

update benchmark on A100
Browse files- README.md +16 -12
- configs/evaluate.json +132 -13
- configs/metadata.json +4 -5
- configs/multi_gpu_train.json +2 -2
- configs/train.json +13 -8
- docs/README.md +16 -12
- models/model.pt +2 -2
- models/stage0/model.pt +2 -2
- scripts/prepare_patches.py +3 -0
README.md
CHANGED
|
@@ -66,31 +66,35 @@ Output: a dictionary with the following keys:
|
|
| 66 |
The achieved metrics on the validation data are:
|
| 67 |
|
| 68 |
Fast mode:
|
| 69 |
-
- Binary Dice: 0.
|
| 70 |
-
- PQ: 0.
|
| 71 |
-
- F1d: 0.
|
|
|
|
|
|
|
|
|
|
|
|
|
| 72 |
|
| 73 |
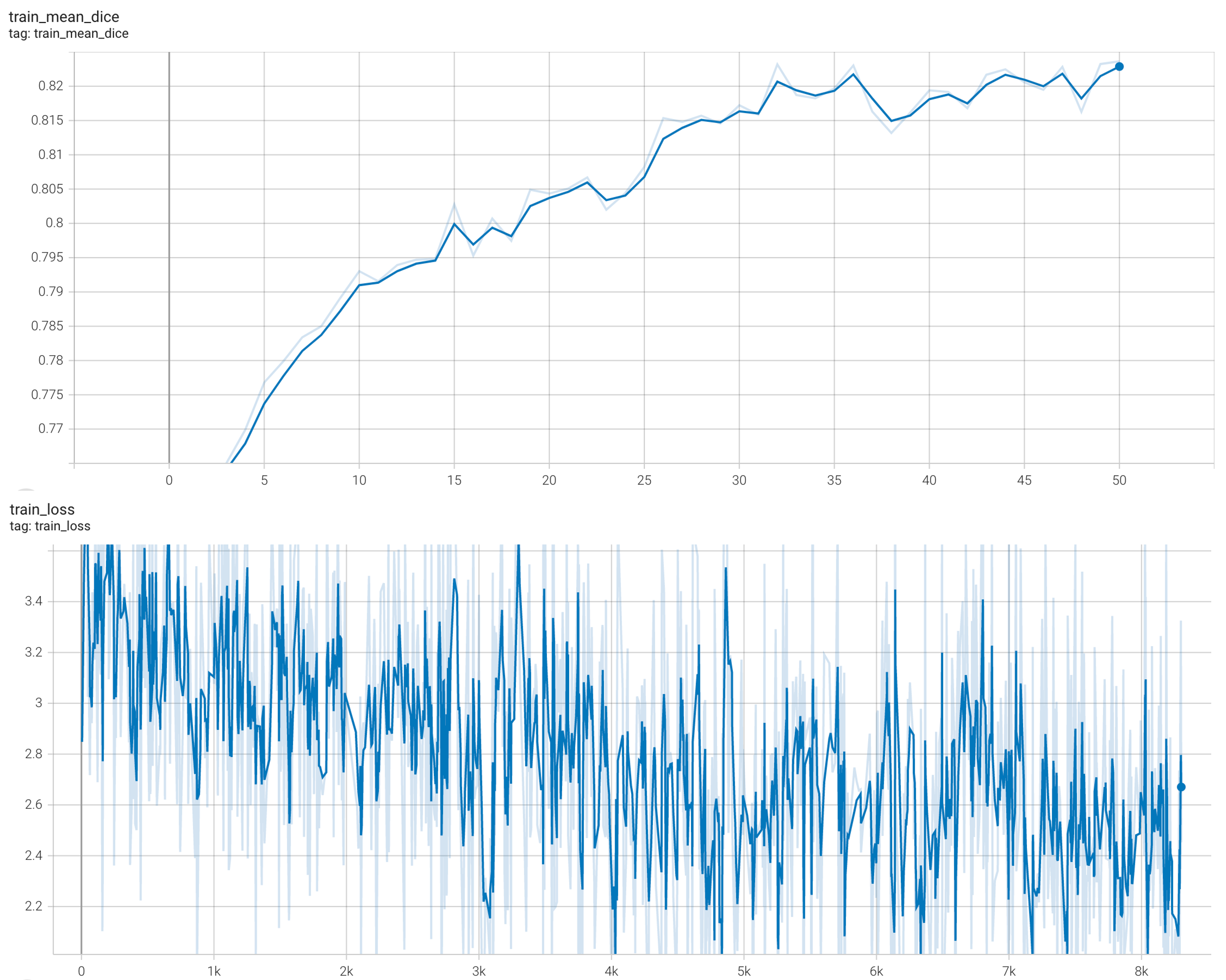
#### Training Loss and Dice
|
| 74 |
|
| 75 |
stage1:
|
| 76 |
-

|
| 81 |
|
| 82 |
stage2:
|
| 83 |
+
|
| 84 |
|
| 85 |
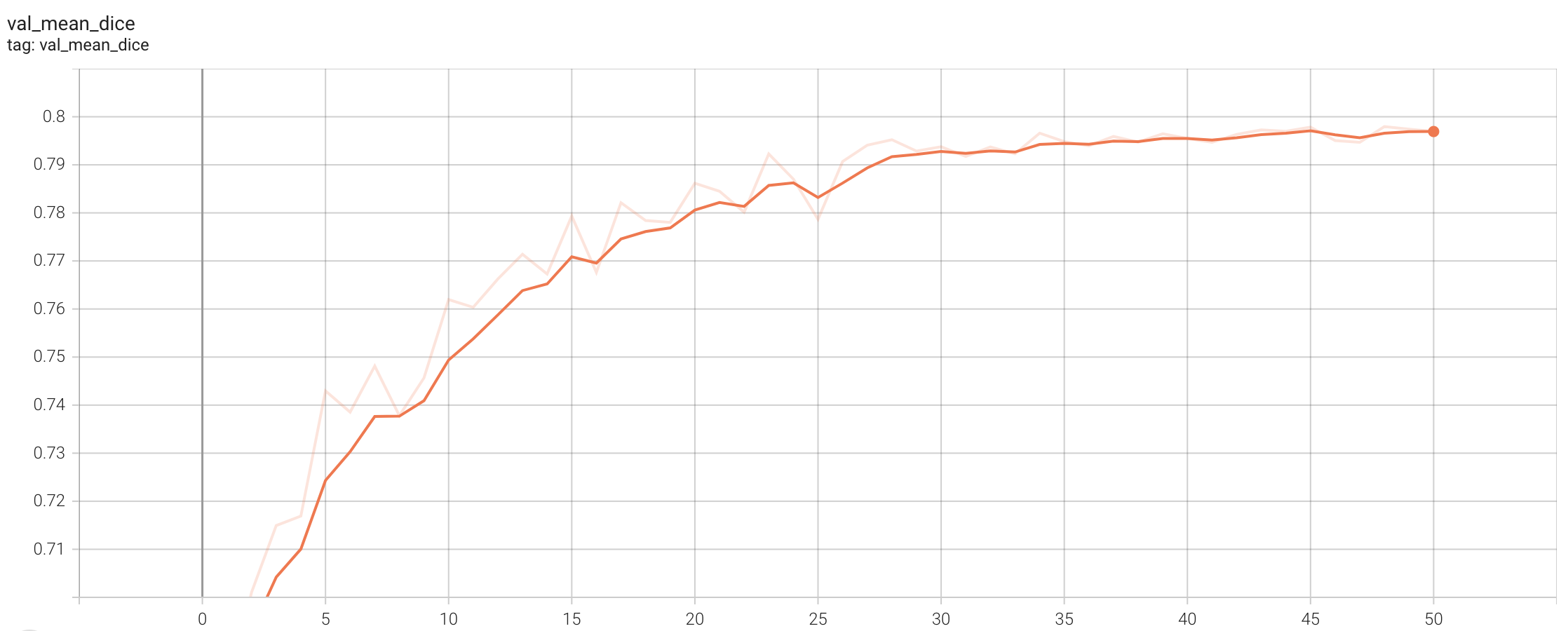
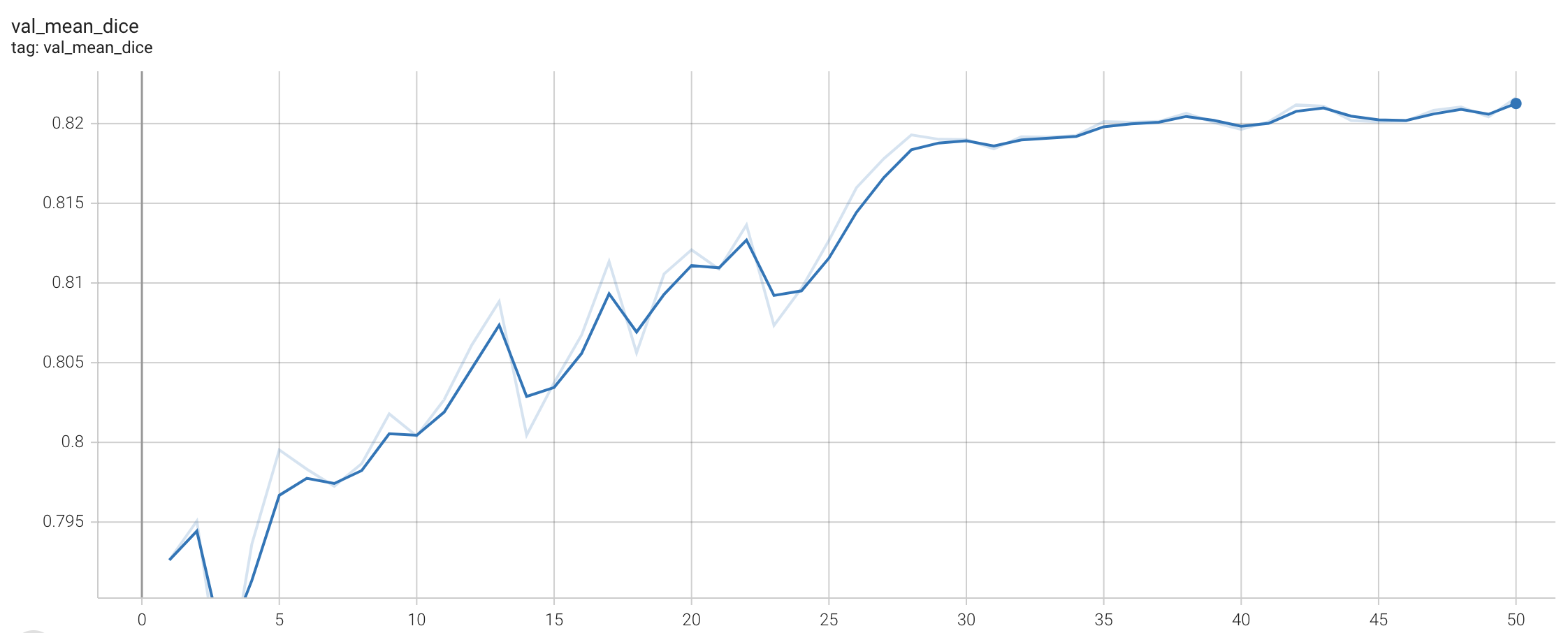
#### Validation Dice
|
| 86 |
|
| 87 |
stage1:
|
| 88 |
|
| 89 |
+
|
| 90 |
|
| 91 |
stage2:
|
| 92 |
|
| 93 |
+
|
| 94 |
|
| 95 |
## commands example
|
| 96 |
|
| 97 |
+
Execute training, the evaluation in the training were evaluated on patches:
|
| 98 |
|
| 99 |
- Run first stage
|
| 100 |
|
|
|
|
| 105 |
- Run second stage
|
| 106 |
|
| 107 |
```
|
| 108 |
+
python -m monai.bundle run --config_file configs/train.json --network_def#freeze_encoder False --network_def#pretrained_url None --stage 1
|
| 109 |
```
|
| 110 |
|
| 111 |
Override the `train` config to execute multi-GPU training:
|
|
|
|
| 113 |
- Run first stage
|
| 114 |
|
| 115 |
```
|
| 116 |
+
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/multi_gpu_train.json']" --batch_size 8 --network_def#freeze_encoder True --network_def#pretrained_url `PRETRAIN_MODEL_URL --stage 0
|
| 117 |
```
|
| 118 |
|
| 119 |
- Run second stage
|
| 120 |
|
| 121 |
```
|
| 122 |
+
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/multi_gpu_train.json']" --batch_size 4 --network_def#freeze_encoder False --network_def#pretrained_url None --stage 1
|
| 123 |
```
|
| 124 |
|
| 125 |
+
Override the `train` config to execute evaluation with the trained model, here we evaluated dice from the whole input instead of the patches:
|
| 126 |
|
| 127 |
```
|
| 128 |
python -m monai.bundle run --config_file "['configs/train.json','configs/evaluate.json']"
|
configs/evaluate.json
CHANGED
|
@@ -1,4 +1,7 @@
|
|
| 1 |
{
|
|
|
|
|
|
|
|
|
|
| 2 |
"network_def": {
|
| 3 |
"_target_": "HoVerNet",
|
| 4 |
"mode": "@hovernet_mode",
|
|
@@ -6,6 +9,77 @@
|
|
| 6 |
"in_channels": 3,
|
| 7 |
"out_classes": 5
|
| 8 |
},
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 9 |
"validate#handlers": [
|
| 10 |
{
|
| 11 |
"_target_": "CheckpointLoader",
|
|
@@ -16,21 +90,66 @@
|
|
| 16 |
},
|
| 17 |
{
|
| 18 |
"_target_": "StatsHandler",
|
| 19 |
-
"
|
| 20 |
-
},
|
| 21 |
-
{
|
| 22 |
-
"_target_": "MetricsSaver",
|
| 23 |
-
"save_dir": "@output_dir",
|
| 24 |
-
"metrics": [
|
| 25 |
-
"val_mean_dice"
|
| 26 |
-
],
|
| 27 |
-
"metric_details": [
|
| 28 |
-
"val_mean_dice"
|
| 29 |
-
],
|
| 30 |
-
"batch_transform": "$monai.handlers.from_engine(['image_meta_dict'])",
|
| 31 |
-
"summary_ops": "*"
|
| 32 |
}
|
| 33 |
],
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 34 |
"initialize": [
|
| 35 |
"$setattr(torch.backends.cudnn, 'benchmark', True)"
|
| 36 |
],
|
|
|
|
| 1 |
{
|
| 2 |
+
"val_images": "$list(sorted(glob.glob(@dataset_dir + '/Test/image*.npy')))",
|
| 3 |
+
"val_labels": "$list(sorted(glob.glob(@dataset_dir + '/Test/label*.npy')))",
|
| 4 |
+
"data_list": "$[{'image': i, 'label': j} for i, j in zip(@val_images, @val_labels)]",
|
| 5 |
"network_def": {
|
| 6 |
"_target_": "HoVerNet",
|
| 7 |
"mode": "@hovernet_mode",
|
|
|
|
| 9 |
"in_channels": 3,
|
| 10 |
"out_classes": 5
|
| 11 |
},
|
| 12 |
+
"sw_batch_size": 16,
|
| 13 |
+
"validate#dataset": {
|
| 14 |
+
"_target_": "CacheDataset",
|
| 15 |
+
"data": "@data_list",
|
| 16 |
+
"transform": "@validate#preprocessing",
|
| 17 |
+
"cache_rate": 1.0,
|
| 18 |
+
"num_workers": 4
|
| 19 |
+
},
|
| 20 |
+
"validate#preprocessing_transforms": [
|
| 21 |
+
{
|
| 22 |
+
"_target_": "LoadImaged",
|
| 23 |
+
"keys": [
|
| 24 |
+
"image",
|
| 25 |
+
"label"
|
| 26 |
+
]
|
| 27 |
+
},
|
| 28 |
+
{
|
| 29 |
+
"_target_": "SplitDimd",
|
| 30 |
+
"keys": "label",
|
| 31 |
+
"output_postfixes": [
|
| 32 |
+
"inst",
|
| 33 |
+
"type"
|
| 34 |
+
],
|
| 35 |
+
"dim": -1
|
| 36 |
+
},
|
| 37 |
+
{
|
| 38 |
+
"_target_": "EnsureChannelFirstd",
|
| 39 |
+
"keys": [
|
| 40 |
+
"image",
|
| 41 |
+
"label_inst",
|
| 42 |
+
"label_type"
|
| 43 |
+
],
|
| 44 |
+
"channel_dim": -1
|
| 45 |
+
},
|
| 46 |
+
{
|
| 47 |
+
"_target_": "CastToTyped",
|
| 48 |
+
"keys": [
|
| 49 |
+
"image",
|
| 50 |
+
"label_inst"
|
| 51 |
+
],
|
| 52 |
+
"dtype": "$torch.int"
|
| 53 |
+
},
|
| 54 |
+
{
|
| 55 |
+
"_target_": "ScaleIntensityRanged",
|
| 56 |
+
"keys": "image",
|
| 57 |
+
"a_min": 0.0,
|
| 58 |
+
"a_max": 255.0,
|
| 59 |
+
"b_min": 0.0,
|
| 60 |
+
"b_max": 1.0,
|
| 61 |
+
"clip": true
|
| 62 |
+
},
|
| 63 |
+
{
|
| 64 |
+
"_target_": "ComputeHoVerMapsd",
|
| 65 |
+
"keys": "label_inst"
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
"_target_": "Lambdad",
|
| 69 |
+
"keys": "label_inst",
|
| 70 |
+
"func": "$lambda x: x > 0",
|
| 71 |
+
"overwrite": "label"
|
| 72 |
+
},
|
| 73 |
+
{
|
| 74 |
+
"_target_": "CastToTyped",
|
| 75 |
+
"keys": [
|
| 76 |
+
"image",
|
| 77 |
+
"label_inst",
|
| 78 |
+
"label_type"
|
| 79 |
+
],
|
| 80 |
+
"dtype": "$torch.float32"
|
| 81 |
+
}
|
| 82 |
+
],
|
| 83 |
"validate#handlers": [
|
| 84 |
{
|
| 85 |
"_target_": "CheckpointLoader",
|
|
|
|
| 90 |
},
|
| 91 |
{
|
| 92 |
"_target_": "StatsHandler",
|
| 93 |
+
"output_transform": "$lambda x: None"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 94 |
}
|
| 95 |
],
|
| 96 |
+
"validate#inferer": {
|
| 97 |
+
"_target_": "SlidingWindowHoVerNetInferer",
|
| 98 |
+
"roi_size": "@patch_size",
|
| 99 |
+
"sw_batch_size": "@sw_batch_size",
|
| 100 |
+
"overlap": "$1.0 - float(@out_size) / float(@patch_size)",
|
| 101 |
+
"padding_mode": "constant",
|
| 102 |
+
"cval": 0,
|
| 103 |
+
"progress": true,
|
| 104 |
+
"extra_input_padding": "$((@patch_size - @out_size) // 2,) * 4"
|
| 105 |
+
},
|
| 106 |
+
"postprocessing_pred": {
|
| 107 |
+
"_target_": "Compose",
|
| 108 |
+
"transforms": [
|
| 109 |
+
{
|
| 110 |
+
"_target_": "HoVerNetInstanceMapPostProcessingd",
|
| 111 |
+
"sobel_kernel_size": 21,
|
| 112 |
+
"marker_threshold": 0.5,
|
| 113 |
+
"marker_radius": 2,
|
| 114 |
+
"device": "@device"
|
| 115 |
+
},
|
| 116 |
+
{
|
| 117 |
+
"_target_": "HoVerNetNuclearTypePostProcessingd",
|
| 118 |
+
"device": "@device"
|
| 119 |
+
},
|
| 120 |
+
{
|
| 121 |
+
"_target_": "SaveImaged",
|
| 122 |
+
"keys": "instance_map",
|
| 123 |
+
"meta_keys": "image_meta_dict",
|
| 124 |
+
"output_ext": ".nii.gz",
|
| 125 |
+
"output_dir": "@output_dir",
|
| 126 |
+
"output_postfix": "instance_map",
|
| 127 |
+
"output_dtype": "uint32",
|
| 128 |
+
"separate_folder": false
|
| 129 |
+
},
|
| 130 |
+
{
|
| 131 |
+
"_target_": "SaveImaged",
|
| 132 |
+
"keys": "type_map",
|
| 133 |
+
"meta_keys": "image_meta_dict",
|
| 134 |
+
"output_ext": ".nii.gz",
|
| 135 |
+
"output_dir": "@output_dir",
|
| 136 |
+
"output_postfix": "type_map",
|
| 137 |
+
"output_dtype": "uint8",
|
| 138 |
+
"separate_folder": false
|
| 139 |
+
},
|
| 140 |
+
{
|
| 141 |
+
"_target_": "Lambdad",
|
| 142 |
+
"keys": "instance_map",
|
| 143 |
+
"func": "$lambda x: x > 0",
|
| 144 |
+
"overwrite": "nucleus_prediction"
|
| 145 |
+
}
|
| 146 |
+
]
|
| 147 |
+
},
|
| 148 |
+
"validate#postprocessing": {
|
| 149 |
+
"_target_": "Lambdad",
|
| 150 |
+
"keys": "pred",
|
| 151 |
+
"func": "@postprocessing_pred"
|
| 152 |
+
},
|
| 153 |
"initialize": [
|
| 154 |
"$setattr(torch.backends.cudnn, 'benchmark', True)"
|
| 155 |
],
|
configs/metadata.json
CHANGED
|
@@ -1,14 +1,15 @@
|
|
| 1 |
{
|
| 2 |
"schema": "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/meta_schema_hovernet_20221124.json",
|
| 3 |
-
"version": "0.1.
|
| 4 |
"changelog": {
|
|
|
|
| 5 |
"0.1.4": "adapt to BundleWorkflow interface",
|
| 6 |
"0.1.3": "add name tag",
|
| 7 |
"0.1.2": "update the workflow figure",
|
| 8 |
"0.1.1": "update to use monai 1.1.0",
|
| 9 |
"0.1.0": "complete the model package"
|
| 10 |
},
|
| 11 |
-
"monai_version": "1.2.
|
| 12 |
"pytorch_version": "1.13.1",
|
| 13 |
"numpy_version": "1.22.2",
|
| 14 |
"optional_packages_version": {
|
|
@@ -28,9 +29,7 @@
|
|
| 28 |
"label_classes": "a dictionary contains binary nuclear segmentation, hover map and pixel-level classification",
|
| 29 |
"pred_classes": "a dictionary contains scalar probability for binary nuclear segmentation, hover map and pixel-level classification",
|
| 30 |
"eval_metrics": {
|
| 31 |
-
"Binary Dice": 0.
|
| 32 |
-
"PQ": 0.4936,
|
| 33 |
-
"F1d": 0.748
|
| 34 |
},
|
| 35 |
"intended_use": "This is an example, not to be used for diagnostic purposes",
|
| 36 |
"references": [
|
|
|
|
| 1 |
{
|
| 2 |
"schema": "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/meta_schema_hovernet_20221124.json",
|
| 3 |
+
"version": "0.1.5",
|
| 4 |
"changelog": {
|
| 5 |
+
"0.1.5": "update benchmark on A100",
|
| 6 |
"0.1.4": "adapt to BundleWorkflow interface",
|
| 7 |
"0.1.3": "add name tag",
|
| 8 |
"0.1.2": "update the workflow figure",
|
| 9 |
"0.1.1": "update to use monai 1.1.0",
|
| 10 |
"0.1.0": "complete the model package"
|
| 11 |
},
|
| 12 |
+
"monai_version": "1.2.0rc4",
|
| 13 |
"pytorch_version": "1.13.1",
|
| 14 |
"numpy_version": "1.22.2",
|
| 15 |
"optional_packages_version": {
|
|
|
|
| 29 |
"label_classes": "a dictionary contains binary nuclear segmentation, hover map and pixel-level classification",
|
| 30 |
"pred_classes": "a dictionary contains scalar probability for binary nuclear segmentation, hover map and pixel-level classification",
|
| 31 |
"eval_metrics": {
|
| 32 |
+
"Binary Dice": 0.8291
|
|
|
|
|
|
|
| 33 |
},
|
| 34 |
"intended_use": "This is an example, not to be used for diagnostic purposes",
|
| 35 |
"references": [
|
configs/multi_gpu_train.json
CHANGED
|
@@ -15,7 +15,7 @@
|
|
| 15 |
},
|
| 16 |
"train#dataloader#sampler": "@train#sampler",
|
| 17 |
"train#dataloader#shuffle": false,
|
| 18 |
-
"train#trainer#train_handlers": "$@train#train_handlers[: -
|
| 19 |
"validate#sampler": {
|
| 20 |
"_target_": "DistributedSampler",
|
| 21 |
"dataset": "@validate#dataset",
|
|
@@ -35,6 +35,6 @@
|
|
| 35 |
"$@train#trainer.run()"
|
| 36 |
],
|
| 37 |
"finalize": [
|
| 38 |
-
"$dist.destroy_process_group()"
|
| 39 |
]
|
| 40 |
}
|
|
|
|
| 15 |
},
|
| 16 |
"train#dataloader#sampler": "@train#sampler",
|
| 17 |
"train#dataloader#shuffle": false,
|
| 18 |
+
"train#trainer#train_handlers": "$@train#train_handlers[: -3 if dist.get_rank() > 0 else None]",
|
| 19 |
"validate#sampler": {
|
| 20 |
"_target_": "DistributedSampler",
|
| 21 |
"dataset": "@validate#dataset",
|
|
|
|
| 35 |
"$@train#trainer.run()"
|
| 36 |
],
|
| 37 |
"finalize": [
|
| 38 |
+
"$dist.is_initialized() and dist.destroy_process_group()"
|
| 39 |
]
|
| 40 |
}
|
configs/train.json
CHANGED
|
@@ -19,6 +19,7 @@
|
|
| 19 |
"device": "$torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')",
|
| 20 |
"stage": 0,
|
| 21 |
"epochs": 50,
|
|
|
|
| 22 |
"val_interval": 1,
|
| 23 |
"learning_rate": 0.0001,
|
| 24 |
"amp": true,
|
|
@@ -32,7 +33,7 @@
|
|
| 32 |
"in_channels": 3,
|
| 33 |
"out_classes": 5,
|
| 34 |
"adapt_standard_resnet": true,
|
| 35 |
-
"pretrained_url":
|
| 36 |
"freeze_encoder": true
|
| 37 |
},
|
| 38 |
"network": "$@network_def.to(@device)",
|
|
@@ -195,7 +196,7 @@
|
|
| 195 |
"name": "ColorJitter",
|
| 196 |
"brightness": [
|
| 197 |
0.9,
|
| 198 |
-
1.
|
| 199 |
],
|
| 200 |
"contrast": [
|
| 201 |
0.95,
|
|
@@ -272,14 +273,16 @@
|
|
| 272 |
"transforms": "$@train#preprocessing_transforms"
|
| 273 |
},
|
| 274 |
"dataset": {
|
| 275 |
-
"_target_": "
|
| 276 |
"data": "$[{'image': i, 'label_inst': j, 'label_type': k} for i, j, k in zip(@train_images, @train_inst_map, @train_type_map)]",
|
| 277 |
-
"transform": "@train#preprocessing"
|
|
|
|
|
|
|
| 278 |
},
|
| 279 |
"dataloader": {
|
| 280 |
"_target_": "DataLoader",
|
| 281 |
"dataset": "@train#dataset",
|
| 282 |
-
"batch_size":
|
| 283 |
"shuffle": true,
|
| 284 |
"num_workers": 4
|
| 285 |
},
|
|
@@ -463,14 +466,16 @@
|
|
| 463 |
"transforms": "$@validate#preprocessing_transforms"
|
| 464 |
},
|
| 465 |
"dataset": {
|
| 466 |
-
"_target_": "
|
| 467 |
"data": "$[{'image': i, 'label_inst': j, 'label_type': k} for i, j, k in zip(@val_images, @val_inst_map, @val_type_map)]",
|
| 468 |
-
"transform": "@validate#preprocessing"
|
|
|
|
|
|
|
| 469 |
},
|
| 470 |
"dataloader": {
|
| 471 |
"_target_": "DataLoader",
|
| 472 |
"dataset": "@validate#dataset",
|
| 473 |
-
"batch_size":
|
| 474 |
"shuffle": false,
|
| 475 |
"num_workers": 4
|
| 476 |
},
|
|
|
|
| 19 |
"device": "$torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')",
|
| 20 |
"stage": 0,
|
| 21 |
"epochs": 50,
|
| 22 |
+
"batch_size": 16,
|
| 23 |
"val_interval": 1,
|
| 24 |
"learning_rate": 0.0001,
|
| 25 |
"amp": true,
|
|
|
|
| 33 |
"in_channels": 3,
|
| 34 |
"out_classes": 5,
|
| 35 |
"adapt_standard_resnet": true,
|
| 36 |
+
"pretrained_url": null,
|
| 37 |
"freeze_encoder": true
|
| 38 |
},
|
| 39 |
"network": "$@network_def.to(@device)",
|
|
|
|
| 196 |
"name": "ColorJitter",
|
| 197 |
"brightness": [
|
| 198 |
0.9,
|
| 199 |
+
1.1
|
| 200 |
],
|
| 201 |
"contrast": [
|
| 202 |
0.95,
|
|
|
|
| 273 |
"transforms": "$@train#preprocessing_transforms"
|
| 274 |
},
|
| 275 |
"dataset": {
|
| 276 |
+
"_target_": "CacheDataset",
|
| 277 |
"data": "$[{'image': i, 'label_inst': j, 'label_type': k} for i, j, k in zip(@train_images, @train_inst_map, @train_type_map)]",
|
| 278 |
+
"transform": "@train#preprocessing",
|
| 279 |
+
"cache_rate": 1.0,
|
| 280 |
+
"num_workers": 4
|
| 281 |
},
|
| 282 |
"dataloader": {
|
| 283 |
"_target_": "DataLoader",
|
| 284 |
"dataset": "@train#dataset",
|
| 285 |
+
"batch_size": "@batch_size",
|
| 286 |
"shuffle": true,
|
| 287 |
"num_workers": 4
|
| 288 |
},
|
|
|
|
| 466 |
"transforms": "$@validate#preprocessing_transforms"
|
| 467 |
},
|
| 468 |
"dataset": {
|
| 469 |
+
"_target_": "CacheDataset",
|
| 470 |
"data": "$[{'image': i, 'label_inst': j, 'label_type': k} for i, j, k in zip(@val_images, @val_inst_map, @val_type_map)]",
|
| 471 |
+
"transform": "@validate#preprocessing",
|
| 472 |
+
"cache_rate": 1.0,
|
| 473 |
+
"num_workers": 4
|
| 474 |
},
|
| 475 |
"dataloader": {
|
| 476 |
"_target_": "DataLoader",
|
| 477 |
"dataset": "@validate#dataset",
|
| 478 |
+
"batch_size": "@batch_size",
|
| 479 |
"shuffle": false,
|
| 480 |
"num_workers": 4
|
| 481 |
},
|
docs/README.md
CHANGED
|
@@ -59,31 +59,35 @@ Output: a dictionary with the following keys:
|
|
| 59 |
The achieved metrics on the validation data are:
|
| 60 |
|
| 61 |
Fast mode:
|
| 62 |
-
- Binary Dice: 0.
|
| 63 |
-
- PQ: 0.
|
| 64 |
-
- F1d: 0.
|
|
|
|
|
|
|
|
|
|
|
|
|
| 65 |
|
| 66 |
#### Training Loss and Dice
|
| 67 |
|
| 68 |
stage1:
|
| 69 |
-

|
| 74 |
|
| 75 |
stage2:
|
| 76 |
+

|
| 77 |
|
| 78 |
#### Validation Dice
|
| 79 |
|
| 80 |
stage1:
|
| 81 |
|
| 82 |
+

|
| 83 |
|
| 84 |
stage2:
|
| 85 |
|
| 86 |
+

|
| 87 |
|
| 88 |
## commands example
|
| 89 |
|
| 90 |
+
Execute training, the evaluation in the training were evaluated on patches:
|
| 91 |
|
| 92 |
- Run first stage
|
| 93 |
|
|
|
|
| 98 |
- Run second stage
|
| 99 |
|
| 100 |
```
|
| 101 |
+
python -m monai.bundle run --config_file configs/train.json --network_def#freeze_encoder False --network_def#pretrained_url None --stage 1
|
| 102 |
```
|
| 103 |
|
| 104 |
Override the `train` config to execute multi-GPU training:
|
|
|
|
| 106 |
- Run first stage
|
| 107 |
|
| 108 |
```
|
| 109 |
+
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/multi_gpu_train.json']" --batch_size 8 --network_def#freeze_encoder True --network_def#pretrained_url `PRETRAIN_MODEL_URL --stage 0
|
| 110 |
```
|
| 111 |
|
| 112 |
- Run second stage
|
| 113 |
|
| 114 |
```
|
| 115 |
+
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/multi_gpu_train.json']" --batch_size 4 --network_def#freeze_encoder False --network_def#pretrained_url None --stage 1
|
| 116 |
```
|
| 117 |
|
| 118 |
+
Override the `train` config to execute evaluation with the trained model, here we evaluated dice from the whole input instead of the patches:
|
| 119 |
|
| 120 |
```
|
| 121 |
python -m monai.bundle run --config_file "['configs/train.json','configs/evaluate.json']"
|
models/model.pt
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f3c427cd3e97f40b77ff612205b706475edc1039d1b8de39afcaf7add204e39c
|
| 3 |
+
size 151228832
|
models/stage0/model.pt
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cf6eb5a0467422c2c1ffbff72e2b4aca17dcdd8d2087bd1a27ce86fea98a1ab6
|
| 3 |
+
size 151228832
|
scripts/prepare_patches.py
CHANGED
|
@@ -176,6 +176,9 @@ def main(cfg):
|
|
| 176 |
img = load_img(f"{img_dir}/{base_name}.{cfg['image_suffix']}")
|
| 177 |
ann = load_ann(f"{ann_dir}/{base_name}.{cfg['label_suffix']}")
|
| 178 |
|
|
|
|
|
|
|
|
|
|
| 179 |
# *
|
| 180 |
img = np.concatenate([img, ann], axis=-1)
|
| 181 |
sub_patches = xtractor.extract(img, cfg["extract_type"])
|
|
|
|
| 176 |
img = load_img(f"{img_dir}/{base_name}.{cfg['image_suffix']}")
|
| 177 |
ann = load_ann(f"{ann_dir}/{base_name}.{cfg['label_suffix']}")
|
| 178 |
|
| 179 |
+
np.save("{0}/label_{1}.npy".format(out_dir, base_name), ann)
|
| 180 |
+
np.save("{0}/image_{1}.npy".format(out_dir, base_name), img)
|
| 181 |
+
|
| 182 |
# *
|
| 183 |
img = np.concatenate([img, ann], axis=-1)
|
| 184 |
sub_patches = xtractor.extract(img, cfg["extract_type"])
|