---
license: apache-2.0
language:
- ko
- en
tags:
- moe
---
# **Synatra-Mixtral-8x7B** [(Original Weight)](https://huggingface.co/maywell/Synatra-Mixtral-8x7B)
 **Synatra-Mixtral-8x7B** is a fine-tuned version of the Mixtral-8x7B-Instruct-v0.1 model using **Korean** datasets.
This model features overwhelmingly superior comprehension and inference capabilities and is licensed under apache-2.0.
# **EXL2 Info**
[measurement.json](./measurement.json)
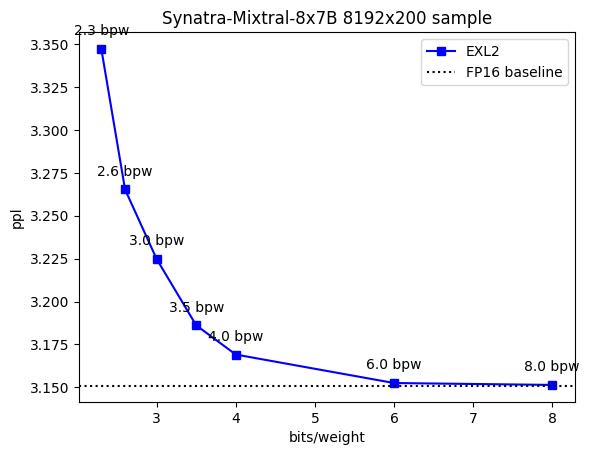
[8.0bpw](https://huggingface.co/maywell/Synatra-Mixtral-8x7B-exl2/tree/8.0bpw), [6.0bpw](https://huggingface.co/maywell/Synatra-Mixtral-8x7B-exl2/tree/6.0bpw), [4.0bpw](https://huggingface.co/maywell/Synatra-Mixtral-8x7B-exl2/tree/4.0bpw), [3.5bpw](https://huggingface.co/maywell/Synatra-Mixtral-8x7B-exl2/tree/3.5bpw), [3.0bpw](https://huggingface.co/maywell/Synatra-Mixtral-8x7B-exl2/tree/3.0bpw), [2.6bpw](https://huggingface.co/maywell/Synatra-Mixtral-8x7B-exl2/tree/2.6bpw), [2.3bpw](https://huggingface.co/maywell/Synatra-Mixtral-8x7B-exl2/tree/2.3bpw)
**Synatra-Mixtral-8x7B** is a fine-tuned version of the Mixtral-8x7B-Instruct-v0.1 model using **Korean** datasets.
This model features overwhelmingly superior comprehension and inference capabilities and is licensed under apache-2.0.
# **EXL2 Info**
[measurement.json](./measurement.json)
[8.0bpw](https://huggingface.co/maywell/Synatra-Mixtral-8x7B-exl2/tree/8.0bpw), [6.0bpw](https://huggingface.co/maywell/Synatra-Mixtral-8x7B-exl2/tree/6.0bpw), [4.0bpw](https://huggingface.co/maywell/Synatra-Mixtral-8x7B-exl2/tree/4.0bpw), [3.5bpw](https://huggingface.co/maywell/Synatra-Mixtral-8x7B-exl2/tree/3.5bpw), [3.0bpw](https://huggingface.co/maywell/Synatra-Mixtral-8x7B-exl2/tree/3.0bpw), [2.6bpw](https://huggingface.co/maywell/Synatra-Mixtral-8x7B-exl2/tree/2.6bpw), [2.3bpw](https://huggingface.co/maywell/Synatra-Mixtral-8x7B-exl2/tree/2.3bpw)
 # **License**
**OPEN**, Apache-2.0.
# **Model Details**
**Base Model**
[mistralai/Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1)
**Trained On**
A100 80GB * 6
**Instruction format**
It follows **Alpaca** format.
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{input}
### Response:
{output}
```
# **Model Benchmark**
TBD
# **Implementation Code**
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("maywell/Synatra-Mixtral-8x7B")
tokenizer = AutoTokenizer.from_pretrained("maywell/Synatra-Mixtral-8x7B")
messages = [
{"role": "user", "content": "아인슈타인의 상대성이론에 대해서 자세히 설명해줘."},
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
```
# **Author's Message**
This model's training got sponsered by no one but support from people around Earth.
[Support Me](https://www.buymeacoffee.com/mwell)
Contact Me on Discord - **is.maywell**
Follow me on twitter: https://twitter.com/stablefluffy
# **License**
**OPEN**, Apache-2.0.
# **Model Details**
**Base Model**
[mistralai/Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1)
**Trained On**
A100 80GB * 6
**Instruction format**
It follows **Alpaca** format.
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{input}
### Response:
{output}
```
# **Model Benchmark**
TBD
# **Implementation Code**
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("maywell/Synatra-Mixtral-8x7B")
tokenizer = AutoTokenizer.from_pretrained("maywell/Synatra-Mixtral-8x7B")
messages = [
{"role": "user", "content": "아인슈타인의 상대성이론에 대해서 자세히 설명해줘."},
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
```
# **Author's Message**
This model's training got sponsered by no one but support from people around Earth.
[Support Me](https://www.buymeacoffee.com/mwell)
Contact Me on Discord - **is.maywell**
Follow me on twitter: https://twitter.com/stablefluffy