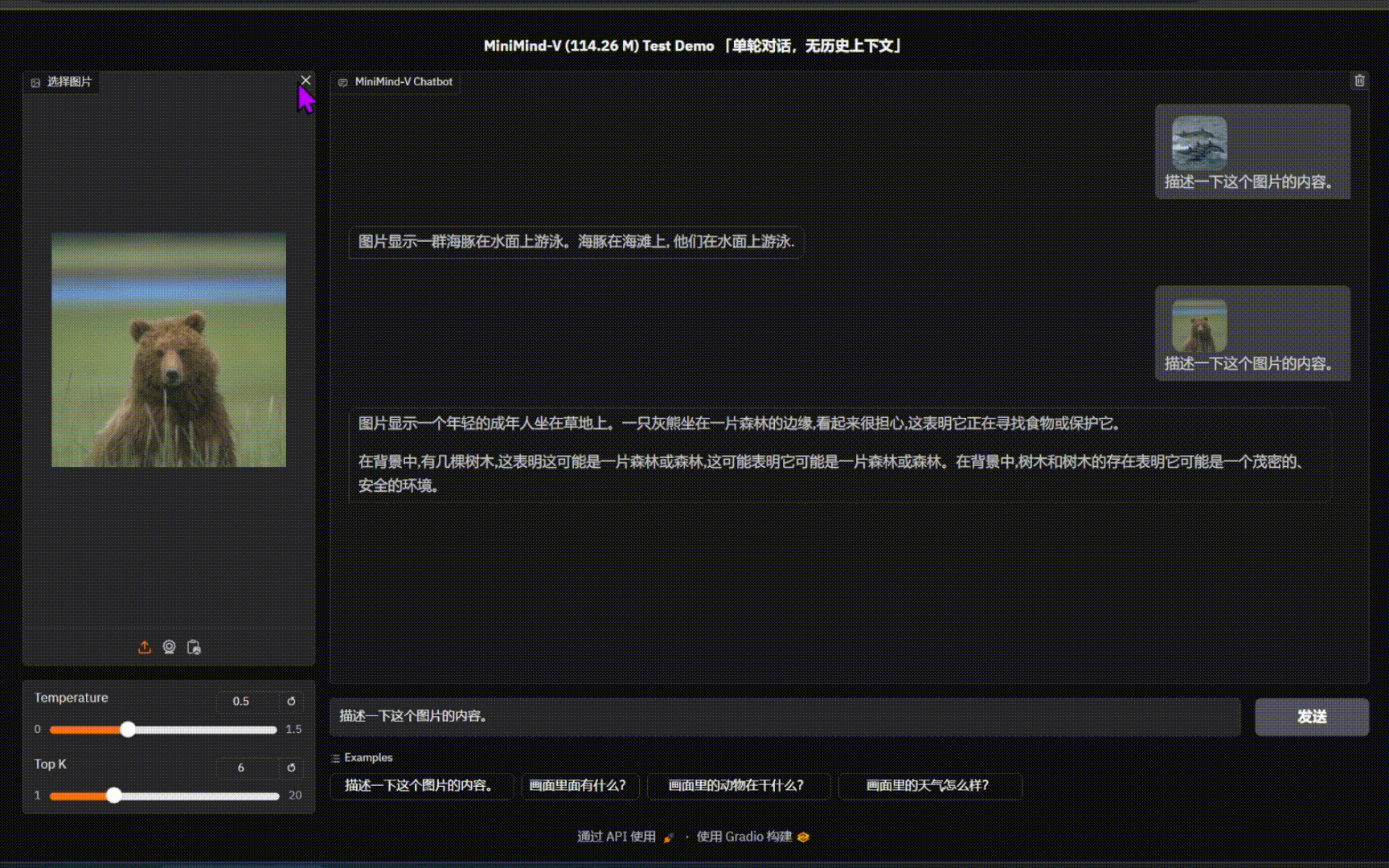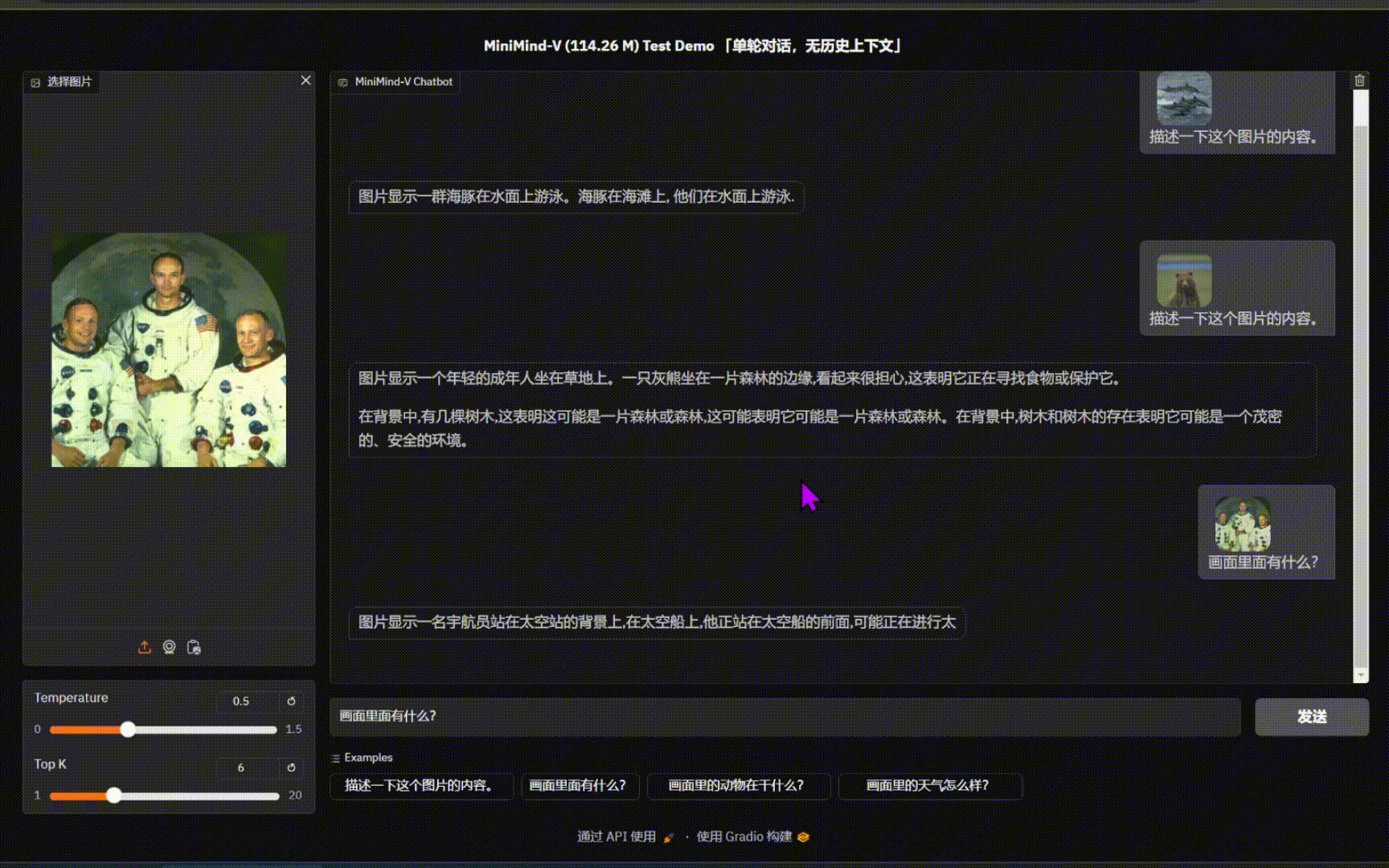
|
Git LFS Details
|
images/web_server1.png
ADDED
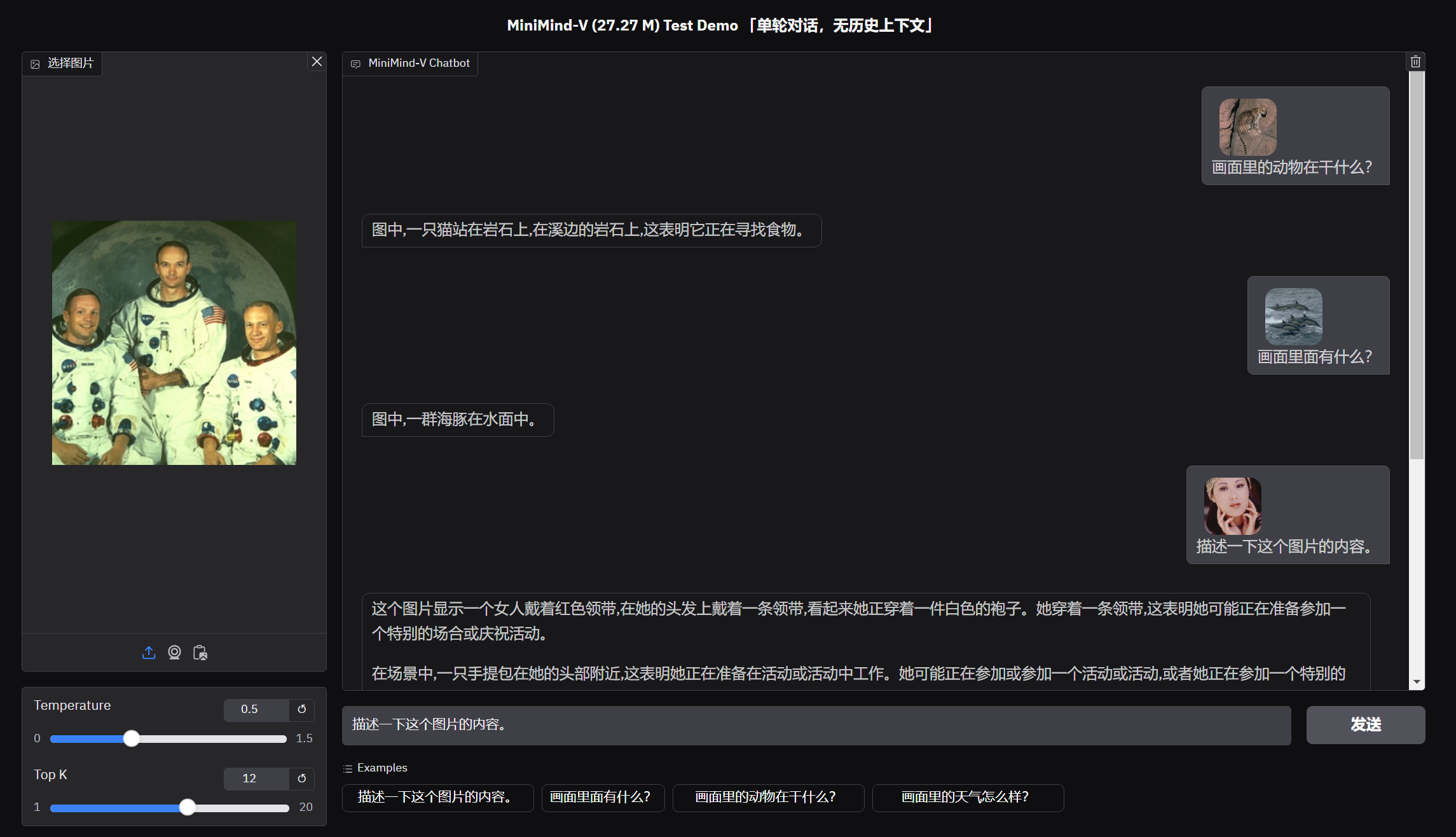
|
images/web_server2.png
ADDED
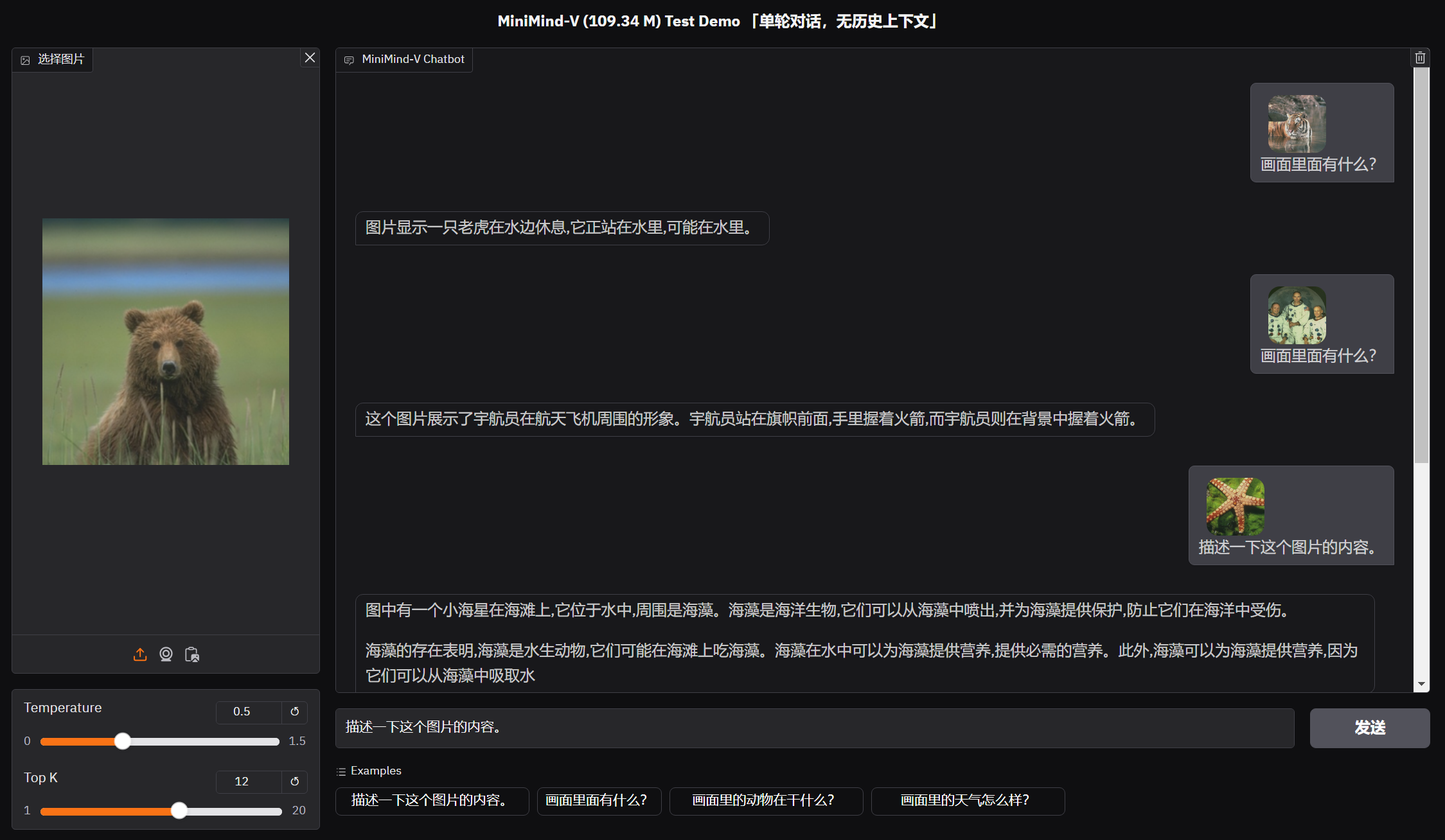
|