

update the readme file with TensorRT convert
Browse files- README.md +27 -1
- configs/metadata.json +3 -2
- docs/README.md +27 -1
README.md
CHANGED
|
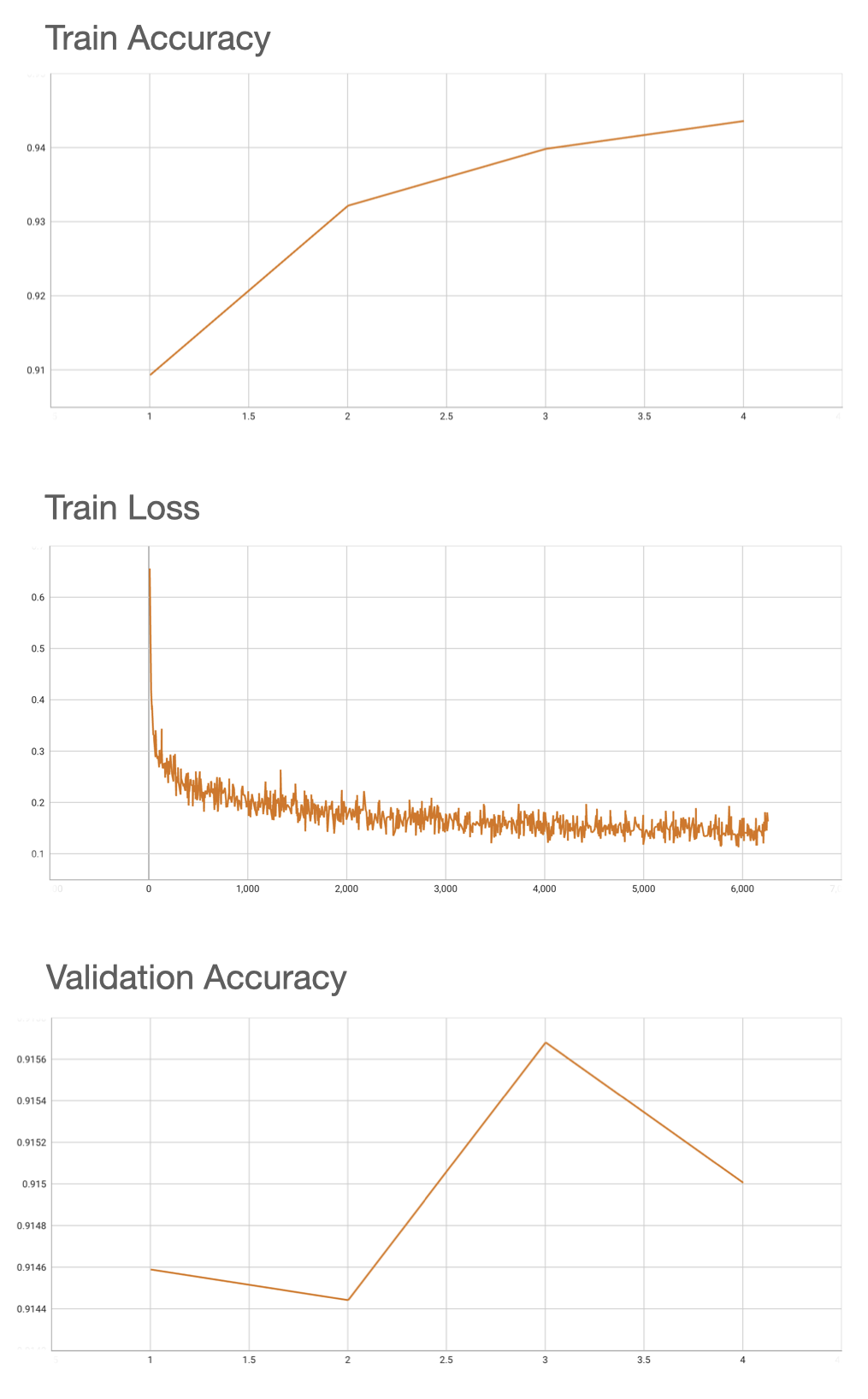
@@ -65,6 +65,24 @@ This model achieve the 0.91 accuracy on validation patches, and FROC of 0.72 on
|
|
| 65 |
|
| 66 |
|
| 67 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 68 |
## MONAI Bundle Commands
|
| 69 |
|
| 70 |
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
|
|
@@ -99,7 +117,15 @@ cd scripts && source evaluate_froc.sh
|
|
| 99 |
|
| 100 |
#### Export checkpoint to TorchScript file
|
| 101 |
|
| 102 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 103 |
|
| 104 |
# References
|
| 105 |
|
|
|
|
| 65 |
|
| 66 |

|
| 67 |
|
| 68 |
+
The `pathology_tumor_detection` bundle supports the TensorRT acceleration. The table below shows the speedup ratios benchmarked on an A100 80G GPU, in which the `model computation` means the speedup ratio of model's inference with a random input without preprocessing and postprocessing and the `end2end` means run the bundle end to end with the TensorRT based model. The `torch_fp32` and `torch_amp` is for the pytorch model with or without `amp` mode. The `trt_fp32` and `trt_fp16` is for the TensorRT based model converted in corresponding precision. The `speedup amp`, `speedup fp32` and `speedup fp16` is the speedup ratio of corresponding models versus the pytorch float32 model, while the `amp vs fp16` is between the pytorch amp model and the TensorRT float16 based model.
|
| 69 |
+
|
| 70 |
+
Please notice that the benchmark results are tested on one WSI image since the images are too large to benchmark. And the inference time in the end2end line stands for one patch of the whole image.
|
| 71 |
+
|
| 72 |
+
| method | torch_fp32(ms) | torch_amp(ms) | trt_fp32(ms) | trt_fp16(ms) | speedup amp | speedup fp32 | speedup fp16 | amp vs fp16|
|
| 73 |
+
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
|
| 74 |
+
| model computation |1.93 | 2.52 | 1.61 | 1.33 | 0.77 | 1.20 | 1.45 | 1.89 |
|
| 75 |
+
| end2end |224.97 | 223.50 | 222.65 | 224.03 | 1.01 | 1.01 | 1.00 | 1.00 |
|
| 76 |
+
|
| 77 |
+
This result is benchmarked under:
|
| 78 |
+
- TensorRT: 8.5.3+cuda11.8
|
| 79 |
+
- Torch-TensorRT Version: 1.4.0
|
| 80 |
+
- CPU Architecture: x86-64
|
| 81 |
+
- OS: ubuntu 20.04
|
| 82 |
+
- Python version:3.8.10
|
| 83 |
+
- CUDA version: 11.8
|
| 84 |
+
- GPU models and configuration: A100 80G
|
| 85 |
+
|
| 86 |
## MONAI Bundle Commands
|
| 87 |
|
| 88 |
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
|
|
|
|
| 117 |
|
| 118 |
#### Export checkpoint to TorchScript file
|
| 119 |
|
| 120 |
+
```
|
| 121 |
+
python -m monai.bundle ckpt_export network_def --filepath models/model.ts --ckpt_file models/model.pt --meta_file configs/metadata.json --config_file configs/inference.json
|
| 122 |
+
```
|
| 123 |
+
|
| 124 |
+
#### Export checkpoint to TensorRT based models with fp32 or fp16 precision:
|
| 125 |
+
|
| 126 |
+
```
|
| 127 |
+
python -m monai.bundle trt_export --net_id network_def --filepath models/model_trt.ts --ckpt_file models/model.pt --meta_file configs/metadata.json --config_file configs/inference.json --precision <fp32/fp16> --dynamic_batchsize "[1, 400, 600]"
|
| 128 |
+
```
|
| 129 |
|
| 130 |
# References
|
| 131 |
|
configs/metadata.json
CHANGED
|
@@ -1,7 +1,8 @@
|
|
| 1 |
{
|
| 2 |
"schema": "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/meta_schema_20220324.json",
|
| 3 |
-
"version": "0.4.
|
| 4 |
"changelog": {
|
|
|
|
| 5 |
"0.4.7": "add name tag",
|
| 6 |
"0.4.6": "modify dataset key name",
|
| 7 |
"0.4.5": "update model weights and perfomance metrics",
|
|
@@ -18,7 +19,7 @@
|
|
| 18 |
"0.1.1": "fix location variable name change",
|
| 19 |
"0.1.0": "initialize release of the bundle"
|
| 20 |
},
|
| 21 |
-
"monai_version": "1.
|
| 22 |
"pytorch_version": "1.13.0",
|
| 23 |
"numpy_version": "1.21.2",
|
| 24 |
"optional_packages_version": {
|
|
|
|
| 1 |
{
|
| 2 |
"schema": "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/meta_schema_20220324.json",
|
| 3 |
+
"version": "0.4.8",
|
| 4 |
"changelog": {
|
| 5 |
+
"0.4.8": "update the readme file with TensorRT convert",
|
| 6 |
"0.4.7": "add name tag",
|
| 7 |
"0.4.6": "modify dataset key name",
|
| 8 |
"0.4.5": "update model weights and perfomance metrics",
|
|
|
|
| 19 |
"0.1.1": "fix location variable name change",
|
| 20 |
"0.1.0": "initialize release of the bundle"
|
| 21 |
},
|
| 22 |
+
"monai_version": "1.2.0rc3",
|
| 23 |
"pytorch_version": "1.13.0",
|
| 24 |
"numpy_version": "1.21.2",
|
| 25 |
"optional_packages_version": {
|
docs/README.md
CHANGED
|
@@ -58,6 +58,24 @@ This model achieve the 0.91 accuracy on validation patches, and FROC of 0.72 on
|
|
| 58 |
|
| 59 |

|
| 60 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 61 |
## MONAI Bundle Commands
|
| 62 |
|
| 63 |
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
|
|
@@ -92,7 +110,15 @@ cd scripts && source evaluate_froc.sh
|
|
| 92 |
|
| 93 |
#### Export checkpoint to TorchScript file
|
| 94 |
|
| 95 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 96 |
|
| 97 |
# References
|
| 98 |
|
|
|
|
| 58 |
|
| 59 |

|
| 60 |
|
| 61 |
+
The `pathology_tumor_detection` bundle supports the TensorRT acceleration. The table below shows the speedup ratios benchmarked on an A100 80G GPU, in which the `model computation` means the speedup ratio of model's inference with a random input without preprocessing and postprocessing and the `end2end` means run the bundle end to end with the TensorRT based model. The `torch_fp32` and `torch_amp` is for the pytorch model with or without `amp` mode. The `trt_fp32` and `trt_fp16` is for the TensorRT based model converted in corresponding precision. The `speedup amp`, `speedup fp32` and `speedup fp16` is the speedup ratio of corresponding models versus the pytorch float32 model, while the `amp vs fp16` is between the pytorch amp model and the TensorRT float16 based model.
|
| 62 |
+
|
| 63 |
+
Please notice that the benchmark results are tested on one WSI image since the images are too large to benchmark. And the inference time in the end2end line stands for one patch of the whole image.
|
| 64 |
+
|
| 65 |
+
| method | torch_fp32(ms) | torch_amp(ms) | trt_fp32(ms) | trt_fp16(ms) | speedup amp | speedup fp32 | speedup fp16 | amp vs fp16|
|
| 66 |
+
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
|
| 67 |
+
| model computation |1.93 | 2.52 | 1.61 | 1.33 | 0.77 | 1.20 | 1.45 | 1.89 |
|
| 68 |
+
| end2end |224.97 | 223.50 | 222.65 | 224.03 | 1.01 | 1.01 | 1.00 | 1.00 |
|
| 69 |
+
|
| 70 |
+
This result is benchmarked under:
|
| 71 |
+
- TensorRT: 8.5.3+cuda11.8
|
| 72 |
+
- Torch-TensorRT Version: 1.4.0
|
| 73 |
+
- CPU Architecture: x86-64
|
| 74 |
+
- OS: ubuntu 20.04
|
| 75 |
+
- Python version:3.8.10
|
| 76 |
+
- CUDA version: 11.8
|
| 77 |
+
- GPU models and configuration: A100 80G
|
| 78 |
+
|
| 79 |
## MONAI Bundle Commands
|
| 80 |
|
| 81 |
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
|
|
|
|
| 110 |
|
| 111 |
#### Export checkpoint to TorchScript file
|
| 112 |
|
| 113 |
+
```
|
| 114 |
+
python -m monai.bundle ckpt_export network_def --filepath models/model.ts --ckpt_file models/model.pt --meta_file configs/metadata.json --config_file configs/inference.json
|
| 115 |
+
```
|
| 116 |
+
|
| 117 |
+
#### Export checkpoint to TensorRT based models with fp32 or fp16 precision:
|
| 118 |
+
|
| 119 |
+
```
|
| 120 |
+
python -m monai.bundle trt_export --net_id network_def --filepath models/model_trt.ts --ckpt_file models/model.pt --meta_file configs/metadata.json --config_file configs/inference.json --precision <fp32/fp16> --dynamic_batchsize "[1, 400, 600]"
|
| 121 |
+
```
|
| 122 |
|
| 123 |
# References
|
| 124 |
|