

Upload 2 files
Browse files- .gitattributes +1 -0
- README.md +72 -0
- train-loss.png +3 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
train-loss.png filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,72 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
library_name: peft
|
| 3 |
+
tags:
|
| 4 |
+
- meta-llama
|
| 5 |
+
- code
|
| 6 |
+
- instruct
|
| 7 |
+
- databricks-dolly-15k
|
| 8 |
+
- Llama-2-70b-hf
|
| 9 |
+
datasets:
|
| 10 |
+
- databricks/databricks-dolly-15k
|
| 11 |
+
base_model: meta-llama/Llama-2-70b-hf
|
| 12 |
+
---
|
| 13 |
+
|
| 14 |
+
Note: This repo contains the base weights already merged with lora, pls check qblocks/llama2_70B_dolly15k repo for LORA adapters only
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
### Finetuning Overview:
|
| 18 |
+
|
| 19 |
+
**Model Used:** meta-llama/Llama-2-70b-hf
|
| 20 |
+
**Dataset:** Databricks-dolly-15k
|
| 21 |
+
|
| 22 |
+
#### Dataset Insights:
|
| 23 |
+
|
| 24 |
+
The Databricks-dolly-15k dataset is an impressive compilation of over 15,000 records, made possible by the hard work and dedication of a multitude of Databricks professionals. It has been tailored to:
|
| 25 |
+
|
| 26 |
+
- Elevate the interactive capabilities of ChatGPT-like systems.
|
| 27 |
+
- Provide prompt/response pairs spanning eight distinct instruction categories, inclusive of the seven categories from the InstructGPT paper and an exploratory open-ended category.
|
| 28 |
+
- Ensure genuine and original content, largely offline-sourced with exceptions for Wikipedia in particular categories, and free from generative AI influences.
|
| 29 |
+
|
| 30 |
+
The contributors had the opportunity to rephrase and answer queries from their peers, highlighting a focus on accuracy and clarity. Additionally, some data subsets feature Wikipedia-sourced reference texts, marked by bracketed citation numbers like [42].
|
| 31 |
+
|
| 32 |
+
#### Finetuning Details:
|
| 33 |
+
|
| 34 |
+
Using [MonsterAPI](https://monsterapi.ai)'s user-friendly [LLM finetuner](https://docs.monsterapi.ai/fine-tune-a-large-language-model-llm), the finetuning:
|
| 35 |
+
|
| 36 |
+
- Stands out for its cost-effectiveness.
|
| 37 |
+
- Was executed in a total of 17.5 hours for 3 epochs with an A100 80GB GPU.
|
| 38 |
+
- Broke down to just 5.8 hours and `$19.25` per epoch, culminating in a combined cost of `$57.75` for all epochs.
|
| 39 |
+
|
| 40 |
+
#### Hyperparameters & Additional Details:
|
| 41 |
+
|
| 42 |
+
- **Epochs:** 3
|
| 43 |
+
- **Cost Per Epoch:** $19.25
|
| 44 |
+
- **Total Finetuning Cost:** $57.75
|
| 45 |
+
- **Model Path:** meta-llama/Llama-2-70b-hf
|
| 46 |
+
- **Learning Rate:** 0.0002
|
| 47 |
+
- **Data Split:** Training 90% / Validation 10%
|
| 48 |
+
- **Gradient Accumulation Steps:** 4
|
| 49 |
+
|
| 50 |
+
---
|
| 51 |
+
|
| 52 |
+
### Prompt Structure:
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
```
|
| 56 |
+
### INSTRUCTION:
|
| 57 |
+
[instruction]
|
| 58 |
+
|
| 59 |
+
[context]
|
| 60 |
+
|
| 61 |
+
### RESPONSE:
|
| 62 |
+
[response]
|
| 63 |
+
```
|
| 64 |
+
|
| 65 |
+
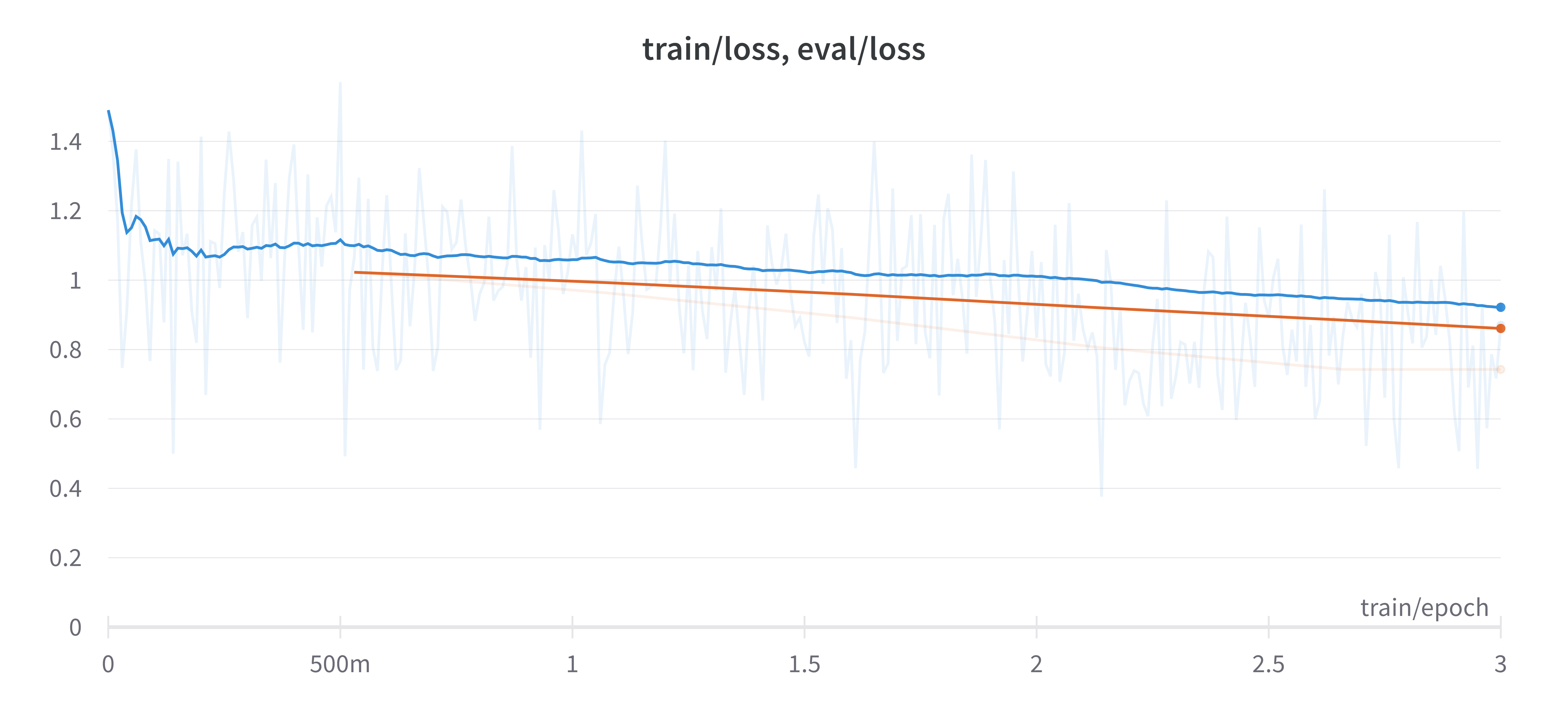
Loss metrics
|
| 66 |
+
|
| 67 |
+
Training loss (Blue) Validation Loss (orange):
|
| 68 |
+

|
| 69 |
+
|
| 70 |
+
---
|
| 71 |
+
|
| 72 |
+
license: apache-2.0
|
train-loss.png
ADDED
|
Git LFS Details
|