---
license: apache-2.0
pipeline_tag: text-classification
tags:
- transformers
- sentence-transformers
language:
- en
- zh
- ja
- ko
---
BCEmbedding: Bilingual and Crosslingual Embedding for RAG


最新、最详细bce-reranker-base_v1相关信息,请移步(The latest "Updates" should be checked in):
GitHub
## 主要特点(Key Features):
- 中英日韩四个语种,以及中英日韩四个语种的跨语种能力(Multilingual and Crosslingual capability in English, Chinese, Japanese and Korean);
- RAG优化,适配更多真实业务场景(RAG adaptation for more domains, including Education, Law, Finance, Medical, Literature, FAQ, Textbook, Wikipedia, etc.);
- BCEmbedding适配长文本做rerank(Handle long passages reranking more than 512 limit in BCEmbedding);
- RerankerModel可以提供 **“平滑”的“绝对”相关性分数**,**“平滑”对排序友好**,**“绝对”分数用于过滤低质量passage**,低质量passage过滤阈值推荐0.35或0.4。(RerankerModel provides **"smooth" (for reranking) and "meaningful" (for filtering bad passages with a threshold of 0.35 or 0.4) similarity score**, which help you figure out how relavent the query and passages are!)
- **最佳实践(Best practice)** :embedding召回top50-100片段,reranker对这50-100片段精排,最后取top5-10片段。(1. Get top 50-100 passages with [bce-embedding-base_v1](https://huggingface.co/maidalun1020/bce-embedding-base_v1) for "`recall`"; 2. Rerank passages with [bce-reranker-base_v1](https://huggingface.co/maidalun1020/bce-reranker-base_v1) and get top 5-10 for "`precision`" finally. )
## News:
- `BCEmbedding`技术博客( **Technical Blog** ): [为RAG而生-BCEmbedding技术报告](https://zhuanlan.zhihu.com/p/681370855)
- Related link for **EmbeddingModel** : [bce-embedding-base_v1](https://huggingface.co/maidalun1020/bce-embedding-base_v1)
## Third-party Examples:
- RAG applications: [QAnything](https://github.com/netease-youdao/qanything), [HuixiangDou](https://github.com/InternLM/HuixiangDou), [ChatPDF](https://github.com/shibing624/ChatPDF).
- Efficient inference framework: [ChatLLM.cpp](https://github.com/foldl/chatllm.cpp), [Xinference](https://github.com/xorbitsai/inference), [mindnlp (Huawei GPU, 华为GPU)](https://github.com/mindspore-lab/mindnlp/tree/master/llm/inference/bce).

-----------------------------------------
Click to Open Contents
- 🌐 Bilingual and Crosslingual Superiority
- 💡 Key Features
- 🚀 Latest Updates
- 🍎 Model List
- 📖 Manual
- Installation
- Quick Start (`transformers`, `sentence-transformers`)
- Integrations for RAG Frameworks (`langchain`, `llama_index`)
- ⚙️ Evaluation
- Evaluate Semantic Representation by MTEB
- Evaluate RAG by LlamaIndex
- 📈 Leaderboard
- Semantic Representation Evaluations in MTEB
- RAG Evaluations in LlamaIndex
- 🛠 Youdao's BCEmbedding API
- 🧲 WeChat Group
- ✏️ Citation
- 🔐 License
- 🔗 Related Links
**B**ilingual and **C**rosslingual **Embedding** (`BCEmbedding`), developed by NetEase Youdao, encompasses `EmbeddingModel` and `RerankerModel`. The `EmbeddingModel` specializes in generating semantic vectors, playing a crucial role in semantic search and question-answering, and the `RerankerModel` excels at refining search results and ranking tasks.
`BCEmbedding` serves as the cornerstone of Youdao's Retrieval Augmented Generation (RAG) implmentation, notably [QAnything](http://qanything.ai) [[github](https://github.com/netease-youdao/qanything)], an open-source implementation widely integrated in various Youdao products like [Youdao Speed Reading](https://read.youdao.com/#/home) and [Youdao Translation](https://fanyi.youdao.com/download-Mac?keyfrom=fanyiweb_navigation).
Distinguished for its bilingual and crosslingual proficiency, `BCEmbedding` excels in bridging Chinese and English linguistic gaps, which achieves
- **A high performence on Semantic Representation Evaluations in MTEB**;
- **A new benchmark in the realm of RAG Evaluations in LlamaIndex**.
`BCEmbedding`是由网易有道开发的双语和跨语种语义表征算法模型库,其中包含`EmbeddingModel`和`RerankerModel`两类基础模型。`EmbeddingModel`专门用于生成语义向量,在语义搜索和问答中起着关键作用,而`RerankerModel`擅长优化语义搜索结果和语义相关顺序精排。
`BCEmbedding`作为有道的检索增强生成式应用(RAG)的基石,特别是在[QAnything](http://qanything.ai) [[github](https://github.com/netease-youdao/qanything)]中发挥着重要作用。QAnything作为一个网易有道开源项目,在有道许多产品中有很好的应用实践,比如[有道速读](https://read.youdao.com/#/home)和[有道翻译](https://fanyi.youdao.com/download-Mac?keyfrom=fanyiweb_navigation)
`BCEmbedding`以其出色的双语和跨语种能力而著称,在语义检索中消除中英语言之间的差异,从而实现:
- **强大的双语和跨语种语义表征能力【基于MTEB的语义表征评测指标】。**
- **基于LlamaIndex的RAG评测,表现SOTA【基于LlamaIndex的RAG评测指标】。**
## 🌐 Bilingual and Crosslingual Superiority
Existing embedding models often encounter performance challenges in bilingual and crosslingual scenarios, particularly in Chinese, English and their crosslingual tasks. `BCEmbedding`, leveraging the strength of Youdao's translation engine, excels in delivering superior performance across monolingual, bilingual, and crosslingual settings.
`EmbeddingModel` supports ***Chinese (ch) and English (en)*** (more languages support will come soon), while `RerankerModel` supports ***Chinese (ch), English (en), Japanese (ja) and Korean (ko)***.
现有的单个语义表征模型在双语和跨语种场景中常常表现不佳,特别是在中文、英文及其跨语种任务中。`BCEmbedding`充分利用有道翻译引擎的优势,实现只需一个模型就可以在单语、双语和跨语种场景中表现出卓越的性能。
`EmbeddingModel`支持***中文和英文***(之后会支持更多语种);`RerankerModel`支持***中文,英文,日文和韩文***。
## 💡 Key Features
- **Bilingual and Crosslingual Proficiency**: Powered by Youdao's translation engine, excelling in Chinese, English and their crosslingual retrieval task, with upcoming support for additional languages.
- **RAG-Optimized**: Tailored for diverse RAG tasks including **translation, summarization, and question answering**, ensuring accurate **query understanding**. See RAG Evaluations in LlamaIndex.
- **Efficient and Precise Retrieval**: Dual-encoder for efficient retrieval of `EmbeddingModel` in first stage, and cross-encoder of `RerankerModel` for enhanced precision and deeper semantic analysis in second stage.
- **Broad Domain Adaptability**: Trained on diverse datasets for superior performance across various fields.
- **User-Friendly Design**: Instruction-free, versatile use for multiple tasks without specifying query instruction for each task.
- **Meaningful Reranking Scores**: `RerankerModel` provides relevant scores to improve result quality and optimize large language model performance.
- **Proven in Production**: Successfully implemented and validated in Youdao's products.
- **双语和跨语种能力**:基于有道翻译引擎的强大能力,我们的`BCEmbedding`具备强大的中英双语和跨语种语义表征能力。
- **RAG适配**:面向RAG做了针对性优化,可以适配大多数相关任务,比如**翻译,摘要,问答**等。此外,针对**问题理解**(query understanding)也做了针对优化,详见 基于LlamaIndex的RAG评测指标。
- **高效且精确的语义检索**:`EmbeddingModel`采用双编码器,可以在第一阶段实现高效的语义检索。`RerankerModel`采用交叉编码器,可以在第二阶段实现更高精度的语义顺序精排。
- **更好的领域泛化性**:为了在更多场景实现更好的效果,我们收集了多种多样的领域数据。
- **用户友好**:语义检索时不需要特殊指令前缀。也就是,你不需要为各种任务绞尽脑汁设计指令前缀。
- **有意义的重排序分数**:`RerankerModel`可以提供有意义的语义相关性分数(不仅仅是排序),可以用于过滤无意义文本片段,提高大模型生成效果。
- **产品化检验**:`BCEmbedding`已经被有道众多真实产品检验。
## 🚀 Latest Updates
- ***2024-01-03***: **Model Releases** - [bce-embedding-base_v1](https://huggingface.co/maidalun1020/bce-embedding-base_v1) and [bce-reranker-base_v1](https://huggingface.co/maidalun1020/bce-reranker-base_v1) are available.
- ***2024-01-03***: **Eval Datasets** [[CrosslingualMultiDomainsDataset](https://huggingface.co/datasets/maidalun1020/CrosslingualMultiDomainsDataset)] - Evaluate the performence of RAG, using [LlamaIndex](https://github.com/run-llama/llama_index).
- ***2024-01-03***: **Eval Datasets** [[Details](https://github.com/netease-youdao/BCEmbedding/blob/master/BCEmbedding/evaluation/c_mteb/Retrieval.py)] - Evaluate the performence of crosslingual semantic representation, using [MTEB](https://github.com/embeddings-benchmark/mteb).
- ***2024-01-03***: **模型发布** - [bce-embedding-base_v1](https://huggingface.co/maidalun1020/bce-embedding-base_v1)和[bce-reranker-base_v1](https://huggingface.co/maidalun1020/bce-reranker-base_v1)已发布.
- ***2024-01-03***: **RAG评测数据** [[CrosslingualMultiDomainsDataset](https://huggingface.co/datasets/maidalun1020/CrosslingualMultiDomainsDataset)] - 基于[LlamaIndex](https://github.com/run-llama/llama_index)的RAG评测数据已发布。
- ***2024-01-03***: **跨语种语义表征评测数据** [[详情](https://github.com/netease-youdao/BCEmbedding/blob/master/BCEmbedding/evaluation/c_mteb/Retrieval.py)] - 基于[MTEB](https://github.com/embeddings-benchmark/mteb)的跨语种评测数据已发布.
## 🍎 Model List
| Model Name | Model Type | Languages | Parameters | Weights |
|:-------------------------------|:--------:|:--------:|:--------:|:--------:|
| bce-embedding-base_v1 | `EmbeddingModel` | ch, en | 279M | [download](https://huggingface.co/maidalun1020/bce-embedding-base_v1) |
| bce-reranker-base_v1 | `RerankerModel` | ch, en, ja, ko | 279M | [download](https://huggingface.co/maidalun1020/bce-reranker-base_v1) |
## 📖 Manual
### Installation
First, create a conda environment and activate it.
```bash
conda create --name bce python=3.10 -y
conda activate bce
```
Then install `BCEmbedding` for minimal installation:
```bash
pip install BCEmbedding==0.1.1
```
Or install from source:
```bash
git clone git@github.com:netease-youdao/BCEmbedding.git
cd BCEmbedding
pip install -v -e .
```
### Quick Start
#### 1. Based on `BCEmbedding`
Use `EmbeddingModel`, and `cls` [pooler](./BCEmbedding/models/embedding.py#L24) is default.
```python
from BCEmbedding import EmbeddingModel
# list of sentences
sentences = ['sentence_0', 'sentence_1', ...]
# init embedding model
model = EmbeddingModel(model_name_or_path="maidalun1020/bce-embedding-base_v1")
# extract embeddings
embeddings = model.encode(sentences)
```
Use `RerankerModel` to calculate relevant scores and rerank:
```python
from BCEmbedding import RerankerModel
# your query and corresponding passages
query = 'input_query'
passages = ['passage_0', 'passage_1', ...]
# construct sentence pairs
sentence_pairs = [[query, passage] for passage in passages]
# init reranker model
model = RerankerModel(model_name_or_path="maidalun1020/bce-reranker-base_v1")
# method 0: calculate scores of sentence pairs
scores = model.compute_score(sentence_pairs)
# method 1: rerank passages
rerank_results = model.rerank(query, passages)
```
NOTE:
- In [`RerankerModel.rerank`](./BCEmbedding/models/reranker.py#L137) method, we provide an advanced preproccess that we use in production for making `sentence_pairs`, when "passages" are very long.
#### 2. Based on `transformers`
For `EmbeddingModel`:
```python
from transformers import AutoModel, AutoTokenizer
# list of sentences
sentences = ['sentence_0', 'sentence_1', ...]
# init model and tokenizer
tokenizer = AutoTokenizer.from_pretrained('maidalun1020/bce-embedding-base_v1')
model = AutoModel.from_pretrained('maidalun1020/bce-embedding-base_v1')
device = 'cuda' # if no GPU, set "cpu"
model.to(device)
# get inputs
inputs = tokenizer(sentences, padding=True, truncation=True, max_length=512, return_tensors="pt")
inputs_on_device = {k: v.to(self.device) for k, v in inputs.items()}
# get embeddings
outputs = model(**inputs_on_device, return_dict=True)
embeddings = outputs.last_hidden_state[:, 0] # cls pooler
embeddings = embeddings / embeddings.norm(dim=1, keepdim=True) # normalize
```
For `RerankerModel`:
```python
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# init model and tokenizer
tokenizer = AutoTokenizer.from_pretrained('maidalun1020/bce-reranker-base_v1')
model = AutoModelForSequenceClassification.from_pretrained('maidalun1020/bce-reranker-base_v1')
device = 'cuda' # if no GPU, set "cpu"
model.to(device)
# get inputs
inputs = tokenizer(sentence_pairs, padding=True, truncation=True, max_length=512, return_tensors="pt")
inputs_on_device = {k: v.to(device) for k, v in inputs.items()}
# calculate scores
scores = model(**inputs_on_device, return_dict=True).logits.view(-1,).float()
scores = torch.sigmoid(scores)
```
#### 3. Based on `sentence_transformers`
For `EmbeddingModel`:
```python
from sentence_transformers import SentenceTransformer
# list of sentences
sentences = ['sentence_0', 'sentence_1', ...]
# init embedding model
## New update for sentence-trnasformers. So clean up your "`SENTENCE_TRANSFORMERS_HOME`/maidalun1020_bce-embedding-base_v1" or "~/.cache/torch/sentence_transformers/maidalun1020_bce-embedding-base_v1" first for downloading new version.
model = SentenceTransformer("maidalun1020/bce-embedding-base_v1")
# extract embeddings
embeddings = model.encode(sentences, normalize_embeddings=True)
```
For `RerankerModel`:
```python
from sentence_transformers import CrossEncoder
# init reranker model
model = CrossEncoder('maidalun1020/bce-reranker-base_v1', max_length=512)
# calculate scores of sentence pairs
scores = model.predict(sentence_pairs)
```
### Integrations for RAG Frameworks
#### 1. Used in `langchain`
```python
from langchain.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.vectorstores.utils import DistanceStrategy
query = 'apples'
passages = [
'I like apples',
'I like oranges',
'Apples and oranges are fruits'
]
# init embedding model
model_name = 'maidalun1020/bce-embedding-base_v1'
model_kwargs = {'device': 'cuda'}
encode_kwargs = {'batch_size': 64, 'normalize_embeddings': True, 'show_progress_bar': False}
embed_model = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
# example #1. extract embeddings
query_embedding = embed_model.embed_query(query)
passages_embeddings = embed_model.embed_documents(passages)
# example #2. langchain retriever example
faiss_vectorstore = FAISS.from_texts(passages, embed_model, distance_strategy=DistanceStrategy.MAX_INNER_PRODUCT)
retriever = faiss_vectorstore.as_retriever(search_type="similarity", search_kwargs={"score_threshold": 0.5, "k": 3})
related_passages = retriever.get_relevant_documents(query)
```
#### 2. Used in `llama_index`
```python
from llama_index.embeddings import HuggingFaceEmbedding
from llama_index import VectorStoreIndex, ServiceContext, SimpleDirectoryReader
from llama_index.node_parser import SimpleNodeParser
from llama_index.llms import OpenAI
query = 'apples'
passages = [
'I like apples',
'I like oranges',
'Apples and oranges are fruits'
]
# init embedding model
model_args = {'model_name': 'maidalun1020/bce-embedding-base_v1', 'max_length': 512, 'embed_batch_size': 64, 'device': 'cuda'}
embed_model = HuggingFaceEmbedding(**model_args)
# example #1. extract embeddings
query_embedding = embed_model.get_query_embedding(query)
passages_embeddings = embed_model.get_text_embedding_batch(passages)
# example #2. rag example
llm = OpenAI(model='gpt-3.5-turbo-0613', api_key=os.environ.get('OPENAI_API_KEY'), api_base=os.environ.get('OPENAI_BASE_URL'))
service_context = ServiceContext.from_defaults(llm=llm, embed_model=embed_model)
documents = SimpleDirectoryReader(input_files=["BCEmbedding/tools/eval_rag/eval_pdfs/Comp_en_llama2.pdf"]).load_data()
node_parser = SimpleNodeParser.from_defaults(chunk_size=512)
nodes = node_parser.get_nodes_from_documents(documents[0:36])
index = VectorStoreIndex(nodes, service_context=service_context)
query_engine = index.as_query_engine()
response = query_engine.query("What is llama?")
```
## ⚙️ Evaluation
### Evaluate Semantic Representation by MTEB
We provide evaluateion tools for `embedding` and `reranker` models, based on [MTEB](https://github.com/embeddings-benchmark/mteb) and [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB).
我们基于[MTEB](https://github.com/embeddings-benchmark/mteb)和[C_MTEB](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB),提供`embedding`和`reranker`模型的语义表征评测工具。
#### 1. Embedding Models
Just run following cmd to evaluate `your_embedding_model` (e.g. `maidalun1020/bce-embedding-base_v1`) in **bilingual and crosslingual settings** (e.g. `["en", "zh", "en-zh", "zh-en"]`).
运行下面命令评测`your_embedding_model`(比如,`maidalun1020/bce-embedding-base_v1`)。评测任务将会在**双语和跨语种**(比如,`["en", "zh", "en-zh", "zh-en"]`)模式下评测:
```bash
python BCEmbedding/tools/eval_mteb/eval_embedding_mteb.py --model_name_or_path maidalun1020/bce-embedding-base_v1 --pooler cls
```
The total evaluation tasks contain ***114 datastes*** of **"Retrieval", "STS", "PairClassification", "Classification", "Reranking" and "Clustering"**.
评测包含 **"Retrieval", "STS", "PairClassification", "Classification", "Reranking"和"Clustering"** 这六大类任务的 ***114个数据集***。
***NOTE:***
- **All models are evaluated in their recommended pooling method (`pooler`)**.
- `mean` pooler: "jina-embeddings-v2-base-en", "m3e-base", "m3e-large", "e5-large-v2", "multilingual-e5-base", "multilingual-e5-large" and "gte-large".
- `cls` pooler: Other models.
- "jina-embeddings-v2-base-en" model should be loaded with `trust_remote_code`.
```bash
python BCEmbedding/tools/eval_mteb/eval_embedding_mteb.py --model_name_or_path {moka-ai/m3e-base | moka-ai/m3e-large} --pooler mean
python BCEmbedding/tools/eval_mteb/eval_embedding_mteb.py --model_name_or_path jinaai/jina-embeddings-v2-base-en --pooler mean --trust_remote_code
```
***注意:***
- 所有模型的评测采用各自推荐的`pooler`。"jina-embeddings-v2-base-en", "m3e-base", "m3e-large", "e5-large-v2", "multilingual-e5-base", "multilingual-e5-large"和"gte-large"的 `pooler`采用`mean`,其他模型的`pooler`采用`cls`.
- "jina-embeddings-v2-base-en"模型在载入时需要`trust_remote_code`。
#### 2. Reranker Models
Run following cmd to evaluate `your_reranker_model` (e.g. "maidalun1020/bce-reranker-base_v1") in **bilingual and crosslingual settings** (e.g. `["en", "zh", "en-zh", "zh-en"]`).
运行下面命令评测`your_reranker_model`(比如,`maidalun1020/bce-reranker-base_v1`)。评测任务将会在 **双语种和跨语种**(比如,`["en", "zh", "en-zh", "zh-en"]`)模式下评测:
```bash
python BCEmbedding/tools/eval_mteb/eval_reranker_mteb.py --model_name_or_path maidalun1020/bce-reranker-base_v1
```
The evaluation tasks contain ***12 datastes*** of **"Reranking"**.
评测包含 **"Reranking"** 任务的 ***12个数据集***。
#### 3. Metrics Visualization Tool
We proveide a one-click script to sumarize evaluation results of `embedding` and `reranker` models as [Embedding Models Evaluation Summary](https://github.com/netease-youdao/BCEmbedding/blob/master/Docs/EvaluationSummary/embedding_eval_summary.md) and [Reranker Models Evaluation Summary](https://github.com/netease-youdao/BCEmbedding/blob/master/Docs/EvaluationSummary/reranker_eval_summary.md).
我们提供了`embedding`和`reranker`模型的指标可视化一键脚本,输出一个markdown文件,详见[Embedding模型指标汇总](https://github.com/netease-youdao/BCEmbedding/blob/master/Docs/EvaluationSummary/embedding_eval_summary.md)和[Reranker模型指标汇总](https://github.com/netease-youdao/BCEmbedding/blob/master/Docs/EvaluationSummary/reranker_eval_summary.md)。
```bash
python BCEmbedding/evaluation/mteb/summarize_eval_results.py --results_dir {your_embedding_results_dir | your_reranker_results_dir}
```
### Evaluate RAG by LlamaIndex
[LlamaIndex](https://github.com/run-llama/llama_index) is a famous data framework for LLM-based applications, particularly in RAG. Recently, the [LlamaIndex Blog](https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83) has evaluated the popular embedding and reranker models in RAG pipeline and attract great attention. Now, we follow its pipeline to evaluate our `BCEmbedding`.
[LlamaIndex](https://github.com/run-llama/llama_index)是一个著名的大模型应用的开源工具,在RAG中很受欢迎。最近,[LlamaIndex博客](https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83)对市面上常用的embedding和reranker模型进行RAG流程的评测,吸引广泛关注。下面我们按照该评测流程验证`BCEmbedding`在RAG中的效果。
First, install LlamaIndex:
```bash
pip install llama-index==0.9.22
```
#### 1. Metrics Definition
- Hit Rate:
Hit rate calculates the fraction of queries where the correct answer is found within the top-k retrieved documents. In simpler terms, it's about how often our system gets it right within the top few guesses. ***The larger, the better.***
- Mean Reciprocal Rank (MRR):
For each query, MRR evaluates the system's accuracy by looking at the rank of the highest-placed relevant document. Specifically, it's the average of the reciprocals of these ranks across all the queries. So, if the first relevant document is the top result, the reciprocal rank is 1; if it's second, the reciprocal rank is 1/2, and so on. ***The larger, the better.***
- 命中率(Hit Rate)
命中率计算的是在检索的前k个文档中找到正确答案的查询所占的比例。简单来说,它反映了我们的系统在前几次猜测中答对的频率。***该指标越大越好。***
- 平均倒数排名(Mean Reciprocal Rank,MRR)
对于每个查询,MRR通过查看最高排名的相关文档的排名来评估系统的准确性。具体来说,它是在所有查询中这些排名的倒数的平均值。因此,如果第一个相关文档是排名最靠前的结果,倒数排名就是1;如果是第二个,倒数排名就是1/2,依此类推。***该指标越大越好。***
#### 2. Reproduce [LlamaIndex Blog](https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83)
In order to compare our `BCEmbedding` with other embedding and reranker models fairly, we provide a one-click script to reproduce results of the LlamaIndex Blog, including our `BCEmbedding`:
为了公平起见,运行下面脚本,复现LlamaIndex博客的结果,将`BCEmbedding`与其他embedding和reranker模型进行对比分析:
```bash
# There should be two GPUs available at least.
CUDA_VISIBLE_DEVICES=0,1 python BCEmbedding/tools/eval_rag/eval_llamaindex_reproduce.py
```
Then, sumarize the evaluation results by:
```bash
python BCEmbedding/tools/eval_rag/summarize_eval_results.py --results_dir results/rag_reproduce_results
```
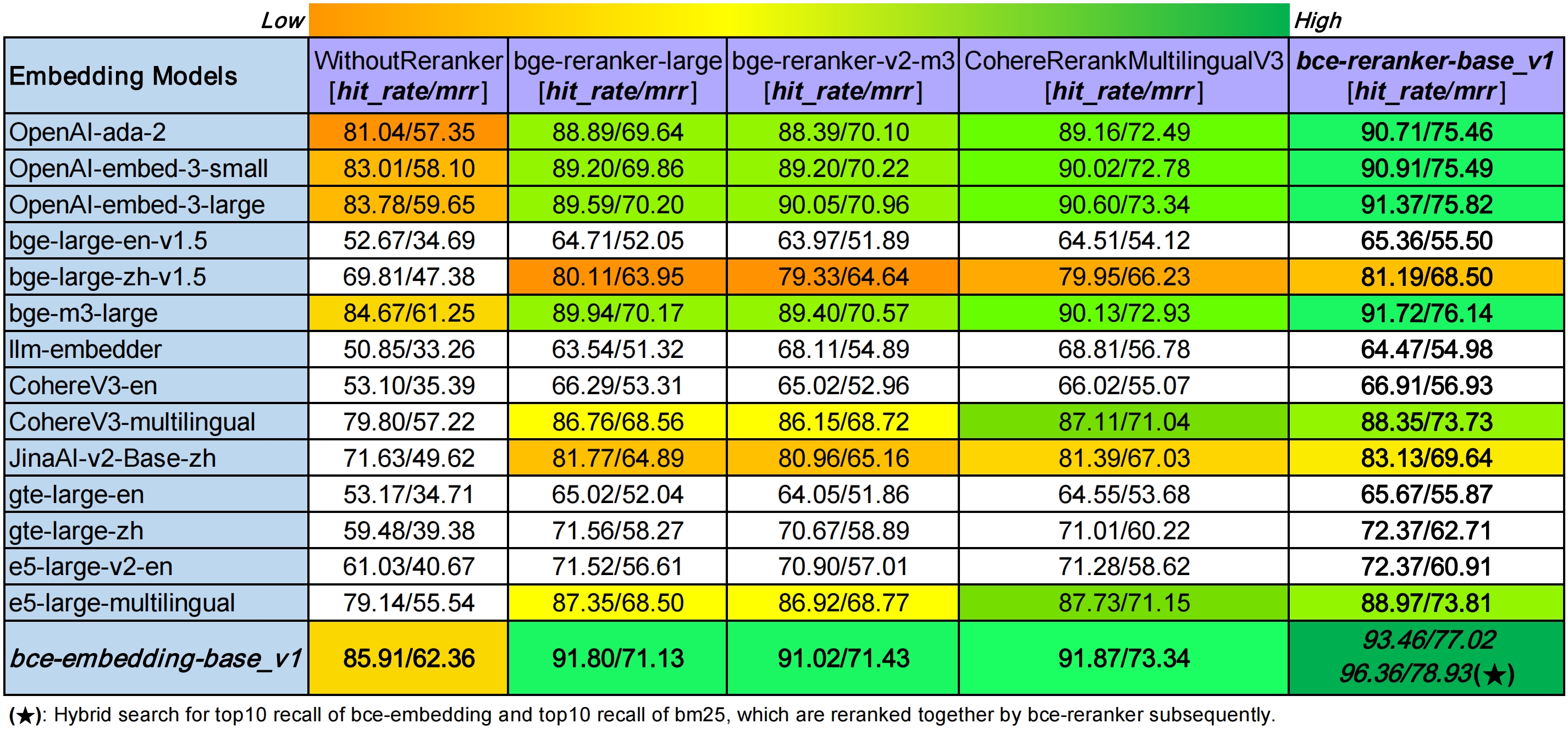
Results Reproduced from the LlamaIndex Blog can be checked in ***[Reproduced Summary of RAG Evaluation](https://github.com/netease-youdao/BCEmbedding/blob/master/Docs/EvaluationSummary/rag_eval_reproduced_summary.md)***, with some obvious ***conclusions***:
- In `WithoutReranker` setting, our `bce-embedding-base_v1` outperforms all the other embedding models.
- With fixing the embedding model, our `bce-reranker-base_v1` achieves the best performence.
- ***The combination of `bce-embedding-base_v1` and `bce-reranker-base_v1` is SOTA.***
输出的指标汇总详见 ***[LlamaIndex RAG评测结果复现](https://github.com/netease-youdao/BCEmbedding/blob/master/Docs/EvaluationSummary/rag_eval_reproduced_summary.md)***。从该复现结果中,可以看出:
- 在`WithoutReranker`设置下(**竖排对比**),`bce-embedding-base_v1`比其他embedding模型效果都要好。
- 在固定embedding模型设置下,对比不同reranker效果(**横排对比**),`bce-reranker-base_v1`比其他reranker模型效果都要好。
- ***`bce-embedding-base_v1`和`bce-reranker-base_v1`组合,表现SOTA。***
#### 3. Broad Domain Adaptability
The evaluation of [LlamaIndex Blog](https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83) is **monolingual, small amount of data, and specific domain** (just including "llama2" paper). In order to evaluate the **broad domain adaptability, bilingual and crosslingual capability**, we follow the blog to build a multiple domains evaluation dataset (includding "Computer Science", "Physics", "Biology", "Economics", "Math", and "Quantitative Finance"), named [CrosslingualMultiDomainsDataset](https://huggingface.co/datasets/maidalun1020/CrosslingualMultiDomainsDataset), **by OpenAI `gpt-4-1106-preview` for high quality**.
在上述的[LlamaIndex博客](https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83)的评测数据只用了“llama2”这一篇文章,该评测是 **单语种,小数据量,特定领域** 的。为了兼容更真实更广的用户使用场景,评测算法模型的 **领域泛化性,双语和跨语种能力**,我们按照该博客的方法构建了一个多领域(计算机科学,物理学,生物学,经济学,数学,量化金融等)的双语种、跨语种评测数据,[CrosslingualMultiDomainsDataset](https://huggingface.co/datasets/maidalun1020/CrosslingualMultiDomainsDataset)。**为了保证构建数据的高质量,我们采用OpenAI的`gpt-4-1106-preview`。**
First, run following cmd to evaluate the most popular and powerful embedding and reranker models:
```bash
# There should be two GPUs available at least.
CUDA_VISIBLE_DEVICES=0,1 python BCEmbedding/tools/eval_rag/eval_llamaindex_multiple_domains.py
```
Then, run the following script to sumarize the evaluation results:
```bash
python BCEmbedding/tools/eval_rag/summarize_eval_results.py --results_dir results/rag_results
```
The summary of multiple domains evaluations can be seen in Multiple Domains Scenarios.
## 📈 Leaderboard
### Semantic Representation Evaluations in MTEB
#### 1. Embedding Models
| Model | Dimensions | Pooler | Instructions | Retrieval (47) | STS (19) | PairClassification (5) | Classification (21) | Reranking (12) | Clustering (15) | ***AVG*** (119) |
|:--------|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| bge-base-en-v1.5 | 768 | `cls` | Need | 37.14 | 55.06 | 75.45 | 59.73 | 43.00 | 37.74 | 47.19 |
| bge-base-zh-v1.5 | 768 | `cls` | Need | 47.63 | 63.72 | 77.40 | 63.38 | 54.95 | 32.56 | 53.62 |
| bge-large-en-v1.5 | 1024 | `cls` | Need | 37.18 | 54.09 | 75.00 | 59.24 | 42.47 | 37.32 | 46.80 |
| bge-large-zh-v1.5 | 1024 | `cls` | Need | 47.58 | 64.73 | 79.14 | 64.19 | 55.98 | 33.26 | 54.23 |
| e5-large-v2 | 1024 | `mean` | Need | 35.98 | 55.23 | 75.28 | 59.53 | 42.12 | 36.51 | 46.52 |
| gte-large | 1024 | `mean` | Free | 36.68 | 55.22 | 74.29 | 57.73 | 42.44 | 38.51 | 46.67 |
| gte-large-zh | 1024 | `cls` | Free | 41.15 | 64.62 | 77.58 | 62.04 | 55.62 | 33.03 | 51.51 |
| jina-embeddings-v2-base-en | 768 | `mean` | Free | 31.58 | 54.28 | 74.84 | 58.42 | 41.16 | 34.67 | 44.29 |
| m3e-base | 768 | `mean` | Free | 46.29 | 63.93 | 71.84 | 64.08 | 52.38 | 37.84 | 53.54 |
| m3e-large | 1024 | `mean` | Free | 34.85 | 59.74 | 67.69 | 60.07 | 48.99 | 31.62 | 46.78 |
| multilingual-e5-base | 768 | `mean` | Need | 54.73 | 65.49 | 76.97 | 69.72 | 55.01 | 38.44 | 58.34 |
| multilingual-e5-large | 1024 | `mean` | Need | 56.76 | 66.79 | 78.80 | 71.61 | 56.49 | 43.09 | 60.50 |
| ***bce-embedding-base_v1*** | 768 | `cls` | Free | 57.60 | 65.73 | 74.96 | 69.00 | 57.29 | 38.95 | 59.43 |
***NOTE:***
- Our ***bce-embedding-base_v1*** outperforms other opensource embedding models with comparable model size.
- ***114 datastes*** of **"Retrieval", "STS", "PairClassification", "Classification", "Reranking" and "Clustering"** in `["en", "zh", "en-zh", "zh-en"]` setting.
- The [crosslingual evaluation datasets](https://github.com/netease-youdao/BCEmbedding/blob/master/BCEmbedding/evaluation/c_mteb/Retrieval.py) we released belong to `Retrieval` task.
- More evaluation details please check [Embedding Models Evaluation Summary](https://github.com/netease-youdao/BCEmbedding/blob/master/Docs/EvaluationSummary/embedding_eval_summary.md).
***要点:***
- 对比其他开源的相同规模的embedding模型,***bce-embedding-base_v1*** 表现最好,效果比最好的large模型稍差。
- 评测包含 **"Retrieval", "STS", "PairClassification", "Classification", "Reranking"和"Clustering"** 这六大类任务的共 ***114个数据集***。
- 我们开源的[跨语种语义表征评测数据](https://github.com/netease-youdao/BCEmbedding/blob/master/BCEmbedding/evaluation/c_mteb/Retrieval.py)属于`Retrieval`任务。
- 更详细的评测结果详见[Embedding模型指标汇总](https://github.com/netease-youdao/BCEmbedding/blob/master/Docs/EvaluationSummary/embedding_eval_summary.md)。
#### 2. Reranker Models
| Model | Reranking (12) | ***AVG*** (12) |
| :--------------------------------- | :-------------: | :--------------------: |
| bge-reranker-base | 59.04 | 59.04 |
| bge-reranker-large | 60.86 | 60.86 |
| ***bce-reranker-base_v1*** | **61.29** | ***61.29*** |
***NOTE:***
- Our ***bce-reranker-base_v1*** outperforms other opensource reranker models.
- ***12 datastes*** of **"Reranking"** in `["en", "zh", "en-zh", "zh-en"]` setting.
- More evaluation details please check [Reranker Models Evaluation Summary](https://github.com/netease-youdao/BCEmbedding/blob/master/Docs/EvaluationSummary/reranker_eval_summary.md).
***要点:***
- ***bce-reranker-base_v1*** 优于其他开源reranker模型。
- 评测包含 **"Reranking"** 任务的 ***12个数据集***。
- 更详细的评测结果详见[Reranker模型指标汇总](https://github.com/netease-youdao/BCEmbedding/blob/master/Docs/EvaluationSummary/reranker_eval_summary.md)
### RAG Evaluations in LlamaIndex
#### 1. Multiple Domains Scenarios

***NOTE:***
- Evaluated in **["en", "zh", "en-zh", "zh-en"] setting**.
- In `WithoutReranker` setting, our `bce-embedding-base_v1` outperforms all the other embedding models.
- With fixing the embedding model, our `bce-reranker-base_v1` achieves the best performence.
- **The combination of `bce-embedding-base_v1` and `bce-reranker-base_v1` is SOTA**.
***要点:***
- 评测是在["en", "zh", "en-zh", "zh-en"]设置下。
- 在`WithoutReranker`设置下(**竖排对比**),`bce-embedding-base_v1`优于其他Embedding模型,包括开源和闭源。
- 在固定Embedding模型设置下,对比不同reranker效果(**横排对比**),`bce-reranker-base_v1`比其他reranker模型效果都要好,包括开源和闭源。
- ***`bce-embedding-base_v1`和`bce-reranker-base_v1`组合,表现SOTA。***
## 🛠 Youdao's BCEmbedding API
For users who prefer a hassle-free experience without the need to download and configure the model on their own systems, `BCEmbedding` is readily accessible through Youdao's API. This option offers a streamlined and efficient way to integrate BCEmbedding into your projects, bypassing the complexities of manual setup and maintenance. Detailed instructions and comprehensive API documentation are available at [Youdao BCEmbedding API](https://ai.youdao.com/DOCSIRMA/html/aigc/api/embedding/index.html). Here, you'll find all the necessary guidance to easily implement `BCEmbedding` across a variety of use cases, ensuring a smooth and effective integration for optimal results.
对于那些更喜欢直接调用api的用户,有道提供方便的`BCEmbedding`调用api。该方式是一种简化和高效的方式,将`BCEmbedding`集成到您的项目中,避开了手动设置和系统维护的复杂性。更详细的api调用接口说明详见[有道BCEmbedding API](https://ai.youdao.com/DOCSIRMA/html/aigc/api/embedding/index.html)。
## 🧲 WeChat Group
Welcome to scan the QR code below and join the WeChat group.
欢迎大家扫码加入官方微信交流群。

## ✏️ Citation
If you use `BCEmbedding` in your research or project, please feel free to cite and star it:
如果在您的研究或任何项目中使用本工作,烦请按照下方进行引用,并打个小星星~
```
@misc{youdao_bcembedding_2023,
title={BCEmbedding: Bilingual and Crosslingual Embedding for RAG},
author={NetEase Youdao, Inc.},
year={2023},
howpublished={\url{https://github.com/netease-youdao/BCEmbedding}}
}
```
## 🔐 License
`BCEmbedding` is licensed under [Apache 2.0 License](https://github.com/netease-youdao/BCEmbedding/blob/master/LICENSE)
## 🔗 Related Links
[Netease Youdao - QAnything](https://github.com/netease-youdao/qanything)
[FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding)
[MTEB](https://github.com/embeddings-benchmark/mteb)
[C_MTEB](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB)
[LLama Index](https://github.com/run-llama/llama_index) | [LlamaIndex Blog](https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83)