
Upload 77 files
Browse files- .gitattributes +1 -0
- images/agora-banner.png +0 -0
- images/andromeda-banner.png +3 -0
- images/andromeda_performance.png +0 -0
- train_simple.py +128 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 35 |
Andromeda/images/andromeda-banner.png filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 35 |
Andromeda/images/andromeda-banner.png filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
images/andromeda-banner.png filter=lfs diff=lfs merge=lfs -text
|
images/agora-banner.png
ADDED

|
images/andromeda-banner.png
ADDED

|
Git LFS Details
|
images/andromeda_performance.png
ADDED
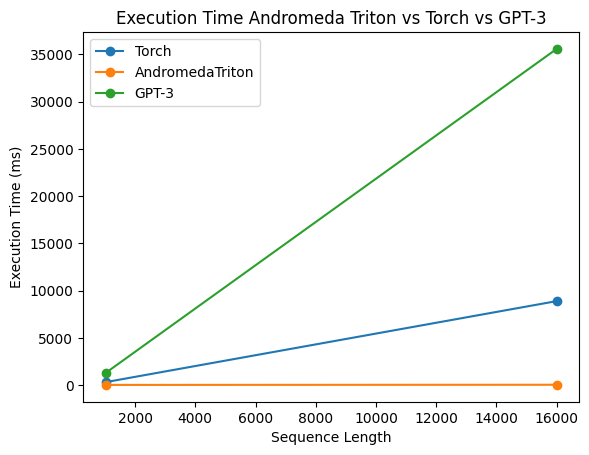
|
train_simple.py
ADDED
|
@@ -0,0 +1,128 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gzip
|
| 2 |
+
import random
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
import torch.optim as optim
|
| 7 |
+
import tqdm
|
| 8 |
+
from torch.utils.data import DataLoader, Dataset
|
| 9 |
+
|
| 10 |
+
from Andromeda.model import Andromeda
|
| 11 |
+
|
| 12 |
+
from Andromeda.core.transformer import Decoder, AndromedaEmbedding, Transformer
|
| 13 |
+
from Andromeda.core.autoregressive_wrapper import AutoregressiveWrapper
|
| 14 |
+
# constants
|
| 15 |
+
|
| 16 |
+
NUM_BATCHES = int(1e5)
|
| 17 |
+
BATCH_SIZE = 4
|
| 18 |
+
GRADIENT_ACCUMULATE_EVERY = 1
|
| 19 |
+
LEARNING_RATE = 1e-4
|
| 20 |
+
VALIDATE_EVERY = 100
|
| 21 |
+
GENERATE_EVERY = 500
|
| 22 |
+
GENERATE_LENGTH = 1024
|
| 23 |
+
SEQ_LEN = 1024
|
| 24 |
+
|
| 25 |
+
# helpers
|
| 26 |
+
|
| 27 |
+
def cycle(loader):
|
| 28 |
+
while True:
|
| 29 |
+
for data in loader:
|
| 30 |
+
yield data
|
| 31 |
+
|
| 32 |
+
def decode_token(token):
|
| 33 |
+
return str(chr(max(32, token)))
|
| 34 |
+
|
| 35 |
+
def decode_tokens(tokens):
|
| 36 |
+
return ''.join(list(map(decode_token, tokens)))
|
| 37 |
+
|
| 38 |
+
# instantiate GPT-like decoder model
|
| 39 |
+
|
| 40 |
+
model = Transformer(
|
| 41 |
+
num_tokens=50432,
|
| 42 |
+
max_seq_len=8192,
|
| 43 |
+
use_abs_pos_emb=False,
|
| 44 |
+
embedding_provider=AndromedaEmbedding(),
|
| 45 |
+
attn_layers=Decoder(
|
| 46 |
+
dim=2560,
|
| 47 |
+
depth=32,
|
| 48 |
+
dim_head=128,
|
| 49 |
+
heads=24,
|
| 50 |
+
alibi_pos_bias=True,
|
| 51 |
+
alibi_num_heads=12,
|
| 52 |
+
rotary_xpos=True,
|
| 53 |
+
attn_flash=True,
|
| 54 |
+
# deepnorm=deepnorm,
|
| 55 |
+
# shift_tokens=shift_tokens,
|
| 56 |
+
attn_one_kv_head=True,
|
| 57 |
+
qk_norm=True,
|
| 58 |
+
attn_qk_norm=True,
|
| 59 |
+
attn_qk_norm_dim_scale=True
|
| 60 |
+
)
|
| 61 |
+
)
|
| 62 |
+
|
| 63 |
+
model = AutoregressiveWrapper(model)
|
| 64 |
+
|
| 65 |
+
model.cuda()
|
| 66 |
+
|
| 67 |
+
# prepare enwik8 data
|
| 68 |
+
|
| 69 |
+
with gzip.open('./data/enwik8.gz') as file:
|
| 70 |
+
data = np.frombuffer(file.read(int(95e6)), dtype=np.uint8).copy()
|
| 71 |
+
train_x, valid_x = np.split(data, [int(90e6)])
|
| 72 |
+
data_train, data_val = torch.from_numpy(train_x), torch.from_numpy(valid_x)
|
| 73 |
+
|
| 74 |
+
class TextSamplerDataset(Dataset):
|
| 75 |
+
def __init__(self, data, seq_len):
|
| 76 |
+
super().__init__()
|
| 77 |
+
self.data = data
|
| 78 |
+
self.seq_len = seq_len
|
| 79 |
+
|
| 80 |
+
def __getitem__(self, index):
|
| 81 |
+
rand_start = torch.randint(0, self.data.size(0) - self.seq_len - 1, (1,))
|
| 82 |
+
full_seq = self.data[rand_start: rand_start + self.seq_len + 1].long()
|
| 83 |
+
return full_seq.cuda()
|
| 84 |
+
|
| 85 |
+
def __len__(self):
|
| 86 |
+
return self.data.size(0) // self.seq_len
|
| 87 |
+
|
| 88 |
+
train_dataset = TextSamplerDataset(data_train, SEQ_LEN)
|
| 89 |
+
val_dataset = TextSamplerDataset(data_val, SEQ_LEN)
|
| 90 |
+
train_loader = cycle(DataLoader(train_dataset, batch_size = BATCH_SIZE, drop_last = True))
|
| 91 |
+
val_loader = cycle(DataLoader(val_dataset, batch_size = BATCH_SIZE, drop_last = True))
|
| 92 |
+
|
| 93 |
+
# optimizer
|
| 94 |
+
|
| 95 |
+
optim = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE)
|
| 96 |
+
|
| 97 |
+
# training
|
| 98 |
+
|
| 99 |
+
for i in tqdm.tqdm(range(NUM_BATCHES), mininterval=10., desc='training'):
|
| 100 |
+
model.train()
|
| 101 |
+
|
| 102 |
+
for __ in range(GRADIENT_ACCUMULATE_EVERY):
|
| 103 |
+
loss = model(next(train_loader))
|
| 104 |
+
(loss / GRADIENT_ACCUMULATE_EVERY).backward()
|
| 105 |
+
|
| 106 |
+
print(f'training loss: {loss.item()}')
|
| 107 |
+
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)
|
| 108 |
+
optim.step()
|
| 109 |
+
optim.zero_grad()
|
| 110 |
+
|
| 111 |
+
if i % VALIDATE_EVERY == 0:
|
| 112 |
+
model.eval()
|
| 113 |
+
with torch.no_grad():
|
| 114 |
+
loss = model(next(val_loader))
|
| 115 |
+
print(f'validation loss: {loss.item()}')
|
| 116 |
+
|
| 117 |
+
#save the model weights
|
| 118 |
+
torch.save(model.state_dict(), f"./model_{i}.pth")
|
| 119 |
+
|
| 120 |
+
if i % GENERATE_EVERY == 0:
|
| 121 |
+
model.eval()
|
| 122 |
+
inp = random.choice(val_dataset)[:-1]
|
| 123 |
+
prime = decode_tokens(inp)
|
| 124 |
+
print('%s \n\n %s', (prime, '*' * 100))
|
| 125 |
+
|
| 126 |
+
sample = model.generate(inp, GENERATE_LENGTH)
|
| 127 |
+
output_str = decode_tokens(sample)
|
| 128 |
+
print(output_str)
|