---
license: apache-2.0
---
# A Touch, Vision, and Language Dataset for Multimodal Alignment
by Max (Letian) Fu, Gaurav Datta*, Huang Huang*, William Chung-Ho Panitch*, Jaimyn Drake*, Joseph Ortiz, Mustafa Mukadam, Mike Lambeta, Roberto Calandra, Ken Goldberg at UC Berkeley, Meta AI, TU Dresden, and CeTI (*equal contribution).
[[Paper](https://arxiv.org/abs/2402.13232)] | [[Project Page](https://tactile-vlm.github.io/)] | [[Checkpoints](https://huggingface.co/mlfu7/Touch-Vision-Language-Models)] | [[Dataset](https://huggingface.co/datasets/mlfu7/Touch-Vision-Language-Dataset)] | [[Citation](#citation)]
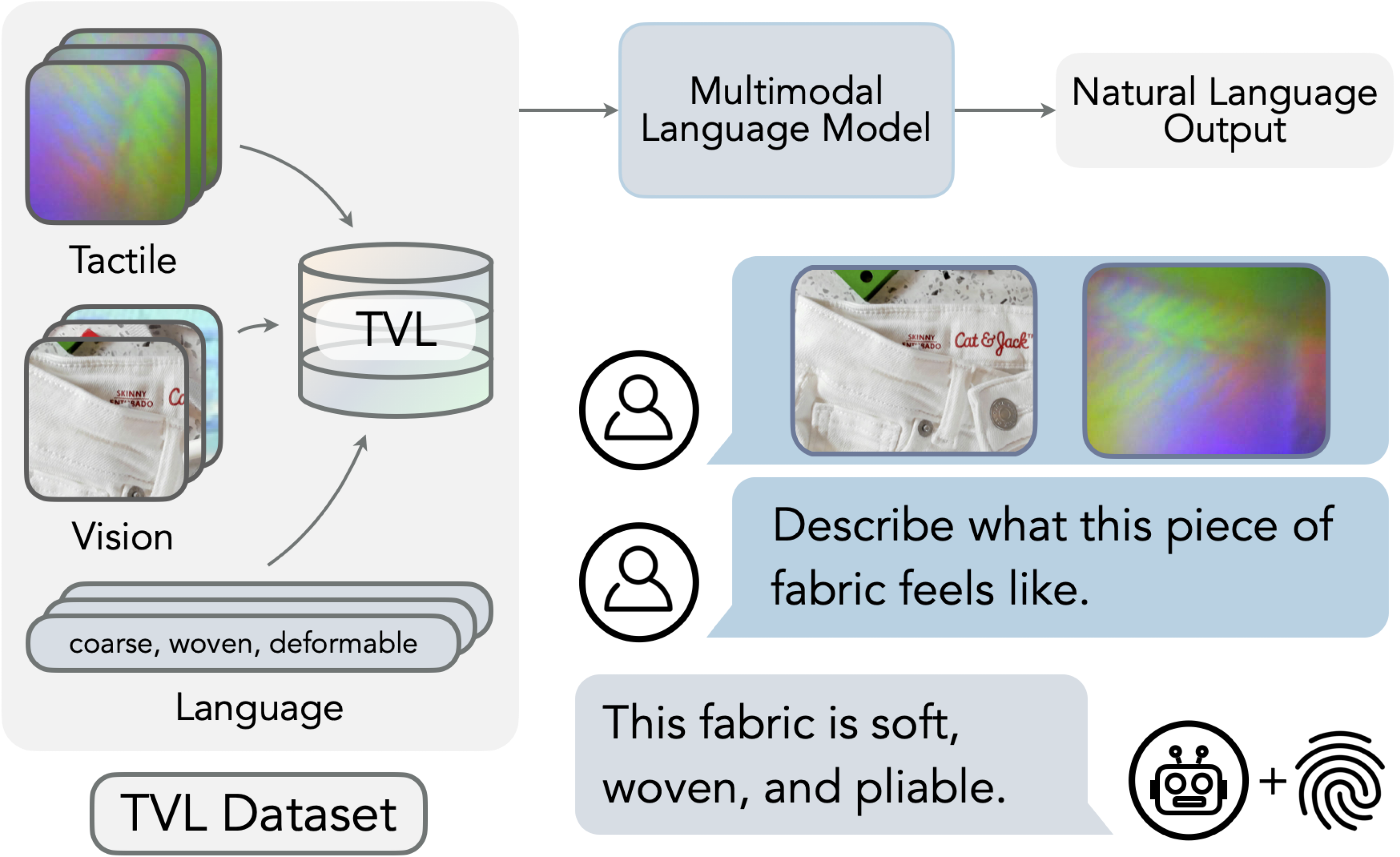
This repo contains the official checkpoints for *A Touch, Vision, and Language Dataset for Multimodal Alignment*.
The tactile encoders comes in three different sizes: ViT-Tiny, ViT-Small, and ViT-Base, all of which are stored in
```bash
ckpt/tvl_enc
```
TVL-LLaMA, the generative counterparts, are stored in
```bash
ckpt/tvl_llama
```
## Inference
For zero-shot classification, we would require [OpenCLIP](https://github.com/mlfoundations/open_clip) with the following configuration:
```bash
CLIP_VISION_MODEL = "ViT-L-14"
CLIP_PRETRAIN_DATA = "datacomp_xl_s13b_b90k"
```
For TVL-LLaMA, please request access to the pre-trained LLaMA-2 from this [form](https://llama.meta.com/llama-downloads/). In particular, we use `llama-2-7b` as the base model. The weights here contains the trained [adapter](https://arxiv.org/abs/2309.03905), the tactile encoder, and the vision encoder for the ease of loading.
For the complete info, please take a look at the [GitHub repo](https://tactile-vlm.github.io/) to see instructions on pretraining, fine-tuning, and evaluation with these models.
## Citation
Please give us a star 🌟 on Github to support us!
Please cite our work if you find our work inspiring or use our code in your work:
```
@article{fu2024tvl,
title={A Touch, Vision, and Language Dataset for Multimodal Alignment},
author={Letian Fu and Gaurav Datta and Huang Huang and William Chung-Ho Panitch and Jaimyn Drake and Joseph Ortiz and Mustafa Mukadam and Mike Lambeta and Roberto Calandra and Ken Goldberg},
journal={arXiv preprint arXiv:2402.13232},
year={2024}
}
```